

Adaptive Locomotion Learning for Quadruped Robots by Combining DRL with a Cosine Oscillator Based Rhythm Controller


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- (1)
- Eight cosine oscillators are used to construct the quadruped robot’s locomotion rhythm controller, and then the coordination of different legs is coupled just by the phase relationship among the eight joints. This simple weak coupling has fewer restrictions on the robot movement, which makes the generation of legged robots’ locomotion rhythm simpler and easier, and it is also easy to realize all kinds of gaits, as well as applying to most kinds of legged robots.
- (2)
- The Soft Actor-Critic (SAC), a kind of DRL algorithm, is used to train the parameters of the rhythm controller, which addresses the challenge of automatic acquisition and adjustment of the controller parameters. The reward function designed in this paper not only considers the robot’s general locomotion abilities, such as attitude balance and yaw control, but also takes its adaption to complex terrain into account. Therefore, a state estimation method is proposed, and the achieved slope information is integrated into the reward function to finally enable the robot to better cope with an unknown environment.
2. The Robot
2.1. The Quadruped Robot
2.2. Gait Planner
3. Locomotion Learning Algorithm
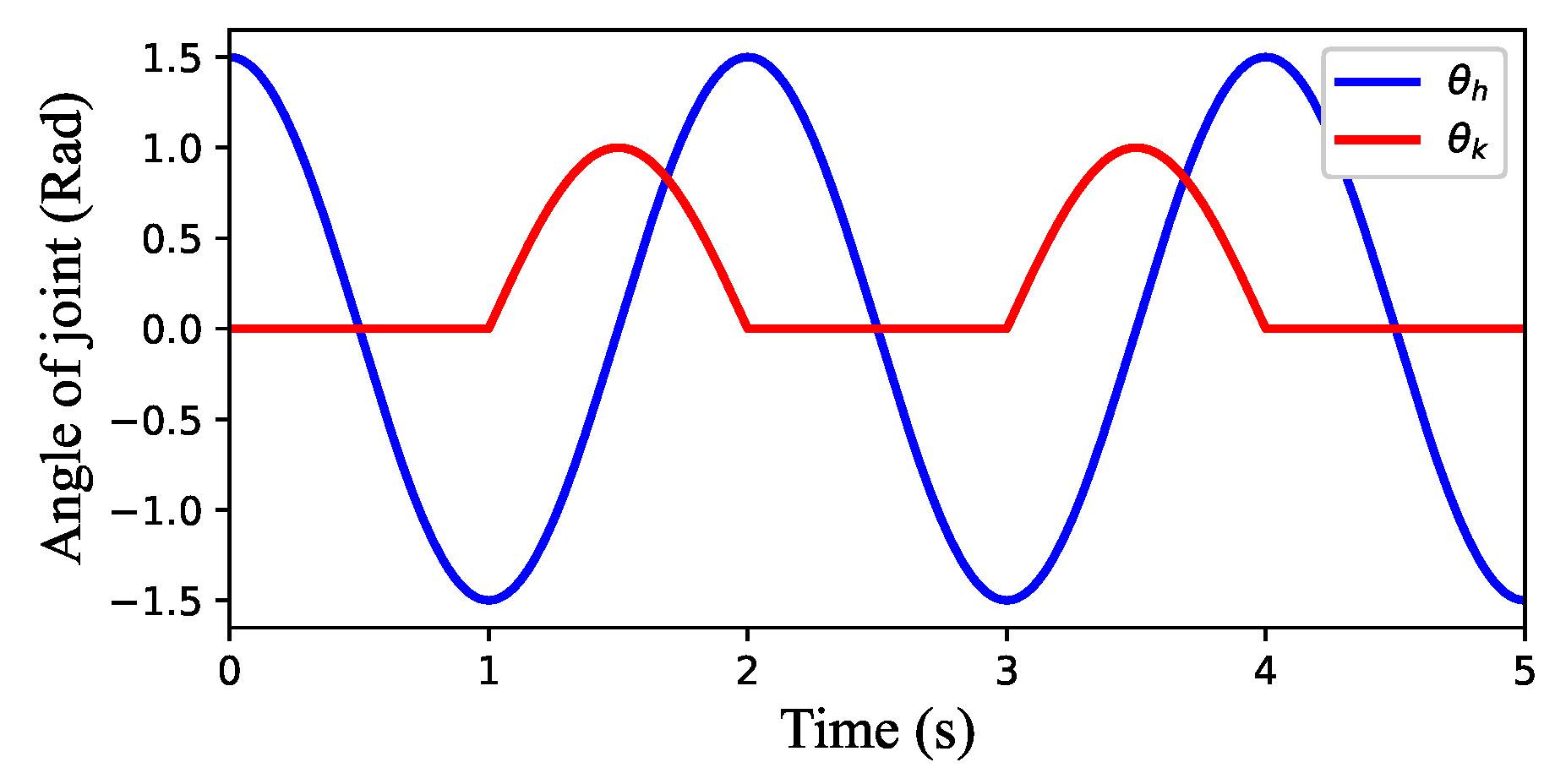
3.1. Rhythm Controller Based on a Cosine Oscillator
3.1.1. Single-Legged Control Unit
3.1.2. Four-Legged Rhythm Controller
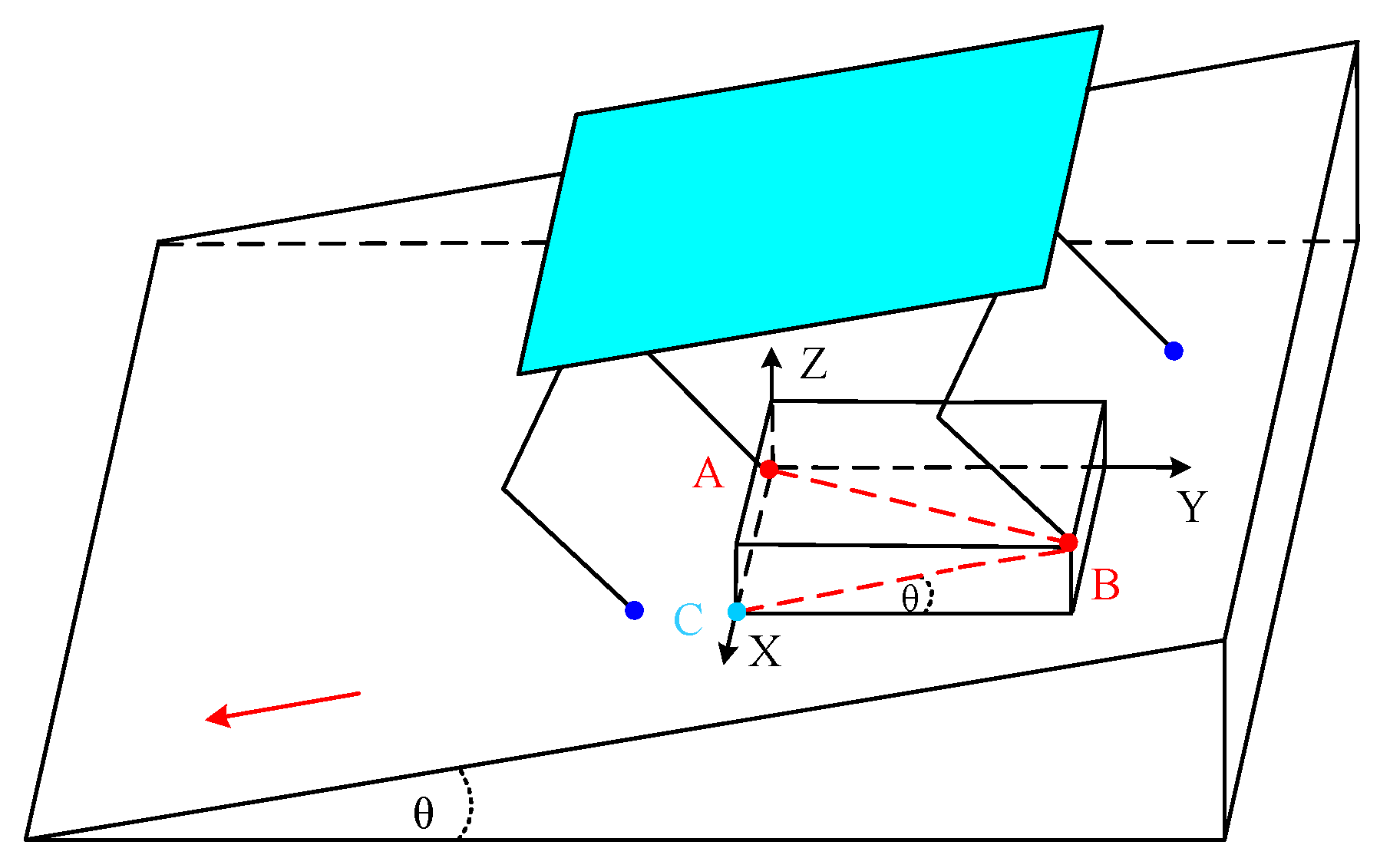
3.2. Slope Angle Estimation
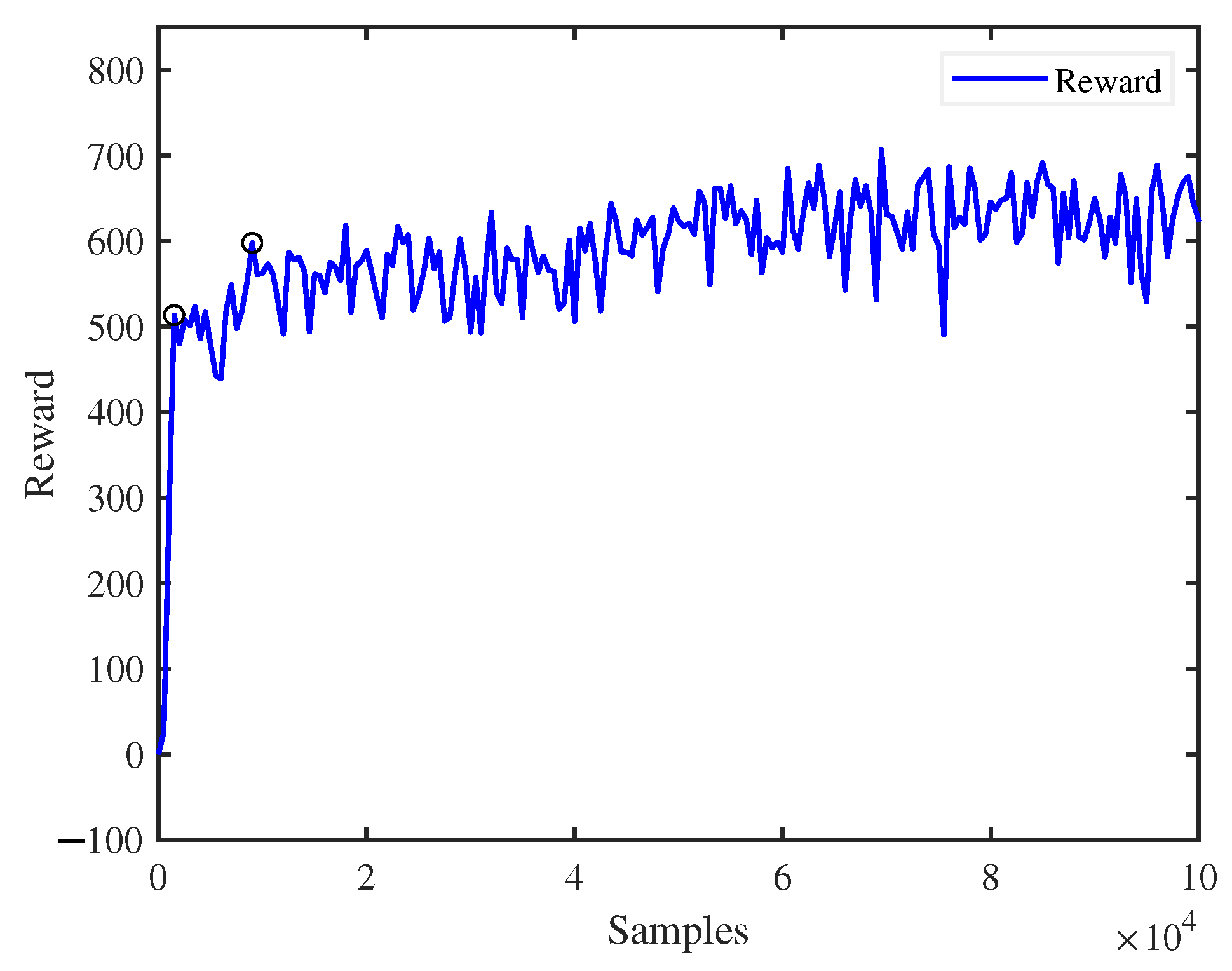
3.3. Deep Reinforcement Learning Algorithm
4. Simulation Results and Analysis
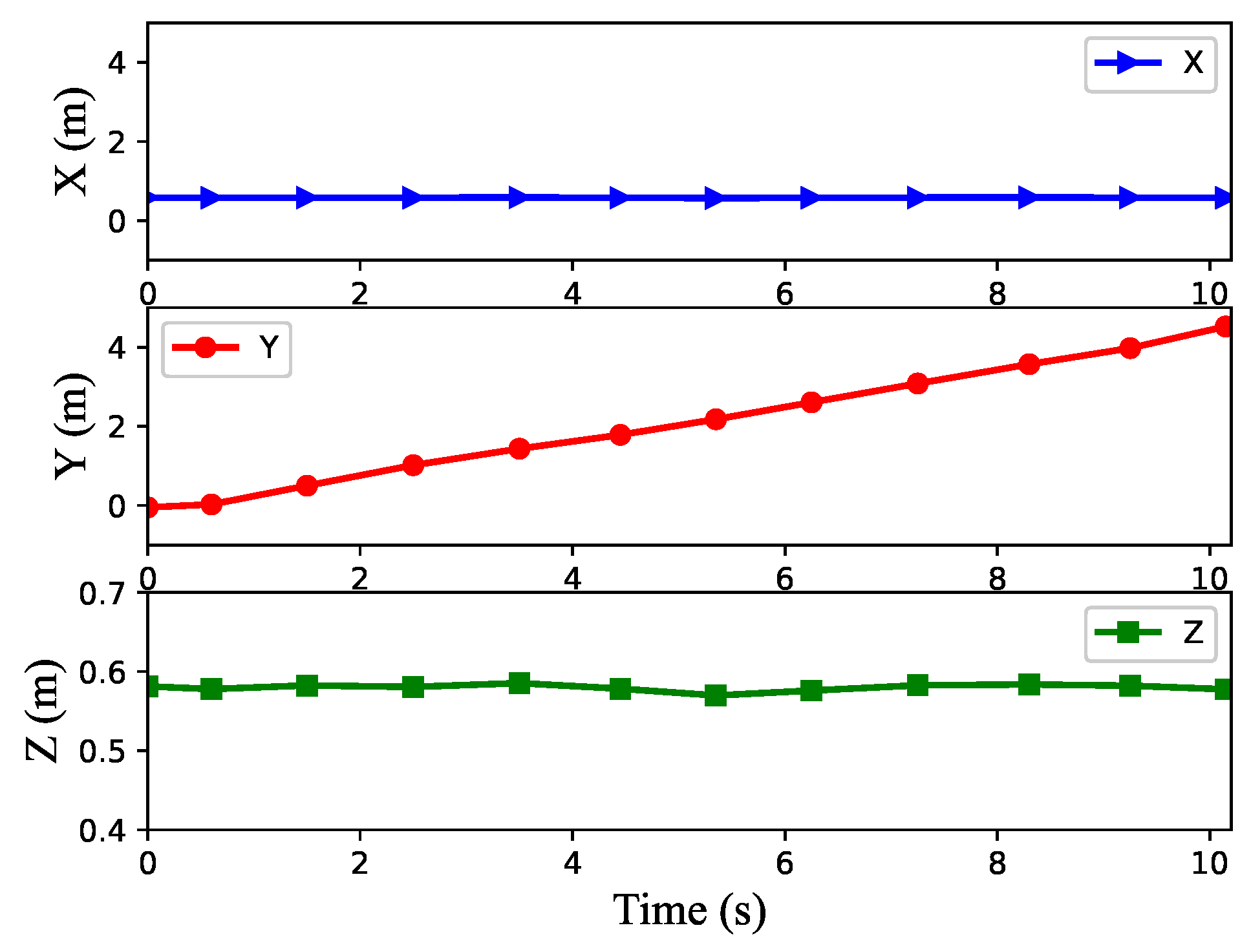
4.1. Flat Walking Task
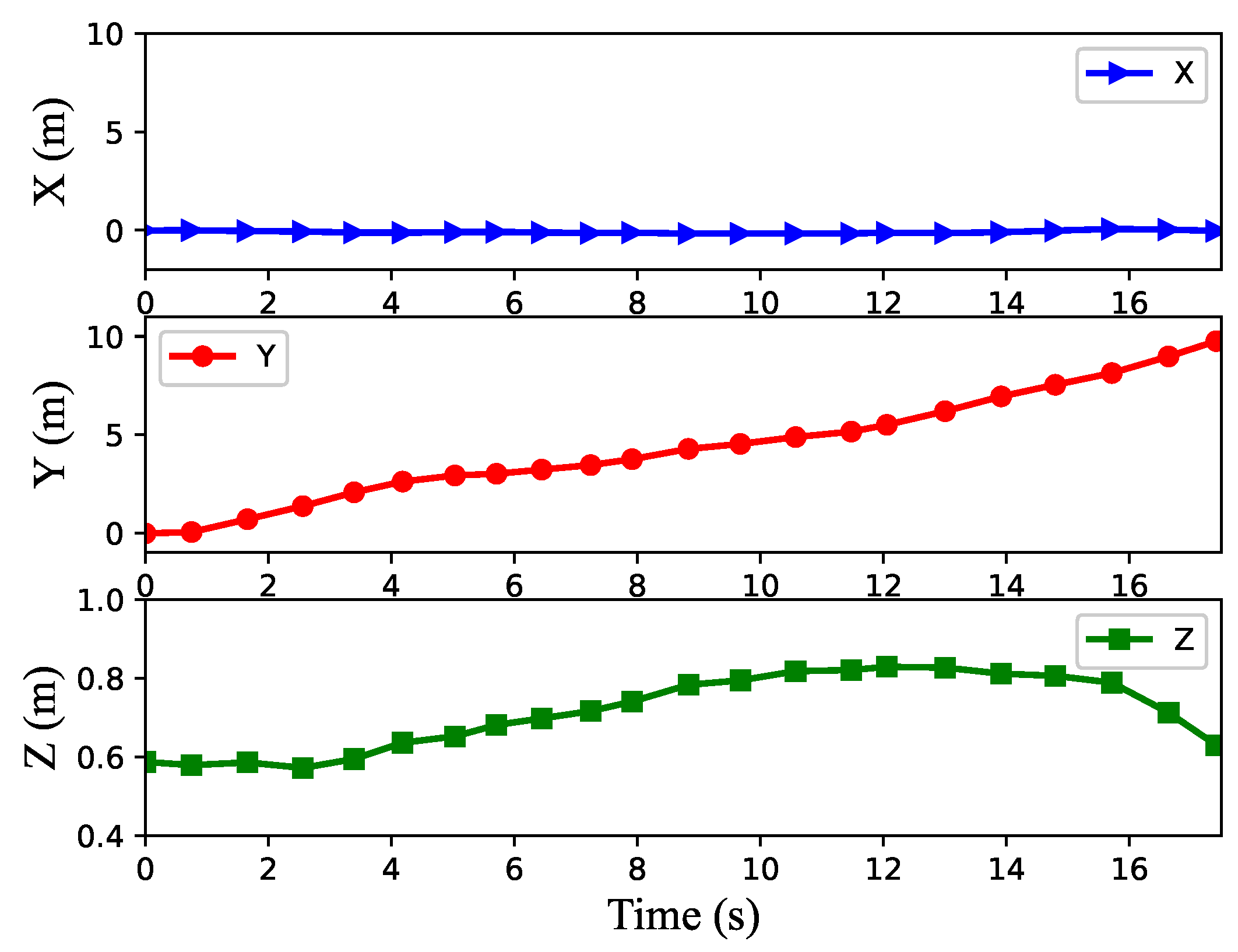
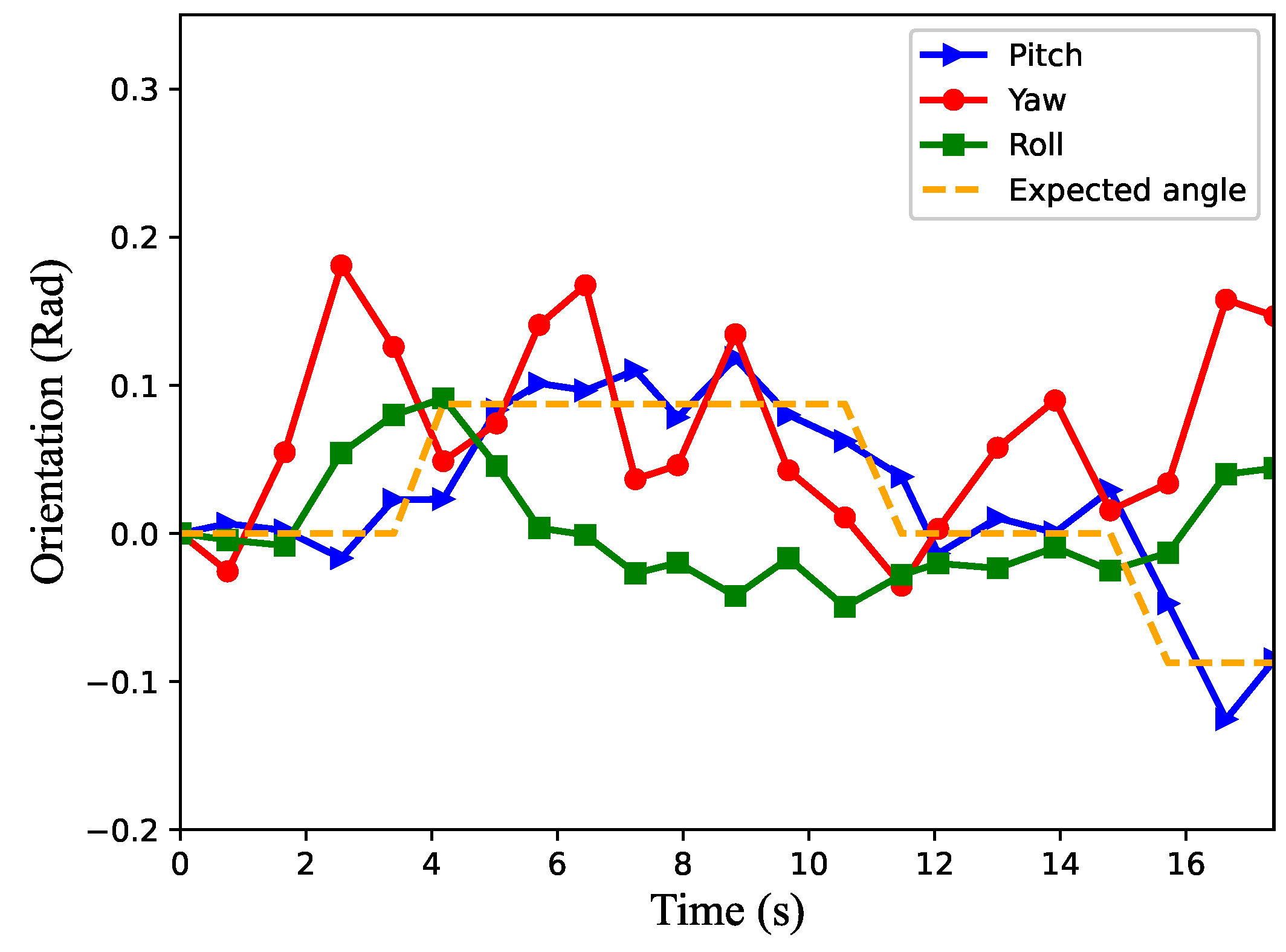
4.2. Uphill and Downhill Task
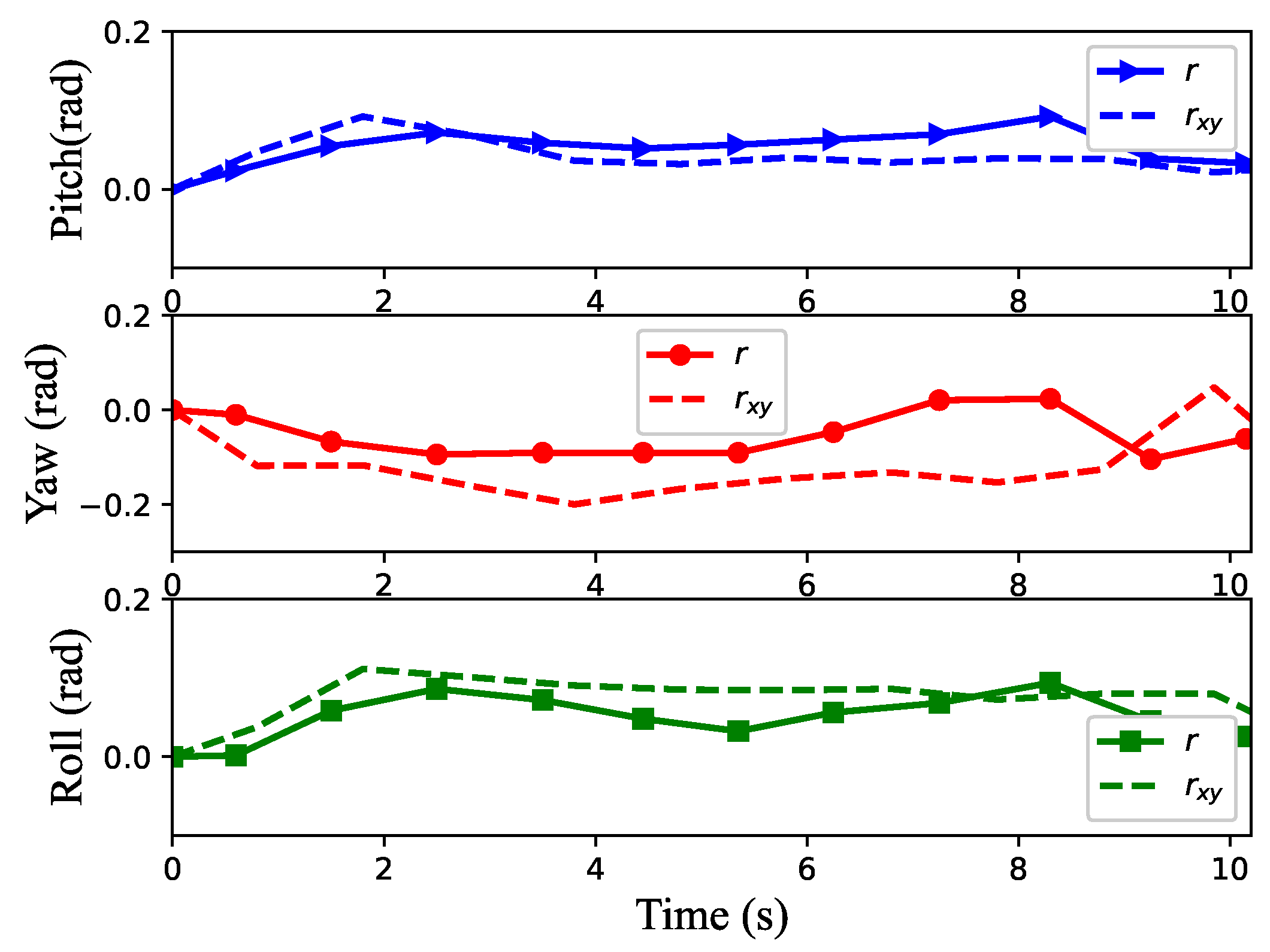
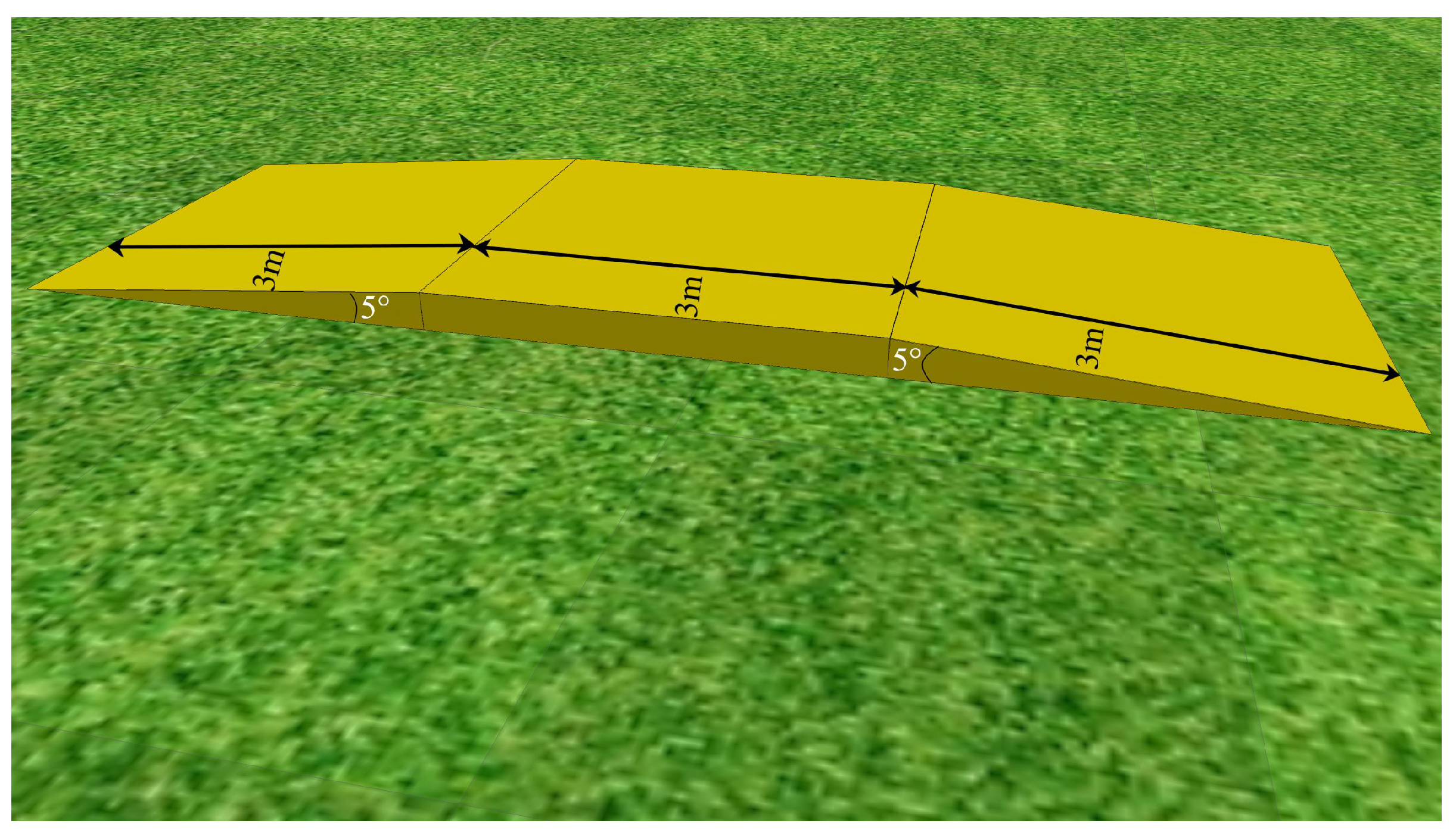
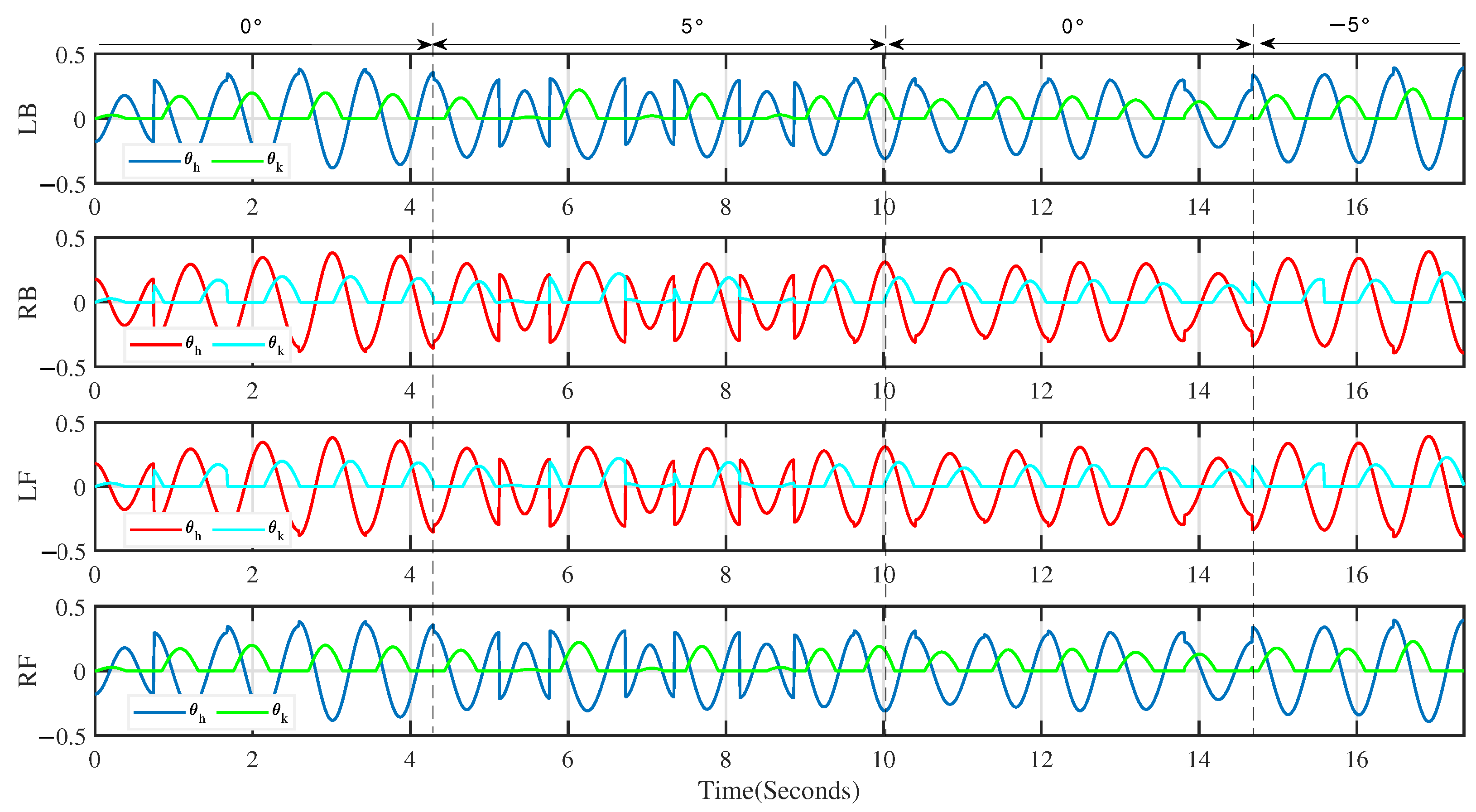
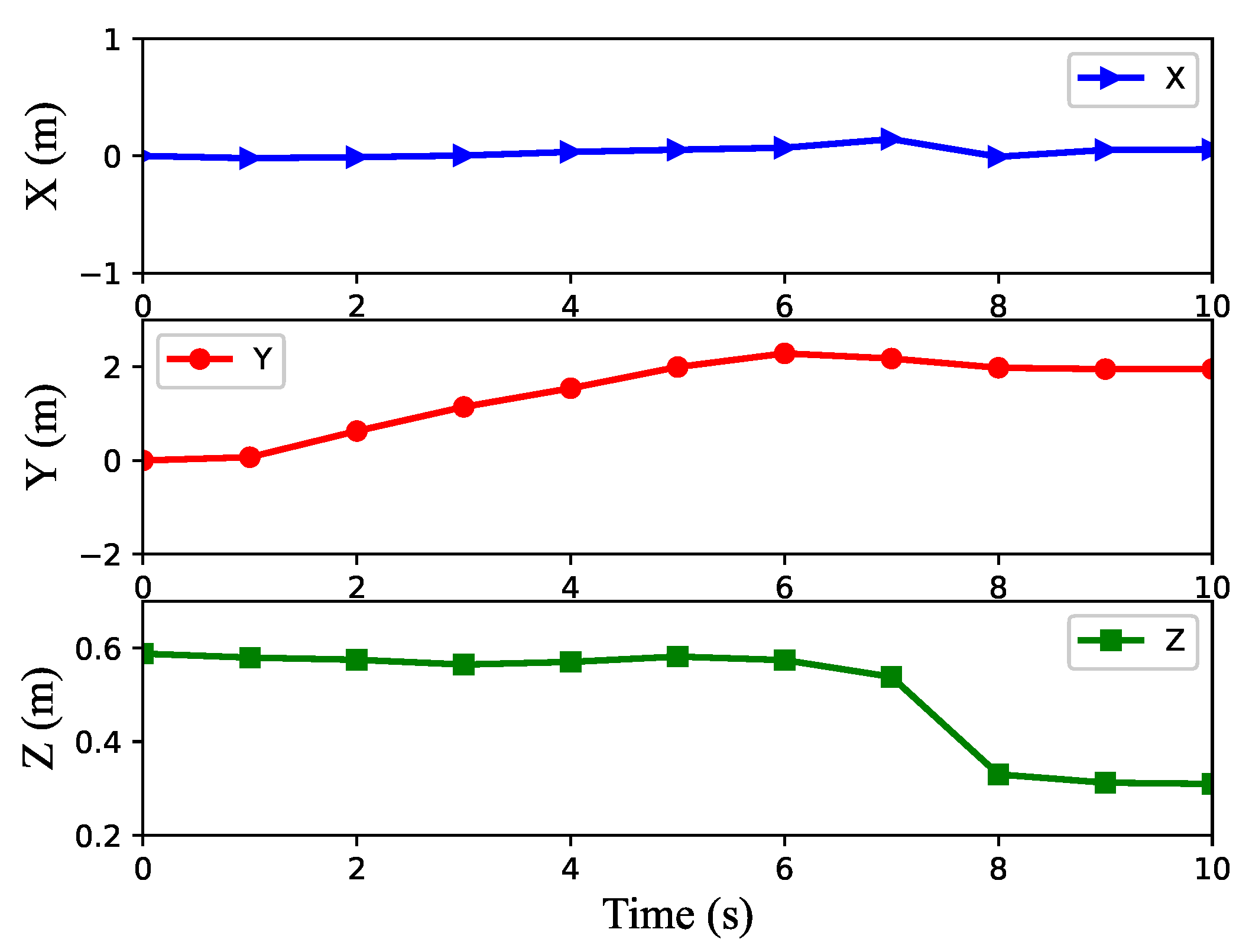
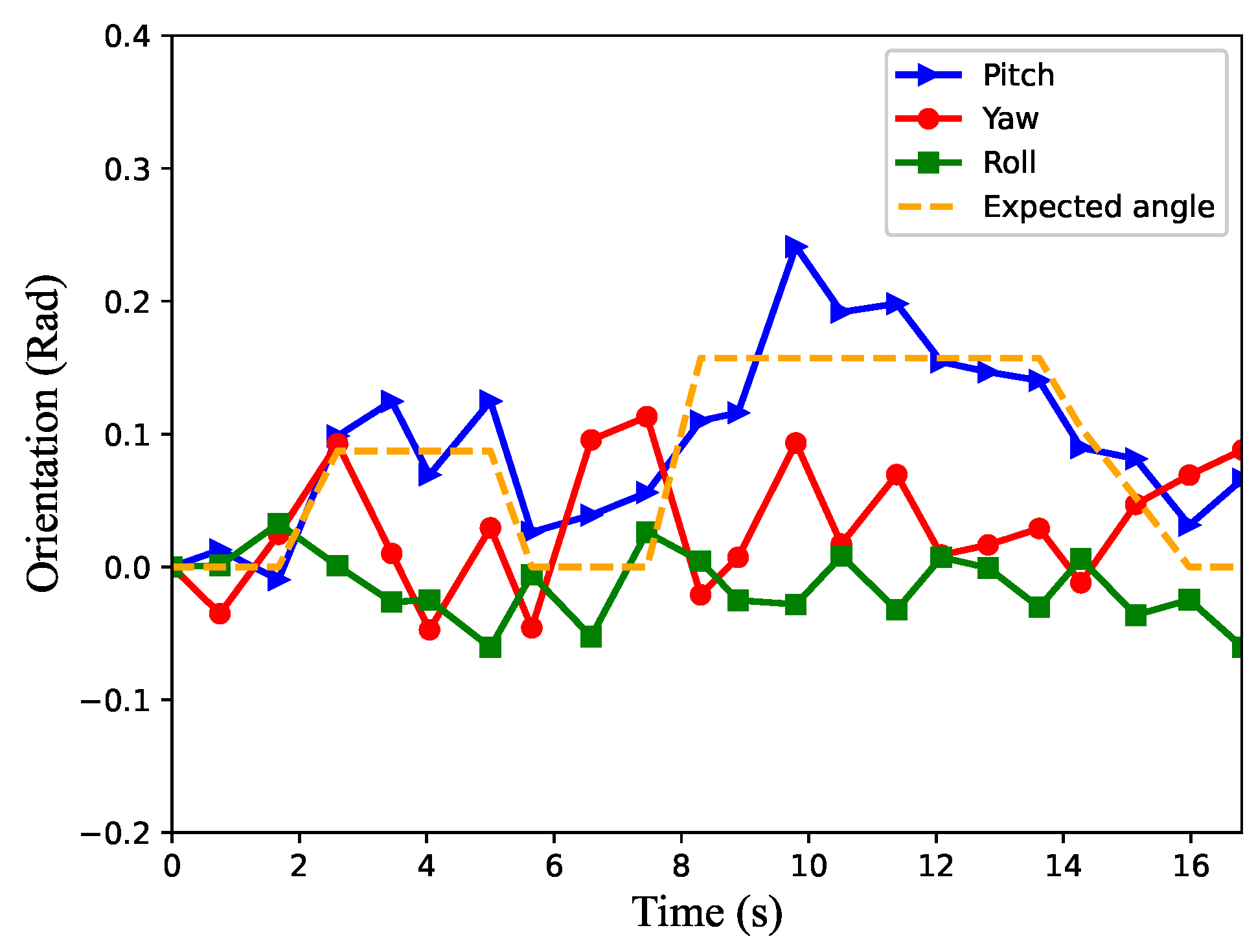
4.3. Unknown Scenario Task
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chang, X.; Ma, H.; An, H. Quadruped robot control through model predictive control with pd compensator. Int. J. Control. Autom. Syst. 2021, 19, 3776–3784. [Google Scholar] [CrossRef]
- Kim, J.; Ba, D.X.; Yeom, H.; Bae, J. Gait optimization of a quadruped robot using evolutionary computation. J. Bionic Eng. 2021, 18, 306–318. [Google Scholar] [CrossRef]
- Sakakibara, Y.; Kan, K.; Hosoda, Y.; Hattori, M.; Fujie, M. Foot trajectory for a quadruped walking machine. In Proceedings of the IEEE International Workshop on Intelligent Robots and Systems, Towards a New Frontier of Applications, Ibaraki, Japan, 3–6 July 1990; pp. 315–322. [Google Scholar]
