A Feasible Temporal Links Prediction Framework Combining with Improved Gravity Model



Abstract
1. Introduction
2. Related Works

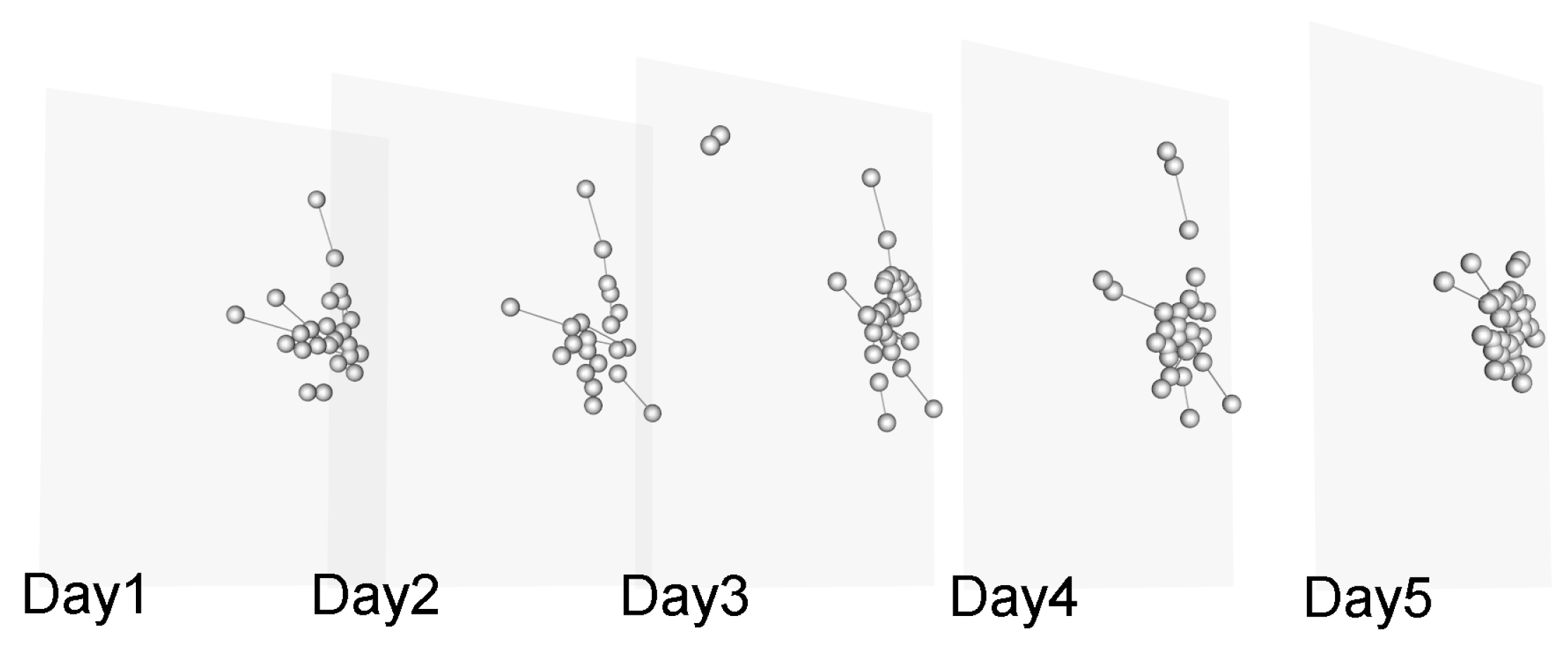{kind=link}
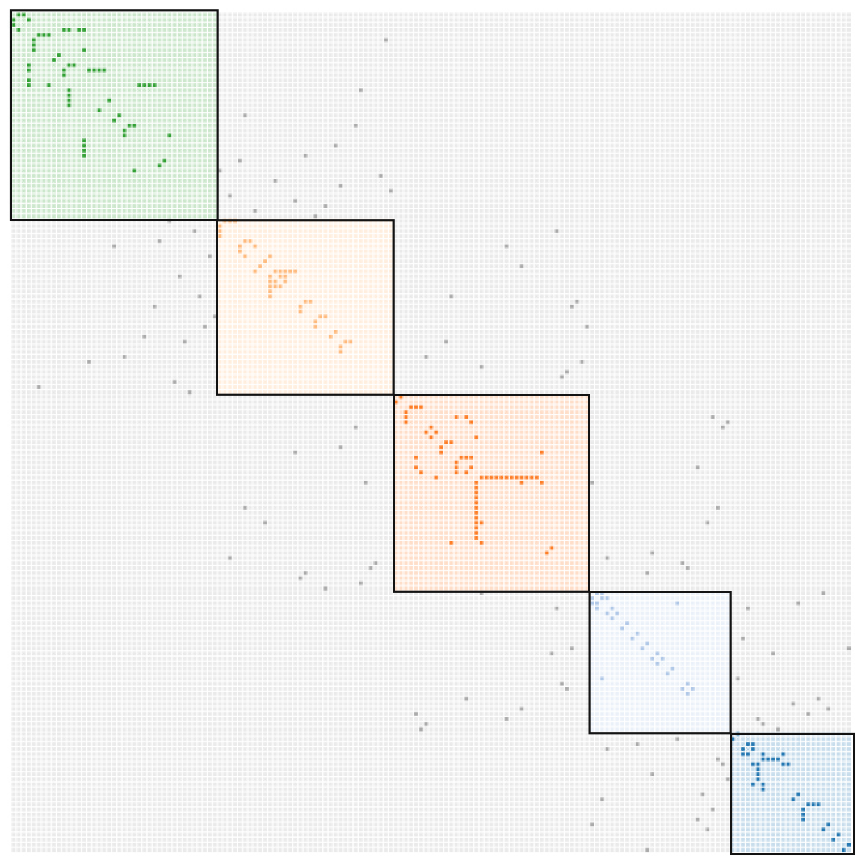{kind=link}
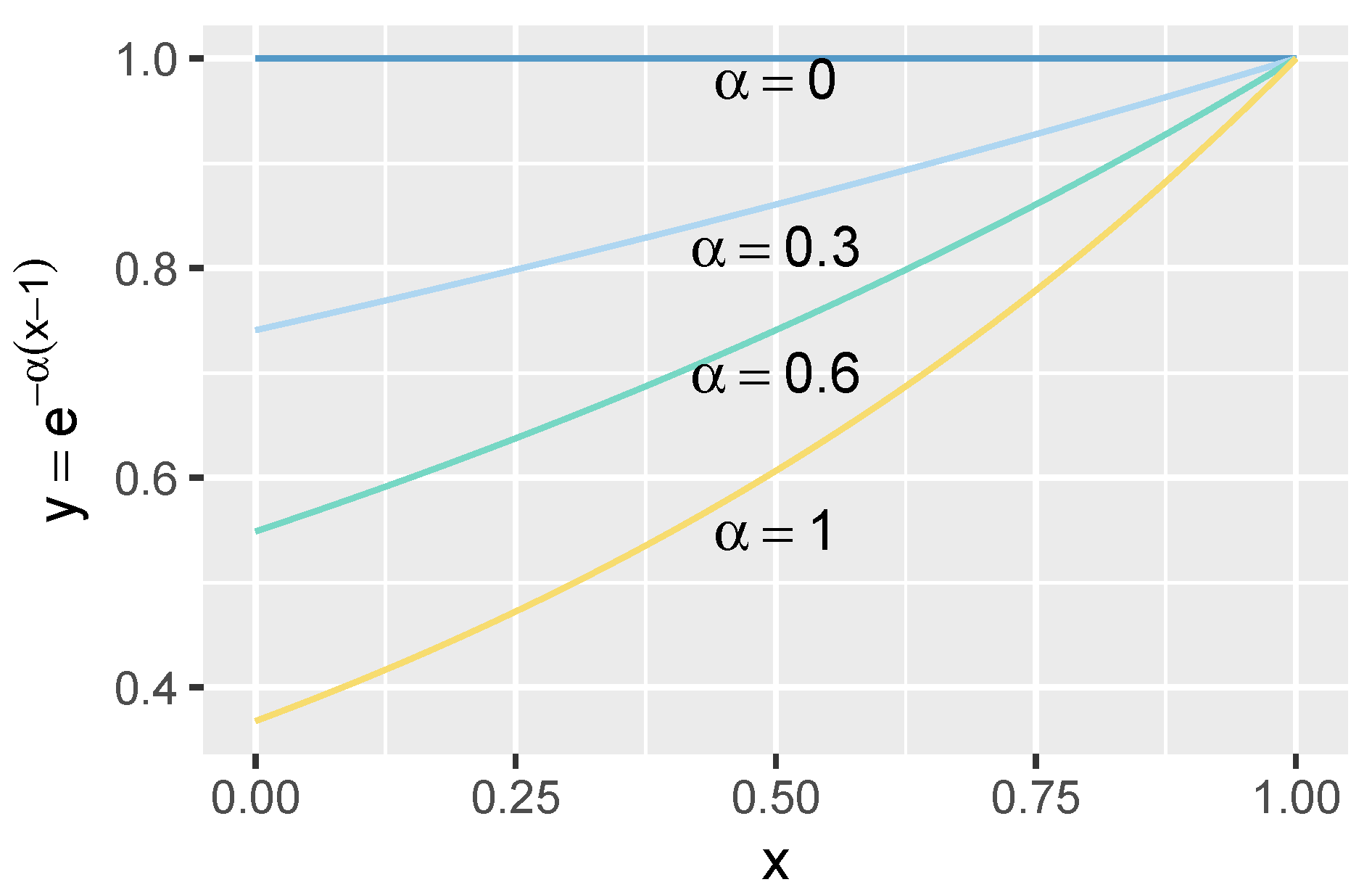{kind=link}
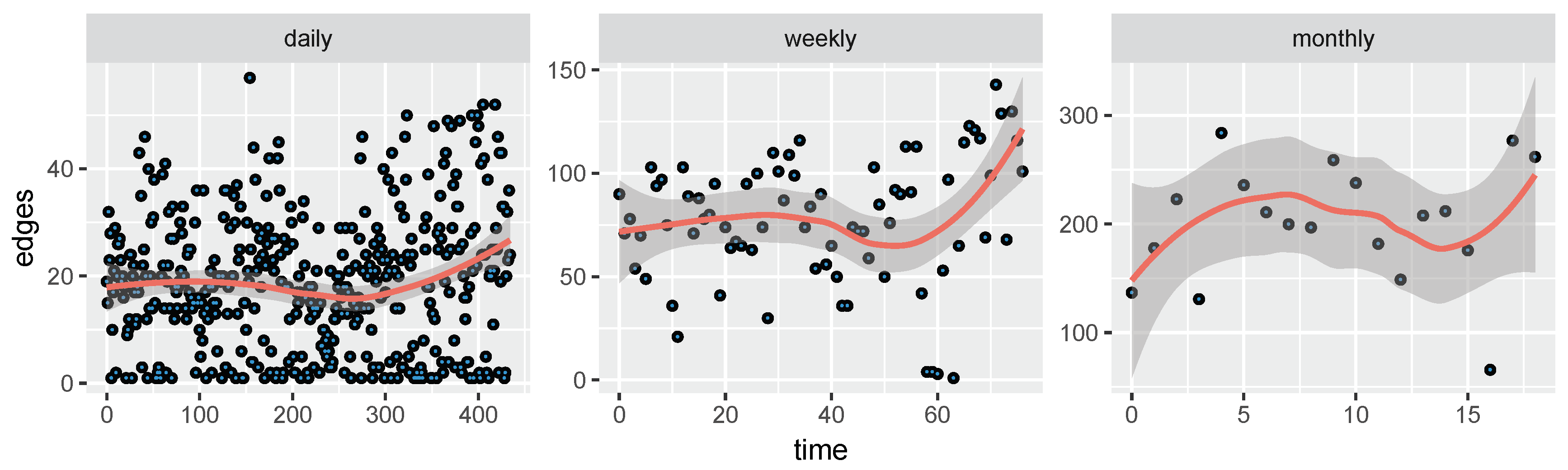{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indicator | Topology | Definition 1 | Complexity 2 |
|---|---|---|---|
| CN [24] | Local | ||
| Salton [25] | Local | ||
| Jaccard [26] | Local | ||
| Sorenson [27] | Local | ||
| HPI [28] | Local | ||
| HDI [29] | Local | ||
| LHN-I [29] | Local | ||
| AA [30] | Local | ||
| RA [31] | Local | ||
| PA [32] | Local | ||
| LP [33] | Semi-Local | ||
| Katz [34] | Global | ||
| LHN-II [35] | Global | ||
| LRW [36] | Semi-Local | ||
| SRW [36] | Semi-Local | ||
| RWR [37] | Semi-Local | ||
| ACT [38] | Semi-Local | ||
| SimR [39] | Global | ||
| Cos+ [40] | Semi-Local | ||
| TS [41] | Global | ||
| LowRank [11] | Global | ||
| MFI [42] | Global |
3. Modeling and Methods
3.1. Model
3.2. Definitions
| Algorithm 1: Temporal links prediction framework. |
 |
3.3. Complexity Analysis
4. Experiments and Discussion
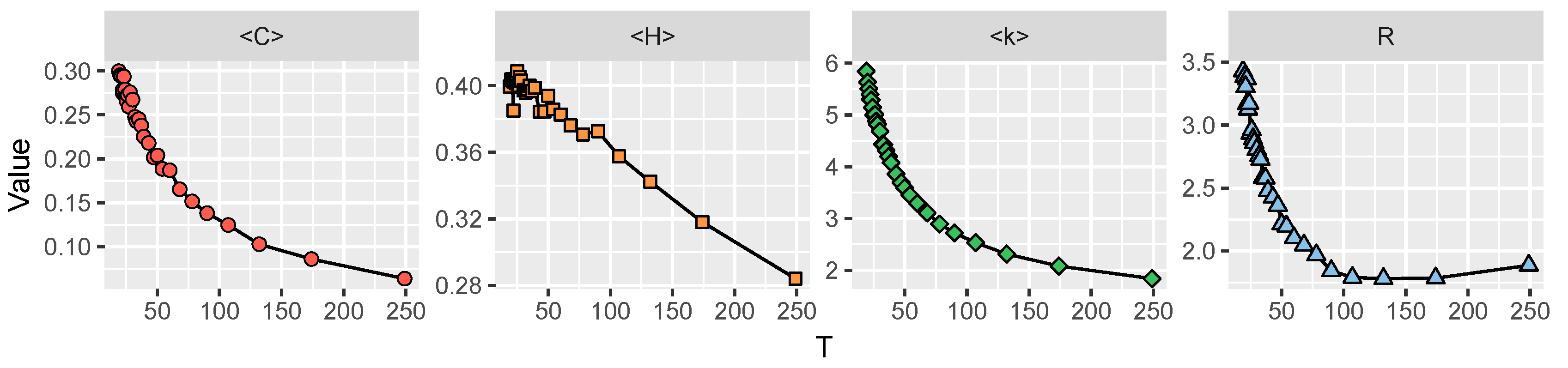
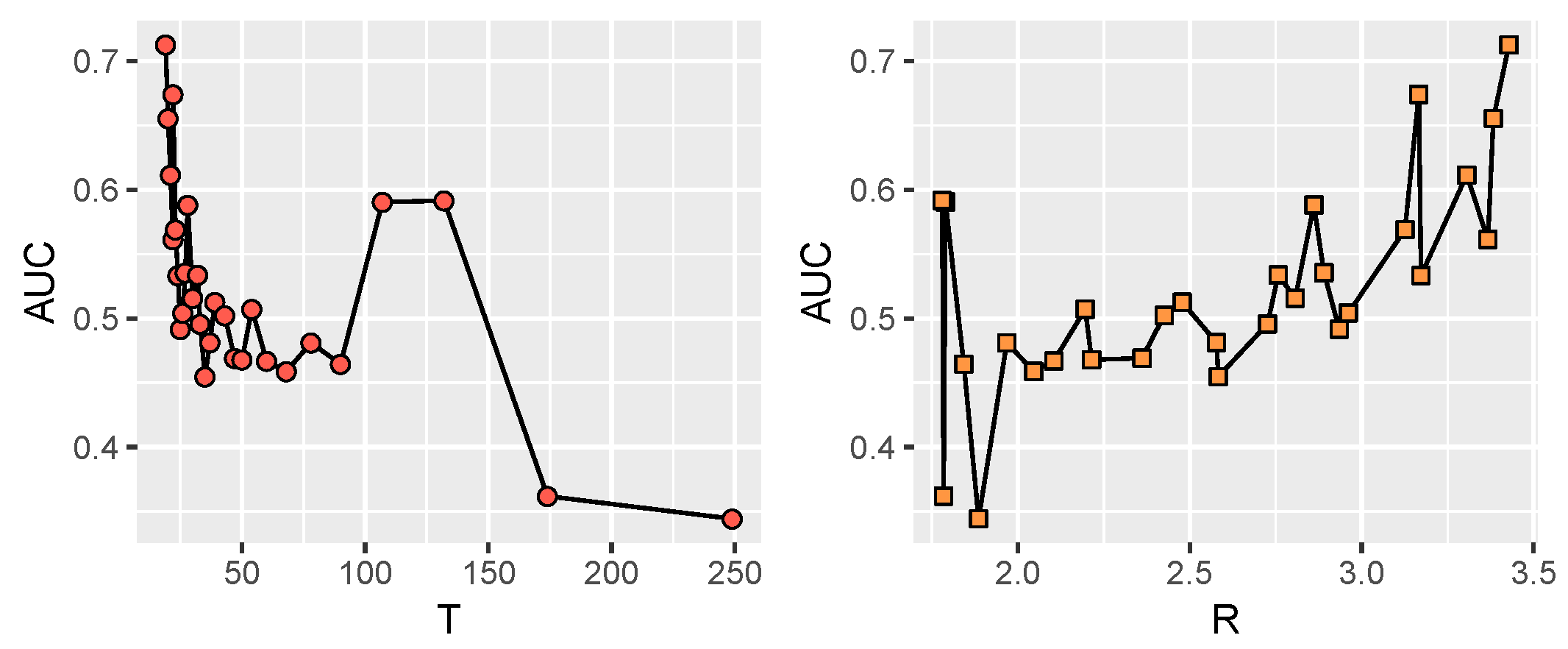
4.1. Experimental Datasets
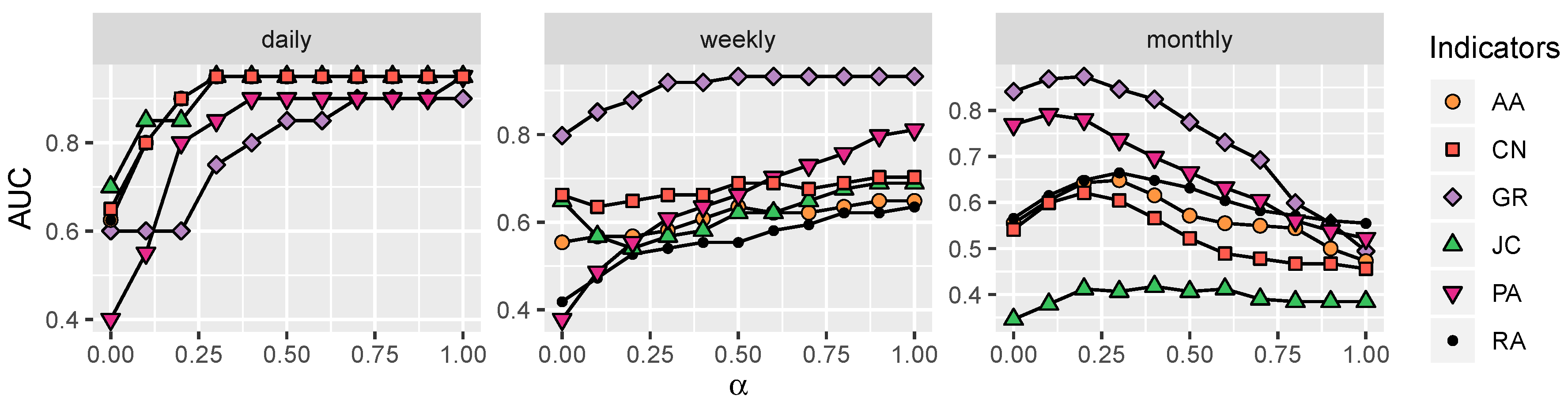
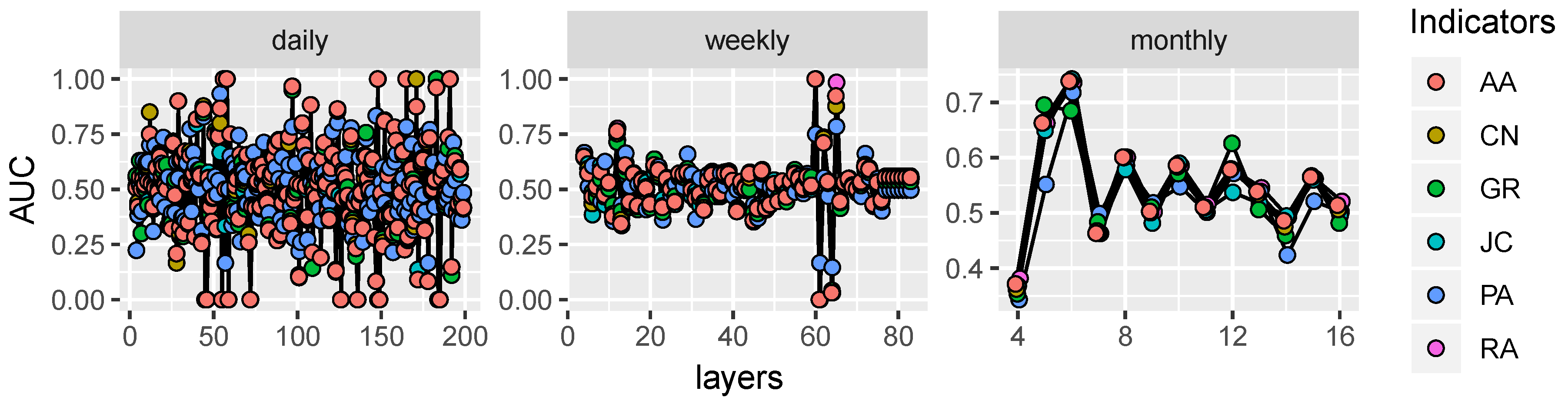
4.2. Performance Comparison
4.3. Parameters Analysis
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| AA | Adamic-Adar |
| ACT | Average commute time |
| ARIMA | Autoregressive Integrated Moving Average |
| AUC | Area Under the receiver operating characteristic Curve |
| CN | Common Neighbors |
| DS | Dynamic Similarity |
| EPS | Exponential Smoothing |
