
GAPSO: Cloud-Edge-End Collaborative Task Offloading Based on Genetic Particle Swarm Optimization



Abstract
1. Introduction
- (1)
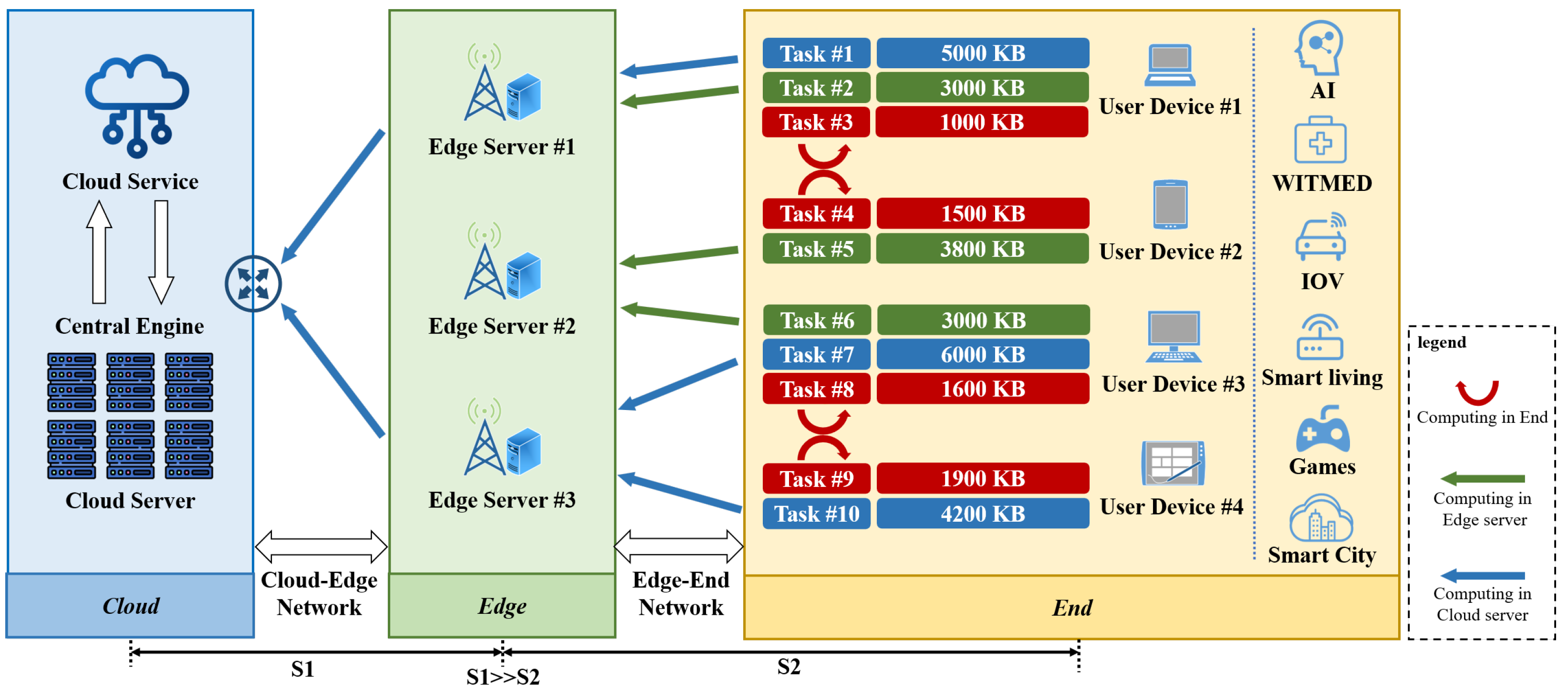
- This paper proposes a task processing framework for a cloud–edge–end collaborative environment. User devices can choose between three computing modes: local computing, edge computing, and cloud computing. Compared with the traditional mode, the cloud–edge–end collaborative environment can better utilize limited computing resources and improve data processing efficiency.
- (2)
- This paper implements a task transmission method that fully considers the bandwidth resources of edge servers. The transmission process of tasks from user devices (UDs) to edge servers (ESs) and ES to cloud servers (CSs) is more in line with the actual situation.
