Abstract
Statistical modeling of historical crash data can provide essential insights to safety managers for proactive highway safety management. While numerous studies have contributed to the advancement from the statistical methodological front, minimal research efforts have been dedicated to real-time monitoring of highway safety situations. This study advocates the use of statistical monitoring methods for real-time highway safety surveillance using three years of crash data for rural highways in Saudi Arabia. First, three well-known count data models (Poisson, negative binomial, and Conway–Maxwell–Poisson) are applied to identify the best fit model for the number of crashes. Conway–Maxwell–Poisson was identified as the best fit model, which was used to find the significant explanatory variables for the number of crashes. The results revealed that the road type and road surface conditions significantly contribute to the number of crashes. From the perspective of real-time highway safety monitoring, generalized linear model (GLM)-based exponentially weighted moving average (EWMA) and cumulative sum (CUSUM) control charts are proposed using the randomized quantile residuals and deviance residuals of Conway–Maxwell (COM)–Poisson regression. A detailed simulation-based study is designed for predictive performance evaluation of the proposed control charts with existing counterparts (i.e., Shewhart charts) in terms of the run-length properties. The study results showed that the EWMA type control charts have better detection ability compared with the CUSUM type and Shewhart control charts under small and/or moderate shift sizes. Finally, the proposed monitoring methods are successfully implemented on actual traffic crash data to highlight the efficacy of the proposed methods. The outcome of this study could provide the analysts with insights to plan sound policy recommendations for achieving desired safety goals.
1. Introduction
Traffic collisions account for over 1.35 million annual fatalities and approximately 50 million injuries worldwide, and are predicted to become the fifth leading cause of death by the year 2030 [1]. On average, road traffic crashes account for approximately 3% of nations’ gross domestic product (GDP) worldwide, irrespective of their growth and rate of motorization [2,3]. Road traffic injuries are the third leading cause of death in Saudi Arabia, which poses a major socio-economic and public health concern for road safety agencies. The country has witnessed rapid economic growth and motorization, particularly after the oil boom in the early 1970s [4,5]. The fatality index (deaths/100,000 population) due to traffic crashes in Saudi Arabia is estimated to be around 27.4, which is significantly high compared with developed countries like the United States, Australia, Sweden, Netherland, the United Kingdom, and the neighboring Gulf states [1]. The average crash to injury ratios of 8:4 and 8:6 reported for different regions in Saudi Arabia are also significantly high compared with the global ratio of 8:1 [6,7]. Several studies have investigated the crash causation factors in Saudi Arabia and neighboring Gulf countries in recent years. Al Kaaf and Abdel-Aty [8] investigated the risk factors for crash occurrence on urban four-lane divided roadway segments in Riyadh, Saudi Arabia. Factors such as annual average daily traffic, speed limit, segment length, and driveway density were found to increase the likelihood of fatal and injury crashes. Islam et al. [9] utilized panel regression models and pooled ordinary least square methods to analyze ten years (2003–2013) of annual crash data from 13 provinces in Saudi Arabia. The study results showed that adverse weather conditions, sandstorms, and the number of vehicles involved were identified as statistically significant for traffic crashes in the country. Poor roadway conditions, road geometry, and tires burst due to intense pavement temperature during summer were also identified as the most common causes of traffic crashes in Saudi Arabia [10,11,12]. Driver distractions, speeding, and non-compliance to traffic rules are among the other predominant causes of traffic crashes in Saudi Arabia [13,14]. Studies conducted by Al-Kheder and Al-Rashidi [15] and Mohamed et al. [16] for neighboring Gulf state Abu Dhabi in United Arab Emirates (UAE) also reported that factors responsible for increased traffic crashes include road type, road surface conditions, excessive speeds, and non-compliance to traffic rules. A generalized linear model (GLM)-based safety appraisal study conducted for Salalah City in Oman also indicated that road geometry and traffic variables (volumes and 85th percentile speed) were the most significant variables affecting the frequency of crashes [17]. Recently, some safety measures and policies have been initiated; however, the situations seem to have marginally improved. Concrete and authentic research is required to explore key risk factors for crash occurrence and severity.
Over the years, researchers have constantly sought various approaches with an aim to gain a better understanding of factors affecting crash occurrences to suggest appropriate countermeasures, and provide directions for policies to improve road safety [18,19,20,21,22,23,24,25,26]. However, road traffic crashes are complex events involving a large number of factors having multi-faceted interactions, making it very challenging to comprehend them fully. Traffic crashes are the outcomes of several contributing factors such as driver attributes, vehicle factors, traffic exposure, roadway geometric features, spatial attributes of surrounding built environment, lighting and weather conditions, and so forth [25,27,28,29]. Among driver’s attributes, distracted driving and speeding are reported to be the leading factors causing increased motor vehicle crashes [30,31,32,33,34,35,36]. Similarly, the likelihood of crash occurrences along the rural multi-lane highway is increased in the presence of a steep roadway gradient, sharp horizontal curve, and acute curve deflection angle [37,38]. Contrarily, lower crash occurrences on the same facilities are associated with the decrease in curve length and horizontal curve radius and an increase in the degree of curvature and number of lanes [20,39]. Likewise, poor road surface conditions, nighttime travel, adverse weather, and precipitation are reported to have a strong bearing on high crash frequencies [40,41,42,43]. A better understanding of all of these factors associated with traffic crashes is essential to promote and enhance the safety performance of road traffic systems. Advances on the methodological front for highway safety research continue to be investigated.
The GLM-based Poisson regression model has been widely proposed to model the equi-dispersed crash frequency data. Poisson models outperform the standard regression approaches in handling random, non-negative sporadic, and discrete features of crash counts. However, crash data are frequently characterized by relatively large sample variance compared with the sample mean, which limits the application of Poisson regression [44]. Therefore, a negative binomial or Poisson gamma regression model is preferred for such datasets that account for the over-dispersion issue, while the GLM-based binomial regression model is often used to fit under-dispersed data. In practice, it is challenging to differentiate the characteristics of data. However, there exist a few standard testing procedures to differentiate the data characteristics. However, the mentioned procedures require excellent expertise, high computational efforts, and time. The Conway–Maxwell (COM)–Poisson (COM–Poisson) model proposed by Guikema and Goffelt [45] is the better alternative, which is a flexible model and able to handle any type of disperse data [46]. Lord et al. [47] and Lord et al. [48] have successfully used COM–Poisson regression to model the traffic crash data.
In the literature, studies have mostly focused on statistical modeling of the traffic crash data. However, factors contributing to crash occurrences and frequency exhibit spatial heterogeneity and vary from one location to another. In an effort to achieve better surveillance of highway safety, large amounts of data are collected by road safety organizations worldwide. Traditionally, the majority of existing crash prediction models rely on aggregated information with relatively large time-scales, usually on a yearly basis. However, researchers have argued that the likelihood of crash potential is significantly influenced by short-term fluctuations in crash contributing factors such as traffic, weather, complex terrains, and so on. Crash frequency models developed using aggregated data are designed to yield the prediction results on average data over a more extended period of time that may lead to loss of potentially useful information about some important explanatory variables. They also result in an error due to unobserved heterogeneity. Therefore, it is crucial to investigate the disaggregate models, also known as real-time crash risk evaluation models, for estimating crash potential in smaller time-scales such as an hour, a day, or a week. Crash prediction models with more refined time-scales are useful as they lead to timely and better safety decisions to improve highway safety. To fill this research gap, this study proposes the application of the statistical process control (SPC) method for real-time monitoring of crash data in the Kingdom of Saudi Arabia. A control chart is a well-known tool for statistical process control (SPC), which is often used to detect abrupt changes in the data [49]. There exist several GLM-based control charts, which are designed on the residuals estimated through GLM modeling. For example, GLM-based control charts based on the Poisson model were proposed by Skinner et al. [50] and Asgari et al. [51] in their studies. Skinner et al. [50] and Jearkpaporn et al. [52] discussed GLM-based control charts based on the Gamma model, while a chart based on the binomial model was proposed by Shang et al. [53] and Amiri et al. [54]. The GLM-based control charts under the negative binomial model were discussed by Alencar et al. [55] and Urbieta et al. [56]. In their study, Kinat et al. [57,58] proposed GLM-based control charts by assuming an inverse Gaussian distributed response variable, while Mahmood [59] proposed GLM-based control charts under the zero-inflated models.
