Training of Deep Convolutional Neural Networks to Identify Critical Liver Alterations in Histopathology Image Samples




 ,
,  ,
,  ,
, 
Abstract
1. Introduction
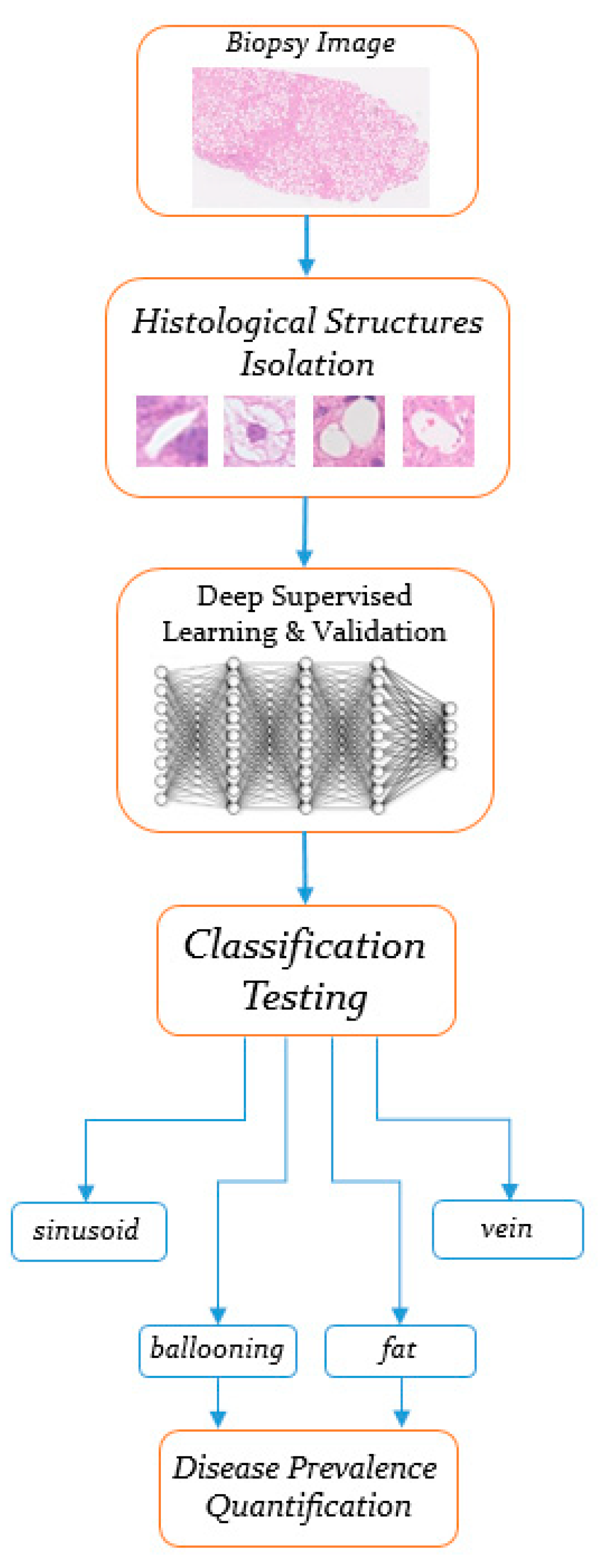
2. Materials and Methods
- Step 1.
- Collection of a sufficient number of isolated training samples from digitized biopsies, pointing to the 4-class tissue alterations.
- Step 2.
- Training two convolutional neural networks carrying the same architecture, but employing different optimization algorithms, as well as estimating their classification performance in several testing images. Also, applying transfer learning updates to well-known pre-trained CNN models and comparing their quantitative performance with the one produced from the new CNN topology. Finally, comparing the same performance with that of a conventional neural network algorithm.
