
A Spatial Fuzzy Co-Location Pattern Mining Method Based on Interval Type-2 Fuzzy Sets


Abstract
:1. Introduction
2. Innovation
- (1)
- In the fuzzy processing of corresponding attribute information based on the original type-1 fuzzy membership function, a granular type-2 fuzzy membership function based on an elliptic curve is generated from the evaluation data. We adopt a gradual method to adjust the parameters of the function so that the type-2 membership function not only meets the connectivity [11] but also makes its confidence reach the given threshold (set to 85%).
- (2)
- Based on the abovementioned granular type-2 fuzzy membership function, we define the concepts of fuzzy membership interval, upper bound participation ratio, lower bound participation ratio of fuzzy features, upper bound participation index, and lower bound participation index for FCP mining. Further, to smooth the “sharp boundary” of pattern prevalence and reduce the deviation caused by the subjective understanding of the prevalence degree of FCPs, we propose the concepts of absolutely prevalent FCPs, FCPs with a prevalence tendency degree, and absolutely non-prevalent FCPs.
- (3)
- Based on spatial cliques, a method of mining FCPs is proposed. First, an algorithm for generating spatial cliques from spatial datasets is presented, and then an Apriori-like algorithm and two pruning strategies are proposed to discover the absolutely prevalent FCPs and FCPs with a prevalence tendency degree. In addition, we apply interval type-2 fuzzy sets to traditional co-location pattern mining algorithms and form an FCPs mining method based on interval