
XSShield: Defending Against Stored XSS Attacks Using LLM-Based Semantic Understanding


Abstract
1. Introduction
- New framework. We propose XSShield, the first detection framework leveraging LLMs’ code semantic understanding capabilities to defend against stored XSS attacks. This framework transcends traditional detection paradigms based on differential analysis and regular expression matching by deeply understanding JavaScript code’s behavioral patterns and semantic intentions, pioneering new approaches to defending against stored XSS attacks.
- Lightweight, effective and efficient approach. We designed a Prompt Optimizer based on semantic gradient descent and UCB-R selection algorithms, along with a Data Adaptor based on PDGs, achieving code processing that balances real-time performance with fine granularity. Experimental evaluation of XSShield shows that when facing non-obfuscated stored XSS attacks, XSShield achieves an F1 score of 0.9266 on the GPT-4 model, significantly outperforming existing solutions with an average accuracy improvement of 88.8%. XSShield’s average processing time in test data is 0.205 s (excluding model communication overhead), maintaining detection precision while keeping time overhead within a range that does not affect user experience, demonstrating practical deployability.
- Novel insights. Through extensive experiments and analysis, we uncover several key findings about LLM-based XSS attack defense: (1) the critical role of semantic-aware code representation in attack detection, (2) the impact of prompt optimization on detection accuracy, and (3) the trade-offs between model complexity and detection performance. These insights provide valuable guidance for future research in LLM-based security applications.
2. Backgroud and Motivation
2.1. XSS Attack Mechanisms
- Reflected XSS Scenario:Code: <input type="text" value="{payload}">
- Stored XSS Scenario:Code: <img src="avatar.jpg" onerror="{payload}">
2.2. Motivation
2.3. Challenges
3. XSShield Design
- Solution for Challenge 1: LLM-based Semantic Analysis
- Solution for Challenge 2: Efficient and Precise Detection Components
3.1. Prompt Optimizer
3.1.1. Prompt Expander
3.1.2. Prompt Selector
3.1.3. Optimization Orchestrator
3.2. Data Adaptor
3.2.1. PDG Generator
| Algorithm 1 Prompt-Optimization Workflow. |
|
3.2.2. PDG Partitioner
| Algorithm 2 PDG Partitioning via Community Detection. |
|
3.2.3. Code Representation Generator
3.3. LLM-Based Detector
4. Experiment
4.1. Implementation
| Listing 1. A code fragment demonstrating ActiveX component detection via stored cross-site scripting vulnerability. |
 |
4.2. Evaluation
- RQ1—Comparativeness: What advantages does the XSShield framework offer compared to existing mainstream malware-detection tools? We evaluate the framework’s defense effectiveness against various attack vectors and compare it with other SOAT open source malware detectors to identify its advantages.
- RQ2—Effectiveness: Are all components of XSShield performing their intended functions? This question is addressed by analyzing each module’s contribution to the framework’s overall accuracy and defense capabilities.
- RQ3—Efficiency: How much runtime overhead does the code-transformation process introduce? We quantify the framework’s time consumption through detailed performance analysis.
