1. Introduction
Software is used to control the entire hardware system. Due to this, it has become part of the most complex components and its use has grown more and more. Indeed, its growth has caused new algorithms and development methodologies to be implemented, and thus, software is being applied to a large number of different areas. What is more, software can also support symmetry as its use has been widespread across entire systems and independent content. Symmetry can be identified as an extraordinary characteristic that has been widely deployed in diverse research fields of computer engineering.
Software testing constitutes the process of executing a software product or a portion of it in a controlled environment with a given set of input (test cases) [
1]. Moreover, it involves the execution and examination of a program or a software system in order to identify errors or faults. The main goal of software testing is to determine the errors in a complete software product (or in a component of it) to ensure a high probability that the corresponding software is correct [
2].
Search-Based Software Engineering (SBSE) is an emerging field of research and practice in Software Engineering, where the term “search” refers to the metaheuristic search-based optimization techniques used. SBSE aims to reformulate problems in the area of software engineering, particularly in software testing problems, into search-based optimization problems. A comprehensive survey of SBSE is proposed in Ref. [
3], where related research fields are organized into categories drawn from the corresponding ACM subject categories within the Software Engineering body of knowledge.
In software testing, mutants form simulated and artificially generated faults that behave in a similar way to the realistic ones [
4,
5]. In addition, mutants can be used for test data generation in a software testing activity [
6]. These are created by systematic injection of faults using some predefined mutation operators [
7]. Mutation testing is thus a form of white-box testing initially suggested in Ref. [
8] and later explored by different researchers [
9,
10,
11]. Execution of a test case (test inputs) against mutants results in the adequacy score of that test case, where this result is also called the Mutation Score (MS).
In recent years, a number of search-based algorithms, metaheuristic methods, Evolutionary Algorithms (EA) and optimization techniques have already been developed to automatically generate test data in the area of software testing. Different EAs like Genetic Algorithms (GA), PSO, ACO, Monarch Butterfly Optimization Algorithm (MBO), Slime Mold Algorithm (SMA), Moth Search Algorithm (MS), RUNge–Kutta method (RUN), Colony Predation Algorithm (CPA), Weighted Mean of Vectors (INFO), and Harris Hawks Optimization (HHO) have been proposed in unit level testing to generate optimized test data for path testing and these path coverage-based testing methods can only generate test data to traverse target paths [
12]. However, these techniques may fail to detect all software faults because information about fault detection is not incorporated into the process of generating test data [
13]. So, existing path coverage-based techniques may not always guarantee that the test data can effectively detect all faults in target paths. Hence, it is vital to implement the best of each test case through Mutation Analysis [
14].
Monarch Butterfly Optimization Algorithm (MBO) employs the migration behaviors of butterflies where all monarch butterflies are located at two different lands. These lands are fixed and unchanged during the whole optimization process. A parameter
p is used for calculation at the beginning stage of the search process [
15]. The Slime Mold Algorithm basically refers to Physarum Polycephalum [
16]. It is an eukaryote that inhabits cool and humid places. Also, the main nutritional stage is considered the Plasmodium; in this stage, the organic matter in slime mold seeks food, surrounds and secretes enzymes with the aim of digesting it. In the optimization process, the front end extends into a fan-shape, followed by an interconnected venous network that allows cytoplasm to flow inside. It can be used for multiple food sources at the same time to form a venous network connecting them. This metaheuristic algorithm is mainly used to solve many graph theory problems and also for generating different networks.
In addition, moths are like butterflies that belong to the order Lepidoptera. The main features of moths are Phototaxis, signifying movement of an organism towards or away from a source of light and Levy flights. Taking all the features of moths, a new kind of metaheuristic algorithm has been developed, called Moths Search Algorithm (MSA) [
17]. The phototaxis and levy flights of the moths can be used to build up a general-purpose optimization method. Also, the Colony Predation Algorithm (CPA) is based on the co-existence of animals and mimics the supportive behavior of social animals as well as the predation strategy of hunting animals [
18]. The different operations applied in CPA are communications and collaboration, disperse food, encircle foods, supporting the closest individual and searching for foods. Through these five processes, the global optimum solution can be achieved.
