
Big–Little Adaptive Neural Networks on Low-Power Near-Subthreshold Processors


Abstract
:1. Introduction
- We evaluate state-of-the-art near-threshold processors with adaptive voltage scaling and compare them to a standard edge processor.
- We optimize a popular edge application targeting a human activity recognition (HAR) model based on TensorFlow for MCU deployment using different vendor toolchains and compilers.
- We propose novel ‘big–little’ strategies suitable for adaptive neural network systems achieving fast inference and energy savings.
- We made our work open source at https://github.com/DarkSZChao/Big-Little_NN_Strategies (accessed on 9 March 2022) to further promote work in this field.
2. Background and Related Work
2.1. Hardware for Low-Power Edge AI
2.2. Algorithmic Techniques for Low-Power Edge AI
2.3. Frameworks for Low-Power Edge AI
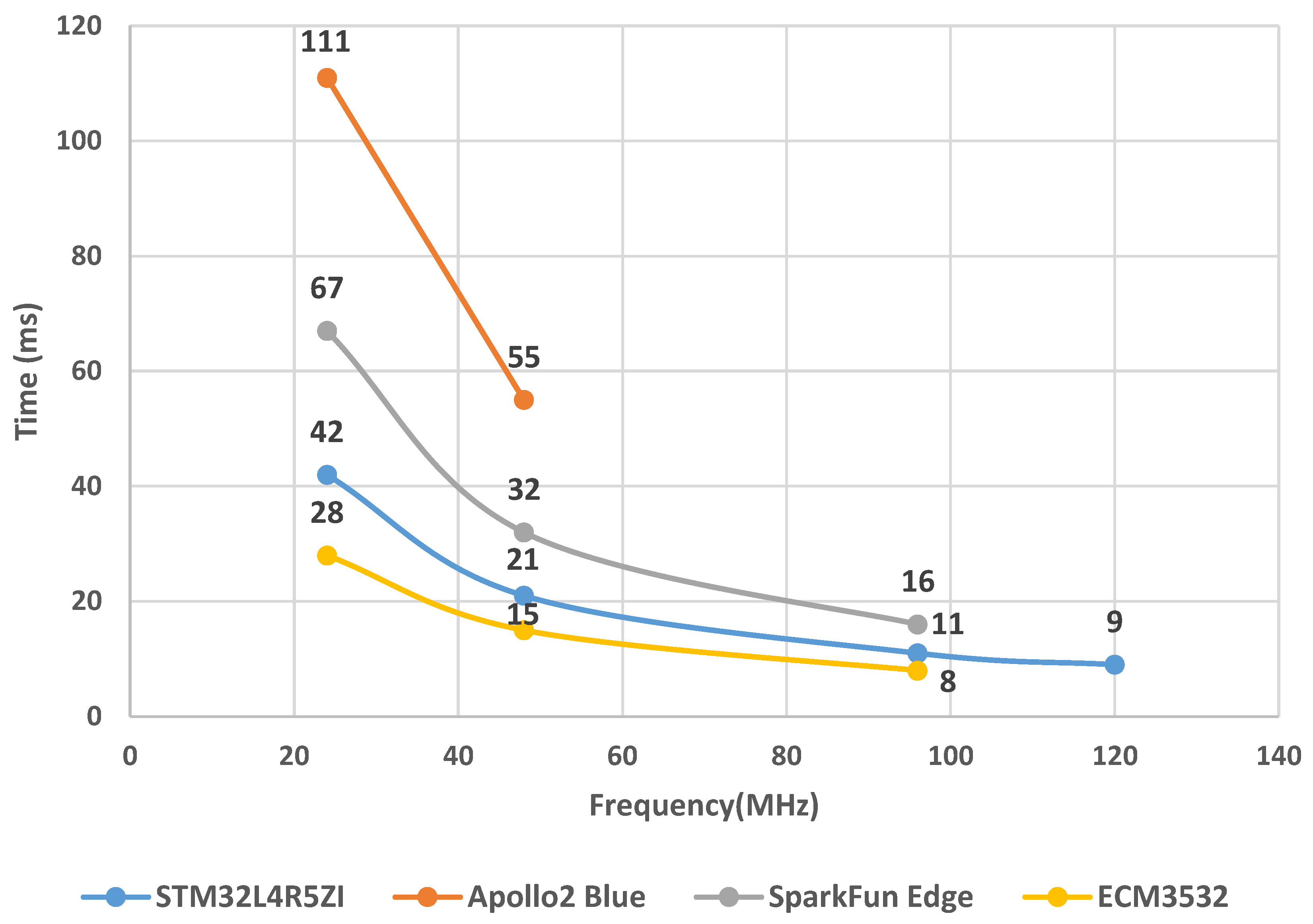
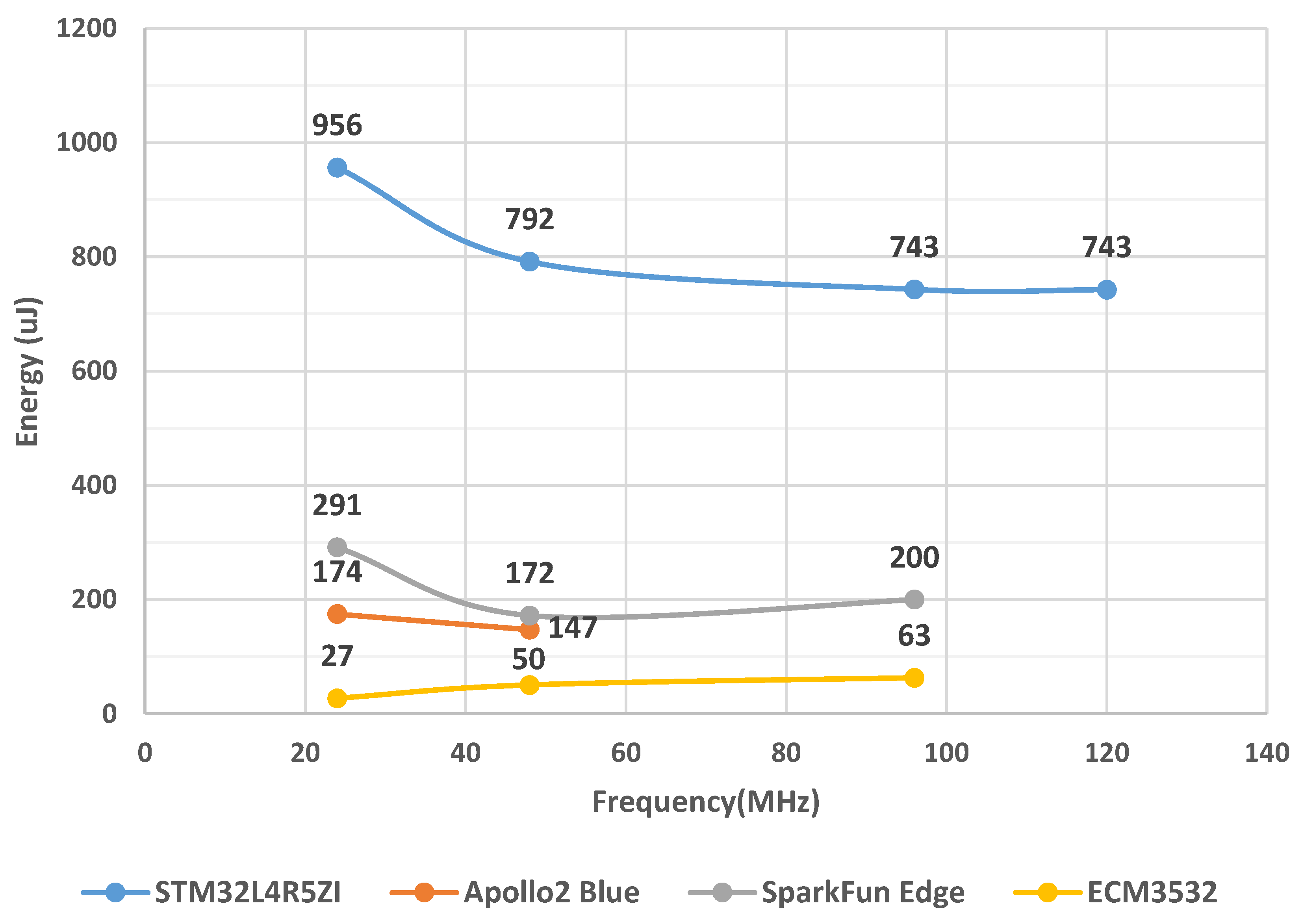
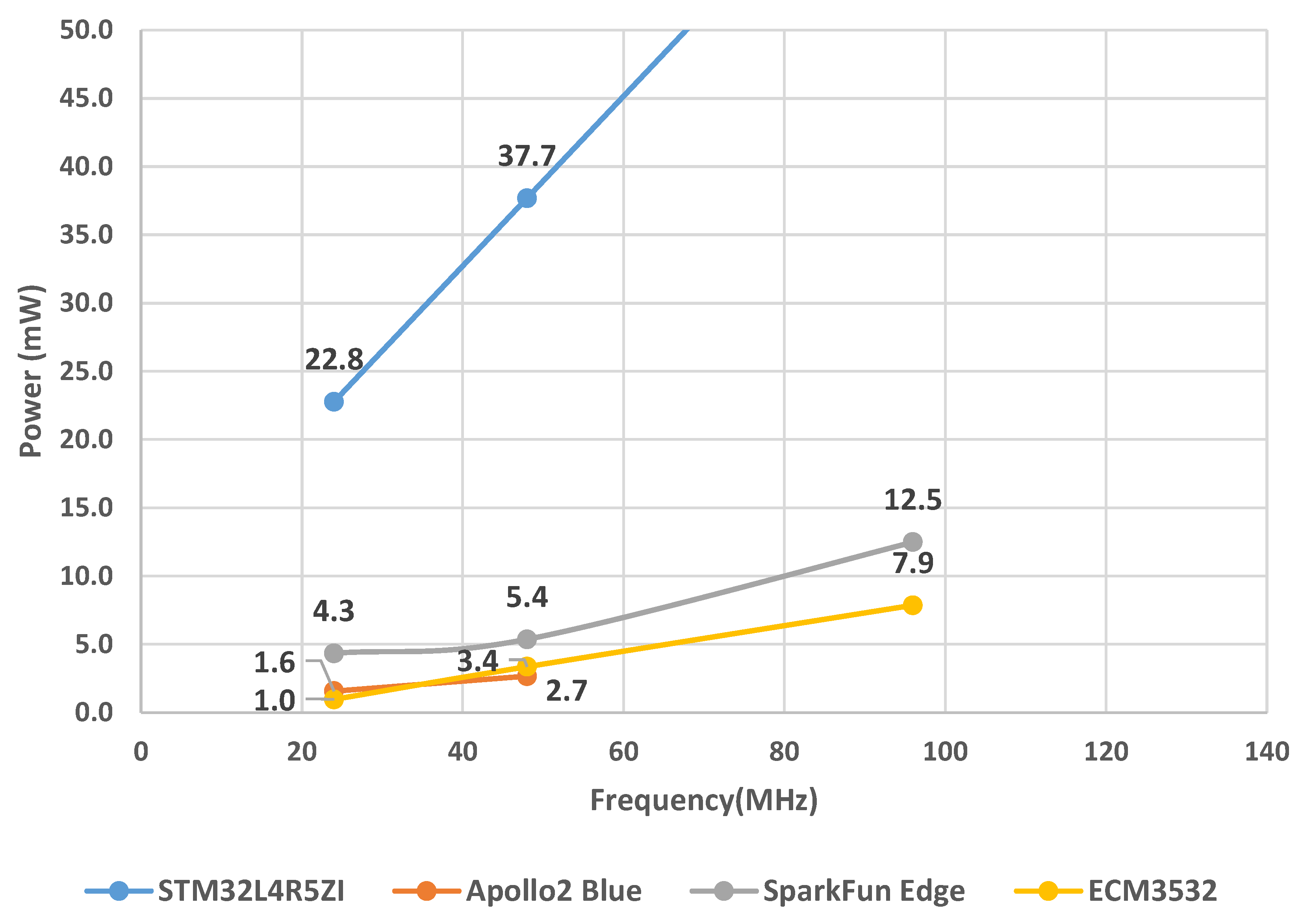
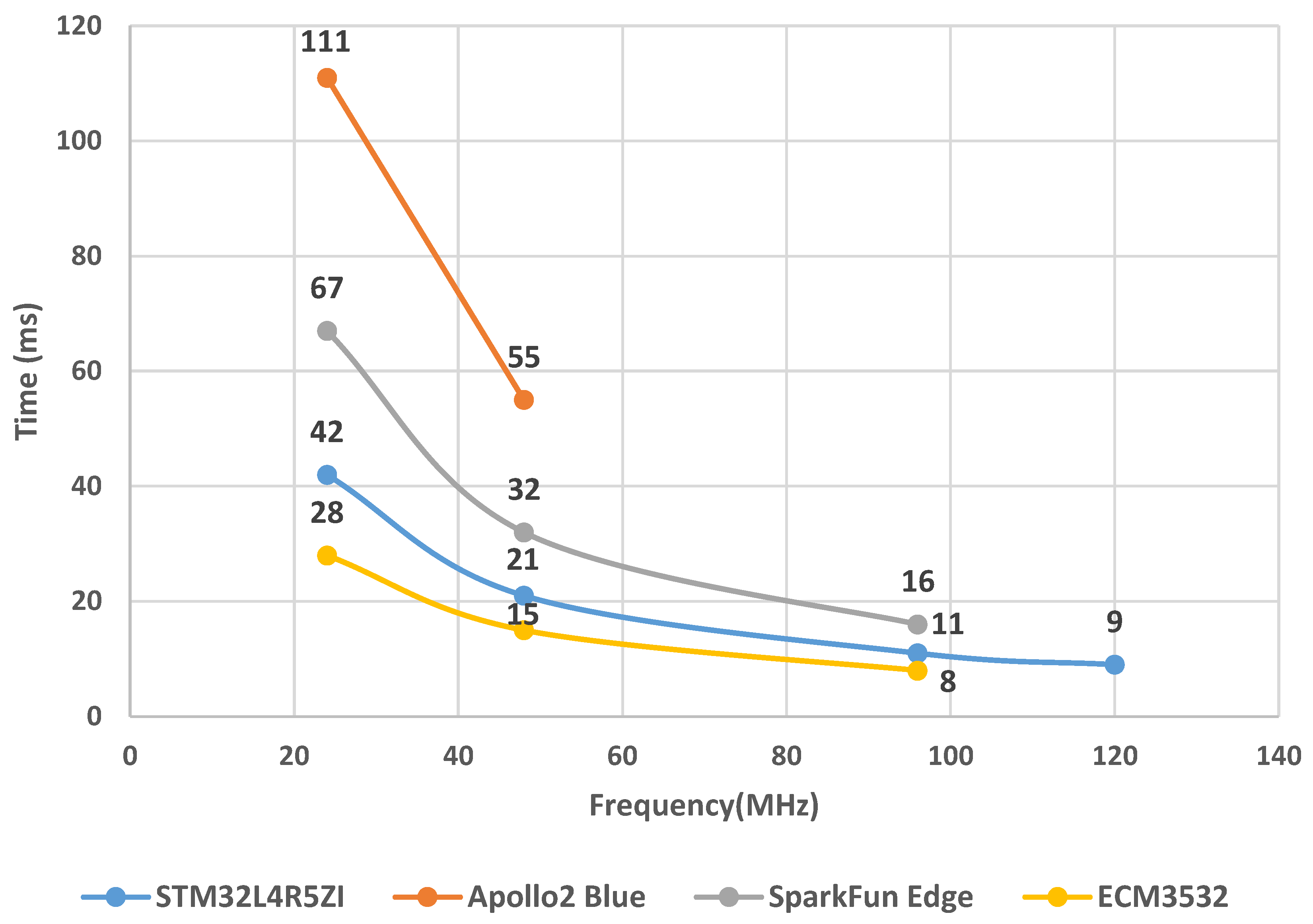
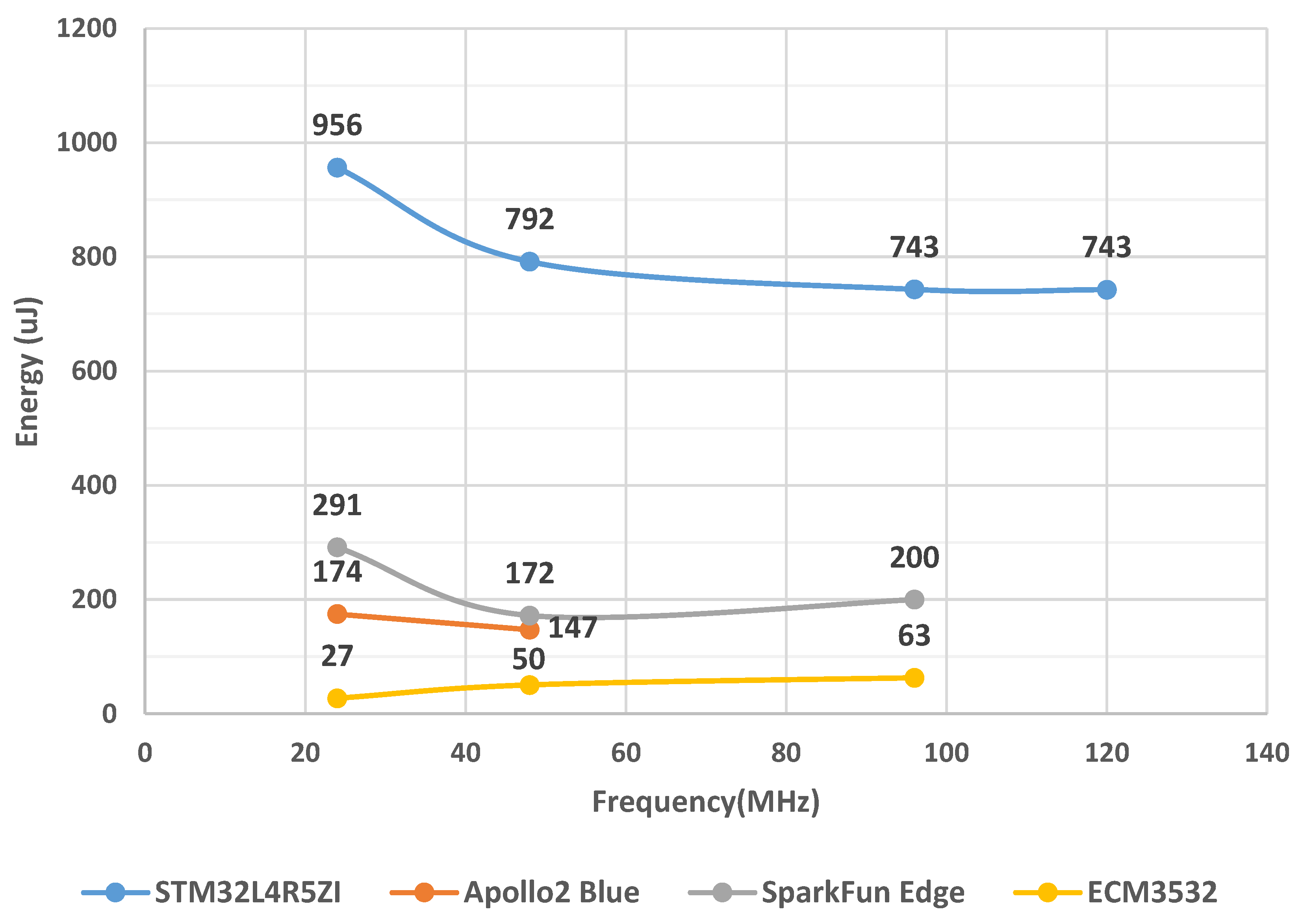
3. Low-Power Microcontroller Evaluation
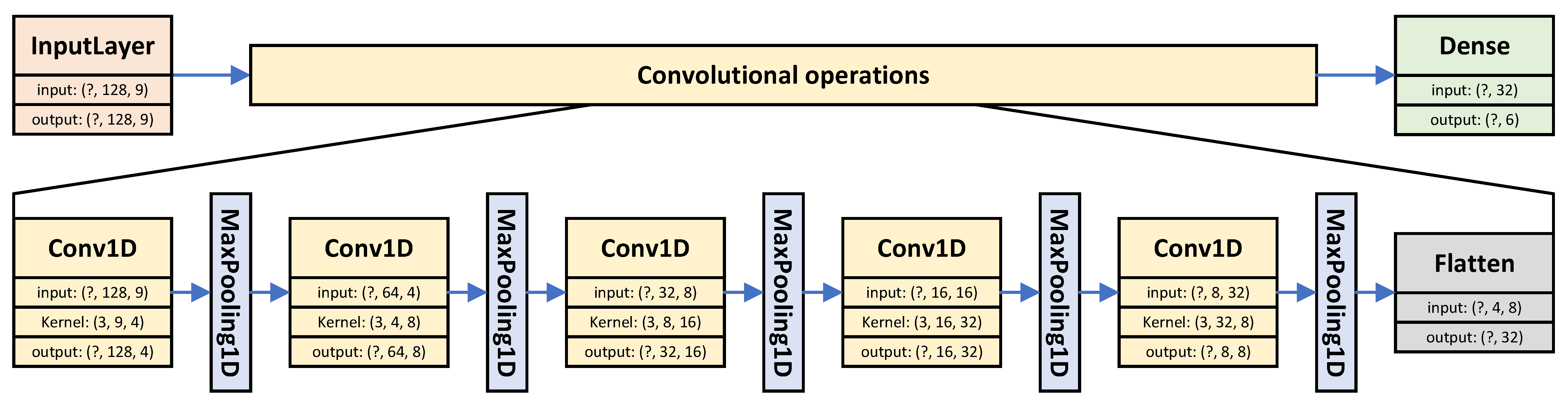
