1. Introduction
The task of detecting Chinese characters is not only an important step in Chinese character recognition and processing, but also widely used in the fields of cultural heritage preservation, calligraphy analysis, and font generation. However, due to the multi-scale characteristics, complex background, and dense distribution of Chinese character components, traditional image segmentation methods are difficult to meet the requirements of practical applications.
The main challenges of handwritten Chinese character detection can be summarized as follows: first, the structure of Chinese characters is inherently complex, with each glyph consisting of multiple strokes and complex relative positional relationships between the strokes. Some Chinese characters have large differences in stroke order, curvature, and structural combinations, making recognition more difficult. Compared with Latin letters or numbers, the structure of Chinese characters is not only more complex but also varied. Secondly, there are significant individual differences in the writing styles of handwritten Chinese characters. Factors such as writing styles, stroke thickness, and inclination of characters by different writers can lead to differences in the performance of the same character shape among different individuals. The issues of blurred handwriting, overlapping characters, and hyphenation, all caused by excessive writing speed, can significantly affect the accurate recognition of characters. Furthermore, in practical applications, background noise, texture interference, and other non-target elements often appear in handwritten Chinese character images, and these factors place higher demands on character localization and segmentation. Finally, in some low-quality handwritten texts, characters may overlap and occlude, which makes the boundaries between characters blurred and increases the difficulty of detection and segmentation.
Wang [
1] and others proposed a text region detection method based on multi-scale sliding windows, which efficiently identifies text regions with good results by sliding classification of each window through a convolutional network. Tian [
2] proposed the CTPN (Connectionist Text Proposal Network) text detection network, which holds a significant position in the field of text detection, and is especially suitable for the detection task of scene text box narrow, because the size of the text box varies greatly. CTPN uses fixed text anchor frames of different sizes and combines them with the Faster-RCNN concept to efficiently detect small-size text regions. Meanwhile, CTPN uses a text line construction method to connect multiple candidate text boxes into complete text boxes. Subsequently, the network further processes the convolutional features through a bidirectional LSTM structure to enhance the representation of spatial as well as sequential information.
On this basis, the EAST (Efficient and Accurate Scene Text Detector) algorithm proposed by Zhou [
3] draws on the concept of U-Net [
4], employing a fully convolutional neural network (FCN) and non-maximum suppression (NMS) algorithms to streamline intermediate processing steps, enabling efficient detection at the single-character level. SegLink [
5] is an improved version of CTPN, which not only makes tilt improvement for text box prediction but also optimizes the positioning of text boxes by connecting candidate boxes through neural networks. PixelLink [
6] predicts text pixels and non-text pixels separately by training a convolutional neural network model and connecting them for instance segmentation. Based on this, the TextSnake [
7] algorithm handles irregular text regions more flexibly by predicting the position of the centerline of the text, the radius of the central disc, and the angle between the centers of adjacent discs, thus avoiding the dependence of traditional prediction frames (e.g., quadrangles and rotated rectangles) on the shape and length of the text. Diverging from traditional methods using bbox instance segmentation, BoundarySpotter [
8] employs multi-scale boundary point localization and adaptive topology reconstruction for geometric/semantic modeling of irregular text, proving boundary representations enhance accuracy in complex scenes. R50_DBU [
9] introduces an enhanced differential binarization network, integrating U-Net’s feature architecture, to address challenges in automated text detection such as inadequate recognition of special characters and incomplete detection of dense and lengthy text segments. TextFuse [
10] proposes a dual-stage fusion framework addressing single-feature dependency limitations in scene text detection through multi-modal feature aggregation and multi-algorithm consensus integration.
