Ensemble of Filter-Based Rankers to Guide an Epsilon-Greedy Swarm Optimizer for High-Dimensional Feature Subset Selection


Abstract
1. Introduction
- A novel binary swarm intelligence algorithm, called the Epsilon-greedy Swarm Optimizer (ESO), is proposed as a new wrapper algorithm. In each iteration of the ESO, a particle is randomly selected, then the nearest-better neighbor of this particle in the swarm is found, and finally a new particle is created based on these particles using a new epsilon-greedy method. If the quality of new particle is better than the randomly-selected particle, the new particle is replaced in the swarm, otherwise the new particle is discarded.
- A novel hybrid filter-wrapper algorithm is proposed for solving high-dimensional feature subset selection, where the knowledge about the feature importance obtained by the ensemble of filter-based rankers is used to weight the feature probabilities in the ESO. The higher the feature importance, the more likely it is to be chosen in the next generation. In the best of our knowledge, no empirical research has been conducted on the using feature importance obtained by the ensemble of filter-based rankers to weight the feature probabilities in the wrapper algorithms.
2. Literature Review
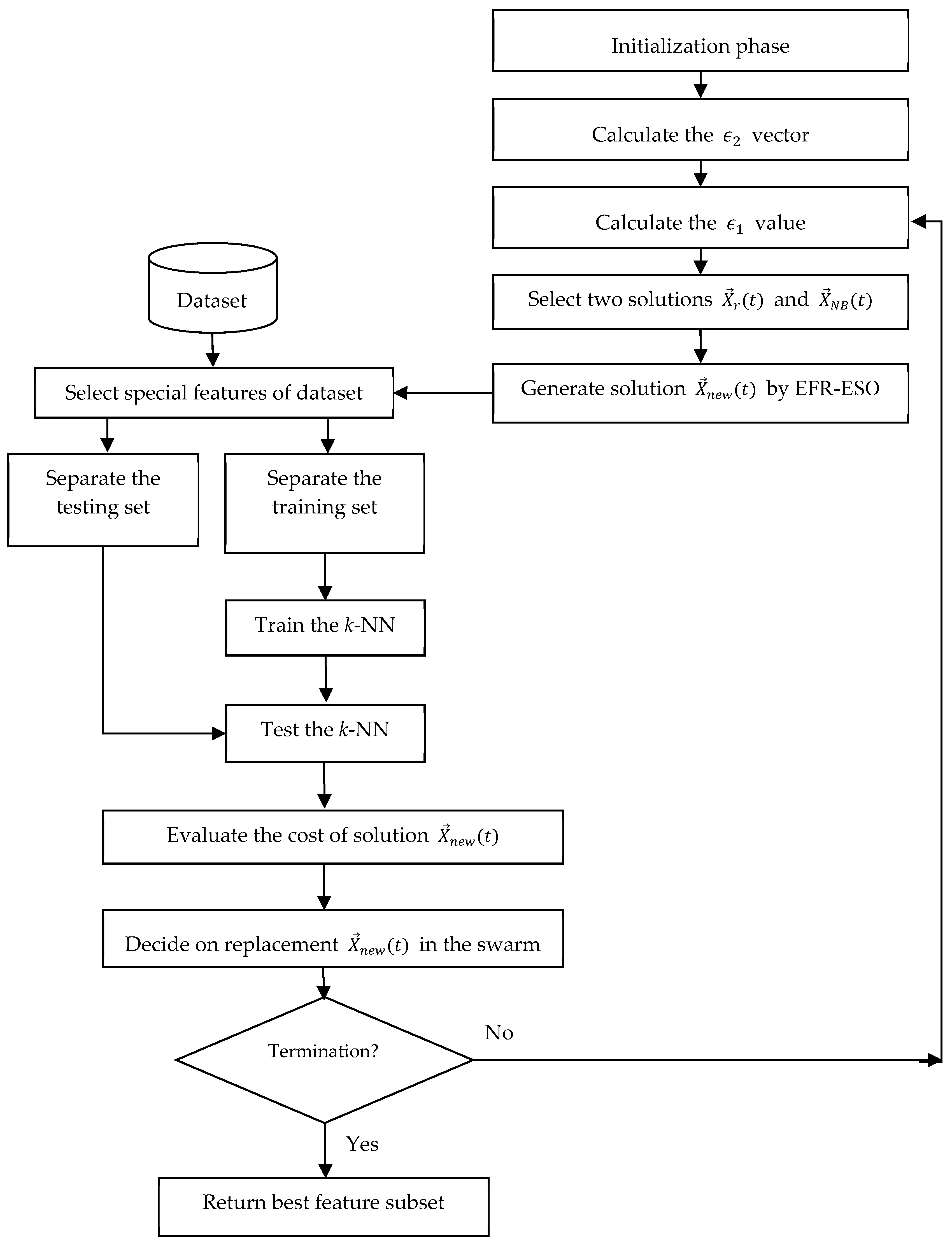
3. The Proposed Algorithm
| Algorithm 1: General outline of EFR-ESO. |
| t = 0; Randomly generate the initial swarm ; Evaluate the initial swarm with the evaluation function; Calculate the rank of each feature by ensemble of filter rankers; Calculate the feature probabilities; While stopping criterion is not satisfied Do Randomly select a particle in the swarm, named . Find the nearest-better neighbor of , named . Generate a new particle based on and by Epsilon-greedy algorithm. Evaluate the fitness of . If the fitness of is better than , then replace in the swarm. t = t + 1; End while Output: The best solution found. |
