
FGS-YOLOv8s-seg: A Lightweight and Efficient Instance Segmentation Model for Detecting Tomato Maturity Levels in Greenhouse Environments

Abstract
1. Introduction
- (1)
- In order to improve the recognition ability of tomato boundaries, the GCT attention mechanism was embedded after the Split operation in the C2f module so that the model could more accurately recognize the target boundary when extracting multi-scale features. At the same time, the FasterNet module was added to form a lightweight C2f_Faster_GCT module, which significantly reduced the computational complexity and improved the model efficiency.
- (2)
- To address the interference of overall structural orientation, peduncle distribution patterns, and occluded backgrounds in tomato detection, the SegNext_Attention mechanism was constructed. By enhancing the spatial attention performance of the model, the model can better utilize global semantic dependencies and adaptively focus on discriminative areas at different scales.
- (3)
- Different types of experiments have demonstrated that the FGS-YOLOv8s-seg instance segmentation model outperforms existing mainstream instance segmentation models for small-target tomato maturity detection in greenhouse environments. This enhanced segmentation framework shows significant potential for practical applications in tomato-picking robotics.
2. Materials and Methods
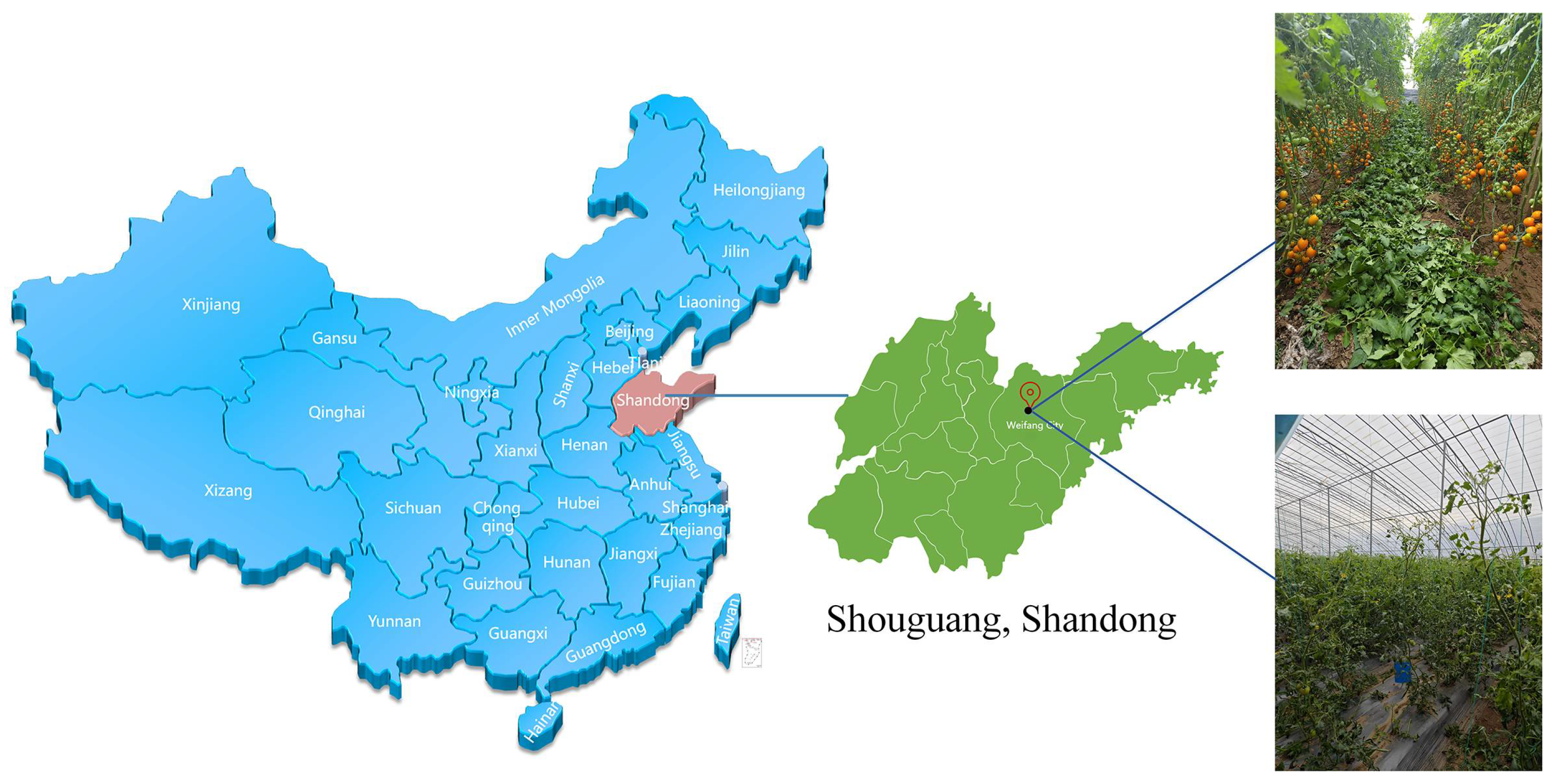
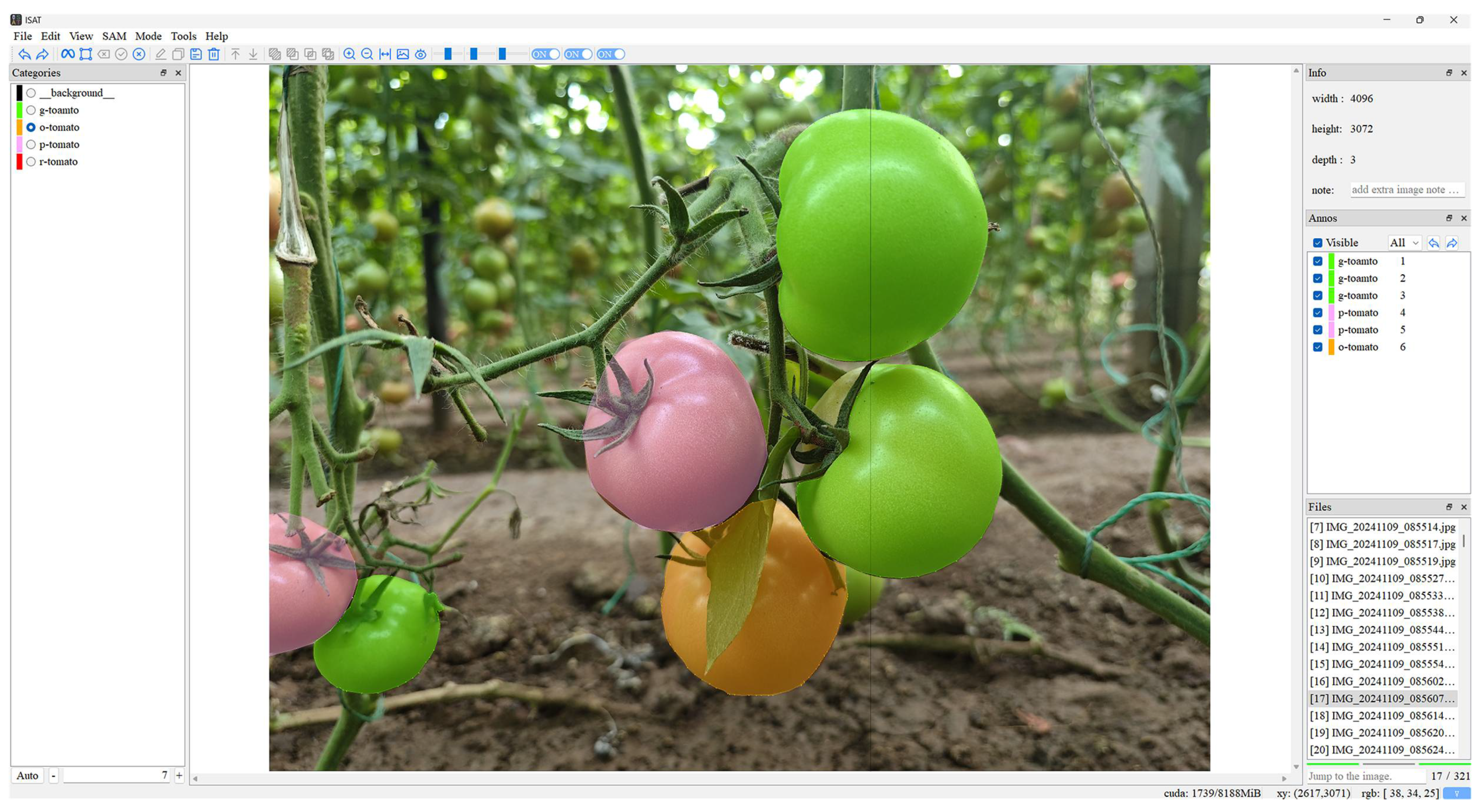
2.1. Image Acquisition and Data Processing