- Sun, L.; Meng, M.Q.H.; Chen, W.; Liang, H.; Mei, T. Design of quadruped robot based neural network. In Proceedings of the Advances in Neural Networks—ISNN 2007: 4th International Symposium on Neural Networks, ISNN 2007, Nanjing, China, 3–7 June 2007; Proceedings, Part I 4. Springer: Berlin/Heidelberg, Germany, 2007; pp. 843–851. [Google Scholar]
- Li, X.; Zhang, X.; Niu, J.; Li, C. A stable walking strategy of quadruped robot based on zmp in trotting gait. In Proceedings of the 2022 IEEE International Conference on Mechatronics and Automation (ICMA), Guangxi, China, 7–10 August 2022; IEEE: New York, NY, USA, 2022; pp. 858–863. [Google Scholar]
- Ding, Y.; Pandala, A.; Park, H.W. Real-time model predictive control for versatile dynamic motions in quadrupedal robots. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; IEEE: New York, NY, USA, 2019; pp. 8484–8490. [Google Scholar]
- Zhang, G.; Rong, X.; Hui, C.; Li, Y.; Li, B. Torso motion control and toe trajectory generation of a trotting quadruped robot based on virtual model control. Adv. Robot. 2016, 30, 284–297. [Google Scholar] [CrossRef]