3.1. Solution Representation
3.2. Nearest-Better Neighborhood
| Algorithm 2: Outline of finding the nearest-better neighbor for particle r. |
| Inputs: . ; ; For i = 1 to N Do If ; ; End if End for If ; End if Output: . |
3.3. Particle Generation by the Epsilon-Greedy Algorithm
- is a constant scalar for each feature of dataset and its value is used to balance between exploration and exploitation. It should be noted that depending on the value of this parameter, there are three different types of behavior for the algorithm. In the first situation, if the value of is very close to 0.5, then the algorithm behaves similarly to a “pure random search” algorithm and, therefore, strongly encourages exploration [34,35]. In this case, the knowledge gained during the search process is completely ignored. In the second situation, if the value of is very close to 1, then the algorithm behaves similarly to an “opposition-based learning” algorithm [36]. In this case, the algorithm is trying to move in the opposite direction to the knowledge that it has gained. In the third situation, if the value of is very close to 0, then algorithm strongly promotes exploitation. In this case, the algorithm tries to move in line with the knowledge that it has gained. As a general heuristic, to avoid being trapped into a local optimum, each algorithm must start with exploration, and change into exploitation by a lapse of iterations. Such a strategy can be easily implemented with an updating equation in which is a non-increasing function of the generation t. In this paper, we use the following equation to update the value of :where is the initial value of the parameter, and t and NFE are the number of iterations elapsed and the maximal number of fitness evaluation, respectively.
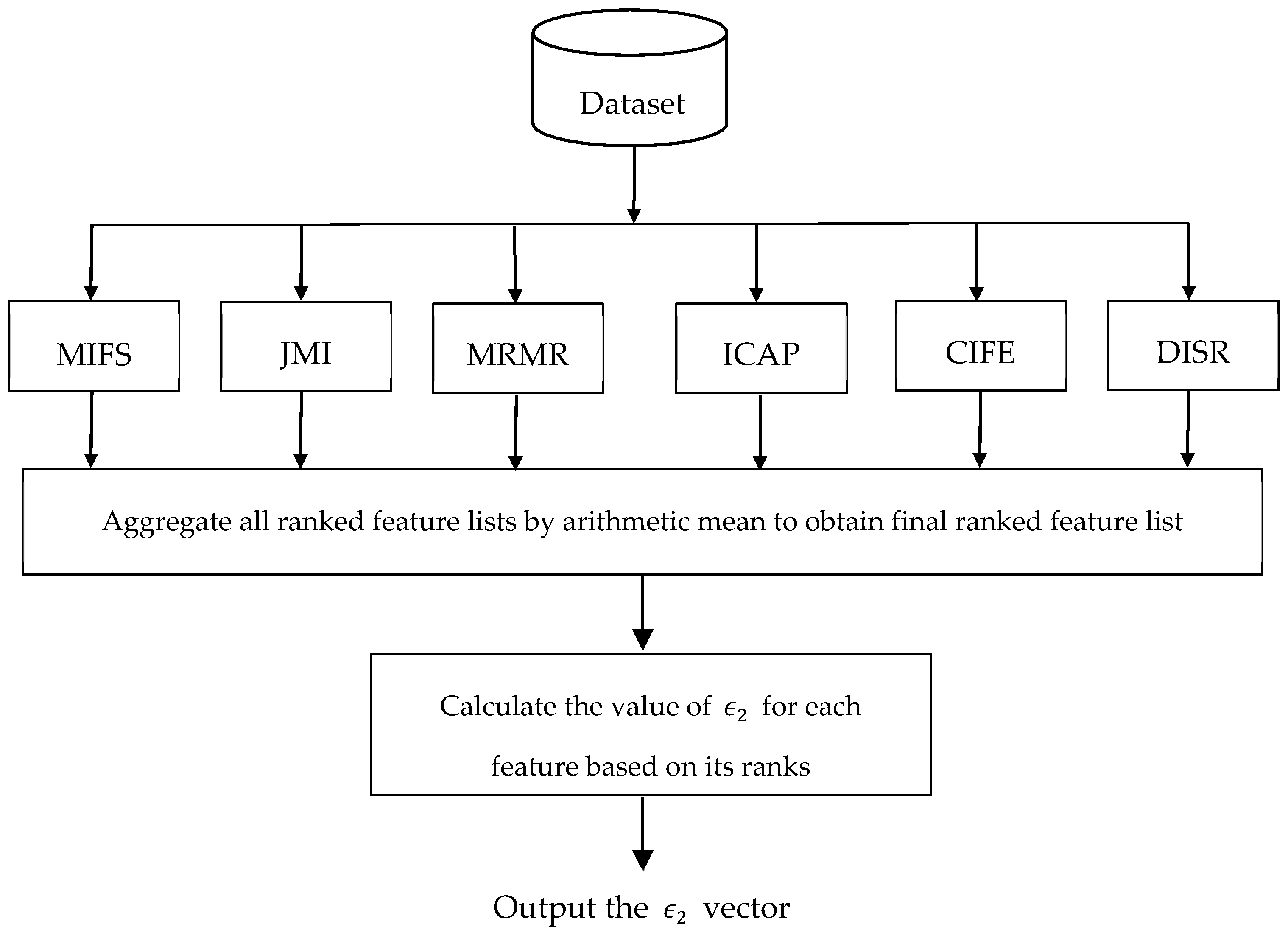
