1. Introduction
Marine habitats have many benefits to the environment and humans. For example, they provide shelter and food for various aquatic species [
1,
2,
3,
4]. Moreover, the fishing and tourism and transportation industries largely benefit from marine ecosystems [
5,
6,
7]. Despite the importance of marine habitats, they are significantly threatened by natural and anthropogenic activities, such as climate change, shipping, and extensive fishing [
8,
9,
10]. Thus, it is necessary to use advanced and practical tools for mapping and monitoring these habitats.
Various remote sensing systems, such as optical satellites, bathymetric Light Detection and Ranging (LiDAR), Sound Navigation And Ranging (SONAR), and drones, provide valuable geospatial datasets to facilitate marine habitat studies over large and remote ocean environments with a minimum cost and over a minimal amount of time [
1,
2,
3,
4,
11]. For example, airborne bathymetric LiDAR systems have widely been applied to classify marine habitats due to their ability to generate high-density point cloud data over relatively deep-water bodies compared to other airborne and spaceborne remote sensing systems, such as multispectral and Synthetic Aperture Radar (SAR) sensors [
7,
12,
13,
14,
15]. LiDARs are active systems and have their own source of illumination. Thus, they can operate during both day and night times. Bathymetric LiDAR systems transmit laser pulses, usually in the green and blue ranges of the spectrum (e.g., wavelength = 530 nm), to the water bodies (e.g., oceans) and measure the distance and intensity. The derived distance and intensity values can later be applied to bathymetric mapping and for classifying different marine habitat types, respectively. It should be noted that the main difference between the bathymetric and terrestrial LiDAR systems is the fact that the first one uses green and blue electromagnetic pulses, but the second one uses the red and infrared pulses. This is because blue and green lights have a higher penetration into water and can see the bottom of the water up to a specific depths (e.g., 20 m in inland water bodies) [
2]. Bathymetric LiDAR pulses can be attenuated in water due to several water quality parameters, such as sediment, turbidity, and color [
16].
Multiple studies have so far employed bathymetric LiDAR data for marine habitat mapping. For instance, the authors of [
17] used an airborne bathymetric lidar system at Lake Banook, Nova Scotia to study the limitations of the lidar sensor for the application of monitoring submerged aquatic vegetation (SAV) distribution and biomass. Through their project, several products, such as a Digital Surface Model (DSM), a lidar reflectance grid, a Digital Terrain Model (DTM), and an aerial orthophoto were collected. They classified the aquatic vegetation and normalized the reflectance data and aerial photographs for depth. The authors of [
18] also measured the area, height, and biomass of macroalga, and Ascophyllum nodosum using topo-bathymetric LiDAR data in southwestern Nova Scotia, Canada. The comparison of LiDAR-derived seabed elevations with ground-truth data collected using a survey grade Global Navigation Satellite System (GNSS) system showed that the low tide survey data had a positive bias of 15 cm possibly because the seaweed was lying over the surface. Despite the suspended canopy, which reduced the lidar point density, the data collected at high tide did not show this change. Moreover, the authors of [
19] developed a novel method to map seagrasses, and their spatial distribution and extent using full waveform topo-bathymetric LiDAR data in Corsica, France. The data were analyzed to generate a seagrass meadows map with a classification accuracy of 86%. Furthermore, the seagrass height was extracted, allowing for the assessment of the structural complexity and the quantification of the ecosystem services.
Along with remote sensing data, it is important to develop a robust algorithm to produce an accurate habitat map. For example, machine learning models have shown promising results in identifying marine habitat types using LiDAR data [
11,
13,
20,
21]. So far, many studies have developed various machine learning algorithms for mapping marine habitats. For instance, the authors of [
15] applied a decision tree algorithm to classify marine habitat features using a combination of LiDAR point cloud data, reflectance, and bathymetry images. They reported that they could produce a habitat map with a classification accuracy of 70%. Moreover, the authors of [
21] produced a habitat map derived from a decision tree classifier and LiDAR data over a coastal area in Australia. They took the advantage of hydrodynamic features derived from numerical models (e.g., current speed and wave height) to boost the final classification accuracy derived from LiDAR features. They considered several classes, such as invertebrates, coral, seagrass, algae, and no-epibenthos areas, and obtained a classification accuracy of 90%. Finally, the authors of [
20] produced 3D marine habitat maps using high-resolution LiDAR data over several coastal areas in France. They employed a combination of waveform, elevation, and intensity features within a Random Forest (RF) classifier to obtain an average accuracy of around 90%.
Newfoundland’s offshore area contains various marine habitats that need to be effectively monitored. In this study, in situ data along with a supervised classification algorithm were employed to produce an accurate habitat map over the Bonne Bay area in Newfoundland. It is expected to use a similar approach to map marine habitats in other offshore areas in the near future.