- Zhang, S.; Gao, J.; Duan, X.; Li, H.; Yu, Z.; Chen, X.; Li, J.; Liu, H.; Li, X.; Liu, Y.; et al. Trot pattern generation for quadruped robot based on the zmp stability margin. In Proceedings of the In 2013 ICME International Conference on Complex Medical Engineering, Beijing, China, 25–28 May 2013; IEEE: New York, NY, USA, 2013; pp. 608–613. [Google Scholar]
- Du, Y.; Gao, S.; Huiping Li, H.; Cui, D. Mpc-based tilting and forward motion control of quadruped robots. In Proceedings of the 2022 5th International Symposium on Autonomous Systems (ISAS), Hangzhou, China, 8–10 April 2022; IEEE: New York, NY, USA, 2022; pp. 1–6. [Google Scholar]
- Harris-Warrick, R.M. Neuromodulation and flexibility in central pattern generator networks. Curr. Opin. Neurobiol. 2011, 21, 685–692. [Google Scholar] [CrossRef] [PubMed]
- Wang, T.; Guo, W.; Li, M.; Zha, F.; Sun, L. Cpg control for biped hopping robot in unpredictable environment. J. Bionic Eng. 2012, 9, 29–38. [Google Scholar] [CrossRef]
- Matsuoka, K. Sustained oscillations generated by mutually inhibiting neurons with adaptation. Biol. Cybern. 1985, 52, 367–376. [Google Scholar] [CrossRef] [PubMed]
- Kimura, H.; Akiyama, S.; Sakurama, K. Realization of dynamic walking and running of the quadruped using neural oscillator. Auton. Robot. 1999, 7, 247–258. [Google Scholar] [CrossRef]