- (3)
- This paper designs a GAPSO algorithm, which improves the diversity of initial particles through the Opposition-Based Learning (OBL) algorithm, introduces adaptive inertia weights and adjustive acceleration coefficients, and uses a genetic algorithm (GA) to optimize the local optimal solution of particles.
- (4)
- This paper uses a symmetrical training method to conduct multiple experiments. The experimental results show that the GAPSO algorithm can achieve higher convergence accuracy, stability, and convergence speed.
2. Related Work
2.1. Task Offloading for Edge Computing
2.2. Task Offloading for Cloud–Edge Collaboration
2.3. Task Offloading for Cloud–Edge–End Collaboration
3. System Model and Problem Formulation
3.1. Response Time Model
- (1)
- Local computing mode: The local computing mode means that the tasks generated by the user device are directly executed on the user device. The local computing mode is not affected by the transmission delay factor. The task response time is the sum of the execution waiting time and the execution time. When UD is idle, the response time of task in UD is the local execution time of the task, and the task execution waiting time is 0. Otherwise, the response time of task needs to take into account the waiting time of the task. The task response time of the local computing mode is defined as follows:where represents the execution waiting time of task.
- (2)
- Edge computing mode: The edge computing mode refers to the transmission of tasks generated by user devices to edge servers for execution. The edge computing mode needs to consider the transmission delay of tasks between user devices and edge servers. Since the result data after the task is executed is small, the transmission delay of the result data transmitted back to the user device is ignored here. The transmission time of task is the transmission delay of task from UD to ES. The task response time is the sum of the transmission waiting time, transmission time, execution waiting time, and execution time. When the edge server bandwidth resources are not occupied, the transmission waiting time of task is 0. When ES is idle, of task is 0. The transmission rate [36] between UD and ES is defined as follows:The task response time of the edge computing model is defined as follows:where represents the transmission waiting time of task, and represents the transmission end time of task.
- (3)
- Cloud computing mode: The cloud computing model refers to the task generated by the user device being transmitted to the cloud server for execution. The task is transmitted to the cloud server, with the edge server as the transit transmission node. The selection method of the transit edge node is determined by comprehensively considering the amount of tasks to be transmitted, bandwidth resources of the edge node, and the distance between the user UD and the CS to which the task is transited using the edge node. And the occupation of the edge bandwidth resources by the task transmission is not released until it is transmitted to the cloud server. Since the result data after the task is executed is small, the transmission delay of the result data from the cloud server back to the edge server and from the edge server back to the user device is also ignored here. The transmission time of task is the sum of the transmission delays of task from UD to ES and ES to CS. The task response time is the sum of the transmission waiting time, transmission time, execution waiting time, and execution time. Similarly, when the edge server bandwidth resources are not occupied, of task is 0. When CS is idle, of task is 0. The transmission rate between ES and CS is defined as follows:The task response time of the cloud computing model is defined as follows:
3.2. Energy Consumption Model
- (1)
- Local computing mode: Since the local computing mode does not perform task transmission, there is no energy consumption generated by task transmission. Therefore, the energy consumption of task is the execution energy consumption of task. The energy consumption of the local computing mode is defined as follows:where v is a positive constant.
