
Audlet Filter Banks: A Versatile Analysis/Synthesis Framework Using Auditory Frequency Scales

 , , ,
, , ,
Abstract
Featured Application
Abstract
1. Introduction
2. Preliminaries
2.1. Notations and Definition
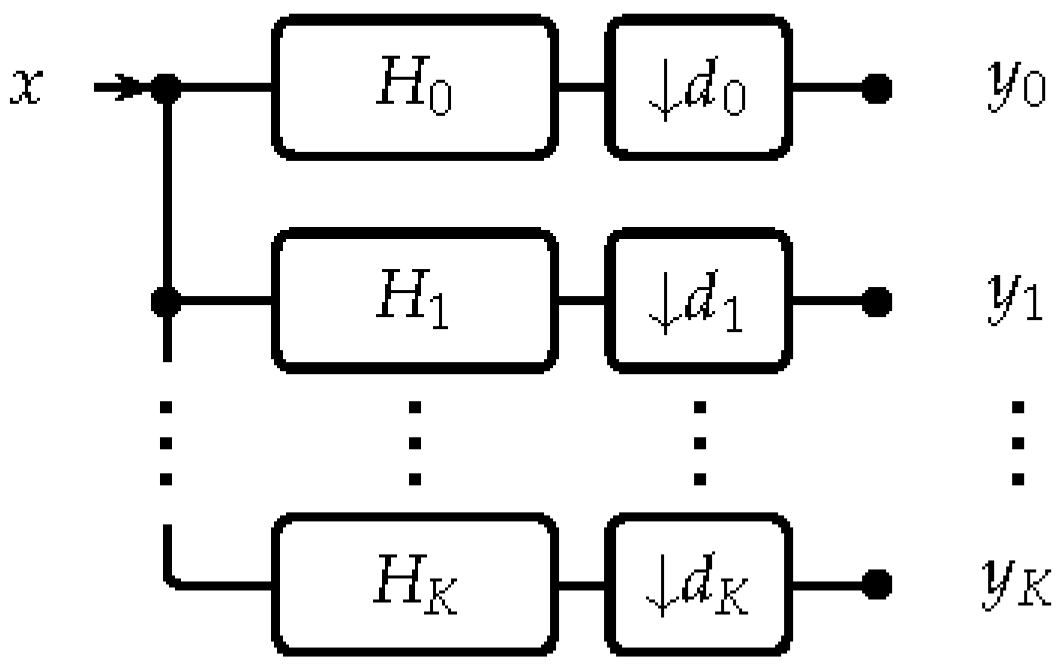
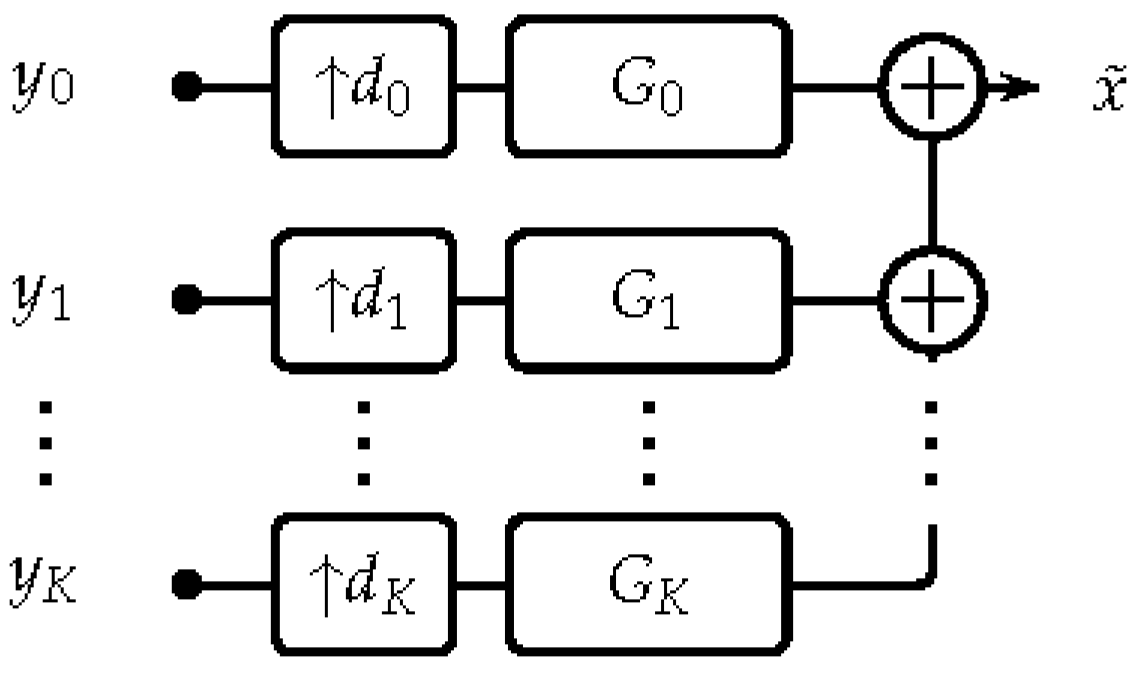
2.2. Filter Banks and Frames
2.3. Auditory Frequency Scales
3. The Proposed Approach
3.1. Analysis Filter Bank
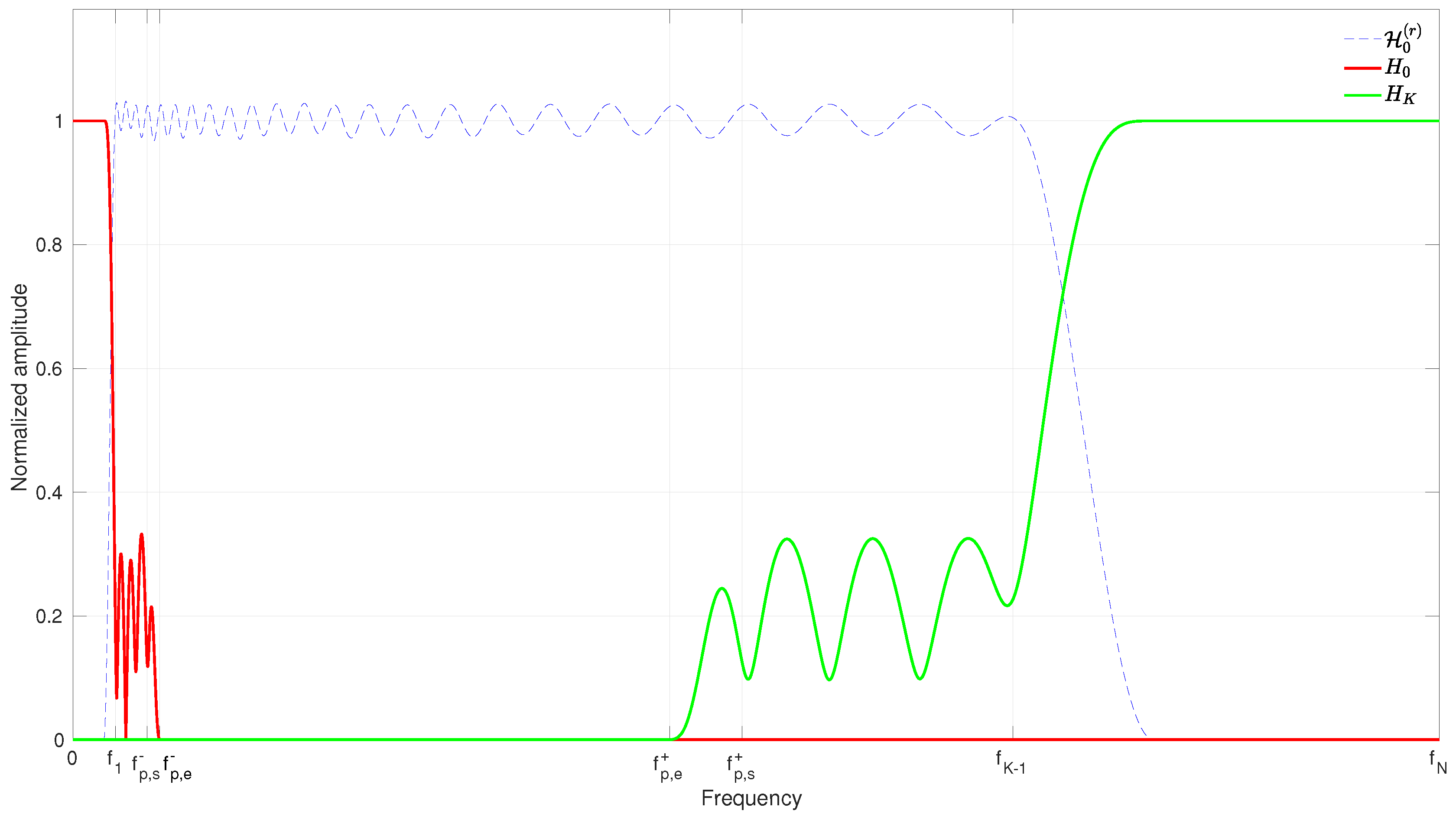
3.1.1. Construction of the Set
3.1.2. Construction of and
3.1.3. Construction of the Set
3.2. Invertibility Test
- An eigenvalue analysis of the linear operator corresponding to analysis with followed by FB synthesis with . The frame bounds A and B correspond to the smallest (infinimum) and largest (supremum) eigenvalues of the resulting operator, respectively. The largest eigenvalue can be estimated by numerical methods with reasonable efficiency but estimating the smallest eigenvalue directly is highly computationally expensive. In the next section we discuss an alternative method that consists in approximating the inverse operator and estimating its largest eigenvalue, the reciprocal of which is the desired lower frame bound A (see also Section 5 for an example frame bounds analysis).
