1. Introduction
As an important component of future transportation systems, intelligent driving has significant development advantages. In the actual operation of intelligent driving vehicles [
1,
2,
3,
4], tracking task repetition is one of the common tasks. This repetition typically involves the repeated driving of vehicles along specific paths or trajectories, and it occurs in fixed-route buses, logistics delivery vehicles, park shuttle buses, port container transportation, airport baggage transportation, and factory material transportation. These operations are usually highly regular and predictable, making them well-suited for automated processing by intelligent driving systems. By continuously optimizing path-tracking algorithms and control strategies, intelligent driving vehicles can achieve efficient and safe operation in these scenarios.
For trajectory-tracking tasks that are repeated within a finite time interval, which is different to asymptotic tracking over infinite time [
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18], iterative learning control [
19,
20,
21,
22,
23,
24,
25,
26] is an effective control strategy which performs the same task repeatedly over a finite time interval. The core idea is to improve tracking performance from one execution (called a “trial”, “pass”, or “iteration”) to the next by utilizing data (like tracking errors and control signals) from previous executions, leveraging past control experience to enhance the current tracking performance of dynamic systems. For example, iterative learning control effectively addresses the challenges of repetitive operations for underwater robots in complex hydrodynamic environments such as subsea pipeline inspection systems and underwater equipment maintenance scenarios. These applications have promoted the proposal of iterative learning control methods. Wei et al. proposed an iterative learning control (ILC) approach for nonlinear systems with iteratively varying reference trajectories and random initial state shifts, and established theoretical proofs of error convergence [
26]. The advantage of the iterative learning control method is that it does not require a precisely known system model, the controller structure is simple, and it is suitable for controlled systems with high tracking accuracy requirements, strong coupling, or complex nonlinearity. In the past three decades, significant progress has been made in iterative learning control in both basic theory and experimental applications [
23,
24,
25,
26].
However, most existing iterative learning control designs require that the system object, initial state, reference trajectory, and test length in the iterative learning control process remain constant as the number of iterations increases [
22], especially for processing the same test length [
26,
27]. In fact, it is difficult to repeatedly perform the same task within a fixed time interval in practice. For example, during underwater robotic seabed inspections, when the multimodal sensor array detects deviations in critical hydroacoustic signal characteristics beyond preset thresholds, the system activates failure determination protocols, terminates the current operation, and autonomously transitions to the next inspection target. Another example is in the field of fully automated precision manufacturing, where semi-finished products undergo a series of processing steps to ultimately form highly integrated end products. This method intertwines the processing and inspection stages in a complex manner; any defect in the processing operation can jeopardize the success of the entire production line, and detecting irreparable faults in semi-finished products during the inspection phase can lead to automatic stoppage of the manufacturing process. Therefore, non-uniform trial lengths are quite common in real life. For non-uniform trial lengths, the average operator technique and modified tracking error are used to provide corresponding iterative learning control algorithms [
28,
29], and the robustness and convergence of iterative learning control errors are analyzed using constant norms. On the other hand, most of the research has focused on discrete-time linear systems [
30,
31], mainly due to the beneficial system structure and mature discrete random variable analysis techniques. Although for nonlinear systems [
32], the nonlinear function involved needs to satisfy the global Lipschitz condition.
In the past few decades, by introducing the concept of adaptive control into the design of iterative learning control, an important class of iterative learning control algorithms has been proposed, known as adaptive iterative learning control methods [
33,
34,
35]. The main features of such methods are the estimation of uncertain control parameters between successive iterations and the use of these parameters to generate the current control input. Adaptive iterative learning control is a control method applied to dynamic systems in continuous or discrete time. It combines the ideas of adaptive control and iterative learning control methods and gradually improves the control performance of the system through learning during the iterative process. In the adaptive iterative learning control method, the controller adjusts according to the error between the real-time response of the system and the desired output. Through continuous iteration, the controller can gradually learn the dynamic characteristics of the system and improve the control strategy based on the learned knowledge, thereby achieving better control performance. Adaptive iterative learning control methods are typically employed for underwater robots performing repetitive operational tasks in complex hydrodynamic environments, such as subsea trajectory tracking or precision manipulation of seabed equipment. They can gradually reduce the tracking error of the system through multiple iterations and improve the stability and robustness of the system. In practical applications, adaptive iterative learning control methods need to consider factors such as the dynamic characteristics, learning speed, and convergence of the system. At the same time, selecting the appropriate learning algorithm and control strategy is also a crucial step. Adaptive iterative learning control methods have obvious advantages in relaxing the global Lipschitz continuity condition, handling non-uniform initial states, iteratively changing reference trajectories, and dealing with external disturbances. Liu et al. studied the problem of variable test length for continuous-time nonlinear systems based on adaptive iterative learning control methods [
33]. However, their system was a single-input single-output system, and the input gain or control direction was a scalar value. An adaptive iterative learning method was proposed to solve the problem of random changes in the length of the experiment. However, the system involved in the study involved multiple input and multiple output systems [
34]. The system was parameterized, and the control gain matrix of the system was assumed to be known.
