Likelihood-Based Inference for the Asymmetric Beta-Skew Alpha-Power Distribution


Abstract
1. Introduction
2. The Asymmetric Beta-Skew Alpha-Power Distribution
- (i)
- If , then .
- (ii)
- If , then .
- (iii)
- If and , then .
- (i)
- The cdf of Z, which we denote by , is given by
- (ii)
- The survival function, denoted by , is
- (iii)
- The Hazard function , is
- (i)
- .
- (ii)
- .
- (iii)
- .
- (iv)
- .
- (i)
- .
- (ii)
- .
- (iii)
- .
- (iv)
- .
2.1. Location and Scale Extension for BSAP Model
2.2. Maximum Likelihood Estimation for BSAP Model
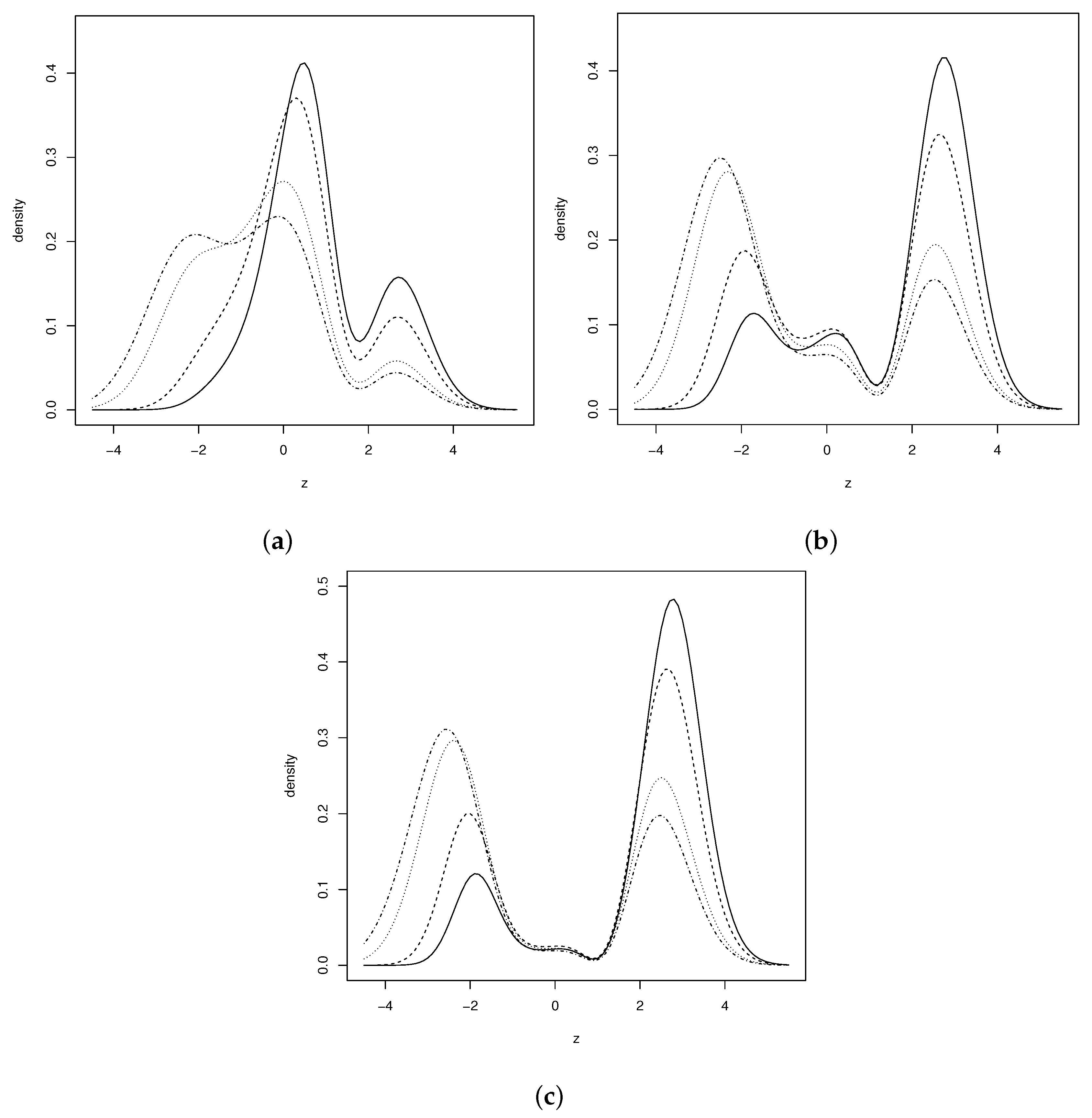