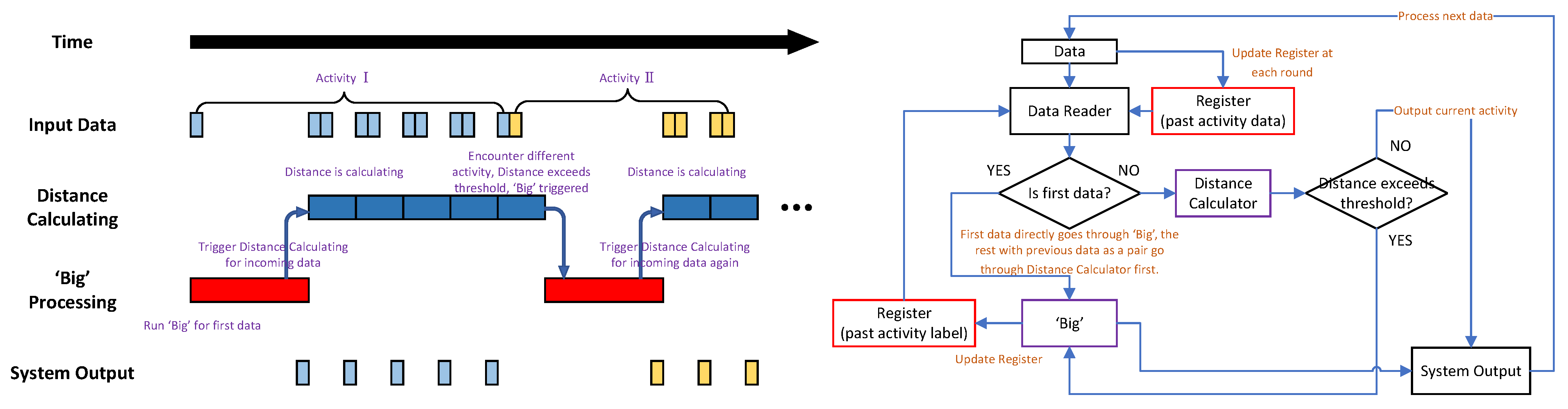
4. Adaptive Neural Network Methodology
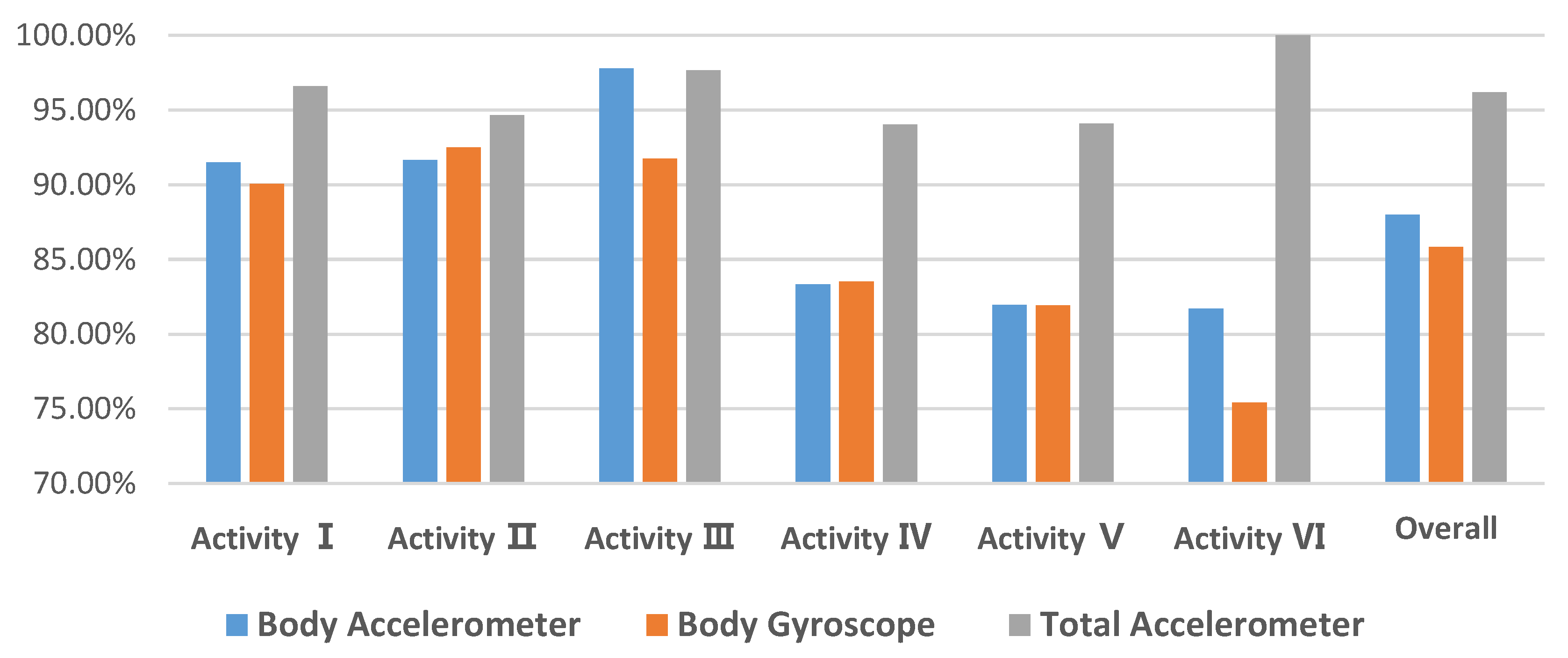
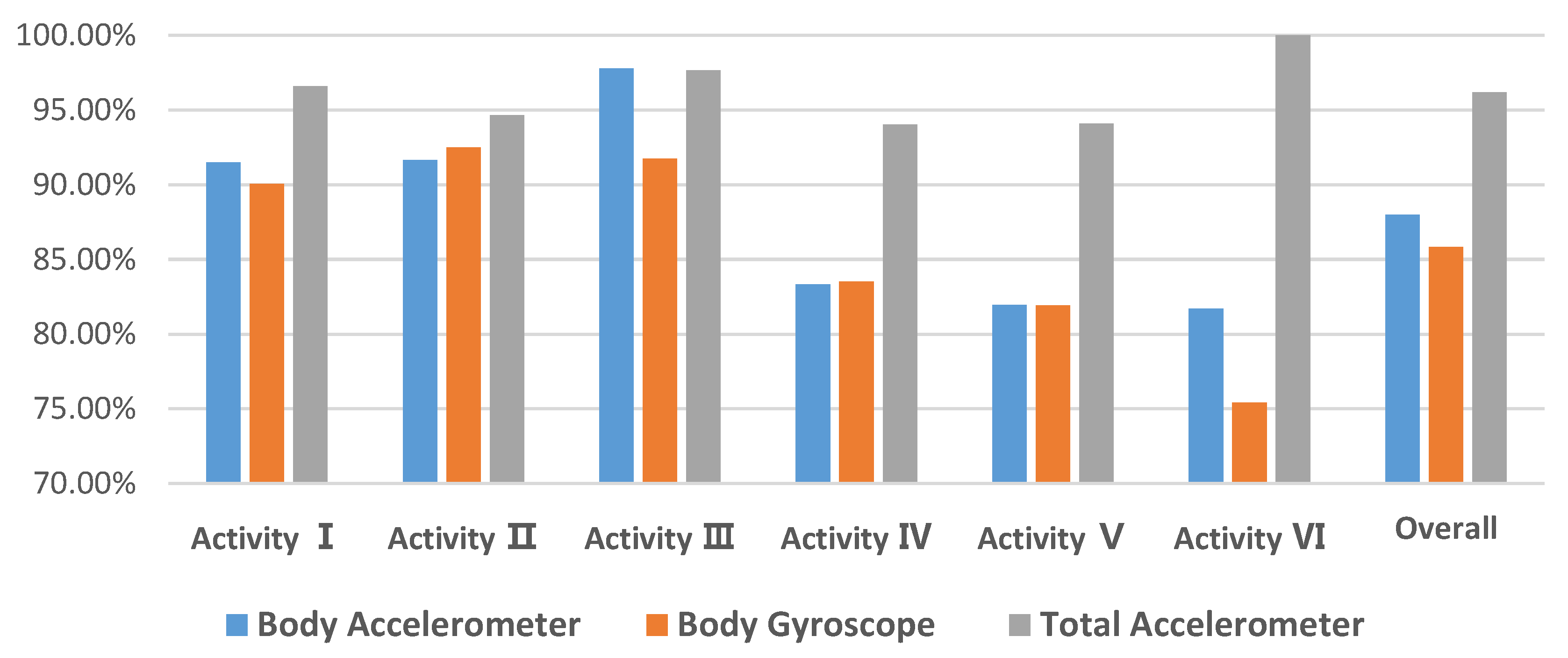
- Activity I = WALKING
- Activity II = WALKING_UPSTAIRS
- Activity III = WALKING_DOWNSTAIRS
- Activity IV = SITTING
- Activity V = STANDING
- Activity VI = LAYING
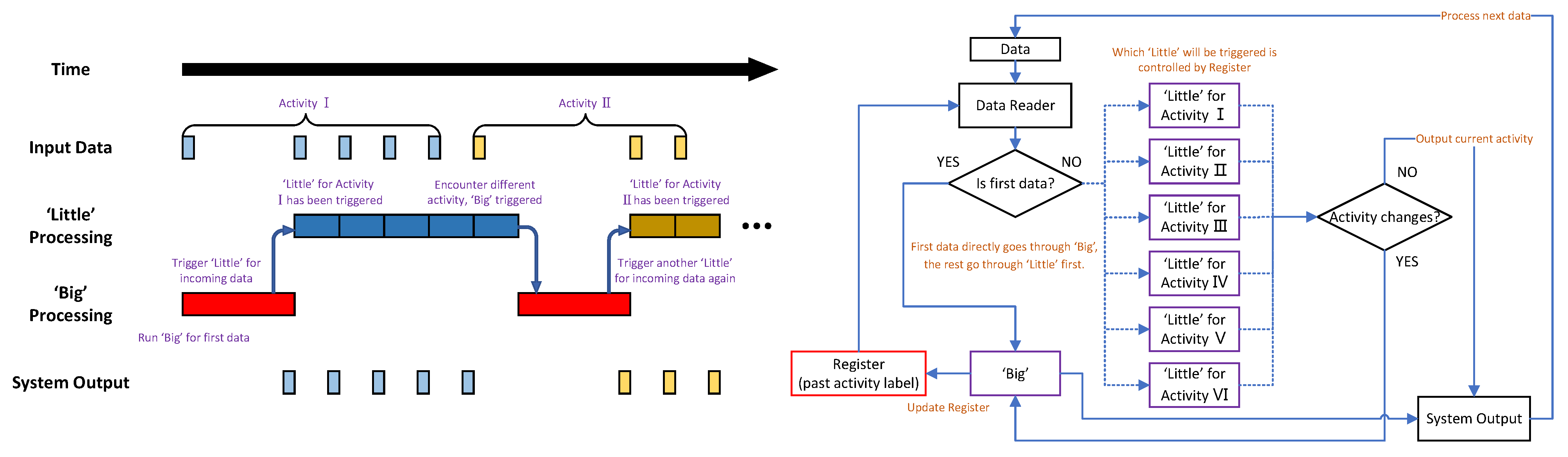
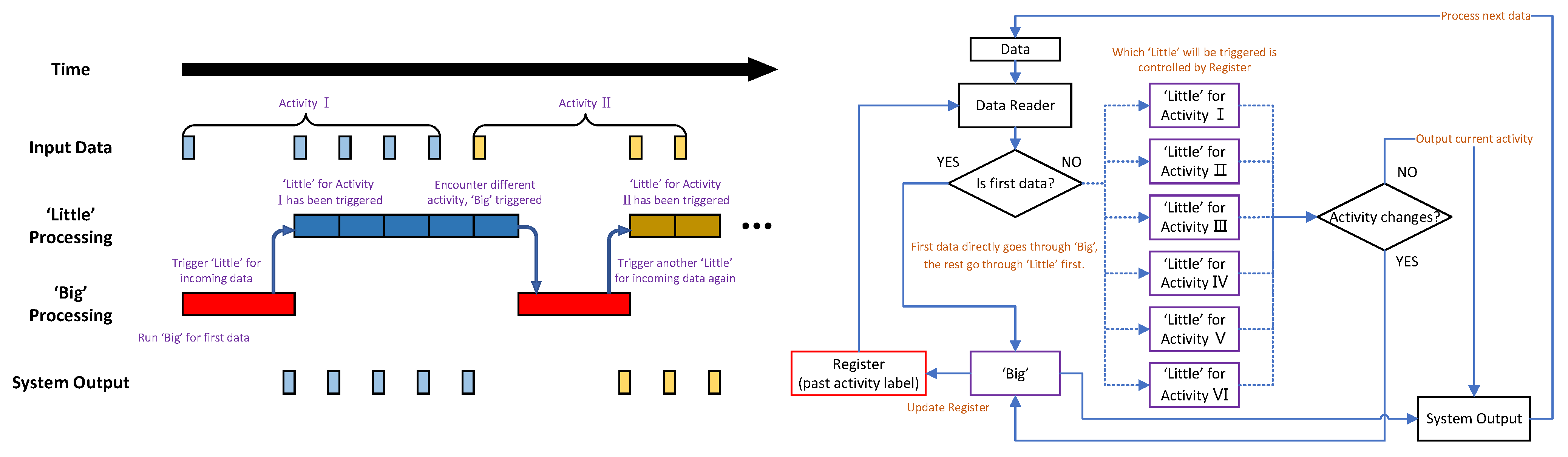
- ‘Big’-only (original method)
- ‘Big’ + six ‘little’
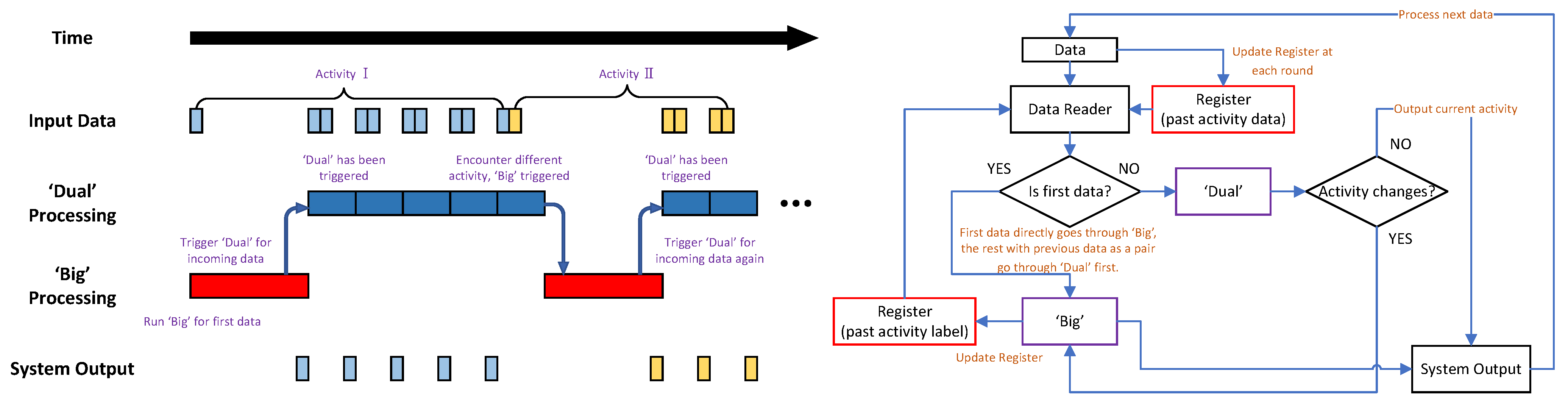
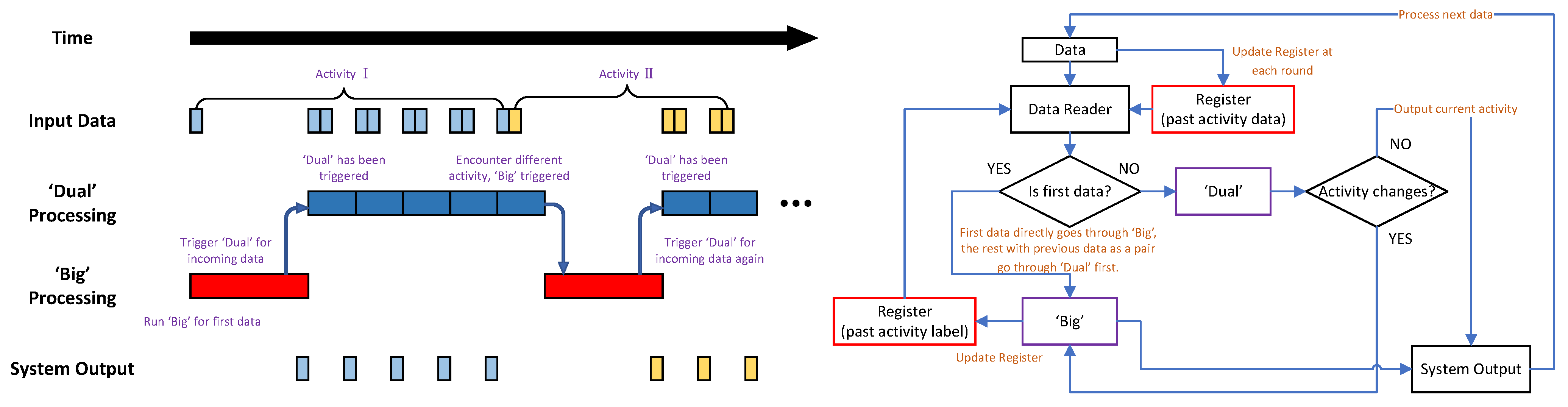
- ‘Big’ + ‘dual’
- ‘Big’ + distance.
