Data-Augmented Hybrid Named Entity Recognition for Disaster Management by Transfer Learning


 ,
,
Abstract
1. Introduction
1.1. Demand for Natural Language Processing (NLP) in Disaster Management
1.2. Drawbacks of General NER Models
1.3. Model Revision for Disaster Management
2. Literature Review
2.1. Review of Related Work
2.2. Evolution of NER
2.3. Introduction to Transfer Learning
2.4. The Implementation of Hybrid NER
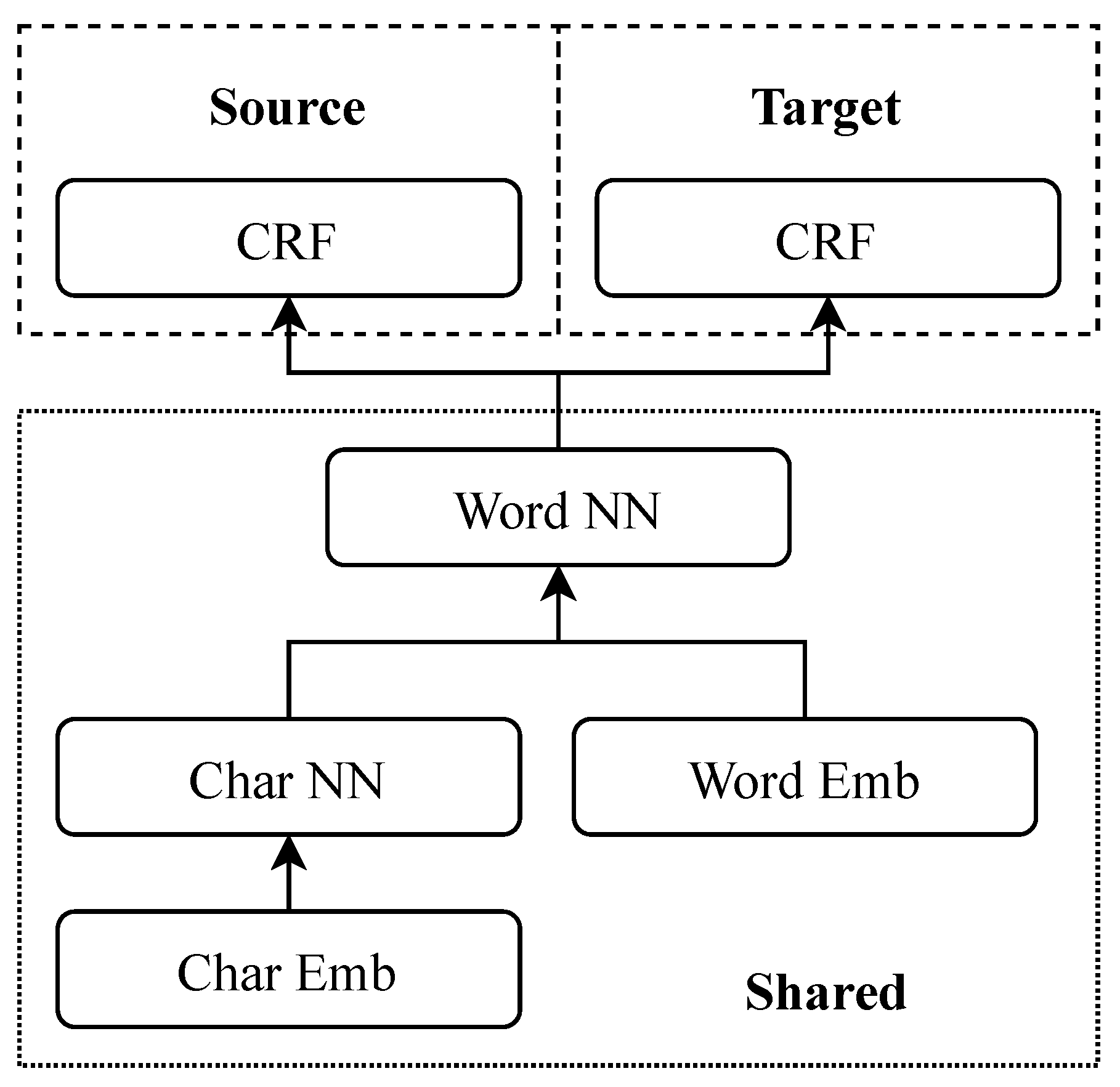