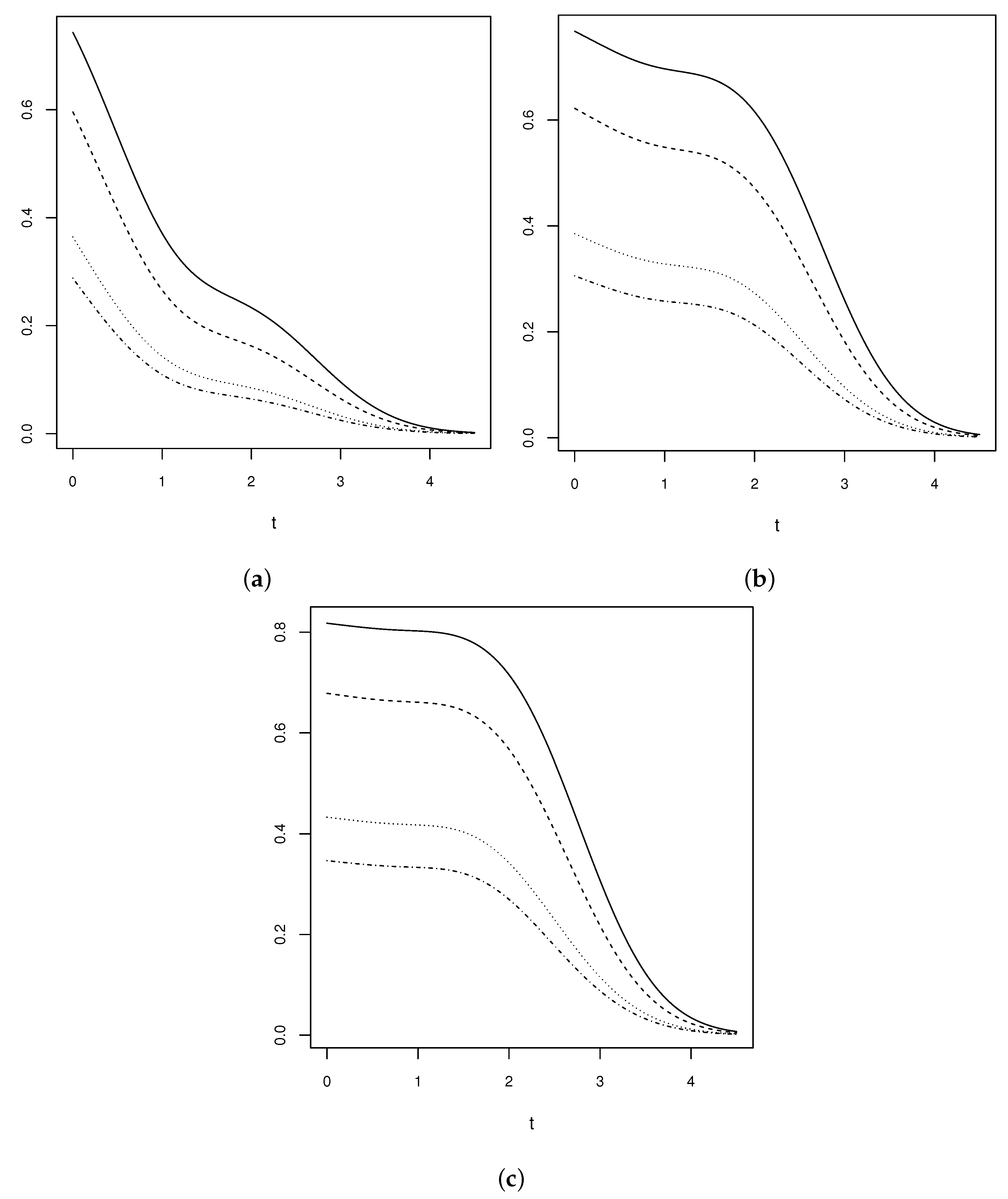
3. Simulation Study
4. Real Data Applications
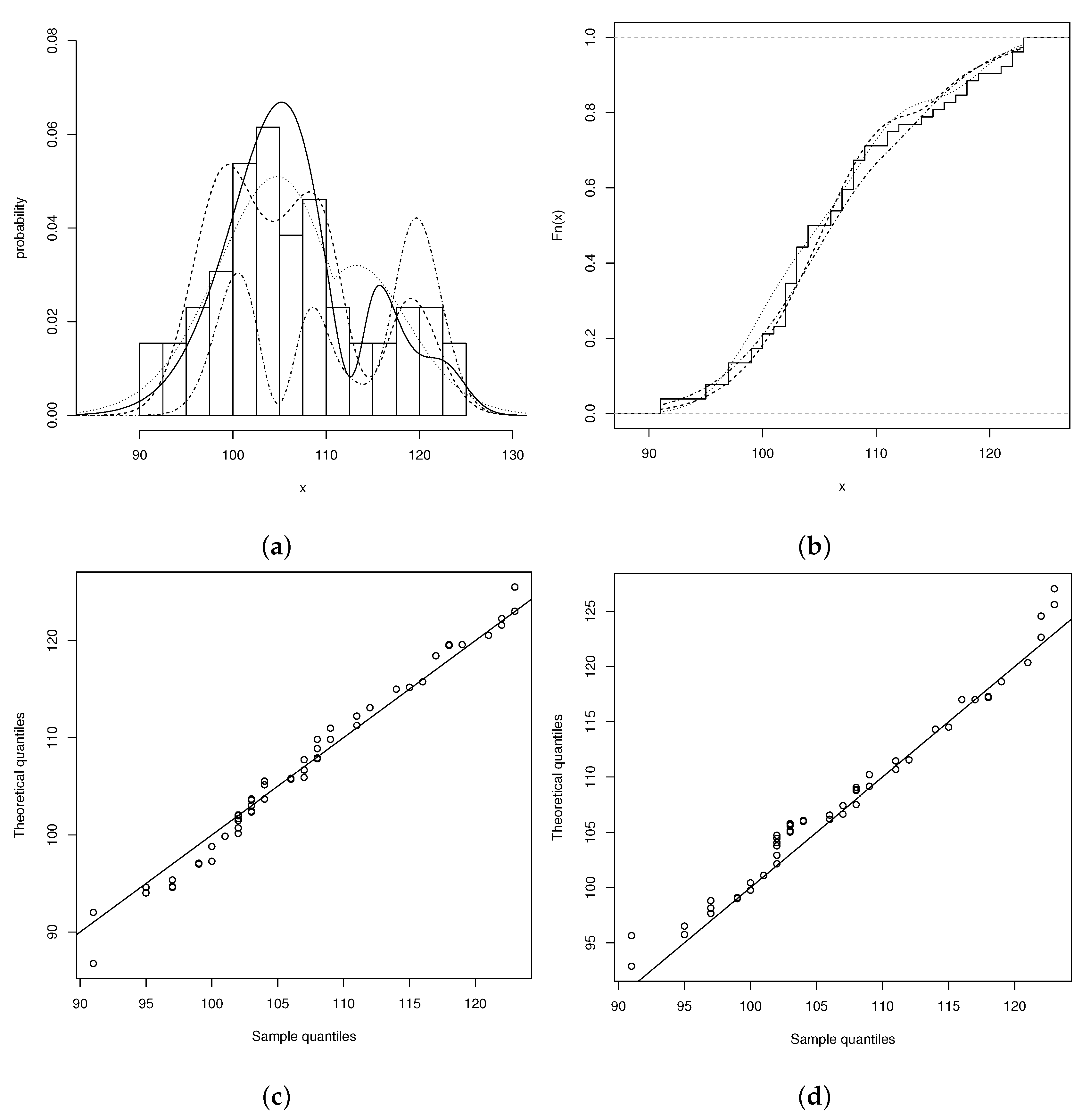
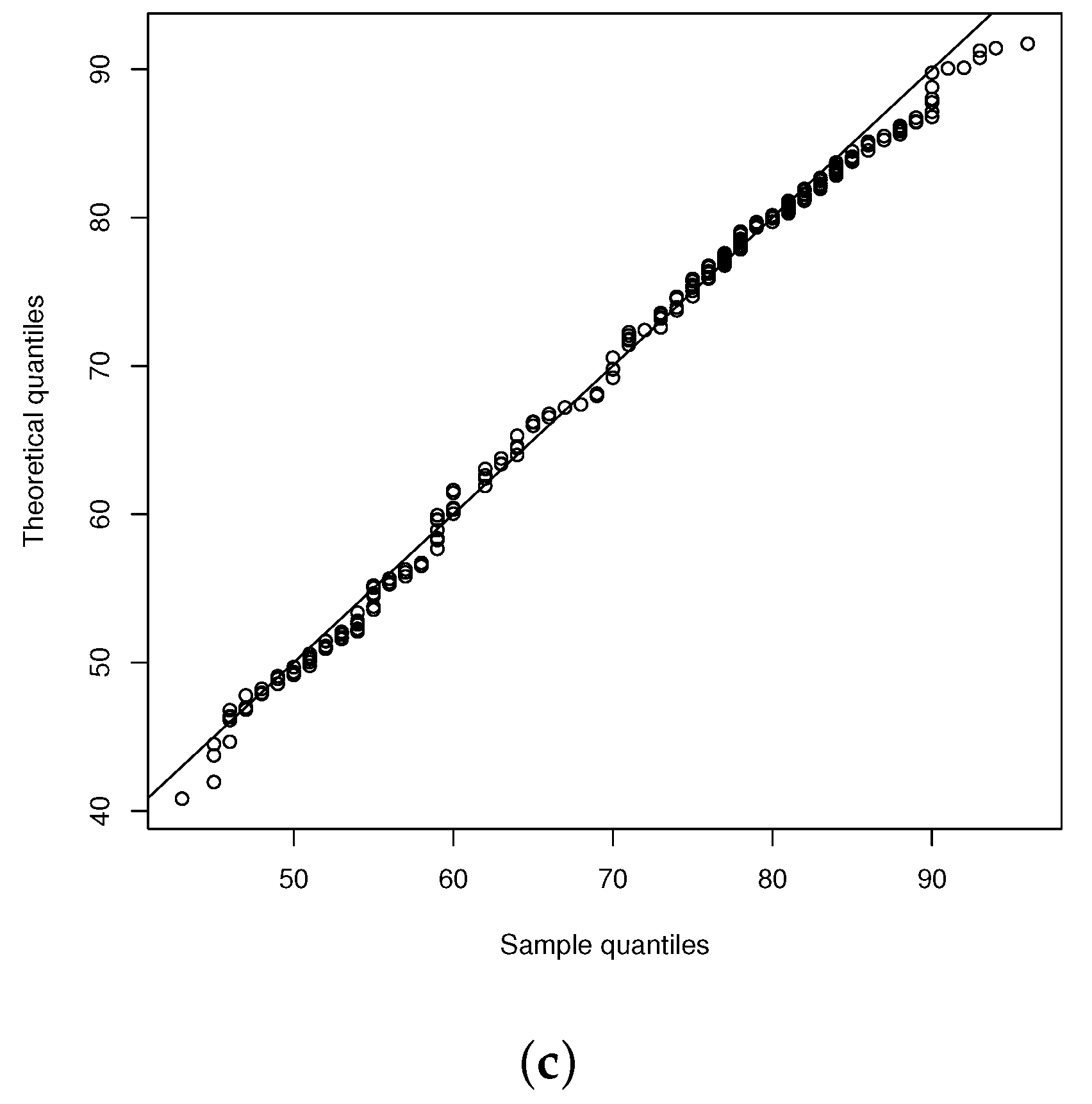
4.1. Application 1: The Otis IQ Scores Data
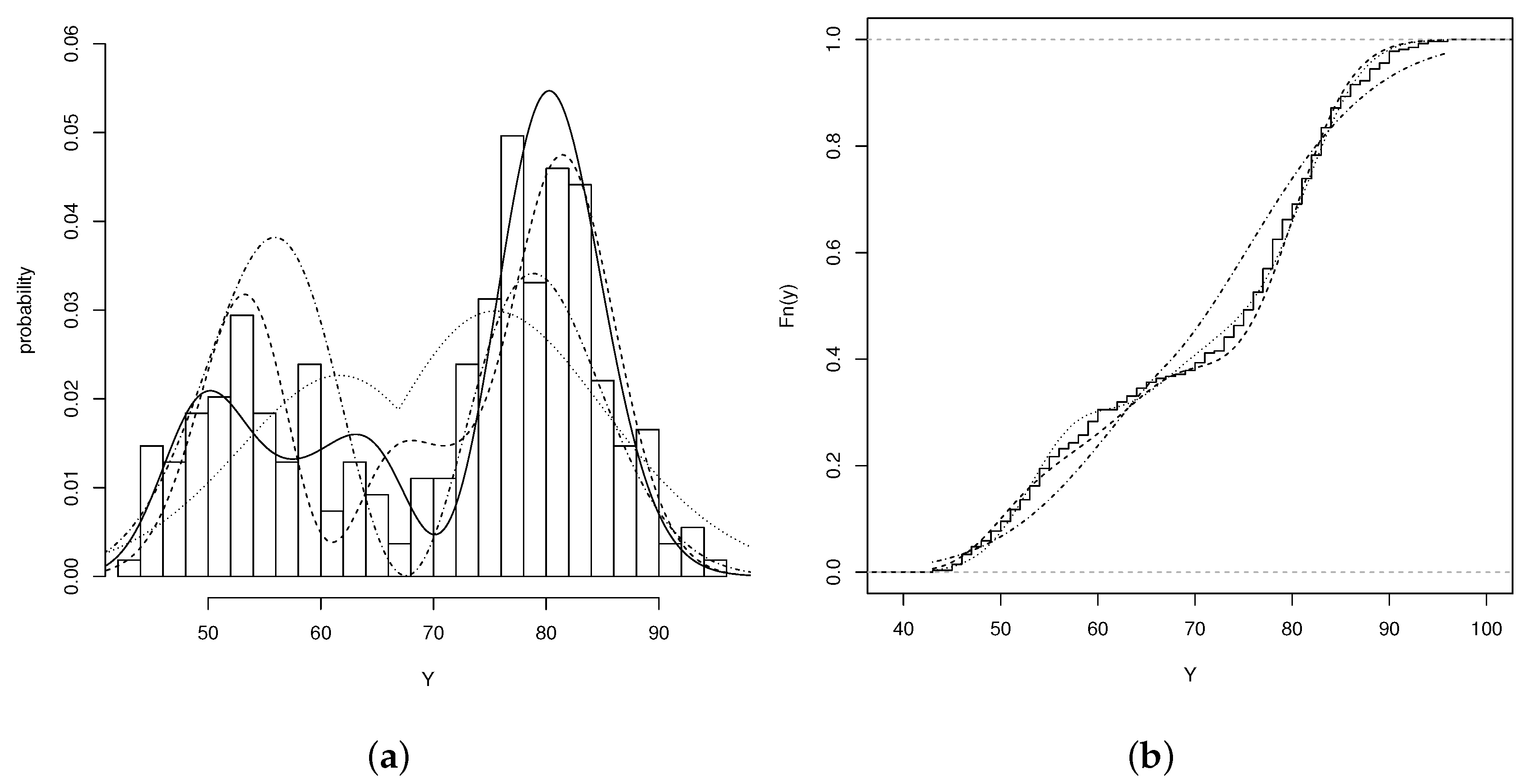
4.2. Application 2: Old Faithful Geyser Data
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Information Matrix for the BSAP Model
References
- Azzalini, A. A class of distributions which includes the normal ones. Scand. J. Stat. 1985, 12, 171–178. [Google Scholar]