3. Methodology
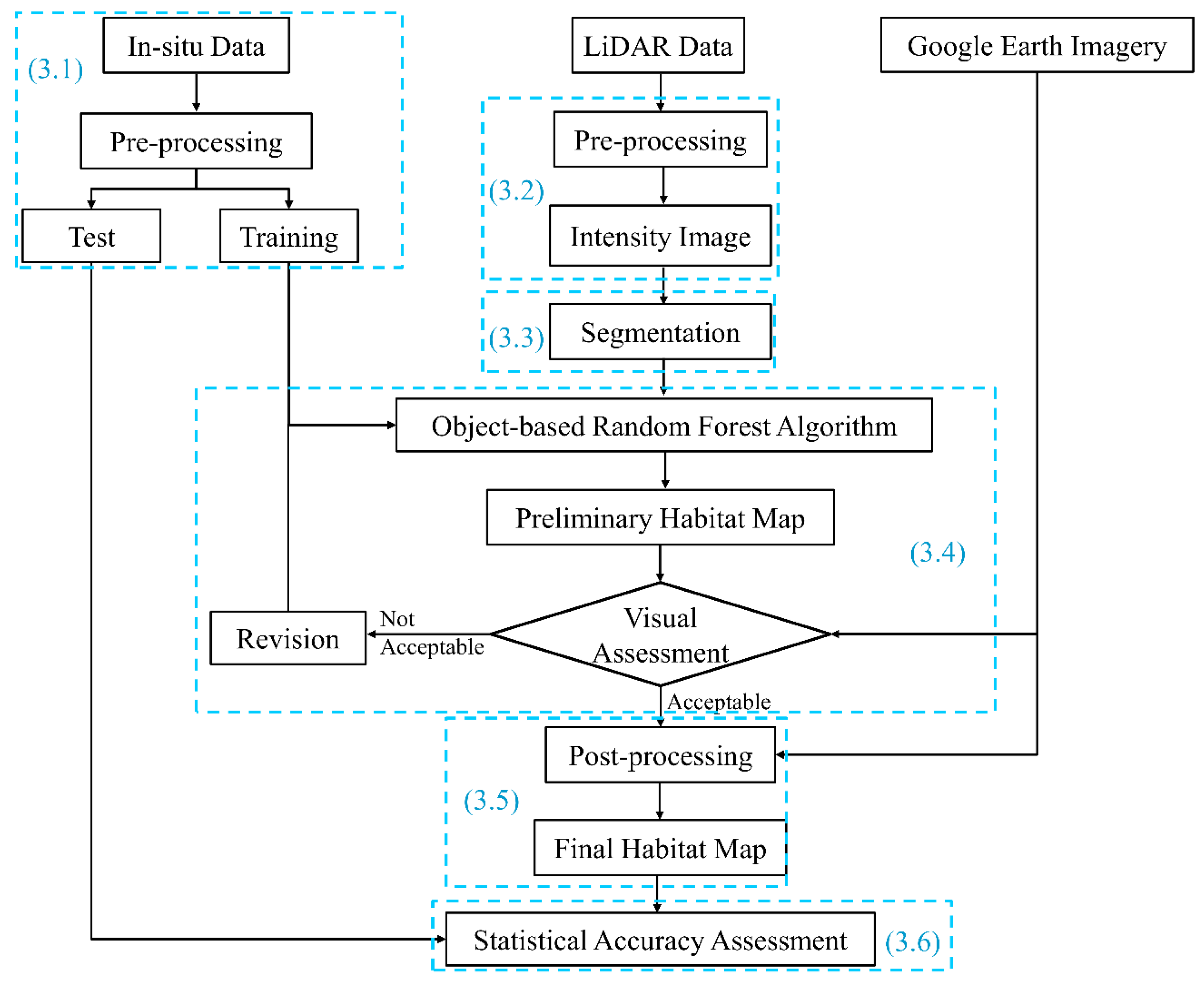
The flowchart of the method to produce the marine habitat map of Bonne Bay using the LiDAR data is illustrated in
Figure 2. The detail of each step is also provided below. It should be noted that this flowchart was used to develop two different models to produce two habitat maps based on the Category 1 and Category 2 classes (see
Table 1).
3.1. Field Data Preprocessing
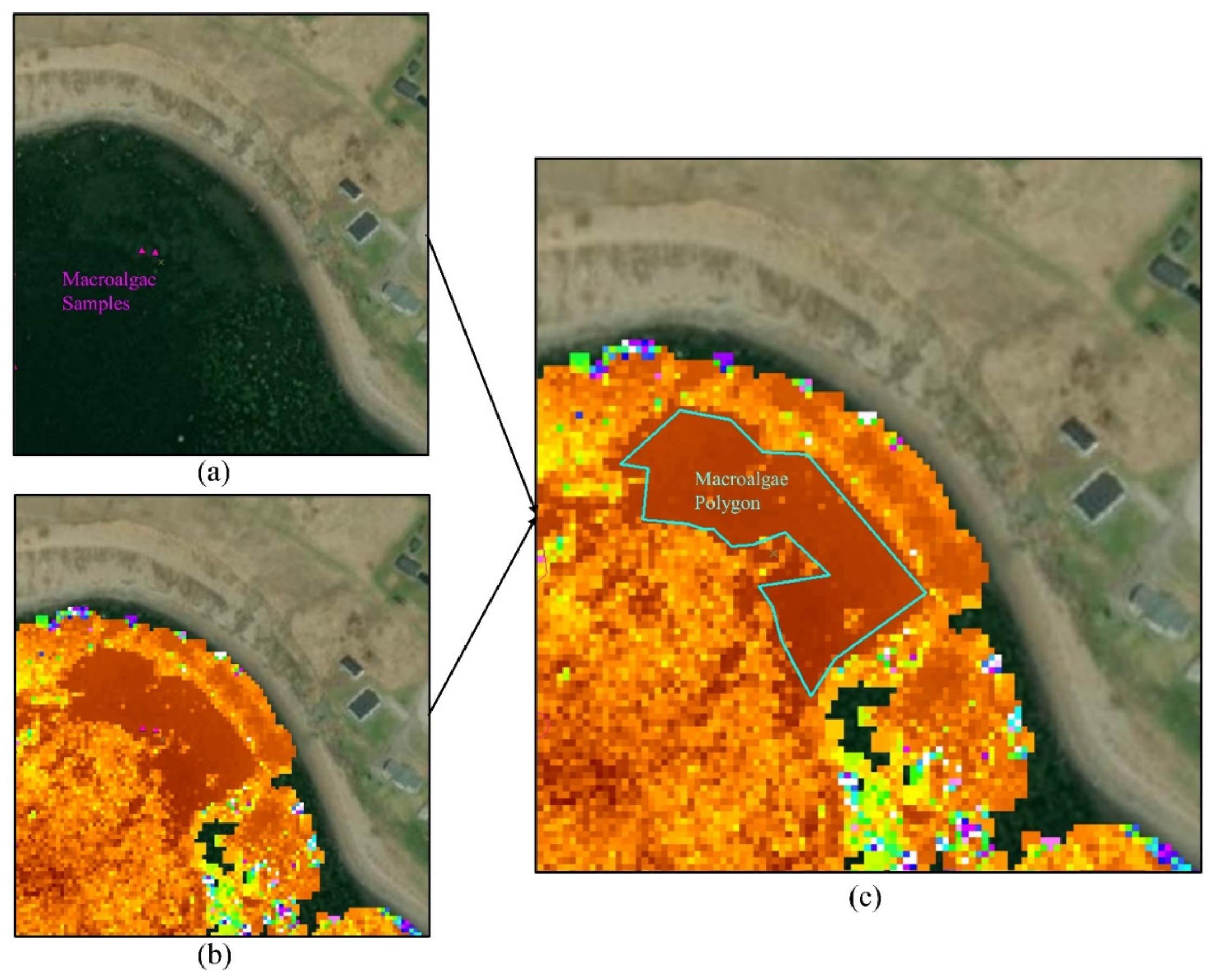
The field samples, which were point-based GPS locations of different habitat types, were inserted into ArcGIS and were converted to polygons where it was possible to do so. To this end, high-resolution Google Earth imagery and the LiDAR intensity product were used. Through this process, the boundary of each homogeneous habitat type at each sample location was delineated.
Figure 3 illustrates this procedure for creating a polygon of macroalgae. As it is clear, the intensity values for a macroalgae area were very similar, and they were higher than those of the surrounding pixels. Thus, they belonged to a specific habitat type. By converting field point-based samples to polygons, the number of samples was increased. Finally, all of the polygons were randomly divided into training (70%) and test (30%) data. The training and test polygons were, respectively used for training the machine learning algorithm (see
Section 3.4) and an accuracy assessment of the produced marine habitat map (see
Section 3.6).
3.2. LiDAR Data Preprocessing
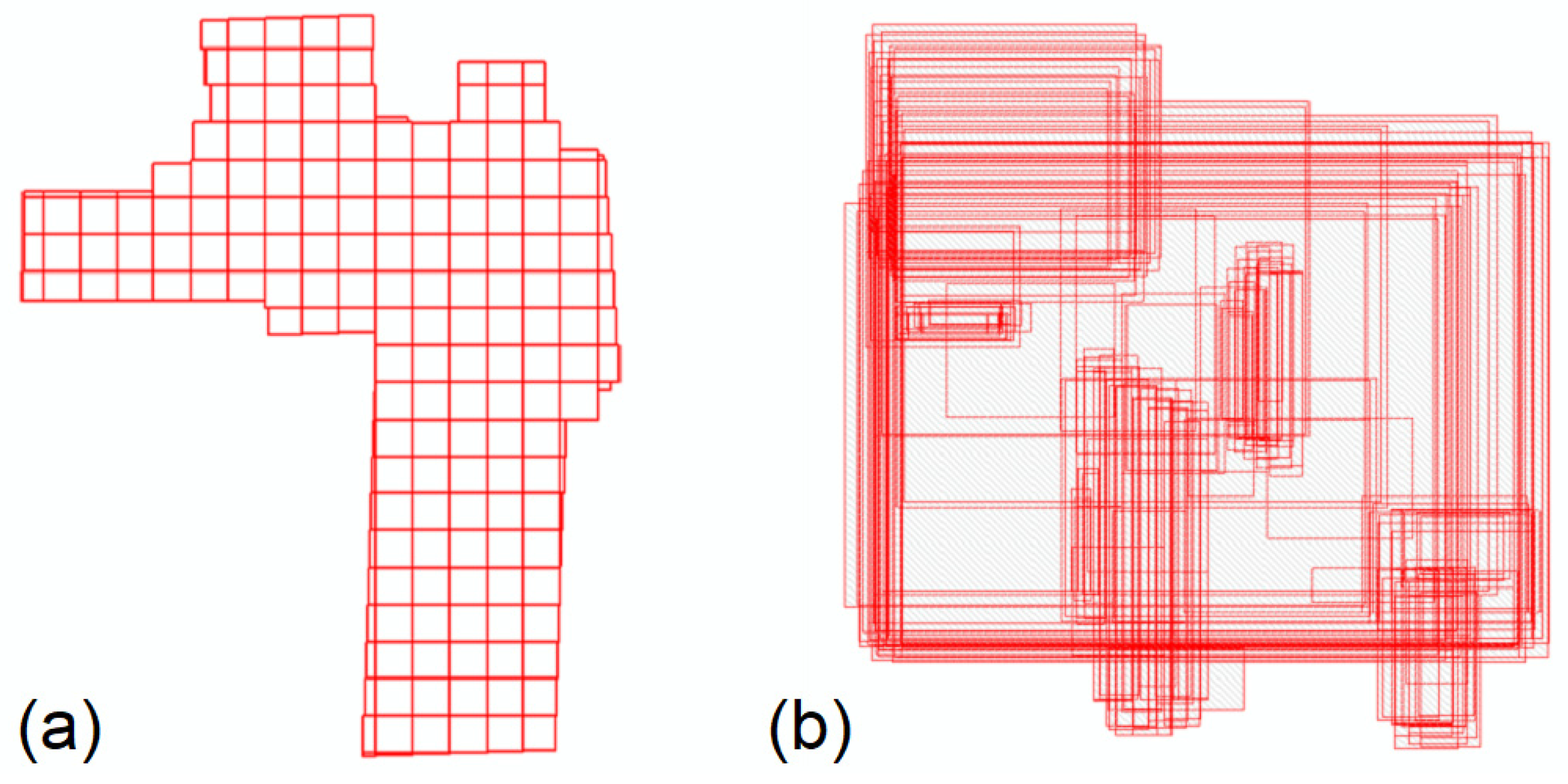
The LiDAR data were provided as three separate groups of LASer (LAS) files: S1, S2, and S3. S1 contained 92 LAS files, while S2 and S3 contained 76 LAS files. The S1 dataset was collected with the LiDAR sensor’s topographic (red) laser, and the other two were collected with the sensor’s bathymetric (green) laser. These two