
Integrating Remote Sensing, Landscape Metrics, and Random Forest Algorithm to Analyze Crop Patterns, Factors, Diversity, and Fragmentation in a Kharif Agricultural Landscape

 , , ,
, , ,  and
and 
Abstract
1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Methods
2.2.1. Data Used
2.2.2. Crop Classification Using Random Forest
2.2.3. Accuracy Assessment
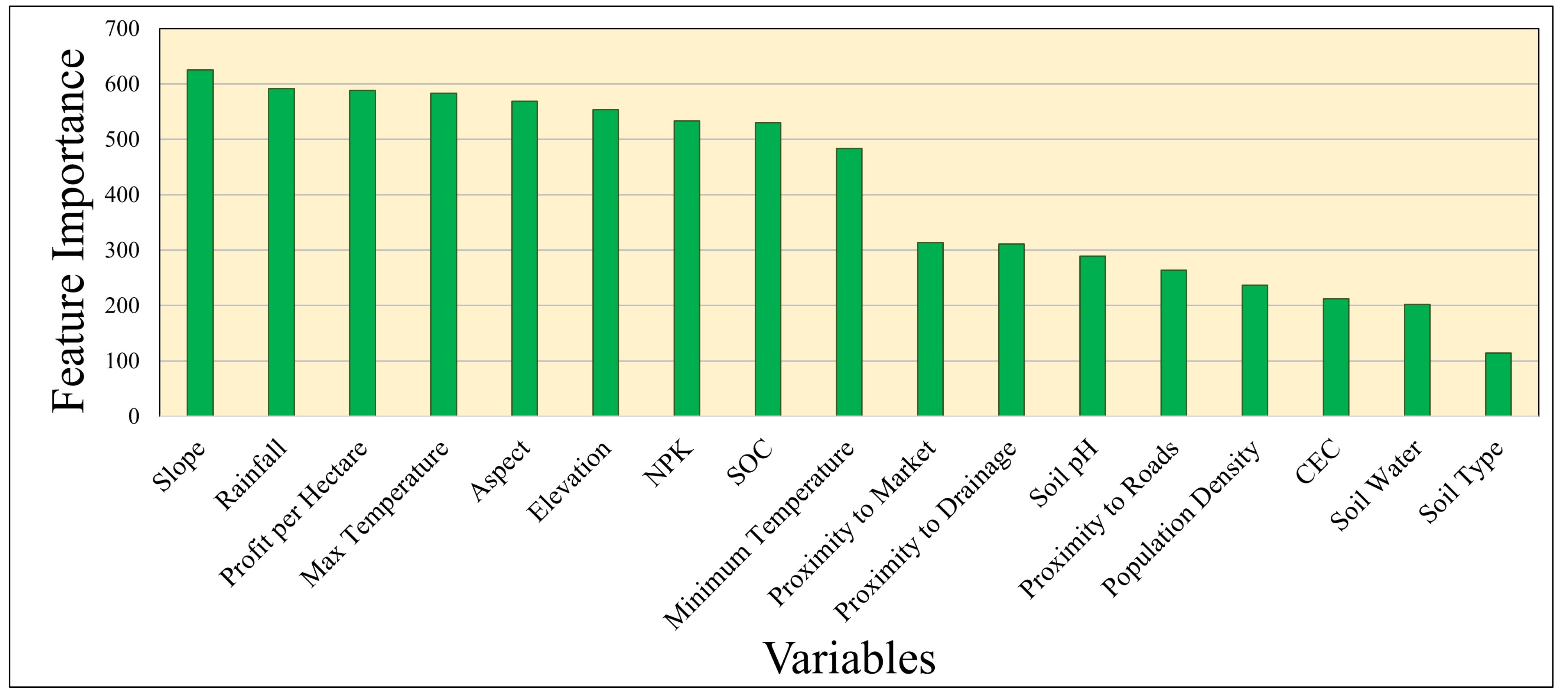
2.2.4. Feature Importance Computation
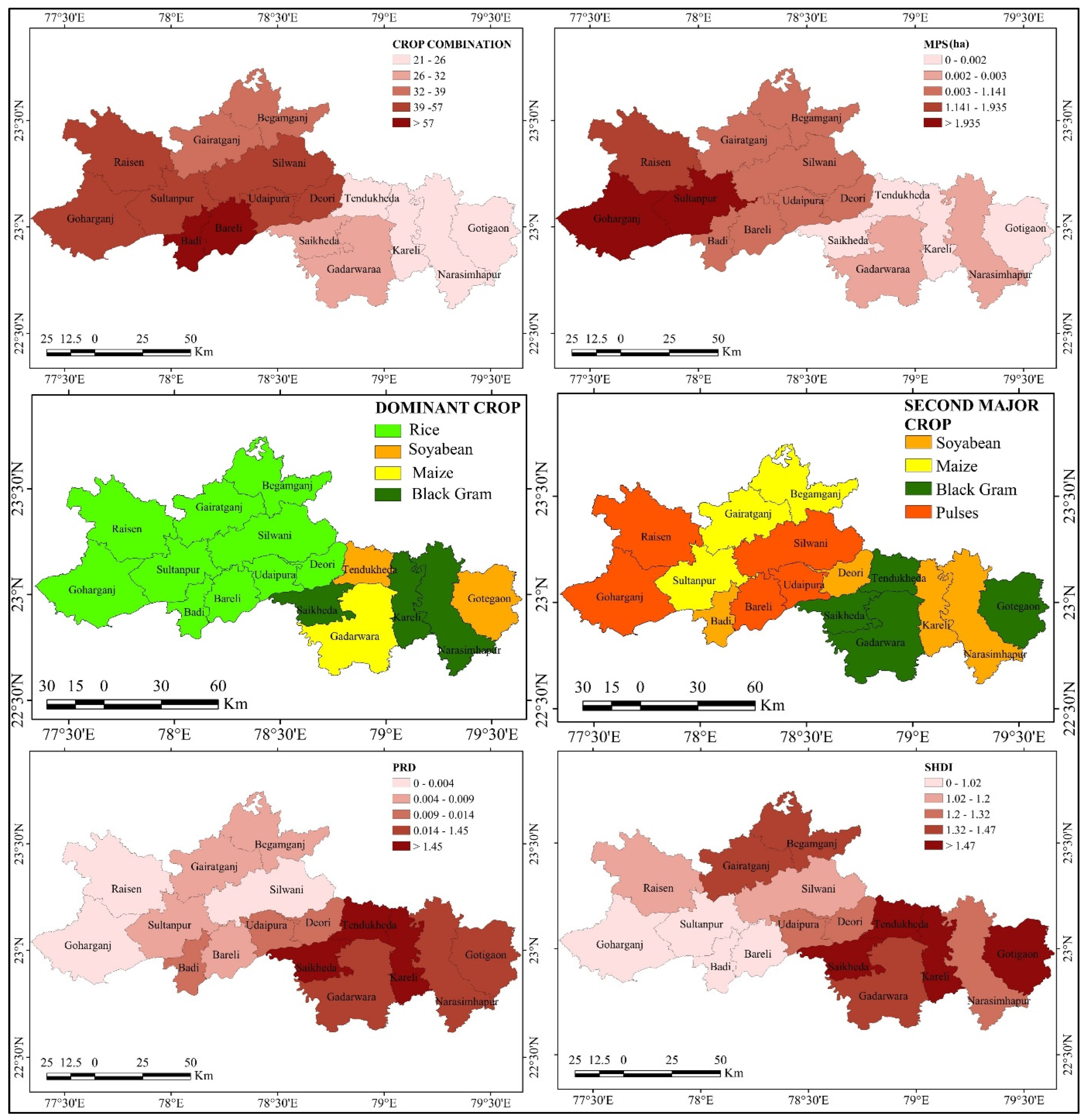
2.2.5. Crop Diversity and Combinations
2.2.6. Calculation of Landscape Metrics
2.2.7. Fragmentation Index
3. Results
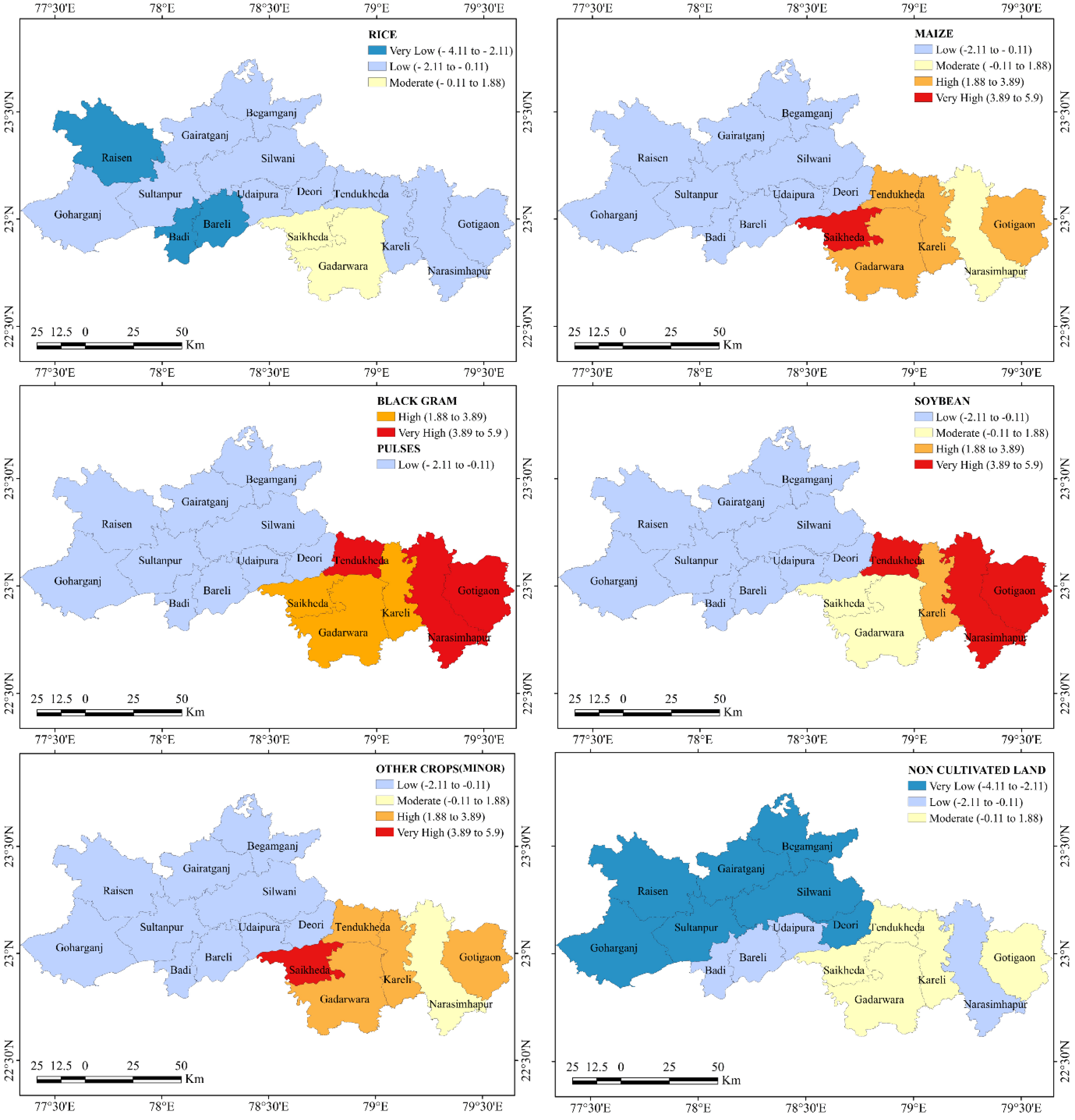
3.1. Crop Pattern and Their Driving Factors
3.2. Crop Combination and Diversity Status
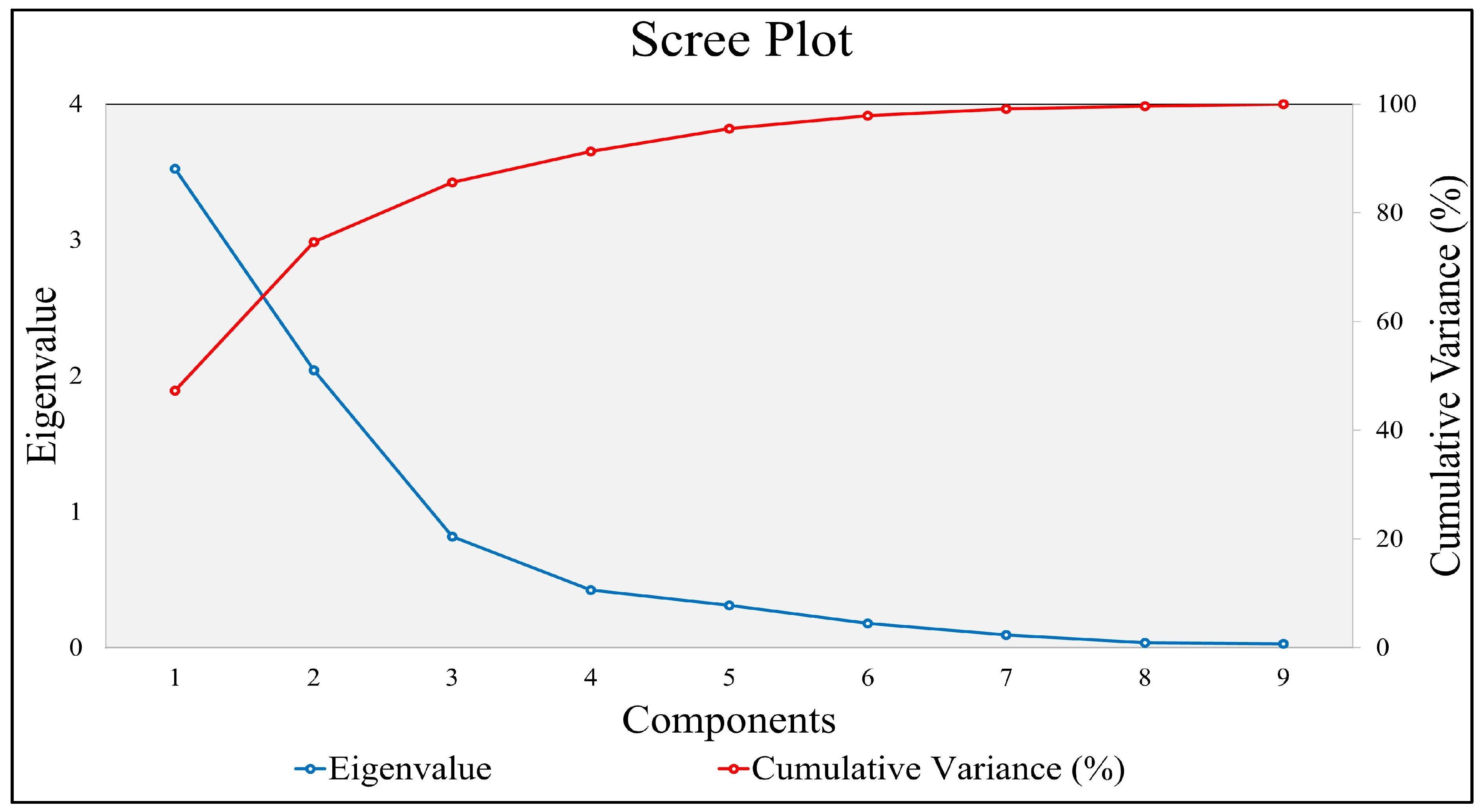