The RUNge–Kutta method (RUN) is an iterative process used to solve the numerical Cauchy problems for a system of ordinary differential equations. To solve the differential equations, both the arithmetic and the geometric mean are applied [
19]. The most important strategy of Harris Hawks Optimization (HHO) is catching its prey in order to hunt in groups and to collaborate with the hawks, as opposed to other predators [
20]. In this process, a number of hawks attack from different ways their chosen prey in collaboration with simultaneous delusion and approached in a controlled manner. The attack is desired to be completed in a few seconds and it continues until the hunting is successful or, on the other hand, the prey manages to completely escape. Finally, the hunting process is completed as the prey, which has low energy and has lost its defensive abilities, is easily hunted by the leader. HHO is a population-based optimization technique and it can be applied to any optimization problem with appropriate limitations and constraints. The optimum solution can be found in the prey itself.
Although there are various studies related to generating test data for path coverage, few researchers have proposed techniques to detect faults via path coverage-based test data. The purpose of this particular research is to generate test data for path coverage as well as to detect faults lying in the System Under Test (SUT). In the relevant literature, some of these methods not only generate test data with the aim of covering a single or multiple paths, but also attempt to find the mutation score of every test case for a specific SUT [
21].
In this paper, we propose an SBSE algorithm that can effectively identify the maximum mutation score (coverage) by taking into account all the corresponding test cases, which are generated through path coverage-based testing. Initially, path coverage-based test cases are generated and then the proposed algorithm aims to find the mutation score for every test case by employing different mutation operators. In particular, a real coded Genetic Algorithm (GA) is proposed, which automatically generates test data to cover multiple paths at a time and further exercises the test data to achieve the maximum mutation score. The proposed algorithm is abbreviated as RGA-MS (Real coded Genetic Algorithm for maximizing the Mutation Score).
The rest part of the paper is organized in different sections as follows: In
Section 2 some basic concepts on mutation testing are described along with some relevant studies. In
Section 3, the steps of the proposed RGA-MS algorithm are outlined. Experimental setup along with the analysis of the experiment results are discussed in
Section 4. The same Section also presents a comparative study of the proposed approach with other existing methods focusing on achieving the highest mutation score, and the threats to validity regarding the proposed technique. Finally, our research’s conclusion and future scopes are outlined in
