
Automatic Classification of Equivalent Mutants in Mutation Testing of Android Applications

 , , and
, , and
Abstract
:1. Introduction
2. Related Works
3. Materials and Methods
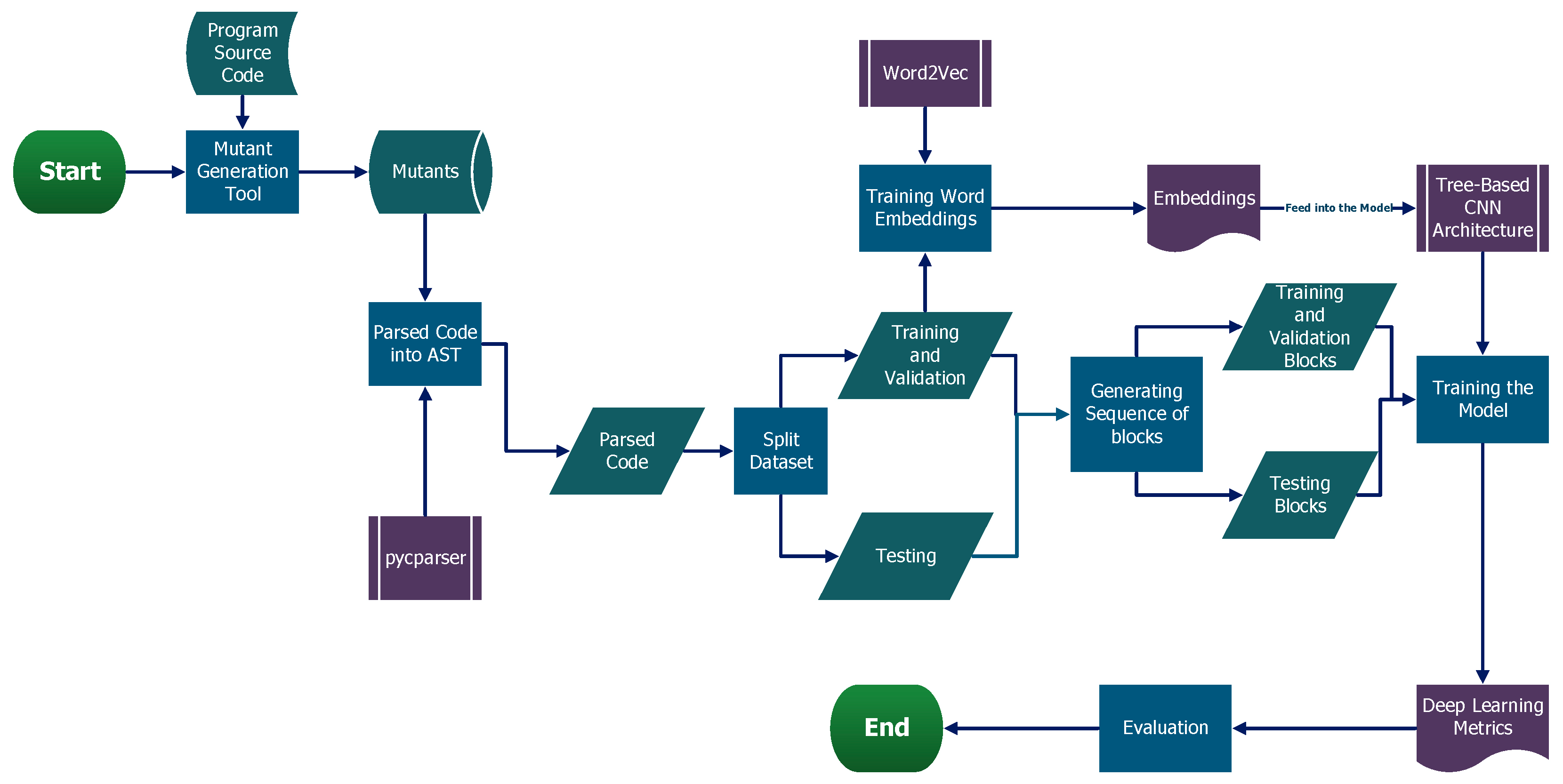
