Frequentist and Bayesian Estimation Under Progressive Type-II Random Censoring for a Two-Parameter Exponential Distribution



Abstract
1. Introduction
2. Model Formulation and Assumptions
3. Maximum Likelihood Estimation
Asymptotic Confidence Intervals
- (i)
- (ii)
- , where
4. Bayesian Estimation
4.1. Gibbs Sampling Algorithm
- Step 1:
- Generate from the Marginal of
- (a)
- Generate a random number u from a Uniform(0,1) distribution.
- (b)
- Find the value that solves the equation , where is the CDF from Equation (17). This requires a numerical root-finding method (e.g., bisection or Newton–Raphson) as the integral is computed numerically. This is one sample from the marginal posterior of .
- Step 2:
- Generate from the Conditionals of and . Given the sampled value from Step 1,
- (a)
- Generate a random sample from the Inverse-Gamma distribution in (14)
- (b)
- Generate a random sample from the Inverse-Gamma distribution in (15)
- Step 3:
- Repeat for MCMC Samples Repeat Step 1 and 2 for to obtain a set of samples .
- Step 4:
- Bayes Estimation. After discarding an initial burn-in period of B samples, the Bayes estimates of the parameters under SELF are obtained by averaging the remaining samples
4.2. Highest Posterior Density (HPD) Credible Intervals
- Sort the MCMC samples to obtain the ordered values: .
- Identify all possible candidate intervals of the form for , where .
- The HPD interval is the specific interval which has the minimum length. This is found by minimizing the difference over all possible values of j.
5. Simulation Study
- As expected, the estimation accuracy for all parameters improved as the number of observed failures (m) increased, leading to lower MSEs and shorter interval lengths.
