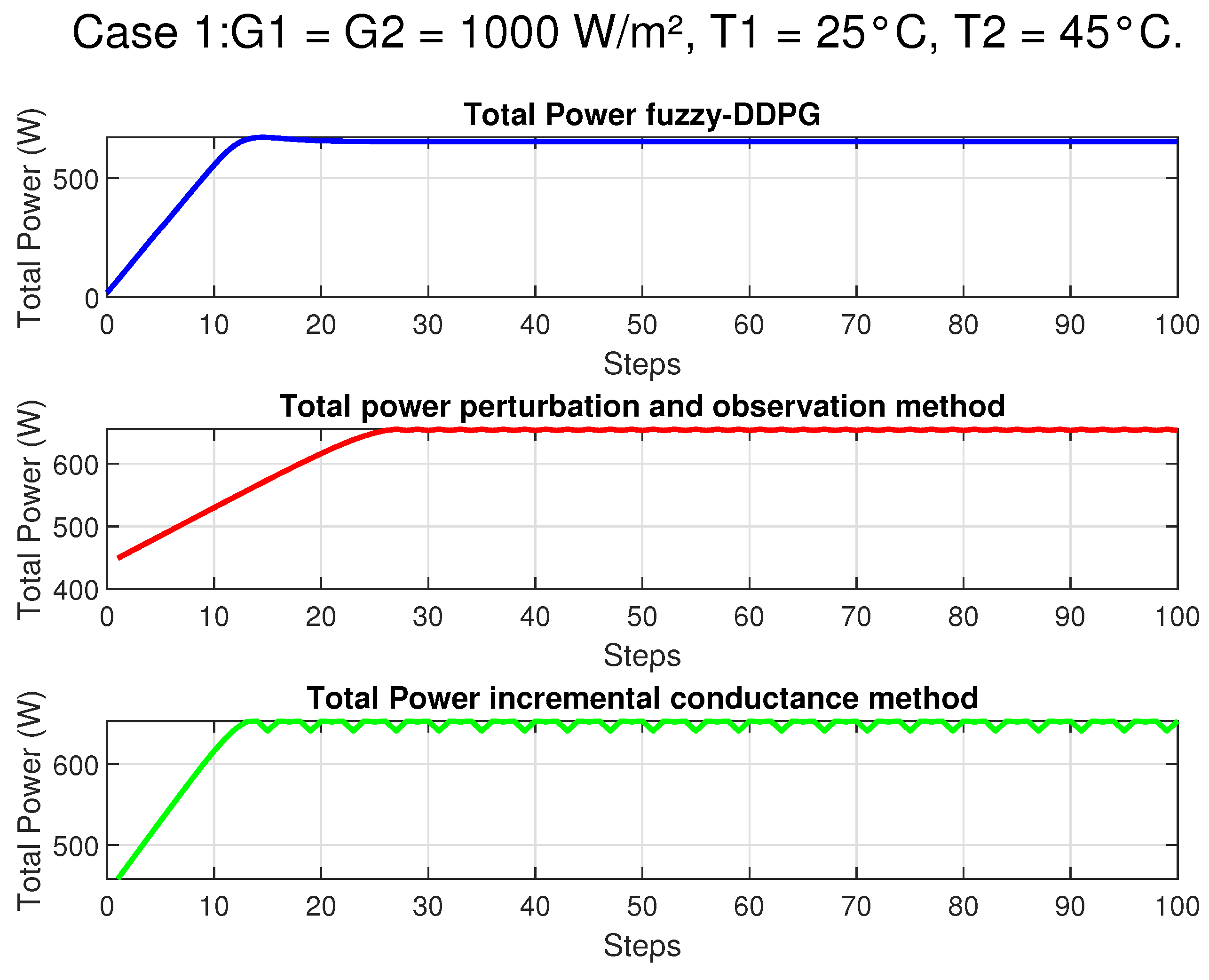
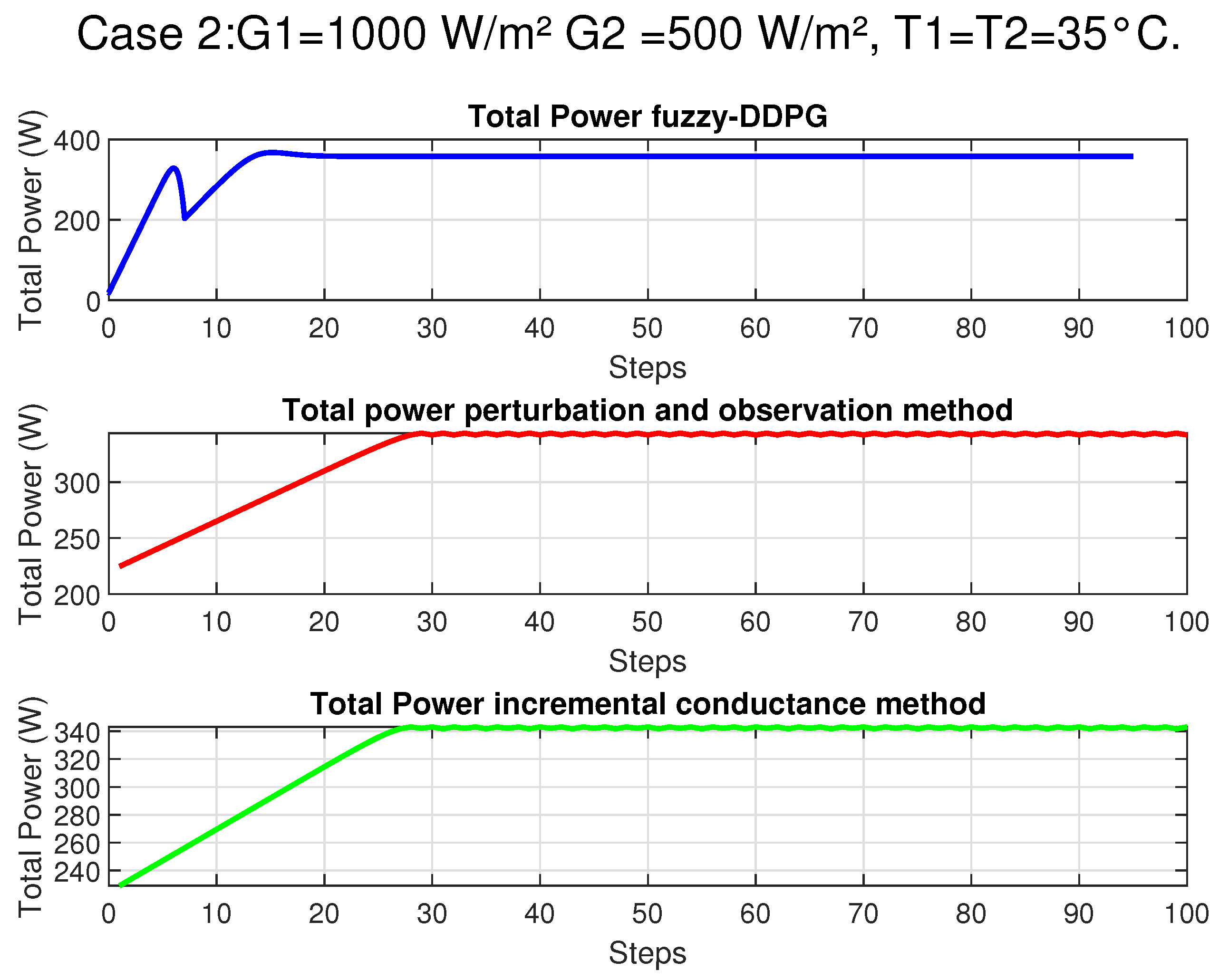
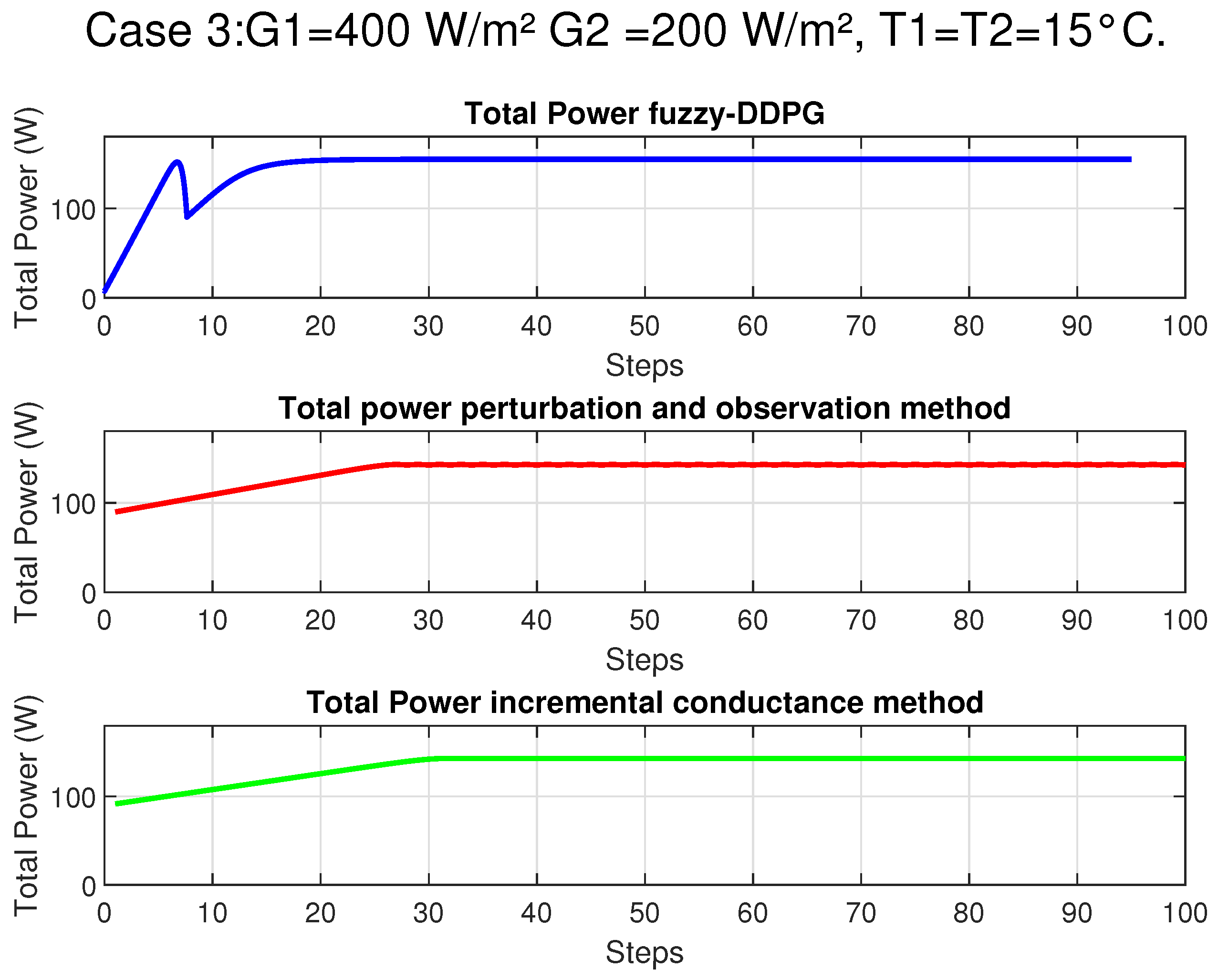
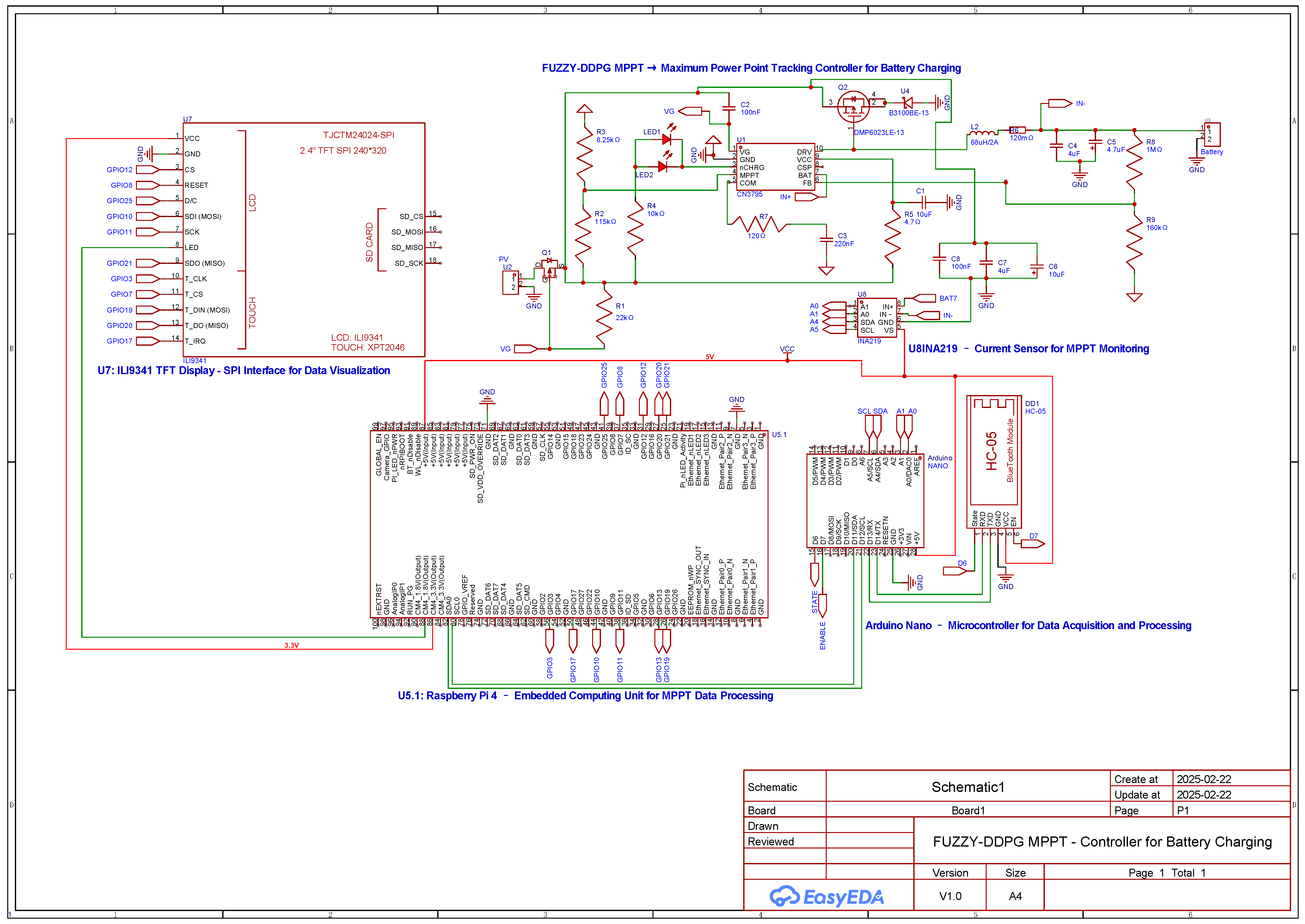
In this section, we provide an overview of the methodologies employed to address the Maximum Power Point Tracking (MPPT) challenge in photovoltaic systems under partial shading conditions. Initially, we describe a rigorous mathematical model based on the single-diode equivalent circuit to accurately capture the nonlinear behavior of the photovoltaic panel. Subsequently, our proposed control strategy, which integrates fuzzy logic with Deep Deterministic Policy Gradient (DDPG), is introduced to enhance state representation and expedite convergence in complex, non-convex operational environments. Finally, a theoretical justification rooted in the contraction properties of the Bellman operator is presented to establish the stability and robustness of the hybrid approach.
