2. Literature Review
During the past few decades, forecasting the price of crude oil has made extensive use of conventional statistical and econometric methods [
10,
11]. Amano made one of the first study proposals about oil market forecasting [
12]. The author predicted the oil market using a small-scale econometric model. In order to forecast crude oil prices in the 1980s, Huntington used an advanced econometric model [
13]. Furthermore, a probabilistic model was used by Abramson and Finizza to forecast oil prices [
14]. When the price series being studied is linear or nearly linear, the models mentioned above can produce accurate forecast results. However, there is a significant amount of nonlinearity and irregularity in real-world crude oil price series [
10,
11,
15].
To deal with the limitations of classic models, some nonlinear and advanced artificial intelligence (AI) models have been applied to predict crude oil [
15]. Wang, Yu, and Lai integrated an ANN model with a knowledge database that includes historical events and their influence on oil prices. According to the authors, performance for a hybrid ANN approach was 81%, and it was 61% for a pure ANN system [
16]. Mirmirani and Li applied genetic algorithms for predicting the price of crude oil and compared their findings with the VAR model [
17].
Using intrinsic mode function inputs and an adaptive linear ANN learning paradigm, Yu, Wang, and Keung forecasted the West Texas Intermediate (WTI) crude oil and Brent petrol spot prices for the years 1986–2006 [
10]. Kulkarni and Haidar provided an excellent description of building an ANN model [
2]. They employed a multilayer feedforward neural network to estimate the direction of the crude oil spot price up to three days ahead of time, using data spanning from 1996 to 2007. For one, two, and three days in the future, respectively, their forecast accuracy was 78%, 66%, and 53%.
Gori et al. trained and tested an ANFIS method that was able to estimate oil prices for the years 1999 to 2003 by using data on oil prices from July 1973 to January 1999 [
18]. Chiroma et al. applied a novel approach, a co-active neuro-fuzzy inference system (CANFIS), to predict crude oil price by using monthly data of WTI [
19]. They developed this approach in place of ANFIS and frequently used techniques to increase forecast accuracy. Mombeini and Yazdani suggested a hybrid model based on ARIMA (AutoRegressive Integrated Moving Average) and ANFIS to study the fluctuation and volatility of prices of West Texas Intermediate (WTI) crude oil markets to create a more exact and accurate model. Several statistical studies utilizing the MAPE, R2, and PI tests were carried out in order to reach this purpose [
20]. The objective of Abdollahi and Ebrahimi in their study was to present a strong hybrid model for accurate Brent oil price forecasts [
21]. The suggested hybrid model includes ANFIS, Autoregressive Fractionally Integrated Moving Average (ARFIMA), and Markov-switching models. To effectively capture the linear and nonlinear characteristics, these three techniques were combined. The technique put out by AbdElaziz et al. depends on using a modified salp swarm algorithm (SSA) to improve the ANFIS’s performance [
22]. They compared the outcome with nine further modified ANFIS approaches. Anshori et al. examined a case study and optimized the initial ANFIS parameters using the Cuckoo Search technique to estimate global crude oil prices [
23]. Eliwa et al. [
24] used 30-year gasoline prices to anticipate prices using the ANFIS model. By supporting this model with VAR (Vector Autoregression) and ARIMA models, they were able to obtain high accuracy and significant correlation.
Recently, deep learning and hybrid models, such as LSTM (Long Short-Term Memory), GRU (Gated Recurrent Unit), SVM (Support Vector Machine), RF (Random Forest), XGBoost (eXtreme Gradient Boosting), and other hybrid approaches, have begun to appear as novel methodologies in time-series analyses. Awijen et al. [
25] presented a comparative research study on the use of machine learning and deep learning to anticipate oil prices during crises. In the study, processes were performed primarily utilizing RNN (recurrent neural network), LSTM, and SVM algorithms. Jabeur et al. [
26] predicted the fall in oil prices using some machine learning techniques with neural network models. They found that among the methods applied, such as RF, LightGBM (Light Gradient-Boosting Machine), XGBoost, and CatBoost, RF and LightGBM offered the best results. Jiang et al. [
27] compared the LSTM model to other methods such as AR (Autoregression), SVR, RNN (recurrent neural network), and GRU and determined that the LSTM model produced better outcomes for China’s crude oil forecast. In order to predict and test the prices of Brent and WTI crude oil at various time-series frequencies, Hasan et al. [
28] present a model they call LKDSR, which combines machine learning techniques like k-nearest neighbor regression, linear regression, regression tree, support vector regression, and ridge regression. Furthermore, Sezer et al.’s study [
29], a comprehensive literature review on the use of deep learning for forecasting financial time series, is valuable.
Iftikhar et al. [
30] conducted a comprehensive analysis for Brent oil price forecasting by evaluating hybrid combinations of linear and nonlinear time-series models using the Hodrick–Prescott filter. Using European Brent crude oil spot data, Zhao et al. [
31] constructed a three-layer LSTM model to predict prices, with highly positive outcomes. Dong et al. [
32] used VMD to eliminate noise from the data and PSR (Phase Space Reconstruction) to rebuild the price of crude oil. Lastly, they used CNN-BILSTM (a hybrid bidirectional LSTM and CNN architecture) to make multi-step predictions. By using SVM, ARIMA, and LSTM techniques to analyze crude oil prices, Naeem et al. [
33] developed a hybrid model for crude oil price prediction. In order to improve the forecasting accuracy of crude oil prices and properly analyze the linear and nonlinear features of crude oil, Xu et al. [
34] developed hybrid approaches. For this purpose, they used models such as ARIMAX, GRU, LSTM, and MLP (Multilayer Perceptron). Sen et al. [
35] investigated the prediction of crude oil prices using ANN, LSTM, and GRU models. They optimized the hyperparameters of LSTM and GRU using the PSO (Particle Swarm Optimization) method. Jin et al. [
36] forecasted daily and monthly prices for Henry Hub natural gas, New York Harbor No. 2 heating oil, and WTI and Brent crude oil using nonlinear autoregressive neural network models. Various model configurations, training methods, hidden neurons, delays, and data segmentations are taken into account while evaluating the performance.
ANFIS was chosen due to its ability to combine the strengths of both neural networks and fuzzy logic, making it highly suitable for modeling complex, nonlinear systems such as time-series prediction problems. Additionally, ANFIS allows flexible adaptation through learning, while also maintaining interpretability through fuzzy rules.
When compared with hybrid models, ANFIS produces successful results when the proper parameters are introduced for time-series analysis. While hybrid models require more computations and make the model more complicated, they cannot produce a noticeable effect. As a result, thanks to ANFIS, we achieve successful results in a simpler way without the need for further processing.
In this study, metaheuristic algorithms were employed in the training process of ANFIS. Achieving effective results with ANFIS largely depends on the quality of the training process. A review of the literature shows that metaheuristic algorithms are commonly used for training ANFIS and have led to successful outcomes in various applications. Therefore, in the context of Brent oil price prediction, metaheuristic optimization was selected as the training strategy for ANFIS. Specifically, nine widely used and literature-supported metaheuristic algorithms—known for their strong performance in ANFIS training—were implemented in this study.