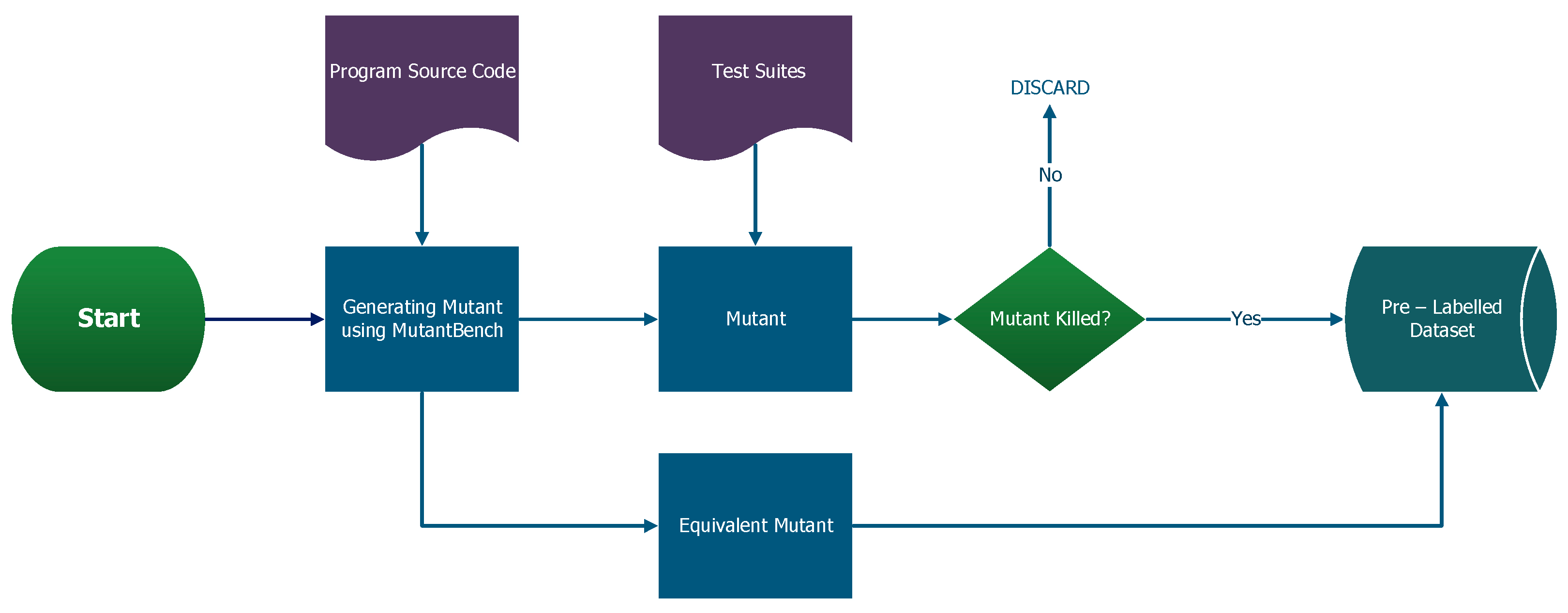
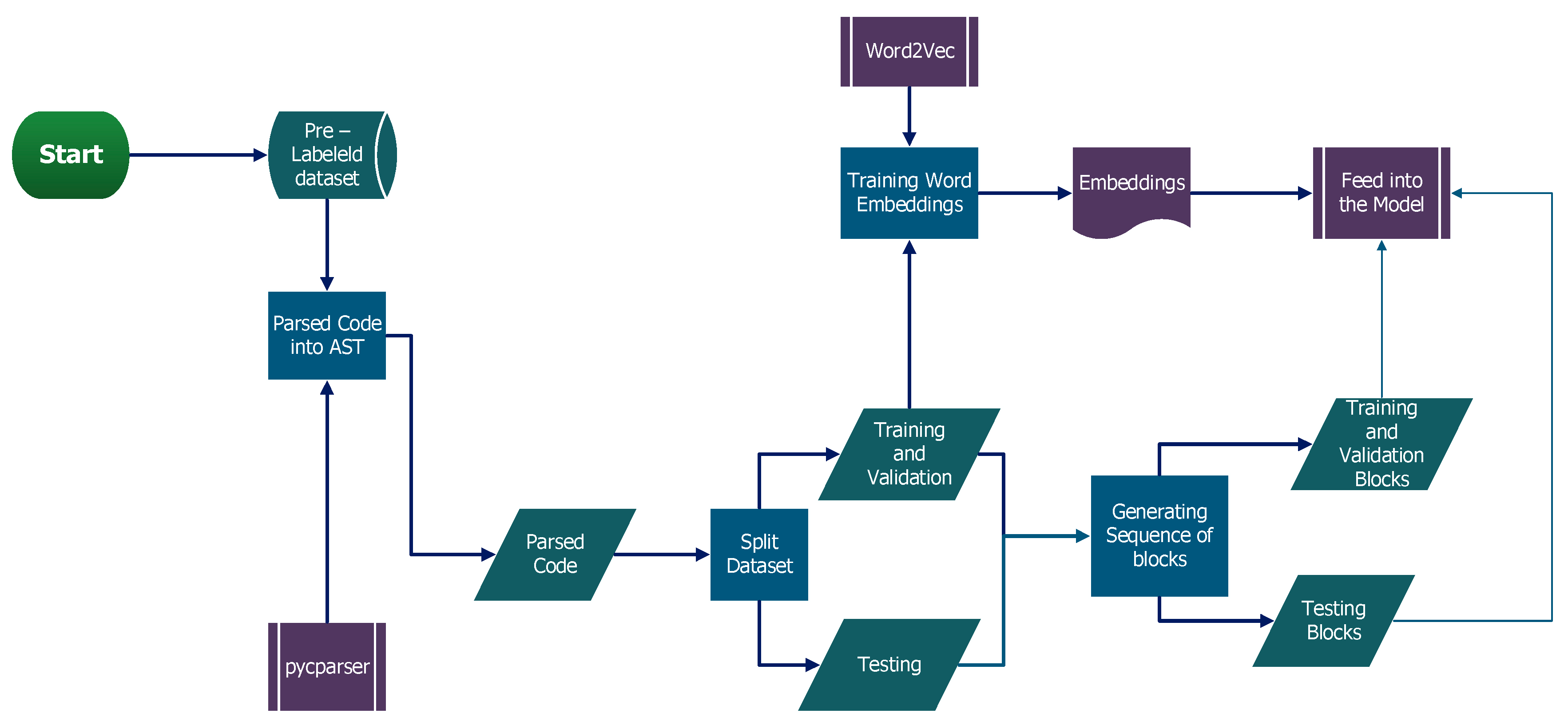
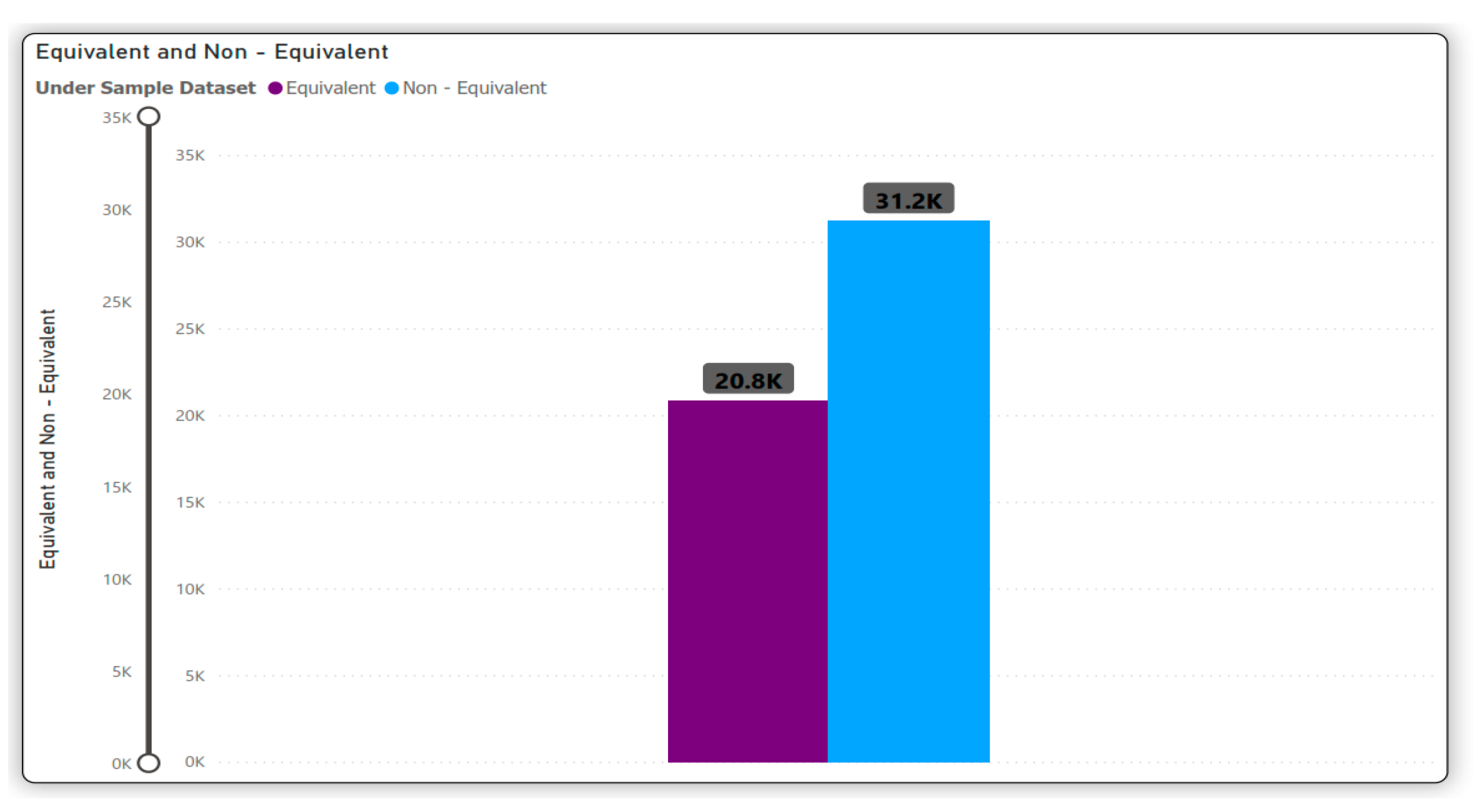
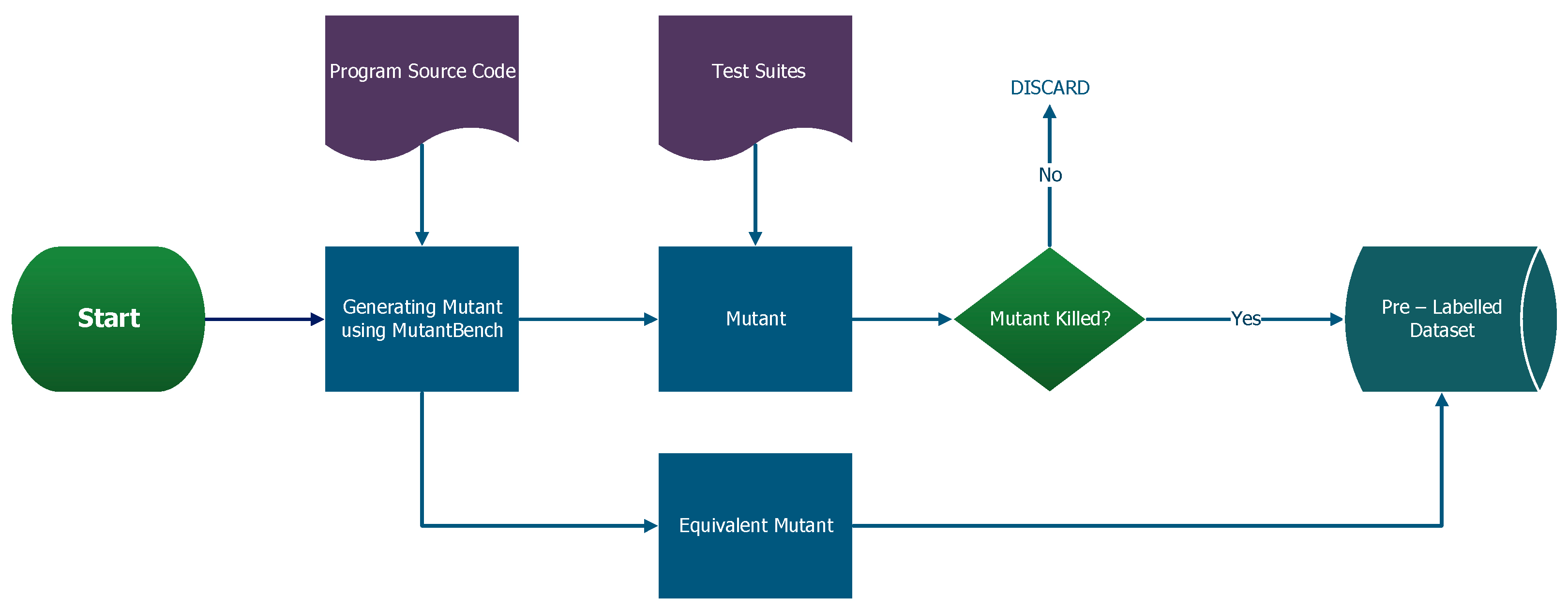
3.1. Data Generation and Processing