2.1. Mathematical Model of a Photovoltaic Panel
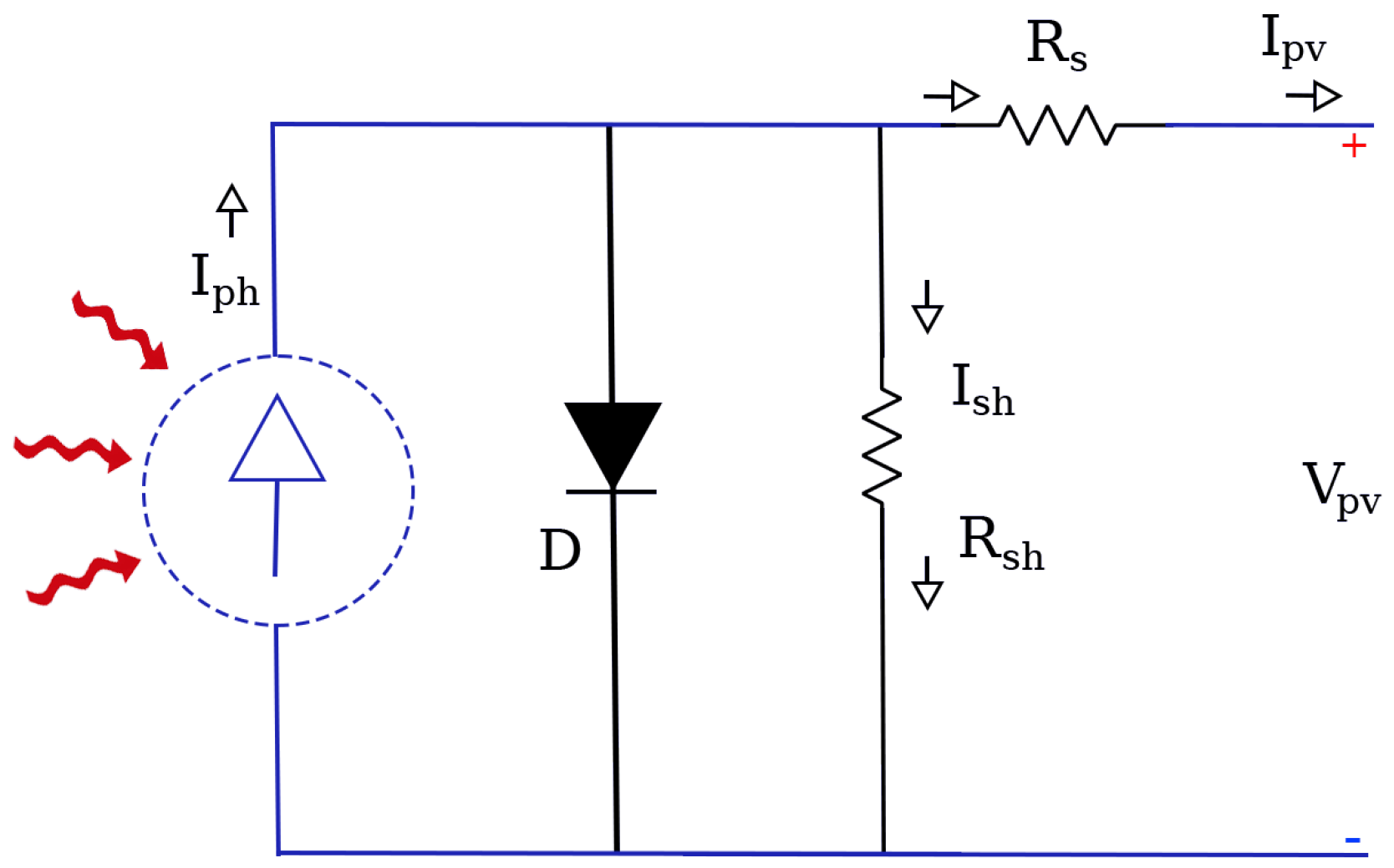
To comprehensively characterize the nonlinear behavior of the photovoltaic panel, the following mathematical model is presented. By employing the single-diode equivalent circuit, this formulation encapsulates the interactions among photocurrent generation, diode conduction dynamics, and resistive losses, thereby providing a robust foundation for developing advanced MPPT strategies. This model is essential for deriving control laws that guarantee convergence to the global maximum power point under varying irradiance and temperature conditions, including partial shading.
As shown in
Figure 1, the equivalent circuit of a photovoltaic (PV) cell consists of a current source representing the photocurrent (
), a diode (
D) modeling the p-n junction behavior, a series resistance (
), and a parallel (shunt) resistance (
) that accounts for leakage currents.
The output current
of the PV cell is given by Kirchhoff’s law as follows [
33]:
where:
is the light-generated current, proportional to the solar irradiance.
is the diode current.
is the shunt leakage current.
The shunt current is modeled as follows:
where:
The diode current
follows the Shockley diode equation:
where:
is the reverse saturation current of the diode.
C is the electronic charge.
J/K is the Boltzmann constant.
A is the diode ideality factor.
is the cell temperature in Kelvin.
is the voltage across the diode:
The light-generated current
is affected by solar irradiance and temperature:
where:
is the short-circuit current at standard test conditions (STC) ( °C, W/m2).
is the short-circuit current temperature coefficient.
is the reference temperature.
G is the actual solar irradiance.
For a PV module with
series-connected cells, the overall output current is as follows:
2.2. Reinforcement Learning Fuzzy–DDPG
Reinforcement learning (RL), as discussed in [
35], is a machine learning paradigm in which an agent learns to make optimal decisions by interacting with an environment. This process is typically formulated as a Markov Decision Process (MDP), which is characterized by key components:
State (S): Represents the current situation or context of the agent. At each time step, the agent observes the state of the environment.
Action (A): The agent selects an action from a set of possible actions based on the current state.
Transition Probability (P): P(s’|s, a) denotes the probability of transitioning to state s’ after taking action a in state s. This captures the dynamics of the environment.
Reward (R): R(s, a, s’) represents the immediate reward received by the agent after taking action a in state s and transitioning to state s’.
Discount Factor (): A value between 0 and 1 that determines the importance of future rewards. A higher discount factor prioritizes long-term rewards.
Policy (): A mapping from states to actions, defining the agent’s behavior. The policy can be deterministic, , or stochastic,
The primary objective in RL is to find an optimal policy that maximizes the expected cumulative discounted reward, formally expressed as follows:
In continuous state spaces, the exponential growth of the state–action pair complexity—often referred to as the curse of dimensionality—renders traditional tabular methods impractical. This challenge necessitates the use of function approximation techniques, where neural networks and other parametric models are employed to estimate value functions or to directly parameterize policies. Such approaches have led to the development of advanced RL methods including Deep Q-Networks (DQN), policy gradient methods, and actor–critic architectures like Deep Deterministic Policy Gradient (DDPG) [
36].
Beyond these foundational aspects, modern RL methods have evolved to incorporate strategies such as curriculum learning and adaptive exploration [
37], which further enhance training stability and convergence. In our study, RL is applied to dynamically adjust the duty cycle of a DC–DC converter in a photovoltaic system under partial shading conditions. This formulation not only addresses the inherent non-stationarity and high-dimensionality of the environment but also demonstrates how RL, when combined with fuzzy logic enhancements, provides a robust and adaptive framework for achieving Maximum Power Point Tracking in complex, real-world settings.