- Computation of A and B directly from the overall FB response, i.e., verification that for some constants and almost every .
3.3. Synthesis Stage
| Algorithm 1 Synthesis by means of conjugate gradients |
| Initialize , |
| (arbitrary) |
| and (error tolerance) |
| for do |
| end for |
| while do |
| end while |
4. Implementation
4.1. Practical Issues
4.2. Code
4.3. Computational Complexity
5. Evaluation
- The construction of uniform and non-uniform gammatone FBs and examination of their stability and reconstruction property at low and high redundancies. For this purpose we replicated the simulations described in [44] (Section IV), which we consider as state of the art.
- The construction of various analysis–synthesis systems and use to perform sub-band processing. For this purpose we considered the example application of audio source separation because it is intuitive, clear, and it easily demonstrates the behavior of the system when attempting modification of an audio signal. In this application we assess the effects of perfect reconstruction, bandwidth and shape of the filters, and auditory scale on the quality of sub-channel processing.
5.1. Construction of Perfect-Reconstruction Gammatone FBs
5.1.1. Method
5.1.2. Results and Discussion
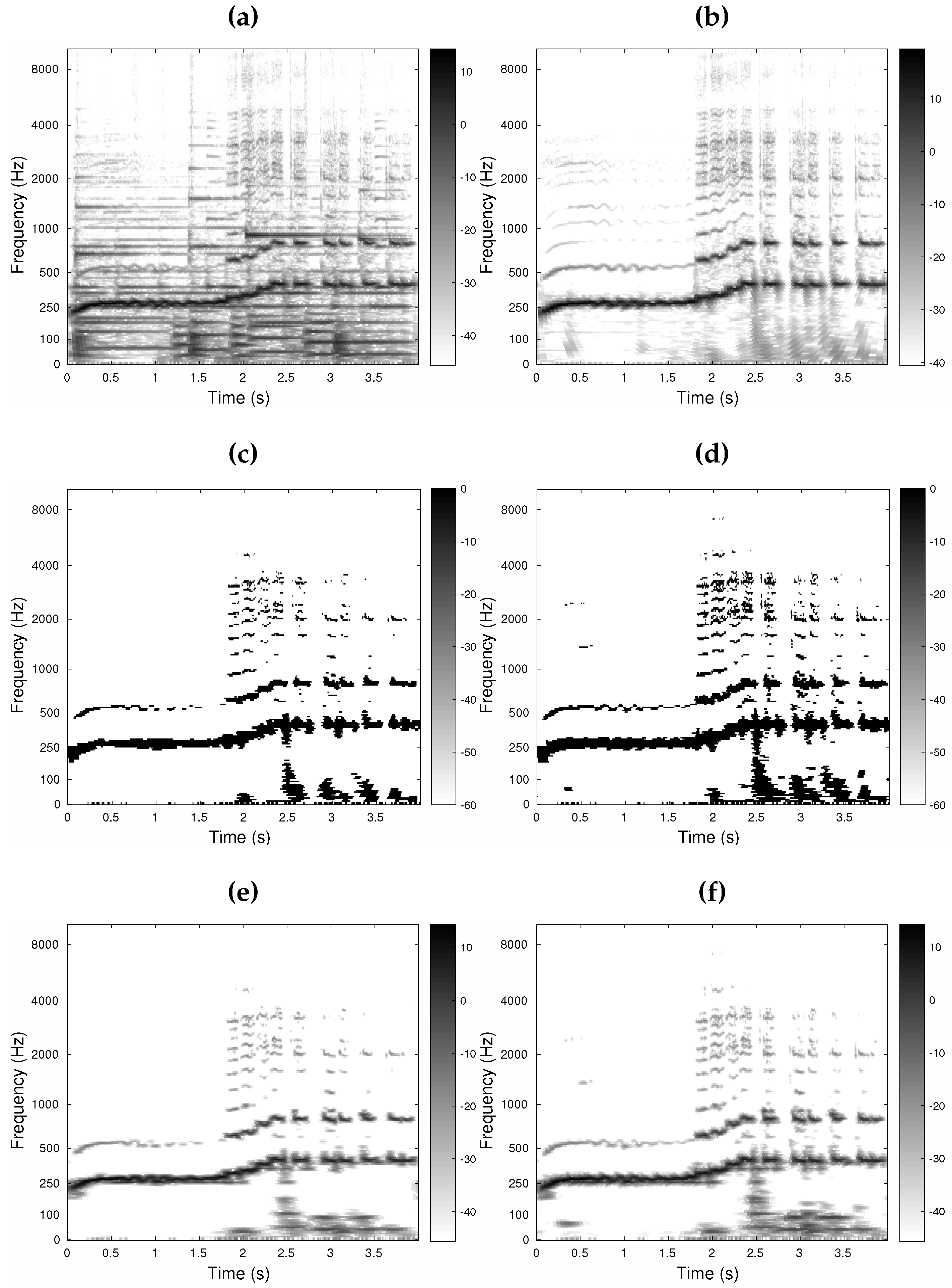
5.2. Utility for Audio Applications
5.2.1. Method
- trev_gfb:
- Audlet_gfb:
- an Audlet FB with a gammatone prototype. The ’s were computed as in trev_gfb but the synthesis stage was Algorithm 1. This system aims to compare to the baseline system and assess the effect of perfect reconstruction.
- Audlet_hann:
- an Audlet FB with a Hann prototype. This system aims to assess the effect of filter shape.
- STFT_hann:
- an STFT using a 1024-point Hann window. Synthesis was achieved by the dual window [2]. The time step was then adapted to match the desired redundancy . This corresponds to the baseline system used in most audio applications (e.g., [10,66]). This system aims to assess the use of an auditory frequency scale.
5.2.2. Results and Discussion
6. Conclusions
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Flandrin, P. Time-Frequency/Time-Scale Analysis; Wavelet Analysis and Its Application; Academic Press: San Diego, CA, USA, 1999; Volume 10. [Google Scholar]
- Gröchenig, K. Foundations of Time-Frequency Analysis; Birkhäuser: Boston, MA, USA, 2001. [Google Scholar]
- Kamath, S.; Loizou, P. A multi-band spectral subtraction method for enhancing speech corrupted by colored noise. In Proceedings of the 2002 IEEE International Conference on Acoustics, Speech, and Signal Processing, Orlando, FL, USA, 13–17 May 2002; Volume 4. [Google Scholar]
