
RL-BMAC: An RL-Based MAC Protocol for Performance Optimization in Wireless Sensor Networks


Abstract
1. Introduction
- Proposing an optimal approach to enhance the performance of the B-MAC protocol through the integration of intelligent sleep scheduling.
- Exploiting DQN to dynamically optimize the sleep and wake-up schedule of nodes based on real-time network conditions.
- Demonstrating the effectiveness of the proposed approach through extensive simulations, showcasing substantial performance improvement while maintaining reliable communication.
2. Related Work
3. Proposed Protocol
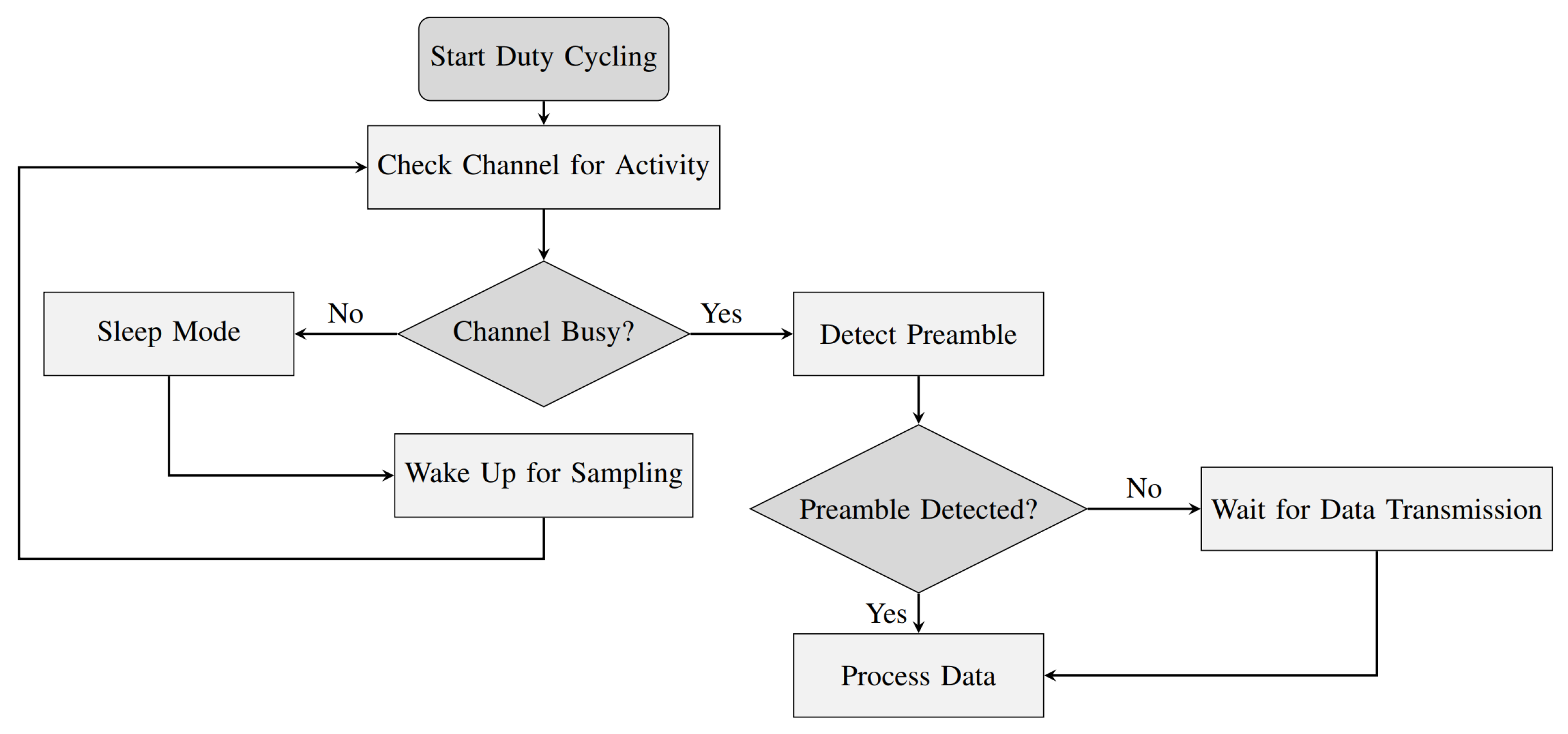
3.1. B-MAC
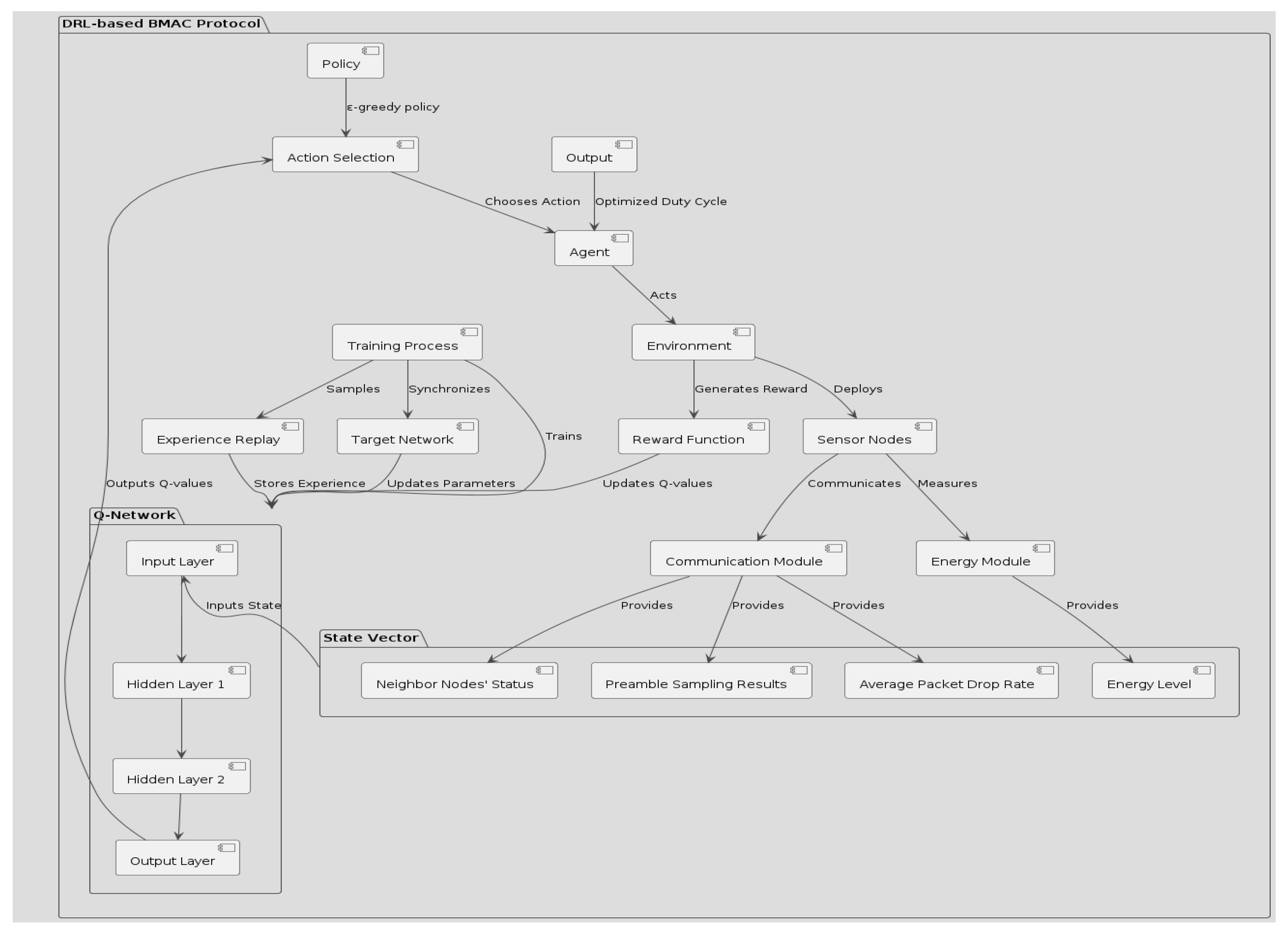
3.2. RL-BMAC
| Algorithm 1: RL-BMAC: Modified MAC Protocol with Deep RL |
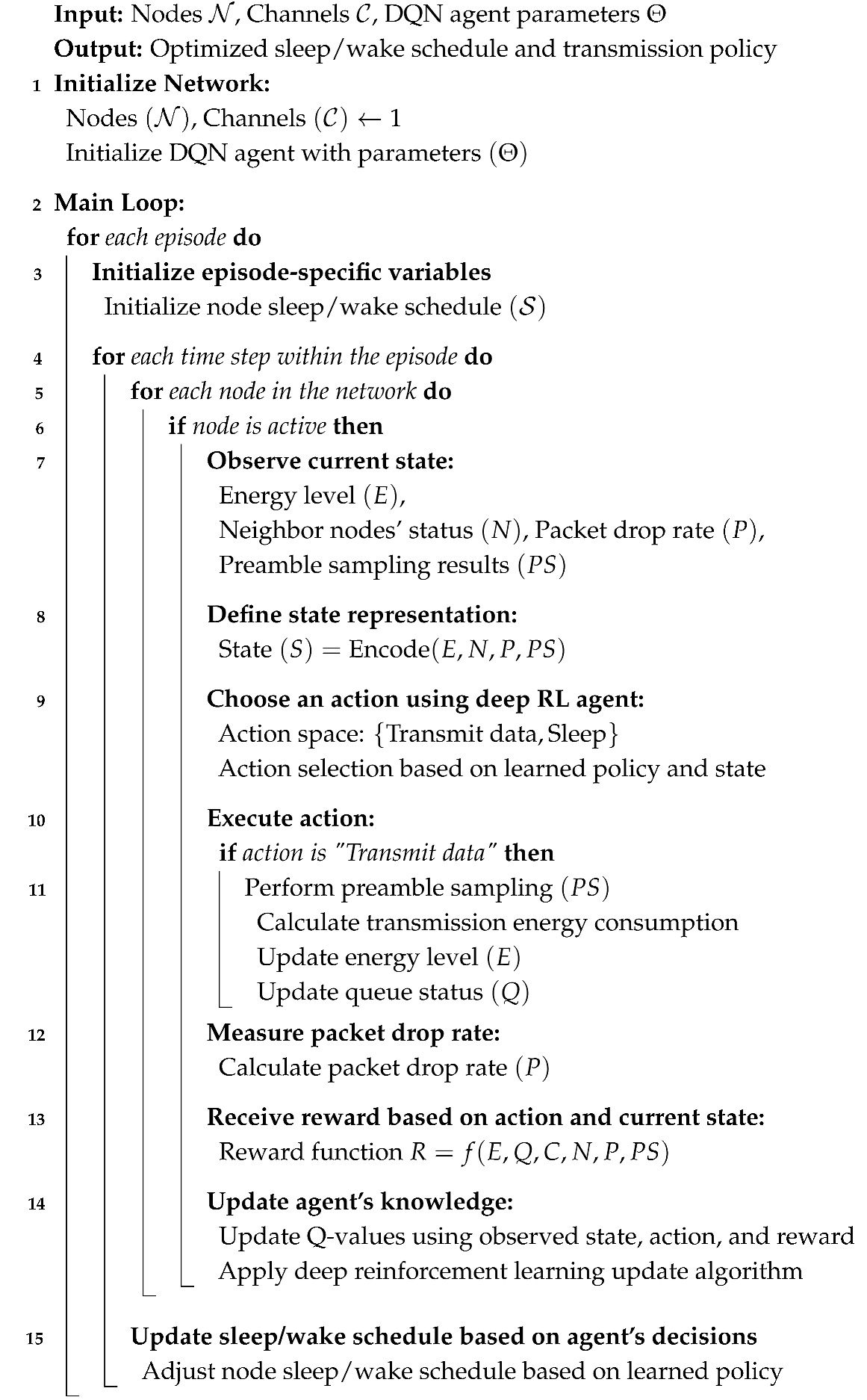 |
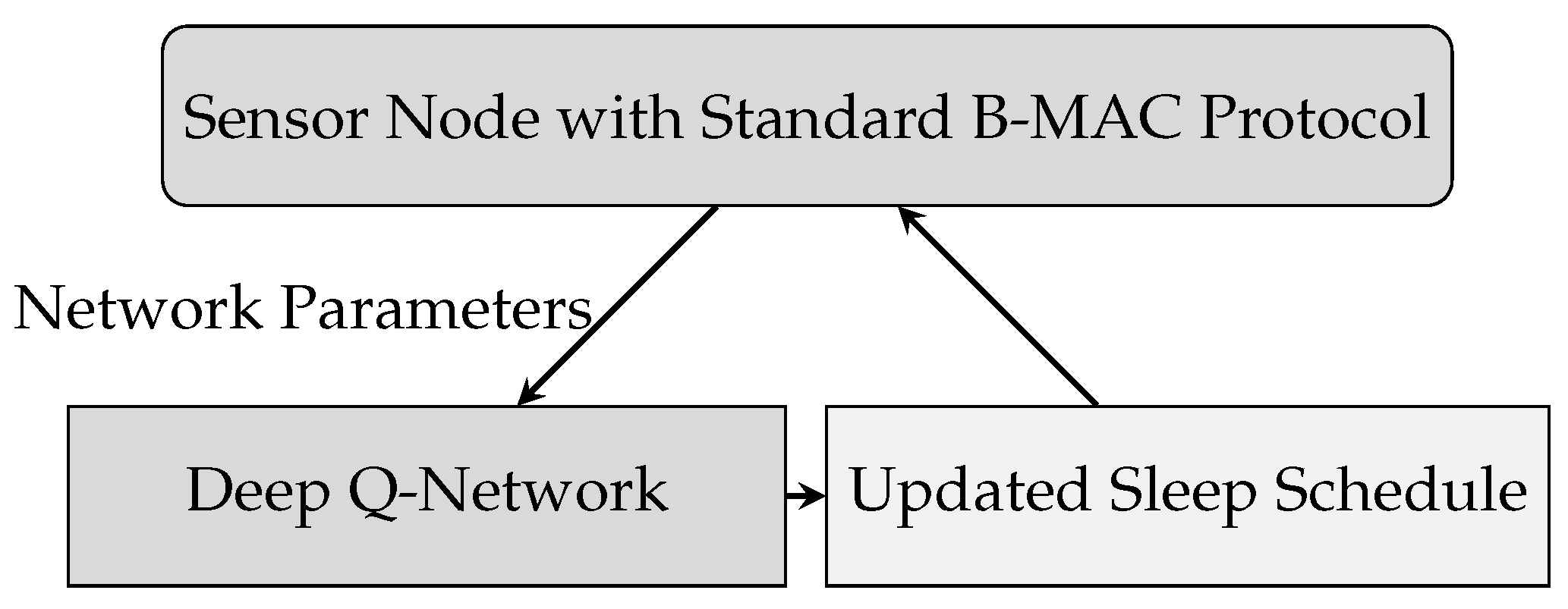
Deep Q-Network Agent Deployment in RL-BMAC
4. Simulation Results and Discussion
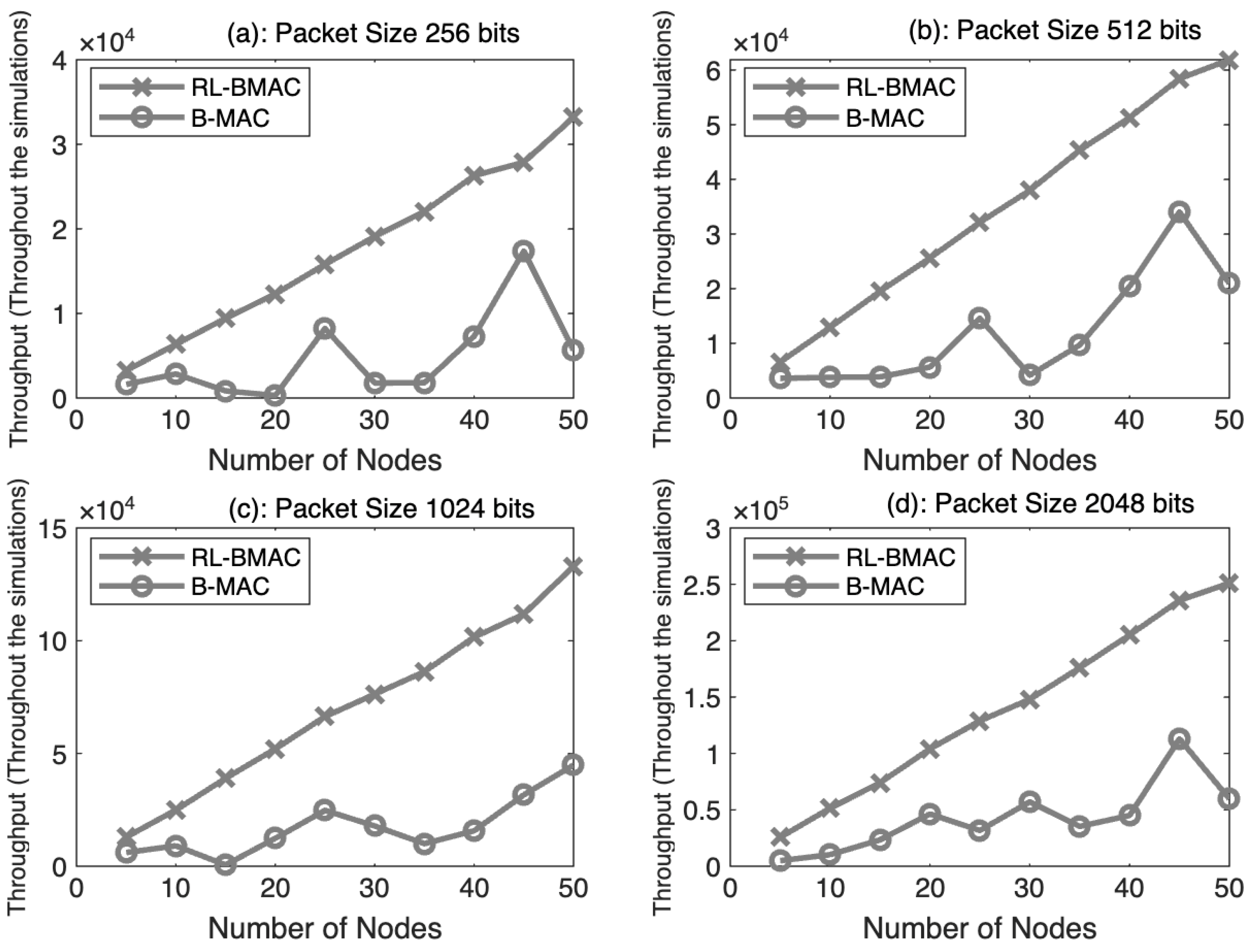
4.1. Throughput with Respect to Number of Nodes
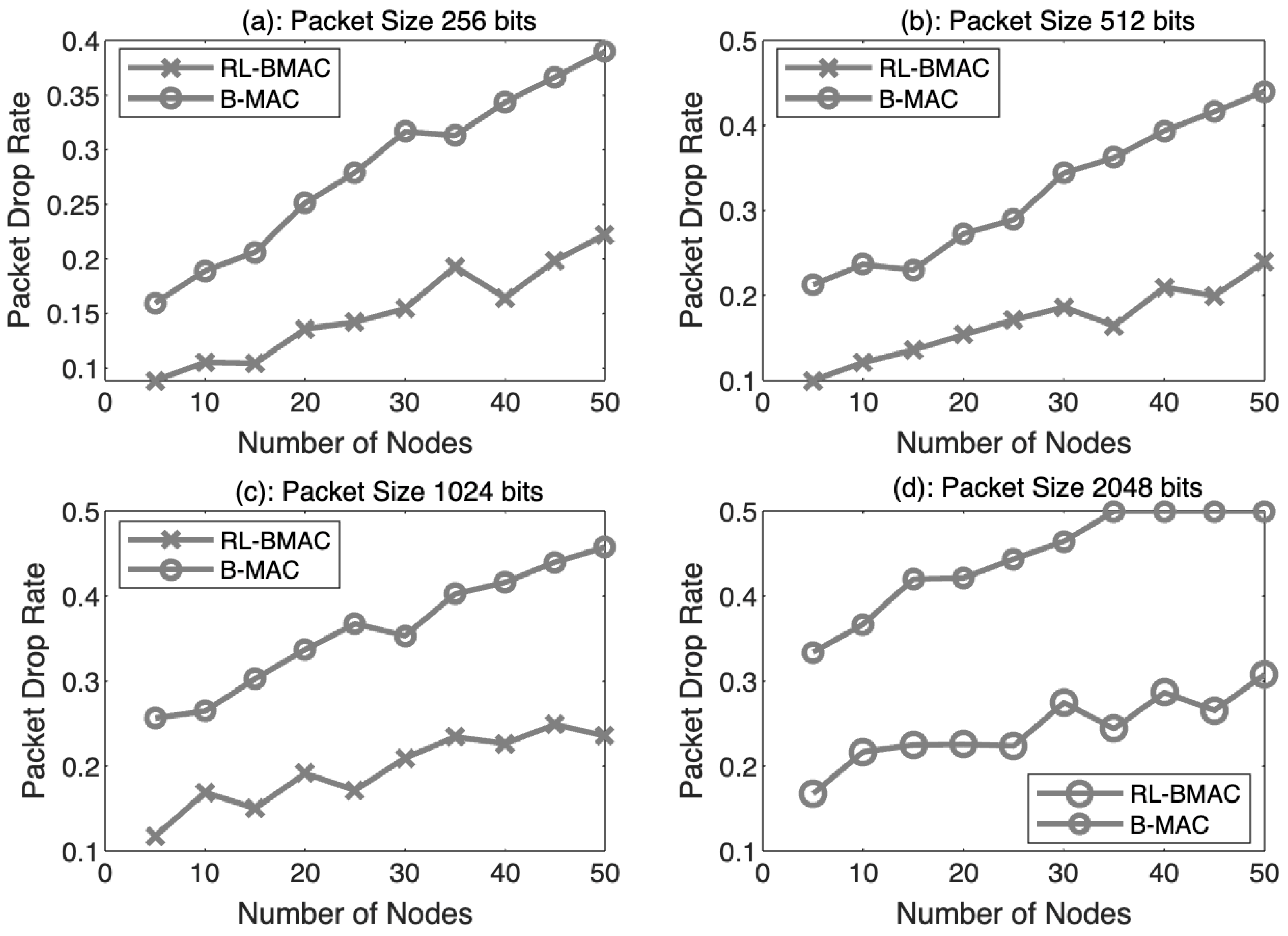
4.2. Packet Drop Rate with Respect to Number of Nodes
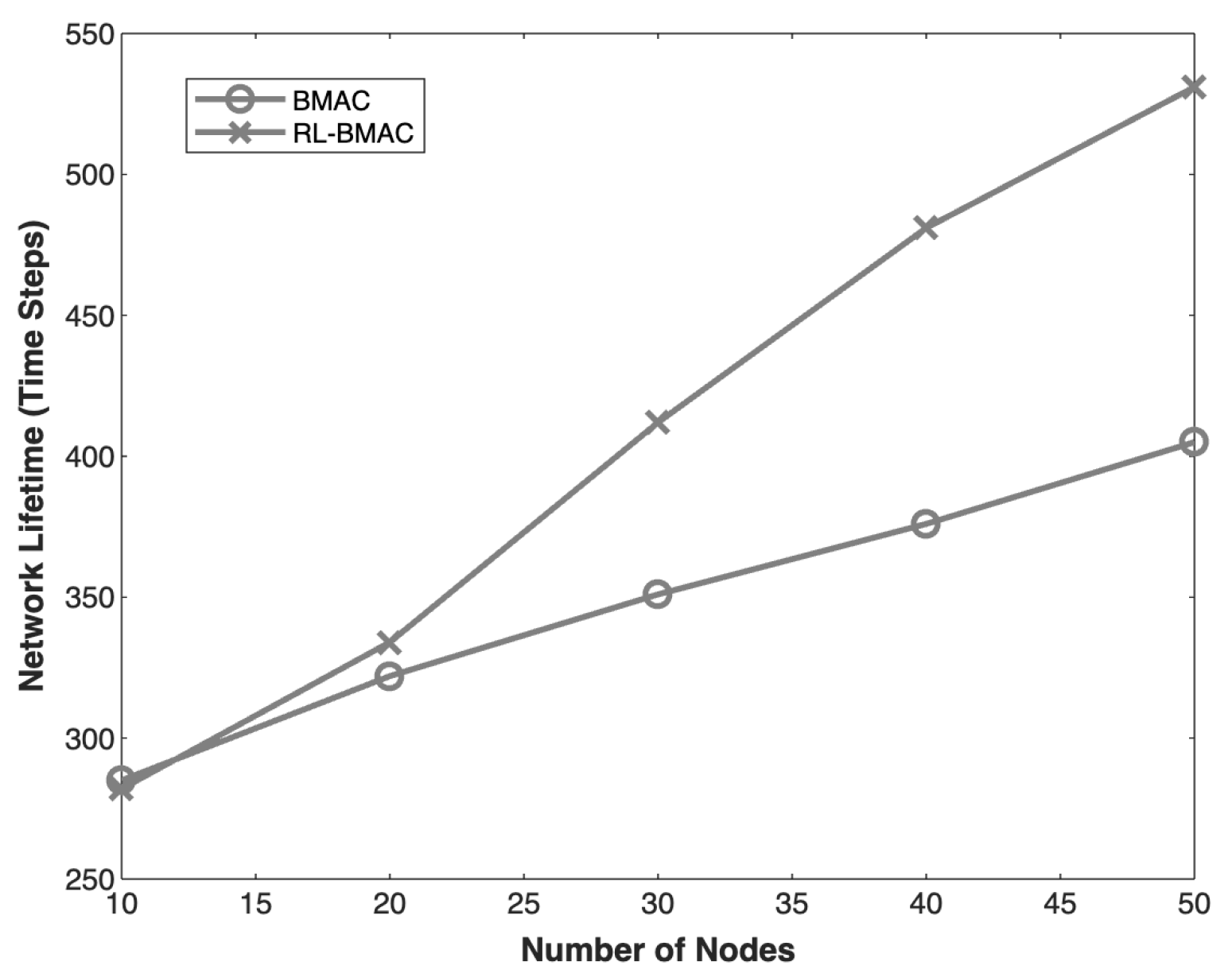
4.3. Network Lifetime with Respect to Number of Nodes
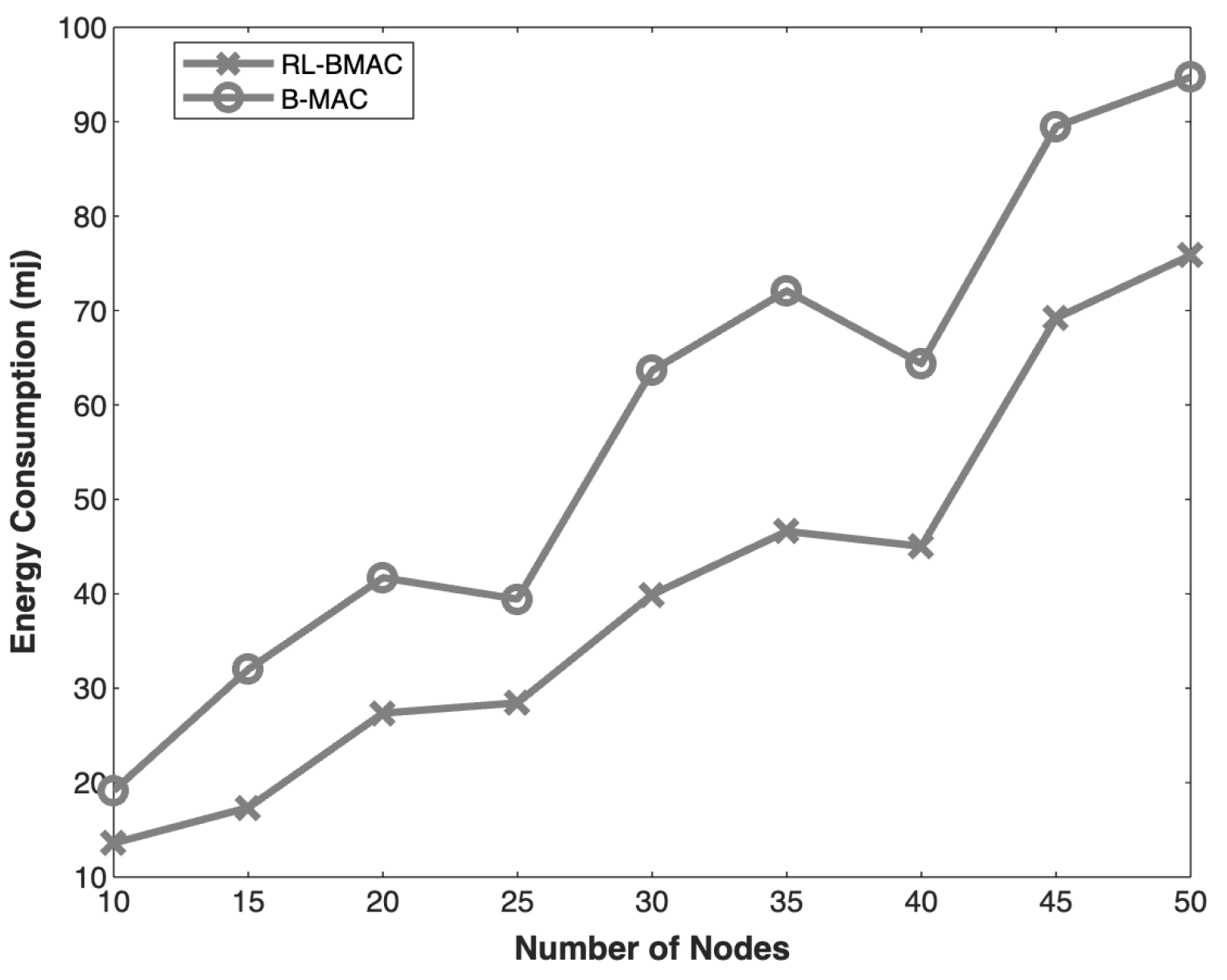
4.4. Energy Consumption with Respect to Number of Nodes
4.5. Packet Drop Rate with Respect to Packet Arrival Rate
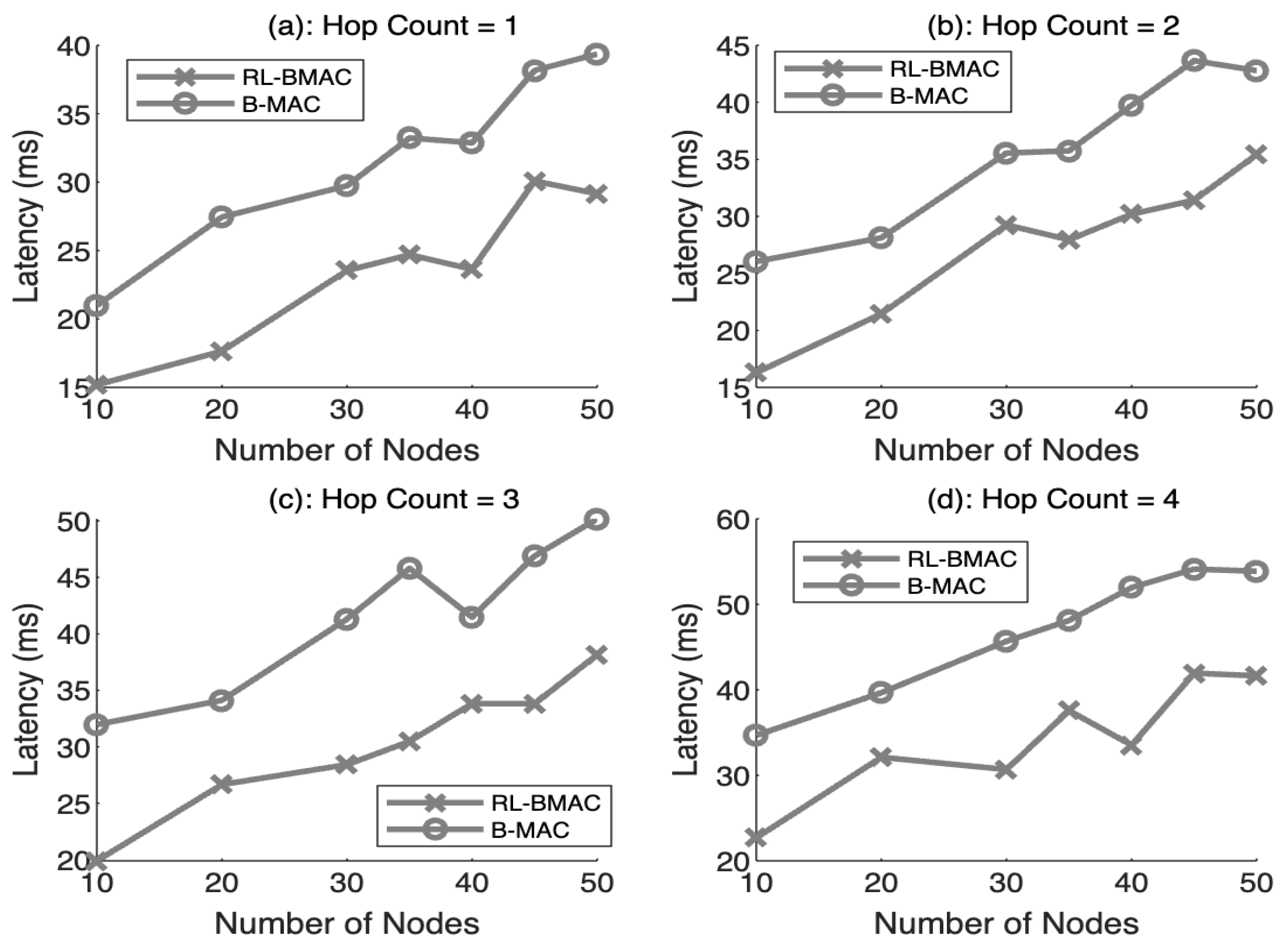
4.6. Latency with Respect to Number of Nodes for Varying Number of Hop Counts