- is a vector which their values are used to bias the swarm toward a special part of the search space. If the value of be near to 0.5, then the chance of choosing the dth feature are equal to the chance of not being selected. In multi-objective feature subset selection, we tend to select fewer features. This means that we tend to generate a particle on that part of the search space in which there exist fewer features. In the other words, we prefer new solutions containing a large number of 0s instead of 1s. In this case, we can set the value of in the interval [0, 0.5). Note that this simple rule helps the algorithm to find a small number of features which minimize the classification error. To calculate the value of , we recommend using the rank of the dth feature obtained by an ensemble of different filter methods, as discussed in Section 3.4.
3.4. Ensemble of Filter-Based Rankers to Set the Value of
3.5. Particle Evaluation
3.6. Particle Replacement
3.7. Algorithmic Details and Flowchart
| Algorithm 3: Outline of EFR-ESO for minimization. |
| Initialize (0), N, and stopping criterion; t = 0; For i = 1 to N Do Randomly generate the initial solution ; End for // feature probabilities calculation: Calculate the rank of each feature by ensemble of filter rankers; Calculate the feature probabilities, i.e., vector; While stopping criterion is not satisfied Do Update the value of ; // Particle selection: Randomly select a particle in the swarm, named . Find the nearest-better neighbor of , named . // Particle generation: For d = 1 to n Do Generate a random number rand in interval [0, 1]; Update the value of by mutual information obtained by filter method; End for // Particle replacement: If ; Else ; End if t = t + 1; End while Output: The best solution found. |
4. Theoretical Convergence Analysis of EFR-ESO Algorithm
- If , then and .
- If , then and .
- If , then and .