4.2.1. Experimental Setup
4.2.2. Effectiveness Evaluation
4.2.3. Ablation Experiment
4.2.4. Efficiency Evaluation
5. Discussion
5.1. Why Choose Prompt Optimization over Fine-Tuning and Retrieval-Augmented Generation?
5.2. Why Is Network Latency Not a Key Bottleneck for XSShield Deployment?
5.3. How Does Current Large Language Model Performance Affect Obfuscated Code Detection?
5.4. How Does Domain-Specific Optimization Impact Stored XSS Detection Performance?
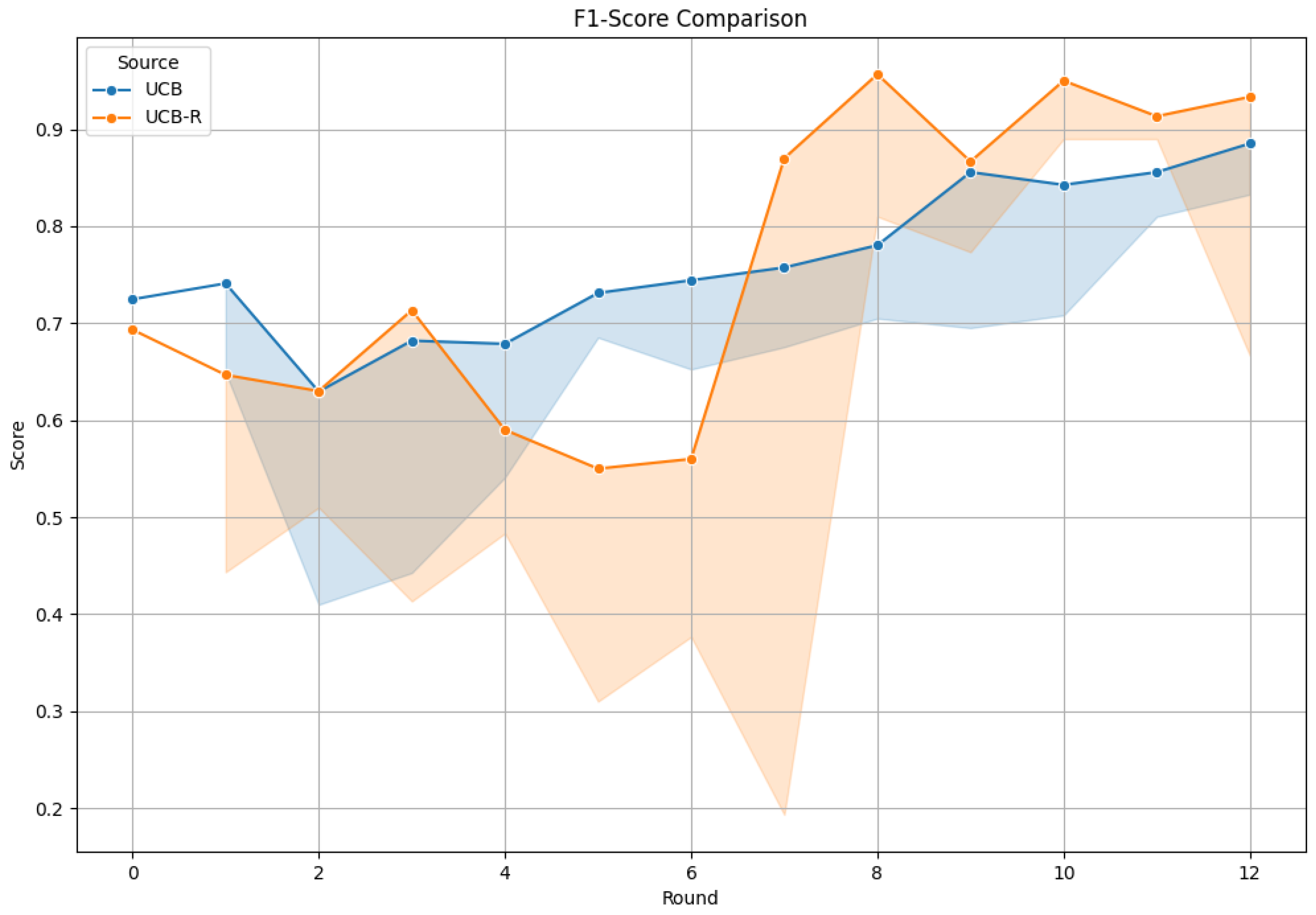
5.5. How Does UCB-R Handle Potential Dependencies Between Prompts?
5.5.1. Limitations
5.5.2. Future Work
6. Related Work
6.1. XSS Defense
6.2. Malicious JavaScript Detection
6.3. Prompt Crafting
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| XSS | Cross Site Scripting |
| LLM | Large Language Model |
| PDG | Program Dependence Graph |
| AST | Abstract Syntax Tree |
| CFG | Control Flow Graph |
| MCC | Matthews Correlation Coefficient |
| CSP | Content Security Policy |
| UCB | Upper Confidence Bound Bandits |
| UCB-R | Upper Confidence Bound Bandits with Weighted Randomization |
Appendix A. Attack Vector Calssification
Appendix B. Prompt Template in Prompt Expander


References
- Foundation, O. Cross-Site Scripting (XSS). 2021. Available online: https://owasp.org/www-community/attacks/xss/ (accessed on 3 December 2024).
- HackerOne. 8th Annual Hacker-Powered Security Report. 2024. Available online: https://hackerpoweredsecurityreport.com/ (accessed on 3 December 2024).
- Project, C. cvelistV5. 2023. Available online: https://github.com/CVEProject/cvelistV5/ (accessed on 3 December 2024).