| GR | Gravity |
| JC | Jaccard |
| LR | Linear Regression |
| LRW | Local Random Walk |
| MFI | Matrix-forest index |
| PCA | Principal Component Analysis |
| RA | Resource Allocation |
| RWR | Random Walk with Restart |
| SimR | SimRank |
| SRW | Superposed Random Walk |
| TMLP | Time-aware Multi-relational Link Prediction |
| TS | Transferring Similarity |
References
- Wasserman, S.; Faust, K. Social Network Analysis: Methods and Applications; Cambridge University Press: Cambridge, UK, 1994; Volume 8. [Google Scholar]
- Antonacci, G.; Fronzetti Colladon, A.; Stefanini, A.; Gloor, P. It is rotating leaders who build the swarm: Social network determinants of growth for healthcare virtual communities of practice. J. Knowl. Manag. 2017, 21, 1218–1239. [Google Scholar] [CrossRef]
- Sett, N.; Basu, S.; Nandi, S.; Singh, S.R. Temporal link prediction in multi-relational network. World Wide Web 2018, 21, 395–419. [Google Scholar] [CrossRef]
- Getoor, L.; Diehl, C.P. Link mining: A survey. ACM SIGKDD Explor. Newslett. 2005, 7, 3–12. [Google Scholar] [CrossRef]
- Srinivas, V.; Mitra, P. Link Prediction Using Thresholding Nodes Based on Their Degree. In Link Prediction in Social Networks; Springer: Berlin/Heidelberg, Germany, 2016; pp. 15–25. [Google Scholar]
- Oyama, S.; Hayashi, K.; Kashima, H. Cross-temporal link prediction. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining, Vancouver, BC, Canada, 11–14 December 2011; pp. 1188–1193. [Google Scholar]
- Slokom, M.; Ayachi, R. A New Social Recommender System Based on Link Prediction Across Heterogeneous Networks. In Proceedings of the International Conference on Intelligent Decision Technologies, Sorrento, Italy, 17–19 June 2017; pp. 330–340. [Google Scholar]
