
A Fast Maritime Target Identification Algorithm for Offshore Ship Detection


Abstract
:1. Introduction
2. Related Work
3. Methodology
3.1. Process of FMTI
- The classified image is gridded and there are the Bounding Boxes (Bbox) in the grid cell. Each Bbox contains five features, (x, y, w, h, Scoreconfidence). Where (x, y) is the offset of the Bbox center relative to the cell boundary, (w, h) denotes the ratio of width and height in the whole image, and Scoreconfidence is the Confidence Score.Pr(object) means whether the target exists or not. The existing value is 1, and the opposite value is 0.The GIOU [39] was optimized from the IOU, (Figure 1A). The intersection of Prediction and Ground Truth is shown by IOU. Where Area(pred) denotes the area of the detection boxes and Area(true) denotes the area of the true value.To calculate GIOU, it is necessary to find the smallest box that can fully cover the Prediction box (Area(pred)) and the Ground Truth box (Area(true)), named Area(full). The schematic diagram is indicated in Figure 1.
- The second step is feature extraction and prediction. Target prediction is performed in the final layer of the fully connected. If the target exists, the Cell gives the Pr(class|object), and the probability of each class in the whole network is calculated, then the detection Scoreconfidence is calculated. The comprehensive calculation is as
- Setting the detection limitation of Scoreconfidence, adjusting and filtering the borders with scores lower than the default value. The remaining borders are the correct detection boxes and the final judgment results are outputted sequentially.
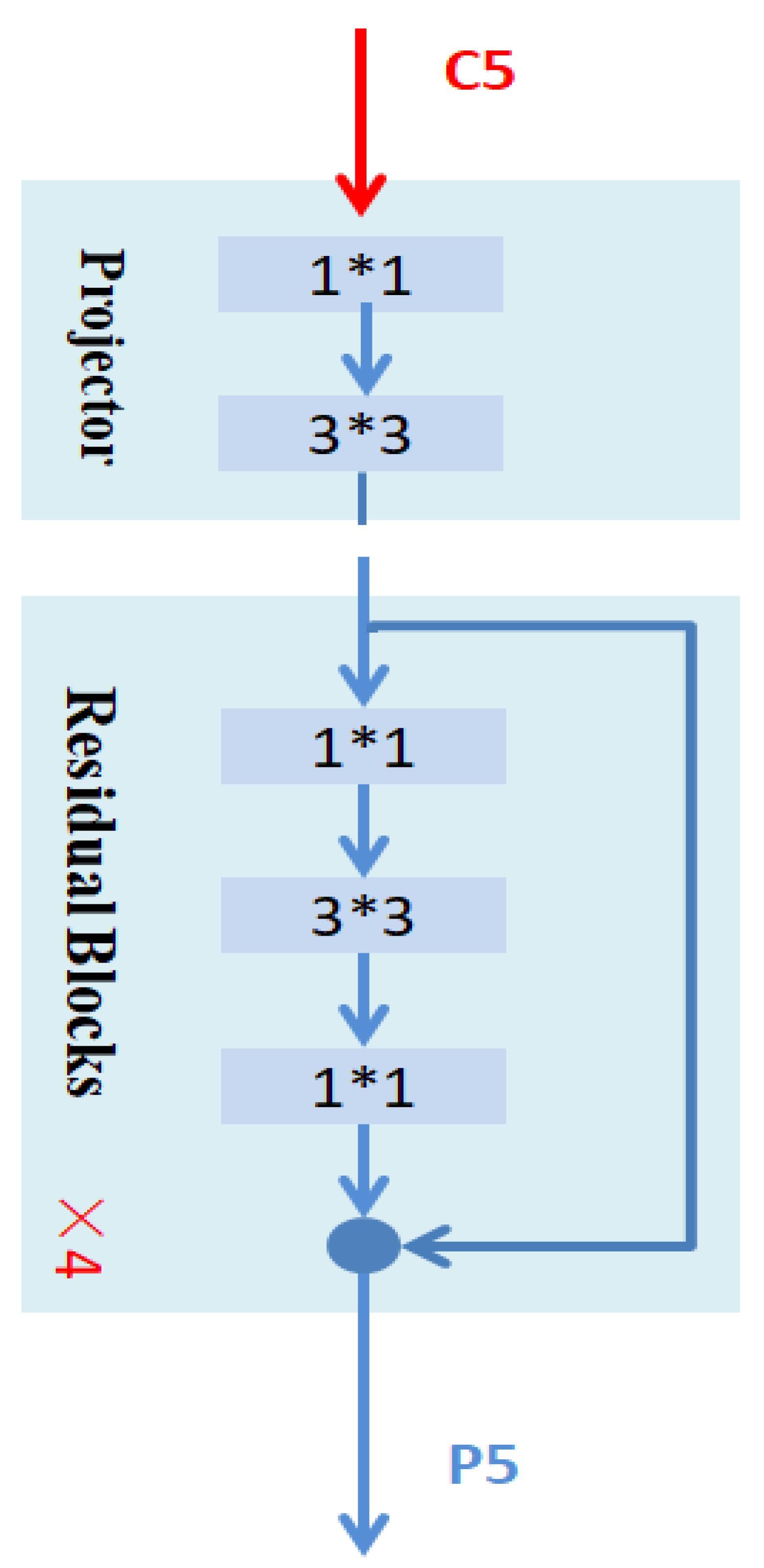
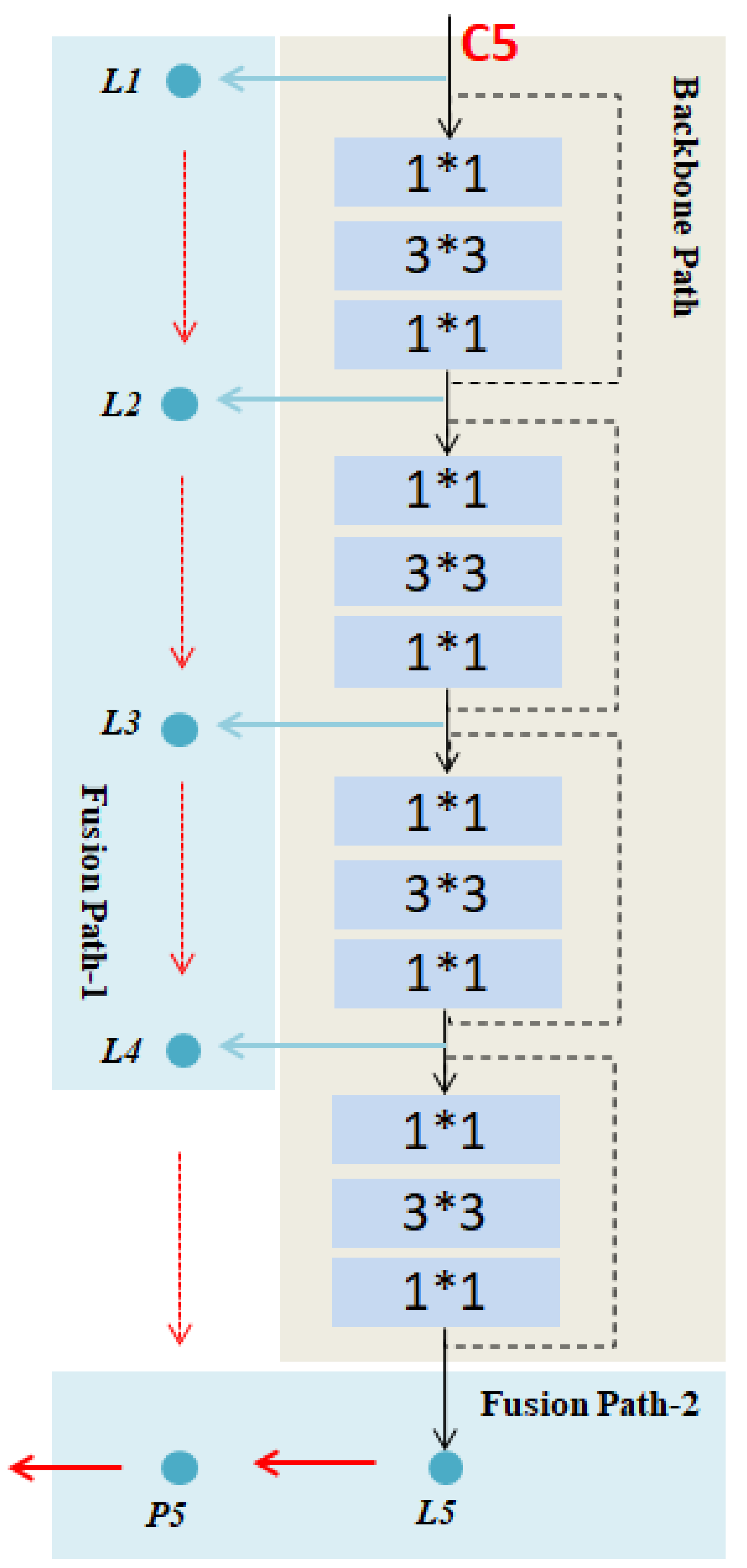
3.2. Multi-Scale Feature Fusion
3.3. Activation and Loss Function
4. Experiments
4.1. Dataset Composition
4.2. Establishment of Computer Platform
4.3. Evaluation Indexes
4.4. Results Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, R.; Wu, J.; Cao, L. Ship target detection of unmanned surface vehicle base on efficientdet. Syst. Sci. Control. Eng. 2022, 10, 264–271. [Google Scholar] [CrossRef]