- Arnold, B.C.; Gómez, H.W.; Salinas, H.S. On multiple constraint skewed models. Statistics 2009, 43, 279–293. [Google Scholar] [CrossRef]
- Gómez, H.W.; Elal-Olivero, D.; Salinas, H.S.; Bolfarine, H. Bimodal extension based on the skew-normal distribution with application to pollen data. Environmetrics 2011, 22, 50–62. [Google Scholar] [CrossRef]
- Kim, H.J. On a class of two–piece skew-normal distributions. Statistics 1985, 39, 537–553. [Google Scholar] [CrossRef]
- Durrans, S.R. Distributions of fractional order statistics in hydrology. Water Resour. Res. 1992, 28, 1649–1655. [Google Scholar] [CrossRef]
- Bolfarine, H.; Martínez-Flórez, G.; Salinas, H.S. Bimodal symmetric–asymmetric power–normal families. Commun. Stat. Theory Methods 2018, 47, 259–276. [Google Scholar] [CrossRef]
- Elal-Olivero, D. Alpha-skew-normal distribution. Proyecc. J. Math. 2010, 29, 224–240. [Google Scholar] [CrossRef]
- Elal-Olivero, D.; Gómez, H.W.; Quintana, F.A. Bayesian modeling using a class of bimodal skew–elliptical distributions. J. Stat. Plan. Inference 2010, 139, 1484–1492. [Google Scholar] [CrossRef]
- Ma, Y.; Genton, M.G. Flexible Class of Skew–Symmetric Distributions. Scand. J. Stat. 2004, 31, 459–468. [Google Scholar] [CrossRef]
- Shafiei, S.; Doostparast, M.; Jamalizadeh, A. The alpha–beta skew normal distribution: Properties and applications. Statistics 2016, 50, 338–349. [Google Scholar] [CrossRef]
- Pewsey, A.; Gómez, H.W.; Bolfarine, H. Likelihood–based inference for power distributions. Test 2012, 21, 775–789. [Google Scholar] [CrossRef]
- Martínez-Flórez, G.; Bolfarine, H.; Gómez, H.W. Skew–normal alpha-power model. Statistics 2014, 48, 1414–1428. [Google Scholar] [CrossRef]
- R Development Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2019; Available online: http://www.R-project.org (accessed on 10 December 2019).
