
Symmetry-Guided Prototype Alignment and Entropy Consistency for Multi-Source Pedestrian ReID in Power Grids: A Domain Adaptation Framework


 ,
,
Abstract
1. Introduction
- The RAFF module recovers cross-domain feature symmetry between source and target domains, reducing the domain gap and improving the discriminability of pedestrian identity features.
- The SCPL loss function implements symmetry-driven noise suppression to mitigate the impact of erroneous pseudo-labels.
- The method demonstrates competitive advanced performance in multi-source domain adaptation (MUDA) on benchmark ReID datasets, outperforming most other approaches.
- ReID technology is applied to the power industry for the first time. Our method is validated on a self-constructed power industry dataset, demonstrating strong generalization ability.
2. Related Work
2.1. Supervised Person Re-Identification
2.2. Research Progress in Unsupervised Person Re-Identification
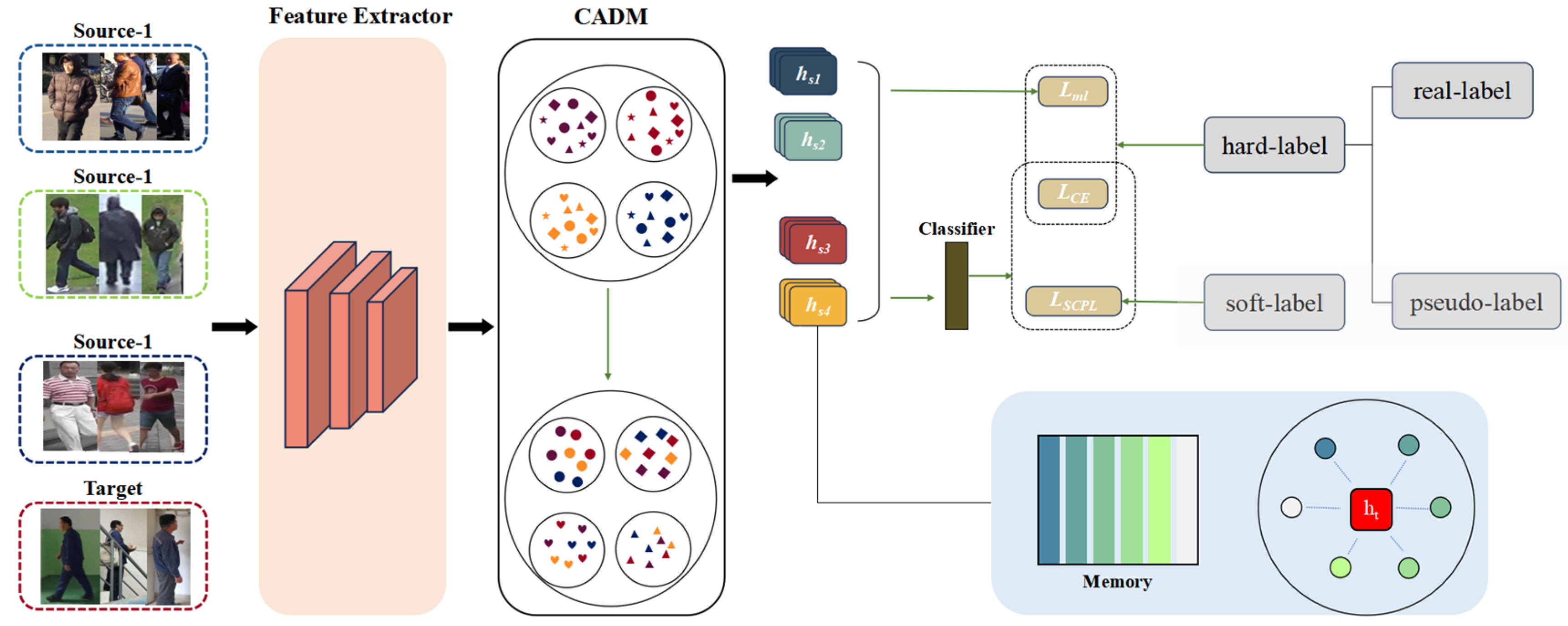
3. Methodology
3.1. General
3.2. Reverse Attention-Based Domain Merging Module
- (1)
- Domain Prototype Computation
- (2)
- Reverse Attention Mechanisms
- (3)
- Attention weight calculation
3.3. Adaptive Reverse Cross-Entropy Loss
3.4. Optimization
4. Experimental
4.1. Datasets and Evaluation Indicators
4.2. Realization Details
4.3. Comparison with State-of-the-Art Methods
4.4. Ablation Studies
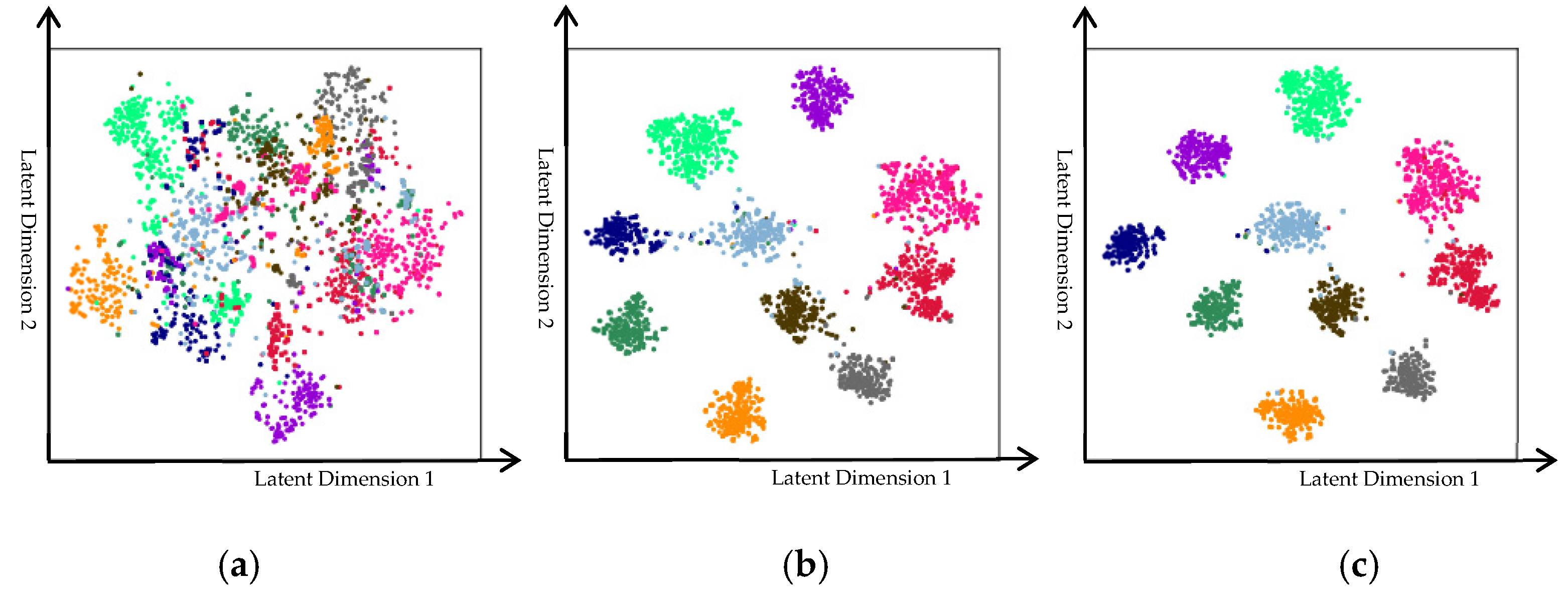
4.5. Visualization of Experimental Results
4.6. Parametric Analysis
4.7. Further Validation on the Power Field Operator Dataset
4.7.1. Introduction to Datasets
4.7.2. Experimental Settings
4.7.3. Experimental Results and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| RAFF | Reverse Attention-based Feature Fusion |
| SCPL | Self-Correcting Pseudo-Label Loss |
| ReID | Person Re-Identification |
| mAP | Mean Average Precision |
| CMC | Cumulative Matching Characteristics |
| EMA | Exponential Moving Average |
| Adam | Adaptive Moment Estimation |
| GPU | Graphics Processing Unit |
| UDA | Unsupervised Domain Adaptation |
| MUDA | Multi-source Unsupervised Domain Adaptation |
| MLP | Multi-Layer Perceptron |
References
- Sun, Z.; Wang, X.; Zhang, Y.; Song, Y.; Zhao, J.; Xu, J.; Yan, W.; Lv, C. A comprehensive review of pedestrian re-identification based on deep learning. Complex Intell. Syst. 2024, 10, 1733–1768. [Google Scholar] [CrossRef]
- Zheng, L.; Yang, Y.; Hauptmann, A.G. Person re-identification: Past, present and future. arXiv 2016, arXiv:1610.02984. [Google Scholar]
- Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Shao, L.; Hoi, S.C. Deep learning for person re-identification: A survey and outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 2872–2893. [Google Scholar] [CrossRef] [PubMed]