Recently, Park et al. [60] and Park et al. [61] proposed Shewhart type GLM-based control charts by assuming the COM–Poisson distributed response variable. Park et al. [60] considered deviance residuals as the plotting statistics, while in another study, the authors utilized randomized quantile residuals as the plotting statistics. In general, the Shewhart type charts are designed based on the current information, and they are used to detect a large deviation from the mean of data. Practitioners are usually interested in detecting small changes as early as possible, for which exponentially weighted moving average (EWMA) and cumulative sum (CUSUM) are especially designed structures. Both EWMA and CUSUM charts are designed based on past and current information, which makes them more efficient to detect small or/and moderate shifts in the process mean. This study intends to design EWMA and CUSUM type GLM-based control charts using the deviance and randomized quantile residuals of the COM–Poisson regression model. Further, the performance evaluation and comparative analysis are conducted using the simulated data, and the proposed methods are implemented to monitor the number of crashes reported in Saudi Arabia.
The remainder of this paper is structured as follows. Section 2 presents a description of the data utilized in the current study. Section 3 highlights the proposed research methodology for crash frequency modeling and statistical process monitoring. Section 4 provides a comparative study of the proposed control charts using an extensive simulation study. Section 5 presents the implementation of proposed methods on the traffic collisions data. Finally, Section 6 summarizes key findings, study limitations, and outlook for future research.
2. Data Description
Motor vehicle crash data used in this study were procured from the ministry of transport, Riyadh, Saudi Arabia. A total of 47,984 crashes were reported during the three years (January 2017 to December 2019) of the study period. The study is focused explicitly on crashes involving only motor vehicles along inter-cities rural highways that fall under the ministry of transport jurisdiction. A significant proportion of these highways in the study area run through plain and desert terrain, having warm to high temperatures during most part of the year. Road inventory data are collected from the ministry for available sections, and for others, the geographic information system (GIS) tool was used to extract roadway geometric features. Each crash comprises several explanatory variables (shown in Table 1), including road type, road surface conditions at those sites, damage type post-crash, weather conditions, and presence or absence of road markings and cat eyes.

Table 1.
Descriptive statistics of explanatory variables.
In this study, frequency-based modeling was carried out for crashes aggregated on a daily basis. Figure 1 shows a time series plot of aggregated daily count data of the number of crashes. To access the best-fitting distribution of the aggregated crashes, we have implemented three well-known count models, i.e., Poisson, negative binomial, and COM–Poisson. The detailed diagnostic analysis and model estimation results (shown in Table 2) indicate that COM–Poisson distribution is the best-fitting model as it produced the minimum values of decision criteria (i.e., loglikelihood, Akaike information criteria (AIC), and Bayesian information criteria (BIC)) compared with other models.
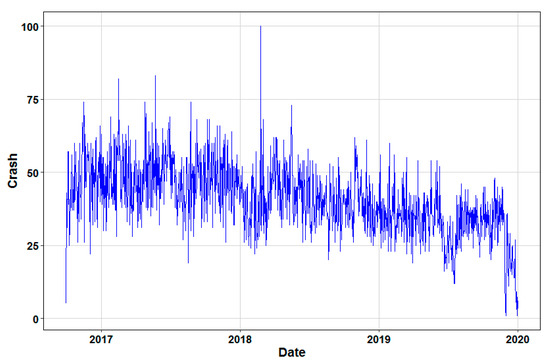
Figure 1.
Temporal variations of observed crashes during the study period.
Table 2.
Diagnosis analysis of best-fitted distribution for aggregated crashes. AIC, Akaike information criteria; BIC, Bayesian information criteria; COM, Conway–Maxwell.
As discussed earlier, each crash comprises a number of explanatory variables that were used in the modeling of the crash data set. To tackle the challenge of summing explanatory variables under each category against aggregated daily crashes, we have used the weighted average of the responses. The mathematical expression of the indexed value is defined below:
where i is used to index days, j is used to index categories, Cij is the code value of category j on day i, Nij is the number of responses of category j on day I, and Nc is the total number of categories. For example, on day i, two crashes happened on the divided highway, one crash noted on the expressway, and five crashes reported on the single highway. Then, the indexed value for road type on day i can be obtained as follows:
Hence, all of the values of explanatory variables were converted into indexed values. Further, the Pearson correlation among all variables is estimated, and the plot is presented in Figure 2. It is noted that all the explanatory variables have a negative relation with the number of crashes. The road surface condition is highly correlated, weather conditions are weakly correlated, and all other variables have a mild correlation with the number of crashes.
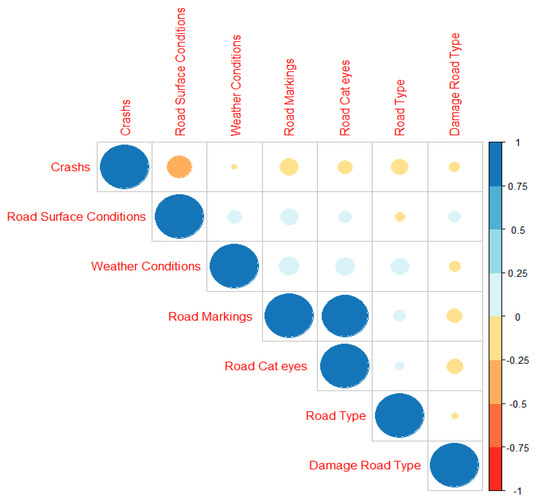
Figure 2.
Matrix of correlation among the explanatory variables.
In brief, the COM–Poisson distribution is the best-fitting distribution for the crashes, and there exist some significant correlated explanatory variables. Therefore, the COM–Poisson regression is further used to measure the relationship between the crashes and the corresponding significant explanatory variables. The description of the COM–Poisson regression and the relevant control charting design structure is provided in the next section.
3. Methodology
As discussed in the previous section, the COM–Poisson distribution was identified as the best-fitting distribution for the crashes, so this section consists of the COM–Poisson regression to assess the statistically significant explanatory variables for the crashes. Further, the existing monitoring schemes based on the COM–Poisson regression and the proposed structures are also discussed in this section.
3.1. COM–Poisson Regression
Conway and Maxwell [62] proposed the Conway–Maxwell (COM)–Poisson (COM–Poisson) distribution, which is a flexible distribution to model the over/equi/under dispersed data. Let be the random variable, then the probability mass function of the COM–Poisson distribution is defined as follows:
where is the rate parameter, is the dispersion parameter, and is the normalizing factor. It should be noted that, when , the COM–Poisson distribution reduces to the Poisson distribution; when , the COM–Poisson distribution turns into the geometric distribution; and, when , it approaches the Bernoulli distribution. The mean and variance of the COM–Poisson distribution are expressed as follows [63]:
where approximations hold for or . Further, the COM-Poisson regression model is used to describe the relationship between the response variable and the explanatory variables as a function of , where is the vector of unknown parameters. In this study, we are assuming link function such as by following [64]. Suppose the likelihood function of the fitted model is represented by and for the saturated model is denoted by then the overall deviance can be expressed as follows:
where and the deviance residuals can be obtained by the following expression:
where the deviance residuals are constrained such that for . Moreover, the randomized quantile residuals of the COM–Poisson regression model are obtained as follows [60]:
where is the cumulative distribution function of the standard normal distribution and is a uniform random variable between and . It is noted that is the cumulative distribution function of the response variable and is the maximum likelihood estimate of the parameter .