type-2 fuzzy sets and the traditional Join-based algorithm, as well as another FCPs mining algorithm based on interval type-2 fuzzy sets and the traditional Joinless algorithm.
3. Related Definitions and Theorems
3.1. Definitions
3.2. Lemma and Theorem
4. Methods
4.1. A Mining Method Based on Spatial Cliques
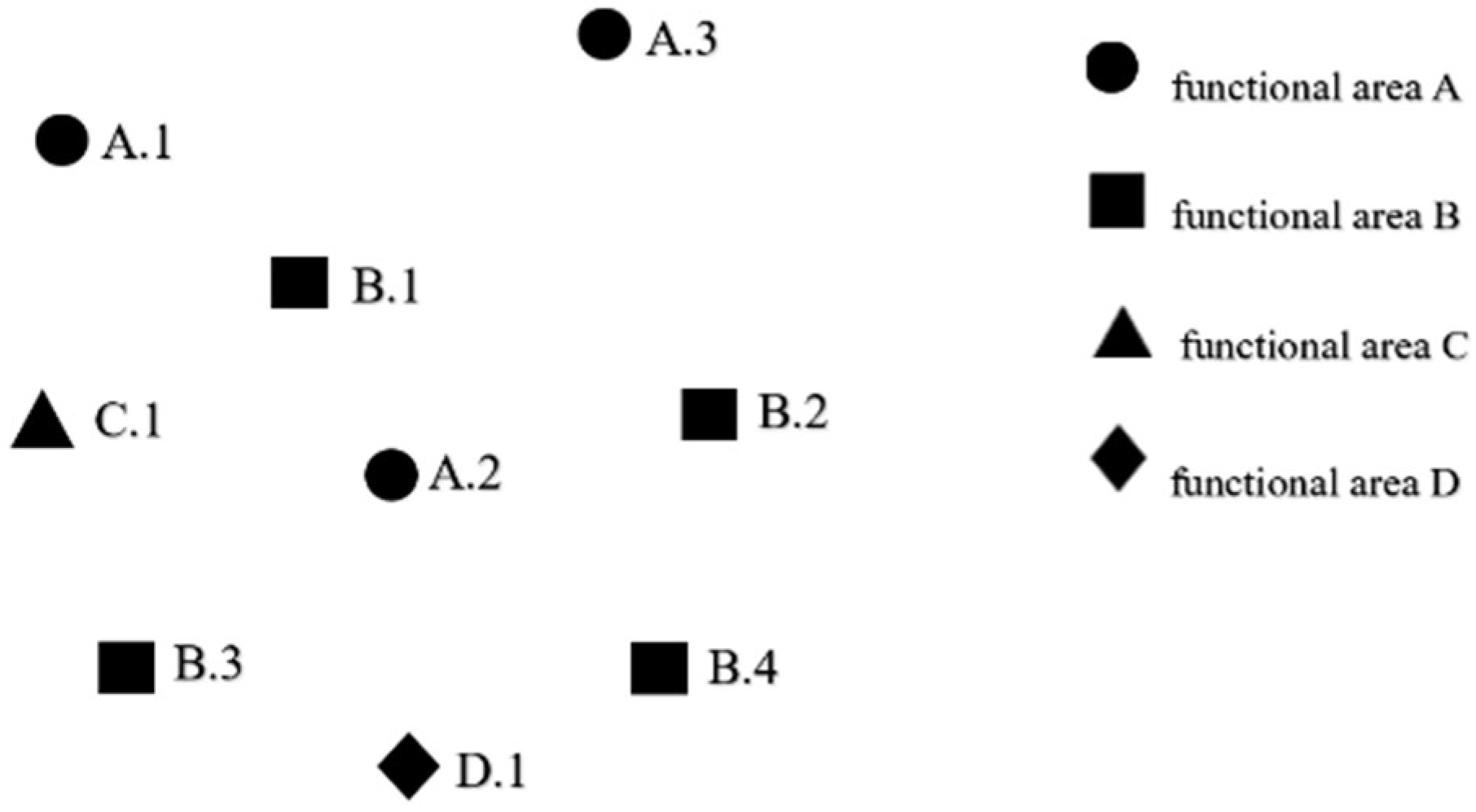
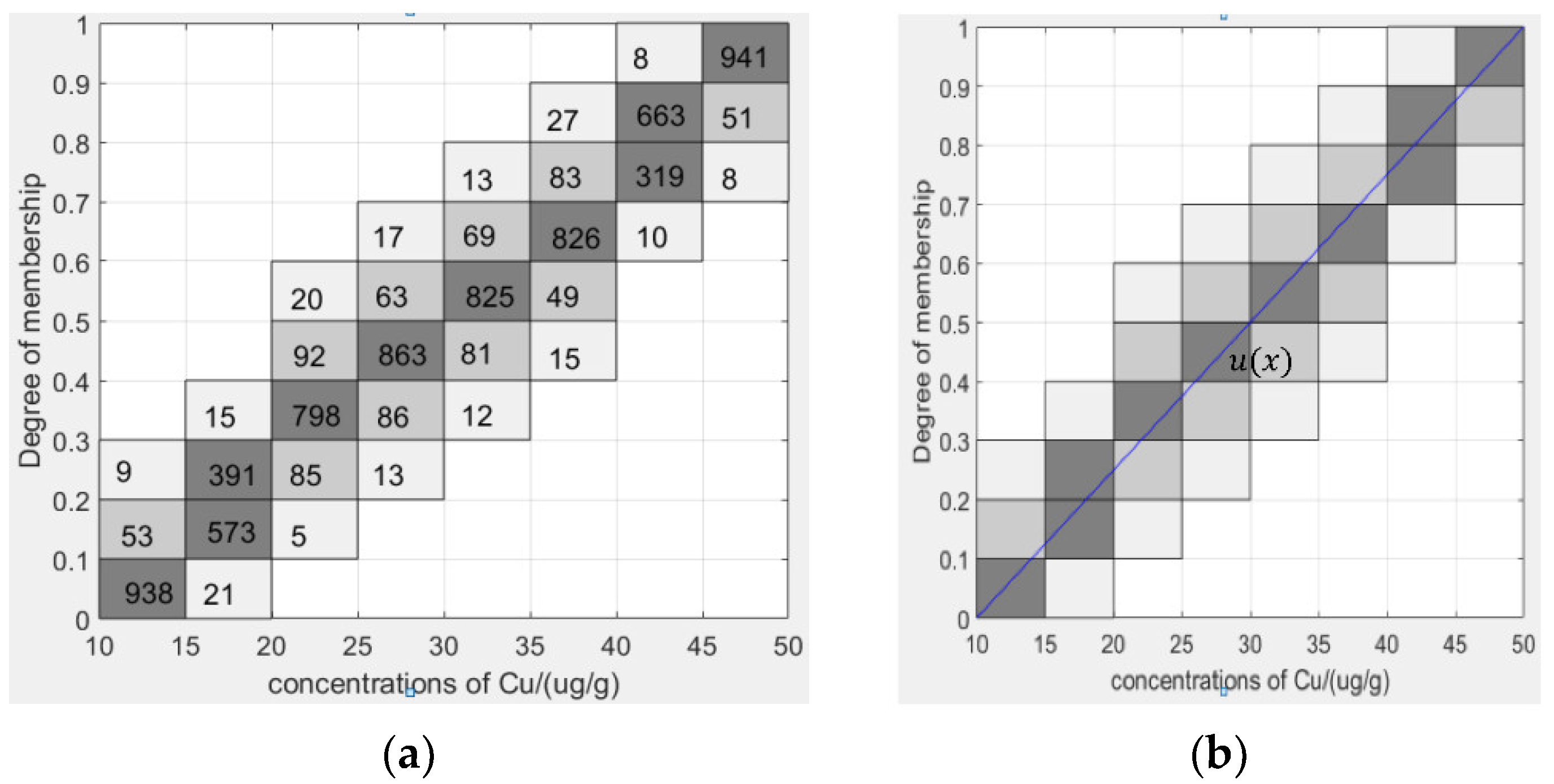
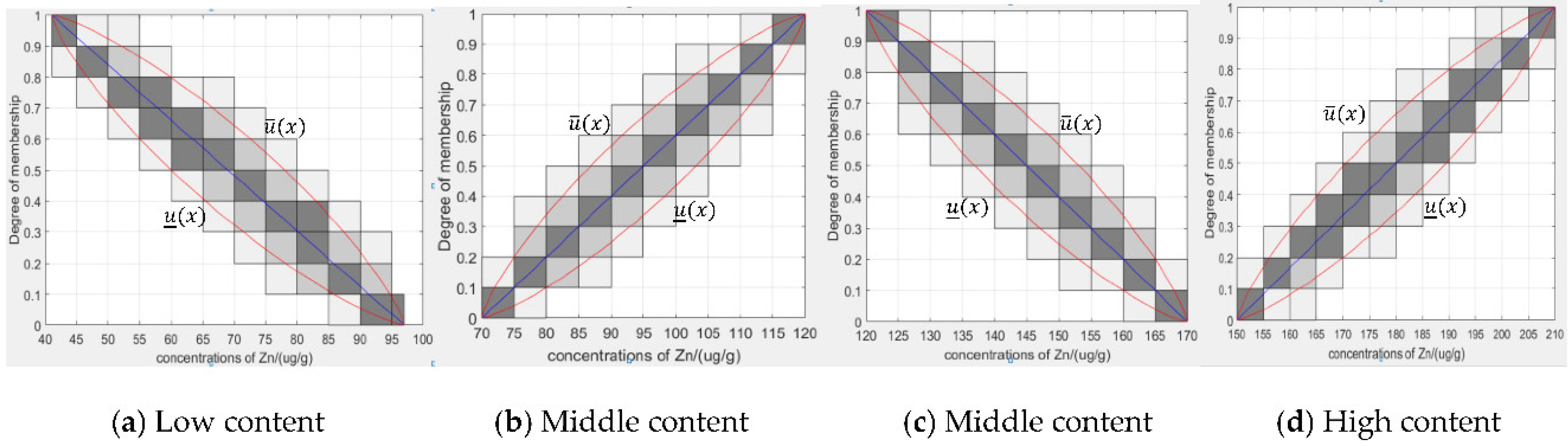
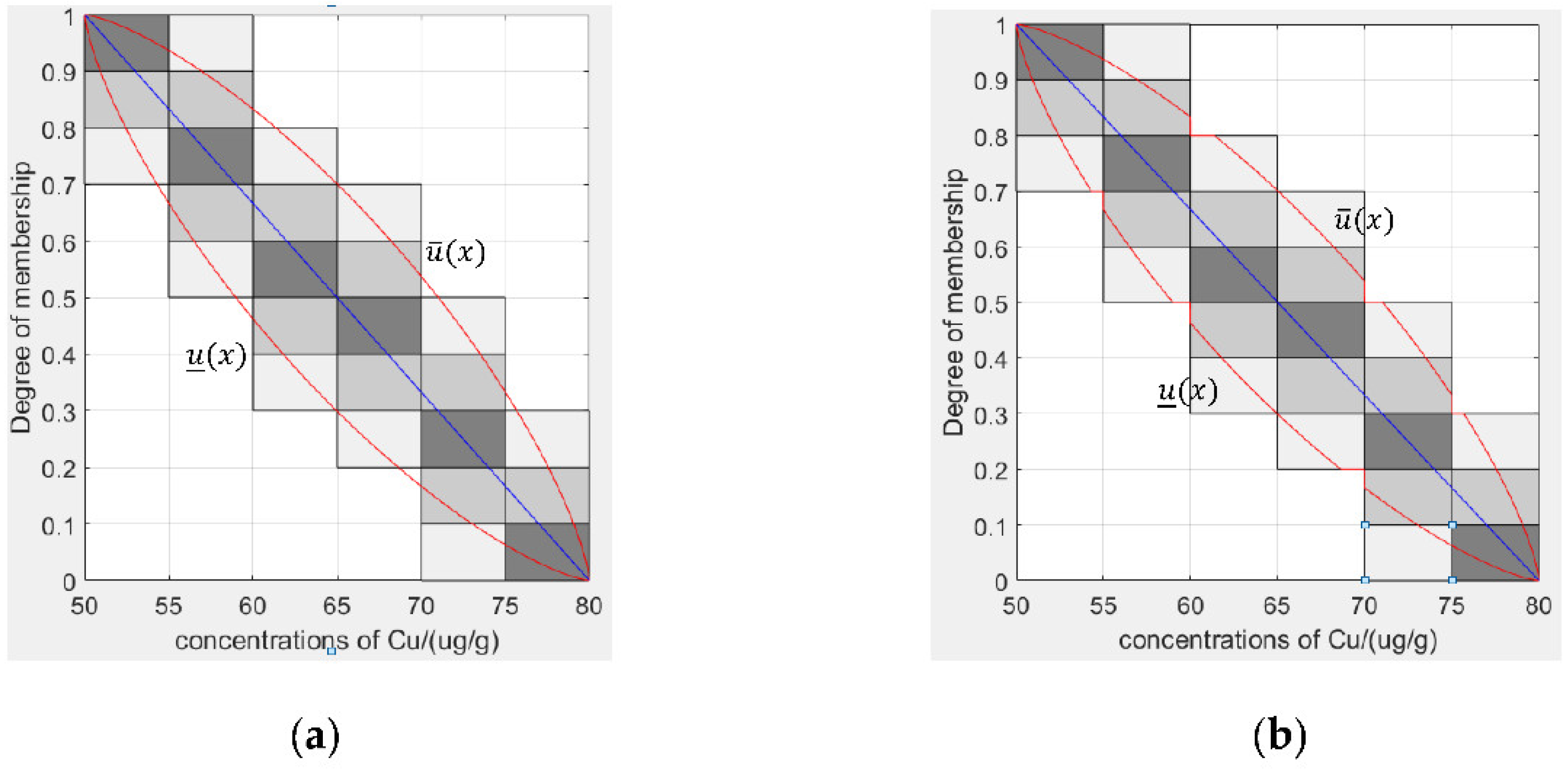
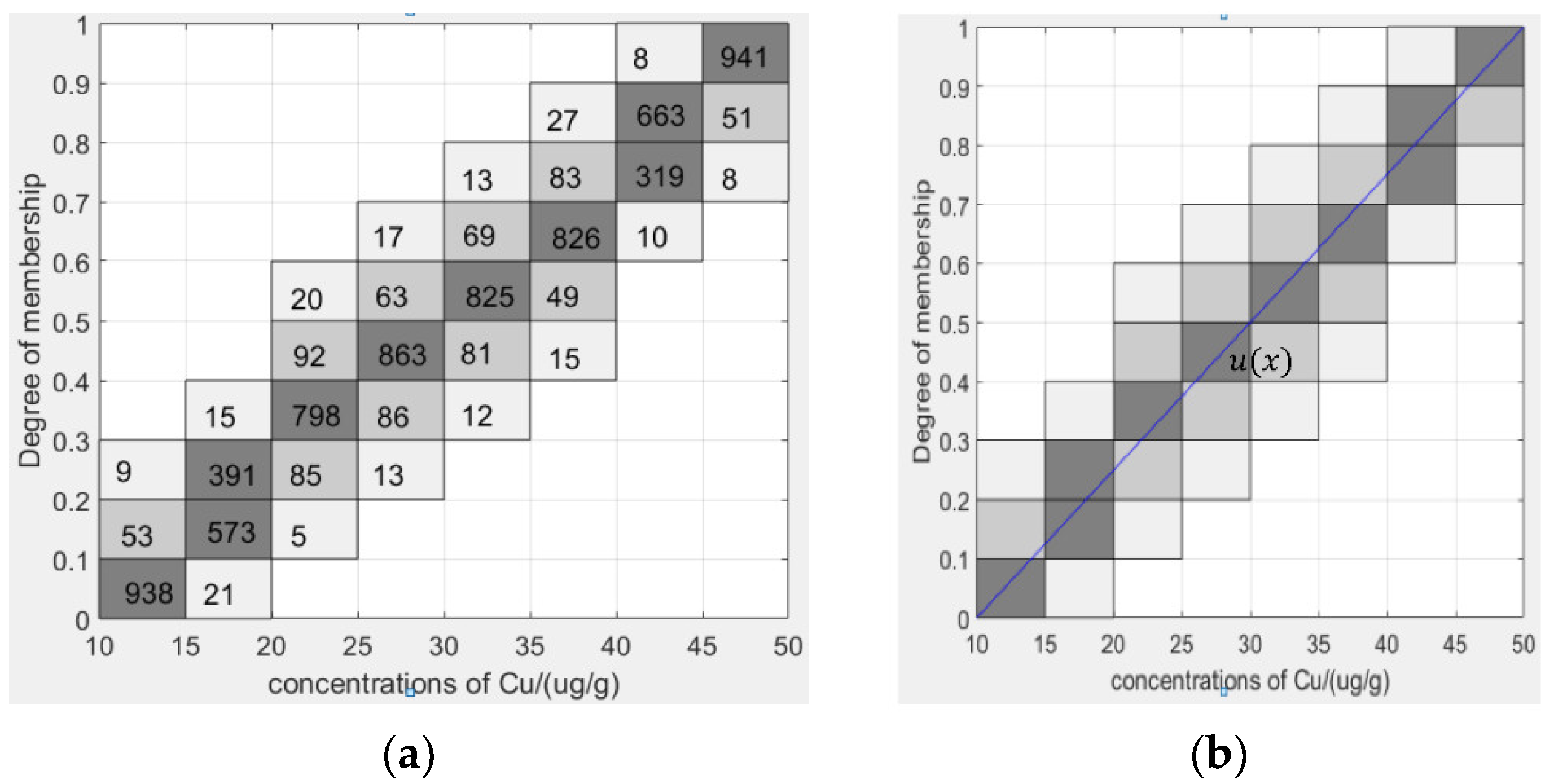
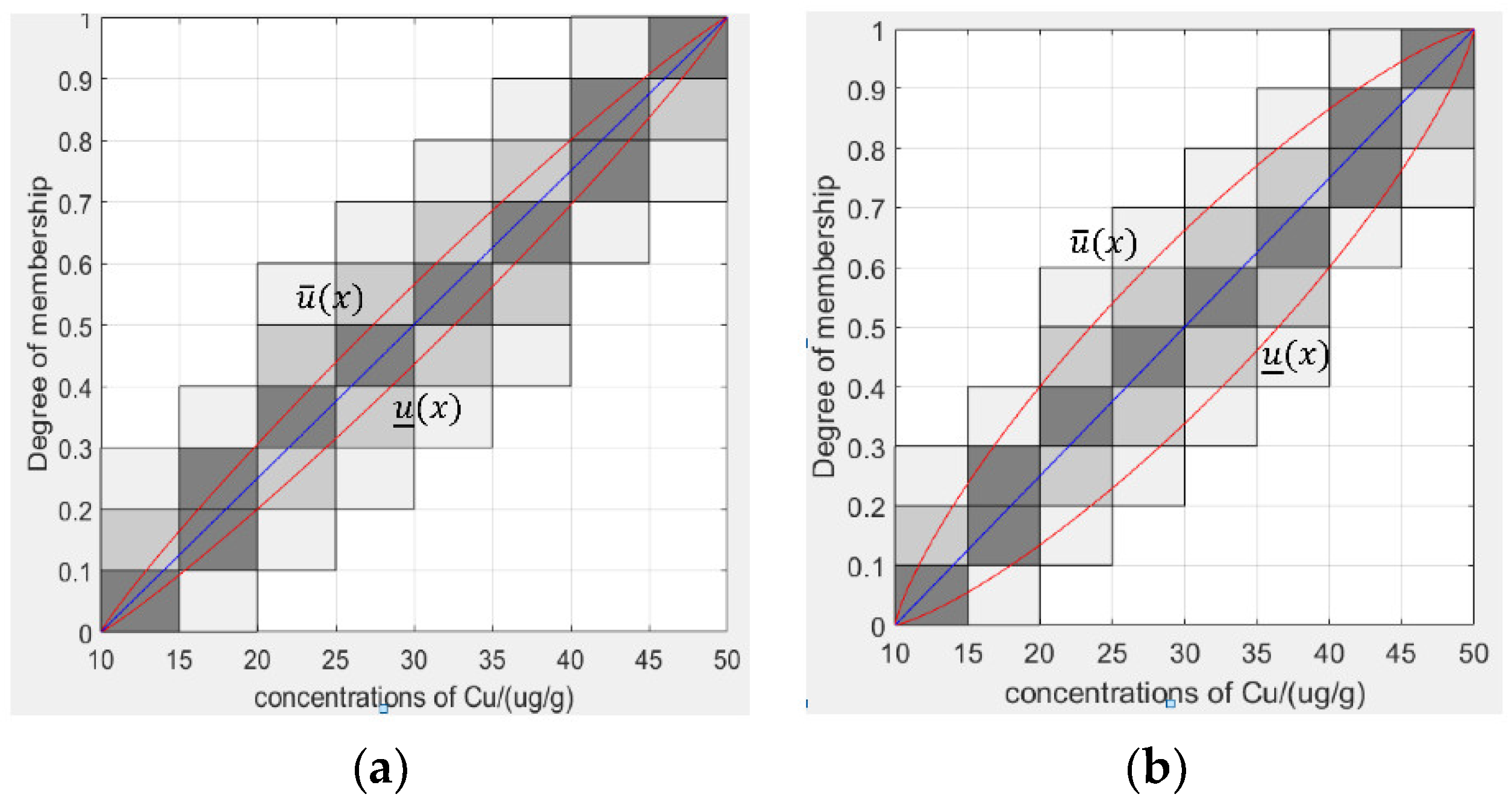
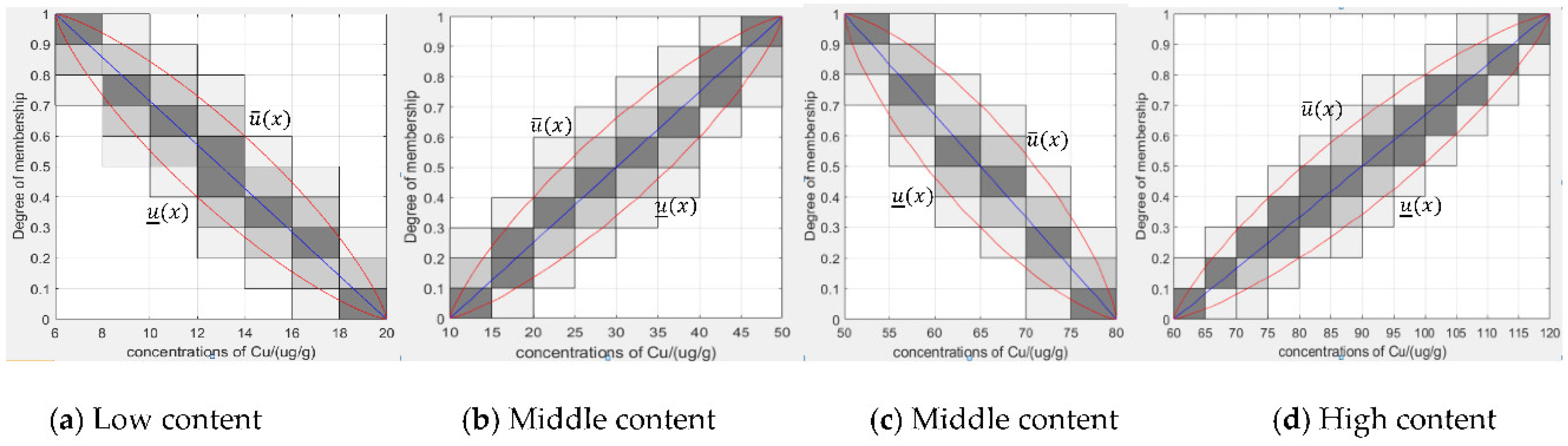
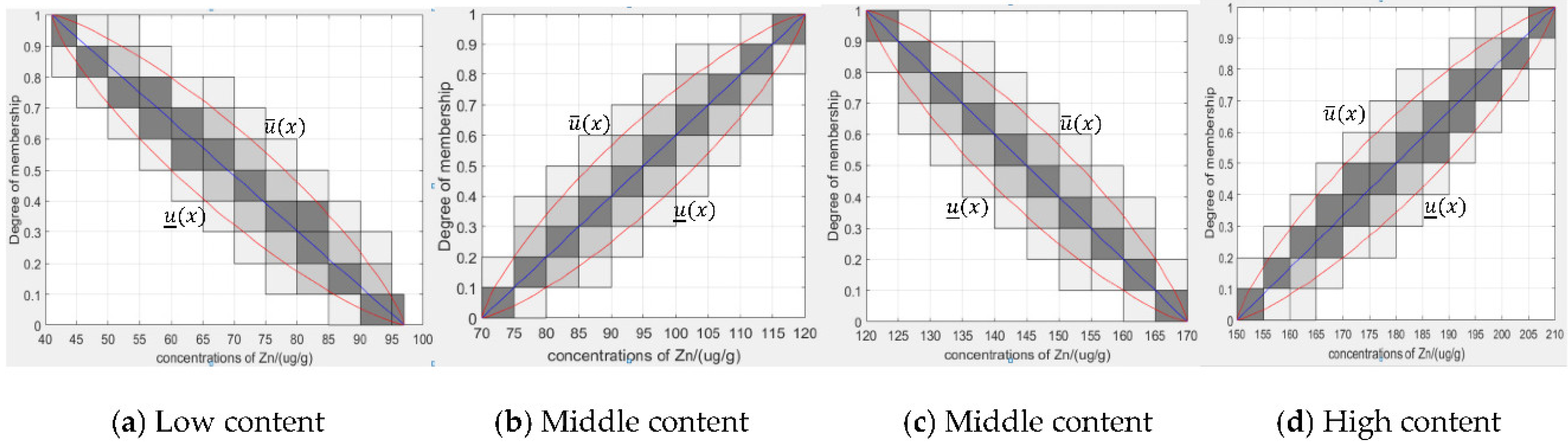
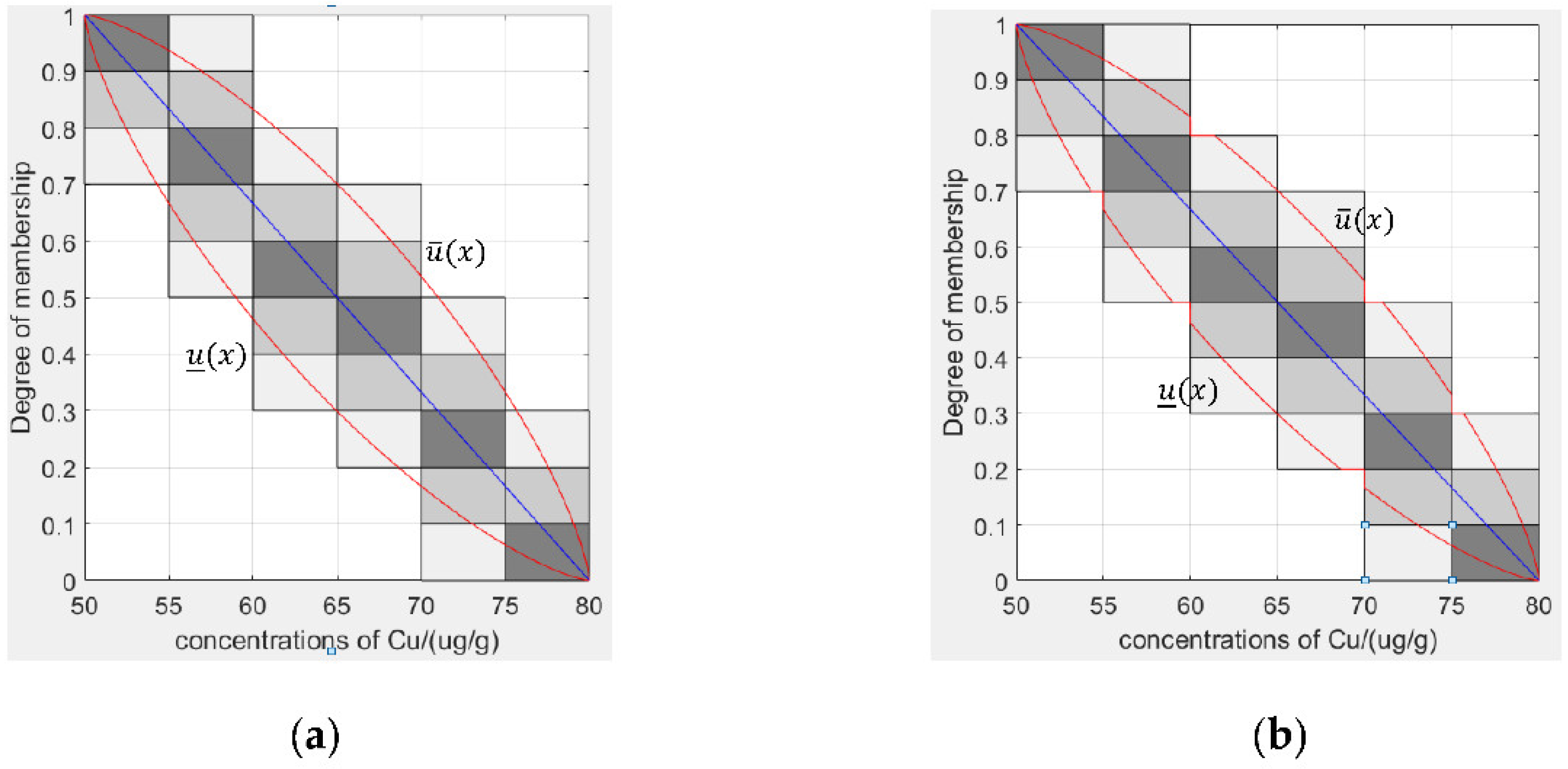
4.1.1. Generating Granular Type-2 Fuzzy Membership Functions from Type-1 Fuzzy Membership Functions Based on Granular Data
- (1)
