1. Introduction
In life testing experiments, one of the major reasons for the removal of experimental units is saving the working experimental units for future use, saving the cost and time associated with testing. This leads us to the use of censoring schemes. The most common schemes are considered Type-I and Type-II censoring. These types have been studied by several statisticians; see, for instance, Kundu and Howlader [
1] and Fujii [
2]. In terms of the procedure, in Type-I censoring, all units
n are put in the test for a pre-specified time and at the end of the specified time, the test ends. In Type-II censoring, all units
n are put in the test, and the test is terminated at the failure of the pre-specified
m-th unit
. The disadvantages of these types are represented in that the units cannot be removed during the test. Thus, progressive Type-II censoring (PT2C) was proposed, which has more flexibility in allowing units to be withdrawn within the duration of the test.
An excellent reference that accurately describes this type of censoring scheme is Balakrishnan and Sandhu [
3], who add to the steps of generation, which is useful to achieve the desired goals of using censoring schemes. Several authors have discussed inference under PT2C with applications, see, for example, Chen et al. [
4], Xu et al. [
5], Luo et al. [
6], and EL-Sagheer [
7].
Although the experimental efficiency under PT2C can be significantly improved, the duration of the test is still too long. So, Johnson [
8] described a life test in which the experimenter can be decided to divide the units under test into several groups and then run all the units simultaneously until the occurrence of the first failure in each group. Such a censoring scheme is called first-failure censoring (FFC). However, using this censoring scheme does not enable the experimenter to remove experimental units from the test until the first failure is observed. For this reason, Wu and Kuş [
9] introduced life testing, which combined FFC with PT2C, and is named the progressive first-failure censoring (Pro-F-F-C) scheme. Many authors have discussed inference under a Pro-F-F-C scheme for different lifetime distributions, see, for example, Soliman et al. [
10], Soliman et al. [
11,
12], Soliman et al. [
13], Mahmoud et al. [
14,
15], Abushal [
16], Ahemd [
17], Xie and Gui [
18], Shi and Shi [
19], and EL-Sagheer et al. [
20].
A new Weibull–Pareto distribution (NWPD) is a generalization of the Weibull and Pareto distributions, as discussed in Suleman and Albert [
21]. The probability density function (pdf) and cumulative distribution function (cdf) of a random variable
X has an NWPD given, respectively, by
and
where
and
are the scale parametersand
is the shape parameter. The reliability function
, hazard rate function
, and coefficient of variation
of the NWPD (
) are, respectively, given by
and
The importance of studying this model is due to the fact that it is an interesting three-parameter lifetime model, and it can be a useful characterization of the survival time of a given system because of its analytical structure. In addition, it occupies an important position in reliability analysis, biomedical, and life-test experiences. From
, the following can be observed: If
the
is constant and given by
, this makes the NWPD suitable for modeling systems or components with constant failure rate. If
, the hazard rate function is an increasing function of
x, which makes the NWPD suitable for modeling components that wear faster with time. If
, the hazard rate function is a decreasing function of
x, which makes the NWPD suitable for modeling components that wear slower with time. For more details about the NWPD, including its properties and applications see Suleman and Albert [
21]. Several authors have discussed the statistical inference of censored data on the NWPD, for example, Almetwally et al. [
22], Al-Omari et al. [
23], EL-Sagheer et al. [
24], and Mahmoud et al. [
25].
This article aims to discuss the statistical inference of the NWPD parameters as well as some lifetime indices such as reliability function, hazard rate function, and coefficient of variation in the presence of Pro-F-F-C scheme. To this end, both point and interval estimations are discussed by implementing classical and Bayesian approaches. Moreover, delta, log transformation (T) and arc sine transformation (AST) methods are used to construct the ACIs for , , and . In the Bayesian framework, Lindley and MCMC techniques under two different loss functions (balanced linear exponential (BLINEX) and general entropy (GE)) are proposed. A simulation study is carried out to determine the performance of the ML, Lindley, and MCMC estimation and compare the performance of different corresponding confidence intervals. Finally, the application to real-life data on gastric cancer survival times is analyzed for illustrative purposes.
