
Enhancing Online Learning Through Multi-Agent Debates for CS University Students


Abstract
1. Introduction
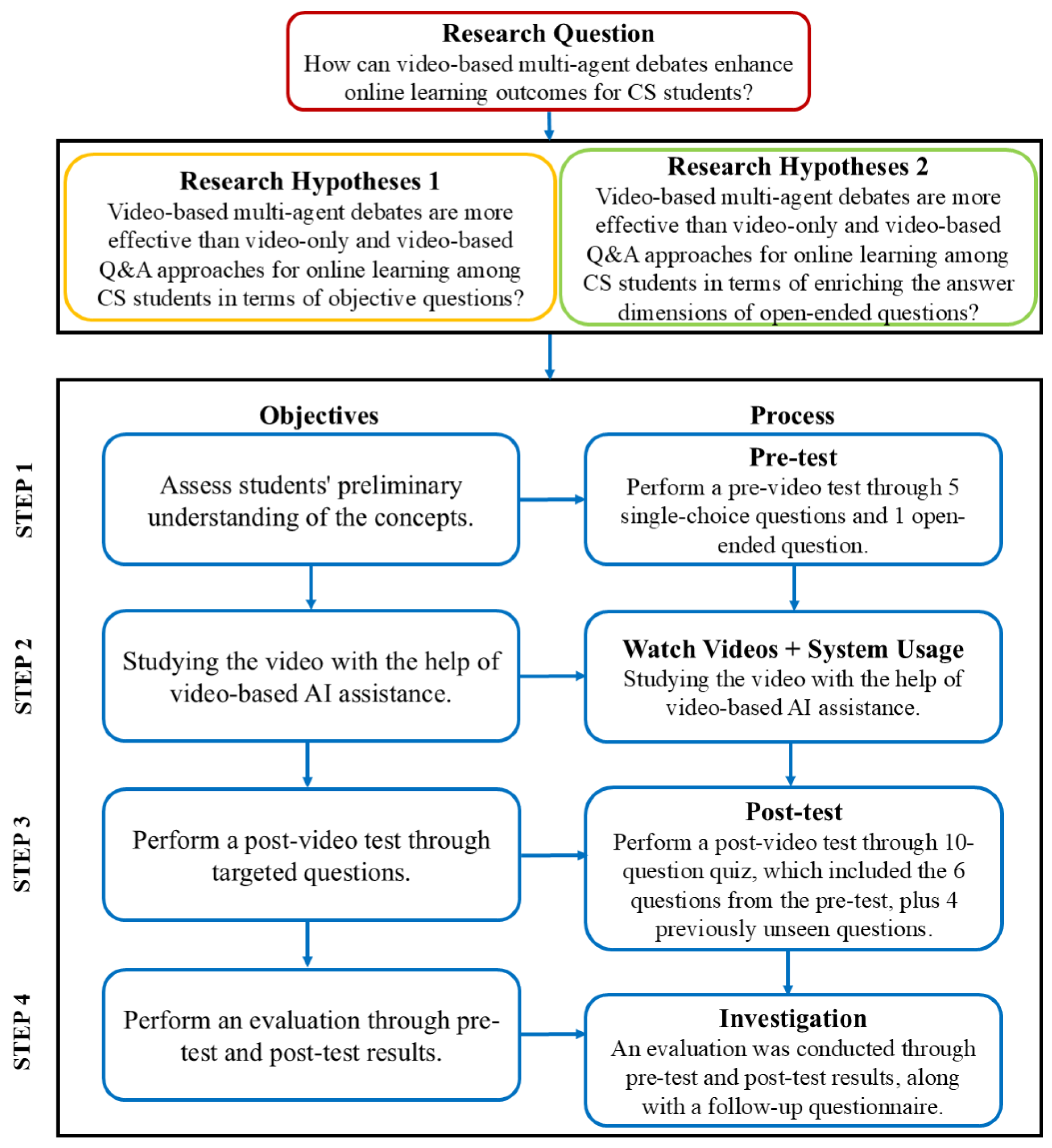
- RQ. How can video-based multi-agent debates enhance online learning outcomes for CS students?
- H1. Video-based multi-agent debates are more effective than video-only and video-based Q&A approaches for online learning among CS students in terms of objective questions.
- H2. Video-based multi-agent debates are more effective than video-only and video-based Q&A approaches for online learning among CS students in terms of enriching the answer dimensions of open-ended questions.
2. Literature Review
2.1. MOOCs
2.2. Online Learning Environment
2.3. LLM-Based Learning Systems
3. Materials and Methods
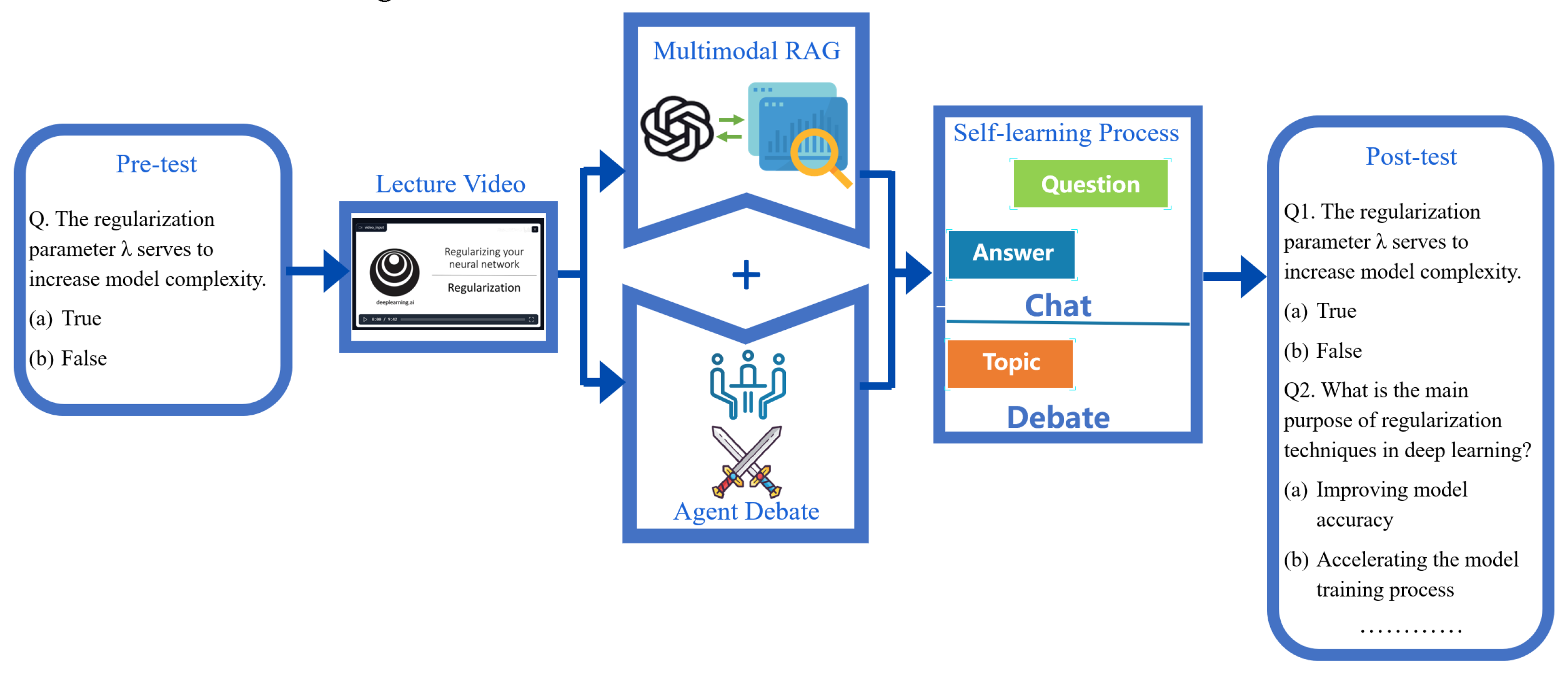
3.1. Design of Evaluation System
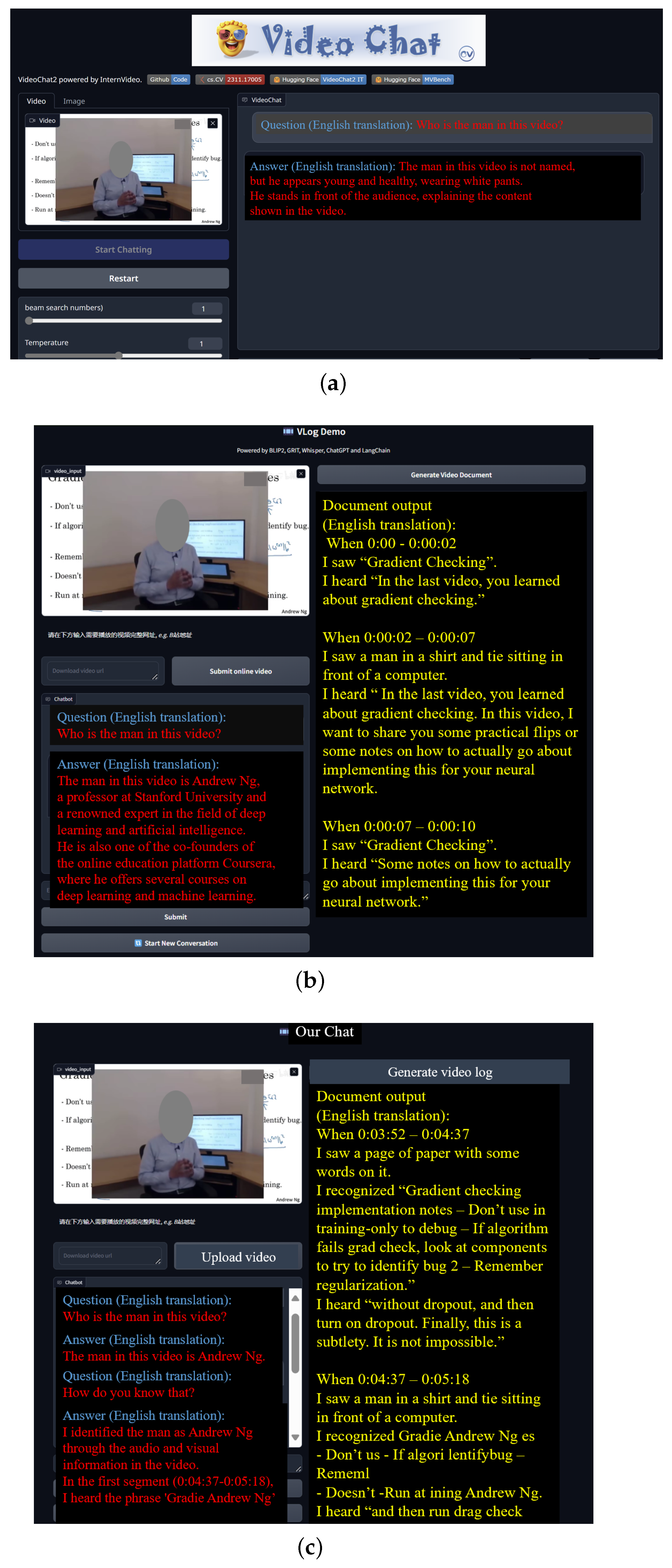
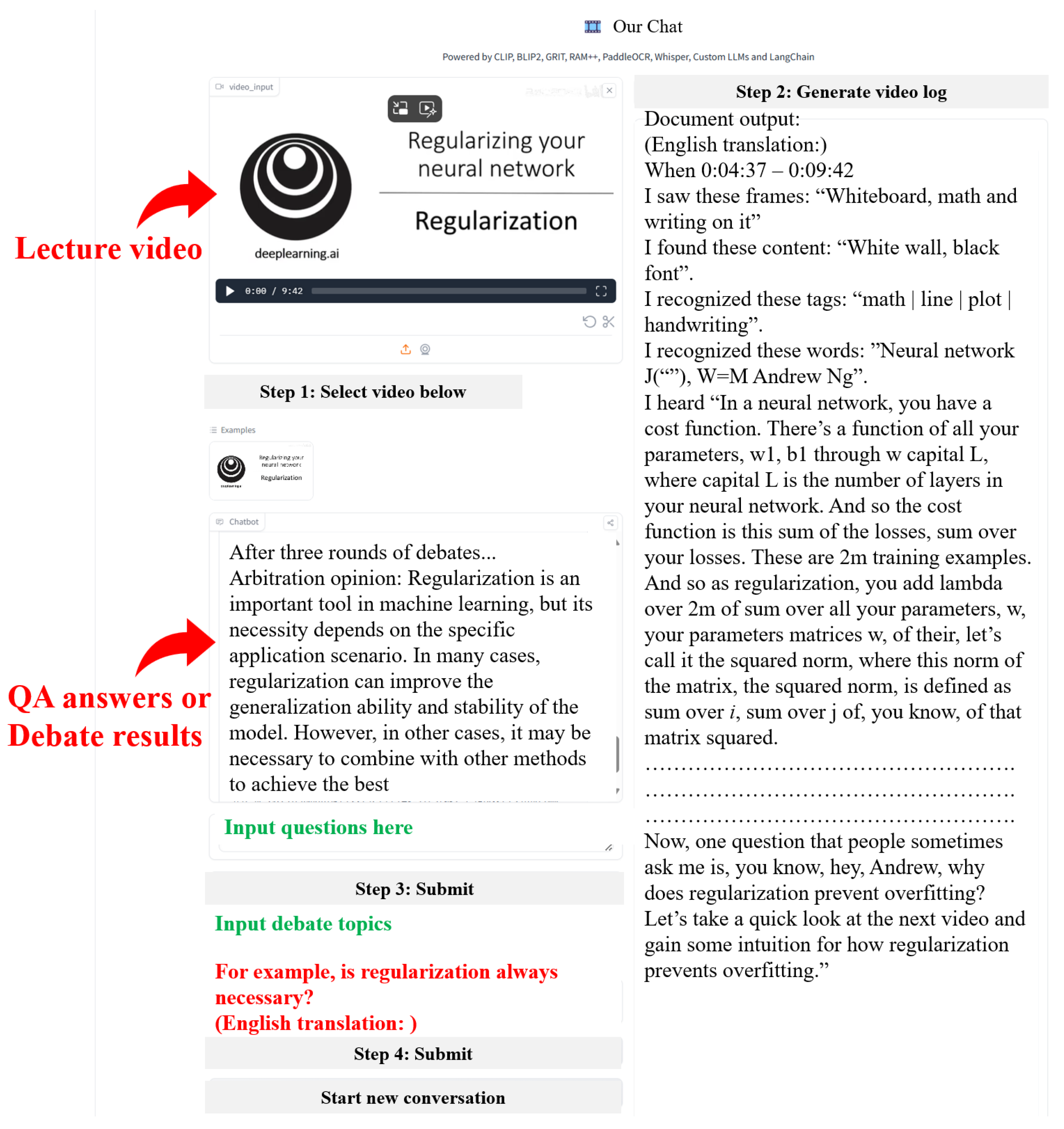
3.1.1. LLM RAG-Based Video Understanding Function
3.1.2. Multi-Agent Debate-Assisted Learning Function
| Algorithm 1 Multi-Agent Debate Process |
Input: The debate topic provided by the user and the number of rounds (n). Output: The debate topic and a complete debate process text. Step 1: Initialize Agents Create three agents: Affirmative, Negative, and Moderator Inject meta-prompts for each agent role Embed the debate topic into the preset prompt templates Step 2: Commence the Debate Affirmative agent presents the initial argument Negative agent reads the affirmative argument and generates a refutation Moderator evaluates both arguments and broadcasts