- (2)
- Edge computing mode: Since the edge computing mode requires the transmission of tasks between user devices and edge servers, the transmission energy consumption of tasks needs to be considered. Since the result data after the task is executed is small, the transmission energy consumption of the result data transmitted from the edge server back to the user device is ignored here. The transmission energy consumption only considers the transmission energy consumption of task from UD to ES. The energy consumption of task is the sum of the transmission energy consumption and the execution energy consumption. The energy consumption of the edge computing mode is defined as follows:
- (3)
- Cloud computing mode: Since the cloud computing model requires edge servers as transit nodes, it is necessary to consider the transmission energy consumption of tasks from user devices to edge servers and from edge servers to cloud servers. Since the result data after the task is executed is small, the transmission energy consumption of the result data from the cloud server back to the edge server and from the edge server back to the user device is also ignored here. The energy consumption of the cloud computing model is defined as follows:
3.3. Problem Formulation
4. Task Offloading Based on GAPSO
4.1. Standard Particle Swarm Optimization (SPSO) Algorithm and Coding
- (1)
- SPSO: The particle swarm optimization algorithm is a swarm intelligence optimization technology that simulates the foraging behavior of bird flocks. It finds the optimal solution by simulating information sharing between individuals in a bird flock [37]. In the algorithm, each solution is regarded as a particle flying in the solution space. The particle adjusts its flight direction and velocity according to the individual’s historical best position (individual extremum) and the group’s historical best position (global extremum). Each particle has only two attributes: speed and position. The speed indicates the particle’s moving speed, and the position indicates the particle’s moving direction [38]. Specifically, since there are M tasks in total, the spatial dimension is M, and there are L particles in the population, then the solution space can be expressed as , where the lth particle consists of two M-dimensional vectors, and . represents the position of the particle, and represents the position after h rounds of iteration. At the same time, the speed of each particle is expressed as . As the iteration proceeds, the position and speed of the particle will change according to the individual historical optimal solution and the global optimal solution , as shown in Formulas (18) and (19). The solution can be obtained by iterative execution until the end.where and are random numbers in the range .
- (2)
- Coding: The position and speed of particles in the PSO algorithm are two important properties, since each task has execution modes. The position and speed of particles are expressed by Formulas (20) and (21). Among them, means that task m is not executed at node o, and means that task m is executed at node o. The particle position is constrained by Formula (22). And is a random number between . After the calculation of Formula (18), will be calculated by Formula (23), and each value will be converted into a probability between . Formula (19) indicates that roulette is used to select execution nodes to avoid falling into local optimality. In the particle position matrix of this paper, the higher the number of rows, the lower the corresponding task transmission and execution priority. Formula (24) is used as the particle fitness.where . .
4.2. Adaptive Inertia Weight w
4.3. Adaptive Acceleration Coefficients ,
4.4. OBL Algorithm Initialization Population
4.5. Crossover and Mutation
| Algorithm 1 Initialize the population-based OBL |
Input: L (population size), M (number of tasks), O (number of execution modes)
|
| Algorithm 2 Update local optimal solution based GA |
Input: p (current particle), (position matrix of the local optimal solution of the current particle), (position matrix of the global optimal solution of the population), (mutation probability)
|
4.6. GAPSO Algorithm
| Algorithm 3 The algorithm steps of GAPSO |
| Initialization parameters: , , , Output: The offloading solution for all tasks corresponding to the global optimal solution
|
5. Experiments and Analysis
5.1. Experimental Settings
5.2. Performance Evaluation
- (1)
- Parameter sensitivity analysis: Figure 4a,b are experiments conducted while keeping and unchanged. In Figure 4a, is kept unchanged. It can be seen from the figure that the curve converges earlier when is 0.2. This is because the low inertia weight in the middle and late stages of the iteration causes the particles to ignore the historical speed and completely rely on the current optimal position, resulting in too fast convergence. When is 0.6, the curve converges more slowly and the final effect is poor. This is because the particle speed is insufficiently attenuated, and a strong exploration inertia is always maintained, resulting in the inability to converge well in the over-exploration search space. In Figure 4b, is kept unchanged. It can be seen from the figure that the curve converges the worst when is 0.7. This is because when is small, the inertial component of the particle speed is weak, so the particles rely on the attraction of and earlier, which accelerates the development to the current optimal position, resulting in insufficient exploration, and the particles are easy to quickly gather in the local optimal area. When is 1.1, the effect of faster exploration of the optimal solution is shown in the early stage of the iteration. This is because the inertial component of the particle velocity is higher and more dependent on the historical velocity, which reduces the attraction of and , thereby promoting a wider exploration of the search space, so there is a greater probability of finding a better solution in the early stage, but it will not be able to converge to the optimal solution quickly in the later stage. Figure 4c,d are experiments carried out while keeping and unchanged. In Figure 4c, is kept unchanged. It can be seen from the figure that the convergence effect is the worst when is 0.2. This may be because the particles in the later stage mainly rely on inertial motion, lack traction to the optimal solution, and cannot jump out of the suboptimal solution. When is 0.8, the convergence effect is poor. This is because the and coefficients are too high in the middle and late stages, forcing the particles to develop to the current optimal position too early and fall into the local optimal solution. In Figure 4d, is kept unchanged. It can be seen from the figure that when is 2.2, the convergence is slow and the convergence effect is the worst. This is because the maximum step size is limited in the early stage, the exploration ability is insufficient, and it is impossible to jump out of the local optimum. When is set to 2.6, the initial optimization is faster, but the convergence effect is poor. This is because the higher the value, the greater the exploration advantage in the early stage. However, this will also make the particle movement step too large, which makes it easy to miss the optimal solution. Therefore, in order to achieve a balance between exploration and development and ensure robust convergence, is set to 0.9, is set to 0.4, is set to 2.5, and is set to 0.5.