- Database, N.V. CVE-2023-40000. 2023. Available online: https://nvd.nist.gov/vuln/detail/CVE-2023-40000/ (accessed on 3 December 2024).
- Bing, L.; Fengyu, Z. Study and Design of Stored-XSS Vulnerability Detection. Comput. Appl. Softw. 2013, 17–21. [Google Scholar]
- Somorovsky, J.; Heiderich, M.; Jensen, M.; Schwenk, J.; Gruschka, N.; Lo Iacono, L. All your clouds are belong to us: Security analysis of cloud management interfaces. In Proceedings of the 3rd ACM Workshop on Cloud Computing Security Workshop (CCSW ‘11), New York, NY, USA, 21 October 2011; pp. 3–14. [Google Scholar] [CrossRef]
- Gupta, S.; Gupta, B.B. Cross-Site Scripting (XSS) attacks and defense mechanisms: Classification and state-of-the-art. Int. J. Syst. Assur. Eng. Manag. 2017, 8, 512–530. [Google Scholar] [CrossRef]
- Barth, A.; Jackson, C.; Mitchell, J.C. Robust defenses for cross-site request forgery. In Proceedings of the 15th ACM Conference on Computer and Communications Security, Alexandria, VA, USA, 27–31 October 2008. [Google Scholar] [CrossRef]
- Heiderich, M.; Niemietz, M.; Schuster, F.; Holz, T.; Schwenk, J. Scriptless attacks: Stealing the pie without touching the sill. In Proceedings of the 2012 ACM Conference on Computer and Communications Security (CCS ‘12), New York, NY, USA, 16–18 October 2012; pp. 760–771. [Google Scholar] [CrossRef]
- Gupta, S.; Gupta, B.B. XSS-SAFE: A Server-Side Approach to Detect and Mitigate Cross-Site Scripting (XSS) Attacks in JavaScript Code. Arab. J. Sci. Eng. 2015, 41, 897–920. [Google Scholar] [CrossRef]
- Noever, D. Can Large Language Models Find and Fix Vulnerable Software? arXiv 2023, arXiv:2308.10345. [Google Scholar]
- Gupta, M.; Akiri, C.; Aryal, K.; Parker, E.; Praharaj, L. From ChatGPT to ThreatGPT: Impact of Generative AI in Cybersecurity and Privacy. IEEE Access 2023, 11, 80218–80245. [Google Scholar] [CrossRef]
- Ganguli, D.; Lovitt, L.; Kernion, J.; Askell, A.; Bai, Y.; Kadavath, S.; Mann, B.; Perez, E.; Schiefer, N.; Ndousse, K.; et al. Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned. arXiv 2022, arXiv:2209.07858. [Google Scholar]
- Yang, W.; Dong, Y.; Li, X.; Zhang, D.; Wang, J.; Zhu, H.; Deng, Y. Security foundation of deep learning: Formalization, verification, and applications. ACM Comput. Surv. 2022, 55, 1–35. [Google Scholar] [CrossRef]
- Roth, S.; Gröber, L.; Backes, M.; Krombholz, K.; Stock, B. 12 Angry Developers—A Qualitative Study on Developers’ Struggles with CSP. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security (CCS ‘21), New York, NY, USA, 15–19 November 2021; pp. 3085–3103. [Google Scholar] [CrossRef]
- Xu, G.; Xie, X.; Huang, S.; Zhang, J.; Pan, L.; Lou, W.; Liang, K. JSCSP: A Novel Policy-Based XSS Defense Mechanism for Browsers. IEEE Trans. Dependable Secur. Comput. 2022, 19, 862–878. [Google Scholar] [CrossRef]
- Pan, X.; Cao, Y.; Liu, S.; Zhou, Y.; Chen, Y.; Zhou, T. CSPAutoGen: Black-box Enforcement of Content Security Policy upon Real-world Websites. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security (CCS ‘16), New York, NY, USA, 24–28 October 2016; pp. 653–665. [Google Scholar] [CrossRef]
- Alhindi, M.; Hallett, J. Sandboxing Adoption in Open Source Ecosystems. arXiv 2024, arXiv:2405.06447. [Google Scholar]
- Oren, Y.; Kemerlis, V.P.; Sethumadhavan, S.; Keromytis, A.D. The Spy in the Sandbox—Practical Cache Attacks in JavaScript. arXiv 2015, arXiv:1502.07373. [Google Scholar]
- Bisht, P.; Venkatakrishnan, V.N. XSS-GUARD: Precise Dynamic Prevention of Cross-Site Scripting Attacks. In Detection of Intrusions and Malware, and Vulnerability Assessment; Zamboni, D., Ed.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 23–43. [Google Scholar]