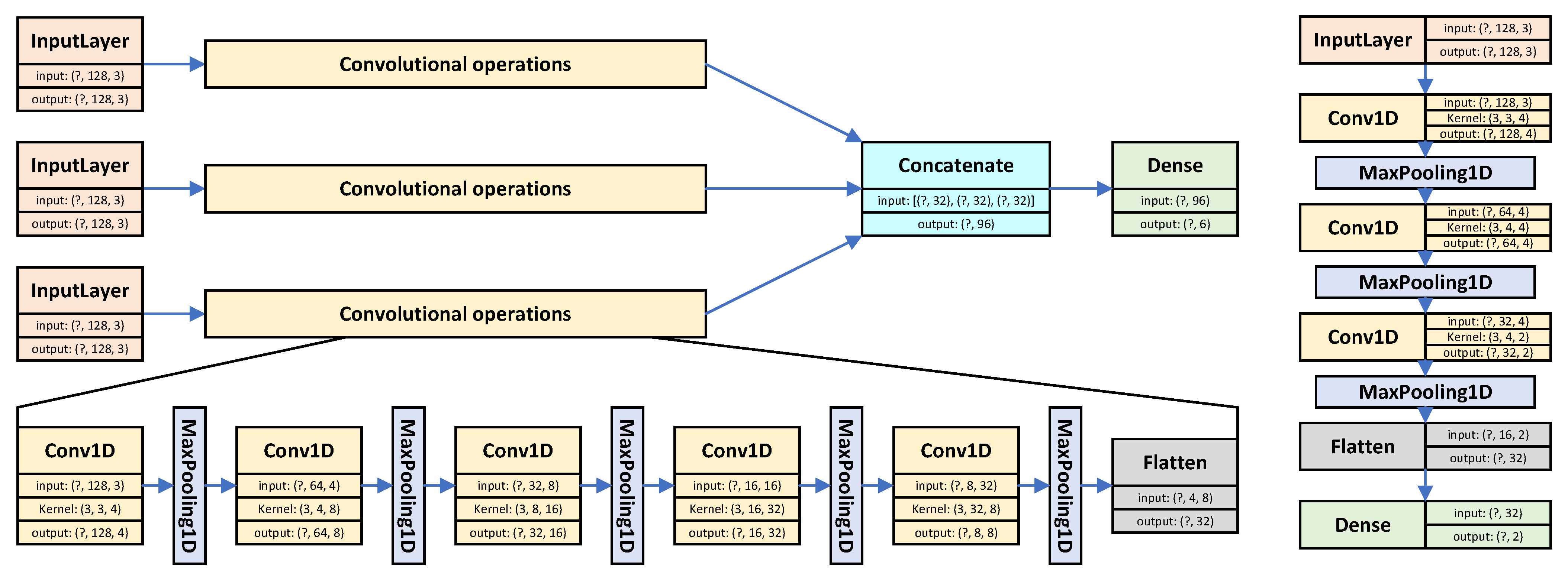
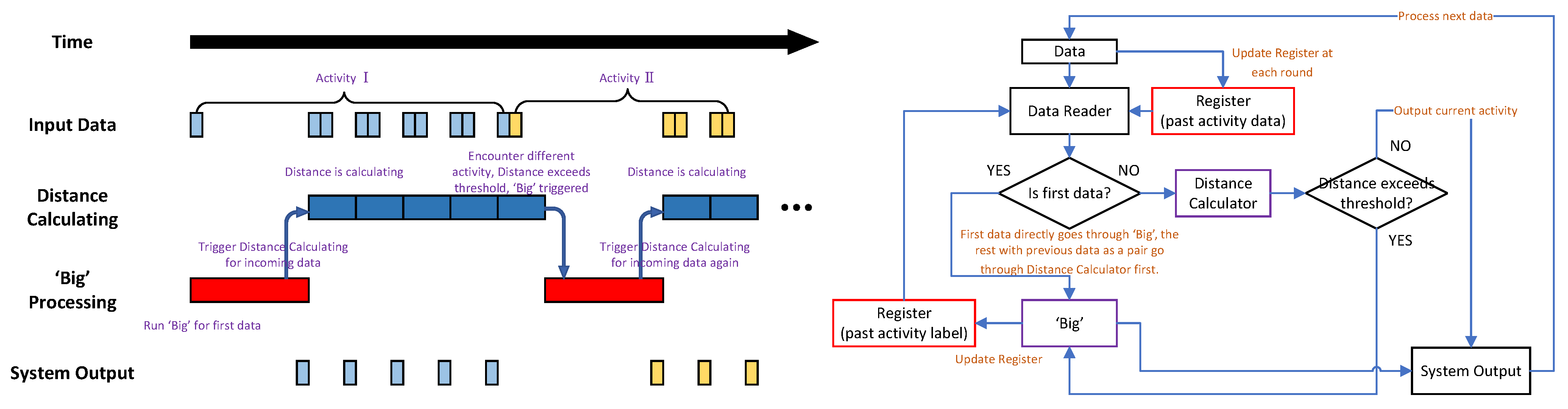
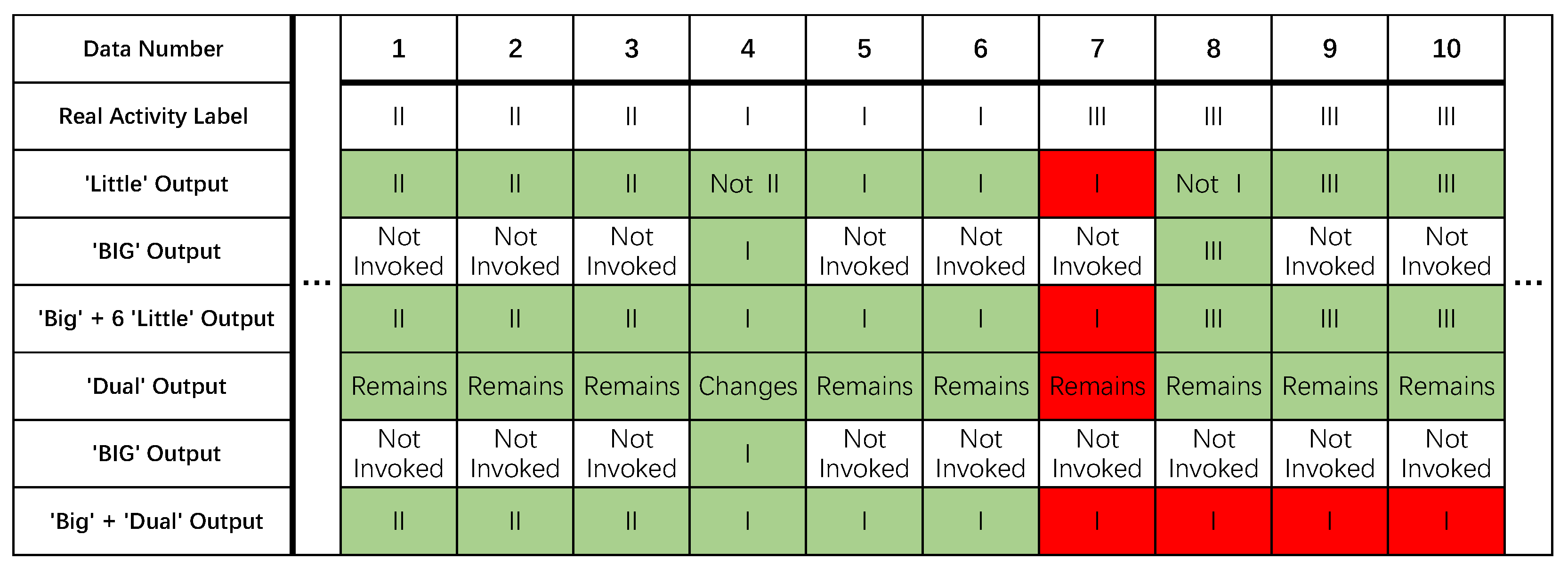
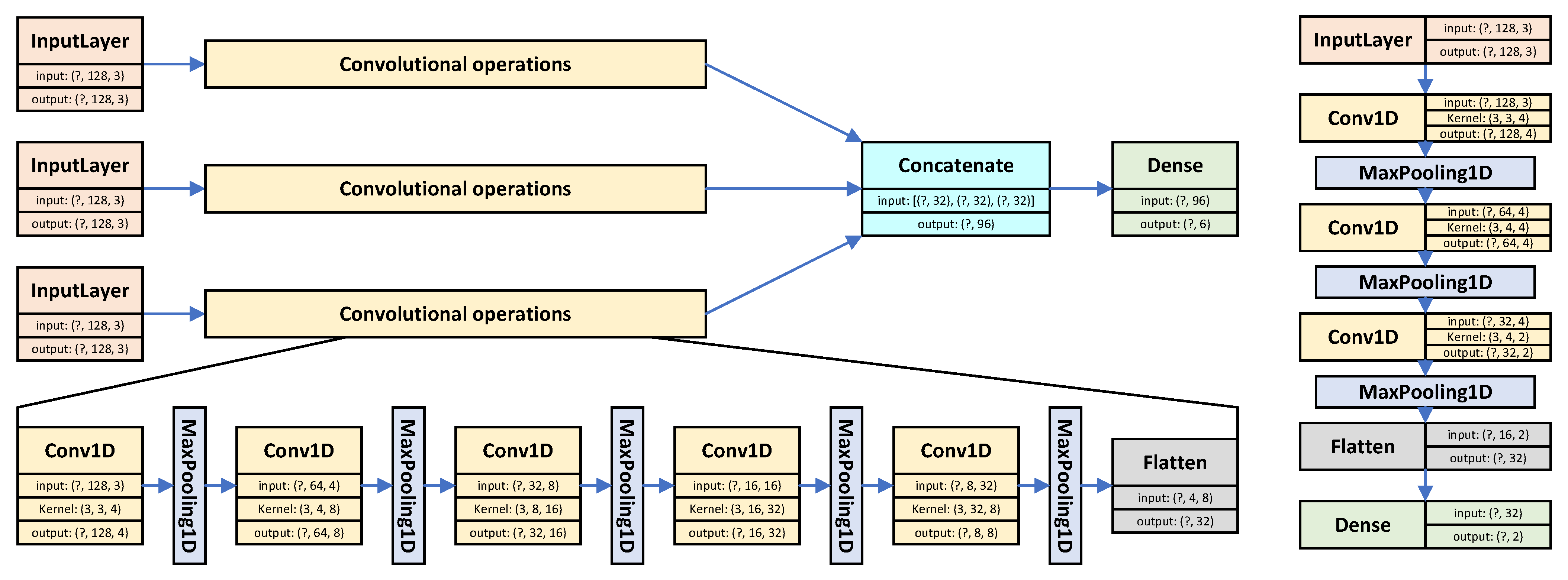
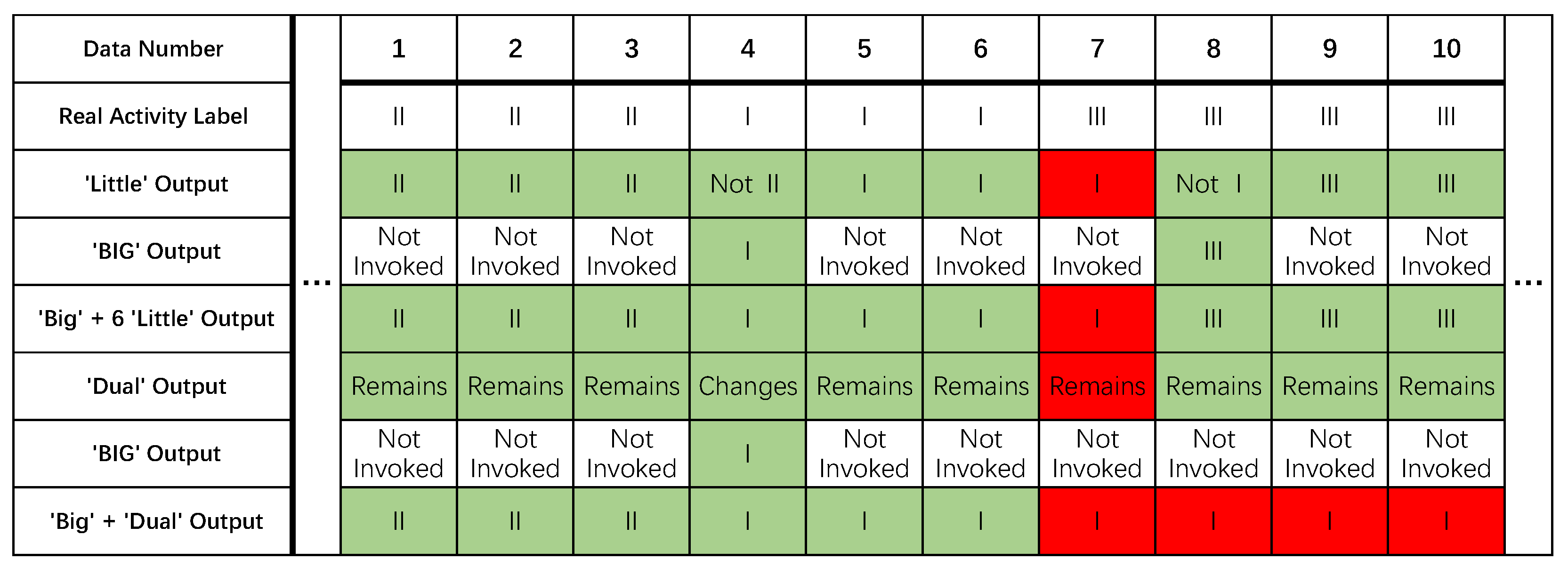
4.1. ‘Big’ + Six ‘Little’ Configuration
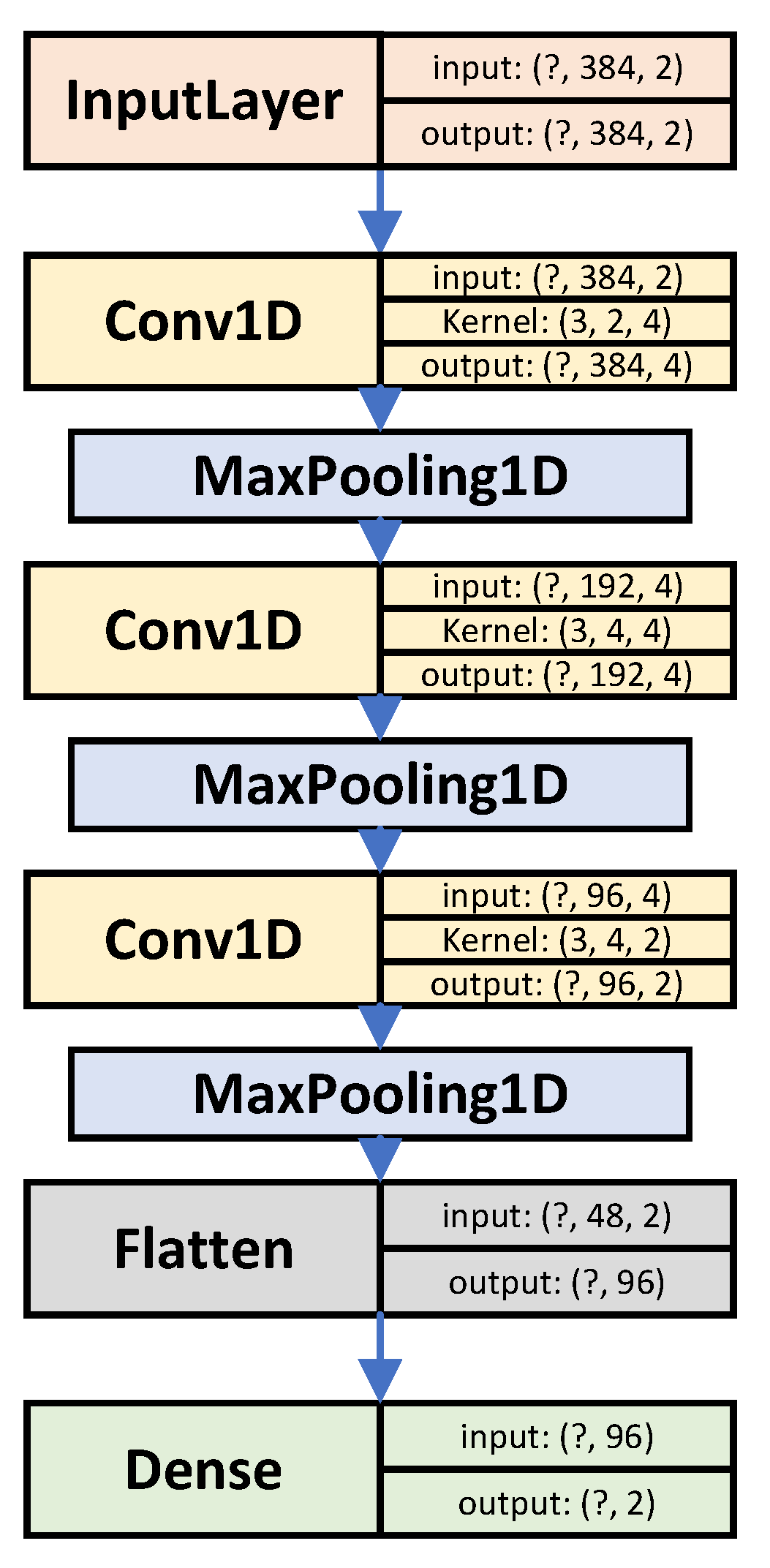
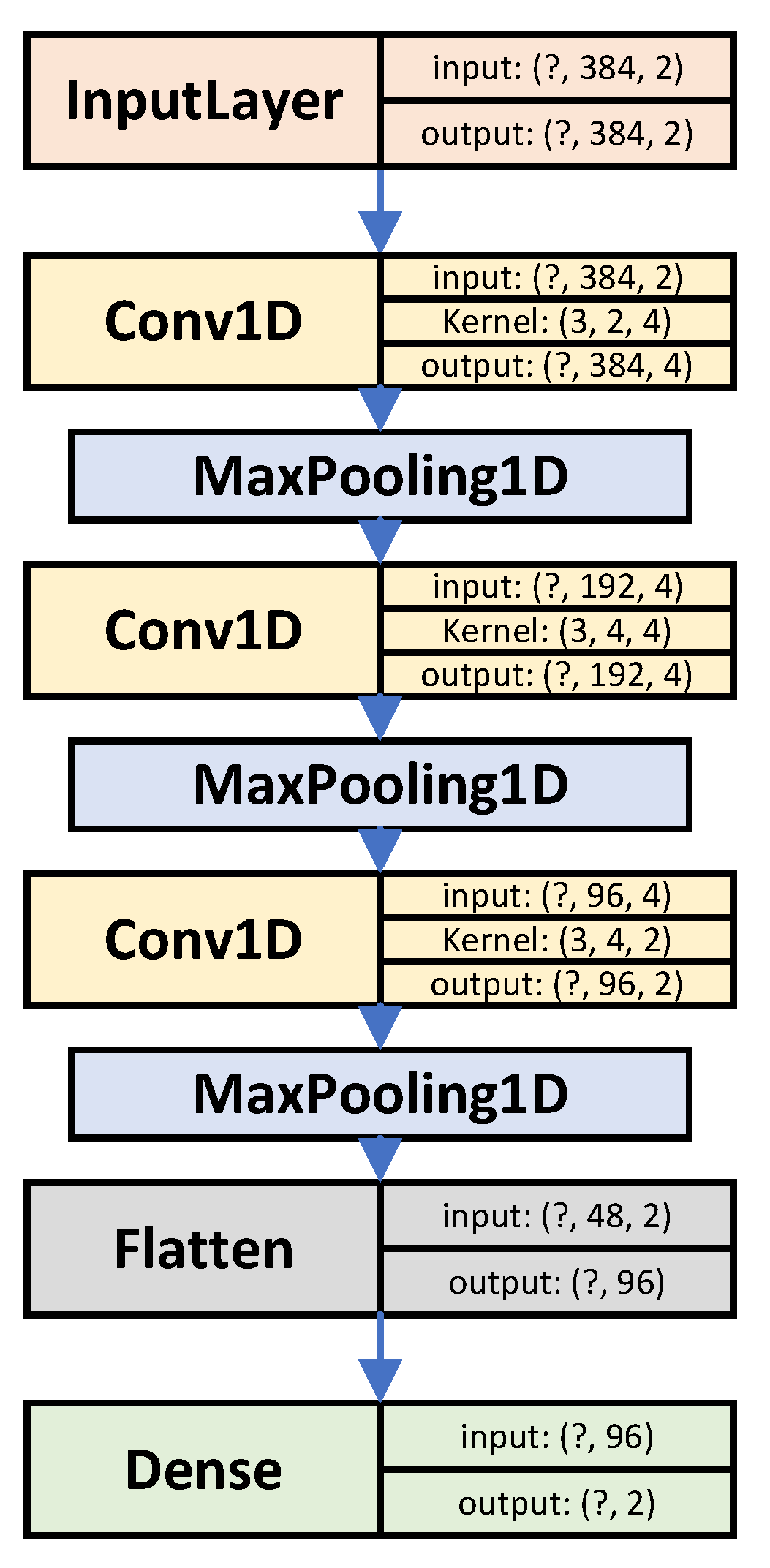
4.2. ‘Big’ + ‘Dual’ Configuration
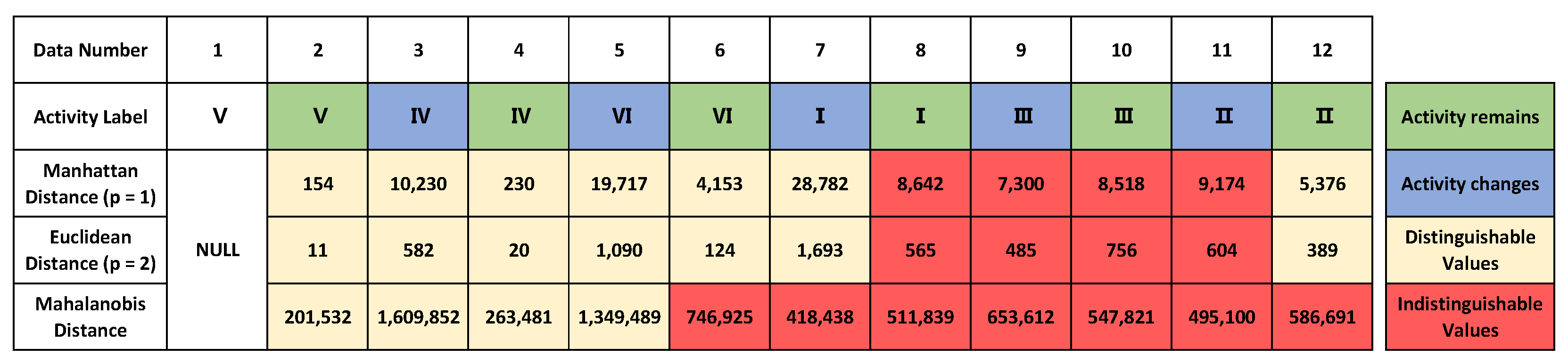
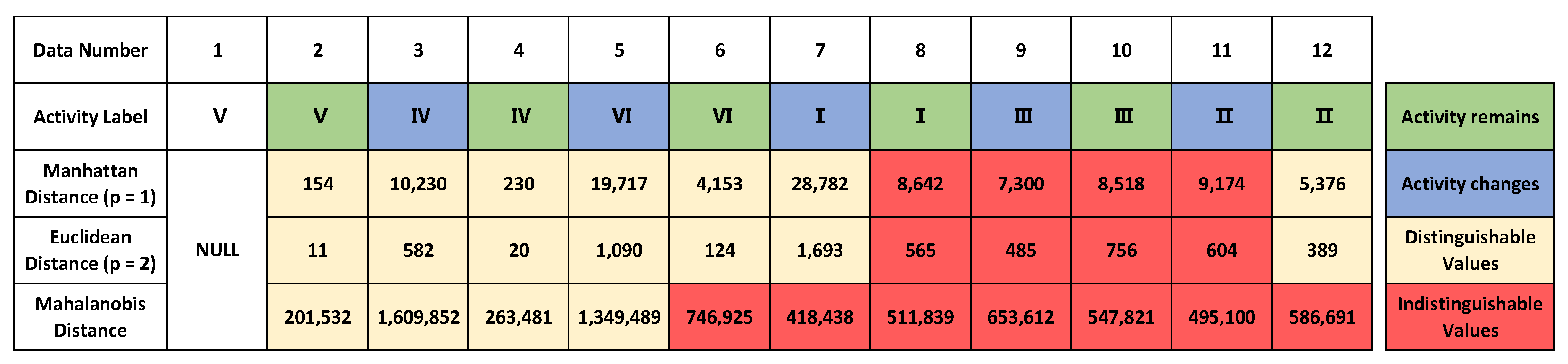
4.3. ‘Big’ + Distance Configuration
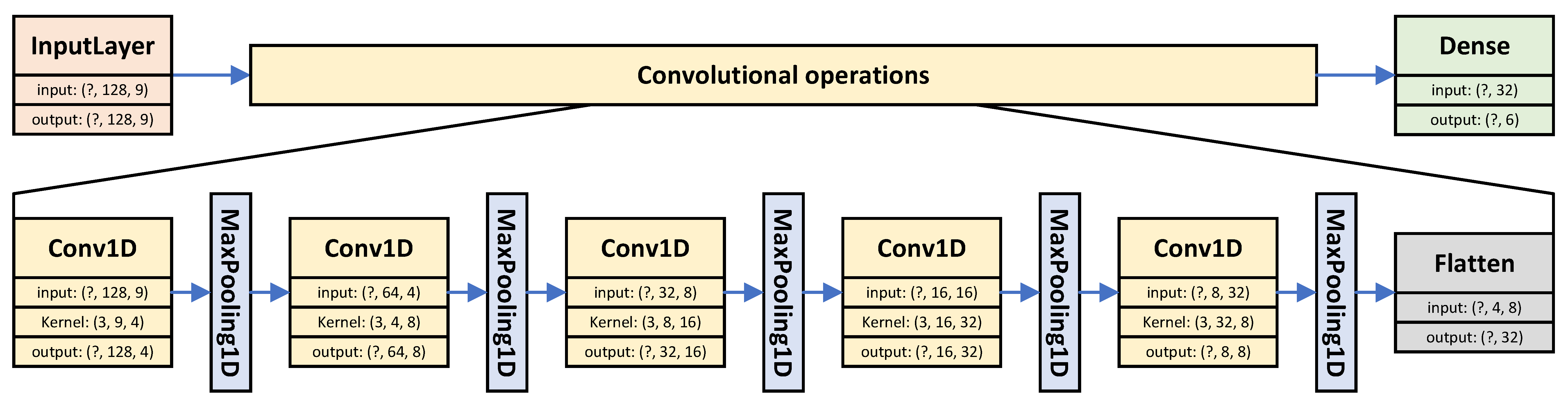
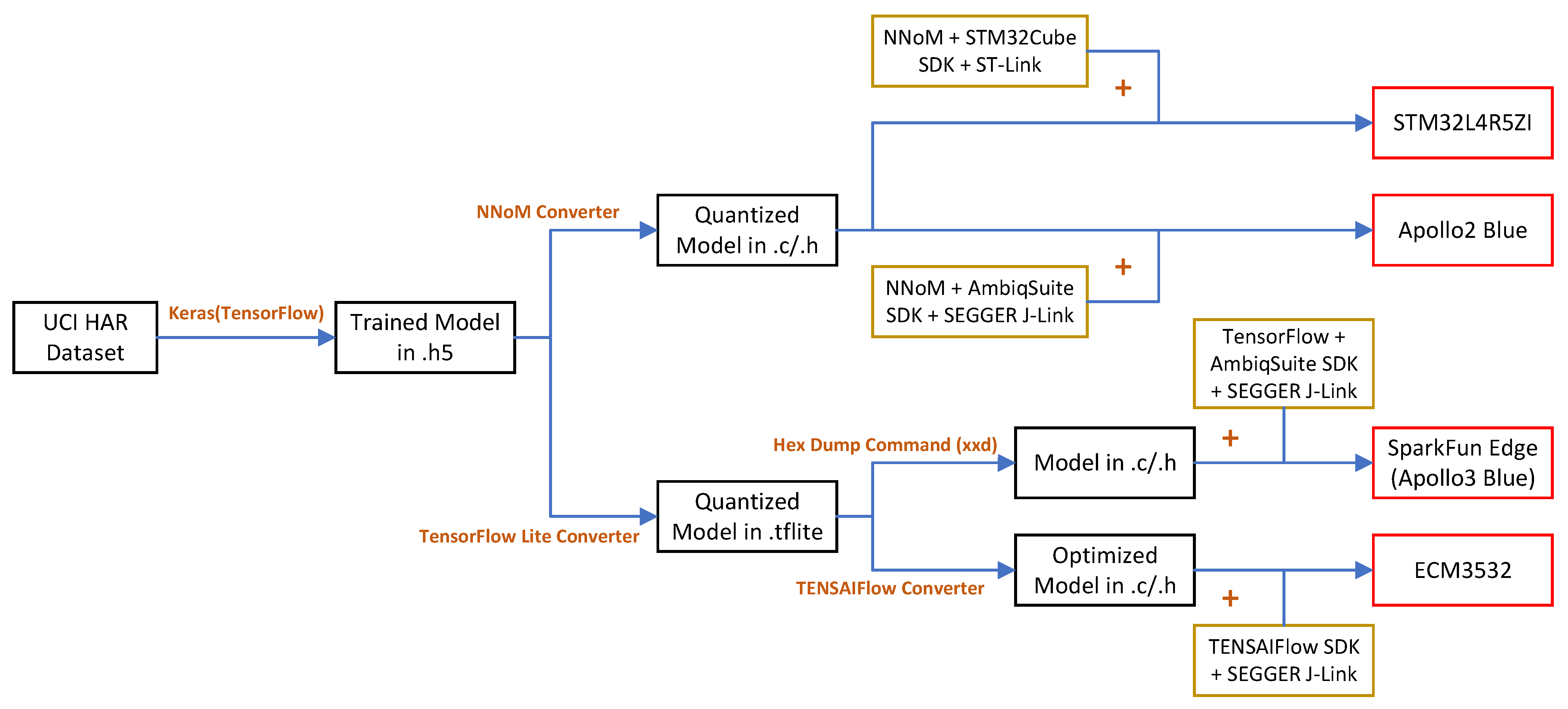
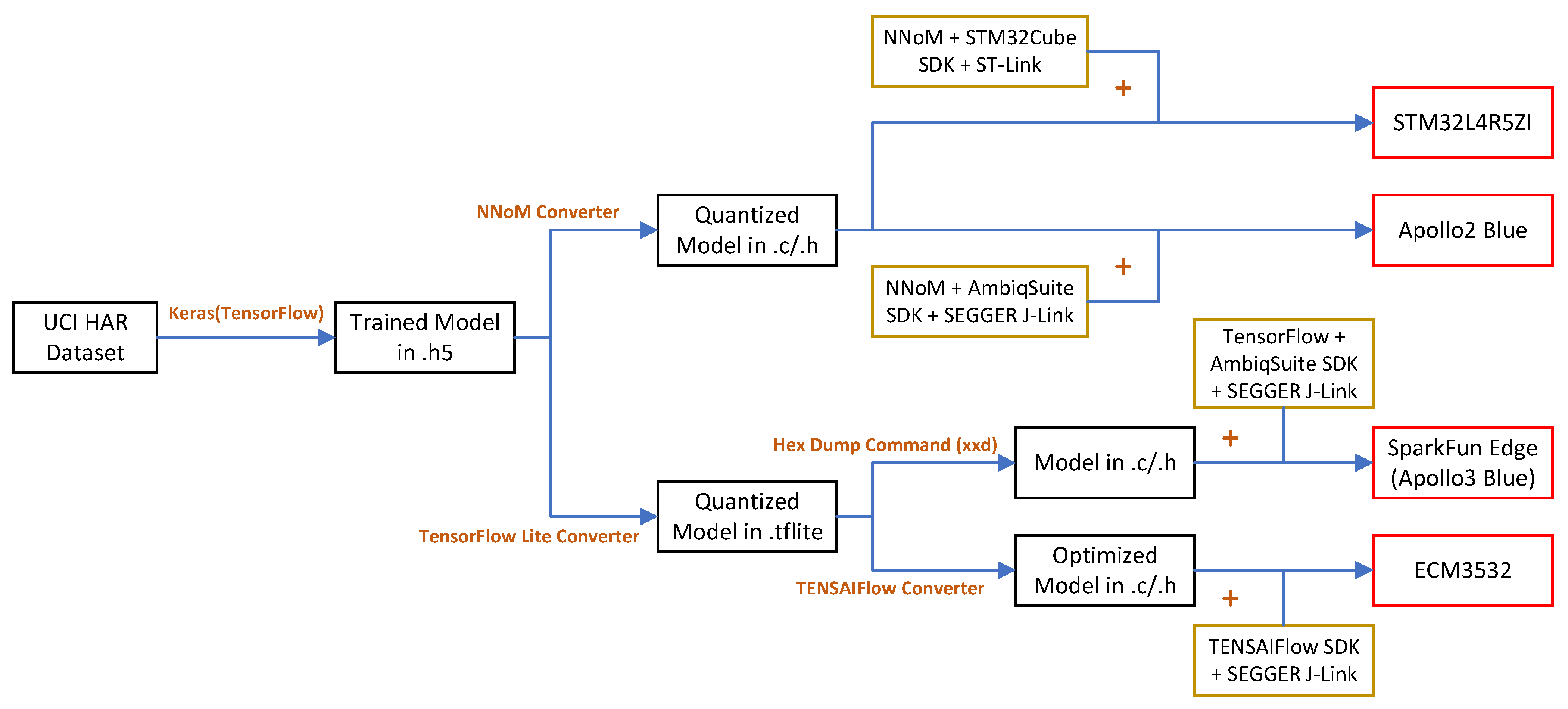
5. Neural Network Microcontroller Deployment
5.1. STM32L4R5ZI
| Listing 1 NNoM converter Python function for quantized model generation. |
| generate_model(model, x_test, name=‘weight.h’) |
5.2. Apollo2 Blue
5.3. SparkFun Edge (Apollo3 Blue)
| Listing 2 TensorFlow Lite converter command lines for ‘big’ model quantization. |
|
| Listing 3 TensorFlow Lite converter command lines for ‘little’ model quantization. |
|
5.4. ECM3532
| Listing 4 TENSAIFlow converter command lines for model conversion. |
|
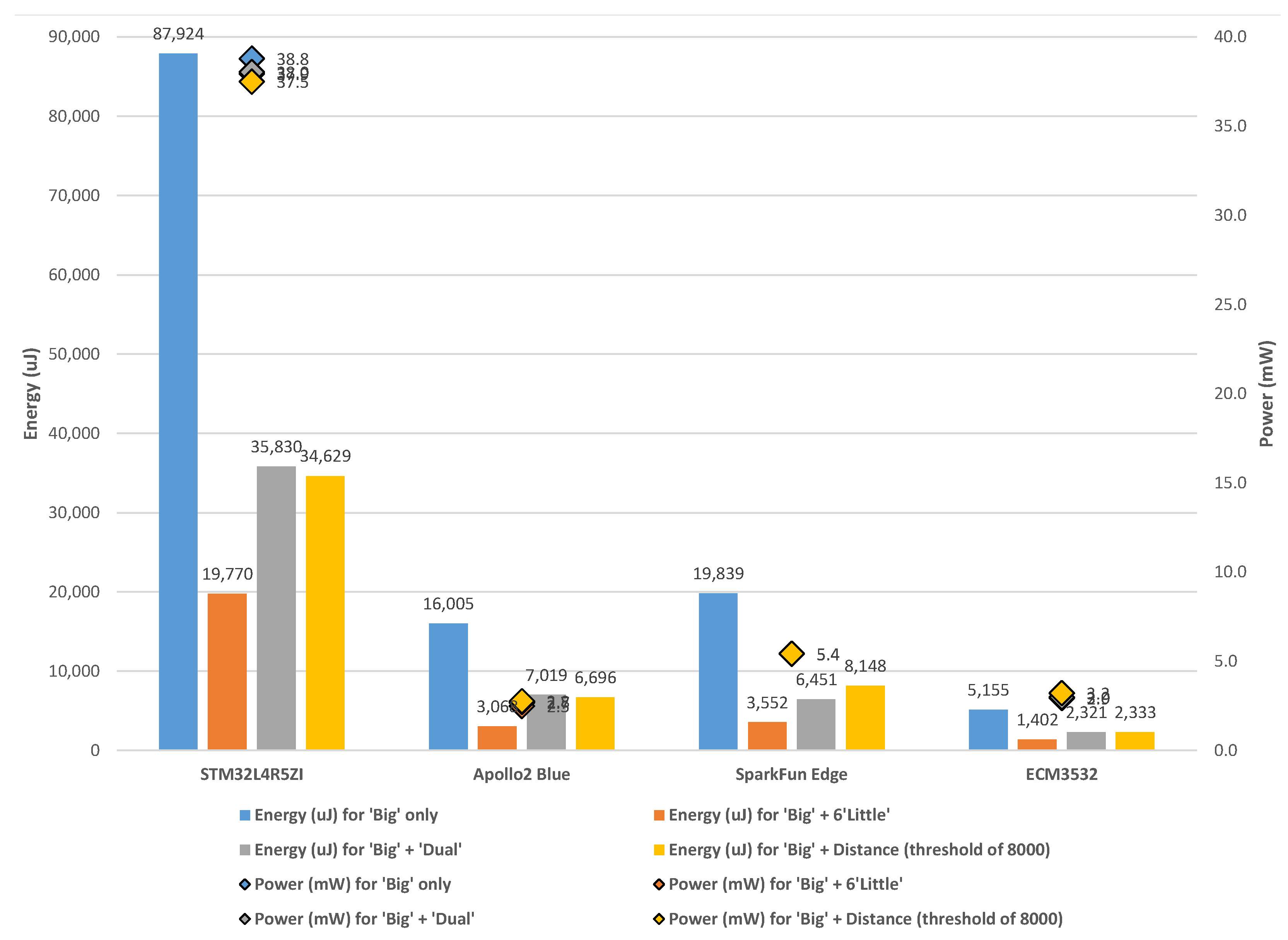
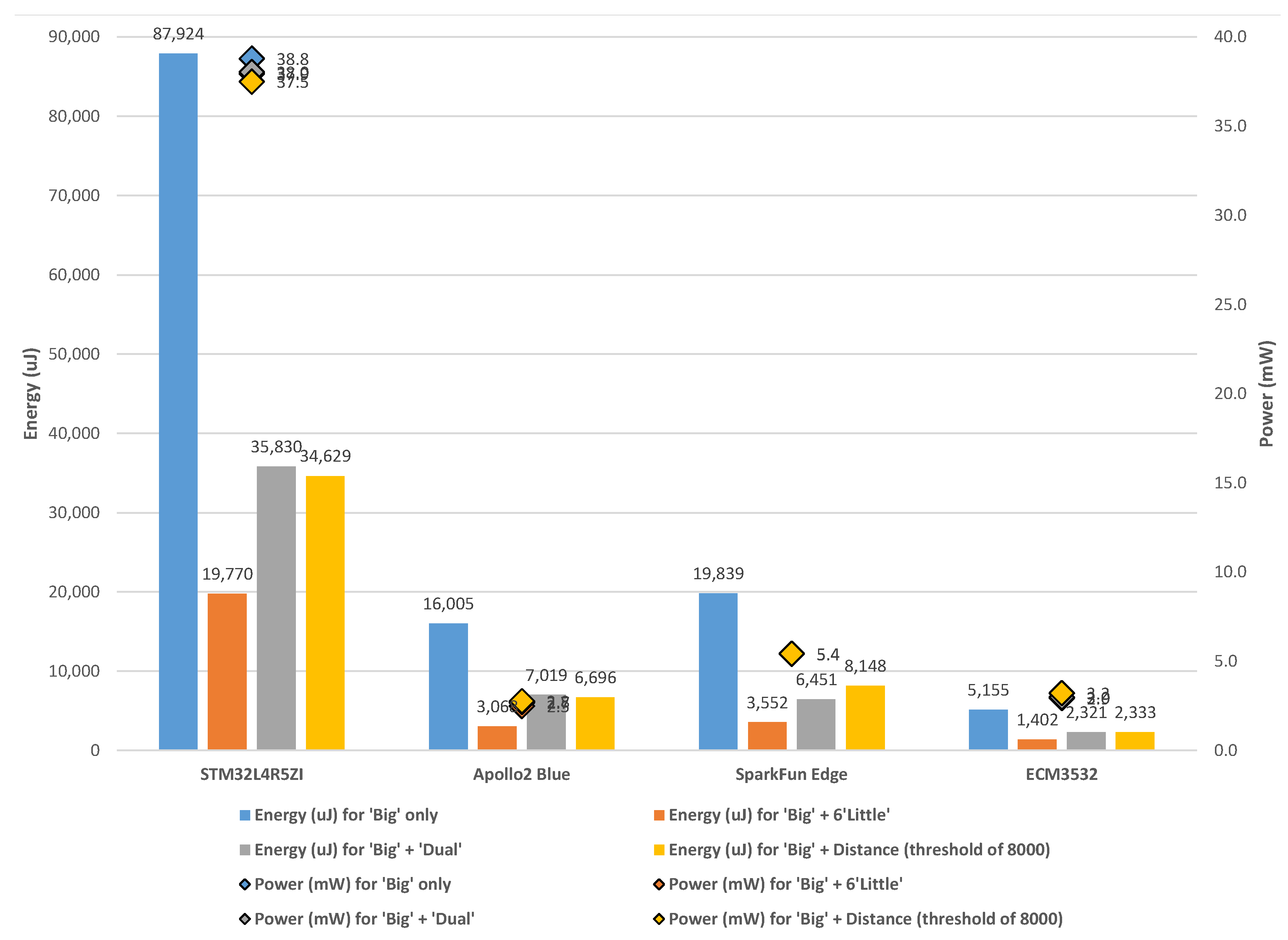
6. Results and Discussion
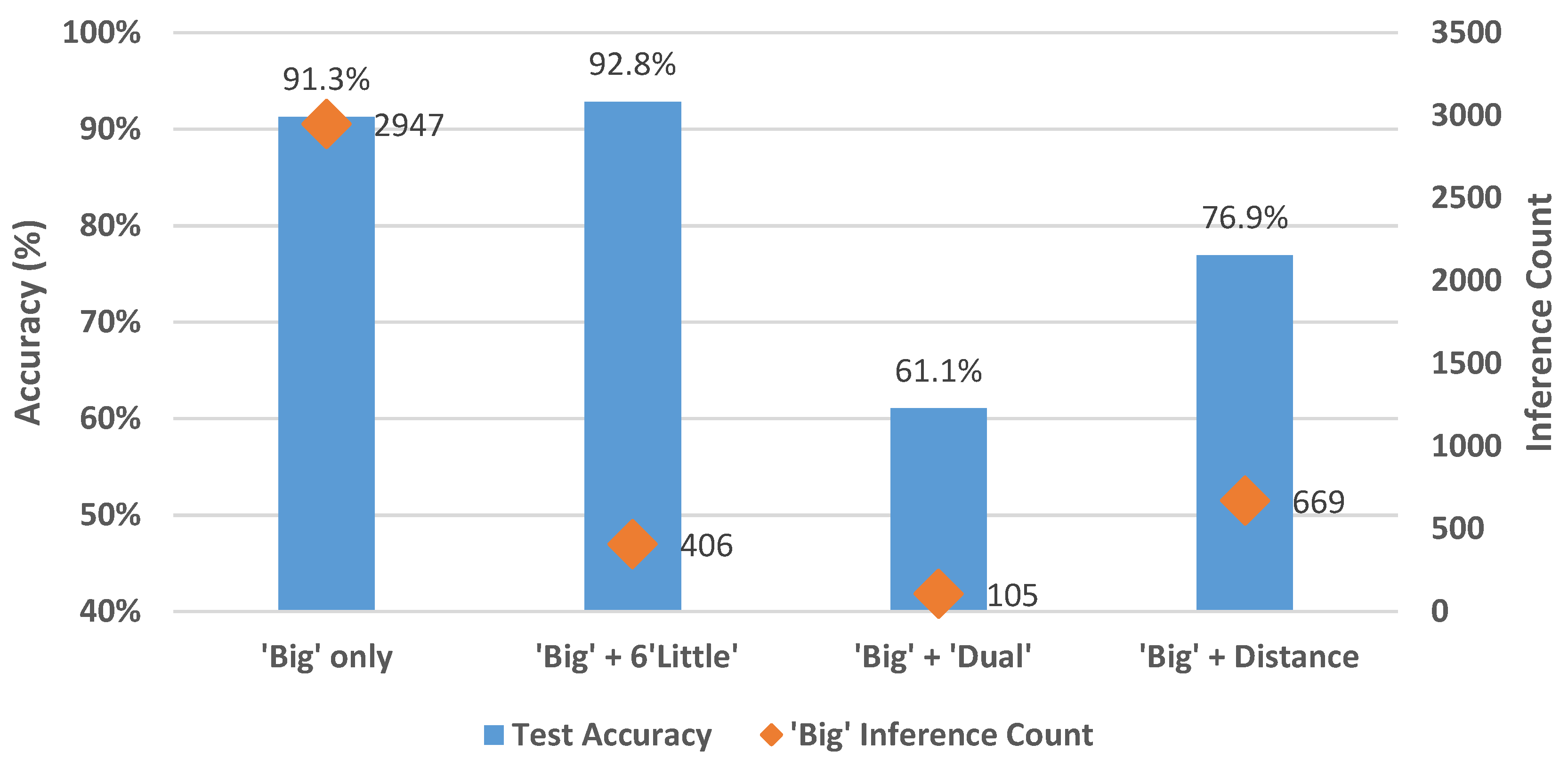
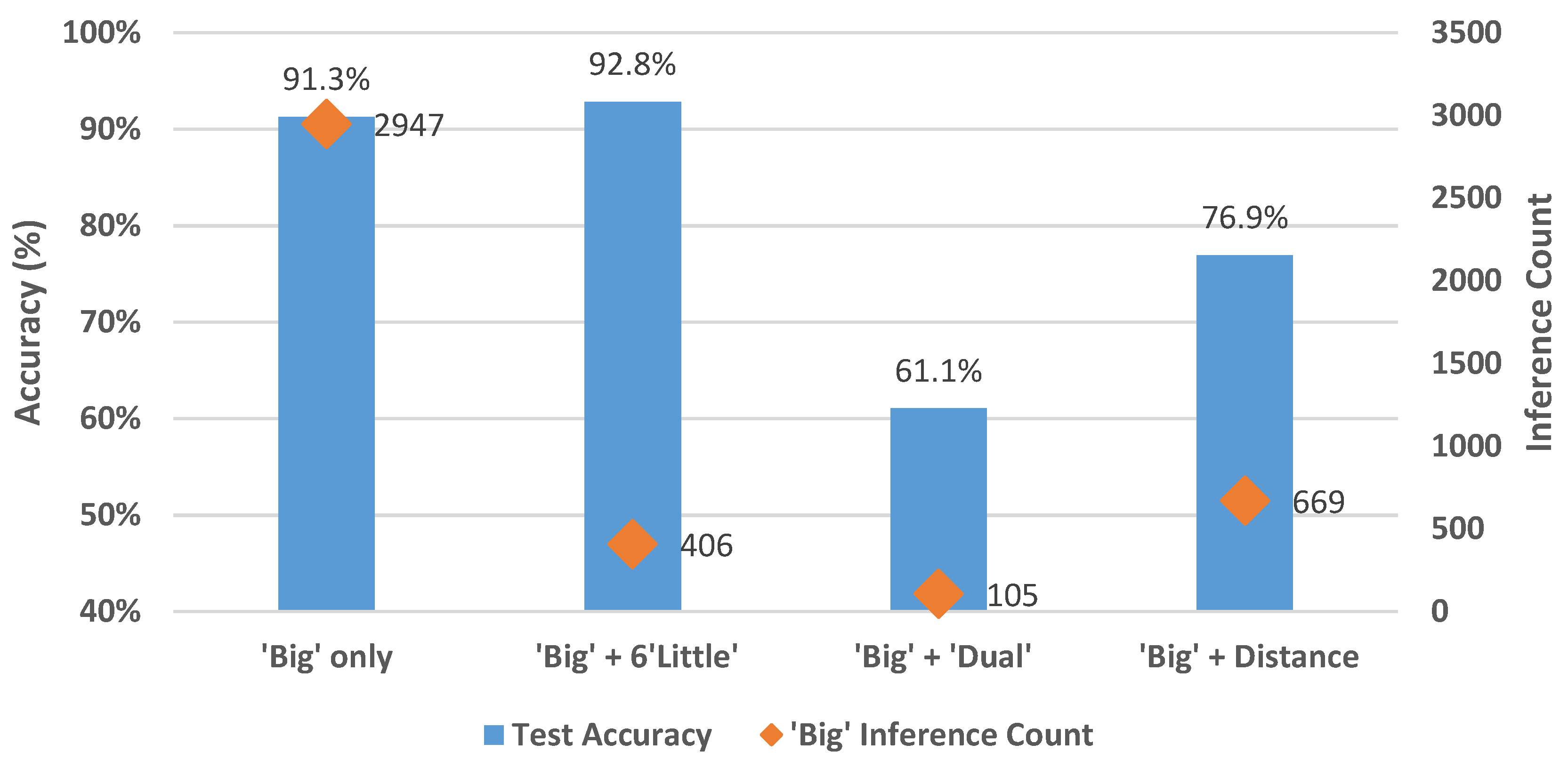
6.1. ‘Big’ Only
6.2. ‘Big’ + Six ‘Little’
6.3. ‘Big’ + ‘Dual’
6.4. ‘Big’ + Distance
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MCU | Microcontroller Unit |
| LoT | Internet of Things |
| CNN | Convolutional Neural Network |
| UCI-HAR | UCI-Human Activity Recognition |
References
- Zhou, Z.; Chen, X.; Li, E.; Zeng, L.; Luo, K.; Zhang, J. Edge intelligence: Paving the last mile of artificial intelligence with edge computing. Proc. IEEE 2019, 107, 1738–1762. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Ran, X. Deep learning with edge computing: A review. Proc. IEEE 2019, 107, 1655–1674. [Google Scholar] [CrossRef]
