Authentication of Rice (Oryza sativa L.) Using Near Infrared Spectroscopy Combined with Different Chemometric Classification Strategies





Abstract
1. Introduction
Techniques Used in Rice Authentication
2. Materials and Methods
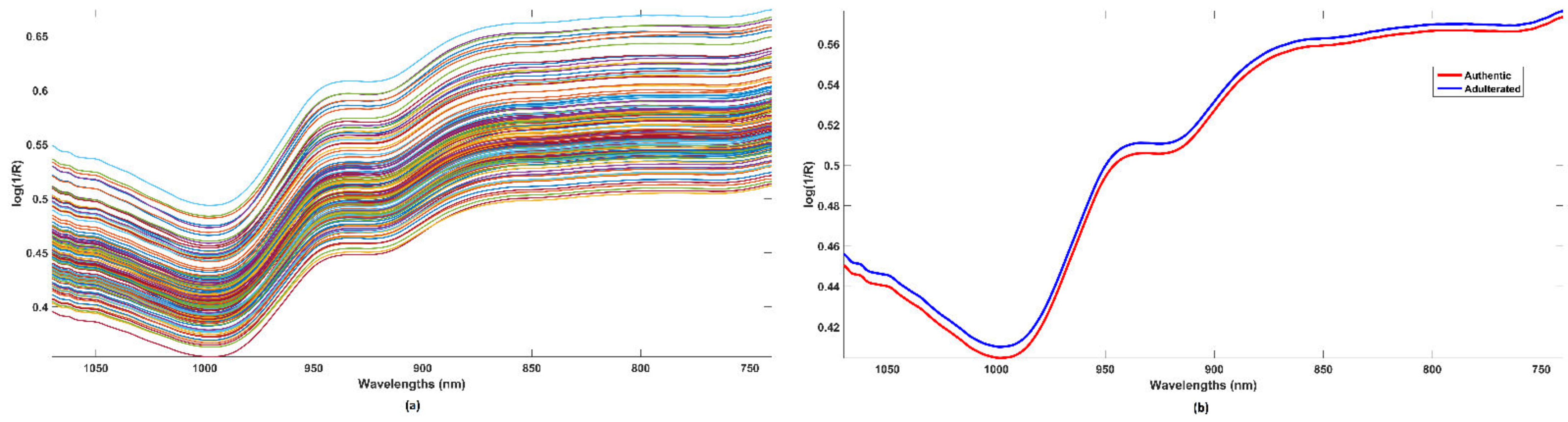
2.1. Spectral Acquisition
2.2. Rice Data Set
2.3. Spectral Preprocessing Techniques
2.4. Chemometric Methods
2.4.1. Partial Least Squares Discriminant Analysis (PLS-DA)
2.4.2. Soft Independent Modelling of Class Analogies (SIMCA)
2.4.3. Software Details
3. Results
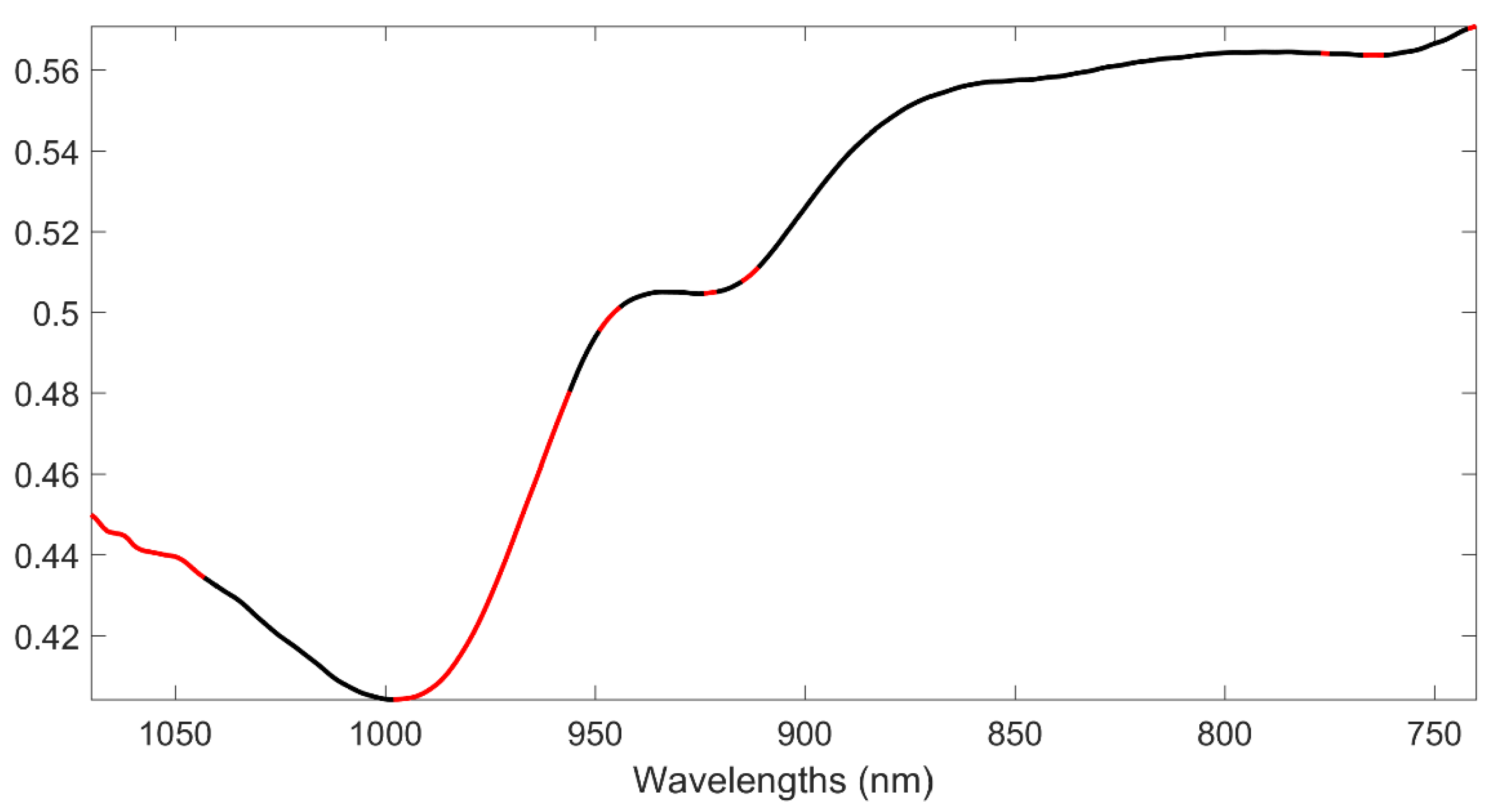
3.1. PLS-DA Analysis
3.2. SIMCA Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fiamohe, R.; Demont, M.; Saito, K.; Roy-Macauley, H.; Tollens, E. How Can West African Rice Compete in Urban Markets? A Demand Perspective for Policymakers. EuroChoices 2018, 17, 51–57. [Google Scholar] [CrossRef]
- Statista. The Statistics Portal for Market Data, Marker Results and Market Studies. Available online: www.statista.com (accessed on 31 December 2020).
- Kambo, R.; Yerpude, A. Classification of Basmati Rice Grain Variety using Image Processing and Principal Component Analysis. Int. J. Comput. Trends Technol. 2014, 11. [Google Scholar] [CrossRef]
- Singh, K.R.; Chaudhury, S. Efficient technique for rice grain classification using back-propagation neural network and wavelet decomposition. IET Comput. Vis. 2016, 10, 780–787. [Google Scholar] [CrossRef]
- Zareiforoush, H.; Minaei, S.; Alizadeh, M.R.; Banakar, A. Qualitative classification of milled rice grains using computer vision and metaheuristic techniques. J. Food Sci. Technol. 2016, 53, 118–131. [Google Scholar] [CrossRef]
- Cheajesadagul, P.; Arnaudguilhem, C.; Shiowatana, J.; Siripinyanond, A.; Szpunar, J. Discrimination of geographical origin of rice based on multi-element fingerprinting by high resolution inductively coupled plasma mass spectrometry. Food Chem. 2013, 141, 3504–3509. [Google Scholar] [CrossRef]
- Promchan, J.; Günther, D.; Siripinyanond, A.; Shiowatana, J. Elemental imaging and classifying rice grains by using laser ablation inductively coupled plasma mass spectrometry and linear discriminant analysis. J. Cereal Sci. 2016, 71, 198–203. [Google Scholar] [CrossRef]
- Barbosa, R.M.; de Paula, E.S.; Paulelli, A.C.; Moore, A.F.; Souza, J.M.O.; Batista, B.L.; Campiglia, A.D.; Barbosa, F. Recognition of organic rice samples based on trace elements and support vector machines. J. Food Compos. Anal. 2016, 45, 95–100. [Google Scholar] [CrossRef]