- For a fixed n and m, censoring schemes with more evenly distributed removals consistently outperformed schemes with heavy early-life censoring, resulting in lower estimation errors.
- The Bayesian approach generally provided more accurate point estimates, yielding consistently lower MSEs than the MLE method, particularly for the scale parameters () under censored conditions.
- The Bayesian method was substantially more reliable for interval estimation. Its Credible Intervals (CRIs) maintain coverage probabilities close to the nominal 0.95 level, whereas the MLE-based Asymptotic Confidence Intervals (ACIs) often exhibited significant undercoverage, especially in scenarios with heavy censoring.
- The location parameter was estimated with significantly higher precision (lower MSE) than the scale parameters and across all scenarios.
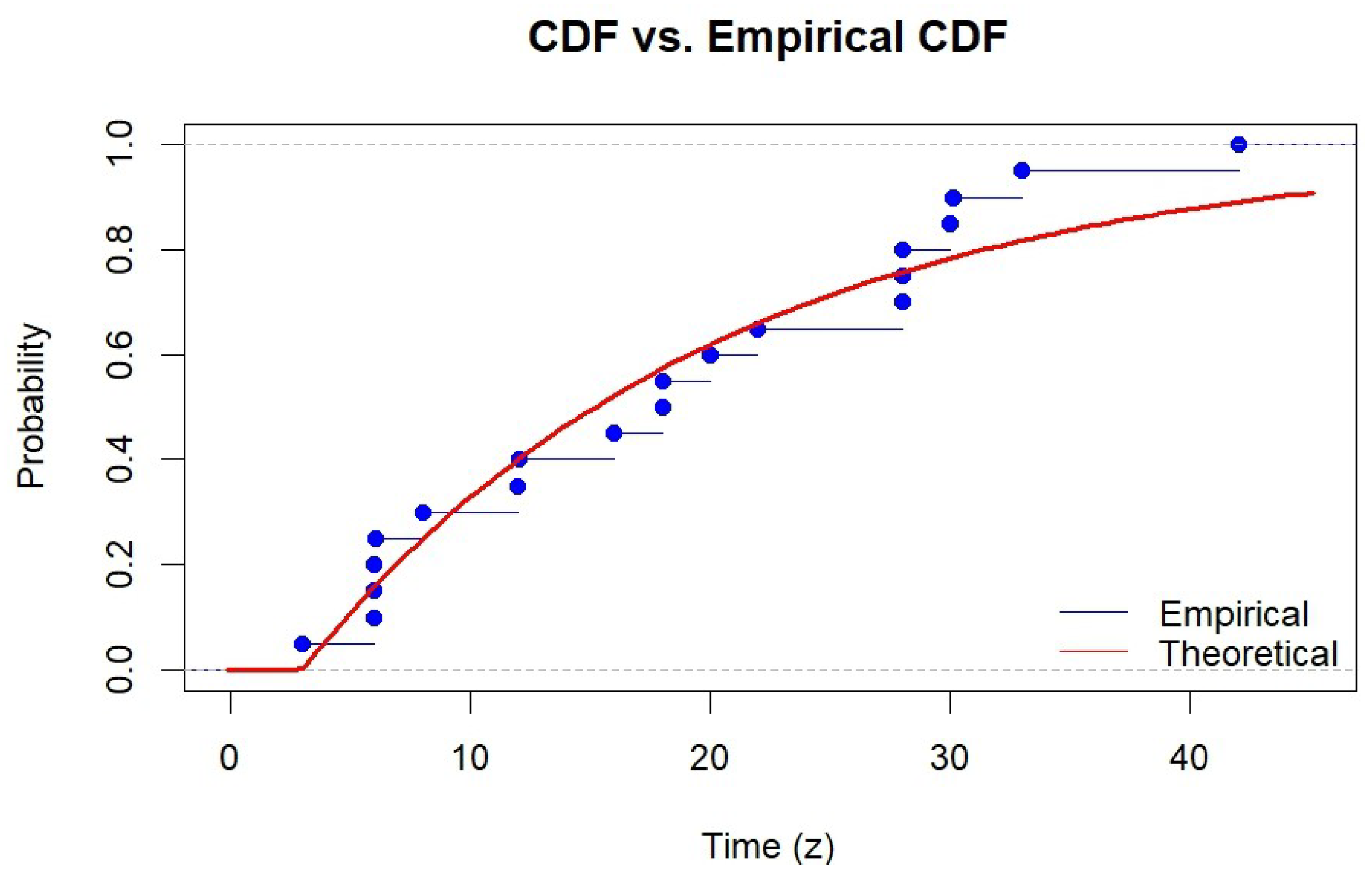
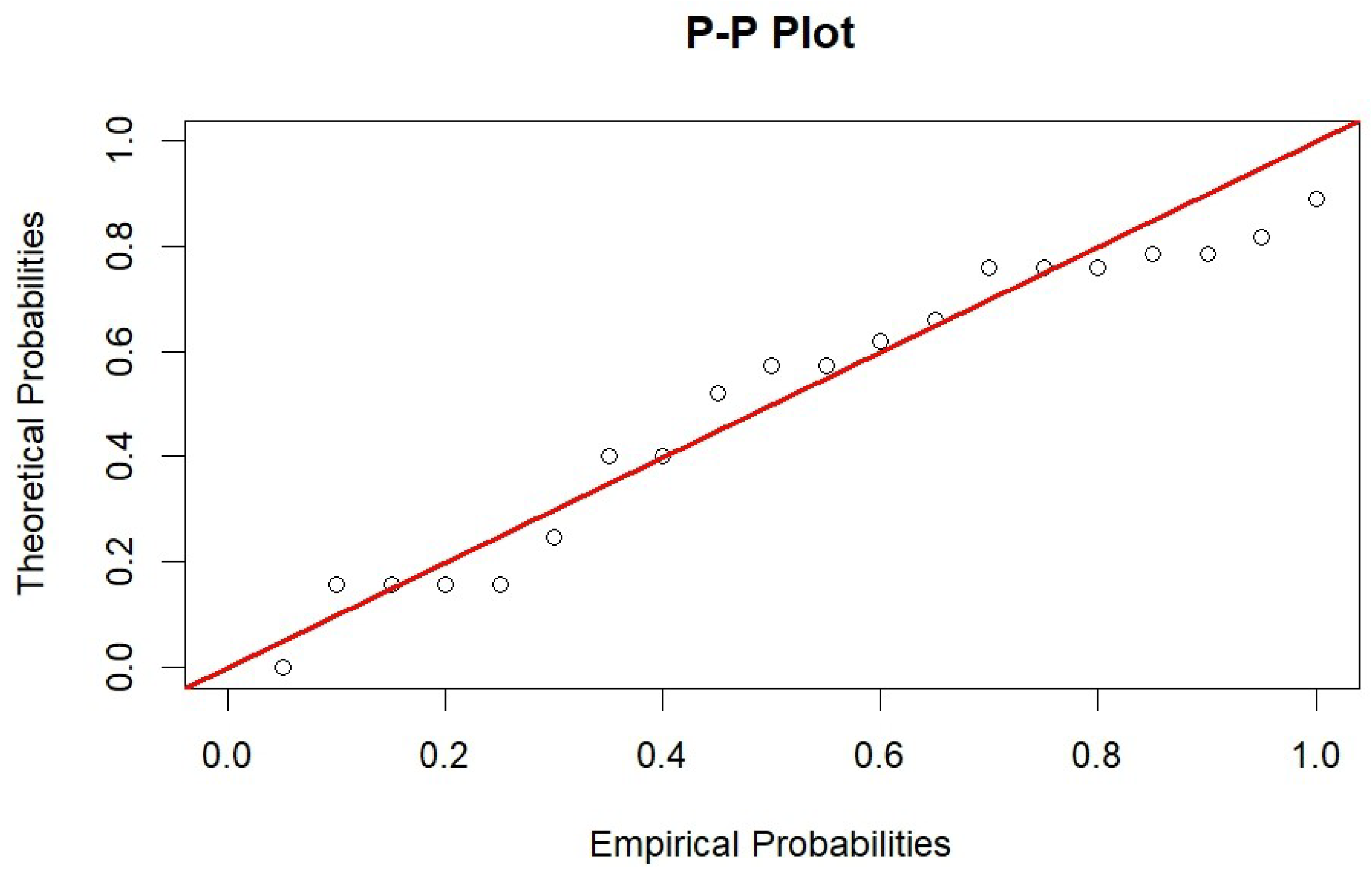
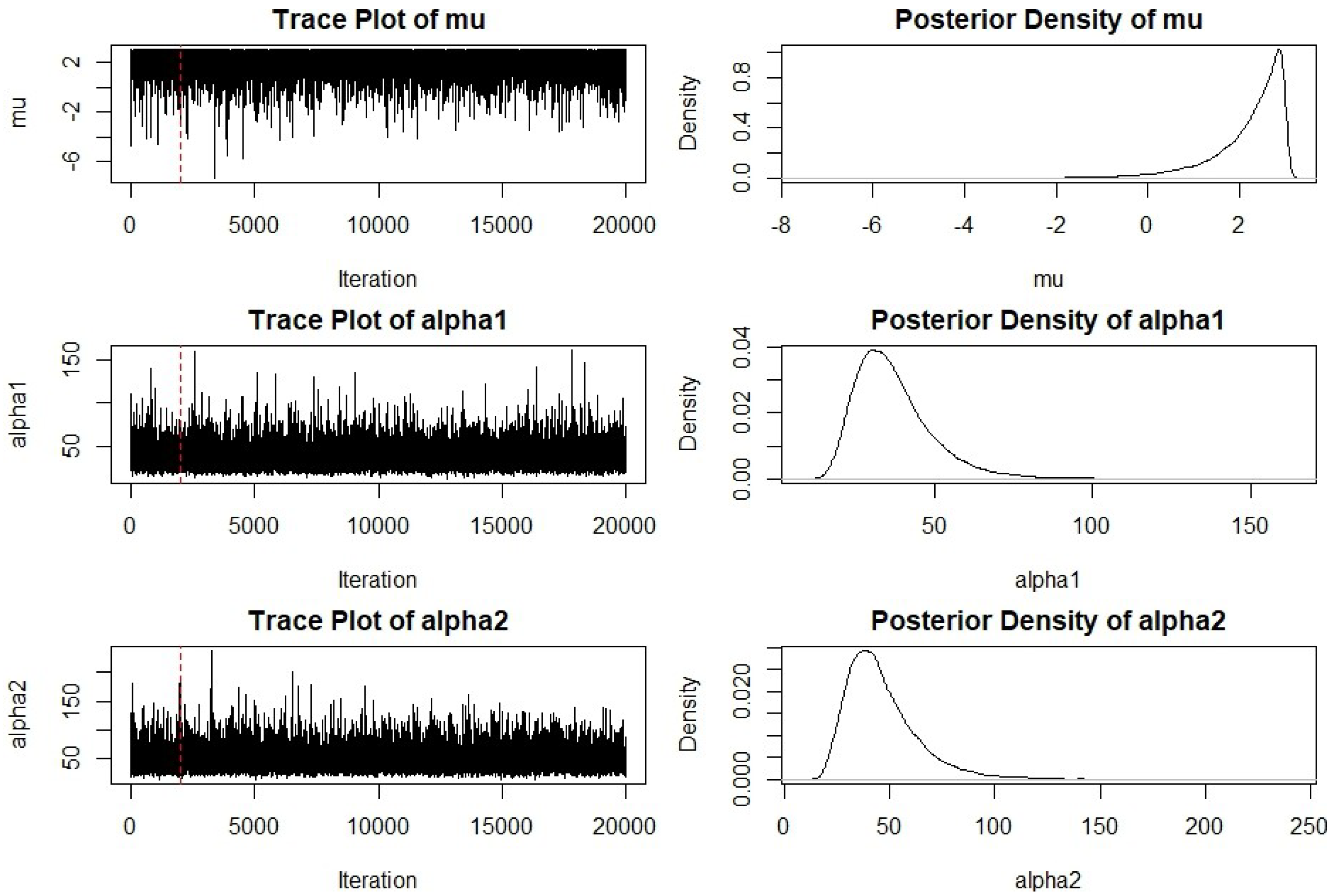
6. Real Data Analysis
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Balakrishnan, N.; Aggarwala, R. Progressive Censoring: Theory, Methods, and Applications; Springer Science Business Media: Berlin, Germany, 2000. [Google Scholar]
- Balakrishnan, N.; Cramer, E. The Art of Progressive Censoring; Springer: Berlin/Heidelberg, Germany, 2014; Volume 138. [Google Scholar]
- Abu-Moussa, M.H.; Alsadat, N.; Sharawy, A. On estimation of reliability functions for the extended rayleigh distribution under progressive first-failure censoring model. Axioms 2023, 12, 680. [Google Scholar] [CrossRef]