In this study, the entire experimental setup was constructed with a methodologically symmetric design. All metaheuristic algorithms were applied under the same training conditions, including identical datasets, ANFIS configurations, input–output pairings, and evaluation metrics. This symmetry in training and evaluation ensured fairness, consistency, and repeatability across the experiments. Such a structured and balanced framework contributes not only to the reliability of the comparative analysis but also reflects the core principles of symmetric design in artificial intelligence research.
4. Simulation Results and Discussion
Within the scope of this study, ANFIS training was carried out using nine different metaheuristic algorithms to estimate the daily, weekly, and monthly minimum and maximum values of Brent oil price, and the obtained results were analyzed in detail. The algorithms used in ANFIS training were SHO, BBO, MVO, TLBO, CS, MFO, MPA, FPA, and ABC.
The Brent oil data used in this study were taken from the investing.com website as daily, weekly, and monthly datasets. The daily dataset covered the period between 3 January 2022, and 29 December 2023. Here, it is crucial to note that daily databases did not include data for weekends and holidays. The weekly dataset contained data from 1 January 2014 to 31 December 2023, and the monthly dataset spanned from 1 January 2014 to 1 January 2024. We collected 515 data points for the daily dataset and 522 data points for the weekly dataset to achieve more fitting analysis results. In contrast, since the monthly data collection contained fewer data over a larger range, 121 data points were collected to guarantee consistency. It is also worth noting that these daily, weekly, and monthly data were acquired separately for the lowest and highest values in the specified date ranges.
In this study, six prediction problems, as outlined in
Table 1, are addressed. Specifically, the aim is to estimate the minimum and maximum values that Brent oil prices can reach on a daily, weekly, and monthly basis. The data used in these estimations are structured as time series. The time-series data were transformed into input–output pairs suitable for the training of ANFIS. The main goal of this transformation is to predict future values by using past data. However, in time-series problems, it is not always clear how many past values should be used to achieve the best prediction accuracy. To reduce this uncertainty, separate datasets were prepared for daily, weekly, and monthly predictions, each consisting of two, three, and four inputs, respectively, along with one output. Through these multiple configurations, the effect of the number of inputs on prediction performance was systematically investigated.