- (2)
- Comparison of average response time, total energy consumption, and number of tasks: Figure 5 and Figure 6 show the changing trends of the average response time for completing each task and the total energy consumption for completing all tasks in different environments. In the four operating environments, as the number of tasks increases, the amount of tasks waiting to be processed in different execution modes increases due to the total amount of computing resources, resulting in an upward trend in the average response time and total energy consumption of tasks. In Figure 5, under the same number of tasks, CEE has a maximum acceleration effect of 49.64% in response time compared with CE2, a maximum acceleration effect of 27.26% compared with EE, and a maximum acceleration effect of 4.31% compared with CE1, showing a significant advantage overall. In Figure 6, under the same number of tasks, CEE has a maximum energy saving of 24.83% compared with CE2 and a maximum energy saving of 22.89% compared with CE1, showing a significant advantage. Compared with EE, CEE takes the cloud computing model into consideration. Since the distance from CS to ES is significantly increased compared to the distance from ES to UD, a large amount of transmission energy is required to offload tasks to CS for processing, resulting in more total energy consumption for CEE than EE. These two figures show that the emergence of edge computing will greatly reduce the response time and energy consumption of completing tasks. At the same time, it can also show that cloud–edge–end collaboration has significant advantages and broad development prospects.
- (3)
- Algorithm performance: Under the cloud–edge–end collaborative processing framework proposed in this paper, the time complexity of the GAPSO, GA, SPSO, AICLPSO, and CAPSO algorithms is consistent with . The average change in the objective function value obtained by repeating 10 experiments for each algorithm to process the same task data in the same cloud–edge–end collaborative environment is shown in Figure 7. From the change in the curve, the GAPSO algorithm proposed in this paper shows obvious optimization effect. In the early stage of iteration, the GAPSO algorithm can obtain better initial solutions than the GA, SPSO, and AICLPSO algorithms, which highlights that the introduction of the OBL algorithm in the GAPSO algorithm can increase the diversity of the initial population and overcome the obstacle of falling into the local optimum to a certain extent. In the later stage of iteration, the GAPSO algorithm achieves better convergence accuracy than the other four algorithms and can reduce the objective function value by about 6–12%, indicating that the algorithm can find a better task allocation solution. The objective function value does not change after 1200 consecutive iterations, which is used as the basis for judging the convergence of the algorithm. From the convergence points marked in the figure, it can be seen that the GAPSO algorithm converges faster than the GA and SPSO algorithms. As can be seen from Table 5, GAPSO has obvious advantages over other algorithms in terms of mean, variance, and standard deviation, indicating that the algorithm has high stability. In general, the GAPSO algorithm we proposed has higher convergence accuracy and stronger stability. It can effectively avoid falling into local optimal solutions and is easier to search for global optimal solutions.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gao, H.; Wang, X.; Wei, W.; Al-Dulaimi, A.; Xu, Y. Com-DDPG: Task offloading based on multiagent reinforcement learning for information-communication-enhanced mobile edge computing in the internet of vehicles. IEEE Trans. Veh. Technol. 2023, 73, 348–361. [Google Scholar] [CrossRef]
