

Symmetry-Guided Identification of Spatial Electricity Price Anomalies via Data Partitioning and Density Analysis

Abstract
1. Introduction
2. Overview of the Proposed Method
2.1. Abnormal Electricity Price Signal Characteristics
- (1)
- Abnormal mean value of electricity price: The mean electricity price deviates from a reasonable range of values, violating the set threshold requirements, and is considered an endogenous abnormal electricity price. The mean value of electricity price at time t can be obtained from Equation (1):where represents the node electricity price of the node in time period , and refers to the total number nodes. This type of anomaly indicates that the overall electricity price level deviates from the normal condition. When exceeds a set threshold, it indicates a high electricity price.
- (2)
- Abnormal electricity price in time-series: This indicates a sharp change in the price of electricity before and after a node. This type of abnormal electricity price is also considered an endogenous abnormal electricity price and is the most common type in the electricity market, which can be measured by the rate of change in electricity price, that is, the changing rate of the electricity price of the node in the time period compared with the previous period, which can be calculated by Equation (2):This type of abnormal electricity price mainly focuses on the time-series characteristics of electricity price signals. When is positive and exceeds the threshold value, the change in electricity price shows a steep rise. When is negative and exceeds the threshold value, the electricity price drops sharply. When and both exceed the threshold value and the symbols are opposite, it is a price spike. When n frequently exceeds the threshold and changes in positive and negative directions within a certain period, it is a violent fluctuation. This represents a typical time-series anomaly signal, which has been extensively studied.