different lasers require different energetic outputs (as penetrating the water column requires more laser energy than penetrating air). The standard post-processing of a LiDAR survey includes the normalization of the returning laser waveforms between the green and red lasers, as well as between the flight lines, and thus, the amplitude of the reflected pulse (i.e., intensity) is consistent and normalized across the entire survey area. After normalization, the waveforms are converted into points, and they are then tiled in a consistent grid format (
Figure 4a) that is ready for converting to a raster. The LAS files provided for this study have not undergone these standard post-processing steps, and because the different laser returns were provided separately (S1 vs. S2–S3), flight line artifacts remain throughout the datasets, and the LAS files were not arranged in a consistent grid format (
Figure 4b).
In this study, steps were taken to mitigate the lack of standard post-processing during the raster generation process. While this amplitude normalization is not required to derive consistent elevations across a LiDAR survey, it is necessary to produce consistent intensity values across the survey area. For this reason, all three sets of LAS files provided were processed together to produce the Digital Elevation Model (DEM). All LiDAR products were gridded at a spatial resolution of 2 m using a linear interpolation to preserve the integrity of the data while minimizing the data gaps (
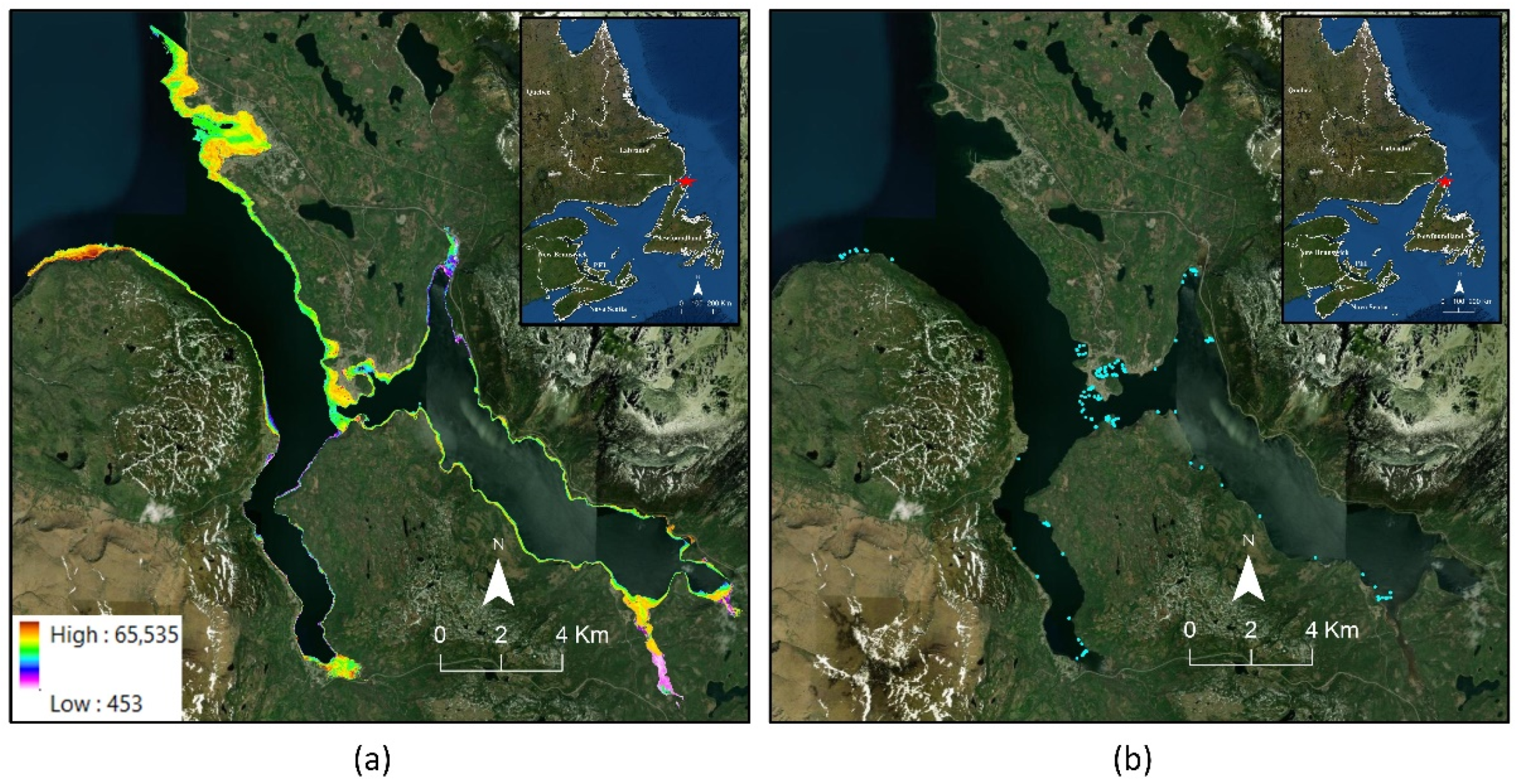
Figure 5). To remove the land, a mask was made based on land elevation. Through iterative visual analysis, the geomorphic coastline was determined to be roughly 1.8 m in elevation. A buffer of 20 cm elevation was added to this value, and so land over 2 m elevation was removed, and the results were visually checked to ensure no pertinent data were being removed.
