
Innovative Approaches to Traffic Anomaly Detection and Classification Using AI




Abstract
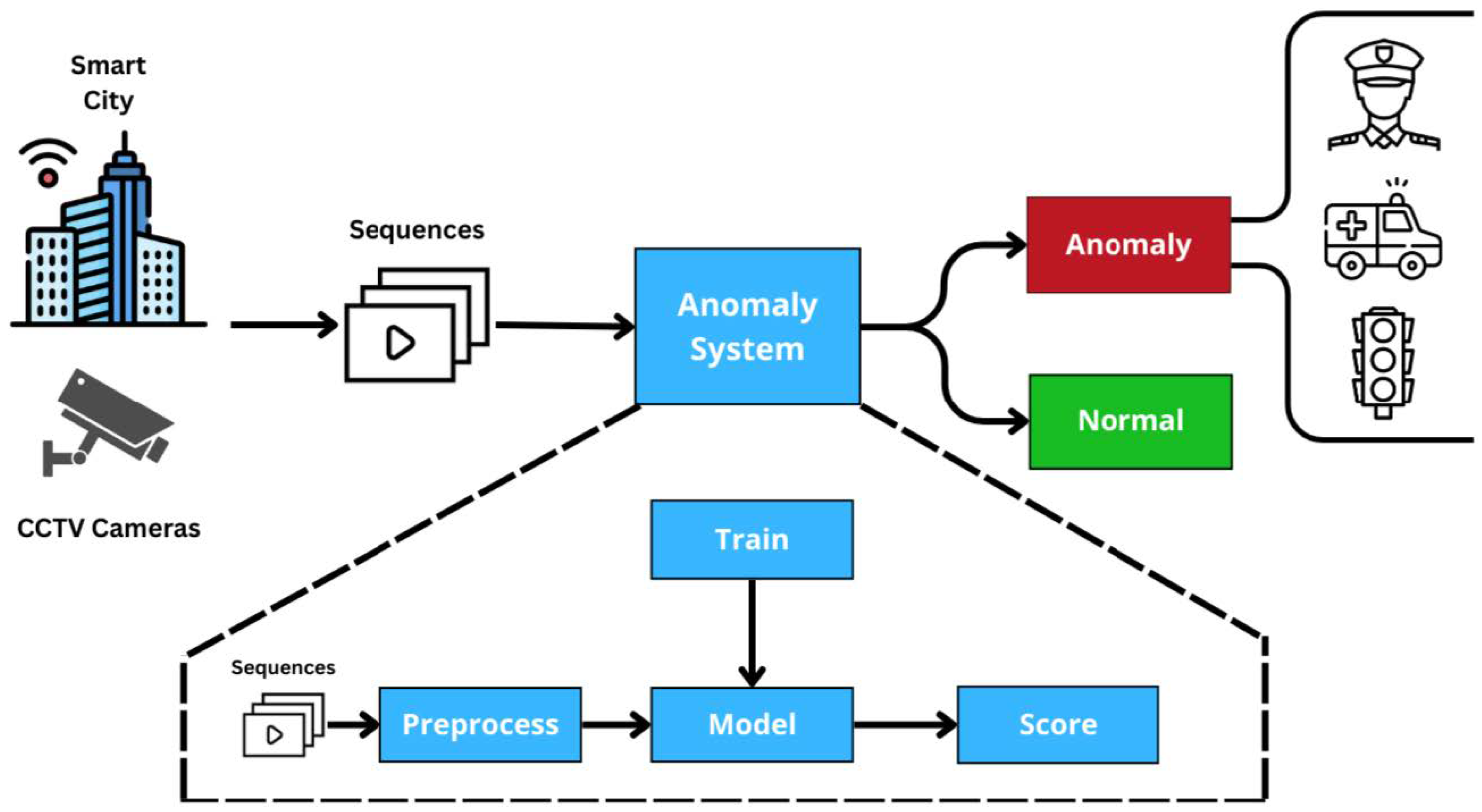
1. Introduction
- Quality: Due to the production and transportation of food and products, it has also been necessary to create systems such as in [3,4] that capable of detecting anomalies in defective products for their correct disposal, as well as to check the quality of the products before their distribution and sale.
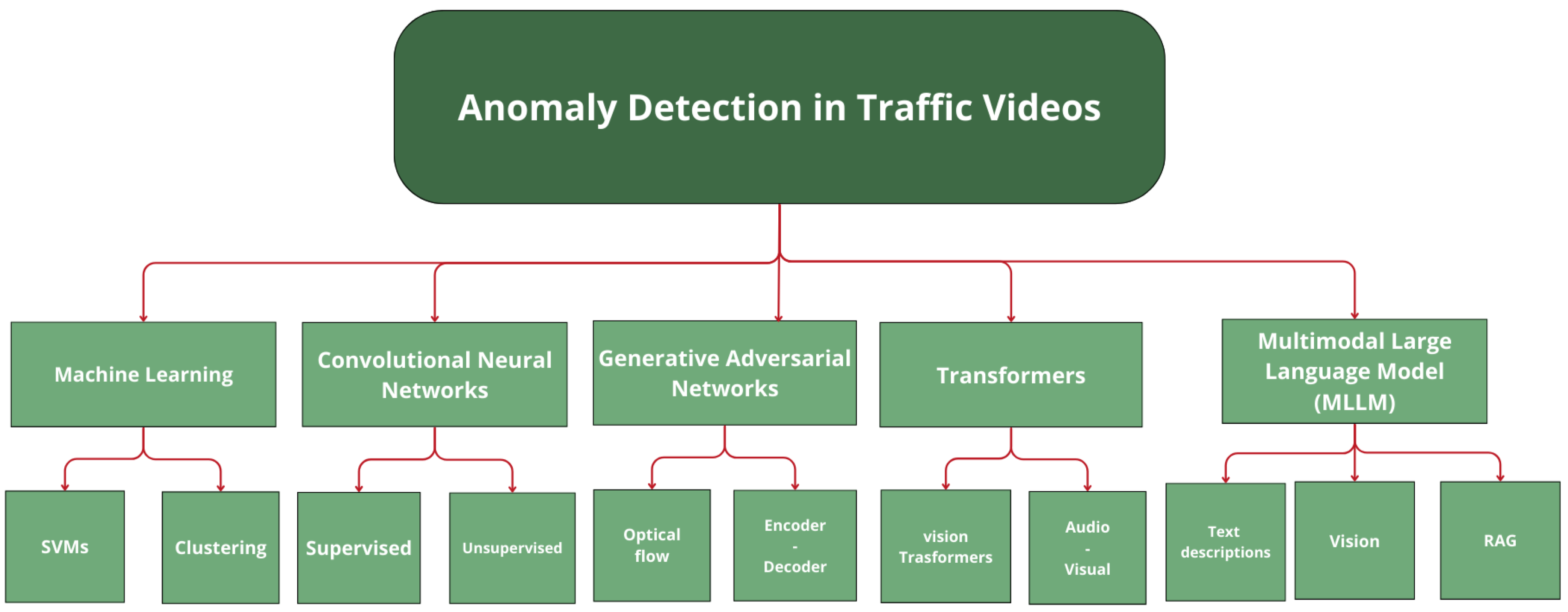
2. Algorithms and Methods
2.1. Machine Learning
2.2. Convolutional Neural Networks (CNNs)
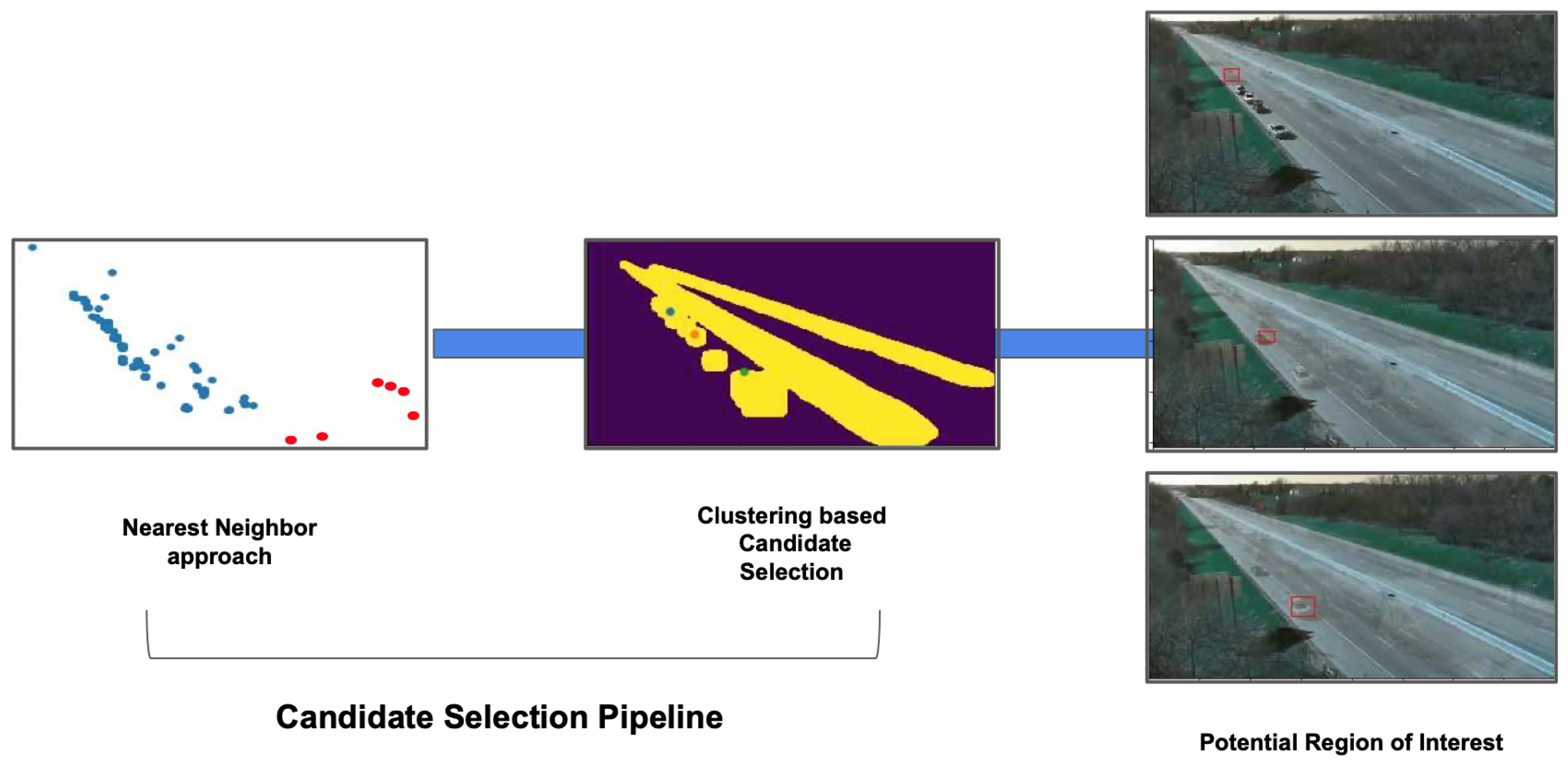
- Preprocessing module: Detects stationary objects using background modeling, road segmentation, and YOLO object detection.