- Kim, W.; Kwon, K.; Kwon, S.; Lee, S. The identification power of smoothness assumptions in models with counterfactual outcomes. Quantit. Econ. 2018, 9, 617–642. [Google Scholar] [CrossRef]
- Liben-Nowell, D.; Kleinberg, J. The link-prediction problem for social networks. J. Am. Soc. Inf. Sci. Technol. 2007, 58, 1019–1031. [Google Scholar] [CrossRef]
- Lü, L.; Zhou, T. Link prediction in complex networks: A survey. Phys. A Stat. Mech. Appl. 2011, 390, 1150–1170. [Google Scholar] [CrossRef]
- Pech, R.; Hao, D.; Pan, L.; Cheng, H.; Zhou, T. Link prediction via matrix completion. EPL (Europhys. Lett.) 2017, 117, 38002. [Google Scholar] [CrossRef]
- Munasinghe, L.; Ichise, R. Time aware index for link prediction in social networks. In Proceedings of the International Conference on Data Warehousing and Knowledge Discovery, Toulouse, France, 29 August–2 September 2011; pp. 342–353. [Google Scholar]
- Yasami, Y.; Safaei, F. A novel multilayer model for missing link prediction and future link forecasting in dynamic complex networks. Phys. A Stat. Mech. Appl. 2018, 492, 2166–2197. [Google Scholar] [CrossRef]
- Kostakos, V. Temporal graphs. Phys. A Stat. Mech. Appl. 2009, 388, 1007–1023. [Google Scholar] [CrossRef]
- Alhajj, R.; Rokne, J. Encyclopedia of Social Network Analysis and Mining; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Casteigts, A.; Flocchini, P.; Quattrociocchi, W.; Santoro, N. Time-varying graphs and dynamic networks. Int. J. Parallel Emerg. Distrib. Syst. 2012, 27, 387–408. [Google Scholar] [CrossRef]
- Hua, T.D.; Nguyen-Thi, A.T.; Nguyen, T.A.H. Link prediction in weighted network based on reliable routes by machine learning approach. In Proceedings of the 2017 4th NAFOSTED Conference on Information and Computer Science, Hanoi, Vietnam, 24–25 November 2017; pp. 236–241. [Google Scholar]