To produce the critically important intensity models, the S1 LAS files (a result of the topographic red laser) were processed as one dataset, and the S2–S3 LAS files (results of the bathymetric green laser) were processed as another dataset. Flightline artifacts permeate the intensity dataset (
Figure 6), resulting in differing intensity values across homogeneous ground features. Attempts were made to normalize the intensity between the flight lines by comparing the mean intensity of a homogeneous patch of seabed under a flight line divide and applying the mean difference as a linear equation. However, the difference in intensity values varied across the survey area; thus, any corrections in one area enhanced the issues in another area. For this reason, a subsequent analysis was performed using uncorrected gridded intensity data, and separate S1 and S2–S3 intensity raster data.
3.3. Segmentation
It is widely reported that object-based classification methods are more accurate than pixel-based techniques are [
8,
9,
13]. Considering this fact, an object-based classification model was developed in this study to obtain accurate marine habitat maps from the study area. The first step in an object-based image analysis is implementing a segmentation algorithm. In this study, the LiDAR intensity product with a spatial resolution of 2 m was used to segment the study area within the eCognition software package. eCognition provides many toolboxes to implement segmentation and classification, and it usually provides better classification results compared to those produced from commonly used software packages such as ArcGIS and ENVI. In this study, the multiresolution segmentation algorithm available in eCognition was employed. This algorithm merges spectrally similar pixels into segments (objects) with various sizes based on several tuning parameters, such as scale, shape, and compactness [