- Fayomi, A.; Almetwally, E.M.; Qura, M.E. Bivariate length-biased exponential distribution under progressive type-ii censoring: Incorporating random removal and applications to industrial and computer science data. Axioms 2024, 13, 664. [Google Scholar] [CrossRef]
- Gao, X.; Gui, W. Statistical inference of burr–hatke exponential distribution with partially accelerated life test under progressively type ii censoring. Mathematics 2023, 11, 2939. [Google Scholar] [CrossRef]
- Laumen, B.; Cramer, E. Progressive censoring with fixed censoring times. Statistics 2019, 53, 569–600. [Google Scholar] [CrossRef]
- Lee, K. Inference for parameters of exponential distribution under combined type ii progressive hybrid censoring scheme. Mathematics 2024, 12, 820. [Google Scholar] [CrossRef]
- Tian, Y.; Liang, Y.; Gui, W. Inference and optimal censoring scheme for a competing-risks model with type-ii progressive censoring. Math. Popul. Stud. 2024, 31, 1–39. [Google Scholar] [CrossRef]
- Gilbert, J.P. Random Censorship. Ph.D. Thesis, University of Chicago, Department of Statistics, Chicago, IL, USA, 1962. [Google Scholar]
- Hasaballah, M.M.; Balogun, O.S.; Bakr, M.E. On a randomly censoring scheme for generalized logistic distribution with applications. Symmetry 2024, 16, 1240. [Google Scholar] [CrossRef]
- Krishna, H.; Goel, R. Inferences based on correlated randomly censored gumbel’s type-i bivariate exponential distribution. Ann. Data Sci. 2024, 11, 1185–1207. [Google Scholar] [CrossRef]
- Saleem, M.; Raza, A. On bayesian analysis of the exponential survival time assuming the exponential censor time. Pak. J. Sci. 2011, 63, 44–48. [Google Scholar]