- Chen, X.; Liu, Y.; Achuthan, K.; Zhang, X. A ship movement classification based on Automatic Identification System (AIS) data using Convolutional Neural Network. Ocean. Eng. 2020, 218, 108182. [Google Scholar] [CrossRef]
- Shen, S.; Yang, H.; Yao, X.; Li, J.; Xu, G.; Sheng, M. Ship Type Classification by Convolutional Neural Networks with Auditory-like Mechanisms. Sensors 2020, 20, 253. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Springer: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef] [Green Version]
- Purkait, P.; Zhao, C.; Zach, C. SPP-Net: Deep Absolute Pose Regression with Synthetic Views. arXiv 2017, arXiv:1712.03452. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Taimuri, G.; Matusiak, J.; Mikkola, T.; Kujala, P.; Hirdaris, S. A 6-DoF maneuvering model for the rapid estimation of hydrodynamic actions in deep and shallow waters. Ocean. Eng. 2020, 218, 108103. [Google Scholar] [CrossRef]
- Rezazadegan, F.; Shojaei, K.; Sheikholeslam, F.; Chatraei, A. A novel approach to 6-DOF adaptive trajectory tracking control of an AUV in the presence of parameter uncertainties. Ocean. Eng. 2015, 107, 246–258. [Google Scholar] [CrossRef]
- Tello, M.; Lopez-Martinez, C.; Mallorqui, J.J. A Novel Algorithm for Ship Detection in SAR Imagery Based on the Wavelet Transform. IEEE Geosci. Remote Sens. Lett. 2005, 2, 201–205. [Google Scholar] [CrossRef]
- Chang, Y.-L.; Anagaw, A.; Chang, L.; Wang, Y.; Hsiao, C.-Y.; Lee, W.-H. Ship Detection Based on YOLOv2 for SAR Imagery. Remote Sens. 2019, 11, 786. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.; Chen, D.; Zhang, Y.; Cheng, X.; Zhang, M.; Wu, C. Deep learning for autonomous ship-oriented small ship detection. Saf. Sci. 2020, 130, 104812. [Google Scholar] [CrossRef]
- Arcos-García, Á.; Álvarez-García, J.A.; Soria-Morillo, L.M. Evaluation of deep neural networks for traffic sign detection systems. Neurocomputing 2018, 316, 332–344. [Google Scholar] [CrossRef]
- Lopac, N.; Hržić, F.; Vuksanović, I.P.; Lerga, J. Detection of Non-Stationary GW Signals in High Noise From Cohen’s Class of Time-Frequency Representations Using Deep Learning. IEEE Access 2022, 10, 2408–2428. [Google Scholar] [CrossRef]