- Xiao, W.; Wang, W. Hopf oscillator-based gait transition for a quadruped robot. In Proceedings of the 2014 IEEE International Conference on Robotics and Biomimetics (ROBIO 2014), Bali, Indonesia, 5–10 December 2014; IEEE: New York, NY, USA, 2014; pp. 2074–2079. [Google Scholar]
- Xie, J.; Ma, H.; Wei, Q.; An, H.; Su, B. Adaptive walking on slope of quadruped robot based on cpg. In Proceedings of the 2019 2nd World Conference on Mechanical Engineering and Intelligent Manufacturing (WCMEIM), Shanghai, China, 22–24 November 2019; IEEE: New York, NY, USA, 2019; pp. 487–493. [Google Scholar]
- Zhang, J.; Gao, F.; Han, X.; Chen, X.; Han, X. Trot gait design and cpg method for a quadruped robot. J. Bionic Eng. 2014, 11, 18–25. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, H.; Ding, Y.; Hou, B. Adaptive walking control for a quadruped robot on irregular terrain using the complexvalued cpg network. Symmetry 2021, 13, 2090. [Google Scholar] [CrossRef]
- Tan, J.; Zhang, T.; Coumans, E.; Iscen, A.; Bai, Y.; Hafner, D.; Bohez, S.; Vanhoucke, V. Sim-to-real: Learning agile locomotion for quadruped robots. arXiv 2018, arXiv:1804.10332. [Google Scholar]
- Tsounis, V.; Alge, M.; Lee, J.; Farshidian, F.; Hutter, M. Deepgait: Planning and control of quadrupedal gaits using deep reinforcement learning. IEEE Robot. Autom. Lett. 2020, 5, 3699–3706. [Google Scholar] [CrossRef]