- Count the granular evaluation data.
- (2)
- The original type-1 fuzzy membership function is drawn based on the granular evaluation data.
- (3)
- Constructing a type-2 membership function based on the original type-1 membership function.
- (4)
- Determine the parameters of the granular type-2 fuzzy membership function.
- (5)
- Removing unconnected areas in the FOU.
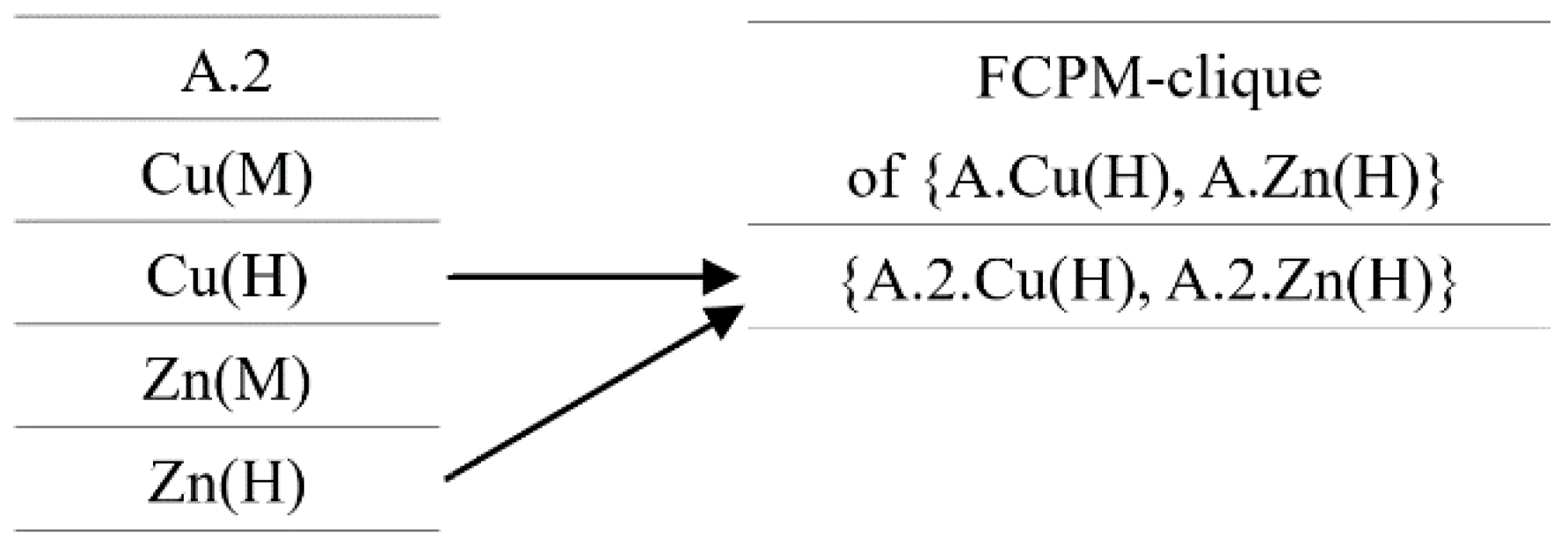
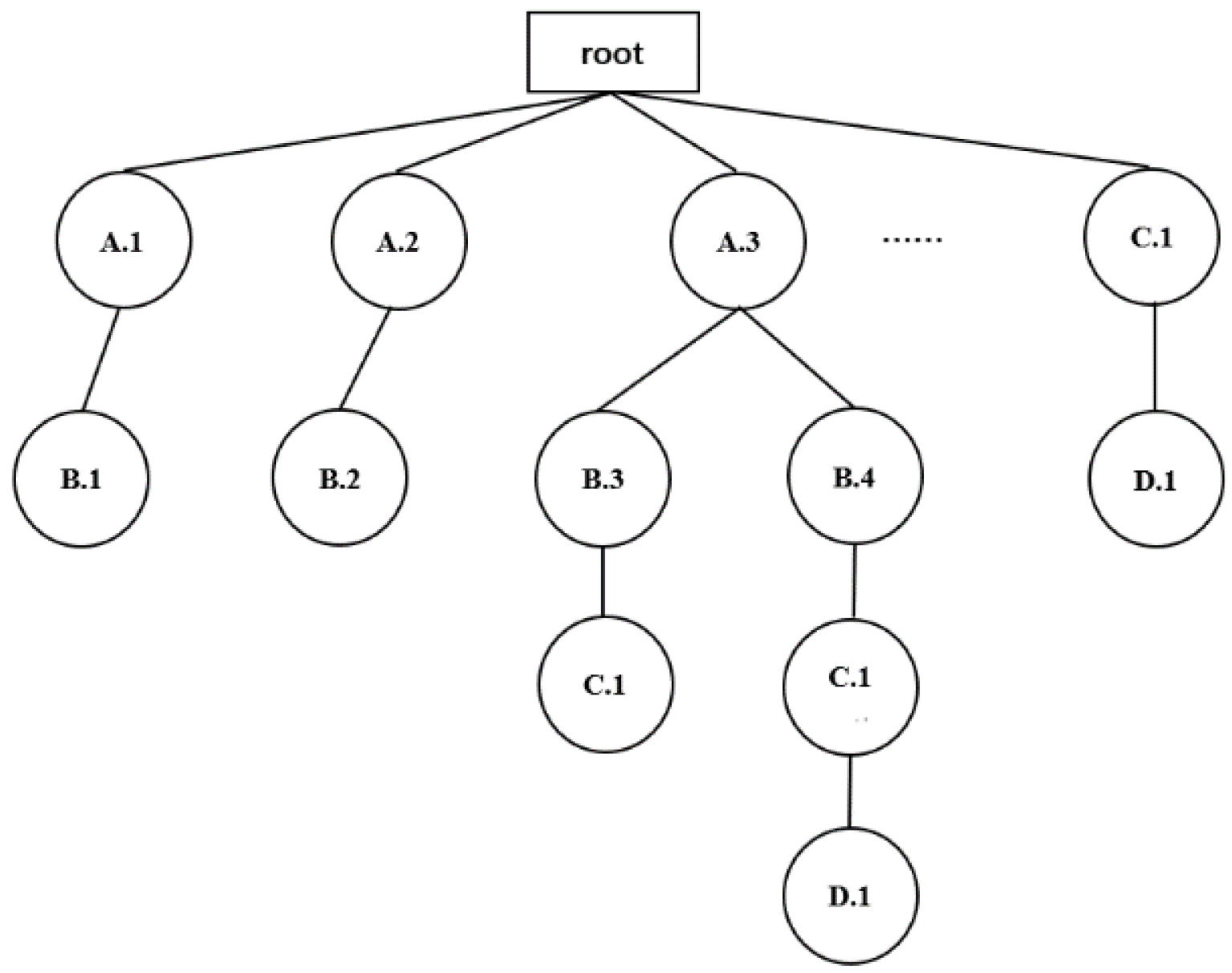
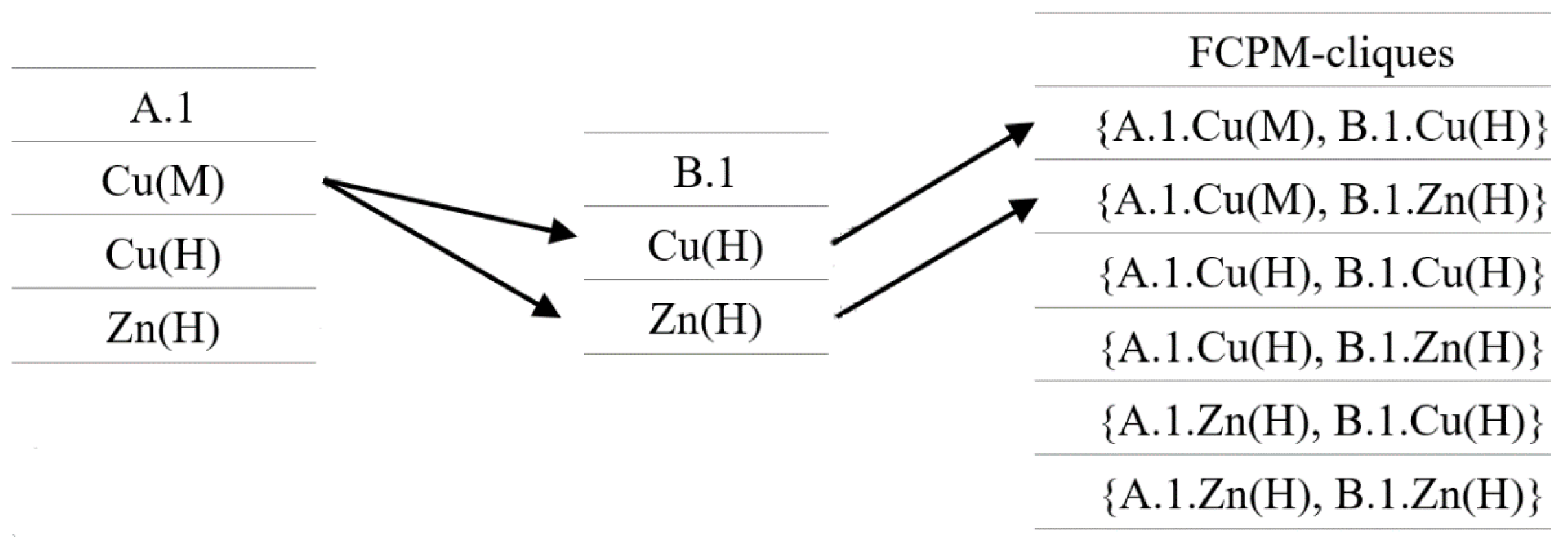
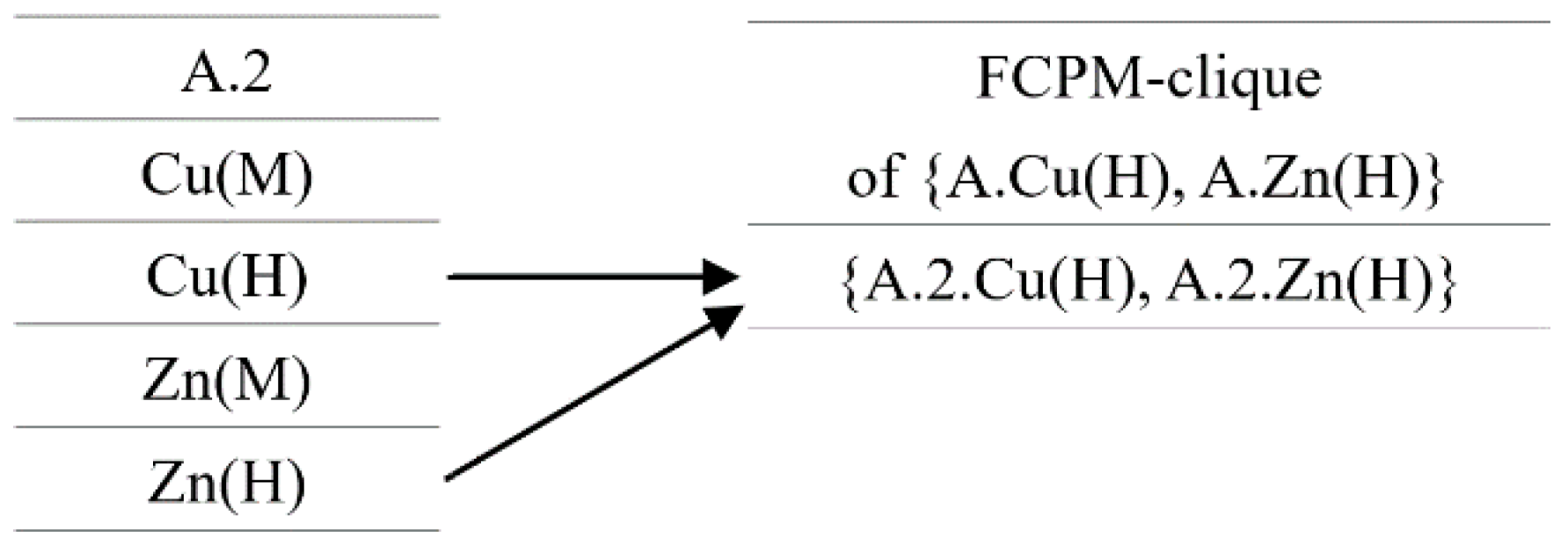
4.1.2. Generating FCP Mining Cliques (FCPM-Cliques)
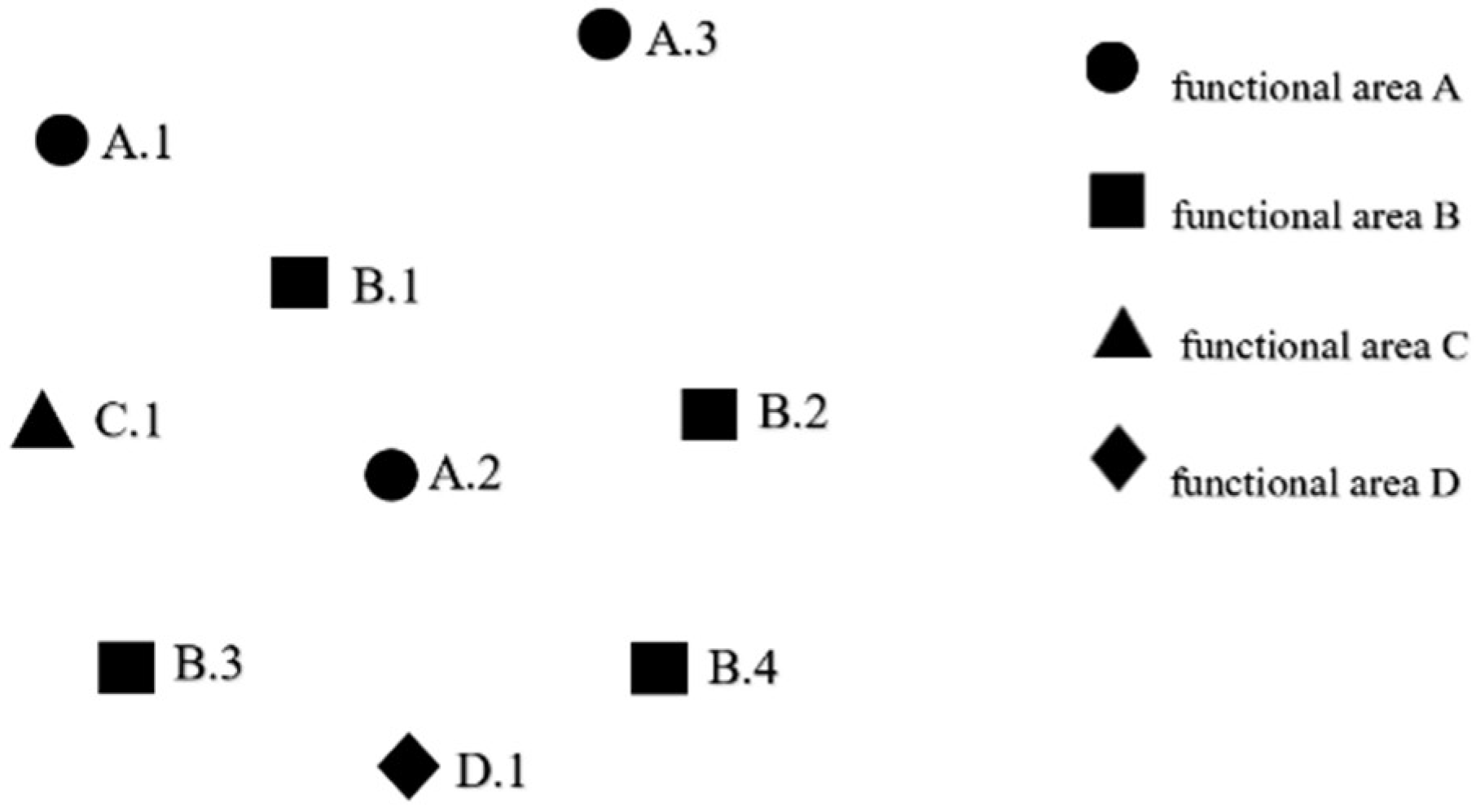
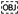 . Last, all the cliques with instance as the head are represented by -clique. For example, for a clique = {A.1, B.2, C.2, D.3}, = A.1, = {B.2, C.2, D.3}, is a -clique.