- Coral. Edge TPU. Available online: https://coral.ai/docs/edgetpu/faq/ (accessed on 20 February 2022).
- Ambiq Micro. Apollo3 Blue Datasheet. Available online: https://cdn.sparkfun.com/assets/learn_tutorials/9/0/9/Apollo3_Blue_MCU_Data_Sheet_v0_9_1.pdf (accessed on 15 December 2021).
- Eta Compute. Eta Compute ECM3532 AI Sensor Product Brief. Available online: https://media.digikey.com/pdf/Data%20Sheets/Eta%20Compute%20PDFs/ECM3532-AI-Vision-Product-Brief-1.0.pdf (accessed on 15 December 2021).
- Chaudhary, H. Eta Compute’s ECM3532 Board Provides AI Vision Works for Months on a Single Battery. Available online: https://opencloudware.com/eta-computes-ecm3532-board-provides-ai-vision-that-can-work-for-months-on-a-single-battery/ (accessed on 20 February 2022).
- Flamand, E.; Rossi, D.; Conti, F.; Loi, I.; Pullini, A.; Rotenberg, F.; Benini, L. GAP-8: A RISC-V SoC for AI at the Edge of the IoT. In Proceedings of the 2018 IEEE 29th International Conference on Application-specific Systems, Architectures and Processors (ASAP), Milan, Italy, 10–12 July 2018; pp. 1–4. [Google Scholar]
- Clarke, P. CEO Interview: Minima’s Tuomas Hollman on Why Static Timing Sign-Off Is Over. Available online: https://www.eenewseurope.com/en/ceo-interview-minimas-tuomas-hollman-on-why-static-timing-sign-off-is-over/ (accessed on 20 February 2022).
- Clarke, P. Minima, ARM Apply ‘Real-Time’ Voltage Scaling to Cortex-M3. Available online: https://www.eenewsanalog.com/news/minima-arm-apply-real-time-voltage-scaling-cortex-m3 (accessed on 20 February 2022).
- Flaherty, N. €100m Project to Develop Low Power Edge AI Microcontroller. Available online: https://www.eenewseurope.com/en/e100m-project-to-develop-low-power-edge-ai-microcontroller/ (accessed on 20 February 2022).
- Novac, P.E.; Hacene, G.B.; Pegatoquet, A.; Miramond, B.; Gripon, V. Quantization and deployment of deep neural networks on microcontrollers. Sensors 2021, 21, 2984. [Google Scholar] [CrossRef] [PubMed]
