4.1. mFFA1-EPF: Unbalanced Prime
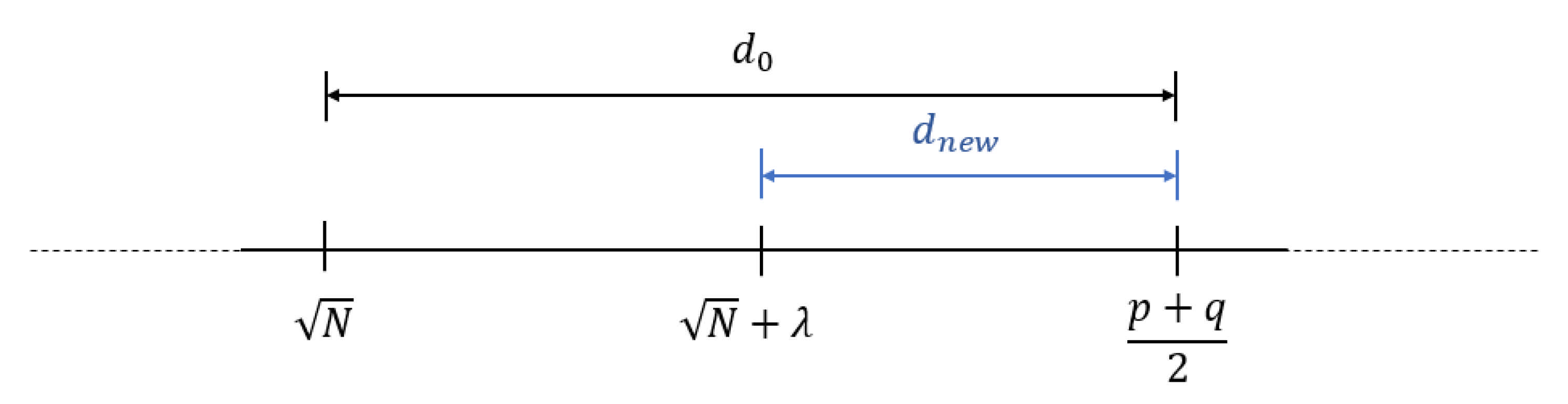
This section is dedicated for the modulus N with unbalanced primes factor. From Observation 1, we setting as the improved initial value in FFA1 algorithm is which less than . Let us start with the following question.
Question 1. Is there any other potential initial values aside from that can be selected to shorten the distance towards ?
Answer. Interestingly, if we can find other candidates for initial values in which potentially reduces the distance
, then it can be useful to reduce the loop count to search for the value of
. Suppose the value of
is considered as the other candidate of potential values (i.e., the value of
). Then, such value is supposed close to
. However, in general, it position is undecided whether
is larger (as shown by
Figure 4) or is smaller than
(i.e., similar to Lemma 1).
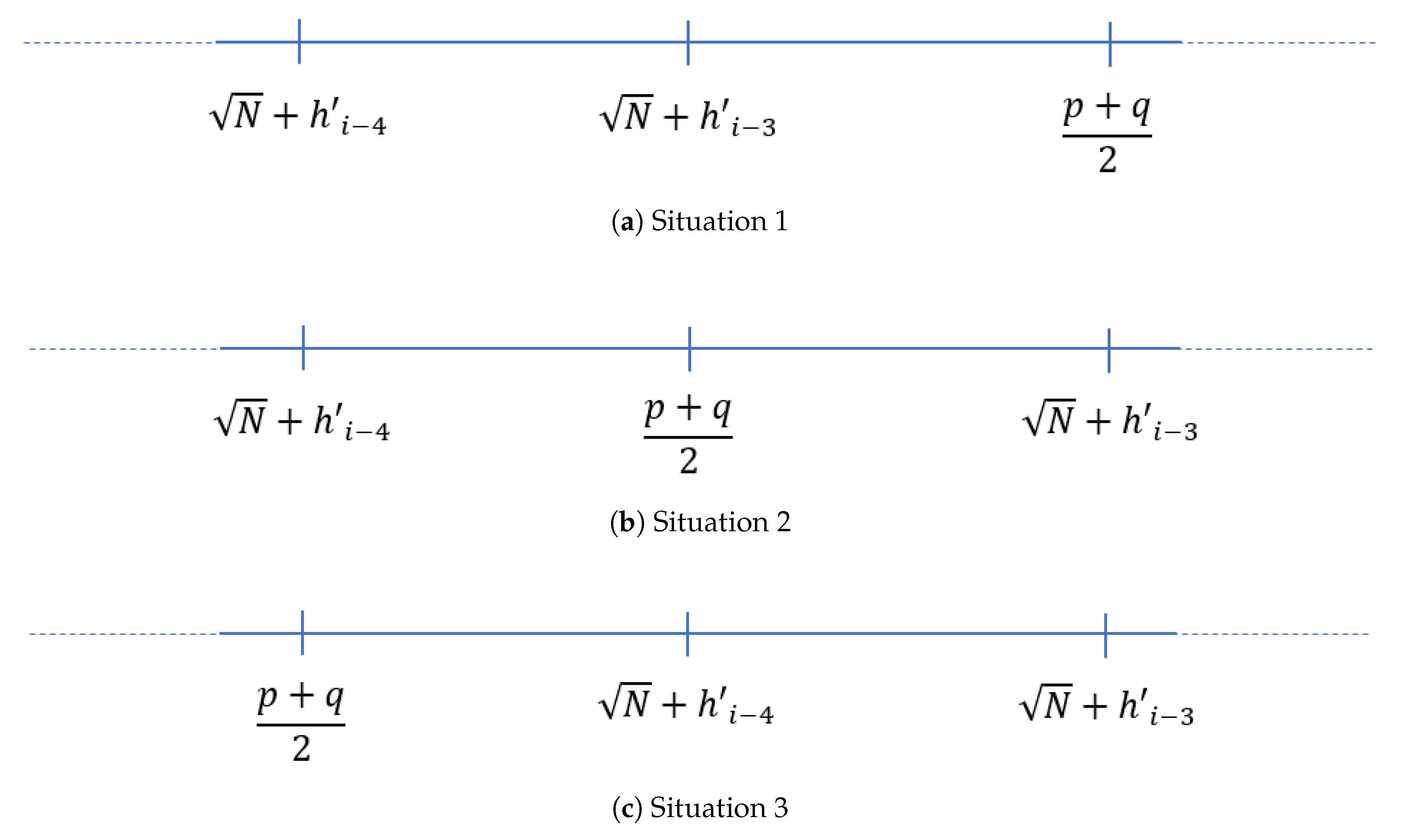
Next, suppose there exist
such that
is from the convergent list of
with
. By empirical evident, the value
can be considered as another candidate of additional extension for FFA1. Based on the empirical evident, it shows that the position of
and
are unpredictable as illustrated in
Figure 5a,b.
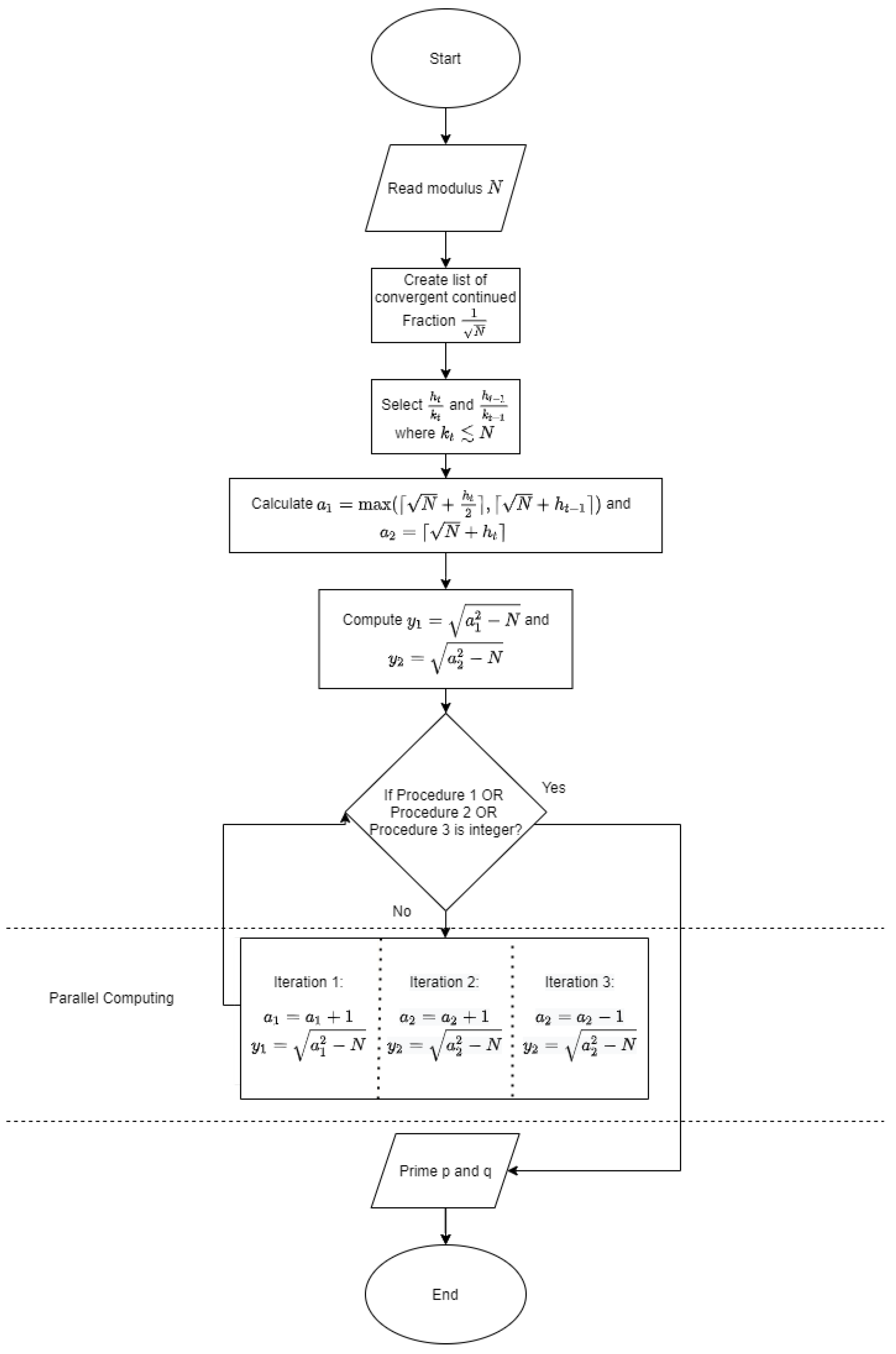
There are three candidates for the potential values for : and . In answering Question 1, the algorithm will start to compute the first value, , while the second value is . Once and are established, then two values— and —are computed.