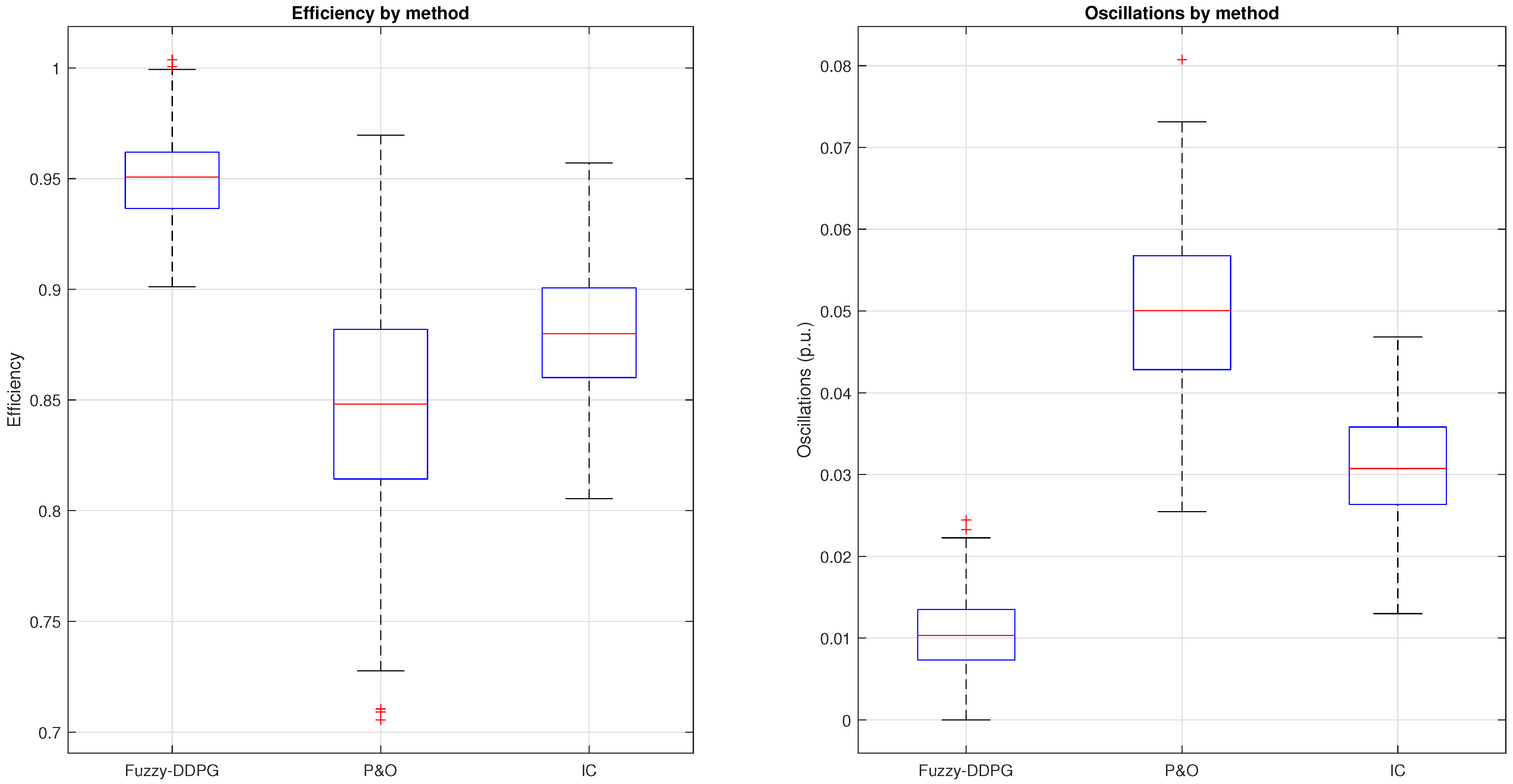
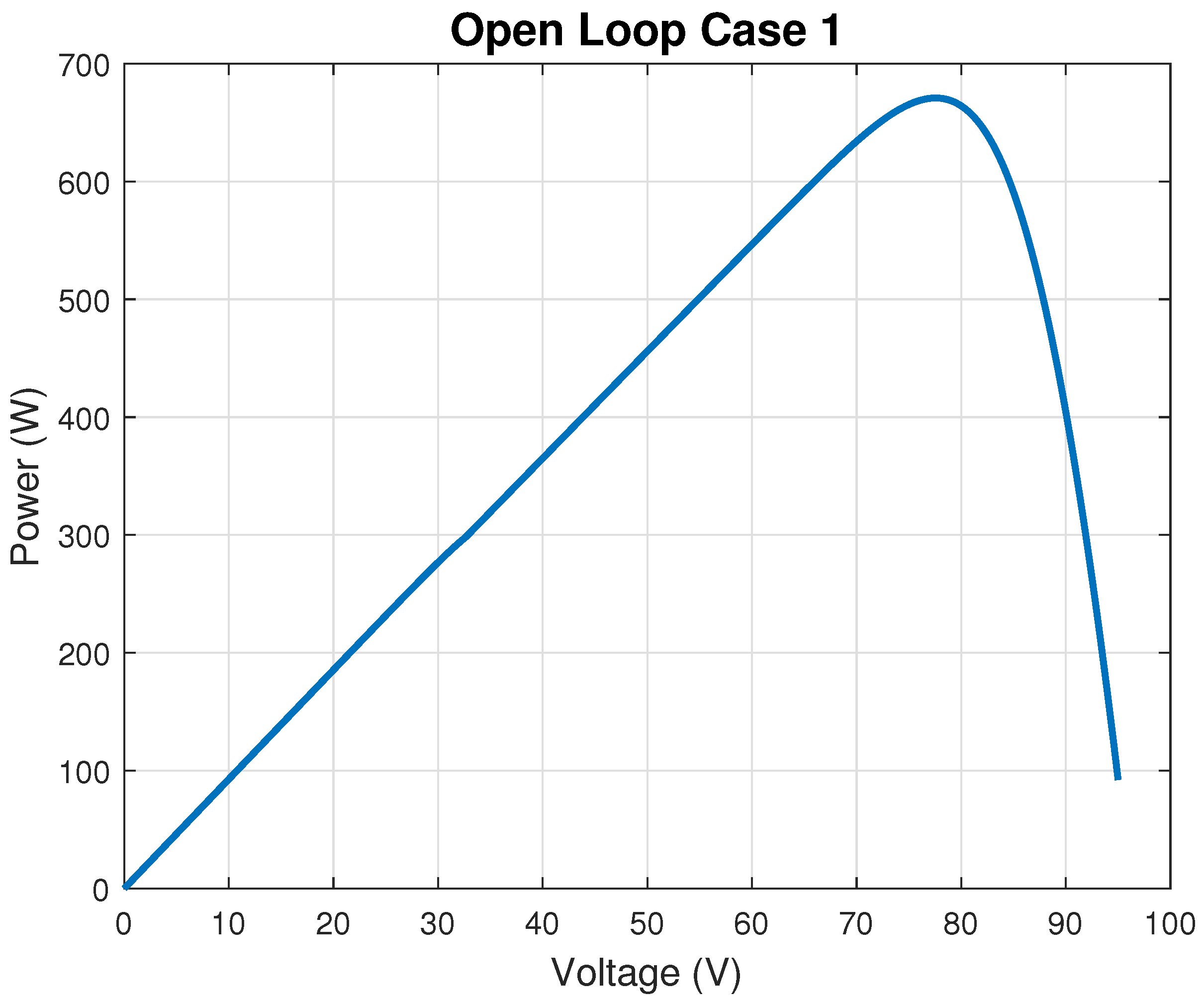
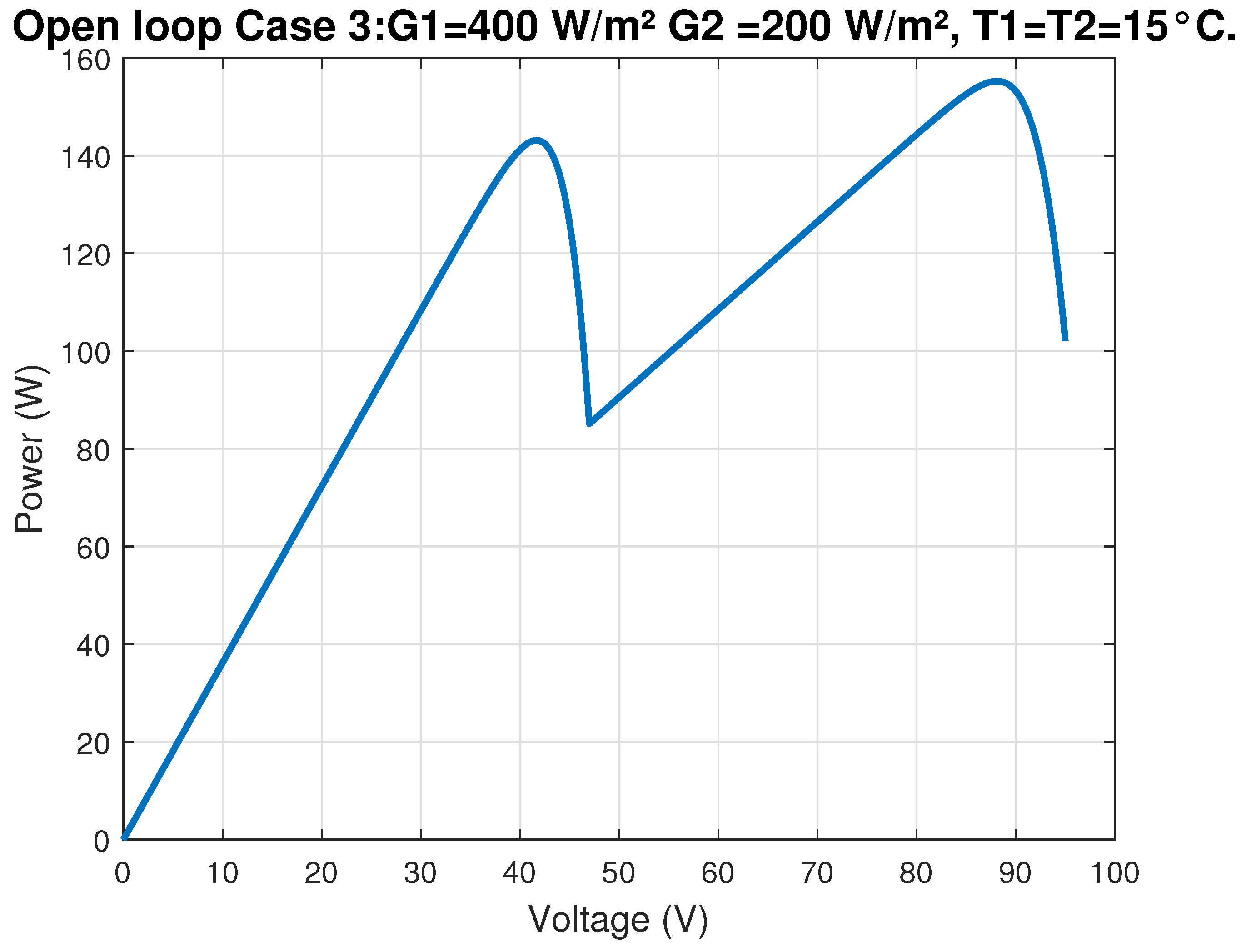
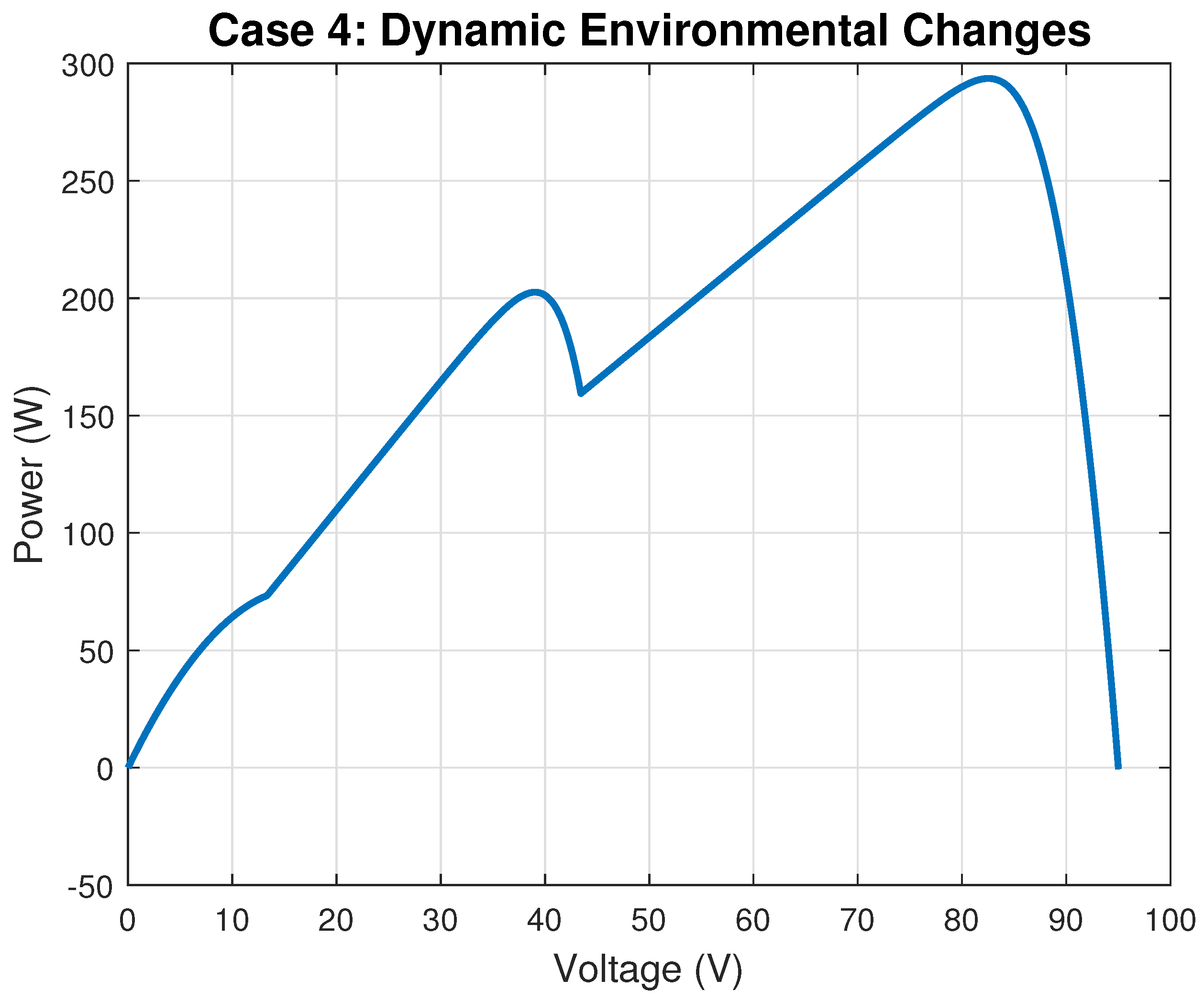
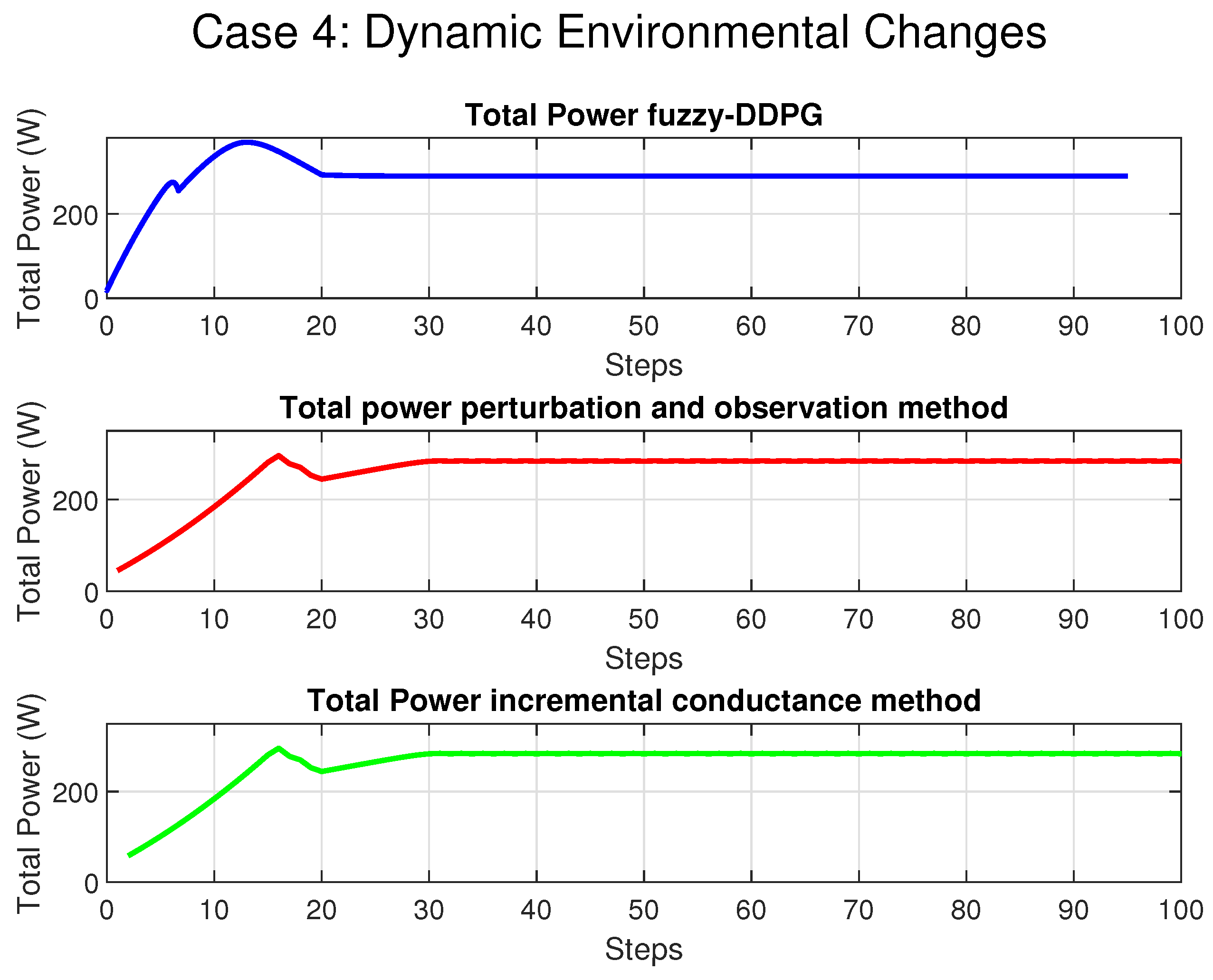
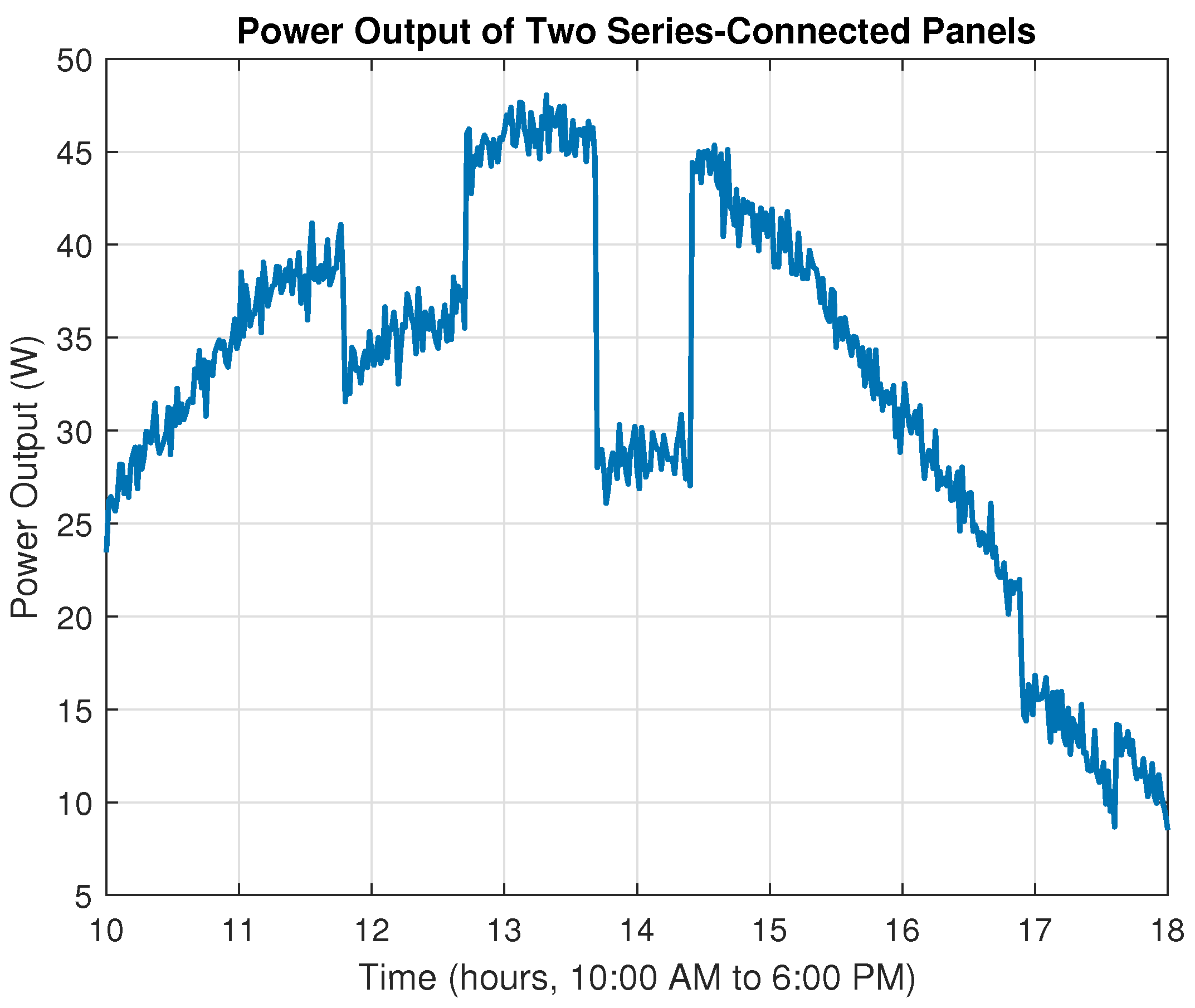
In the context of Maximum Power Point Tracking for photovoltaic systems under partial shading conditions, the RL agent learns to adjust the duty cycle of a DC-DC converter to maximize the power output of the PV system. Partial shading occurs when some parts of a PV array receive less sunlight than others, leading to multiple peaks in the power–voltage curve. Traditional MPPT methods can get stuck at local maxima, resulting in suboptimal power generation. RL offers a promising solution to this problem by learning to navigate the complex power landscape and find the global maximum power point.
Traditional RL algorithms like Q-learning [
38] and SARSA are designed for discrete state and action spaces. Extensions to continuous spaces often involve function approximation techniques, such as tile coding [
39], radial basis functions (a common function approximation technique, though not directly referenced in the current search results), or neural networks (neural networks are widely used in RL, see for example [
40]). However, these approximations can suffer from instability and divergence issues [
41].
Policy gradient methods, which directly optimize the policy, are naturally suited for continuous action spaces. Algorithms like REINFORCE and actor–critic methods have been developed to handle such scenarios. The Deterministic Policy Gradient algorithm [
42] extends the policy gradient theorem to deterministic policies, laying the groundwork for DDPG [
43].
The deterministic policy gradient algorithm [