- (3)
- Spatial abnormal electricity price: The electricity price of a node or zone is significantly different from that of surrounding zones and nodes. It is regarded as an exogenous change due to some external shock affecting the price consistency between different zones, and the ordering of prices has no impact on the identification of this anomaly. Spatial electricity price anomalies are determined by the deviation degree of electricity price by the difference of electricity price between different nodes. The electricity price difference between the ith node and the jth node in time period can be calculated by Equation (3):When the values of for both node i and the surrounding nodes exceed the threshold, the electricity price of the ith node in time period is an electricity price deviation anomaly; when there are multiple nodes with electricity price deviation anomalies with an approximate value of , these similar nodes form an electricity price anomaly zone.
2.2. Spatial Electricity Price Anomaly Signals Identification Method
3. Modeling of Electricity Price Partitioning Algorithms Based on Dimensionality Reduction and Clustering
3.1. Dimensionality Reduction of Electricity Price Data Based on t-SNE Algorithm
| Algorithm 1: t-SNE-Based Dimensionality Reduction of Electricity Price Data |
|
3.2. Node Electricity Price Partitioning After Dimensionality Reduction Based on DBSCAN Algorithm
| Algorithm 2: DBSCAN progress |
|
4. Capture of Exogenous Spatial Electricity Price Anomalies Based on Data Distribution Density
4.1. Anomalous Electricity Price Identification in Zones