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yadav, A.K.; Kumar, A. The Smart Analysis of Prolong Lifetime in Industrial Wireless Sensor Networks. In Proceedings of the 2023 International Conference on Distributed Computing and Electrical Circuits and Electronics (ICDCECE), Ballar, India, 29–30 April 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Adu-Manu, K.S.; Engmann, F.; Sarfo-Kantanka, G.; Baiden, G.E.; Dulemordzi, B.A. WSN Protocols and Security Challenges for Environmental Monitoring Applications: A Survey. J. Sens. 2022, 2022, 1628537. [Google Scholar] [CrossRef]
- Ye, W.; Heidemann, J.; Estrin, D. An Energy-Efficient MAC Protocol for Wireless Sensor Networks. In Proceedings of the Twenty-First Annual Joint Conference of the IEEE Computer and Communications Societies, New York, NY, USA, 23–27 June 2002. [Google Scholar]
- Polastre, J.; Hill, J.; Culler, D. Versatile low power media access for wireless sensor networks. In Proceedings of the 2nd International Conference on Embedded Networked Sensor Systems, Baltimore, MD, USA, 3–5 November 2004; pp. 95–107. [Google Scholar]
- Ruan, Z.; Luo, H.; Xu, G. Time-Aware and Energy Efficient Data Collection Mechanism for Duty-Cycled Wireless Sensor Networks. In Proceedings of the Artificial Intelligence and Security, New York, NY, USA, 26–28 July 2019; Sun, X., Pan, Z., Bertino, E., Eds.; Springer: Cham, Switzerland, 2019; pp. 199–210. [Google Scholar]
- Lee, H.; Kim, S. Optimizing LoRa Networks with Deep Reinforcement Learning. arXiv 2023, arXiv:2309.08965. [Google Scholar]
- Sharma, A.; Gupta, P. Energy and Security Trade-off in Wireless Sensor Networks using DRL. Sensors 2024, 24, 1993. [Google Scholar]
