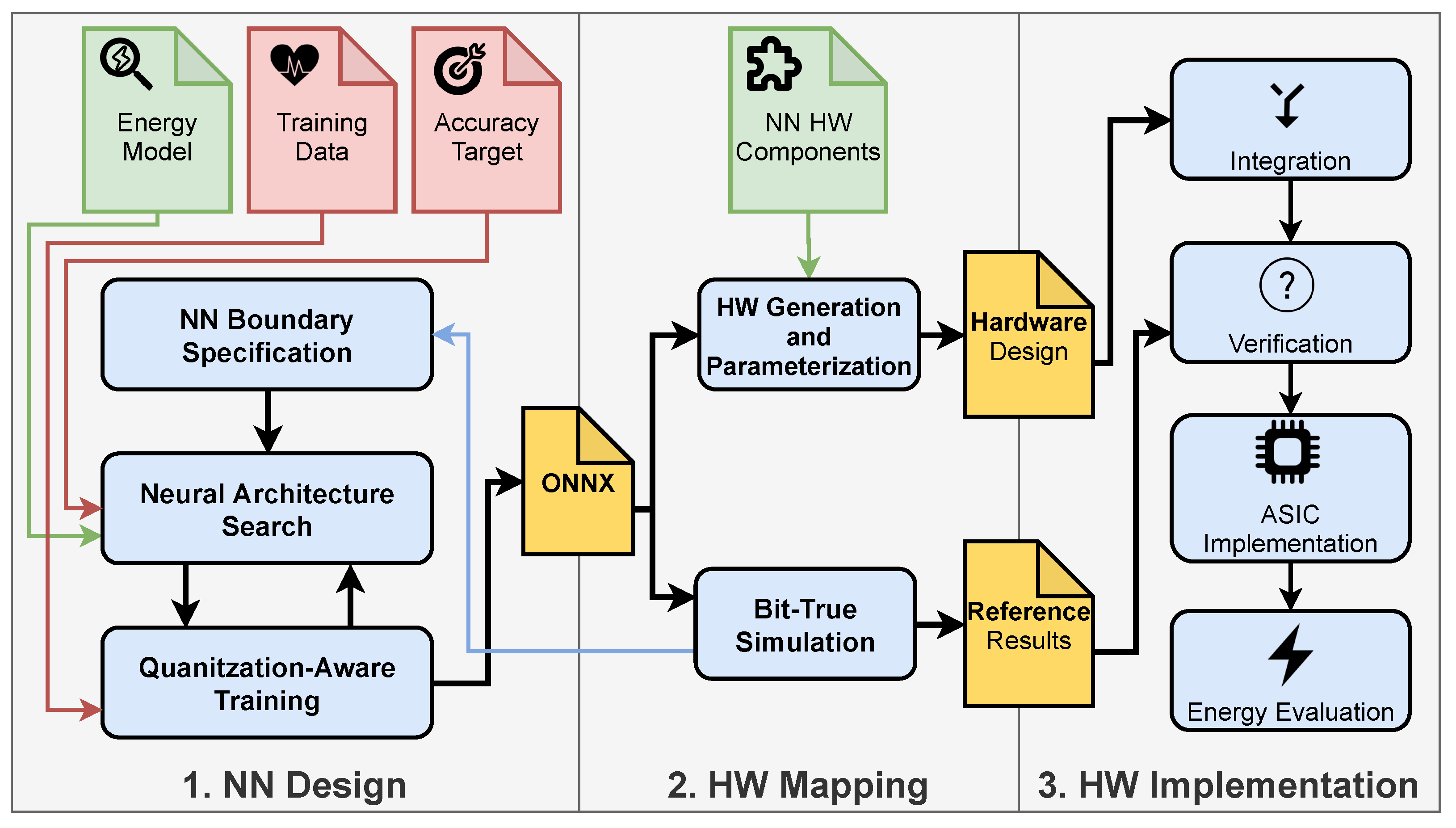
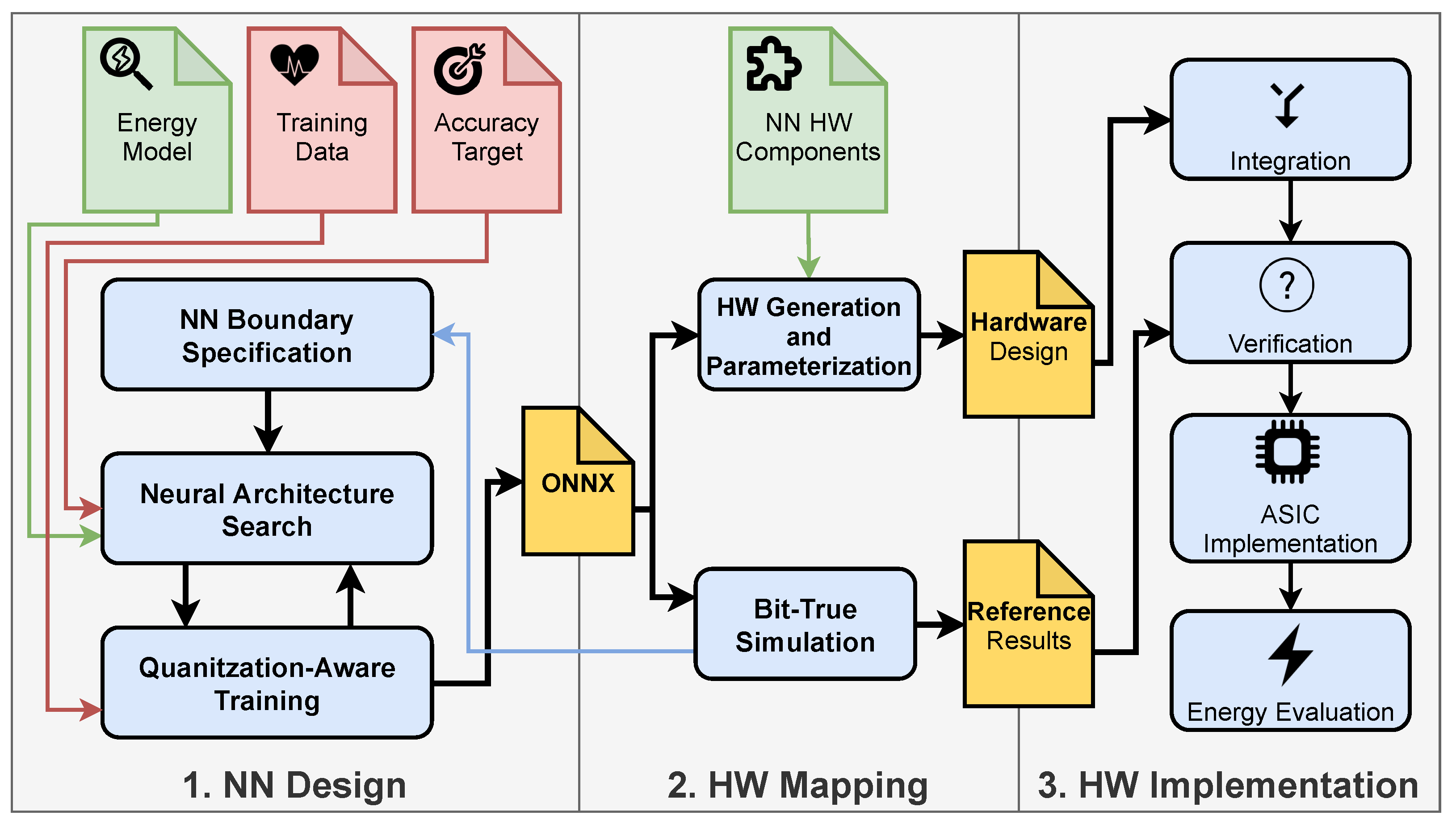
At the start of the design process, boundary conditions for the NN can be specified by the designer. This allows for the constraining of the design space of the NN and to integrate prior knowledge about beneficial NN configurations into the NN design process. Parameters include the type of layers and activation functions to be used as well as possible quantization levels for parameters and partial sums of different layers. In the next step an NAS is used, which finds a NN with minimal energy consumption for the desired accuracy. To evaluate, if the desired accuracy is reached, a full quantization-aware training of the NN is done. When an optimal network regarding a certain goal is found, the trained network is exported in
ONNX format. This format provides a common standard for NN specifications [
21]. In the second phase, the network defined this way can be imported into a self-developed
Bit-True simulator written in Python. It uses a fixed-point library to exactly model the arithmetic behavior of the hardware on bit level, which leads to the aforementioned name. With the help of this tool an evaluation of overflow and quantization effects on the accuracy can be conducted. From this, possible options for the NN boundary conditions can be identified, especially suitable quantization levels. This flow greatly reduces the time needed for a design space exploration of different NN configurations, as up to this point no hardware needs to be generated. The results of the
Bit-True simulation also act as reference for hardware verification later on. The
ONNX model is also used in our
hardware generation and parametrization tool, which parses and analyzes the network definition and creates an HDL design based on hardware components that we designed. In the third phase, all hardware components are integrated, and the functionality is verified by testbenches. Then a hardware implementation can be performed using commonly available EDA tools. Our framework is not limited to a specific toolset, because the hardware components are available as HDL description or hardware libraries. After the implementation, an energy evaluation of the whole design can be carried out (with tools such as
Synopsys PrimePower).