a neutral judgment Step 3: Make the Judging while debate less than n rounds do if Moderator identifies a clear preferred side then Terminate the debate, summarize reasoning and final decision and go to Step 4 else Proceed to the next round: Affirmative and Negative agent update their memory and perform turn-based rebuttals end if end while Invoke the alternative judgment prompt for Moderator: a. Extract all answer candidates b. Summarize reasoning and produce final decision Step 4: Finish the Debate Return the debate topic, arguments from both sides, full speech log, final decision, and reasoning |
3.2. Participants and Design
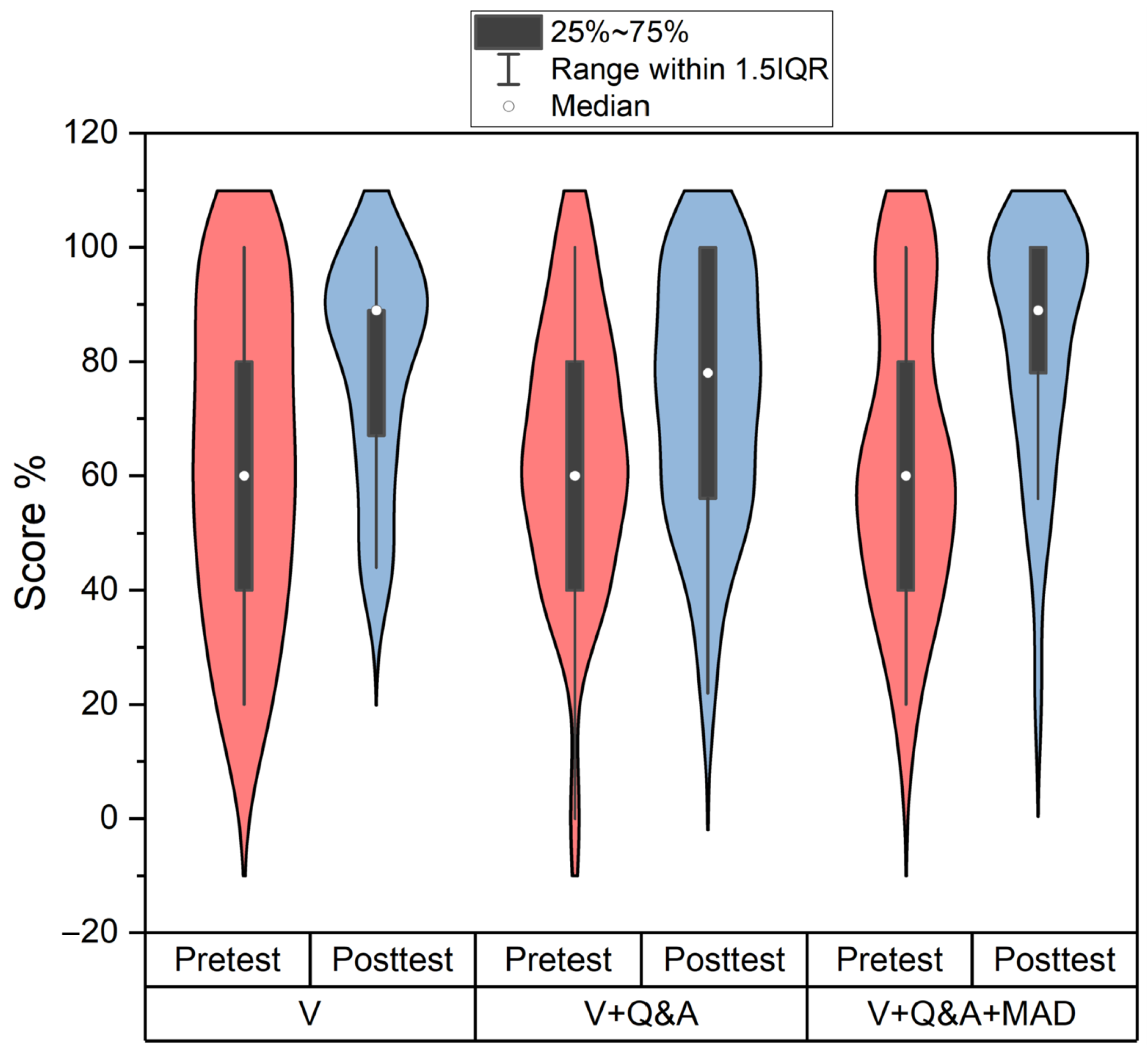
4. Results
4.1. Data Analysis
Response using the “video only” (English translation): Although L2 regularization is more commonly used in deep learning, its widespread application does not render L1 regularization obsolete. L1 regularization offers unique advantages in feature selection and generating sparse models, making it highly effective in specific scenarios. Therefore, depending on the requirements of a particular task, both L1 and L2 regularization have their irreplaceable roles.
Response using the “video-based Q&A” (English translation): In machine learning and deep learning, L1 and L2 regularization are two commonly used techniques to prevent model overfitting. L1 regularization penalizes large weights by adding the absolute values of the weights to the loss function, while L2 regularization achieves this by adding the squared values of the weights.