- Zhou, J.; Huang, D.; Wang, H. A dynamic logistic regression for network link prediction. Sci. China Math. 2017, 60, 165–176. [Google Scholar] [CrossRef]
- Tabourier, L.; Bernardes, D.F.; Libert, A.S.; Lambiotte, R. RankMerging: A supervised learning-to-rank framework to predict links in large social networks. Mach. Learn. 2019, 108, 1729–1756. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Athanasopoulos, G. Forecasting: Principles and Practice; OTexts: Melbourne, Australia, 2018. [Google Scholar]
- Hyndman, R.; Koehler, A.B.; Ord, J.K.; Snyder, R.D. Forecasting with Exponential Smoothing: The State Space Approach; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Divakaran, A.; Mohan, A. Temporal Link Prediction: A Survey. New Gener. Comput. 2019. [Google Scholar] [CrossRef]
- Özcan, A.; Öğüdücü, Ş.G. Multivariate temporal link prediction in evolving social networks. In Proceedings of the 2015 IEEE/ACIS 14th International Conference on Computer and Information Science (ICIS), Las Vegas, NV, USA, 28 June–1 July 2015; pp. 185–190. [Google Scholar]
- Lorrain, F.; White, H.C. Structural equivalence of individuals in social networks. J. Math. Soc. 1971, 1, 49–80. [Google Scholar] [CrossRef]
- Worth, D. Introduction to modern information retrieval. Aust. Acad. Res. Libr. 2010, 41, 305–306. [Google Scholar] [CrossRef][Green Version]
- Jaccard, P. Étude comparative de la distribution florale dans une portion des Alpes et des Jura. Bull. Soc. Vaudoise Sci. Nat. 1901, 37, 547–579. [Google Scholar]
- Sorensen, T.A. A method of establishing groups of equal amplitude in plant sociology based on similarity of species content and its application to analyses of the vegetation on Danish commons. Biol. Skar. 1948, 5, 1–34. [Google Scholar]