4.1. Neural Network Design
In our framework, the NN design plays an important role, as optimizations on the algorithm level have the biggest impact on the energy consumption of the final hardware implementation. Therefore, a lot of effort was directed towards creating a generic approach for finding an energy efficient NN and optimizing its so-called hyperparameters. Many hyperparameters of a NN have a big influence on the energy consumption of a hardware implementation. These hyperparameters include, but are not limited to:
Length of the NN input (window)
Number of convolutional layers and for each layer:
- −
Filter length
- −
Number of filters
- −
Stride of each filter
Number of Fully-Connected layers and number of neurons in each layer
Activation function used
Quantization of the weights
Quantization of the partial sums and activations
However, these hyperparameters also directly affect the accuracy of the classification task and the time a classification takes. As the design space for creating a NN and defining theses hyperparameters is very broad, a trade-off between energy efficiency, accuracy and duration of the classification must be found. For this task an NAS can be used [
13]. An NAS helps in finding an optimal NN configuration regarding certain optimization criteria in a defined search space. It can be distinguished by the search space that is covered, the search strategy that is used, and the performance estimation that is applied to compare different models.
In contrast to a state-of-the-art NAS, which often treats the target hardware as an abstract model, if at all, we have adapted our NAS specifically to our hardware architecture [
22,
23]. We can therefore incorporate prior knowledge about time series classification tasks. As an example, we constrain our search space to reach shorter search times by limiting possible basic blocks of the NN to those that are well suited for time series classification while being efficiently implementable in hardware. These blocks include convolutional layers, Fully-Connected layers, ReLU activation functions and Max Pooling layers. With our framework, the search space can be constrained even further by setting possible quantization configurations, for weights, inputs and partial sums. These constraints can be specified as a configuration file and be adapted to other application needs by a designer. For the search strategy, we use a grid-based search to increase the speed of finding a promising model.
Unlike state-of-the-art NAS, our approach simultaneously maximizes classification accuracy and minimizes the actual energy of a hardware implementation based on our architecture. To find the optimal trade-off, we created an energy model, which helps to identify the impact of different hyperparameters on the overall energy consumption. The model specifies values for the power consumption of MAC operations (PMAC) and RRAM cells (Pmem) for different configurations. These values are stored in a lookup table. They were extracted from hardware simulation of our architecture components and are not based on abstract energy models as in other approaches. The parameterization is done using the bit widths (i.e., quantization levels) of the input values (xbits), weights (wbits), and output values (obits), respectively. For MAC operations the consumed energy can be calculated by summing up the power estimates of all layers, parametrized with the respective bit widths and multiplying the sum with the duration of MAC operations, depending on the targeted clock frequency. The energy consumed by the memory can be calculated by summing up all power estimates and multiplying the sum with the overall duration of a classification. However, for comparing different models for the same application a fixed clock cycle and duration can be assumed and therefore, the sums of the power values can be compared directly. To compare the accuracy of different models, we further divide it into sensitivity (proportion of positive cases that are correctly identified) and specificity (proportion of negative cases that are correctly identified).
Our NAS is described by Algorithm 1. We initialize the search space with a model found by a random search and then search for better models iteratively. In each iteration, a small grid (set of adjustable hyperparameters) is defined, while the rest of the hyperparameters is fixed to limit the search space. The three metrics (estimated energy/power, sensitivity, and specificity) are then calculated for each candidate model after a full training. The best of these candidate models is then chosen, and a new grid is defined for the next iteration. The influence of the three optimization goals can be adapted towards a certain goal of the application by weighting them before comparison. To create an ultra-low-power accelerator, more emphasis can be given to the estimated power than to the sensitivity or specificity, for example. For applications, where it is critical to classify an event as soon as it appears for the first time, it can be useful to prioritize sensitivity over specificity as a false alarm might be better than missing the event. However, when aiming for long-term monitoring in a wearable device it can be even more important to optimize for estimated power, as thousands of classification runs will be done per day and a condition is likely to appear in multiple classification runs. The optimization is finished when no better NN configuration can be found.
It is difficult to compare the potential savings of our NAS against other NAS or optimization approaches from the literature since there are multiple degrees of freedom and NAS often targets generic hardware architectures. However, to get an idea of how much energy can be saved using our NAS, a fixed specificity and sensitivity can be chosen. Then the energy minimization is the only optimization criterion. In this case, energy savings of up to 70% compared to an initial NN configuration can be achieved. Therefore, this NAS is worthwhile and can yield far better energy consumption than by applying individual optimizations alone.
| Algorithm 1: Our Neural Architecture Search. |
![Jlpea 12 00002 i001]() |
Unlike the other hyperparameters of a NN, quantization needs special attention. It influences not only the arithmetic operations, but also the amount of memory required for the parameters of the NN. NNs usually allow for heavy quantization, because of their inherent redundancy. While general purpose accelerators, like CPUs or GPUs, use the same bit widths for all arithmetic operations, in an ASIC architecture it is useful to set this quantization per layer of a NN in order to achieve an optimal compromise between accuracy and energy consumption. We adapt the NN to the designed hardware by developing a training method where the reduction of precision is exactly modeled, and the network can be forced to only use efficiently implementable operations. Rather than just quantizing to an arbitrary number of states we look at characteristics of the used RRAM cells first. In addition to their non-volatile property, they can in general store multiple states. However, this requires additional hardware circuitry for reading and writing the cell states reliably, which results in a more power intensive circuit.
In our NAS, the energy required to read out the values stored in a RRAM cell is considered in the energy model (depending on the numbers of states). Therefore, the NAS can be performed for different quantization levels of the parameter values. However, we have found that a three-state configuration usually is best for minimal energy when using RRAM memory. The reason for this lies in the trade-off between parameter quantization and NN size. While fewer states of the NN parameters also mean less energy for storage and arithmetic operations, binary weights are not optimal. With binary weights only two operations (e.g., multiplication with −1 and +1 or multiplication with 0 and 1) can be realized and the accuracy of the NN might suffer. Ternary weights (i.e., −1, 0, +1) are beneficial, as layers can amplify, attenuate, or ignore certain features, which would not be possible with only binary weights [
18]. This results in a small network topology that achieves a high classification accuracy. At the same time, the resulting operations can be realized in hardware very efficiently and all three states can be stored in a single RRAM cell. Other parameters of the NN, like
bias values, can be stored into multiple (
n) of these cells, resulting in
possible states. Storing more than three states in a single RRAM cell is also possible but requires a more than linear increase in the required read and write energy.
Creating a quantized NN is not straightforward [
11]. While inference of a NN using quantized operators can be realized without any implications, training an NN requires high precision calculations to find a minimum of a loss function. Using full precision weights and then quantizing them severely at the end of a training would result in significant accuracy degradation [
24]. Therefore, we implemented a quantization aware training procedure that accounts for the quantization during training. In contrast to quantization after training, this achieves higher accuracy. Each training step consists of forward-propagation, backward-propagation, and weight update. The real-valued weights are quantized during the forward propagation which calculates the output and loss function. The gradients are then computed using the backward-propagation. Finally, the gradients are used to update the real-valued (not the quantized) weights. This way the real-valued weights can be updated slowly and eventually, and some of them might shift across the threshold and be quantized to a different value during the forward-propagation. This approach prevents the introduction of a bias in the gradient due to quantization [
11]. At the end of the training, the quantized weights are used in our design. The real-valued weights are discarded, as they are only needed during the training process.