3.2. Monitoring Methods Based on the COM–Poisson Regression
Control charts are a well-known methodology of the SPC tool kit because of their efficacy in temporal monitoring of the time series process. A traditional control chart has two decision lines (i.e., lower control limit (LCL) and upper control limit (UCL)) along with a centerline. A plotting point refers to an in-control (IC) state if it lies between decision lines; otherwise, the plotting point is considered as out-of-control (OOC). Control charts have been used for numerous applications across various domains [65,66,67,68,69,70,71,72,73,74].
3.2.1. Existing COM–Poisson Model-Based Control Charts
Park et al. [60] and Park et al. [61] proposed Shewhart model-based control charts to monitor the COM–Poisson process. In these studies, the authors have used deviance residuals and randomized quantile residuals to define the plotting statistics. In the Shewhart model-based control charts, we define the plotting quantity as or This quantity of the COM–Poisson regression is used as a plotting statistic against the control limits given below:
where and are specified to achieve the fixed in-control average run length . The chart declared an OOC point when any plotting statistic falls outside of the above-defined control limits; otherwise, points are declared as IC. It is noted that, when , the said chart is known as the DR-COM–P Shewhart chart, while when , it is named as the QR-COM–P Shewhart chart.
3.2.2. Proposed COM–Poisson Model-Based Control Charts
The Shewhart charts are memory-less charts, which means they are designed based on current information [75]. Therefore, they are less prone to detect small shifts in the process. When the objective of the monitoring is to detect small to moderate shifts in the process, then EWMA and CUSUM charts are the alternatives [76]. The EWMA and CUSUM structures are also known as memory type charts as they used past information along with current information [77,78]. Hence, for the monitoring of small to moderate shifts, we have designed EWMA and CUSUM based charts in this study.
DR/QR-COM–P EWMA Control Charts
The EWMA statistic based on the residuals (i.e., or ) given in Equations (6) and (7) for the COM–Poisson regression is defined as follows:
where is the smoothing parameter such that and the starting value of the EWMA statistic is the process target (i.e., ). The limits of the EWMA charts are given as follows:
The charting constant and is set to obtain the fixed . When , the chart is named as the DR-COM–P EWMA chart, while when , it is known as the QR-COM–P EWMA chart. The EWMA chart signals an OOC point when any plotting statistic exceeds the control limits; otherwise, processes are declared as IC.
DR/QR-COM–P CUSUM Control Charts
The structure of the CUSUM chart is divided into two separate one-sided CUSUM statistics, i.e., and , which are defined as follows:
where is the reference value, and the starting values of the afore-mentioned CUSUM statistics are taken equal to zero (i.e., ). The upper CUSUM statistic monitors the deviations above the target value, while deviations below the target value are monitored through the lower CUSUM statistic The CUSUM chart signals an OOC residual when and/or ; otherwise, residuals are considered IC. Moreover, the parameters K, , and are carefully chosen against the pre-specified to determine the performance of the CUSUM chart. Furthermore, it is to be noted that the CUSUM chart is known as the DR-COM–P CUSUM chart when and the QR-COM–P CUSUM chart when .
4. Simulation-Based Assessment of Proposed Charts
In this section, we will provide a simulation study and the algorithm used to determine the coefficients of control limits. Moreover, the evaluation of the proposed charts and their comparison with the existing Shewhart structures are also presented.
4.1. Simulation Settings of COM–Poisson Model
For the evaluation of the proposed EWMA and CUSUM charts and the comparative analysis with existing Shewhart charts, we have used the following data generation model:
where , is the mean function and is the dispersion parameter. The and are independent auxiliary variables, generated through a standard normal distribution (i.e., and ). The parameters are considered equal to 0.5, and the sample size is fixed as 1000 (i.e., ). Further, for the full coverage COM–Poisson model, varying choices of dispersion parameters were considered (i.e., ) to assess the performance of the proposed charts.
In the COM–Poisson model, and are the fundamental parameters, where the main objective is to detect an increasing shift in at the fixed dispersion parameter . Therefore, we evaluated the performance of the control charts by considering the shifts in the such that the process changes from to . It is to be mentioned that the choices of δ and ν are made as listed below:
δ = 0(0.02)0.24 when ν = 0.5,
δ = 0(0.25)3 when ν = 1.0 or 1.5.
Previous studies have proposed different evaluation metrics to assess the predictive performance of control charts. For example, Mahmood [59] used run length (RL) properties such as average run length (ARL) and standard deviation of run length (SDRL) to evaluate the model-based charts under zero-inflated models. For the current study, we are also evaluating the proposed EWMA and CUSUM charts based on the ARL and SDRL metrics. The ARL is the average number of samples until a signal occurs, which is further categorized into in-control ARL and out-of-control ARL . The charts are designed based on the fixed and a chart having minimum is declared as the best chart among all others.
4.2. Algorithm for Charting Constants
As mentioned in Section 3.2, the control limits of each chart depend on the charting constants such as and . The procedure to find the control charting constants for the stated charts at pre-specified is illustrated in the following steps:
- i.
- Generate a data set of fixed sample size n using simulated model structure given in Section 4.1.
- ii.
- Fit the COM–Poisson model on the data set and obtain the deviance residuals (dr) given in (6) and randomized quantile residuals (qr) expressed in (7). Further, estimate the mean and standard error of the dr and qr.
- iii.
- For the Shewhart charts, set the values of LS1 and LS2, and fix LE1 and LE2 for the EWMA chart. Similarly, fix the random values h1 and h2 for each CUSUM chart. Further, obtain the control limit(s) and control chart statistic(s) using the estimates from step ii and selected values.
- iv.
- In the case of Shewhart control charts, plot the dr and qr values against their respective control limits given in (8). For the EWMA control charts, use the respective dr and qr for obtaining the respective EWMA statistics using (9) and plot it against the respective control limits given in (10). However, in the case of CUSUM control charts, use the respective dr and qr for obtaining the respective CUSUM statistics using (11) and (12), and compare these statistics with their respective decision intervals.
- v.
- Repeat steps i–iv for a large number of runs to obtain specified .
If pre-specified is not obtained, then adjust the afore-mentioned selected values and repeat steps i–v until pre-specified is achieved. It is noted that residuals sometimes showed asymmetry behavior. Therefore, we have set the limits in such a way that each side of the chart shows to obtain an overall . Further, the control charting constants are reported in Table 3 at different choices of dispersion parameters.
Table 3.
Control charting constants for the existing and proposed charts. EWMA, exponentially weighted moving; CUSUM, cumulative sum.
4.3. Performance Analysis
In this section, we have presented a comparative performance evaluation of existing and proposed charts schemes using the results obtained from an extensive simulation study with iterations. The performance of memory type and memoryless control charts is assessed and reported in terms of and in Table 4, Table 5 and Table 6. In addition, the impact of the reference value on the performance of the CUSUM control charts is investigated. Similarly, the impact of the smoothing parameter (λ) on the performance of the EWMA control charts is also evaluated. Figure 3 shows the impact of charting parameters on the performance of the proposed charts.
