




Underwater-YCC: Underwater Target Detection Optimization Algorithm Based on YOLOv7

Abstract
1. Introduction
- Underwater data collection poses challenges due to the poor image quality and limited number of learnable samples. To overcome these challenges, this paper adopts data-enhancement methods, including random flipping, stretching, mosaic enhancement, and mixup, to enrich the learnable samples of the model. This approach improves the generalization ability of the model and helps to prevent overfitting.
- In order to extract more comprehensive semantic information and enhance the feature extraction capability of the model, we incorporate the CBAM attention mechanism into each component of the YOLOv7 architecture. Specifically, we introduce the CBAM attention mechanism into the Backbone, Neck, and Head structures, respectively, to identify the most effective location for the attention mechanism. Our experimental results reveal that embedding the CBAM attention mechanism into the Neck structure yields the best performance, as it allows the model to capture fine-grained semantic information and more effectively detect targets.
- To enhance the ability of the model to detect objects in underwater images with poor quality, this paper introduces Conv2Former as the Neck component of the network. The Conv2Former model can effectively handle images with different resolutions and extract useful features for fusion, thereby improving the overall detection performance of the network on blurred underwater images.
- As low-quality underwater images can negatively affect the model’s generalization ability, this paper introduces Wise-IoU as a bounding box regression loss function. This function improves the detection accuracy of the model by weighing the learning of samples of different qualities, resulting in more accurate localization and regression of targets in low-quality underwater images.
2. Related Work
2.1. Underwater Dataset Acquisition and Analysis
2.2. Data Augmentation
2.2.1. Geometric Transformation
2.2.2. Mixup Data Augmentation
2.2.3. Mosaic Data Augmentation
2.3. Attention Mechanism
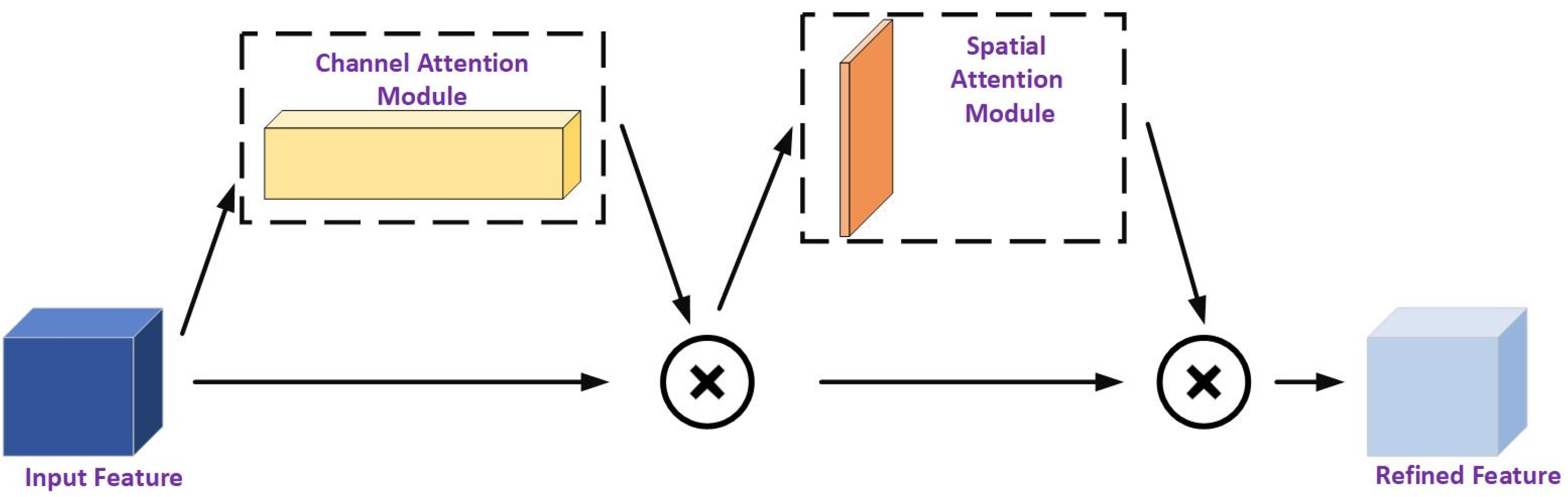
Convolutional Block Attention Module
2.4. YOLOv7 Network Architecture
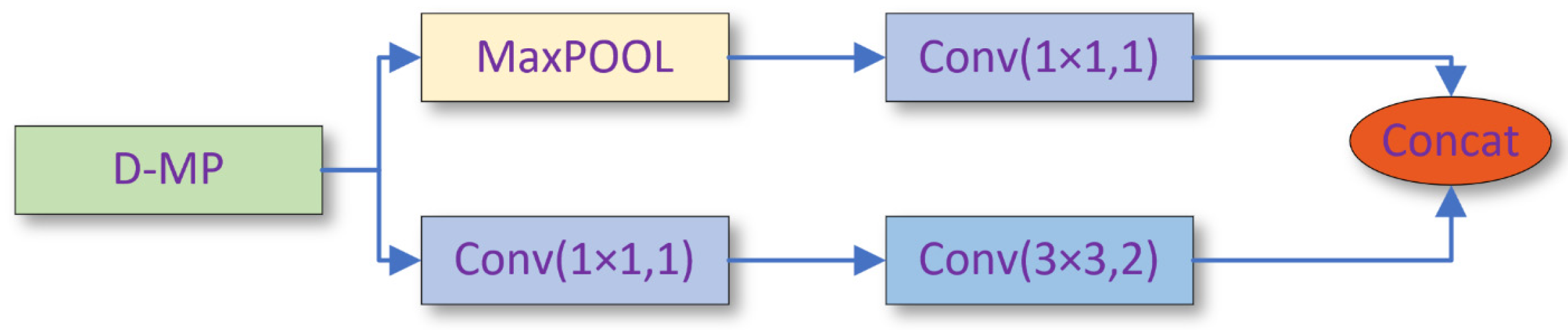
2.4.1. Backbone
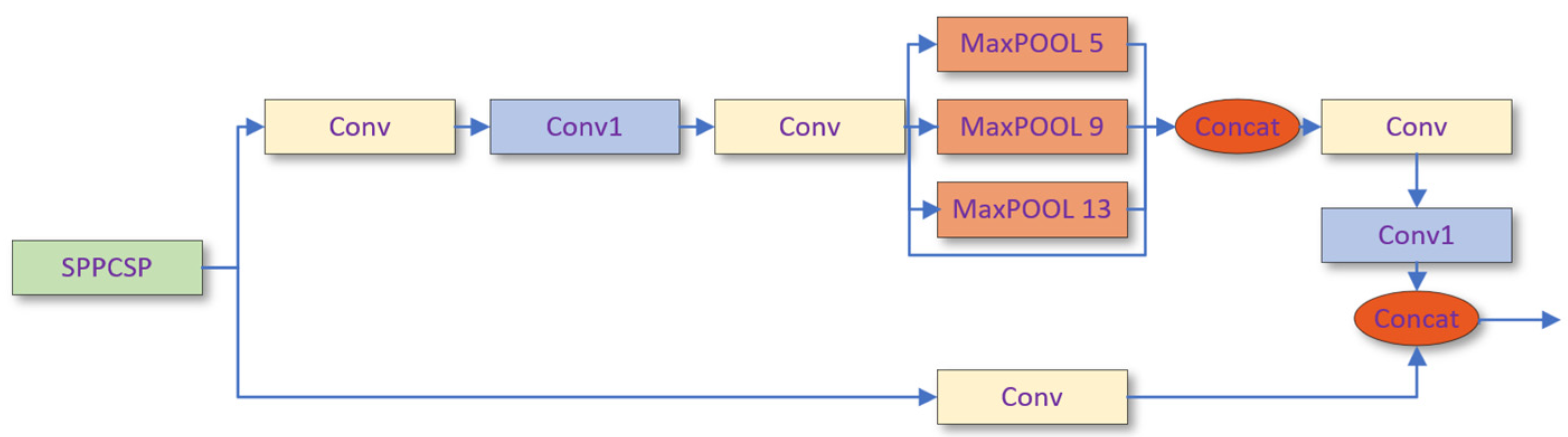
2.4.2. Neck
2.4.3. Head
3. Underwater-YCC Algorithm
3.1. YOLOv7 with CBAM
3.2. Neck Improvement Based on Conv2Former
3.3. Introduction of Wise-IoU Bounding Box Loss Function
4. Experiments