After establishing the values of a’s and y’s, three procedures run simultaneously:
Procedure 1: The iteration with potential initial value and . The value is increased by 1 until is integer.
Procedure 2: The iteration with potential initial value and . The value is increased by 1 until is integer.
Procedure 3: The iteration with potential initial value and . The value is decreased by 1 until is integer.
Remark 3. Note that the same value is applied in both Procedure 2 and Procedure 3. As the value might be larger than , the main role of Procedure 3 is to prevent the mFFA1-EPF algorithm to keep running forever. All of the procedure is done by parallel computing, which means that the algorithm will completely be stopped whenever one of the procedures outputs or as an integer. Eventually, p and q will be obtained.
Unbalanced prime is demonstrated in Algorithm 1 as follows and flowchart on
Figure A1 in
Appendix B.1.
| Algorithm 1: mFFA1-EPF: Unbalanced Prime |
 |
Remark 4. For the Type 2 case, Step 1 on Algorithm 1 is changed by selecting and . Beside that, Step 3 will be modified with and .
Examples 1–4 are presented as illustrations of mFFA1-EPF for unbalanced primes. Example 1 demonstrates Type 1 of convergent-type selection, while Example 2 demonstrates Type 2 of convergent-type selection. Example 3 shows the importance of
for this algorithm, and Example 4 shows the application of a previous example from Wu et al. [
1].
Example 1. Let . By the continued fraction method, the following list of fraction is createdWe select as a candidate of and as a candidate of since . Now, the potential initial values are computed as follows: 26,676
26,746
With and , Algorithm 1 is performed. The algorithm is stopped when Procedure 2 satisfy the searching on Algorithm 1 where become an integer . Finally, and are computed.
Example 2. Let . By continued fraction method, the following convergent list of is created is selected as (the last convergent on the list) and as as . The potential initial values are computed as follows:
With and , Algorithm 1 is performed. The algorithm is stopped when Procedure 2 satisfies the searching on Algorithm 1 where become an integer . Last, and are computed.
Example 3. Suppose . By continued fraction method, the following convergent list of is created is selected as and as as . Now, the potential initial values are computed as follows:
With and , Algorithm 1 is performed. The algorithm is stopped when Procedure 3 satisfies the searching on Algorithm 1 where become integer . Last, and are computed.
Example 4. Suppose which adapted from the numerical example of Wu et al. [1]. By continued fraction method, the following convergent list of is created is selected as a candidate of and as a candidate of since . Two potential initial values are computed as follows:
Algorithm 1 is performed and stop when Procedure 1 satisfies that is an integer . Last, and are computed.