- van Dam, T.; Langendoen, K. An Adaptive Energy-Efficient MAC Protocol for Wireless Sensor Networks. In Proceedings of the 1st International Conference on Embedded Networked Sensor Systems, Los Angeles, CA, USA, 5–7 November 2003. [Google Scholar]
- El-Hoiydi, A.; Decotignie, J.D. WiseMAC: An Ultra Low Power MAC Protocol for Multi-hop Wireless Sensor Networks. In International Symposium on Algorithms and Experiments for Sensor Systems, Wireless Networks and Distributed Robotics; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Buettner, M.; Yee, G.V.; Anderson, E.; Han, R. X-MAC: A Short Preamble MAC Protocol for Duty-Cycled Wireless Sensor Networks. In Proceedings of the 4th International Conference on Embedded Networked Sensor Systems, Boulder, CO, USA, 31 October–3 November 2006. [Google Scholar]
- van Hoesel, L.; Havinga, P. A Lightweight Medium Access Protocol (LMAC) for Wireless Sensor Networks. In Proceedings of the INSS’04. Society of Instrument and Control Engineers (SICE), Tokyo, Japan, 22–23 June 2024. [Google Scholar]
- Rhee, I.; Warrier, A.; Aia, M.; Min, J. Z-MAC: A Hybrid MAC for Wireless Sensor Networks. In Proceedings of the 3rd International Conference on Embedded Networked Sensor Systems, San Diego, CA, USA, 2–4 November 2005. [Google Scholar]
- Blok, V. Sleep Scheduling for Enhancing the Lifetime of Three-Dimensional Heterogeneous Wireless Sensor Networks. In Proceedings of the CCF Conference on Computer Supported Cooperative Work and Social Computing, Taiyuan, China, 25–27 November 2022. [Google Scholar] [CrossRef]
- Pulipati, B.; Pat, D.U.; Miryala, A.; Sathish, K.; Ravi Kumar, C.V. Energy aware multilevel clustering scheme with Wake-Up Sleep Algorithm in underwater wireless sensor networks. J. Eng. Appl. Sci. 2023, 18, 1547–1553. [Google Scholar] [CrossRef]
