



Evolution of Data-Driven Flood Forecasting: Trends, Technologies, and Gaps—A Systematic Mapping Study


Abstract
1. Introduction
2. Background of Flood Forecasting
- (i)
- Physical-based models, also known as process-based, physics-based or numerical models, attempt to represent real-world physical processes using formulae adhering to mass and energy conservation principles [34,35]. Examples include the XinAnJiang (XAJ) model, the TOPography based hydrological MODEL (TOPMODEL), and the Hydrologic Engineering Centre-Hydrologic Modelling Systems (HEC-HMS). Whilst these models have established the foundation for flood forecasting over decades, they face numerous limitations. These include increased system complexity with more factors, poor portability, and complex calibration processes that require significant expertise [35]. Additional challenges include high computational demands [36], substantial data requirements for accurate parameterisation, difficulty in representing spatiotemporal variability at different scales, inherent uncertainty in model structure and parameters [37], limited applicability in ungauged basins, and reduced performance in extreme event scenarios due to non-linear hydrological responses that exceed calibration ranges [38]. Moreover, these models often struggle with integrating real-time data and adapting to changing environmental conditions [39].
- (ii)
- Data-driven models, in contrast, overcome these limitations by analysing hydrological and hydrodynamic data to identify underlying time series patterns without explaining the physics-based development of river flow [40]. These models efficiently create correlations between historical and future data to provide reasonably accurate time series forecasting whilst reducing computational expenses and eliminating the need for boundary conditions [41]. Data-driven approaches can be further categorised into time series statistical models and ML or DL models. (a) Time series statistical models represent the traditional data-driven approach to flood forecasting. Models such as Autoregressive (AR), Moving Average (MA), and Autoregressive Integrated Moving Average (ARIMA) have been widely used since the 1970s [42]. Whilst these models work well for stationary time series and normal error distributions, they struggle mainly with non-linear relationships common in hydrological time series [43]. (b) ML approaches like ANNs, Support Vector Machines (SVMs), Random Forest (RF), and Naive Bayes have shown promise in handling non-linear relationships and processing large amounts of data. However, these models may have limited ability to fully capture long-term temporal dependencies and spatial dependencies [44]. (c) DL models, particularly Recurrent Neural Networks (RNNs), have emerged as powerful tools for flood forecasting due to their ability to handle sequential data and capture temporal dependencies [45]. Advanced architectures like LSTM, Gated Recurrent Units (GRUs) and Convolutional Neural Networks (CNNs) have demonstrated superior performance in many studies by addressing the vanishing gradient problem common in traditional RNNs [46]. Recent advances in DL have introduced more sophisticated architectures, such as attention mechanisms, Graph Neural Networks (GNNs), and transformer models. These innovations help models to better capture spatial-temporal relationships and handle long-term dependencies more effectively [28,47].
- (iii)
- Hybrid approaches in data-driven modelling have gained significant attention in recent years. These methods can be broadly categorised into: (i) hybrids combining different ML/DL models [48] and (ii) hybrids integrating physics-based and data-driven models [27]. The first category includes combinations like CNN-LSTM, which leverage CNN’s spatial feature extraction capabilities with LSTM’s temporal modelling strengths [49,50], and FastGRNN-FCN, which combines the efficiency of FastGRNN with the feature extraction capabilities of FCN [51]. The second category of hybrids integrates physical models with data-driven models to leverage the strengths of both paradigms. Examples include MIKE21-LSTM, XAJ-MCQRNN, and HEC-HMS-LSTM combinations [45,52]. These hybrid models demonstrate the ongoing efforts to create more comprehensive and accurate flood forecasting systems that can capture both the data-driven patterns and the underlying physical processes of hydrological systems. Despite these advancements, a systematic understanding of the current landscape, trends, and gaps in data-driven flood forecasting research remains necessary, which motivates the present SMS.