- Ge, Y.; Chen, D.; Li, H. Mutual mean-teaching: Pseudo label refinery for unsupervised domain adaptation on person re-identification. arXiv 2020, arXiv:2001.01526. [Google Scholar]
- Song, L.; Wang, C.; Zhang, L.; Du, B.; Zhang, Q.; Huang, C.; Wang, X. Unsupervised domain adaptive re-identification: Theory and practice. Pattern Recognit. 2020, 102, 107173. [Google Scholar] [CrossRef]
- Yang, F.; Li, K.; Zhong, Z.; Luo, Z.; Sun, X.; Cheng, H.; Guo, X.; Huang, F.; Ji, R.; Li, S. Asymmetric co-teaching for unsupervised cross-domain person re-identification. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12597–12604. [Google Scholar] [CrossRef]
- Navneet, D.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; pp. 1150–1157. [Google Scholar]
- Chen, L.; Chen, H.; Li, S.; Zhu, J. Person re-identification based on Weber local descriptor and color features. In Proceedings of the 2015 12th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP), Chengdu, China, 18–20 December 2015; p. 33. [Google Scholar]
- Koestinger, M.; Hirzer, M.; Wohlhart, P.; Roth, P.M.; Bischof, H. Large scale metric learning from equivalence constraints. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2288–2295. [Google Scholar]
- Liao, S.; Hu, Y.; Zhu, X.; Li, S.Z. Person re-identification by local maximal occurrence representation and metric learning. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2197–2206. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Chen, S.; Wang, H.; Jin, C.; Zhang, W. Person re-identification based on siamese network and re-ranking. J. Comput. Appl. 2018, 38, 3161–3166. [Google Scholar]
- Liu, J.; Zha, Z.-J.; Tian, Q.; Liu, D.; Yao, T.; Ling, Q.; Mei, T. Multi-scale triplet cnn for person re-identification. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 192–196. [Google Scholar]
- Qian, X.; Fu, Y.; Jiang, Y.-G.; Xiang, T.; Xue, X. Multi-scale deep learning architectures for person re-identification. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5399–5408. [Google Scholar]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 480–496. [Google Scholar]
- Chen, Y.; Wang, H.; Sun, X.; Fan, B.; Tang, C.; Zeng, H. Deep attention aware feature learning for person re-identification. Pattern Recognit. 2022, 126, 108567. [Google Scholar] [CrossRef]
- Wu, Y.; Bourahla, O.E.F.; Li, X.; Wu, F.; Tian, Q.; Zhou, X. Adaptive graph representation learning for video person re-identification. IEEE Trans. Image Process. 2020, 29, 8821–8830. [Google Scholar] [CrossRef]
- Lin, Y.; Dong, X.; Zheng, L.; Yan, Y.; Yang, Y. A bottom-up clustering approach to unsupervised person re-identification. Proc. AAAI Conf. Artif. Intell. 2019, 33, 8738–8745. [Google Scholar] [CrossRef]
- Lin, Y.; Xie, L.; Wu, Y.; Yan, C.; Tian, Q. Unsupervised person re-identification via softened similarity learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3390–3399. [Google Scholar]