5. Experimental Study
5.1. Dataset Properties and Experimental Settings
5.2. Results and Comparisons
6. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Gheyas, I.A.; Smith, L.S. Feature subset selection in large dimensionality domains. Pattern Recognit. 2010, 43, 5–13. [Google Scholar] [CrossRef]
- Garey, M.R.; Johnson, D.S. A Guide to the Theory of NP-Completeness, 1st ed.; WH Freemann: New York, NY, USA, 1979. [Google Scholar]
- Xue, B.; Zhang, M.; Browne, W.N.; Yao, X. A survey on evolutionary computation approaches to feature selection. IEEE Ttans. Evolut. Comput. 2016, 20, 606–626. [Google Scholar] [CrossRef]
- Pudil, P.; Novovičová, J.; Kittler, J. Floating search methods in feature selection. Pattern Recogn Lett. 1994, 15, 1119–1125. [Google Scholar] [CrossRef]
- Alpaydin, E. Introduction to Machine Learning, 3rd ed.; MIT Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Talbi, E.G. Meta-Heuristics: From Design to Implementation; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- Han, K.H.; Kim, J.H. Quantum-inspired evolutionary algorithm for a class of combinatorial optimization. IEEE Trans. Evolut. Comput. 2002, 6, 580–593. [Google Scholar] [CrossRef]
- Banks, A.; Vincent, J.; Anyakoha, C. A review of particle swarm optimization. Part II: Hybridisation, combinatorial, multicriteria and constrained optimization, and indicative applications. Nat. Comput. 2008, 7, 109–124. [Google Scholar] [CrossRef]
- Cheng, R.; Jin, Y. A competitive swarm optimizer for large scale optimization. IEEE Trans. Cybern. 2015, 45, 191–204. [Google Scholar] [CrossRef] [PubMed]
- Dowlatshahi, M.B.; Rezaeian, M. Training spiking neurons with gravitational search algorithm for data classification. In Proceedings of the Swarm Intelligence and Evolutionary Computation (CSIEC), Bam, Iran, 9–11 March 2016; pp. 53–58. [Google Scholar]
- Dowlatshahi, M.B.; Derhami, V. Winner Determination in Combinatorial Auctions using Hybrid Ant Colony Optimization and Multi-Neighborhood Local Search. J. AI Data Min. 2017, 5, 169–181. [Google Scholar]
- Siedlecki, W.; Sklansky, J. A note on genetic algorithms for large-scale feature selection. Pattern Recognit Lett. 1989, 10, 335–347. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, S.; Zeng, X. Research of multi-population agent genetic algorithm for feature selection. Expert Syst. Appl. 2009, 36, 11570–11581. [Google Scholar] [CrossRef]
- Kabir, M.M.; Shahjahan, M.; Murase, K. A new local search based hybrid genetic algorithm for feature selection. Neurocomputing 2011, 74, 2914–2928. [Google Scholar] [CrossRef]
- Huang, C.L.; Dun, J.F. A distributed PSO–SVM hybrid system with feature selection and parameter optimization. Appl. Soft Comput. 2008, 8, 1381–1391. [Google Scholar] [CrossRef]
- Chuang, L.Y.; Yang, C.H.; Li, J.C. Chaotic maps based on binary particle swarm optimization for feature selection. Appl. Soft Comput. 2011, 11, 239–248. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, S.; Phillips, P.; Ji, G. Binary PSO with mutation operator for feature selection using decision tree applied to spam detection. Knowl.-Based Syst. 2014, 64, 22–31. [Google Scholar] [CrossRef]
- Gu, S.; Cheng, R.; Jin, Y. Feature selection for high-dimensional classification using a competitive swarm optimizer. Soft Comput. 2016, 1–12. [Google Scholar] [CrossRef]
- Tanaka, K.; Kurita, T.; Kawabe, T. Selection of import vectors via binary particle swarm optimization and cross-validation for kernel logistic regression. In Proceedings of the International Joint Conference on Networks, Orlando, FL, USA, 12–17 August 2007. [Google Scholar]
- Wang, X.; Yang, J.; Teng, X.; Xia, W.; Jensen, R. Feature selection based on rough sets and particle swarm optimization. Pattern Recognit. Lett. 2007, 28, 459–471. [Google Scholar] [CrossRef]
- Sahu, B.; Mishra, D. A novel feature selection algorithm using particle swarm optimization for cancer microarray data. Procedia Eng. 2012, 38, 27–31. [Google Scholar] [CrossRef]
- Xue, B.; Zhang, M.; Browne, W.N. Particle swarm optimization for feature selection in classification: A multi-objective approach. IEEE Trans. Cybern. 2013, 43, 1656–1671. [Google Scholar] [CrossRef] [PubMed]