Table 4.
Average run length (ARL) profiles of the control charts at fixed v = 1.5. SDRL, standard deviation of run length.
Table 5.
ARL profiles of the control charts at fixed v = 1.0.
Table 6.
ARL profiles of the control charts at fixed v = 0.5.
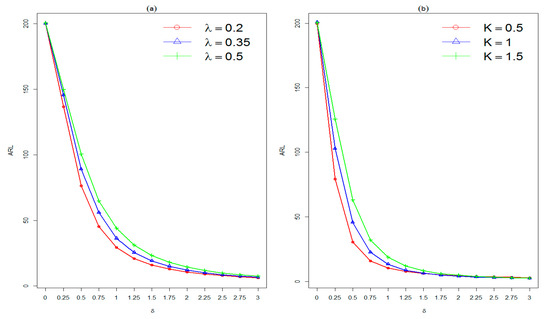
Figure 3.
Impact of charting parameters: (a) impact of the smoothing parameter on the performance of the QR-Conway–Maxwell–Poisson (COM–P) exponentially weighted moving (EWMA) chart at fixed v = 1.5 and (b) effect of the reference value on the performance of the DR-COM–P cumulative sum (CUSUM) control chart at fixed v = 1. ARL, average run length.
4.3.1. Analysis Based on Under-Dispersed Data
By assuming the detection ability of the proposed EWMA and CUSUM charts is compared with the existing Shewhart charts in Table 4. The findings depict that the charts based on deviance residuals (i.e., DR-COM–P Shewhart, DR-COM–P EWMA, and DR-COM–P CUSUM) are relatively more efficient to detect increasing shifts in the mean. For example, when , the of the DR-COM–P Shewhart chart is reported as 26.73, which is lower than the value of 27.08 of the QR-COM–P Shewhart chart. Further, at fixed a shift may cause 85 and 87 percent reduction in the of the QR-COM–P EWMA and DR-COM–P EWMA charts, respectively. Similarly, at fixed a 192.47-unit and 191.42-unit decrease is noted in the of QR-COM–P CUSUM and DR-COM–P CUSUM charts, respectively, due to a shift .
It is also noted that the EWMA type charts (i.e., QR-COM–P EWMA and DR-COM–P EWMA) have relatively better detection ability compared with CUSUM and Shewhart type charts. For example, at fixed and when , the of QR-COM–P Shewhart is reported as 69.32, while values of 29.33 and 32.98 are noted for the QR-COM–P EWMA and QR-COM–P CUSUM charts, respectively. Similarly, a shift may cause 79, 93, and 92 percent reduction in the of DR-COM–P Shewhart, DR-COM–P EWMA, and DR-COM–P CUSUM charts, respectively.
4.3.2. Analysis Based on Equi-Dispersed Data
The findings of the comparative analysis between the proposed and existing charts at fixed are given in Table 5. The results showed that the QR-COM–P Shewhart and DR-COM–P Shewhart charts depicted almost similar performance. Moreover, the deviance residuals-based charts (i.e., DR-COM–P EWMA and DR-COM–P CUSUM) have better detection ability as compared with quantile residual-based charts (i.e., QR-COM–P EWMA and QR-COM–P CUSUM). For example, at fixed when , the of the DR-COM–P EWMA chart is reported as 36.21, which is lower than the value of 38.11 of the QR-COM–P EWMA chart. Further, at fixed a shift may cause 97 and 98 percent reduction in the of QR-COM–P CUSUM and DR-COM–P CUSUM charts, respectively.
Similar to the findings of under-dispersed data, the EWMA type charts (i.e., QR-COM–P EWMA and DR-COM–P EWMA) under equi-dispersed data showed relatively better performance compared with Shewhart and CUSUM type charts. For example, at fixed and a shift may cause 92, 96, and 95 percent reduction in the of QR-COM-P Shewhart, QR-COM–P EWMA, and QR-COM–P CUSUM charts, respectively. Similarly, when , the of DR-COM–P Shewhart is reported as 8.59, while values of 4.70 and 4.92 are noted for the DR-COM–P EWMA and DR-COM–P CUSUM charts, respectively.
4.3.3. Analysis Based on Over-Dispersed Data
By fixing the performance of the proposed EWMA and CUSUM charts is compared with the that of Shewhart charts in Table 6. Once again, it is noted that the charts based on deviance residuals (i.e., DR-COM–P Shewhart, DR-COM–P EWMA, and DR-COM–P CUSUM) have relatively better detection ability as compared with the quantile residual-based charts (i.e., QR-COM–P Shewhart, QR-COM–P EWMA, and QR-COM–P CUSUM). For example, when , the of the DR-COM–P Shewhart chart is reported as 60.21, which is lower than the value of 61.08 of the QR-COM–P Shewhart chart. Further, at fixed a shift may cause 63 and 66 percent reduction in the of QR-COM–P EWMA and DR-COM–P EWMA charts, respectively. Similarly, at fixed a 186.21-unit and 187.01-unit decrease is noted in the of the QR-COM–P CUSUM and DR-COM–P CUSUM charts due to a shift .
Similar to the other findings, under over-dispersion data, the EWMA type charts (i.e., QR-COM–P EWMA and DR-COM–P EWMA) have relatively better detection ability as compared with Shewhart and CUSUM type charts. For example, at fixed and when the of QR-COM–P Shewhart is reported as 82.39, while values of 51.00 and 68.21 are noted for the QR-COM–P EWMA and QR-COM–P CUSUM charts, respectively. Similarly, a shift may cause 89, 93, and 92 percent reduction in the of DR-COM–P Shewhart, DR-COM–P EWMA, and DR-COM–P CUSUM charts, respectively.
4.4. Impact of Charting Parameters and
The smoothing parameter plays a vital role in the detection ability of the EWMA chart. Therefore, for brevity, the performance of the QR-COM–P EWMA chart for three choices of (i.e., , and at fixed is plotted in Figure 3a. It is clearly seen that the detection ability of the QR-COM–P EWMA chart increases with the decrease of . For example, when , the values of QR-COM–P EWMA are reported as 16.00, 19.19, and 23.34 against and , respectively.
In the CUSUM chart, the reference value is used to set the detection ability of the CUSUM chart. To notice the effect of , we have drawn the results of the DR-COM–P CUSUM chart for three choices of (i.e., and at fixed . The curves revealed an inverse relationship between the detection ability of the CUSUM chart and reference value . For example, when the values of the DR-COM–P CUSUM chart are reported as 79.19, 102.87, and 125.53 against and , respectively. The impact of charting parameters λ and K is shown above in Figure 3.
5. Implementation of Proposed Methods for Real-Time Crash Monitoring
In this section, we have applied the COM–Poisson regression to observe the significant factors contributing to the crash occurrences. Further, based on the estimated model, we have implemented the proposed charts for real-time monitoring.
A close view of Figure 1 shows that daily crash counts witness a steady downward trend after December 2018 and do not exceed this point again. This downward trend in observed crash record may be attributed to the implementation and enforcement of a new automated citation system introduced at the start of 2018 under the SAHER program [79]. SAHER is an automated system adopted for controlling traffic using a digital network of cameras connected to the central information center. Hence, crash data to this point act as IC data and are used for establishing control chart structure, and the remaining data are considered for the monitoring phase (in an OOC state).
