
Employing Machine Learning and Deep Learning Models for Mental Illness Detection


Abstract
1. Introduction
- Collect and preprocess data, including handling language challenges like sarcasm or negations;
- Build and optimize models with attention to tuning and evaluation;
- Use appropriate metrics for datasets where depressive posts are a minority.
Key Takeaways and New Best Practices
- End-to-end reproducibility: This tutorial provides a complete, open-source workflow—including dataset selection, code, and standardized modeling steps—enabling transparent and replicable research.
- Rigorous data partitioning and class imbalance handling: The manuscript demonstrates effective use of train–validation–test splits and class-weighted metrics, ensuring robust evaluation even for underrepresented categories.
- Appropriate metric selection: It advocates for moving beyond accuracy and demonstrates the use of weighted F1-score and AUROC as more meaningful metrics for imbalanced multi-class tasks.
- Standardized preprocessing pipeline: Clear, replicable steps for text cleaning, lemmatization, and feature extraction are provided, which can serve as a template for future studies.
- Separation of linguistic patterns and clinical interpretation: The paper explicitly distinguishes between computational signals in user-generated text and clinical diagnoses, emphasizing responsible interpretation and ethical reporting.
- Ethical transparency and data stewardship: Throughout the workflow, considerations of privacy, transparency, and limitations of non-clinical labels are highlighted to guide responsible use and reporting.
2. Method
2.1. Data Preparation
2.1.1. Data Sources and Collection Methods
2.1.2. Data Preprocessing
- Text Cleaning: Social media text often contains noise such as URLs, HTML tags, mentions, hashtags, special characters, and extra whitespace. These elements were systematically removed using regular expressions to create cleaner input for both ML and DL models.
- Lowercasing: All text was converted to lowercase to maintain uniformity across the dataset and minimize redundancy in text representation.
- Stopword Removal: Commonly used words that provide little semantic value (e.g., ‘the,’ ‘and,’ ‘is’) were excluded using the stopword list available in the Natural Language Toolkit (NLTK) [13], reducing noise while retaining meaningful content.
- Lemmatization: Words were reduced to their base forms (e.g., ‘running,’ ‘ran,’ ‘runs’ → ‘run’) using NLTK’s Lemmatizer. This step normalized variations of words, aiding both feature extraction and embedding generation.
2.1.3. Class Labeling
2.1.4. Feature Transformation for ML Models
2.2. Model Development
2.2.1. Logistic Regression
2.2.2. Support Vector Machine (SVM)
- Regularization parameter C: values of {0.1, 1, 10}.
- Kernel type: linear and RBF.
- Class weight: balanced or none.
- Gamma (for RBF kernel): scale and auto.
2.2.3. Tree-Based Models
Random Forests
Light Gradient Boosting Machine (LightGBM)
2.2.4. A Lite Version of Bidirectional Encoder Representations from Transformers (ALBERT)
2.2.5. Gated Recurrent Units (GRUs)
- Embedding Layer: Converts token indices into dense vector representations of a fixed embedding dimension.
- GRU Layer: Processes input sequences and retains contextual information across time steps, utilizing only the final hidden state for classification.
- Fully Connected Layer: Maps the hidden state to output logits corresponding to the number of classes.