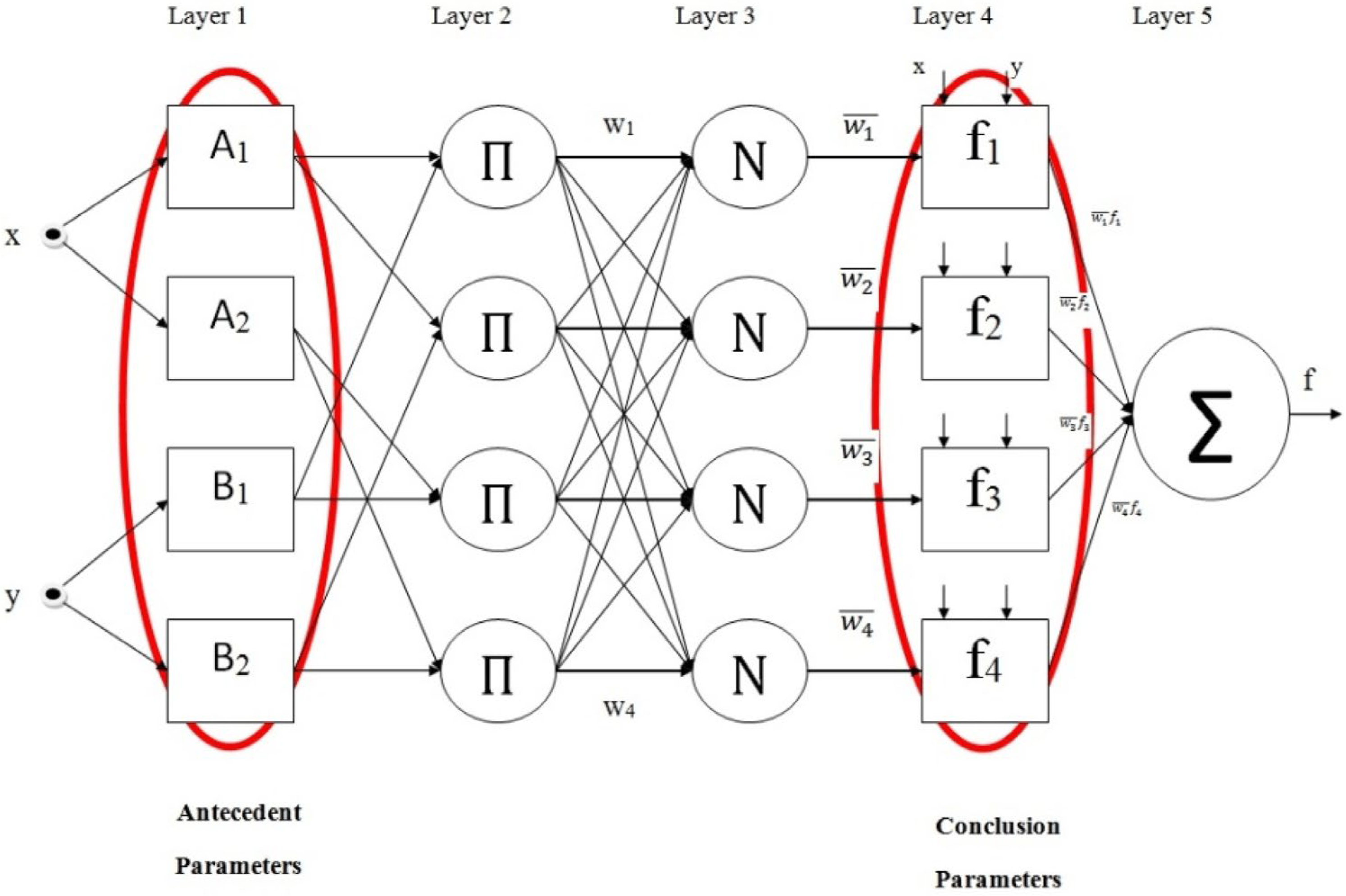
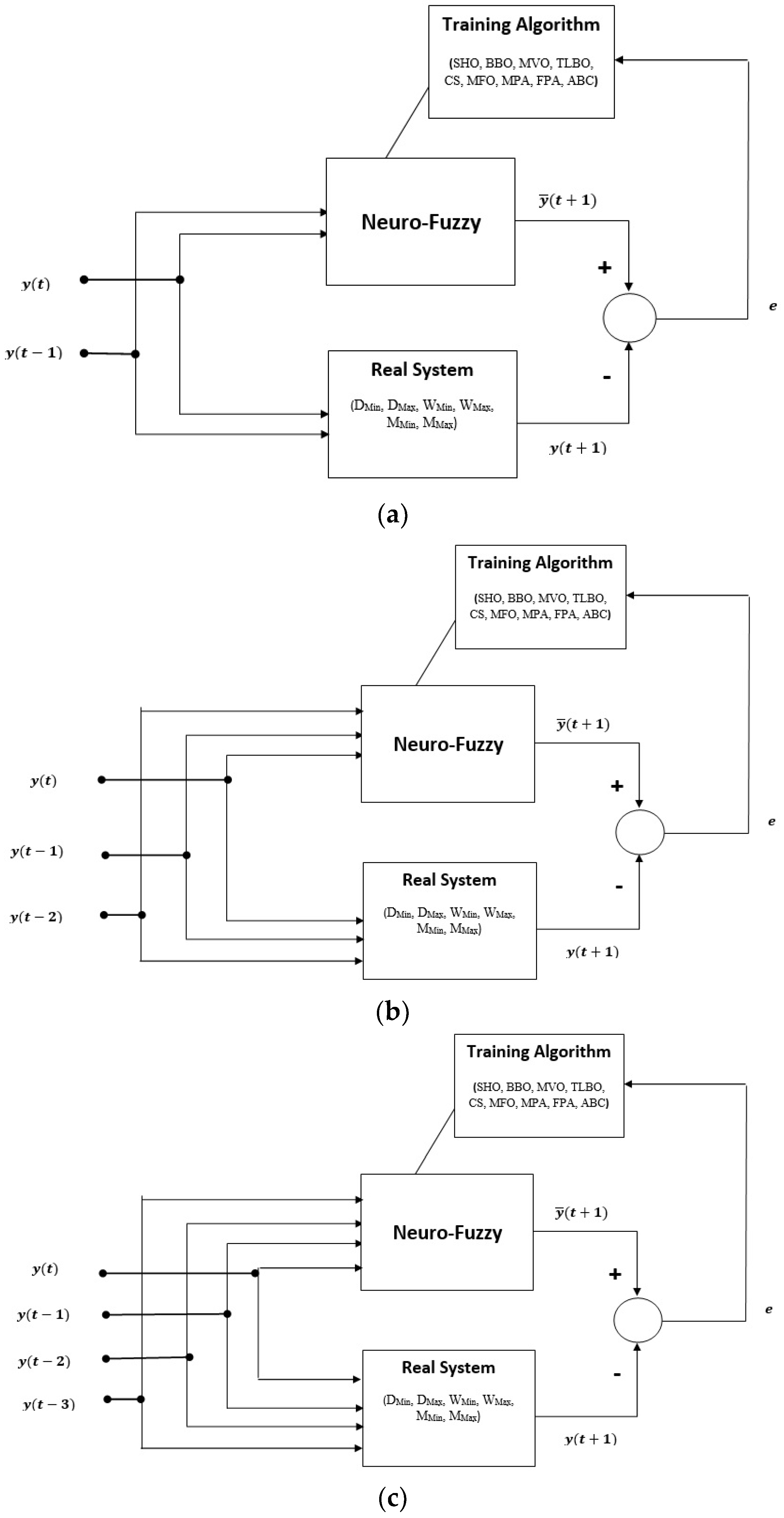
The ANFIS structures used in the study are illustrated in
Figure 2.
Figure 2a shows the block diagram of an ANFIS model with two inputs, while
Figure 2b presents the training process and error calculation steps for a three-input model.
Figure 2c displays the system structure when four inputs are used. In all these models, the output represents the subsequent time step value in the series.
In the preprocessing phase, normalization plays an important role, especially when the dataset is large or contains high variability. For this reason, all input and output values were normalized to the [0, 1] range. All results and evaluations were made based on these normalized values.
Another critical factor that influences the performance of ANFIS is the type and number of membership functions (MFs). According to the literature, generalized bell-shaped membership functions (gbellmf) are effective in modeling normalized time-series data. Therefore, gbellmf was selected in this study to remain consistent with existing studies and to avoid unnecessary experimentation.
Additionally, the number of membership functions significantly affects learning performance. In this work, systems with different input counts were trained using two, three, and four membership functions, respectively, in order to analyze their impact on prediction accuracy. Since the number of parameters to be optimized increases with more inputs, the number of MFs was adjusted accordingly. For example, in the model with four inputs, only two MFs were used to reduce the complexity of the learning process.
Notably, 80% of the obtained dataset is used in the training process, and 20% is utilized in the testing process. All error values in the study are calculated as mean squared error (MSE). To compare the results obtained with each algorithm fairly, the population size and maximum generation number were evaluated similarly. In other words, the population size and maximum generation number were set as 20 and 2500, respectively.