- Beboratta, S.; Senapati, D.; Rajput, N. Evidence of power-law behavior in cognitive IoT applications. Neural Comput. Appl. 2020, 32, 16043–16055. [Google Scholar] [CrossRef]
- Ruan, T.; Chew, Z.J.; Zhu, M. Energy-aware approaches for energy harvesting powered wireless sensor nodes. IEEE Sens. J. 2017, 17, 2165–2173. [Google Scholar] [CrossRef]
- Mukherjee, R.; Kundu, A.; Mukherjee, I.; Gupta, D.; Tiwari, P.; Khanna, A.; Shorfuzzaman, M. IoT-cloud based healthcare model for COVID-19 detection: An enhanced k-nearest neighbour classifier based approach. Computing 2021, 105, 849–869. [Google Scholar] [CrossRef]
- Magsi, H.; Sodhro, A.H.; Al-Rakhami, M.S.; Zahid, N.; Pirbhulal, S.; Wang, L. A novel adaptive battery-aware algorithm for data transmission in IoT-based healthcare applications. Electronics 2021, 10, 367. [Google Scholar] [CrossRef]
- Sodhro, A.H.; Li, Y.; Shah, M.A. Energy-efficient adaptive transmission power control for wireless body area networks. IET Commun. 2016, 10, 81–90. [Google Scholar] [CrossRef]
- Sandhu, M.M.; Khalifa, S.; Jurdak, R.; Portmann, M. Task scheduling for energy-harvesting-based IoT: A survey and critical analysis. IEEE Internet Things J. 2021, 8, 13825–13848. [Google Scholar] [CrossRef]
- Shah, R.C.; Rabaey, J.M. Energy aware routing for low energy ad hoc sensor networks. In Proceedings of the IEEE Wireless Communications and Networking Conference, Orlando, FL, USA, 17–21 March 2002; IEEE: Piscataway, NJ, USA, 2002; Volume 1, pp. 350–355. [Google Scholar]