- Borges, E.M.; Gelinski, J.M.L.N.; de Oliveira Souza, V.C.; Barbosa, F., Jr.; Batista, B.L. Monitoring the authenticity of organic rice via chemometric analysis of elemental data. Food Res. Int. 2015, 77, 299–309. [Google Scholar] [CrossRef]
- Gonzálvez, A.; Armenta, S.; de la Guardia, M. Geographical traceability of “Arròs de Valencia” rice grain based on mineral element composition. Food Chem. 2011, 126, 1254–1260. [Google Scholar] [CrossRef]
- Chung, I.-M.; Kim, J.-K.; Lee, J.-K.; Kim, S.-H. Discrimination of geographical origin of rice (Oryza sativa L.) by multielement analysis using inductively coupled plasma atomic emission spectroscopy and multivariate analysis. J. Cereal Sci. 2015, 65, 252–259. [Google Scholar] [CrossRef]
- Li, G.; Nunes, L.; Wang, Y.; Williams, P.N.; Zheng, M.; Zhang, Q.; Zhu, Y. Profiling the ionome of rice and its use in discriminating geographical origins at the regional scale, China. J. Environ. Sci. 2013, 25, 144–154. [Google Scholar] [CrossRef]
- Chung, I.-M.; Kim, J.-K.; Lee, K.-J.; Park, S.-K.; Lee, J.-H.; Son, N.-Y.; Jin, Y.-I.; Kim, S.-H. Geographic authentication of Asian rice (Oryza sativa L.) using multi-elemental and stable isotopic data combined with multivariate analysis. Food Chem. 2018, 240, 840–849. [Google Scholar] [CrossRef] [PubMed]
- Kuo, T.-Y.; Chung, C.-L.; Chen, S.-Y.; Lin, H.-A.; Kuo, Y.-F. Identifying rice grains using image analysis and sparse-representation-based classification. Comput. Electron. Agric. 2016, 127, 716–725. [Google Scholar] [CrossRef]
- Huo, Y.; Kamal, G.M.; Wang, J.; Liu, H.; Zhang, G.; Hu, Z.; Anwar, F.; Du, H. 1H NMR-based metabolomics for discrimination of rice from different geographical origins of China. J. Cereal Sci. 2017, 76, 243–252. [Google Scholar] [CrossRef]
- Yang, J.; Sun, J.; Du, L.; Chen, B.; Zhang, Z.; Shi, S.; Gong, W. Monitoring of Paddy Rice Varieties Based on the Combination of the Laser-Induced Fluorescence and Multivariate Analysis. Food Anal. Methods 2017, 10, 2398–2403. [Google Scholar] [CrossRef]
- Liu, W.; Liu, C.; Hu, X.; Yang, J.; Zheng, L. Application of terahertz spectroscopy imaging for discrimination of transgenic rice seeds with chemometrics. Food Chem. 2016, 210, 415–421. [Google Scholar] [CrossRef]
- Long, Z.; Shan-shan, W.; Yan-fei, D.; Jia-rong, P.A.N.; Cheng, Z.H.U. Discrimination of Transgenic Rice Based on Near Infrared Reflectance Spectroscopy and Partial Least Squares Regression Discriminant Analysis. Rice Sci. 2015, 22, 245–249. [Google Scholar] [CrossRef]
- Rodriguez-Saona, L.; Ayvaz, H.; Wehling, R.L. Infrared and Raman Spectroscopy. In Food Analysis; Nielsen, S.S., Ed.; Springer International Publishing: Cham, Germany, 2017; pp. 107–127. [Google Scholar] [CrossRef]