| Algorithm 3: Isolation Forest Training |
| Data: dataset , number of trees , sub-sample size Result: ensemble of isolation trees
|
4.2. Electricity Price Anomaly Zoning Identification Process
5. Case Study
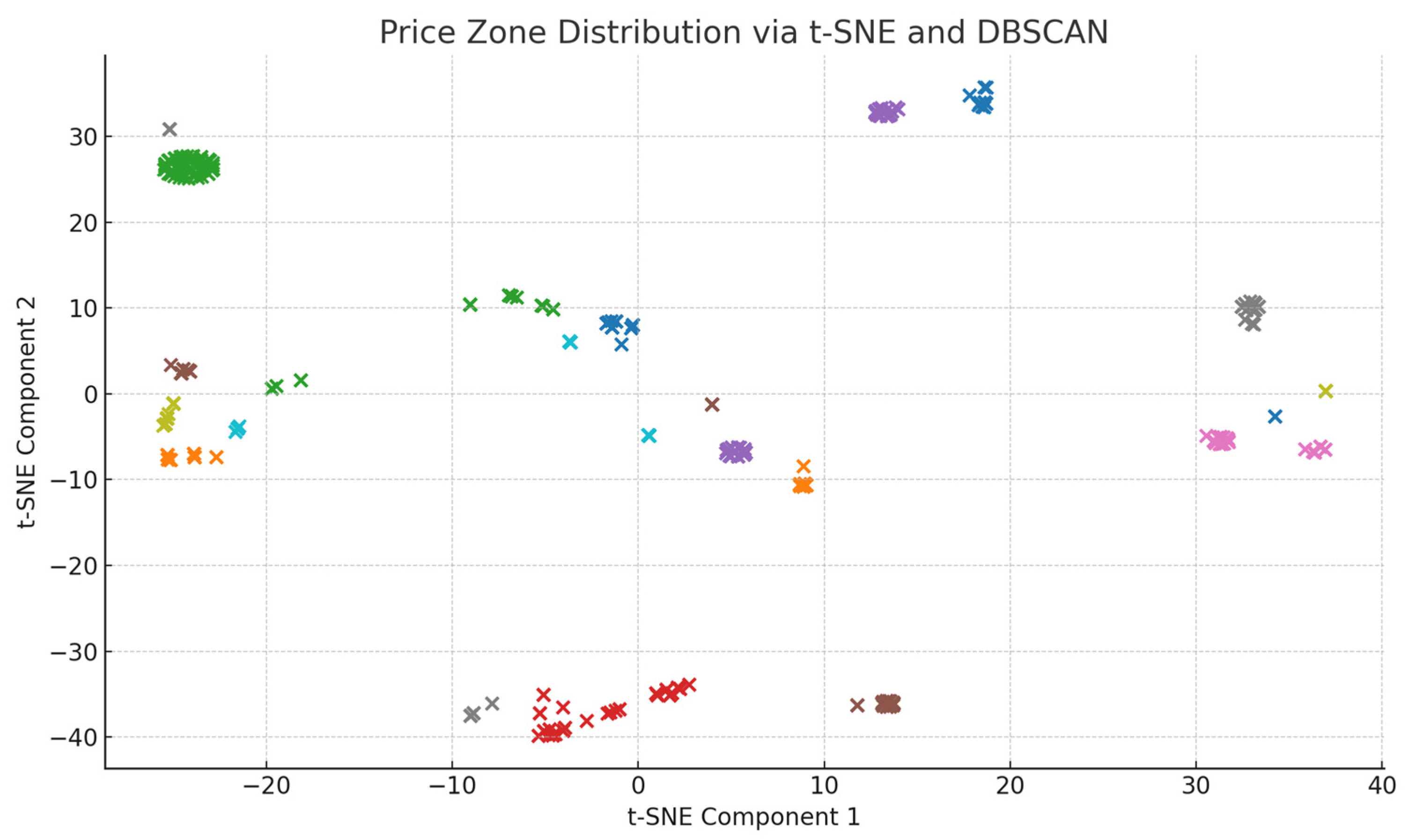
5.1. Selection of Electricity Price Zoning Parameters and Zoning Results
5.2. Comparison of the Effectiveness of Different Spatial Electricity Price Anomaly Signal Identification Methods
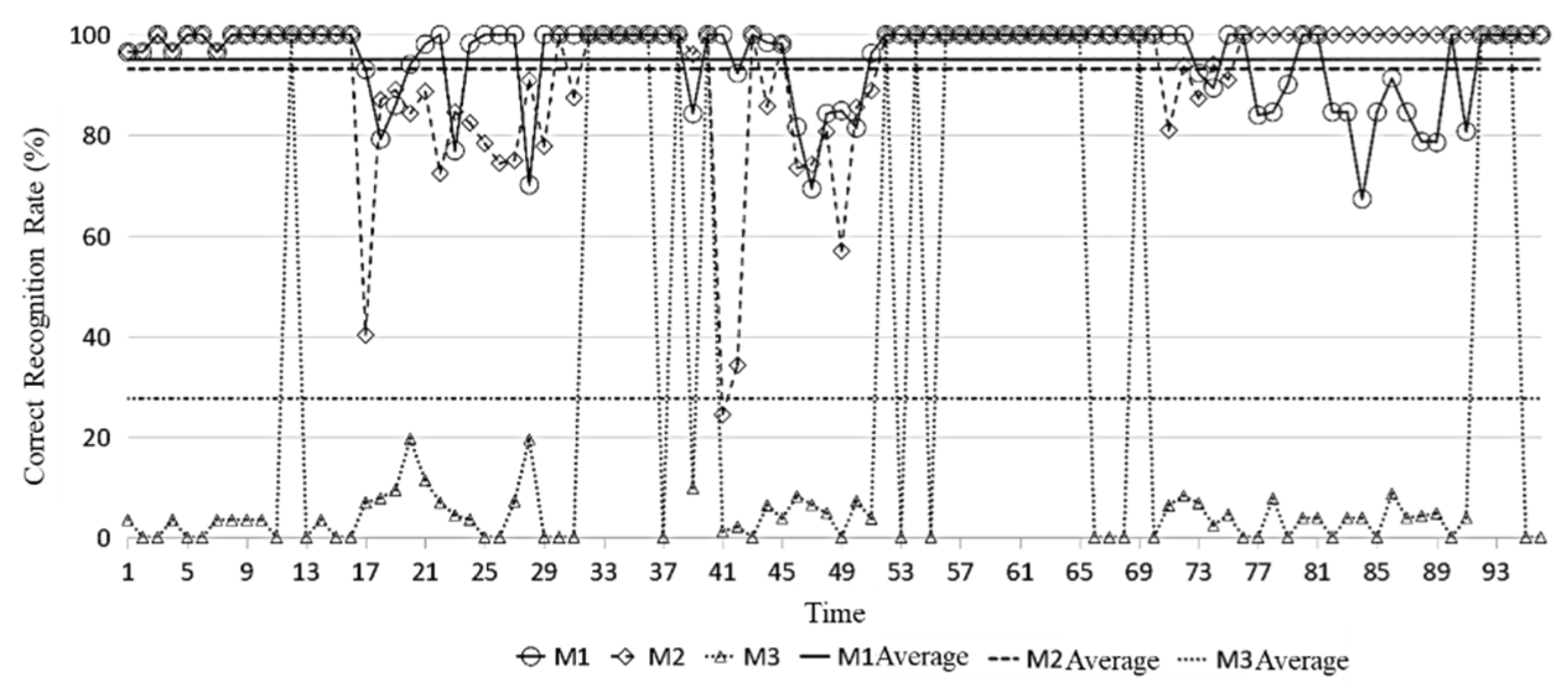
5.2.1. Effectiveness of Spatial Abnormal Electricity Price Identification
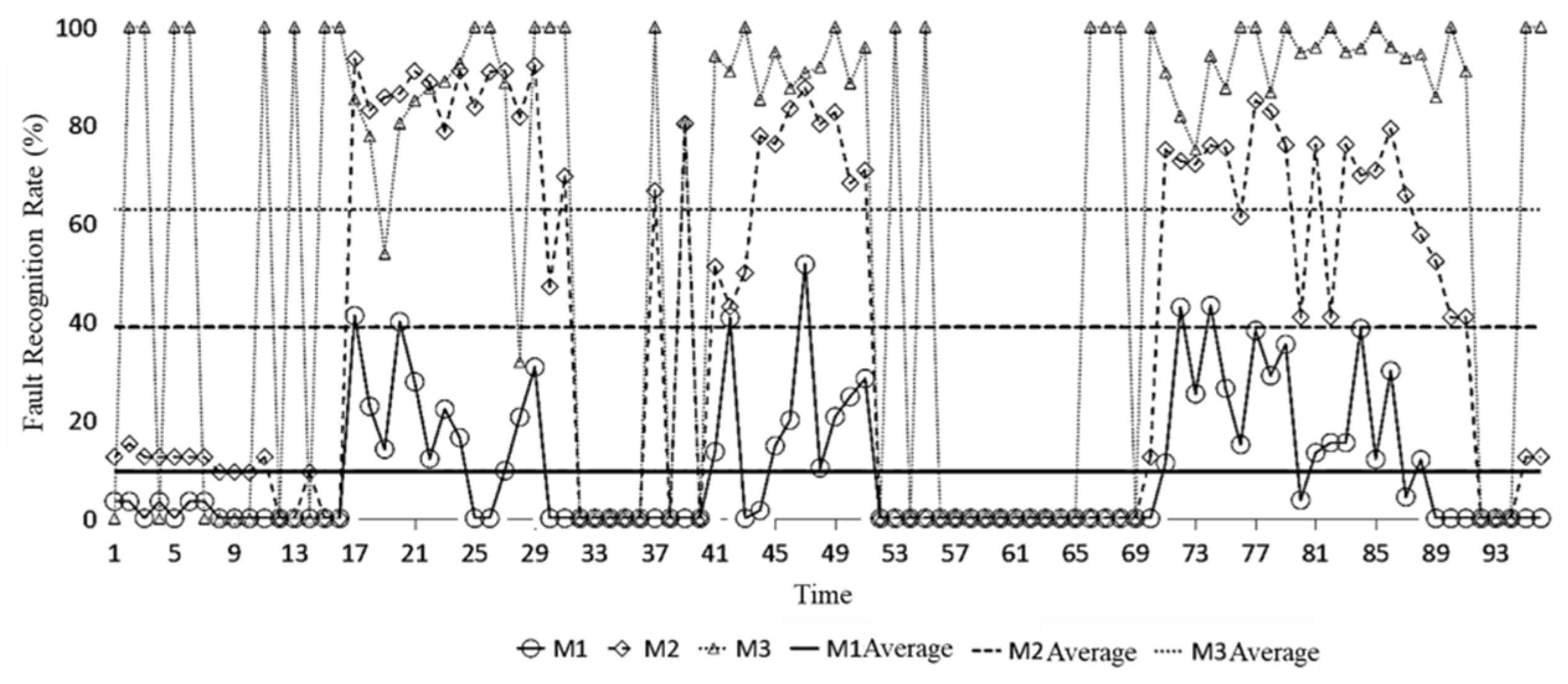
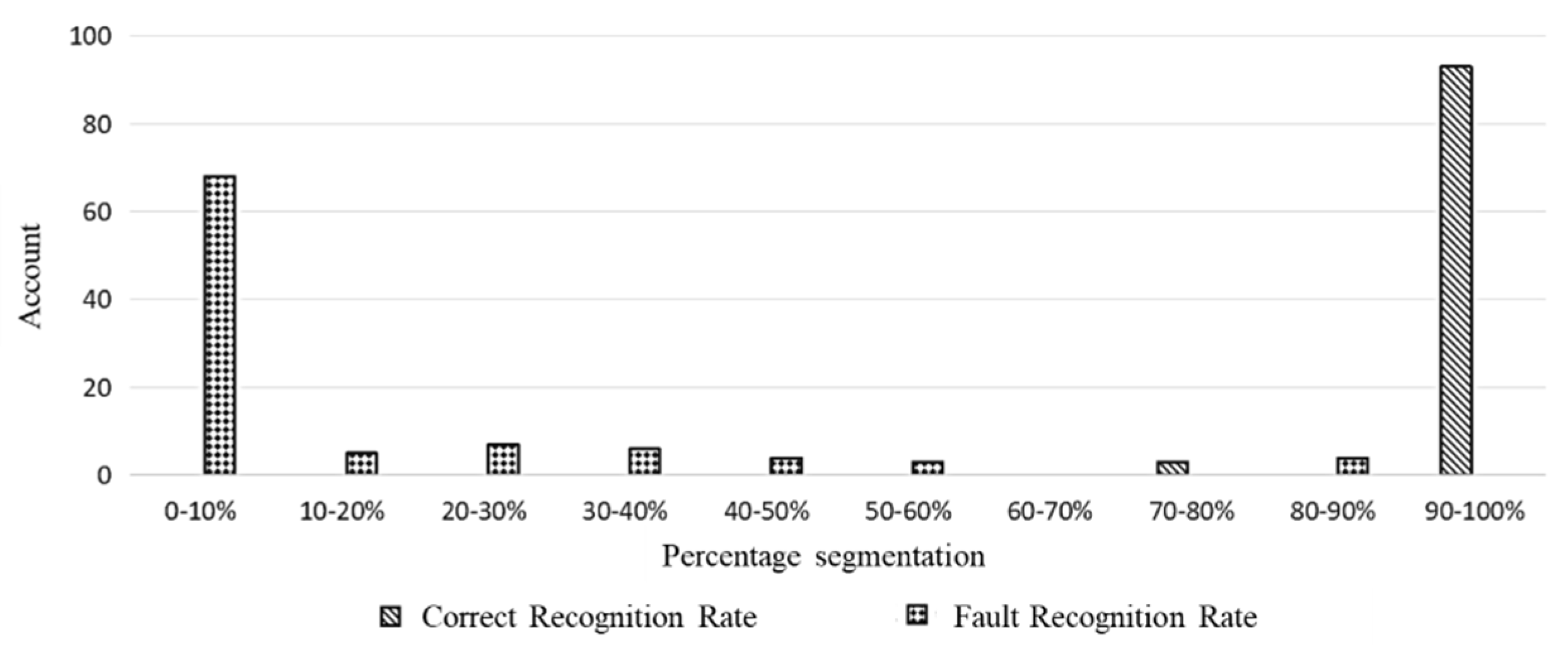
5.2.2. Effectiveness of Electricity Price Anomaly Zoning Identification
6. Limitations and Computational Considerations
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, M.; Xiao, D.; Deng, W.; Tahir, M.F.; Zhu, D. Multi-regional energy sharing approach for shared energy storage and local renewable energy resources considering efficiency optimization. Int. J. Electr. Power Energy Syst. 2025, 167, 110592. [Google Scholar]
- Ji, T.; Wang, J.; Li, M.; Wu, Q. Short-term wind power forecast based on chaotic analysis and multivariate phase space reconstruction. Energy Convers. Manag. 2022, 254, 115196. [Google Scholar] [CrossRef]
- Dai, S.; Lin, D.; Liu, Z. Electricity market margin determination method considering the integrity of electricity assets. Energy Rep. 2023, 9, 1259–1267. [Google Scholar] [CrossRef]
- Lai, W.K.; Wang, Y.C.; Lin, H.C.; Li, J.W. Efficient resource allocation and power control for LTE-A D2D communication with pure D2D model. IEEE Trans. Veh. Technol. 2020, 69, 3202–3216. [Google Scholar] [CrossRef]