- Jin, X.; Lan, C.; Zeng, W.; Chen, Z. Global distance-distributions separation for unsupervised person re-identification. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Proceedings, Part VII, Glasgow, UK, 23–28 August 2020; pp. 735–751. [Google Scholar]
- Wang, D.; Zhang, S. Unsupervised person re-identification via multi-label classification. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10981–10990. [Google Scholar]
- Deng, W.; Zheng, L.; Ye, Q.; Yang, Y.; Jiao, J. Similarity-preserving image-image domain adaptation for person re-identification. arXiv 2018, arXiv:1811.10551. [Google Scholar]
- Wei, L.; Zhang, S.; Gao, W.; Tian, Q. Person transfer gan to bridge domain gap for person re-identification. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 79–88. [Google Scholar]
- Yu, H.-X.; Zheng, W.-S.; Wu, A.; Guo, X.; Gong, S.; Lai, J.-H. Unsupervised person re-identification by soft multilabel learning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2148–2157. [Google Scholar]
- Fu, Y.; Wei, Y.; Wang, G.; Zhou, Y.; Shi, H.; Huang, T. Self-similarity grouping: A simple unsupervised cross domain adaptation approach for person re-identification. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6112–6121. [Google Scholar]
- Zheng, K.; Liu, W.; He, L.; Mei, T.; Luo, J.; Zha, Z.-J. Group-aware label transfer for domain adaptive person re-identification. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5310–5319. [Google Scholar]
- Bai, Z.; Wang, Z.; Wang, J.; Hu, D.; Ding, E. Unsupervised multi-source domain adaptation for person re-identification. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12914–12923. [Google Scholar]
- Qi, L.; Liu, J.; Wang, L.; Shi, Y.; Geng, X. Unsupervised generalizable multi-source person re-identification: A domain-specific adaptive framework. Pattern Recognit. 2023, 140, 109546. [Google Scholar] [CrossRef]
- Wang, H.; Hu, J.; Zhang, G. Multi-source transfer network for cross domain person re-identification. IEEE Access 2020, 8, 83265–83275. [Google Scholar] [CrossRef]
- Chen, Y.; Tang, Q.; Ma, H. Multi-source adaptive meta-learning framework for domain generalization person re-identification. Soft Comput. 2024, 28, 4799–4820. [Google Scholar] [CrossRef]
- Tian, Q.; Cheng, Y. Unsupervised multi-source domain adaptation for person re-identification via sample weighting. Intell. Data Anal. 2024, 28, 943–960. [Google Scholar] [CrossRef]
- Tian, Q.; Cheng, Y.; He, S.; Sun, J. Unsupervised multi-source domain adaptation for person re-identification via feature fusion and pseudo-label refinement. Comput. Electr. Eng. 2024, 113, 109029. [Google Scholar] [CrossRef]