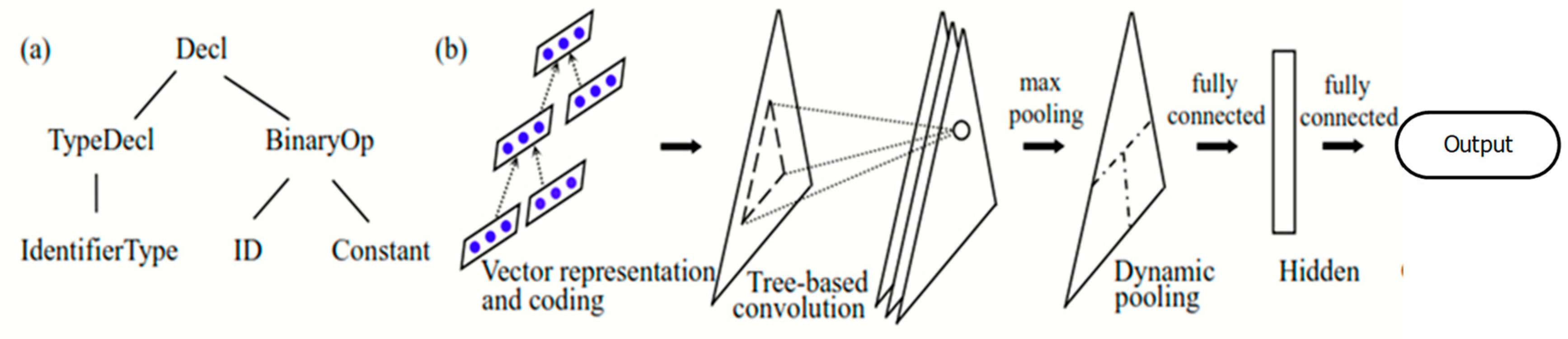
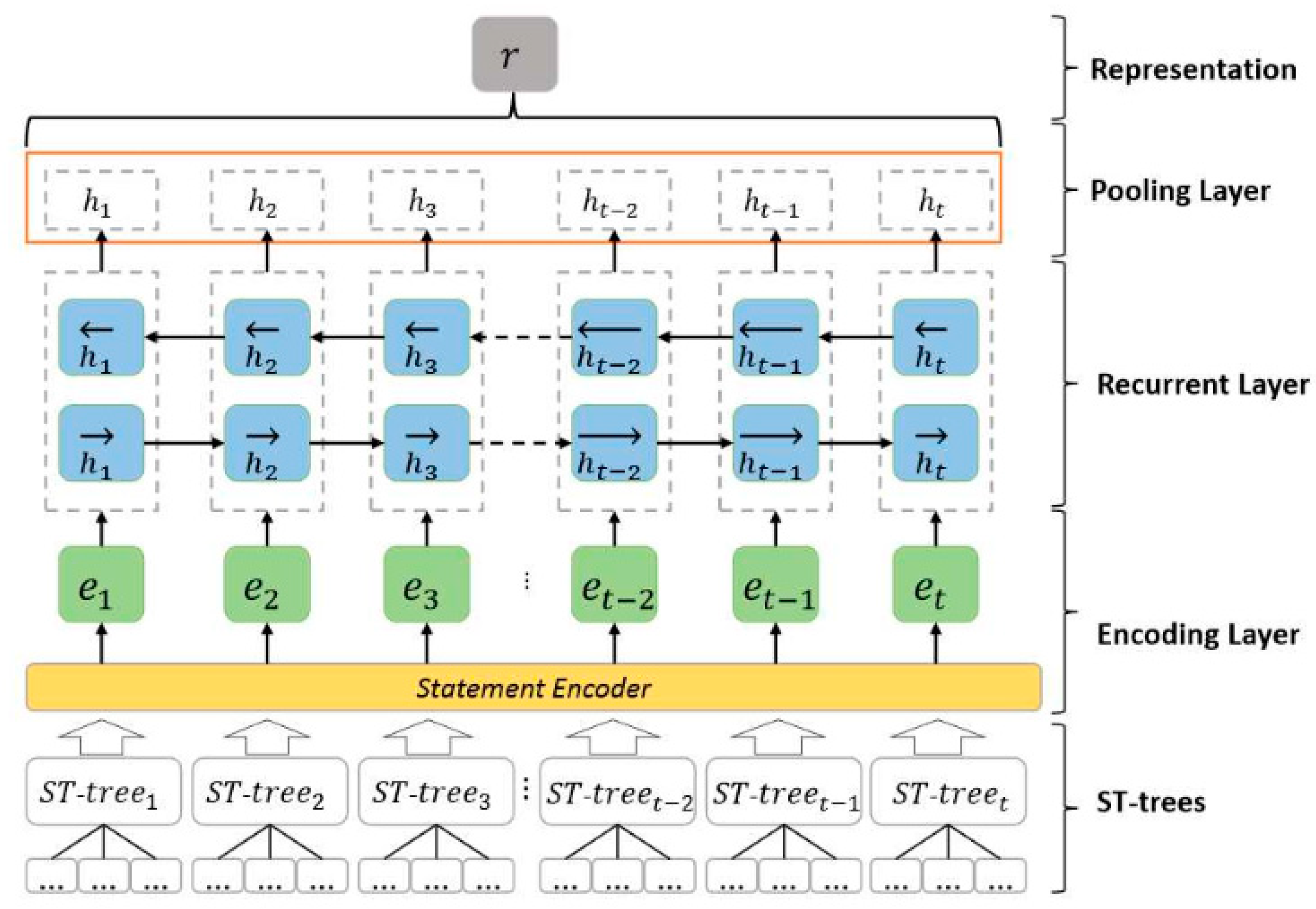
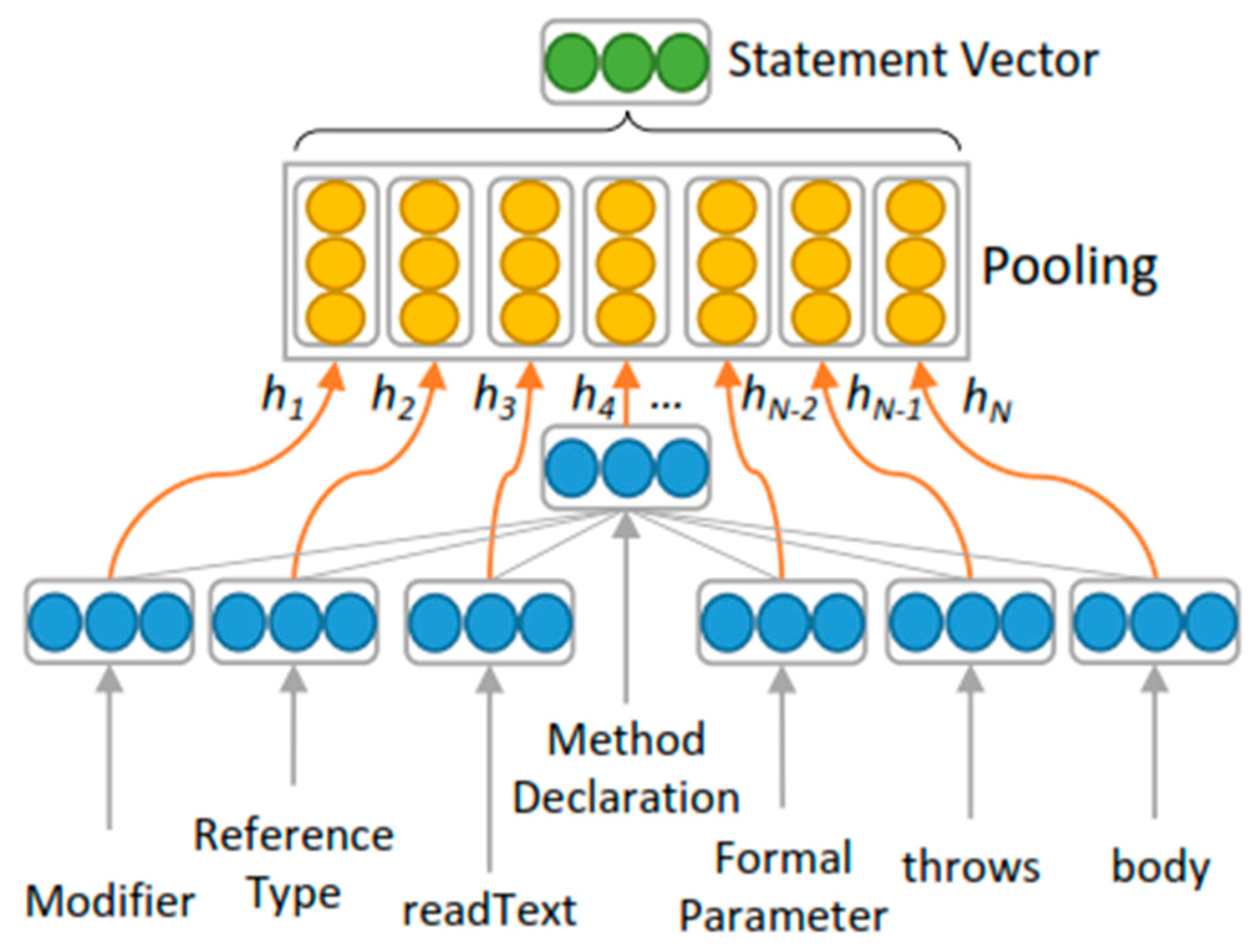
3.2. Model Design and Training
- Initially, the network is trained to classify data into N categories. The data from a new class is presented to the network, and the network then expands to accommodate the new class;
- The network expands by adding a new leaf/branch node to the existing structure;
- The goal of reducing training effort has two components: the number of weights updated and the number of examples, old or new, required for training;
- Lastly, changes have been restricted to a new branch of the tree.