3. Tertiary Study
4. Research Method
4.1. Research Questions
4.2. Study Selection
4.2.1. Sources and Timeframe
4.2.2. Terms and Search String
4.2.3. Inclusion and Exclusion Criteria (IC and EC)
4.3. Data Extraction and Synthesis
4.4. Classification Scheme
4.4.1. Publication Trends and Types (RQ1)
4.4.2. Geographical Distribution (RQ2)
4.4.3. Input Factors, Output Variables, Data Sources, and Temporal Characteristics (RQ3)
4.4.4. Technical Approaches (RQ4)
4.4.5. Evaluation Matrices (RQ5)
5. Temporal Concepts in Flood Forecasting
5.1. Forecasting and Prediction
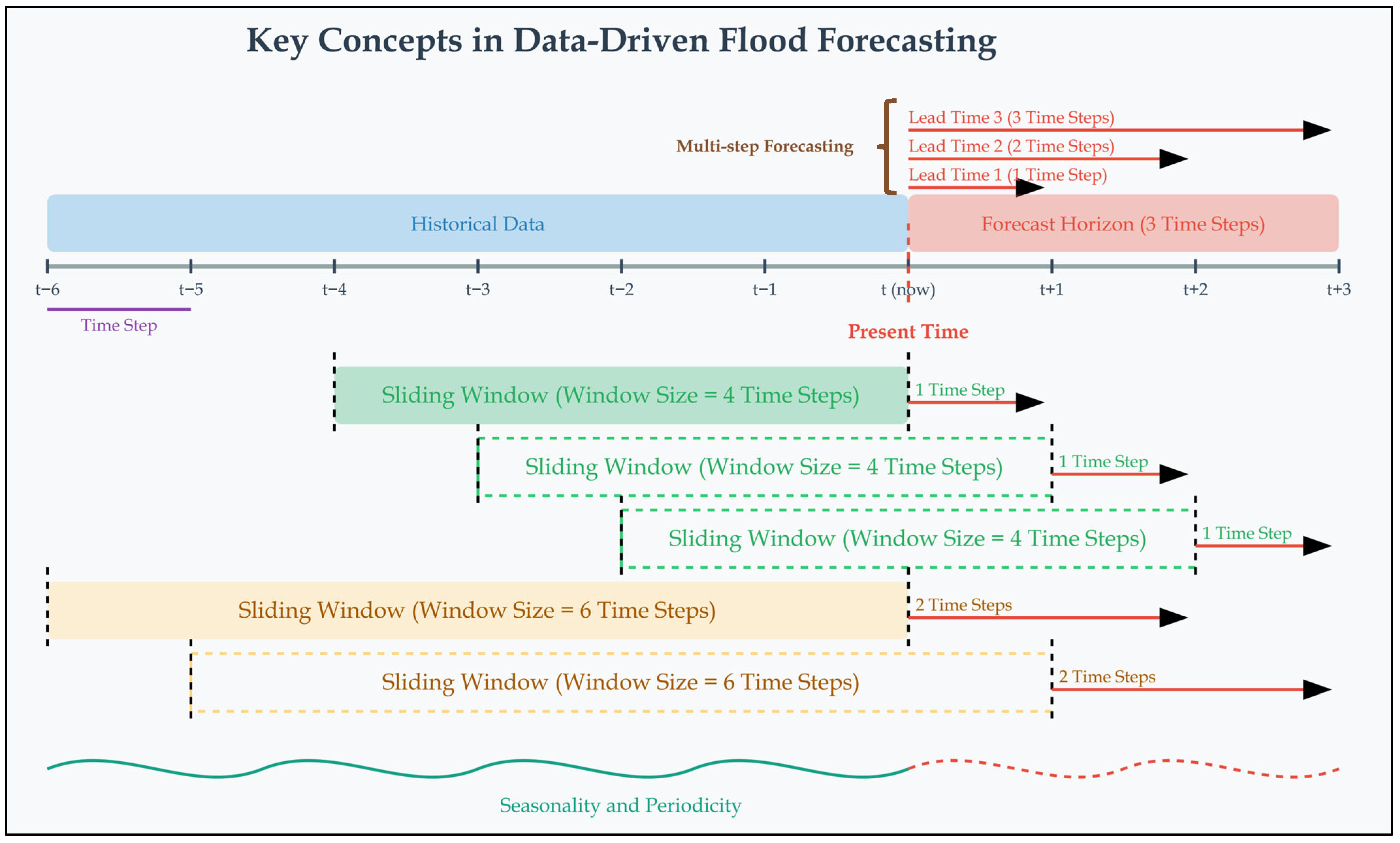
5.2. Time Step
5.3. Forecast Horizon and Lead Time
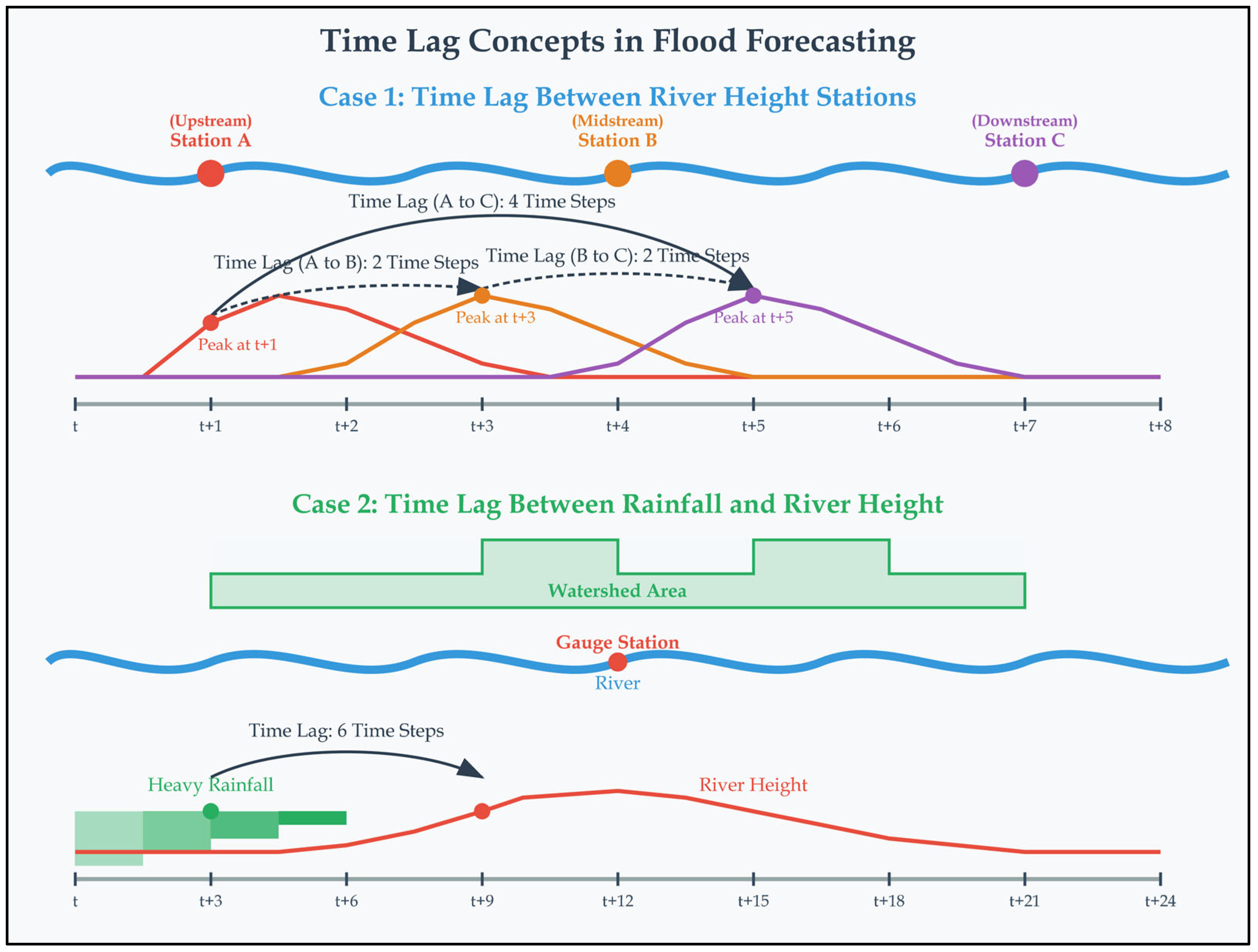
5.4. Lag Time
5.5. Look-Back Window (Historical Input)
6. Results and Discussion
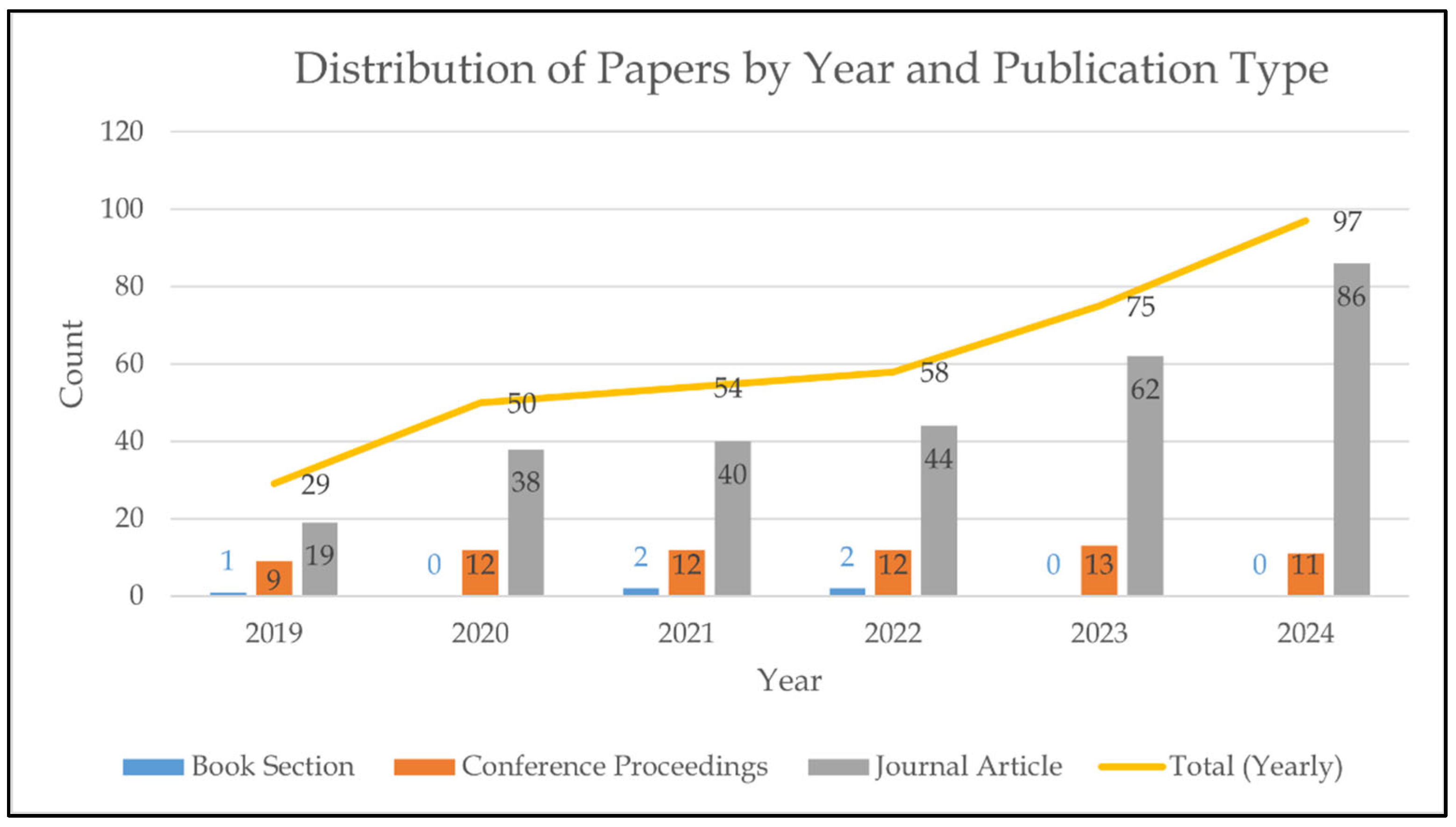
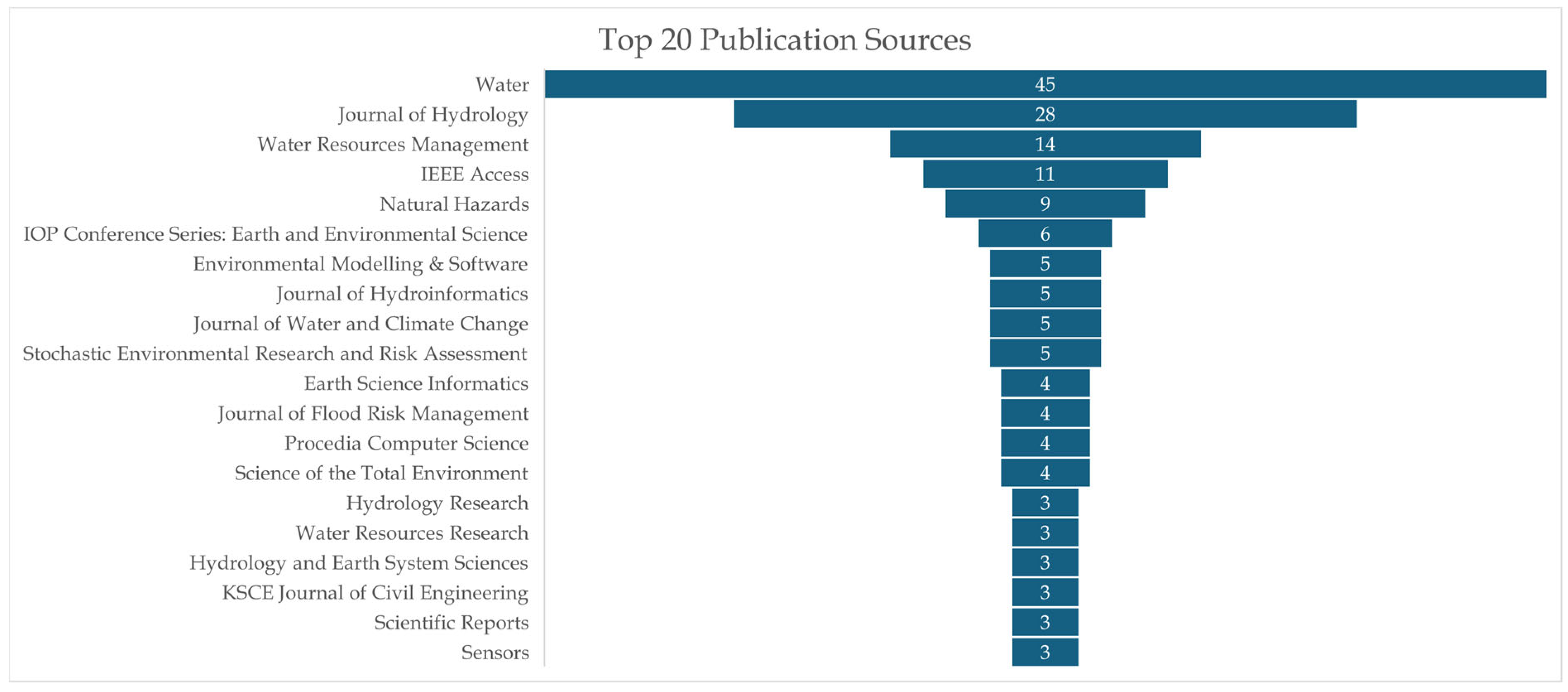