4.2. Student Feedback Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Pre-Test and Post-Test Questions
Appendix A.1. Regularization Pre-Test Questions
- 1.
- Overfitting usually manifests itself as a high variance problem. (T/F)
- 2.
- The regularization parameter serves to increase model complexity. (T/F)
- 3.
- In machine learning and deep learning, L2 regularization is achieved by adding a regularization term to the loss function, which is
- (a)
- The cube of the L2 norm of the model parameters (usually referred to as weights w)
- (b)
- The square of the L2 norm of the model parameters (usually referred to as weights w)
- (c)
- Minus the cube of the L2 norm of model parameters (usually referred to as weights w)
- (d)
- Minus the cube of the L2 norm of model parameters (usually referred to as weights w)
- 4.
- Which of the following options are correct in the description of L2 regularization in neural networks (Multiple choice)?
- (a)
- L2 regularization is achieved by adding a term to the loss function that is proportional to the square of the weights
- (b)
- L2 regularization terms usually do not include bias terms
- (c)
- During gradient descent, L2 regularization causes the weights to shrink towards zero, thus preventing overfitting
- (d)
- The larger the L2 regularization factor (), the weaker the effect of regularization
- (e)
- L2 regularization is achieved by directly modifying the weights during the forward propagation of the neural network
- 5.
- What is the main difference between L1 regularization and L2 regularization in deep learning?