- Bates, D.; Barth, A.; Jackson, C. Regular expressions considered harmful in client-side XSS filters. In Proceedings of the 19th International Conference on World Wide Web (WWW ‘10), New York, NY, USA, 26–30 April 2010; pp. 91–100. [Google Scholar] [CrossRef]
- Pelizzi, R.; Sekar, R. Protection, usability and improvements in reflected XSS filters. In Proceedings of the 7th ACM Symposium on Information, Computer and Communications Security (ASIACCS ‘12), New York, NY, USA, 2–4 May 2012; p. 5. [Google Scholar] [CrossRef]
- Gupta, S.; Gupta, B.B. XSS-immune: A Google chrome extension-based XSS defensive framework for contemporary platforms of web applications. Sec. Commun. Netw. 2016, 9, 3966–3986. [Google Scholar] [CrossRef]
- Chaudhary, P.; Gupta, B.B.; Gupta, S. A Framework for Preserving the Privacy of Online Users Against XSS Worms on Online Social Network. Int. J. Inf. Technol. Web Eng. 2019, 14, 85–111. [Google Scholar] [CrossRef]
- Gupta, S.; Gupta, B.B.; Chaudhary, P. Hunting for DOM-Based XSS vulnerabilities in mobile cloud-based online social network. Future Gener. Comput. Syst. 2018, 79, 319–336. [Google Scholar] [CrossRef]
- Lalia, S.; Sarah, A. XSS Attack Detection Approach Based on Scripts Features Analysis. In Trends and Advances in Information Systems and Technologies; Rocha, Á., Adeli, H., Reis, L.P., Costanzo, S., Eds.; Springer: Cham, Switzerland, 2018; pp. 197–207. [Google Scholar]
- Gupta, S.; Gupta, B.B. XSS-secure as a service for the platforms of online social network-based multimedia web applications in cloud. Multimed. Tools Appl. 2018, 17, 4829–4861. [Google Scholar] [CrossRef]
- Aurore54F. static-pdg-js; Licensed Under AGPL-3.0. 2024. Available online: https://github.com/Aurore54F/static-pdg-js (accessed on 3 December 2024).
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 2008, P10008. [Google Scholar] [CrossRef]
- Microsoft. LMOps; Licensed Under MIT. 2024. Available online: https://github.com/microsoft/LMOps (accessed on 3 December 2024).
- beefproject. beef. 2024. Available online: https://github.com/beefproject/beef (accessed on 10 March 2025).
- JavaScript-obfuscator. 2024. Available online: https://github.com/JavaScript-obfuscator/JavaScript-obfuscator (accessed on 10 March 2025).
- Raychev, V.; Bielik, P.; Vechev, M.; Krause, A. Learning programs from noisy data. ACM SIGPLAN Not. 2016, 51, 61–774. [Google Scholar] [CrossRef]
- VirusTotal. 2024. Available online: https://www.virustotal.com/gui/home/upload (accessed on 10 March 2025).
- HynekPetrak. JavaScript Malware Collection. 2024. Available online: https://github.com/HynekPetrak/JavaScript-malware-collection (accessed on 10 March 2025).
- geeksonsecurity. Malicious JavaScript Dataset. 2017. Available online: https://github.com/geeksonsecurity/js-malicious-dataset (accessed on 10 March 2025).
- Romano, A.; Lehmann, D.; Pradel, M.; Wang, W. Wobfuscator: Obfuscating JavaScript Malware via Opportunistic Translation to WebAssembly. In Proceedings of the 2022 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 22–26 May 2022; pp. 1574–1589. [Google Scholar] [CrossRef]
- Rieck, K.; Krueger, T.; Dewald, A. CUJO: Efficient detection and prevention of drive-by-download attacks. In Proceedings of the 26th Annual Computer Security Applications Conference, Austin, TX, USA, 6–10 December 2010; pp. 31–39. [Google Scholar]
- Aurore54F. lexical-jsdetector. 2024. Available online: https://github.com/Aurore54F/lexical-jsdetector (accessed on 10 March 2025).