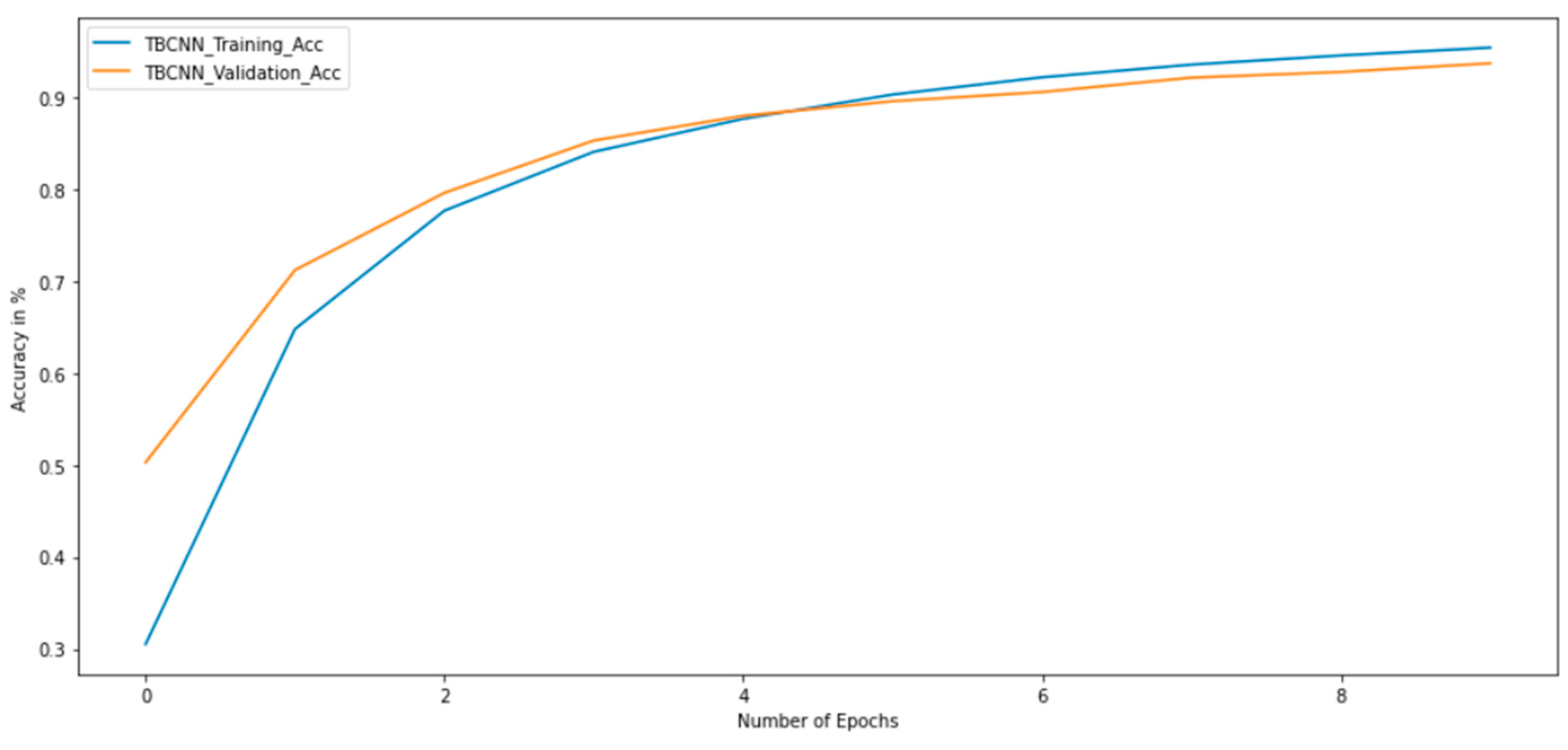
Training and Validation
- True Positive (TP)—Mutant is equivalent, as anticipated by our model;
- False Positive (FP)—Mutant is not equivalent, but our model predicted it was equivalent;
- True Negative (TN)—Mutant is not equivalent, and our model predicted it was not equivalent;
- False Negative (FN)—Mutant is equivalent, but our model predicted it was not equivalent.