. Last, all the cliques with instance as the head are represented by -clique. For example, for a clique = {A.1, B.2, C.2, D.3}, = A.1, = {B.2, C.2, D.3}, is a -clique.| Algorithm 1: Neighborhood Driven Method. |
| Input: nbsl: neighborhood relationship list (including SNs and BNs of each instance) S: a set of instances Output: list of N-cliques Steps: 1. nTree = Initialize N-tree; 2. For each instance s In nbsl.Instances Do 3. queue = SNs(s); 4. While NotEmpty(queue) Do 5. head = nTree.AddHeadNode(queue.Out); 6. bodies = GetCurrentBodies(head); 7. relation = queue∩BNs(head); 8. If bodies == null || relation == null Then 9. head.AddNode(s) 10. Else 11. For Each list l in bodies do 12. If l == relation Then 13. s and cli can form a new clique; 14. Else If relation ⊇ l Then 15. s and cli can form a new clique; 16. Else If relation ⊆ l Then 17. s and relation ∪s1 can form a new clique; 18. Else If NotEmpty(l ∩ relation) Then 19. s and relation ∩ l ∪s1 can form a new clique; 20. End If 21. End For 22. End If 23. End While 24. End For |
4.1.3. Generating Candidate FCPs
| Algorithm 2: The algorithm for generating candidate FCPs based on buckets. |
| Input:} } (3) Instance set of fuzzy features S = {s1, s2,…, sn} (4) Spatial proximity relation R (5) Minimum distance threshold min_dist (6) Minimum prevalence threshold min_prev Output:: k + 1 size candidate FCPs Step: 1.if (k == 1) 2. for each Fuzz_f in Fuzz_Fea do 3. SetId(Fuzz_f) 4. Initialize_bucket(Fuzz_f) 5.else if (k == 2) 6. for each Fuzz_f_1 in one feature 7. for each Fuzz_f_2 in other feature 8. Generate a candidate pattern from Fuzz_f_1 and Fuzz_f_2 9. for each Fea in Fea_List 10. for each Fuzz_f_1 in the first attribute 11. for each Fuzz_f_2 in the second attribute 12. Generate a candidate pattern from Fuzz_f_1 and Fuzz_f_2 13. Put fuzzy patterns with the same features and the same attributes into the same bucket 14.else 15. for(i = 1; i < bucket_count; i++) 16. for each fuzzy pattern in bucket[i] 17. for(j = i + 1; j < bucket_count; j++) 18. for each fuzzy pattern in bucket[j] 19. if the first k – 1 fuzzy features of the two k-size fuzzy patterns are the same 20. Generate a fuzzy pattern ck+1 21. if (check(k − 1, ck+1, bucket)) 22. ck+1 is a new candidate fuzzy pattern 23. Put fuzzy patterns with the same features and the same attributes into the same bucket |
4.1.4. Find the Row-Instances of the Candidate FCPs by the Column-Filter Method
| Algorithm 3: The column-filter method. |
| Input: } Table-instance Table_c of co-location pattern that contains the candidate FCP Output: Table-instances of candidate FCP Table[n] Step: 1. Table = Table_c; in the candidate FCP Fuzz_c 3. for each row-instance in Table 4. if (the row-instance doesn’t contain Fuzz_f_i) 5. Table.Delete(the row-instance); 6. end for 7. Table[i] = Table; 8. end for 9. if i == n 10. Table[i] is the table-instance of the candidate FCP |
4.1.5. Filtering Prevalent FCPs
4.1.6. Time Performance Analysis
, and for any instance s of the neighborhood table, the number of small neighbor instances is |SN(s)| on average. There is E * |SN(s)|, where E is the number of edges in the neighborhood relation of the spatial dataset, so the computational complexity of constructing N-cliques is O(E). In the NDM algorithm, the main time cost is to compute queue ∩ BNs(head). In the process of finding the table-instances for the candidates, the time complexity is O(T), where T is the number of all row-instances found from the cliques for all candidates on average (that on average), there is O(T) = O )).4.2. Extending Traditional Algorithms to Discover Prevalent FCPs
4.2.1. An Extended Join-Based Algorithm for Mining Prevalent FCPs
| Algorithm 4: The row-filter method. |
| Input: cps: the set of candidate FCPs : the table-instance of the co-location pattern consisting of non-recurring features in the candidate FCP Output: all row-instances of candidate FCPs Steps: In cps Do } (1 ≤ k ≤ j); Do 4. if |sf | == 1 that have all the fuzzy features in the candidate fuzzy pattern simultaneously) .instance) 7. else that have all the fuzzy features in the candidate fuzzy pattern simultaneously) ) 10. End For 11. End For |
4.2.2. An Extended Joinless Algorithm for Mining Prevalent FCPs
| Algorithm 5: The extended Joinless algorithm. |
| Input:} (2) Instance set of fuzzy features S = {s1,s2,…,sn} } (4) Spatial proximity relation R (5) Minimum distance threshold min_dist (6) Minimum prevalence threshold min_prev Output: Prevalent FCP set Fre_P Variable: k: The size of FCPs : candidate k size FCPs : Star instance set of k size candidate patterns : Group instance set of k size candidate patterns : The set of star instances have all fuzzy features in candidate patterns simultaneously : prevalent k-size FCPs MemSum_up[k]: The sum of upper bound membership degrees of all instances of all fuzzy features in k size FCP. MemSum_down[k]: The sum of lower bound membership degrees of all instances of all fuzzy features in k size FCP. Step: 1. SN = gen_star_neighbor(Fea,S,R); 2. = Fuzz_Fea; k = 1; 3. while( ){ 4. = gen_candidate(); 5. for i in 1 to n 6. for x where =, is the first feature of 7. = gen_star_instance(, x); 8. end for 9. end for 10. if t = 1 (t is the number of non recurring features in a candidate fuzzy pattern) = The instances of the only feature that have all fuzzy feature of the candidate fuzzy co-location pattern; ; 13. if t = 2 which have all fuzzy features of the candidate fuzzy co-location pattern; ; 16. else do that have all fuzzy features of the candidate fuzzy co-location pattern; , minprev); ); 20. end do , min_prev); 22. k = k + 1; ; 24. } |