- (a)
- L1 regularization takes into account the square of the weights, while L2 regularization does not take into account the square of the weights.
- (b)
- There is no difference in effect between L1 regularization and L2 regularization.
- (c)
- L1 regularization focuses on preventing overfitting, while L2 regularization is usually used for feature selection.
- (d)
- L1 regularization tends to produce sparse weight matrices, while L2 regularization makes the weights smoother.
- 6.
- There is a growing tendency to use L2 regularization when training networks to better achieve the effect of avoiding overfitting, does it mean that L1 regularization has gradually lost its usefulness? Please write down what you think.
Appendix A.2. Regularization Post-Test Questions
- 1.
- Overfitting usually manifests itself as a high variance problem. (T/F)
- 2.
- The regularization parameter serves to increase model complexity. (T/F)
- 3.
- Why is L2 regularization usually performed only for the parameter w and not for the parameter “b”?
- (a)
- “b” is one of many parameters that have a small effect on model complexity.
- (b)
- The dimension of “b” is usually higher than that of “w”.
- (c)
- The range of values for “b” is usually larger than for “w”, which does not lend itself easily to regularization.
- (d)
- The update of “b” has no significant effect on model performance.
- 4.
- What is the main purpose of regularization techniques in deep learning?
- (a)
- Improving model accuracy
- (b)
- Accelerating the model training process
- (c)
- Reducing model overfitting
- (d)
- Simplifying model complexity
- 5.
- In machine learning and deep learning, L2 regularization is achieved by adding a regularization term to the loss function, which is
- (a)
- The cube of the L2 norm of the model parameters (usually referred to as weights w)
- (b)
- The square of the L2 norm of the model parameters (usually referred to as weights w)
- (c)
- Minus the cube of the L2 norm of model parameters (usually referred to as weights w)
- (d)
- Minus the cube of the L2 norm of model parameters (usually referred to as weights w)
- 6.
- How can Dropout help improve model performance in neural networks (Multiple choice)?
- (a)
- Reducing overfitting
- (b)
- Increasing the complexity of the model
- (c)
- Improving the generalization of models
- (d)
- Accelerating the training process
- 7.
- What are the correct statements about the regularization term (the Frobenius paradigm) (Multiple choice)?
- (a)
- It sums the sum of squares of all layer weight matrices W
- (b)
- It helps to reduce the number of paradigms in the weight matrix, thus avoiding overfitting
- (c)
- It has the same effect as L2 regularization in logistic regression
- (d)
- It only applies to fully connected layers, not to convolutional layers
- 8.
- Which of the following options are correct in the description of L2 regularization in neural networks (Multiple choice)?
- (a)
- L2 regularization is achieved by adding a term to the loss function that is proportional to the square of the weights
- (b)
- L2 regularization terms usually do not include bias terms
- (c)
- During gradient descent, L2 regularization causes the weights to shrink towards zero, thus preventing overfitting
- (d)
- The larger the L2 regularization factor (), the weaker the effect of regularization
- (e)
- L2 regularization is achieved by directly modifying the weights during the forward propagation of the neural network
- 9.
- What is the main difference between L1 regularization and L2 regularization in deep learning?
- (a)
- L1 regularization takes into account the square of the weights, while L2 regularization does not take into account the square of the weights.
- (b)
- There is no difference in effect between L1 regularization and L2 regularization.
- (c)
- L1 regularization focuses on preventing overfitting, while L2 regularization is usually used for feature selection.
- (d)
- L1 regularization tends to produce sparse weight matrices, while L2 regularization makes the weights smoother.
- 10.
- There is a growing tendency to use L2 regularization when training networks to better achieve the effect of avoiding overfitting, does it mean that L1 regularization has gradually lost its usefulness? Please write down what you think.
Appendix A.3. Numerical Approximation of Gradients Pre-Test Questions
- 1.
- What is the main purpose of gradient numerical approximation?
- (a)
- Directly calculate the derivative of a function at a certain point
- (b)
- Test the accuracy of the derivative by approximation method
- (c)
- Taylor series expansion of the solution function
- (d)
- Computational efficiency of optimization function
- 2.
- What kind of function is the gradient numerical approximation method mainly suitable for?
- (a)
- Differentiable continuous functions
- (b)
- Functions that are not differentiable
- (c)
- Discrete function
- (d)
- Any function
- 3.
- Which of the following formulas is the standard formula for the two-sided difference method?
- (a)
- (b)
- (c)
- (d)
- 4.
- What is the main difference between unilateral difference and bilateral difference in gradient numerical approximation?
- (a)
- Computational complexity
- (b)
- The magnitude of the approximation error
- (c)
- Type of function used
- (d)
- Whether a derivation formula is needed
- 5.
- In the gradient test, which one is more effective?
- (a)
- Unilateral difference
- (b)
- Bilateral difference
- 6.
- Please briefly describe basic principles and differences of unilateral difference and bilateral difference.
Appendix A.4. Numerical Approximation of Gradients Post-Test Questions
- 1.
- What is the main purpose of gradient numerical approximation?
- (a)
- Directly calculate the derivative of a function at a certain point
- (b)
- Test the accuracy of the derivative by approximation method
- (c)
- Taylor series expansion of the solution function
- (d)
- Computational efficiency of optimization function
- 2.
- What kind of function is the gradient numerical approximation method mainly suitable for?
- (a)
- Differentiable continuous functions
- (b)
- Functions that are not differentiable
- (c)
- Discrete function
- (d)
- Any function
- 3.
- Which of the following formulas is the standard formula for the two-sided difference method?
- (a)
- (b)
- (c)
- (d)
- 4.
- What is the main difference between unilateral difference and bilateral difference in gradient numerical approximation?
- (a)
- Computational complexity
- (b)
- The magnitude of the approximation error
- (c)
- Type of function used
- (d)
- Whether a derivation formula is needed
- 5.
- In the gradient test, which one is more effective?
- (a)
- Unilateral difference
- (b)
- Bilateral difference
- 6.
- In gradient test, the main calculation of unilateral difference is
- (a)
- Gradient caused by a large change in a function at a certain point in a certain direction
- (b)
- An approximation of the gradient caused by a small change in the function at a point in a certain direction
- (c)
- The average value of the gradient caused by the change of the function in all directions at one point
- (d)
- The gradient difference caused by a change in the opposite direction of a function at a certain point
- 7.
- The main difference between two-sided difference and one-sided difference in calculating the gradient approximation is
- (a)
- Bilateral difference only takes into account changes in one direction
- (b)
- Bilateral differences consider changes in two opposite directions
- (c)
- Bilateral difference does not consider the change of the function, only the gradient
- (d)
- There is no difference in calculation between bilateral difference and unilateral difference
- 8.
- In practical applications, what factors may affect the choice of unilateral difference or bilateral difference for gradient testing?
- (a)
- Derivability of the function
- (b)
- Limitations on computing resources
- (c)
- Requirements for accuracy
- (d)
- All of the above factors
- 9.
- In practical applications, which strategies might be adopted to balance computational efficiency and accuracy of gradient tests?
- (a)
- Select the difference method according to the function characteristics
- (b)
- Always use bilateral differences
- (c)
- Always use unilateral difference
- (d)
- No gradient test
- 10.
- Please briefly describe basic principles and differences of unilateral difference and bilateral difference.
Appendix B. Follow-Up Questionnaire
- 1.
- How satisfied are you with the system overall?