23]. For example, the scale parameter, which is the most important tuning parameter of the multiresolution segmentation algorithm, defines the maximum standard deviation of the homogeneity of the pixels. In this study, the optimum values of these three parameters were selected based on several trial and errors. Finally, the values of 150, 0.4, and 0.5 were selected for the scale, shape, and compactness, respectively.
3.4. Classification
In this study, an RF algorithm was applied to classify the marine habitats. RF had proved higher accuracies compared to other commonly used classification techniques for various applications [
24,
25]. RF includes a group of decision trees. The final label of a pixel/object is defined based on the votes of the decision trees [
26,
27]. RF contains two important tuning parameters (i.e., depth and minimum sample number), the optimal values of which should be selected to obtain a high classification accuracy. The depth and minimum sample number, respectively, determine the number of nodes in each tree and the minimum number of samples per node in each tree. In this study, the optimal values of these two parameters were selected based on several trial-and-error attempts, and finally, twenty and five were selected for them, respectively. It should be noted that since object-based image analysis was used in this study, the RF algorithm was applied to the objects produced from the segmentation algorithm. As discussed before, 70% of the field samples were applied to train the RF algorithm. The result of the RF algorithm was the preliminary habitat map which was visually investigated to ensure the accuracy is acceptable. If the result was not satisfactory, the algorithm was refined (e.g., by changing the tuning parameters of the algorithm) to obtain a suitable map.