- Majdak, P.; Balazs, P.; Kreuzer, W.; Dörfler, M. A time-frequency method for increasing the signal-to-noise ratio in system identification with exponential sweeps. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011. [Google Scholar]
- International Organization for Standardization. ISO/IEC 11172-3: Information Technology—Coding of Moving Pictures and Associated Audio for Digital Storage Media at up to About 1.5 Mbits/s, Part 3: Audio; Technical Report; International Organization for Standardization (ISO): Geneva, Switzerland, 1993. [Google Scholar]
- International Organization for Standardization. ISO/IEC 13818-7: 13818-7: Generic Coding of Moving Pictures and Associated Audio: Advanced Audio Coding; Technical Report; International Organization for Standardization (ISO): Geneva, Switzerland, 1997. [Google Scholar]
- International Organization for Standardization. ISO/IEC 14496-3/AMD-2: Information Technology—Coding of Audio-Visual Objects, Amendment 2: New Audio Profiles; Technical Report; International Organization for Standardization (ISO): Geneva, Switzerland, 2006. [Google Scholar]
- Průša, Z.; Holighaus, N. Phase vocoder done right. In Proceedings of the 25th European Signal Processing Conference (EUSIPCO–2017), Kos Island, Greece, 28 August–2 September 2017; pp. 1006–1010. [Google Scholar]
- Sirdey, A.; Derrien, O.; Kronland-Martinet, R. Adjusting the spectral envelope evolution of transposed sounds with gabor mask prototypes. In Proceedings of the 13th International Conference on Digital Audio Effects (DAFx-10), Graz, Austria, 10 September 2010; pp. 1–7. [Google Scholar]
- Leglaive, S.; Badeau, R.; Richard, G. Multichannel Audio Source Separation with Probabilistic Reverberation Priors. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 2453–2465. [Google Scholar] [CrossRef]
- Gao, B.; Woo, W.L.; Khor, L.C. Cochleagram-based audio pattern separation using two-dimensional non-negative matrix factorization with automatic sparsity adaptation. J. Acoust. Soc. Am. 2014, 135, 1171–1185. [Google Scholar]
- Unoki, M.; Akagi, M. A method of signal extraction from noisy signal based on auditory scene analysis. Speech Commun. 1999, 27, 261–279. [Google Scholar] [CrossRef]
- Bertin, N.; Badeau, R.; Vincent, E. Enforcing Harmonicity and Smoothness in Bayesian Non-Negative Matrix Factorization Applied to Polyphonic Music Transcription. IEEE Trans. Audio Speech Lang. Process. 2010, 18, 538–549. [Google Scholar] [CrossRef]
- Cvetković, Z.; Johnston, J.D. Nonuniform oversampled filter banks for audio signal processing. IEEE Speech Audio Process. 2003, 11, 393–399. [Google Scholar] [CrossRef]
- Smith, J.O. Spectral Audio Signal Processing. Online Book. 2011. Available online: http://ccrma.stanford.edu/~jos/sasp/ (accessed on 9 January 2018).