In fact, the control gain matrix in a multi-input multi-output system [
36,
37,
38] is the derivative of the system output to the control input, and it is usually required to be symmetric and positive definite (or negative definite). However, in most underwater robotic propulsion systems (e.g., multi-thruster power distribution systems [
36] and articulated drive systems [
37]), the control gain matrices consistently exhibit off-diagonal coupling characteristics, which constitutes a prominent system feature arising from hydrodynamic anisotropy. Obviously, the assumption of the positive (or negative) definiteness of the control gain matrix, or even the assumption of knownness, greatly limits the development of adaptive iterative learning control.
This paper proposes a new adaptive iterative control strategy for multi-input multi-output nonlinear vehicle systems with non-uniform test lengths and asymmetric control gain matrices, which relaxes the assumption requirements that stipulate that the traditional control gain matrices are positive definite (or negative definite) or even known. The key features and contributions of the paper are as follows:
Vehicle systems for intelligent driving are investigated for reference trajectory tracking in an infinite iteration domain with non-uniform trial lengths.
In the adaptive control community, it is generally required that the control gain matrices of plants be real, symmetric, and positive definite (or negative definite), but, in this paper, only the asymmetric control gain matrices in the vehicle systems are assumed.
Unlike those fuzzy systems or neural network-based techniques used for adaptive iterative learning control, less adaptive variables are designed for adjusting or updating in the proposed method such that the structure of the controller is very simple and the memory space for computing is greatly saved.
2. Problem Formulation
2.1. Intelligent Driving Vehicle System
This paper focuses on an in-depth study of a control system for intelligent driving vehicles in interactive environments. In real-world traffic scenarios, intelligent driving vehicles do not operate in isolation but constantly interact with other traffic participants, such as other vehicles and pedestrians. This interaction has a crucial impact on the safety and efficiency of intelligent driving vehicles. Therefore, constructing an accurate and reasonable dynamic model of the control system is a key foundation for achieving safe and efficient intelligent driving. Consider the following dynamic model of a control system for intelligent driving vehicles in an interactive environment that moves within a finite time interval:
Here, k represents the system iteration number. During the system optimization and parameter adjustment process, the accuracy and adaptability of the model are continuously improved through multiple iterations. represents continuous time, where T is the set upper limit of the finite time, covering the time period of vehicle motion analysis that we are concerned about. is the state vector of the p-th vehicle at the k-th iteration and time t. This vector usually includes key state variables such as the vehicle’s position, velocity, and acceleration, comprehensively describing the vehicle’s motion state in space. is the state vector of the q-th vehicle at the corresponding time and iteration number, also recording various motion information of this vehicle. is the control input vector of the p-th vehicle. For example, control commands such as the steering wheel angle, accelerator pedal opening, and braking force are used to adjust the vehicle’s operating state. is the control gain matrix. It not only determines the direction of the effect of the control input on the system output but also, essentially, represents the derivative of the system output with respect to the control input, reflecting the sensitivity of the vehicle state change to the control commands. However, in practical applications, is unknown, its values are bounded, and it is non-symmetric, which poses challenges for the design of the control system. is the unknown nonlinear vector function of vehicle p itself, used to describe the parts of the vehicle’s own motion characteristics that cannot be expressed by linear relationships, such as the changes in the vehicle’s dynamic characteristics when driving on complex road surfaces.