4.2. Discussion of Algorithm 1 (mFFA1-EPF: Unbalanced Primes)
This section presents a comparative analysis between the mFFA1-EPF and the previous technique, based on loop count and computational time. Note that all experimental results were using a computer running on 2.1 GHz on Intel® Core i3 with 4 GB of RAM.
According to
Table 2, the loop count on Procedure 2 of Examples 1 and 2 is the shortest one. It shows that the mFFA1-EPF has the smallest loop count compared to the other methods. For Example 3, Procedure 3 has the shortest path (630), at the same time it indicates
is larger than
. Thus far, the results give a good visualization representing the factorization of modulus
N by our method experimentally. Example 4 is the same example as given in Wu et al. [
1]. Procedure 1 obtained the smallest loop count (346) compared to other methods. This N/A (Not Applicable) means that all the procedure in Algorithm 1 is stopped when one of the
y’s from any procedures got the integer first.
The mFFA1-EPF is performed by parallel computing, which means Procedures 1–3 were run simultaneously. We recorded the computational time for the three different procedures. In
Table 3, mFFA1-EPF is faster than FFA1 by 4 numerical examples. This seems to be a slight improvement for FFA1 as there is an involvement of additional extension. mFFA1-EPF is good in term of loop count, running without failure and computational time (compared to FFA1).
To make mFFA1-EPF more convincing, there are numerical examples from Somsuk [
6] provided in
Table 4.
This comparison highlights the improvement made by mFFA1-EPF compared to the method FFA-Euler, provided by Somsuk [
6]. By two examples from in [
6], the exhaustive search is improved with shortest loop counts, and the potential initial values are shorter than the FFA-Euler loop count. This shows that our method can be compatible with all unbalanced prime.
4.3. mFFA1-EPF: Balanced Prime
Previously, in the case of a modulus with unbalanced primes, three candidates are determined as the . Only two potential initial values that possibly shorten the were selected. In this section, we will explore the case of a modulus with balanced primes. The aim is to dictate the proper candidates from the convergent list (i.e., mFFA1-EPF) for the potential initial values via a similar approach.
Recall that
with index
t, where
, deemed as the indicator for selecting a good convergent to additional extension of initial values for FFA2-EPF [
1]. When the EPF technique applied for the balanced prime case on FFA1, by empirical evidence, it shows that such indicator leads to the initial value (
) relatively far away from the target value (exceeded by
). Therefore, we conjecture that the EPF method seems not to be an effective method to factor the modulus
N with a balanced prime. Furthermore, the result in Somsuk [
5] agreed that EPF is only suitable for unbalanced prime. It failed to address the convergent with index
t as a suitable index to improve the initial value.
Therefore, in this section, we provide the strategies to address such drawback of factoring the modulus
N with a balanced prime by imposing modification in the mFFA1-EPF algorithm. The strategies involve convergent selection and modification of potential initial values. Therefore, to enhance the effectiveness via mFFA1-EPF, the additional extension
until
is observe empirically to determine the smallest value of
. The result of the observation is presented on
Figure 6, and the discussion follows.