- Akkarakaran, S.; Vaidyanathan, P. Nonuniform filter banks: New results and open problems. In Beyond Wavelets; Studies in Computational Mathematics; Elsevier: Amsterdam, The Netherlands, 2003; Volume 10, pp. 259–301. [Google Scholar]
- Vaidyanathan, P. Multirate Systems And Filter Banks; Electrical Engineering, Electronic and Digital Design; Prentice Hall: Englewood Cliffs, NJ, USA, 1993. [Google Scholar]
- Vetterli, M.; Kovačević, J. Wavelets and Subband Coding; Prentice Hall PTR: Englewood Cliffs, NJ, USA, 1995. [Google Scholar]
- Kovačević, J.; Vetterli, M. Perfect reconstruction filter banks with rational sampling factors. IEEE Trans. Signal Process. 1993, 41, 2047–2066. [Google Scholar]
- Balazs, P.; Holighaus, N.; Necciari, T.; Stoeva, D. Frame theory for signal processing in psychoacoustics. In Excursions in Harmonic Analysis; Applied and Numerical Harmonic Analysis; Birkäuser: Basel, Switzerland, 2017; Volume 5, pp. 225–268. [Google Scholar]
- Bölcskei, H.; Hlawatsch, F.; Feichtinger, H. Frame-theoretic analysis of oversampled filter banks. IEEE Trans. Signal Process. 1998, 46, 3256–3268. [Google Scholar] [CrossRef]
- Cvetković, Z.; Vetterli, M. Oversampled filter banks. IEEE Trans. Signal Process. 1998, 46, 1245–1255. [Google Scholar] [CrossRef]
- Strohmer, T. Numerical algorithms for discrete Gabor expansions. In Gabor Analysis and Algorithms: Theory and Applications; Feichtinger, H.G., Strohmer, T., Eds.; Birkhäuser: Boston, MA, USA, 1998; pp. 267–294. [Google Scholar]
- Härmä, A.; Karjalainen, M.; Savioja, L.; Välimäki, V.; Laine, U.K.; Huopaniemi, J. Frequency-Warped Signal Processing for Audio Applications. J. Audio Eng. Soc. 2000, 48, 1011–1031. [Google Scholar]
- Gunawan, T.S.; Ambikairajah, E.; Epps, J. Perceptual speech enhancement exploiting temporal masking properties of human auditory system. Speech Commun. 2010, 52, 381–393. [Google Scholar] [CrossRef]
- Balazs, P.; Laback, B.; Eckel, G.; Deutsch, W.A. Time-Frequency Sparsity by Removing Perceptually Irrelevant Components Using a Simple Model of Simultaneous Masking. IEEE Trans. Audio Speech Lang. Process. 2010, 18, 34–49. [Google Scholar] [CrossRef]
- Chardon, G.; Necciari, T.; Balazs, P. Perceptual matching pursuit with Gabor dictionaries and time-frequency masking. In Proceedings of the 39th International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2014), Florence, Italy, 4–9 May 2014. [Google Scholar]
- Wang, D.; Brown, G.J. Computational Auditory Scene Analysis: Principles, Algorithms, and Applications; Wiley-IEEE Press: Hoboken, NJ, USA, 2006. [Google Scholar]
- Li, P.; Guan, Y.; Xu, B.; Liu, W. Monaural Speech Separation Based on Computational Auditory Scene Analysis and Objective Quality Assessment of Speech. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 2014–2023. [Google Scholar] [CrossRef]
- Glasberg, B.R.; Moore, B.C.J. Derivation of auditory filter shapes from notched-noise data. Hear. Res. 1990, 47, 103–138. [Google Scholar] [CrossRef]
- Rosen, S.; Baker, R.J. Characterising auditory filter nonlinearity. Hear. Res. 1994, 73, 231–243. [Google Scholar] [CrossRef]
- Lyon, R. All-pole models of auditory filtering. Divers. Audit. Mech. 1997, 205–211. [Google Scholar]