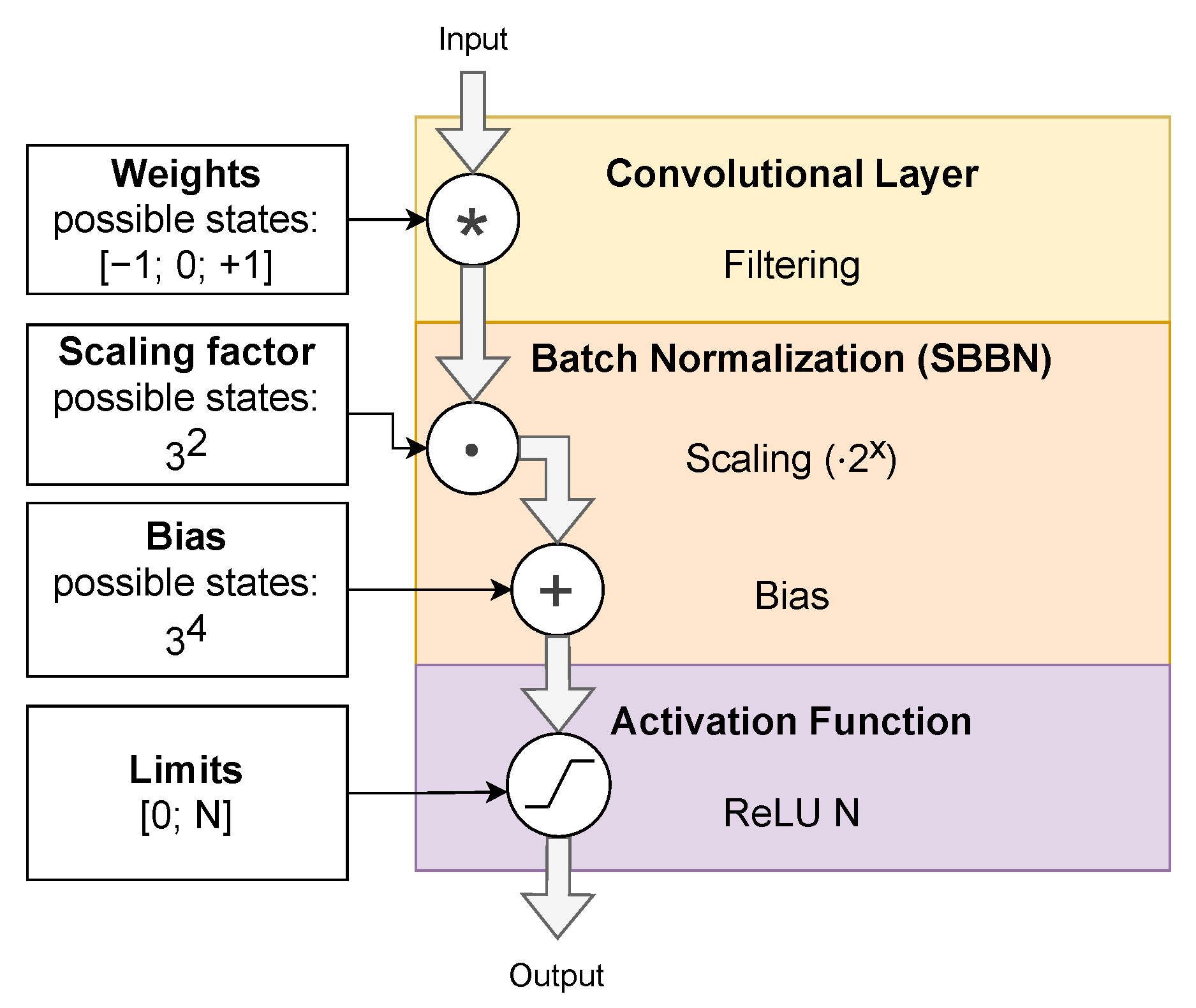
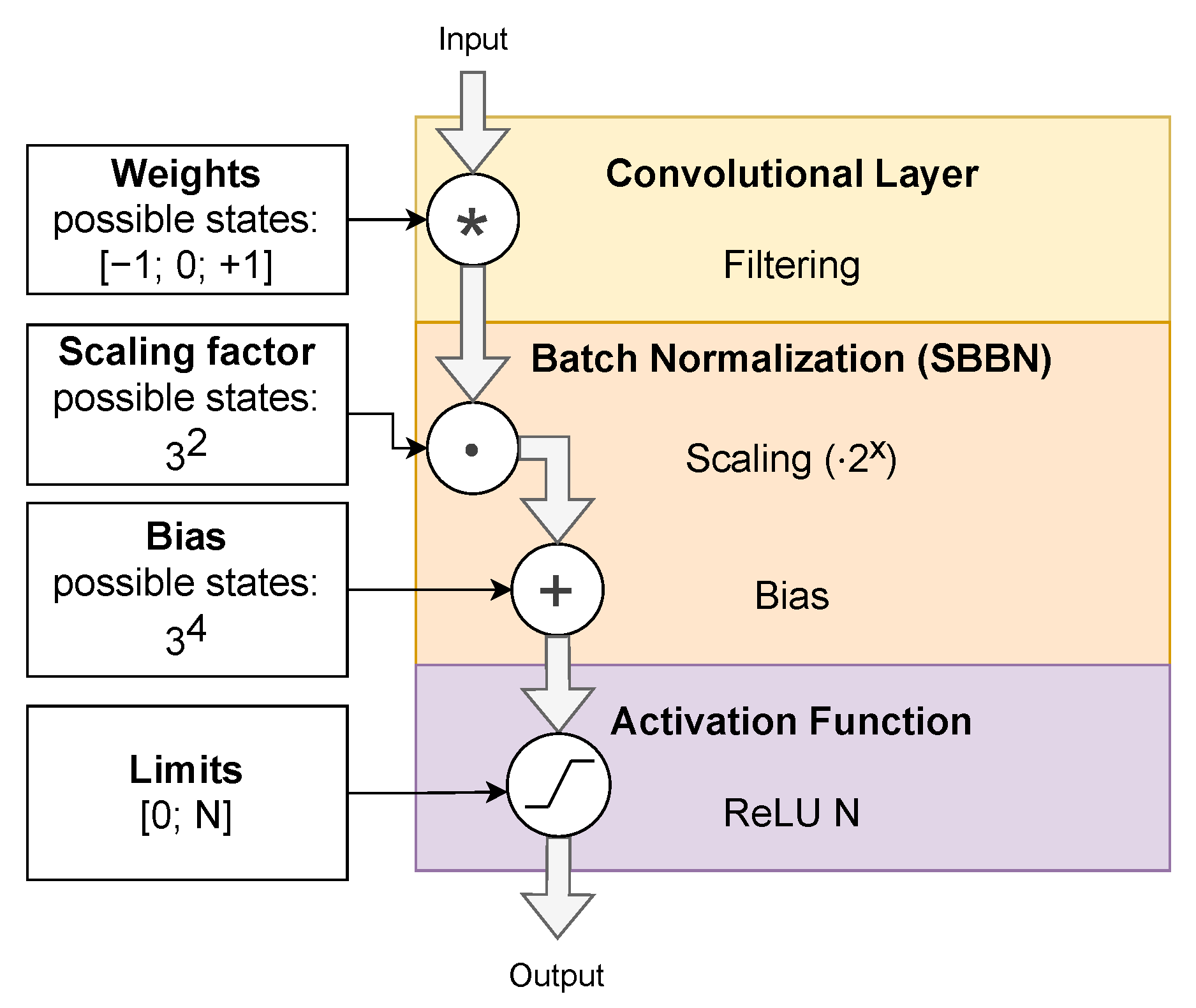
To make the final quantized NN more energy efficient, we have specified some further constraints, which we found to be beneficial for time series classification applications: We use a
Batch Normalization layer after each
Convolutional and
Fully-Connected layer. This type of layer helps to extend the range of values of strongly quantized NNs by multiplying input values by a
scaling factor and adding a
bias value. Both parameters will be learned during training. To keep
Batch Normalization energy efficient, we constrain the
scaling factor to a power of two and only store the exponent. We call this type of layer
Shift-Based Batch Normalization (SBBN). This enables the realization of the multiplication with a
scaling factor using an energy efficient shift operation. The exponent as well as the
bias value for the
Batch Normalization layer are also quantized (e.g., to
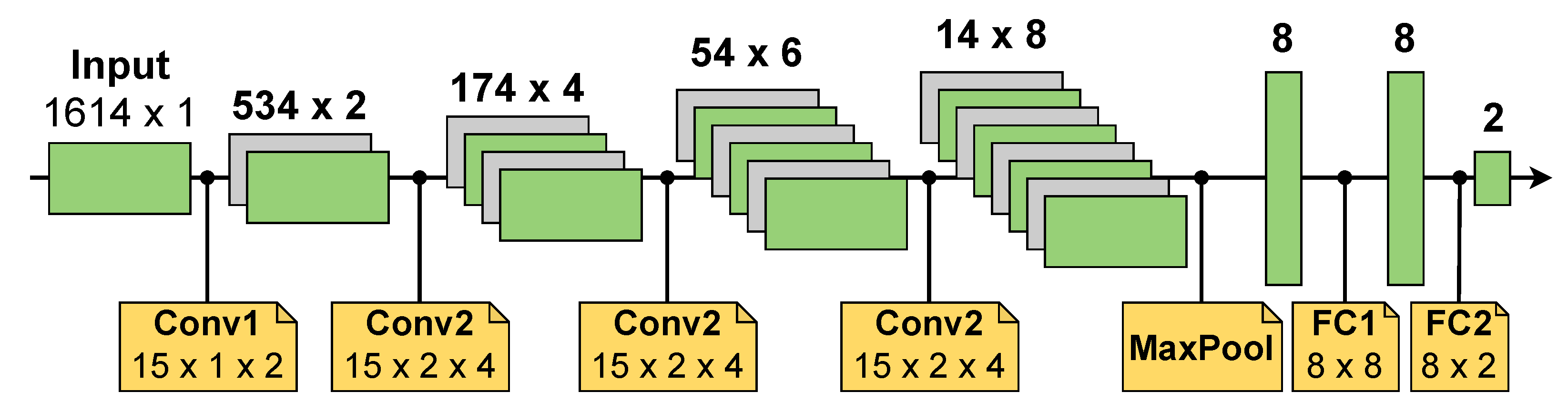
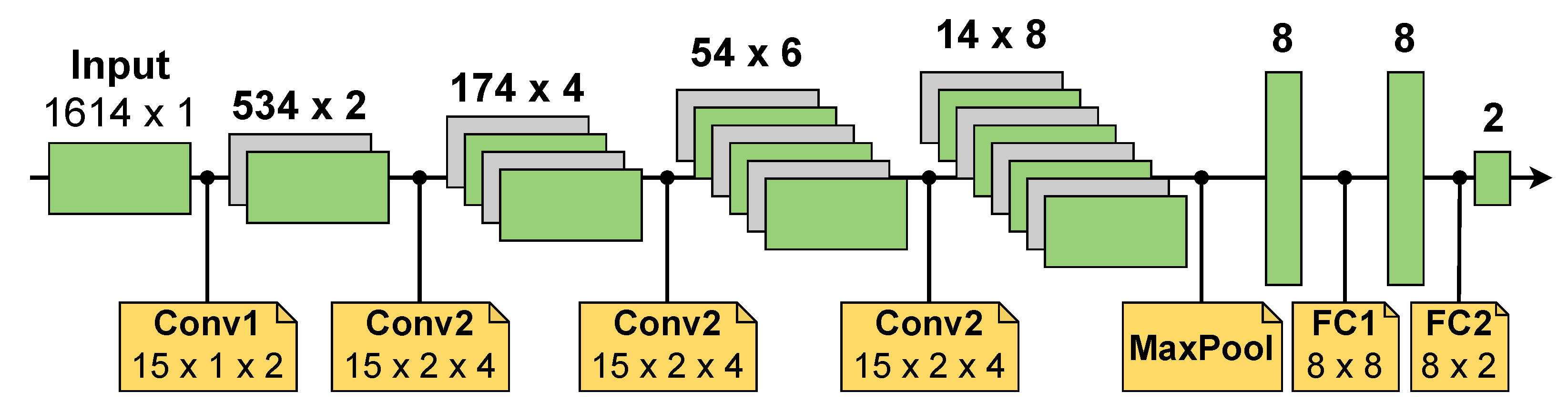
states). An example of a customized layer configuration extracted from our NN used for ECG classification is given in
Figure 3. The weights of the
Convolutional layer posess three states. The exponent of the
scaling factor is quantized to
states (
). For the
bias value
is used. This enables a broad range of values to be used. On the other hand, we save up to
and
the amount of memory cells, respectively, compared to binary 8 bit values. Similar to training the weights, the
Batch Normalization coefficients are quantized during the forward-propagation and the real-values are updated in the backward-propagation. However, two training runs are done to achieve the quantization of the
Batch Normalization. During the first run the statistics for normalization (mean and variance) are collected. The second run continues with the model already trained in the first run. Before the second run, the collected statistics are fixed and quantized. These values are then used along with the trained coefficients to normalize the activations. This approach is necessary, as quantizing the mean and variance during collection is not possible because the accuracy hit introduced by this quantization would be too big to successfully train the network. In addition to the coefficients, we also quantize the activations and partial sums in the layers to save even more power for the arithmetic operations, data transfer and registers needed. For that, we use a saturated rectified linear unit (
ReLU N) as the activation function. In contrast to the regular
ReLU function, it not only cuts off values smaller than zero, but also cuts of values higher than a certain saturation limit (
N). This limit depends on the quantization of the input values of the following NN layer.