2.3. Evaluation Metrics
2.3.1. Precision
2.3.2. Recall (Sensitivity)
2.3.3. F1 Score
2.3.4. Area Under the Receiver Operating Characteristic Curve (AUROC)
3. Results
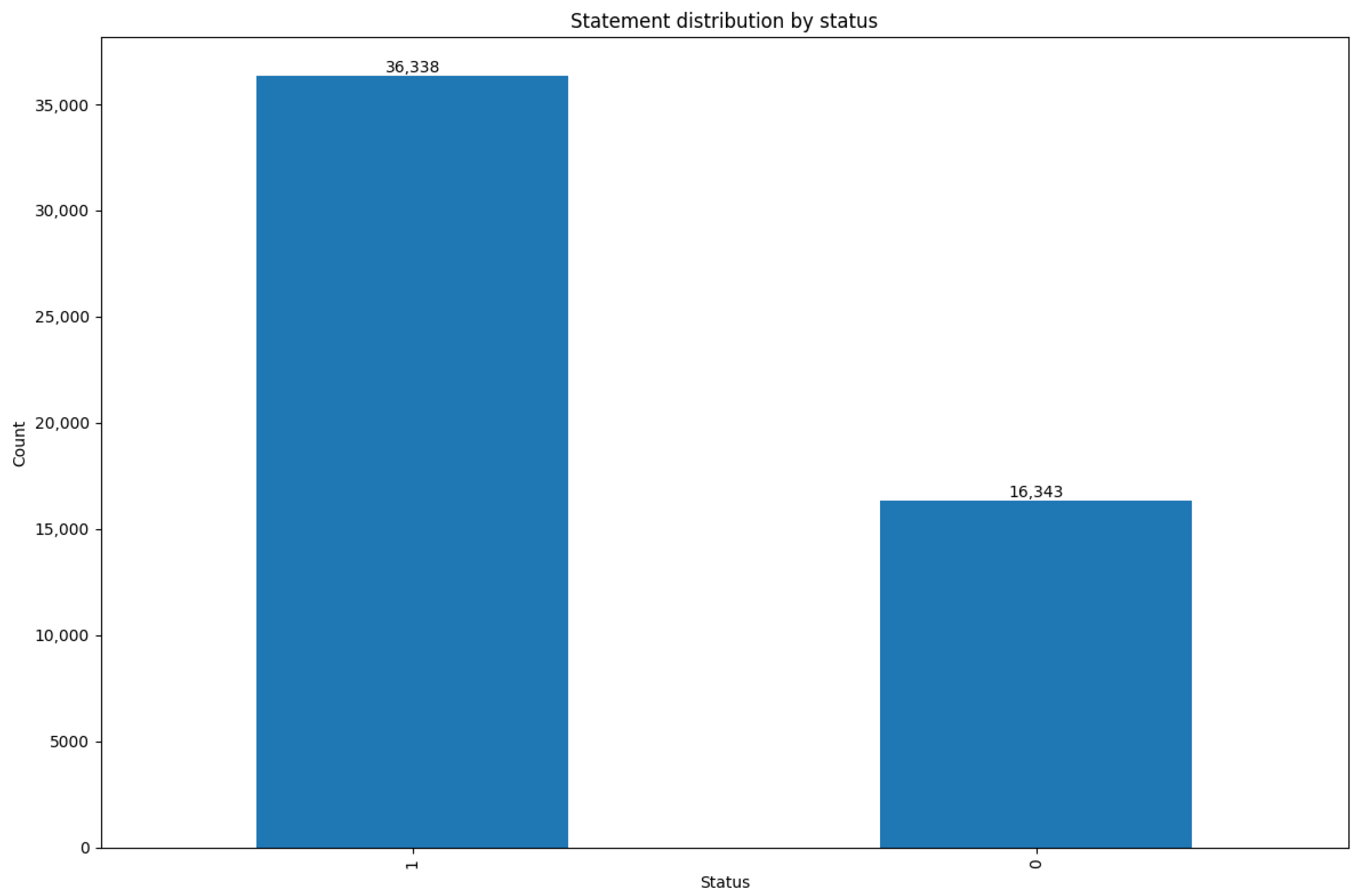
3.1. Overview of Mental Health Distribution
3.2. Hyperparameter Optimization
3.3. Model Performance Evaluation
3.4. Error Analysis and Practical Implications
- Semantic Overlap and Ambiguous Boundaries: The classes of ‘Depression’, ‘Personality Disorder’, and ‘Suicidal’ exhibit lower F1-scores and AUC values compared to other categories. Errors are most pronounced where semantic cues are ambiguous or context-dependent, resulting in frequent misclassification between these classes. This is especially apparent in Depression, which demonstrates both the lowest F1-score (0.7086) and AUC (0.90), reflecting underlying ambiguity in textual expression and label assignment.
- Impact of Data Integration: Given that the dataset pools user-generated content from diverse platforms and annotation schemes, some class boundaries are inherently noisy or inconsistent. This heterogeneity may dilute signal strength for models and complicate the task of reliably distinguishing between closely related mental health states.
- Underrepresented Classes: Categories such as Stress and Suicidal, while clinically important, are both minority classes in the dataset and yield lower precision, recall, and F1-scores. This underlines a persistent challenge for real-world applications—ensuring fair and effective detection across all relevant mental health categories, not just the most prevalent ones.
4. Discussion
4.1. Main Contributions and Practical Implications
4.2. Limitations and Future Directions
4.3. Conclusions Statement
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- WHO. Mental Disorders. 2023. Available online: https://www.who.int/news-room/fact-sheets/detail/mental-disorders (accessed on 9 February 2025).