- Quy, V.K.; Hau, N.V.; Anh, D.V.; Ngoc, L.A. Smart healthcare IoT applications based on fog computing: Architecture, applications and challenges. Complex Intell. Syst. 2022, 8, 3805–3815. [Google Scholar] [CrossRef]
- Mahajan, H.B.; Junnarkar, A.A. Smart healthcare system using integrated and lightweight ECC with private blockchain for multimedia medical data processing. Multimed. Tools Appl. 2023, 82, 44335–44358. [Google Scholar] [CrossRef] [PubMed]
- Sharma, M.; Tomar, A.; Hazra, A. Edge computing for industry 5.0: Fundamental, applications and research challenges. IEEE Internet Things J. 2024, 11, 19070–19093. [Google Scholar] [CrossRef]
- Tang, S.; Chen, L.; He, K.; Xia, J.; Fan, L.; Nallanathan, A. Computational intelligence and deep learning for next-generation edge-enabled industrial IoT. IEEE Trans. Netw. Sci. Eng. 2022, 10, 2881–2893. [Google Scholar] [CrossRef]
- Islam, A.; Debnath, A.; Ghose, M.; Chakraborty, S. A survey on task offloading in multi-access edge computing. J. Syst. Archit. 2021, 118, 102225. [Google Scholar] [CrossRef]
- Liu, B.; Xu, X.; Qi, L.; Ni, Q.; Dou, W. Task scheduling with precedence and placement constraints for resource utilization improvement in multi-user MEC environment. J. Syst. Archit. 2021, 114, 101970. [Google Scholar] [CrossRef]
- Wang, X.; Xing, X.; Li, P.; Zhang, S. Optimization Scheme of Single-Objective Task Offloading with Multi-user Participation in Cloud-Edge-End Environment. In Proceedings of the 2022 IEEE Smartworld, Ubiquitous Intelligence & Computing, Scalable Computing & Communications, Digital Twin, Privacy Computing, Metaverse, Autonomous & Trusted Vehicles (SmartWorld/UIC/ScalCom/DigitalTwin/PriComp/Meta), Haikou, China, 15–18 December 2022; pp. 1166–1171. [Google Scholar]
- Saeik, F.; Avgeris, M.; Spatharakis, D.; Santi, N.; Dechouniotis, D.; Violos, J.; Leivadeas, A.; Athanasopoulos, N.; Mitton, N.; Papavassiliou, S. Task offloading in Edge and Cloud Computing: A survey on mathematical, artificial intelligence and control theory solutions. Comput. Netw. 2021, 195, 108177. [Google Scholar] [CrossRef]
- Zhang, Y.; Yu, H.; Zhou, W.; Man, M. Application and research of IoT architecture for End-Net-Cloud Edge computing. Electronics 2022, 12, 1. [Google Scholar] [CrossRef]
- Pan, L.; Liu, X.; Jia, Z.; Xu, J.; Li, X. A multi-objective clustering evolutionary algorithm for multi-workflow computation offloading in mobile edge computing. IEEE Trans. Cloud Comput. 2021, 11, 1334–1351. [Google Scholar] [CrossRef]
- Gong, T.; Zhu, L.; Yu, F.R.; Tang, T. Edge intelligence in intelligent transportation systems: A survey. IEEE Trans. Intell. Transp. Syst. 2023, 24, 8919–8944. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, G.; Wen, T.; Yuan, Q.; Wang, B.; Hu, B. A cloud-edge collaborative framework and its applications. In Proceedings of the 2021 IEEE International Conference on Emergency Science and Information Technology (ICESIT), Chongqing, China, 22–24 November 2021; pp. 443–447. [Google Scholar]
- McEnroe, P.; Wang, S.; Liyanage, M. A survey on the convergence of edge computing and AI for UAVs: Opportunities and challenges. IEEE Internet Things J. 2022, 9, 15435–15459. [Google Scholar] [CrossRef]