- Curtsinger, C.; Livshits, B.; Zorn, B.; Seifert, C. ZOZZLE: Fast and Precise In-Browser JavaScript Malware Detection. In Proceedings of the USENIX Security Symposium, USENIX Security Symposium, San Francisco, CA, USA, 10–12 August 2011. [Google Scholar]
- Aurore54F. syntactic-jsdetector. 2024. Available online: https://github.com/Aurore54F/syntactic-jsdetector (accessed on 10 March 2025).
- Fass, A.; Backes, M.; Stock, B. JStap: A Static Pre-Filter for Malicious JavaScript Detection. In Proceedings of the 35th Annual Computer Security Applications Conference, San Juan, Puerto Rico, 9–13 December 2019; pp. 257–269. [Google Scholar]
- Aurore54F. JStap. 2024. Available online: https://github.com/Aurore54F/JStap (accessed on 10 March 2025).
- Dehghantanha, A.; Yazdinejad, A.; Parizi, R.M. Autonomous Cybersecurity: Evolving Challenges, Emerging Opportunities, and Future Research Trajectories. In Proceedings of the Workshop on Autonomous Cybersecurity (AutonomousCyber ‘24), New York, NY, USA, 14–18 October 2024; pp. 1–10. [Google Scholar] [CrossRef]
- Yazdinejad, A.; Dehghantanha, A.; Karimipour, H.; Srivastava, G.; Parizi, R.M. A Robust Privacy-Preserving Federated Learning Model Against Model Poisoning Attacks. IEEE Trans. Inf. Forensics Secur. 2024, 19, 6693–6708. [Google Scholar] [CrossRef]
- Jim, T.; Swamy, N.; Hicks, M. Defeating script injection attacks with browser-enforced embedded policies. In Proceedings of the 16th International Conference on World Wide Web (WWW ‘07), New York, NY, USA, 8–12 May 2007; pp. 601–610. [Google Scholar] [CrossRef]
- Gundy, M.V.; Chen, H. Noncespaces: Using Randomization to Enforce Information Flow Tracking and Thwart Cross-Site Scripting Attacks. In Proceedings of the Network and Distributed System Security Symposium, San Diego, CA, USA, 8–11 February 2009. [Google Scholar]
- Stock, B.; Lekies, S.; Mueller, T.; Spiegel, P.; Johns, M. Precise client-side protection against DOM-based cross-site scripting. In Proceedings of the 23rd USENIX Conference on Security Symposium (SEC’14), Anaheim, CA, USA, 9–11 August 2014; pp. 655–670. [Google Scholar]
- Samuel, M.; Saxena, P.; Song, D. Context-sensitive auto-sanitization in web templating languages using type qualifiers. In Proceedings of the 18th ACM Conference on Computer and Communications Security, New York, NY, USA, 17–21 October 2011; pp. 587–600. [Google Scholar] [CrossRef]
- Weinberger, J.; Saxena, P.; Akhawe, D.; Finifter, M.; Shin, R.; Song, D. A Systematic Analysis of XSS Sanitization in Web Application Frameworks. In Computer Security—ESORICS 2011; Atluri, V., Diaz, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 150–171. [Google Scholar]
- Melicher, W.; Das, A.; Sharif, M.; Bauer, L.; Jia, L. Riding out DOMsday: Towards Detecting and Preventing DOM Cross-Site Scripting. In Proceedings of the Network and Distributed System Security Symposium, San Diego, CA, USA, 18–21 February 2018. [Google Scholar]
- West Mike, A.B.; Veditz, D. Content Security Policy Level 2. 2016. Available online: https://www.w3.org/TR/CSP2/ (accessed on 9 March 2025).