Section 5.
3. Proposed Algorithm for Mutation Testing (RGA-MS)
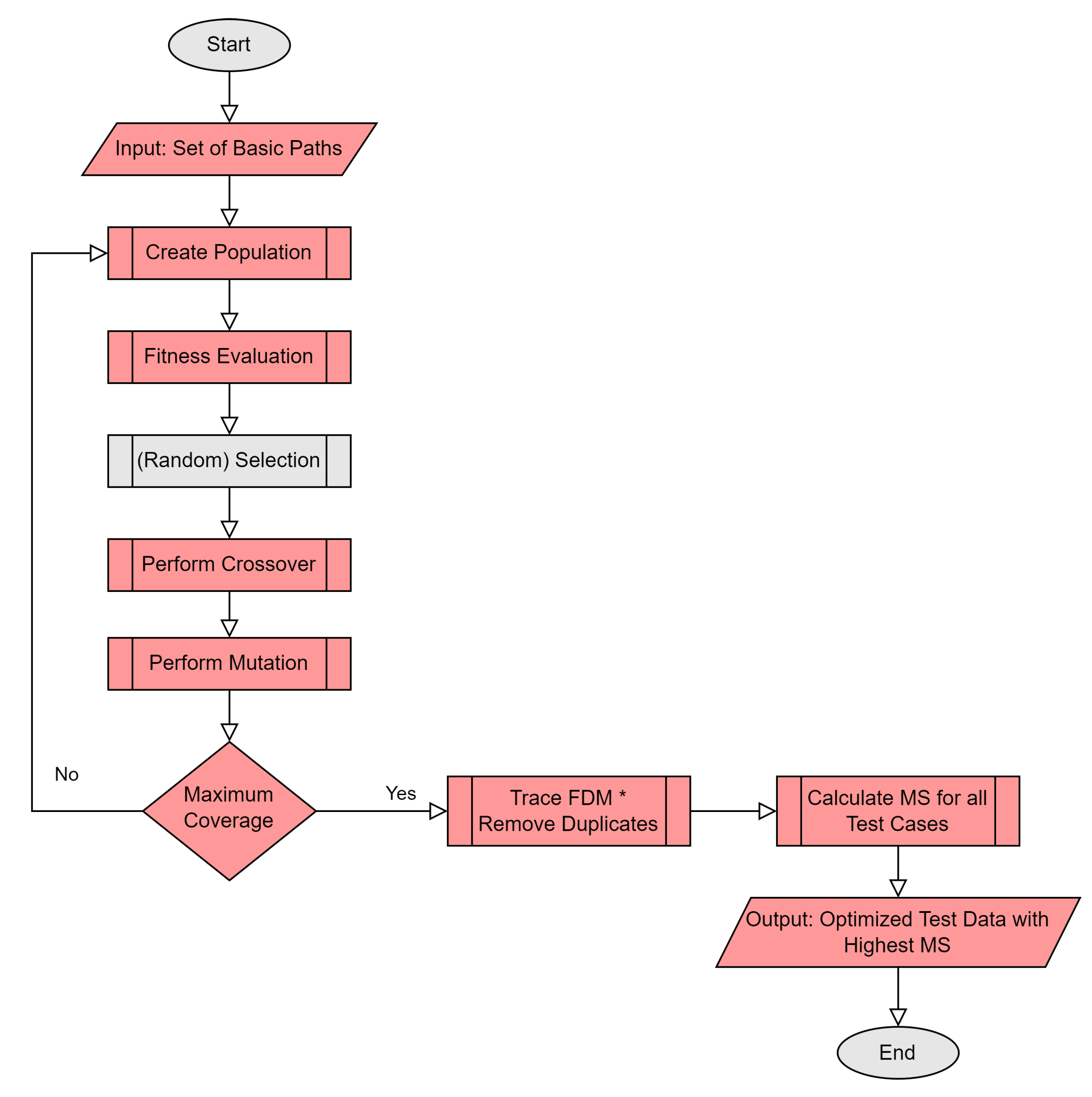
The proposed algorithm in this paper is designed to identify and extract a representative test suite, which achieves maximum path coverage. In the following, this test suite is exercised for mutation testing, i.e., to find the maximum mutation score. The algorithm is entitled Real Coded Genetic Algorithm for highest Mutation Score (RGA-MS) and is outlined in Algorithm 1.
Initially, the RGA-MS generates the test data for maximum path coverage by using the fitness, which is designed by considering the total number of paths covered by a chromosome. The fitness for path coverage is defined in following Equation (
2) as it is calculated by the ratio of paths covered by a chromosome given the total number of paths.
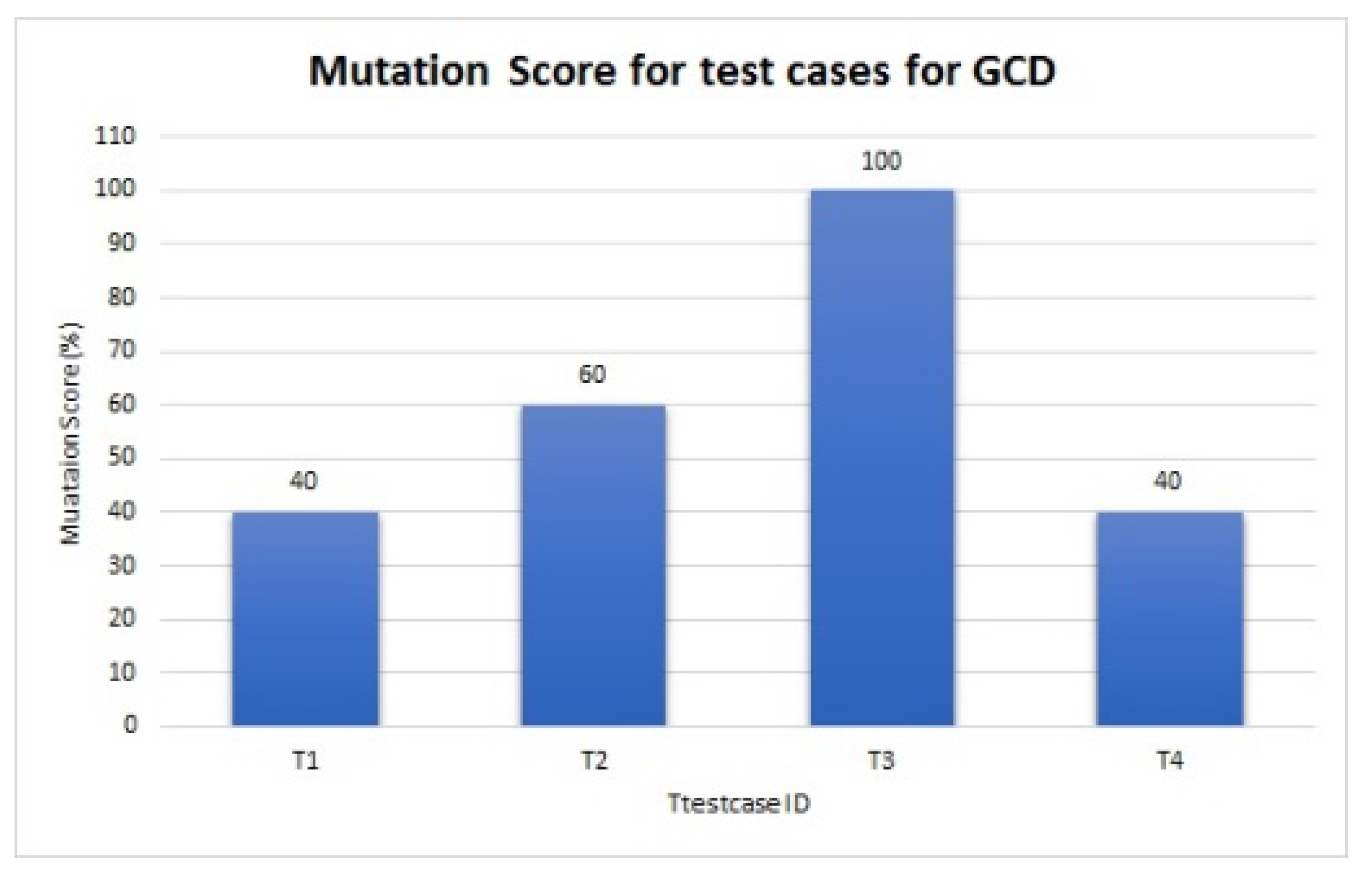
In the following, the two best populations are selected and the maximum path coverage is calculated. If the maximum path coverage is achieved, then the optimized test suite can be printed, otherwise the mutation must be applied and the new chromosomes should be replaced with their duplicates. The generated test data are exercised to find the mutation score.
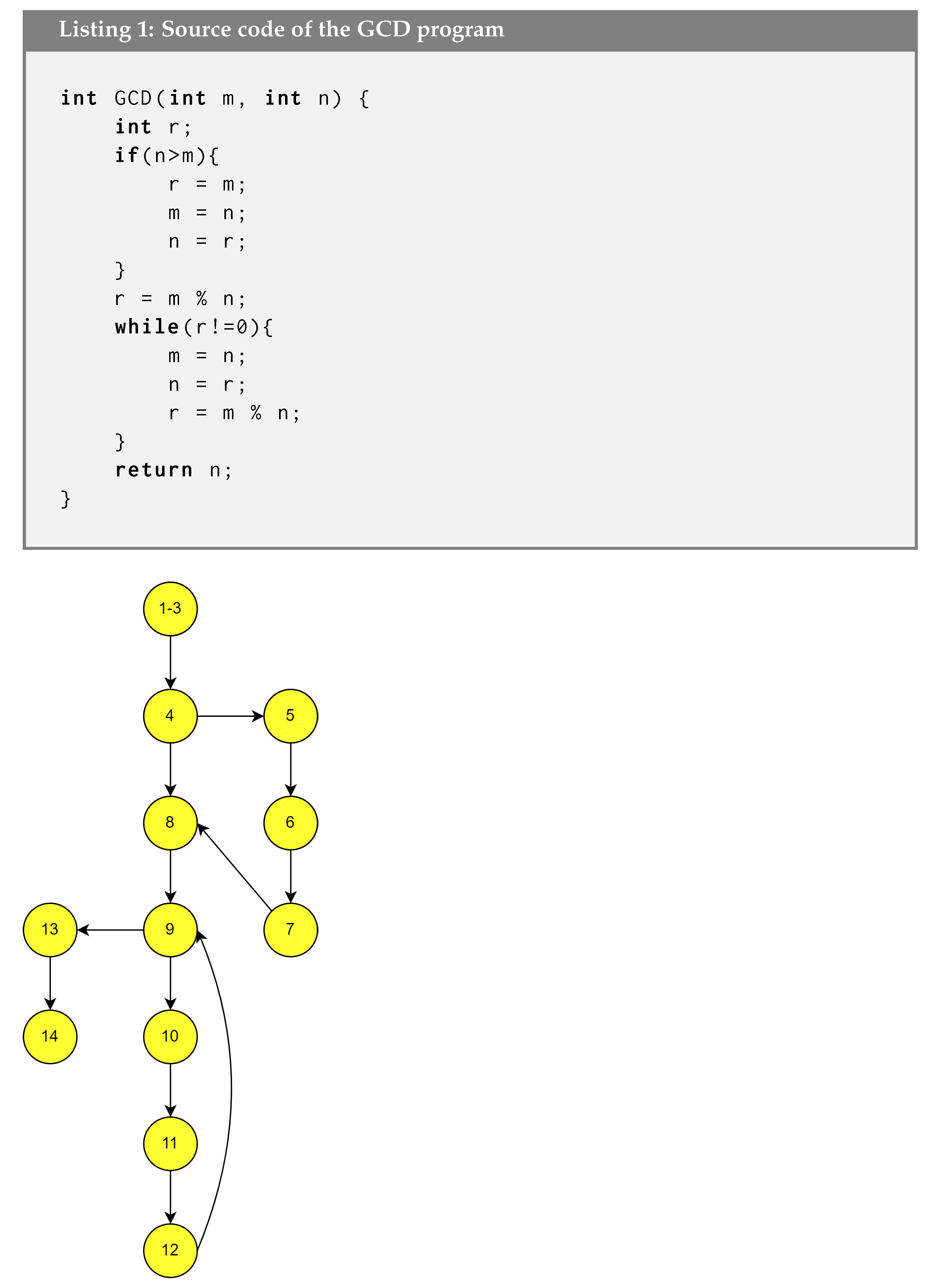
Different mutation operators are inserted in the source code of different SUTs, which are listed in
Table 1.