- Ravasz, E.; Somera, A.L.; Mongru, D.A.; Oltvai, Z.N.; Barabási, A.L. Hierarchical organization of modularity in metabolic networks. Science 2002, 297, 1551–1555. [Google Scholar] [CrossRef]
- Molloy, M.; Reed, B. A critical point for random graphs with a given degree sequence. Random Struct. Algorithms 1995, 6, 161–180. [Google Scholar] [CrossRef]
- Adamic, L.A.; Adar, E. Friends and neighbors on the web. Soc. Netw. 2003, 25, 211–230. [Google Scholar] [CrossRef]
- Zhou, T.; Lü, L.; Zhang, Y.C. Predicting missing links via local information. Eur. Phys. J. B 2009, 71, 623–630. [Google Scholar] [CrossRef]
- Barabási, A.L.; Albert, R. Emergence of scaling in random networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef] [PubMed]
- Lü, L.; Jin, C.H.; Zhou, T. Similarity index based on local paths for link prediction of complex networks. Phys. Rev. E 2009, 80, 046122. [Google Scholar] [CrossRef] [PubMed]
- Katz, L. A new status index derived from sociometric analysis. Psychometrika 1953, 18, 39–43. [Google Scholar] [CrossRef]
- Leicht, E.A.; Holme, P.; Newman, M.E. Vertex similarity in networks. Phys. Rev. E 2006, 73, 026120. [Google Scholar] [CrossRef]
- Liu, W.; Lü, L. Link prediction based on local random walk. EPL (Europhys. Lett.) 2010, 89, 58007. [Google Scholar] [CrossRef]
- Vragović, I.; Louis, E. Network community structure and loop coefficient method. Phys. Rev. E 2006, 74, 016105. [Google Scholar] [CrossRef]
- Klein, D.J.; Randić, M. Resistance distance. J. Math. Chem. 1993, 12, 81–95. [Google Scholar] [CrossRef]
- Jeh, G.; Widom, J. SimRank: A measure of structural-context similarity. In Proceedings of the eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Edmonton, AB, Canada, 23–26 July 2002; pp. 538–543. [Google Scholar]