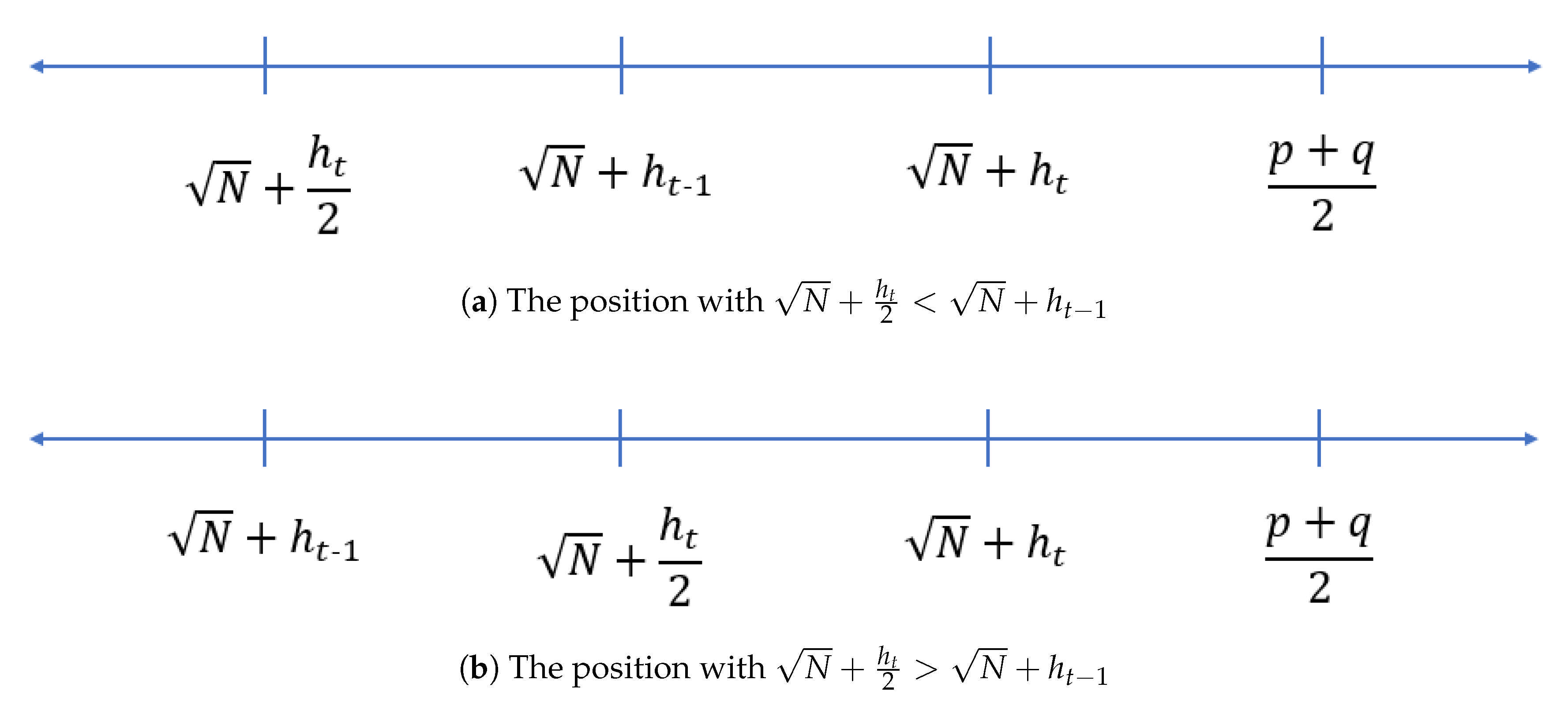
Suppose
with index
t where
is chosen via EPF. Note that for the modulus
N with balanced primes case, the value
. Therefore, the additional extension from
to
is analysed. Interestingly, the additional extension
for
can be a potential initial values as it moves closer to the value of
.
Figure 6a–f shows comparison of potential initial values between the additional extension of
for
and
, respectively. The potential initial values decrease, because the value of additional extension is become smaller from
to
(i.e.,
).
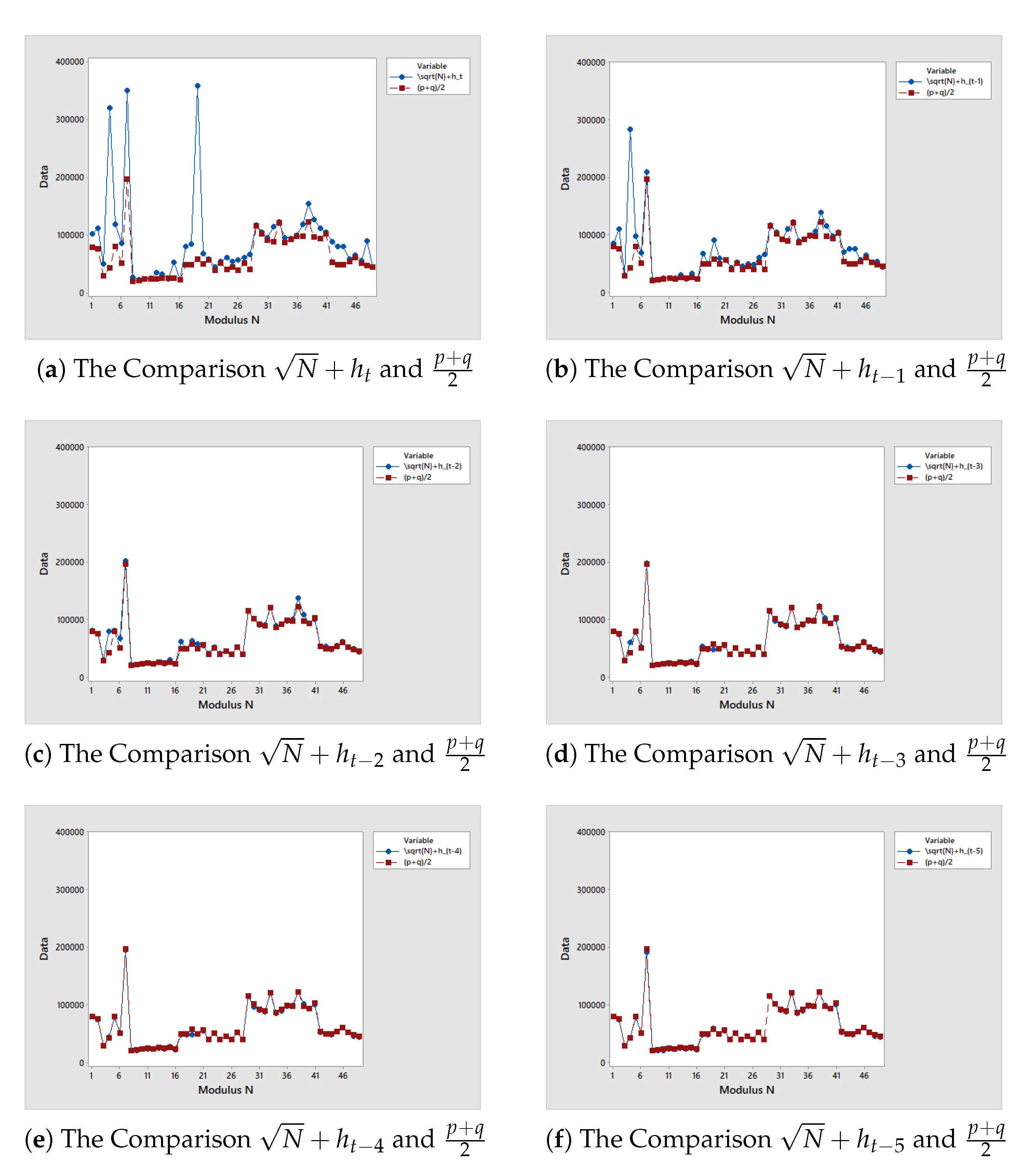
Question 2. What are the suitable initial values that need to be implemented on mFFA1-EPF with balanced primes?
Answer. Based on
Figure 6, the line graph between the initial value (represented by the blue dots) starts closer to the target value
(represented by the red dots) as the value of initial values changes. A hindrance to the development process for this approach is that we can not determine the smallest value of
via additional extension
to
. In other words, the “closeness” of the potential initial values with additional extension unable to be decided simply from the results of
Figure 6. This is because the additional extension a random value from the generation of convergent list of
. It requests further analysis. A statistical analysis of 50 distinct moduli
N with balanced primes is conducted to determine the closeness of potential initial value through index
t to
, as follows.
In this work, a measurement called Mahalanobis Distance (MD) is implemented. MD is the distance between two points in multivariate space. According to Çakmakçı et al. [
15], MD measures the distance between a multidimensional point of probability distribution and distribution of distance. The smaller the value of MD, the closer the mean of candidate of potential initial values to the mean of the target value.
In the one-dimensional case on the mFFA1-EPF for balanced prime, MD is used to calculate the normalized distance between the mean of each
to
and the mean of the target value
. The measurement formula is
where
is a mean of each data potential initial value of
to
while
is mean of actual value
. The value
is calculated from combination data from potential initial value and the actual value
. The following formula is represented for MD between
and
,
We calculate MD for
to
by same data of 50 moduli
N and represent the MD value on
Table 5.
Table 5 shows the comparison of the MD index of “closer distance” between several potential initial values from
to
and
.
Table 5 reported that the MD index value of
and
are the smallest MD values among other potential initial values, that is, 0.0114 and 0.0116, respectively. It means that
and
are the most suitable candidates for potential initial values, because they have the smallest
on average with respect to MD measurement.
Observation 3. The candidates and have the smallest value of MD. Therefore, it is highly suggested to select convergents with index and to improve the initial values.