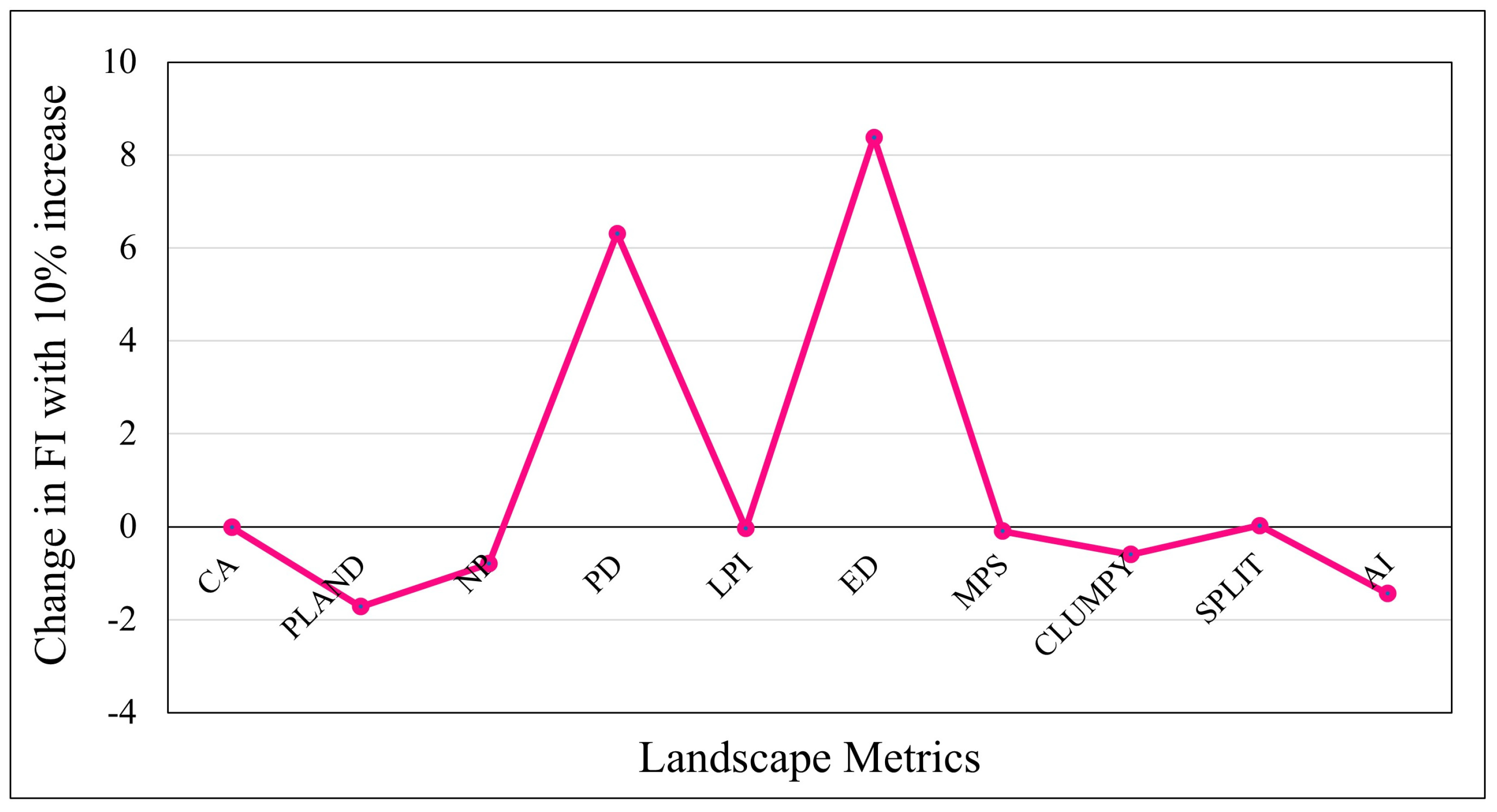
3.3. Crop-Specific Landscape Metrics and Fragmentation
4. Discussion
4.1. Integrating Remote Sensing, Machine Learning, and Landscape Metrics
4.2. Interconnection of Crop Pattern, Diversity, and Fragmentation
4.3. Sustainable Land Use and Resilience to Climate Change
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lal, R. Soil degradation as a reason for inadequate human nutrition. Food Secur. 2009, 1, 45–57. [Google Scholar] [CrossRef]
- Sklenicka, P. Classification of farmland ownership fragmentation as a cause of land degradation: A review on typology, consequences, and remedies. Land Use Policy 2016, 57, 694–701. [Google Scholar] [CrossRef]