Our quantization-aware training was implemented in the NN framework TensorFlow by extending already existing functionality. Based on the
Fully-Connected (TF FC) and
Convolutional (TC Conv) layer provided by the framework, new layer types have been created. We use the prefix ‘quasi’ for these layers as they implement the previously described quantization process during training. As defined by our constraints, each
Quasi Quantized Fully-Connected (Quasi QFC) and
Quasi Quantized Convolutional (Quasi QConv) is followed by a Quasi
SBBN then a
saturated ReLU. According to our tests, this order in combination with the strong quantization causes the least reduction in accuracy.
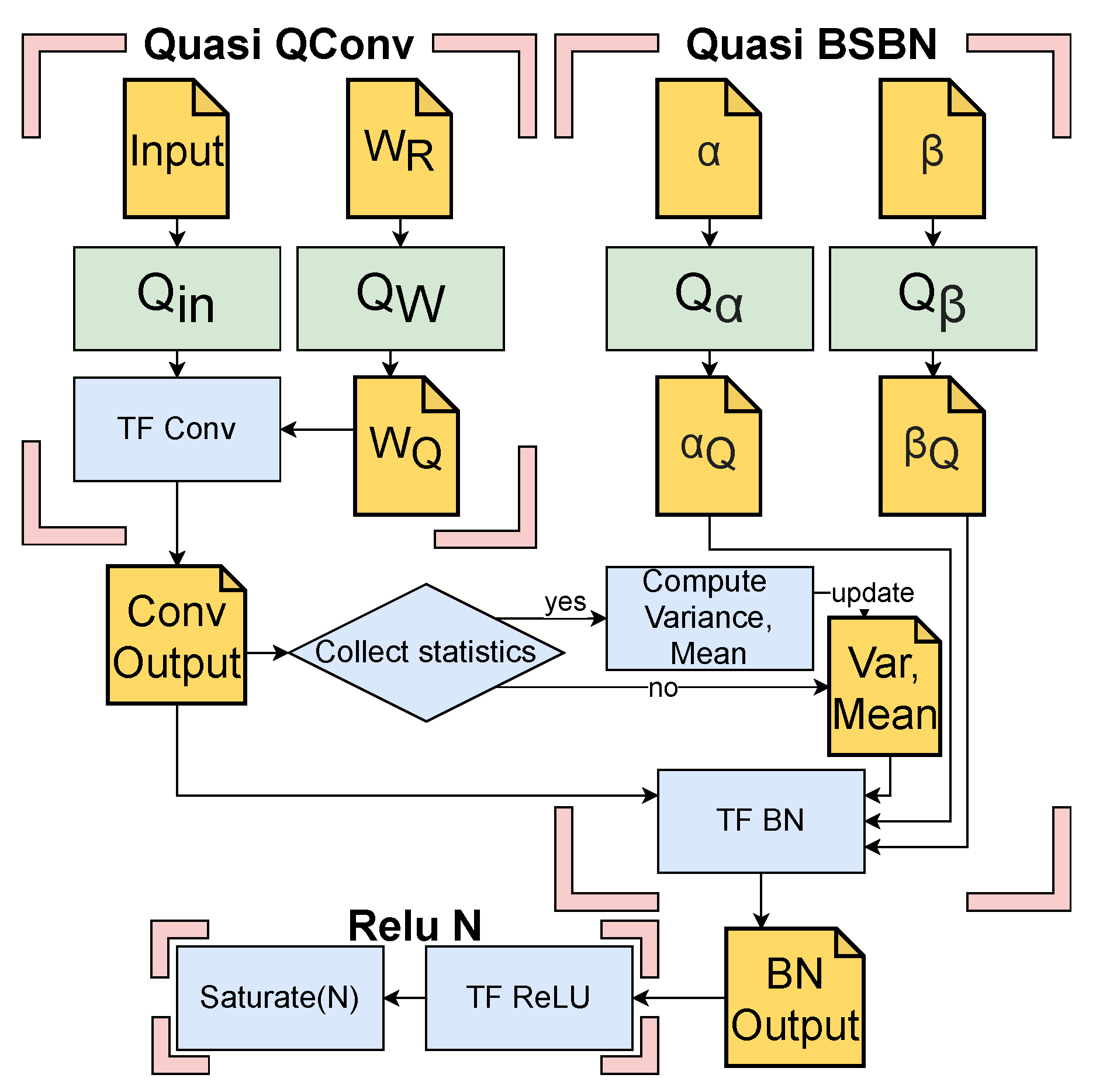
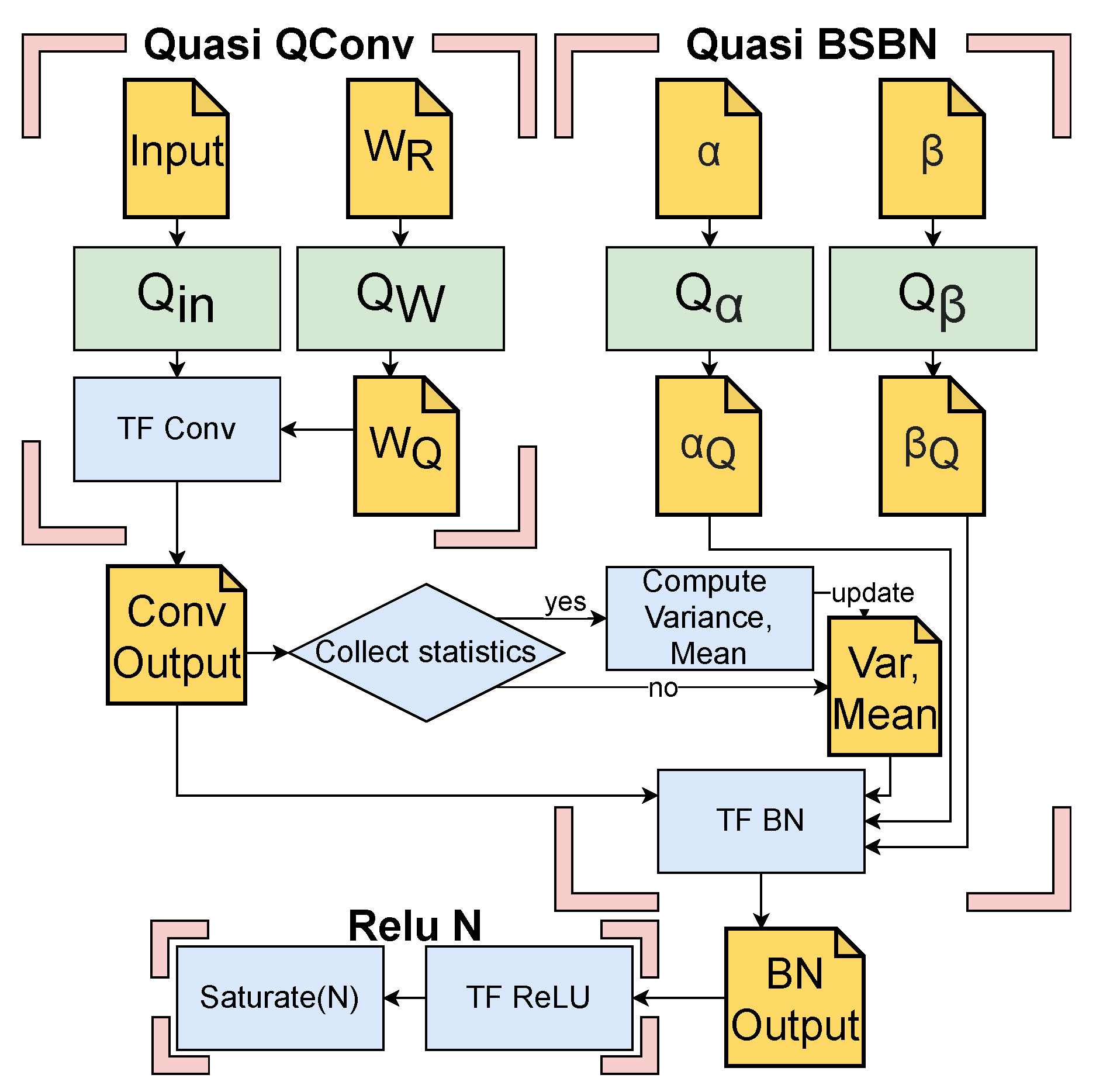
Figure 4 shows exemplary for one layer the extension of the TF Conv, TensorFlow
Batch Normalization (TF BN) and Tensorflow
ReLU (TF ReLU) module to achieve the quantization-aware training. Here,
and
are the functions that quantize the the weights, inputs, the scale and bias of the
Batch Normalization, respectively. The parameters
represent the real valued weights, scale and bias values that are to be quantized. These values are stored and updated during the training process, but only the quantized weights (
), scale (
) and bias (
) values are used in the hardware implementation for inference. Finally,
is a function implementing the saturation of the activations at a configurable level
N, which is synonymous with the quantization of the activations. All arithmetic operations in the network are realized using fixed point value representation, resulting in smaller and more energy efficient hardware than a floating point implementation. Compared to generic NN accelerators, which use a fixed bit width for all operands, we can show that our individual quantization per layer can save a lot of energy using our energy model. Thus, compared to an accelerator using 16 bit operands, up to 90% of energy is saved for arithmetic operations and storage alone, without significant impact on the accuracy. In contrast to accelerators using 8 bit operands it is still as high as 60%.