- (a)
- Very satisfied (5 points)
- (b)
- Fairly satisfied (4 points)
- (c)
- Neutral (3 points)
- (d)
- Fairly dissatisfied (2 points)
- (e)
- Very dissatisfied (1 point)
- 2.
- Do you find the UI design of the system simple and easy to understand?
- (a)
- Very satisfied (5 points)
- (b)
- Fairly satisfied (4 points)
- (c)
- Neutral (3 points)
- (d)
- Fairly dissatisfied (2 points)
- (e)
- Very dissatisfied (1 point)
- 3.
- How fast do you think the system response?
- (a)
- Very rapid (5 points)
- (b)
- Comparative speed (4 points)
- (c)
- Neutral (3 points)
- (d)
- Less rapid (2 points)
- (e)
- Very slow (1 point)
- 4.
- Are you satisfied with the effectiveness of the system’s video-based Q&A function?
- (a)
- Very satisfied (5 points)
- (b)
- Fairly satisfied (4 points)
- (c)
- Neutral (3 points)
- (d)
- Fairly dissatisfied (2 points)
- (e)
- Very dissatisfied (1 point)
- 5.
- Please give the corresponding reason based on your rating of the effectiveness of the system’s video-based Q&A function.
- 6.
- Are you satisfied with the effectiveness of the system’s video-based MAD function (If applicable)?
- (a)
- Very satisfied (5 points)
- (b)
- Fairly satisfied (4 points)
- (c)
- Neutral (3 points)
- (d)
- Fairly dissatisfied (2 points)
- (e)
- Very dissatisfied (1 point)
- 7.
- Please give the corresponding reason based on your rating of the effectiveness of the system’s video-based MAD function. (If applicable).
- 8.
- What feature would you most like to see added to the current system? Please provide examples if possible.
References
- Aristovnik, A.; Karampelas, K.; Umek, L.; Ravšelj, D. Impact of the COVID-19 Pandemic on Online Learning in Higher Education: A Bibliometric Analysis. Front. Educ. 2023, 8, 1225834. [Google Scholar] [CrossRef]
- Van Alten, D.C.; Phielix, C.; Janssen, J.; Kester, L. Self-regulated Learning Support in Flipped Learning Videos Enhances Learning Outcomes. Comput. Educ. 2020, 158, 104000. [Google Scholar] [CrossRef]
- Moos, D.; Bonde, C. Flipping the Classroom: Embedding Self-Regulated Learning Prompts in Videos. Technol. Knowl. Learn. 2016, 21, 225–242. [Google Scholar] [CrossRef]
- Kim, J.; Guo, P.J.; Cai, C.J.; Li, S.W.; Gajos, K.Z.; Miller, R.C. Data-driven Interaction Techniques for Improving Navigation of Educational Videos. In Proceedings of the 27th Annual ACM Symposium on User Interface Software and Technology, Honolulu, HI, USA, 5–8 October 2014; pp. 563–572. [Google Scholar]
- Yang, S.; Yim, J.; Kim, J.; Shin, H.V. CatchLive: Real-time Summarization of Live Streams with Stream Content and Interaction Data. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems, New Orleans, LA, USA, 29 April–5 May 2022. [Google Scholar]
- Pavel, A.; Reed, C.; Hartmann, B.; Agrawala, M. Video Digests: A Browsable, Skimmable Format for Informational Lecture Videos. In Proceedings of the 27th Annual ACM Symposium on User Interface Software and Technology, Honolulu, HI, USA, 5–8 October 2014; pp. 573–582. [Google Scholar] [CrossRef]
- Shimada, A.; Okubo, F.; Yin, C.; Ogata, H. Automatic Summarization of Lecture Slides for Enhanced Student PreviewTechnical Report and User Study. IEEE Trans. Learn. Technol. 2018, 11, 165–178. [Google Scholar] [CrossRef]
- OpenAI. GPT-4 Technical Report. arXiv 2024, arXiv:2303.08774. [Google Scholar]
- Bernabei, M.; Colabianchi, S.; Falegnami, A.; Costantino, F. Students’ Use of Large Language Models in Engineering Education: A Case Study on Technology Acceptance, Perceptions, Efficacy, and Detection Chances. Comput. Educ. Artif. Intell. 2023, 5, 100172. [Google Scholar] [CrossRef]
- Kohnke, L.; Moorhouse, B.; Zou, D. ChatGPT for Language Teaching and Learning. RELC J. 2023, 54, 537–550. [Google Scholar] [CrossRef]
- Sallam, M. ChatGPT Utility in Healthcare Education, Research, and Practice: Systematic Review on the Promising Perspectives and Valid Concerns. Healthcare 2023, 11, 887. [Google Scholar] [CrossRef]
- Kaddour, J.; Harris, J.; Mozes, M.; Bradley, H.; Raileanu, R.; McHardy, R. Challenges and Applications of Large Language Models. arXiv 2023, arXiv:2307.10169. Available online: https://www.frontiersin.org/journals/education/articles/10.3389/feduc.2023.1225834 (accessed on 27 April 2025).
- Bender, E.; Gebru, T.; McMillan-Major, A.; Shmitchell, S. On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, Virtual Event Canada, 3–10 March 2021; pp. 610–623. [Google Scholar]
- Kasneci, E.; Sessler, K.; Küchemann, S.; Bannert, M.; Dementieva, D.; Fischer, F.; Gasser, U.; Groh, G.; Günnemann, S.; Hüllermeier, E.; et al. ChatGPT for Good? On Opportunities and Challenges of Large Language Models for Education. Learn. Individ. Differ. 2023, 103, 102274. [Google Scholar] [CrossRef]
- Sahoo, P.; Singh, A.; Saha, S.; Jain, V.; Mondal, S.; Chadha, A. A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications. arXiv 2024, arXiv:2402.07927. [Google Scholar]
- Kojima, T.; Gu, S.; Reid, M.; Matsuo, Y.; Iwasawa, Y. Large Language Models Are Zero-shot Reasoners. In Proceedings of the 36th International Conference on Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022. [Google Scholar]
- Wang, X.; Wei, J.; Schuurmans, D.; Le, Q.V.; Chi, E.H.; Narang, S.; Chowdhery, A.; Zhou, D. Self-Consistency Improves Chain of Thought Reasoning in Language Models. arXiv 2022, arXiv:2203.11171. [Google Scholar]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.; Rocktäschel, T.; et al. Retrieval-augmented Generation for Knowledge-intensive NLP Tasks. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- Wang, L.; Ma, C.; Feng, X.; Zhang, Z.; Yang, H.; Zhang, J.; Chen, Z.; Tang, J.; Chen, X.; Lin, Y.; et al. A Survey on Large Language Model based Autonomous Agents. Front. Comput. Sci. 2024, 18, 3. [Google Scholar] [CrossRef]
- Wu, Q.; Bansal, G.; Zhang, J.; Wu, Y.; Li, B.; Zhu, E.; Jiang, L.; Zhang, X.; Zhang, S.; Liu, J.; et al. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation. arXiv 2023, arXiv:2308.08155. [Google Scholar]
- McAuley, A.; Stewart, B.; Siemens, G.; Cornier, D. The MOOC Model for Digital Practice: Massive Open Online Courses: Digital Ways of Knowing and Learning; University of Prince Edward Island: Charlottetown, PE, Canada, 2010; Available online: https://books.google.com.hk/books?id=VIYSzgEACAAJ (accessed on 27 April 2025).