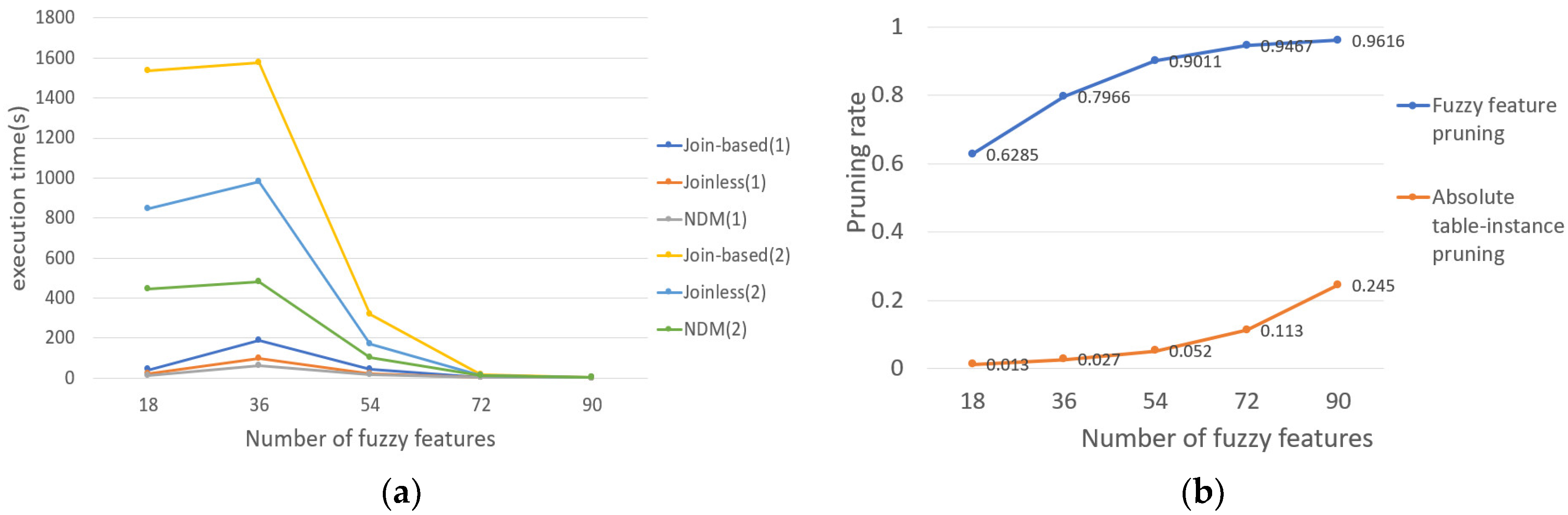
5. Results
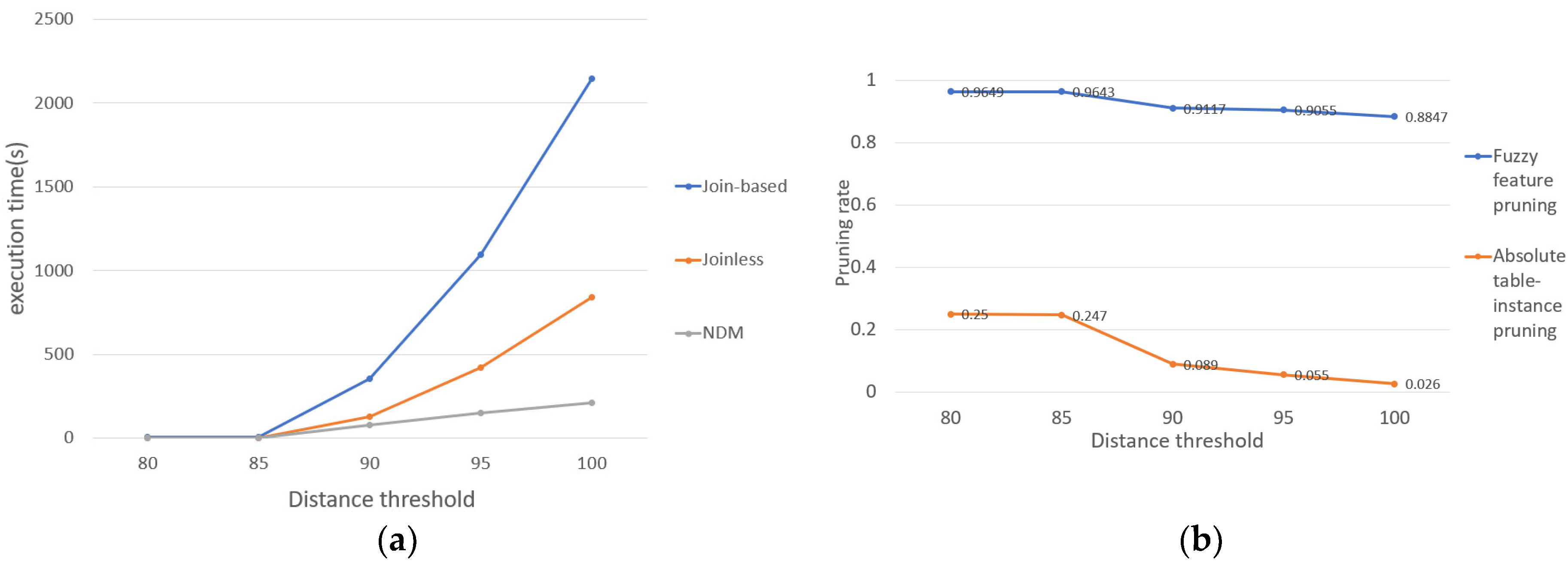
5.1. Results for Synthetic Datasets
- (1)
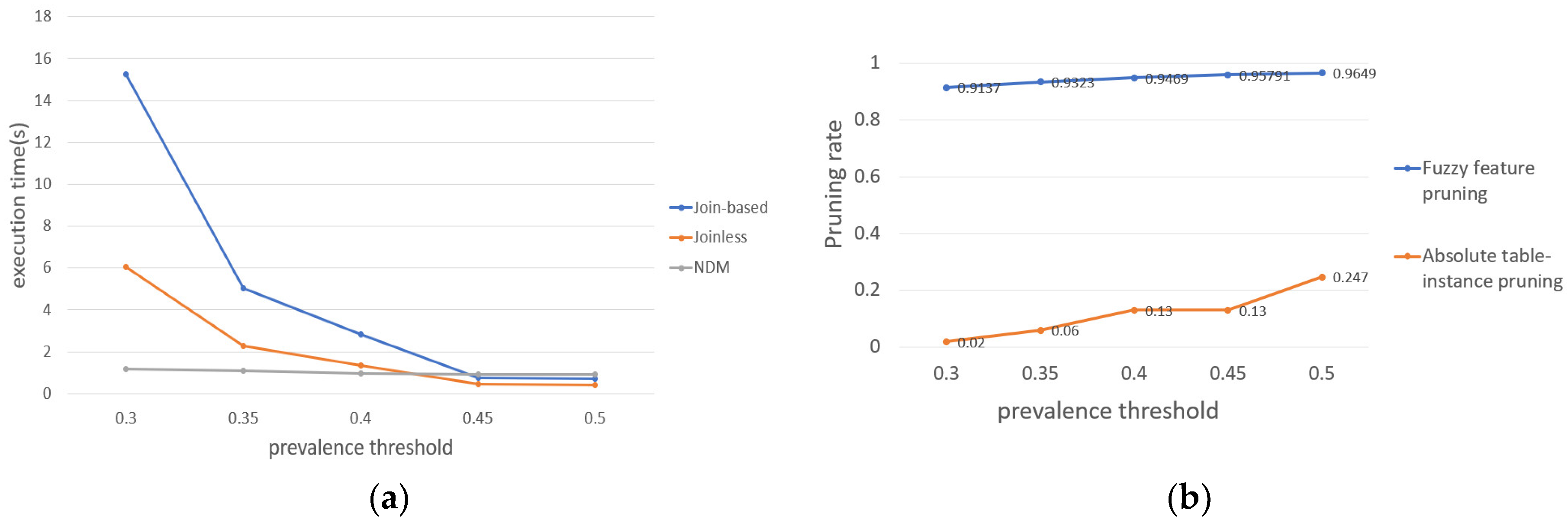
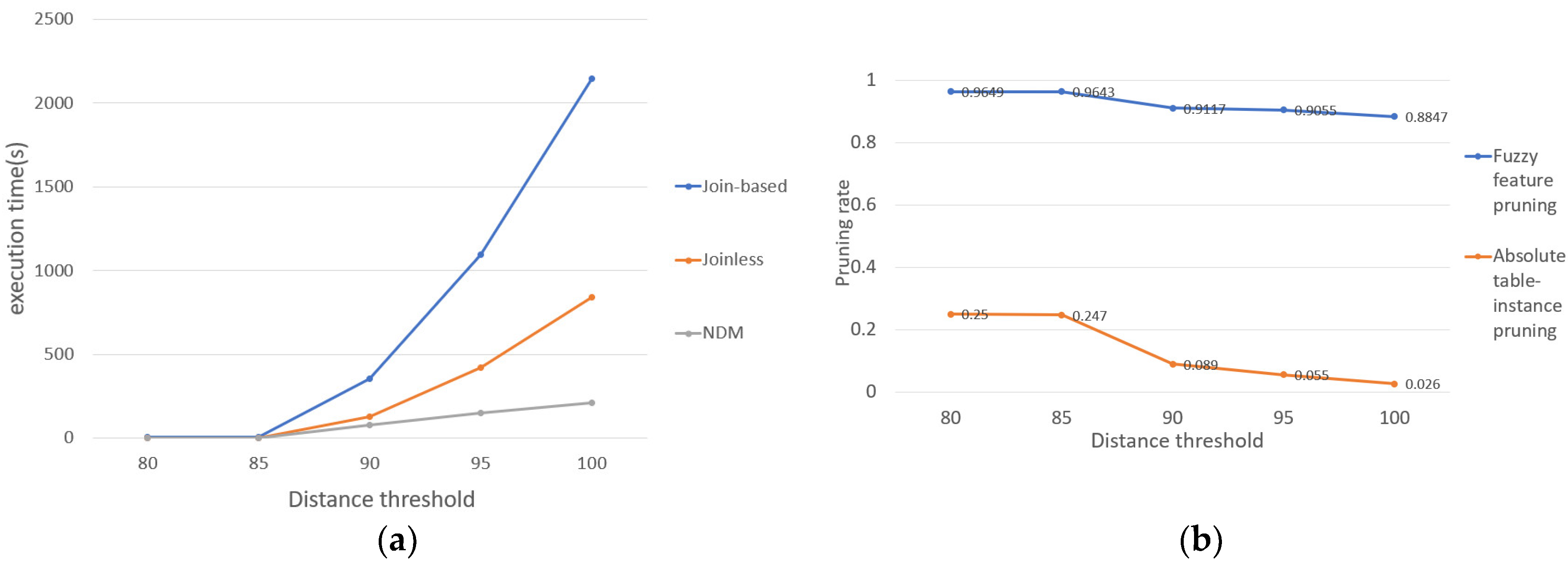
- The effect of distance thresholds on the results
- (2)
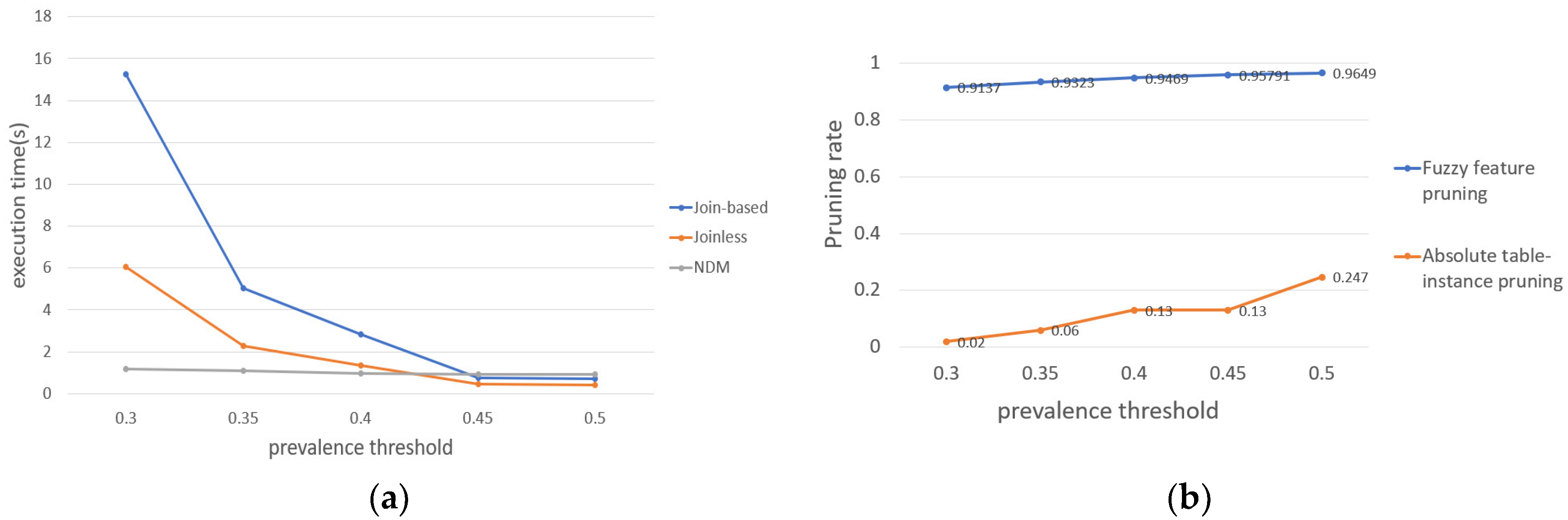
- The effect of prevalence threshold on the results
- (3)
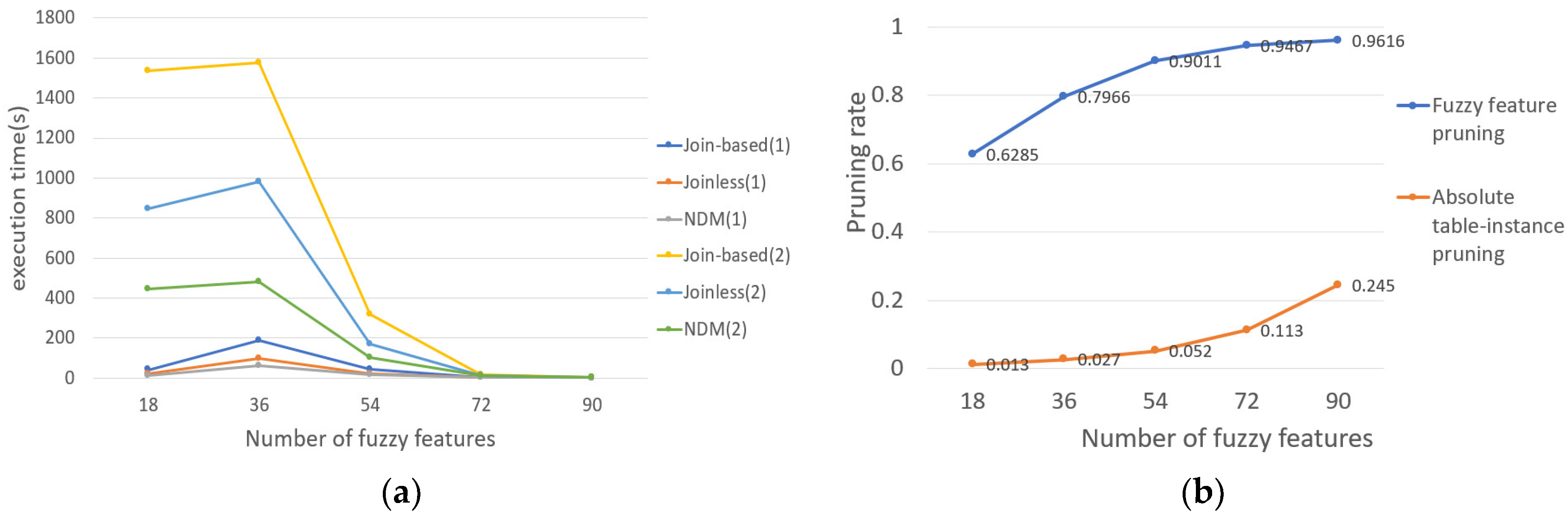
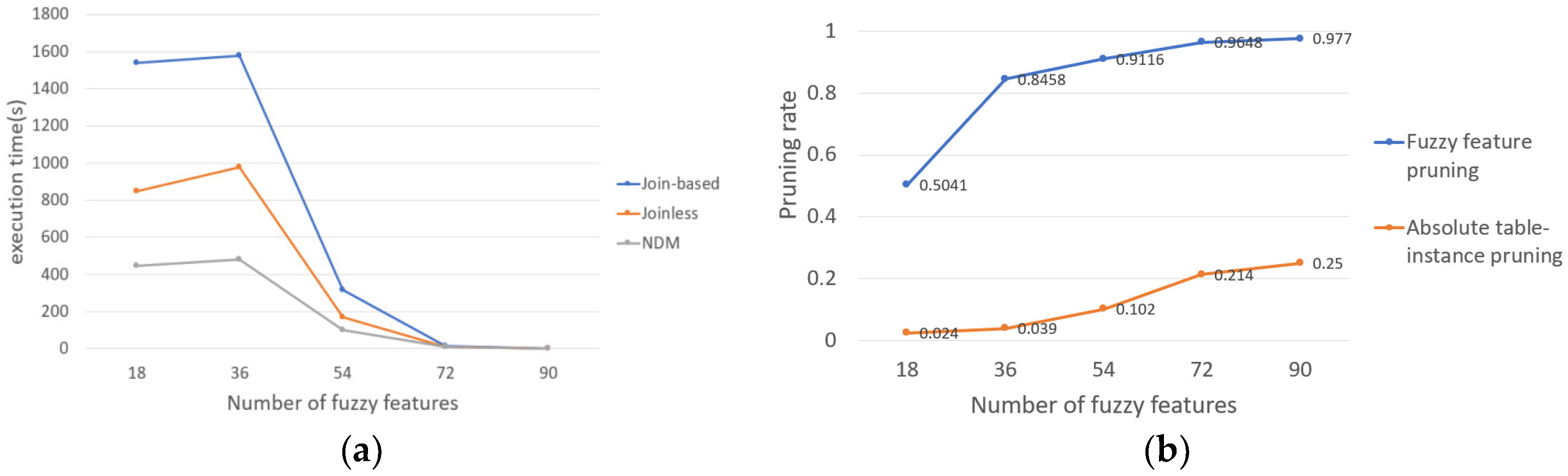
- The effect of the number of fuzzy features on the results
- (4)
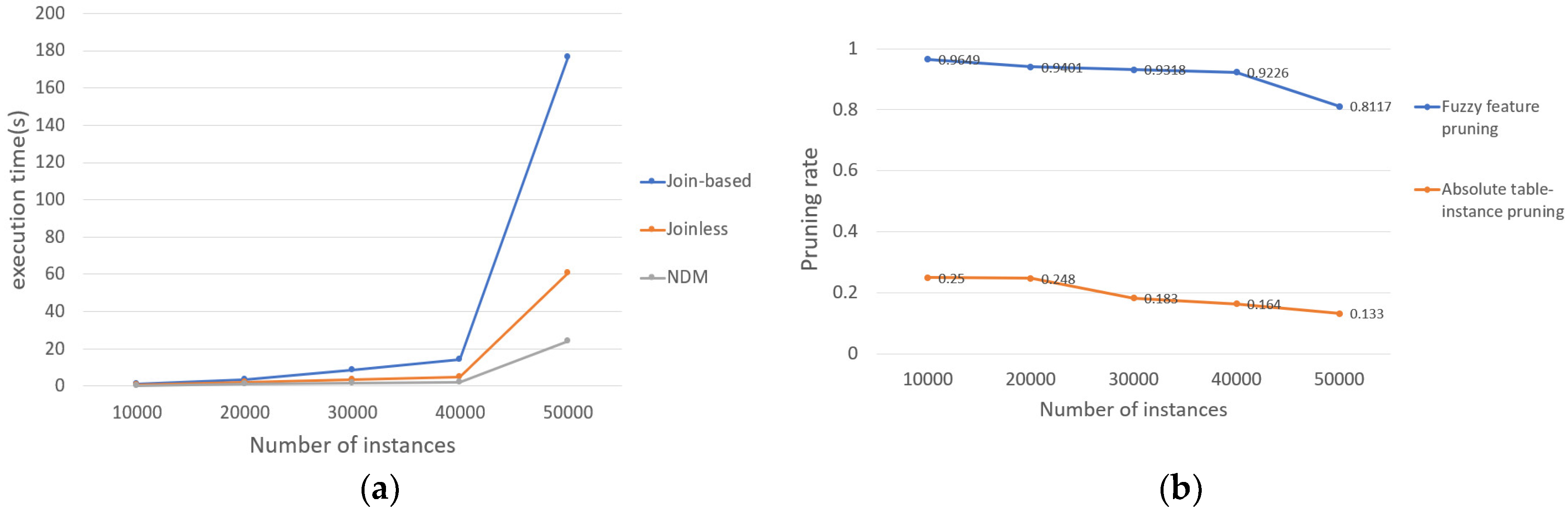
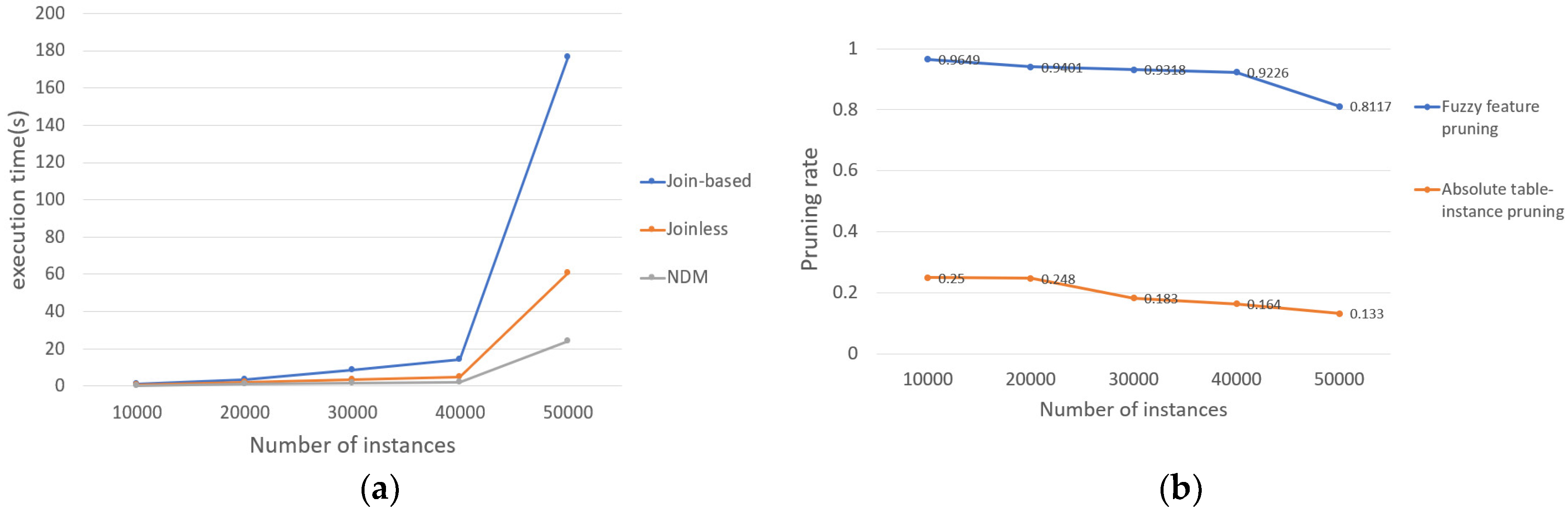
- The effect of the number of instances on the results
- (5)
- The effect of the number of attributes on the results
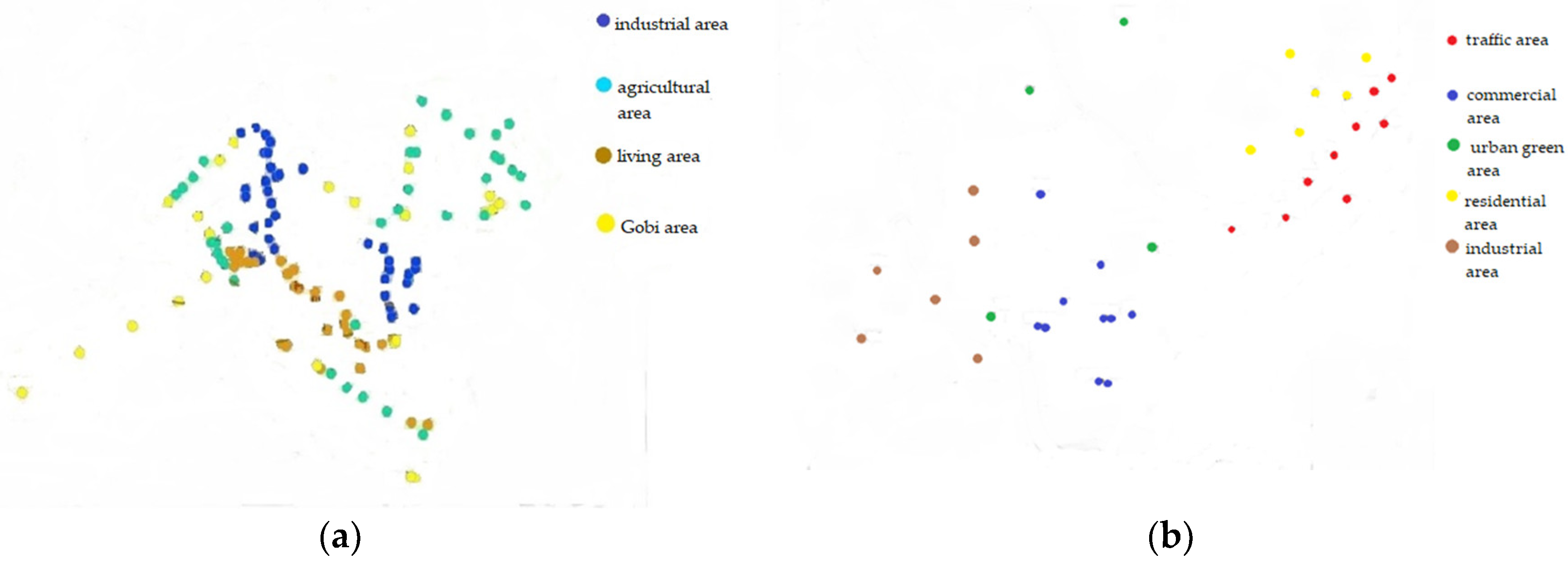
5.2. Results for Real Datasets
6. Discussion
- (1)
- By constructing granular type-2 fuzzy membership functions, we reduce the deviation caused by the uncertainty of type-1 fuzzy membership functions. In this paper, the membership degrees of the attributes of spatial instances are expressed by interval values, and then the mined FCPs have an upper bound participation index and a lower bound participation index. We propose a method to measure the prevalence degree of FCPs when there is uncertainty in the fuzzy membership function, which provides a basis for judging the influence of the uncertainty of the fuzzy membership function on the results of mining FCPs.
- (2)
- Due to the uncertainty of fuzzy membership functions, we find FCPs whose lower bound participation index is less than the prevalence threshold but the upper bound participation index is higher than the threshold. This shows that in all the possible values of the participation index of these FCPs, some values are higher than the prevalence threshold and some values are lower. That is to say, such an FCP has a certain tendency to be prevalent, but also has a certain tendency to be non-prevalent; we regard this as a kind of potential prevalent FCP. For example, in the real dataset 1, the FCP {A.Cu(M), C.Cu(M)} has a lower bound membership of 0.1567, an upper bound membership of 0.3513, and a prevalence tendency degree of 0.2636. We can find that when there is uncertainty in the fuzzy membership function, {A.Cu(M), C.Cu(M)} has a 26.36% tendency degree to be prevalent. However, in the traditional method based on type-1 fuzzy sets, the participation index of the FCP is 0.2384 when the prevalence threshold is 0.3; we can only find that it is non-prevalent and cannot find the influence of the uncertainty of the fuzzy membership function on its participation index and prevalence degree. When using type-1 fuzzy sets, we cannot find the potential association between the middle concentration of copper in the industrial area and the middle concentration of copper in the living area, even if the association is very significant.
- (3)
- We use the prevalence tendency degree to measure the prevalence degree of FCPs. This allows us to find the FCPs whose lowest possible value of participation index is higher than the prevalence threshold. These FCPs are still prevalent when there is uncertainty in the fuzzy membership function, so we define them as absolutely prevalent FCPs and we regard them as a kind of stable and prevalent FCP. However, in the traditional method based on type-1 fuzzy sets, it is difficult to find this kind of FCP according to the participation index and the prevalence threshold. For example, in the real dataset 1, an absolutely prevalent FCP {B.Cu(M), B.Zn(L), C.Cu(M), C.Zn(L)} has a lower bound membership of 0.3933 and an upper bound membership of 0.738. We can easily find that the pattern is stably prevalent and we can find the influence of the uncertainty of the fuzzy membership function on the prevalence degree of FCPs. However, in the traditional method based on type-1 fuzzy sets, the participation index of the FCP is 0.5726 and it is difficult to judge whether this pattern is prevalent when there is uncertainty in the fuzzy membership function.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, L.; Wu, P.; Chen, H. Finding Probabilistic Prevalent Colocations in Spatially Uncertain Data Sets. IEEE Trans. Knowl. Data Eng. 2011, 25, 790–804. [Google Scholar] [CrossRef]
- Bao, X.; Wang, L. A clique-based approach for co-location pattern mining. Inf. Sci. 2019, 490, 244–264. [Google Scholar] [CrossRef]
- Bao, X.; Lu, J.; Gu, T.; Chang, L.; Xu, Z.; Wang, L. Mining Non-Redundant Co-Location Patterns. IEEE Trans. Neural Netw. Learn. Syst. 2021, 99, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Wu, P.; Wang, L.; Zhou, Y. Research on spatial co-location pattern mining with fuzzy attributes. Comput. Sci. Explor. 2013, 7, 348–358. [Google Scholar] [CrossRef]
- Ouyang, Z.; Wang, L.; Wu, P. Spatial Co-Location Pattern Discovery from Fuzzy Objects. Int. J. Artif. Intell. Tools 2017, 26, 1750003. [Google Scholar] [CrossRef] [Green Version]
- Yoo, J.S.; Shekhar, S.; Smith, J.; Kumquat, J.P. A partial join approach for mining co-location patterns. In Proceedings of the 12th Annual ACM International Workshop on Geographic Information Systems—GIS ’04, Washington, DC, USA, 12–13 November 2004; pp. 241–249. [Google Scholar] [CrossRef]
- Yoo, J.S.; Shekhar, S. A join-less approach for co-location pattern mining. IEEE Trans. Knowl. Data Eng. 2006, 18, 1323–1337. [Google Scholar] [CrossRef]