As discussed in Section 2, the indexed values of road type, road surface conditions, damage type post-crash, weather conditions, road markings, and cat eyes are considered as possible explanatory variables for the crashes. Therefore, to assess the most significant explanatory variables, we have computed pairwise COM–Poisson regression models based on IC data. Out of 63 different models, the following model is considered as the best model based on the minimum values of , , and .
where IVRT and IVRSC represent the indexed values of road type and road surface conditions, respectively. It is evident from the results of the IC model that the intercept term, road type, and road surface conditions are statistically significant explanatory/predictor variables for the crashes with p-values < 0.01 and standard errors of and 0.0120, respectively. Moreover, it is also observed that the estimated dispersion parameter is observed as which is also statistically significant with a p-value of less than 0.01 and a standard error of .
For the development of the control chart setup, we have considered the above-mentioned IC model. Further, using the normal probability plots plotted in Figure 4, it is observed that the IVRT is a normally distributed variable with a mean of 1.86 and variance of 0.017 (cf. Figure 4a). Similarly, the road surface conditions also follow a normal distribution, having a mean of 1.81 and variance of 0.08 (cf. Figure 4b). Hence, based on these estimates and following Section 4.1, we have set up the simulation settings of the COM–Poisson model, and control charting constants are obtained using the algorithm given in Section 4.1, and are reported in Table 7. It is noted that we have assumed , , and .
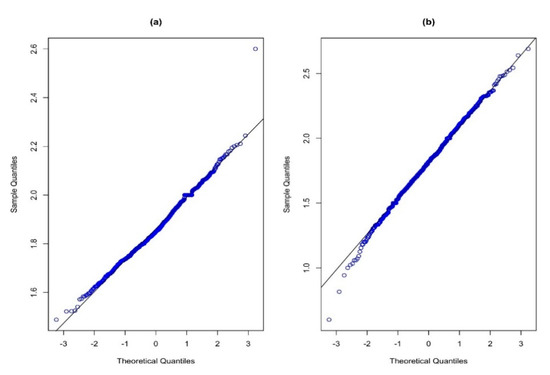
Figure 4.
The normal probability plots: (a) for the indexed value of road type and (b) for the indexed value of road surface conditions.
Table 7.
Control charting constants of the charts based on the in-control (IC) model of crashes data.
The randomized quantile residual-based charts (i.e., QR-COM–P Shewhart, QR-COM–P EWMA, and QR-COM–P CUSUM) and deviance residuals-based charts (i.e., DR-COM–P Shewhart, DR-COM–P EWMA, and DR-COM–P CUSUM) are implemented on the crash data set. The QR-COM–P Shewhart, QR-COM–P EWMA, and QR-COM–P CUSUM charts are plotted in Figure 5, whereas the DR-COM–P Shewhart, DR-COM–P EWMA, and DR-COM–P CUSUM are given in Figure 6. In every chart, the red line represents plotting statistics based on the residuals from IC model, while the blue line is used to show plotting statistics based on OOC residuals. Further, green dotted lines are used to show the control limits of every chart.
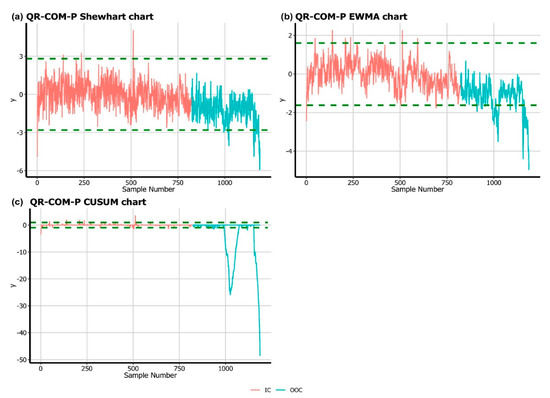
Figure 5.
Implementation of randomized quantile residual-based charts on crash data. IC, in-control; OOC, out-of-control.
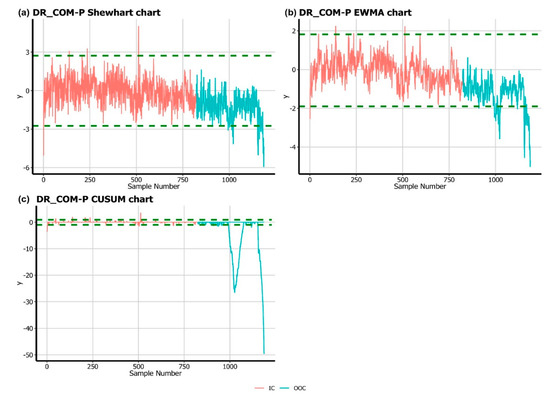
Figure 6.
Implementation of deviance residual-based charts on crash data.
It is observed from Figure 5 and Figure 6 that the QR-COM–P Shewhart chart signaled four false alarms with 26 OOC points, while the same number of signals is detected by the DR-COM–P Shewhart chart. The QR-COM–P EWMA and DR-COM–P EWMA charts show 13 and 14 false alarms, while 76 and 80 OOC signals are reported by QR-COM–P EWMA and DR-COM–P EWMA charts, respectively. Further, 22 and 23 false alarms are reported by the QR-COM–P CUSUM and DR-COM–P CUSUM charts, respectively, while 124 and 126 OOC points are signaled by the QR-COM–P CUSUM and DR-COM–P CUSUM charts, respectively.
6. Summary, Conclusions, and Recommendations
During the past few decades, many studies have proposed a wide range of statistical modeling approaches to explore the relationships between causal factors and crash occurrence. However, very few have focused on developing germane procedures for real-time highway safety surveillance using available crash records. Control charts are useful tools in SPC with numerous applications for active event monitoring. Traditionally, the Poisson distribution is frequently used to interpret the data for a control chart; however, it may be inappropriate to model under-dispersed or over-dispersed data. This study proposes the EWMA and CUSUM control chart scheme for highway safety monitoring using three years of crash data (2017–2019) for rural highways in Saudi Arabia. During the first stage of the study, three well-known count data distribution models (Poisson, negative binomial, and COM–Poisson) were investigated to identify the most appropriate distribution model for the data. The findings showed that the COM–Poisson regression model is the best fitted statistical model.
During the second stage of the study, EWMA and CUSUM type charts based on the residuals (i.e., deviance or randomized quantile residuals) of the COM–Poisson regression model were developed from a crash monitoring perspective. An extensive simulation study was designed to assess the performance evaluation of the proposed control charts scheme and their comparison with the existing Shewhart type chart. The results revealed that the charts based on deviance residuals (i.e., DR-COM–P Shewhart, DR-COM–P EWMA, and DR-COM–P CUSUM) were relatively more flexible and efficient in detecting increasing shifts in the mean. Further, it was noted the EWMA type charts (i.e., QR-COM–P EWMA and DR-COM–P EWMA) outperformed Shewhart and CUSUM type charts in terms of considered evaluation metrics (both ARL and SDRL). The results from the simulation study also indicated an inverse relationship of the reference value (smoothing parameter with the performance of the GLM-based CUSUM EWMA control charts. Finally, during the third stage of the study, the proposed monitoring methods were successfully implemented on real-time crash data. The findings of this study could provide useful essential guidance to policy- and decision-makers for initiating concrete steps to improve users’ road safety. The proposed real-time monitoring for highway safety surveillance can guide on effective and proactive implementation of different hazard control measures to mitigate the occurrence of future traffic crashes. Some of the quick hazard control measures suggested in this regard include measures such as improving the surface conditions, installation of variable message signs for guidance and warnings, raised pavements, delineators on horizontal curves, weather warning systems, ramp metering, and induction of speed and traffic calming measures at crash hotpots, among others.
