Learning Large Margin Multiple Granularity Features with an Improved Siamese Network for Person Re-Identification


Abstract
1. Introduction
- We propose a novel symmetric Siamese network model called SMGN, the backbone CNN of which is composed by two branches, i.e., a local branch and a global branch. Compared with the traditional Siamese network model, SMGN can obtain LMMG features of person images, including local features and global features, which would be of great benefit to person re-identification.
- By fusing the verification and the identification information, a new MCWF loss function is designed for the SMGN model. Compared with traditional cross entropy loss, MCWF loss function takes into account decision boundary information in identification channels, so LMMG features extracted from SMGN can be guaranteed to have the character of margin maximization for classification.
2. Related Work
2.1. Hand-Crafted Feature-Based Person Re-ID
2.2. Deep Learned Feature-Based Person Re-ID
2.3. Loss Function-Based Person Re-ID
3. The Proposed Method
3.1. The Structure of SMGN
3.2. Multiple Granularity Features
3.3. Multi-Channel Weighted Fusion Loss
3.3.1. Identification Loss
3.3.2. Verification Loss
3.3.3. Fusion Loss
3.4. Person re-Identification Based on SMGN
4. Experiment Results
4.1. Datasets and Protocols
4.1.1. CUHK01
4.1.2. CUHK03
4.1.3. Market-1501
4.1.4. DukeMTMC-REID
4.1.5. Metric Protocols
4.2. Implementation Details
4.2.1. Data Preparation
4.2.2. Parameter Settings
4.2.3. Data Augmentation
4.3. Parameter Analysis
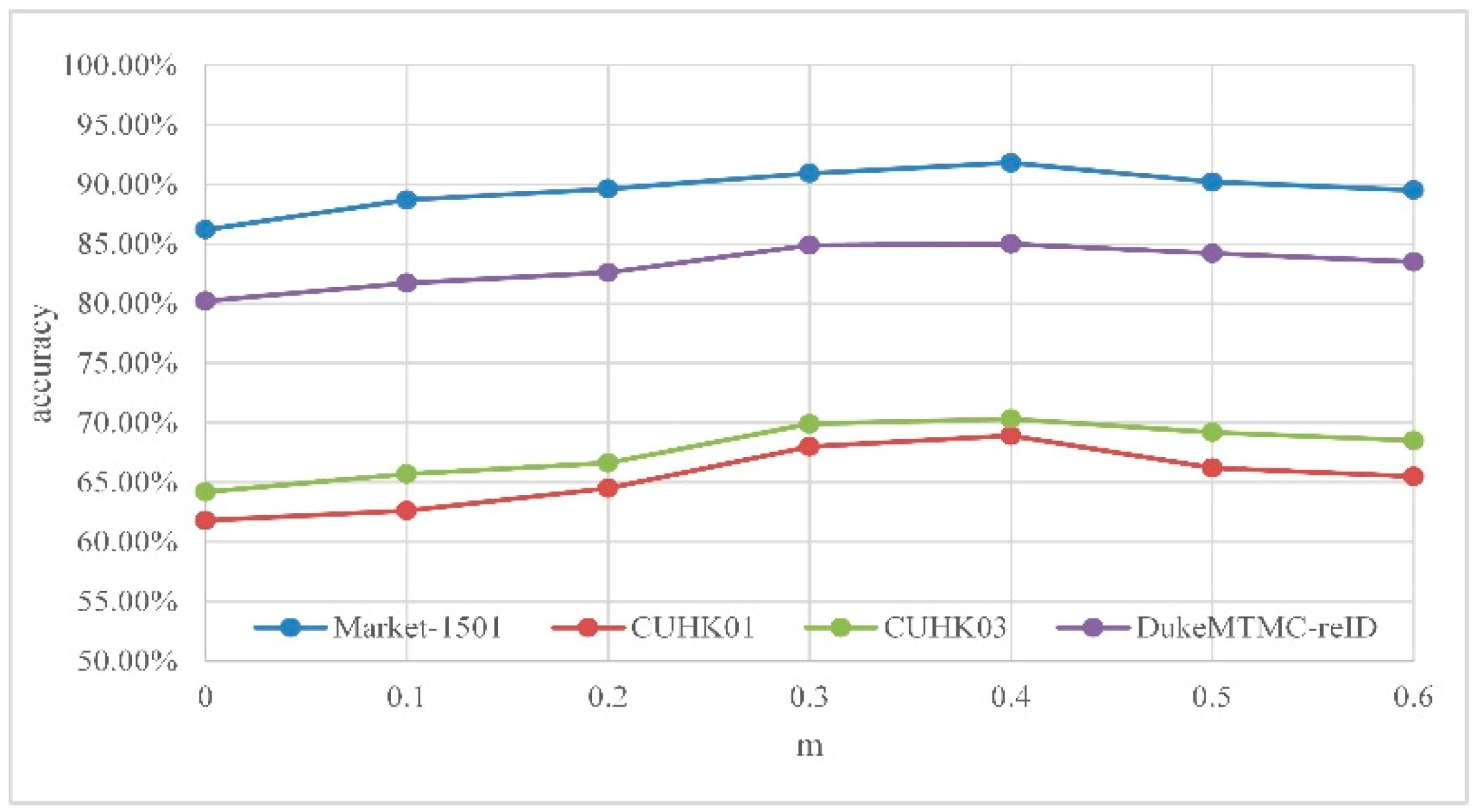
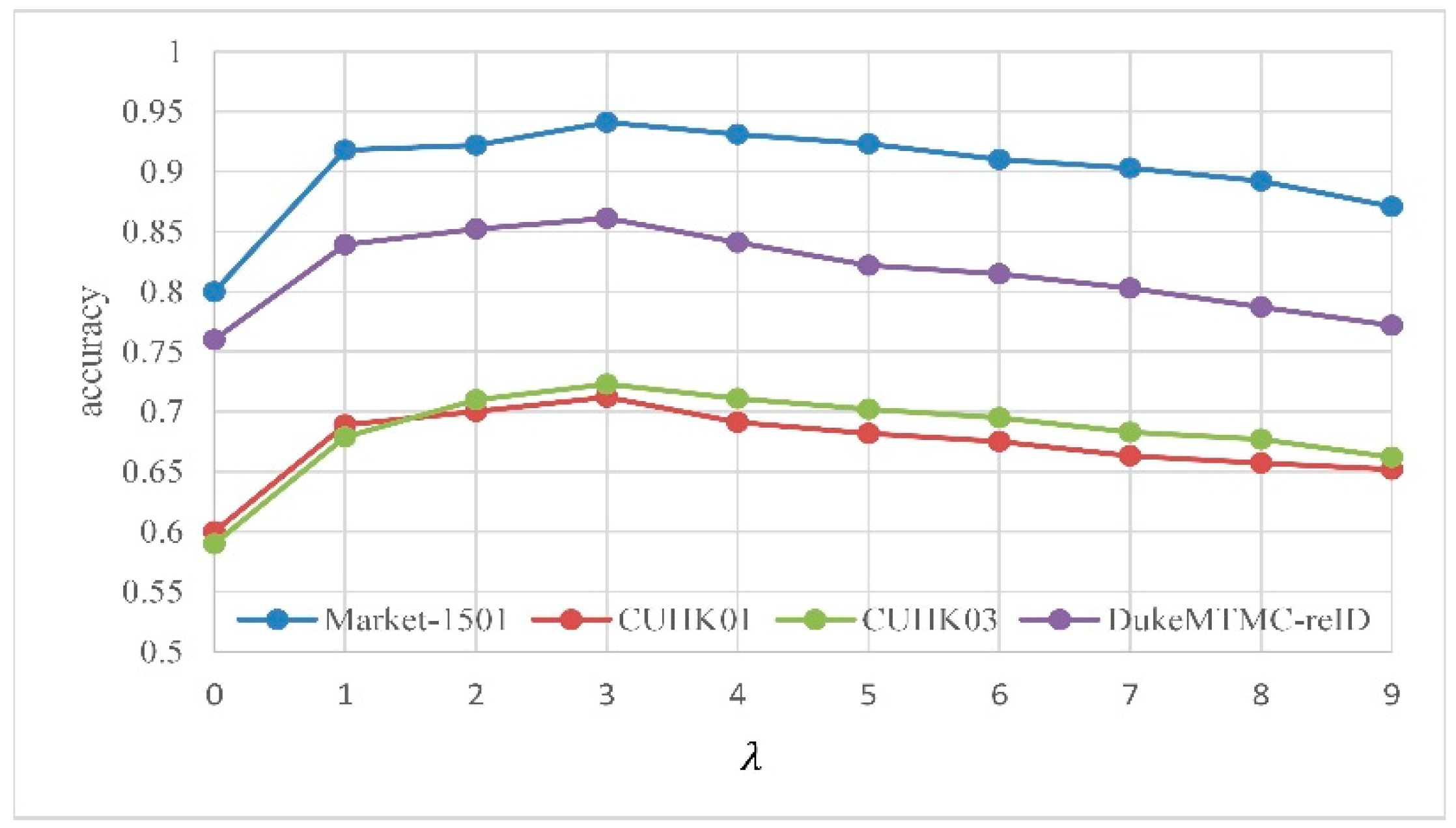
4.3.1. Effect of
4.3.2. Effect of
4.4. Performance Evaluation
4.4.1. Performance on the CUHK01 Dataset
4.4.2. Performance on the CUHK03 Dataset