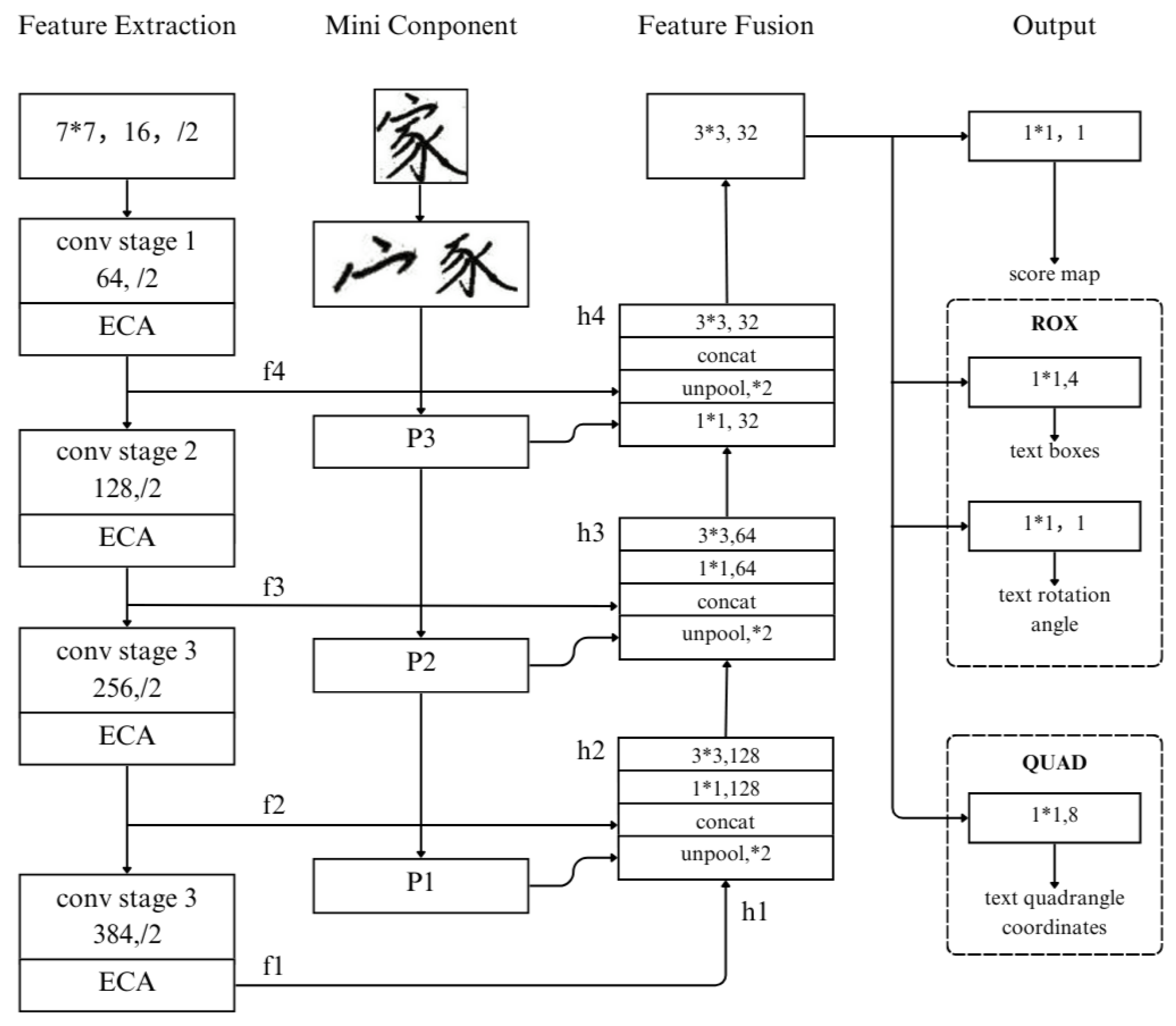
In this paper, an improved EAST network CEE (Components-ECA-EAST Network) that integrates the attention mechanism and the feature pyramid structure is proposed based on the structural analysis of Chinese character mini components. The ECA (Efficient Channel Attention) attention structure is introduced in the feature extraction phase to refine the weight distribution between feature channels and improve the shortcomings of traditional EAST in attention allocation; for the tiny component dataset, the features are first enhanced and refined by convolutional layers, and then cascaded fusion with the feature pyramid is carried out, to better retain the fine-grained features in the multi-scale feature aggregation to better preserve fine-grained information, and finally, Dice Loss is utilized as the loss function for the regression task. The above improvements improve the network’s performance in detecting and segmenting the ultra-small components and fine strokes of handwritten Chinese characters.
3. Results
3.1. Dataset
The dataset was constructed in the context of the writing grade examination for primary and secondary school students in Shanghai, 240 students who were about to take the writing grade examination were invited and their handwritten images of Chinese characters were collected as the research samples. The dataset covers different writing scenarios: first, formal writing on exam-specific papers, and second, unconstrained daily writing practice. To fully represent the differences between these two writing environments, 480 high-quality images of handwritten Chinese characters were collected, covering more than 40,000 Chinese characters and presenting rich background variations and diverse writing styles. This dataset aims to simulate the actual differences between the test scenarios and daily writing and to better meet the needs of handwritten Chinese character detection in writing grade tests. All samples are dense text images containing a large number of Chinese characters.