This study has a few limitations that might be addressed in future studies. It is worth noting that the present study was designed assuming the known parameters. It will be interesting to see the effect of parameter estimation on the charts in forthcoming studies. The performance of the proposed control chart scheme was verified using limited (three years) real-life crash data. Further investigations using other detailed datasets are needed for a more precise assessment of the statistical properties of the suggested monitoring procedures. Future studies could also consider the application of the proposed methods for real-life monitoring of crashes by individual severity groups (fatal, injury, and property damage) or specific crash types. The monitoring scheme based on crash severity classes will be helpful in prioritizing prevention strategies with the emphasis placed on more severe crashes. Future studies could also investigate the impact of auto-correlated response variables. Furthermore, one may adopt advanced charting structures such as moving average, progressive moving average, mixed EWMA–CUSUM, and HEWMA type charts.
Author Contributions
Conceptualization, A.J., T.M. and M.R.; methodology, A.J. and T.M.; software, T.M. and M.R.; validation, A.J., T.M. and H.M.A.-A.; formal analysis, T.M.; investigation, A.J. and M.R.; resources, M.R. and H.M.A.-A.; data curation, A.J.; writing—original draft preparation, A.J. and H.M.A.-A.; writing—review and editing, M.R.; visualization, H.M.A.-A.; supervision, M.R. and H.M.A.-A.; project administration, M.R.; funding acquisition, M.R. All authors have read and agreed to the published version of the manuscript.
Funding
This research is supported by the Deanship of Scientific Research (DSR) at the King Fahd University of Petroleum and Minerals (KFUPM) under Project SB191043.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Acknowledgments
The authors acknowledge and appreciate the support of KFUPM for providing all the essential resources to conduct this study.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Global Status Report on Road Safety 2018; World Health Organization: Geneva, Switzerland, 2019.
- Yu, R.; Wang, Y.; Quddus, M.; Li, J. A Marginalized Random Effects Hurdle Negative Binomial Model for Analyzing Refined-Scale Crash Frequency Data. Anal. Methods Accid. Res. 2019, 22, 100092. [Google Scholar] [CrossRef]
- Global Status Report on Road Safety 2015; World Health Organization: Geneva, Switzerland, 2015.
- Jamal, A.; Rahman, M.T.; Al-Ahmadi, H.M.; Ullah, I.M.; Zahid, M. Intelligent Intersection Control for Delay Optimization: Using Meta-Heuristic Search Algorithms. Sustainability 2020, 12, 1896. [Google Scholar] [CrossRef]
- Al-Turki, M.; Jamal, A.; Al-Ahmadi, H.M.; Al-Sughaiyer, M.A.; Zahid, M. On the Potential Impacts of Smart Traffic Control for Delay, Fuel Energy Consumption, and Emissions: An NSGA-II-Based Optimization Case Study from Dhahran, Saudi Arabia. Sustainability 2020, 12, 7394. [Google Scholar] [CrossRef]
- Mohamed, H.A. Estimation of Socio-Economic Cost of Road Accidents in Saudi Arabia: Willingness-To-Pay Approach (WTP). Adv. Manag. Appl. Econ. 2015, 5, 43. [Google Scholar]
- Jamal, A.; Umer, W. Exploring the Injury Severity Risk Factors in Fatal Crashes with Neural Network. IJERPH 2020, 17, 7466. [Google Scholar] [CrossRef]
- Kaaf, K.A.; Abdel-Aty, M. Transferability and Calibration of Highway Safety Manual Performance Functions and Development of New Models for Urban Four-Lane Divided Roads in Riyadh, Saudi Arabia. Transp. Res. Rec. 2015, 2515, 70–77. [Google Scholar] [CrossRef]
- Islam, M.; Alharthi, M.; Alam, M. The Impacts of Climate Change on Road Traffic Accidents in Saudi Arabia. Climate 2019, 7, 103. [Google Scholar] [CrossRef]
- Alarifi, S.A.; Alkahtani, K.F.; Abdel-Aty, M.A.; Kher, S.O.; Mohammed, A.M.; AlMojil, A.H. Corridor Safety Evaluation in a Developing Country Using a Survey Based Approach. J. Transp. Saf. Secur. 2019, 11, 189–206. [Google Scholar] [CrossRef]
- Shanks, N.J.; Ansari, M.; Ai-Kalai, D. Road Traffic Accidents in Saudi Arabia. Public Health 1994, 108, 27–34. [Google Scholar] [CrossRef]
- Touahmia, M. Identification of Risk Factors Influencing Road Traffic Accidents. Eng. Technol. Appl. Sci. Res. 2018, 8, 2417–2421. [Google Scholar] [CrossRef]
- Al-Tit, A.A.; Ben Dhaou, I.; Albejaidi, F.M.; Alshitawi, M.S. Traffic Safety Factors in the Qassim Region of Saudi Arabia. Sage Open 2020, 10. [Google Scholar] [CrossRef]
- Jamal, A.; Rahman, M.T.; Al-Ahmadi, H.M.; Mansoor, U. The Dilemma of Road Safety in the Eastern Province of Saudi Arabia: Consequences and Prevention Strategies. Int. J. Environ. Res. Public Health 2020, 17, 157. [Google Scholar] [CrossRef]
- AlKheder, S.; Al-Rashidi, M. Bayesian Hierarchical Statistics for Traffic Safety Modelling and Forecasting. Int. J. Inj. Control Saf. Promot. 2020, 27, 99–111. [Google Scholar] [CrossRef] [PubMed]
- Mohamed, S.A.; Mohamed, K.; Al-Harthi, H.A. Investigating Factors Affecting the Occurrence and Severity of Rear-End Crashes. Transp. Res. Procedia 2017, 25, 2098–2107. [Google Scholar] [CrossRef]
- Farag, S.G.; Hashim, I.H. Safety Performance Appraisal at Roundabouts: Case Study of Salalah City in Oman. J. Transp. Saf. Secur. 2017, 9, 67–82. [Google Scholar] [CrossRef]
- Cafiso, S.; Di Graziano, A.; Di Silvestro, G.; La Cava, G.; Persaud, B. Development of Comprehensive Accident Models for Two-Lane Rural Highways Using Exposure, Geometry, Consistency and Context Variables. Accid. Anal. Prev. 2010, 42, 1072–1079. [Google Scholar] [CrossRef] [PubMed]