4.4.3. Performance on the Market-1501dataset
4.4.4. Performance on DukeMTMC-reID
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Zheng, L.; Yang, Y.; Hauptmann, A.G. Person Re-Identification: Past, Present and Future. Available online: https://arxiv.org/abs/1610.02984 (accessed on 5 June 2019).
- Karanam, S.; Gou, M.; Wu, Z.; Rates-Borras, A.; Camps, O.; Radke, R.J. A systematic evaluation and benchmark for person re-identification: Features, metrics, and datasets. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 523–536. [Google Scholar] [CrossRef] [PubMed]
- Farenzena, M.; Bazzani, L.; Perina, A.; Murino, V.; Cristani, M. Person re-identification by symmetry-driven accumulation of local features. In Proceedings of the Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2360–2367. [Google Scholar]
- Liao, S.; Hu, Y.; Zhu, X.; Li, S.Z. Person re-identification by local maximal occurrence representation and metric learning. In Proceedings of the Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2197–2206. [Google Scholar]
- Yang, Y.; Yang, J.; Yan, J.; Liao, S.; Yi, D.; Li, S. Salient color names for person re-identification. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Volume 8689, pp. 536–551. [Google Scholar]
- Matsukawa, T.; Okabe, T.; Suzuki, E.; Sato, Y. Hierarchical Gaussian descriptor for person re-identification. In Proceedings of the Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1363–1372. [Google Scholar]
- Koestinger, M.; Hirzer, M.; Wohlhart, P.; Roth, P.M.; Bischof, H. Large scale metric learning from equivalence constraints. In Proceedings of the Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2288–2295. [Google Scholar]