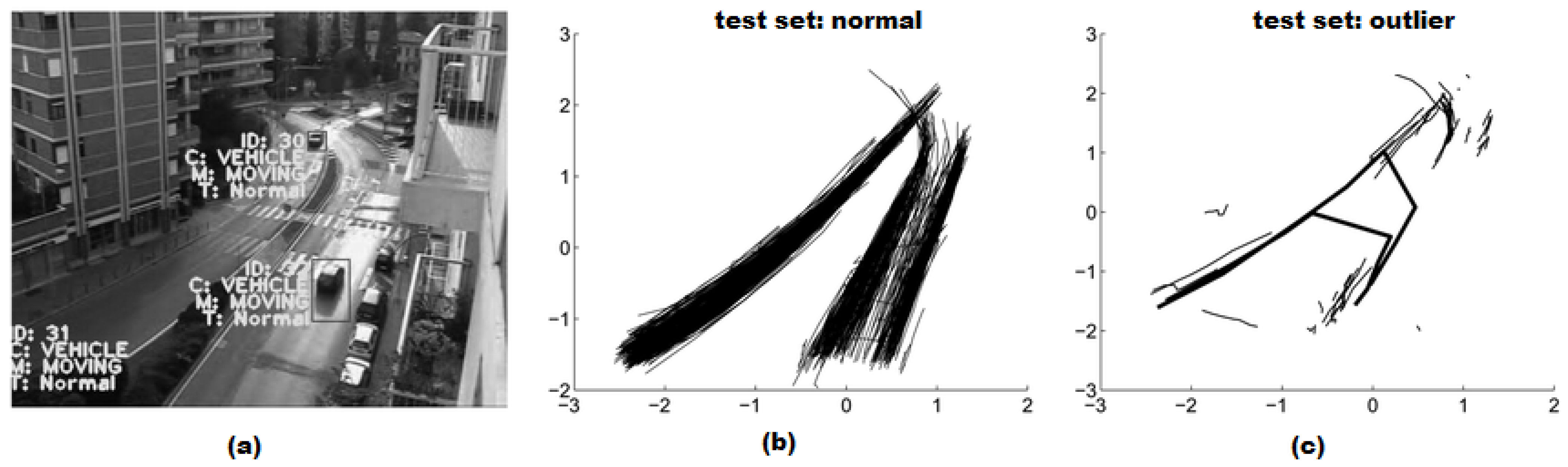
- Candidate selection module: Filters out misclassified stationary objects (e.g., road signs) using a nearest neighbor approach and K-means clustering. Objects forming dense clusters are considered normal, while sporadic outliers are flagged as anomalies (Figure 7).
- Backtracking anomaly detection module: Computes a similarity statistic (SSim) between the current frame and previous frames to detect anomalies such as stopped vehicles.
- Vehicle detection: YOLOv5 [28] identifies vehicles within video frames.
- Anomaly analysis: The system estimates the scene background by computing the median of randomly selected frames. A road mask delimits vehicular traffic zones, and a decision tree evaluates anomalies based on detection factors such as object size, detection probability, and overlap with the road mask. This process pinpoints the start and end points of anomalies.
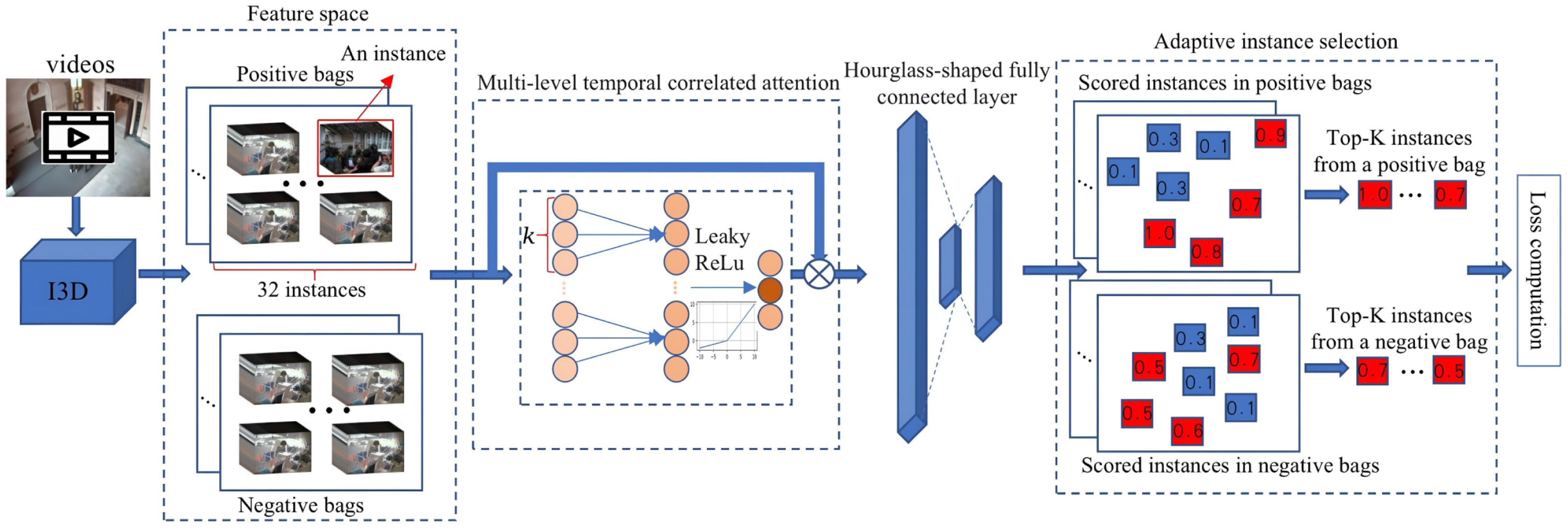
- Multilevel temporal correlation attention module (MTA): Captures temporal relationships between video clips of varying duration.
- Hourglass fully connected layer (HFC): Reduces parameters by half compared to conventional layers, maintaining performance while improving efficiency.
- Adaptive instance selection strategy (AIS): Dynamically selects reliable instances with the highest anomaly scores for loss computation, addressing the uncertainty of weakly labeled data.
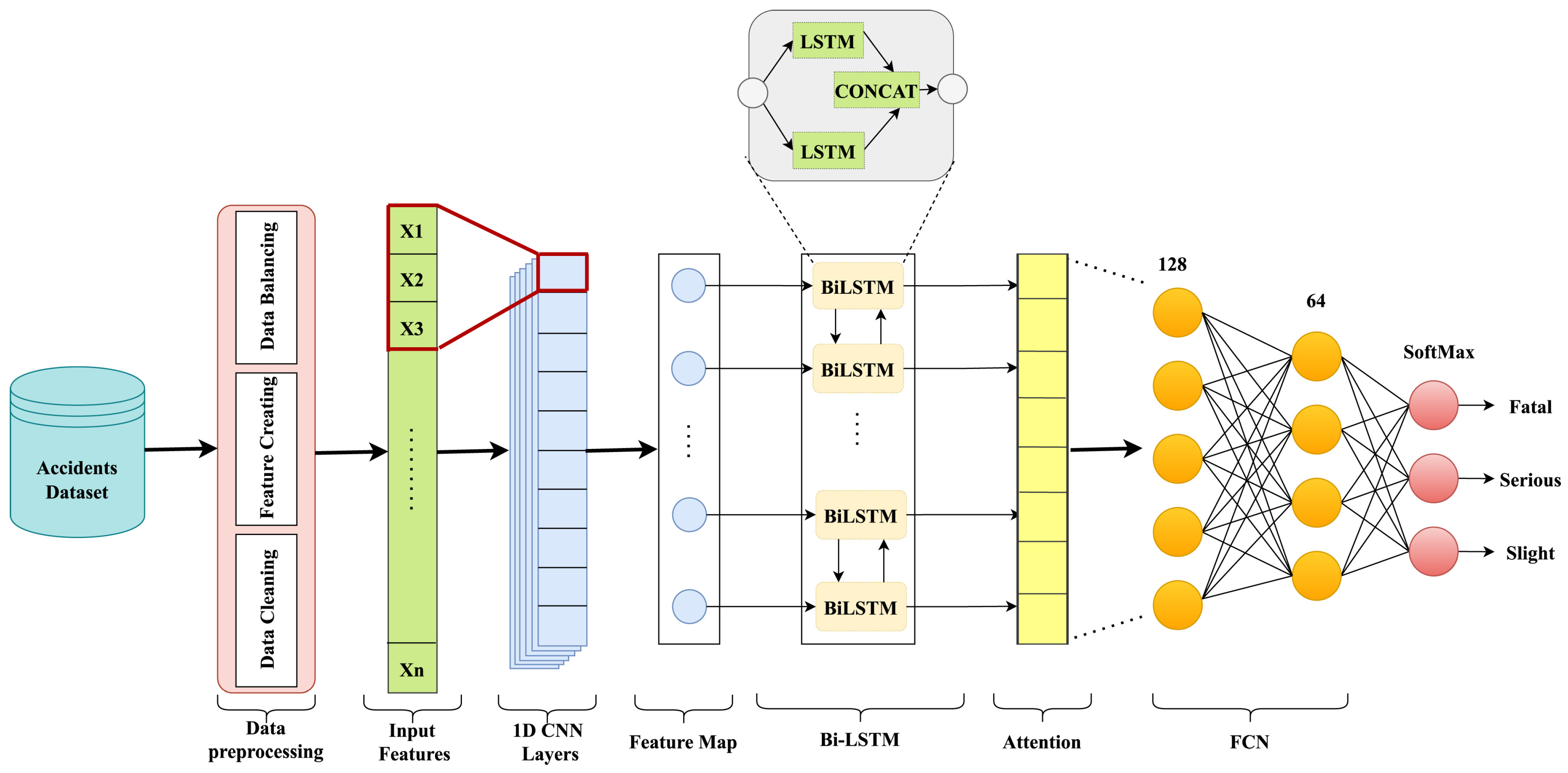
- Data preparation: The Accident Detection From CCTV Footage dataset, consisting of 990 balanced images of accidents and non-accidents, is used. Preprocessing techniques such as data augmentation, normalization, and resizing are applied to optimize training.