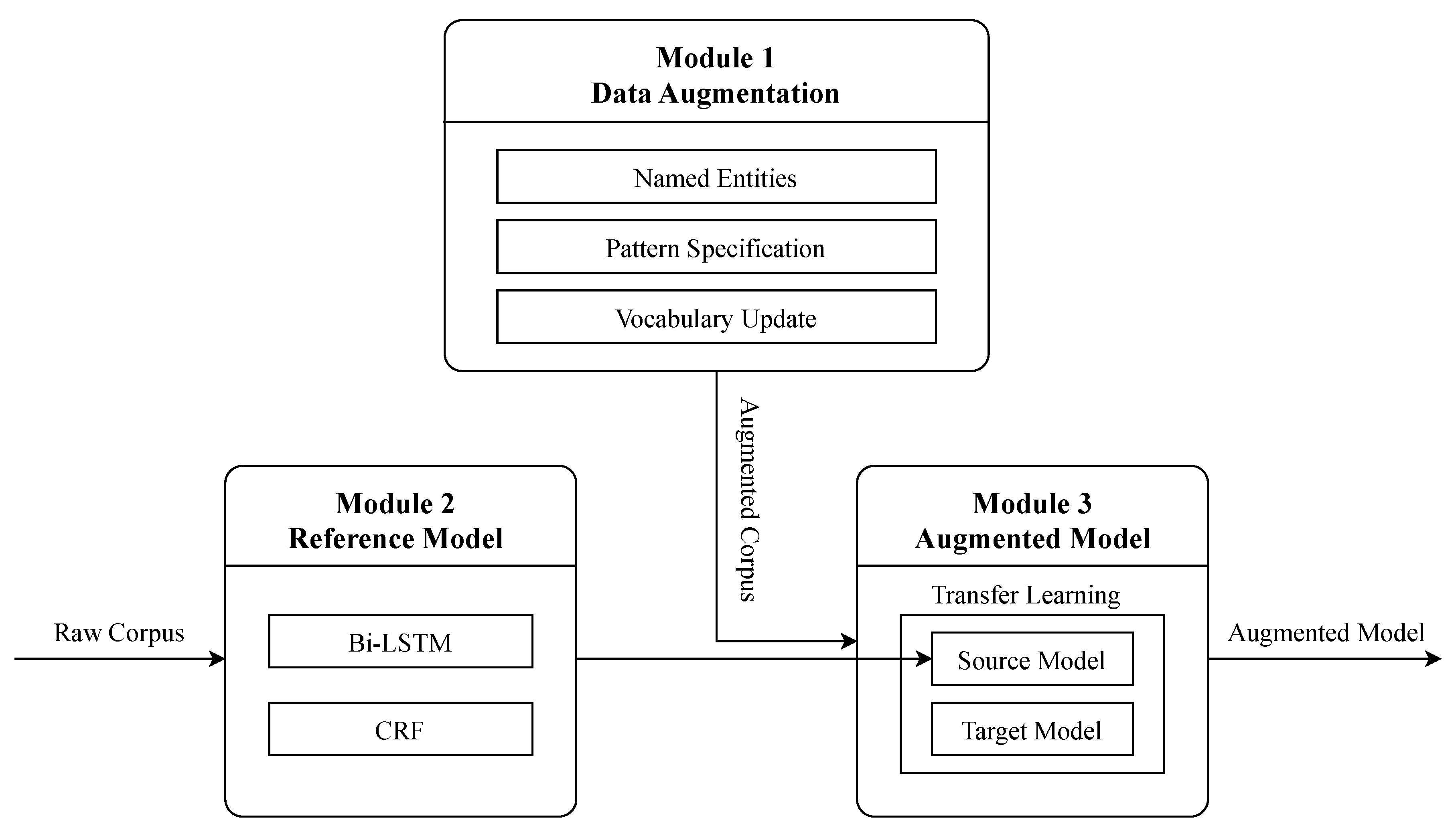
3. Methodology
3.1. Data Augmentation
3.1.1. Named Entities
- National Science and Technology Center for Disaster Reduction (NCDR), which is the official dictionary for formal terms in Taiwan; and
- The historical messages regarding school building safety inspections from the associated LINE chatbot proposed in our related work contain the most frequently used terms, colloquial usages, and abbreviations.