- Rodoplu, V.; Meng, T.H. Minimum energy mobile wireless networks. IEEE J. Sel. Areas Commun. 1999, 17, 1333–1344. [Google Scholar] [CrossRef]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Konda, V.R.; Tsitsiklis, J.N. Actor-critic algorithms. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 1 January 2000; pp. 1008–1014. [Google Scholar]
- Rummery, G.A.; Niranjan, M. On-Line Q-Learning Using Connectionist Systems; Technical Report, Technical Report CUED/F-INFENG/TR 166; Cambridge University Engineering Department: Cambridge, UK, 1994. [Google Scholar]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double Q-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Kosunalp, S. A new energy prediction algorithm for energy-harvesting wireless sensor networks with Q-learning. IEEE Access 2016, 4, 5755–5763. [Google Scholar] [CrossRef]
- Sharma, A.; Kakkar, A. Forecasting daily global solar irradiance generation using machine learning. Renew. Sustain. Energy Rev. 2018, 82, 2254–2269. [Google Scholar] [CrossRef]
- Kumar, D.P.; Tarachand, A.; Annavarapu, C.S.R. Machine learning algorithms for wireless sensor networks: A survey. Inf. Fusion 2019, 49, 1–25. [Google Scholar] [CrossRef]
- Alsheikh, M.A.; Lin, S.; Niyato, D.; Tan, H.P. Machine learning in wireless sensor networks: Algorithms, strategies, and applications. IEEE Commun. Surv. Tutor. 2014, 16, 1996–2018. [Google Scholar] [CrossRef]
- Sharma, H.; Haque, A.; Blaabjerg, F. Machine learning in wireless sensor networks for smart cities: A survey. Electronics 2021, 10, 1012. [Google Scholar] [CrossRef]