- Irino, T.; Patterson, R.D. A Dynamic Compressive Gammachirp Auditory Filterbank. Audio Speech Lang. Process. 2006, 14, 2222–2232. [Google Scholar] [CrossRef] [PubMed]
- Verhulst, S.; Dau, T.; Shera, C.A. Nonlinear time-domain cochlear model for transient stimulation and human otoacoustic emission. J. Acoust. Soc. Am. 2012, 132, 3842–3848. [Google Scholar] [CrossRef] [PubMed]
- Feldbauer, C.; Kubin, G.; Kleijn, W.B. Anthropomorphic coding of speech and audio: A model inversion approach. EURASIP J. Adv. Signal Process. 2005, 2005, 1334–1349. [Google Scholar] [CrossRef]
- Decorsière, R.; Søndergaard, P.L.; MacDonald, E.N.; Dau, T. Inversion of Auditory Spectrograms, Traditional Spectrograms, and Other Envelope Representations. IEEE Trans. Audio Speech Lang. Process. 2015, 23, 46–56. [Google Scholar] [CrossRef]
- Lyon, R.; Katsiamis, A.; Drakakis, E. History and future of auditory filter models. In Proceedings of the 2010 IEEE International Symposium on Circuits and Systems (ISCAS), Paris, France, 30 May–2 June 2010; pp. 3809–3812. [Google Scholar]
- Patterson, R.D.; Robinson, K.; Holdsworth, J.; McKeown, D.; Zhang, C.; Allerhand, M.H. Complex sounds and auditory images. In Proceedings of the Auditory Physiology and Perception: 9th International Symposium on Hearing, Carcens, France, 9–14 June 1991; pp. 429–446. [Google Scholar]
- Hohmann, V. Frequency analysis and synthesis using a Gammatone filterbank. Acta Acust. United Acust. 2002, 88, 433–442. [Google Scholar]
- Lin, L.; Holmes, W.; Ambikairajah, E. Auditory filter bank inversion. In Proceedings of the 2001 IEEE International Symposium on Circuits and Systems (ISCAS 2001), Sydney, Australia, 6–9 May 2001; Volume 2, pp. 537–540. [Google Scholar]
- Slaney, M. An Efficient Implementation of the Patterson-Holdsworth Auditory Filter Bank; Apple Computer Technical Report No. 35; Apple Computer, Inc.: Cupertino, CA, USA; 1993; pp. 1–42. [Google Scholar]
- Holdsworth, J.; Nimmo-Smith, I.; Patterson, R.D.; Rice, P. Implementing a Gammatone Filter Bank; Annex c of the Svos Final Report (Part A: The Auditory Filterbank); MRC Applied Psychology Unit: Cambridge, UK, 1988. [Google Scholar]
- Darling, A. Properties and Implementation of the Gammatone Filter: A Tutorial; Technical Report; University College London, Department of Phonetics and Linguistics: London, UK, 1991; pp. 43–61. [Google Scholar]
- Strahl, S.; Mertins, A. Analysis and design of gammatone signal models. J. Acoust. Soc. Am. 2009, 126, 2379–2389. [Google Scholar] [PubMed]
- Balazs, P.; Dörfler, M.; Holighaus, N.; Jaillet, F.; Velasco, G. Theory, Implementation and Applications of Nonstationary Gabor Frames. J. Comput. Appl. Math. 2011, 236, 1481–1496. [Google Scholar] [CrossRef] [PubMed]
- Holighaus, N.; Dörfler, M.; Velasco, G.; Grill, T. A framework for invertible, real-time constant-Q transforms. Audio Speech Lang. Process. 2013, 21, 775–785. [Google Scholar] [CrossRef]
- Holighaus, N.; Wiesmeyr, C.; Průša, Z. A class of warped filter bank frames tailored to non-linear frequency scales. arXiv, 2016; arXiv:1409.7203. [Google Scholar]