- Bogdanovic, M.; Khadiv, M.; Righetti, L. Model-free reinforcement learning for robust locomotion using trajectory optimization for exploration. arXiv 2021, arXiv:2107.06629v1. [Google Scholar]
- Hu, B.; Shao, S.; Cao, Z.; Xiao, Q.; Li, Q.; Ma, C. Learning a faster locomotion gait for a quadruped robot with model-free deep reinforcement learning. In Proceedings of the 2019 IEEE International Conference on Robotics and Biomimetics (ROBIO), Dali, China, 6–8 December 2019; IEEE: New York, NY, USA, 2019; pp. 1097–1102. [Google Scholar]
- Haarnoja, T.; Ha, S.; Zhou, A.; Tan, J.; Tucker, G.; Levine, S. Learning to walk via deep reinforcement learning. arXiv 2018, arXiv:1812.11103. [Google Scholar]
- Zhu, X.; Wang, M.; Ruan, X.; Chen, L.; Ji, T.; Liu, X. Adaptive motion skill learning of quadruped robot on slopes based on augmented random search algorithm. Electronics 2022, 11, 842. [Google Scholar] [CrossRef]
- Lee, H.; Shen, Y.; Yu, C.H.; Singh, G.; Ng, A.Y. Quadruped robot obstacle negotiation via reinforcement learning. In Proceedings of the 2006 IEEE International Conference on Robotics and Automation, 2006, ICRA 2006, Orlando, FL, USA, 15–19 May 2006; IEEE: New York, NY, USA, 2006; pp. 3003–3010. [Google Scholar]
- Bellegarda, G.; Ijspeert, A. Cpg-rl: Learning central pattern generators for quadruped locomotion. IEEE Robot. Autom. Lett. 2022, 7, 12547–12554. [Google Scholar] [CrossRef]