3.5. Post-Processing
The post-processing step was performed by manually removing any errors and refining the boundaries of some of the classes to improve the produced habitat maps. For example, the maps were compared with the Google Earth imagery near coastlines to see if the aquatic vegetation (e.g., rockweeds) was correctly identified and the errors were removed where it was possible. Moreover, while the machine learning results were acceptable in most parts of the study area, there were several shallow rivers and estuaries where the classification appeared to underestimate the amount of eelgrass. These areas, such as Lomond River, Southeast Arm, and Horseback Brook’s estuary, are environments with significant and complex patches of eelgrass. Many of these eelgrass areas were visually identified in both the imagery and the LiDAR intensity data. After post-processing, the final marine habitat maps were produced.
3.6. Accuracy Assessment
The accuracy of the produced habitat map was assessed using the test data (i.e., 30% of the independent field samples) to obtain the classification accuracy level. To this end, the confusion matrix of the classification was generated, and several accuracy indices, such as overall accuracy, kappa coefficient, and producer and user accuracies were evaluated. It is worth noting that the statistical accuracy assessment was performed before and after the post-processing step to evaluate the accuracies of both developed RF model and the final refined habitat map, respectively.
4. Results and Discussion
The method described in
Section 3 was applied to produce two marine habitat maps based on the classes described in
Table 1: a two-class habitat map (Category 1) and a five-class habitat map (Category 2). In the following two subsections, the corresponding maps and the accuracy levels are provided.
4.1. Two-Class Habitat Map (Category-1)
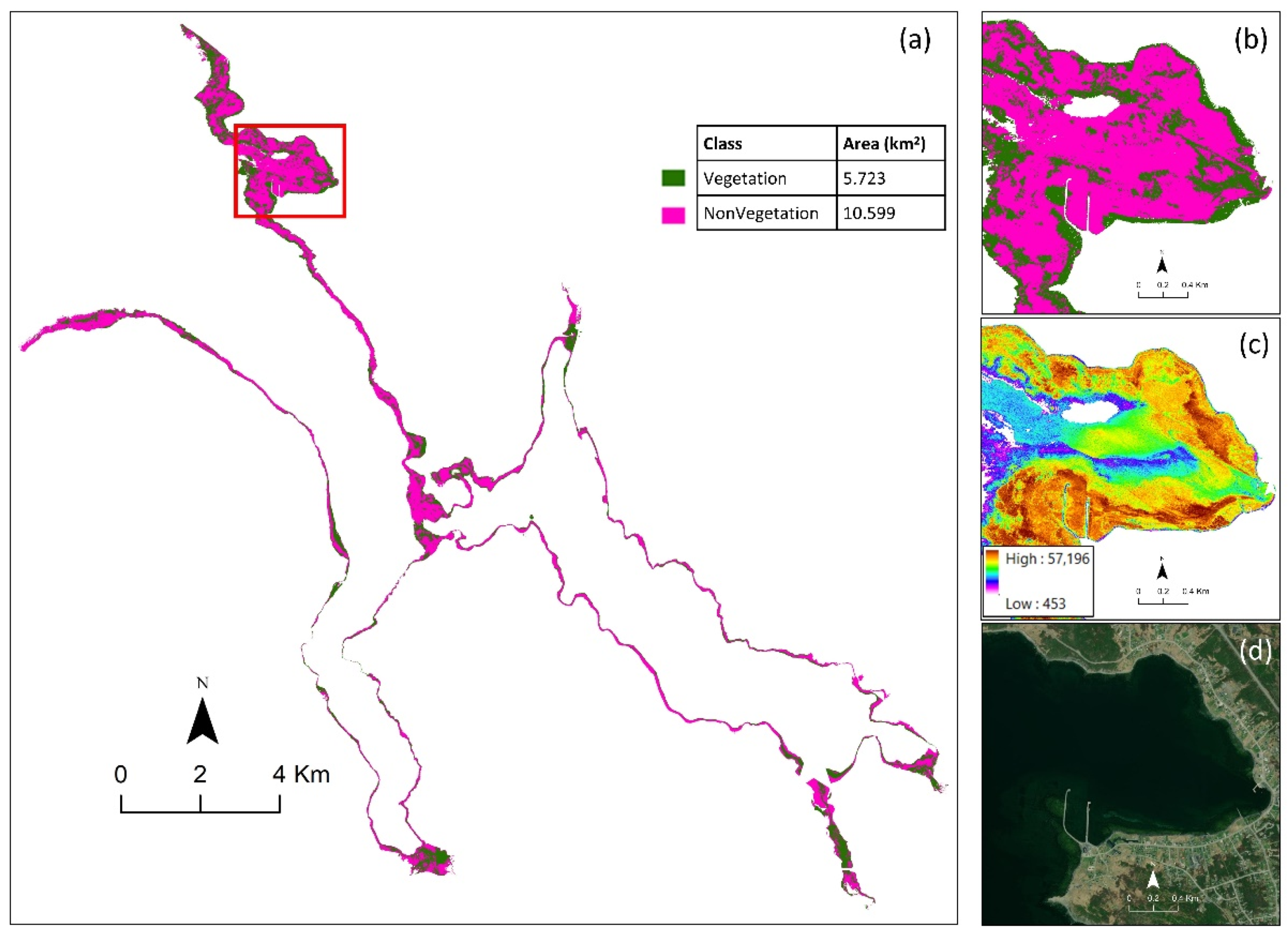
Figure 7 shows the classified habitat map based on the Category 1 classes obtained from the object-based RF algorithm. First, the accuracy of this map was visually investigated by comparing it with high-resolution Google Earth images and LiDAR intensity products. The identified areas had a good correlation with the real Vegetation and Non-Vegetation areas. The areas of the classes were also calculated, and the results are reported in
Figure 7. Vegetation and Non-vegetation cover approximately 5.7 km
2 (35%) and 10.6 km
2 (65%) of the study area, respectively.