4.2. Dataflow Driven Architecture
An essential part of the
HW mapping step in the framework is the hardware architecture used to realize the calculation of the NN. While generic accelerators such as CPUs or GPUs can be used to run the calculations of a NN, they are far from optimal regarding energy consumption. They offer a high degree of flexibility, but require a lot of control overhead (i.e., instruction decoder, branch prediction unit etc.) which greatly contributes to the required energy. This accommodates different applications and flexible programming, but creates an additional energy budget for applications, where a fixed procedure is known beforehand. For NN-specific architectures this additional overhead can be omitted to reduce the energy consumption. Even when constraining to NNs and building specialized architectures like Eyeriss V2, a lot of energy is needed for the control logic [
25]. Other approaches, like the TPU by Google, achieve a large reduction of the control logic, but still need large buffering structures, which occupy up to 29% of the chip area [
26]. To solve this problem, a hardware architecture is required that is in complete contrast to freely programmable accelerators. Data paths should be defined at synthesis time and a data flow should be chosen which does not require buffering structures. For this, weight stationary architectures are already well researched and found to be a good approach for energy efficiency [
5]. Especially when applying NNs with a small number of parameters, weight values can be kept in local storage and do not need to be reloaded. This saves memory bandwidth and energy. Therefore, we designed a completely new optimized hardware architecture based on the idea of systolic arrays, where part of the control logic is implicitly defined by the structure of the hardware architecture. It is derived from our optimization strategies for time series classification tasks discussed in
Section 3 and designed to be generic and energy efficient. Different
hardware components based on this hardware architecture are implemented and can be used with a hardware generation tool to create a complete hardware design. One of the unique features of our architecture is that it internally works completely without control logic and buffers for the calculation of the NN. The data flow is given by the connection of the components and is derived from the design of the NN during hardware generation.
Nevertheless, the goal of our architectural concept is furthermore to enable the use for different applications with different NN designs. It should be possible to use the
HW generation and parametrization tool from our design flow to create and parametrize an optimal hardware depending on the NN configuration. Therefore, all hardware blocks designed are flexible regarding their (automated) mapping and arrangement.
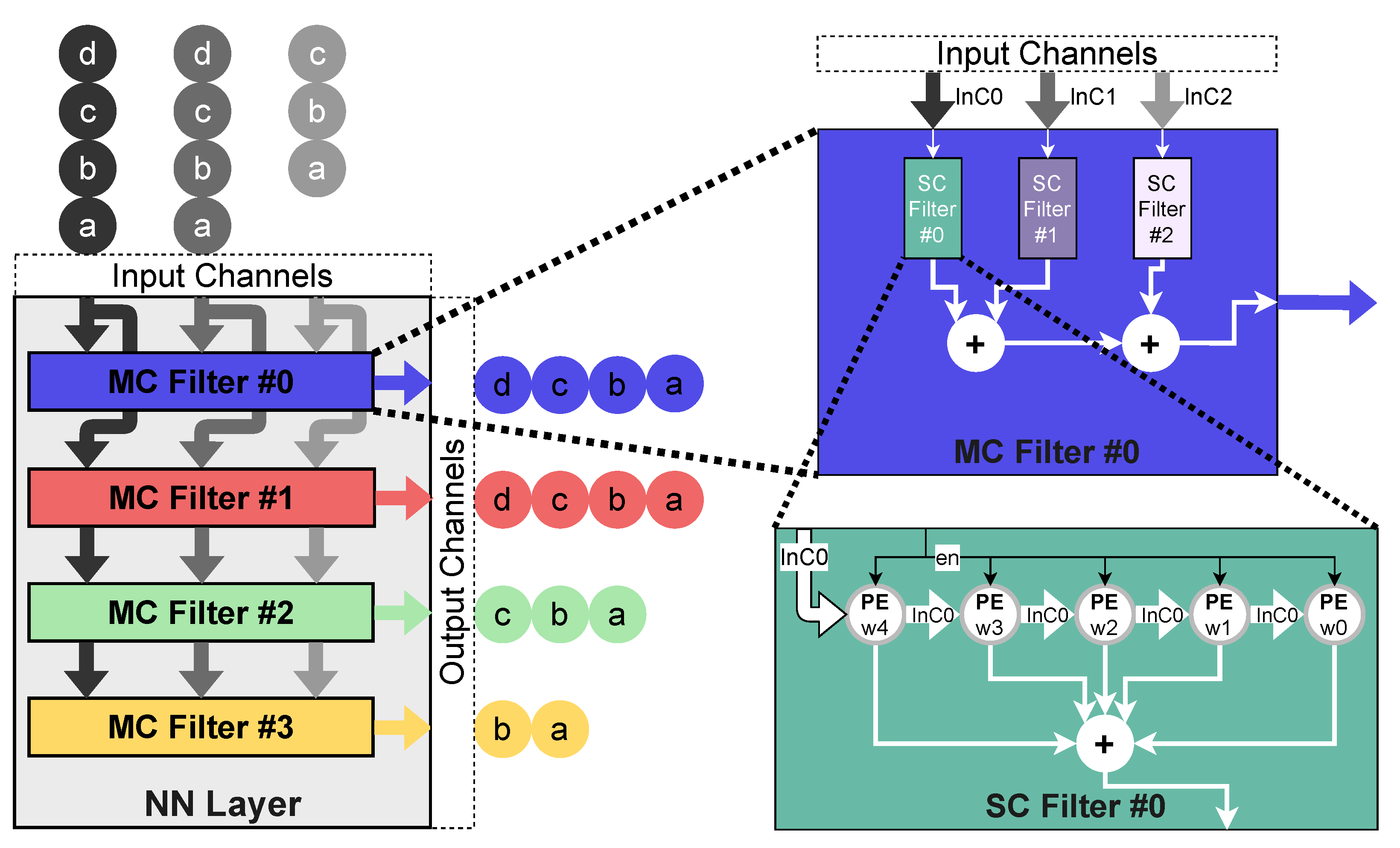
Figure 5 shows an overview of the hardware architecture of a
Convolutional layer. As the share of the static power of the Processing Core design is small compared to the dynamic power and can be optimized by reducing the on-time, the hardware is designed to minimize dynamic power. Therefore, the data arrives at each layer in a systolic manner. This means that the first two input channels deliver values in parallel. The following channels deliver values with an offset of one clock cycle each. The layer itself consists of several multichannel (MC) filters, which correspond to the number of filters inside the layer defined by the NN. Each MC filter consists of multiple single channel (SC) filters, corresponding to the amount of input channels that the filter has. The SC filter is composed of a regular structure of multiple processing elements (PEs). Each PE has its own weight memory in form of a RRAM cell, which is physically not inside the PE, but in a RRAM block close to the actual PE. However, its output is routed directly into the PE. The input values are passed from one PE to another and a multiplication with the weight is carried out. Each arithmetic operation is enabled by a simple counter-based controller, depending on the stride value defined for the filter in the NN. The output values of each PE are summed using an adder tree. Each SC filter possesses a simple 1D topology of PEs. The output of multiple of these 1D structures is summed up inside the MC filters, which are themselves grouped to a regular 2D structure inside one layer. In our design, filter coefficients that are moved over the input signal are directly accounted for and do not need to be stored multiple times. This design also significantly reduces dynamic energy, as the stride value is realized using clock gating and no unused partial sums are calculated. The dataflow between the layers is optimized in a way that multiple layers can be directly concatenated without the need for buffering in between.
The architecture of the Fully-Connected (FC) layer is the same as the Convolutional layer. The length of the filter is mapped to the amount of input values as well as the stride value. This results in a very low duty cycle. However, it was tested to be more energy efficient than mapping multiple weights into one PE. The reason is a much lower dynamic power requirement caused by less toggling, while the higher static power requirement for inactive PEs has an insignificant overall impact. Other hardware modules, like the ReLU activation function, the scaling and the bias addition of the BatchNorm layer as well as the Max Pooling layer are built of a vector of PEs. Each PE operates on its own channel. One PE in a scaling layer shifts the input value by the amount defined in the NN. Each PE in a bias addition layer adds the trained bias value to all inputs of one channel. The overall dataflow is delayed by one clock cycle by all of these modules, keeping the dataflow intact and enabling a concatenation of all layers in any order.
Implementing an architecture, which calculates all outputs of a layer fully parallel is not possible when designing a chip that should be integrable into a wearable device or a similar embedded environment. Even with a small network, a fully parallel configuration, extrapolated from the components of our design, reaches a chip size of over 500 mm2. This is not practical for embedded use cases, therefore, our architecture does not calculate each individual output value in parallel, but one value of each channel in parallel. This is a good compromise to achieve a realistic chip size of a few multiples of 10 mm2, depending on the NN size. It needs more clock cycles to calculate a classification, but the individual PEs are utilized with a high duty cycle, depending on the layer and the stride used. In comparison to a time multiplexed architecture, where multiple operations are mapped to the same PE, our design achieves an overall reduction of the average power. Mapping multiple operations to the same PE results in frequent changes of the operands in the PE and therefore a higher dynamic power. We implemented such a design for exemplary FC layers and compared the energy after synthesis. We could show that even in these FC layers, where the PEs possess only a low duty cycle, mapping multiple operations to the same PE and switching the weight values requires more energy than not using some PEs for multiple cycles.