- D’Odorico, P.; Rosa, L.; Bhattachan, A.; Okin, G.S. Desertification and Land Degradation. In Dryland Ecohydrology; D’Odorico, P., Porporato, A., Wilkinson Runyan, C., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 573–602. Available online: http://link.springer.com/10.1007/978-3-030-23269-6_21 (accessed on 8 April 2025).
- Baude, M.; Meyer, B.C.; Schindewolf, M. Land use change in an agricultural landscape causing degradation of soil based ecosystem services. Sci. Total. Environ. 2019, 659, 1526–1536. [Google Scholar] [CrossRef] [PubMed]
- Winkler, K.; Fuchs, R.; Rounsevell, M.; Herold, M. Global land use changes are four times greater than previously estimated. Nat. Commun. 2021, 12, 2501. [Google Scholar] [CrossRef]
- Mishra, P.K.; Rai, A.; Abdelrahman, K.; Rai, S.C.; Tiwari, A. Land degradation, overland flow, soil erosion, and nutrient loss in the Eastern Himalayas, India. Land 2022, 11, 179. [Google Scholar] [CrossRef]
- Altieri, M.A.; Nicholls, C.I.; Henao, A.; Lana, M.A. Agroecology and the design of climate change-resilient farming systems. Agron. Sustain. Dev. 2015, 35, 869–890. [Google Scholar] [CrossRef]
- Kim, S.M.; Mendelsohn, R. Climate change to increase crop failure in US. Environ. Res. Lett. 2023, 18, 14014. [Google Scholar] [CrossRef]
- Das, K. Traditional Agronomic Practices: Understanding and Mitigating the Risks of Climate Change. In Recent Advancements in Sustainable Agricultural Practices; Yasheshwar, Mishra, A.K., Kumar, M., Eds.; Springer Nature: Singapore, 2024; pp. 43–79. Available online: https://link.springer.com/10.1007/978-981-97-2155-9_3 (accessed on 8 April 2025).