- Model architecture: EfficientNet-B7 is combined with additional Conv2D, Flatten, and Dense layers to create a hybrid model that extracts spatial features effectively, ensuring high performance.
- Training and evaluation: The model achieves a training accuracy of 99.24%, a cross-validation accuracy of 94.98%, and an area under the curve (AUC) of 1.00, confirming its robustness in distinguishing accidents from non-accidents.
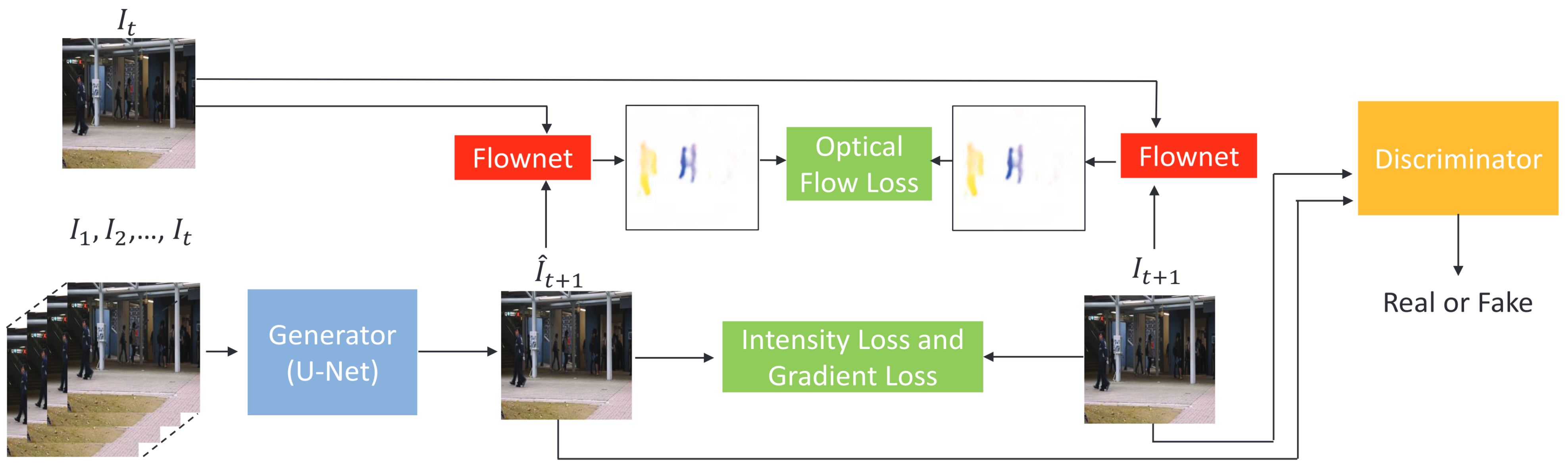
- Conv3D layers: Extract spatial and temporal features from video sequences.
- ConvLSTM2D layers: Combine CNN and LSTM capabilities for improved spatio-temporal processing.
- ConvTranspose3D layers: Enhance spatial resolution for better reconstruction accuracy.
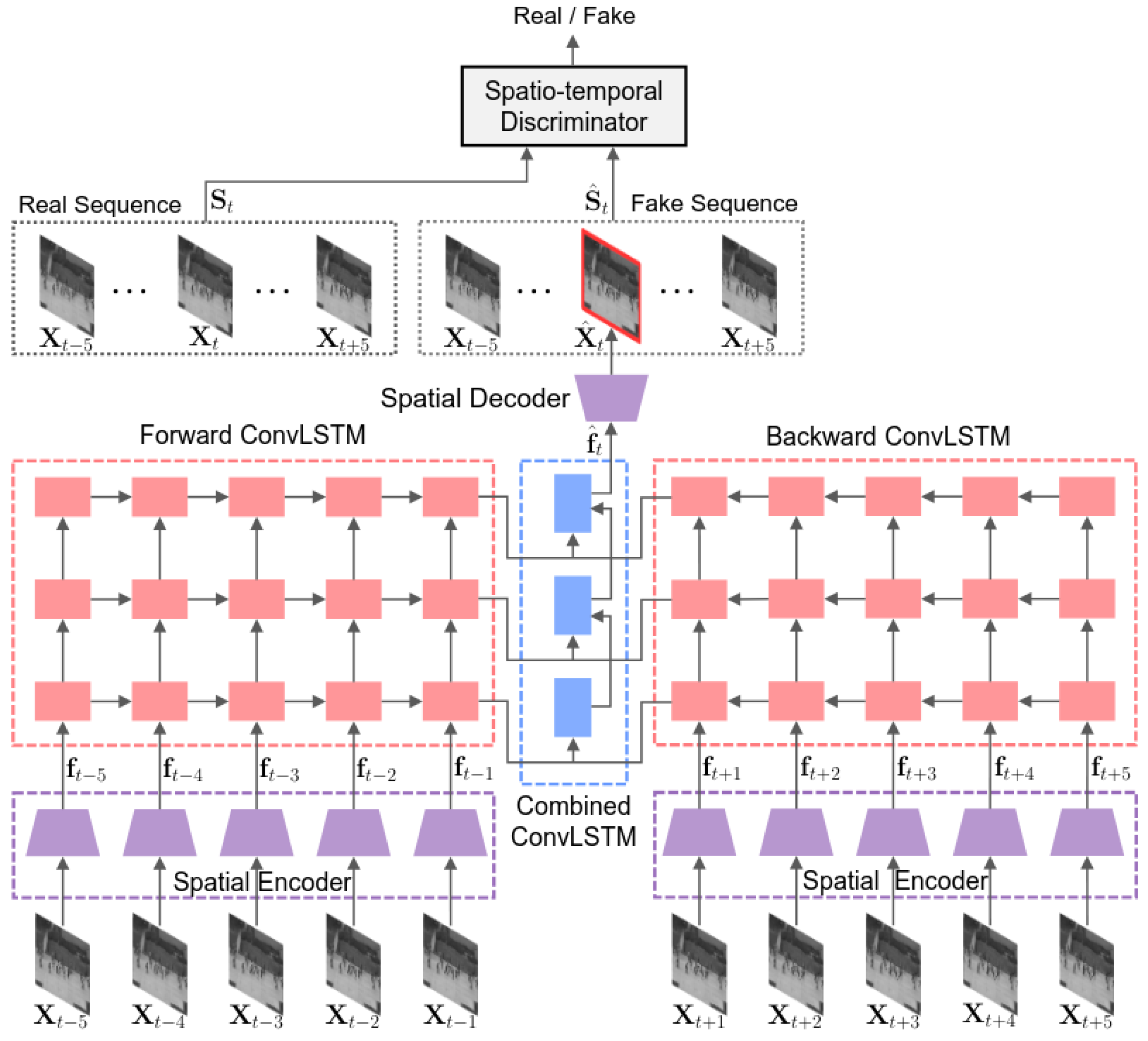
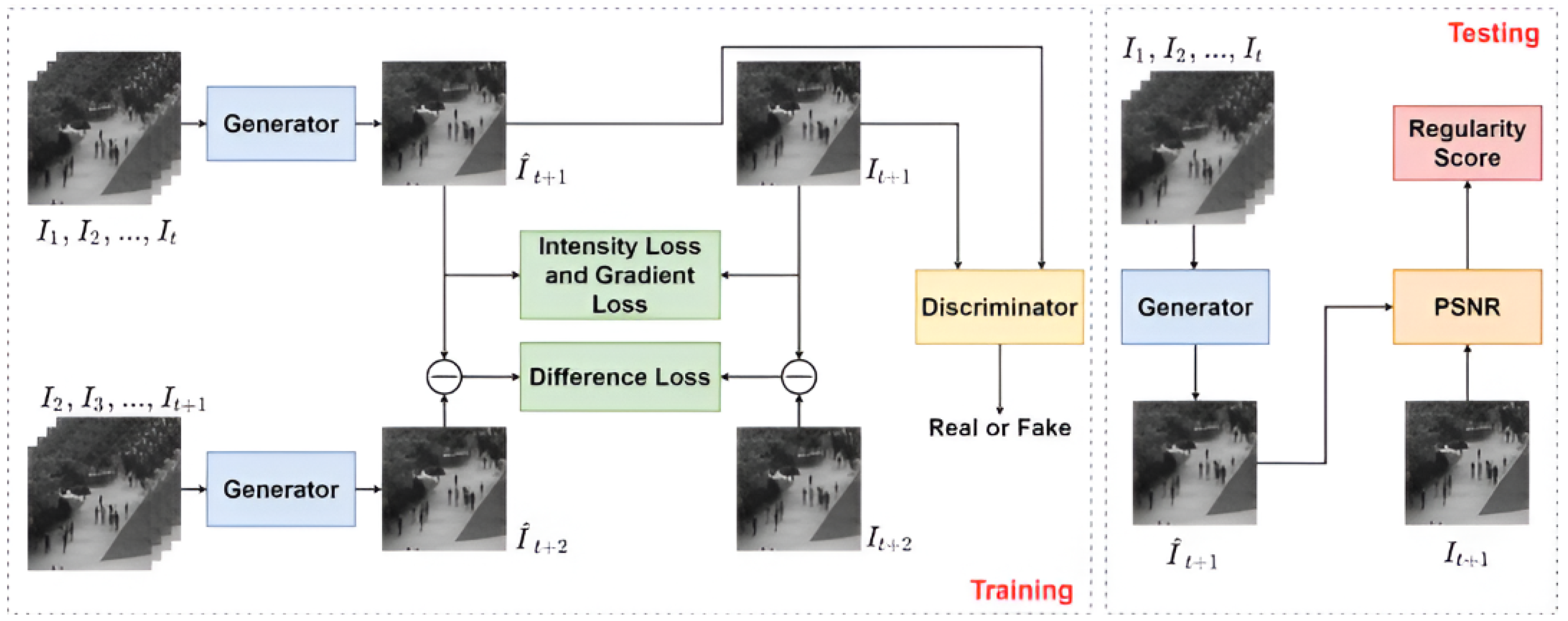