42] states that the gradient of the expected return with respect to the policy parameters
is:
where:
is the action-value function under policy .
is the discounted state visitation distribution under .
In [
44] is introduced a fuzzy Q-iteration algorithm for approximate dynamic programming, addressing the curse of dimensionality by using a fuzzy partition of the state space and discretization of the action space to approximate the Q-function, making it applicable to continuous state and action spaces. This approach allows for handling larger state spaces than traditional dynamic programming, which struggles with the exponential growth of computational complexity as the number of state variables increases.
Fuzzy Q-Iteration approximates the Q-function using fuzzy basis functions:
where:
are fuzzy basis functions representing the degree of membership of in fuzzy sets.
are the weights to be learned.
The update rule minimizes the Bellman residual:
The fuzzy Q-iteration algorithm iteratively improves the Q-function approximation, converging to the optimal Q-function under certain conditions.
The proposed method combines the strengths of fuzzy techniques and DDPG to achieve global Maximum Power Point Tracking under partial shading conditions. The fuzzy component handles the action space, while the DDPG component addresses the continuous state space, resulting in a hybrid approach that is both scalable and able to operate in complex environments [
28,
45].
By integrating fuzzy basis functions into the actor and critic networks of DDPG, we aim to approximate both the policy and value function using fuzzy features, as follows:
The fuzzy feature vector captures the essential characteristics of the state space, facilitating learning in continuous domains. This hybrid approach combines the strengths of fuzzy approximation and deep reinforcement learning, enabling the agent to efficiently navigate the complex power landscape and find the global maximum power point under partial shading conditions.