- Liu, Y.; Deng, Q.; Zeng, Z.; Liu, A.; Li, Z. A hybrid optimization framework for age of information minimization in UAV-assisted MCS. IEEE Trans. Serv. Comput. 2025, 18, 527–542. [Google Scholar] [CrossRef]
- Chen, M.; Liu, A.; Xiong, N.N.; Song, H.; Leung, V.C. SGPL: An intelligent game-based secure collaborative communication scheme for metaverse over 5G and beyond networks. IEEE J. Sel. Areas Commun. 2023, 42, 767–782. [Google Scholar] [CrossRef]
- Zhou, J.; Zhang, X. Fairness-aware task offloading and resource allocation in cooperative mobile-edge computing. IEEE Internet Things J. 2021, 9, 3812–3824. [Google Scholar] [CrossRef]
- Sun, Y.; Zhang, X. A2C learning for tasks segmentation with cooperative computing in edge computing networks. In Proceedings of the GLOBECOM 2022—2022 IEEE Global Communications Conference, Rio de Janeiro, Brazil, 4–8 December 2022; pp. 2236–2241. [Google Scholar]
- Chen, Q.; Yang, C.; Lan, S.; Zhu, L.; Zhang, Y. Two-Stage Evolutionary Search for Efficient Task Offloading in Edge Computing Power Networks. IEEE Internet Things J. 2024, 11, 30787–30799. [Google Scholar] [CrossRef]
- Zhu, A.; Wen, Y. Computing offloading strategy using improved genetic algorithm in mobile edge computing system. J. Grid Comput. 2021, 19, 38. [Google Scholar] [CrossRef]
- Chen, H.; Qin, W.; Wang, L. Task partitioning and offloading in IoT cloud-edge collaborative computing framework: A survey. J. Cloud Comput. 2022, 11, 86. [Google Scholar] [CrossRef]
- Hu, S.; Xiao, Y. Design of cloud computing task offloading algorithm based on dynamic multi-objective evolution. Future Gener. Comput. Syst. 2021, 122, 144–148. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, H.; Zhou, X.; Yuan, D. Energy minimization task offloading mechanism with edge-cloud collaboration in IoT networks. In Proceedings of the 2021 IEEE 93rd Vehicular Technology Conference (VTC2021-Spring), Helsinki, Finland, 25–28 April 2021; pp. 1–7. [Google Scholar]
- Gao, J.; Chang, R.; Yang, Z.; Huang, Q.; Zhao, Y.; Wu, Y. A task offloading algorithm for cloud-edge collaborative system based on Lyapunov optimization. Clust. Comput. 2023, 26, 337–348. [Google Scholar] [CrossRef]
- Lei, Y.; Zheng, W.; Ma, Y.; Xia, Y.; Xia, Q. A novel probabilistic-performance-aware and evolutionary game-theoretic approach to task offloading in the hybrid cloud-edge environment. In Proceedings of the Collaborative Computing: Networking, Applications and Worksharing: 16th EAI International Conference, CollaborateCom 2020, Shanghai, China, 16–18 October 2020; Proceedings, Part I 16. Springer: Berlin/Heidelberg, Germany, 2021; pp. 255–270. [Google Scholar]
- Liu, F.; Huang, J.; Wang, X. Joint task offloading and resource allocation for device-edge-cloud collaboration with subtask dependencies. IEEE Trans. Cloud Comput. 2023, 11, 3027–3039. [Google Scholar] [CrossRef]
- Zhu, D.; Li, T.; Tian, H.; Yang, Y.; Liu, Y.; Liu, H.; Geng, L.; Sun, J. Speed-aware and customized task offloading and resource allocation in mobile edge computing. IEEE Commun. Lett. 2021, 25, 2683–2687. [Google Scholar] [CrossRef]
- Qu, X.; Wang, H. Emergency task offloading strategy based on cloud-edge-end collaboration for smart factories. Comput. Netw. 2023, 234, 109915. [Google Scholar] [CrossRef]