Figure 4a,b show the partial writing grade exam dataset constructed in this paper, while
Figure 5a,b present the corresponding unconstrained text dataset, respectively.
In addition, to improve the capability of the Chinese character detection model in recognizing diverse structural components of Chinese characters, this paper further integrates a set of image datasets designed specifically for the task of Chinese character component segmentation. The dataset covers a variety of different structures of Chinese character components, including left-right structure, top-bottom structure, wraparound structure, etc., to cope with the diversity of Chinese character component morphology as well as the complexity of the background.
Figure 6 shows the diagram of some Chinese character components.
Finally, the dataset was expanded to 960 images by data enhancement methods such as randomly rotating different angles to improve the adaptability of our model in different scenes, and all the images were uniformly scaled to a fixed size of 1200 × 1200. Ultimately, the dataset was partitioned into training, validation, and test sets with a ratio of 8:1:1, respectively.
3.2. Experimental Parameters
In this paper, the network model is implemented through PyTorch, the code is written and run on Linux CentOS 7.7 system, and the experimental hardware envi-ronment is NVIDIA A100 Tensor Core GPU 80G, provided by NVIDIA Corporation, located in Santa Clara, CA, USA. Adam (Adaptive Moment Estimation) optimizer is used for training, the learning rate is set to 0.001, the batch size was set to 24.
3.3. Evaluation Indicators
The segmentation model performance was evaluated using three key metrics: precision, recall, and F-score. These metrics quantify segmentation accuracy, detection reliability, and overall robustness, respectively.
Precision serves as one of the fundamental evaluation metrics in object segmentation tasks, quantifying the accuracy of positive class predictions generated by the model. Specifically, Precision indicates how many of the samples predicted by the model as positive class are true targets, and is calculated as follows:
TP (True Positive) represents the number of true target samples correctly identified. FP (False Positive) denotes the number of non-target samples misclassified as targets.
- 2.
Recall
Recall reflects the proportion of correct targets detected by the model overall targets, which is defined as:
TP represents the number of accurately identified targets, while FN corresponds to the quantity of undetected targets.
- 3.
F-score
The harmonic mean of precision and recall, employed to comprehensively evaluate model performance. The calculation formula is:
3.4. Experimental Result
The segmentation performance results of the original model and the CEE model on different Chinese character structures are shown in
Table 1, from the left-right structure, the Precision of CEE model reaches 85.7%, which is 7.1 percentage points higher than the 78.6% of the original model, the F-score is improved from 77.8% to 84.8%, and the Recall is improved from 77.1% to 84.2%, which indicates that the performance of CEE model is greatly improved in the regular left-right structure. In the top and bottom structure, the Precision of the CEE model is 84.3%, which is 6.5 percentage points higher than the 77.8% of the original model, the F-score increases from 76.7% to 83.4%, and the Recall increases from 75.4% to 82.5%, which further proves that the CEE model is more accurate in the processing of the rule structure. The advantage of the CEE model is more obvious in the complex enclosing structure, where its Precision increases by 10.2 percentage points from 69.2% to 79.4%, F-score increases from 67.7% to 78.5%, and Recall increases from 66.4% to 77.8%.
Taken together, the CEE model performs well on all Chinese character structures, especially in complex tasks such as encircling structures, by introducing a feature pyramid network and convolutional module with a channel attention mechanism, it significantly enhances the segmentation accuracy and robustness in complex contexts, and at the same time, reduces the leakage rate, demonstrating strong adaptive ability and improvement effect.