The rest of this article is organized as follows: MLEs for the unknown quantities are presented in
Section 2. In
Section 3, the ACIs are constructed. Bayes estimators relative to different loss functions are also considered in
Section 4.
Section 5 provided the illustration of the proposed procedure by using a real-life example. Simulation results are discussed in
Section 6. Finally, concluding remarks are investigated in
Section 7.
4. Bayesian Estimation
In this section, we discuss how to obtain the Bayes estimates and construct the corresponding CRIs for
,
, and
,
,
, and
under BLINEX and GE loss functions. Therefore, we consider that the unknown parameters
,
, and
are stochastically independently distributed with conjugate gamma prior. Hence, the joint prior density can be formulated as follows
where the hyperparameters
and
(where
) are reflected prior knowledge about
,
, and
. Consequently, from (6) and (25), the joint posterior density can be expressed as follows
The Bayes estimate of the unknown quantity
under BLINEX and GE loss functions is given by
where the posterior expectations of
under BLINEX and GE loss functions can be written as
It is noticeable that the Bayes estimates in both kinds of loss functions include three integrals and cannot be constructed in closed forms. Therefore, the Lindley and MCMC techniques will be implemented to obtain the Bayes estimates of the unknown quantities.
4.1. Lindley’s Approximation
There are various methods suggested to approximate the ratio of integrals of the above form, maybe the simplest one is the Lindley [
30] approximation method, which approximates the Bayes estimates into a form containing no integrals. Many authors have used this approximation, see for example, Sarhan et al. [
31], Sultan et al. [
32], Singh et al. [
33], Singh et al. [
34], and Rastogi and Tripathi [
35]. In short, this method works as follows: for any ratio of the integral of the form
where
is the function of
,
, and
only,
, and
is the joint prior density. Hence,
can be estimated as
where
,
, and
are the MLEs of
,
, and
, respectively, and subscripts 1, 2, and 3 on the right-hand sides refer to
,
, and
.
where
,
,
,
, and
are the
elements of
in (17). If
,
, and
are orthogonal, then
for
. The
can be obtained as follows:
and
From the joint prior density in (25), we get
4.1.1. Bayes Estimate under BLINEX Loss Function
In this subsection, we obtain the Bayes estimates of , and under the BLINEX loss function
- (i)
When
, then
,
, and
. The Bayes estimate of
is given by
where
- (ii)
When
, then
,
, and
. The Bayes estimate of
is given by
where
- (iii)
When
, then
,
, and
. The Bayes estimate of
is given by
where
- (iv)
When
, then the Bayes estimate of
is given by
where
- (v)
When
, then the Bayes estimate of
is given by
where
- (vi)
When
, then the Bayes estimate of
is given by
where
4.1.2. Bayes Estimate under GE Loss Function
We discuss the Bayes estimates of and under the GE loss function.
- (i)
When
, then
,
, and
. The Bayes estimate of
is given by
where
- (ii)
When
, then
,
, and
. The Bayes estimate of
is given by
where
- (iii)
When
, then
,
, and
. The Bayes estimate of
is given by
where
- (iv)
When
, then the Bayes estimate of
is given by
where
- (v)
When
, then the Bayes estimate of
is given by
where
When
, then the Bayes estimate of
is given by
where
Unfortunately, Lindley’s approximation does not calculate the interval estimation, so we resort to the MCMC technique.