- Qin, M.; Yang, Y.; Zhao, X.; Xu, Q.; Yuan, L. Low-carbon economic multi-objective dispatch of integrated energy system considering the price fluctuation of natural gas and carbon emission accounting. Prot. Control Mod. Power Syst. 2023, 8, 61. [Google Scholar] [CrossRef]
- Spodniak, P.; Ollikka, K.; Honkapuro, S. The impact of wind power and electricity demand on the relevance of different short-term electricity markets: The Nordic case. Appl. Energy 2021, 283, 116063. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, F.; Shi, Q.; Tomsovic, K.; Sun, J.; Ren, L. Profit-oriented false data injection on electricity market: Reviews, analyses, and insights. IEEE Trans. Ind. Inform. 2020, 17, 5876–5886. [Google Scholar] [CrossRef]
- Fabra, N.; Motta, M.; Peitz, M. Learning from electricity markets: How to design a resilience strategy. Energy Policy 2022, 168, 113116. [Google Scholar] [CrossRef]
- Tschora, L.; Pierre, E.; Plantevit, M.; Robardet, C. Electricity price forecasting on the day-ahead market using machine learning. Appl. Energy 2022, 313, 118752. [Google Scholar] [CrossRef]
- El-Hadad, R.; Tan, Y.F.; Tan, W.N. Anomaly prediction in electricity consumption using a combination of machine learning techniques. Int. J. Technol. 2022, 13, 1317–1325. [Google Scholar] [CrossRef]
- Li, Y.; Yu, N.; Wang, W. Machine learning-driven virtual bidding with electricity market efficiency analysis. IEEE Trans. Power Syst. 2021, 37, 354–364. [Google Scholar] [CrossRef]
- Jain, P.K.; Bajpai, M.S.; Pamula, R. A modified DBSCAN algorithm for anomaly detection in time-series data with seasonality. Int. Arab J. Inf. Technol. 2022, 19, 23–28. [Google Scholar] [CrossRef] [PubMed]
- Iftikhar, H.; Turpo-Chaparro, J.E.; Canas Rodrigues, P.; López-Gonzales, J.L. Forecasting day-ahead electricity prices for the Italian electricity market using a new decomposition-combination technique. Energies 2023, 16, 6669. [Google Scholar] [CrossRef]