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.; Adam, H.; Kalenichenko, D. Quantization and training of neural networks for efficient integer-arithmetic-only inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2704–2713. [Google Scholar]
- Hubara, I.; Courbariaux, M.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Quantized neural networks: Training neural networks with low precision weights and activations. J. Mach. Learn. Res. 2017, 18, 6869–6898. [Google Scholar]
- Courbariaux, M.; Hubara, I.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized neural networks: Training deep neural networks with weights and activations constrained to +1 or —1. arXiv 2016, arXiv:1602.02830. [Google Scholar]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. Xnor-net: Imagenet classification using binary convolutional neural networks. In Computer Vision—ECCV 2016, Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 525–542. [Google Scholar]
- Mocerino, L.; Calimera, A. CoopNet: Cooperative convolutional neural network for low-power MCUs. In Proceedings of the 2019 26th IEEE International Conference on Electronics, Circuits and Systems (ICECS), Genova, Italy, 27–29 November 2019; pp. 414–417. [Google Scholar]
- Amiri, S.; Hosseinabady, M.; McIntosh-Smith, S.; Nunez-Yanez, J. Multi-precision convolutional neural networks on heterogeneous hardware. In Proceedings of the 2018 Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 19–23 March 2018; pp. 419–424. [Google Scholar]
- Romaszkan, W.; Li, T.; Gupta, P. 3PXNet: Pruned-Permuted-Packed XNOR Networks for Edge Machine Learning. ACM Trans. Embed. Comput. Syst. 2020, 19, 5. [Google Scholar] [CrossRef]
- Yu, J.; Lukefahr, A.; Das, R.; Mahlke, S. Tf-net: Deploying sub-byte deep neural networks on microcontrollers. ACM Trans. Embed. Comput. Syst. 2019, 18, 45. [Google Scholar] [CrossRef]
- Teerapittayanon, S.; McDanel, B.; Kung, H.T. Branchynet: Fast inference via early exiting from deep neural networks. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 2464–2469. [Google Scholar]