- Javed Awan, M.; Mohd Rahim, M.S.; Salim, N.; Mohammed, M.A.; Garcia-Zapirain, B.; Abdulkareem, K.H. Efficient Detection of Knee Anterior Cruciate Ligament from Magnetic Resonance Imaging Using Deep Learning Approach. Diagnostics 2021, 11, 105. [Google Scholar] [CrossRef] [PubMed]
- Qiblawey, Y.; Tahir, A.; Chowdhury, M.E.H.; Khandakar, A.; Kiranyaz, S.; Rahman, T.; Ibtehaz, N.; Mahmud, S.; Maadeed, S.A.; Musharavati, F.; et al. Detection and Severity Classification of COVID-19 in CT Images Using Deep Learning. Diagnostics 2021, 11, 893. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Yang, Y.; Li, Z.; Ning, X.; Qin, Y.; Cai, W. An Improved Encoder-Decoder Network Based on Strip Pool Method Applied to Segmentation of Farmland Vacancy Field. Entropy 2021, 23, 435. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Hao, L.-Y.; Guo, G. A feature enriching object detection framework with weak segmentation loss. Neurocomputing 2019, 335, 72–80. [Google Scholar] [CrossRef]
- Li, T.; Li, R.; Li, J. Decentralized adaptive neural control of nonlinear interconnected large-scale systems with unknown time delays and input saturation. Neurocomputing 2011, 74, 2277–2283. [Google Scholar] [CrossRef]
- Li, T.; Li, R.; Wang, D. Adaptive neural control of nonlinear MIMO systems with unknown time delays. Neurocomputing 2012, 78, 83–88. [Google Scholar] [CrossRef]
- Gu, X.; Liu, C.; Wang, S.; Zhao, C. Feature extraction using adaptive slow feature discriminant analysis. Neurocomputing 2015, 154, 139–148. [Google Scholar] [CrossRef]
- Guo, G.; Wang, H.; Yan, Y.; Zheng, J.; Li, B. A fast face detection method via convolutional neural network. Neurocomputing 2020, 395, 128–137. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Li, X.; Li, Q.; Xue, Y.; Liu, H.; Gao, Y. Robot recognizing humans intention and interacting with humans based on a multi-task model combining ST-GCN-LSTM model and YOLO model. Neurocomputing 2021, 430, 174–184. [Google Scholar] [CrossRef]
- Zheng, Y.; Bao, H.; Meng, C.; Ma, N. A method of traffic police detection based on attention mechanism in natural scene. Neurocomputing 2021, 458, 592–601. [Google Scholar] [CrossRef]