- American Psychiatric Association. Diagnostic and Statistical Manual of Mental Disorders, 5th ed.; American Psychiatric Publishing: Washington, DC, USA, 2013. [Google Scholar]
- World Health Organization. International Statistical Classification of Diseases and Related Health Problems, 10th Revision (ICD-10); World Health Organization: Geneva, Switzerland, 1992. [Google Scholar]
- De Choudhury, M.; Counts, S.; Horvitz, E. Social media as a measurement tool of depression in populations. In Proceedings of the 5th Annual ACM Web Science Conference, Paris, France, 2–4 May 2013. [Google Scholar]
- Guntuku, S.C.; Yaden, D.B.; Kern, M.L.; Ungar, L.H.; Eichstaedt, J.C. Detecting depression and mental illness on social media: An integrative review. Curr. Opin. Psychol. 2017, 18, 43–49. [Google Scholar] [CrossRef]
- Shatte, A.B.R.; Hutchinson, D.M.; Teague, S.J. Social Media Markers to Identify Fathers at Risk of Postpartum Depression: A Machine Learning Approach. Cyberpsychology Behav. Soc. Netw. 2020, 23, 611–618. [Google Scholar] [CrossRef]
- Yazdavar, A.H.; Mahdavinejad, M.S.; Bajaj, G.; Romine, W.; Sheth, A.; Monadjemi, A.H.; Thirunarayan, K.; Meddar, J.M.; Myers, A.; Pathak, J.; et al. Multimodal mental health analysis in social media. PLoS ONE 2020, 15, e0226248. [Google Scholar] [CrossRef]
- Cao, Y.; Dai, J.; Wang, Z.; Zhang, Y.; Shen, X.; Liu, Y.; Tian, Y. Machine Learning Approaches for Depression Detection on Social Media: A Systematic Review of Biases and Methodological Challenges. J. Behav. Data Sci. 2025, 5, 67–102. [Google Scholar] [CrossRef]
- Hargittai, E. Is Bigger Always Better? Potential Biases of Big Data Derived from Social Network Sites. Ann. Am. Acad. Political Soc. Sci. 2015, 659, 63–76. [Google Scholar] [CrossRef]
- Helmy, A.; Nassar, R.; Ramdan, N. Depression Detection for Twitter Users Using Sentiment Analysis in English and Arabic Tweets. Artif. Intell. Med. 2024, 147, 102716. [Google Scholar] [CrossRef]
- Xu, S.; Cao, Y.; Wang, Z.; Tian, Y. Fraud Detection in Online Transactions: Toward Hybrid Supervised–Unsupervised Learning Pipelines. Preprints 2025, 2025051101. [Google Scholar] [CrossRef]
- Liu, Y.; Shen, X.; Zhang, Y.; Wang, Z.; Tian, Y.; Dai, J.; Cao, Y. A Systematic Review of Machine Learning Approaches for Detecting Deceptive Activities on Social Media: Methods, Challenges, and Biases. Int. J. Data Sci. Anal. 2025. [Google Scholar] [CrossRef]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python; O’Reilly Media Inc.: Sebastopol, CA, USA, 2009. [Google Scholar]
- Harris, Z.S. Distributional Structure. Word 1954, 10, 146–162. [Google Scholar] [CrossRef]
- Jones, K.S. A Statistical Interpretation of Term Specificity and Its Application in Retrieval. J. Doc. 1972, 28, 11–21. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. In Proceedings of the International Conference on Learning Representations (ICLR), Scottsdale, AZ, USA, 2–4 May 2013. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. In Proceedings of the Transactions of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Volume 5, pp. 135–146. [Google Scholar]
- Hosmer, D.W.; Lemeshow, S. Applied Logistic Regression, 2nd ed.; John Wiley & Sons, Inc.: New York, NY, USA, 2000. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V.N. Support-Vector Networks; Springer: Berlin/Heidelberg, Germany, 1995; Volume 20, pp. 273–297. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Wadsworth & Brooks/Cole Advanced Books & Software: Monterey, CA, USA, 1984. [Google Scholar]
- Breiman, L. Random Forests; Springer: Berlin/Heidelberg, Germany, 2001; Volume 45, pp. 5–32. [Google Scholar]