| Algorithm 1: Real Coded Genetic Algorithm for highest Mutation Score (RGA-MS) |
- 1:
input Set of basic paths for a specific SUT ( Table 1) - 2:
parameters - 3:
output An optimized test data with maximum Mutation Score (MS) - 4:
Step 1: Create - 5:
Step 2: Initialize the Population as Test Suites (where Test Suite = number of Chromosomes) - 6:
Step 3: Calculate Fitness using Equation ( 2) /* Fitness Value */ - 7:
Step 4: Select two best Populations - 8:
Step 5: do - 9:
Average Crossover for selected Chromosomes /* Maximum Path Coverage */ - 10:
while ( ) - 11:
Step 6: if ( ) - 12:
Goto Step 8 - 13:
else - 14:
- 15:
Step 7: do - 16:
Replace the new Chromosome with the duplicate one - 17:
while ( ) - 18:
Step 8: if ( ) then - 19:
Print the optimized Test Suite with Path Coverage - 20:
else - 21:
Goto Step 1 - 22:
Step 9: - 23:
Step 10: Remove redundant test data covering same mutants - 24:
Step 11: using Equation ( 1) - 25:
Step 12: Print optimized test data with highest MS
|
The proposed algorithm aims to identify the minimum test data that covers all mutants by eliminating the redundant test data. The redundant test data is traced using a Fault Detection Matrix (FDM) [
25]. A fault-detection matrix contains sufficient information for finding minimal-length, fault-diagnosis test sets. The necessary condition is that any sub-matrix of this matrix should not contain equal rows. The flow of the proposed algorithm is shown in
Figure 1.
5. Conclusions and Future Work
The automatic test data generation regarding white box testing is considered vital in accomplishing both qualitative and reliable software. Although mutation testing is computationally costly, thus it can improve the test data quality in terms of higher mutation scores. In addition, it can enhance the reliability of the software by killing the active mutants present in the source code of a SUT.
In this paper, a Search-Based Software Engineering algorithm, which can effectively identify the maximum mutation score by considering all the corresponding test cases generated through path coverage-based testing, is proposed. Initially, path coverage-based test cases are produced. Using different mutation operators, the proposed algorithm aims to find the mutation score for every test case. Then, a real-coded Genetic Algorithm is utilized, automatically generating test data to cover multiple paths simultaneously and further exercising the test data to achieve maximum mutation score. This proposed Real coded Genetic Algorithm for maximizing the Mutation Score is called RGA-MS.
The proposed RGA-MS-based method can generate test data for both path testing and mutation testing. Real coded GA is applied to generate an optimized test suite that achieves maximum path coverage, and further, the suite is exercised to kill the mutants present in the SUT. The proposed method can achieve optimized test data with the highest mutation score.
Regarding future work, we think more tools could be developed towards having a standardized mutant dataset, as this will increase the research interest in other areas of mutation testing. Furthermore, more mutation operators like SDL, VDL, ODL, EHF, OBAF, NPDF, etc., should be used to implement the proposed technique further, and the framework could be further developed into an android application to ease access and increase the use of the model. Lastly, we could implement an additional number of experiments to ensure that our proposed method can be utilized in different kinds of programs.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}