- Nath, P.K.; Behera, B. A critical review of impact of and adaptation to climate change in developed and developing economies. Environ. Dev. Sustain. 2011, 13, 141–162. [Google Scholar] [CrossRef]
- Roy, S.; Hazra, S.; Chanda, A. Changing characteristics of meteorological drought and its impact on monsoon-rice production in sub-humid red and laterite zone of West Bengal, India. Theor. Appl. Climatol. 2023, 151, 1419–1433. [Google Scholar] [CrossRef]
- Ogwu, M.C.; Izah, S.C.; Ntuli, N.R.; Odubo, T.C. Food security complexities in the global south. In Food Safety and Quality in the Global South; Springer: Berlin/Heidelberg, Germany, 2024; pp. 3–33. Available online: https://link.springer.com/chapter/10.1007/978-981-97-2428-4_1 (accessed on 9 April 2025).
- Pattanayak, A.; Srinivasan, M.; Kumar, K.K. Crop Diversity and Resilience to Droughts: Evidence from Indian Agriculture. Rev. Dev. Change 2023, 28, 166–188. [Google Scholar] [CrossRef]
- Ju, F.; Yang, R.; Yang, C. Analysis of Spatiotemporal Dynamics and Driving Factors of China’s Nationally Important Agricultural Heritage Systems. Agriculture 2025, 15, 221. [Google Scholar] [CrossRef]
- Kumar, R.; Bhanu, M.; Mendes-Moreira, J.; Chandra, J. Spatio-Temporal Predictive Modeling Techniques for Different Domains: A Survey. ACM Comput. Surv. 2025, 57, 1–42. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, J.; Wang, X.; Wu, Z.; Prodhan, F.A. Incorporating Multi-Temporal Remote Sensing and a Pixel-Based Deep Learning Classification Algorithm to Map Multiple-Crop Cultivated Areas. Appl. Sci. 2024, 14, 3545. [Google Scholar] [CrossRef]
- Chowdhury, M.S. Comparison of accuracy and reliability of random forest, support vector machine, artificial neural network and maximum likelihood method in land use/cover classification of urban setting. Environ. Chall. 2024, 14, 100800. [Google Scholar] [CrossRef]
- Yimer, S.M.; Bouanani, A.; Kumar, N.; Tischbein, B.; Borgemeister, C. Comparison of different machine-learning algorithms for land use land cover mapping in a heterogenous landscape over the Eastern Nile river basin, Ethiopia. Adv. Space Res. 2024, 74, 2180–2199. [Google Scholar] [CrossRef]
- Aryal, J.; Sitaula, C.; Frery, A.C. Land use and land cover (LULC) performance modeling using machine learning algorithms: A case study of the city of Melbourne, Australia. Sci. Rep. 2023, 13, 13510. [Google Scholar] [CrossRef]
- Kasahun, M.; Legesse, A. Machine learning for urban land use/cover mapping: Comparison of artificial neural network, random forest and support vector machine, a case study of Dilla town. Heliyon 2024, 10, e39146. Available online: https://www.cell.com/heliyon/fulltext/S2405-8440(24)15177-8 (accessed on 9 April 2025). [CrossRef] [PubMed]
- Feng, S.; Zhao, J.; Liu, T.; Zhang, H.; Zhang, Z.; Guo, X. Crop type identification and mapping using machine learning algorithms and sentinel-2 time series data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3295–3306. [Google Scholar] [CrossRef]
- Rasti, P.; Ahmad, A.; Samiei, S.; Belin, E.; Rousseau, D. Supervised image classification by scattering transform with application to weed detection in culture crops of high density. Remote Sens. 2019, 11, 249. [Google Scholar] [CrossRef]
- Erdanaev, E.; Kappas, M.; Wyss, D. The Identification of Irrigated Crop Types Using Support Vector Machine, Random Forest and Maximum Likelihood Classification Methods with Sentinel-2 Data in 2018: Tashkent Province, Uzbekistan. Int. J. Geoinformatics 2022, 18, 37–53. Available online: https://www.researchgate.net/profile/Elbek-Erdanaev-2/publication/360672412_The_Identification_of_Irrigated_Crop_Types_Using_Support_Vector_Machine_Random_Forest_and_Maximum_Likelihood_Classification_Methods_with_Sentinel-2_Data_in_2018_Tashkent_Province_Uzbekistan/links/6284dd9519994305918ec116/The-Identification-of-Irrigated-Crop-Types-Using-Support-Vector-Machine-Random-Forest-and-Maximum-Likelihood-Classification-Methods-with-Sentinel-2-Data-in-2018-Tashkent-Province-Uzbekistan.pdf (accessed on 8 April 2025).