Table 2 presents a summary of the overall workflow followed in this study. The process begins with data collection, where time-series data relevant to Brent oil prices are obtained. This is followed by the normalization and feature setup stage, where raw data are scaled to a uniform range and input–output pairs are prepared for model training. In the next step, the ANFIS structure is defined, including the selection of membership function types and their quantities. The model is then subjected to training and testing, allowing performance evaluation based on different configurations. Finally, the results are assessed through various evaluation metrics to determine prediction accuracy and overall model effectiveness.
4.1. Analysis for Predicting the Lowest and Highest Daily Prices of Brent Oil
The results obtained in estimating the daily minimum value of Brent oil price are presented in
Table 3. When the results obtained for all applications of all algorithms are examined, it is seen that the average training error values do not exceed the 10
−3 level. The mean training error values were found to be in the range of 1.7 × 10
−3 to 2.6 × 10
−3. The best mean training error value, 1.7 × 10
−3, was achieved with TLBO, BBO, and MPA. The worst mean training error value was found with SHO. The results of other algorithms, except SHO, are 1.9 × 10
−3 or better. Due to the structure of the problem, increasing the number of membership functions did not clearly improve or worsen the mean training error values. Minor behavioral differences were observed between the algorithms. The best training error value was found as 1.5 × 10
−3 on the four-input system with BBO. Low standard deviation values were achieved for the training process. Except for a few applications, the value was at the 10
−5 level. The best mean test error value was found to be 1.6 × 10
−3, and this value was obtained from many algorithms and many applications. The training algorithms could not make the mean test error value better than 1.6 × 10
−3. In addition, the best mean training error and the best mean test error values are parallel to each other. The best test error value was 1.4 × 10
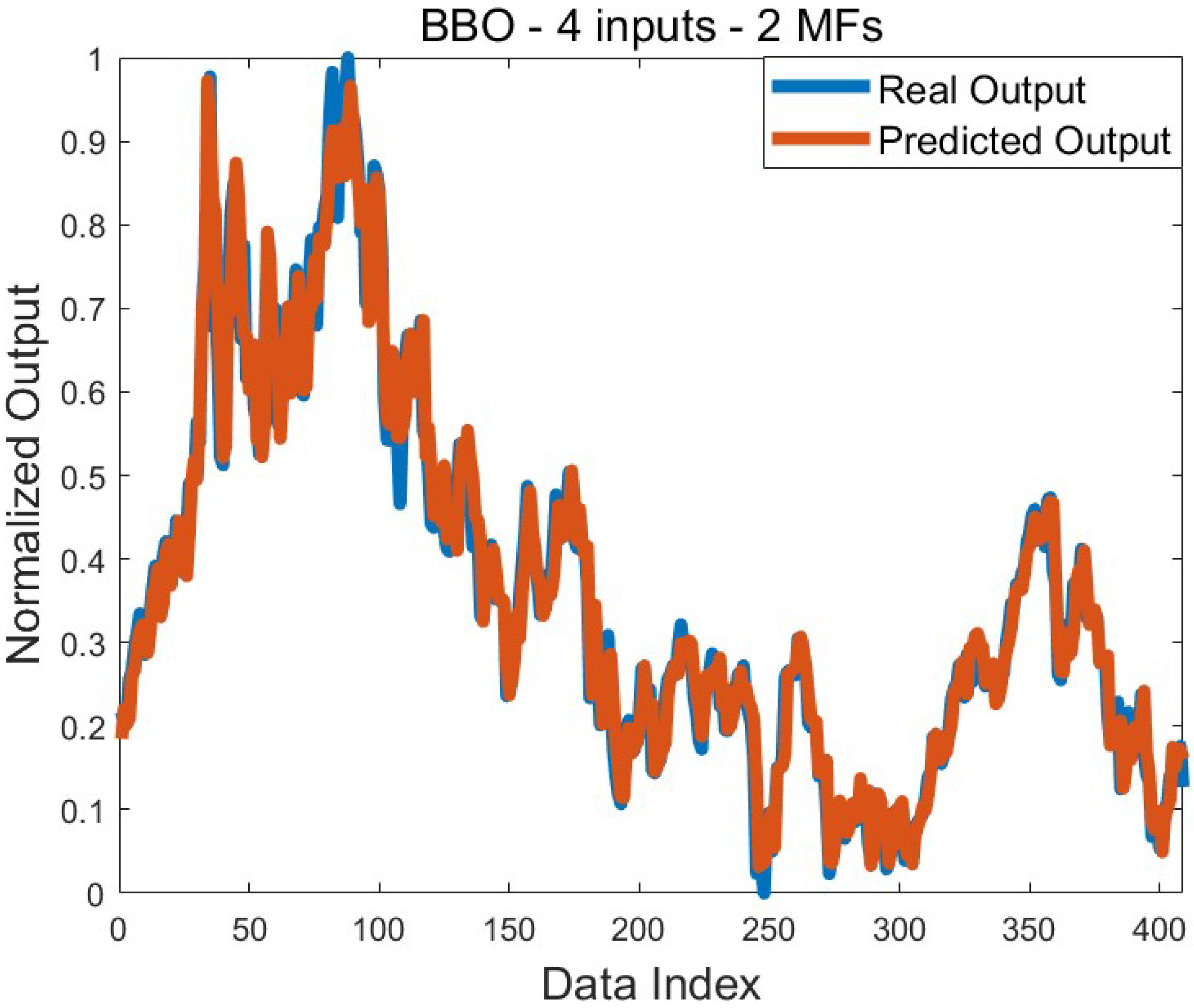
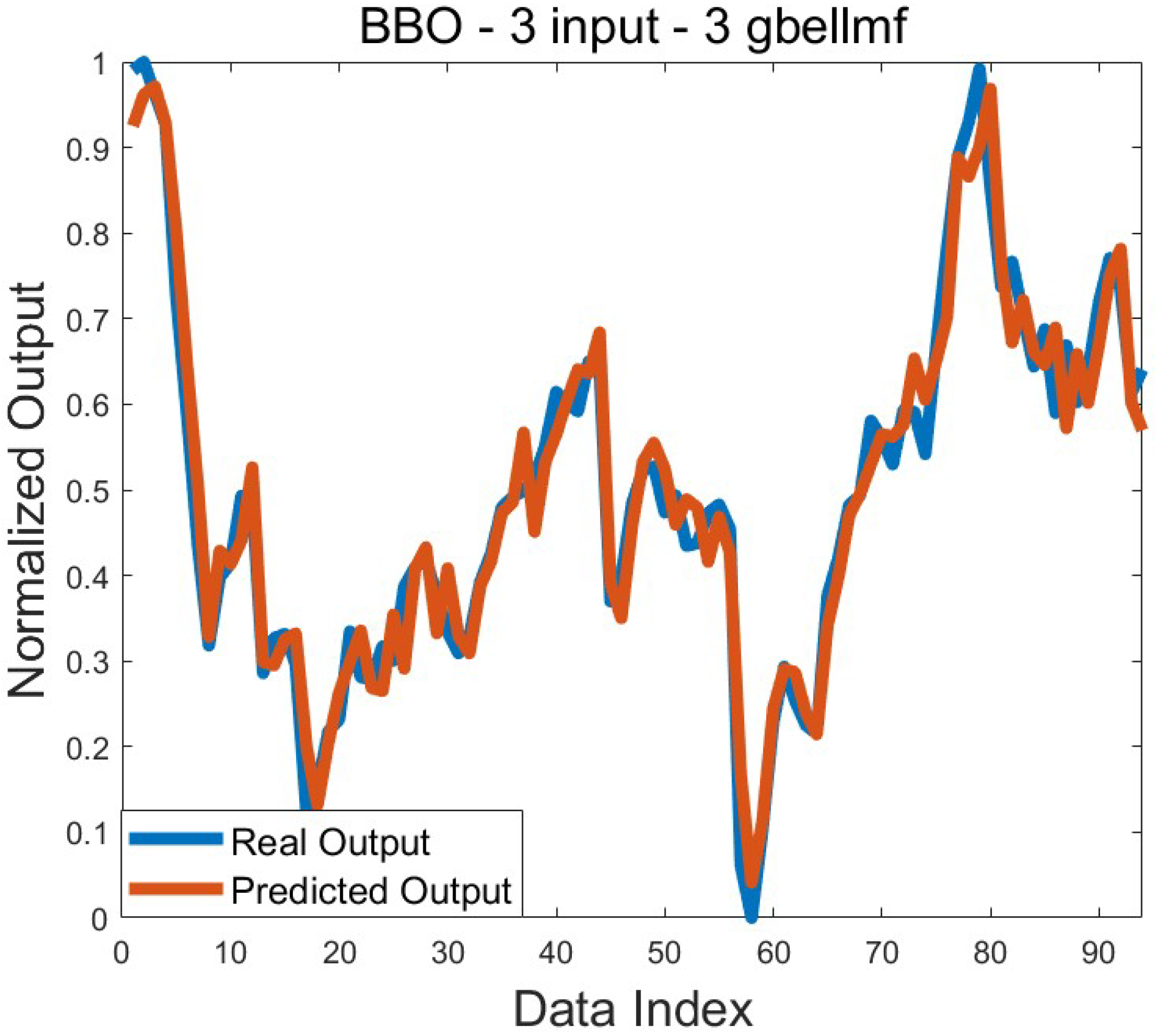
−3. This value can be obtained with different algorithms. Good standard deviation values were also achieved for the test, except for a few applications. The comparison graph for the real output and the predicted output, taking into account the best training error value obtained with BBO, is presented in
Figure 3.