- Fouss, F.; Pirotte, A.; Renders, J.M.; Saerens, M. Random-walk computation of similarities between nodes of a graph with application to collaborative recommendation. IEEE Trans. Knowl. Data Eng. 2007, 19, 355–369. [Google Scholar] [CrossRef]
- Sun, D.; Zhou, T.; Liu, J.G.; Liu, R.R.; Jia, C.X.; Wang, B.H. Information filtering based on transferring similarity. Phys. Rev. E 2009, 80, 017101. [Google Scholar] [CrossRef]
- Chebotarev, P.Y.; Shamis, E. A matrix-forest theorem and measuring relations in small social group. Avtomatika i Telemekhanika 1997, 58, 125–137. [Google Scholar]
- Boccaletti, S.; Bianconi, G.; Criado, R.; Del Genio, C.I.; Gómez-Gardenes, J.; Romance, M.; Sendina-Nadal, I.; Wang, Z.; Zanin, M. The structure and dynamics of multilayer networks. Phys. Rep. 2014, 544, 1–122. [Google Scholar] [CrossRef]
- Paranjape, A.; Benson, A.R.; Leskovec, J. Motifs in temporal networks. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 601–610. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Li, Z.; Ren, T.; Ma, X.; Liu, S.; Zhang, Y.; Zhou, T. Identifying influential spreaders by gravity model. Sci. Rep. 2019, 9, 8387. [Google Scholar] [CrossRef] [PubMed]
- Chen, D.; Kong, L.; Wang, D.; Huang, X.; Fang, B. TNLCD: A Feasible Algorithm for Local Community Discovery in Temporal Networks. In FSDM; IOS Press: Amsterdam, The Netherlands, 2018; pp. 459–464. [Google Scholar]
- Wang, P.; Xu, B.; Wu, Y.; Zhou, X. Link prediction in social networks: The state-of-the-art. Sci. China Inf. Sci. 2015, 58, 1–38. [Google Scholar] [CrossRef]
- Zachary, W.W. An information flow model for conflict and fission in small groups. J. Anthropol. Res. 1977, 33, 452–473. [Google Scholar] [CrossRef]