3.1.2. Pattern Specification
3.1.3. Vocabulary Update
3.2. Reference Model
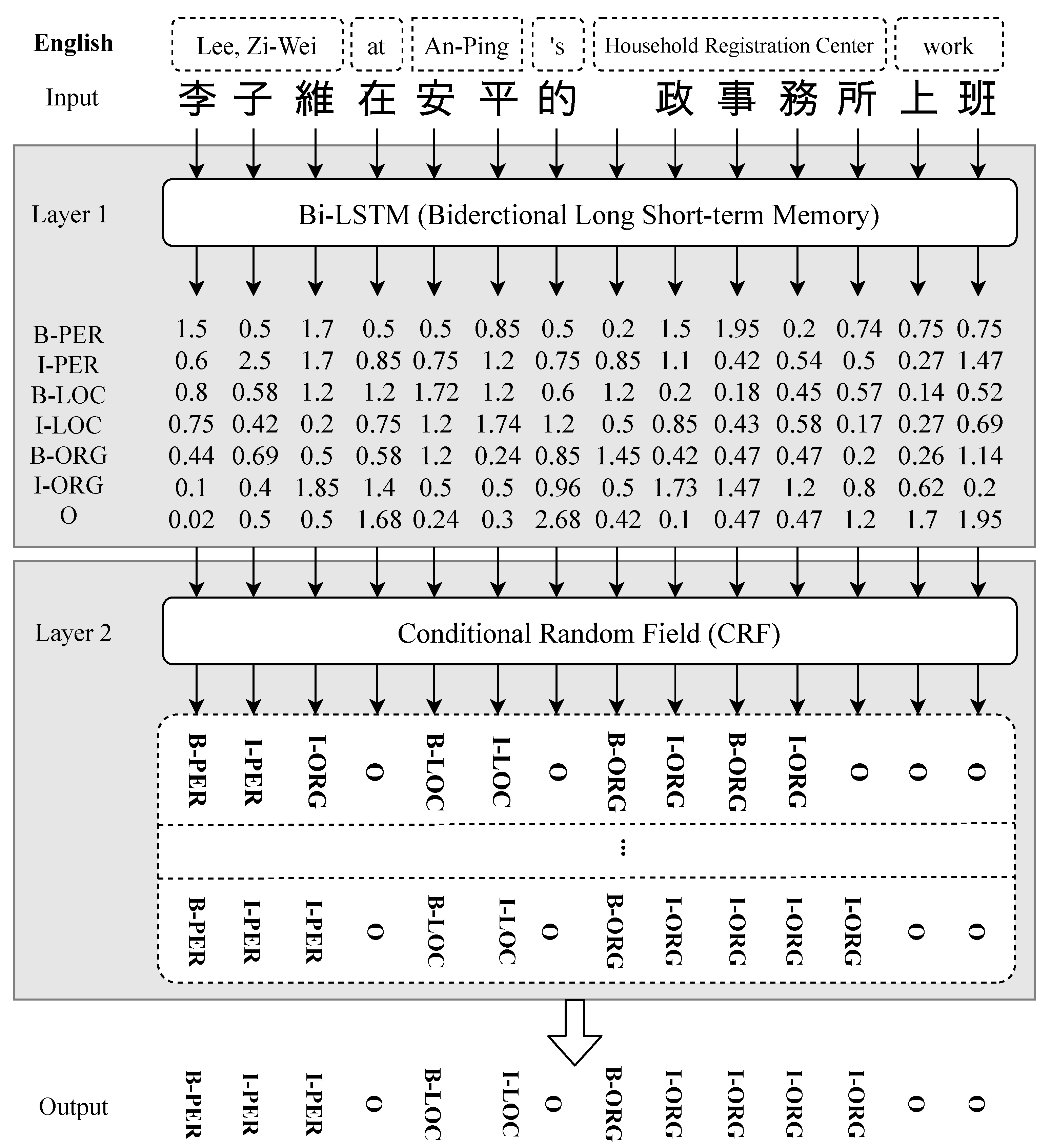
3.2.1. Layer 1: Bidirectional Long Short-Term Memory, Bi-LSTM
3.2.2. Layer 2: Conditional Random Field, CRF
- Reading of input sentence,
- Splitting of words into characters,
- Layer 1: Bi-LSTM, results in a series of entity-tag predictions,
- Layer 2: CRF, screens and revises the primitive outcome of Layer 1,
- Comparison of the results of the previous process with tagged entities to minimize losses recursively.
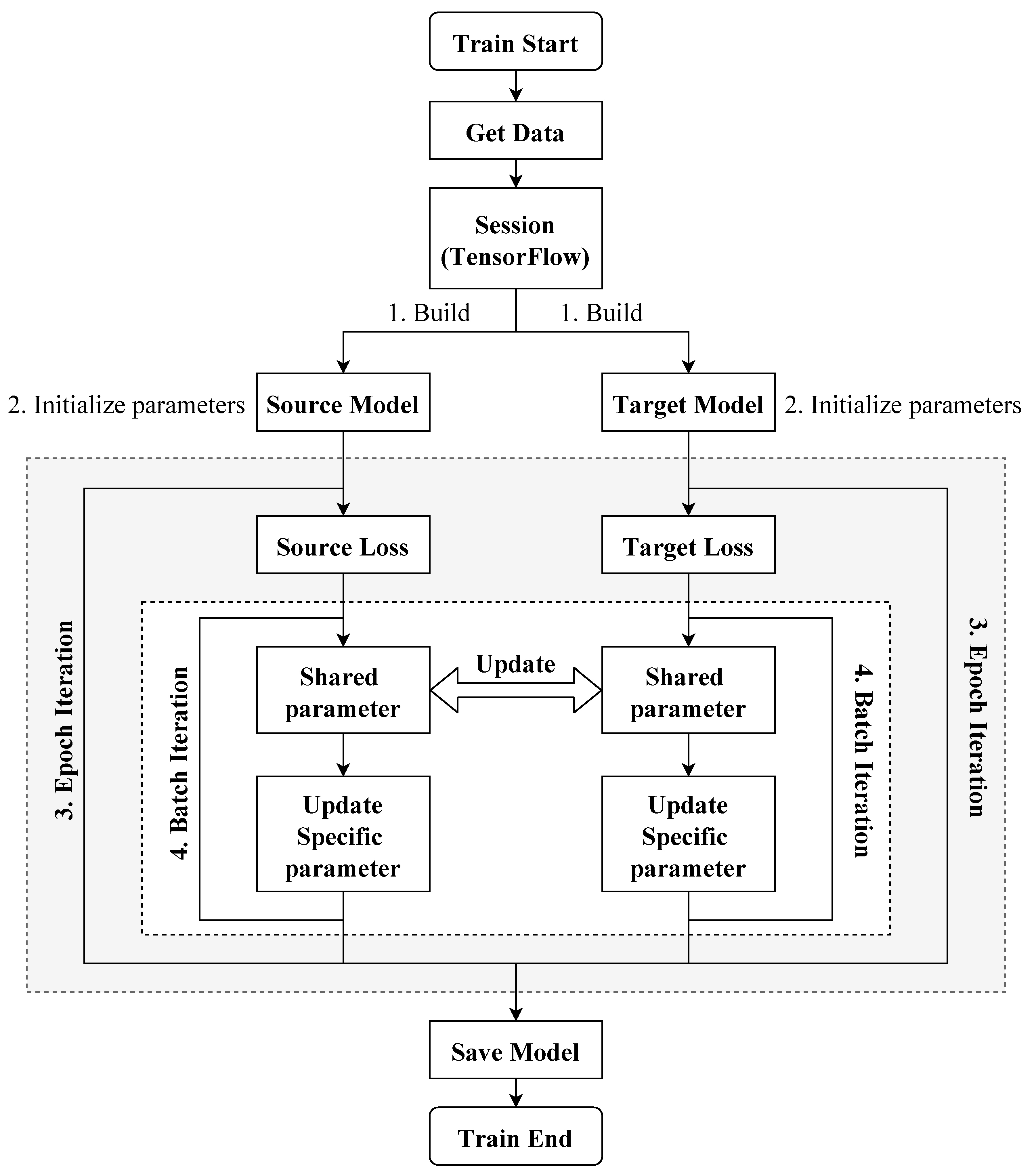
3.3. Augmented Model
4. Results
4.1. Performance of Augmented Model
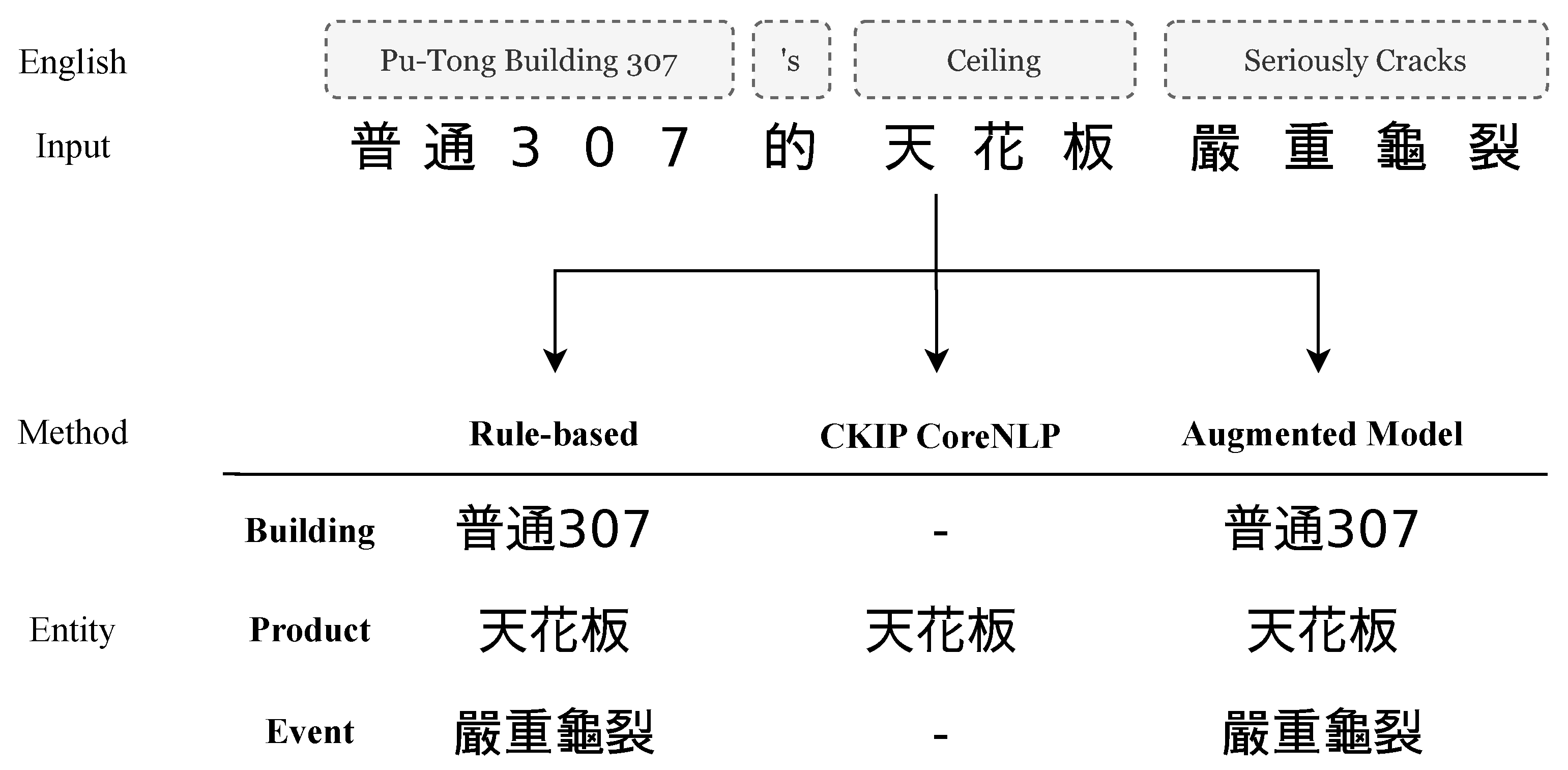
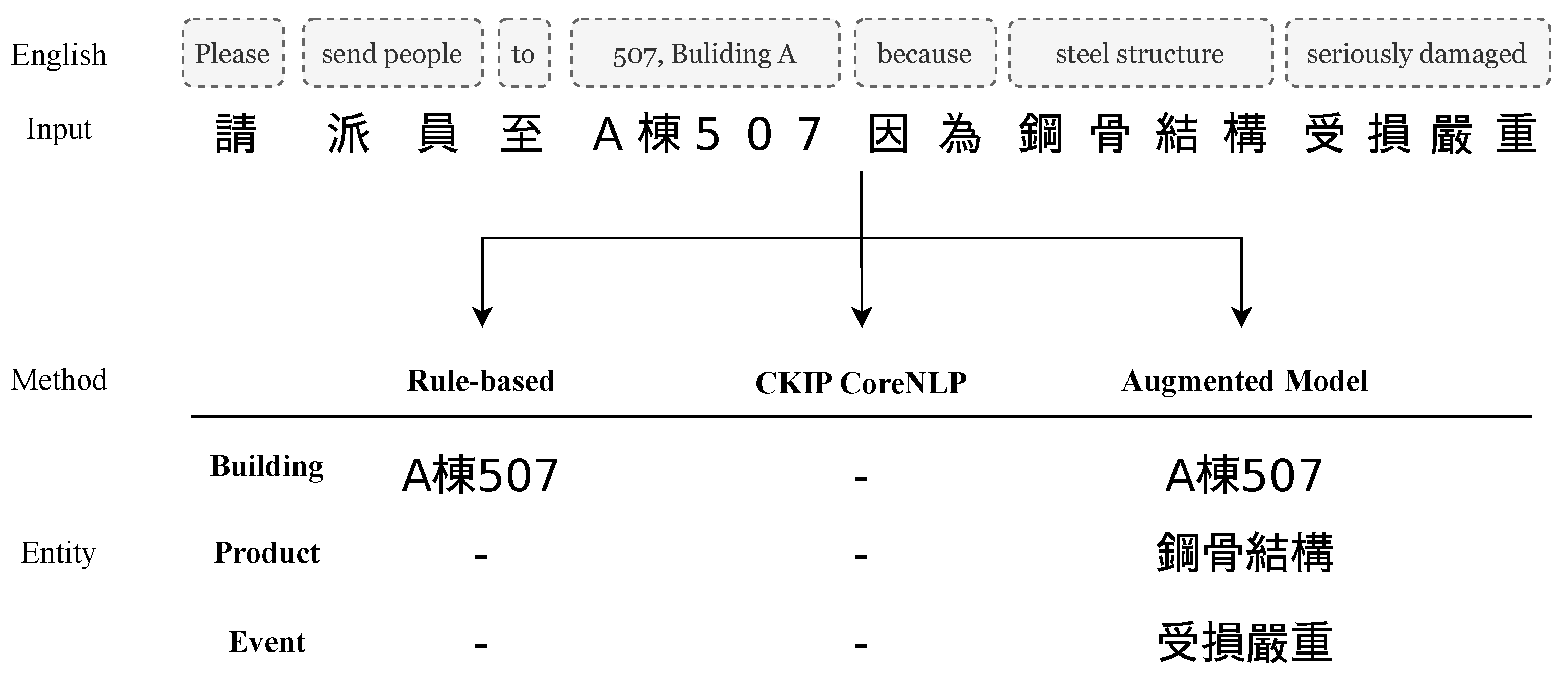
4.2. Recognition of Named Entities
4.3. Vocabulary Database Update