2.3. Generative Adversarial Networks (GANs)
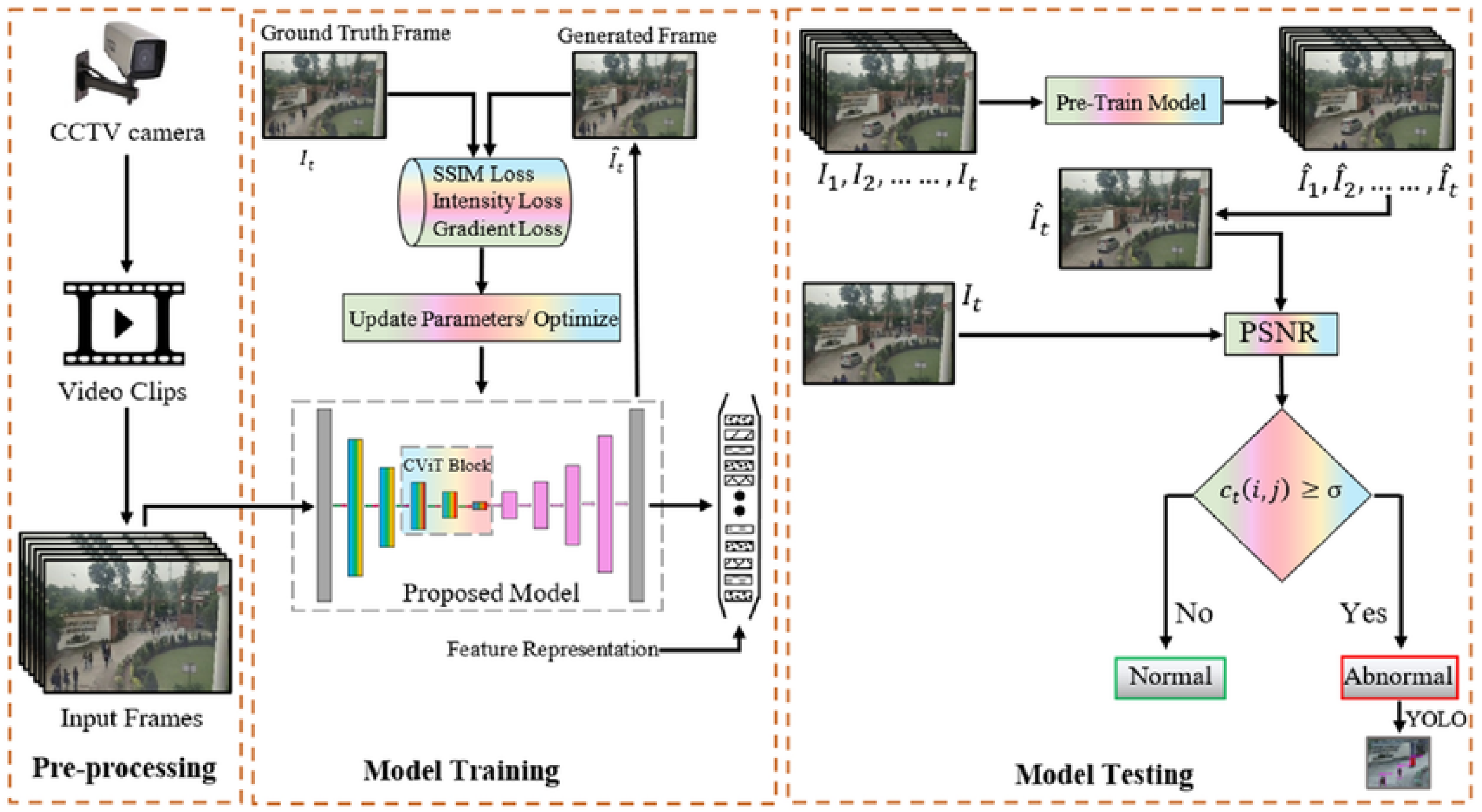
2.4. Transformers
2.5. Multimodal Large Language Model (MLLM)
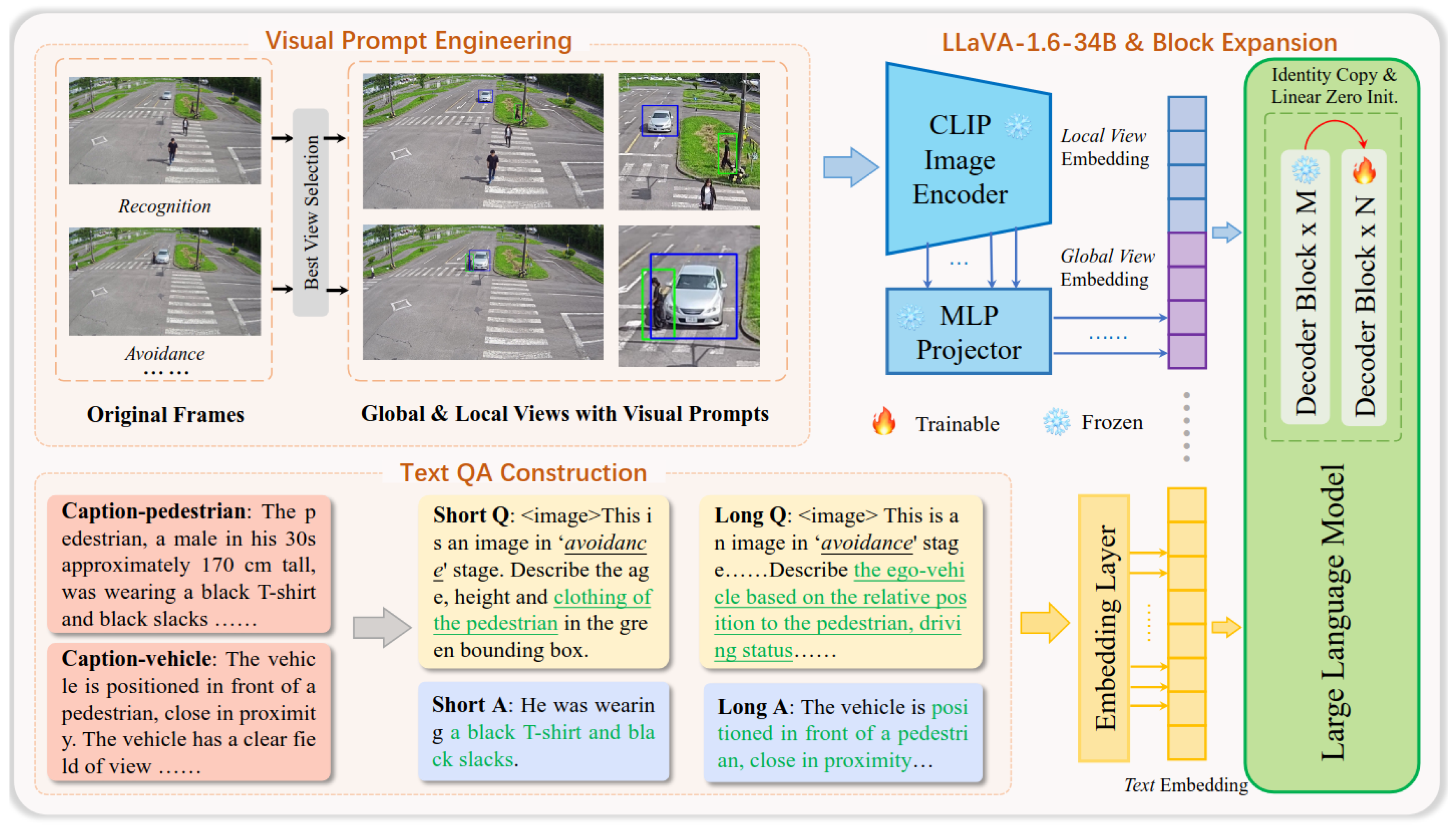
CityLLaVA Efficient Fine-Tunning for VLMs in City Scenario
- Bounding boxes optimize data preprocessing by selecting the best video views and focusing analysis on areas of interest, such as pedestrians and vehicles.
- Question sequences and textual prompts guide the model to evaluate key elements like position, movement, and environment, adapting to various traffic scenarios.
- Block expansion introduces additional decoder blocks, improving accuracy without significant overhead.
- Increased prediction based on sequential questioning enhances accuracy by using previously obtained information in an ordered questioning approach.
3. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| RNN | Recurrent Neural Network |
| GAN | Generative Adversarial Networks |
| LLM | Large Language Model |
| VLM | Visual Large Model |
| MLLM | Multimodal Large Language Model |
| CAN | Controller Area Network |
| YOLO | You Only Look Once |
| NN | Neural Network |
| SVM | Support Vector Machine |
| DTW | Dynamic time Warping |
| LCSS | Longest Common Subsequence |
| PF | Procrustes Fitting |
| CCR | Correct Clustering Ratius |
| MIL | Multiple Instance Learning |
| RMSE | Root Mean Squared Error |
| SSD | Single Shot Detection |
| KCF | Kernelized Correlation Filter |
| MOSSE | Minimum Output Sum of Squared Error |
| GPS | Global Positioning System |
| MTA | Multilevel temporal correlation attention |
| HFC | Hourglass Fully Connected |
| AIS | Adaptive Instance Selection Strategy |
| AUC | Area Under the Curve |
| LSTM | Long Short-Term Memory |
| KDE | Kernel Density Estimation |
| PSNR | Peak Signal to Noise Ratio |
| STAN | Spatio-Temporal Adversarial Networks |
| ViT | Vision Transformer |
| ViViT | Video Vision Transformer |
| CViT | Convolution Vision Transformer |
| WSVAD | Weakly Supervised Video Anomaly Detection |
| RTFM | Robust Temporal Feature Magnitude Learning |
| SSIM | Structural Similarity Index Measure |
| MAVAD | Malta Audio-Visual Anomaly Detection |
| AVACA | Audio-Visual Anomaly Cross Attention |
| LDMIL | Dynamic Multiple Instance Learning Loss |
| LC | Center Loss |
| MOVAD | Memory-augmented Online Video Anomaly Detection |
| VAD | Video Detection Anomaly |
| AVs | Autonomous vehicles |
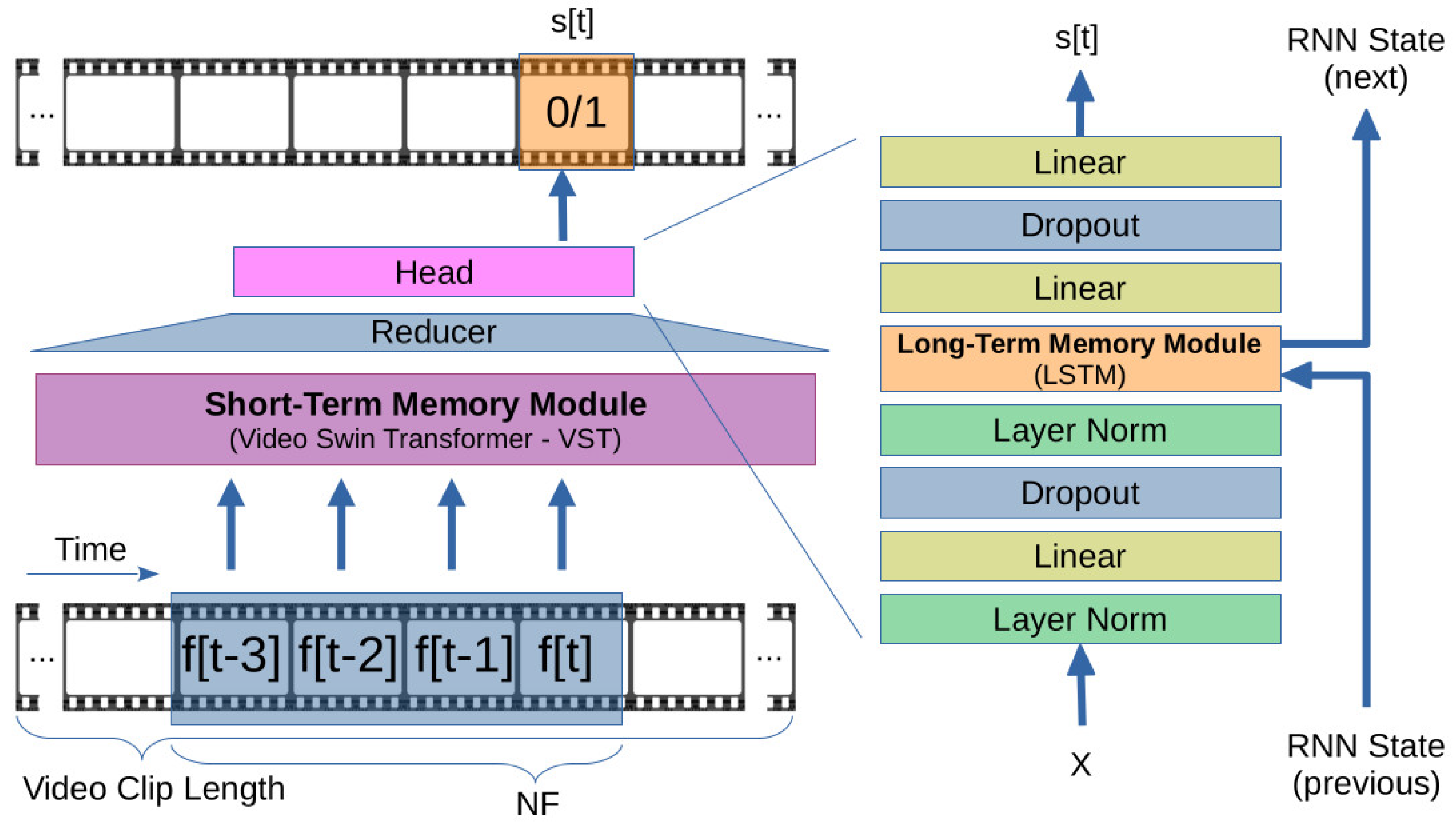
| STMM | Short-Term Memory Module |
| LTMM | Long-Term Memory Module |
| MLLM | Multimodal Large Language Models |
| CLIP | Contrastive Language-Image Pre-Training |
| RAG | Retrieval-augmented Generation |
References
- Xiang, S.; Zhu, M.; Cheng, D.; Li, E.; Zhao, R.; Ouyang, Y.; Chen, L.; Zheng, Y. Semi-supervised credit card fraud detection via attribute-driven graph representation. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 14557–14565. [Google Scholar]
- Ram, P.; Gray, A.G. Fraud detection with density estimation trees. In Proceedings of the KDD 2017 Workshop on Anomaly Detection in Finance, PMLR, Halifax, NS, Canada, 14 August 2017; pp. 85–94. [Google Scholar]
- Hung, Y.H. Developing an Anomaly Detection System for Automatic Defective Products’ Inspection. Processes 2022, 10, 1476. [Google Scholar] [CrossRef]
- Vasafi, P.S.; Paquet-Durand, O.; Brettschneider, K.; Hinrichs, J.; Hitzmann, B. Anomaly detection during milk processing by autoencoder neural network based on near-infrared spectroscopy. J. Food Eng. 2021, 299, 110510. [Google Scholar] [CrossRef]
- Sedik, A.; Emara, H.M.; Hamad, A.; Shahin, E.M.; El-Hag, N.A.; Khalil, A.; Ibrahim, F.; Elsherbeny, Z.M.; Elreefy, M.; Zahran, O.; et al. Efficient anomaly detection from medical signals and images. Int. J. Speech Technol. 2019, 22, 739–767. [Google Scholar] [CrossRef]
- Tschuchnig, M.E.; Gadermayr, M. Anomaly detection in medical imaging-a mini review. In Proceedings of the Data Science—Analytics and Applications: Proceedings of the 4th International Data Science Conference–iDSC2021, Virtual, 20–21 October 2021; pp. 33–38. [Google Scholar]
- Dias, M.A.; Silva, E.A.d.; Azevedo, S.C.d.; Casaca, W.; Statella, T.; Negri, R.G. An incongruence-based anomaly detection strategy for analyzing water pollution in images from remote sensing. Remote Sens. 2019, 12, 43. [Google Scholar] [CrossRef]
- Wei, Y.; Jang-Jaccard, J.; Xu, W.; Sabrina, F.; Camtepe, S.; Boulic, M. LSTM-autoencoder-based anomaly detection for indoor air quality time-series data. IEEE Sensors J. 2023, 23, 3787–3800. [Google Scholar] [CrossRef]
- Bawaneh, M.; Simon, V. Anomaly detection in smart city traffic based on time series analysis. In Proceedings of the 2019 International Conference on Software, Telecommunications and Computer Networks (SoftCOM), Split, Croatia, 19–21 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Zhang, M.; Chen, C.; Wo, T.; Xie, T.; Bhuiyan, M.Z.A.; Lin, X. SafeDrive: Online driving anomaly detection from large-scale vehicle data. IEEE Trans. Ind. Inform. 2017, 13, 2087–2096. [Google Scholar] [CrossRef]
- Cobilean, V.; Mavikumbure, H.S.; Wickramasinghe, C.S.; Varghese, B.J.; Pennington, T.; Manic, M. Anomaly Detection for In-Vehicle Communication Using Transformers. In Proceedings of the IECON 2023—49th Annual Conference of the IEEE Industrial Electronics Society, Singapore, 16–19 October 2023. [Google Scholar]
- Redmon, J. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Piciarelli, C.; Micheloni, C.; Foresti, G.L. Trajectory-based anomalous event detection. IEEE Trans. Circuits Syst. Video Technol. 2008, 18, 1544–1554. [Google Scholar] [CrossRef]
- Morris, B.; Trivedi, M. Learning trajectory patterns by clustering: Experimental studies and comparative evaluation. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 312–319. [Google Scholar]
- Morris, B.T. Understanding Activity from Trajectory Patterns; University of California: San Diego, CA, USA, 2010. [Google Scholar]
- Pathak, D.; Sharang, A.; Mukerjee, A. Anomaly localization in topic-based analysis of surveillance videos. In Proceedings of the 2015 IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 389–395. [Google Scholar]
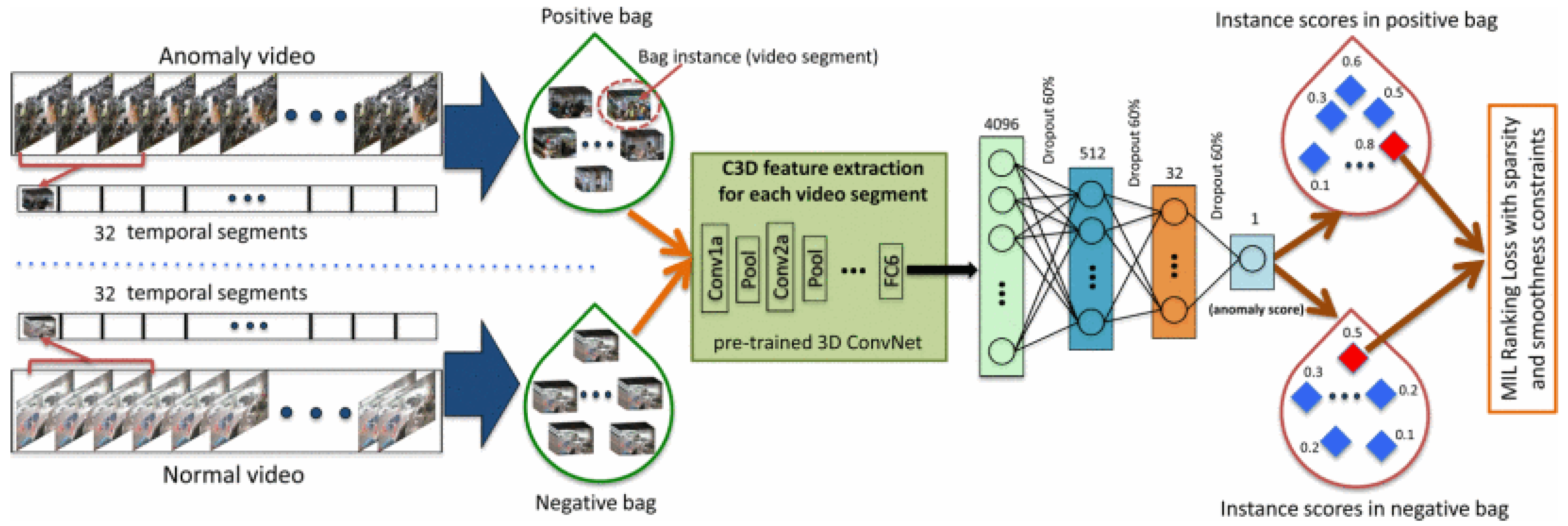
- Sultani, W.; Chen, C.; Shah, M. Real-world anomaly detection in surveillance videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6479–6488. [Google Scholar]
- Doshi, K.; Yilmaz, Y. Fast unsupervised anomaly detection in traffic videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 624–625. [Google Scholar]
- Wang, S.; Anastasiu, D.C.; Tang, Z.; Chang, M.C.; Yao, Y.; Zheng, L.; Rahman, M.S.; Arya, M.S.; Sharma, A.; Chakraborty, P.; et al. The 8th AI City Challenge. In Proceedings of the The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Seattle, WA, USA, 17–18 June 2024. [Google Scholar]
- Minnikhanov, R.; Dagaeva, M.; Anikin, I.; Bolshakov, T.; Makhmutova, A.; Mingulov, K. Detection of traffic anomalies for a safety system of smart city. In Proceedings of the CEUR Workshop Proceedings, Bergen, Norway, 17 July 2020; Volume 2667, pp. 337–342. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. pp. 21–37. [Google Scholar]
- Grabner, H.; Grabner, M.; Bischof, H. Real-time tracking via on-line boosting. In Proceedings of the British Machine Vision Conference, Edinburgh, UK, 4–7 September 2006. [Google Scholar]
- Babenko, B.; Yang, M.H.; Belongie, S. Visual tracking with online multiple instance learning. In Proceedings of the 2009 IEEE Conference on computer vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 983–990. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 583–596. [Google Scholar] [CrossRef]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar]
- Aboah, A. A vision-based system for traffic anomaly detection using deep learning and decision trees. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4207–4212. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; NanoCode012; Kwon, Y.; Michael, K.; Xie, T.; Fang, J.; Imyhxy; et al. YOLOv5 by Ultralytics. 2020. Available online: https://zenodo.org/records/7347926 (accessed on 1 January 2020).