- Xian, Y.; Peng, Y.X.; Sun, X.; Zheng, W.S. Distilling consistent relations for multi-source domain adaptive person re-identification. Pattern Recognit. 2025, 157, 110821. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Fan, H.; Zheng, L.; Yan, C.; Yang, Y. Unsupervised person re-identification: Clustering and fine-tuning. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2018, 14, 83. [Google Scholar] [CrossRef]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable person re-identification: A benchmark. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1116–1124. [Google Scholar]
- Ristani, E.; Solera, F.; Zou, R.; Cucchiara, R.; Tomasi, C. Performance measures and a data set for multi-target, multi-camera tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–10 & 15–16 October 2016; pp. 17–35. [Google Scholar]
- Li, W.; Zhao, R.; Xiao, T.; Wang, X. Deepreid: Deep filter pairing neural network for person re-identification. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 152–159. [Google Scholar]
- Kingma, D.P. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zhong, Z.; Zheng, L.; Luo, Z.; Li, S.; Yang, Y. Invariance matters: Exemplar memory for domain adaptive person re-identification. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 598–607. [Google Scholar]
- Zhai, Y.; Lu, S.; Ye, Q.; Shan, X.; Chen, J.; Ji, R.; Tian, Y. Ad-cluster: Augmented discriminative clustering for domain adaptive person re-identification. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9021–9030. [Google Scholar]
- Zhao, F.; Liao, S.; Xie, G.-S.; Zhao, J.; Zhang, K.; Shao, L. Unsupervised domain adaptation with noise resistible mutual-training for person re-identification. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Proceedings, Part XI, Glasgow, UK, 23–28 August 2020; pp. 526–544. [Google Scholar]
- Zhai, Y.; Ye, Q.; Lu, S.; Jia, M.; Ji, R.; Tian, Y. Multiple Expert Brainstorming for Domain Adaptive Person Re-Identification. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Proceedings of the Computer Vision—ECCV 2020, Part VII, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 594–611. [Google Scholar]
- Yang, Q.; Yu, H.-X.; Wu, A.; Zheng, W.-S. Patch-based discriminative feature learning for unsupervised person re-identification. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3633–3642. [Google Scholar]
- Ge, Y.; Zhu, F.; Chen, D.; Zhao, R. Self-paced contrastive learning with hybrid memory for domain adaptive object re-id. Adv. Neural Inf. Process. Syst. 2020, 33, 11309–11321. [Google Scholar]
- Zheng, K.; Lan, C.; Zeng, W.; Zhang, Z.; Zha, Z.-J. Exploiting sample uncertainty for domain adaptive person re-identification. Proc. AAAI Conf. Artif. Intell. 2021, 35, 3538–3546. [Google Scholar] [CrossRef]
- Xian, Y.; Hu, H. Enhanced multi-dataset transfer learning method for unsupervised person re-identification using co-training strategy. IET Comput. Vis. 2018, 12, 1219–1227. [Google Scholar] [CrossRef]