6.1. RQ1: What Are the Temporal and Types of Publication Trends?
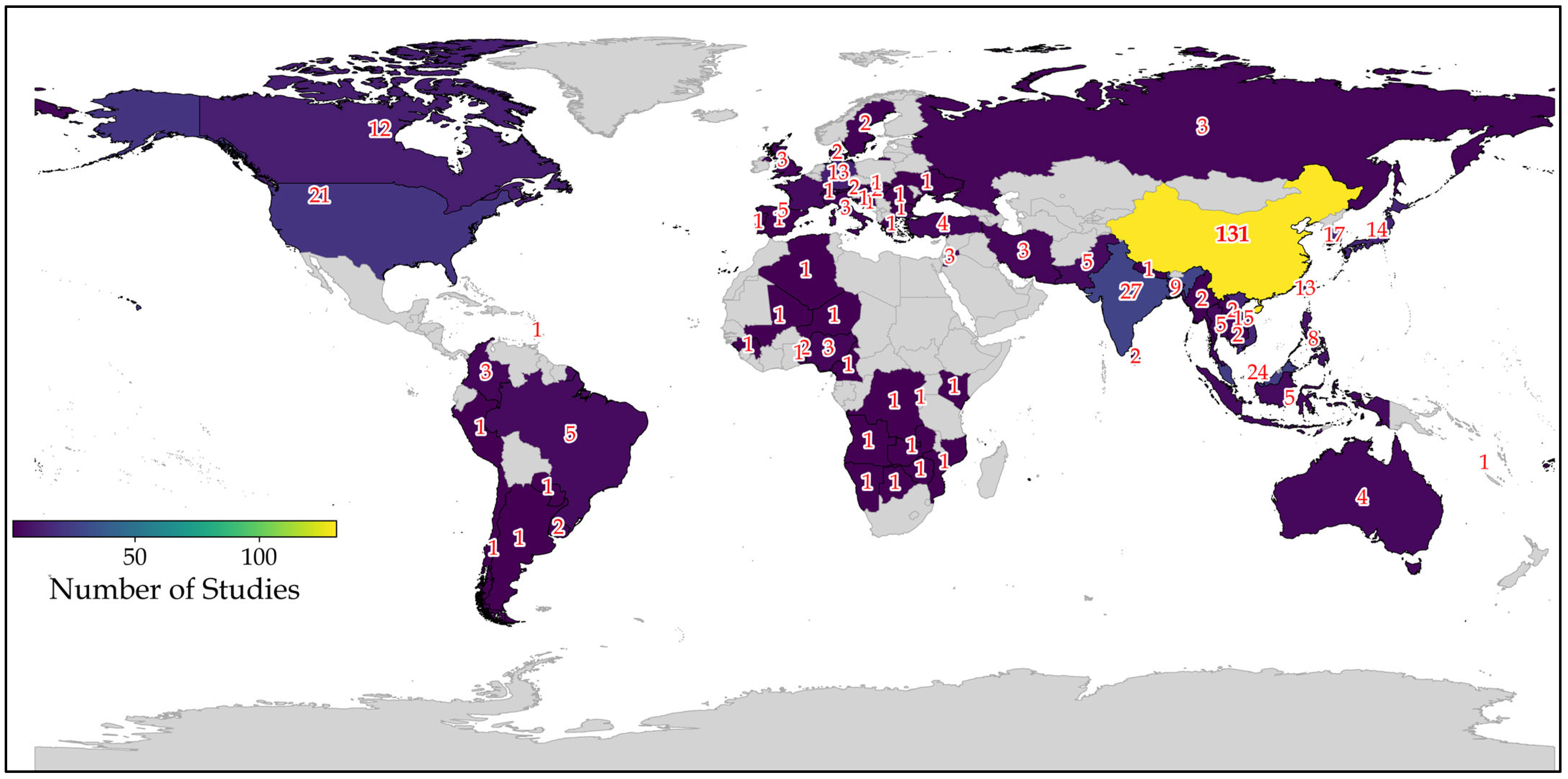
6.2. RQ2: Which Countries Were the Studies Based on?
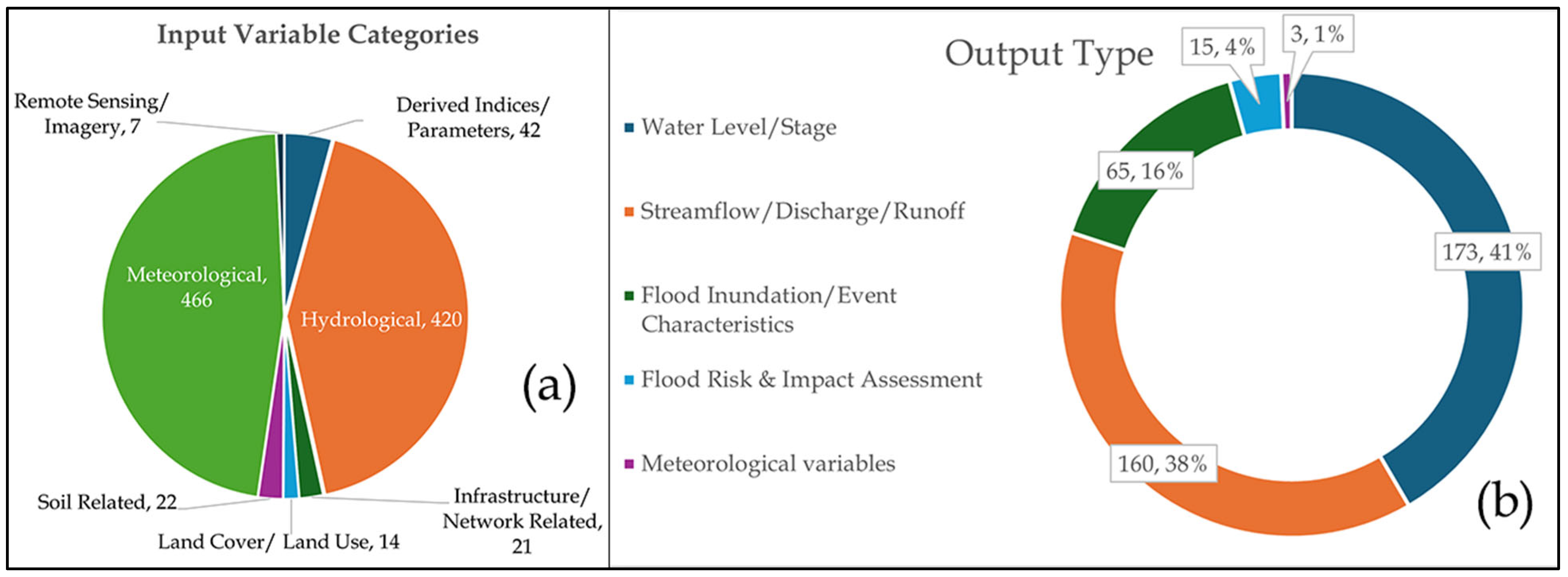
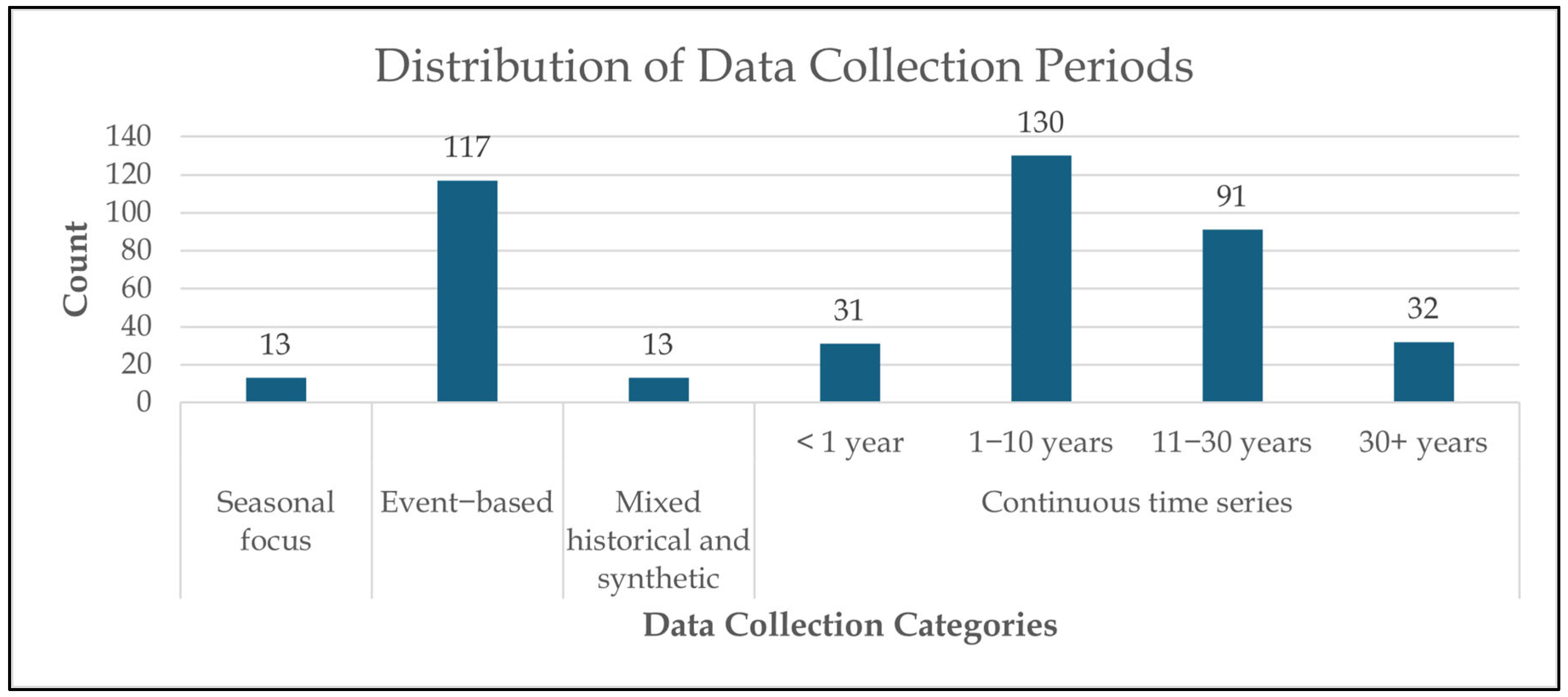
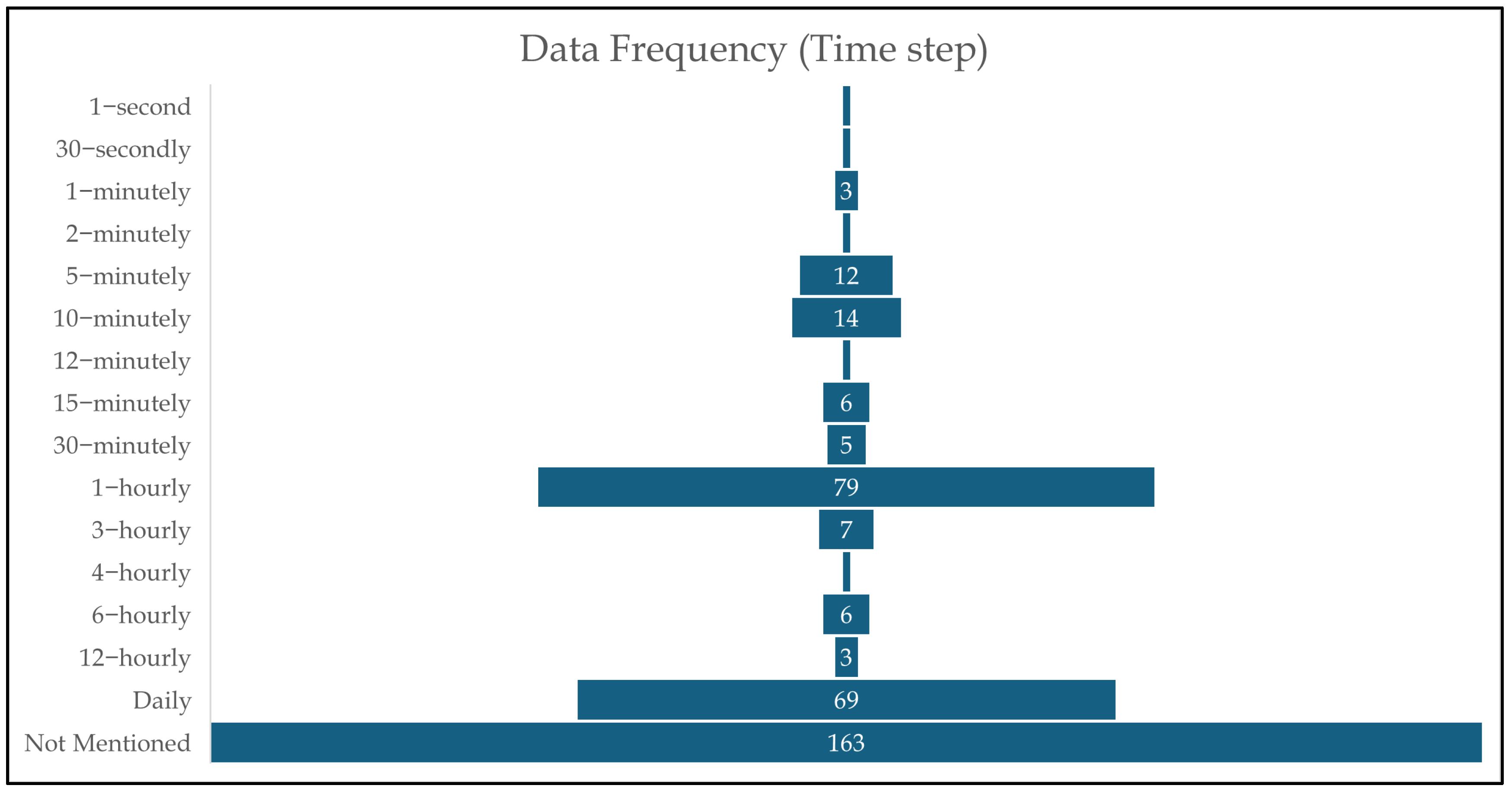
6.3. RQ3: What Input Factors, Output Variables, Data Sources, Collection Periods, and Temporal Resolutions Were Utilised in Flood Forecasting Studies?