- Liao, S.; Li, S. Efficient PSD constrained asymmetric metric learning for person re-identification. In Proceedings of the Computer Vision and Pattern Recognition, Santiago, Chile, 11–18 December 2015; pp. 3685–3693. [Google Scholar]
- Li, W.; Zhao, R.; Xiao, T.; Wang, X. DeepReID: Deep filter pairing neural network for person re-identification. In Proceedings of the Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 152–159. [Google Scholar]
- Ahmed, E.; Jones, M.; Marks, T.K. An improved deep learning architecture for person re-identification. In Proceedings of the Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3908–3916. [Google Scholar]
- Zheng, Z.; Zheng, L.; Yang, Y. A discriminatively learned CNN embedding for person reidentification. ACM Trans. Multimed. Comput. Commun. Appl. 2017, 14, 1–20. [Google Scholar] [CrossRef]
- Xiao, T.; Li, S.; Wang, B.; Lin, L.; Wang, X. Joint detection and identification feature learning for person search. In Proceedings of the Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3376–3385. [Google Scholar]
- Wu, L.; Wang, Y.; Gao, J.; Li, X. Where-and-when to look: Deep siamese attention networks for video-based person re-identification. IEEE Trans. Multimed. 2019, 21, 1412–1424. [Google Scholar] [CrossRef]
- Chung, D.; Tahboub, K.; Delp, E.J. A two stream siamese convolutional neural network for person re-identification. In Proceedings of the Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 1983–1991. [Google Scholar]
- Yan, Y.; Ni, B.; Song, Z.; Ma, C.; Yan, Y.; Yang, X. Person re-identification via recurrent feature aggregation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 701–716. [Google Scholar]
- Wang, G.; Yuan, Y.; Chen, X.; Li, J.; Zhou, X. Learning Disriminative Features with Multiple Granularities for Person Re-Identification. Available online: https://arxiv.org/abs/1804.01438 (accessed on 25 June 2019).