- Ijspeert, A.J.; Crespi, A.; Ryczko, D.; Cabelguen, J.M. From swimming to walking with a salamander robot driven by a spinal cord model. Science 2007, 315, 1416–1420. [Google Scholar] [CrossRef] [PubMed]
- Rudin, N.; Kolvenbach, H.; Tsounis, V.; Hutter, M. Cat-like jumping and landing of legged robots in low gravity using deep reinforcement learning. IEEE Trans. Robot. 2021, 38, 317–328. [Google Scholar] [CrossRef]
- Lee, C.; An, D. Reinforcement learning and neural network-based artificial intelligence control algorithm for self-balancing quadruped robot. J. Mech. Sci. Technol. 2021, 35, 307–322. [Google Scholar] [CrossRef]
- Liu, K.; Zhao, J.; Wang, M.; Wang, Z.; Liang, W. Gait planning and simulation analysis of quadruped robot. In Proceedings of the 2021 IEEE 5th Information Technology, Networking, Electronic andAutomation Control Conference (ITNEC), Xi’an, China, 15–17 October 2021; IEEE: New York, NY, USA, 2021; Volume 5, pp. 274–278. [Google Scholar]
- Liu, Z.; Ding, X. Gait generation of quadruped robot based on cosine oscillator. Comput. Simul. 2013, 30, 365–369. [Google Scholar]
- Zhang, X.L. Biological-Inspired Rhythmic Motion and Environmental Adaptability for Quadruped Robot. Ph.D. Thesis, Tsinghua University, Beijing, China, 2004. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1861–1870. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Hartikainen, K.; Tucker, G.; Ha, S.; Tan, J.; Kumar, V.; Zhu, H.; Gupta, A.; Abbeel, P.; et al. Soft actor-critic algorithms and applications. arXiv 2018, arXiv:1812.05905. [Google Scholar]
- CoppeliaSim. Available online: https://www.coppeliarobotics.com (accessed on 19 March 2022).








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Wu, Y.; Wang, H.; Iida, F.; Wang, L. Adaptive Locomotion Learning for Quadruped Robots by Combining DRL with a Cosine Oscillator Based Rhythm Controller. Appl. Sci. 2023, 13, 11045. https://doi.org/10.3390/app131911045
Zhang X, Wu Y, Wang H, Iida F, Wang L. Adaptive Locomotion Learning for Quadruped Robots by Combining DRL with a Cosine Oscillator Based Rhythm Controller. Applied Sciences. 2023; 13(19):11045. https://doi.org/10.3390/app131911045
Chicago/Turabian StyleZhang, Xiaoping, Yitong Wu, Huijiang Wang, Fumiya Iida, and Li Wang. 2023. "Adaptive Locomotion Learning for Quadruped Robots by Combining DRL with a Cosine Oscillator Based Rhythm Controller" Applied Sciences 13, no. 19: 11045. https://doi.org/10.3390/app131911045
APA StyleZhang, X., Wu, Y., Wang, H., Iida, F., & Wang, L. (2023). Adaptive Locomotion Learning for Quadruped Robots by Combining DRL with a Cosine Oscillator Based Rhythm Controller. Applied Sciences, 13(19), 11045. https://doi.org/10.3390/app131911045