- Sharma, T.; Balyan, A.; Nair, R.; Jain, P.; Arora, S.; Ahmadi, F. ReLeC: A Reinforcement Learning-Based Clustering-Enhanced Protocol for Efficient Energy Optimization in Wireless Sensor Networks. Wirel. Commun. Mob. Comput. 2022, 2022, 3337831. [Google Scholar] [CrossRef]
- Dutta, H.; Bhuyan, A.K.; Biswas, S. Reinforcement Learning for Protocol Synthesis in Resource-Constrained Wireless Sensor and IoT Networks. arXiv 2023, arXiv:2302.05300. [Google Scholar]
- Keshtiarast, N.; Renaldi, O.; Petrova, M. Wireless MAC Protocol Synthesis and Optimization with Multi-Agent Distributed Reinforcement Learning. arXiv 2024, arXiv:2408.05884. [Google Scholar] [CrossRef]
- Kim, H.Y.; Kim, S.C. A Reinforcement Learning-Based Energy Efficient and QoS Supporting MAC Protocol for Wireless Sensor Networks. J. Southwest Jiaotong Univ. 2023, 58. [Google Scholar] [CrossRef]
- Joshi, U.; Kumar, R. Reinforcement Learning Based Energy Efficient Protocol for Wireless Multimedia Sensor Networks. Multimed. Tools Appl. 2022, 81, 2827–2840. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Protocol Used | Problem Addressed | Methodology | Limitations |
|---|---|---|---|
| TMAC Protocol [8] | Energy-efficient communication | Adaptive Duty Cycling through Adaptive Time Interval | Performance degradation in low-traffic scenarios due to early sleeping; can miss incoming transmissions. |
| S-MAC [3] | Energy conservation in sensor networks | Duty cycling for sleep synchronization to minimize idle listening | Fixed sleep schedules lead to increased latency and reduced throughput, especially under variable traffic loads. |
| EAR [21] | Energy-aware routing in ad hoc networks | Routing protocol with energy-based metrics for route selection | Inability to react to rapid topology changes due to static route assumptions; leads to sub-optimal path selection. |