4.2. MCMC Technique
Now, we explain how the MCMC technique is applied to compute the Bayes estimates and construct the corresponding CRIs of
, and
. A common technique in the MCMC technique is the Gibbs sampler, which was introduced by Geman and Geman [
36], and the M-H algorithm, which was developed by Metropolis et al. [
37] and later extended by Hastings [
38]. In this technique, the samples can be drawn by making use of the conditional density and proposal distributions for each of the parameters. Thereafter, by using the drawn samples, the Bayes estimates and the corresponding CRIs can be computed. From (26), the conditional densities can be obtained as follows
and
It is noticeable that Equation (
69) represents a gamma density, thus the samples of
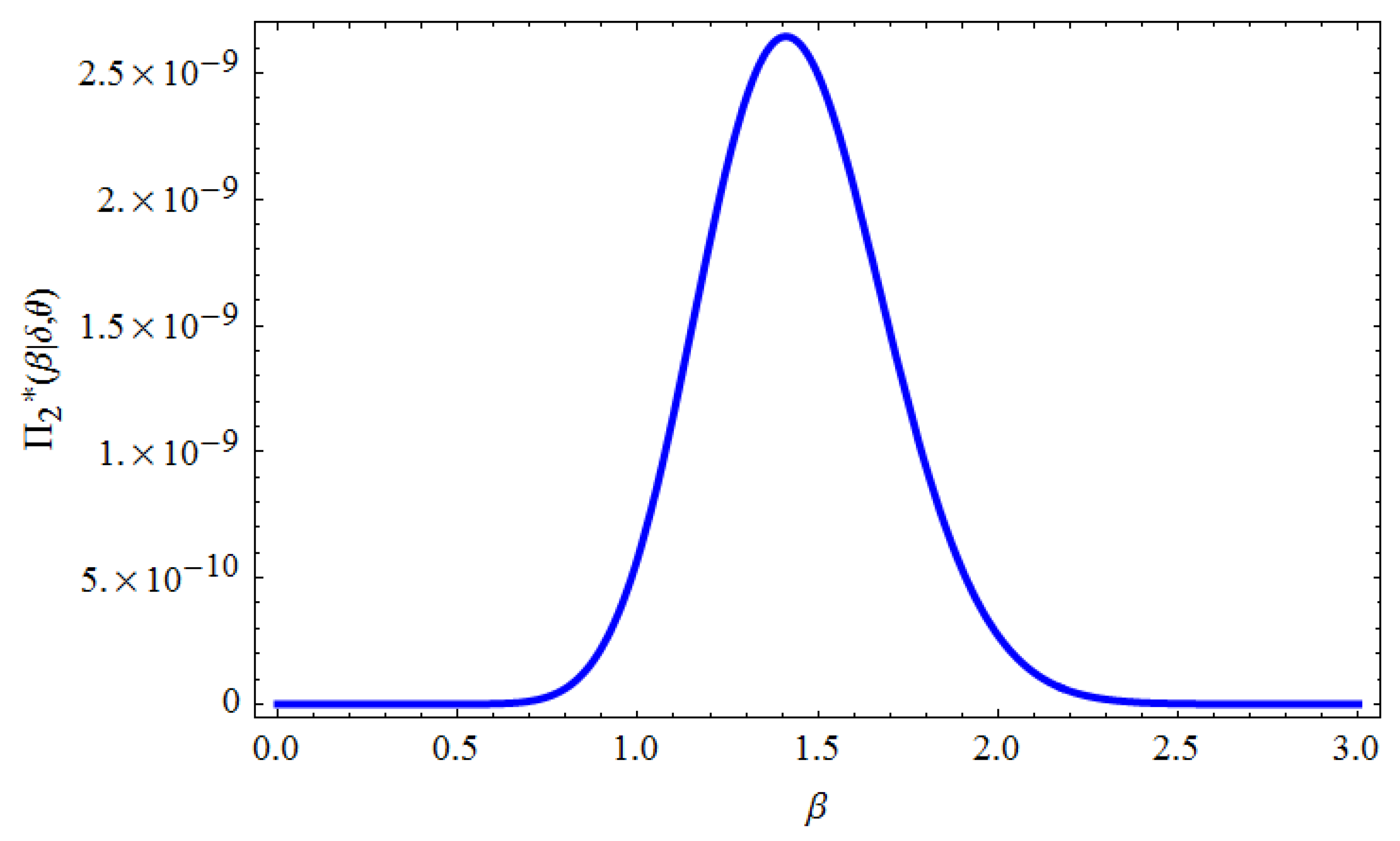
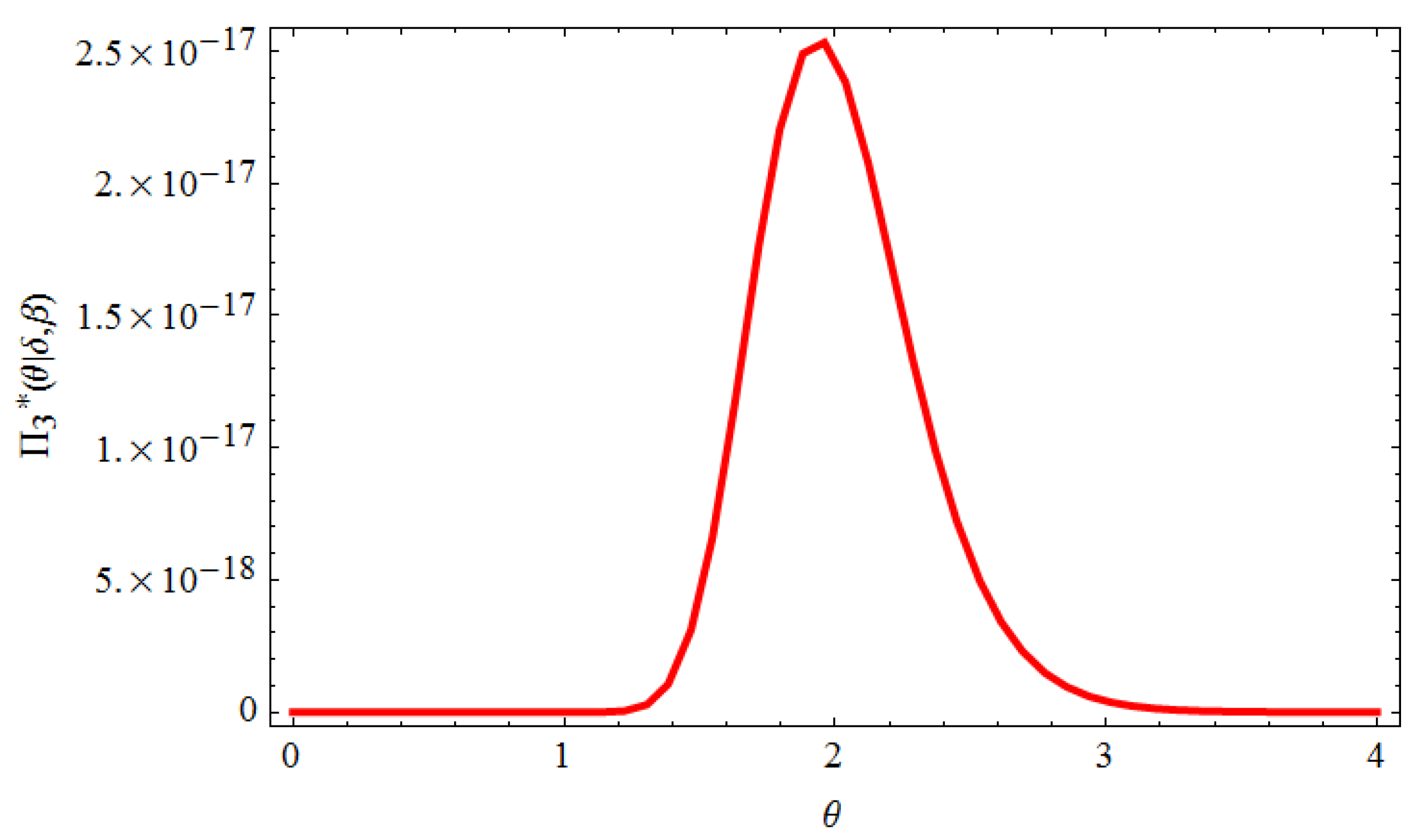