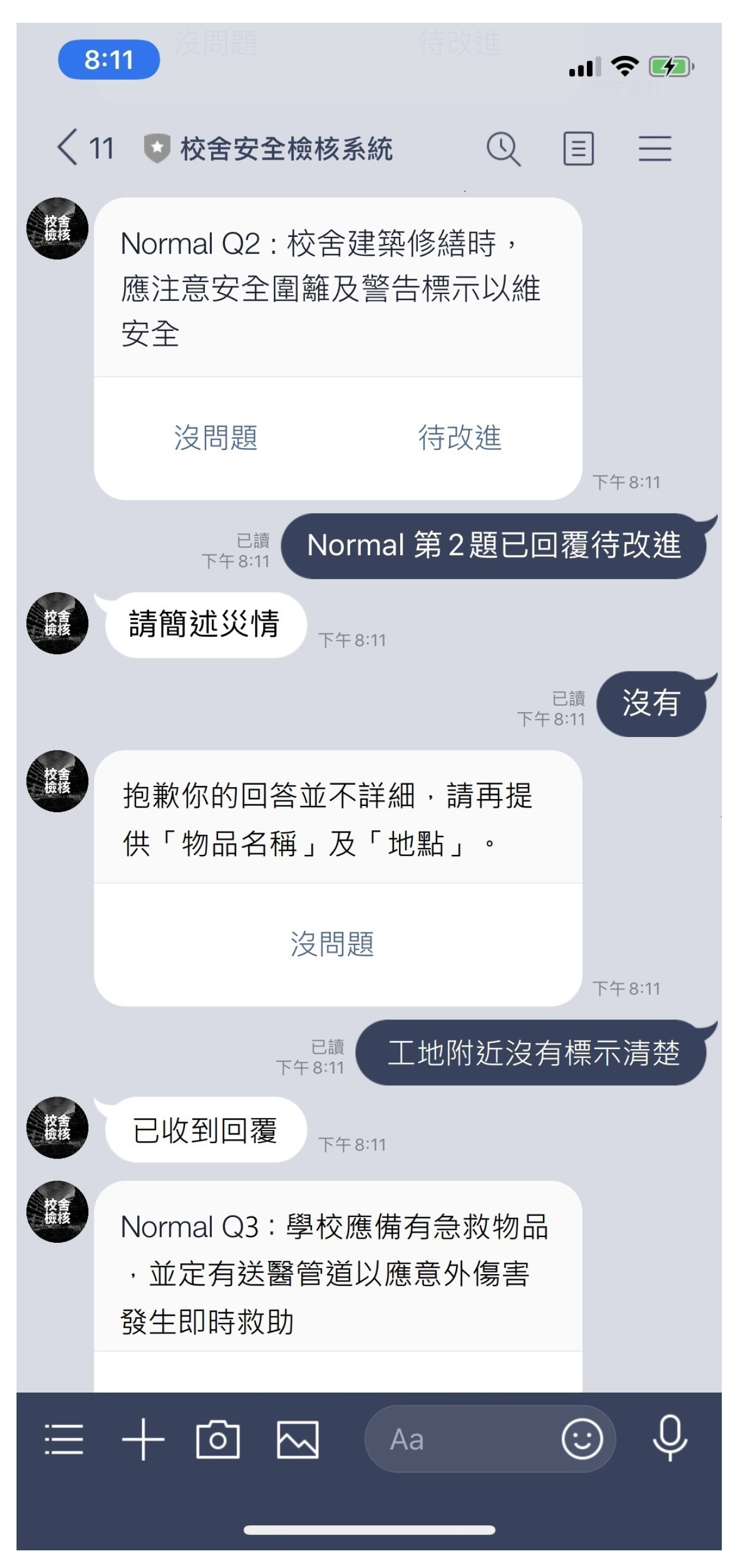
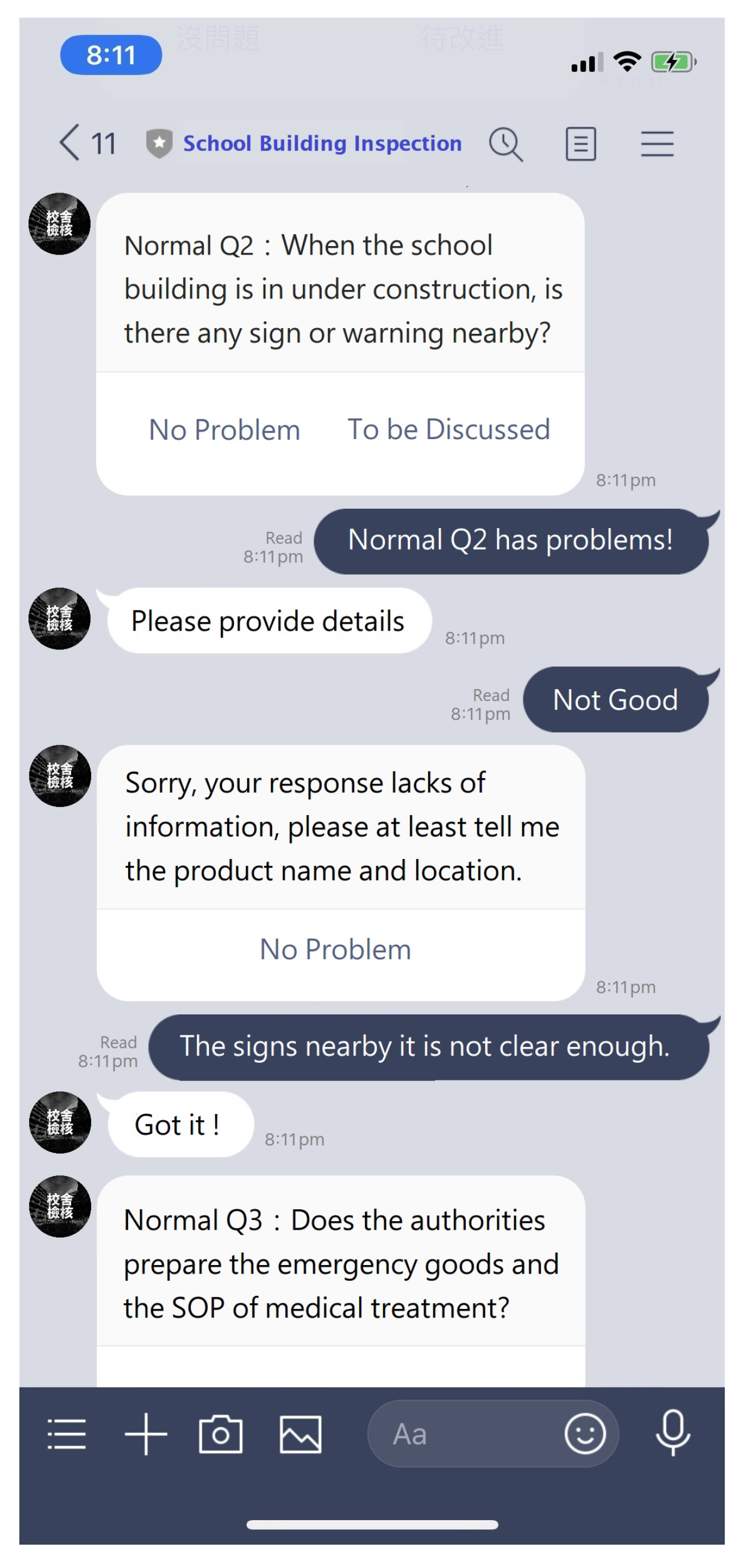
4.4. Interfacing with Messaging Apps
5. Discussion
5.1. Contribution
5.2. Improvement in Application
5.3. Limitation
5.4. Future Work
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| Bi-LSTM | Bidirectional Long Short-term Memory |
| BNER | Biomedical Named Entity Recognition |
| CASIA | Institute of Automation, Chinese Academy of Sciences |
| CRF | Conditional Random1 Field |
| HMM | Hidden Markov Model |
| NER | Named Entity Recognition |
| NLP | Natural Language Process |
| NLU | Natural Language Understanding |
| NTUST | National Taiwan University of Science and Technology |
| RNNs | Recurrent Neural Networks |
Appendix A. Tags of the Label Set in the Augmented Model