In an interactive environment, to accurately depict the interactions between vehicles, it is necessary to determine the interaction relationships according to the behavioral characteristics of traffic participants. Taking vehicle-to-vehicle interactions as an example, the influence of vehicle p on vehicle q may be reflected in many aspects. Common ones include car-following behavior: vehicle p adjusts its own speed according to the speed and distance of the preceding vehicle q to maintain a safe following distance; evasion behavior: when vehicle p detects that vehicle q may pose a collision risk, it actively changes its driving direction or speed to avoid the collision; and path adjustment: vehicle p may re-plan its driving route due to the influence of vehicle q’s driving path on its own planned path.
Based on the characteristics of these interaction relationships, further quantifying the interaction intensity is an important part of constructing an accurate model. In the quantification process, various indicators can be used. For example, physical quantities such as distance, speed difference, and acceleration difference are used to measure the degree of interaction between vehicles. At the same time, in order to reflect the differences in the importance of different state variables during the interaction process, weight coefficients are introduced to represent the influence degree of different state variables. Finally, the quantified interaction intensity is represented in matrix form as follows:
The element in the matrix represents the influence weight of the j-th state variable of the q-th vehicle on the i-th state variable of the p-th vehicle. The entire matrix comprehensively describes the influence of vehicle q on vehicle p.
Assumption 1.
Let the nonlinear mapping satisfy the sublinear growth constraint as follows:where and denote positive-definite parameters. Assumption 2.
The iterative learning process satisfies the uniform boundedness conditions: all iterative initial values , expected trajectories are iterative transformations, external disturbances , and .
Assumption 1 is often used in iterative learning control designs for nonlinear dynamic systems and practical applications. Assumption 2 is a common constraint condition and is reasonable in practical physical systems. In fact, if the nonlinear function of a system changes too rapidly or the initial value of the system is unbounded, it is obvious that it will not meet the requirements of an actual system.
2.2. Design of Adaptive Iterative Learning Controller for Non-Uniform Test Length
2.2.1. Non-Uniform Trial Length
In conventional iterative learning control (ILC) algorithms, the task execution time interval is strictly confined to a fixed duration to facilitate an idealized iterative learning process. However, in practical applications, this requirement frequently becomes infeasible due to inherent uncertainties and unpredictable disturbances. This fundamental challenge has motivated substantial research addressing uneven trial lengths. The following representative scenarios exemplify typical manifestations of non-uniform trial durations in real-world implementations.
As a foundational step in constructing the adaptive iterative learning control (AILC) framework, the system’s tracking error must be formally defined:
where
represents the desired trajectory and
.
Under non-uniform trial length conditions,
denotes the duration of each iterative operation. The modified tracking error is formulated as follows:
It can be concluded that , where . When , the system stops halfway during task execution and fails to reach the desired trial duration; conversely, when , the system reaches the desired duration.
2.2.2. Controller Design
Building upon Assumptions 1–3 as the theoretical foundation, this study develops an adaptive iterative learning control scheme with the following architectural configuration:
where
, and
is the learning gain to be designed. Equation (
3) formulates the control input that constitutes the core controller architecture, while Equation (
4) defines the adaptive parameter-updating mechanism. The algorithm’s innovation resides in its synergistic optimization process, which integrates cross-iteration parameter transfer with error feedback, dynamically calibrating control parameters through historical iteration data and real-time error signals to achieve progressive input refinement.
2.2.3. Stability Analysis
Theorem 1.
Based on Assumptions 1 and 2, under the action of the adaptive control law (3) and adaptive parameter update laws (4) and (5), when the control gain matrix of the vehicle system satisfies and is satisfied, the tracking error of the system is . Proof. Because of
, there exists a positive-definite symmetric matrix
satisfying
Building upon the theoretical foundation of Assumptions 1 and 2, we establish the following formal definition:
and
A composite-type energy function is formulated as follows:
where the estimated error of
is
, and
is the estimated value of
.
Step 1: To prove that sequence
is a monotone non-increasing sequence, the difference in
is first defined in the iterative direction:
It can be observed that the difference in consists of two parts: the error term and the adaptive parameter estimation error term.