- Yu, X.; Wu, S.; Lu, X.; Gao, G. Adaptive multiscale feature for object detection. Neurocomputing 2021, 449, 146–158. [Google Scholar] [CrossRef]
- Zhang, C.; Pan, X.; Li, H.; Gardiner, A.; Sargent, I.; Hare, J.; Atkinson, P.M. A hybrid MLP-CNN classifier for very fine resolution remotely sensed image classification. ISPRS J. Photogramm. Remote Sens. 2018, 140, 133–144. [Google Scholar] [CrossRef] [Green Version]
- Sharifzadeh, F.; Akbarizadeh, G.; Seifi Kavian, Y. Ship Classification in SAR Images Using a New Hybrid CNN–MLP Classifier. J. Indian Soc. Remote Sens. 2019, 47, 551–562. [Google Scholar] [CrossRef]
- Wu, F.; Wang, C.; Jiang, S.; Zhang, H.; Zhang, B. Classification of Vessels in Single-Pol COSMO-SkyMed Images Based on Statistical and Structural Features. Remote Sens. 2015, 7, 5511–5533. [Google Scholar] [CrossRef] [Green Version]
- Tao, D.; Anfinsen, S.N.; Brekke, C. Robust CFAR Detector Based on Truncated Statistics in Multiple-Target Situations. IEEE Trans. Geosci. Remote Sens. 2016, 54, 117–134. [Google Scholar] [CrossRef]
- Tao, D.; Doulgeris, A.P.; Brekke, C. A Segmentation-Based CFAR Detection Algorithm Using Truncated Statistics. IEEE Trans. Geosci. Remote Sens. 2016, 54, 2887–2898. [Google Scholar] [CrossRef] [Green Version]
- Srinivas, U.; Monga, V.; Raj, R.G. SAR Automatic Target Recognition Using Discriminative Graphical Models. IEEE Trans. Aerosp. Electron. Syst. 2014, 50, 591–606. [Google Scholar] [CrossRef]
- Ma, Y.; Zhao, Y.; Incecik, A.; Yan, X.; Wang, Y.; Li, Z. A collision avoidance approach via negotiation protocol for a swarm of USVs. Ocean. Eng. 2021, 224, 108713. [Google Scholar] [CrossRef]
- Ma, Y.; Nie, Z.; Hu, S.; Li, Z.; Malekian, R.; Sotelo, M. Fault Detection Filter and Controller Co-Design for Unmanned Surface Vehicles under DoS Attacks. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1422–1434. [Google Scholar] [CrossRef]