2.1. Histological Features Isolation
2.2. Convolutional Neural Network Model Construction
- In the first convolution layer, 64 convolution filters consisting of a 5-by-5 kernel size are defined to detect “low-level” features, such as edges, from the raw image data. In each convolution operation, zero-padding is utilized to assign 0 values around the inputs to maintain an output size equal to the input of each kernel filter [14]. Subsequently, batch normalization is applied to normalize the convolved values, as well as the Rectified Linear Unit (ReLU), being the nonlinear activation function, which is considered ideal for minimizing the vanishing gradient problem [15]. Even though ReLUs are widely used in most deep learning applications, their unboundedness on the positive side tends to cause overfitting. To circumvent this issue, max pooling filtering with a stride of 2 is set to decrease overfitting by reducing the spatial size (width and height) of the data representation [16].
- The second convolution layer applies 32 filters with a 3-by-3 kernel size to search for “higher-level” features within each liver tissue object, including hepatocytes within a ballooning area, as well as multiple occurring pixels pointing at blood cells in hepatic veins. Batch normalization, ReLU function, and max pooling are included again, while dropout with a 0.5 probability is applied with the purpose to prevent overfitting [17].
- In the third convolution layer, 16 filters with a 3-by-3 kernel size aim to emphasize on connected pixels that can differentiate the textural features among the four examined histological structures. Max pooling is no longer applied and the training process makes a transition to the fully connected layer.
- The fully connected layer defines a dense layer with 4096 flattened neurons to gather the filtered anatomical features from the three convolution layers. These neurons are further connected to the final softmax layer. Dense and softmax layer connections act similar to a multilayer perceptron (MLP) artificial neural network, with the softmax function allocating probability distributions during the prediction of the four hepatic classes [18].
2.3. Applied Optimization Algorithms
3. Results
3.1. Training and Validation Results
3.2. Testing Results
3.3. Performance Comparison with Pre-Trained CNN Models
3.4. Performance Comparison with a Conventional Neural Network
3.5. Visualization of Filtered Anatomical Features
4. Discussion
4.1. Discussion of Research Findings
4.1.1. Training and Validation Results
4.1.2. Testing Performance
4.1.3. Methodology Performance Compared to Other Classification Models
4.2. Visualization of Learned Features
4.3. Qualitative Performance Comparison with Prior Methodologies
4.4. Future Thoughts and Ideas
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sumida, Y.; Yoneda, M. Current and future pharmacological therapies for NAFLD/NASH. J. Gastroenterol. 2018, 53, 362–376. [Google Scholar] [CrossRef]
- Germani, G.; Laryea, M.; Rubbia-Brandt, L.; Egawa, H.; Burra, P.; OʼGrady, J.; Watt, K.D. Management of Recurrent and De Novo NAFLD/NASH After Liver Transplantation. Transplantation 2019, 103, 57–67. [Google Scholar] [CrossRef] [PubMed]
- Fujimori, N.; Umemura, T.; Kimura, T.; Tanaka, N.; Sugiura, A.; Yamazaki, T.; Joshita, S.; Komatsu, M.; Usami, Y.; Sano, K.; et al. Serum autotaxin levels are correlated with hepatic fibrosis and ballooning in patients with non-alcoholic fatty liver disease. World J. Gastroenterol. 2018, 24, 1239–1249. [Google Scholar] [CrossRef] [PubMed]