4.3. Non-Volatile on-Chip RRAM
Another important part of the
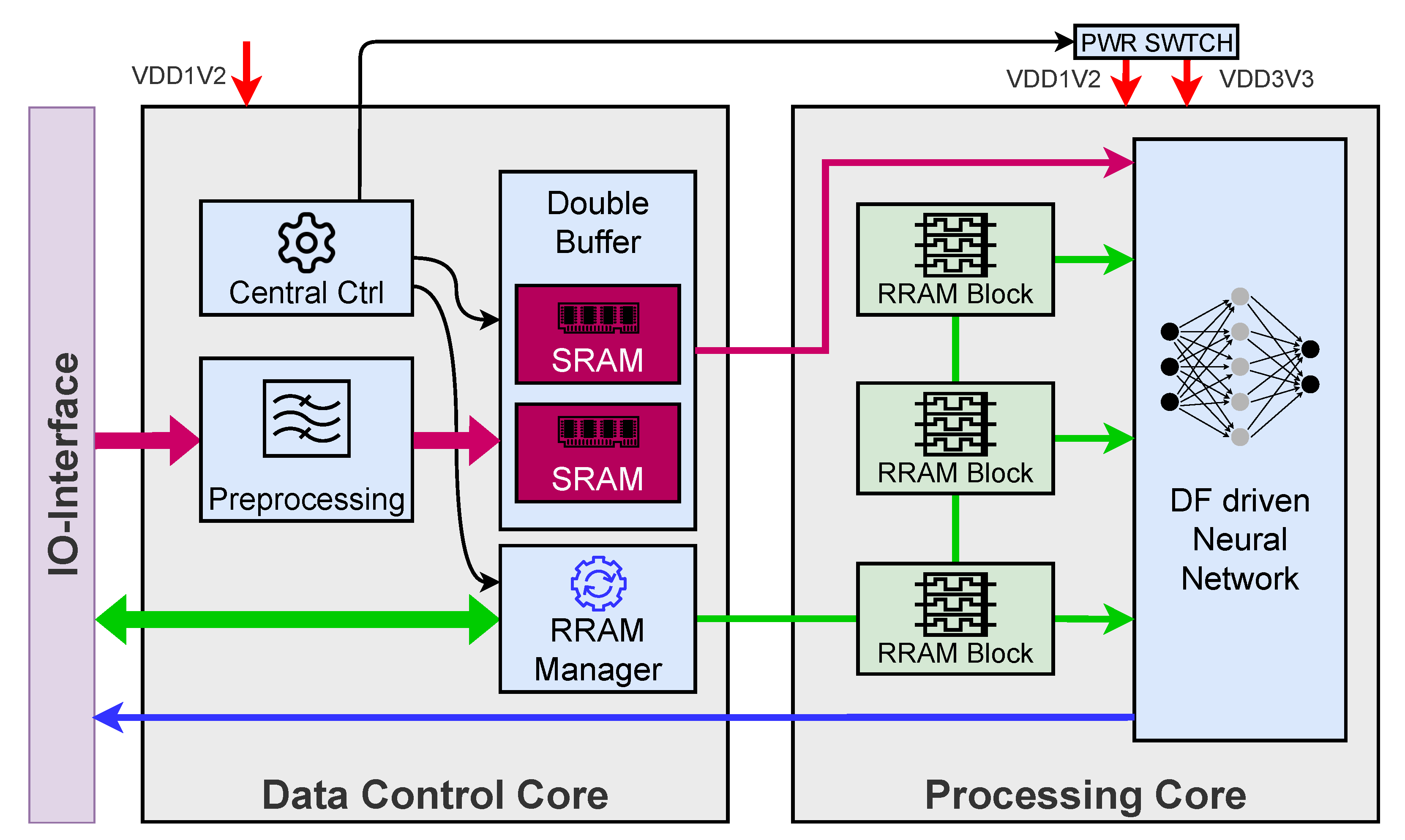
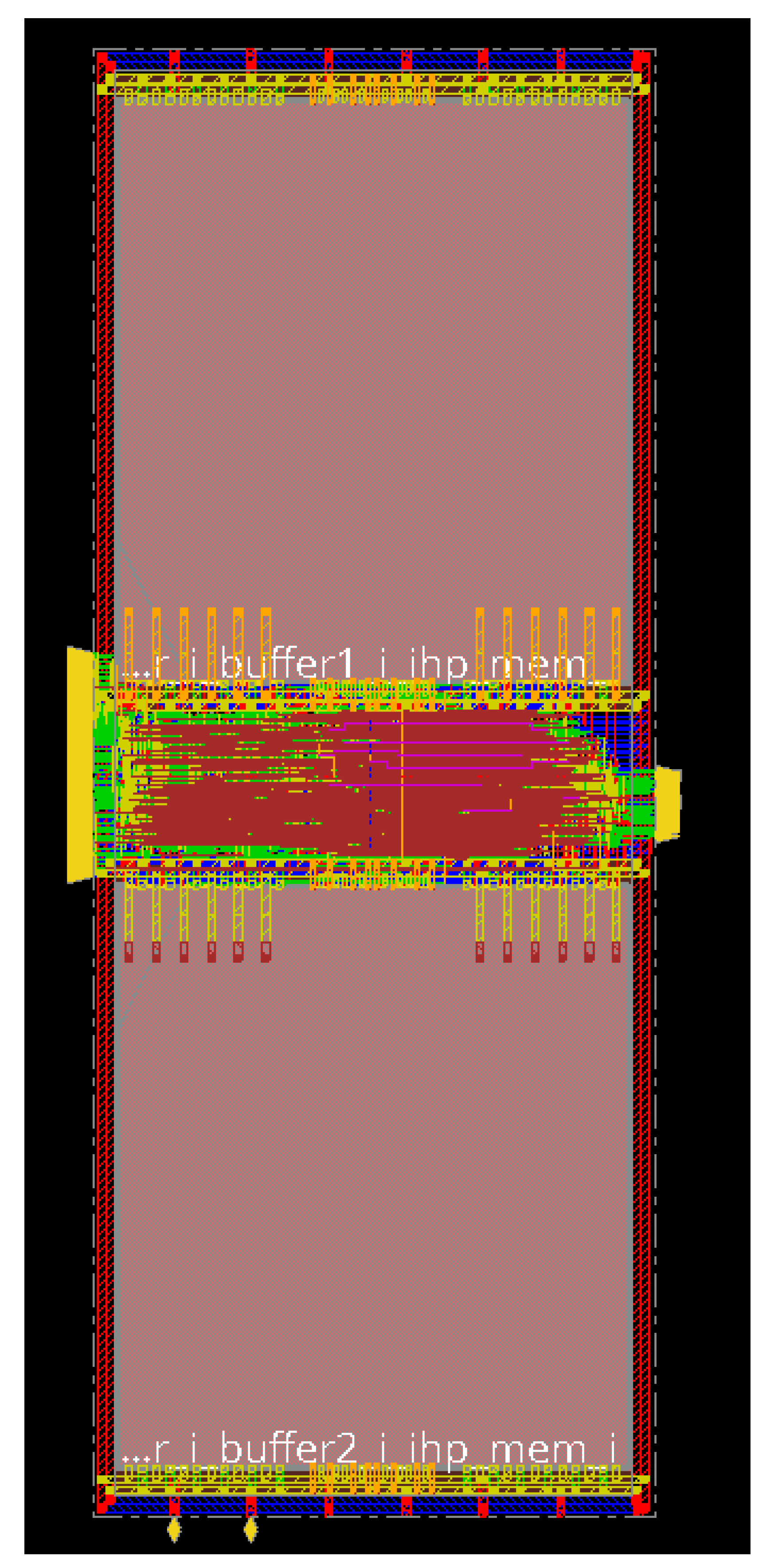
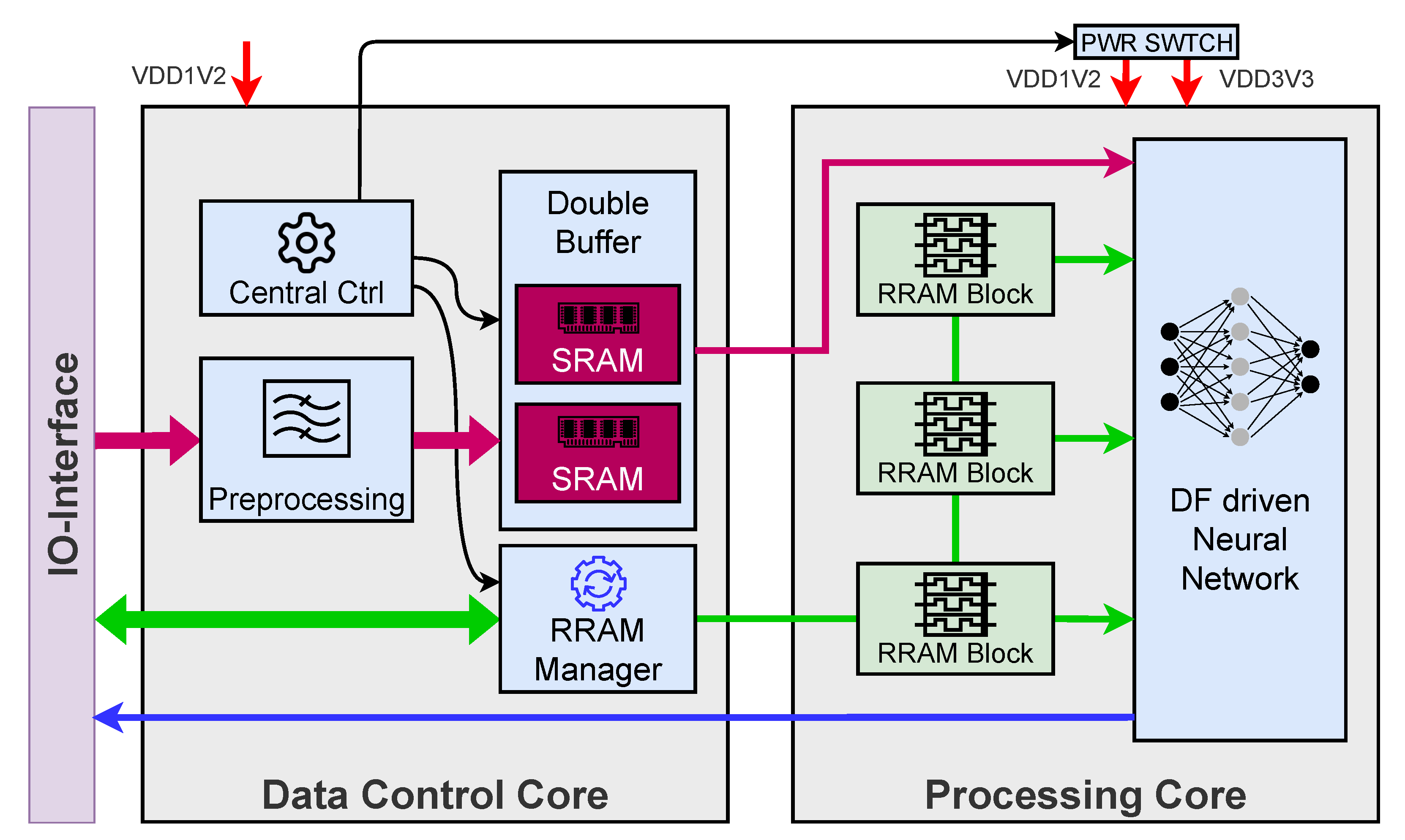
hardware components designed by us is the embedded RRAM memory. For a classification task in an embedded device, it is usually necessary to collect multiple seconds of data sampled at a low rate, while no actual classification must be carried out. In our architecture the classification is the task of the Processing Core, which could be in a sleep state during this data acquisition process. However, in traditional architectures, mainly volatile memory is used to store the NN parameters (e.g., NN weights, scaling factors) locally in accelerators. This means after every power cycle of the chip these parameters must be reloaded from external non-volatile storage. Reloading data from external memory requires a huge amount of energy. This contradicts the goal of reducing energy and prevents an efficient design with a power-down mode. To overcome this problem, we use non-volatile memory in form of RRAMs to store data in an embedded way. This RRAM cells can be read in parallel and allow for a quick availability of all parameters after power is (re)supplied. The division into two power domains, as seen in
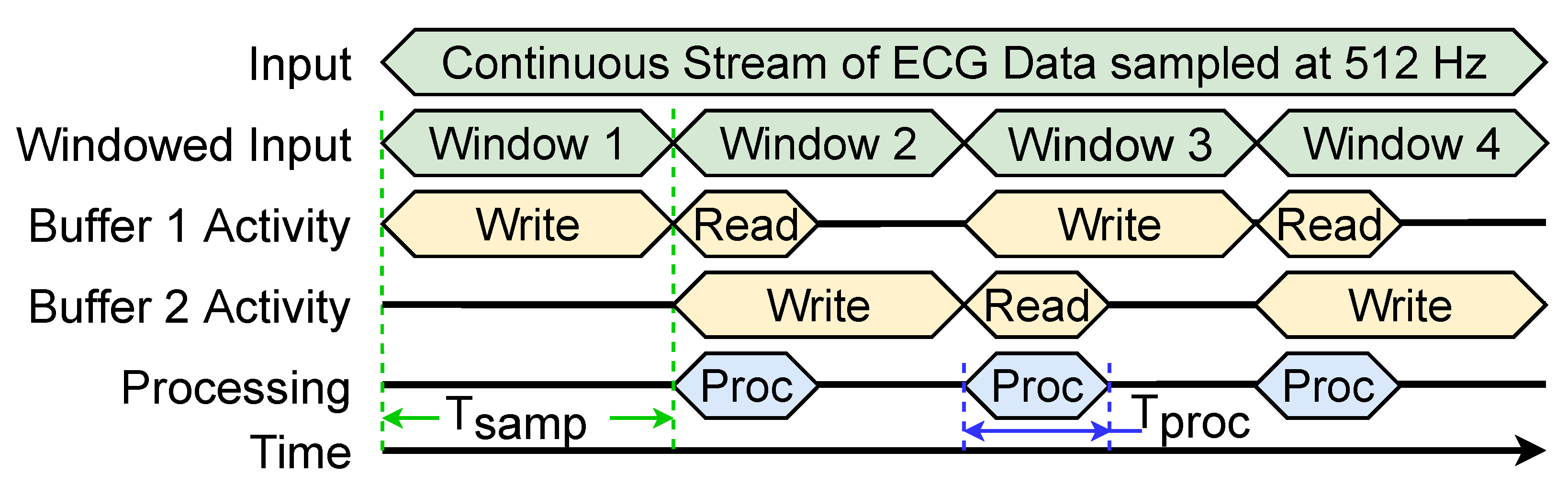
Figure 1, enables us to put the Processing Core into a deep sleep mode where it draws almost no power and after waking up the chip, all the parameters of the NN are still present.