For each state variable
, we define
M membership functions
, typically Gaussian functions:
The parameters are defined as follows:
The actor and critic networks take this fuzzy feature vector as input, and the output represents the actor policy and critic value function, respectively.
The actor network architecture is as follows:
Input Layer: Receives fuzzy feature vector .
Hidden Layers: Multiple fully connected layers with nonlinear activations.
Output Layer: Produces action , using a bounded activation function like tanh.
The critic network architecture is as follows:
State Input Layer: Receives fuzzy feature vector .
Action Input Layer: Receives action a.
Hidden Layers: Concatenates and a, followed by fully connected layers.
Output Layer: Outputs scalar value .
The actor network processes the fuzzy feature vector
obtained from the state
s. It comprises two fully connected hidden layers with ReLU activations, and an output layer with a bounded activation function (e.g., tanh) to produce the action:
The critic network receives the concatenated fuzzy feature vector and the action, and processes this input through two hidden layers with ReLU activations to output the scalar Q-value:
The fuzzy feature vector captures the essential characteristics of the state space, facilitating learning in continuous domains. By integrating fuzzy basis functions into the actor and critic networks, we aim to approximate both the policy and value function using fuzzy features, enabling efficient navigation of the complex power landscape and global Maximum Power Point tracking under partial shading conditions.