- Chalasani, N.; Younossi, Z.; Lavine, J.E.; Charlton, M.; Cusi, K.; Rinella, M.; Harrison, S.A.; Brunt, E.M.; Sanyal, A.J. The diagnosis and management of nonalcoholic fatty liver disease: Practice guidance from the American association for the study of liver diseases. Hepatology 2018, 67, 328–357. [Google Scholar] [CrossRef]
- Goceri, E.; Shah, Z.K.; Layman, R.; Jiang, X.; Gurcan, M.N. Quantification of liver fat: A comprehensive review. Comput. Biol. Med. 2016, 71, 174–189. [Google Scholar] [CrossRef]
- Nativ, N.I.; Chen, A.I.; Yarmush, G.; Henry, S.D.; Lefkowitch, J.H.; Klein, K.M.; Maguire, T.J.; Schloss, R.; Guarrera, J.V.; Berthiaume, F.; et al. Automated image analysis method for detecting and quantifying macrovesicular steatosis in hematoxylin and eosin-stained histology images of human livers. Liver Transplant. 2014, 20, 228–236. [Google Scholar] [CrossRef] [PubMed]
- Sumitpaibul, P.; Damrongphithakkul, A.; Watchareeruetai, U. Fat detection algorithm for liver biopsy images. In Proceedings of the International Electrical Engineering Congress (iEECON), Chonburi, Thailand, 19–21 March 2014; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2014. [Google Scholar] [CrossRef]
- Hall, A.; Covelli, C.; Manuguerra, R.; Luong, T.V.; Buzzetti, E.; Tsochatzis, E.; Pinzani, M.; Dhillon, A.P. Transaminase abnormalities and adaptations of the liver lobule manifest at specific cut-offs of steatosis. Sci. Rep. 2017, 7. [Google Scholar] [CrossRef]
- Roy, M.; Wang, F.; Teodoro, G.; Vos, M.B.; Farris, A.B.; Kong, J. Segmentation of overlapped steatosis in whole-slide liver histopathology microscopy images. In Proceedings of the 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–31 July 2018; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2018; pp. 810–813. [Google Scholar] [CrossRef]
- Vanderbeck, S.; Bockhorst, J.; Komorowski, R.; Kleiner, D.E.; Gawrieh, S. Automatic classification of white regions in liver biopsies by supervised machine learning. Hum. Pathol. 2014, 45, 785–792. [Google Scholar] [CrossRef]
- Segovia-Miranda, F.; Morales-Navarrete, H.; Kucken, M.; Moser, V.; Seifert, S.; Repnik, U.; Rost, F.; Hendriks, A.; Hinz, S.; Rocken, C.; et al. 3D spatially-resolved geometrical and functional models of human liver tissue reveal new aspects of NAFLD progression. bioRxiv 2019. [Google Scholar] [CrossRef]
- Vanderbeck, S.; Bockhorst, J.; Kleiner, D.; Komorowski, R.; Chalasani, N.; Gawrieh, S. Automatic quantification of lobular inflammation and hepatocyte ballooning in nonalcoholic fatty liver disease liver biopsies. Hum. Pathol. 2015, 46, 767–775. [Google Scholar] [CrossRef]
- Vicas, C.; Rusu, I.; Al Hajjar, N.; Lupsor-Platon, M. Deep convolutional neural nets for objective steatosis detection from liver samples. In Proceedings of the 13th IEEE International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 7–9 September 2017; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2017; pp. 385–390. [Google Scholar] [CrossRef]
- Geron, A. Hands-On Machine Learning with Scikit-Learn and Tensorflow: Concepts, Tools, and Techniques to Build Intelligent Systems; Tache, N., Ed.; O’Reilly Media: Sebastopol, CA, USA, 2017. [Google Scholar]
- Zhou, S.K.; Greenspan, H.; Shen, D. Deep Learning for Medical Image Analysis; Pitts, T., Ed.; Academic Press: Cambridge, MA, USA; Elsevier: Amsterdam, The Netherlands, 2017. [Google Scholar]