- Wu, H.; Geng, J.; Bai, X.; Jin, S. Deep reinforcement learning-based online task offloading in mobile edge computing networks. Inf. Sci. 2024, 654, 119849. [Google Scholar] [CrossRef]
- Ji, Z.; Qin, Z. Computational offloading in semantic-aware cloud-edge-end collaborative networks. IEEE J. Sel. Top. Signal Process. 2024, 18, 1235–1248. [Google Scholar] [CrossRef]
- Zhou, Z.; Abawajy, J. Reinforcement learning-based edge server placement in the intelligent internet of vehicles environment. IEEE Trans. Intell. Transp. Syst. 2025. [Google Scholar] [CrossRef]
- Cai, J.; Liu, W.; Huang, Z.; Yu, F.R. Task decomposition and hierarchical scheduling for collaborative cloud-edge-end computing. IEEE Trans. Serv. Comput. 2024, 17, 4368–4382. [Google Scholar] [CrossRef]
- Wang, J.; Feng, D.; Zhang, S.; Liu, A.; Xia, X.G. Joint computation offloading and resource allocation for MEC-enabled IoT systems with imperfect CSI. IEEE Internet Things J. 2020, 8, 3462–3475. [Google Scholar] [CrossRef]
- An, X.; Fan, R.; Hu, H.; Zhang, N.; Atapattu, S.; Tsiftsis, T.A. Joint task offloading and resource allocation for IoT edge computing with sequential task dependency. IEEE Internet Things J. 2022, 9, 16546–16561. [Google Scholar] [CrossRef]
- Fan, W.; Liu, X.; Yuan, H.; Li, N.; Liu, Y. Time-slotted task offloading and resource allocation for cloud-edge-end cooperative computing networks. IEEE Trans. Mob. Comput. 2024, 23, 8225–8241. [Google Scholar] [CrossRef]
- Tong, Z.; Deng, X.; Mei, J.; Liu, B.; Li, K. Response time and energy consumption co-offloading with SLRTA algorithm in cloud–edge collaborative computing. Future Gener. Comput. Syst. 2022, 129, 64–76. [Google Scholar] [CrossRef]
- Alqarni, M.A.; Mousa, M.H.; Hussein, M.K. Task offloading using GPU-based particle swarm optimization for high-performance vehicular edge computing. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 10356–10364. [Google Scholar] [CrossRef]
- Ma, S.; Song, S.; Yang, L.; Zhao, J.; Yang, F.; Zhai, L. Dependent tasks offloading based on particle swarm optimization algorithm in multi-access edge computing. Appl. Soft Comput. 2021, 112, 107790. [Google Scholar] [CrossRef]
- Wang, Y.; Ru, Z.Y.; Wang, K.; Huang, P.Q. Joint deployment and task scheduling optimization for large-scale mobile users in multi-UAV-enabled mobile edge computing. IEEE Trans. Cybern. 2019, 50, 3984–3997. [Google Scholar] [CrossRef]
- Tong, Z.; Deng, X.; Ye, F.; Basodi, S.; Xiao, X.; Pan, Y. Adaptive computation offloading and resource allocation strategy in a mobile edge computing environment. Inf. Sci. 2020, 537, 116–131. [Google Scholar] [CrossRef]
- Yuan, C.; Su, Y.; Chen, R.; Zhao, W.; Li, W.; Li, Y.; Sang, L. Multimedia task scheduling based on improved PSO in cloud environment. In Proceedings of the 2023 IEEE International Symposium on Broadband Multimedia Systems and Broadcasting (BMSB), Beijing, China, 14–16 June 2023; pp. 1–6. [Google Scholar]
- Duan, Y.; Chen, N.; Chang, L.; Ni, Y.; Kumar, S.S.; Zhang, P. CAPSO: Chaos adaptive particle swarm optimization algorithm. IEEE Access 2022, 10, 29393–29405. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Task Offloading Environment | Optimization Objective | Algorithm | |||
|---|---|---|---|---|---|---|
| Cloud | Edge | End | Completion Time | Energy Consumption | ||
| [17] | ✗ | ✓ | ✗ | ✓ | ✗ | APGTO + FGRA two-level algorithm. |
| [18] | ✗ | ✓ | ✗ | ✓ | ✗ | Advantage Actor Critic (A2C) algorithm. |
| [19] | ✗ | ✓ | ✓ | ✓ | ✗ | Two-stage evolutionary search scheme (TESA). |