- Agten, P.; Acker, S.V.; Brondsema, Y.; Phung, P.H.; Desmet, L.; Piessens, F. JSand: Complete client-side sandboxing of third-party JavaScript without browser modifications. In Proceedings of the Asia-Pacific Computer Systems Architecture Conference, Matsue, Japan, 28–31 August 2012. [Google Scholar]
- Kolbitsch, C.; Livshits, B.; Zorn, B.; Seifert, C. Rozzle: De-cloaking Internet Malware. In Proceedings of the 2012 IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 20–23 May 2012; pp. 443–457. [Google Scholar] [CrossRef]
- Fass, A.; Krawczyk, R.P.; Backes, M.; Stock, B. JaSt: Fully Syntactic Detection of Malicious (Obfuscated) JavaScript. In Detection of Intrusions and Malware, and Vulnerability Assessment; Giuffrida, C., Bardin, S., Blanc, G., Eds.; Springer: Cham, Switzerland, 2018; pp. 303–325. [Google Scholar]
- Wang, Y.; Cai, W.d.; Wei, P.c. A deep learning approach for detecting malicious JavaScript code. Sec. Commun. Netw. 2016, 9, 1520–1534. [Google Scholar] [CrossRef]
- Ndichu, S.; Kim, S.; Ozawa, S.; Misu, T.; Makishima, K. A machine learning approach to detection of JavaScript-based attacks using AST features and paragraph vectors. Appl. Soft Comput. 2019, 84, 105721. [Google Scholar] [CrossRef]
- Shin, T.; Razeghi, Y.; Logan, R.L., IV; Wallace, E.; Singh, S. AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts. arXiv 2020, arXiv:2010.15980. [Google Scholar]
- Gao, T.; Fisch, A.; Chen, D. Making Pre-trained Language Models Better Few-shot Learners. arXiv 2021, arXiv:2012.15723. [Google Scholar]
- Schick, T.; Schütze, H. Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference. arXiv 2021, arXiv:2001.07676. [Google Scholar]
- Li, X.L.; Liang, P. Prefix-Tuning: Optimizing Continuous Prompts for Generation. arXiv 2021, arXiv:2101.00190. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Wu, G.; Wu, W.; Liu, X.; Xu, K.; Wan, T.; Wang, W. Cheap-Fake Detection with LLM Using Prompt Engineering. In Proceedings of the 2023 IEEE International Conference on Multimedia and Expo Workshops (ICMEW), Brisbane, Australia, 10–14 July 2023; pp. 105–109. [Google Scholar] [CrossRef]
- Wang, E.; Chen, J.; Xie, W.; Wang, C.; Gao, Y.; Wang, Z.; Duan, H.; Liu, Y.; Wang, B. Where URLs Become Weapons: Automated Discovery of SSRF Vulnerabilities in Web Applications. In Proceedings of the 2024 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2024; pp. 239–257. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Development Set | Evaluation Set | |
|---|---|---|
| Malicious | HynekPetrak/JavaScript-malware-collection | BeEF Implement |
| geeksonsecurity/js-malicious-dataset | ||
| VirusTotal | ||
| Benign | JS150k (excluding low-redundancy samples) | 305 low-redundancy JS files |
| Module Category | XSShield | Cujo | Zozzle | JStap (Pdgngrams) | JStap (Pdgvalues) | JStap (Astngram) | JStap (Astvalue) | ||
|---|---|---|---|---|---|---|---|---|---|
| BeEF | Information Gathering | non-obf | 72.90% (78/107) | 0% (0/107) | 1.87% (2/107) | 0% (0/107) | 0% (0/107) | 0% (0/107) | 0% (0/107) |
| obf | 59.81% (64/107) | 0% (0/107) | 72.90% (78/107) | 9.35% (10/107) | 0% (0/107) | 9.35% (10/107) | 0% (0/107) | ||