- Naphade, M.; Wang, S.; Anastasiu, D.C.; Tang, Z.; Chang, M.C.; Yang, X.; Yao, Y.; Zheng, L.; Chakraborty, P.; Lopez, C.E.; et al. The 5th AI City Challenge. In Proceedings of the The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Pi, Y.; Duffield, N.; Behzadan, A.H.; Lomax, T. Visual recognition for urban traffic data retrieval and analysis in major events using convolutional neural networks. Comput. Urban Sci. 2022, 2, 2. [Google Scholar] [CrossRef]
- Khan, S.W.; Hafeez, Q.; Khalid, M.I.; Alroobaea, R.; Hussain, S.; Iqbal, J.; Almotiri, J.; Ullah, S.S. Anomaly detection in traffic surveillance videos using deep learning. Sensors 2022, 22, 6563. [Google Scholar] [CrossRef]
- Wang, Y.; Zhou, J.; Guan, J. A lightweight video anomaly detection model with weak supervision and adaptive instance selection. Neurocomputing 2025, 613, 128698. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, D.; Chen, S.; Gao, S.; Ma, Y. Single-image crowd counting via multi-column convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 589–597. [Google Scholar]
- Singh, R.; Sharma, N.; Rajput, K.; Pokhariya, H.S. EfficientNet-B7 Enhanced Road Accident Detection Using CCTV Footage. In Proceedings of the 2024 Asia Pacific Conference on Innovation in Technology (APCIT), Mysore, India, 26–27 July 2024; pp. 1–6. [Google Scholar]
- Alhaek, F.; Liang, W.; Rajeh, T.M.; Javed, M.H.; Li, T. Learning spatial patterns and temporal dependencies for traffic accident severity prediction: A deep learning approach. Knowl.-Based Syst. 2024, 286, 111406. [Google Scholar] [CrossRef]
- Mishra, S.; Jabin, S. Anomaly detection in surveillance videos using deep autoencoder. Int. J. Inf. Technol. 2024, 16, 1111–1122. [Google Scholar] [CrossRef]
- Chan, A.B.; Vasconcelos, N. Modeling, clustering, and segmenting video with mixtures of dynamic textures. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 909–926. [Google Scholar] [CrossRef] [PubMed]
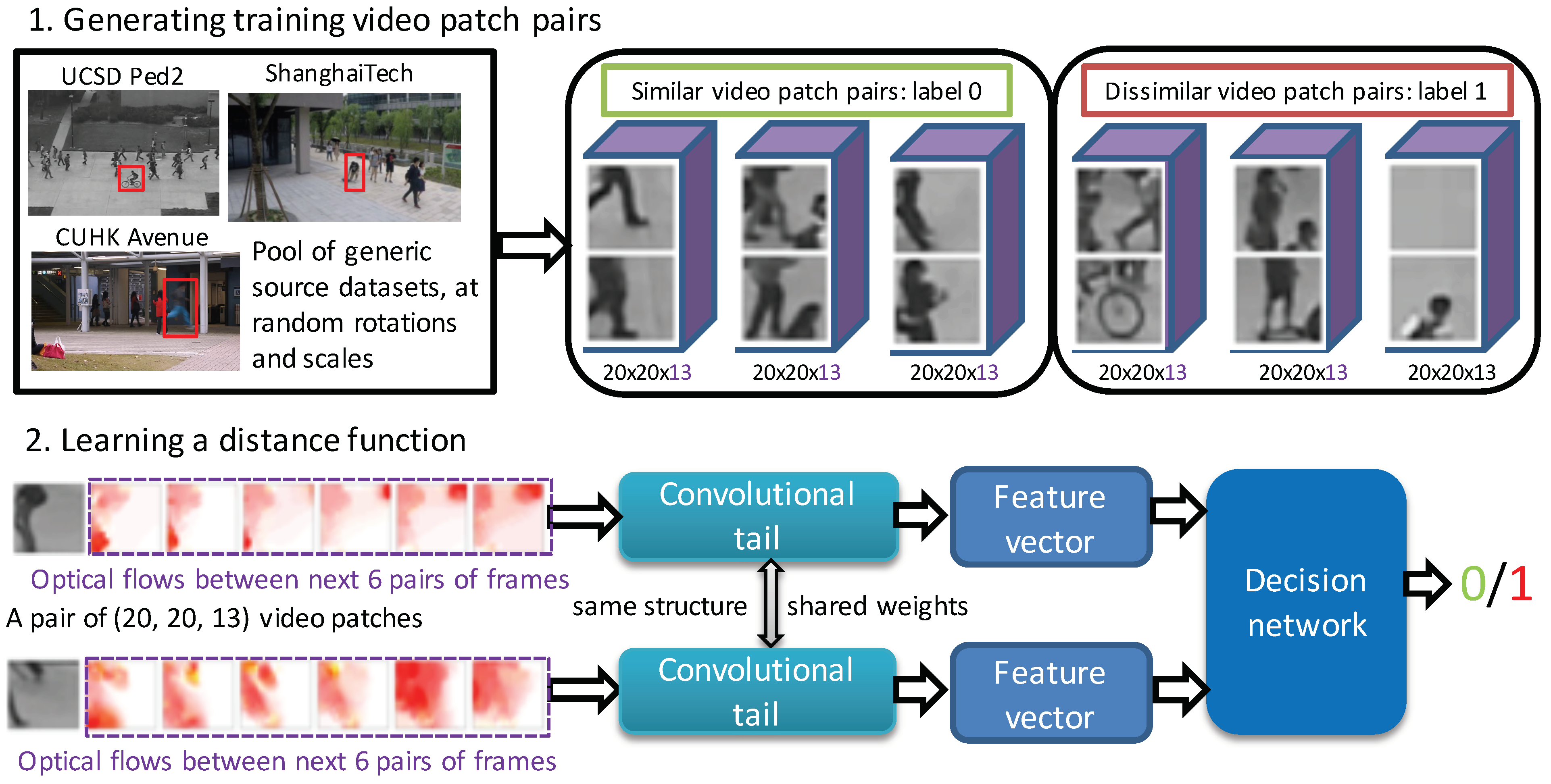
- Lu, C.; Shi, J.; Jia, J. Abnormal event detection at 150 fps in matlab. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2720–2727. [Google Scholar]
- Ramachandra, B.; Jones, M.; Vatsavai, R. Learning a distance function with a Siamese network to localize anomalies in videos. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 2598–2607. [Google Scholar]
- Liu, W.; Luo, W.; Lian, D.; Gao, S. Future frame prediction for anomaly detection–a new baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6536–6545. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. pp. 234–241. [Google Scholar]
- Lee, S.; Kim, H.G.; Ro, Y.M. STAN: Spatio-temporal adversarial networks for abnormal event detection. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 1323–1327. [Google Scholar]
- Dong, F.; Zhang, Y.; Nie, X. Dual discriminator generative adversarial network for video anomaly detection. IEEE Access 2020, 8, 88170–88176. [Google Scholar] [CrossRef]
- Yuan, H.; Cai, Z.; Zhou, H.; Wang, Y.; Chen, X. Transanomaly: Video anomaly detection using video vision transformer. IEEE Access 2021, 9, 123977–123986. [Google Scholar] [CrossRef]
- Deshpande, K.; Punn, N.S.; Sonbhadra, S.K.; Agarwal, S. Anomaly detection in surveillance videos using transformer based attention model. In Proceedings of the International Conference on Neural Information Processing, IIT, Indore, India, 22–26 November 2022; pp. 199–211. [Google Scholar]
- Chen, J.; Wang, J.; Pu, J.; Zhang, R. A Three-Stage Anomaly Detection Framework for Traffic Videos. J. Adv. Transp. 2022, 2022, 9463559. [Google Scholar] [CrossRef]
- Roka, S.; Diwakar, M. Cvit: A convolution vision transformer for video abnormal behavior detection and localization. SN Comput. Sci. 2023, 4, 829. [Google Scholar] [CrossRef]
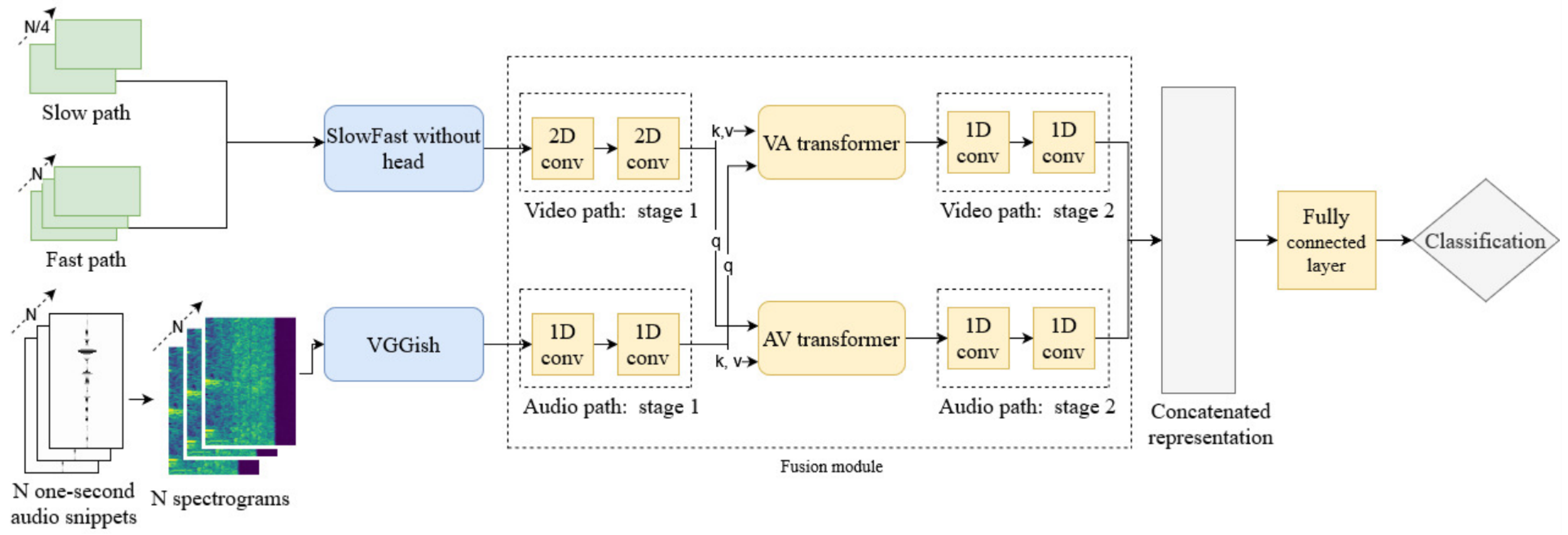
- Leporowski, B.; Bakhtiarnia, A.; Bonnici, N.; Muscat, A.; Zanella, L.; Wang, Y.; Iosifidis, A. Audio-Visual Dataset and Method for Anomaly Detection in Traffic Videos. arXiv 2023, arXiv:2305.15084. [Google Scholar]
- Lu, X.; Zhang, D.; Xiao, J. A Hybrid Model for Traffic Incident Detection based on Generative Adversarial Networks and Transformer Model. arXiv 2024, arXiv:2403.01147. [Google Scholar]