- Lusseau, D.; Schneider, K.; Boisseau, O.J.; Haase, P.; Slooten, E.; Dawson, S.M. The bottlenose dolphin community of Doubtful Sound features a large proportion of long-lasting associations. Behav. Ecol. Sociobiol. 2003, 54, 396–405. [Google Scholar] [CrossRef]
- Tsvetovat, M.; Kouznetsov, A. Social Network Analysis for Startups: Finding Connections on the Social Web; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2011. [Google Scholar]
- Newman, M.E. Modularity and community structure in networks. Proc. Natl. Acad. Sci. USA 2006, 103, 8577–8582. [Google Scholar] [CrossRef]
- Girvan, M.; Newman, M.E. Community structure in social and biological networks. Proc. Natl. Acad. Sci. USA 2002, 99, 7821–7826. [Google Scholar] [CrossRef]
- Watts, D.J.; Strogatz, S.H. Collective dynamics of ‘small-world’ networks. Nature 1998, 393, 440. [Google Scholar] [CrossRef]
- Hu, H.B.; Wang, X.F. Unified index to quantifying heterogeneity of complex networks. Phys. A Stat. Mech. Appl. 2008, 387, 3769–3780. [Google Scholar] [CrossRef]









| Dataset Name | |E| | <k> | |C| | <c> | |D| | r | |
|---|---|---|---|---|---|---|---|
| Zachary karate Club [49] | 34 | 78 | 4.59 | 0.57 | 2.41 | 2.22 | −0.48 |
| Dolphins social network [50] | 62 | 159 | 5.13 | 0.26 | 3.06 | 3.36 | −0.04 |
| Terriers of 9/11 [51] | 69 | 159 | 4.61 | 0.47 | 1.76 | 3.22 | −0.04 |
| NEUSNCP dataset 1 | 89 | 365 | 4.10 | 0.54 | 3.15 | 1.92 | −0.40 |
| Books about US politics [52] | 105 | 411 | 8.40 | 0.49 | 5.26 | 3.08 | −0.13 |
| American college football network [53] | 115 | 613 | 10.66 | 0.40 | 10.23 | 2.51 | 0.16 |
| Scientist collaboration network [52] | 1589 | 2742 | 4.60 | 0.64 | 0.08 | 5.99 | −0.09 |
| Dataset Name | Days | ||