- Lin, L.; He, Y.; Xiao, Z.; Zhao, K.; Dong, T.; Nie, P. Rapid-Detection Sensor for Rice Grain Moisture Based on NIR Spectroscopy. Appl. Sci. 2019, 9, 1654. [Google Scholar] [CrossRef]
- Biancolillo, A.; Firmani, P.; Bucci, R.; Magrì, A.; Marini, F. Determination of insect infestation on stored rice by near infrared (NIR) spectroscopy. Microchem. J. 2019, 145, 252–258. [Google Scholar] [CrossRef]
- Sampaio, P.S.; Castanho, A.; Almeida, A.S.; Oliveira, J.; Brites, C. Identification of rice flour types with near-infrared spectroscopy associated with PLS-DA and SVM methods. Eur. Food Res. Technol. 2020, 246, 527–537. [Google Scholar] [CrossRef]
- Firmani, P.; Bucci, R.; Marini, F.; Biancolillo, A. Authentication of “Avola almonds” by near infrared (NIR) spectroscopy and chemometrics. J. Food Compos. Anal. 2019, 82, 103235. [Google Scholar] [CrossRef]
- Teye, E.; Amuah, C.L.Y.; McGrath, T.; Elliott, C. Innovative and rapid analysis for rice authenticity using hand-held NIR spectrometry and chemometrics. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2019, 217, 147–154. [Google Scholar] [CrossRef] [PubMed]
- Firmani, P.; Nardecchia, A.; Nocente, F.; Gazza, L.; Marini, F.; Biancolillo, A. Multi-block classification of Italian semolina based on Near Infrared Spectroscopy (NIR) analysis and alveographic indices. Food Chem. 2020, 309, 125677. [Google Scholar] [CrossRef] [PubMed]
- Maione, C.; Barbosa, R.M. Recent applications of multivariate data analysis methods in the authentication of rice and the most analyzed parameters: A review. Crit. Rev. Food Sci. Nutr. 2019, 59, 1868–1879. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Li, M.; Pan, T.; Pang, L.; Yao, L.; Zhang, J. Rapid and non-destructive analysis for the identification of multi-grain rice seeds with near-infrared spectroscopy. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2019, 219, 179–185. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Tan, C.; Lin, Z. Authenticity Detection of Black Rice by Near-Infrared Spectroscopy and Support Vector Data Description. Int. J. Anal. Chem. 2018, 2018, 8032831. [Google Scholar] [CrossRef] [PubMed]
- Chen, K.J.; Huang, M. Prediction of milled rice grades using Fourier transform near-infrared spectroscopy and artificial neural networks. J. Cereal Sci. 2010, 52, 221–226. [Google Scholar] [CrossRef]
- Firmani, P.; La Piscopia, G.; Bucci, R.; Marini, F.; Biancolillo, A. Authentication of P.G.I. Gragnano pasta by near infrared (NIR) spectroscopy and chemometrics. Microchem. J. 2020, 152, 104339. [Google Scholar] [CrossRef]