4.1. Experimental Platform
4.2. Evaluation Metrics
4.3. Experimental Results and Analysis
4.3.1. Data Augmentation
4.3.2. Fusion Attention Mechanism Comparison Test
4.3.3. Ablation Experiments
4.3.4. Target Detection Network Comparison Experiment Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sarkar, P.; De, S.; Gurung, S. A Survey on Underwater Object Detection. In Intelligence Enabled Research; Springer: Singapore, 2022; pp. 91–104. [Google Scholar]
- Jian, M.; Liu, X.; Luo, H.; Lu, X.; Yu, H.; Dong, J. Underwater image processing and analysis: A review. Signal Process. Image Commun. 2021, 91, 116088. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object detection with deep learning. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Uijlings, J.R.R.; Van De Sande, K.E.A.; Gevers, T.; Smeulders, A.W.M. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Deng, J.; Xuan, X.; Wang, W.; Li, Z.; Yao, H.; Wang, Z. A review of research on object detection based on deep learning. J. Phys. Conf. Ser. 2020, 1684, 012028. [Google Scholar] [CrossRef]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhao, S.; Zheng, J.; Sun, S.; Zhang, L. An Improved YOLO Algorithm for Fast and Accurate Underwater Object Detection. Symmetry 2022, 14, 1669. [Google Scholar] [CrossRef]
- Zhang, M.; Xu, S.; Song, W.; He, Q.; Wei, Q. Lightweight underwater object detection based on yolo v4 and multi-scale attentional feature fusion. Remote Sens. 2021, 13, 4706. [Google Scholar] [CrossRef]
- Li, Y.; Bai, X.; Xia, C. An Improved YOLOV5 Based on Triplet Attention and Prediction Head Optimization for Marine Organism Detection on Underwater Mobile Platforms. J. Mar. Sci. Eng. 2022, 10, 1230. [Google Scholar] [CrossRef]
- Zhai, X.; Wei, H.; He, Y.; Shang, Y.; Liu, C. Underwater Sea Cucumber Identification Based on Improved YOLOv5. Appl. Sci. 2022, 12, 9105. [Google Scholar] [CrossRef]
- Liu, Z.; Zhuang, Y.; Jia, P.; Wu, C.; Xu, H.; Liu, Z. A Novel Underwater Image Enhancement and Improved Underwater Biological Detection Pipeline. J. Mar. Sci. Eng. 2022, 10, 1204. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Guo, M.-H.; Xu, T.-X.; Liu, J.-J.; Liu, Z.-N.; Jiang, P.-T.; Mu, T.-J.; Zhang, S.-H.; Martin, R.R.; Cheng, M.-M.; Hu, S.-M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Hou, Q.; Lu, C.Z.; Cheng, M.M.; Feng, J. Conv2Former: A Simple Transformer-Style ConvNet for Visual Recognition. arXiv 2022, arXiv:2211.11943. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configuration | Parameter |
|---|---|