|---|---|---|---|
| Email-Eu-core temporal network | 986 | 332,334 | 803 |
| Email-Eu-core-temporal-Dept1 | 309 | 61,046 | 803 |
| Email-Eu-core-temporal-Dept2 | 162 | 46,772 | 803 |
| Email-Eu-core-temporal-Dept3 | 89 | 12,216 | 803 |
| Email-Eu-core-temporal-Dept4 | 142 | 48,141 | 803 |
| Dataset Name | GR | AA | RA | JC | PA | CN |
|---|---|---|---|---|---|---|
| Zachary karate Club | 0.8790 | 0.8784 | 0.8784 | 0.6281 | 0.8773 | 0.8433 |
| Dolphins social network | 0.7442 | 0.7428 | 0.7425 | 0.7431 | 0.6621 | 0.7379 |
| Terriers of 9/11 | 0.9374 | 0.9339 | 0.9371 | 0.9151 | 0.7144 | 0.9103 |
| NEUSNCP dataset | 0.9110 | 0.9105 | 0.9096 | 0.8855 | 0.6725 | 0.9012 |
| Books about US politics | 0.8310 | 0.8299 | 0.8299 | 0.8397 | 0.2573 | 0.8304 |
| American college football network | 0.8775 | 0.8750 | 0.8769 | 0.7494 | 0.8381 | 0.8657 |
| Scientist collaboration network | 0.9431 | 0.9431 | 0.9431 | 0.9430 | 0.6725 | 0.9429 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, X.; Chen, D.; Ren, T. A Feasible Temporal Links Prediction Framework Combining with Improved Gravity Model. Symmetry 2020, 12, 100. https://doi.org/10.3390/sym12010100
Huang X, Chen D, Ren T. A Feasible Temporal Links Prediction Framework Combining with Improved Gravity Model. Symmetry. 2020; 12(1):100. https://doi.org/10.3390/sym12010100
Chicago/Turabian StyleHuang, Xinyu, Dongming Chen, and Tao Ren. 2020. "A Feasible Temporal Links Prediction Framework Combining with Improved Gravity Model" Symmetry 12, no. 1: 100. https://doi.org/10.3390/sym12010100
APA StyleHuang, X., Chen, D., & Ren, T. (2020). A Feasible Temporal Links Prediction Framework Combining with Improved Gravity Model. Symmetry, 12(1), 100. https://doi.org/10.3390/sym12010100