- Necciari, T.; Balazs, P.; Holighaus, N.; Søndergaard, P. The ERBlet transform: An auditory-based time-frequency representation with perfect reconstruction. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 498–502. [Google Scholar]
- Trefethen, L.N.; Bau, D., III. Numerical Linear Algebra; SIAM: Philadelphia, PA, USA, 1997. [Google Scholar]
- Moore, B.C.J. An Introduction to the Psychology of Hearing, 6th ed.; Emerald Group Publishing: Bingley, UK, 2012. [Google Scholar]
- Zwicker, E.; Terhardt, E. Analytical expressions for critical-band rate and critical bandwidth as a function of frequency. J. Acoust. Soc. Am. 1980, 68, 1523–1525. [Google Scholar] [CrossRef]
- O’shaughnessy, D. Speech Communication: Human and Machine; Addison-Wesley: Boston, MA, USA, 1987. [Google Scholar]
- Daubechies, I.; Grossmann, A.; Meyer, Y. Painless nonorthogonal expansions. J. Math. Phys. 1986, 27, 1271–1283. [Google Scholar] [CrossRef]
- Průša, Z.; Søndergaard, P.L.; Rajmic, P. Discrete Wavelet Transforms in the Large Time-Frequency Analysis Toolbox for Matlab/GNU Octave. ACM Trans. Math. Softw. 2016, 42, 32:1–32:23. [Google Scholar] [CrossRef]
- Hestenes, M.R.; Stiefel, E. Methods of conjugate gradients for solving linear systems. J. NBS 1952, 49, 409–436. [Google Scholar] [CrossRef]
- Gröchenig, K. Acceleration of the frame algorithm. IEEE Trans. Signal Process. 1993, 41, 3331–3340. [Google Scholar] [CrossRef]
- Eisenstat, S.C. Efficient implementation of a class of preconditioned conjugate gradient methods. SIAM J. Sci. Stat. Comput. 1981, 2, 1–4. [Google Scholar] [CrossRef]
- Balazs, P.; Feichtinger, H.G.; Hampejs, M.; Kracher, G. Double preconditioning for Gabor frames. IEEE Trans. Signal Process. 2006, 54, 4597–4610. [Google Scholar] [CrossRef]
- Christensen, O. An Introduction to Frames and Riesz Bases; Applied and Numerical Harmonic Analysis; Birkhäuser: Boston, MA, USA, 2016. [Google Scholar]
- Smith, J.O. Audio FFT filter banks. In Proceedings of the 12th International Conference on Digital Audio Effects (DAFx-09), Como, Italy, 1–4 September 2009; pp. 1–8. [Google Scholar]
- Søndergaard, P.L.; Torrésani, B.; Balazs, P. The Linear Time Frequency Analysis Toolbox. Int. J. Wavelets Multiresolut. Inf. Process. 2012, 10, 1250032. [Google Scholar] [CrossRef]
- Průša, Z.; Søndergaard, P.L.; Holighaus, N.; Wiesmeyr, C.; Balazs, P. The large time-frequency analysis toolbox 2.0. In Sound, Music, and Motion; Springer: Berlin, Germany, 2014; pp. 419–442. [Google Scholar]
- Schörkhuber, C.; Klapuri, A.; Holighaus, N.; Dörfler, M. A matlab toolbox for efficient perfect reconstruction time-frequency transforms with log-frequency resolution. In Proceedings of the Audio Engineering Society 53rd International Conference on Semantic Audio, London, UK, 27–29 January 2014. [Google Scholar]
- Velasco, G.A.; Holighaus, N.; Dörfler, M.; Grill, T. Constructing an invertible constant-Q transform with nonstationary Gabor frames. In Proceedings of the 14th International Conference on Digital Audio Effects (DAFx-11), Paris, France, 19–23 September 2011; pp. 93–99. [Google Scholar]
- Lehoucq, R.; Sorensen, D.C. Deflation Techniques for an Implicitly Re-Started Arnoldi Iteration. SIAM J. Matrix Anal. Appl. 1996, 17, 789–821. [Google Scholar] [CrossRef]