- Gupta, R.C.; Gupta, R.D. Generalized skew normal model. Test 2004, 13, 501–524. [Google Scholar] [CrossRef]
- Sharafi, M.; Behboodian, J. The Balakrishnan skew–normal density. Stat. Papers 2008, 49, 769–778. [Google Scholar] [CrossRef]
- Roberts, H. Data Analysis for Managers with MINITAB, 1st ed.; Scientific Press: Redwood City, CA, USA, 1988. [Google Scholar]
- Akaike, H. A new look at statistical model identification. IEEE Trans. Autom. Contr. 1974, 19, 716–722. [Google Scholar] [CrossRef]
- Hastie, T.J.; Tibshirani, R.J. Generalized Additive Models, 1st ed.; Chapman and Hall/CRC: New York, NY, USA, 1990. [Google Scholar]
- Hannan, E.J.; Quinn, B.G. The determination of the order of an autoregression. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 1979, 41, 190–195. [Google Scholar] [CrossRef]
- Hartigan, J.A.; Hartigan, P.M. The dip test of unimodality. Ann. Stat. 1985, 13, 70–84. [Google Scholar] [CrossRef]
- Hartigan, P.M. Algorithm AS 217: Computation of the dip statistic to test for unimodality. J. R. Stat. Soc. Ser. C (Appl. Stat.) 1985, 34, 320–325. [Google Scholar] [CrossRef]
- Azzalini, A.; Bowman, A.W. A look at some data on the old faithful geyser. J. R. Stat. Soc. Ser. C (Appl. Stat.) 1990, 39, 357–365. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 0.5 | 1.0 | 40 | 0.0140 | 0.2647 | 0.0120 | 0.0808 | 2.2831 | 6.1943 | 0.0078 | 0.1752 |
| 80 | 0.0105 | 0.1791 | 0.0053 | 0.0580 | 0.6356 | 3.4120 | 0.0061 | 0.1259 | ||
| 120 | 0.0065 | 0.1433 | 0.0040 | 0.0461 | 0.2566 | 2.2942 | 0.0017 | 0.0940 | ||
| 160 | 0.0036 | 0.1212 | 0.0018 | 0.0398 | 0.0996 | 0.7387 | 0.0024 | 0.0803 | ||
| 320 | 0.0010 | 0.0835 | 0.0011 | 0.0270 | 0.0332 | 0.1650 | 0.0014 | 0.0557 | ||
| 1.75 | 40 | 0.0197 | 0.2170 | 0.0093 | 0.0728 | 6.4625 | 9.3573 | 0.0047 | 0.1543 | |
| 80 | 0.0165 | 0.1518 | 0.0064 | 0.0515 | 3.9608 | 8.2540 | 0.0023 | 0.1078 | ||
| 120 | 0.0113 | 0.1270 | 0.0046 | 0.0416 | 2.6714 | 7.6473 | 0.0018 | 0.0884 | ||
| 160 | 0.0097 | 0.1074 | 0.0026 | 0.0355 | 1.6530 | 6.1734 | 0.0001 | 0.0751 | ||
| 320 | 0.0044 | 0.0748 | 0.0014 | 0.0254 | 0.3783 | 2.3064 | 0.0001 | 0.0532 | ||
| 3.0 | 40 | 0.0152 | 0.1938 | 0.0085 | 0.0685 | 9.1202 | 11.7713 | 0.0063 | 0.1449 | |
| 80 | 0.0146 | 0.1371 | 0.0048 | 0.0479 | 8.2167 | 11.0228 | 0.0023 | 0.1007 | ||
| 120 | 0.0125 | 0.1127 | 0.0034 | 0.0389 | 7.6172 | 10.9091 | 0.0024 | 0.0819 | ||