Table 4 presents a comparison of the estimates for the highest daily price of Brent oil. Changing the number of membership functions affected the results differently depending on the training algorithms. When the training results are evaluated, it is seen that the change in the number of membership functions does not change the mean error values obtained with ABC, CS, and MVO. In all applications of these algorithms, the 1.1 × 10
−3 value was reached as the mean error value. The increase in the number of membership functions improved the mean training error in BBO and TLBO. The opposite situation was observed in MPA. The best mean training error value was obtained on a two-input system using MPA. This value is 9.3 × 10
−4. After MPA, the best mean training error value belongs to BBO. The best training error value was found to be 7.7 × 10
−4 on the four-input system using TLBO. For at least one implementation of algorithms other than CS, the best training errors are at a level of 10
−4. Effective standard deviation values were obtained, especially because the training error values found by the algorithms were close to each other. When we look at the mean test error values, we see that the algorithms mostly obtain results that are close to each other. The mean test error values are in the range of 1.0 × 10
−3 to 1.6 × 10
−3. The best mean error value was found to be 1.0 × 10
−3 with BBO, MFO, and TLBO. According to all test results, the mean error value is frequently obtained as 1.1 × 10
−3. In fact, these results are parallel to the training results. As with the mean test error value, the best test error value also belongs to BBO. It is 8.3 × 10
−4. In addition to that, effective standard deviation values were obtained in the test results.
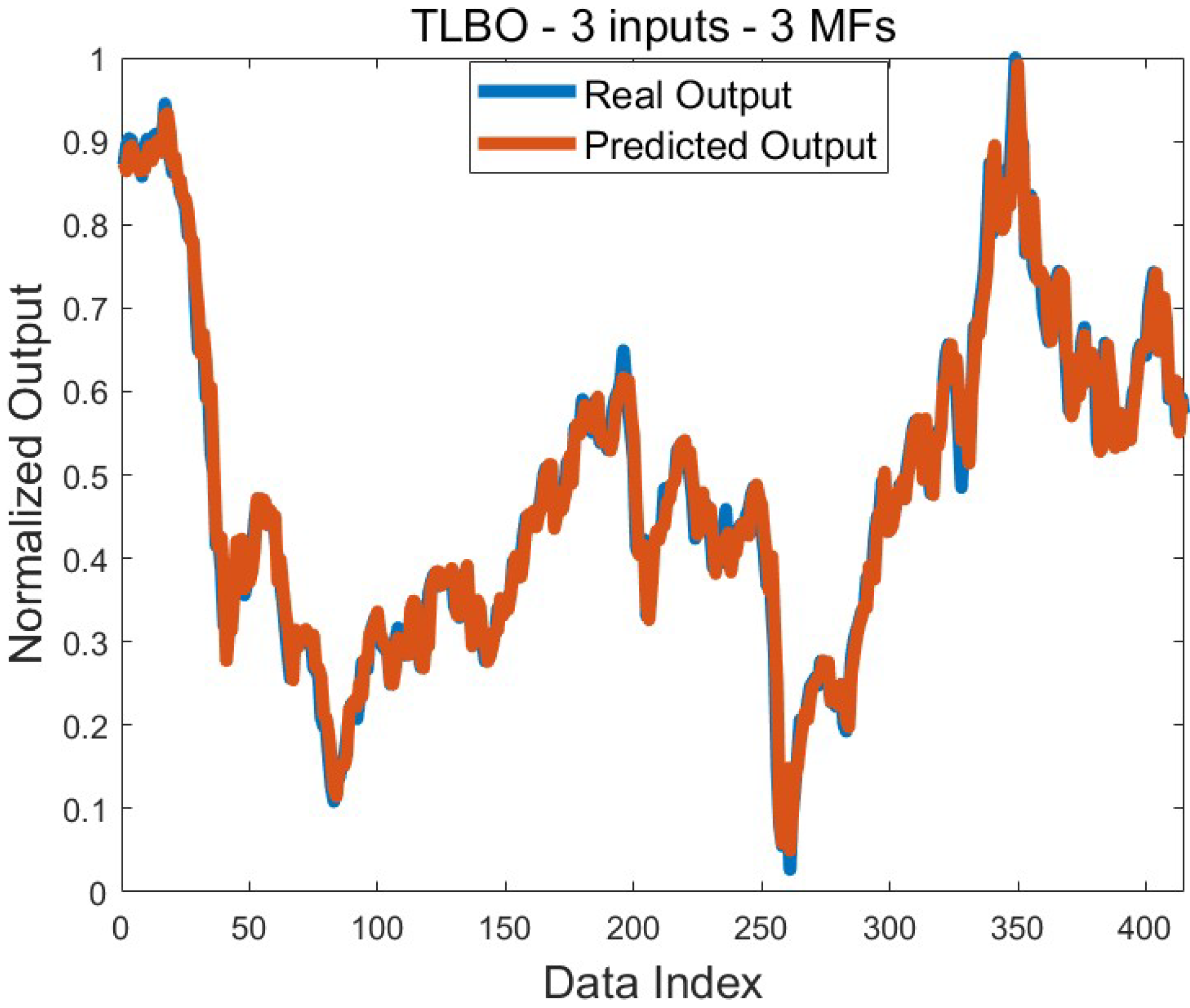
Figure 4 presents the comparison of graphs of real and predicted outputs plotted according to the best training error obtained for the highest daily Brent oil price. It is seen that a very successful prediction was made, and the predicted output mostly coincides with the actual output.
4.2. Analysis for Predicting the Lowest and Highest Weekly Prices of Brent Oil
Table 5 shows the results obtained with the training algorithms for predicting the lowest weekly price. Although it varies according to the training algorithms, the increase in the number of membership functions usually does not significantly affect the mean training error values. Except for a few applications of SHO, the mean training error value at a level of 10
−4 was achieved. The best mean training error value was found to be 7.1 × 10
−4 with BBO, MPA, and TLBO. The worst mean training error value for this problem was obtained on the four-input system using SHO. In other words, the mean training error value in all applications is in the range of 7.1 × 10
−4 to 1.1 × 10
−3. In addition, the best training error value was found to be 6.6 × 10
−4 using TLBO and BBO. When we look at the training results, generally, successful results were obtained in all algorithms. It is seen that these results are supported by low standard deviation values. Standard deviations were found especially at the 10
−4, 10
−5, and 10
−6 levels. No algorithm was able to find a better result than 1.0 × 10
−3 in the mean test error values. In this respect, it is a fact that test error values lag behind training error values. The best mean test error was found using FPA, BBO, MFO, CS, MPA, MVO, and TLBO. The worst mean error value was reached with SHO. In other words, it is possible to say that the mean test error values were obtained in the range of 1.0 × 10
−3 to 1.5 × 10
−3. The best test error value was found to be 9.4 × 10
−4. The effective standard deviation value was reached in the testing process as well as in the training process.