- Ahmad, A.; Saraswat, D.; El Gamal, A. A survey on using deep learning techniques for plant disease diagnosis and recommendations for development of appropriate tools. Smart Agric. Technol. 2023, 3, 100083. [Google Scholar] [CrossRef]
- Wu, B.; Zhang, M.; Zeng, H.; Tian, F.; Potgieter, A.B.; Qin, X.; Loupian, E. Challenges and opportunities in remote sensing-based crop monitoring: A review. Natl. Sci. Rev. 2023, 10, nwac290. [Google Scholar] [CrossRef] [PubMed]
- Siotra, V.; Kumari, S. Assessing spatiotemporal patterns of crop combination and crop concentration in Jammu Division of Jammu and Kashmir. J. Soc. Econ. Dev. 2024, 1–28. [Google Scholar] [CrossRef]
- Kumar, M.; Denis, D.M.; Singh, S.K.; Szabó, S.; Suryavanshi, S. Landscape metrics for assessment of land cover change and fragmentation of a heterogeneous watershed. Remote Sens. Appl. Soc. Environ. 2018, 10, 224–233. [Google Scholar] [CrossRef]
- Ntshanga, N.K.; Procheş, S.; Slingsby, J.A. Assessing the threat of landscape transformation and habitat fragmentation in a global biodiversity hotspot. Austral Ecol. 2021, 46, 1052–1069. [Google Scholar] [CrossRef]
- Banerjee, S.; Sati, V.P.; Almazroui, M.; Chakraborty, S. Spatio-Temporal Assessment of Areal Fragmentation and Volume of Snow Cover in the Central Himalaya. Earth Syst. Environ. 2024, 8, 1639–1656. [Google Scholar] [CrossRef]
- Sati, V.P.; Banerjee, S.; Roy, C. Land Use and Land Cover Dynamics and Factors Affecting It in the Central Himalaya. Available online: https://www.researchgate.net/profile/Vishwambhar-Sati/publication/383123033_Land_Use_and_Land_Cover_Dynamics_and_Factors_Affecting_It_in_The_Central_Himalaya/links/66bdc0078d00735592528a0a/Land-Use-and-Land-Cover-Dynamics-and-Factors-Affecting-It-in-The-Central-Himalaya.pdf (accessed on 9 April 2025).
- Rogan, J.; Wright, T.M.; Cardille, J.; Pearsall, H.; Ogneva-Himmelberger, Y.; Riemann, R.; Riitters, K.; Partington, K. Forest fragmentation in Massachusetts, USA: A town-level assessment using Morphological spatial pattern analysis and affinity propagation. GIScience Remote Sens. 2016, 5, 506–519. [Google Scholar] [CrossRef]
- Kowe, P.; Mutanga, O.; Dube, T. Advancements in the remote sensing of landscape pattern of urban green spaces and vegetation fragmentation. Int. J. Remote Sens. 2021, 42, 3797–3832. [Google Scholar] [CrossRef]
- De Matos, T.P.V.; De Matos, V.P.V.; De Mello, K.; Valente, R.A. Protected areas and forest fragmentation: Sustainability index for prioritizing fragments for landscape restoration. Geol. Ecol. Landsc. 2021, 5, 19–31. [Google Scholar] [CrossRef]
- Jumani, S.; Deitch, M.J.; Valle, D.; Machado, S.; Lecours, V.; Kaplan, D.; Krishnaswamy, J.; Howard, J. A new index to quantify longitudinal river fragmentation: Conservation and management implications. Ecol. Indic. 2022, 136, 108680. [Google Scholar] [CrossRef]
- Sahu, S. Fluvio-dynamics and Groundwater System in the Narmada River Basin, India. In Riverine Systems: Understanding the Hydrological, Hydrosocial and Hydro-Heritage Dynamics; Springer: Berlin/Heidelberg, Germany, 2022; pp. 171–185. Available online: https://link.springer.com/chapter/10.1007/978-3-030-87067-6_10 (accessed on 9 April 2025).
- Duhan, D.; Pandey, A.; Gahalaut, K.P.S.; Pandey, R.P. Spatial and temporal variability in maximum, minimum and mean air temperatures at Madhya Pradesh in central India. Comptes Rendus Geosci. 2013, 345, 3–21. [Google Scholar] [CrossRef]
- Singh, G.; Singh, B.; Tomar, U.K.; Sharma, S. A Manual for Dryland Afforestation and Management. Scientific Publishers-AFARI: Jodhpur, India, 2017. Available online: https://books.google.com/books?hl=en&lr=&id=8BWNDwAAQBAJ&oi=fnd&pg=PP1&dq=Singh,+G.,+Singh,+B.,+Tomar,+U.+K.,+%26+Sharma,+S.+(2017).+A+manual+for+dryland+afforestation+and+management.+Scientific+Publishers-AFARI.&ots=QNAvXr-BZe&sig=Mq08fVVAF-lbZpSZviWkFzvAQug (accessed on 9 April 2025).