- Huang, Y.; Shekhar, S.; Xiong, H. Discovering co-location patterns from spatial datasets: A general approach. IEEE Trans. Knowl. Data Eng. 2004, 16, 1472–1485. [Google Scholar] [CrossRef] [Green Version]
- Berry, A.; Pogorelcnik, R. A simple algorithm to generate the minimal separators and the maximal cliques of a chordal graph. Inf. Process. Lett. 2011, 111, 508–511. [Google Scholar] [CrossRef] [Green Version]
- Dasari, N.S.; Desh, R.; Zubair, M. pbitMCE: A bit-based approach for maximal clique enumeration on multicore processors. In Proceedings of the 20th IEEE International Conference on Parallel and Distributed Systems (ICPADS), Hsinchu, Taiwan, 16–19 December 2014; pp. 478–485. [Google Scholar] [CrossRef]
- Wang, L.; Bao, Y.; Lu, Z. Efficient Discovery of Spatial co-location Patterns Using the iCPI-tree. Open Inf. Syst. J. 2009, 3, 69–80. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Zhou, L.; Lu, J.; Yip, J. An Order-clique-based Approach for Mining Maximal Co-locations. Inf. Sci. 2009, 179, 3370–3382. [Google Scholar] [CrossRef]
- Yang, P.; Wang, L.; Wang, X. A MapReduce approach for spatial co-location pattern mining via ordered-clique growth. Distrib. Parallel Databases 2020, 38, 531–560. [Google Scholar] [CrossRef]
- Tran, V.; Wang, L.; Chen, H.; Xiao, Q. MCHT: A maximal clique and hash table-based maximal prevalent co-location pattern mining algorithm. Expert Syst. Appl. 2021, 175, 114830. [Google Scholar] [CrossRef]
- Wang, F.; Mo, H. Some fundamental issues on type-2 fuzzy sets. Acta Autom. Sin. 2017, 43, 1141. [Google Scholar] [CrossRef]
- Torshizi, A.D.; Zarandi, M.H.F. A new cluster validity measure based on general type-2 fuzzy sets: Application in gene expression data clustering. Knowl. Based Syst. 2014, 64, 81–93. [Google Scholar] [CrossRef]
- Tabakov, M.; Chlopowiec, A.; Chlopowiec, A.; Dlubak, A. Classification with Fuzzification Optimization Combining Fuzzy Information Systems and Type-2 Fuzzy Inference. Appl. Sci. 2021, 11, 3484. [Google Scholar] [CrossRef]
- Lin, C.-J.; Jeng, S.-Y.; Lin, H.-Y.; Shiou-Yun, J. Design and Verification of an Interval Type-2 Fuzzy Neural Network Based on Improved Particle Swarm Optimization. Appl. Sci. 2020, 10, 3041. [Google Scholar] [CrossRef]
- Son, L.H. Enhancing clustering quality of geo-demographic analysis using context fuzzy clustering type-2 and particle swarm optimization. Appl. Soft Comput. 2014, 22, 566–584. [Google Scholar] [CrossRef]
- Heidarzade, A.; Mahdavi, I.; Mahdavi-Amiri, N. Supplier selection using a clustering method based on a new distance for interval type-2 fuzzy sets: A case study. Appl. Soft Comput. 2016, 38, 213–231. [Google Scholar] [CrossRef]
- Anuradha, R.; Rajkumar, N. A Novel Approach in Mining Specialized Coherent Rules in a Level-Crossing Hierarchy. Int. J. Fuzzy Syst. 2017, 19, 1782–1792. [Google Scholar] [CrossRef]
- Lin, J.C.-W.; Zhang, Y.; Fournier-Viger, P.; Hong, T.-P. Efficiently Updating the Discovered Multiple Fuzzy Frequent Itemsets with Transaction Insertion. Int. J. Fuzzy Syst. 2018, 20, 2440–2457. [Google Scholar] [CrossRef]
- Kalia, H.; Dehuri, S.; Ghosh, A.; Cho, S.-B. Surrogate-Assisted Multi-objective Genetic Algorithms for Fuzzy Rule-Based Classification. Int. J. Fuzzy Syst. 2018, 20, 1938–1955. [Google Scholar] [CrossRef]
- Wang, X.; Lei, L.; Wang, L.; Yang, P.; Chen, H. Spatial Co-location Pattern Discovery Incorporating Fuzzy Theory. IEEE Trans. Fuzzy Syst. 2021, 30, 2055–2072. [Google Scholar] [CrossRef]
- Yang, P.; Wang, L.; Wang, X.; Zhou, L. SCPM-CR: A Novel Method for Spatial Co-location Pattern Mining with Coupling Relation Consideration. IEEE Trans. Knowl. Data Eng. 2021, 99, 1. [Google Scholar] [CrossRef]
- Molina, C.; Ruiz, M.D.; Serrano, J.M. Representation by levels: An alternative to fuzzy sets for fuzzy data mining. Fuzzy Sets Syst. 2019, 401, 113–132. [Google Scholar] [CrossRef]
- Lin, J.C.-W.; Ahmed, U.; Srivastava, G.; Wu, J.M.-T.; Hong, T.-P.; Djenouri, Y. Linguistic frequent pattern mining using a compressed structure. Appl. Intell. 2021, 51, 4806–4823. [Google Scholar] [CrossRef]
- Zhang, Z.; Huang, J.; Hao, J.; Gong, J.; Chen, H. Extracting relations of crime rates through fuzzy association rules mining. Appl. Intell. 2019, 50, 448–467. [Google Scholar] [CrossRef]
- Wang, T.; Zhou, M. Zhou. Integrating rough set theory with customer satisfaction to construct a novel approach for mining product design rules. J. Intell. Fuzzy Syst. 2021, 41, 331–353. [Google Scholar] [CrossRef]
- Anari, Z.; Hatamlou, A.; Anari, B. Finding Suitable Membership Functions for Mining Fuzzy Association Rules in Web Data Using Learning Automata. Int. J. Pattern Recognit. Artif. Intell. 2021, 35, 2159026. [Google Scholar] [CrossRef]
- Gupta, P.; Mehlawat, M.K.; Grover, N. A Generalized TOPSIS Method for Intuitionistic Fuzzy Multiple Attribute Group Decision Making Considering Different Scenarios of Attributes Weight Information. Int. J. Fuzzy Syst. 2019, 21, 369–387. [Google Scholar] [CrossRef]
- Sun, P.; Chen, S.; Zhi, Y. Multiple Attribute Variable Weight Fuzzy Decision-Making Based on Optimistic Coefficient Method. Int. J. Fuzzy Syst. 2021, 23, 573–583. [Google Scholar] [CrossRef]
- Meng, F.; Li, S. A new multiple attribute decision making method for selecting design schemes in sponge city construction with trapezoidal interval type-2 fuzzy information. Appl. Intell. 2020, 50, 2252–2279. [Google Scholar] [CrossRef]
- Yan, T.; Han, C. A Novel Approach of Rough Conditional Entropy-Based Attribute Selection for Incomplete Decision System. Math. Probl. Eng. 2014, 2014, 1–15. [Google Scholar] [CrossRef]