- Goel, R.; Krishna, H. Progressive type-II random censoring scheme with Lindley failure and censoring time distributions. Int. J. Agric. Stat. Sci. 2020, 16, 23–34. [Google Scholar]
- Goel, R.; Kumar, K.; Ng, H.K.T.; Kumar, I. Statistical inference in burr type xii lifetime model based on progressive randomly censored data. Qual. Eng. 2024, 36, 150–165. [Google Scholar] [CrossRef]
- Beg, M. On the estimation of pr Y¡ X for the two-parameter exponential distribution. Metrika 1980, 27, 29–34. [Google Scholar] [CrossRef]
- Cheng, C.; Chen, J.; Bai, J. Exact inferences of the two-parameter exponential distribution and pareto distribution with censored data. J. Appl. Stat. 2013, 40, 1464–1479. [Google Scholar] [CrossRef]
- Ganguly, A.; Mitra, S.; Samanta, D.; Kundu, D. Exact inference for the two-parameter exponential distribution under type-ii hybrid censoring. J. Stat. Plan. Inference 2012, 142, 613–625. [Google Scholar] [CrossRef]
- Krishna, H.; Goel, N. Classical and bayesian inference in two parameter exponential distribution with randomly censored data. Comput. Stat. 2018, 33, 249–275. [Google Scholar] [CrossRef]
- Tomy, L.; Jose, M.; Veena, G. A review on recent generalizations of exponential distribution. Biom. Biostat. Int. J. 2020, 9, 152–156. [Google Scholar] [CrossRef]
- Lehmann, E.L.; Casella, G. Theory of Point Estimation; Springer Science & Business Media: Berlin, Germany, 1998. [Google Scholar]
- Gelf, A.E.; Smith, A.F. Sampling-based approaches to calculating marginal densities. J. Am. Stat. Assoc. 1990, 85, 398–409. [Google Scholar] [CrossRef]
- Chen, M.; Shao, Q. Monte carlo estimation of bayesian credible and hpd intervals. J. Comput. Graph. Stat. 1999, 8, 69–92. [Google Scholar] [CrossRef]