- Le Roux, J.; Vincent, E. Consistent Wiener Filtering for Audio Source Separation. Signal Process. Lett. IEEE 2013, 20, 217–220. [Google Scholar] [CrossRef]
- Emiya, V.; Vincent, E.; Harlander, N.; Hohmann, V. Subjective and Objective Quality Assessment of Audio Source Separation. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 2046–2057. [Google Scholar] [CrossRef]
- Balazs, P. Basic Definition and Properties of Bessel Multipliers. J. Math. Anal. Appl. 2007, 325, 571–585. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| K | Framework | |||||
|---|---|---|---|---|---|---|
| 51 | Audlet | 1.124 | 1.124 | 1.125 | 1.134 | 1.157 |
| S–M | 1.100 | > 10 | > 10 | > 10 | > 10 | |
| 76 | Audlet | 1.007 | 1.007 | 1.009 | 1.021 | 1.073 |
| S–M | 1.100 | 2 | 2 | 3 | 6 | |
| 101 | Audlet | 1.003 | 1.003 | 1.005 | 1.017 | 1.068 |
| S–M | 1.003 | 1.003 | 1.003 | 2 | 4 | |
| 151 | Audlet | 1.015 | 1.015 | 1.016 | 1.025 | 1.066 |
| S–M | 1.003 | 1.003 | 1.003 | 1.100 | 2 |
| Based on (15)–(18) | from [44] | |||||
|---|---|---|---|---|---|---|
| R | Audlet | S–M | R | Audlet | S–M | |
| 2 | 2.40 | 5 | 2.38 | 10 | ||
| 4 | 4.46 | 7 | 4.38 | 13 | ||
| 8 | 8.60 | 10 | 8.38 | 17 | ||
| 12 | 12.73 | 9 | 12.38 | 18 | ||
| 16 | 16.87 | 15 | 16.38 | 19 | ||
| System | SDR | SAR | OPS | TPS | |||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 1/6 | 1 | 1/6 | 1 | 1/6 | 1 | 1/6 | ||
| trev_gfb | 1.1 | 0.1 | 5.8 | 3.2 | 9.2 | 0.26 | 0.26 | 0.06 | 0.12 |
| Audlet_gfb | 4.7 | 10.7 | 8.5 | 19.0 | 0.25 | 0.31 | 0.11 | 0.20 | |
| Audlet_hann | 4.7 | 11.8 | 7.6 | 18.3 | 0.26 | 0.34 | 0.05 | 0.26 | |
| STFT_hann | −1.7 | 0.5 | 0.46 | 0.02 | |||||
| trev_gfb | 1.5 | 2.4 | 8.5 | 5.7 | 13.5 | 0.24 | 0.30 | 0.11 | 0.17 |
| Audlet_gfb | 6.9 | 11.1 | 12.5 | 20.5 | 0.24 | 0.35 | 0.13 | 0.29 | |
| Audlet_hann | 7.0 | 12.8 | 11.1 | 20.1 | 0.22 | 0.36 | 0.07 | 0.35 | |
| STFT_hann | 2.4 | 9.2 | 0.22 | 0.04 | |||||
| trev_gfb | 4 | 7.0 | 10.7 | 12.0 | 18.9 | 0.24 | 0.37 | 0.24 | 0.34 |
| Audlet_gfb | 9.0 | 11.4 | 18.3 | 21.6 | 0.27 | 0.38 | 0.32 | 0.39 | |
| Audlet_hann | 11.1 | 13.1 | 19.4 | 21.7 | 0.25 | 0.37 | 0.21 | 0.32 | |
| STFT_hann | 11.4 | 20.5 | 0.38 | 0.34 | |||||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Necciari, T.; Holighaus, N.; Balazs, P.; Průša, Z.; Majdak, P.; Derrien, O. Audlet Filter Banks: A Versatile Analysis/Synthesis Framework Using Auditory Frequency Scales. Appl. Sci. 2018, 8, 96. https://doi.org/10.3390/app8010096
Necciari T, Holighaus N, Balazs P, Průša Z, Majdak P, Derrien O. Audlet Filter Banks: A Versatile Analysis/Synthesis Framework Using Auditory Frequency Scales. Applied Sciences. 2018; 8(1):96. https://doi.org/10.3390/app8010096
Chicago/Turabian StyleNecciari, Thibaud, Nicki Holighaus, Peter Balazs, Zdeněk Průša, Piotr Majdak, and Olivier Derrien. 2018. "Audlet Filter Banks: A Versatile Analysis/Synthesis Framework Using Auditory Frequency Scales" Applied Sciences 8, no. 1: 96. https://doi.org/10.3390/app8010096
APA StyleNecciari, T., Holighaus, N., Balazs, P., Průša, Z., Majdak, P., & Derrien, O. (2018). Audlet Filter Banks: A Versatile Analysis/Synthesis Framework Using Auditory Frequency Scales. Applied Sciences, 8(1), 96. https://doi.org/10.3390/app8010096