| [20] | ✗ | ✓ | ✓ | ✓ | ✓ | Improved genetic algorithm (IGA). |
| [23] | ✓ | ✓ | ✗ | ✗ | ✓ | Dichotomy search algorithm. |
| [24] | ✓ | ✓ | ✗ | ✗ | ✓ | Lyapunov optimization method. |
| [25] | ✓ | ✓ | ✗ | ✓ | ✗ | Evolutionary Game Algorithm. |
| [26] | ✓ | ✓ | ✓ | ✓ | ✗ | Mathematical analytical method and Lagrangian dual (LD) method. |
| [27] | ✓ | ✓ | ✓ | ✓ | ✗ | Speed aware and customized TORA scheme based on A2C algorithm. |
| [28] | ✓ | ✓ | ✓ | ✓ | ✗ | Fast Chemical Reaction Optimization (Fast-CRO) algorithm. |
| [29] | ✓ | ✓ | ✓ | ✓ | ✗ | Online task scheduling (Online-TS) algorithm. |
| [30] | ✓ | ✓ | ✓ | ✗ | ✓ | Deep reinforcement learning based hybrid (DRLH) framework. |
| [31] | ✓ | ✓ | ✓ | ✓ | ✓ | Edge Server Placement Algorithm ISC-QL. |
| Ours | ✓ | ✓ | ✓ | ✓ | ✓ | Genetic particle swarm optimization (GAPSO) algorithm. |
| Notation | Description |
|---|---|
| N | The number of UD |
| S | The number of ES |
| The amount of tasks generated by UD | |
| M | Total number of tasks |
| The data size of task | |
| c | The number of CPU clock cycles required per bit |
| The effective switching capacitance of the chip | |
| The communication bandwidth of ES | |
| Power of noise | |
| Path loss index | |
| The CPU clock frequency of UD | |
| The CPU clock frequency of ES | |
| The CPU clock frequency of the CS | |
| The transmit power of UD | |
| The transmit power of ES | |
| Energy consumption per bit in ES | |
| Energy consumption per bit in CS | |
| The distance between UE and ES | |
| Channel gain between UE and ES | |
| The distance between ES and CS | |
| Channel gain between ES and CS | |
| The communication rate between UD and ES | |
| The communication rate between ES and CS | |
| The response time of task | |
| The energy consumption of task |
| Parameters | Value |
|---|---|
| Unif (8, 10) | |
| (KB) | Unif (3000, 5000) |
| c (cycles/bit) | 500 |
| v | 3 |
| 4 | |
| (MHZ) | randint (10, 15) |
| (dBm/HZ) | −174 |
| (GHZ) | Unif (0.5, 1.0) |
| (GHZ) | Unif (5.0, 10.0) |
| (GHZ) | 40 |
| (mW) | 100 |
| (mW) | 200 |
| (J/bit) | Unif (, ) |
| (J/bit) | Unif (, ) |
| Algorithm | Parameter Settings |
|---|---|
| GA | , |
| SPSO | , |
| AICLPSO | , , , , , , , , |
| CAPSO | , , , , , |
| GAPSO | , , , , |
| Algorithm | Count | Mean | Variance | Standard Deviation |
|---|---|---|---|---|
| GA | 10 | 23.2442 | 0.0667 | 0.2582 |
| SPSO | 10 | 21.9417 | 0.0193 | 0.1391 |
| AICLPSO | 10 | 22.3194 | 0.0464 | 0.2153 |
| CAPSO | 10 | 21.8245 | 0.0602 | 0.2453 |
| GAPSO | 10 | 20.3197 | 0.0134 | 0.1156 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wen, W.; Huang, Y.; Xiao, Z.; Tan, L.; Zhang, P. GAPSO: Cloud-Edge-End Collaborative Task Offloading Based on Genetic Particle Swarm Optimization. Symmetry 2025, 17, 1225. https://doi.org/10.3390/sym17081225
Wen W, Huang Y, Xiao Z, Tan L, Zhang P. GAPSO: Cloud-Edge-End Collaborative Task Offloading Based on Genetic Particle Swarm Optimization. Symmetry. 2025; 17(8):1225. https://doi.org/10.3390/sym17081225
Chicago/Turabian StyleWen, Wu, Yibin Huang, Zhong Xiao, Lizhuang Tan, and Peiying Zhang. 2025. "GAPSO: Cloud-Edge-End Collaborative Task Offloading Based on Genetic Particle Swarm Optimization" Symmetry 17, no. 8: 1225. https://doi.org/10.3390/sym17081225
APA StyleWen, W., Huang, Y., Xiao, Z., Tan, L., & Zhang, P. (2025). GAPSO: Cloud-Edge-End Collaborative Task Offloading Based on Genetic Particle Swarm Optimization. Symmetry, 17(8), 1225. https://doi.org/10.3390/sym17081225