- Zhou, X.X.; Zhang, Y.; Ji, G.; Yang, J.; Dong, Z.; Wang, S.; Phillips, P. Detection of abnormal MR brains based on wavelet entropy and feature selection. IEEJ Trans. Electr. Electron. Eng. 2016, 11, 364–373. [Google Scholar] [CrossRef]
- Emary, E.; Zawbaa, H.M.; Hassanien, A.E. Binary ant lion approaches for feature selection. Neurocomputing 2016, 213, 54–65. [Google Scholar] [CrossRef]
- Zawbaa, H.M.; Emary, E.; Grosan, C. Feature selection via chaotic antlion optimization. PLoS ONE 2016, 11, e0150652. [Google Scholar] [CrossRef] [PubMed]
- Shunmugapriya, P.; Kanmani, S. A hybrid algorithm using ant and bee colony optimization for feature selection and classification (AC-ABC Hybrid). Swarm Evolut. Comput. 2017, 36, 27–36. [Google Scholar] [CrossRef]
- Bello, R.; Gomez, Y.; Garcia, M.M.; Nowe, A. Two-step particle swarm optimization to solve the feature selection problem. In Proceedings of the 7th International Conference on Intelligent Systems Design and Applications, Rio de Janeiro, Brazil, 22–24 October 2007; pp. 691–696. [Google Scholar]
- Oreski, S.; Oreski, G. Genetic algorithm-based heuristic for feature selection in credit risk assessment. Expert Syst. Appl. 2014, 41, 2052–2064. [Google Scholar] [CrossRef]
- Tan, F.; Fu, X.Z.; Zhang, Y.Q.; Bourgeois, A. A genetic algorithm based method for feature subset selection. Soft Comput. 2008, 12, 111–120. [Google Scholar] [CrossRef]
- Han, J.; Pei, J.; Kamber, M. Data Mining: Concepts and Techniques, 3rd ed.; Elsevier: Waltham, MA, USA, 2011. [Google Scholar]
- Liu, H.L.; Chen, L.; Deb, K.; Goodman, E.D. Investigating the effect of imbalance between convergence and diversity in evolutionary multi-objective algorithms. IEEE Trans. Evolut. Comput. 2017, 21, 408–425. [Google Scholar] [CrossRef]
- Dowlatshahi, M.B.; Nezamabadi-Pour, H.; Mashinchi, M. A discrete gravitational search algorithm for solving combinatorial optimization problems. Inf. Sci. 2014, 258, 94–107. [Google Scholar] [CrossRef]
- Rafsanjani, M.K.; Dowlatshahi, M.B. A Gravitational search algorithm for finding near-optimal base station location in two-tiered WSNs. In Proceedings of the 3rd International Conference on Machine Learning and Computing, Singapore, 26–28 February 2011; pp. 213–216. [Google Scholar]
- Črepinšek, M.; Liu, S.H.; Mernik, M. Exploration and exploitation in evolutionary algorithms: A survey. ACM Comput. Surv. 2013, 45, 1–35. [Google Scholar] [CrossRef]
- Mahdavi, S.; Rahnamayan, S.; Deb, K. Opposition based learning: A literature review. Swarm Evolut. Comput. 2017. [Google Scholar] [CrossRef]
- Battiti, R. Using mutual information for selecting features in supervised neural net learning. IEEE Trans. Neural Netw. 1994, 5, 537–550. [Google Scholar] [CrossRef] [PubMed]
- Yang, H.; Moody, J. Data visualization and feature selection: New algorithms for non-gaussian data. In Advances in Neural Information Processing Systems; Walker Road: Beaverton, OR, USA, 1999; pp. 687–693. [Google Scholar]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information: Criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef] [PubMed]
- Jakulin, A. Machine Learning Based on Attribute Interactions. Ph.D. Thesis, University of Ljubljana, Ljubljana, Slovenia, 2005. [Google Scholar]
- Lin, D.; Tang, X. Conditional infomax learning: An integrated framework for feature extraction and fusion. In Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006. [Google Scholar]
- Meyer, P.; Bontempi, G. On the use of variable complementarity for feature selection in cancer classification. In Evolutionary Computation and Machine Learning in Bioinformatics; Springer: Berlin/Heidelberg, Germany, 2006; pp. 91–102. [Google Scholar]
- Abbasifard, M.R.; Ghahremani, B.; Naderi, H. A survey on nearest neighbor search methods. Int. J. Comput. Appl. 2014, 95, 39–52. [Google Scholar]
- Chen, Y.; Xie, W.; Zou, X. A binary differential evolution algorithm learning from explored solutions. Neurocomputing 2015, 149, 1038–1047. [Google Scholar] [CrossRef]
- UCI Repository of Machine Learning Databases. Available online: http://www.ics.uci.edu/mlearn/MLRepository.html (accessed on 22 September 2017).