3.5. Ablation Experiment
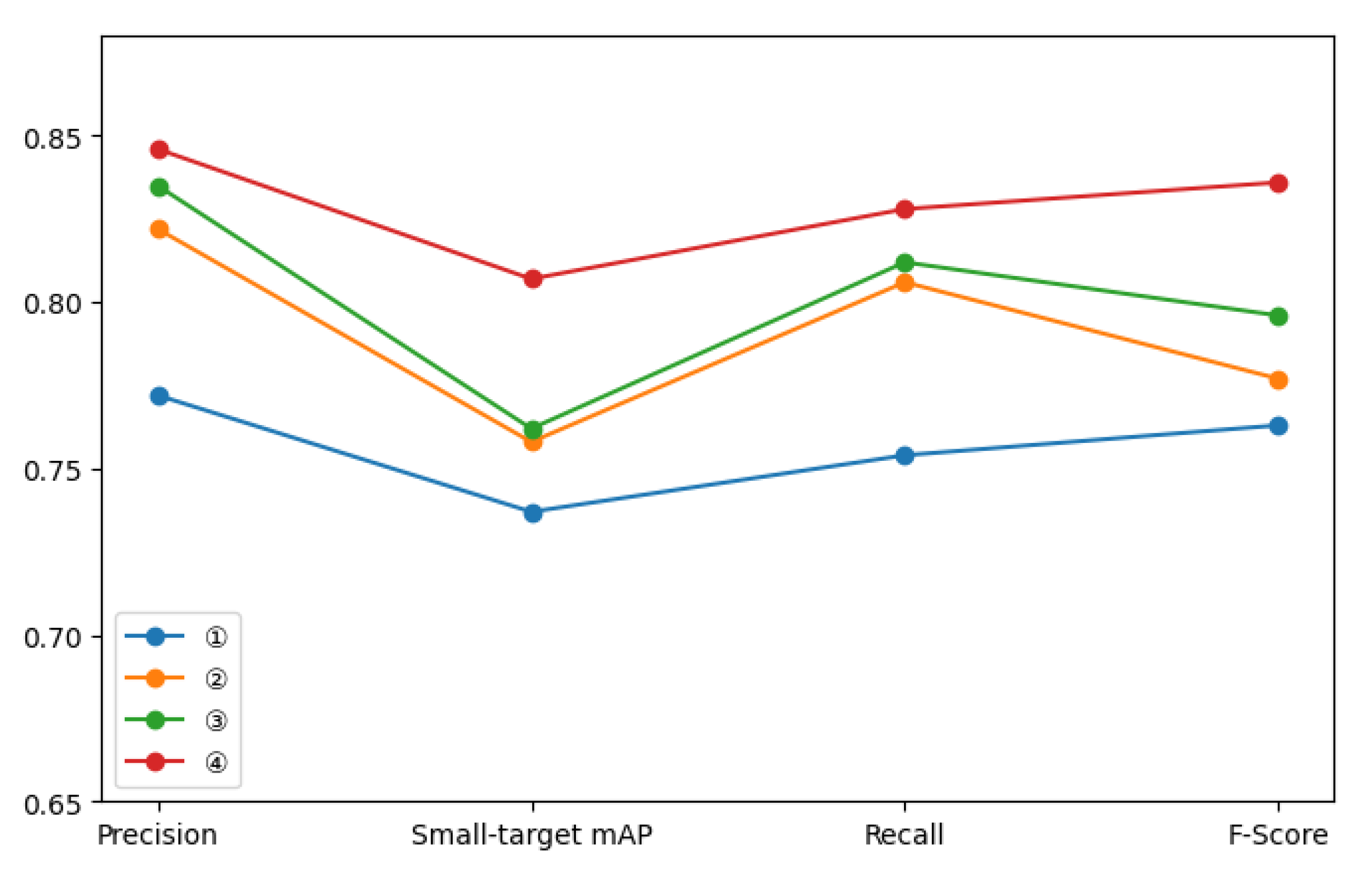
To validate the performance improvement of the proposed model modifications on the overall architecture, ablation studies were conducted on our custom dataset. As shown in the
Table 2, method ① is the EAST base network (Basic), method ② is the mini-component dataset through the feature pyramid as a multi-scale feature fusion (Mini-Component-Basic), method ③ is the addition of the attention mechanism of the ECA module (ECA-Basic), and method ④ is the CEE model in this paper. A comparative analysis of different approaches is presented in
Table 2, demonstrating that the proposed model achieves significant accuracy improvement through the integration of the attention mechanism and multi-scale fusion strategy.
According to
Figure 7, the part feature fusion and ECA module each play a unique role in model performance enhancement, demonstrating significant improvements in overall performance and small target detection. In terms of Precision, the performance of the base model is 77.2%, which improves to 82.2% after fusing part features, an increase of 5.0%. This result indicates that fusing part features improves the recognition performance of complex Chinese character part shapes by enhancing the representation of local features. After adding the ECA module, Precision improves to 83.5%, indicating that the dynamic weighting mechanism can effectively highlight important part features and suppress the interference of background noise. When feature fusion is combined with the ECA module, the Precision of the final model reaches 84.6%, with a total improvement of 7.4%, verifying the significant contribution of the synergistic optimization effect of the two modules to the overall detection performance.