- Tan, L.; Liu, X.; Liu, D.; Liu, S.; Wu, W.; Jiang, H. An improved dung beetle optimizer for random forest optimization. arXiv 2024, arXiv:2411.17738. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A highly efficient gradient boosting decision tree. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 3149–3157. [Google Scholar]
- Tian, Y.; Xu, S.; Cao, Y.; Wang, Z.; Wei, Z. An Empirical Comparison of Machine Learning and Deep Learning Models for Automated Fake News Detection. Mathematics 2025, 13, 2086. [Google Scholar] [CrossRef]
- Huang, T.; Cui, Z.; Du, C.; Chiang, C.E. CL-ISR: A Contrastive Learning and Implicit Stance Reasoning Framework for Misleading Text Detection on Social Media. arXiv 2025, arXiv:2506.05107. [Google Scholar] [CrossRef]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. arXiv 2020, arXiv:1909.11942. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar] [CrossRef]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Wang, Y.; Guo, Y.; Wei, Z.; Huang, Y.; Liu, X. Traffic Flow Prediction Based on Deep Neural Networks. In Proceedings of the 2019 International Conference on Data Mining Workshops (ICDMW), Beijing, China, 8–11 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 302–309. [Google Scholar] [CrossRef]
- Bradford, A.; Meyer, A.N.D.; Khan, S.; Giardina, T.D.; Singh, H. Diagnostic error in mental health: A review. BMJ Qual. Saf. 2024, 33, 663–672. [Google Scholar] [CrossRef]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. J. Mach. Learn. Technol. 2011, 2, 37–63. [Google Scholar]
- Davis, J.; Goadrich, M. The relationship between Precision-Recall and ROC curves. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; ACM: New York, NY, USA, 2006; pp. 233–240. [Google Scholar]
- Zhang, Z.; Wang, X.; Zhang, X.; Zhang, J. Simultaneously detecting spatiotemporal changes with penalized Poisson regression models. arXiv 2024, arXiv:2405.06613. [Google Scholar]
- Xu, S.; Tian, Y.; Cao, Y.; Wang, Z.; Wei, Z. Benchmarking Machine Learning and Deep Learning Models for Fake News Detection Using News Headlines. Preprints 2025, 2025061183. [Google Scholar] [CrossRef]
- Cummins, N.; Scherer, S.; Krajewski, J.; Schnieder, S.; Epps, J.; Quatieri, T.F. A review of depression and suicide risk assessment using speech analysis. Speech Commun. 2015, 71, 10–49. [Google Scholar] [CrossRef]
- Al Hanai, T.; Ghassemi, M.M.; Glass, J.R. Detecting depression with audio/text sequence modeling of interviews. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018; pp. 1716–1720. [Google Scholar]
- Valstar, M.; Gratch, J.; Schuller, B.; Ringeval, F.; Lalanne, D.; Torres Torres, M.; Scherer, S.; Stratou, G.; Cowie, R.; Pantic, M. Avec 2016: Depression, mood, and emotion recognition workshop and challenge. In Proceedings of the 6th International Workshop on Audio/Visual Emotion Challenge, Amsterdam, The Netherlands, 15–19 October 2016; pp. 3–10. [Google Scholar]
- Acharya, U.R.; Oh, S.L.; Hagiwara, Y.; Tan, J.H.; Adeli, H.; Subha, D.P. Automated EEG-based screening of depression using deep convolutional neural network. Comput. Methods Programs Biomed. 2015, 161, 103–113. [Google Scholar] [CrossRef] [PubMed]
- Craik, A.; He, Y.; Contreras-Vidal, J.L. Deep learning for electroencephalogram (EEG) classification tasks: A review. J. Neural Eng. 2019, 16, 031001. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
| Model | Best Parameters (Binary) | Best Parameters (Multi-Class) | Interpretation |
|---|---|---|---|
| Logistic Regression | {C: 10, solver: ‘liblinear’, penalty: ‘l2’, class_weight: None} | {C: 10, solver: ‘lbfgs’, penalty: ‘l2’, multi_class: ‘multinomial’, class_weight: ‘balanced’} | For binary tasks, liblinear is chosen for smaller datasets. For multi-class, lbfgs supports a ‘multinomial’ strategy to optimize across multiple categories. The regularization strength (C) of 10 prevents overfitting. |