| 160 | 0.0111 | 0.0986 | 0.0029 | 0.0334 | 6.4907 | 10.2152 | 0.0015 | 0.0718 | ||
| 320 | 0.0094 | 0.0709 | 0.0014 | 0.0240 | 3.4155 | 8.9261 | 0.0013 | 0.0504 | ||
| 2.0 | 2.0 | 40 | 0.0192 | 0.2110 | 0.0083 | 0.0615 | 1.1333 | 5.4692 | 0.0195 | 0.4858 |
| 80 | 0.0079 | 0.1414 | 0.0029 | 0.0428 | 0.1469 | 1.3480 | 0.0148 | 0.3384 | ||
| 120 | 0.0070 | 0.1127 | 0.0027 | 0.0340 | 0.0632 | 0.6112 | 0.0044 | 0.2674 | ||
| 160 | 0.0036 | 0.0933 | 0.0012 | 0.0286 | 0.0339 | 0.1686 | 0.0065 | 0.2219 | ||
| 320 | 0.0021 | 0.0667 | 0.0008 | 0.0205 | 0.0171 | 0.1122 | 0.0074 | 0.1594 | ||
| 1.75 | 40 | 0.0239 | 0.1801 | 0.0066 | 0.0523 | 6.4470 | 11.389 | 0.0102 | 0.4745 | |
| 80 | 0.0144 | 0.1276 | 0.0035 | 0.0368 | 2.4806 | 7.4704 | 0.0001 | 0.3290 | ||
| 120 | 0.0084 | 0.1012 | 0.0018 | 0.0288 | 1.3470 | 5.6921 | 0.0077 | 0.2633 | ||
| 160 | 0.0039 | 0.0875 | 0.0011 | 0.0256 | 0.7014 | 4.0847 | 0.0079 | 0.2326 | ||
| 320 | 0.0026 | 0.0589 | 0.0011 | 0.0180 | 0.1161 | 0.6428 | 0.0041 | 0.1546 | ||
| 3.0 | 40 | 0.0171 | 0.1697 | 0.0042 | 0.0506 | 11.8522 | 12.4302 | 0.0224 | 0.4768 | |
| 80 | 0.0151 | 0.1173 | 0.0028 | 0.0341 | 7.8559 | 12.6750 | 0.0085 | 0.3171 | ||
| 120 | 0.0123 | 0.0948 | 0.0031 | 0.0276 | 6.7534 | 11.9330 | 0.0155 | 0.2591 | ||
| 160 | 0.0092 | 0.0860 | 0.0015 | 0.0246 | 5.3014 | 11.2255 | 0.0052 | 0.2308 | ||
| 320 | 0.0053 | 0.0598 | 0.0012 | 0.0172 | 2.2874 | 7.9028 | 0.0073 | 0.1593 | ||
| 5.0 | 1.0 | 40 | 0.0135 | 0.4798 | 0.0023 | 0.1224 | 3.3512 | 8.2619 | 0.8576 | 4.6909 |
| 80 | 0.0070 | 0.2775 | 0.0029 | 0.0743 | 0.9887 | 4.8077 | 0.2170 | 1.7650 | ||
| 120 | 0.0035 | 0.2031 | 0.0036 | 0.0556 | 0.3442 | 2.8067 | 0.1157 | 0.9897 | ||
| 160 | 0.0027 | 0.1646 | 0.0029 | 0.0459 | 0.1134 | 1.1807 | 0.0759 | 0.7488 | ||
| 320 | 0.0027 | 0.1103 | 0.0014 | 0.0308 | 0.0270 | 0.1628 | 0.0398 | 0.4915 | ||
| 1.75 | 40 | 0.0740 | 0.6027 | 0.0108 | 0.1297 | 9.3726 | 10.9680 | 12.947 | 6.5324 | |
| 80 | 0.0118 | 0.3007 | 0.0003 | 0.0712 | 6.8694 | 10.6797 | 0.3210 | 2.4019 | ||
| 120 | 0.0061 | 0.2077 | 0.0018 | 0.0522 | 5.0132 | 10.3183 | 0.1211 | 1.3300 | ||
| 160 | 0.0051 | 0.1609 | 0.0021 | 0.0416 | 3.5124 | 8.9549 | 0.0546 | 0.8401 | ||
| 320 | 0.0024 | 0.1044 | 0.0021 | 0.0278 | 0.9693 | 4.8586 | 0.0151 | 0.5193 | ||
| 3.0 | 40 | 0.1627 | 0.6833 | 0.0280 | 0.1400 | 10.8613 | 12.6877 | 1.9876 | 8.3799 | |
| 80 | 0.0219 | 0.3255 | 0.0019 | 0.0720 | 10.8081 | 11.4270 | 0.4140 | 3.1350 | ||