- McIllmurray, M.; Turkie, W. Controlled trial of gamma linolenic acid in duke’s c colorectal cancer. Br. Med. J. (Clin. Res. Ed.) 1987, 294, 1260. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| n | m | R (Scheme) | Parameter | MLE_AE | MLE_MSE | Bayes_AE | Bayes_MSE |
|---|---|---|---|---|---|---|---|
| 50 | 50 | 2.0175 | 0.0006 | 2.0000 | 0.0003 | ||
| 1.4906 | 0.0802 | 1.5187 | 0.0793 | ||||
| 2.0083 | 0.2056 | 2.0568 | 0.1788 | ||||
| 50 | 40 | 2.0178 | 0.0006 | 2.0001 | 0.0003 | ||
| 1.5044 | 0.1050 | 1.5180 | 0.0417 | ||||
| 2.0298 | 0.2745 | 2.0032 | 0.1117 | ||||
| 50 | 40 | 2.0219 | 0.0009 | 2.0041 | 0.0005 | ||
| 1.5059 | 0.1146 | 1.5196 | 0.1036 | ||||
| 2.0414 | 0.2849 | 2.0368 | 0.1302 | ||||
| 50 | 30 | 2.0287 | 0.0016 | 2.0110 | 0.0009 | ||
| 1.4890 | 0.1458 | 1.5442 | 0.2126 | ||||
| 2.0172 | 0.3301 | 2.1859 | 0.2657 | ||||
| 30 | 30 | 2.0292 | 0.0018 | 1.9998 | 0.0010 | ||
| 1.4877 | 0.1481 | 1.5433 | 0.1150 | ||||
| 2.0242 | 0.4925 | 2.0024 | 0.2263 | ||||
| 50 | 25 | 2.0323 | 0.0021 | 2.0146 | 0.0013 | ||
| 1.4717 | 0.1755 | 1.5610 | 0.1714 | ||||
| 2.0060 | 0.4541 | 2.0442 | 0.3850 | ||||
| 50 | 25 | 2.0185 | 0.0007 | 2.0006 | 0.0003 | ||
| 1.4804 | 0.1814 | 1.5698 | 0.1823 | ||||
| 2.0457 | 0.5503 | 2.0936 | 0.6920 | ||||
| 30 | 25 | 2.0351 | 0.0023 | 2.0052 | 0.0011 | ||
| 1.4922 | 0.2034 | 1.4845 | 0.1216 | ||||
| 2.0673 | 0.5523 | 2.0234 | 0.1584 | ||||
| 50 | 20 | 2.0428 | 0.0037 | 2.0248 | 0.0025 | ||
| 1.4918 | 0.2485 | 1.5453 | 0.1552 | ||||
| 2.0270 | 0.7585 | 2.0994 | 0.0707 | ||||
| 30 | 20 | 2.0433 | 0.0038 | 2.0133 | 0.0021 | ||