- Li, W.; Zhao, R.; Wang, X. Human re-identification with transferred metric learning. In Lecture Notes in Computer Science, Proceedings of the Asian Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2013; pp. 31–44. [Google Scholar]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable person re-identification: A benchmark. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1116–1124. [Google Scholar]
- Zheng, Z.; Zheng, L.; Yang, Y. Unlabeled samples generated by GAN improve the person re-identification baseline in vitro. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3754–3762. [Google Scholar]
- He, N.; Paoletti, M.E.; Haut, J.M.; Fang, L.; Li, S.; Plaza, A.J.; Plaza, J. Feature extraction with multiscale covariance maps for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 755–769. [Google Scholar] [CrossRef]
- Shih, Y.; Yeh, Y.; Lin, Y.; Weng, M.; Lu, Y.; Chuang, Y. Deep co-occurrence feature learning for visual object recognition. In Proceedings of the Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7302–7311. [Google Scholar]
- Gupta, U.; Chatterjee, A.; Srikanth, R.; Agrawal, P. A Sentiment-and-Semantics-Based Approach for Emotion Detection in Textual Conversations. July 2017. Available online: https://arxiv.org/abs/1707.06996 (accessed on 5 August 2019).
- Li, D.; Chen, X.; Zhang, Z.; Huang, K. Learning deep context-aware features over body and latent parts for person re-identification. In Proceedings of the Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 384–393. [Google Scholar]
- Su, C.; Li, J.; Zhang, S.; Xing, J.; Gao, W.; Tian, Q. Pose-driven deep convolutional model for person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3980–3989. [Google Scholar]
- Xiao, T.; Li, H.; Ouyang, W.; Wang, X. Learning deep feature representations with domain guided dropout for person re-identification. In Proceedings of the Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1249–1258. [Google Scholar]
- Subramaniam, A.; Chatterjee, M.; Mittal, A. Deep neural networks with inexact matching for person re-identification. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2667–2675. [Google Scholar]
- Varior, R.R.; Haloi, M.; Wang, G. Gated siamese convolutional neural network architecture for human re-identification. In Proceedings of the European Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; pp. 791–808. [Google Scholar]
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y. A discriminative feature learning approach for deep face recognition. In Lecture Notes in Computer Science, Proceedings of the European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 499–515. [Google Scholar]
- Hermans, A.; Beyer, L.; Leibe, B. In Defense of the Triplet Loss for Person Re-Identification. Available online: https://arxiv.org/abs/1703.07737 (accessed on 1 October 2019).
- Liu, W.; Wen, Y.; Yu, Z.; Yang, M. Large-Margin Softmax Loss for Convolutional Neural Networks. Available online: https://arxiv.org/abs/1612.02295 (accessed on 10 October 2019).
- Liu, W.; Wen, Y.; Yu, Z.; Li, M.; Raj, B.; Song, L. SphereFace: Deep hypersphere embedding for face recognition. In Proceedings of the Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6738–6746. [Google Scholar]
- Wang, F.; Cheng, J.; Liu, W.; Liu, H. Additive margin softmax for face verification. Signal Process. 2018, 25, 926–930. [Google Scholar] [CrossRef]
- Almazán, J.; Gajic, B.; Murray, N.; Larlus, D. Re-Id Done Right: Towards Good Practices for Person Re-Identification. Available online: https://arxiv.org/abs/1801.05339 (accessed on 13 December 2019).