- Skabardonis, A.; Petty, K.F.; Bertini, R.L.; Varaiya, P.P.; Noeimi, H.; Rydzewski, D. I-880 field experiment: Analysis of incident data. Transp. Res. Rec. 1997, 1603, 72–79. [Google Scholar] [CrossRef]
- Zhang, W.; Xiong, L.; Ji, Q.; Liu, H.; Zhang, F.; Chen, H. Dissipative Structure Properties of Traffic Flow in Expressway Weaving Areas. Promet-Traffic Transp. 2024, 36, 717–732. [Google Scholar] [CrossRef]
- Rossi, L.; Bernuzzi, V.; Fontanini, T.; Bertozzi, M.; Prati, A. Memory-Augmented Online Video Anomaly Detection. In Proceedings of the ICASSP 2024–2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 6590–6594. [Google Scholar]
- Yao, Y.; Wang, X.; Xu, M.; Pu, Z.; Wang, Y.; Atkins, E.; Crandall, D. DoTA: Unsupervised detection of traffic anomaly in driving videos. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 444–459. [Google Scholar] [CrossRef]
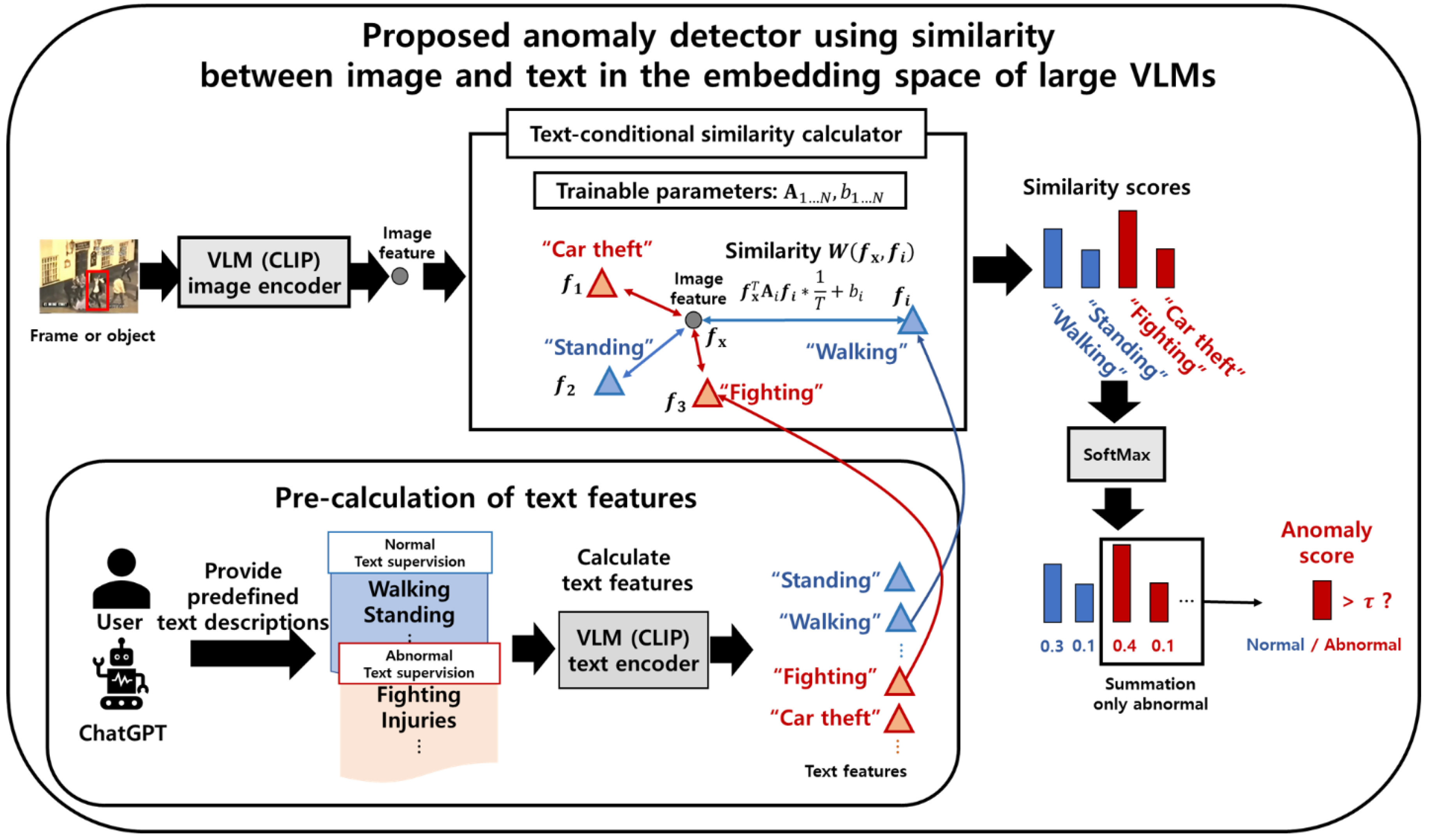
- Kim, J.; Yoon, S.; Choi, T.; Sull, S. Unsupervised video anomaly detection based on similarity with predefined text descriptions. Sensors 2023, 23, 6256. [Google Scholar] [CrossRef] [PubMed]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Online, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
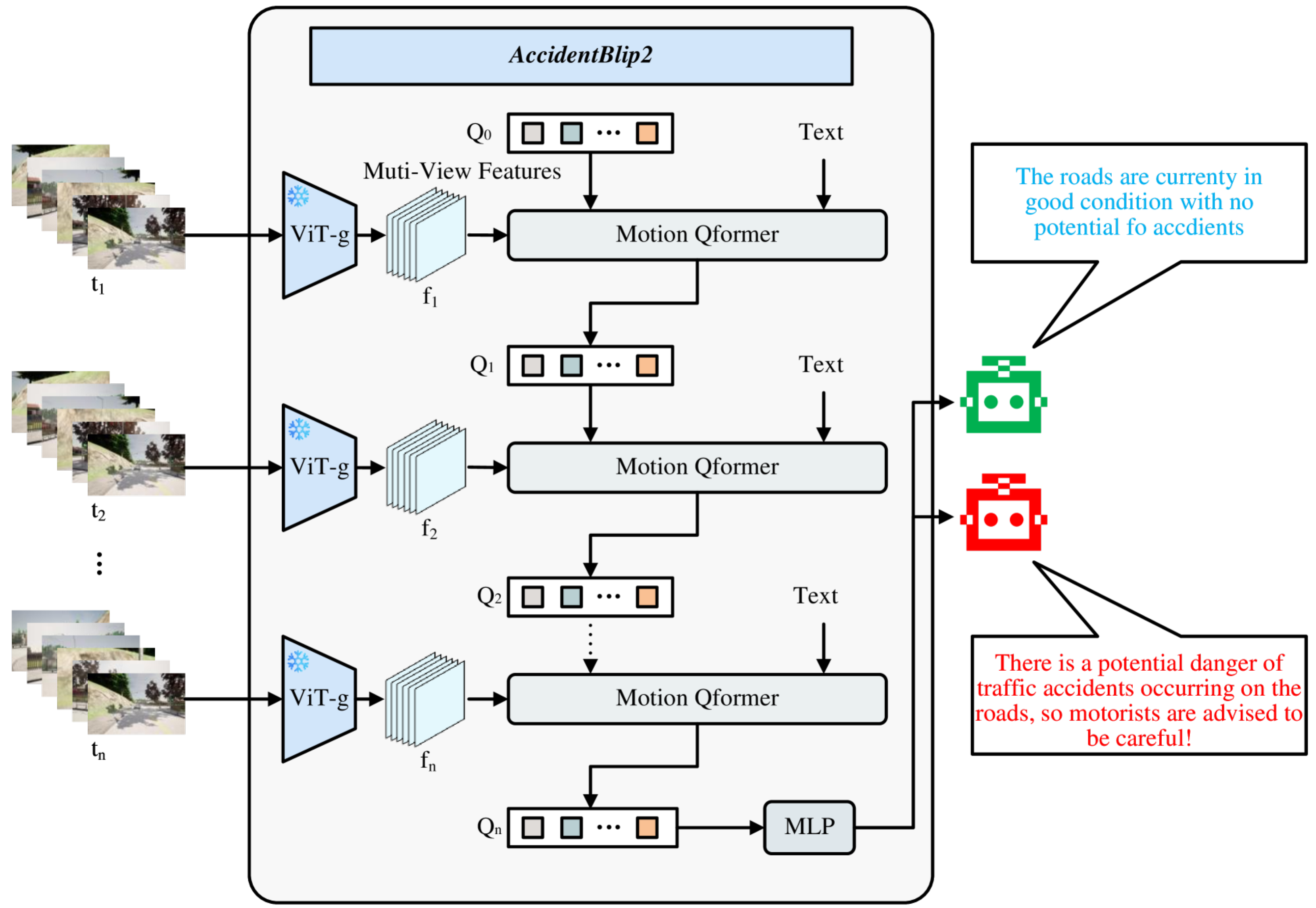
- Shao, Y.; Cai, H.; Long, X.; Lang, W.; Wang, Z.; Wu, H.; Wang, Y.; Yin, J.; Yang, Y.; Lv, Y.; et al. AccidentBlip2: Accident Detection with Multi-View MotionBlip2. arXiv 2024, arXiv:2404.12149. [Google Scholar]
- Wang, T.; Kim, S.; Wenxuan, J.; Xie, E.; Ge, C.; Chen, J.; Li, Z.; Luo, P. DeepAccident: A Motion and Accident Prediction Benchmark for V2X Autonomous Driving. Proc. AAAI Conf. Artif. Intell. 2024, 38, 5599–5606. [Google Scholar] [CrossRef]
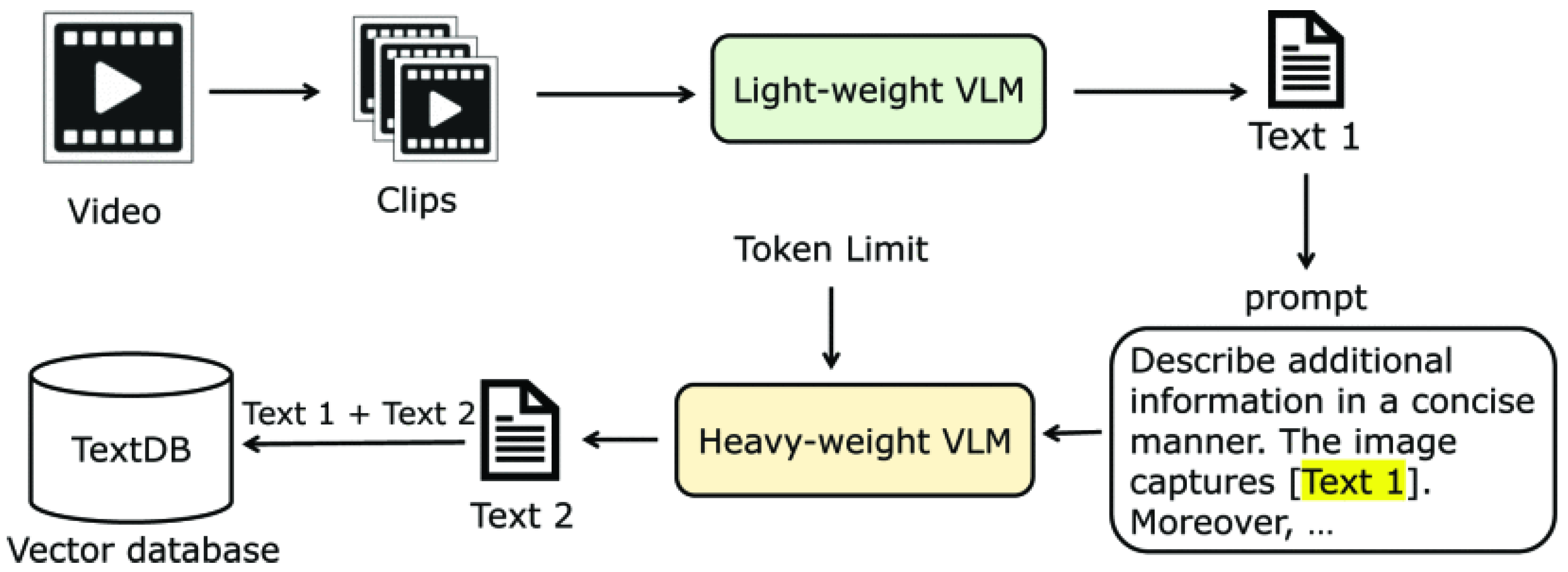
- Arefeen, M.A.; Debnath, B.; Uddin, M.Y.S.; Chakradhar, S. ViTA: An Efficient Video-to-Text Algorithm using VLM for RAG-based Video Analysis System. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 2266–2274. [Google Scholar]
- Piadyk, Y.; Rulff, J.; Brewer, E.; Hosseini, M.; Ozbay, K.; Sankaradas, M.; Chakradhar, S.; Silva, C. StreetAware: A High-Resolution Synchronized Multimodal Urban Scene Dataset. Sensors 2023, 23, 3710. [Google Scholar] [CrossRef]
- Kossmann, F.; Wu, Z.; Lai, E.; Tatbul, N.; Cao, L.; Kraska, T.; Madden, S. Extract-Transform-Load for Video Streams. Proc. VLDB Endow. 2023, 16, 2302–2315. [Google Scholar] [CrossRef]
- Abu Tami, M.; Ashqar, H.I.; Elhenawy, M.; Glaser, S.; Rakotonirainy, A. Using Multimodal Large Language Models (MLLMs) for Automated Detection of Traffic Safety-Critical Events. Vehicles 2024, 6, 1571–1590. [Google Scholar] [CrossRef]
- Malla, S.; Choi, C.; Dwivedi, I.; Choi, J.H.; Li, J. Drama: Joint risk localization and captioning in driving. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 1043–1052. [Google Scholar]
- Duan, Z.; Cheng, H.; Xu, D.; Wu, X.; Zhang, X.; Ye, X.; Xie, Z. Cityllava: Efficient fine-tuning for vlms in city scenario. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 7180–7189. [Google Scholar]
- Liu, H.; Li, C.; Li, Y.; Li, B.; Zhang, Y.; Shen, S.; Lee, Y.J. Llava-Next: Improved Reasoning, OCR, and World Knowledge. 2024. Available online: https://llava-vl.github.io/blog/2024-01-30-llava-next/ (accessed on 1 January 2024).
- Wu, C.; Gan, Y.; Ge, Y.; Lu, Z.; Wang, J.; Feng, Y.; Luo, P.; Shan, Y. Llama pro: Progressive llama with block expansion. arXiv 2024, arXiv:2401.02415. [Google Scholar]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. Lora: Low-rank adaptation of large language models. arXiv 2021, arXiv:2106.09685. [Google Scholar]
- Wang, H.; Qin, J.; Bastola, A.; Chen, X.; Suchanek, J.; Gong, Z.; Razi, A. VisionGPT: LLM-Assisted Real-Time Anomaly Detection for Safe Visual Navigation. arXiv 2024, arXiv:2403.12415. [Google Scholar]
- Ashqar, H.I.; Jaber, A.; Alhadidi, T.I.; Elhenawy, M. Advancing Object Detection in Transportation with Multimodal Large Language Models (MLLMs): A Comprehensive Review and Empirical Testing. arXiv 2024, arXiv:2409.18286. [Google Scholar]