- Hao, Y.; Geng, P.; Wu, W.; Wen, Q.; Rao, M. Identification of Rice Varieties and Transgenic Characteristics Based on Near-Infrared Diffuse Reflectance Spectroscopy and Chemometrics. Molecules 2019, 24, 4568. [Google Scholar] [CrossRef]
- Natsuga, M.; Kawamura, S. Visible and Near-Infrared reflectance spectroscopy for determining physicochemical properties of rice. Trans. ASABE 2006, 49, 1069–1076. [Google Scholar] [CrossRef]
- Kong, W.; Zhang, C.; Liu, F.; Nie, P.; He, Y. Rice seed cultivar identification using near-infrared hyperspectral imaging and multivariate data analysis. Sensors 2013, 13, 8916–8927. [Google Scholar] [CrossRef] [PubMed]
- Zhang, B.; Rong, Z.Q.; Shi, Y.; Wu, J.G.; Shi, C.H. Prediction of the amino acid composition in brown rice using different sample status by near-infrared reflectance spectroscopy. Food Chem. 2011, 127, 275–281. [Google Scholar] [CrossRef]
- Xie, L.H.; Tang, S.Q.; Chen, N.; Luo, J.; Jiao, G.A.; Shao, G.N.; Wei, X.J.; Hu, P.S. Optimisation of near-infrared reflectance model in measuring protein and amylose content of rice flour. Food Chem. 2014, 142, 92–100. [Google Scholar] [CrossRef] [PubMed]
- Li, B.; Zhao, M.; Zhou, Y.; Hou, B.; Zhang, D. Detection of Waxed Rice Using Visible-near Infrared Hyperspectral Imaging. J. Food Nutr. Res. 2016, 4, 267–275. [Google Scholar] [CrossRef]
- Siriphollakul, P.; Nakano, K.; Kanlayanarat, S.; Ohashi, S.; Sakai, R.; Rittiron, R.; Maniwara, P. Eating quality evaluation of Khao Dawk Mali 105 rice using near-infrared spectroscopy. LWT-Food Sci. Technol. 2017, 79, 70–77. [Google Scholar] [CrossRef]
- Biancolillo, A.; Marini, F. Chapter Four-Chemometrics Applied to Plant Spectral Analysis. In Vibrational Spectroscopy for Plant Varieties and Cultivars Characterization; Lopes, J., Sousa, C., Eds.; Comprehensive Analytical Chemistry, 80; Elsevier: Amsterdam, The Netherlands, 2018; pp. 69–104. [Google Scholar]
- Biancolillo, A.; Marini, F.; Ruckebusch, C.; Vitale, R. Chemometric Strategies for Spectroscopy-Based Food Authentication. Appl. Sci. 2020, 10, 6544. [Google Scholar] [CrossRef]
- Snee, R.D. Validation of Regression Models: Methods and Examples. Technometrics 1977, 19, 415–428. [Google Scholar] [CrossRef]
- Rinnan, Å.; Berg, F.v.d.; Engelsen, S.B. Review of the most common pre-processing techniques for near-infrared spectra. TrAC Trends Anal. Chem. 2009, 28, 1201–1222. [Google Scholar] [CrossRef]
- Savitzky, A.; Golay, M.J.E. Smoothing and Differentiation of Data by Simplified Least Squares Procedures. Anal. Chem. 1964, 36, 1627–1639. [Google Scholar] [CrossRef]