- Park, E.; Kim, D.; Kim, S.; Kim, Y.D.; Kim, G.; Yoon, S.; Yoo, S. Big/little deep neural network for ultra low power inference. In Proceedings of the 2015 International Conference on Hardware/Software Codesign and System Synthesis (CODES+ ISSS), Amsterdam, The Netherlands, 4–9 October 2015; pp. 124–132. [Google Scholar]
- Nunez-Yanez, J.; Howard, N. Energy-efficient neural networks with near-threshold processors and hardware accelerators. J. Syst. Arch. 2021, 116, 102062. [Google Scholar] [CrossRef]
- Ordóñez, F.J.; Roggen, D. Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [Green Version]
- Turaga, P.; Chellappa, R.; Subrahmanian, V.S.; Udrea, O. Machine recognition of human activities: A survey. IEEE Trans. Circuits Syst. Video Technol. 2008, 18, 1473–1488. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Magno, M.; Cavigelli, L.; Benini, L. FANN-on-MCU: An open-source toolkit for energy-efficient neural network inference at the edge of the Internet of Things. IEEE Internet Things J. 2020, 7, 4403–4417. [Google Scholar] [CrossRef]
- Ma, J.; parai.; Mabrouk, H.; BaptisteNguyen; idog ceva; Xu, J.; LÊ, M.T. Majianjia/nnom, version 0.4.3; Zendo: Geneva, Switzerland, 2021. [CrossRef]
- TensorFlow. TensorFlow Lite Guide. Available online: https://www.tensorflow.org/lite/guide (accessed on 10 May 2021).
- STMicroelectronics. Artificial Intelligence Ecosystem for STM32. Available online: https://www.st.com/content/st_com/en/ecosystems/artificial-intelligence-ecosystem-stm32.html (accessed on 8 June 2021).
- Eta Compute. TENSAI®Flow. Available online: https://etacompute.com/tensai-flow/ (accessed on 10 May 2021).
- STMicroelectronics. STM32L4R5xx Datasheet. Available online: https://www.st.com/resource/en/datasheet/stm32l4r5zg.pdf (accessed on 8 June 2021).
- Ambiq Micro. Apollo2 MCU Datasheet. Available online: https://ambiq.com/wp-content/uploads/2020/10/Apollo2-MCU-Datasheet.pdf (accessed on 19 July 2021).