- Santhosh, K.K.; Dogra, D.P.; Roy, P.P. Anomaly detection in road traffic using visual surveillance: A survey. Acm Comput. Surv. (CSUR) 2020, 53, 1–26. [Google Scholar] [CrossRef]
- Bogdoll, D.; Nitsche, M.; Zöllner, J.M. Anomaly detection in autonomous driving: A survey. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 4488–4499. [Google Scholar]
- Chew, J.V.L.; Asli, M.F. A survey on vehicular traffic flow anomaly detection using machine learning. In Proceedings of the ITM Web of Conferences, Marrakech, Morocco, 20–24 November 2024; Volume 63, p. 01023. [Google Scholar]
- El Manaa, I.; Benjelloun, F.; Sabri, M.A.; Yahyaouy, A.; Aarab, A. Road traffic anomaly detection: A survey. In Proceedings of the International Conference on Digital Technologies and Applications, Fez, Morocco, 28–30 January 2022; pp. 772–781. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Specifications | Advantages | Disadvantages | Applications |
|---|---|---|---|---|
| ML [13,14,16] | Events by trajectories Feature extraction Unsupervised learning Anomaly by trajectory analysis | Automation Adaptable Detects subtle anomalies | Sensitivity to parameters Need for large datasets Complex results Complex algorithm | Vehicle tracking Traffic flow analysis Early warning systems |
| CNN [17,18,20,27,30,31,32,34,35,36,39] | Layered architecture Convolutional layers for local patterns, filter, and feature maps Pooling Spatio-temporal feature Anomaly detection from deviations | High performance Robust Machine learning Versatility | Need large datasets Complexity Black box Quality of data affects performance | Surveillance video analysis Traffic signal control Accident detection |
| GAN [40,42,43,44] | GAN architecture Generator makes predictions of normal sequence Predictions. Constraints to increase robustness. Generator inference for predictions. Anomaly identified as large difference. | Generation of realistic synthetic data for training Detection of variety of anomalies Robustness | Instability of GAN architecture Large training datasets needed Complex evaluation. | Rare event simulation Real-time anomaly prediction Data augmentation |
| Transformers [45,46,47,48,49,52] | Self-attention mechanism analyze elements’ relationships Encoder–decoder architecture Global relationships between elements Fewer annotations | Capture complex relationships between events Superior performance Parallel higher efficiency Applicability | Complexity Need large datasets Complex interpretability | Multi-camera tracking Real-time traffic incident detection Predictive modeling |
| MLLM [54,56,58,61,63,67,68] | LLM with VLM combination to analyze data. Three components: encoder, backbone, LLM, and interface connector Learning methods depending on training Integrations with object detection systems to improve accuracy and contextual understanding | Ability to understand context from multiple sources and deeper analysis Highly scalable Better performance Logical and visual reasoning | Training and inference computationally expensive Limitations in understanding the order and complex relationships MLLMs can generate incorrect outputs or “hallucinations” Limited generalization | Multimodal urban surveillance Situation-aware traffic reporting Decision support systems |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pérez, B.; Resino, M.; Seco, T.; García, F.; Al-Kaff, A. Innovative Approaches to Traffic Anomaly Detection and Classification Using AI. Appl. Sci. 2025, 15, 5520. https://doi.org/10.3390/app15105520
Pérez B, Resino M, Seco T, García F, Al-Kaff A. Innovative Approaches to Traffic Anomaly Detection and Classification Using AI. Applied Sciences. 2025; 15(10):5520. https://doi.org/10.3390/app15105520
Chicago/Turabian StylePérez, Borja, Mario Resino, Teresa Seco, Fernando García, and Abdulla Al-Kaff. 2025. "Innovative Approaches to Traffic Anomaly Detection and Classification Using AI" Applied Sciences 15, no. 10: 5520. https://doi.org/10.3390/app15105520
APA StylePérez, B., Resino, M., Seco, T., García, F., & Al-Kaff, A. (2025). Innovative Approaches to Traffic Anomaly Detection and Classification Using AI. Applied Sciences, 15(10), 5520. https://doi.org/10.3390/app15105520