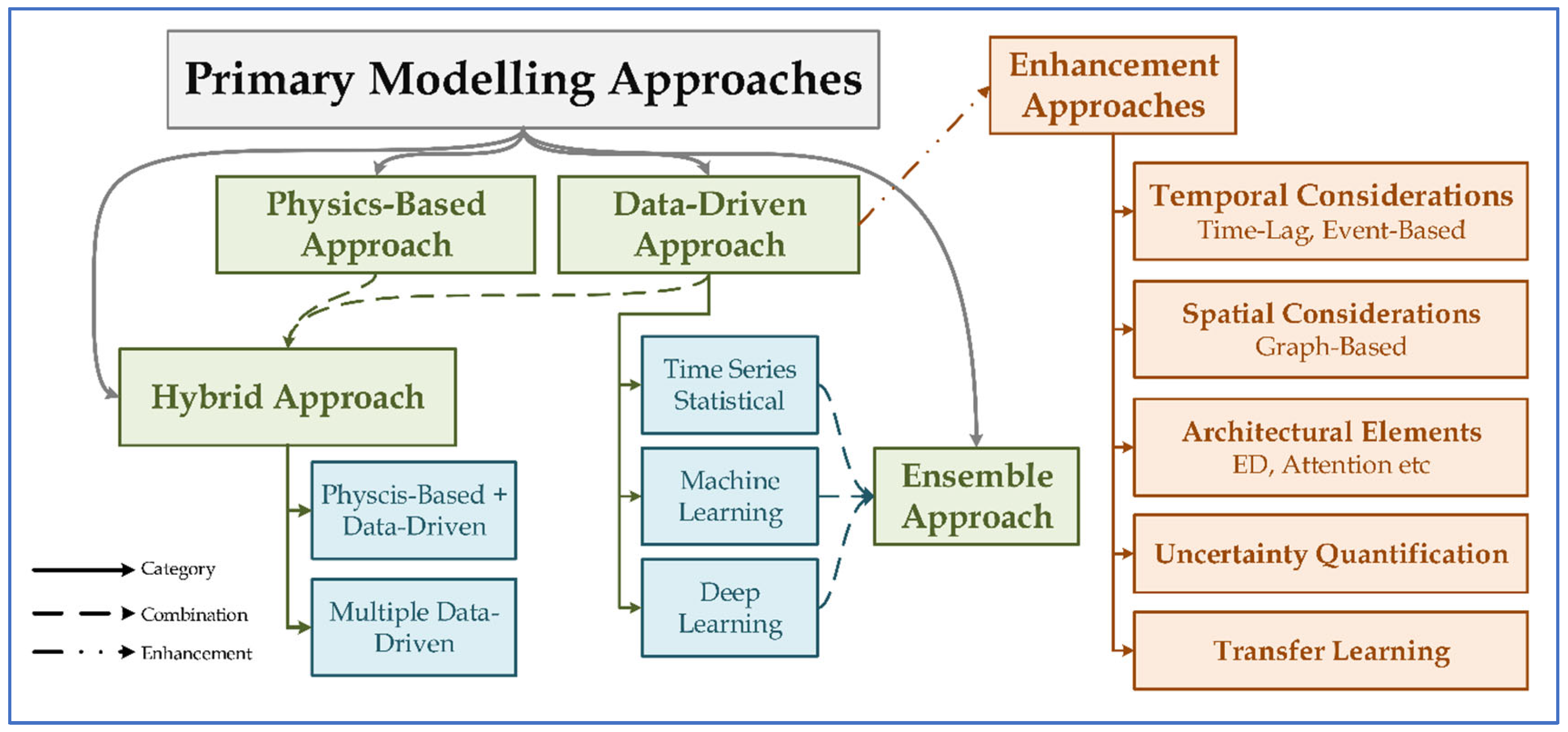
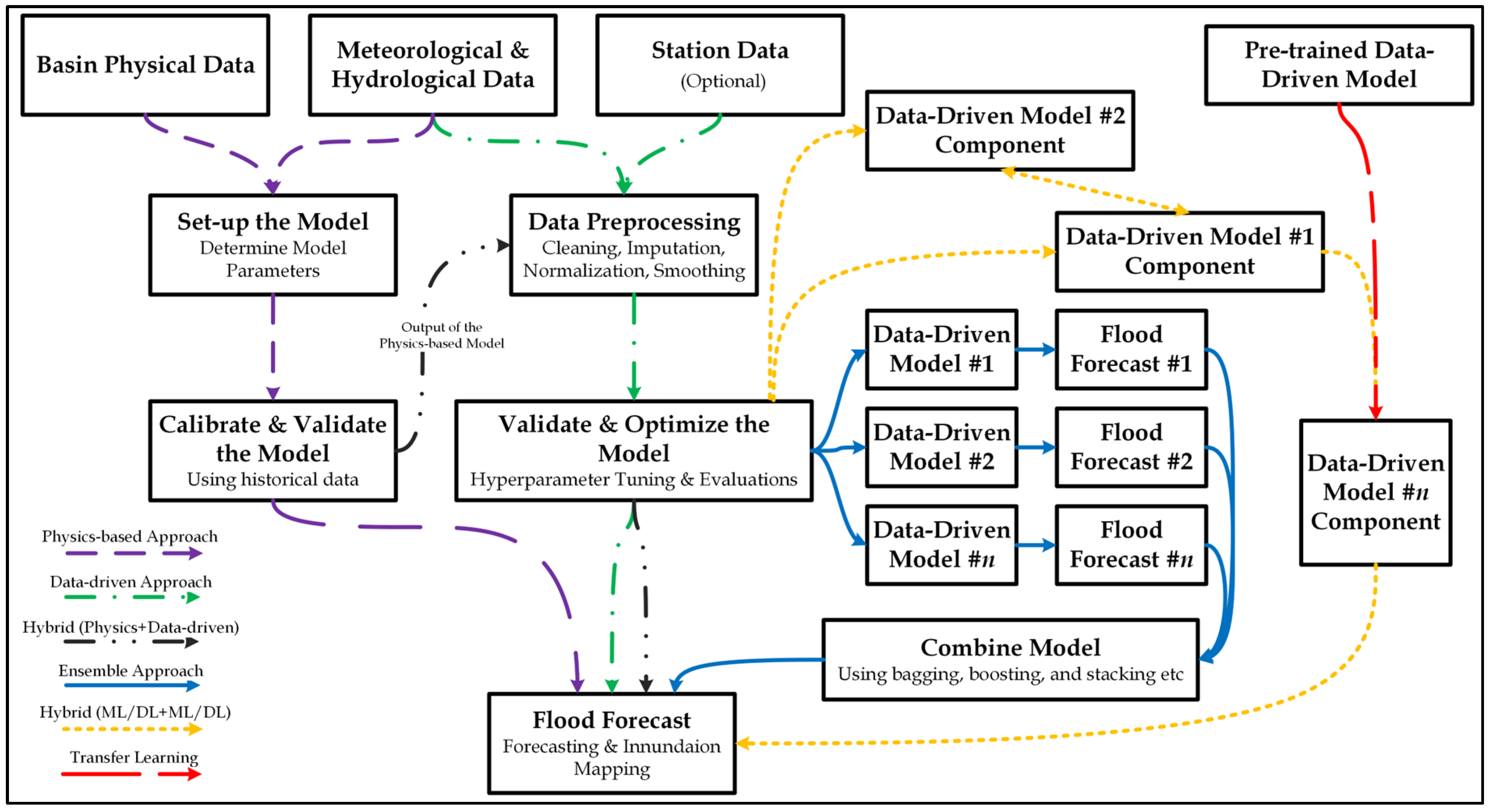
6.4. RQ4: What Algorithms Were Implemented in the Studies?
6.4.1. Data Preprocessing
6.4.2. Forecasting Models
6.4.3. Optimisation and Hyperparameter Tuning
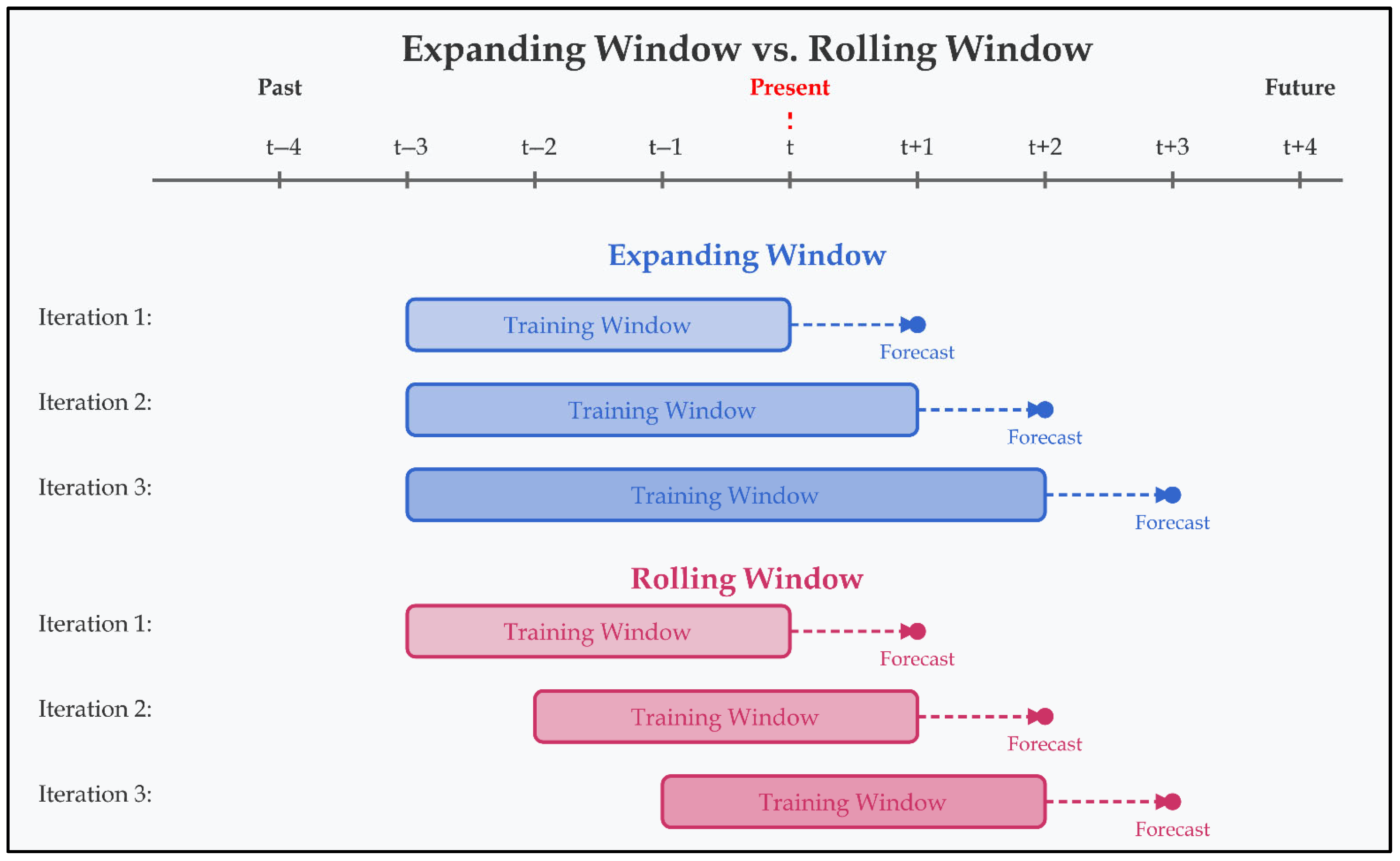
6.4.4. Look-Back Window and Lead Times
6.5. RQ5: What Evaluation Metrics Were Employed to Assess Model Performance?
6.6. Potential Research Directions
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- WMO. Weather-Related Disasters Increase over Past 50 Years, Causing More Damage but Fewer Deaths. Available online: https://wmo.int/media/news/weather-related-disasters-increase-over-past-50-years-causing-more-damage-fewer-deaths (accessed on 11 July 2024).
- Zeleňáková, M.; Gaňová, L.; Purcz, P.; Horský, M.; Satrapa, L.; Blišťan, P.; Diaconu, D. Mitigation of the Adverse Consequences of Floods for Human Life, Infrastructure, and the Environment. Nat. Hazards Rev. 2017, 18, 05017002. [Google Scholar] [CrossRef]
- Dharmarathne, G.; Waduge, A.; Bogahawaththa, M.; Rathnayake, U.; Meddage, D. Adapting Cities to the Surge: A Comprehensive Review of Climate-induced Urban Flooding. Results Eng. 2024, 22, 102123. [Google Scholar] [CrossRef]
- Hakim, D.K.; Gernowo, R.; Nirwansyah, A.W. Flood Prediction with Time Series Data Mining: Systematic Review. Nat. Hazards Res. 2024, 4, 194–220. [Google Scholar] [CrossRef]
- WMO. Early Warning System. Available online: https://wmo.int/topics/early-warning-system (accessed on 24 February 2025).
- Kuller, M.; Schoenholzer, K.; Lienert, J. Creating Effective Flood Warnings: A Framework from a Critical Review. J. Hydrol. 2021, 602, 126708. [Google Scholar] [CrossRef]
- Qin, Y. Urban Flooding Mitigation Techniques: A Systematic Review and Future Studies. Water 2020, 12, 3579. [Google Scholar] [CrossRef]
- Byaruhanga, N.; Kibirige, D.; Gokool, S.; Mkhonta, G. Evolution of Flood Prediction and Forecasting Models for Flood Early Warning Systems: A Scoping Review. Water 2024, 16, 1763. [Google Scholar] [CrossRef]
- Senthan, P.; Rathnayaka, R.; Banujan, K.; Kumara, B. Development of churn prediction Model Using XGBoost-Telecommunication Industry in Sri Lanka. In Proceedings of the 2021 IEEE International IOT, Electronics and Mechatronics Conference (IEMTRONICS), Toronto, ON, Canada, 21–24 April 2021; pp. 1–7. [Google Scholar]
- Mishoba, S.; Banujan, K.; Prasanth, S.; Kumara, B. A Machine Learning Approach to Classify the Telecommunication Customers Based on Their Profitability. In Social Customer Relationship Management (Social-CRM) in the Era of Web 4.0; IGI Global: Hershey, PA, USA, 2022; pp. 1–25. [Google Scholar]
- Singh, R.; Srivastava, S. Stock Prediction Using Deep Learning. Multimed. Tools Appl. 2017, 76, 18569–18584. [Google Scholar] [CrossRef]
- Kajanan, S.; Kumara, B.; Banujan, K.; Prasanth, S.; Manitheepan, K. Classify the Outcome of Arterial Blood Gas Test to Detect the Respiratory Failure Using Machine Learning. In Proceedings of the 2022 International Conference on Decision Aid Sciences and Applications (DASA), Chiangrai, Thailand, 23–25 March 2022; pp. 1139–1143. [Google Scholar]
- Prasanth, S.; Banujan, K.; Kumara, B. Hyper Parameter Tuned Ensemble Approach for Gestational Diabetes Prediction. In Proceedings of the 2021 International Conference on Innovation and Intelligence for Informatics, Computing, and Technologies (3ICT), Zallaq, Bahrain, 29–30 September 2021; pp. 18–23. [Google Scholar]
- Premisha, P.; Prasanth, S.; Kanagarathnam, M.; Banujan, K. An Ensemble Machine Learning Approach for Stroke Prediction. In Proceedings of the 2022 International Research Conference on Smart Computing and Systems Engineering (SCSE), Colombo, Sri Lanka, 1 September 2022; pp. 165–170. [Google Scholar]
- Banujan, K.; Ifham, M.; Kumara, B. Boosting Ensemble Machine Learning Approach for Covid-19 Death Prediction. Sri Lanka J. Soc. Sci. Humanit. 2023, 3, 81–89. [Google Scholar] [CrossRef]
- Sandagiri, S.; Kumara, B.; Banujan, K. Detecting Crime Related Twitter Posts Using Artificial Neural Networks Based Approach. In Proceedings of the 2020 20th International Conference on Advances in ICT for Emerging Regions (ICTer), Colombo, Sri Lanka, 4–7 November 2020; pp. 5–10. [Google Scholar]
- Wijeratne, A.K.; Ravikumar, N.; Bandara, P.M.; Banujan, K. Prognostication of Crime Using Bagging Regression Model: A Case Study of London. In Handbook of Research on Technological Advances of Library and Information Science in Industry 5.0; IGI Global: Hershey, PA, USA, 2023; pp. 462–478. [Google Scholar]
- Banujan, K.; Kumara, B.; Prasanth, S.; Ravikumar, N. Revolutionising Educational Assessment: Automated Question Classification Using Bloom’s Taxonomy and Deep Learning Techniques- A Case Study on Undergraduate Examination Questions. Int. J. Educ. Dev. Using Inf. Commun. Technol. 2023, 19, 259–278. [Google Scholar]
- Banujan, K.; Kumara, B.; Paik, I. Strengthening Post-Disaster Management Activities by Rating Social Media Corpus. In Research Anthology on Managing Crisis and Risk Communications; IGI Global Scientific Publishing: Hershey, PA, USA, 2023; pp. 711–729. [Google Scholar]
- Aswin, S.; Geetha, P.; Vinayakumar, R. Deep Learning Models for the Prediction of Rainfall. In Proceedings of the 2018 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 3–5 April 2018; pp. 0657–0661. [Google Scholar]
- Kekulanadara, K.; Kumara, B.; Banujan, K. Comparative Analysis of Machine Learning Algorithms for Predicting Air Quality Index. In Proceedings of the 2021 from Innovation to Impact (FITI), Colombo, Sri Lanka, 8 December 2021; pp. 1–5. [Google Scholar]
- Zhu, H.; Leandro, J.; Lin, Q. Optimization of Artificial Neural Network (ANN) for Maximum Flood Inundation Forecasts. Water 2021, 13, 2252. [Google Scholar] [CrossRef]
- Patel, M.; Parekh, F. Forecasting of Flood Flow of Panam River Basin Using Adaptive Neuro-Fuzzy Inference System (ANFIS) and ANN with Comparative Study. J. Adv. Res. Appl. Sci. Eng. Technol. 2023, 32, 346–359. [Google Scholar] [CrossRef]
- Malik, H.; Feng, J.; Shao, P.; Abduljabbar, Z.A. Improving Flood Forecasting Using Time-Distributed CNN-LSTM Model: A Time-Distributed Spatiotemporal Method. Earth Sci. Inform. 2024, 17, 3455–3474. [Google Scholar] [CrossRef]
- Wang, F.; Wang, W.; Bi, W.; Lin, W.; Zhang, D. Dual-Stage Attention-Based LSTM Network for Multiple Time Steps Flood Forecasting. Proc. Int. Assoc. Hydrol. Sci. 2024, 386, 141–146. [Google Scholar] [CrossRef]
- Liu, C.; Xie, T.; Li, W.; Hu, C.; Jiang, Y.; Li, R.; Song, Q. Research on Machine Learning Hybrid Framework by Coupling Grid-Based Runoff Generation Model and Runoff Process Vectorization for Flood Forecasting. J. Environ. Manag. 2024, 364, 121466. [Google Scholar] [CrossRef] [PubMed]