| CPU | Intel(R) Core(TM) i9-10920X |
| GPU | NVIDIA GeForce RTX 3090 |
| Operating system | Windows10 |
| Frame | Pytorch1.7 |
| CUDA | 11.7 |
| Batch Size | 16 |
| Epochs | 300 |
| Image Size | 640 * 640 |
| Mixup | Mosaic | Precision | Recall | mAP |
|---|---|---|---|---|
| × | × | 66.93% | 60.63% | 64.59% |
| √ | × | 73.34% | 64.08% | 69.50% |
| × | √ | 81.82% | 75.09% | 81.91% |
| √ | √ | 84.21% | 80.97% | 85.67% |
| Model | Precision | Recall | mAP |
|---|---|---|---|
| YOLOv7 | 84.21% | 80.97% | 85.67% |
| v7_Backbone | 84.00% | 81.57% | 86.11% |
| v7_Neck | 84.90% | 80.67% | 86.68% |
| v7_Head | 83.15% | 81.05% | 85.61% |
| Model | CBAM | Conv2Former | Wise-IoU | Precision | Recall | mAP |
|---|---|---|---|---|---|---|
| YOLOv7 | × | × | × | 84.21% | 80.97% | 85.67% |
| (a) YOLOv7_A | √ | × | × | 84.90% | 80.67% | 86.68% |
| (b) YOLOv7_B | × | √ | × | 83.97% | 81.84% | 86.52% |
| (c) YOLOv7_C | × | × | √ | 82.53% | 82.01% | 86.55% |
| (d) YOLOv7_D | √ | × | √ | 85.24% | 79.84% | 86.84% |
| (e) YOLOv7_E | × | √ | √ | 84.26% | 81.06% | 86.93% |
| Underwater-YCC | √ | √ | √ | 84.64% | 81.38% | 87.16% |
| Model | Precision | Recall | mAP | F1 Score | FPS |
|---|---|---|---|---|---|
| Faster-RCNN | 38.3% | 55.26% | 62.1% | 45.24 | 16 |
| YOLOv3 | 76.6% | 64.3% | 80.9% | 69.91 | |
| YOLOv5s | 83.34% | 78.96% | 83.88% | 81.09 | 46.51 |
| YOLOv6 | 82.1% | 63.6% | 82.09% | 71.67 | |
| YOLOv7-Tiny | 81.44%% | 79.14% | 84.21% | 80.27 | 32.89 |
| YOLOv7 | 84.21% | 80.97% | 85.67% | 82.55 | 26.42 |
| Underwater-YCC | 84.64% | 81.38% | 87.16% | 82.97 | 21.17 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Yuan, M.; Yang, Q.; Yao, H.; Wang, H. Underwater-YCC: Underwater Target Detection Optimization Algorithm Based on YOLOv7. J. Mar. Sci. Eng. 2023, 11, 995. https://doi.org/10.3390/jmse11050995
Chen X, Yuan M, Yang Q, Yao H, Wang H. Underwater-YCC: Underwater Target Detection Optimization Algorithm Based on YOLOv7. Journal of Marine Science and Engineering. 2023; 11(5):995. https://doi.org/10.3390/jmse11050995
Chicago/Turabian StyleChen, Xiao, Mujiahui Yuan, Qi Yang, Haiyang Yao, and Haiyan Wang. 2023. "Underwater-YCC: Underwater Target Detection Optimization Algorithm Based on YOLOv7" Journal of Marine Science and Engineering 11, no. 5: 995. https://doi.org/10.3390/jmse11050995
APA StyleChen, X., Yuan, M., Yang, Q., Yao, H., & Wang, H. (2023). Underwater-YCC: Underwater Target Detection Optimization Algorithm Based on YOLOv7. Journal of Marine Science and Engineering, 11(5), 995. https://doi.org/10.3390/jmse11050995