- Farhadinia, B. Hesitant fuzzy set lexicographical ordering and its application to multi-attribute decision making. Inf. Sci. 2016, 327, 233–245. [Google Scholar] [CrossRef]
- Choi, B.-I.; Rhee, F.C.-H. Interval type-2 fuzzy membership function generation methods for pattern recognition. Inf. Sci. 2009, 179, 2102–2122. [Google Scholar] [CrossRef]
- Lee, C.-H.; Pan, H.-Y. Performance enhancement for neural fuzzy systems using asymmetric membership functions. Fuzzy Sets Syst. 2009, 160, 949–971. [Google Scholar] [CrossRef]
- Liao, T. A Procedure for the Generation of Interval Type-2 Membership Functions from Data. Appl. Soft Comput. 2017, 52, 925–936. [Google Scholar] [CrossRef]
- Kayacan, E.; Sarabakha, A.; Coupland, S.; John, R.; Khanesar, M.A. Type-2 fuzzy elliptic membership functions for modeling uncertainty. Eng. Appl. Artif. Intell. 2018, 70, 170–183. [Google Scholar] [CrossRef] [Green Version]
- Kayacan, E.; Maslim, R. Type-2 Fuzzy Logic Trajectory Tracking Control of Quadrotor VTOL Aircraft with Elliptic Membership Functions. IEEE/ASME Trans. Mechatron. 2017, 22, 339–348. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Functional Area | The Number of Sampling Points | The Content of Copper | The Content of Zinc |
|---|---|---|---|
| A | 1 | 62 | 226 |
| A | 2 | 31 | 105 |
| A | 3 | 46 | 136 |
| B | 1 | 86 | 183 |
| B | 2 | 29 | 112 |
| B | 3 | 45 | 150 |
| B | 4 | 57 | 124 |
| C | 1 | 63 | 210 |
| D | 1 | 51 | 155 |
| Functional Area | Number of Sampling Points | Cu(L) | Cu(M) | Cu(H) | Zn(L) | Zn(M) | Zn(H) |
|---|---|---|---|---|---|---|---|
| A | 1 | 0 | [0.4403, 0.7456] | [0.0104, 0.0831] | 0 | 0 | 1 |
| A | 2 | 0 | [0.3614, 0.6848] | 0 | 0 | [0.5414, 0.8298] | 0 |
| A | 3 | 0 | [0.8, 0.9591] | 0 | 0 | [0.5191, 0.8146] | 0 |
| B | 1 | 0 | 0 | [0.283, 0.5931] | 0 | 0 | [0.3905, 0.7023] |
| B | 2 | 0 | [0.3152, 0.6386] | 0 | 0 | [0.7138, 0.9252] | 0 |
| B | 3 | 0 | [0.7633, 0.9455] | 0 | 0 | [0.2495, 0.5656] | 0 |
| B | 4 | 0 | [0.5786, 0.8991] | 0 | 0 | [0.8315, 0.9695] | 0 |
| C | 1 | 0 | [0.4069, 0.717] | [0.0174, 0.1141] | 0 | 0 | 1 |
| D | 1 | 0 | [0.9169, 0.9896] | 0 | 0 | [0.1702, 0.4586] | [0.0335, 0.1698] |
| 1.1 | 1.2 | 1.3 | 1.4 | 1.5 | 1.6 | 1.7 | 1.8 | 1.9 | 2.0 | |
| Is it connected? | Yes | Yes | No | No | No | No | No | No | No | No |
| 1.21 | 1.22 | 1.23 | 1.24 | 1.25 | 1.26 | 1.27 | 1.28 | 1.29 | 1.3 | |
| Is it connected? | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No |
| 1.281 | 1.282 | 1.283 | 1.284 | 1.285 | 1.286 | 1.287 | 1.288 | 1.289 | 1.29 | |
| Is it connected? | Yes | Yes | Yes | No | No | No | No | No | No | No |
| SNs | Instance | BNs |
|---|---|---|
| - | A.1 | {B.1} |
| - | A.2 | {B.2} |
| - | A.3 | {B.3, B.4, C.1, D.1} |
| {A.1} | B.1 | - |
| {A.2} | B.2 | - |
| {A.3} | B.3 | {C.1} |
| {A.3} | B.4 | {C.1, D.1} |
| {A.3, B.3, B.4} | C.1 | {D.1} |
| {A.3, B.3, B.4, C.1} | D.1 | - |
| Phase 1 | Phase 2 | Phase 3 | ||
|---|---|---|---|---|
| Star Instances of Feature A | A | {A, B} | {A.Cu(M), B.Cu(M)} | {A.Cu(M), A.Zn(M)} |
| A.1, B.2, C.2 A.2, B.3, C.1 A.3, B.5, C.2 A.4, C.3 | A.1 A.2 A.3 A.4 | A.1, B.2 A.2, B.3 A.3, B.5 | A.1, B.2 A.2, B.3 | A.1 |
| Prevalent Fuzzy Co-Location Pattern | Prevalence Tendency Degree | Lower Participation Index and Upper Participation Index | Participation Index for the Traditional Method |
|---|---|---|---|
| {A.Cu(L), C.Cu(L)} | 0.6125 | 0.0709, 0.6621 | 0.2312 |
| {A.Cu(L), D.Cu(L)} | 0.2328 | 0.036, 0.3801 | 0.1169 |
| {A.Cu(M), C.Cu(M)} | 0.2636 | 0.1567, 0.3513 | 0.2384 |
| {D.Cu(M), D.Zn(H)} | 1 | 0.4781, 0.9135 | 0.6599 |
| {D.Cu(L), D.Zn(M)} | 0.9096 | 0.2414, 0.8896 | 0.6681 |
| {A.Zn(L), A.Cu(M), C.Zn(L)} | 0.2636 | 0.1567, 0.3513 | 0.2384 |
| {A.Zn(L), C.Zn(L), D.Cu(M)} | 0.2167 | 0.1749, 0.3346 | 0.2492 |
| {B.Cu(L), B.Zn(L), C.Zn(L)} | 0.8586 | 0.2597, 0.5448 | 0.4342 |
| {B.Cu(M), B.Zn(L), C.Cu(M), C.Zn(M)} | 0.7039 | 0.1804, 0.5844 | 0.3358 |
| {B.Cu(M), B.Zn(L), C.Cu(M), C.Zn(L)} | 1 | 0.3933, 0.738 | 0.5726 |
| Prevalent Fuzzy Co-Location Pattern | Prevalence Tendency Degree | Lower Participation Index and Upper Participation Index | Participation Index for the Traditional Method |
|---|---|---|---|
| {A.Cu(M), A.Zn(M)} | 0.7965 | 0.2438, 0.5199 | 0.3661 |
| {A.Zn(H), D.Zn(H)} | 1 | 0.4114, 0.966 | 0.8528 |
| {A.Cu(M), D.Zn(H)} | 0.8208 | 0.2438, 0.5575 | 0.3661 |
| {E.Cu(L), E.Zn(L)} | 1 | 0.3657, 0.4952 | 0.4425 |
| {A.Cu(M), A.Zn(M), D.Cu(M)} | 0.7965 | 0.2438, 0.5199 | 0.3661 |
| {A.Cu(M), A.Zn(H), D.Zn(M)} | 0.9047 | 0.2828, 0.4633 | 0.3853 |
| {A.Cu(M), A.Zn(M), D.Cu(M), D.Zn(H)} | 0.7965 | 0.2438, 0.5199 | 0.3661 |
| {A.Cu(M), A.Zn(H), D.Cu(M), D.Zn(H)} | 0.9047 | 0.2828, 0.4633 | 0.3853 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, J.; Wang, L. A Spatial Fuzzy Co-Location Pattern Mining Method Based on Interval Type-2 Fuzzy Sets. Appl. Sci. 2022, 12, 6259. https://doi.org/10.3390/app12126259
Guo J, Wang L. A Spatial Fuzzy Co-Location Pattern Mining Method Based on Interval Type-2 Fuzzy Sets. Applied Sciences. 2022; 12(12):6259. https://doi.org/10.3390/app12126259
Chicago/Turabian StyleGuo, Jinyu, and Lizhen Wang. 2022. "A Spatial Fuzzy Co-Location Pattern Mining Method Based on Interval Type-2 Fuzzy Sets" Applied Sciences 12, no. 12: 6259. https://doi.org/10.3390/app12126259
APA StyleGuo, J., & Wang, L. (2022). A Spatial Fuzzy Co-Location Pattern Mining Method Based on Interval Type-2 Fuzzy Sets. Applied Sciences, 12(12), 6259. https://doi.org/10.3390/app12126259