In terms of small target detection, the advantages of the improved model are even more obvious. The small target mAP of the baseline model is only 69.2%, and the introduction of part features improves it to 74.3%, an increase of 5.1%. This reflects the fact that feature fusion improves the model’s fitness on complex parts and narrow regions by enhancing the saliency of small target parts. The introduction of the ECA module improves the small target mAP to 73.6% and reaches 76.2% in the full model, for a total improvement of 8.0%. This reflects that the ECA module significantly improves the localization accuracy of the segmentation boundary by dynamically selecting key features, adapting to the complex and diverse characteristics of the boundaries of Chinese character components, and reflecting the fundamental role of the convolution module in constructing the boundary space representation.
The comparative analysis in
Figure 8a,b (unconstrained detection) reveals the CEE model’s enhanced capability in detecting suboptimal-scale Chinese characters, particularly evident in the complete segmentation of the character “星” (star) (Row 1), where the basic model achieved only partial recognition. This validates the mini-component fusion strategy’s effectiveness in resolving scale-dependent ambiguities. However, residual limitations emerge in processing characters with pronounced curvature, attributable to insufficient robustness against nonlinear morphological variations.
Complementarily,
Figure 9a,b (standardized examination sheet detection) demonstrates the CEE model’s superiority in structured grid environments while exposing paradoxical failures: systematic misclassifications persist for geometrically simple characters such as “了” (completed) and “入” (enter). This phenomenon fundamentally stems from a mechanistic contradiction between the attention module’s intrinsic bias toward high stroke-density patterns and the morphological feature extraction requirements for characters with minimal topological complexity.
The comparison of the experimental results, in general, fully verifies the significant performance improvement of the mini component feature fusion and ECA module in the task of Chinese character component segmentation, and the synergistic design of the two modules overcomes the limitations of the traditional model, which provides a reliable technical support and theoretical basis for the task of segmentation of complex targets.
3.6. Method Comparisons
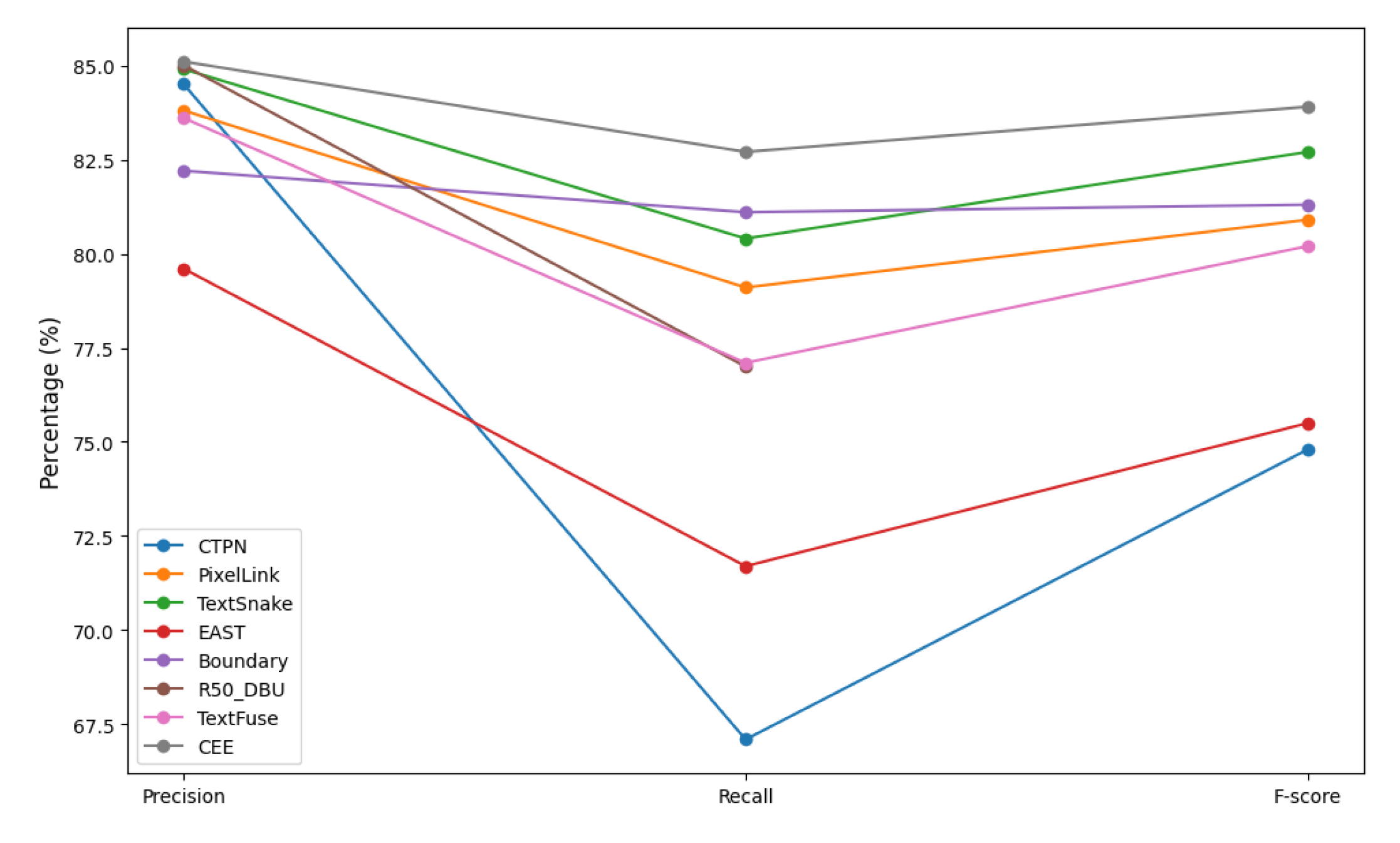
To further validate the performance of the handwriting detection model algorithm proposed in this paper, experimental comparisons with other mainstream text detection algorithms, CTPN [
5], PixelLink [
6], TextSnake [
7], Boundary [
8], R50_DBU [
9] and TextFuse [
10] were conducted on the ICDAR2015 dataset. The ICDAR [
30] dataset is used for the ICDAR Challenge, in which the ICDAR2015 dataset contains 1500 images, 1000 images are used for the training set and the remaining 500 images are used for the test set.