- Bushnell, J. California’s electricity crisis: A market apart? Energy Policy 2004, 32, 1045–1052. [Google Scholar] [CrossRef]
- Lee, J.; Cho, Y. National-scale electricity peak load forecasting: Traditional, machine learning, or hybrid model? Energy 2022, 239, 122366. [Google Scholar] [CrossRef]
- Jan, F.; Shah, I.; Ali, S. Short-term electricity prices forecasting using functional time series analysis. Energies 2022, 15, 3423. [Google Scholar] [CrossRef]
- Miraftabzadeh, S.M.; Colombo, C.G.; Longo, M.; Foiadelli, F. K-means and alternative clustering methods in modern power systems. IEEE Access 2023, 11, 119596–119633. [Google Scholar] [CrossRef]
- Liu, X.; Lu, S.; Ren, Y.; Wu, Z. Wind turbine anomaly detection based on SCADA data mining. Electronics 2020, 9, 751. [Google Scholar] [CrossRef]
- Lin, C.; Han, G.; Wang, T.; Bi, Y.; Du, J.; Zhang, B. Fast node clustering based on an improved birch algorithm for data collection towards software-defined underwater acoustic sensor networks. IEEE Sens. J. 2021, 21, 25480–25488. [Google Scholar] [CrossRef]
- He, Q.; Wang, H.; Li, C.; Zhou, W.; Ye, Z.; Hong, L.; Yu, X.; Yu, S.; Peng, L. A Clone Selection Algorithm Optimized Support Vector Machine for AETA Geoacoustic Anomaly Detection. Electronics 2023, 12, 4847. [Google Scholar] [CrossRef]
- Ambrosius, M.; Grimm, V.; Kleinert, T.; Liers, F.; Schmidt, M.; Zöttl, G. Endogenous price zones and investment incentives in electricity markets: An application of multilevel optimization with graph partitioning. Energy Econ. 2020, 92, 104879. [Google Scholar] [CrossRef]
- Bernardi, M.; Lisi, F. Point and interval forecasting of zonal electricity prices and demand using heteroscedastic models: The IPEX case. Energies 2020, 13, 6191. [Google Scholar] [CrossRef]