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lile, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Wang, H.; Wang, Y.; Zhou, Z.; Ji, X.; Gong, D.; Zhou, J.; Li, Z.; Liu, W. CosFace: Large margin cosine loss for deep face recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5265–5274. [Google Scholar]
- Yi, D.; Lei, Z.; Liao, S.; Li, S.Z. Deep metric learning for person re-identification. In Proceedings of the International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 December 2014; pp. 34–39. [Google Scholar]
- Zhong, Z.; Zheng, L.; Cao, D.; Li, S. Re-ranking person re-identification with k-reciprocal encoding. In Proceedings of the Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3652–3661. [Google Scholar]
- Zhang, L.; Xiang, T.; Gong, S. Learning a discriminative null space for person re-identification. In Proceedings of the Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1239–1248. [Google Scholar]
- Chen, Y.; Zheng, W.; Lai, J.; Yuen, P. An asymmetric distance model for cross-view feature mapping in person reidentification. IEEE Trans. Circuits Syst. Video Technol. 2017, 27, 1661–1675. [Google Scholar] [CrossRef]
- Cheng, D.; Gong, Y.; Zhou, S.; Wang, J.; Zheng, N. Person re-identification by multi-channel parts-based CNN with improved triplet loss function. In Proceedings of the Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1335–1344. [Google Scholar]
- Chen, Y.; Zhu, X.; Gong, S. Person re-identification by deep learning multi-scale representations. In Proceedings of the Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 2590–2600. [Google Scholar]
- Sun, Y.; Zheng, L.; Deng, W.; Wang, S. SVDNet for pedestrian retrieval. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3800–3808. [Google Scholar]
- Li, W.; Zhu, X.; Gong, S. Harmonious attention network for person re-identification. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2285–2294. [Google Scholar]
- Song, C.; Huang, Y.; Ouyang, W.; Wang, L. Mask-guided contrastive attention model for personre-Identification. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1179–1188. [Google Scholar]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond part models: Person retrieval with refined part pooling. In Lecture Notes in Computer Science, Proceedings of the European Conference on Computer Vision; Springer: Munich, Germany, 8–14 September 2018; pp. 480–496. [Google Scholar]
- Sarfraz, M.S.; Schumann, A.; Eberle, A.; Stiefelhagen, R. A pose-sensitive embedding for person re-identification with expanded cross neighborhood re-ranking. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 420–429. [Google Scholar]
- Bai, X.; Yang, M.; Huang, T.; Dou, Z.; Yu, R.; Xu, Y. Deep-Person: Learning Discriminative Deep Features for Person Re-Identification. Available online: https:/arxiv.org/abs/1711.10658 (accessed on 10 November 2019).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Branch | Map Size | Dimension | Feature |
|---|---|---|---|
| Global-1 | 12 × 4 | 256 | |
| Global-2 | 12 × 4 | 256 | |
| Local-1 | 24 × 8 | 256 × 3 | |
| Local-2 | 24 × 8 | 256 × 3 |
| Dataset | Release Time | Identities | Cameras | Images | Label Method | Crop Size |
|---|---|---|---|---|---|---|