CTPN is a single-stage model for text detection, which has significant advantages in dealing with oblique and curved text. PixelLink is a pixel-level-based text detection model, particularly suitable for scene text detection and text regions with great morphological variations. TextSnake is particularly good at dealing with curved and bent text. This study focuses on the segmentation task of Chinese character detection, which usually involves multi-scale target detection, complex background processing, and accurate localization of small targets, so these three models that are good at handling complex text are targeted to be chosen as comparison objects to evaluate the performance of CEE networks in Chinese character detection. The results are shown in
Table 3. Boundary is An end-to-end framework utilizing multi-scale boundary point localization and adaptive topology reconstruction to boost accuracy in detecting/recognizing irregularly shaped text within complex scenes, R50_DBU represents a sophisticated segmentation-driven network incorporating U-Net architecture, TextFuse integrates hierarchical feature synthesis with cross-detector consensus mechanisms to resolve single-modality constraints in scene text analysis.
The EAST model using the combination of mini-component in this paper has higher accuracy, recall, and F-score than the classical EAST algorithm. The values are also improved by one to two percentage points in comparison to other algorithms, and the detection results are improved. The algorithm comparison is shown in
Figure 10.
4. Discussion
This study proposes an enhanced EAST-based model, termed the CEE model, for text detection in handwriting proficiency assessment. The incorporation of a custom mini-component dataset and the integration of a Feature Pyramid Network (FPN) in the feature fusion stage significantly improve the model’s capability in dense text feature extraction and multi-scale feature representation. Meanwhile, the ECA attention module is added to the model, which further strengthens the extraction capability of key features and significantly improves the performance of the EAST algorithm in detection accuracy, especially for the optimization of the small target leakage detection problem. In addition, the CEE model improves the loss function and optimizes the training process of the model.
The experimental results show that the CEE model performs well on both the self-constructed dataset and the ICDAR2015 dataset, and compared with the original EAST algorithm, its accuracy and recall are both improved by about 7.4%, the F-score is improved by about 7.3%, and the mAP of small targets is improved by about 7.0%. While large language models (LLMs) have demonstrated remarkable capabilities in semantic understanding, their ability to model fine-grained visual structures (e.g., stroke-level components in handwritten characters) remains underexplored [
31]. In this study, we address these vision-structure alignment challenges through localized attention refinement and multi-scale feature preservation strategies, thereby offering new insights into bridging the gap between high-level semantics and low-level visual patterns. Subsequent investigations will prioritize two key methodological refinements: (1) algorithmic optimization through architectural simplification to streamline computational demands, and (2) systematic expansion of the assessment corpus by diversifying text genres and incorporating multi-level writing samples. These strategic enhancements aim to establish an optimized framework that demonstrates enhanced generalizability and operational efficiency in automated writing evaluation systems, particularly for high-stakes standardized assessments.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}