| sum | 66.36% (142/214) | 0% (0/214) | 37.38% (80/214) | 4.67% (10/214) | 0% (0/214) | 4.67% (10/214) | 0% (0/214) | ||
| Exploit | non-obf | 92.92% (105/113) | 0% (0/113) | 0% (0/113) | 0% (0/113) | 0% (0/113) | 0% (0/113) | 0% (0/113) | |
| obf | 69.03% (78/113) | 0% (0/113) | 97.35% (110/113) | 3.54% (4/113) | 0% (0/113) | 7.96% (9/113) | 0% (0/113) | ||
| sum | 80.97% (183/226) | 0% (0/226) | 48.67% (110/226) | 1.77% (4/226) | 0% (0/226) | 3.98% (9/226) | 0% (0/226) | ||
| Mobile and Cross-Platform | non-obf | 81.25% (13/16) | 0% (0/16) | 0% (0/16) | 0% (0/16) | 0% (0/16) | 0% (0/16) | 0% (0/16) | |
| obf | 56.25% (9/16) | 0% (0/16) | 75% (12/16) | 0% (0/16) | 0% (0/16) | 6.25% (1/16) | 0% (0/16) | ||
| sum | 68.75% (22/32) | 0% (0/32) | 37.5% (12/32) | 0% (0/32) | 0% (0/32) | 3.13% (1/32) | 0% (0/32) | ||
| Persistence and Social Engineering | non-obf | 93.75% (30/32) | 0% (0/32) | 0% (0/32) | 0% (0/32) | 0% (0/32) | 0% (0/32) | 0% (0/32) | |
| obf | 71.88% (23/32) | 0% (0/32) | 87.5% (28/32) | 3.13% (1/32) | 0% (0/32) | 9.38% (3/32) | 0% (0/32) | ||
| sum | 82.81% (53/64) | 0% (0/64) | 43.75% (28/64) | 1.56% (1/64) | 0% (0/64) | 4.69% (3/64) | 0% (0/64) | ||
| Auxiliary and Support | non-obf | 82.14% (23/28) | 0% (0/28) | 0% (0/28) | 0% (0/28) | 0% (0/28) | 0% (0/28) | 0% (0/28) | |
| obf | 64.29% (18/28) | 0% (0/28) | 78.57% (22/28) | 10.71% (3/28) | 3.57% (1/28) | 10.71% (3/28) | 3.57% (1/28) | ||
| sum | 73.21% (41/56) | 0% (0/56) | 39.29% (22/56) | 5.36% (3/56) | 1.79% (1/56) | 5.36% (3/56) | 1.79% (1/56) | ||
| Inter-Protocol Communication | non-obf | 88.89% (8/9) | 0% (0/9) | 0% (0/9) | 0% (0/9) | 0% (0/9) | 0% (0/9) | 0% (0/9) | |
| obf | 66.67% (6/9) | 0% (0/9) | 100% (9/9) | 0% (0/9) | 0% (0/9) | 0% (0/9) | 0% (0/9) | ||
| sum | 77.78% (14/18) | 0% (0/18) | 50% (9/18) | 0% (0/18) | 0% (0/18) | 0% (0/18) | 0% (0/18) | ||
| BeEF Summary | non-obf | 84.26% (257/305) | 0% (0/305) | 0.66% (2/305) | 0% (0/305) | 0% (0/305) | 0% (0/305) | 0% (0/305) | |
| obf | 64.92% (198/305) | 0% (0/305) | 84.92% (259/305) | 5.90% (18/305) | 0.33% (1/305) | 8.52% (26/305) | 0.33% (1/305) | ||
| sum | 74.59% (455/610) | 0% (0/610) | 42.79% (261/610) | 2.95% (18/610) | 0.16% (1/610) | 4.26% (26/610) | 0.16% (1/610) | ||
| Benign | non-obf | 97.05% (296/305) | 100% (305/305) | 95.41% (291/305) | 100% (305/305) | 99.67% (304/305) | 100% (305/305) | 99.67% (304/305) | |
| obf | 80.00% (244/305) | 100% (305/305) | 0% (0/305) | 77.38% (236/305) | 97.05% (296/305) | 82.62% (252/305) | 97.70% (298/305) | ||
| sum | 88.52% (540/610) | 100% (610/610) | 47.70% (291/610) | 88.69% (541/610) | 98.36% (600/610) | 91.31% (557/610) | 98.69% (602/610) | ||
| Summary | non-obf | 90.66% (553/610) | 50% (305/610) | 48.03% (293/610) | 50% (305/610) | 49.84% (304/610) | 50% (305/610) | 49.84% (304/610) | |
| obf | 72.46% (442/610) | 50% (305/610) | 42.46% (259/610) | 41.64% (254/610) | 48.69% (297/610) | 45.57% (278/610) | 49.02% (299/610) | ||
| sum | 81.56% (995/1220) | 50% (610/1220) | 45.25% (552/1220) | 45.82% (559/1220) | 49.26% (601/1220) | 47.79% (583/1220) | 49.43% (603/1220) | ||
| MCC | non-obf | 0.8137 | 0 | −0.0811 | 0 | −0.0393 | 0 | −0.0393 | |
| obf | 0.5973 | 0 | −0.1741 | −0.1900 | −0.0380 | −0.1008 | −0.0261 | ||