4. Discussion of Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Deng, L.; Offutt, J.; Ammann, P.; Mirzaei, N. Mutation operators for testing Android apps. Inf. Softw. Technol. 2017, 81, 154–168. [Google Scholar] [CrossRef]
- Strug, J.; Strug, B. LNCS 7641—Machine Learning Approach in Mutation Testing. In IFIP International Conference on Testing Software and Systems; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Delgado-Pérez, P.; Sánchez, A.B.; Segura, S.; Medina-Bulo, I. Performance Mutation Testing. Softw. Test. Verif. Reliab. 2021, 31, e1728. [Google Scholar] [CrossRef]
- Salihu, I.A.; Ibrahim, R.; Ahmed, B.S.; Zamli, K.Z.; Usman, A. AMOGA: A Static-Dynamic Model Generation Strategy for Mobile Apps Testing. IEEE Access 2019, 7, 17158–17173. [Google Scholar] [CrossRef]
- Naeem, M.R.; Lin, T.; Naeem, H.; Liu, H. A machine learning approach for classification of equivalent mutants. J. Softw. Evol. Process 2020, 32, e2238. [Google Scholar] [CrossRef]
- Liang, H.; Sun, L.; Wang, M.; Yang, Y. Deep Learning with Customized Abstract Syntax Tree for Bug Localization. IEEE Access 2019, 7, 116309–116320. [Google Scholar] [CrossRef]
- Peacock, S.; Deng, L.; Dehlinger, J.; Chakraborty, S. Automatic Equivalent Mutants Classification Using Abstract Syntax Tree Neural Networks. In Proceedings of the 2021 IEEE 14th International Conference on Software Testing, Verification and Validation Workshops (ICSTW), Porto de Galinhas, Brazil, 12–16 April 2021; pp. 13–18. [Google Scholar]
- Escobar-Velásquez, C.; Riveros, D.; Linares-Vásquez, M. MutAPK 2.0: A tool for reducing mutation testing effort of Android apps. In Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Virtual Event, 8–13 November 2020; pp. 1611–1615. [Google Scholar]
- Mateo, P.R.; Usaola, M.P.; Aleman, J.L.F. Validating Second-Order Mutation at System Level. IEEE Trans. Softw. Eng. 2012, 39, 570–587. [Google Scholar] [CrossRef]
- Van Hijfte, L.; Oprescu, A. MutantBench: An Equivalent Mutant Problem Comparison Framework. In Proceedings of the 2021 IEEE 14th International Conference on Software Testing, Verification and Validation Workshops (ICSTW), Porto de Galinhas, Brazil, 12–16 April 2021; pp. 7–12. [Google Scholar] [CrossRef]
- Delgado-Pérez, P.; Chicano, F. An experimental and practical study on the equivalent mutant connection: An evolutionary approach. Inf. Softw. Technol. 2020, 124, 106317. [Google Scholar] [CrossRef]
- Kintis, M.; Papadakis, M.; Jia, Y.; Malevris, N.; Le Traon, Y.; Harman, M. Detecting Trivial Mutant Equivalences via Compiler Optimisations. IEEE Trans. Softw. Eng. 2017, 44, 308–333. [Google Scholar] [CrossRef] [Green Version]
- Ma, L.; Zhang, F.; Sun, J.; Xue, M.; Li, B.; Juefei-Xu, F.; Xie, C.; Li, L.; Liu, Y.; Zhao, J.; et al. DeepMutation: Mutation Testing of Deep Learning Systems. In Proceedings of the 2018 IEEE 29th International Symposium on Software Reliability Engineering (ISSRE), Memphis, TN, USA, 15–18 October 2018; pp. 100–111. [Google Scholar]
- Linares-Vásquez, M.; Bavota, G.; Tufano, M.; Moran, K.; Di Penta, M.; Vendome, C.; Bernal-Cárdenas, C.; Poshyvanyk, D. Enabling mutation testing for Android apps. In Proceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering, Association for Computing Machinery (ACM), Paderborn, Germany, 4–8 September 2017; pp. 233–244. [Google Scholar]
- Moran, K.; Tufano, M.; Bernal-Cárdenas, C.; Linares-Vásquez, M.; Bavota, G.; Vendome, C.; Di Penta, M.; Poshyvanyk, D. MDroid+: A mutation testing framework for android. In Proceedings of the 40th International Conference on Software Engineering: Companion, Gothenburg, Sweden, 27 May–3 June 2018; pp. 33–36. [Google Scholar]
- Da Silva, H.N.; Farah, P.R.; Mendonça, W.D.F.; Vergilio, S.R. Assessing Android Test Data Generation Tools via Mutation Testing. In Proceedings of the IV Brazilian Symposium on Systematic and Automated Software Testing—SAST 2019, Salvador, Brazil, 23–27 September 2019; pp. 32–41. [Google Scholar]
- Yao, X.; Harman, M.; Jia, Y. A study of equivalent and stubborn mutation operators using human analysis of equivalence. In Proceedings of the 36th International Conference on Software Engineering, Hyderabad, India, 31 May 2014–7 June 2014; pp. 919–930. [Google Scholar] [CrossRef] [Green Version]
- Phan, A.V.; Chau, P.N.; Le Nguyen, M.; Bui, L.T. Automatically classifying source code using tree-based approaches. Data Knowl. Eng. 2018, 114, 12–25. [Google Scholar] [CrossRef]
- Hu, Q.; Ma, L.; Xie, X.; Yu, B.; Liu, Y.; Zhao, J. DeepMutation++: A Mutation Testing Framework for Deep Learning Systems. In Proceedings of the 2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE), San Diego, CA, USA, 11–15 November 2019; pp. 1158–1161. [Google Scholar]
- Baer, M.; Oster, N.; Philippsen, M. MutantDistiller: Using Symbolic Execution for Automatic Detection of Equivalent Mutants and Generation of Mutant Killing Tests. In Proceedings of the 2020 IEEE International Conference on Software Testing, Verification and Validation Workshops (ICSTW), Porto, Portugal, 24–28 October 2020; pp. 294–303. [Google Scholar] [CrossRef]
- Tang, D.; Qin, B.; Liu, T. Document Modeling with Gated Recurrent Neural Network for Sentiment Classification. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1422–1432. [Google Scholar]
- Roy, D.; Panda, P.; Roy, K. Tree-CNN: A hierarchical Deep Convolutional Neural Network for incremental learning. Neural Netw. 2020, 121, 148–160. [Google Scholar] [CrossRef] [PubMed]
- Mou, L.; Li, G.; Zhang, L.; Wang, T.; Jin, Z. Convolutional Neural Networks over Tree Structures for Programming Language Processing. 2014. Available online: http://arxiv.org/abs/1409.5718 (accessed on 21 March 2022).