| O | Other, non-specific entity |
| B-product-name | The beginning character of a product entity |
| I-product-name | The non-beginning character of a product entity |
| B-time | The beginning character of a time entity |
| I-time | The non-beginning character of a time entity |
| B-person-name | The beginning character of a person entity |
| I-person-name | The non-beginning character of a person entity |
| B-org-name | The beginning character of a organization entity |
| I-org-name | The non-beginning character of a organization entity |
| B-company-name | The beginning character of a company entity |
| I-company-name | The non-beginning character of a company entity |
| B-location | The beginning character of a location entity |
| I-location | The non-beginning character of a location entity |
| B-event | The beginning character of a event entity |
| I-event | The non-beginning character of a event entity |
References
- Tsai, M.H.; Chan, H.Y.; Liu, L.Y. Conversation-Based School Building Inspection Support System. Appl. Sci. 2020, 10, 3739. [Google Scholar] [CrossRef]
- Neubig, G.; Matsubayashi, Y.; Hagiwara, M.; Murakami, K. Safety Information Mining—What can NLP do in a disaster. In Proceedings of the 5th International Joint Conference on Natural Language Processing, Chiang Mai, Thailand, 8–13 November 2011; pp. 965–973. [Google Scholar]
- Li, H.; Caragea, D.; Caragea, C.; Herndon, N. Disaster response aided by tweet classification with a domain adaptation approach. J. Contin. Crisis Manag. 2018, 26, 16–27. [Google Scholar] [CrossRef]
- Li, P.H.; Fu, T.J.; Ma, W.Y. Why Attention? Analyze BiLSTM Deficiency and Its Remedies in the Case of NER. arXiv 2019, arXiv:1908.11046. [Google Scholar]
- Hsieh, Y.L.; Chang, Y.C.; Huang, Y.J.; Yeh, S.H.; Chen, C.H.; Hsu, W.L. MONPA: Multi-objective Named-entity and Part-of-speech Annotator for Chinese using Recurrent Neural Network. In Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 2: Short Papers), Taipei, Taiwan, 27 November–1 December 2017; pp. 80–85. [Google Scholar]
- Pollard, A. Increasing Awareness and Talk Time through Free Messaging Apps. Eng. Teach. Forum 2015, 53, 25–32. [Google Scholar]
- Business Insider Intelligence. THE MESSAGING APPS REPORT: Messaging Apps Are Now Bigger Than Social Networks. 2016. Available online: https://read.bi/2RTgjhi (accessed on 27 January 2020).