When
, the adaptive parameter estimation error term for
yields the following result:
By incorporating the adaptive parameter update mechanism into Equation (
13) and performing integration on both sides, the following relationship is derived:
Regarding the error dynamics associated with parameter
, the results are established as follows:
where
and
By establishing the algebraic integration framework through Equations (
16) and (
17) within Equation (
15), the subsequent derivation yields the following:
Building upon the theoretical framework established in Equations (
14) and (
18), the mathematical reconstruction of Equation (
12) yields the following:
Under the parametric constraint
, Equation (
14) can be reformulated through the adaptive law (4) into the following equivalent representation:
Under the second operational scenario, Equation (
18) undergoes structural transformation characterized as follows:
Through deductive theoretical pathways, the subsequent relationship is established:
The synergistic analytical framework integrating Equations (
19) and (
22) yields the following fundamental evolutionary relationship:
where
. To date, it can be proven that
.
Step 2: Because
through deductive verification of the initial proposition phase, the following relationship is established:
From Equation (
19) and
, we can obtain the following:
By substituting Equation (
26) into Equation (
25) and taking into account Equations (
16) and (
17), we obtain the following:
Because
, it follows that
=
.
Substituting Equation (
28) into Equation (
27), we can obtain the following:
where
M is defined as a positive-definite scalar parameter. By performing integration on both sides of Equation (
29), we obtain the following:
Step 3: From Equation (
23), the following can be readily derived:
Through deductive theoretical pathways, the subsequent relationship is established:
By combining Equations (
30) and (
31), we derive the following:
Finally, based on the above systematic demonstration process, its is concluded that , and the completeness of the theoretical system of this study is rigorously verified. □
3. Experimental Results and Discussion
Based on the two-vehicle interaction scenario, each vehicle’s state vector includes two variables: position and velocity (). The state vector of the p-th vehicle is , and the state vector of the q-th vehicle is . The control input vector is , where denotes the acceleration control command of the p-th vehicle at time t during the k-th iteration, and represents the steering angle control command.
The unknown nonlinear vector function
of vehicle
p is defined as follows:
where
and
are constants used to model nonlinear factors such as resistance during vehicle motion. The control gain matrix
is configured as an asymmetric matrix as follows:
Here, represents the degree of influence of the acceleration control input on the vehicle’s position ; represents the degree of influence of the steering angle control input on the vehicle’s position ; represents the degree of influence of the acceleration control input on the vehicle’s velocity ; and represents the degree of influence of the steering angle control input on the vehicle’s velocity . Due to the dynamic characteristics of vehicles, different control inputs have varying effects on position and velocity, rendering an asymmetric matrix.
Assuming the interaction between vehicle
q and vehicle
p affects both position and velocity, the interaction matrix
is configured as follows:
where
(
) are weight coefficients quantifying the influence of vehicle
q’s position and velocity on vehicle
p’s position and velocity.
Substituting the above settings into the dynamic model formula
and letting
, we have
where
; the sampling interval is 0.001;
is
; the corresponding random transformation results are as shown in
Figure 1; and the system’s tracking trajectory is
.
1. Control Input Parameters: : The acceleration control command of the p-th vehicle at time t during the k-th iteration is measured in meters per second squared (). It is a command issued by the vehicle control system to adjust vehicle speed and can be implemented by controlling actuators such as the throttle and brakes. : The steering angle control command of the p-th vehicle at time t during the k-th iteration, typically measured in radians (rad). It is used to control the vehicle’s driving direction and is executed through the steering system.
2. Nonlinear Function Parameters: and : Constants used to describe nonlinear factors in the vehicle’s own motion characteristics. mainly reflects the resistance influence related to the first power of velocity, such as rolling friction resistance between the tires and the road surface; mainly reflects the resistance influence related to the square of velocity, such as air resistance. Their values need to be determined through experiments or simulations based on the vehicle’s actual performance and driving environment.
3. Control Gain Matrix Parameters: : The coefficient quantifying the influence of the acceleration control input on the vehicle’s position . In actual vehicle motion, changes in acceleration indirectly affect the distance traveled by the vehicle over time, thereby influencing position. quantifies this effect. : The coefficient quantifying the influence of the steering angle control input on the vehicle’s position . Steering operations change the vehicle’s driving direction, which, in turn, affects its position. measures this influence. : The coefficient quantifying the influence of the acceleration control input on the vehicle’s velocity , typically related to the vehicle’s dynamic performance. It reflects the direct effect of the acceleration command on changes in vehicle velocity. : The coefficient quantifying the influence of the steering angle control input on the vehicle’s velocity . When turning, the vehicle needs to overcome additional resistance, leading to velocity changes. quantifies this effect. Due to the different mechanisms and degrees of influence of acceleration and steering angle on position and velocity, the matrix is asymmetric, with .