The embedded memory blocks for local storage demand efficient read and write circuitry to be integrated in the architecture. The research on the integration of RRAM cells is very recent and due to the manufacturing process, they often possess considerable variations per cell. These can have an influence on the interpretation of the values stored in them [
27]. The RRAM design used in our system is provided by IHP as part of the MEMRES module, integrated into their 130 nm SG13S-process line [
27]. Previous research has been done on the device characteristics of these cells in IHP technology and their system level influence on NN accelerators. The typical device variations have been considered and it has been shown that the accuracy of the NN does not decrease by more than 1% despite the inaccuracy introduced by these variations [
28].
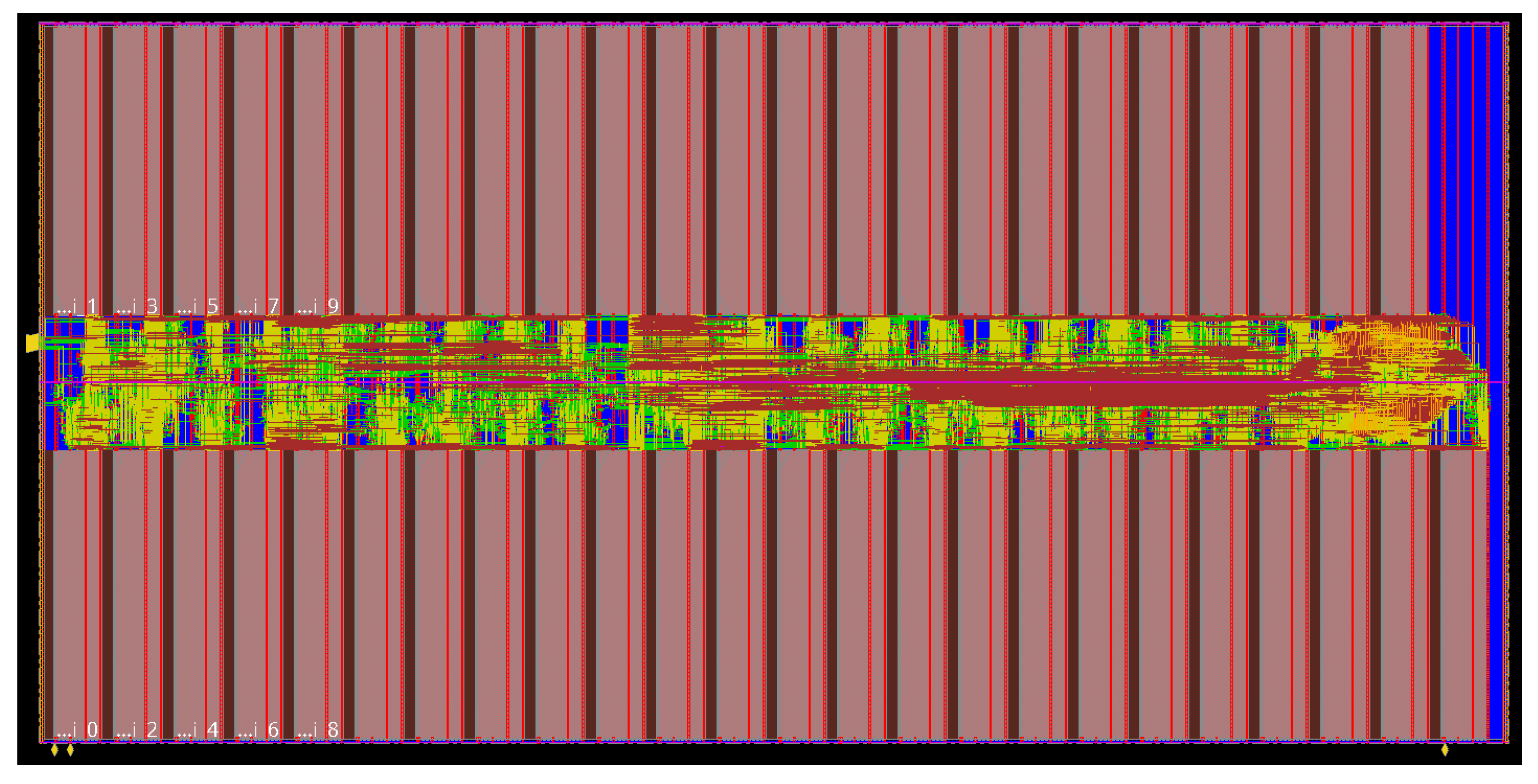
In our architecture the memory cells are grouped into blocks of 32 and all blocks are connected like a long shift register, as shown in
Figure 1. At the same time, the values of all cells are available to the accelerator in parallel. As discussed in
Section 4.1, three states seem like an optimal solution for most NN configurations. Therefore, we consider three resistive states of the RRAM cells (two low resistance states (LRS1 & LRS2) and one high resistance state (HRS)). However, the use of more states is also possible. The design of this RRAM memory block has been optimized specifically for use in low-power accelerators for NNs [
29].