- Xu, C.; Zhong, P.-a.; Zhu, F.; Xu, B.; Wang, Y.; Yang, L.; Wang, S.; Xu, S. A Hybrid Model Coupling Process-Driven and Data-Driven Models for Improved Real-Time Flood Forecasting. J. Hydrol. 2024, 638, 131494. [Google Scholar] [CrossRef]
- Zhang, L.; Qin, H.; Mao, J.; Cao, X.; Fu, G. High Temporal Resolution Urban Flood Prediction Using Attention-Based LSTM Models. J. Hydrol. 2023, 620, 129499. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, Z.; Van Griensven Thé, J.; Yang, S.X.; Gharabaghi, B. Flood Forecasting Using Hybrid LSTM and GRU Models with Lag Time Preprocessing. Water 2023, 15, 3982. [Google Scholar] [CrossRef]
- Petersen, K.; Feldt, R.; Mujtaba, S.; Mattsson, M. Systematic Mapping Studies in Software Engineering. In Proceedings of the 12th International Conference on Evaluation and Assessment in Software Engineering (EASE), Bari, Italy, 26–27 June 2008. [Google Scholar]
- Petersen, K.; Vakkalanka, S.; Kuzniarz, L. Guidelines for Conducting Systematic Mapping Studies in Software Engineering: An Update. Inf. Softw. Technol. 2015, 64, 1–18. [Google Scholar] [CrossRef]
- Kitchenham, B.; Charters, S. Guidelines for Performing Systematic Literature Reviews in Software Engineering; Kitchenham: Hershey, PA, USA, 2007. [Google Scholar]
- Farshchian, B.A.; Dahl, Y. The Role of ICT in Addressing the Challenges of Age-related Falls: A Research Agenda Based on a Systematic Mapping of the Literature. Pers. Ubiquitous Comput. 2015, 19, 649–666. [Google Scholar] [CrossRef]
- Kong, X.; Li, Z.; Liu, Z. Flood Prediction in Ungauged Basins by Physical-based TOPKAPI Model. Adv. Meteorol. 2019, 2019, 4795853. [Google Scholar] [CrossRef]
- Hussain, F.; Wu, R.-S.; Wang, J.-X. Comparative Study of Very Short-term Flood Forecasting Using Physics-based Numerical Model and Data-driven Prediction Model. Nat. Hazards 2021, 107, 249–284. [Google Scholar] [CrossRef]
- Jodhani, K.H.; Patel, D.; Madhavan, N. A Review on Analysis of Flood Modelling Using Different Numerical Models. Mater. Today Proc. 2023, 80, 3867–3876. [Google Scholar] [CrossRef]
- Ardabili, S.; Mosavi, A.; Dehghani, M.; Várkonyi-Kóczy, A.R. Deep Learning and Machine Learning in Hydrological Processes Climate Change and Earth Systems a Systematic Review. In Proceedings of the Engineering for Sustainable Future: Selected papers of the 18th International Conference on Global Research and Education Inter-Academia–2019, 18, Budapest, Hungary, 4–7 September 2019; Springer: Cham, Switzerland, 2020; pp. 52–62. [Google Scholar]
- Taormina, R.; Chau, K.-W. Data-driven Input Variable Selection for Rainfall–runoff Modeling Using Binary-coded Particle Swarm Optimization and Extreme Learning Machines. J. Hydrol. 2015, 529, 1617–1632. [Google Scholar] [CrossRef]
- Chen, C.; Hui, Q.; Xie, W.; Wan, S.; Zhou, Y.; Pei, Q. Convolutional Neural Networks for Forecasting Flood Process in Internet-of-Things Enabled Smart City. Comput. Netw. 2021, 186, 107744. [Google Scholar] [CrossRef]
- Oliveira Santos, V.; Costa Rocha, P.A.; Scott, J.; Thé, J.V.G.; Gharabaghi, B. A New Graph-Based Deep Learning Model to Predict Flooding with Validation on a Case Study on the Humber River. Water 2023, 15, 1827. [Google Scholar] [CrossRef]
- Liang, Z.; Zou, R.; Chen, X.; Ren, T.; Su, H.; Liu, Y. Simulate the Forecast Capacity of a Complicated Water Quality Model Using the Long Short-term Memory Approach. J. Hydrol. 2020, 581, 124432. [Google Scholar] [CrossRef]
- Fan, J.; Zhang, K.; Huang, Y.; Zhu, Y.; Chen, B. Parallel Spatio-temporal Attention-based TCN for Multivariate Time Series Prediction. Neural Comput. Appl. 2023, 35, 13109–13118. [Google Scholar] [CrossRef]
- Li, G.; Zhu, H.; Jian, H.; Zha, W.; Wang, J.; Shu, Z.; Yao, S.; Han, H. A Combined Hydrodynamic Model and Deep Learning Method to Predict Water Level in Ungauged Rivers. J. Hydrol. 2023, 625, 130025. [Google Scholar] [CrossRef]
- Reichstein, M.; Camps-Valls, G.; Stevens, B.; Jung, M.; Denzler, J.; Carvalhais, N.; Prabhat, F. Deep Learning and Process Understanding for Data-driven Earth System Science. Nature 2019, 566, 195–204. [Google Scholar] [CrossRef]
- Khatun, A.; Chatterjee, C.; Sahu, G.; Sahoo, B. A Novel Smoothing-Based Long Short-Term Memory Framework for Short-to Medium-Range Flood Forecasting. Hydrol. Sci. J. 2023, 68, 488–506. [Google Scholar] [CrossRef]
- Kratzert, F.; Klotz, D.; Brenner, C.; Schulz, K.; Herrnegger, M. Rainfall–runoff Modelling Using Long Short-term Memory (LSTM) Networks. Hydrol. Earth Syst. Sci. 2018, 22, 6005–6022. [Google Scholar] [CrossRef]
- Noor, F.; Haq, S.; Rakib, M.; Ahmed, T.; Jamal, Z.; Siam, Z.S.; Hasan, R.T.; Adnan, M.S.G.; Dewan, A.; Rahman, R.M. Water Level Forecasting Using Spatiotemporal Attention-Based Long Short-Term Memory Network. Water 2022, 14, 612. [Google Scholar] [CrossRef]
- Li, W.; Liu, C.; Xu, Y.; Niu, C.; Li, R.; Li, M.; Hu, C.; Tian, L. An Interpretable Hybrid Deep Learning Model for Flood Forecasting Based on Transformer and LSTM. J. Hydrol. Reg. Stud. 2024, 54, 101873. [Google Scholar] [CrossRef]
- Nie, Q.; Wan, D.; Wang, R. CNN-BiLSTM Water Level Prediction Method with Attention Mechanism. J. Phys. Conf. Ser. 2021, 2078, 012032. [Google Scholar] [CrossRef]
- Niu, S. Application of CNN-LSTM and Internet of Things in Rainfall Accumulation Prediction at Urban Flooding Sites. In Proceedings of the 2023 IEEE 6th International Conference on Information Systems and Computer Aided Education (ICISCAE), Dalian, China, 23-25 September 2023; pp. 938–944. [Google Scholar]
- Dong, S.; Yu, T.; Farahmand, H.; Mostafavi, A. A Hybrid Deep Learning Model for Predictive Flood Warning and Situation Awareness Using Channel Network Sensors Data. Comput.-Aided Civ. Infrastruct. Eng. 2021, 36, 402–420. [Google Scholar] [CrossRef]
- Zhou, Y.; Cui, Z.; Lin, K.; Sheng, S.; Chen, H.; Guo, S.; Xu, C.-Y. Short-Term Flood Probability Density Forecasting Using a Conceptual Hydrological Model with Machine Learning Techniques. J. Hydrol. 2022, 604, 127255. [Google Scholar] [CrossRef]
- de Souza, É.F.; de Almeida Falbo, R.; Vijaykumar, N.L. Knowledge Management Initiatives in Software Testing: A Mapping Study. Inf. Softw. Technol. 2015, 57, 378–391. [Google Scholar] [CrossRef]
- Felizardo, K.R.; de Souza, É.F.; Napoleão, B.M.; Vijaykumar, N.L.; Baldassarre, M.T. Secondary Studies in the Academic Context: A Systematic Mapping and Survey. J. Syst. Softw. 2020, 170, 110734. [Google Scholar] [CrossRef]
- IEEE Xplore. Available online: https://ieeexplore.ieee.org (accessed on 1 February 2025).
- Web of Science. Available online: https://webofscience.com (accessed on 1 February 2025).
- Scopus. Available online: https://www.scopus.com (accessed on 1 February 2025).