The training procedure follows the standard DDPG algorithm, with the additional incorporation of fuzzy basis functions, according to Algorithms 1 and 2.
| Algorithm 1 At each time step |
- 1:
repeat - 2:
Compute Fuzzy Features: from current state . - 3:
Select Action: , where is exploration noise. - 4:
Execute Action: Receive reward and next state . - 5:
Store Transition: Store in . - 6:
until Stopping Criterion is Met
|
| Algorithm 2 At each learning step |
- 1:
repeat - 2:
Sample Mini-Batch: Randomly sample N transitions from . - 3:
- 4:
Update Critic: Minimize loss L: - 5:
Update Actor: Update policy parameters using gradient ascent: - 6:
- 7:
until Stopping Criterion is Met
|
This training procedure allows the agent to learn the optimal policy and value function by leveraging the fuzzy feature representation, enabling global Maximum Power Point Tracking under partial shading conditions.
Algorithm 3 in the form of pseudocode could be used to implement the proposed method.
| Algorithm 3 Fuzzy–DDPG Algorithm |
- 1:
Initialize actor network and critic network - 2:
Initialize target networks , - 3:
Initialize replay buffer - 4:
for episode = 1 to max_episodes do - 5:
Initialize state - 6:
for to max_steps do - 7:
Compute fuzzy features - 8:
Select action - 9:
Execute action , observe reward and next state - 10:
Store transition in - 11:
Sample mini-batch of N transitions from - 12:
for each sample do - 13:
- 14:
end for - 15:
Update critic by minimizing: - 16:
Update actor using policy gradient: - 17:
- 18:
end for - 19:
end for
|
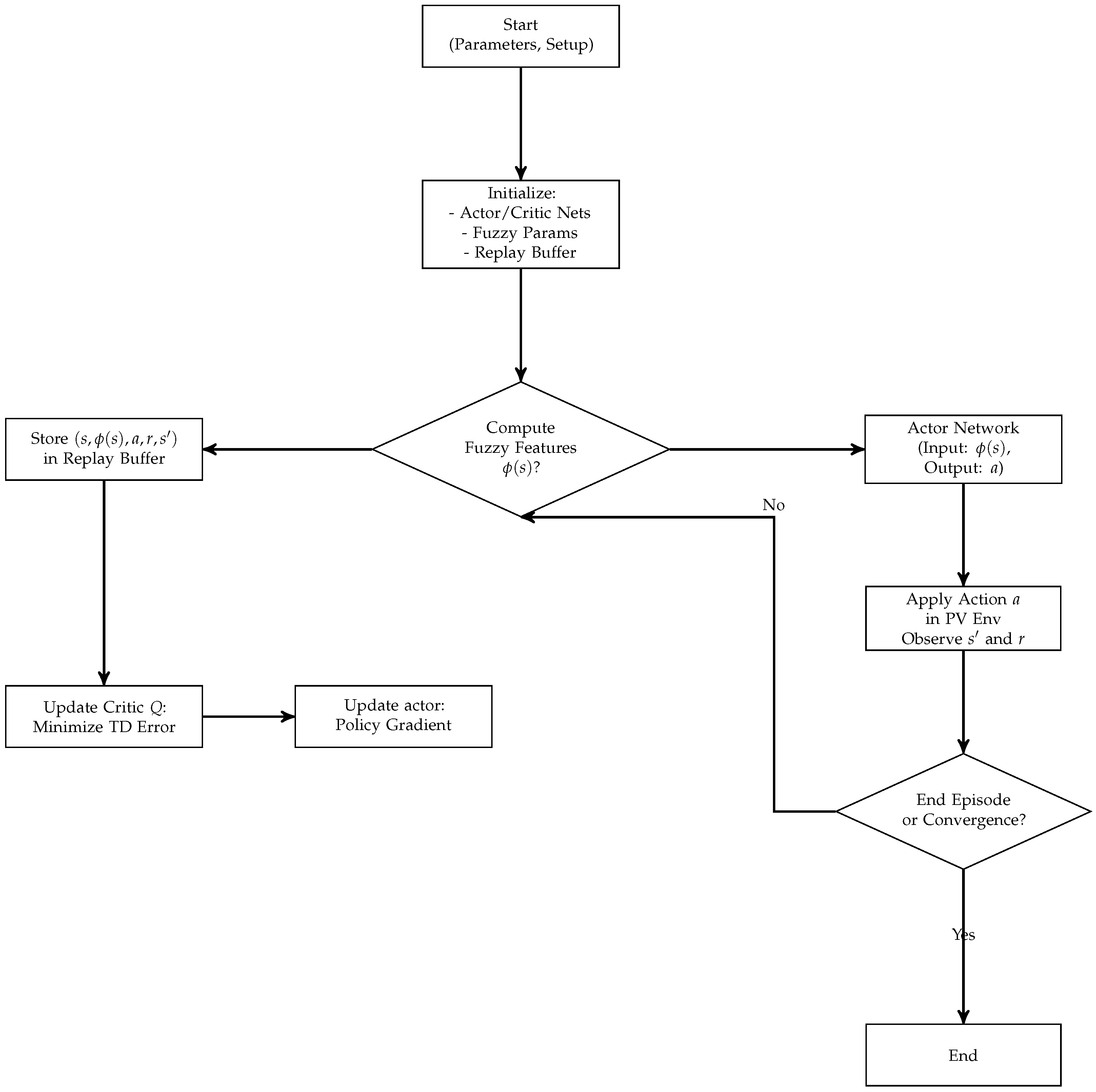
Figure 2 illustrates the main steps of the algorithm, depicting how the state observations from the PV environment are processed to update both the critic and actor networks through a gradient-based rule. Convergence conditions are periodically checked to ensure that the control policy remains near-optimal. The final result is an adaptive, data-driven control strategy capable of guaranteeing a stable operating point at or near the global maximum power region of the PV system.
2.5. Theorem
Theorem 1 (Convergence of Fuzzy-DDPG algorithm). Consider a continuous state space , a continuous action space , and a discount factor . Let be the action-value function and be a deterministic policy parameterized by θ. Assume the reward function is bounded, the fuzzy membership functions form a partition of unity, and the neural networks for critic and actor have sufficient representational capacity with appropriate learning rates. Then the combined Fuzzy–DDPG algorithm converges to a near-optimal policy under the following conditions:
- 1.
Fuzzy Q-iteration satisfies the contraction mapping property via the Bellman operator.
- 2.
The critic network converges to a good approximation of the optimal Q-function .
- 3.
The actor network’s policy gradient updates converge to a near-optimal deterministic policy.
Proof. We prove convergence in three major steps, corresponding to the numbered items in the theorem statement, according to [
34,
46,
47].
We start with the Bellman operator
for a Q-function
Q:
where
is the next state determined by the environment’s transition dynamics
.
In the fuzzy framework, the Q-function is approximated as follows:
where
are fuzzy membership functions (satisfying
for each
s) and
are the learnable parameters for each fuzzy region
i.
Contraction Property. For any two Q-functions
Q and
, the Bellman operator satisfies:
which implies that
is a contraction mapping with factor
. The fuzzy partition
respects this contraction because of the following:
Consequently, repeated application of
converges to a unique fixed point, i.e.,
Hence, the fuzzy Q-iteration converges to an approximate optimal Q-function .
In DDPG, the critic is represented by a neural network and is trained to minimize the mean-squared Bellman error:
where the target
is given by the following:
and
are the parameters of the slowly updated target networks.
In the fuzzy context, the critic’s Q-function is expressed as follows:
where
are the critic network’s parameters for each fuzzy set
i. The update rule for
via gradient descent is the following:
with
Critic convergence relies on:
Bellman Operator Contraction: The targets come from the contraction mapping .
Gradient Descent to Reduce Bellman Error: Iterative updates align with the fixed point .
Thus, for suitable learning rates and sufficient network capacity,
where
is a constant bounded by learning rate and fuzzy approximation smoothness. This iterative improvement implies
in the limit.
The actor learns a deterministic policy
by following the gradient of the expected return:
The actor parameters are updated by gradient ascent to maximize this expected return.
Once the critic converges close to
, the policy gradient points towards actions that maximize
. If the actor’s learning rate is sufficiently small (ensuring stable updates), the actor converges to a local optimum
, where
Hence, is a near-optimal deterministic policy that maximizes the expected return.
Putting all steps together, we conclude:
- 1.
Fuzzy Q-iteration converges to a fixed point that closely approximates due to the contraction property of .
- 2.
The DDPG critic converges to the optimal Q-function by minimizing the Bellman error.
- 3.
The DDPG actor converges to a near-optimal deterministic policy by following the gradient derived from the critic’s Q-function.