- Kontopoulou, V.I.; Panagopoulos, A.D.; Kakkos, I.; Matsopoulos, G.K. A review of ARIMA vs. machine learning approaches for time series forecasting in data driven networks. Future Internet 2023, 15, 255. [Google Scholar] [CrossRef]
- Retiti Diop Emane, C.; Song, S.; Lee, H.; Choi, D.; Lim, J.; Bok, K.; Yoo, J. Anomaly detection based on GCNs and DBSCAN in a large-scale graph. Electronics 2024, 13, 2625. [Google Scholar] [CrossRef]
- Savitski, D.W. LMPs for (Technically-Inclined) Dummies. Energy Law J. 2019, 40, 165–208. [Google Scholar]
- Jain, M.; Sun, X.; Datta, S.; Somani, A. A Machine Learning Framework to Deconstruct the Primary Drivers for Electricity Market Price Events. arXiv 2023, arXiv:2309.06082. [Google Scholar]
- Dvorkin, V.; Fioretto, F. Price-Aware Deep Learning for Electricity Markets. arXiv 2023, arXiv:2308.01436. [Google Scholar]
- Yang, Y.S.; Xie, B.C.; Tan, X. Impact of Green Power Trading Mechanism on Power Generation and Interregional Transmission in China. Energy Policy 2024, 189, 114088. [Google Scholar] [CrossRef]
- Owolabi, O.O.; Schafer, T.L.; Smits, G.E.; Sengupta, S.; Ryan, S.E.; Wang, L.; Sunter, D.A. Role of variable renewable energy penetration on electricity price and its volatility across independent system operators in the United States. Data Sci. Sci. 2023, 2, 2158145. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Gap Parameters | Number of Electricity Price Divisions | Number of Un-Partitioned Nodes | Range | Interquartile Range | Variance | |
|---|---|---|---|---|---|---|
| 3 | 3 | 43 | 8 | 16.87 | 4.25 | 4.57 |
| 5 | 36 | 36 | 19.93 | 4.81 | 5.26 | |
| 10 | 35 | 44 | 20.32 | 4.94 | 5.38 | |
| 20 | 28 | 123 | 22.90 | 4.68 | 5.64 | |
| 5 | 3 | 29 | 2 | 27.55 | 7.74 | 7.59 |