- Salimi, A.; Ghobrial, T.; Bonakdari, H. A Comprehensive Review of AI-Based Methods Used for Forecasting Ice Jam Floods Occurrence, Severity, Timing, and Location. Cold Reg. Sci. Technol. 2024, 227, 104305. [Google Scholar] [CrossRef]
- Chitwatkulsiri, D.; Miyamoto, H. Real-Time Urban Flood Forecasting Systems for Southeast Asia—A Review of Present Modelling and Its Future Prospects. Water 2023, 15, 178. [Google Scholar] [CrossRef]
- Sharma, T.; Pal, A.; Kaushik, A.; Yadav, A.; Chitragupta, A. A Survey on Flood Prediction Analysis Based on ML Algorithm Using Data Science Methodology. In Proceedings of the 2022 IEEE Delhi Section Conference (DELCON), New Delhi, India, 11–13 February 2022; pp. 1–8. [Google Scholar]
- Piadeh, F.; Behzadian, K.; Alani, A.M. A Critical Review of Real-Time Modelling of Flood Forecasting in Urban Drainage Systems. J. Hydrol. 2022, 607, 127476. [Google Scholar] [CrossRef]
- Ozdemir, S.; Yaqub, M.; Yildirim, S.O. A Systematic Literature Review on Lake Water Level Prediction Models. Environ. Model. Softw. 2023, 163, 105684. [Google Scholar] [CrossRef]
- Ullah, T.F.; Prakasi, O.G.; Kanmani, P. A Review on Flood Prediction Algorithms and a Deep Neural Network Model for Estimation of Flood Occurrence. Int. Res. J. Multidiscip. Technovation 2020, 2, 8–14. [Google Scholar] [CrossRef]
- Shetty, P.; Varma, S.; Tripathi, S.; Bhole, C. Advancements in Disaster Prediction: A Systematic Review of Earthquake, Flood, and Cyclone Forecasting Techniques. In Proceedings of the 2024 4th International Conference on Sustainable Expert Systems (ICSES), Kaski, Nepal, 15–17 October 2024; pp. 1665–1673. [Google Scholar]
- Di, Q.; Jinbo, Q.; Mingti, C. Application of Machine Learning in Flood Forecast: A Survey. In Proceedings of the 2022 International Conference on Virtual Reality, Human-Computer Interaction and Artificial Intelligence (VRHCIAI), Changsha, China, 28–30 October 2022; pp. 177–181. [Google Scholar]
- Subashini, M.; Sudarmani, R.; Gobika, S.; Varshini, R. Development of Smart Flood Monitoring and Early Warning System Using Weather Forecasting Data and Wireless Sensor Networks—A Review. In Proceedings of the 2021 Third International Conference on Intelligent Communication Technologies and Virtual Mobile Networks (ICICV), Tirunelveli, India, 4–6 February 2021; pp. 132–135. [Google Scholar]
- Khairudin, N.M.; Mustapha, N.B.; Aris, T.N.M.; Zolkepli, M. In-Depth Review on Machine Learning Models for Long-Term Flood Forecasting. J. Theor. Appl. Inf. Technol. 2022, 100, 3360–3378. [Google Scholar]
- Banujan, K.; Chamanee, G.; Kumara, B. A Comprehensive Review on the Integration of Geographic Information Systems and Artificial Intelligence for Landfill Site Selection: A Systematic Mapping Perspective. Waste Manag. Res. 2025, 43, 137–159. [Google Scholar] [CrossRef]
- Alabadla, M.; Sidi, F.; Ishak, I.; Ibrahim, H.; Affendey, L.S.; Ani, Z.C.; Jabar, M.A.; Bukar, U.A.; Devaraj, N.K.; Muda, A.S. Systematic Review of Using Machine Learning in Imputing Missing Values. IEEE Access 2022, 10, 44483–44502. [Google Scholar] [CrossRef]
- Sit, M.; Demiray, B.Z.; Xiang, Z.; Ewing, G.J.; Sermet, Y.; Demir, I. A Comprehensive Review of Deep Learning Applications in Hydrology and Water Resources. Water Sci. Technol. 2020, 82, 2635–2670. [Google Scholar] [CrossRef] [PubMed]
- Feng, J.; Wang, Z.; Wu, Y.; Xi, Y. Spatial and Temporal Aware Graph Convolutional Network for Flood Forecasting. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Nguyen, D.H.; Kim, S.-H.; Kwon, H.-H.; Bae, D.-H. Uncertainty Quantification of Water Level Predictions from Radar-based Areal Rainfall Using an Adaptive MCMC Algorithm. Water Resour. Manag. 2021, 35, 2197–2213. [Google Scholar] [CrossRef]
- Wang, S.; Xu, O. Uncertainty Forecasting Model for Mountain Flood Based on Bayesian Deep Learning. IEEE Access 2024, 12, 47830–47841. [Google Scholar] [CrossRef]
- Chu, W.; Zhang, C.; Li, H.; Zhang, L.; Shen, D.; Li, R. SHAP-Powered Insights Into Spatiotemporal Effects: Unlocking Explainable Bayesian-Neural-Network Urban Flood Forecasting. Int. J. Appl. Earth Obs. Geoinf. 2024, 131, 103972. [Google Scholar] [CrossRef]
- Xiang, X.; Guo, S.; Cui, Z.; Wang, L.; Xu, C.-Y. Improving Flood Forecast Accuracy Based on Explainable Convolutional Neural Network by Grad-CAM Method. J. Hydrol. 2024, 642, 131867. [Google Scholar] [CrossRef]
- Nayak, M.; Das, S.; Senapati, M.R. Improving Flood Prediction with Deep Learning Methods. J. Inst. Eng. (India) Ser. B 2022, 103, 1189–1205. [Google Scholar] [CrossRef]
- Mosavi, A.; Ozturk, P.; Chau, K.-w. Flood Prediction Using Machine Learning Models: Literature Review. Water 2018, 10, 1536. [Google Scholar] [CrossRef]
- Brown, R.G. Smoothing, Forecasting and Prediction of Discrete Time Series; Courier Corporation: Chelmsford, MA, USA, 2004. [Google Scholar]
- Armstrong, J.S. Principles of Forecasting: A Handbook for Researchers and Practitioners; Springer Science & Business Media: New York, NY, USA, 2001; Volume 30. [Google Scholar]
- Wang, Y.; Huang, Y.; Xiao, M.; Zhou, S.; Xiong, B.; Jin, Z. Medium-Long-Term Prediction of Water Level Based on an Improved Spatio-Temporal Attention Mechanism for Long Short-Term Memory Networks. J. Hydrol. 2023, 618, 129163. [Google Scholar] [CrossRef]
- Ficchì, A.; Perrin, C.; Andréassian, V. Impact of Temporal Resolution of Inputs on Hydrological Model Performance: An Analysis Based on 2400 Flood Events. J. Hydrol. 2016, 538, 454–470. [Google Scholar] [CrossRef]
- Gürsoy, Ö.; Engin, S.N. A Wavelet Neural Network Approach to Predict Daily River Discharge Using Meteorological Data. Meas. Control 2019, 52, 599–607. [Google Scholar] [CrossRef]
- Roodsari, B.K.; Chandler, D.G.; Kelleher, C.; Kroll, C.N. A Comparison of SAC-SMA and Adaptive Neuro-fuzzy Inference System for Real-time Flood Forecasting in Small Urban Catchments. J. Flood Risk Manag. 2019, 12, e12492. [Google Scholar] [CrossRef]
- Haben, S.; Voss, M.; Holderbaum, W. Time Series Forecasting: Core Concepts and Definitions. In Core Concepts and Methods in Load Forecasting: With Applications in Distribution Networks; Springer: Cham, Switzerland, 2023; pp. 55–66. [Google Scholar]
- Kim, B.; Choi, S.Y.; Han, K.-Y. Integrated Real-Time Flood Forecasting and Inundation Analysis in Small–medium Streams. Water 2019, 11, 919. [Google Scholar] [CrossRef]
- Shahabi, A.; Tahvildari, N. A Deep-Learning Model for Rapid Spatiotemporal Prediction of Coastal Water Levels. Coast. Eng. 2024, 190, 104504. [Google Scholar] [CrossRef]
- Dai, W.; Tang, Y.; Liao, N.; Zou, S.; Cai, Z. Urban Flood Prediction Using Ensemble Artificial Neural Network: An Investigation on Improving Model Uncertainty. Appl. Water Sci. 2024, 14, 144. [Google Scholar] [CrossRef]
- Khajehali, M.; Safavi, H.R.; Nikoo, M.R.; Fooladi, M. A Fusion-Based Framework for Daily Flood Forecasting in Multiple-Step-Ahead and Near-Future under Climate Change Scenarios: A Case Study of the Kan River, Iran. Nat. Hazards 2024, 120, 8483–8504. [Google Scholar] [CrossRef]
- Li, Y.; Su, M.; Duan, Z.; Liu, H. A New Integrated Prediction Method of River Level Based on Spatiotemporal Correlation. Stoch. Environ. Res. Risk Assess. 2024, 38, 1121–1143. [Google Scholar] [CrossRef]
- Chieu, T.Q.; Thao, N.T.P.; Thi Hue, D.; Huong, N.T.T. Prediction of the Water Level at the Kien Giang River Based on Regression Techniques. River 2024, 3, 59–68. [Google Scholar] [CrossRef]
- Lin, C.-H.A.; Liu, C.-Y.; Chen, K.-C. Quantum-Train Long Short-Term Memory: Application on Flood Prediction Problem. In Proceedings of the 2024 IEEE International Conference on Quantum Computing and Engineering (QCE), Montreal, QC, Canada, 15-20 September 2024; pp. 268–273. [Google Scholar]
- Kow, P.-Y.; Liou, J.-Y.; Yang, M.-T.; Lee, M.-H.; Chang, L.-C.; Chang, F.-J. Advancing Climate-Resilient Flood Mitigation: Utilizing Transformer-LSTM for Water Level Forecasting at Pumping Stations. Sci. Total Environ. 2024, 927, 172246. [Google Scholar] [CrossRef] [PubMed]
- Luo, Y.; Zhou, Y.; Chen, H.; Xiong, L.; Guo, S.; Chang, F.-J. Exploring a Spatiotemporal Hetero Graph-Based Long Short-Term Memory Model for Multi-Step-Ahead Flood Forecasting. J. Hydrol. 2024, 633, 130937. [Google Scholar] [CrossRef]
- Sharma, A.; Sharma, A. Artificial Neural Network (ANN) for Forecasting of Flood at Kasol in Satluj River, India. In Proceedings of the International Conference on Advanced Production and Industrial Engineering, Delhi, India, 18–19 June 2021; pp. 1085–1094. [Google Scholar]
- Zakaria, M.N.A.; Malek, M.A.; Zolkepli, M.; Ahmed, A.N. Application of Artificial Intelligence Algorithms for Hourly River Level Forecast: A Case Study of Muda River, Malaysia. Alex. Eng. J. 2021, 60, 4015–4028. [Google Scholar] [CrossRef]
- Girihagama, L.; Naveed Khaliq, M.; Lamontagne, P.; Perdikaris, J.; Roy, R.; Sushama, L.; Elshorbagy, A. Streamflow Modelling and Forecasting for Canadian Watersheds Using LSTM Networks With Attention Mechanism. Neural Comput. Appl. 2022, 34, 19995–20015. [Google Scholar] [CrossRef]
- Effrosynidis, D.; Spiliotis, E.; Sylaios, G.; Arampatzis, A. Time Series and Regression Methods for Univariate Environmental Forecasting: An Empirical Evaluation. Sci. Total Environ. 2023, 875, 162580. [Google Scholar] [CrossRef]
- Pungching, J.; Pilailar, S. Developing a Flood Forecasting System With Machine Learning and Applying to Geographic Information System. Geogr. Tech. 2023, 18, 1–18. [Google Scholar] [CrossRef]
- Li, J.; Wu, G.; Zhang, Y.; Shi, W. Optimizing Flood Predictions by Integrating LSTM and Physical-Based Models with Mixed Historical and Simulated Data. Heliyon 2024, 10, e33669. [Google Scholar] [CrossRef]