| 1.4940 | 0.2458 | 1.7476 | 0.1474 | ||||
| 2.0255 | 0.7988 | 2.0030 | 0.1822 | ||||
| 30 | 20 | 2.0289 | 0.0017 | 1.9985 | 0.0010 | ||
| 1.4974 | 0.2256 | 1.5490 | 0.1131 | ||||
| 2.0796 | 0.8337 | 2.1071 | 0.1511 | ||||
| 30 | 15 | 2.0556 | 0.0066 | 2.0246 | 0.0042 | ||
| 1.5006 | 0.3285 | 1.6686 | 0.2739 | ||||
| 2.1015 | 1.3137 | 2.0644 | 0.6006 |
| n | m | R (Scheme) | Parameter | ACI_AL | ACI_CP | CRI_AL | CRI_CP |
|---|---|---|---|---|---|---|---|
| 50 | 50 | 0.0651 | 0.947 | 0.0651 | 0.946 | ||
| 1.1086 | 0.926 | 1.1180 | 0.955 | ||||
| 1.7430 | 0.923 | 1.6637 | 0.954 | ||||
| 50 | 40 | 0.0663 | 0.959 | 0.0662 | 0.958 | ||
| 1.2569 | 0.930 | 1.1165 | 0.951 | ||||
| 1.9826 | 0.934 | 1.3082 | 0.944 | ||||
| 50 | 40 | 0.0664 | 0.933 | 0.0665 | 0.933 | ||
| 1.2583 | 0.922 | 1.2186 | 0.934 | ||||
| 1.9998 | 0.925 | 1.3298 | 0.946 | ||||
| 50 | 30 | 0.0669 | 0.897 | 0.0669 | 0.897 | ||
| 1.4453 | 0.921 | 1.7013 | 0.946 | ||||
| 2.2962 | 0.916 | 2.1316 | 0.959 | ||||
| 30 | 30 | 0.1111 | 0.938 | 0.1111 | 0.939 | ||
| 1.4470 | 0.907 | 1.1060 | 0.943 | ||||
| 2.3289 | 0.896 | 2.9074 | 0.940 | ||||
| 50 | 25 | 0.0670 | 0.932 | 0.0660 | 0.940 | ||
| 1.5747 | 0.908 | 1.6214 | 0.946 | ||||
| 2.5345 | 0.899 | 2.2969 | 0.953 | ||||
| 50 | 25 | 0.0678 | 0.945 | 0.0677 | 0.944 | ||
| 1.5793 | 0.909 | 1.6272 | 0.943 | ||||
| 2.5970 | 0.904 | 2.3886 | 0.944 | ||||
| 30 | 25 | 0.1136 | 0.940 | 0.1136 | 0.939 | ||
| 1.5966 | 0.894 | 1.4506 | 0.943 | ||||
| 2.6385 | 0.905 | 2.4594 | 0.949 | ||||
| 50 | 20 | 0.0689 | 0.789 | 0.0689 | 0.785 | ||
| 1.8089 | 0.912 | 1.3475 | 0.935 | ||||
| 2.9205 | 0.883 | 1.2015 | 0.943 | ||||