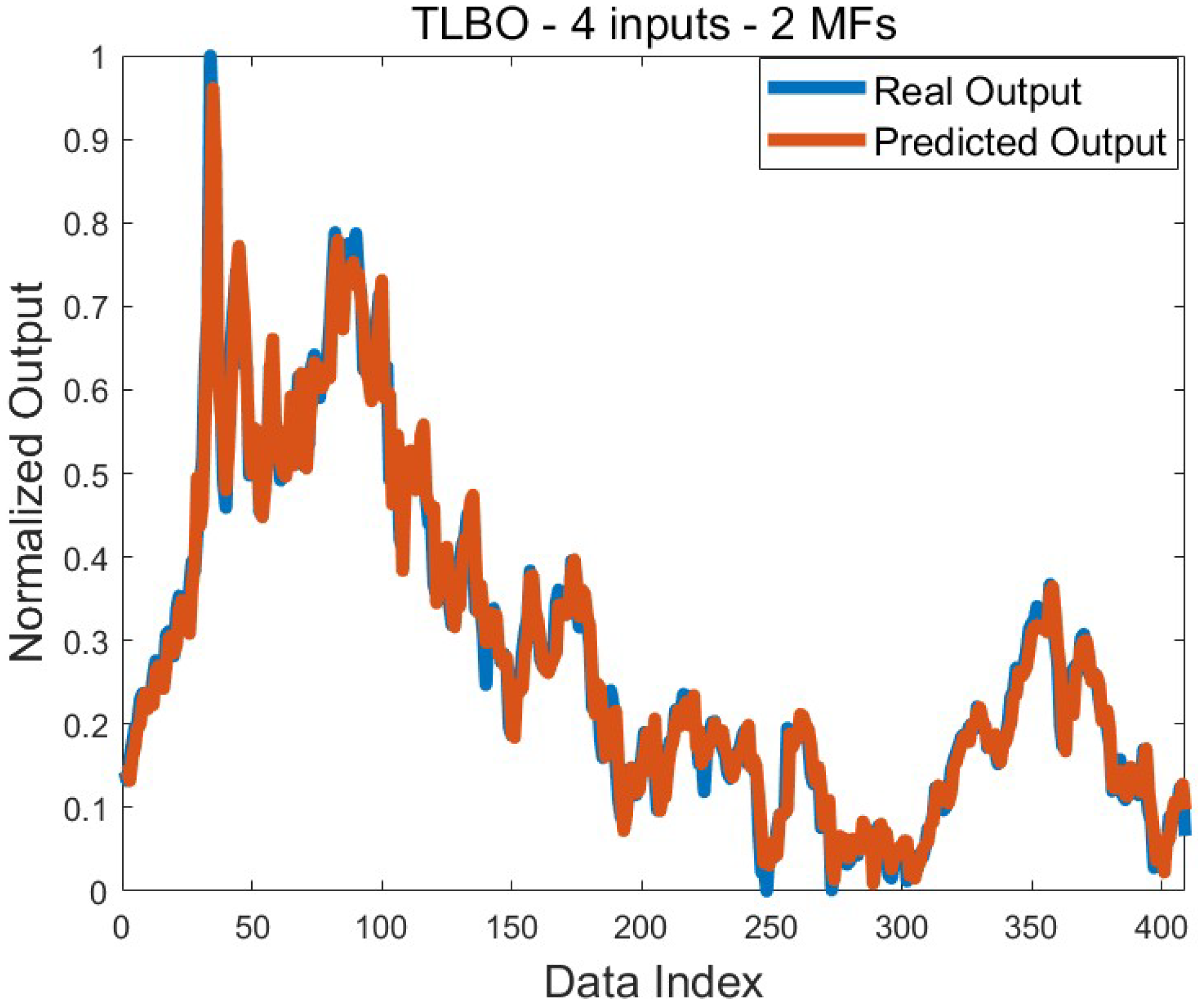
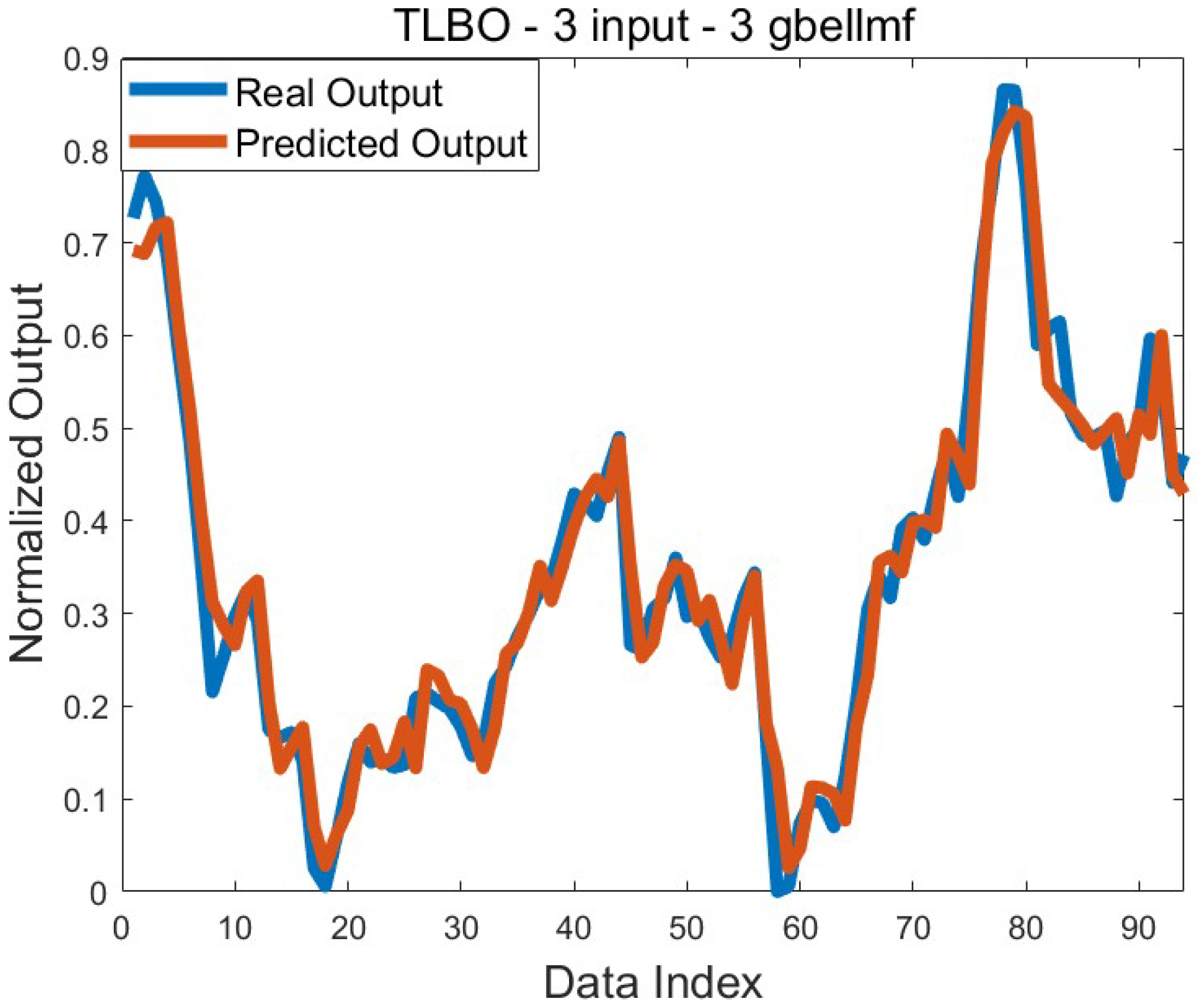
Figure 5 shows the comparison graph of the predicted output and the real output for the mean error value of 7.1 × 10
−4. Since this result was obtained with several algorithms, the graph was drawn by considering only the result found with TLBO. The large overlap of both graphs is an indication that the training process was successful.