- Yu, H.-X.; Wu, A.; Zheng, W.-S. Unsupervised person re-identification by deep asymmetric metric embedding. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 956–973. [Google Scholar] [CrossRef]
- Wu, A.; Zheng, W.-S.; Guo, X.; Lai, J.-H. Distilled person re-identification: Towards a more scalable system. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1187–1196. [Google Scholar]
- Li, J.; Zhang, S. Joint Visual and Temporal Consistency for Unsupervised Domain Adaptive Person Re-identification. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Proceedings of the Computer Vision—ECCV 2020, Part XXIV, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 483–499. [Google Scholar]
- Zou, Y.; Yang, X.; Yu, Z.; Kumar, B.V.K.V.; Kautz, J. Joint Disentangling and Adaptation for Cross-Domain Person Re-Identification. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Proceedings of the Computer Vision—ECCV 2020, Part II, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 87–104. [Google Scholar]
- Luo, C.; Song, C.; Zhang, Z. Generalizing Person Re-Identification by Camera-Aware Invariance Learning and Cross-Domain Mixup. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Proceedings of the Computer Vision—ECCV 2020, Part XV, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 224–241. [Google Scholar]
- Xuan, S.; Zhang, S. Intra-inter camera similarity for unsupervised person re-identification. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 11921–11930. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Reference | Target: Market-1501 | Target: DukeMTMC | ||||
|---|---|---|---|---|---|---|---|
| Source | mAP | Rank-1 | Source | mAP | Rank-1 | ||
| Single-Source UDA Methods | |||||||
| ECN [42] | CVPR’19 | D | 43.0 | 75.1 | M | 40.4 | 63.3 |
| SSG [27] | ICCV’19 | D | 58.3 | 80.0 | M | 53.4 | 73.0 |
| MMCL [23] | CVPR’20 | D | 60.4 | 84.4 | M | 51.4 | 72.4 |
| ACT [6] | AAAI’20 | D | 60.6 | 80.5 | M | 54.5 | 72.4 |
| AD-Cluster [43] | CVPR’20 | D | 68.3 | 86.7 | M | 54.1 | 72.6 |
| NRMT [44] | ECCV’20 | D | 72.2 | 88.0 | M | 62.3 | 78.1 |
| MMT [4] | ICLR’20 | D | 71.2 | 87.7 | M | 65.1 | 78.0 |
| MEB [45] | ECCV’20 | D | 76.0 | 89.9 | M | 66.1 | 79.6 |
| MAR [26] | CVPR’19 | T | 40.0 | 67.7 | T | 48.0 | 67.1 |
| PAUL [46] | CVPR’19 | T | 40.1 | 68.5 | T | 53.2 | 72.0 |
| SpCL [47] | NIPS’20 | T | 77.5 | 89.7 | - | - | - |
| UNRN [48] | AAAI’21 | D | 78.1 | 91.9 | M | 69.1 | 82.0 |
| GLT [28] | CVPR’21 | D | 79.5 | 92.2 | M | 69.2 | 82.0 |
| Multiple-Source UDA Methods | |||||||
| PUCL [49] | IET-CV’18 | D + C | 22.9 | 48.5 | M + C | 19.5 | 33.1 |
| DECAMEL [50] | TPAMI19 | Multi. | 32.4 | 60.2 | - | - | - |
| MASDF [51] | CVPR’19 | Multi. | 33.5 | 61.5 | Multi. | 29.4 | 48.4 |
| MSUDA [29] | CVPR’21 | D + T + C | 86.0 | 94.8 | M + T + C | 68.9 | 82.1 |