Selecting the estimated matrix
we have
The results satisfy the conditions of the theorem. The adaptive iterative learning algorithm is evaluated using the maximum absolute error. By setting the parameter
for the parameter update rule,
Figure 2 illustrates the tracking error of the system.
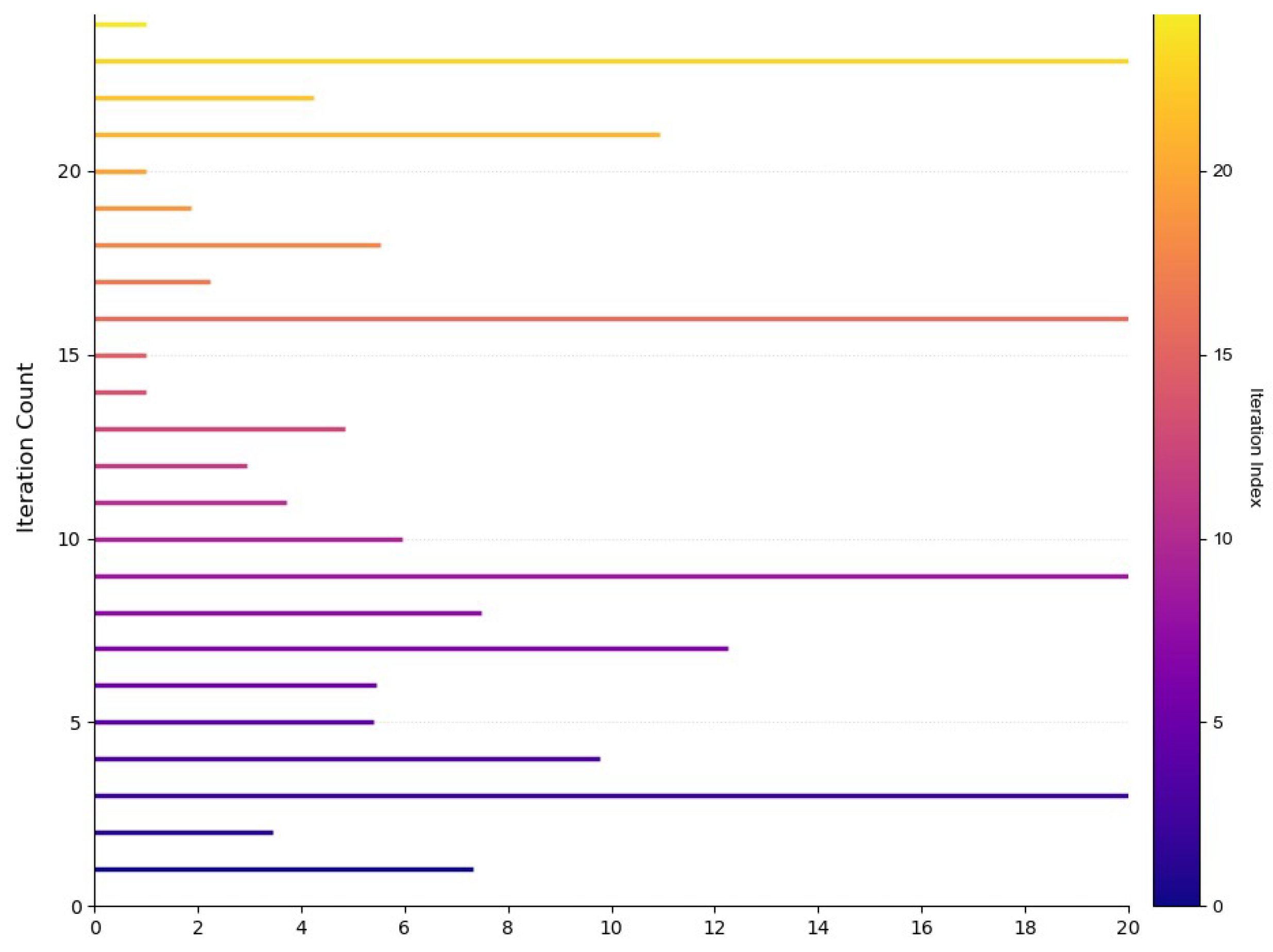
Figure 3 shows that the different iteration periods correspond to different lengths of tracking trajectories. It can be observed that, when the iteration count reaches 50, the tracking error of the system approaches 0.