- Laura, P. The Year of the MOOC. The New York Times, 13 November 2012. [Google Scholar]
- Yuan, L.; Powell, S. MOOCS and Open Education: Implications for Higher Education; JISC Cetis; University of Bolton: Bolton, UK, 2013. [Google Scholar]
- Laurillard, D. The Educational Problem that MOOCs Could Solve: Professional Development for Teachers of Disadvantaged Students. Res. Learn. Technol. 2016, 24, 29369. [Google Scholar] [CrossRef]
- Khan, M.; Vivek; Nabi, M.; Khojah, M.; Tahir, M. Students’ Perception towards E-Learning during COVID-19 Pandemic in India: An Empirical Study. Sustainability 2021, 13, 57. [Google Scholar] [CrossRef]
- Moore, R. Developing Lifelong Learning with Heutagogy: Contexts, Critiques, and Challenges. Distance Educ. 2020, 41, 381–401. [Google Scholar] [CrossRef]
- Suanpang, P.; Netwong, T.; Manisri, T.; Duantrakoonsi, W. The Factors Affecting Learning Outcome Intention of MOOCs for an Online Learning Platform. Psychol. Educ. 2021, 58, 3922–3930. [Google Scholar]
- Jansen, R.; Van Leeuwen, A.; Janssen, J.; Conijn, R.; Kester, L. Supporting Learners’ Self-regulated Learning in Massive Open Online Courses. Comput. Educ. 2020, 146, 103771. [Google Scholar] [CrossRef]
- Lu, Y.; Wang, B.; Lu, Y. Understanding Key Drivers of MOOC Satisfaction and Continuance Intention to Use. J. Electron. Commer. Res. 2019, 20, 105–117. [Google Scholar]
- Aldowah, H.; Al-Samarraie, H.; Alzahrani, A.; Alalwan, N. Factors Affecting Student Dropout in MOOCs: A Cause and Effect Decision-making Model. J. Comput. High. Educ. 2020, 32, 429–454. [Google Scholar] [CrossRef]
- Jordan, K. Initial Trends in Enrollment and Completion of Massive Open Online Courses. Int. Rev. Res. Open Distrib. Learn. 2014, 15, 133–160. [Google Scholar]
- Margaryan, A.; Bianco, M.; Littlejohn, A. Instructional Quality of Massive Open Online Courses (MOOCs). Comput. Educ. 2015, 80, 77–83. [Google Scholar] [CrossRef]
- Kizilcec, R.; Piech, C.; Schneider, E. Deconstructing Disengagement: Analyzing Learner Subpopulations in Massive Open Online Courses. In Proceedings of the Third International Conference on Learning Analytics and Knowledge, Leuven, Belgium, 8–13 April 2013; pp. 170–179. [Google Scholar]
- Hew, K.; Cheung, W. Students’ and Instructors’ Use of Massive Open Online Courses (MOOCs): Motivations and Challenges. Educ. Res. Rev. 2014, 12, 45–58. [Google Scholar] [CrossRef]
- Wei, W.; Liu, J.; Xu, X.; Kolletar-Zhu, K.; Zhang, Y. Effective Interactive Engagement Strategies for MOOC Forum Discussion: A Self-efficacy Perspective. PLoS ONE 2023, 18, e0293668. [Google Scholar] [CrossRef]
- Neha; Kim, E. Designing Effective Discussion Forum in MOOCs: Insights from Learner Perspectives. Front. Educ. 2023, 8, 1223409. [Google Scholar] [CrossRef]
- Galikyan, I.; Admiraal, W.; Kester, L. MOOC Discussion Forums: The Interplay of the Cognitive and the Social. Comput. Educ. 2021, 165, 104133. [Google Scholar] [CrossRef]
- Freitas, M.; Silva, M. Systematic Literature Review about Gamification in MOOCs. Open Learn. J. Open Distance-Learn. 2023, 38, 73–95. [Google Scholar] [CrossRef]
- Meng, C.; Zhao, M.; Pan, Z.; Pan, Q.; Bonk, C. Investigating the Impact of Gamification Components on Online Learners’ Engagement. Smart Learn. Environ. 2024, 11, 47. [Google Scholar] [CrossRef]
- Chauhan, J.; Goel, A. An Analysis of Video Lecture in MOOC. In Proceedings of the International Conference on Information and Communication Technologies in Education, Research, and Industrial Applications, Lviv, Ukraine, 14–16 May 2015; Available online: https://ceur-ws.org/Vol-1356/paper_16.pdf (accessed on 27 April 2025).
- Chen, Y.; Gao, Q.; Yuan, Q.; Tang, Y. Facilitating Students’ Interaction in MOOCs through Timeline-Anchored Discussion. Int. J. Human–Computer Interact. 2019, 35, 1781–1799. [Google Scholar] [CrossRef]
- Yu, J.; Zhang, Z.; Zhang, D.; Tu, S.; Hao, Z.; Li, R.; Li, H.; Wang, Y.; Li, H.; Gong, L.; et al. From MOOC to MAIC: Reshaping Online Teaching and Learning through LLM-driven Agents. arXiv 2024, arXiv:2409.03512. [Google Scholar]
- Reyna, J. Digital Teaching and Learning Ecosystem (DTLE): A Theoretical Approach for Online Learning Environments. In Proceedings of the Ascilite Hobart 2011, Hobart, TAS, Australia, 4–7 December 2011; pp. 1083–1088. Available online: https://ascilite.org/conferences/hobart11/downloads/papers/Reyna-concise.pdf (accessed on 27 April 2025).