- Tomar, A.; Kakkar, A. Maturity model for features of social messaging applications. In Proceedings of the 3rd International Conference on Reliability, Infocom Technologies and Optimization, Noida, India, 8–10 October 2014; pp. 1–6. [Google Scholar]
- LINE Corporation. Messaging API. Available online: https://developers.line.biz/en/docs/messaging-api/overview/ (accessed on 1 January 2019).
- Mansouri, A.; Affendey, L.S.; Mamat, A. Named entity recognition approaches. Int. J. Comput. Sci. Netw. Secur. 2008, 8, 339–344. [Google Scholar]
- Zhou, G.; Su, J. Named entity recognition using an HMM-based chunk tagger. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 473–480. [Google Scholar]
- Budi, I.; Bressan, S. Association rules mining for name entity recognition. In Proceedings of the Fourth International Conference on Web Information Systems Engineering (WISE 2003), Roma, Italy, 10–12 December 2003; pp. 325–328. [Google Scholar]
- Chan, H.Y.; Tsai, M.H. Question-answering dialogue system for emergency operations. Int. J. Disaster Risk Reduct. 2019, 41, 101313. [Google Scholar] [CrossRef]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF models for sequence tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Caruana, R. Multitask learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Yang, Z.; Salakhutdinov, R.; Cohen, W.W. Transfer learning for sequence tagging with hierarchical recurrent networks. arXiv 2017, arXiv:1703.06345. [Google Scholar]
- Yarowsky, D.; Ngai, G.; Wicentowski, R. Inducing multilingual text analysis tools via robust projection across aligned corpora. In Proceedings of the First International Conference on Human Language Technology Research, San Diego, CA, USA, 18–21 March 2001; pp. 1–8. [Google Scholar]
- Srihari, R.K. A hybrid approach for named entity and sub-type tagging. In Proceedings of the Sixth Applied Natural Language Processing Conference, Seattle, WA, USA, 29 April–3 May 2000; pp. 247–254. [Google Scholar]
- Wei, P. A Very Simple BiLSTM-CRF Model for Chinese Named Entity Recognition. 2018. Available online: https://github.com/Determined22/zh-NER-TF (accessed on 30 December 2019).
- Graves, A.; Mohamed, A.R.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Ratinov, L.; Roth, D. Design challenges and misconceptions in named entity recognition. In Proceedings of the Thirteenth Conference on Computational Natural Language Learning (CoNLL-2009), Boulder, CO, USA, 4 June 2009; pp. 147–155. [Google Scholar]
- Giorgi, J.M.; Bader, G.D. Transfer learning for biomedical named entity recognition with neural networks. Bioinformatics 2018, 34, 4087–4094. [Google Scholar] [CrossRef] [PubMed]
- Morwal, S.; Jahan, N.; Chopra, D. Named entity recognition using hidden Markov model (HMM). Int. J. Nat. Lang. Comput. (IJNLC) 2012, 1, 15–23. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sentence Pattern |
|---|
| Start + <Product> + <Event> + End |
| Start + <Location> + prep + <Product> + <Event> + End |
| Action + <Location> + prep + <Product> |
| Start + <Location> + <Product> + <Event> + Action |
| ⋯ |
| Precision | Recall | FB1 | |
|---|---|---|---|
| Location | 93.33% | 94.30% | 93.81% |
| product_name | 87.90% | 90.58% | 89.22% |
| person_name | 70.25% | 78.83% | 74.29% |
| time | 77.90% | 74.48% | 76.15% |
| Event | 70.72% | 70.30% | 70.51% |
| Org_name | 59.62% | 44.29% | 50.82% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kung, H.-K.; Hsieh, C.-M.; Ho, C.-Y.; Tsai, Y.-C.; Chan, H.-Y.; Tsai, M.-H. Data-Augmented Hybrid Named Entity Recognition for Disaster Management by Transfer Learning. Appl. Sci. 2020, 10, 4234. https://doi.org/10.3390/app10124234
Kung H-K, Hsieh C-M, Ho C-Y, Tsai Y-C, Chan H-Y, Tsai M-H. Data-Augmented Hybrid Named Entity Recognition for Disaster Management by Transfer Learning. Applied Sciences. 2020; 10(12):4234. https://doi.org/10.3390/app10124234
Chicago/Turabian StyleKung, Hung-Kai, Chun-Mo Hsieh, Cheng-Yu Ho, Yun-Cheng Tsai, Hao-Yung Chan, and Meng-Han Tsai. 2020. "Data-Augmented Hybrid Named Entity Recognition for Disaster Management by Transfer Learning" Applied Sciences 10, no. 12: 4234. https://doi.org/10.3390/app10124234
APA StyleKung, H.-K., Hsieh, C.-M., Ho, C.-Y., Tsai, Y.-C., Chan, H.-Y., & Tsai, M.-H. (2020). Data-Augmented Hybrid Named Entity Recognition for Disaster Management by Transfer Learning. Applied Sciences, 10(12), 4234. https://doi.org/10.3390/app10124234