- Barnes, R.J.; Dhanoa, M.S.; Lister, S.J. Standard Normal Variate Transformation and De-trending of Near-Infrared Diffuse Reflectance Spectra. Appl. Spectrosc. 1989, 43, 772–777. [Google Scholar] [CrossRef]
- Barker, M.; Rayens, W. Partial least squares for discrimination. J. Chemom. 2003, 17, 166–173. [Google Scholar] [CrossRef]
- Nocairi, H.; Mostafa Qannari, E.; Vigneau, E.; Bertrand, D. Discrimination on latent components with respect to patterns. Application to multicollinear data. Comput. Stat. Data Anal. 2005, 48, 139–147. [Google Scholar] [CrossRef]
- Indahl, U.G.; Martens, H.; Næs, T. From dummy regression to prior probabilities in PLS-DA. J. Chemom. 2007, 21, 529–536. [Google Scholar] [CrossRef]
- Sjöström, M.; Wold, S.; Söderström, B. PLS discriminant plots. In Pattern Recognition in Practice; Gelsema, E.S., Kanal, L.N., Eds.; Elsevier: Amsterdam, The Netherlands, 1986; pp. 461–470. [Google Scholar] [CrossRef]
- Ståhle, L.; Wold, S. Partial least squares analysis with cross-validation for the two-class problem: A Monte Carlo study. J. Chemom. 1987, 1, 185–196. [Google Scholar] [CrossRef]
- Wold, S.; Martens, H.; Wold, H. The multivariate calibration problem in chemistry solved by the PLS method. In Matrix Pencils; Springer: Berlin/Heidelberg, Germany, 1983; pp. 286–293. [Google Scholar]
- Geladi, P.; Kowalski, B.R. Partial least-squares regression: A tutorial. Anal. Chim. Acta 1986, 185, 1–17. [Google Scholar] [CrossRef]
- Martens, H.; Næs, T. Multivariate Calibration; John Wiley & Sons: New York, NY, USA, 1989. [Google Scholar]
- Tharwat, A. Linear vs. quadratic discriminant analysis classifier: A tutorial. Int. J. Appl. Pattern Recognit. 2016, 3, 145–180. [Google Scholar] [CrossRef]
- Pérez, N.F.; Ferré, J.; Boqué, R. Calculation of the reliability of classification in discriminant partial least-squares binary classification. Chemom. Intell. Lab. Syst. 2009, 95, 122–128. [Google Scholar] [CrossRef]
- Wold, S. Pattern recognition by means of disjoint principal components models. Pattern Recognit. 1976, 8, 127–139. [Google Scholar] [CrossRef]
- Wold, S.; Sjöström, M. SIMCA: A Method for Analyzing Chemical Data in Terms of Similarity and Analogy. In Chemometrics: Theory and Application; American Chemical Society: Washington, DC, USA, 1977; Volume 52, pp. 243–282. [Google Scholar]
- Yue, H.H.; Qin, S.J. Reconstruction-Based Fault Identification Using a Combined Index. Ind. Eng. Chem. Res. 2001, 40, 4403–4414. [Google Scholar] [CrossRef]