- Chen, Q.; Wang, Y.; Yang, T.; Zhang, X.; Cheng, J.; Sun, J. You Only Look One-level Feature. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13034–13043. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef] [Green Version]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Ma, N.; Zhang, X.; Liu, M.; Sun, J. Activate or Not: Learning Customized Activation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8028–8038. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar] [CrossRef] [Green Version]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10778–10787. [Google Scholar] [CrossRef]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.0338. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Additional Channels | Shortcuts | |||
|---|---|---|---|---|
| YES | NO | YES | NO | |
| AP | 38.5 | 37.4 | 38.5 | 37.1 |
| Name | Version |
|---|---|
| CPU | Intel(R) Xeon(R) Gold 6130 CPU @ 2.10 GHz |
| GPU | NVIDIA TAITAN RTX 24 G |
| OS | Ubuntu 20.04 |
| python | 3.7.0 |
| Name | FMTI | YOLOF | YOLOF + SFMF | YOLOF (Res101) | YOLOF (Res101) + SFMF |
|---|---|---|---|---|---|
| FPS | 39 | 40 | 38 | 25 | 29 |
| FLOPs | 91 G | 86 G | 91 G | / | / |
| Model_parameter | 48 M | 44 M | 49 M | 64 M | 68 M |
| mAP | >37.7% | 37.7% | 37% | 36% | 37% |
| Name | FMTI | YOLOF |
|---|---|---|
| FPS | 36.66 | 37.53 |
| FLOPs | 98.016 G | 93.52 G |
| mAP | 0.47529 | 0.40382 |
| Model_parameter | 47.137 M | 42.488 M |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, J.; Li, J.; Li, R.; Xi, X.; Gui, D.; Yin, J. A Fast Maritime Target Identification Algorithm for Offshore Ship Detection. Appl. Sci. 2022, 12, 4938. https://doi.org/10.3390/app12104938
Wu J, Li J, Li R, Xi X, Gui D, Yin J. A Fast Maritime Target Identification Algorithm for Offshore Ship Detection. Applied Sciences. 2022; 12(10):4938. https://doi.org/10.3390/app12104938
Chicago/Turabian StyleWu, Jinshan, Jiawen Li, Ronghui Li, Xing Xi, Dongxu Gui, and Jianchuan Yin. 2022. "A Fast Maritime Target Identification Algorithm for Offshore Ship Detection" Applied Sciences 12, no. 10: 4938. https://doi.org/10.3390/app12104938
APA StyleWu, J., Li, J., Li, R., Xi, X., Gui, D., & Yin, J. (2022). A Fast Maritime Target Identification Algorithm for Offshore Ship Detection. Applied Sciences, 12(10), 4938. https://doi.org/10.3390/app12104938