| CDM [35] | PR 2025 | D + T + C | 81.2 | 92.9 | M + T + C | 70.8 | 82.3 |
| RCDL (ours) | This work | D + T + C | 82.4 | 93.1 | M + T + C | 71.9 | 81.8 |
| Methods | Reference | Target Domain: MSMT17 | ||
|---|---|---|---|---|
| Source | mAP | Rank-1 | ||
| Single-Source UDA Methods | ||||
| PTGAN [25] | CVPR’18 | D | 3.3 | 11.8 |
| ECN [42] | CVPR’19 | D | 10.2 | 30.2 |
| SSG [27] | ICCV19 | D | 13.3 | 32.2 |
| MMCL [23] | CVPR’20 | D | 16.2 | 43.6 |
| JVTC [52] | ECCV’20 | D | 19.0 | 42.1 |
| NRMT [44] | ECCV’20 | D | 20.6 | 45.2 |
| DG-Net++ [53] | ECCV20 | D | 22.1 | 48.8 |
| MMT [4] | ICLR’20 | D | 23.3 | 50.0 |
| GPR [54] | ECCV’20 | D | 24.3 | 51.7 |
| SpCL [47] | NIPS20 | M | 26.8 | 53.7 |
| GLT [55] | CVPR’21 | D | 27.7 | 59.5 |
| Multiple-Source UDA Methods | ||||
| MMT-dbscan* | ICLR’20 | M + D + C | 25.9 | 51.8 |
| SpCL* | NIPS’20 | M + D + C | 27.3 | 54.1 |
| CDM [35] | PR 2025 | M + D + C | 32.9 | 63.8 |
| RCDL (ours) | This work | M + D + C | 34.1 | 62.9 |
| Method | D + T + C → M | Notes | |
|---|---|---|---|
| mAP | Rank-1 | ||
| Baseline (w/o RAFF, w/o SCPL) | 72.3 | 83.1 | Baseline performance |
| RAFF (w/o SCPL) | 76.3 | 88.1 | Attention-driven feature fusion |
| SCPL (w/o RAFF) | 74.9 | 87.2 | Constraining pseudo label noise |
| RCDL(RAFF + SCPL) | 82.4 | 93.1 | Optimal performance with synergy observed |
| Methods | Reference | Target: PowerID80 | ||
|---|---|---|---|---|
| Source | mAP | Rank-1 | ||
| MMT-dbscan * | ICLR’20 | D + C | 78.7 | 89.3 |
| MEB * | ECCV’20 | D + C | 80.2 | 91.1 |
| MSUDA * | CVPR’21 | D + C | 88.1 | 93.6 |
| Ours | This work | D + C | 87.5 | 92.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, J.; Zhang, L.; Zhang, X.; Xu, T.; Wang, K.; Li, P.; Liu, X. Symmetry-Guided Prototype Alignment and Entropy Consistency for Multi-Source Pedestrian ReID in Power Grids: A Domain Adaptation Framework. Symmetry 2025, 17, 672. https://doi.org/10.3390/sym17050672
He J, Zhang L, Zhang X, Xu T, Wang K, Li P, Liu X. Symmetry-Guided Prototype Alignment and Entropy Consistency for Multi-Source Pedestrian ReID in Power Grids: A Domain Adaptation Framework. Symmetry. 2025; 17(5):672. https://doi.org/10.3390/sym17050672
Chicago/Turabian StyleHe, Jia, Lei Zhang, Xiaofeng Zhang, Tong Xu, Kejun Wang, Pengsheng Li, and Xia Liu. 2025. "Symmetry-Guided Prototype Alignment and Entropy Consistency for Multi-Source Pedestrian ReID in Power Grids: A Domain Adaptation Framework" Symmetry 17, no. 5: 672. https://doi.org/10.3390/sym17050672
APA StyleHe, J., Zhang, L., Zhang, X., Xu, T., Wang, K., Li, P., & Liu, X. (2025). Symmetry-Guided Prototype Alignment and Entropy Consistency for Multi-Source Pedestrian ReID in Power Grids: A Domain Adaptation Framework. Symmetry, 17(5), 672. https://doi.org/10.3390/sym17050672