The accuracy of the produced habitat map based on the Category 1 classes was also assessed using the confusion matrix, where the results are provided in
Table 2. The overall accuracy was 87%, indicating the high potential of the developed technique for discriminating the Vegetation and Non-Vegetation classes in Bonne Bay. This level of overall accuracy simply means that if we randomly select 100 points pixels of 2 × 2 m considering both classes, 87 of them would be accurately identified within the produced map.
The producer and user accuracies along with the omission and commission errors for each class of Vegetation and Non-Vegetation are also provided in
Table 2. The producer accuracies for both classes and user accuracy for the Vegetation class were high (between 85% and 92%). However, the user accuracy of the non-Vegetation class was relatively low (~79%). This means that there were some Vegetation samples that were wrongly classified as the Non-Vegetation class (high commission error). This can be easily seen in the confusion matrix where 690 pixels of Vegetation (out of 3255 pixels) were incorrectly classified as Non-Vegetation.
The accuracy assessment of the classification model for the two-class habitat mapping was also assessed before post-processing, and it was observed that post-processing did not significantly affect the accuracy assessment. In this case, the overall accuracy and kappa coefficient were 87% and 0.69, respectively.
4.2. Five-Class Habitat Map (Category-2)
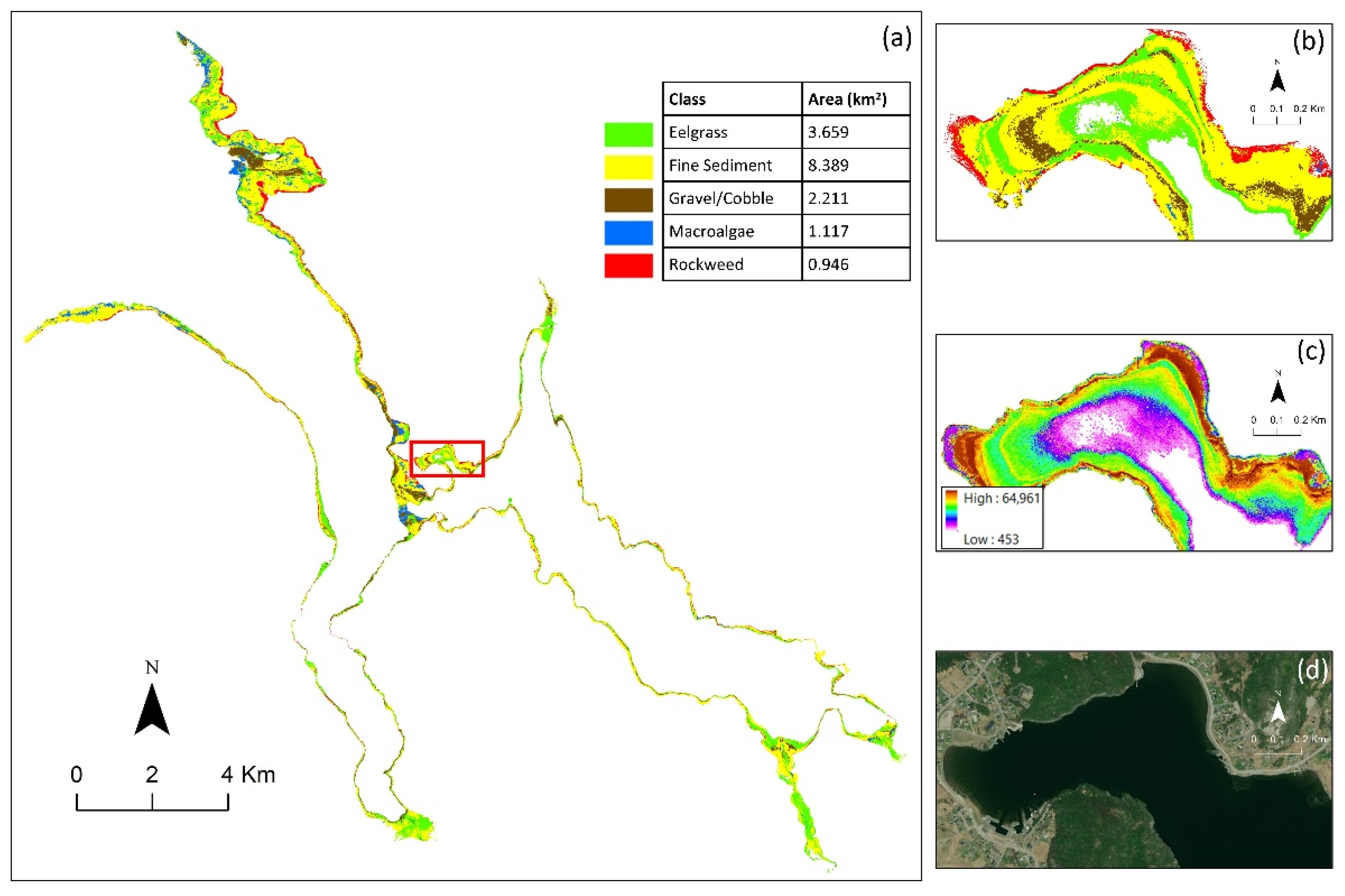
Figure 8 illustrates the habitat map based on the Category 2 classes. First, the accuracy of this map was visually assessed using high-resolution Google Earth images and the LiDAR intensity product, and it was observed that the map was visually accurate. The areas of the classes were also calculated from this map (see
Figure 8). The results showed that the Fine Sediment class had the highest coverage (8.4 km
2). The smallest coverage also belonged to the Rockweed and Macroalgae classes, which cover 0.95 km
2 (5.8%) and 1.1 km
2 (6.8%) of the study area, respectively.