| sum | 0.7055 | 0 | −0.0165 | −0.0950 | −0.0387 | −0.0504 | −0.0327 | ||
| F1 | non-obf | 0.8991 | 0 | 0.0125 | 0 | 0 | 0 | 0 | |
| obf | 0.7018 | 0 | 0.5983 | 0.0915 | 0.0063 | 0.1354 | 0.0064 | ||
| sum | 0.8005 | 0 | 0.4394 | 0.0517 | 0.0032 | 0.0754 | 0.0032 | ||
| Technique | Cujo | Zozzle | JStap (Pdgngrams) | JStap (Pdgvalues) | JStap (Astngram) | JStap (Astvalue) |
|---|---|---|---|---|---|---|
| Benign | 0.99 (39,731 /39,731 + 18) | 39,153/39,153 + 143 | 34,816/34,816 | 34,760/34,760 + 2 | 38,676/38,676 + 1 | 38,687/38,687 + 2 |
| Malicious | 0.85 (4455/4455 + 769) | 0.82 (3839/3839 + 833) | 4462/4462 + 96 | 4417/4417 + 141 | 4585/4585 + 84 | 4541/4541 + 128 |
| Non-Adaptor | Adaptor | ||||
|---|---|---|---|---|---|
| Correct/Total | Accuracy | Correct/Total | Accuracy | ||
| Non-selector | Malicious | 132/305 | 58.36% | 231/305 | 73.11% |
| Benign | 224/305 | 215/305 | |||
| UCB | Malicious | 163/305 | 59.67% | 224/305 | 77.87% |
| Benign | 201/305 | 251/305 | |||
| UCB-R | Malicious | 208/305 | 71.97% | 257/305 | 86.07% |
| Benign | 231/305 | 296/305 | |||
| GPT-3.5-Turbo | GPT-4 | Gemini Pro | |
|---|---|---|---|
| Malicious | 257/305 | 272/305 | 52/305 |
| Benign | 296/305 | 295/305 | 170/305 |
| F1-score | 0.9001 | 0.9266 | 0.2112 |
| XSShield | JaSt | Lex | Syn | JStap (Pdgngrams) | JStap (Pdgvalues) | JStap (Astngram) | JStap (Astvalue) | ||
|---|---|---|---|---|---|---|---|---|---|
| BeEF | non-obf | 5.6322 + Δs | 18.305548429489136s | 4.216928243637085s | 8.048108100891113s | 4.811763833000441s | 5.339117702s | 4.7260363990008045s | 4.901345518001108s |
| obf | 13.7899 + Δs | 22.624483585357666s | 3.9347400665283203s | 9.940247774124146s | 9.44910991800134s | 15.74884632s | 8.460276686000725s | 10.676183636998758s | |
| Benign | non-obf | 34.9327 + Δs | 46.93710374832153s | 6.736656904220581s | 19.76883864402771s | 29.121426600999257s | 58.52059159s | 26.991471764999005s | 35.054263004998575s |
| obf | 195.6354 + Δa | 78.3315646648407s | 9.648104429244995s | 44.17033505439758s | 135.2840869929987s | 276.176368918s | 115.28895020699929s | 151.87477367199972s | |
| avg per file | 0.205 + Δs | 0.136s | 0.020s | 0.067s | 0.146s | 0.292s | 0.127s | 0.191s | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Y.; Wang, E.; Yang, W.; Ge, W.; Yang, S.; Zhang, Y.; Qu, W.; Xie, W. XSShield: Defending Against Stored XSS Attacks Using LLM-Based Semantic Understanding. Appl. Sci. 2025, 15, 3348. https://doi.org/10.3390/app15063348
Zhou Y, Wang E, Yang W, Ge W, Yang S, Zhang Y, Qu W, Xie W. XSShield: Defending Against Stored XSS Attacks Using LLM-Based Semantic Understanding. Applied Sciences. 2025; 15(6):3348. https://doi.org/10.3390/app15063348
Chicago/Turabian StyleZhou, Yuan, Enze Wang, Wantong Yang, Wenlin Ge, Siyi Yang, Yibo Zhang, Wei Qu, and Wei Xie. 2025. "XSShield: Defending Against Stored XSS Attacks Using LLM-Based Semantic Understanding" Applied Sciences 15, no. 6: 3348. https://doi.org/10.3390/app15063348
APA StyleZhou, Y., Wang, E., Yang, W., Ge, W., Yang, S., Zhang, Y., Qu, W., & Xie, W. (2025). XSShield: Defending Against Stored XSS Attacks Using LLM-Based Semantic Understanding. Applied Sciences, 15(6), 3348. https://doi.org/10.3390/app15063348