Figure 4,
Figure 5,
Figure 6 and
Figure 7 show the trial lengths with different iterations, namely,
,
,
, and
showing in
Table 1, where
represents the desired trial length, which demonstrates how the actual output of the system tracks the expected trajectory under varying iteration counts when subjected to non-uniform trial lengths.
Figure 4 shows the actual trajectory and desired trajectory of the vehicle system at the first iteration with trial length
.
Figure 5 shows the actual trajectory and desired trajectory of the vehicle system at the third iteration with trial length
.
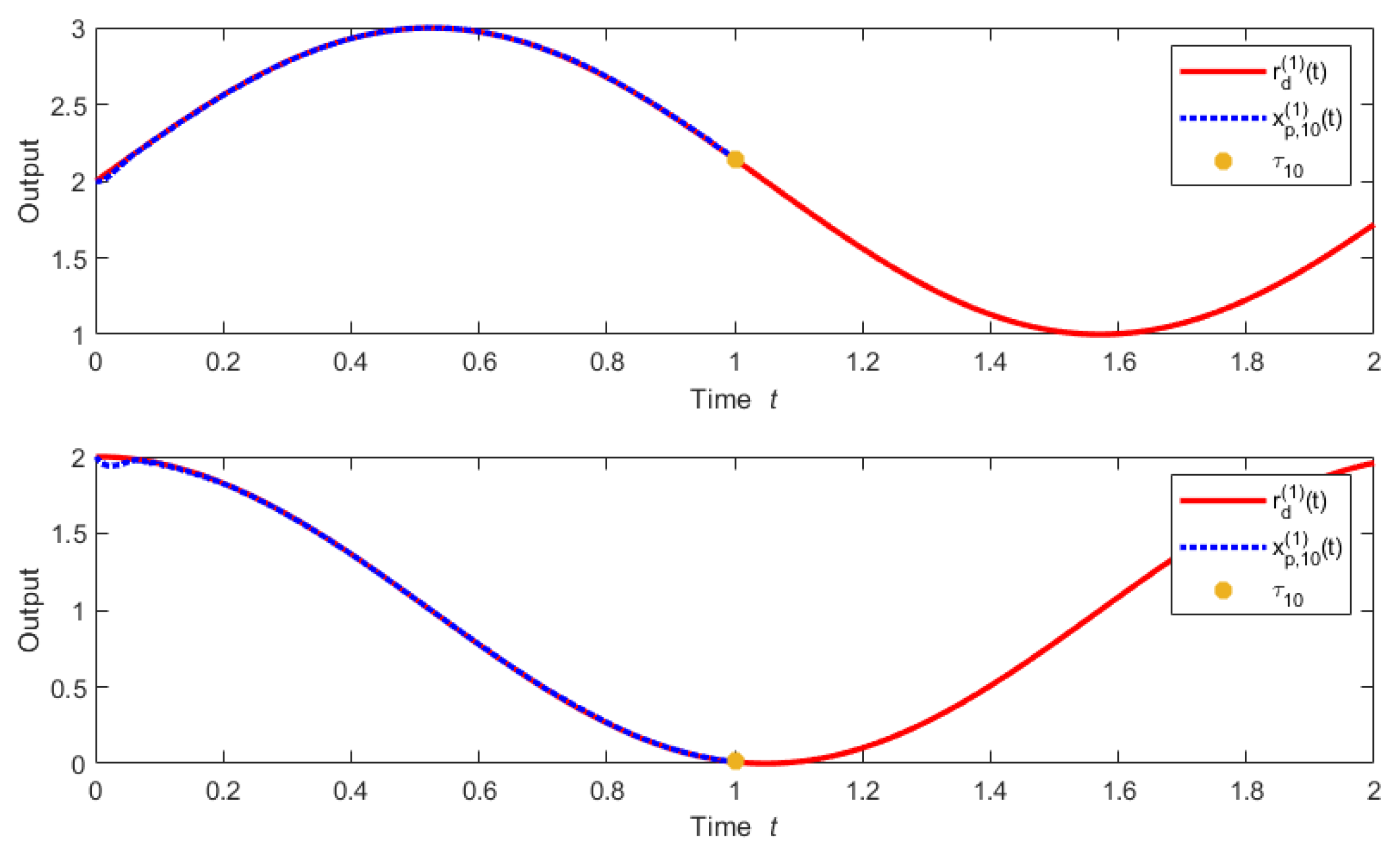
Figure 6 shows the actual trajectory and desired trajectory of the vehicle system at the 10th iteration with trial length
.