The confusion matrix of the five-class habitat map, which shows the overall accuracy and class accuracies, is provided in
Table 3. The overall accuracy and kappa coefficients were 80% and 0.7, respectively, which were reasonable considering that there were several challenges during this project. Overall, based on both producer and user accuracies, Rockweed had the highest accuracies (producer accuracy = 88%, user accuracy = 99%), which was followed by Gravel/Cobble (producer accuracy = 74%, user accuracy = 85%) and Eelgrass (producer accuracy = 86%, user accuracy = 64%). For example, 3958 pixels of the in situ Rockweed samples (out of 4492 pixels) were correctly classified as Rockweed. The lowest accuracies (highest commission and omission errors) were observed for the Macroalgae class (producer accuracy = 44%, user accuracy = 58%). The main reason for this was that a large portion of the Macroalgae samples (95 pixels out of 226 pixels) were wrongly classified as Fine Sediment. There was also some confusion between this class with the Rockweed class, where 31 pixels of Macroalgae were incorrectly classified as Rockweed. Another high confusion was also observed between Fine Sediment and other classes. For instance, 378 in situ pixels of the Fine Sediment (27%) were wrongly classified as Eelgrass. Overall, there was an overestimation of Fine Sediment because there were many in situ samples from other classes which were incorrectly classified as Fine Sediment.
The accuracy assessment of the classification model for the five-class habitat mapping was also assessed before post-processing. In this case, the overall accuracy and kappa coefficient were 76% and 0.68, respectively. Thus, the post-processing step slightly improved the classification result of the five-class habitat map.
4.3. Limitations and Suggestions
In this project, LiDAR data along with a machine learning model were applied to classify the marine habitats in Bonne Bay, Newfoundland. The results showed the potential of the proposed method for habitat classification in other marine areas. Below, the main limitations of the project along with several suggestions are provided to improve the results in future works.
As discussed in
Section 2.3, although several efforts were made to remove the errors of the LiDAR raw data, some of these errors could not be resolved through the post-processing steps. This would negatively affect the results of any studies which utilize similar datasets.
Although the collected in situ data were beneficial to obtain reasonable habitat maps, more samples are required to develop a more accurate and robust machine learning model. For example, the number of samples of the Macroalgae class was very low. In fact, this was one of the main reasons for the low accuracy of this class in the produced map (see
Figure 8 and
Table 3). Overall, a higher number of samples provides a higher classification accuracy in a machine learning model.
One approach to improve the classification results is by utilizing other types of remote sensing datasets, such as very high resolution optical satellites and drone imagery. These imageries would provide valuable information about marine habitats, especially over shallower water areas. Additionally, high-resolution satellite images are very beneficial when the objective is mapping and changing the analysis of marine habitats at regional and global scales.
5. Conclusions
Marine habitats provide many services to both the marine ecosystem and humans, and therefore, they should be accurately monitored using advanced technologies. In this regard, airborne bathymetric LiDAR systems have great advantages for oceanographic applications, such as bathymetric mapping and marine habitat classification. Bathymetric LiDAR pulses can penetrate into water and can identify different marine habitats based on the intensity values. This study used bathymetric LiDAR data to accurately discriminate five habitat types of Eelgrasses, Macroalgae, Rockweed, Fine Sediment, and Gravel/Cobble using LiDAR intensity data. It was observed that LiDAR data has a great potential to discriminate the Vegetation from the Non-Vegetation classes in marine environments. For example, the overall classification accuracy for distinguishing these two classes was 87%. Moreover, the accuracy of the five-class habitat map was reasonably accurate (overall accuracy = 80%). It was concluded that the LiDAR data could identify the Rockweed class with the highest accuracy (e.g., producer and user accuracies were 88% and 99%, respectively). However, the accuracy of identifying the Macroalgae class was relatively low. The main reason for this was the lack of in situ data for this class in our study. Additionally, Macroalgae is usually found in deeper water compared to other aquatic vegetation species, and thus, it can be identified with a lower accuracy using LiDAR data. In summary, lacking enough in situ samples for some of the classes and the errors of the LiDAR data were the main limitations of this study to obtain a better classification accuracy. Therefore, future studies should employ more balanced in situ data and very high resolution satellite and drone imagery along with better LiDAR data to achieve a more classification accuracy. Finally, the proposed method should be applied to other study areas to investigate its robustness at different conditions. In this regard, the effects of water quality and climate conditions on the LiDAR pulses, and consequently, on the classification results could be investigated further.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}