| 5 | 25 | 26 | 27.70 | 5.93 | 6.79 | |
| 10 | 24 | 36 | 28.38 | 6.15 | 6.98 | |
| 22 | 23 | 63 | 28.65 | 5.50 | 6.76 | |
| 10 | 3 | 13 | 2 | 52.43 | 9.63 | 11.02 |
| 5 | 13 | 0 | 52.03 | 7.39 | 12.47 | |
| 10 | 12 | 0 | 53.08 | 7.60 | 9.65 | |
| 20 | 9 | 4 | 66.85 | 9.31 | 11.83 | |
| 20 | 3 | 5 | 0 | 101.51 | 14.33 | 16.01 |
| 5 | 4 | 0 | 109.04 | 11.24 | 14.26 | |
| 10 | 4 | 0 | 114.46 | 15.17 | 16.68 | |
| 20 | 2 | 0 | 205.51 | 21.30 | 24.60 |
| Methodologies | The Proportion of Anomalous Electricity Price Signal Points Identified |
|---|---|
| M1 | 2.06% |
| M2 | 6.37% |
| M3 | 0.93% |
| Methodologies | TP | FP | FN | TN | Precision | Recall | F1-Score | Accuracy |
|---|---|---|---|---|---|---|---|---|
| M1 | 82 | 11 | 18 | 889 | 0.88 | 0.82 | 0.85 | 0.971 |
| M2 | 89 | 52 | 11 | 848 | 0.63 | 0.89 | 0.74 | 0.937 |
| M3 | 28 | 65 | 72 | 835 | 0.30 | 0.28 | 0.29 | 0.863 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dai, S.; Wang, J.; Ji, T. Symmetry-Guided Identification of Spatial Electricity Price Anomalies via Data Partitioning and Density Analysis. Symmetry 2025, 17, 1032. https://doi.org/10.3390/sym17071032
Dai S, Wang J, Ji T. Symmetry-Guided Identification of Spatial Electricity Price Anomalies via Data Partitioning and Density Analysis. Symmetry. 2025; 17(7):1032. https://doi.org/10.3390/sym17071032
Chicago/Turabian StyleDai, Siting, Jiawen Wang, and Tianyao Ji. 2025. "Symmetry-Guided Identification of Spatial Electricity Price Anomalies via Data Partitioning and Density Analysis" Symmetry 17, no. 7: 1032. https://doi.org/10.3390/sym17071032
APA StyleDai, S., Wang, J., & Ji, T. (2025). Symmetry-Guided Identification of Spatial Electricity Price Anomalies via Data Partitioning and Density Analysis. Symmetry, 17(7), 1032. https://doi.org/10.3390/sym17071032