- Hou, Q.; Tarko, A.P.; Meng, X. Investigating Factors of Crash Frequency with Random Effects and Random Parameters Models: New Insights from Chinese Freeway Study. Accid. Anal. Prev. 2018, 120, 1–12. [Google Scholar] [CrossRef]
- Haghighi, N.; Liu, X.C.; Zhang, G.; Porter, R.J. Impact of Roadway Geometric Features on Crash Severity on Rural Two-Lane Highways. Accid. Anal. Prev. 2018, 111, 34–42. [Google Scholar] [CrossRef]
- Xing, F.; Huang, H.; Zhan, Z.; Zhai, X.; Ou, C.; Sze, N.N.; Hon, K.K. Hourly Associations between Weather Factors and Traffic Crashes: Non-Linear and Lag Effects. Anal. Methods Accid. Res. 2019, 24, 100109. [Google Scholar] [CrossRef]
- Lord, D.; Mannering, F. The Statistical Analysis of Crash-Frequency Data: A Review and Assessment of Methodological Alternatives. Transp. Res. Part A Policy Pract. 2010, 44, 291–305. [Google Scholar] [CrossRef]
- Aguero-Valverde, J.; Jovanis, P.P. Analysis of Road Crash Frequency with Spatial Models. Transp. Res. Rec. 2008, 2061, 55–63. [Google Scholar] [CrossRef]
- Pappalardo, G.; Cafiso, S.; Di Graziano, A.; Severino, A. Decision Tree Method to Analyze the Performance of Lane Support Systems. Sustainability 2021, 13, 846. [Google Scholar] [CrossRef]
- Afghari, A.P.; Washington, S.; Haque, M.M.; Li, Z. A Comprehensive Joint Econometric Model of Motor Vehicle Crashes Arising from Multiple Sources of Risk. Anal. Methods Accid. Res. 2018, 18, 1–14. [Google Scholar] [CrossRef]
- Afghari, A.P.; Haque, M.M.; Washington, S.; Smyth, T. Effects of Globally Obtained Informative Priors on Bayesian Safety Performance Functions Developed for Australian Crash Data. Accid. Anal. Prev. 2019, 129, 55–65. [Google Scholar] [CrossRef] [PubMed]
- Valen, A.; Bogstrand, S.T.; Vindenes, V.; Frost, J.; Larsson, M.; Holtan, A.; Gjerde, H. Driver-Related Risk Factors of Fatal Road Traffic Crashes Associated with Alcohol or Drug Impairment. Accid. Anal. Prev. 2019, 131, 191–199. [Google Scholar] [CrossRef]
- Lord, D.; Manar, A.; Vizioli, A. Modeling Crash-Flow-Density and Crash-Flow-V/C Ratio Relationships for Rural and Urban Freeway Segments. Accid. Anal. Prev. 2005, 37, 185–199. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.; Ulfarsson, G.F. Traffic Safety in an Aging Society: Analysis of Older Pedestrian Crashes. J. Transp. Saf. Secur. 2019, 11, 323–332. [Google Scholar] [CrossRef]
- McGwin, G., Jr.; Brown, D.B. Characteristics of Traffic Crashes among Young, Middle-Aged, and Older Drivers. Accid. Anal. Prev. 1999, 31, 181–198. [Google Scholar] [CrossRef]
- Tauhidur Rahman, M.; Jamal, A.; Al-Ahmadi, H.M. Examining Hotspots of Traffic Collisions and Their Spatial Relationships with Land Use: A GIS-Based GeographicallyWeighted Regression Approach for Dammam, Saudi Arabia. ISPRS Int. J. Geo-Inf. 2020, 9, 540. [Google Scholar] [CrossRef]
- Hong, J.; Tamakloe, R.; Park, D. A Comprehensive Analysis of Multi-Vehicle Crashes on Expressways: A Double Hurdle Approach. Sustainability 2019, 11, 2782. [Google Scholar] [CrossRef]
- Zahid, M.; Chen, Y.; Khan, S.; Jamal, A.; Ijaz, M.; Ahmed, T. Predicting Risky and Aggressive Driving Behavior among Taxi Drivers: Do Spatio-Temporal Attributes Matter? Int. J. Environ. Res. Public Health 2020, 17, 3937. [Google Scholar] [CrossRef]
- Ullah, I.; Jamal, A.; Subhan, F. Public Perception of Autonomous Car: A Case Study for Pakistan. Adv. Transp. Stud. 2019, 49, 145–154. [Google Scholar]
- Afghari, A.P.; Haque, M.M.; Washington, S. Applying Fractional Split Model to Examine the Effects of Roadway Geometric and Traffic Characteristics on Speeding Behavior. Traffic Inj. Prev. 2018, 19, 860–866. [Google Scholar] [CrossRef]
- Zahid, M.; Chen, Y.; Jamal, A.; Al-Ahmadi, H.M.; Al-Ofi, A.K. Adopting Machine Learning and Spatial Analysis Techniques for Driver Risk Assessment: Insights from a Case Study. Int. J. Environ. Res. Public Health 2020, 17, 5193. [Google Scholar] [CrossRef]
- Ma, X.; Chen, F.; Chen, S. Modeling Crash Rates for a Mountainous Highway by Using Refined-Scale Panel Data. Transp. Res. Rec. 2015, 2515, 10–16. [Google Scholar] [CrossRef]
- Yu, R.; Xiong, Y.; Abdel-Aty, M. A Correlated Random Parameter Approach to Investigate the Effects of Weather Conditions on Crash Risk for a Mountainous Freeway. Transp. Res. Part C Emerg. Technol. 2015, 50, 68–77. [Google Scholar] [CrossRef]
- Ahmed, M.M.; Abdel-Aty, M.; Yu, R. Assessment of Interaction of Crash Occurrence, Mountainous Freeway Geometry, Real-Time Weather, and Traffic Data. Transp. Res. Rec. 2012, 2280, 51–59. [Google Scholar] [CrossRef]
- Hammad, H.M.; Ashraf, M.; Abbas, F.; Bakhat, H.F.; Qaisrani, S.A.; Mubeen, M.; Fahad, S.; Awais, M. Environmental Factors Affecting the Frequency of Road Traffic Accidents: A Case Study of Sub-Urban Area of Pakistan. Environ. Sci. Pollut. Res. 2019, 26, 11674–11685. [Google Scholar] [CrossRef] [PubMed]
- Qiu, L.; Nixon, W.A. Effects of Adverse Weather on Traffic Crashes: Systematic Review and Meta-Analysis. Transp. Res. Rec. 2008, 2055, 139–146. [Google Scholar] [CrossRef]
- Lee, J.; Nam, B.; Abdel-Aty, M. Effects of Pavement Surface Conditions on Traffic Crash Severity. J. Transp. Eng. 2015, 141, 04015020. [Google Scholar] [CrossRef]
- National Highway Traffic Safety Administration. A Compilation of Motor Vehicle Crash Data from the Fatality Analysis Reporting System and the General Estimates System; United States Department of Transportation: Washington, DC, USA, 2014.