can be drawn simply from any gamma-generating routine. Furthermore, Equations (70) and (71) do not represent a well-known distributions. However, when plotted, they appear similar to the normal distribution, see
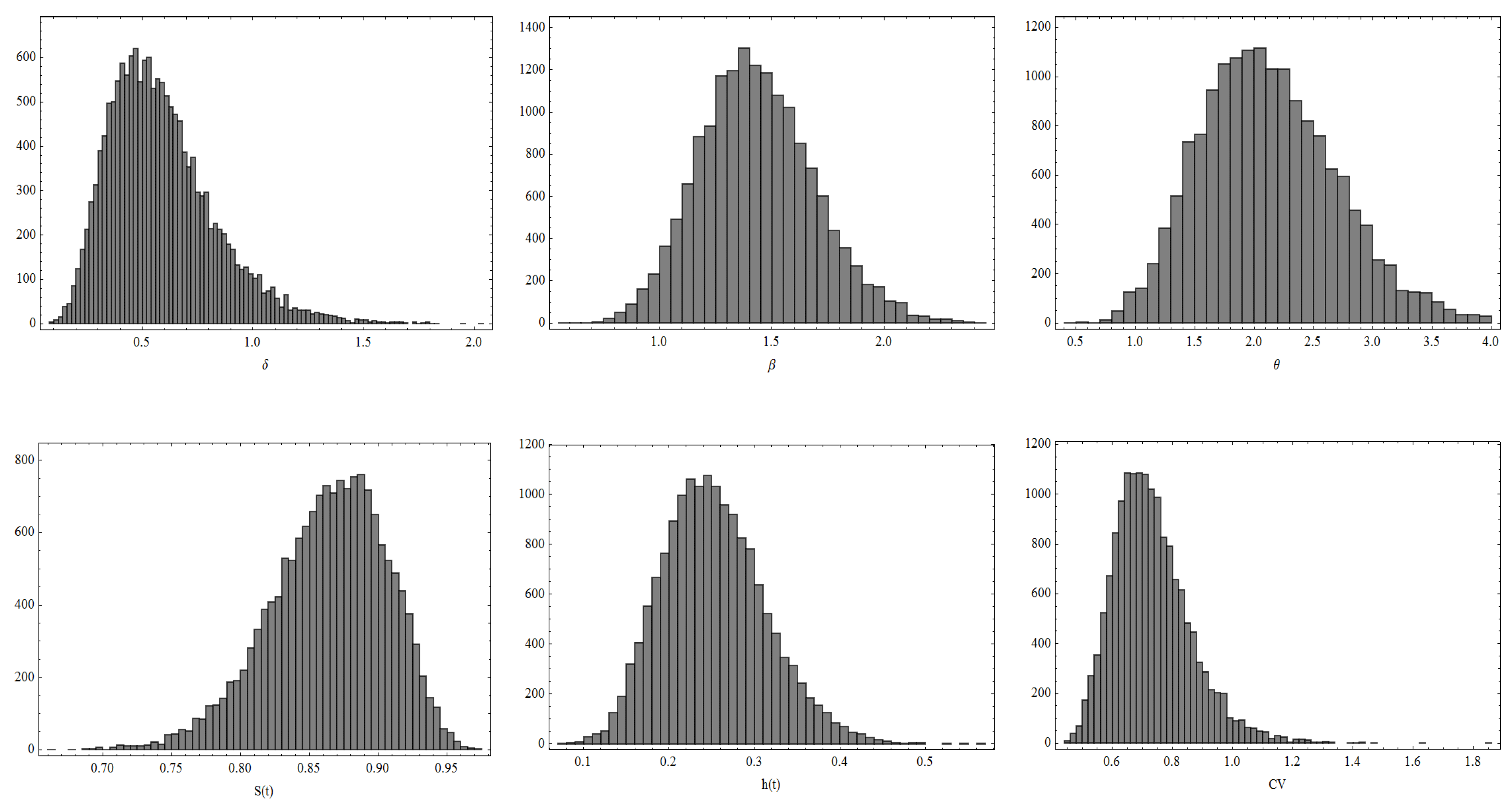
Figure 1 and
Figure 2. Consequently, the hybrid procedure of the Gibbs sampling and M-H algorithm will be run in the following steps:
- (1)
Start with initial guess .