| 30 | 20 | 0.1149 | 0.902 | 0.1149 | 0.905 | ||
| 1.8121 | 0.905 | 1.3483 | 0.945 | ||||
| 2.9342 | 0.876 | 2.7181 | 0.941 | ||||
| 30 | 20 | 0.1164 | 0.947 | 0.1164 | 0.946 | ||
| 1.8052 | 0.898 | 1.3341 | 0.949 | ||||
| 3.0327 | 0.893 | 1.8529 | 0.944 | ||||
| 30 | 15 | 0.1205 | 0.852 | 0.1205 | 0.854 | ||
| 2.1281 | 0.869 | 2.0567 | 0.941 | ||||
| 3.6647 | 0.891 | 3.2281 | 0.939 |
| Parameter | MLE | 95% ACI | Bayes Estimate | 95% CRI |
|---|---|---|---|---|
| 3.0000 | [0.2927, 4.9814] | 2.1889 | [0.0000, 2.9822] | |
| 32.0255 | [13.1000, 50.9509] | 37.0208 | [19.8635, 47.7169] | |
| 39.1422 | [13.5698, 64.7147] | 46.5209 | [23.1941, 71.0820] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Goel, R.; Abdelwahab, M.M.; Kamble, T. Frequentist and Bayesian Estimation Under Progressive Type-II Random Censoring for a Two-Parameter Exponential Distribution. Symmetry 2025, 17, 1205. https://doi.org/10.3390/sym17081205
Goel R, Abdelwahab MM, Kamble T. Frequentist and Bayesian Estimation Under Progressive Type-II Random Censoring for a Two-Parameter Exponential Distribution. Symmetry. 2025; 17(8):1205. https://doi.org/10.3390/sym17081205
Chicago/Turabian StyleGoel, Rajni, Mahmoud M. Abdelwahab, and Tejaswar Kamble. 2025. "Frequentist and Bayesian Estimation Under Progressive Type-II Random Censoring for a Two-Parameter Exponential Distribution" Symmetry 17, no. 8: 1205. https://doi.org/10.3390/sym17081205
APA StyleGoel, R., Abdelwahab, M. M., & Kamble, T. (2025). Frequentist and Bayesian Estimation Under Progressive Type-II Random Censoring for a Two-Parameter Exponential Distribution. Symmetry, 17(8), 1205. https://doi.org/10.3390/sym17081205