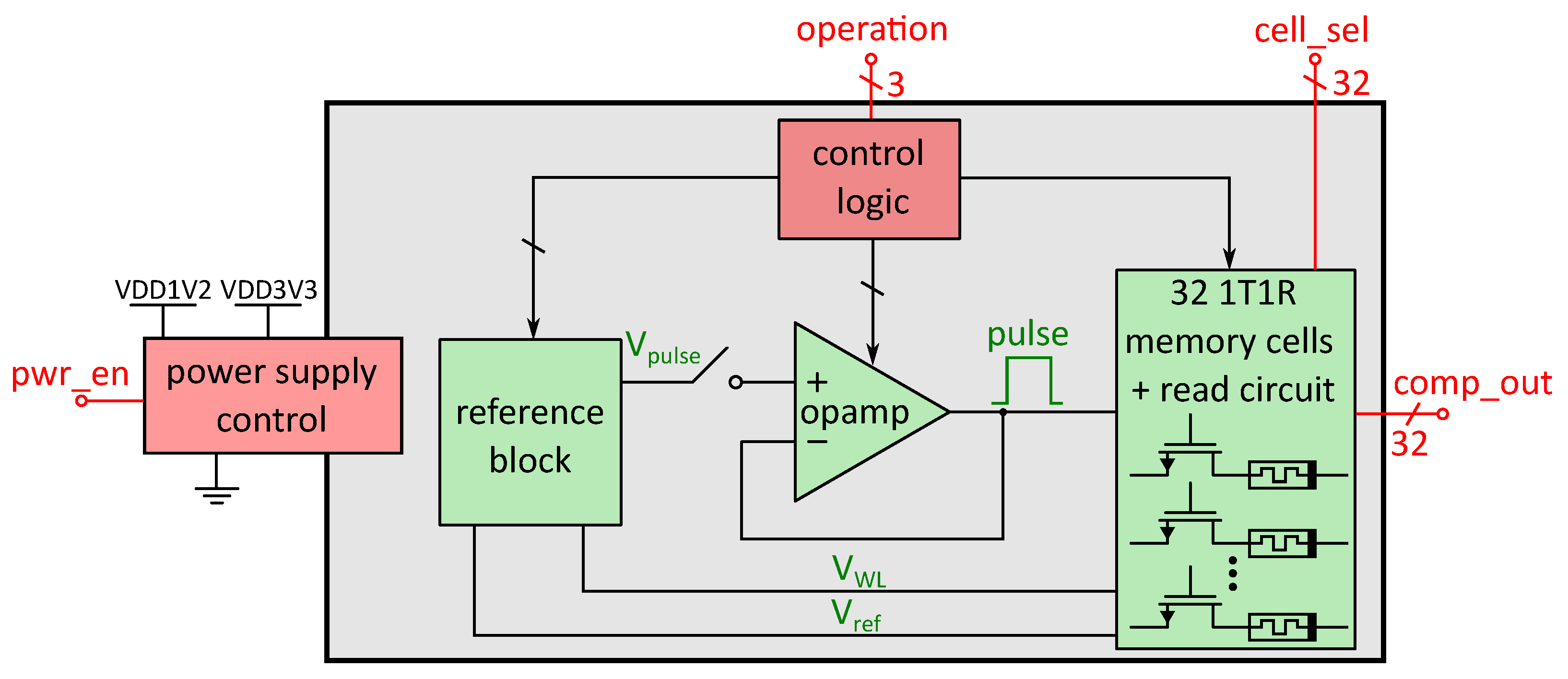
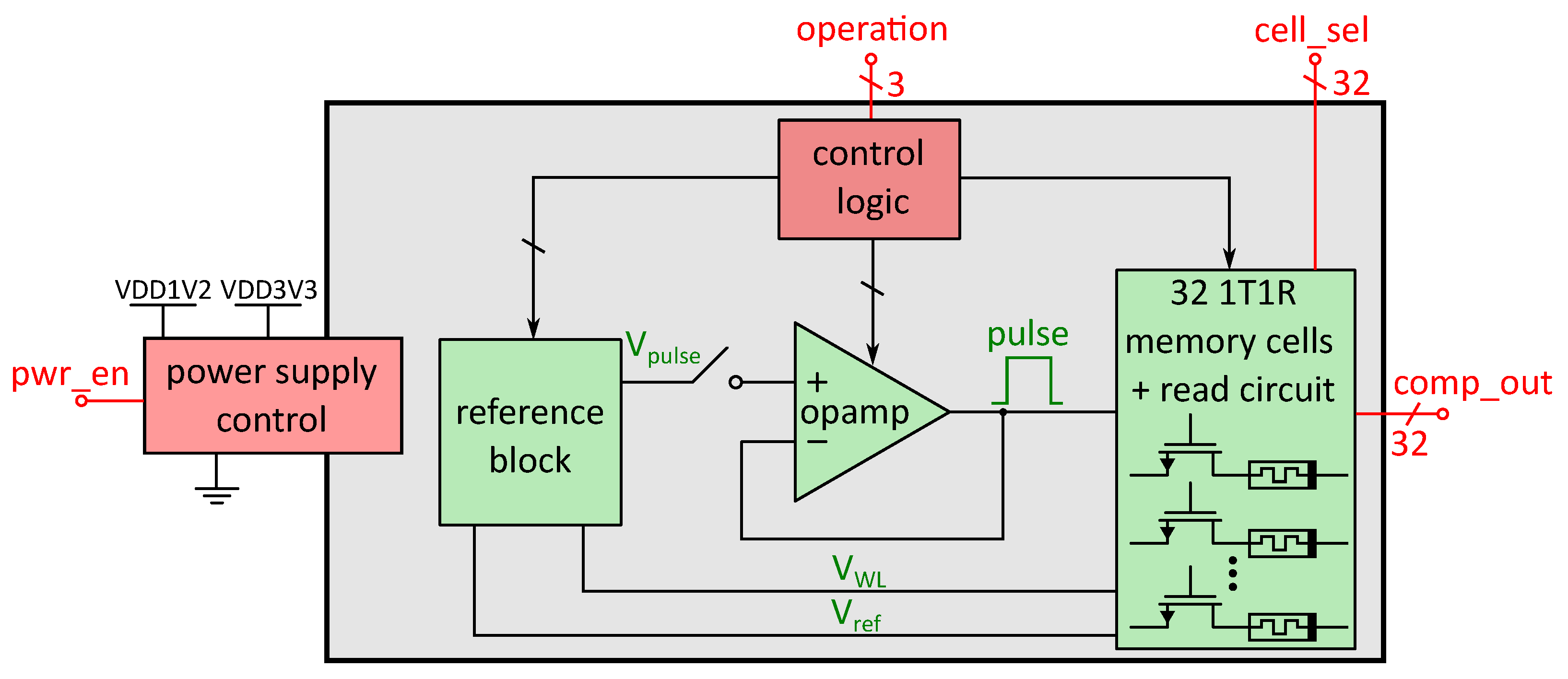
For reading and programming the RRAM cells, an analog circuit block was designed that is used for each memory block. A diagram of this memory block and the surrounding circuitry is shown in
Figure 6. It contains 32 1T1R RRAM cells, consisting of one transistor and one resistive switching element (hence the name 1T1R), each equipped with a read circuit, so all cells can be read simultaneously. The red digital control signals are provided by the RRAM manager (shown in
Figure 1), while the green signals are analog signals used inside the memory block for interactions with the 1T1R cells. Each interaction with the RRAM cells is based on analog voltage pulses of specific height, in
Figure 6 indicated as “V
pulse”, which are buffered by an operational amplifier, that can provide sufficient output current for reading and programming the cells in parallel. The read method is based on a voltage divider and is done with low voltage pulses in order to prevent unintended programming of the cells during a read operation. For programming, voltage levels above the 1.2 V supply voltage (VDD1V2) of the digital core are necessary, therefore, the analog circuitry is also provided with an additional 3.3 V supply rail (VDD3V3). A reference block provides the necessary analog voltage levels for all operations. Besides the previous mentioned pulse height of the pulses, each operation (reading, writing LRS1, LRS2 or HRS) needs specific voltage levels at the selection transistor of the 1T1R cell, in
Figure 6 shown as “V
WL”. “V
ref”, which is used by the comparators to determine the state of the RRAM cells during read operations, is also provided by the reference block. The external operation bits provided by the RRAM manager are then processed by an internal control logic which applies the necessary signals to apply the voltage levels from the reference block that are needed for the corresponding operation. Furthermore, the “cell_sel” bits determine which cells are to be read from or written to, respectively. The power supply control is triggered by the “pwr_en” signal, which is also provided by the RRAM manager and can detatch the block from the supply rails, therefore saving energy. Compared to the overall design, the read-write circuitry of the RRAM cells possesses a high static power consumption and reading the cell state multiple times costs additional energy. Therefore, in our design the data from the RRAM cells (“comp_out”) is read into latches once after each power up phase of the Processing Core. After reading from the non-volatile cells, the RRAM block is put to sleep again (controlled by the “pwr_en”-signal), thereby preventing the relatively high power consumption of the analog circuitry compared to the static dissipation of the latches. The output values of the latches are routed into the PEs of our design by providing the saved parameters for the NN. Our design was created using Cadence Virtuoso with the IHP SG13S process PDK and its functionality was verified by simulation [
30].


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}