- Patterson, J.; Gibson, A. Deep Learning: A Practitioner’s Approach; Loukides, M., McGovern, T., Eds.; O’Reilly Media: Sebastopol, CA, USA, 2017. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Hernandez, M.V.; Gonzalez-Castro, V. Medical image understanding and analysis (MIUA). In Proceedings of the Communications in Computer and Information Science, 21st Annual Conference, Edinburgh, UK, 11–13 July 2017; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; Dietterich, T., Bishop, C., Heckerman, D., Jordan, M., Kearns, M., Eds.; The MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Chollet, F. Deep Learning with Python; Arritola, T., Gaines, J., Dragosavljevic, A., Taylor, T., Eds.; Manning Publications Co.: Shelter Island, NY, USA, 2018. [Google Scholar]
- Vernon, G.; Baranova, A.; Younossi, Z.M. Systematic review: The epidemiology and natural history of non-alcoholic fatty liver disease and non-alcoholic steatohepatitis in adults. Aliment. Pharmacol. Ther. 2011, 34, 274–285. [Google Scholar] [CrossRef] [PubMed]
- Arjmand, A.; Angelis, C.T.; Tzallas, A.T.; Tsipouras, M.G.; Glavas, E.; Forlano, R.; Manousou, P.; Giannakeas, N. Deep learning in liver biopsies using convolutional neural networks. In Proceedings of the 42nd International Conference on Telecommunications and Signal Processing (TSP), Budapest, Hungary, 1–3 July 2019; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2019. [Google Scholar] [CrossRef]
- Wilson, A.C.; Roelofs, R.; Stern, M.; Srebro, N.; Recht, B. The marginal value of adaptive gradient methods in machine learning. arXiv 2017, arXiv:1705.08292. [Google Scholar]
- Keskar, N.S.; Socher, R. Improving generalization performance by switching from Adam to SGD. arXiv 2017, arXiv:1712.07628. [Google Scholar]
- Potter, C. Methods for presenting statistical information: The box plot. Gi-Ed. Lect. Notes Inform. 2006, 4, 97–106. [Google Scholar]
- Arjmand, A.; Tzallas, A.T.; Tsipouras, M.G.; Forlano, R.; Manousou, P.; Katertsidis, N.; Giannakeas, N. Fat droplet identification in liver biopsies using supervised learning techniques. In Proceedings of the 11th Pervasive Technologies Related to Assistive Environments Conference, Corfu, Greece, 26–29 June 2018. [Google Scholar]
- Arjmand, A.; Giannakeas, N. Fat quantitation in liver biopsies using a pretrained classification based system. Eng. Technol. Appl. Sci. Res. 2018, 8, 3550–3555. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 27th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colombus, OH, USA, 24–27 June 2014; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2014. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2016. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. arXiv 2016, arXiv:1512.02325v5. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Deep Model | Classification Results (%) | |||||||
|---|---|---|---|---|---|---|---|---|
| Liver Class Accuracy | Mean Performance Metrics 1 | |||||||
| Ballooning | Fat | Sinusoid | Vein | Accuracy | Precision | Recall | F-Score | |
| CNNAdam | 100 | 100 | 70 | 100 | 92.5 | 93.6 | 92.5 | 93 |
| CNNSGDM | 90 | 100 | 90 | 100 | 95 | 95 | 95 | 95 |
| Deep Model | Classification Results (%) | |||
|---|---|---|---|---|
| Accuracy | Precision (PPV) | Recall (Sensitivity) | Specificity (TNR) | |
| CNNSGDM | 95 | 95 | 95 | 98.3 |
| AlexNet | 97 | 97 | 97 | 99 |
| VGG-16 | 94 | 94.1 | 94 | 98 |
| Conventional Model | Accuracy | Precision (PPV) | Recall (Sensitivity) | Specificity (TNR) |
| MLP-ANN | 90.3 | 90.3 | 90.3 | 96.8 |
| Deep Model | Trainable Parameters | Training “from Scratch” (Minutes) | Transfer Learning (Minutes) |
|---|---|---|---|