| SVM | {C: 1, kernel: ‘rbf’, class_weight: ‘balanced’, gamma: ‘scale’} | {C: 1, kernel: ‘rbf’, class_weight: ‘balanced’, gamma: ‘scale’} | The RBF kernel captures nonlinear relationships in text data, while class_weight: ‘balanced’ was selected to address class imbalance. Regularization strength (C) balances margin maximization and misclassification. |
| Random Forest | {n_estimators: 100, max_depth: None, min_samples_split: 5, min_samples_leaf: 1, class_weight: ‘balanced’} | {n_estimators: 200, max_depth: None, min_samples_split: 2, min_samples_leaf: 2, class_weight: ‘balanced’} | For binary tasks, 100 trees ensure stability. For multi-class, 200 trees improve coverage of complex class distributions. Weighted class adjustments handle imbalances. |
| LightGBM | {n_estimators: 100, learning_rate: 0.1, max_depth: -1, num_leaves: 50, min_child_samples: 10, class_weight: None} | {n_estimators: 100, learning_rate: 0.1, max_depth: None, num_leaves: 63, class_weight: ‘balanced’} | For both tasks, LightGBM achieves efficiency via leaf-wise tree growth. For multi-class, additional leaves (63) improve the representation of minority classes. |
| ALBERT | {lr: 1.46 × 10−5, epochs: 4, dropout: 0.11} | {lr: 1.17 × 10−5, epochs: 4, dropout: 0.15} | ALBERT’s lightweight architecture fine-tunes well with minimal learning rates and dropout for regularization. Minor adjustments improve class representation in multi-class settings. |
| GRU | {embedding_dim: 156, hidden_dim: 467, lr: 0.0004, epochs: 5} | {embedding_dim: 236, hidden_dim: 730, lr: 0.0003, epochs: 6} | Embedding dimensions and hidden states effectively capture sequential dependencies in text. Multi-class configurations benefit from higher hidden dimensions and epochs. |
| Model | Binary Classification | Multi-Class Classification |
|---|---|---|
| Support Vector Machine (SVM) | 0.9401 | 0.7610 |
| Logistic Regression | 0.9345 | 0.7498 |
| Random Forest | 0.9359 | 0.7478 |
| LightGBM | 0.9358 | 0.7747 |
| ALBERT | 0.9576 | 0.7841 |
| Gated Recurrent Units (GRU) | 0.9512 | 0.7756 |
| Model | Binary Classification AUROC | Multi-Class Classification Micro-Average AUROC |
|---|---|---|
| SVM | 0.93 | 0.95 |
| Logistic Regression | 0.93 | 0.96 |
| Random Forest | 0.92 | 0.96 |
| LightGBM | 0.93 | 0.97 |
| ALBERT | 0.95 | 0.97 |
| GRU | 0.94 | 0.97 |
| Class | Precision | Recall | F1-Score | AUC |
|---|---|---|---|---|
| Anxiety (0) | 0.7947 | 0.8358 | 0.8147 | 0.98 |
| Bipolar (1) | 0.8809 | 0.8140 | 0.8462 | 0.98 |
| Depression (2) | 0.7158 | 0.7016 | 0.7086 | 0.90 |
| Normal (3) | 0.9078 | 0.9202 | 0.9140 | 0.99 |
| Personality Disorder (4) | 0.8750 | 0.5612 | 0.6838 | 0.97 |
| Stress (5) | 0.6331 | 0.5989 | 0.6155 | 0.96 |
| Suicidal (6) | 0.6613 | 0.7011 | 0.6806 | 0.92 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Wang, Z.; Ding, Z.; Tian, Y.; Dai, J.; Shen, X.; Liu, Y.; Cao, Y. Employing Machine Learning and Deep Learning Models for Mental Illness Detection. Computation 2025, 13, 186. https://doi.org/10.3390/computation13080186
Zhang Y, Wang Z, Ding Z, Tian Y, Dai J, Shen X, Liu Y, Cao Y. Employing Machine Learning and Deep Learning Models for Mental Illness Detection. Computation. 2025; 13(8):186. https://doi.org/10.3390/computation13080186
Chicago/Turabian StyleZhang, Yeyubei, Zhongyan Wang, Zhanyi Ding, Yexin Tian, Jianglai Dai, Xiaorui Shen, Yunchong Liu, and Yuchen Cao. 2025. "Employing Machine Learning and Deep Learning Models for Mental Illness Detection" Computation 13, no. 8: 186. https://doi.org/10.3390/computation13080186
APA StyleZhang, Y., Wang, Z., Ding, Z., Tian, Y., Dai, J., Shen, X., Liu, Y., & Cao, Y. (2025). Employing Machine Learning and Deep Learning Models for Mental Illness Detection. Computation, 13(8), 186. https://doi.org/10.3390/computation13080186