- Thorneycroft, S. Defining a Next-generation Ecosystem for Online Learning: From Changing the Platform to Shifting the Paradigm. In Proceedings of the 39th International Conference on Innovation, Practice and Research in the Use of Educational Technologies in Tertiary Education, Sydney, Australia, 4–7 December 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Hsu, H.; Wang, C.; Levesque-Bristol, C. Reexamining the Impact of Self-determination Theory on Learning Outcomes in the Online Learning Environment. Educ. Inf. Technol. 2019, 24, 2159–2174. [Google Scholar] [CrossRef]
- Petersen, G.; Petkakis, G.; Makransky, G. A Study of How Immersion and Interactivity Drive VR Learning. Comput. Educ. 2022, 179, 104429. [Google Scholar] [CrossRef]
- Pedaste, M.; Mäeots, M.; Siiman, L.; Jong, T.; Riesen, S.; Kamp, E.; Manoli, C.; Zacharia, Z.; Tsourlidaki, E. Phases of Inquiry-based Learning: Definitions and The Inquiry Cycle. Educ. Res. Rev. 2015, 14, 47–61. [Google Scholar] [CrossRef]
- Kizilcec, R.; Pérez-Sanagustín, M.; Maldonado, J. Self-regulated Learning Strategies Predict Learner Behavior and Goal Attainment in Massive Open Online Courses. Comput. Educ. 2017, 104, 18–33. [Google Scholar] [CrossRef]
- Xu, Z.; Zhao, Y.; Liew, J.; Zhou, X.; Kogut, A. Synthesizing Research Evidence on Self-regulated Learning and Academic Achievement in Online and Blended Learning Environments: A Scoping Review. Educ. Res. Rev. 2023, 39, 100510. [Google Scholar] [CrossRef]
- Huang, C.; Han, Z.; Li, M.; Wang, X.; Zhao, W. Sentiment Evolution with Interaction Levels in Blended Learning Environments: Using Learning Analytics and Epistemic Network Analysis. Australas. J. Educ. Technol. 2021, 37, 81–95. [Google Scholar] [CrossRef]
- Li, Y.; Meng, N.; Ye, X.; Syed Shah, A. Self-determination and Perceived Learning in Online Learning Communities. Sci. Rep. 2024, 14, 24538. [Google Scholar] [CrossRef]
- Zhang, L.; Carter, R.A., Jr.; Qian, X.; Yang, S.; Rujimora, J.; Wen, S. Academia’s Responses to Crisis: A Bibliometric Analysis of Literature on Online Learning in Higher Education during COVID-19. Br. J. Educ. Technol. 2022, 53, 620–646. [Google Scholar] [CrossRef] [PubMed]
- Ng, D.; Leung, J.; Su, J.; Ng, R.; Chu, S. Teachers’ AI Digital Competencies and Twenty-first Century Skills in the Post-pandemic World. Educ. Technol. Res. Dev. 2023, 71, 137–161. [Google Scholar] [CrossRef]
- Wang, P.; Wang, F.; Li, Z. Exploring the Ecosystem of K-12 Online Learning: An Empirical Study of Impact Mechanisms in the Post-pandemic Era. Front. Psychol. 2023, 14, 1241477. [Google Scholar] [CrossRef]
- Ayeni, O.; Hamad, N.; Chisom, O.; Osawaru, B.; Adewusi, E. AI in Education: A Review of Personalized Learning and Educational Technology. GSC Adv. Res. Rev. 2024, 18, 261–271. [Google Scholar] [CrossRef]
- Wooldridge, M.; Jennings, N. Intelligent Agents: Theory and Practice. Knowl. Eng. Rev. 1995, 10, 115–152. [Google Scholar] [CrossRef]
- Xi, Z.; Chen, W.; Guo, X.; He, W.; Ding, Y.; Hong, B.; Zhang, M.; Wang, J.; Jin, S.; Zhou, E.; et al. The Rise and Potential of Large Language Model Based Agents: A Survey. arXiv 2023, arXiv:2309.07864. [Google Scholar]
- Guo, T.; Chen, X.; Wang, Y.; Chang, R.; Pei, S.; Chawla, N.; Wiest, O.; Zhang, X. Large Language Model based Multi-Agents: A Survey of Progress and Challenges. arXiv 2024, arXiv:2402.01680. [Google Scholar]
- Park, J.; O’Brien, J.; Cai, C.; Morris, M.; Liang, P.; Bernstein, M. Generative Agents: Interactive Simulacra of Human Behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST ’23), San Francisco, CA, USA, 29 October–1 November 2023. [Google Scholar]
- Zhu, X.; Chen, Y.; Tian, H.; Tao, C.; Su, W.; Yang, C.; Huang, G.; Li, B.; Lu, L.; Wang, X.; et al. Ghost in the Minecraft: Generally Capable Agents for Open-World Environments via Large Language Models with Text-based Knowledge and Memory. arXiv 2023, arXiv:2305.17144. [Google Scholar]
- Fu, Y.; Peng, H.; Khot, T.; Lapata, M. Improving Language Model Negotiation with Self-Play and In-Context Learning from AI Feedback. arXiv 2023, arXiv:2305.10142. [Google Scholar]
- Extance, A. ChatGPT has Entered the Classroom: How LLMs Could Transform Education. Nature 2023, 623, 474–477. [Google Scholar] [CrossRef]
- Yue, M.; Mifdal, W.; Zhang, Y.; Suh, J.; Yao, Z. MathVC: An LLM-Simulated Multi-Character Virtual Classroom for Mathematics Education. arXiv 2024, arXiv:2404.06711. [Google Scholar]
- Zhang, Z.; Zhang-Li, D.; Yu, J.; Gong, L.; Zhou, J.; Hao, Z.; Jiang, J.; Cao, J.; Liu, H.; Liu, Z.; et al. Simulating Classroom Education with LLM-Empowered Agents. arXiv 2024, arXiv:2406.19226. [Google Scholar]
- Huber, S.; Kiili, K.; Nebel, S.; Ryan, R.; Sailer, M.; Ninaus, M. Leveraging the Potential of Large Language Models in Education Through Playful and Game-Based Learning. Educ. Psychol. Rev. 2024, 36, 25. [Google Scholar] [CrossRef]
- Baillifard, A.; Gabella, M.; Lavenex, P.; Martarelli, C. Effective Learning with a Personal AI Tutor: A Case Study. Educ. Inf. Technol. 2025, 30, 297–312. [Google Scholar] [CrossRef]
- Park, M.; Kim, S.; Lee, S.; Kwon, S.; Kim, K. Empowering Personalized Learning through a Conversation-based Tutoring System with Student Modeling. In Proceedings of the CHI EA ’24: Extended Abstracts of the CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 11–16 May 2024; pp. 1–10. [Google Scholar]
- Mohamed, A. Exploring the Potential of an AI-based Chatbot (ChatGPT) in Enhancing English as a Foreign Language (EFL) Teaching: Perceptions of EFL Faculty Members. Educ. Inf. Technol. 2024, 29, 3195–3217. [Google Scholar] [CrossRef]
- Tlili, A.; Shehata, B.; Adarkwah, M.; Bozkurt, A.; Hickey, D.; Huang, R.; Agyemang, B. What if the Devil Is My Guardian Angel: ChatGPT as a Case Study of Using Chatbots in Education. Smart Learn. Environ. 2023, 10, 15. [Google Scholar] [CrossRef]
- Zhang, S.; Zhao, X.; Zhou, T.; Kim, J. Do You Have AI Dependency? The Roles of Academic Self-efficacy, Academic Stress, and Performance Expectations on Problematic AI Usage Behavior. Int. J. Educ. Technol. High. Educ. 2024, 21, 2–14. [Google Scholar] [CrossRef]
- Siu, O.; Lui, K.; Huang, Y.; Ng, T.; Yeung, W. An Efficient, Reliable and Valid Assessment for Affective States during Online Learning. Sci. Rep. 2024, 14, 15768. [Google Scholar] [CrossRef]
- Almarzouqi, A.; Aburayya, A.; Alfaisal, R.; Elbadawi, M.A.; Salloum, S.A. Ethical Implications of Using ChatGPT in Educational Environments: A Comprehensive Review. In Artificial Intelligence in Education: The Power and Dangers of ChatGPT in the Classroom; Springer Nature: Cham, Switzerland, 2024; pp. 185–199. [Google Scholar] [CrossRef]
- Li, K.; He, Y.; Wang, Y.; Li, Y.; Wang, W.; Luo, P.; Wang, Y.; Wang, L.; Qiao, Y. VideoChat: Chat-Centric Video Understanding. arXiv 2023, arXiv:2305.06355. [Google Scholar]
- Liang, T.; He, Z.; Jiao, W.; Wang, X.; Wang, Y.; Wang, R.; Yang, Y.; Shi, S.; Tu, Z. Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate. arXiv 2023, arXiv:2305.19118. [Google Scholar]
- Cohen, J. A Power Primer. Psychol. Bull. 1992, 112, 155–159. [Google Scholar] [CrossRef]
- Gonzalez, H.; Li, J.; Jin, H.; Ren, J.; Zhang, H.; Akinyele, A.; Wang, A.; Miltsakaki, E.; Baker, R.; Callison-Burch, C. Automatically Generated Summaries of Video Lectures May Enhance Students’ Learning Experience. In Proceedings of the 18th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2023), Toronto, ON, Canada, 13 July 2023; pp. 382–393. Available online: https://aclanthology.org/2023.bea-1.31 (accessed on 27 April 2025).