- Thaisiam, W.; Yomwilai, K.; Wongchaisuwat, P. Utilizing Sequential Modeling in Collaborative Method for Flood Forecasting. J. Hydrol. 2024, 636, 131290. [Google Scholar] [CrossRef]
- Benson, B.; Pan, W.; Prasad, A.; Gary, G.; Hu, Q. Forecasting Solar Cycle 25 Using Deep Neural Networks. Sol. Phys. 2020, 295, 65. [Google Scholar] [CrossRef]
- Zeng, C.; Aboagye, E.M.; Li, H.; Che, S. Comments and Recommendations on Sponge City China’s Solutions to Prevent Flooding Risks. Heliyon 2023, 9, e12745. [Google Scholar] [CrossRef] [PubMed]
- Olawade, D.B.; Wada, O.Z.; Ige, A.O.; Egbewole, B.I.; Olojo, A.; Oladapo, B.I. Artificial Intelligence in Environmental Monitoring: Advancements, Challenges, and Future Directions. Hyg. Environ. Health Adv. 2024, 12, 100114. [Google Scholar] [CrossRef]
- Abu-Saymeh, R.K.; Godrej, A.; Alexander, K.A. Modeling Large River Basins and Flood Plains with Scarce Data: Development of the Large Basin Data Portal. Hydrology 2023, 10, 87. [Google Scholar] [CrossRef]
- Petersen, O.H. Inequality of Research Funding Between Different Countries and Regions is a Serious Problem for Global Science. Function 2021, 2, zqab060. [Google Scholar] [CrossRef]
- Van Bavel, B.; Curtis, D.R.; Soens, T. Economic Inequality and Institutional Adaptation in Response to Flood Hazards. Ecol. Soc. 2018, 23, 30. [Google Scholar] [CrossRef]
- Ma, K.; He, D.; Liu, S.; Ji, X.; Li, Y.; Jiang, H. Novel Time-Lag Informed Deep Learning Framework for Enhanced Streamflow Prediction and Flood Early Warning in Large-Scale Catchments. J. Hydrol. 2024, 631, 130841. [Google Scholar] [CrossRef]
- Tang, X.; Yin, Z.; Qin, G.; Guo, L.; Li, H. Integration of Satellite Precipitation Data and Deep Learning for Improving Flash Flood Simulation in a Poor-gauged Mountainous Catchment. Remote Sens. 2021, 13, 5083. [Google Scholar] [CrossRef]
- Kardhana, H.; Valerian, J.R.; Rohmat, F.I.W.; Kusuma, M.S.B. Improving Jakarta’s Katulampa Barrage Extreme Water Level Prediction Using Satellite-Based Long Short-Term Memory (LSTM) Neural Networks. Water 2022, 14, 1469. [Google Scholar] [CrossRef]
- Huang, Z.; Wu, H.; Gu, G.; Li, X.; Nanding, N.; Adler, R.F.; Yilmaz, K.K.; Alfieri, L.; Chen, S. Paired Satellite and NWP Precipitation for Global Flood Forecasting. J. Hydrometeorol. 2023, 24, 2191–2205. [Google Scholar] [CrossRef]
- Kumar, A.; Singh, V. Real-Time Flood Forecasting Using Satellite Precipitation Product and Machine Learning Approach in Bagmati River Basin, India. Acta Geophys. 2024, 72, 4431–4451. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, H.; Guan, X.; Meng, Y.; Xu, H. Urban Flood Depth Prediction and Visualization Based on the XGBoost-SHAP Model. Water Resour. Manag. 2024, 39, 1353–1375. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, J.; Li, C.; Liu, Y.; Xu, L.; Yu, F. A Data-driven Approach for Flood Prediction Using Grid-based Meteorological Data. Hydrol. Process. 2023, 37, e14837. [Google Scholar] [CrossRef]
- Tiu, E.S.K.; Huang, Y.F.; Ng, J.L.; Aldahoul, N.; Ahmed, A.N.; Elshafie, A. An Evaluation of Various Data Pre-Processing Techniques with Machine Learning Models for Water Level Prediction. Nat. Hazards 2022, 110, 121–153. [Google Scholar] [CrossRef]
- Waqas, M.; Humphries, U.W. A Critical Review of RNN and LSTM Variants in Hydrological Time Series Predictions. MethodsX 2024, 13, 102946. [Google Scholar] [CrossRef]
- Ahmed, A.M.; Akther, S.; Nguyen-Huy, T.; Raj, N.; Jui, S.J.J.; Farzana, S. Real-Time Prediction of the Week-Ahead Flood Index Using Hybrid Deep Learning Algorithms with Synoptic Climate Mode Indices. J. Hydro-Environ. Res. 2024, 57, 12–26. [Google Scholar] [CrossRef]
- Cao, Q.; Zhang, H.; Zhu, F.; Hao, Z.; Yuan, F. Multi-step-ahead Flood Forecasting Using an Improved BiLSTM-S2S Model. J. Flood Risk Manag. 2022, 15, e12827. [Google Scholar] [CrossRef]
- Xia, Y.; Lu, J. Short-Term Flood Prediction Model Based on Pre-Training Enhancement. Electronics 2024, 13, 2203. [Google Scholar] [CrossRef]
- Cui, Z.; Guo, S.; Chen, H.; Liu, D.; Zhou, Y.; Xu, C.-Y. Quantifying and Reducing Flood Forecast Uncertainty by the CHUP-BMA Method. Hydrol. Earth Syst. Sci. 2024, 28, 2809–2829. [Google Scholar] [CrossRef]
- Selva Jeba, G.; Chitra, P. River Flood Prediction Through Flow Level Modeling Using Multi-Attention Encoder-Decoder-Based TCN with Filter-Wrapper Feature Selection. Earth Sci. Inform. 2024, 17, 5233–5249. [Google Scholar] [CrossRef]
- Kashem, A.; Das, P.; Hasan, M.M.; Karim, R.; Nasher, N.R. Hybrid Deep Learning Models for Multi-Ahead River Water Level Forecasting. Earth Sci. Inform. 2024, 17, 3021–3037. [Google Scholar] [CrossRef]
- Roudbari, N.S.; Punekar, S.R.; Patterson, Z.; Eicker, U.; Poullis, C. From Data to Action in Flood Forecasting Leveraging Graph Neural Networks and Digital Twin Visualization. Sci. Rep. 2024, 14, 18571. [Google Scholar] [CrossRef] [PubMed]
- Kimura, N.; Minakawa, H.; Fukushige, Y.; Kimura, M.; Baba, D. Water Level Predictions in a Drainage Pumping Station Using a Deep Learning Model, Coupled with a Physical Model and a Transfer Learning Approach. J. Jpn. Soc. Civ. Eng. Ser. B1 (Hydraul. Eng.) 2024, 77, I_319–I_324. [Google Scholar] [CrossRef]
- Ueda, F.; Tanouchi, H.; Egusa, N.; Yoshihiro, T. A Transfer Learning Approach Based on Radar Rainfall for River Water-Level Prediction. Water 2024, 16, 607. [Google Scholar] [CrossRef]
- Noymanee, J.; Theeramunkong, T. Flood Forecasting with Machine Learning Technique on Hydrological Modeling. Procedia Comput. Sci. 2019, 156, 377–386. [Google Scholar] [CrossRef]
- Sheng, Z.; Zheng, M. Pipe Network Water Level Prediction Platform Coupled with SWMM and LSTM. In Proceedings of the International Conference on Water Resource and Environment, Online, 21–24 November 2024; pp. 140–150. [Google Scholar]
- Olivetti, L.; Messori, G. Advances and Prospects of Deep Learning for Medium-range Extreme Weather Forecasting. Geosci. Model Dev. 2024, 17, 2347–2358. [Google Scholar] [CrossRef]
- Watson, P.A. Machine Learning Applications for Weather and Climate Need Greater Focus on Extremes. Environ. Res. Lett. 2022, 17, 111004. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Concept | Keywords |
|---|---|
| Flood | “flood*”, “river level”, “water level”, “river discharge”, “river height” |
| Technology | “deep*learning”, “artificial*intelligence”, “machine*learning”, “data*mining”, “neural network”, “transformer”, “reinforcement learning”, “long short*term memory”, “lstm”, “decision tree”, “support vector machine”, “svm”, “ensemble*learning”, “ai”, etc. |
| Forecasting | “predict*”, “forecast*” |
| Type | Criteria |
|---|---|
| IC | IC1: Study discusses data-driven flood forecasting |
| Specific ECs | EC1: Studies not addressing quantitative hydrological forecasting
|
EC2: Studies with inappropriate temporal characteristics
| |
EC3: Studies with methodological misalignment
| |
| EC4: Studies not utilising hydrological variables (such as river discharge, water level, runoff) as target forecast variables | |
EC5: Studies with limited practical applicability
| |
| Generic ECs | EC6: Conference summaries/editorials/guidelines |
| EC7: Tertiary study (review article, etc.) | |
| EC8: Non-English studies | |
| EC9: Study without full-text access | |
| EC10: Books and grey literature | |
| EC11: Duplicate study |
| Stage | Applied Criteria | Analysed Content | Initial # of Studies | Final # of Studies | Reduction % |
|---|---|---|---|---|---|
| 1 | EC 11 | Title and Abstract | 2760 | 1908 | 31 |
| 2 | IC1, EC6–10 | Title and Abstract | 1908 | 1711 | 10 |
| 3 | IC1, EC1–5 | Title and Abstract | 1711 | 696 | 59 |
| 4 | IC1, EC1–5 | Full Paper | 696 | 348 | 50 |
| 5 | Snowballing, Research Groups, IC1, EC1–5 | Title and Abstract | 348 | 407 | −17 (increased) |
| 6 | Snowballing, Research Groups, IC1, EC1–10 | Full Paper | 407 | 363 | 11 |
| Category | Subcategory | RQ |
|---|---|---|
| Reference Information | Title Publication Year Authors Publication Type (Journal/Conference/Book) Publication Source | RQ1 |
| Geographical Context | Country/Region of Study River Basin/Watershed | RQ2 |
| Data Characteristics | Input Variables Output Variables Data Sources Data Collection Period Data Collection Frequency (Time Step) Lag Time Implementation | RQ3 |
| Technical Implementation | Preprocessing Techniques Forecasting Algorithms Physics-Based Models Used Look-back Window Approach Lead Time/Forecast Horizon Uncertainty Quantification Optimisation Methods | RQ4 |
| Evaluation Framework | Error-based Metrics Goodness-of-fit Metrics Classification Metrics Probabilistic Metrics Hydrological-specific Metrics Computational Performance | RQ5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kuhaneswaran, B.; Sorwar, G.; Alaei, A.R.; Tong, F. Evolution of Data-Driven Flood Forecasting: Trends, Technologies, and Gaps—A Systematic Mapping Study. Water 2025, 17, 2281. https://doi.org/10.3390/w17152281
Kuhaneswaran B, Sorwar G, Alaei AR, Tong F. Evolution of Data-Driven Flood Forecasting: Trends, Technologies, and Gaps—A Systematic Mapping Study. Water. 2025; 17(15):2281. https://doi.org/10.3390/w17152281
Chicago/Turabian StyleKuhaneswaran, Banujan, Golam Sorwar, Ali Reza Alaei, and Feifei Tong. 2025. "Evolution of Data-Driven Flood Forecasting: Trends, Technologies, and Gaps—A Systematic Mapping Study" Water 17, no. 15: 2281. https://doi.org/10.3390/w17152281
APA StyleKuhaneswaran, B., Sorwar, G., Alaei, A. R., & Tong, F. (2025). Evolution of Data-Driven Flood Forecasting: Trends, Technologies, and Gaps—A Systematic Mapping Study. Water, 17(15), 2281. https://doi.org/10.3390/w17152281