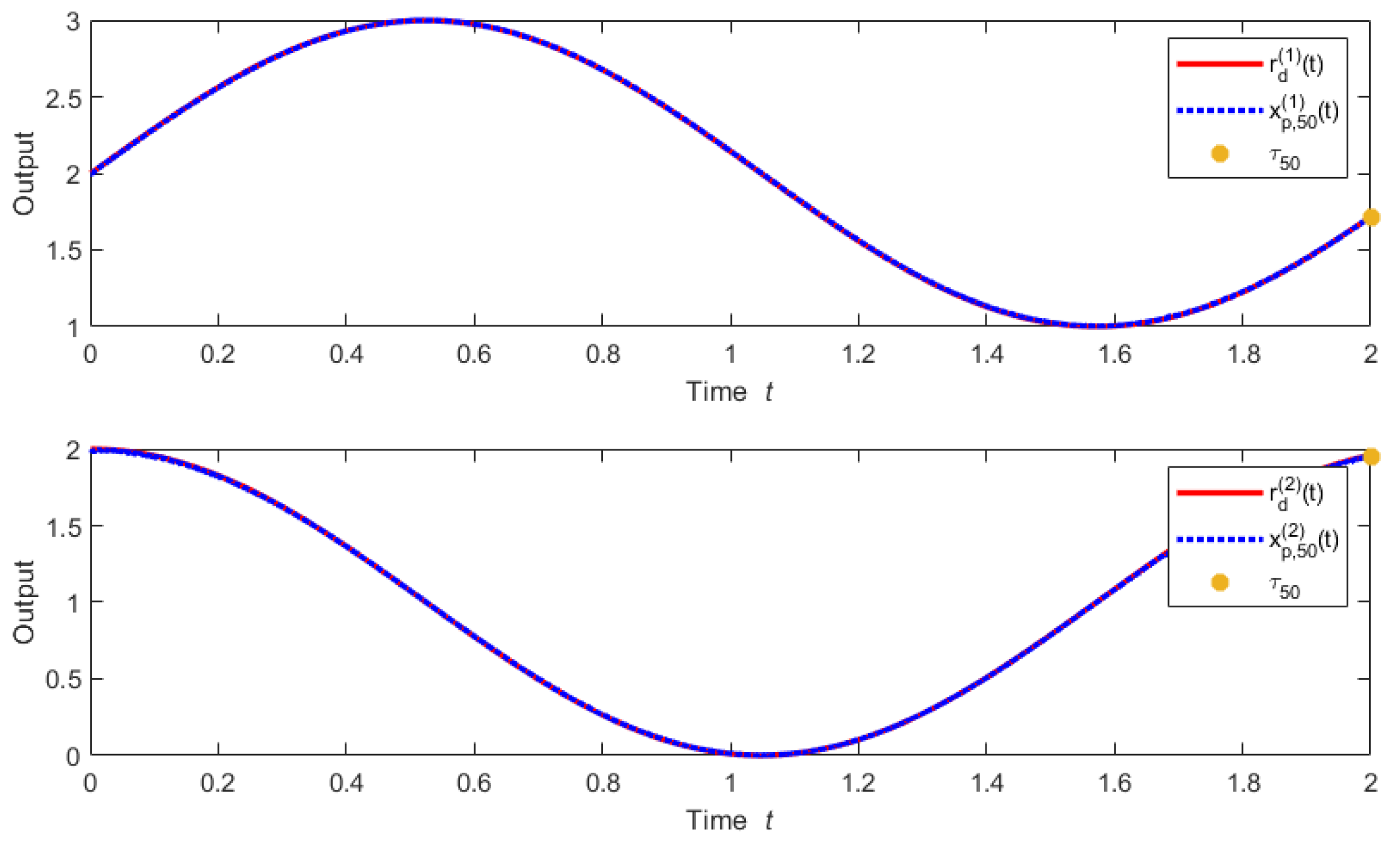
Figure 7 shows the actual trajectory and desired trajectory of the vehicle system at the 50th iteration with trial length
. Notably, when the iteration number is 50, the actual output of the system fully tracks the expected trajectory.