- Gene Expression Omnibus (GEO). Available online: https://www.ncbi.nlm.nih.gov/geo/ (accessed on 19 October 2017).
- Mitchell, A.L.; Divoli, A.; Kim, J.H.; Hilario, M.; Selimas, I.; Attwood, T.K. METIS: Multiple extraction techniques for informative sentences. Bioinformatics 2005, 21, 4196–4197. [Google Scholar] [CrossRef] [PubMed]
- Burczynski, M.E.; Peterson, R.L.; Twine, N.C.; Zuberek, K.A.; Brodeur, B.J.; Casciotti, L.; Maganti, V.; Reddy, P.S.; Strahs, A.; Immermann, F.; et al. Molecular classification of Crohn’s disease and ulcerative colitis patients using transcriptional profiles in peripheral blood mononuclear cells. J. Mol. Diagn. 2006, 8, 51–61. [Google Scholar] [CrossRef] [PubMed]
- Derrac, J.; García, S.; Molina, D.; Herrera, F. A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms. Swarm Evolut. Comput. 2011, 1, 3–18. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Dataset | No. of Features | No. of Instances | No. of Calsses |
|---|---|---|---|
| Movement | 90 | 360 | 15 |
| Musk | 167 | 6598 | 2 |
| Arrhythmia | 279 | 452 | 16 |
| Madelon | 500 | 2600 | 2 |
| Isolet5 | 617 | 1559 | 26 |
| Melanoma | 864 | 57 | 2 |
| Lung | 866 | 36 | 2 |
| InterAd | 1588 | 3279 | 2 |
| Alt | 2112 | 4157 | 2 |
| Function | 2708 | 3907 | 2 |
| Subcell | 4031 | 7977 | 2 |
| Acq | 7495 | 12,897 | 2 |
| Earn | 9499 | 12,897 | 2 |
| Crohen | 22,283 | 127 | 3 |
| Dataset | EFR-ESO | GA | CSO | PSO | Xue1-PSO | Xue2-PSO | Xue3-PSO | Xue4-PSO | PCA |
|---|---|---|---|---|---|---|---|---|---|
| Movement | 0.1918 | 0.2861 + | 0.2345 + | 0.2798 + | 0.2846 + | 0.2897 + | 0.2827 + | 0.2853 + | 0.2556 + |
| (0.0267) | (0.0399) | (0.0398) | (0.0401) | (0.0387) | (0.0436) | (0.0395) | (0.0301) | ||
| Musk | 0.0012 | 0.0039 + | 0.0010 ≈ | 0.0038 + | 0.0031 + | 0.0017 ≈ | 0.0034 + | 0.0014 ≈ | 0.0028 + |
| (0.0010) | (0.0018) | (0.0008) | (0.0021) | (0.0017) | (0.0016) | (0.0015) | (0.0012) | ||
| Arrhythmia | 0.2991 | 0.4466 + | 0.3222 + | 0.4051 + | 0.4071 + | 0.3484 + | 0.4095 + | 0.3483 + | 0.4491 + |
| (0.0203) | (0.0071) | (0.0203) | (0.0217) | (0.0223) | (0.0312) | (0.0238) | (0.0254) | ||
| Madelon | 0.1253 | 0.4244 + | 0.1545 + | 0.4105 + | 0.4062 + | 0.2712 + | 0.4087 + | 0.3673 + | 0.4812 + |
| (0.0203) | (0.0246) | (0.0343) | (0.0177) | (0.0207) | (0.1043) | (0.0214) | (0.0942) | ||
| Isolet5 | 0.1386 | 0.1866 + | 0.1401≈ | 0.1872 + | 0.1853 + | 0.1910 + | 0.1901 + | 0.1803 + | 0.4359 + |
| (0.0113) | (0.0110) | (0.0105) | (0.0115) | (0.0136) | (0.0142) | (0.0178) | (0.0162) | ||
| Melanoma | 0.1948 | 0.2981 + | 0.2350 + | 0.3173 + | 0.3154 + | 0.2920 + | 0.3064 + | 0.2796 + | 0.3721 + |
| (0.0192) | (0.0296) | (0.0284) | (0.0342) | (0.0491) | (0.0301) | (0.0429) | (0.0307) | ||
| Lung | 0.2139 | 0.3312 + | 0.2607 + | 0.3515 + | 0.3603 + | 0.3249 + | 0.3618 + | 0.3242 + | 0.3965 + |