- Inglada, J.; Arias, M.; Tardy, B.; Hagolle, O.; Valero, S.; Morin, D.; Dedieu, G.; Sepulcre, G.; Bontemps, S.; Defourny, P.; et al. Assessment of an operational system for crop type map production using high temporal and spatial resolution satellite optical imagery. Remote Sens. 2015, 7, 12356–12379. [Google Scholar] [CrossRef]
- Rajput, D.; Wang, W.J.; Chen, C.C. Evaluation of a decided sample size in machine learning applications. BMC Bioinform. 2023, 24, 48. [Google Scholar] [CrossRef]
- Amankulova, K.; Farmonov, N.; Abdelsamei, E.; Szatmári, J.; Khan, W.; Zhran, M.; Rustamov, J.; Akhmedov, S.; Sarimsakov, M.; Mucsi, L. A Novel Fusion Method for Soybean Yield Prediction Using Sentinel-2 and PlanetScope Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 13694–13707. [Google Scholar] [CrossRef]
- Hasan, M.M.; Pramanik, M.; Alam, I.; Kumar, A.; Avtar, R.; Zhran, M. Assessing the efficacy of artificial intelligence based city-scale blue green infrastructure mapping using Google Earth Engine in the Bangkok metropolitan region. J. Urban Manag. 2024, 14, 434–450. [Google Scholar] [CrossRef]
- Pappaka, R.K.; Nakkala, A.B.; Badapalli, P.K.; Gugulothu, S.; Anguluri, R.; Hasher, F.F.B.; Zhran, M. Machine Learning-Driven Groundwater Potential Zoning Using Geospatial Analytics and Random Forest in the Pandameru River Basin, South India. Sustainability 2025, 17, 3851. [Google Scholar] [CrossRef]
- Mondal, S.; Parveen, M.T.; Alam, A.; Rukhsana Islam, N.; Calka, B.; Bashir, B.; Zhran, M. Future Site Suitability for Urban Waste Management in English Bazar and Old Malda Municipalities, West Bengal: A Geospatial and Machine Learning Approach. ISPRS Int. J. Geo-Inf. 2024, 13, 388. [Google Scholar] [CrossRef]
- Diksha; Mishra, V.N.; Kumar, D.; Kumari, M.; Bashir, B.; Pramanik, M.; Zhran, M. Dynamic Quantification and Characterization of Spatial Heterogeneity in Mid-Sized Urban Landscape of India. Land 2024, 13, 1989. [Google Scholar] [CrossRef]
- Badola, S.; Pandey, M.; Mishra, V.N.; Parkash, S.; Zhran, M. Landslide Susceptibility Mapping in Complex Topo-Climatic Himalayan Terrain, India Using Machine Learning Models: A Comparative Study of XGBoost, RF and ANN. Geol. J. 2025. [Google Scholar] [CrossRef]
- Fang, G.; Wang, C.; Dong, T.; Wang, Z.; Cai, C.; Chen, J.; Liu, M.; Zhang, H. A Landscape-Clustering Zoning Strategy to Map Multi-Crops in Fragmented Cropland Regions Using Sentinel-2 and Sentinel-1 Imagery with Feature Selection. Agriculture 2025, 15, 186. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees. Routledge. 2017. Available online: https://www.taylorfrancis.com/books/mono/10.1201/9781315139470/classification-regression-trees-leo-breiman-jerome-friedman-olshen-charles-stone (accessed on 8 April 2025).
- Rafiullah, S.M. A new approach to functional classification of towns. Geographer 1965, 12, 40–53. [Google Scholar]
- Turner, M.G. Spatial and temporal analysis of landscape patterns. Landsc Ecol. 1990, 4, 21–30. [Google Scholar] [CrossRef]
- McGarigal, K. FRAGSTATS Help; University of Massachusetts: Amherst, MA, USA, 2015. [Google Scholar]
- Mihrete, T.B.; Mihretu, F.B. Crop Diversification for Ensuring Sustainable Agriculture, Risk Management and Food Security. Glob. Chall. 2025, 9, 2400267. [Google Scholar] [CrossRef]
- Shukla, A.K.; Singh, A.; Banerjee, T.; Chaudhary, S.K. Impact of Agricultural Chemical Inputs on Human Health and Environment in India. Agric. Chem. Inputs 2021. [Google Scholar]
- Shukla, A.K.; Behera, S.K.; Chaudhari, S.K.; Singh, G. Fertilizer use in Indian agriculture and its impact on human health and environment. Indian J. Fertil. 2022, 18, 218–237. [Google Scholar]
- Chakraborty, S.K. River Pollution and Perturbation: Perspectives and Processes. In Riverine Ecology Volume 2; Springer International Publishing: Cham, Switzerland, 2021; pp. 443–530. Available online: https://link.springer.com/10.1007/978-3-030-53941-2_5 (accessed on 8 April 2025).
- Cho, S.; Yoon, H. Evaluating the economic and environmental benefits of rice-soybean diversification in South Korea. Agric. Syst. 2025, 224, 104258. [Google Scholar] [CrossRef]
- Deininger, K.; Savastano, S.; Carletto, C. Land fragmentation, cropland abandonment, and land market operation in Albania. World Dev. 2012, 40, 2108–2122. [Google Scholar] [CrossRef]
- Guja, M.M.; Bedeke, S.B. Smallholders’ climate change adaptation strategies: Exploring effectiveness and opportunities to be capitalized. Environ. Dev. Sustain. 2024. Available online: https://link.springer.com/10.1007/s10668-024-04750-y (accessed on 8 April 2025).
- Ononogbo, C.; Ohwofadjeke, P.O.; Chukwu, M.M.; Nwawuike, N.; Obinduka, F.; Nwosu, O.U.; Ugenyi, A.U.; Nzeh, I.C.; Nwosu, E.C.; Nwakuba, N.R.; et al. Agricultural and environmental sustainability in nigeria: A review of challenges and possible eco-friendly remedies. Environ. Dev. Sustain. 2024, 1–47. [Google Scholar] [CrossRef]
- Singh, R.; Hasanain, M.; Babu, S.; Nath, C.P.; Ansari, M.A.; Kumar, A.; Sofi, M.U.D.; Kumar, S.; Kumar, S. Organic pulse production: Exploring opportunities and overcoming challenges. J. Food Legum. 2024, 37, 144–162. [Google Scholar] [CrossRef]
- Layek, J.; Das, A.; Mitran, T.; Nath, C.; Meena, R.S.; Yadav, G.S.; Shivakumar, B.G.; Kumar, S.; Lal, R. Cereal+Legume Intercropping: An Option for Improving Productivity and Sustaining Soil Health. In Legumes for Soil Health and Sustainable Management; Meena, R.S., Das, A., Yadav, G.S., Lal, R., Eds.; Springer Singapore: Singapore, 2018; pp. 347–386. Available online: http://link.springer.com/10.1007/978-981-13-0253-4_11 (accessed on 9 April 2025).