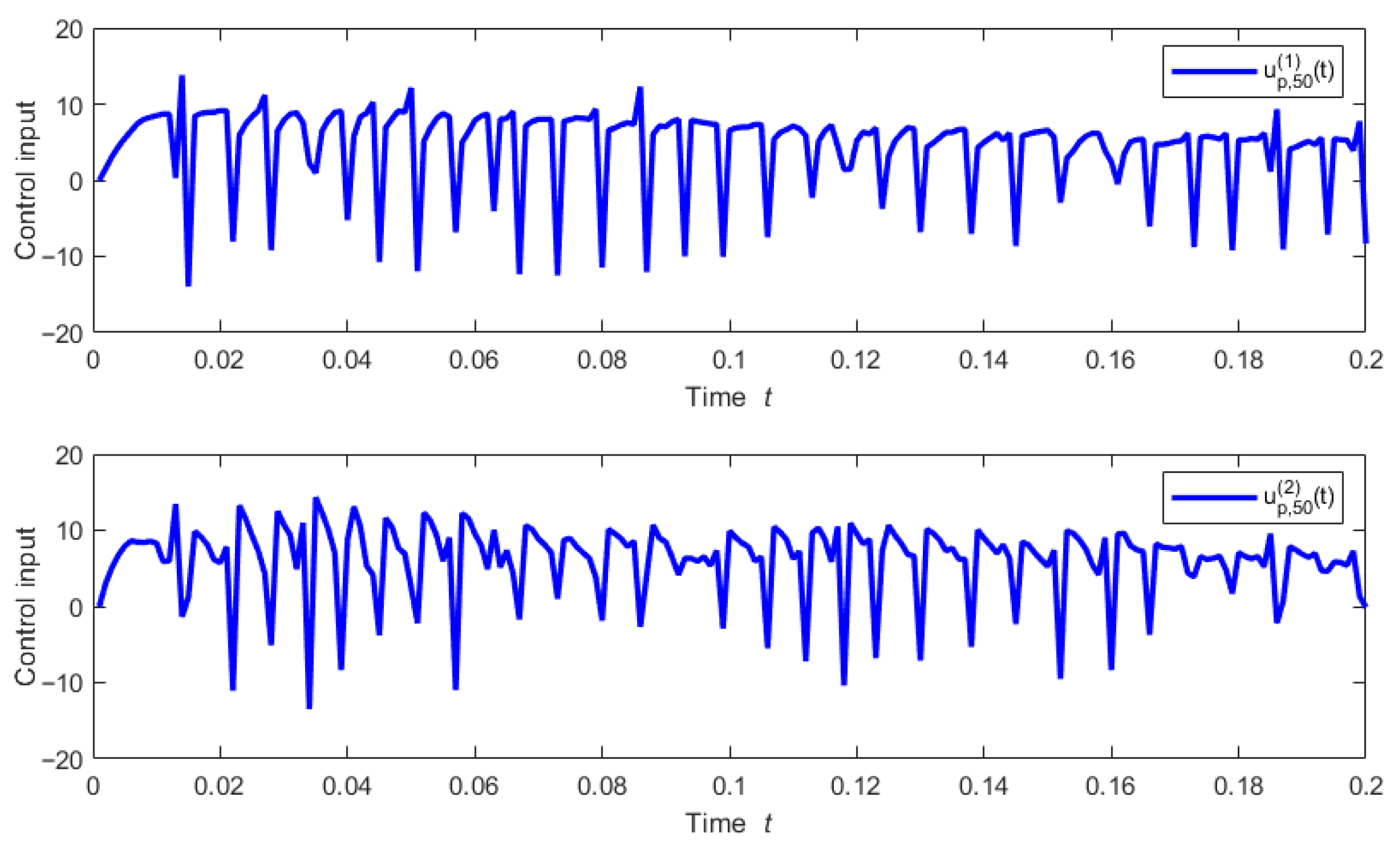
Figure 8 shows the control input.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}