- Yeo, K.S.; Roy, K. Low Voltage, Low Power VLSI Subsystems; McGraw-Hill, Inc.: New York, NY, USA, 2004; p. 44. [Google Scholar]
- Nunez-Yanez, J. Energy proportional neural network inference with adaptive voltage and frequency scaling. IEEE Trans. Comput. 2018, 68, 676–687. [Google Scholar] [CrossRef] [Green Version]
- UCI Machine Learning. Human Activity Recognition Using Smartphones Data Set. Available online: https://archive.ics.uci.edu/ml/datasets/human+activity+recognition+using+smartphones (accessed on 2 March 2021).
- De Maesschalck, R.; Jouan-Rimbaud, D.; Massart, D.L. The mahalanobis distance. Chemom. Intell. Lab. Syst. 2000, 50, 1–18. [Google Scholar] [CrossRef]
- McLachlan, G.J. Mahalanobis distance. Resonance 1999, 4, 20–26. [Google Scholar] [CrossRef]
- TensorFlow. Converter Command Line Reference. Available online: https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/g3doc/r1/convert/cmdline_reference.md (accessed on 29 March 2021).
- GCC Team. GCC, the GNU Compiler Collection. Available online: https://gcc.gnu.org/ (accessed on 25 May 2021).
- Arm Developer. GNU Arm Embedded Toolchain. Available online: https://developer.arm.com/tools-and-software/open-source-software/developer-tools/gnu-toolchain/gnu-rm (accessed on 25 May 2021).


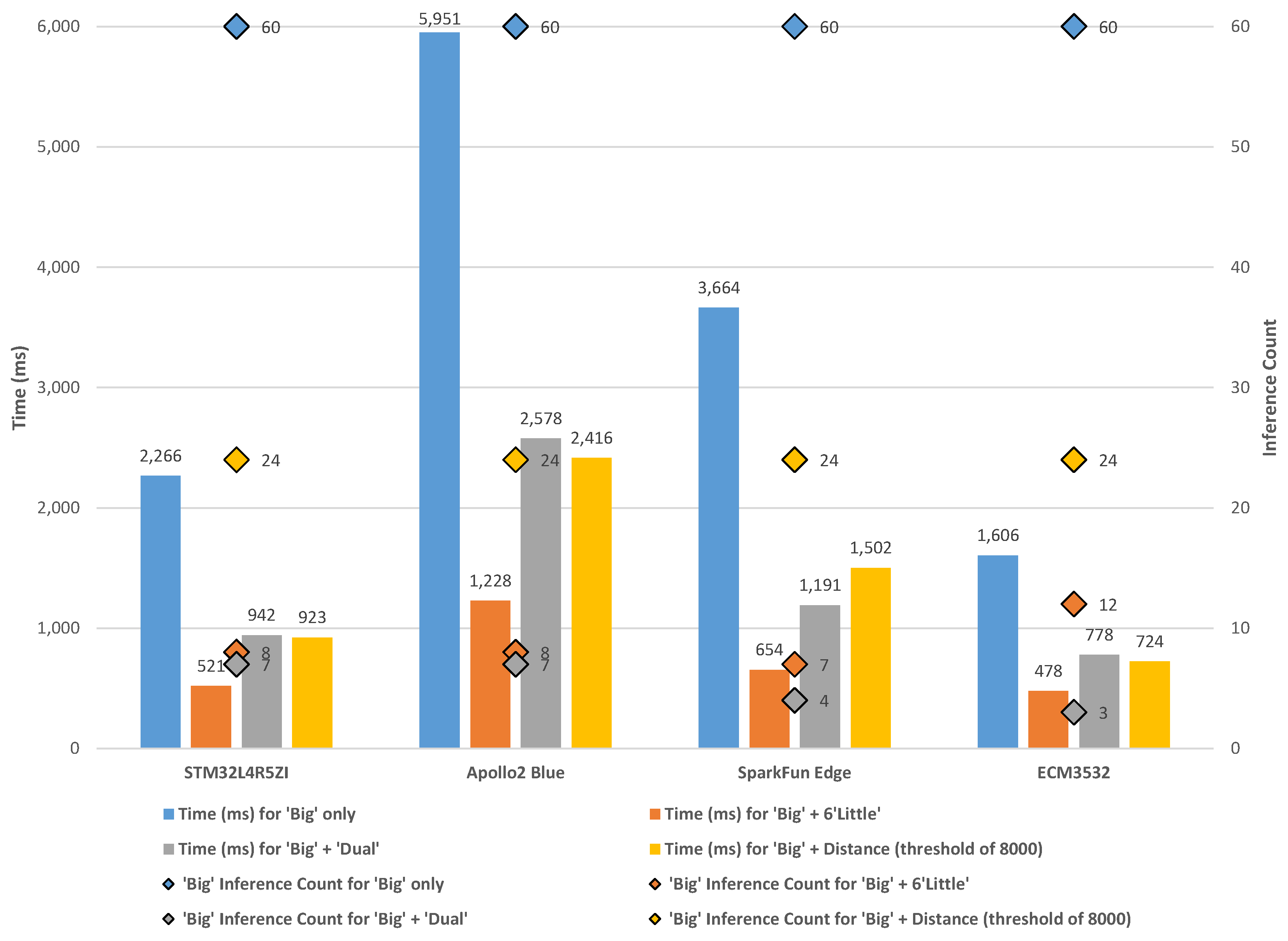

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
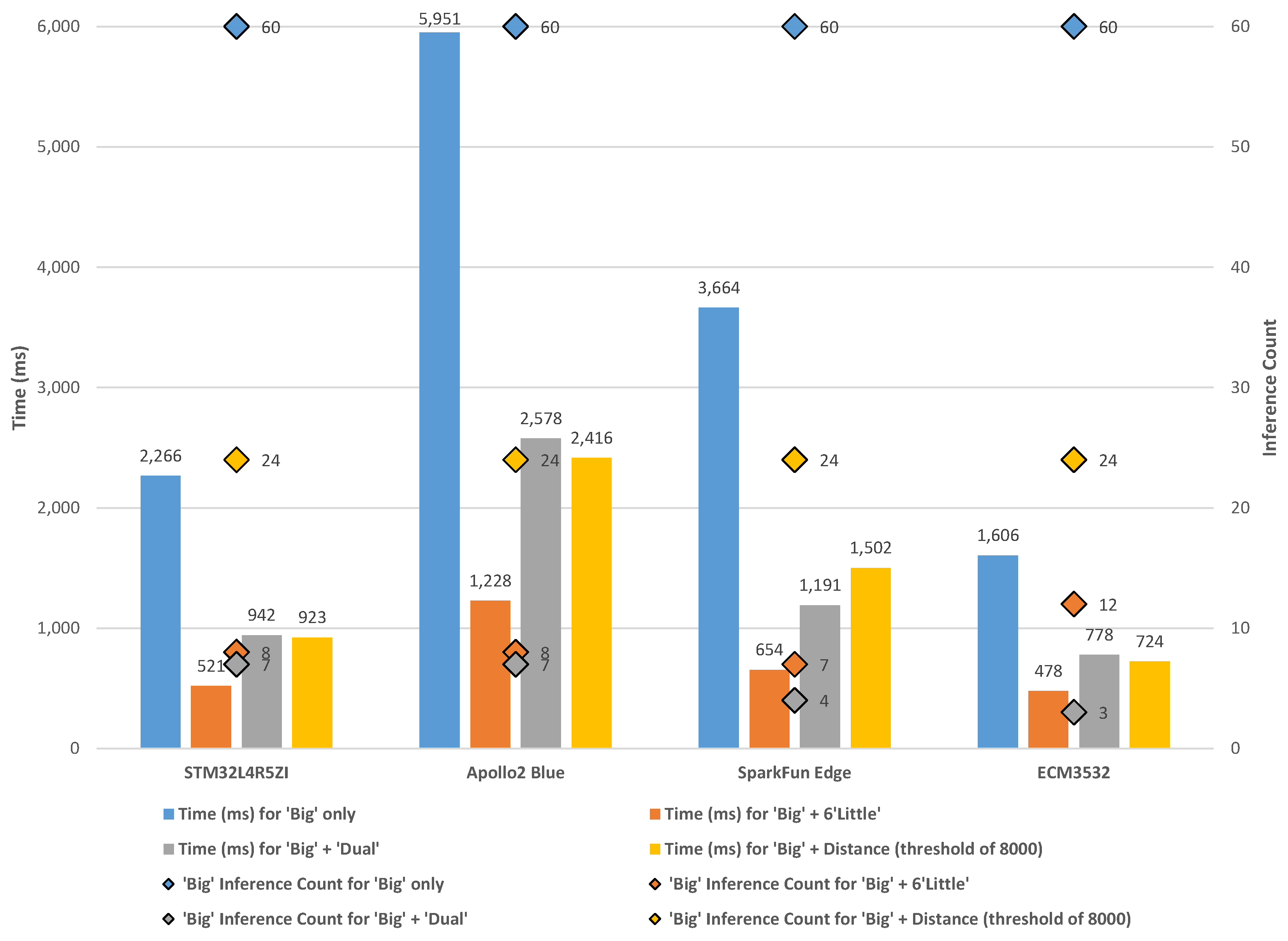{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Devices | Manufacturer | Architecture | Embedded Memory (Flash/SRAM/Cache) | Clock Frequency | Core Voltage | Sleeping Mode Current | Work Mode Current | Power Scaling Capabilities |
|---|---|---|---|---|---|---|---|---|
| STM32L4R5ZI | STMicroelectronics | 32-bit Cortex-M4 CPU with FPU | 1 MB/320 KB | up to 120 MHz | 1.05 V | <5 µA with RTC | 110 µA/MHz | Dynamic voltage scaling with two main voltage ranges |
| Apollo2 Blue | Ambiq | 32-bit Cortex-M4 CPU with FPU | 1 MB/256 KB/16 KB | up to 48 MHz | 0.5 V | <3 µA with RTC | 10 µA/MHz | SPOT (Subthreshold Power Optimized Technology) |
| SparkFun Edge (Apollo3 Blue) | Ambiq | 32-bit Cortex-M4 CPU with FPU | 1 MB/384 KB/16 KB | up to 96 MHz (with TurboSPOT Mode) | 0.5 V | 1 µA with RTC | 6 µA/MHz | SPOT (Subthreshold Power Optimized Technology) with TurboSPOT |
| ECM3532 | Eta Compute | 32-bit Cortex-M3 CPU with 16-bit ‘CoolFlux’ DSP | 512 KB/256 KB/0 KB | up to 100 MHz | 0.55 V | 1 µA with RTC | 5 µA/MHz | CVFS (Continuous Voltage Frequency Scaling) with multiple frequency and voltage points |
| Model: ‘Big’ | Model: ‘Little’ | ||||
|---|---|---|---|---|---|
| Layer (Type) | Output Shape | Param# | Layer (Type) | Output Shape | Param# |
| model_input1 | [(None, 128, 3)] | 0 | model_input | [(None, 128, 3)] | 0 |
| model_input2 | [(None, 128, 3)] | 0 | conv1d | (None, 128, 4) | 40 |
| model_input3 | [(None, 128, 3)] | 0 | conv1d_1 | (None, 64, 4) | 52 |
| conv1d | (None, 128, 4) | 40 | conv1d_2 | (None, 32, 2) | 26 |
| conv1d_5 | (None, 128, 4) | 40 | model_output | (None, 2) | 66 |
| conv1d_10 | (None, 128, 4) | 40 | |||
| conv1d_1 | (None, 64, 8) | 104 | |||
| conv1d_6 | (None, 64, 8) | 104 | |||
| conv1d_11 | (None, 64, 8) | 104 | |||
| conv1d_2 | (None, 32, 16) | 400 | |||
| conv1d_7 | (None, 32, 16) | 400 | |||
| conv1d_12 | (None, 32, 16) | 400 | |||
| conv1d_3 | (None, 16, 32) | 1568 | |||
| conv1d_8 | (None, 16, 32) | 1568 | |||
| conv1d_13 | (None, 16, 32) | 1568 | |||
| conv1d_4 | (None, 8, 8) | 776 | |||
| conv1d_9 | (None, 8, 8) | 776 | |||
| conv1d_14 | (None, 8, 8) | 776 | |||
| concatenate | (None, 96) | 0 | |||
| model_output | (None, 6) | 582 | |||
| Total params: 9246 | Total params: 184 | ||||
| Model: ‘Dual’ | ||
|---|---|---|
| Layer (Type) | Output Shape | Param# |
| model_input | [(None, 384, 2)] | 0 |
| conv1d | (None, 384, 4) | 28 |
| conv1d_1 | (None, 192, 4) | 52 |
| conv1d_2 | (None, 96, 2) | 26 |
| model_output | (None, 2) | 194 |
| Total params: 300 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, Z.; Howard, N.; Nunez-Yanez, J. Big–Little Adaptive Neural Networks on Low-Power Near-Subthreshold Processors. J. Low Power Electron. Appl. 2022, 12, 28. https://doi.org/10.3390/jlpea12020028
Shen Z, Howard N, Nunez-Yanez J. Big–Little Adaptive Neural Networks on Low-Power Near-Subthreshold Processors. Journal of Low Power Electronics and Applications. 2022; 12(2):28. https://doi.org/10.3390/jlpea12020028
Chicago/Turabian StyleShen, Zichao, Neil Howard, and Jose Nunez-Yanez. 2022. "Big–Little Adaptive Neural Networks on Low-Power Near-Subthreshold Processors" Journal of Low Power Electronics and Applications 12, no. 2: 28. https://doi.org/10.3390/jlpea12020028
APA StyleShen, Z., Howard, N., & Nunez-Yanez, J. (2022). Big–Little Adaptive Neural Networks on Low-Power Near-Subthreshold Processors. Journal of Low Power Electronics and Applications, 12(2), 28. https://doi.org/10.3390/jlpea12020028