| MECN [22] | Minimum energy communication in mobile wireless networks | Sub-network construction using localized algorithms | High control overhead and computational complexity; unsuitable for highly dynamic or dense topologies. |
| Q-learning [23] | Optimal energy routing in dynamic networks | Model-free RL approach for learning optimal routing policies | Slow convergence in large state-action spaces; performance deteriorates without sufficient exploration control |
| DQN [24] | Energy optimization under dynamic network conditions | DQN using neural networks for Q-value approximation | High resource consumption during training; requires a large replay buffer and is impractical for deployment on constrained nodes without simplification. |
| Actor–Critic [25] | Dynamic energy management | Model-free RL with separate value and policy networks | Susceptible to instability due to non-stationary targets; requires careful synchronization between actor and critic networks. |
| SARSA [26] | Energy-efficient routing in wireless networks | On-policy RL for learning state-action values directly | Slower convergence compared to Q-learning |
| Double DQN [27] | Mitigating overestimation in Q-learning | Improved DQN with separate networks to reduce overestimation bias | Tends to converge more slowly than off-policy methods; sensitive to exploration policy and may underperform in sparse reward settings. |
| Parameter | Value |
|---|---|
| Queue Status | Initial queue empty |
| State Size | 4 (Energy, Neighbors, Packet drop rate, Preamble sampling) |
| Action Size | 2 ({Transmit data, Sleep}) |
| Learning Rate | 0.001 |
| Discount Factor | 0.95 |
| Epsilon | 1.0 (Initial) |
| Epsilon Decay | 0.995 |
| Epsilon Minimum | 0.01 |
| Batch Size | 32 |
| Maximum Memory Size | 5000 (Replay Memory) |
| S. No. | Experiment | Average Performance Improvement of RL-BAC |
|---|---|---|
| 1 | Throughput Vs. Number of Nodes | 58.5% |
| 2 | Packet Drop Rate with respect to Number of Nodes | 44.8% |
| 3 | Network Life Time with respect to Number of Nodes | 16.69% |
| 4 | Energy Consumption with respect to Number of Node | 35% |
| 6 | Packet Drop Rate with respect to Packet Arrival Rates | 65% |
| 7 | Latency with respect to Number of Hops | 26.93% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, O.; Ullah, S.; Khan, M.; Chao, H.-C. RL-BMAC: An RL-Based MAC Protocol for Performance Optimization in Wireless Sensor Networks. Information 2025, 16, 369. https://doi.org/10.3390/info16050369
Khan O, Ullah S, Khan M, Chao H-C. RL-BMAC: An RL-Based MAC Protocol for Performance Optimization in Wireless Sensor Networks. Information. 2025; 16(5):369. https://doi.org/10.3390/info16050369
Chicago/Turabian StyleKhan, Owais, Sana Ullah, Muzammil Khan, and Han-Chieh Chao. 2025. "RL-BMAC: An RL-Based MAC Protocol for Performance Optimization in Wireless Sensor Networks" Information 16, no. 5: 369. https://doi.org/10.3390/info16050369
APA StyleKhan, O., Ullah, S., Khan, M., & Chao, H.-C. (2025). RL-BMAC: An RL-Based MAC Protocol for Performance Optimization in Wireless Sensor Networks. Information, 16(5), 369. https://doi.org/10.3390/info16050369