- Chen, W.; Lin, L.; Pang, W. Learning via Video: The Effects of Summarizing Strategies and Self-explanation Prompts. Educ. Inf. Technol. 2025, 30, 3541–3572. [Google Scholar] [CrossRef]
- Yang, Z.; Wang, J.; Wu, D.; Chen, X. Exploring the Impact of ChatGPT/AIGC on Education and Strategies for Response. J. East China Norm. Univ. (Educ. Sci.) 2023, 41, 26–35. [Google Scholar]
- Ministry of Education Singapore. Managing the Use of Artificial Intelligence (AI) Bots such as ChatGPT in Schools. 2023. Available online: www.moe.gov.sg (accessed on 27 April 2025).
- Hobert, S.; Berens, F. Developing a Digital Tutor as an Intermediary Between Students, Teaching Assistants, and Lecturers. Educ. Technol. Res. Dev. 2024, 72, 797–818. [Google Scholar] [CrossRef]
- DeepSeek-AI. DeepSeek-V3 Technical Report. arXiv 2025, arXiv:2412.19437.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author Keywords | Articles | Keywords Plus | Articles | |
|---|---|---|---|---|
| 1 | ONLINE LEARNING | 270 | EDUCATION | 264 |
| 2 | LEARNING | 227 | STUDENTS | 231 |
| 3 | E-LEARNING | 189 | ONLINE | 186 |
| 4 | EDUCATION | 172 | PERFORMANCE | 145 |
| 5 | FLIPPED CLASSROOM | 137 | IMPACT | 141 |
| 6 | HIGHER EDUCATION | 135 | TECHNOLOGY | 131 |
| 7 | BLENDED LEARNING | 121 | VIDEO | 114 |
| 8 | ONLINE | 121 | ENGAGEMENT | 113 |
| 9 | VIDEO | 112 | MOTIVATION | 95 |
| 10 | TECHNOLOGY | 103 | PERCEPTIONS | 95 |
| 〈 debate topic 〉: Is regularization always necessary? Affirmative Argument: As a debater for the affirmative side, I believe that in many cases, regularization is essential. Here are several points to support this argument: 1. Preventing Overfitting: The primary goal of regularization is to prevent the model from overfitting the training data. Overfitting occurs when a model becomes too complex and overly learns the details and noise of the training data, leading to poor performance on unseen data. By introducing a regularization term, we can constrain the model parameters, thus enhancing its generalization ability. 2. Resource Optimization: Regularization helps strike a balance between model complexity and performance. By controlling the complexity of the model, we can avoid building overly complex models, which may consume excessive computational resources and time. 3. Knowledge Transfer: In transfer learning and multi-task learning, regularization promotes knowledge sharing and transfer between tasks. It prevents each task from learning independently, thus improving overall performance. 4. Algorithm Stability: Regularization can improve the stability of the algorithm, making the model less sensitive to small changes in the data and increasing its robustness. 5. Parameter Constraints: In fields such as medicine or finance, it is sometimes important for model parameters to have physical or economic significance. Regularization can help constrain these parameters within reasonable bounds. However, this does not imply that regularization is necessary in all cases. In situations where the dataset is very large, the relationship between features and the target is simple, or where there is no strict need to limit model complexity, it may be feasible to forgo regularization. Overall, considering the risk of overfitting and resource efficiency, regularization is a valuable tool in most machine learning problems and should be regarded as an important step. Negative Argument: As the opposing debater, I understand the affirmative side’s points, but I believe that regularization is not always necessary in every situation. Here are my arguments: 1. Data Quality: If the training data is large enough and evenly distributed, without noise or outliers, the model may generalize well without regularization. In such cases, the model can naturally learn the main patterns in the data without overfitting. 2. Simple Problems: For simple linear problems or problems with a clear structure, such as linear regression, the model might already have good generalization ability and may not need additional regularization to prevent overfitting. 3. Preprocessing and Feature Selection: Effective data preprocessing and feature selection can reduce noise and irrelevant features, thereby lowering the risk of overfitting, making regularization less necessary. 4. Non-Parametric Methods: Certain non-parametric methods, such as decision trees and random forests, have inherent regularization properties (e.g., limiting tree depth or using bagging) and may not require additional regularization. 5. Hyperparameter Tuning: By carefully adjusting hyperparameters like model complexity and learning rate, it is possible to find an appropriate model without the need for regularization. This is particularly feasible for small or medium-sized datasets. 6. Real-Time and Online Learning: In environments where data streams are continuously updated, regularization may not be required since the model constantly adapts to new data and doesn’t overfit early data points. In conclusion, while regularization is an effective tool for improving generalization in many cases, it is not always necessary. Whether regularization is needed depends on the nature of the data, the complexity of the problem, and the available computational resources. In some specific situations, satisfactory results can be achieved without regularization. After three rounds of debates… Arbitration opinion: Regularization is an important tool in machine learning, but its necessity depends on the specific application scenario. In many cases, regularization can improve the generalization ability and stability of the model. However, in other cases, it may be necessary to combine with other methods to achieve the best effect. Arbitration reason: In the third round of debates, both debaters further deepened their understanding of the role of regularization in machine learning, emphasizing its importance and complementarity with other technologies. Both sides agreed that regularization is a valuable tool, but not the only solution in all cases. They jointly pointed out that the decision on whether and how to use regularization should be made according to specific problems, data, and model selection. |
| Roles | Prompt (English Translation) |
|---|---|
| Moderator | You are the moderator. Two debaters will participate in the debate. They will present their answers and discuss their respective viewpoints on the following topic: 〈debate topic〉. At the end of each round, you will evaluate the answers and determine which one is correct. |
| Affirmative Debater | You are affirmative side. Please express your viewpoints. |
| Negative Debater | You are negative side. You disagree with the affirmative side’s points. Provide your reasons and answer. |
| Condition | N | Pre-Test () | Post-Test () | |
|---|---|---|---|---|
| V | 30 | , 27.50 | , 18.83 | |
| V+Q&A | 31 | , 22.76 | , 22.00 | |
| V+Q&A+MAD | 29 | , 25.29 | , 20.88 |
| General Satisfaction | Easy to Use | System Response Speed | Eval of Q&A | Eval of MAD |
|---|---|---|---|---|
| 4.31 | 4.43 | 3.96 | 4.13 | 4.34 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, J.; Xu, G.; Liu, W.; Zhou, D.; Liu, F. Enhancing Online Learning Through Multi-Agent Debates for CS University Students. Appl. Sci. 2025, 15, 5877. https://doi.org/10.3390/app15115877
Du J, Xu G, Liu W, Zhou D, Liu F. Enhancing Online Learning Through Multi-Agent Debates for CS University Students. Applied Sciences. 2025; 15(11):5877. https://doi.org/10.3390/app15115877
Chicago/Turabian StyleDu, Jing, Guangtao Xu, Wenhao Liu, Dibin Zhou, and Fuchang Liu. 2025. "Enhancing Online Learning Through Multi-Agent Debates for CS University Students" Applied Sciences 15, no. 11: 5877. https://doi.org/10.3390/app15115877
APA StyleDu, J., Xu, G., Liu, W., Zhou, D., & Liu, F. (2025). Enhancing Online Learning Through Multi-Agent Debates for CS University Students. Applied Sciences, 15(11), 5877. https://doi.org/10.3390/app15115877