Based on Observation 3, two potential initial values are set as follows:
Remark that the FFA1 algorithm requires an initial value less than the target value and will keep increasing by one (i.e., +1) until it reaches . Therefore, in mFFA1-EPF, we use the variation technique, which means the value of and need to be increased and decreased by 1 simultaneously. Next, the following values are established:
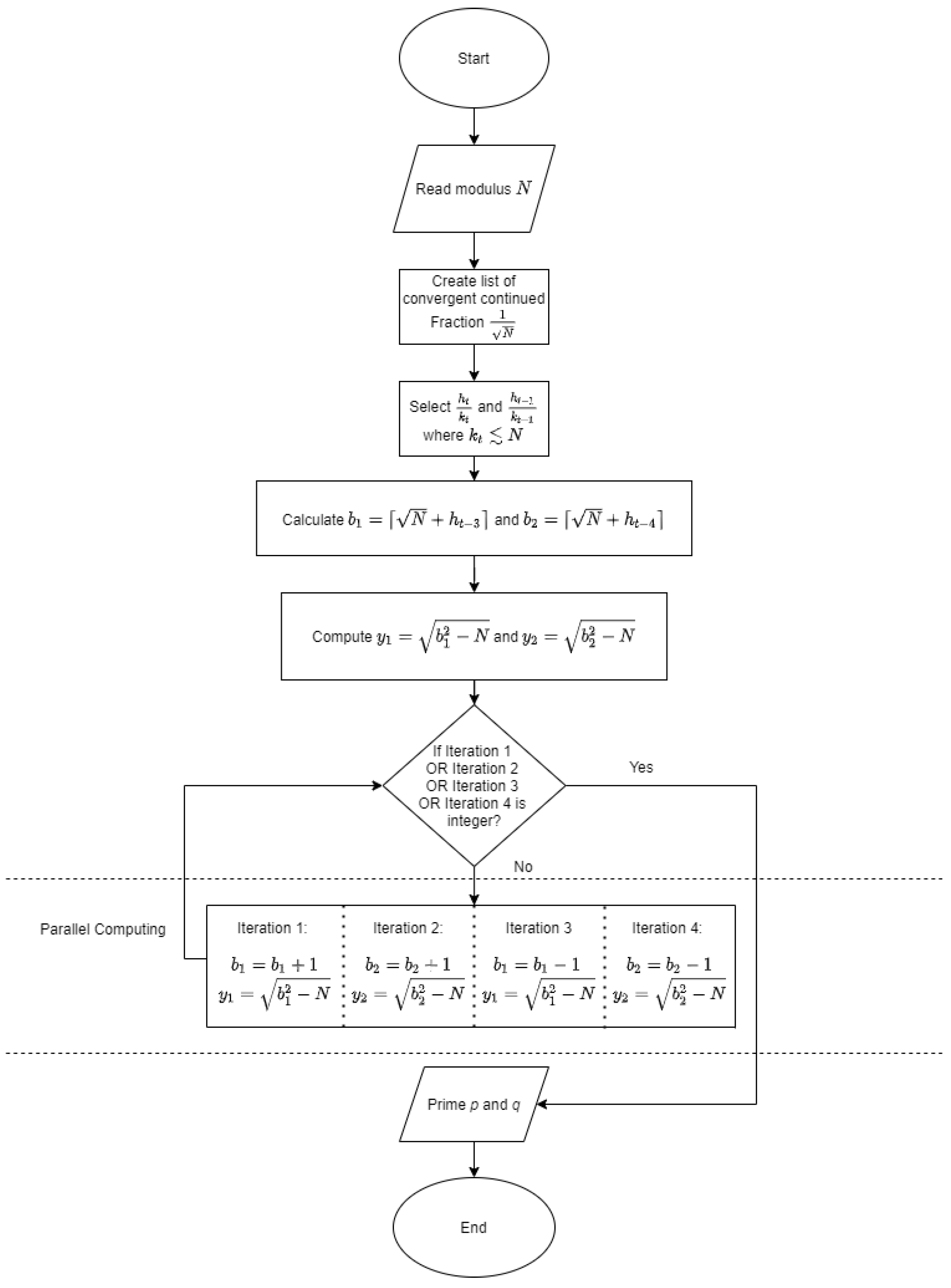
Four procedures are introduced using the above values, with the variation technique as follows:
Procedure 1: The iteration with potential initial values and . The value of is increased by 1 until it is the same as the becomes an integer.
Procedure 2: The iteration with potential initial values and . The value of is increased by 1 until it is the same as becomes an integer.
Procedure 3: The iteration with potential initial values and . The value of is decreased by 1 until it is the same as the becomes an integer.
Procedure 4: The iteration with potential initial values and . The value of is decreased by 1 until it is the same as the becomes an integer.