| (0.0207) | (0.0393) | (0.0236) | (0.0442) | (0.0490) | (0.0405) | (0.0506) | (0.0345) | ||
| InterAd | 0.0251 | 0.0405 + | 0.0291 + | 0.0408 + | 0.0397 + | 0.0395 + | 0.0426 + | 0.0483 + | 0.0685 + |
| (0.0035) | (0.0069) | (0.0052) | (0.0074) | (0.0053) | (0.0048) | (0.0073) | (0.0074) | ||
| Alt | 0.1224 | 0.4018 + | 0.1647 + | 0.4239 + | 0.3904 + | 0.3727 + | 0.4183 + | 0.3572 + | 0.4215 + |
| (0.0135) | (0.0461) | (0.0206) | (0.0490) | (0.0474) | (0.0422) | (0.0445) | (0.0403) | ||
| Function | 0.2248 | 0.4259 + | 0.2303 ≈ | 0.4379 + | 0.4063 + | 0.4403 + | 0.4262 + | 0.3712 + | 0.4539 + |
| (0.0196) | (0.0492) | (0.0216) | (0.0504) | (0.0471) | (0.0513) | (0.0473) | (0.0395) | ||
| Subcell | 0.1650 | 0.2943 + | 0.2071 + | 0.2516 + | 0.2628 + | 0.2816 + | 0.2970 + | 0.2731 + | 0.3604 + |
| (0.0179) | (0.0408) | (0.0249) | (0.0325) | (0.0385) | (0.0401) | (0.0468) | (0.0374) | ||
| Acq | 0.1025 | 0.2743 + | 0.1626 + | 0.2708 + | 0.2519 + | 0.2873 + | 0.2917 + | 0.2495 + | 0.3572 + |
| (0.0137) | (0.0399) | (0.0203) | (0.0352) | (0.0371) | (0.0408) | (0.0439) | (0.0375) | ||
| Earn | 0.0742 | 0.2902 + | 0.1164 + | 0.2663 + | 0.2836 + | 0.2647 + | 0.3082 + | 0.3125 + | 0.3928 + |
| (0.0127) | (0.0375) | (0.0195) | (0.0347) | (0.0358) | (0.0317) | (0.0429) | (0.0491) | ||
| Crohen | 0.1329 | 0.3265 + | 0.1951 + | 0.3329 + | 0.3014 + | 0.3417 + | 0.2943 + | 0.2758 + | 0.4175 + |
| (0.0179) | (0.0360) | (0.0268) | (0.0407) | (0.0342) | (0.0381) | (0.0325) | (0.0351) | ||
| Better | - | 14 | 11 | 14 | 14 | 13 | 14 | 13 | 14 |
| Worse | - | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Similar | - | 0 | 3 | 0 | 0 | 1 | 0 | 1 | 0 |
| Dataset | EFR-ESO | GA | CSO | PSO | Xue1-PSO | Xue2-PSO | Xue3-PSO | Xue4-PSO | PCA |
|---|---|---|---|---|---|---|---|---|---|
| Movement | 21.13 | 43.12 + | 48.21 + | 41.25 + | 43.04 + | 23.04 ≈ | 51.12 + | 40.71 + | 10 – |
| (4.61) | (5.20) | (6.13) | (5.61) | (6.14) | (6.94) | (7.73) | (13.94) | ||
| Musk | 8.66 | 77.41 + | 12.27 + | 68.79 + | 70.37 + | 15.45 + | 72.47 + | 15.72 + | 118 + |
| (3.92) | (6.94) | (4.62) | (6.54) | (6.94) | (7.24) | (10.37) | (5.59) | ||
| Arrhythmia | 12.45 | 150.03 + | 15.84 + | 130.11 + | 131.14 + | 21.05 + | 150.14 + | 26.63 + | 106 + |
| (7.12) | (12.41) | (6.95) | (9.37) | (12.02) | (11.82) | (13.73) | (26.71) | ||
| Madelon | 7.19 | 277.07 + | 6.94 ≈ | 242.52 + | 250.94 + | 33.02 + | 318.63 + | 259.16 + | 417 + |
| (2.03) | (16.83) | (1.93) | (11.70) | (14.91) | (53.12) | (35.72) | (110.61) | ||
| Isolet5 | 97.72 | 281.22 + | 135.15 + | 301.12 + | 309.52 + | 191.38 + | 361.93 + | 365.47 + | 175 + |
| (19.07) | (10.05) | (31.07) | (14.72) | (16.07) | (40.72) | (38.17) | (55.13) | ||
| Melanoma | 15.47 | 41.65 + | 20.52 + | 37.93 + | 36.13 + | 23.18 + | 34.92 + | 30.44 + | 49 + |