| 120 | 0.0112 | 0.2030 | 0.0004 | 0.0495 | 9.0012 | 10.9669 | 0.1059 | 1.2182 | ||
| 160 | 0.0060 | 0.1618 | 0.0021 | 0.0403 | 8.5141 | 9.8583 | 0.0573 | 0.9396 | ||
| 320 | 0.0009 | 0.1039 | 0.0023 | 0.0266 | 6.1416 | 8.0937 | 0.0197 | 0.5351 | ||
| Mean | Variance | Skewness | Kurtosis |
|---|---|---|---|
| 106.653 | 8.309 | 0.364 | 2.337 |
| Estimate | BSAP | BSN | ABSN | ETN |
|---|---|---|---|---|
| 116.98 (1.010) | 108.210 (0.946) | 110.442 (0.459) | 110.812 (1.336) | |
| 2.764 (0.338) | 4.160 (0.280) | 3.625 (0.187) | 8.48 (0.985) | |
| −0.326 (0.107) | 0.367 (0.076) | 1.225 (0.611) | 1.482 (1.025) | |
| 0.120 (0.040) | −0.828 (0.177) | −0.592 (0.280) | ||
| AIC | 366.97 | 368.99 | 400.74 | 370.92 |
| CAIC | 367.82 | 369.49 | 401.59 | 371.77 |
| BIC | 374.78 | 374.84 | 408.55 | 378.72 |
| HQIC | 369.96 | 371.23 | 403.73 | 373.91 |
| Mean | Variance | Skewness | Kurtosis |
|---|---|---|---|
| 70.897 | 13.594 | −0.414 | 1.843 |
| Estimate | BSAP | BSN | ASN | ETN |
|---|---|---|---|---|
| 61.969 (0.850) | 68.052 (0.376) | 67.228 (0.242) | 66.899 (0.916) | |
| 6.778 (0.231) | 5.836 (0.122) | 8.109 (0.204) | 13.036 (0.589) | |
| 0.672 (0.064) | −0.679 (0.066) | 1.547 (0.336) | ||
| 2.637 (0.267) | 25.111 (8.807) | 0.337 (0.107) | ||
| AIC | 2092.42 | 2099.31 | 2127.04 | 2156.88 |
| CAIC | 2092.56 | 2099.39 | 2127.12 | 2157.02 |
| BIC | 2106.85 | 2110.12 | 2137.86 | 2171.31 |
| HQIC | 2098.21 | 2103.65 | 2131.38 | 2162.67 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martínez-Flórez, G.; Tovar-Falón, R.; Jimémez-Narváez, M. Likelihood-Based Inference for the Asymmetric Beta-Skew Alpha-Power Distribution. Symmetry 2020, 12, 613. https://doi.org/10.3390/sym12040613
Martínez-Flórez G, Tovar-Falón R, Jimémez-Narváez M. Likelihood-Based Inference for the Asymmetric Beta-Skew Alpha-Power Distribution. Symmetry. 2020; 12(4):613. https://doi.org/10.3390/sym12040613
Chicago/Turabian StyleMartínez-Flórez, Guillermo, Roger Tovar-Falón, and Marvin Jimémez-Narváez. 2020. "Likelihood-Based Inference for the Asymmetric Beta-Skew Alpha-Power Distribution" Symmetry 12, no. 4: 613. https://doi.org/10.3390/sym12040613
APA StyleMartínez-Flórez, G., Tovar-Falón, R., & Jimémez-Narváez, M. (2020). Likelihood-Based Inference for the Asymmetric Beta-Skew Alpha-Power Distribution. Symmetry, 12(4), 613. https://doi.org/10.3390/sym12040613