- Cocchi, M.; Biancolillo, A.; Marini, F. Chapter Ten-Chemometric Methods for Classification and Feature Selection. In Comprehensive Analytical Chemistry; Jaumot, J., Bedia, C., Tauler, R., Eds.; Elsevier: Amsterdam, The Netherlands, 2018; Volume 82, pp. 265–299. [Google Scholar]
- Stuart, B.H. Infrared Spectroscopy: Fundamentals and Applications; Wiley: New York, NY, USA, 2004. [Google Scholar]
- Franca, A.S.; Nollet, L.M.L. Spectroscopic Methods in Food Analysis; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]



{kind=link}
{kind=link}
| Preprocessing | LVs | % Correct Classification Rate in Cross-Validation | ||
|---|---|---|---|---|
| Authentic (49 Samples) | Adulterated 5% + 10% (91 Samples) | Overall (140 Samples) | ||
| MC | 5 | 67.3 | 73.6 | 70.4 |
| SNV (+MC) | 4 | 65.3 | 75.8 | 70.5 |
| 1st derivative (+MC) | 6 | 73.4 | 91.5 | 82.4 |
| 2nd derivative (+MC) | 4 | 71.4 | 76.6 | 74.1 |
| Preprocessing | LVs | % Correct Classification Rate in Cross-Validation | ||
|---|---|---|---|---|
| Authentic (49 Samples) | Adulterated 10% (47 Samples) | Overall (96 Samples) | ||
| MC | 7 | 67.3 | 83.0 | 75.1 |
| SNV (+MC) | 8 | 83.7 | 91.5 | 87.6 |
| 1st derivative (+MC) | 6 | 73.5 | 91.5 | 82.5 |
| 2nd derivative (+MC) | 5 | 73.5 | 78.7 | 79.3 |
| Preprocessing | PCs | Sensitivity (%) | Specificity (%) vs. 5% + 10% Adulterated | Efficiency (%) |
|---|---|---|---|---|
| MC | 4 | 98.0 | 4.4 | 20.7 |
| SNV (+MC) | 6 | 95.9 | 5.5 | 23.0 |
| 1st derivative (+MC) | 5 | 93.9 | 6.6 | 24.9 |
| 2nd derivative (+MC) | 8 | 98.0 | 11.0 | 32.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Le Nguyen Doan, D.; Nguyen, Q.C.; Marini, F.; Biancolillo, A. Authentication of Rice (Oryza sativa L.) Using Near Infrared Spectroscopy Combined with Different Chemometric Classification Strategies. Appl. Sci. 2021, 11, 362. https://doi.org/10.3390/app11010362
Le Nguyen Doan D, Nguyen QC, Marini F, Biancolillo A. Authentication of Rice (Oryza sativa L.) Using Near Infrared Spectroscopy Combined with Different Chemometric Classification Strategies. Applied Sciences. 2021; 11(1):362. https://doi.org/10.3390/app11010362
Chicago/Turabian StyleLe Nguyen Doan, Duy, Quoc Cuong Nguyen, Federico Marini, and Alessandra Biancolillo. 2021. "Authentication of Rice (Oryza sativa L.) Using Near Infrared Spectroscopy Combined with Different Chemometric Classification Strategies" Applied Sciences 11, no. 1: 362. https://doi.org/10.3390/app11010362
APA StyleLe Nguyen Doan, D., Nguyen, Q. C., Marini, F., & Biancolillo, A. (2021). Authentication of Rice (Oryza sativa L.) Using Near Infrared Spectroscopy Combined with Different Chemometric Classification Strategies. Applied Sciences, 11(1), 362. https://doi.org/10.3390/app11010362