| (8.93) | (19.23) | (10.29) | (21.16) | (18.65) | (15.75) | (16.35) | (17.32) | ||
| Lung | 10.25 | 35.62 + | 14.27 + | 30.44 + | 29.37 + | 17.64 + | 28.14 + | 24.02 + | 35 + |
| (6.17) | (18.52) | (13.43) | (19.17) | (17.44) | (21.49) | (19.62) | (16.71) | ||
| InterAd | 197.49 | 845.61 + | 267.63 + | 755.48 + | 763.71 + | 388.10 + | 892.04 + | 928.19 + | 286 + |
| (72.01) | (42.02) | (92.48) | (26.72) | (36.68) | (83.16) | (98.51) | (151.26) | ||
| Alt | 29.62 | 986.53 + | 40.12 + | 948.72 + | 990.16 + | 338.27 + | 957.35 + | 913.07 + | 1204 + |
| (12.43) | (61.49) | (15.89) | (55.04) | (61.82) | (36.70) | (63.93) | (65.19) | ||
| Function | 32.76 | 1207.45 + | 51.37 + | 1049.28 + | 1102.70 + | 504.56 + | 1319.52 + | 1174.21 + | 1973 + |
| (15.85) | (89.26) | (19.42) | (84.50) | (88.46) | (47.91) | (95.02) | (81.49) | ||
| Subcell | 40.16 | 1952.37 + | 49.37 + | 1775.91 + | 2004.94 + | 916.68 + | 1873.64 + | 1804.26 + | 2735 + |
| (15.93) | (112.04) | (16.30) | (109.78) | (119.73) | (79.83) | (118.33) | (129.37) | ||
| Acq | 51.49 | 3093.46 + | 63.92 + | 2714.05 + | 2993.18 + | 1329.41 + | 2813.20 + | 2951.40 + | 4512 + |
| (21.70) | (162.14) | (28.03) | (150.11) | (175.72) | (95.37) | (152.74) | (146.38) | ||
| Earn | 75.42 | 4617.25 + | 102.17 + | 4056.44 + | 4713.56 + | 2021.52 + | 4396.61 + | 4301.07 + | 6132 + |
| (23.59) | (207.11) | (31.54) | (195.71) | (219.50) | (124.13) | (197.24) | (219.14) | ||
| Crohen | 118.61 | 8752.73 + | 144.07 + | 8126.83 + | 7815.91 + | 3406.15 + | 7916.75 + | 8001.25 + | 12,740 + |
| (38.72) | (469.52) | (45.41) | (443.25) | (401.49) | (194.60) | (420.93) | (412.48) | ||
| Better | - | 14 | 13 | 14 | 14 | 13 | 14 | 14 | 13 |
| Worse | - | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| Similar | - | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dowlatshahi, M.B.; Derhami, V.; Nezamabadi-pour, H. Ensemble of Filter-Based Rankers to Guide an Epsilon-Greedy Swarm Optimizer for High-Dimensional Feature Subset Selection. Information 2017, 8, 152. https://doi.org/10.3390/info8040152
Dowlatshahi MB, Derhami V, Nezamabadi-pour H. Ensemble of Filter-Based Rankers to Guide an Epsilon-Greedy Swarm Optimizer for High-Dimensional Feature Subset Selection. Information. 2017; 8(4):152. https://doi.org/10.3390/info8040152
Chicago/Turabian StyleDowlatshahi, Mohammad Bagher, Vali Derhami, and Hossein Nezamabadi-pour. 2017. "Ensemble of Filter-Based Rankers to Guide an Epsilon-Greedy Swarm Optimizer for High-Dimensional Feature Subset Selection" Information 8, no. 4: 152. https://doi.org/10.3390/info8040152
APA StyleDowlatshahi, M. B., Derhami, V., & Nezamabadi-pour, H. (2017). Ensemble of Filter-Based Rankers to Guide an Epsilon-Greedy Swarm Optimizer for High-Dimensional Feature Subset Selection. Information, 8(4), 152. https://doi.org/10.3390/info8040152