Therefore, under reasonable assumptions on the learning rates, neural network capacity, fuzzy partitioning, and exploration strategy, the hybrid Fuzzy–DDPG algorithm converges to a near-optimal policy. □
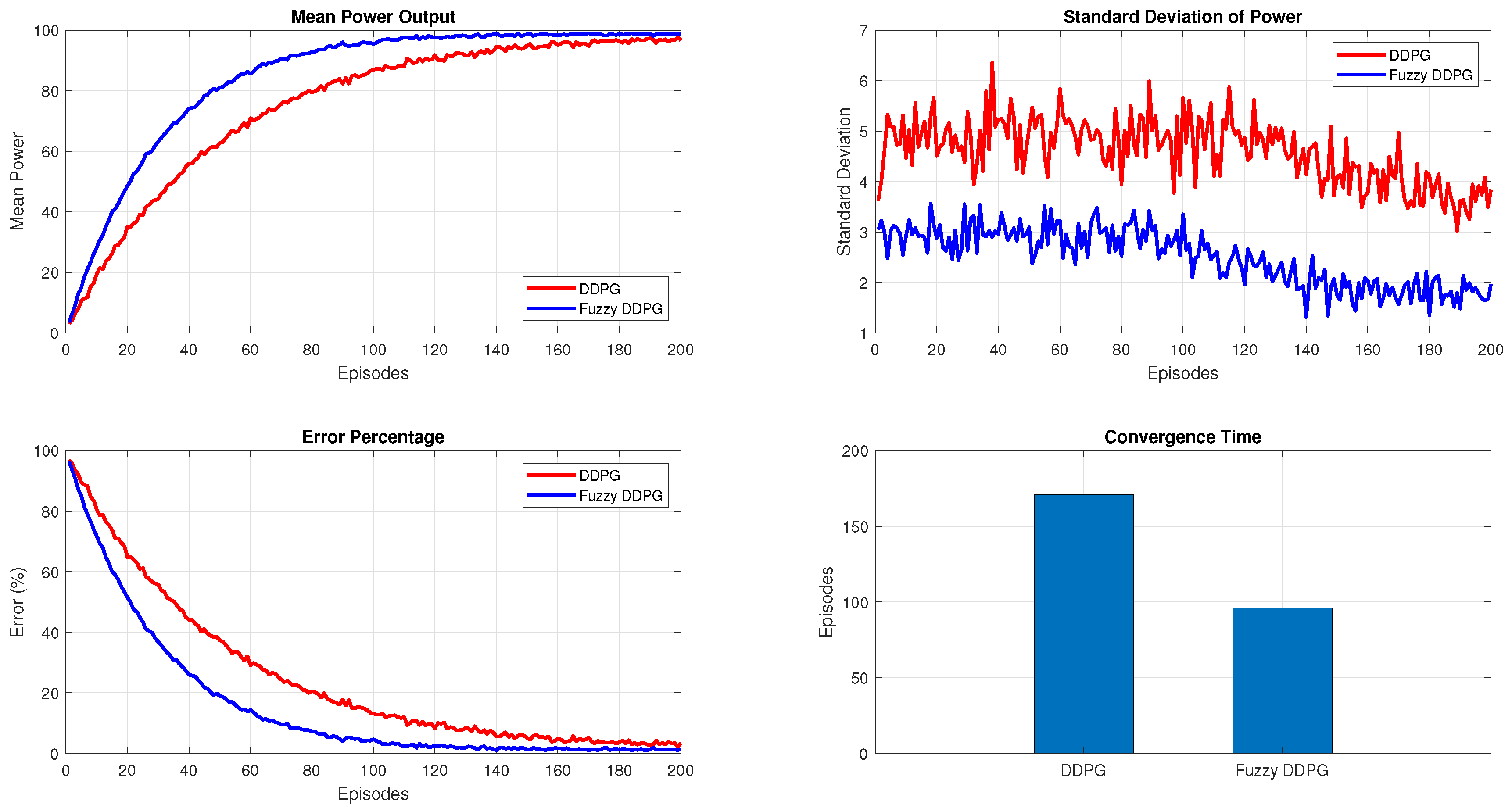
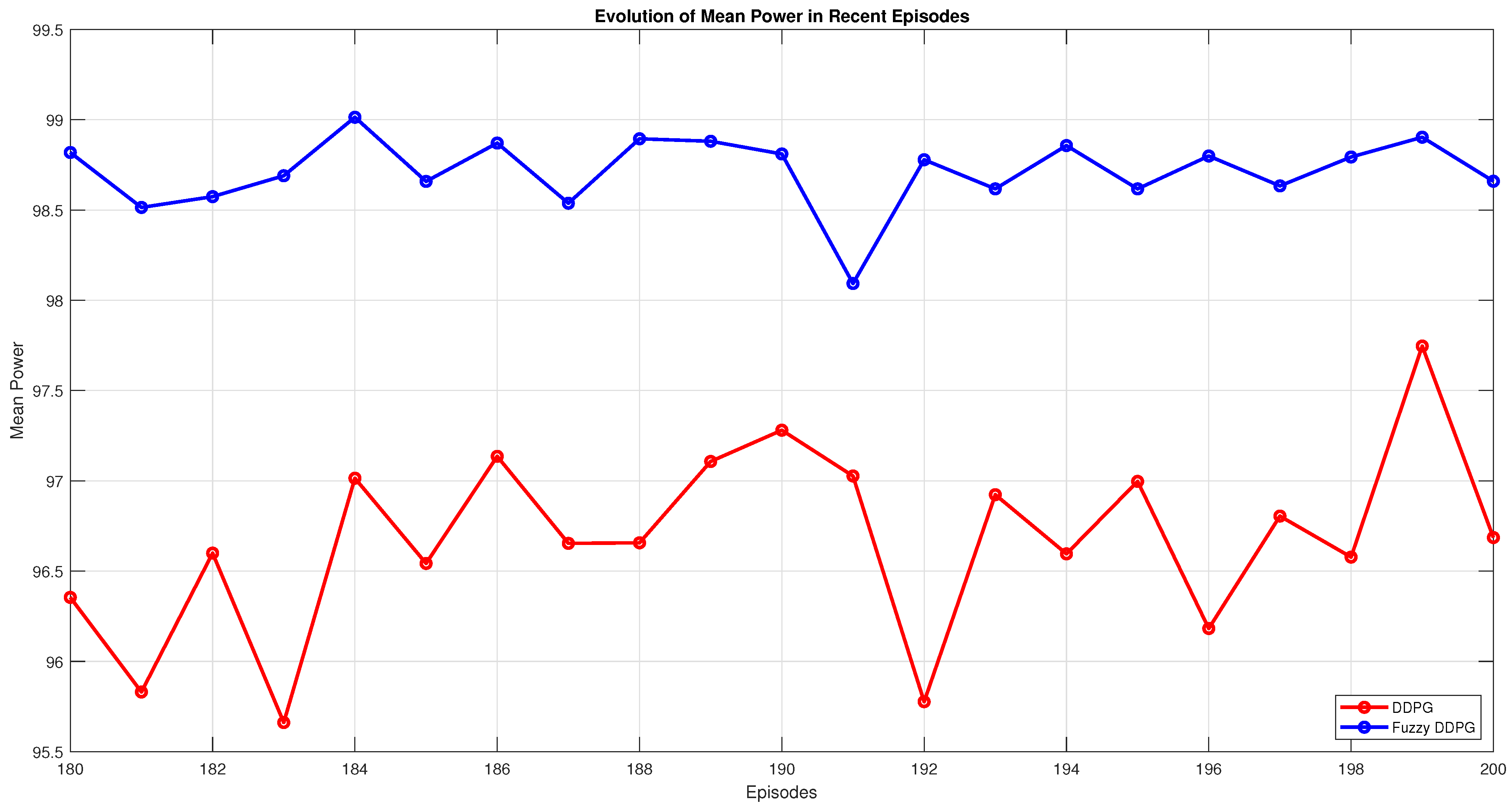
This theorem guarantees convergence toward a near-optimal policy by exploiting the contraction property of the Bellman operator, even under complex fuzzy approximations. Such convergence is instrumental in MPPT under partial shading conditions in PV panels, as it systematically guides the search toward the global maximum rather than local optima. By accommodating continuous variations in solar irradiance, the proposed approach ensures robust policy updates that adaptively track the global peak under dynamically shifting conditions.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}