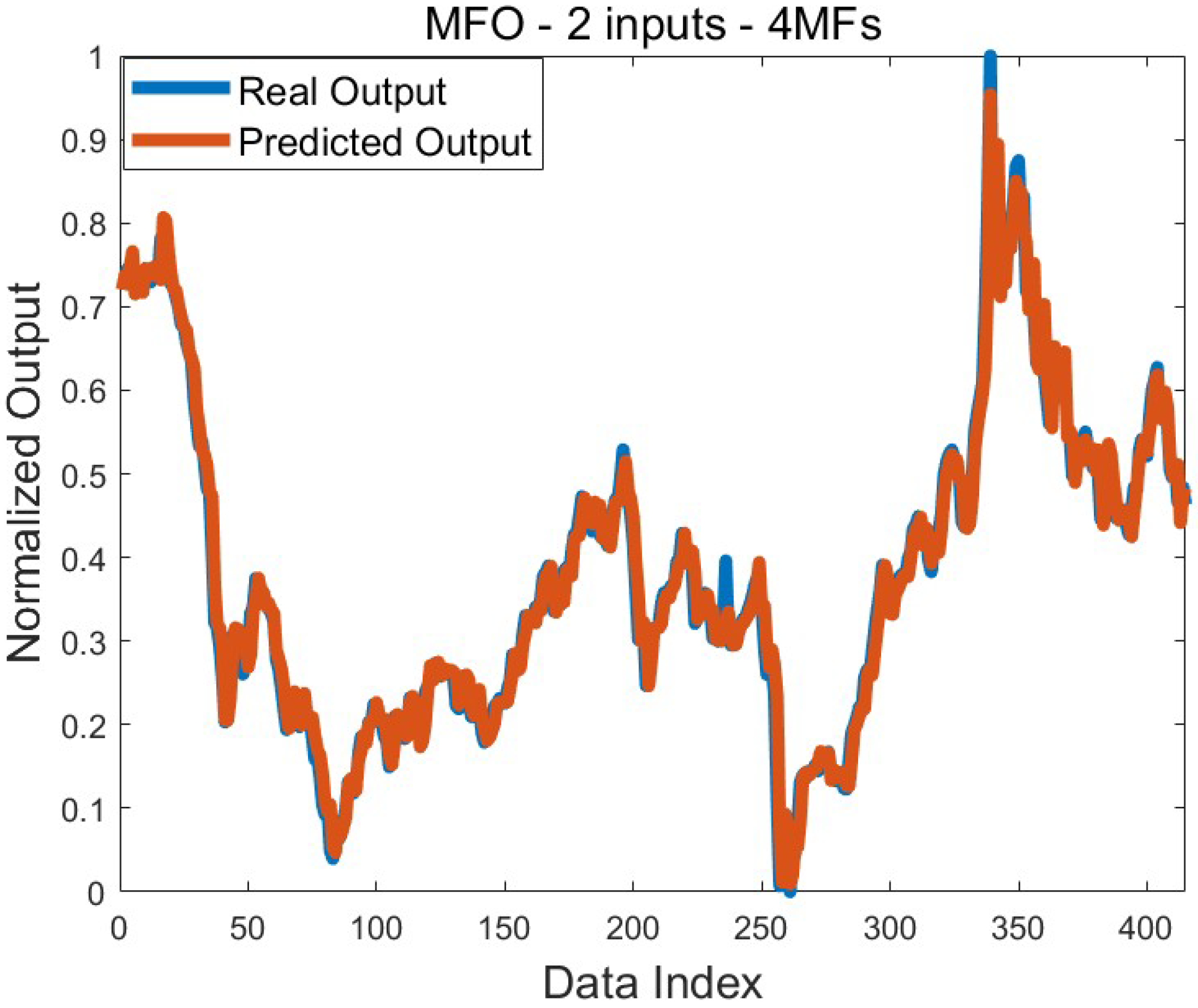
Table 6 shows the results obtained for predicting the highest weekly price. Increasing the number of membership functions of the inputs in ABC, BBO, and MFO also improved the solutions. Mixed behaviors were observed in other algorithms. The best mean training error was obtained by using BBO algorithms and MPAs on the two-input system. This value is 6.0 × 10
−4. The worst mean training error value was found to be 1.0 × 10
−3 with SHO. Other application results are between the best and worst mean values specified. The best training error value was found using MFO, and its value was 5.4 × 10
−4. Effective standard deviation values were reached in the training process. Except for a few applications, standard deviation was found at the 10
−5 level. During the testing process, especially in FPA and TLBO, increasing the number of membership functions used in the inputs improved the mean test error value. A similar situation was observed in three-input systems in ABC, BBO, and MVO. In other applications, stable behavior was not exhibited. The best mean error value was found on four-input systems with TLBO and MVO. This value is 5.8 × 10
−4. In addition, the best error value was found to be 4.6 × 10
−4. This value was obtained with four different training algorithms. Successful standard deviation values were achieved in the testing process as well as in the training process. It is seen that the standard deviation values obtained in all applications are in the 10
−4 or 10
−5 level.
Figure 6 shows a comparison graph of the predicted output and the real output based on the best training result. It is seen that the graphs overlap except for a few output values. This shows that the training process carried out to solve the relevant problem was successful.
4.3. Analysis for Predicting the Lowest and Highest Monthly Prices of Brent Oil
Table 7 shows the results of estimating the lowest monthly price of Brent oil. According to the mean error values of the training process, the increase in the number of membership functions in ABC, BBO, MFO, and TLBO algorithms generally partially improved the results. In the FPA and some results of CS, it is seen that the increase in the number of membership functions does not affect the result. Effective results were obtained in MPA with low membership numbers. In CS, better results were obtained in two-input systems. The effect of the number of membership functions is limited. In SHO, increasing the number of membership functions worsened the mean error. The best training mean error value was found to be 2.9 × 10
−3 with BBO. A 3.0 × 10
−3 mean error value was achieved with MPA and TLBO algorithms. The worst mean value among all algorithms was found with SHO on the four-input system. This value is 4.3 × 10
−3. The best training error value was found to be 2.1 × 10
−3 with the BBO algorithm. After BBO, the best training error value belongs to TLBO. The value of TLBO is 2.2 × 10
−3. Standard deviation values were reached at 10
−4 and 10
−5 levels for the training process. It is particularly noteworthy that the standard deviation values obtained in the training results of CS are at the 10
−5 level. When all algorithms are considered, it is seen that average test error values are reached in the 4.7 × 10
−3 to 6.3 × 10
−3 range. The best mean test error value was found with MFO on a three-input system. This value is 4.7 × 10
−3. Especially in BBO, MFO, MPA, MVO, SHO, and TLBO, it was observed that the mean test error values worsened as the number of membership functions increased. The best test error value was obtained as 4.0 × 10
−3 using SHO. It is seen that in other algorithms, error values of 4.3 × 10
−3, 4.4 × 10
−3, 4.5 × 10
−3, and 4.6 × 10
−3 are mostly obtained. In the testing process, effective standard deviation values were generally achieved. In the test condition, standard deviation values were found at the 10−4 level except for some applications of MFO, CS, and SHO. As stated before, the best training error was obtained on BBO as 2.9 × 10
−3.
Figure 7 compares the graphs of the predicted output and the real output for this result. It is seen that the real output and the predicted output are consistent with each other except for a few points.