- (2)
Set
- (3)
Generate from gamma .
- (4)
Using M-H to generate and from and with and .
- (i)
Generate from and from
- (ii)
Evaluate the acceptance probabilities
- (iii)
Generate a and from a uniform distribution.
- (iv)
If accept the proposal and set , else set
- (v)
If accept the proposal and set , else set
- (5)
Compute , , and as
- (6)
Set
- (7)
Repeat Steps N times.
- (8)
Based on BLINEX and GE loss functions, the Bayes estimate of
(where
, or
) under MCMC can be obtained by
where
M is burn-in.
- (9)
To compute the CRI of
, order
as
. Then, the
CRI of
can be given by
5. Practical Data Analysis: Gastric Cancer Patients
To clarify the inference methods discussed in the previous sections, we present a real-life example. We use a real dataset recorded in Bekker [
39] that represents the survival times for a group of gastric cancer patients. Several authors have studied reliability function and associated means based on different approaches, such as Xu et al. [
5] and Luo et al. [
6], among others. The data consist of 46 survival times (in years) for 46 patients. The data are randomly divided into 23 groups with
units within each group. The groups can be divided as follows: {0.047, 0.121}, {0.115, 1.589}, {0.466, 0.540}, {0.164, 2,444}, {0.570, 3.658}, {0.203, 0.696}, {0.841, 1.271}, {0.296, 0.334}, {0.132, 1.099}, {0.395, 0.501}, {0.260, 1.219}, {0.282, 1.326}, {0.863, 1.485}, {1.553, 2.416}, {0.458, 0.534}, {1.581, 2.830}, {0.529, 1.447}, {0.507, 2.178}, {2.343, 3.743}, {2.825, 3.578}, {0.644, 3.978}, {0.641, 4.003}, and {0.197, 4.033}. Suppose that a Pro-F-F-C scheme is given by