| CUHK01 | 2012 | 971 | 2 | 3884 | Hand | 160 × 60 |
| CUHK03 | 2014 | 1467 | 10 (5 pairs) | 13,164 | Hand/DPM | Vary |
| Market-1501 | 2015 | 1501 | 6 | 32,217 | Hand/DPM | 128 × 64 |
| DukeMTMC-reID | 2017 | 1812 | 8 | 36,411 | Hand | Vary |
| Method | Rank 1 | Rank 5 | Rank 10 | Rank 20 |
|---|---|---|---|---|
| FPNN [9] | 27.9% | — | — | — |
| Deep CNN [10] | 47.5% | — | — | — |
| KCVDCA [39] | 47.8% | 74.2% | 83.4% | 89.9% |
| LOMO+XQDA [4] | 49.2% | 75.7% | 84.2% | 90.8% |
| TCP [40] | 53.7% | 84.3% | 91.0% | 93.3% |
| GOG+XQDA [6] | 57.8% | 79.1% | 86.2% | 92.1% |
| NFST [38] | 69.1% | 86.9% | 91.8% | 95.4% |
| Ours | 71.2% | 87.2% | 90.9% | 95.5% |
| Ours+re−rank | 72.0% | 88.1% | 91.2% | 96.3% |
| Method | Detected | Labeled | ||||
|---|---|---|---|---|---|---|
| Rank 1 | Rank 5 | Rank 10 | Rank 1 | Rank 5 | Rank 10 | |
| FPNN [9] | 19.9% | 49.0% | 64.3% | 20.7% | 51.7% | 68.3% |
| DPFL [41] | 40.7% | — | — | 43.0% | — | — |
| SVDNet [42] | 41.5% | — | — | 40.9% | — | — |
| HA-CNN [43] | 41.7% | — | — | 44.4% | — | — |
| Deep CNN [10] | 45.0% | 75.7% | 83.0% | 54.7% | 88.3% | 93.3% |
| LOMO+XQDA [4] | 46.3% | 79.0% | 88.6% | 52.2% | 82.3% | 92.1% |
| MGCAM [44] | 46.7% | — | — | 50.1% | — | — |
| LOMO+MLAPG [8] | 51.2% | — | — | 58.0% | — | — |
| NFST [38] | 54.7% | 84.8% | 94.8% | 62.6% | 90.1% | 94.8% |
| PCB+RPP [45] | 63.7% | 80.6% | 86.9% | — | — | — |
| GOG+XQDA [6] | 65.5% | 88.4% | 93.7% | 67.3% | 91.0% | 96.0% |
| MGN [16] | 66.8% | — | — | 68.0% | — | — |
| Ours | 70.2% | 87.2% | 93.9% | 72.3% | 89.1% | 96.7% |
| Ours+re−rank | 71.5% | 88.3% | 94.0% | 73.1% | 90.0% | 97.1% |
| Method | Market-1501 | DukeMTMC-re-ID | ||
|---|---|---|---|---|
| Rank-1 | MAP | Rank-1 | MAP | |
| BoW+kissme [18] | 39.6% | 17.7% | 25.1% | 12.2% |
| LOMO+XQDA [4] | 43.8% | 22.2% | 30.8% | 17.0% |
| NFST [38] | 55.4% | 29.9% | — | — |
| Gated SCNN [27] | 65.9% | 39.6% | — | — |
| SVDNet [42] | 82.3% | 62.1% | 76.7% | 56.8% |
| MGCAM [44] | 83.8% | 74.3% | — | — |
| PSE [46] | 87.7% | 69.0% | 79.8% | 62.0% |
| DPFL [41] | 88.6% | 72.6% | 79.2% | 60.6% |
| HA-CNN [43] | 91.2% | 75.7% | 80.5% | 63.8% |
| Deep-Person [47] | 92.3% | 79.6% | 80.9% | 64.8% |
| PCB+RPP [45] | 93.8% | 81.6% | 83.3% | 69.2% |
| Ours | 94.1% | 79.2% | 86.1% | 75.3% |
| Ours+re-rank | 95.5% | 80.3% | 87.1% | 76.0% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, D.-X.; Fei, G.-Y.; Teng, S.-W. Learning Large Margin Multiple Granularity Features with an Improved Siamese Network for Person Re-Identification. Symmetry 2020, 12, 92. https://doi.org/10.3390/sym12010092
Li D-X, Fei G-Y, Teng S-W. Learning Large Margin Multiple Granularity Features with an Improved Siamese Network for Person Re-Identification. Symmetry. 2020; 12(1):92. https://doi.org/10.3390/sym12010092
Chicago/Turabian StyleLi, Da-Xiang, Guo-Yuan Fei, and Shyh-Wei Teng. 2020. "Learning Large Margin Multiple Granularity Features with an Improved Siamese Network for Person Re-Identification" Symmetry 12, no. 1: 92. https://doi.org/10.3390/sym12010092
APA StyleLi, D.-X., Fei, G.-Y., & Teng, S.-W. (2020). Learning Large Margin Multiple Granularity Features with an Improved Siamese Network for Person Re-Identification. Symmetry, 12(1), 92. https://doi.org/10.3390/sym12010092