- Chemeris, A.; Liu, Y.; Ker, A.P. Insurance subsidies, climate change, and innovation: Implications for crop yield resiliency. Food Policy 2022, 108, 102232. [Google Scholar] [CrossRef]
- Gwambene, B.; Saria, J. Smallholder Farmers’ Resilience in Adapting to Climate Changes in the Southern Highlands of Tanzania. J. Geogr. Assoc. Tanzan. 2024, 44, 1–25. [Google Scholar] [CrossRef]
- Jat, M.L.; Rao, C.S.; Padmaja-Karanam, V.; Singh, R. Innovations, strategies, and policies for Building Resilience of India’s Dryland Farming to Climate Change. In Climate Change and Sustainable Agro-Ecology in Global Drylands; CABI GB: Wallingford, UK, 2024; pp. 230–252. Available online: https://www.cabidigitallibrary.org/doi/abs/10.1079/9781800624870.0011 (accessed on 9 April 2025).
- Frison, E. From industrial agriculture to diversified agroecological systems. Indian J. Plant Genet. Resour. 2016, 29, 237–240. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Crops | Raisen | Narsinghpur |
|---|---|---|
| Rice | 109 | 53 |
| Maize | 58 | 40 |
| Soybean | 46 | 45 |
| Pulses | 59 | NA |
| Black Gram | NA | 48 |
| Other Crops | 30 | 12 |
| Principal Component | ||
|---|---|---|
| 1 | 2 | |
| CA Z | 0.855 | −0.108 |
| NP Z | −0.352 | 0.380 |
| PD Z | −0.327 | 0.847 |
| LPI Z | 0.849 | −0.001 |
| ED Z | −0.284 | 0.877 |
| MPS Z | 0.797 | −0.044 |
| CLUMPY Z | 0.785 | 0.416 |
| SPLIT Z | −0.212 | −0.446 |
| AI Z | 0.773 | 0.475 |
| RAISEN | NARSINGHPUR | ||||
|---|---|---|---|---|---|
| Crop | User Accuracy | Producer Accuracy | Crops | User Accuracy | Producer Accuracy |
| Rice | 0.97812 | 0.96922 | Rice | 0.956521 | 1 |
| Maize | 0.744286 | 0.833 | Maize | 0.843751 | 0.75 |
| Pulses | 0.813751 | 0.9375 | Black gram | 1 | 0.83 |
| Soybean | 0.76923 | 0.857148 | Soybean | 1 | 0.82 |
| Other crop | 0.94382 | 0.875 | Other crop | 0.9238 | 0.8 |
| Crops | FI Scores (Raisen) | Crops | FI Scores (Narsinghpur) |
|---|---|---|---|
| Rice | 0.9535 | Rice | 0.9778 |
| Maize | 0.8080 | Maize | 0.8571 |
| Pulses | 0.8622 | Black Gram | 0.8360 |
| Soybean | 0.8420 | Soybean | 0.9305 |
| Other crops | 0.9369 | Other crops | 0.8571 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Banerjee, S.; Nandi, T.; Sati, V.P.; Mezlini, W.; Alkhuraiji, W.S.; Al-Halbouni, D.; Zhran, M. Integrating Remote Sensing, Landscape Metrics, and Random Forest Algorithm to Analyze Crop Patterns, Factors, Diversity, and Fragmentation in a Kharif Agricultural Landscape. Land 2025, 14, 1203. https://doi.org/10.3390/land14061203
Banerjee S, Nandi T, Sati VP, Mezlini W, Alkhuraiji WS, Al-Halbouni D, Zhran M. Integrating Remote Sensing, Landscape Metrics, and Random Forest Algorithm to Analyze Crop Patterns, Factors, Diversity, and Fragmentation in a Kharif Agricultural Landscape. Land. 2025; 14(6):1203. https://doi.org/10.3390/land14061203
Chicago/Turabian StyleBanerjee, Surajit, Tuhina Nandi, Vishwambhar Prasad Sati, Wiem Mezlini, Wafa Saleh Alkhuraiji, Djamil Al-Halbouni, and Mohamed Zhran. 2025. "Integrating Remote Sensing, Landscape Metrics, and Random Forest Algorithm to Analyze Crop Patterns, Factors, Diversity, and Fragmentation in a Kharif Agricultural Landscape" Land 14, no. 6: 1203. https://doi.org/10.3390/land14061203
APA StyleBanerjee, S., Nandi, T., Sati, V. P., Mezlini, W., Alkhuraiji, W. S., Al-Halbouni, D., & Zhran, M. (2025). Integrating Remote Sensing, Landscape Metrics, and Random Forest Algorithm to Analyze Crop Patterns, Factors, Diversity, and Fragmentation in a Kharif Agricultural Landscape. Land, 14(6), 1203. https://doi.org/10.3390/land14061203