- Saifan, A.A.; Alzyoud, A.A. Mutation Testing to Evaluate Android Applications. Int. J. Open Source Softw. Process. 2020, 11, 23–40. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed Representations of Words and Phrases and Their Compositionality. 2013. Available online: http://arxiv.org/abs/1310.4546 (accessed on 21 March 2022).
- Vieira, S.T.; Rosa, R.L.; Rodríguez, D.Z. A Speech Quality Classifier based on Tree-CNN Algorithm that Considers Network Degradations. J. Commun. Softw. Syst. 2020, 16, 180–187. [Google Scholar] [CrossRef]
- Bui, N.D.Q.; Jiang, L.; Yu, Y. Cross-Language Learning for Program Classification Using Bilateral Tree-Based Convolutional Neural Networks. 2017. Available online: http://arxiv.org/abs/1710.06159 (accessed on 21 March 2022).
- Cai, Z.; Lu, L.; Qiu, S. An Abstract Syntax Tree Encoding Method for Cross-Project Defect Prediction. IEEE Access 2019, 7, 170844–170853. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. 2014. Available online: https://arxiv.org/abs/1412.6980 (accessed on 21 March 2022).
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chicco, D.; Tötsch, N.; Jurman, G. The Matthews correlation coefficient (MCC) is more reliable than balanced accuracy, bookmaker informedness, and markedness in two-class confusion matrix evaluation. BioData Min. 2021, 14, 1–22. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Serial Number | Resources | Version |
|---|---|---|
| 1 | Android Studio | 2020.3.1 |
| 2 | MutantBench | 2021.1.1 |
| 3 | Gumtre | 2.1.2 |
| 4 | Python | 3.10.1 |
| 5 | Pandas | |
| 6 | Gensim | 3.5.0 |
| 7 | Pytorch | 1.6.0 |
| 8 | Dataloader | |
| 9 | Pycparser | 2.18 |
| 10 | Google Colab | - |
| Model | Accuracy | Recall | Precision | Time (s) |
|---|---|---|---|---|
| Binary Classification + Random Forest | 80% | 96% | 89% | - |
| k-Nearest Neighbor | 85% | - | - | - |
| ASTNN | 90% | 96% | 100% | 84.5 |
| ASTNN (With our Standard Dataset) | 94% | 93% | 92% | 314.64 |
| TBCNN | 94% | 96% | 93% | 153.00 |
| Mutation Operator | Accuracy | Recall | Precision | F1-Score | MCC Score | Total Time (s) |
|---|---|---|---|---|---|---|
| ABS | 0.94 | 0.96 | 0.89 | 0.92 | 0.88 | 153.00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kusharki, M.B.; Misra, S.; Muhammad-Bello, B.; Salihu, I.A.; Suri, B. Automatic Classification of Equivalent Mutants in Mutation Testing of Android Applications. Symmetry 2022, 14, 820. https://doi.org/10.3390/sym14040820
Kusharki MB, Misra S, Muhammad-Bello B, Salihu IA, Suri B. Automatic Classification of Equivalent Mutants in Mutation Testing of Android Applications. Symmetry. 2022; 14(4):820. https://doi.org/10.3390/sym14040820
Chicago/Turabian StyleKusharki, Muhammad Bello, Sanjay Misra, Bilkisu Muhammad-Bello, Ibrahim Anka Salihu, and Bharti Suri. 2022. "Automatic Classification of Equivalent Mutants in Mutation Testing of Android Applications" Symmetry 14, no. 4: 820. https://doi.org/10.3390/sym14040820
APA StyleKusharki, M. B., Misra, S., Muhammad-Bello, B., Salihu, I. A., & Suri, B. (2022). Automatic Classification of Equivalent Mutants in Mutation Testing of Android Applications. Symmetry, 14(4), 820. https://doi.org/10.3390/sym14040820