- Shaon, M.R.R.; Qin, X.; Shirazi, M.; Lord, D.; Geedipally, S.R. Developing a Random Parameters Negative Binomial-Lindley Model to Analyze Highly over-Dispersed Crash Count Data. Anal. Methods Accid. Res. 2018, 18, 33–44. [Google Scholar] [CrossRef]
- Guikema, S.D.; Goffelt, J.P. A Flexible Count Data Regression Model for Risk Analysis. Risk Anal. Int. J. 2008, 28, 213–223. [Google Scholar] [CrossRef]
- Chen, J.-H. A Double Generally Weighted Moving Average Chart for Monitoring the COM-Poisson Processes. Symmetry 2020, 12, 1014. [Google Scholar] [CrossRef]
- Lord, D.; Guikema, S.D.; Geedipally, S.R. Application of the Conway–Maxwell–Poisson Generalized Linear Model for Analyzing Motor Vehicle Crashes. Accid. Anal. Prev. 2008, 40, 1123–1134. [Google Scholar] [CrossRef]
- Lord, D.; Geedipally, S.R.; Guikema, S.D. Extension of the Application of Conway-Maxwell-Poisson Models: Analyzing Traffic Crash Data Exhibiting Underdispersion. Risk Anal. Int. J. 2010, 30, 1268–1276. [Google Scholar] [CrossRef] [PubMed]
- Schuh, A.; Camelio, J.A.; Woodall, W.H. Control Charts for Accident Frequency: A Motivation for Real-Time Occupational Safety Monitoring. Int. J. Inj. Control Saf. Promot. 2014, 21, 154–162. [Google Scholar] [CrossRef]
- Skinner, K.R.; Montgomery, D.C.; Runger, G.C. Generalized Linear Model-Based Control Charts for Discrete Semiconductor Process Data. Qual. Reliab. Eng. Int. 2004, 20, 777–786. [Google Scholar] [CrossRef]
- Asgari, A.; Amiri, A.; Niaki, S.T.A. A New Link Function in GLM-Based Control Charts to Improve Monitoring of Two-Stage Processes with Poisson Response. Int. J. Adv. Manuf. Technol. 2014, 72, 1243–1256. [Google Scholar] [CrossRef]
- Jearkpaporn, D.; Borror, C.M.; Runger, G.C.; Montgomery, D.C. Process Monitoring for Mean Shifts for Multiple Stage Processes. Int. J. Prod. Res. 2007, 45, 5547–5570. [Google Scholar] [CrossRef]
- Amiri, A.; Yeh, A.B.; Asgari, A. Monitoring Two-Stage Processes with Binomial Data Using Generalized Linear Model-Based Control Charts. Qual. Technol. Quant. Manag. 2016, 13, 241–262. [Google Scholar] [CrossRef]
- Shang, Y.; Tsung, F.; Zou, C. Profile Monitoring with Binary Data and Random Predictors. J. Qual. Technol. 2011, 43, 196–208. [Google Scholar] [CrossRef]
- Urbieta, P.; Lee HO, L.; Alencar, A. CUSUM and EWMA Control Charts for Negative Binomial Distribution. Qual. Reliab. Eng. Int. 2017, 33, 793–801. [Google Scholar] [CrossRef]
- Alencar, A.P.; Lee HO, L.; Albarracin, O.Y.E. CUSUM Control Charts to Monitor Series of Negative Binomial Count Data. Stat. Methods Med. Res. 2017, 26, 1925–1935. [Google Scholar] [CrossRef]
- Kinat, S.; Amin, M.; Mahmood, T. GLM-Based Control Charts for the Inverse Gaussian Distributed Response Variable. Qual. Reliab. Eng. Int. 2020, 36, 765–783. [Google Scholar] [CrossRef]
- Amin, M.; Mahmood, T.; Kinat, S. Memory Type Control Charts with Inverse-Gaussian Response: An Application to Yarn Manufacturing Industry. Trans. Inst. Meas. Control 2020, 0142331220952965. [Google Scholar] [CrossRef]
- Mahmood, T.; Xie, M. Models and Monitoring of Zero-Inflated Processes: The Past and Current Trends. Qual. Reliab. Eng. Int. 2019, 35, 2540–2557. [Google Scholar] [CrossRef]
- Park, K.; Jung, D.; Kim, J. Control Charts Based on Randomized Quantile Residuals. Appl. Stoch. Models Bus. Ind. 2020, 36, 716–729. [Google Scholar] [CrossRef]
- Park, K.; Kim, J.-M.; Jung, D. GLM-Based Statistical Control-Charts for Dispersed Count Data with Multicollinearity between Input Variables. Qual. Reliab. Eng. Int. 2018, 34, 1103–1109. [Google Scholar] [CrossRef]
- Conway, R.W.; Maxwell, W.L. A Queuing Model with State Dependent Service Rates. J. Ind. Eng. 1962, 12, 132–136. [Google Scholar]
- Shmueli, G.; Minka, T.P.; Kadane, J.B.; Borle, S.; Boatwright, P. A Useful Distribution for Fitting Discrete Data: Revival of the Conway–Maxwell–Poisson Distribution. J. R. Stat. Soc. Ser. C (Appl. Stat.) 2005, 54, 127–142. [Google Scholar] [CrossRef]
- Sellers, K.F.; Shmueli, G. A Flexible Regression Model for Count Data. Ann. Appl. Stat. 2010, 4, 943–961. [Google Scholar] [CrossRef]
- Riaz, M.; Abbas, N.; Mahmood, T. A Communicative Property with Its Industrial Applications. Qual. Reliab. Eng. Int. 2017, 33, 2761–2763. [Google Scholar] [CrossRef]
- Mahmood, T.; Wittenberg, P.; Zwetsloot, I.M.; Wang, H.; Tsui, K.L. Monitoring Data Quality for Telehealth Systems in the Presence of Missing Data. Int. J. Med. Inform. 2019, 126, 156–163. [Google Scholar] [CrossRef]
- Mahmood, T. Generalized Linear Model Based Monitoring Methods for High-Yield Processes. Qual. Reliab. Eng. Int. 2020, 36, 1570–1591. [Google Scholar] [CrossRef]
- Ali, A.; Mahmood, T.; Nazir, H.Z.; Sana, I.; Akhtar, N.; Qamar, S.; Iqbal, M. Control Charts for Process Dispersion Parameter under Contaminated Normal Environments. Qual. Reliab. Eng. Int. 2016, 32, 2481–2490. [Google Scholar] [CrossRef]
- Abbas, N.; Riaz, M.; Mahmood, T. An Improved S 2 Control Chart for Cost and Efficiency Optimization. IEEE Access 2017, 5, 19486–19493. [Google Scholar] [CrossRef]
- Raji, I.A.; Lee, M.H.; Riaz, M.; Abujiya, M.R.; Abbas, N. Outliers Detection Models in Shewhart Control Charts; an Application in Photolithography: A Semiconductor Manufacturing Industry. Mathematics 2020, 8, 857. [Google Scholar] [CrossRef]
- Riaz, M.; Abbasi, S.A.; Abid, M.; Hamzat, K.A. A New HWMA Dispersion Control Chart with an Application to Wind Farm Data. Mathematics 2020, 8, 2136. [Google Scholar] [CrossRef]
- Kim, J.-M.; Wang, N.; Liu, Y.; Park, K. Residual Control Chart for Binary Response with Multicollinearity Covariates by Neural Network Model. Symmetry 2020, 12, 381. [Google Scholar] [CrossRef]
- Aslam, M.; Rao, G.S.; Khan, N.; Al-Abbasi, F.A. EWMA Control Chart Using Repetitive Sampling for Monitoring Blood Glucose Levels in Type-II Diabetes Patients. Symmetry 2019, 11, 57. [Google Scholar] [CrossRef]
- Omar, M.; Arafat, S.; Hossain, M.P.; Riaz, M. Inverse Maxwell Distribution and Statistical Process Control: An Efficient Approach for Monitoring Positively Skewed Process. Symmetry 2021, 13, 189. [Google Scholar] [CrossRef]
- Hussain, S.; Mei, S.; Riaz, M.; Abbasi, S.A. On Phase-I Monitoring of Process Location Parameter with Auxiliary Information-Based Median Control Charts. Mathematics 2020, 8, 706. [Google Scholar] [CrossRef]
- Chen, J.-H.; Lu, S.-L. A New Sum of Squares Exponentially Weighted Moving Average Control Chart Using Auxiliary Information. Symmetry 2020, 12, 1888. [Google Scholar] [CrossRef]
- Ali, S.; Abbas, Z.; Nazir, H.Z.; Riaz, M.; Zhang, X.; Li, Y. On Designing Non-Parametric EWMA Sign Chart under Ranked Set Sampling Scheme with Application to Industrial Process. Mathematics 2020, 8, 1497. [Google Scholar] [CrossRef]
- Abbas, N.; Abujiya, M.R.; Riaz, M.; Mahmood, T. Cumulative Sum Chart Modeled under the Presence of Outliers. Mathematics 2020, 8, 269. [Google Scholar] [CrossRef]
- Alghnam, S.; Towhari, J.; Alkelya, M.; Binahmad, A.; Bell, T.M. The Effectiveness of Introducing Detection Cameras on Compliance with Mobile Phone and Seatbelt Laws: A before-after Study among Drivers in Riyadh, Saudi Arabia. Inj. Epidemiol. 2018, 5, 1–8. [Google Scholar] [CrossRef]






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).