| CNNSGDM | 16,825,876 | 2 | - |
| AlexNet | 60,000,000 | - | 0.45 |
| VGG-16 | 138,000,000 | - | 5.13 |
| Author/Year | Dataset | Image Analysis Method | Histological Structures | Classification Results (%) |
|---|---|---|---|---|
| Nativ et al., 2014 [6] | 54 histological images | Image preprocessing. K-means clustering. Decision Tree (DT) classification | Fat droplets (ld-MaS, sd-MaS) | Sensitivity: 99.3. Specificity: 93.7 R2: 97 |
| Sumitpaibul et al., 2014 [7] | 16 histological images (×400) | Image preprocessing. k-NN classification | Fat droplets | Accuracy: 97.52. TPR: 77.59. FPR: 1.19 |
| Hall et al., 2017 [8] | 21 histological images (×20) | Digital image analysis (DIA) | Fat droplets | 5%, 20% mFPA ALT (p < 0.001). 10% mFPA LR (p < 0.001) |
| Roy et al., 2018 [9] | 11 histological images (30,000 × 20,000) | Image preprocessing. PCA analysis. Supervised classification | Isolated steatosis. Overlapped steatosis | Accuracy ≤ 100 |
| Vanderbeck et al., 2014 [10] | 59 histological images (×20) | Image preprocessing. K-means clustering. SVM classification | Bile ducts. Central veins. Macrosteatosis. Portal arteries. Portal veins. Sinusoids | Accuracy: 89.3. Precision ≥ 82. Recall ≥ 82 |
| Segovia-Miranda et al., 2019 [11] | High-resolution multi-photon microscopy images | 3D Tissue morphology. Cholestatic biomarkers | Bile canaliculi. Cell borders. Lipid droplets. Nuclei. Sinusoids | ALP (p = 0.473). Total BAs (p = 0.505). Primary BA (p = 0.518). GGT (p = 0.680) |
| Vanderbeck et al., 2015 [12] | 59 histological images (×20) | Image preprocessing. Supervised classification | Ballooned hepatocytes. Lobular inflammation | AUC ≤ 98. ROC ≤ 98.3. Precision ≤ 91. Recall ≤ 54 |
| Vicas et al., 2017 [13] | 107 histological images | Image preprocessing. Gradient Boosted Tree (GBT), SVM, LR, RF, CNN classification. U-Net Segmentation | Fat droplets. Tissue fibrosis | R2 ≤ 89.3 2 |
| Proposed methodology | 64 histological images (×20) | MLP-ANN, CNN classifications | Ballooned hepatocytes. Fat droplets. Veins. Sinusoids | Accuracy ≤ 95 3. Precision ≤ 95 3. Recall ≤ 95 3. F-score ≤ 95 3. Specificity ≤ 98.3 3 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arjmand, A.; Angelis, C.T.; Christou, V.; Tzallas, A.T.; Tsipouras, M.G.; Glavas, E.; Forlano, R.; Manousou, P.; Giannakeas, N. Training of Deep Convolutional Neural Networks to Identify Critical Liver Alterations in Histopathology Image Samples. Appl. Sci. 2020, 10, 42. https://doi.org/10.3390/app10010042
Arjmand A, Angelis CT, Christou V, Tzallas AT, Tsipouras MG, Glavas E, Forlano R, Manousou P, Giannakeas N. Training of Deep Convolutional Neural Networks to Identify Critical Liver Alterations in Histopathology Image Samples. Applied Sciences. 2020; 10(1):42. https://doi.org/10.3390/app10010042
Chicago/Turabian StyleArjmand, Alexandros, Constantinos T. Angelis, Vasileios Christou, Alexandros T. Tzallas, Markos G. Tsipouras, Evripidis Glavas, Roberta Forlano, Pinelopi Manousou, and Nikolaos Giannakeas. 2020. "Training of Deep Convolutional Neural Networks to Identify Critical Liver Alterations in Histopathology Image Samples" Applied Sciences 10, no. 1: 42. https://doi.org/10.3390/app10010042
APA StyleArjmand, A., Angelis, C. T., Christou, V., Tzallas, A. T., Tsipouras, M. G., Glavas, E., Forlano, R., Manousou, P., & Giannakeas, N. (2020). Training of Deep Convolutional Neural Networks to Identify Critical Liver Alterations in Histopathology Image Samples. Applied Sciences, 10(1), 42. https://doi.org/10.3390/app10010042