, then a Pro-F-F-C sample of size 16 out of 23 groups of data is obtained as follows:
| 0.047 | 0.466 | 0.570 | 0.696 | 0.841 | 1.099 | 1.219 | 1.326 |
| 1.553 | 1.581 | 1.589 | 2.178 | 2.343 | 2.825 | 4.003 | 4.033 |
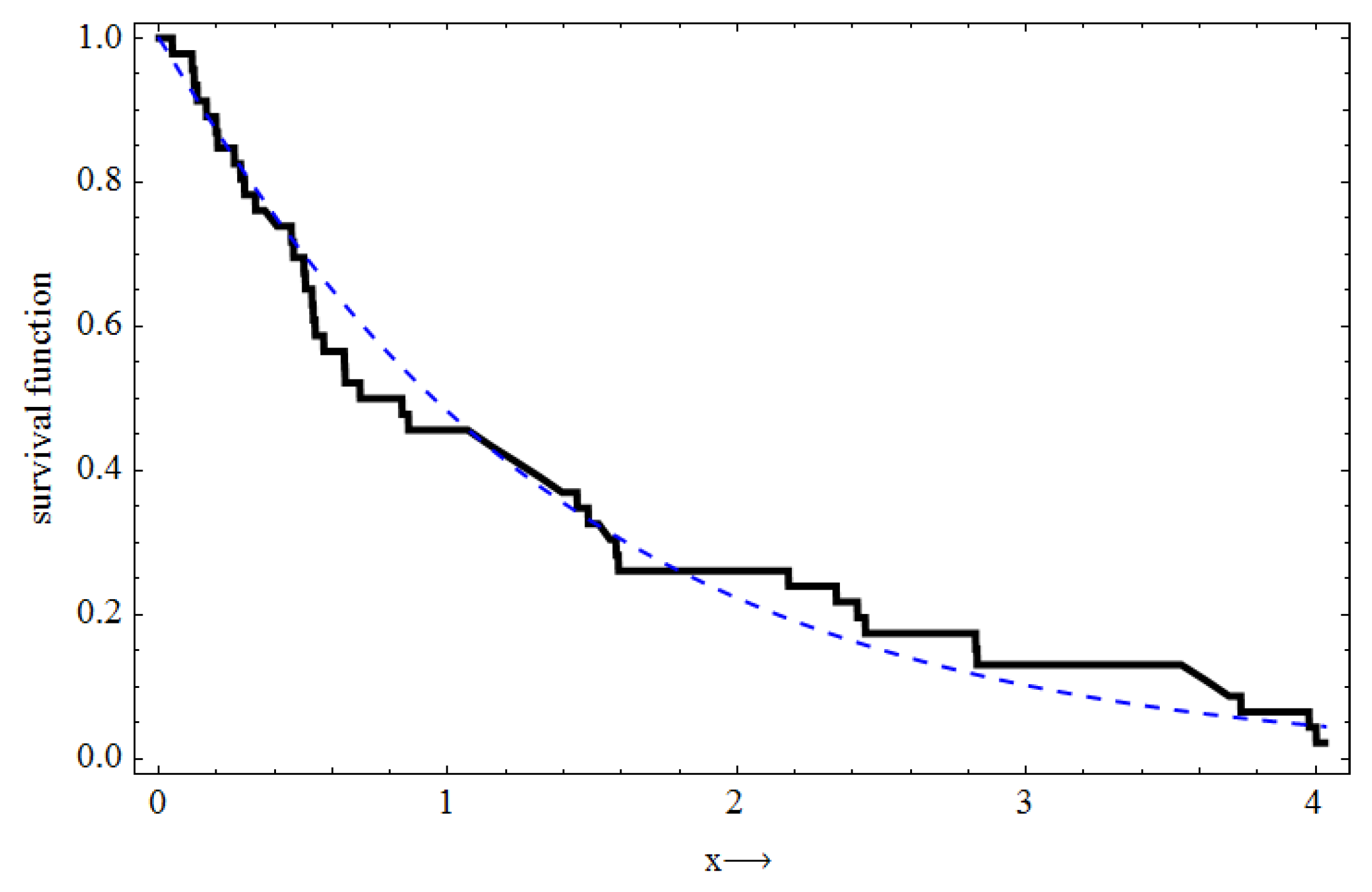
To prove that NWPD fits the data well, we computed the Kolmogorov–Smirnov and the associated
p-value, and the results, respectively, are
and
. From the plot of the empirical survival (ESF) and the estimated survival functions in
Figure 3, it is clear that the NWPD fits the data very well. The
CRIs of
,
, and
are given in
Table 1 and
Table 2.
Table 3 provides the MCMC results. Under the given previous data, we compute the MLEs of
, and
as tabulated in
Table 4. Based on Lindley and MCMC techniques, Bayes estimates of
, and
with respect to BLINEX and GE loss functions are computed under gamma prior for
, and
with hyperparameters
and
where
. Additionally, for different values of
c and
b, respectively, the results are reported in
Table 4 and
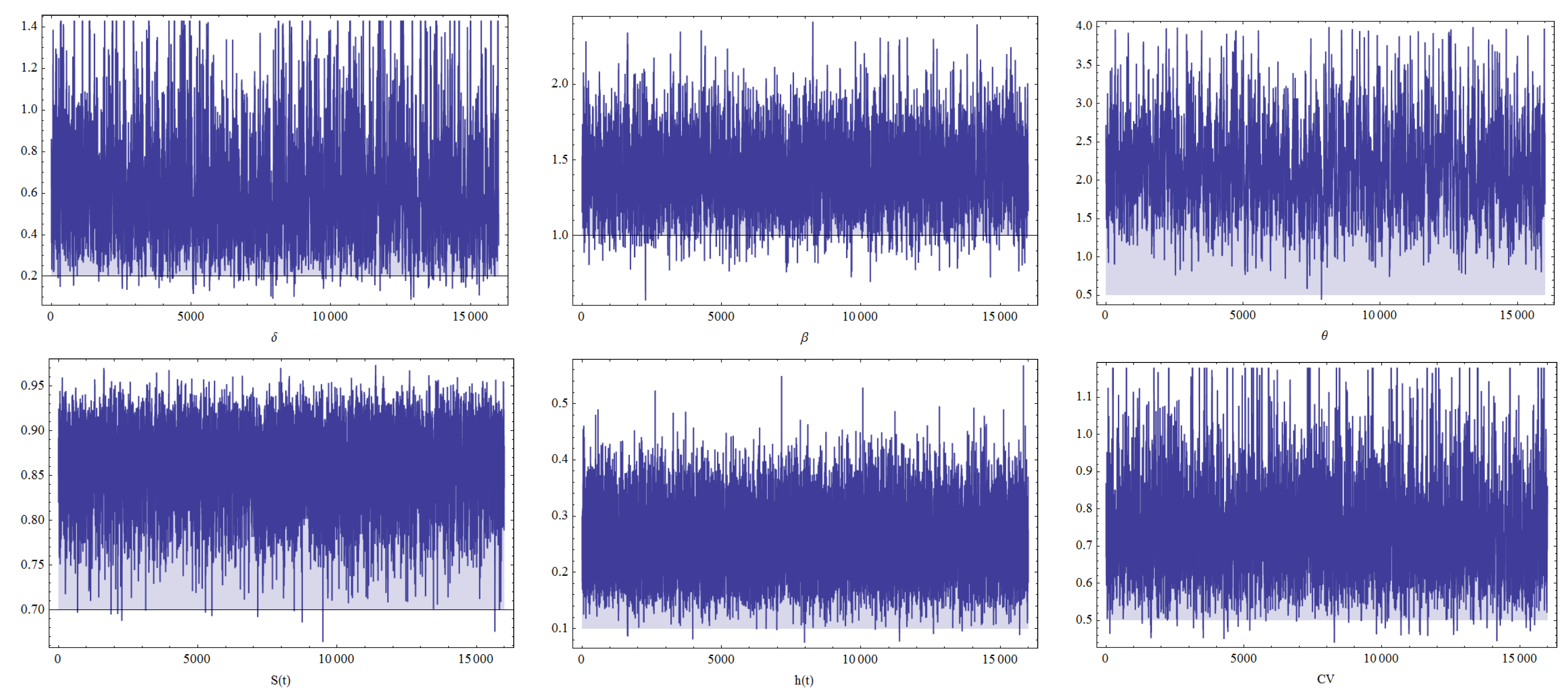
Table 5. The trace plots of the parameters generated by the MCMC approach and the associated histograms are displayed in
Figure 4 and
Figure 5, respectively.
6. Monte Carlo Simulation Study
In our diligent quest to evaluate the performance of the inference methods proposed in this article, some computations are made according to Monte Carlo simulation experiments using
MATHEMATICA version 12 with different combinations of
n,
m, and
k and different censored scheme
R (different
values). Using the algorithm introduced by Balakrishnan and Sandhu [
3], with distribution function
, we generate a Pro-F-F-C sample from the NWPD with the parameters
and
and 1, respectively. The true values of
,
, and
at time
are evaluated to be
,
, and
. The performance of the resulting estimators of
, and
have been considered in terms of their average mean (AVM) and the corresponding mean squared error (MSE), which are computed, for
and
,
,
,
,
and
as
, and
. Additionally, we compare different CIs obtained by using asymptotic distributions of the MLEs, the delta method, and symmetric CRIs, which were made in terms of the average CI, CRI lengths, and coverage percentages (CPs). Under the consideration of informative gamma priors for
,
, and
with hyperparameters
, and
, the Bayes estimators using Lindley and MCMC have been obtained. Moreover, Bayes estimates are obtained under BLINEX and GE loss functions for the choice
with
and
, respectively. In our study, we adopted two different groups
, and the following CS:
CS I: for
CS II: for
CS III: for


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}