The results obtained regarding the estimation of the highest monthly price of Brent oil are given in
Table 8. The increase in the number of membership functions, especially in ABC, BBO, MFO, and TLBO, improved the training mean errors. A similar situation was observed in MVO, except for one application. All mean error values are the same except for when using two gbellmf on a two-input system, which produced a different mean training error value of the MPA. The best mean error value among all applications was found using three gbellmf on a three-input system with BBO and TLBO algorithms. This value is 2.0 × 10
−3. Apart from BBO and TLBO, the best mean training error value belongs to MPA. The worst mean training error value belongs to SHO. This value is 3.1 × 10
−3. In the light of this information, it is seen that the mean error values obtained for the training process in estimating the monthly maximum value are between 2.0 × 10
−3 and 3.1 × 10
−3. It has also been determined that the training mean errors in two- and three-input systems are generally better than in four-input systems, and the best mean training results are obtained in these systems. The best training error value was found to be 1.6 × 10
−3 using TLBO. The best training error values found with BBO and MPA are 1.7 × 10
−3 and 1.9 × 10
−3, respectively. Effective standard deviation values for the training process were reached. Standard deviation values at the 10
−4 or 10
−5 level were obtained. Looking at the test results, the change in the number of memberships generally affected the results differently. It was observed that the mean test error values of BBO and TLBO were not as good as the mean training error values. The best test mean error values were obtained to be 7.5 × 10
−3 using MFO and MVO. The best test error value was found to be 4.9 × 10
−3 with MFO. The test results show that standard deviation values were obtained at 10
−3 and 10
−4 levels. These values are consistent with the results obtained.
Figure 8 shows the comparison of the real output and the predicted output for the best training error value. Both graphs largely overlap. This is one of the indicators demonstrating that the training process was successful.
The findings obtained in this study should be interpreted within the scope of certain limitations. In particular, the number of inputs, the number and type of membership functions, population size, and the maximum number of generations are the primary constraints considered. Exploring alternative configurations beyond these parameters may lead to higher-quality solutions. However, due to the significant time and computational cost required for such evaluations, the scope of the study was intentionally limited.
The use of historical data proved to be more effective in daily and weekly forecasts. The results clearly show that daily and weekly predictions outperform monthly predictions, as demonstrated in the related tables and figures. One possible reason for this difference is the limited number of data points in the monthly dataset. Additionally, the longer time gap between the input data and the predicted output in monthly forecasts increases the likelihood of external factors influencing the outcome, which may also reduce accuracy.
When examining both training and test results for daily, weekly, and monthly predictions, it is observed that standard deviation values are generally low. This indicates that the successful outcomes obtained are consistent and repeatable. The fact that test results largely aligned with training results suggests that the training process was effectively conducted and that no overfitting occurred.
Although all algorithms yielded effective results, it can be stated that BBO and TLBO performed better than the others in solving the target problem. This does not imply that the other algorithms were unsuccessful, but rather that these two algorithms were more suitable for this specific problem and configuration. It should also be considered that the observed performance differences may be influenced by the previously mentioned limitations of the study.
Furthermore, an increase in the number of inputs and membership functions also increases the number of parameters to be optimized during training, which extends the overall training time. Considering that each algorithm was executed 30 times for statistical validity, the increase in training duration should be considered a critical factor.
In addition to the findings discussed above, the study was conducted within a methodologically symmetric framework. Each of the nine metaheuristic algorithms was applied under identical conditions, using the same datasets, ANFIS configurations, and performance metrics. The number of runs, input–output structures, and evaluation criteria were all uniformly defined across algorithms and prediction types (daily, weekly, and monthly). This symmetric design ensured a fair comparison and enhanced the reproducibility and objectivity of the results. Such a balanced experimental structure not only strengthens the internal validity of the study but also aligns with the scientific focus of symmetry, where consistency and structured modeling approaches are emphasized.
These findings offer valuable insights into the energy market, particularly in the context of crude oil price forecasting. The results indicate that accurate short- and medium-term predictions can be achieved using ANFIS models trained with metaheuristic algorithms. The superior performance observed in daily and weekly forecasts, compared to monthly ones, highlights the potential of the proposed approach for short-term decision-making processes such as risk management, investment planning, and dynamic pricing strategies. Moreover, the consistently low standard deviation values observed across multiple runs suggest that the model is stable and reliable, which is essential for supporting data-driven decisions in volatile energy markets like crude oil trading.
5. Conclusions
In this study, an Adaptive Neuro-Fuzzy Inference System (ANFIS) was trained using nine different metaheuristic algorithms—namely SHO, BBO, MVO, TLBO, CS, MFO, MPA, FPA, and ABC—to predict short- and medium-term Brent crude oil prices. The main objective was to evaluate the performance of these training algorithms in estimating the daily, weekly, and monthly minimum and maximum price levels of Brent oil. The raw time-series data were preprocessed and transformed into ANFIS-compatible input–output structures, allowing the use of past values to predict future ones. In addition, the effects of different input sizes and varying numbers of membership functions were also systematically examined. The key findings of the study can be summarized as follows:
All nine metaheuristic algorithms produced effective results when used to train ANFIS models for Brent oil price prediction. These findings confirm that ANFIS models enhanced with metaheuristic optimization are suitable tools for handling nonlinear and dynamic characteristics in energy market forecasting.
A strong consistency was observed between training and test results, indicating that the models were not overfitted and maintained generalizability across different problem sets. This also highlights the robustness of the training process and the reliability of the optimized ANFIS configurations.
Distinct mean error values were observed for daily, weekly, and monthly predictions. While some algorithms performed well in daily or weekly predictions, their effectiveness declined in monthly contexts. This observation emphasizes the need for context-specific tuning of algorithms depending on the prediction window.
The number and type of membership functions significantly influenced the prediction performance in some cases, while in others, variations in membership function count had a negligible impact. This suggests that for certain complex problem structures, the optimization process may reach saturation, preventing further improvement regardless of parameter adjustments. Such limitations might stem from the intrinsic difficulty of the problem or insufficient input diversity.
Across all experiments, both training and testing phases yielded low standard deviation values. This indicates that the algorithms provided stable and repeatable solutions even though each training phase started from random initial conditions. This reinforces the statistical reliability of the proposed approach.
Although all algorithms achieved acceptable performance levels, BBO and TLBO consistently outperformed the others in most scenarios. These two algorithms demonstrated stronger optimization capabilities in guiding ANFIS training toward more accurate predictions, especially in terms of lower error rates and faster convergence.
The symmetric structure of the evaluation process—equal iterations, consistent datasets, and identical parameter settings—strengthens the objectivity and reliability of the findings.
Overall, this study provides evidence that combining ANFIS with metaheuristic optimization offers a powerful framework for short- and medium-term energy price forecasting. The models developed here are particularly useful for stakeholders in the energy market who require reliable, interpretable, and adaptable prediction tools. These results are not only relevant in the context of Brent oil price forecasting but also offer broader insights into the use of adaptive hybrid AI systems in energy economics. The methodology demonstrated here can be adapted to other commodities and financial markets where nonlinear patterns dominate, and high prediction reliability is required. Future research may focus on exploring hybrid training strategies, incorporating additional economic indicators, or evaluating the models under real-time constraints to enhance practical applicability.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}