Note that these four procedures were run simultaneously by parallel computing which will stop when one of the
y’s become the first integer. Algorithm 2 shows how the workflow runs.
| Algorithm 2: mFFA1-EPF: Balanced Prime |
 |
4.4. Discussion on Algorithm 2 (mFFA1-EPF: Balanced Primes)
Algorithm 2 is also illustrated as a flowchart in
Figure A2 in
Appendix B.2. The experimental result is represented using the mFFA1-EPF via balanced prime on Example 5 while applying mFFA1-EPF is represented on Somsuk’s numerical example [
6] in Example 6.
Example 5. (Procedure 1 satisfies on Example 5). Let . By continued fraction method, the following convergent list is created is selected as a candidate of and as a candidate of since . Now, there are two candidates of potential initial value and 2 y’s are computed as follows:
Algorithm 2 is performed because and not integers. The values and in Procedure 1 and 2 are increased by 1 while initial values in Procedure 3 and 4 are decreased by 1. The algorithm stop where from Procedure 1 is integer . Finally, compute and .
Example 6. [6] (Procedure 1 satisfies on Example 6) Say . By continued fraction method, a list of fraction is created is selected as a candidate of and as a candidate of since . Now, there are two candidates of potential initial value and 2 y’s are computed as follows: Algorithm 2 is performed because and not integer. The values and in Procedure 1 and 2 are increased by 1 while initial values in Procedure 3 and 4 are decreased by 1. The algorithm stop where from Procedure 1 is integer . We compute and .
Table 6 shows the comparison on count loop and computational time in seconds (s), between several FFAs with our proposed method toward Example 5. The loop count on Procedure 1 (15412) is the least number of loop count compared to previous methods. Besides, FFA2-EPF can not undergo the process and the loop count is not available since the initial value exceeded the value of
and
. When it goes on computational time, the algorithm is not shown the fastest one but it still improves from FFA1.
For
Table 7, mFFA1-EPF is applied toward [
6] to compare the loop count and computational time. It shows the shortest loop count even the initial value is exactly the value of
(
). Using Algorithm 2, the loop count reduced significantly, which result in the exhaustive search to run without fail.
Remark 5. Consider Type 2 of the continued fraction convergent selection of the modulus N with balanced primes. For Type 2, we use Algorithm 2 with a changes in Step 2 where and and .
Now, we replicate a numerical example from the Algorithm 2 with respect to Remark 5 on Example 7.
Example 7. (Procedure 4 satisfies on Example 7). Suppose . By continued fraction method, a convergent list of is createdAs is the last convergent on the list, is selected as a candidate of and as a candidate of as . We compute two candidates of initial value of x, and as follows:
Since and are not integer, the values and in Procedures 1 and 2 are increased by 1 while initial values in Procedures 3 and 4 are decreased by 1. The algorithm stop where in Procedure 4 is integer . We compute and .
Table 8 shows the comparison on loop count and computational time in second between several FFAs with our propose method toward Example 7. Procedure 4 shows the smallest loop count with 1092 compared to FFA1 (1590) and FFA2 (10,553). The loop count of FFA2-EPF is unavailable as the initial values are exceeded the value of
and
. On computational time, our algorithm is slightly better than FFA1. Procedure 4 plays it crucial part to achieve the value
, and, at the same time, Procedure 4 obtains the indicators of whether the value is larger or smaller than
. Therefore, Algorithm 2 with Remark 5 helps to search for the value of
without failure.
Recall that there is . For mFFA1-EPF, the varies according to type of modulus N; and for a modulus with unbalanced primes while and for a modulus with balanced primes. Multiple can lead to the shortest path toward . For comparison on mFFA1-EPF with FFA1, both methods use the same process of calculating the square roots to reach the target value . However, mFFA1-EPF uses the additional extension on its potential initial values where is the loop count of FFA1. Based on the empirical results in this work, the loop count and computational time of mFFA1-EPF are improved compared to FFA1. Consequently, it reduces the cost of running the exhaustive search.
The uniqueness of FFA2 is that it uses multiplication operation as the main process, it has less cost in computational time compared to the mFFA1-EPF which uses square root operation. Alas, FFA2 requires a greater number of iterations to achieve and . In this regard, the mFFA1-EPF uses less cost in terms of computational memory and less space to run the iteration compared to FFA2.
The objective of establishing additional extension on FFA2-EPF is the same as mFFA1-EPF, to shorten the path toward and . mFFA1-EPF has a shorter loop count than FFA2-EPF because the main operation comes from FFA2, which uses a huge number of iteration to achieve its target values: and . Thus, mFFA1-EPF requires less cost in terms of space compared to FFA2-EPF.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}