2.2. General Framework for Maturity Grading of Greenhouse Tomatoes
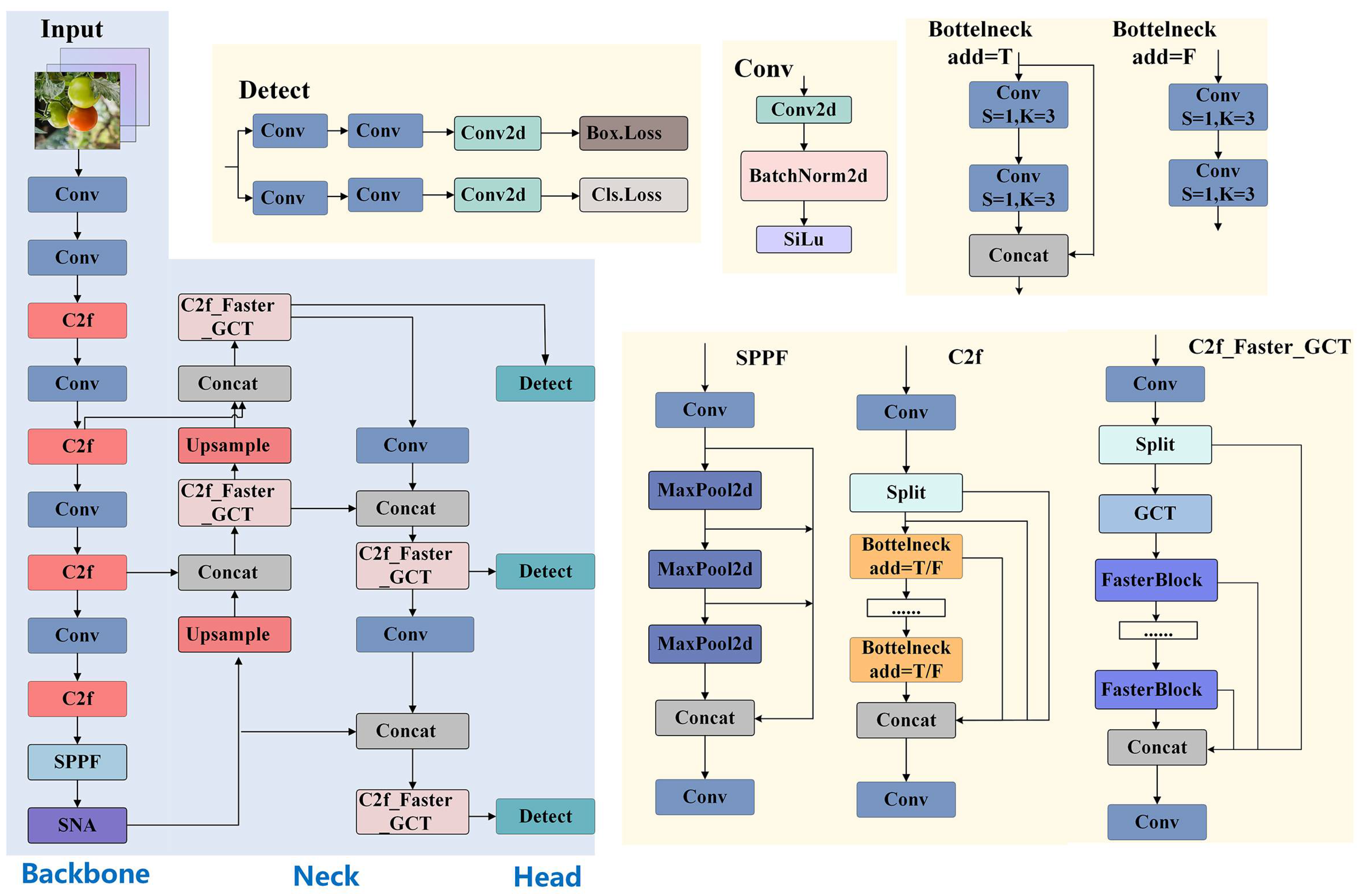
2.3. Construction of FGS-YOLOv8s-seg Model
2.3.1. YOLOv8 Instance Segmentation Algorithm
2.3.2. SegNext_Attention Module
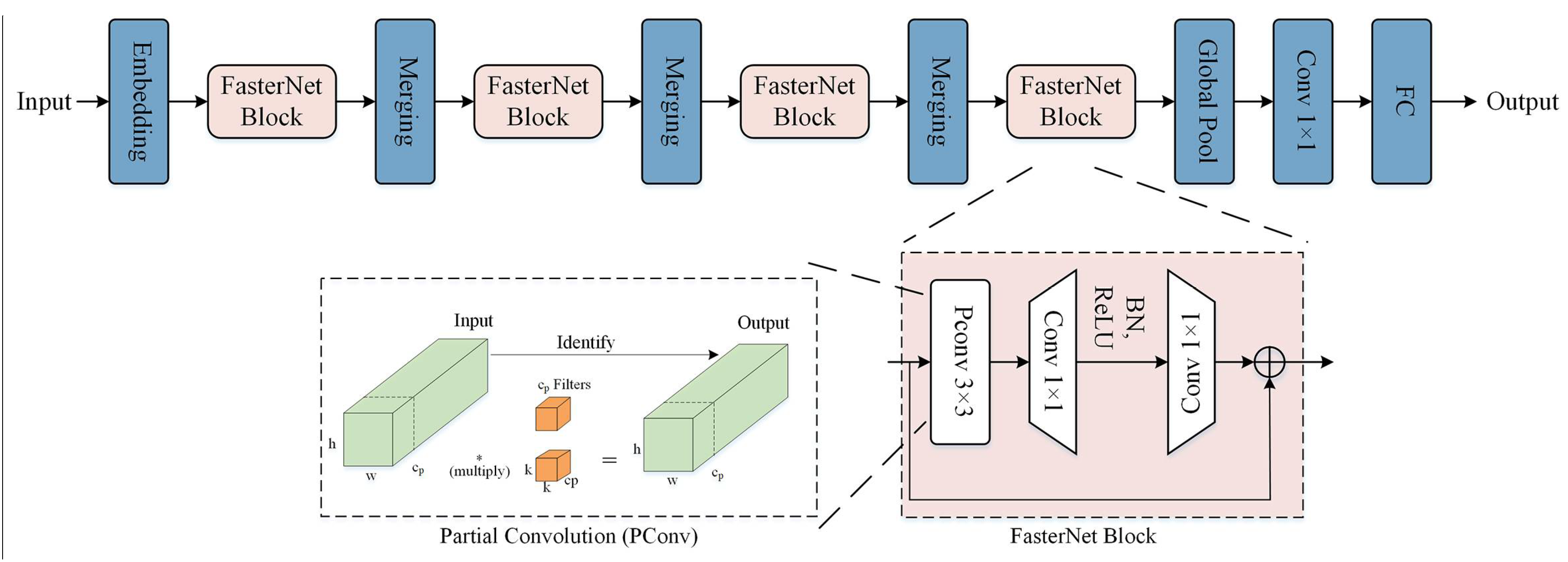
2.3.3. C2f_FasterNet_GCT Module
2.4. Experimental Setup and Evaluation Indicators
3. Results and Discussion
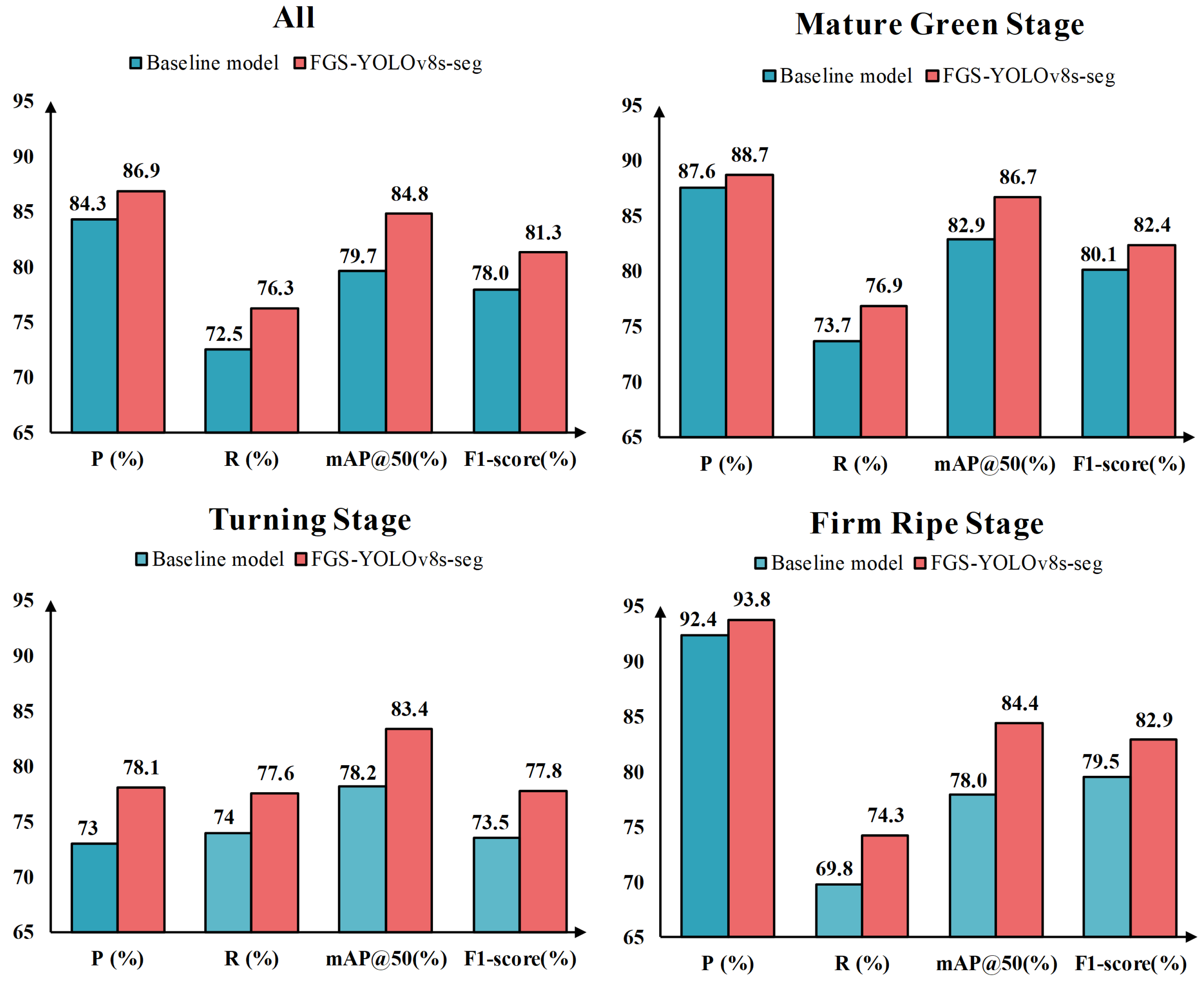
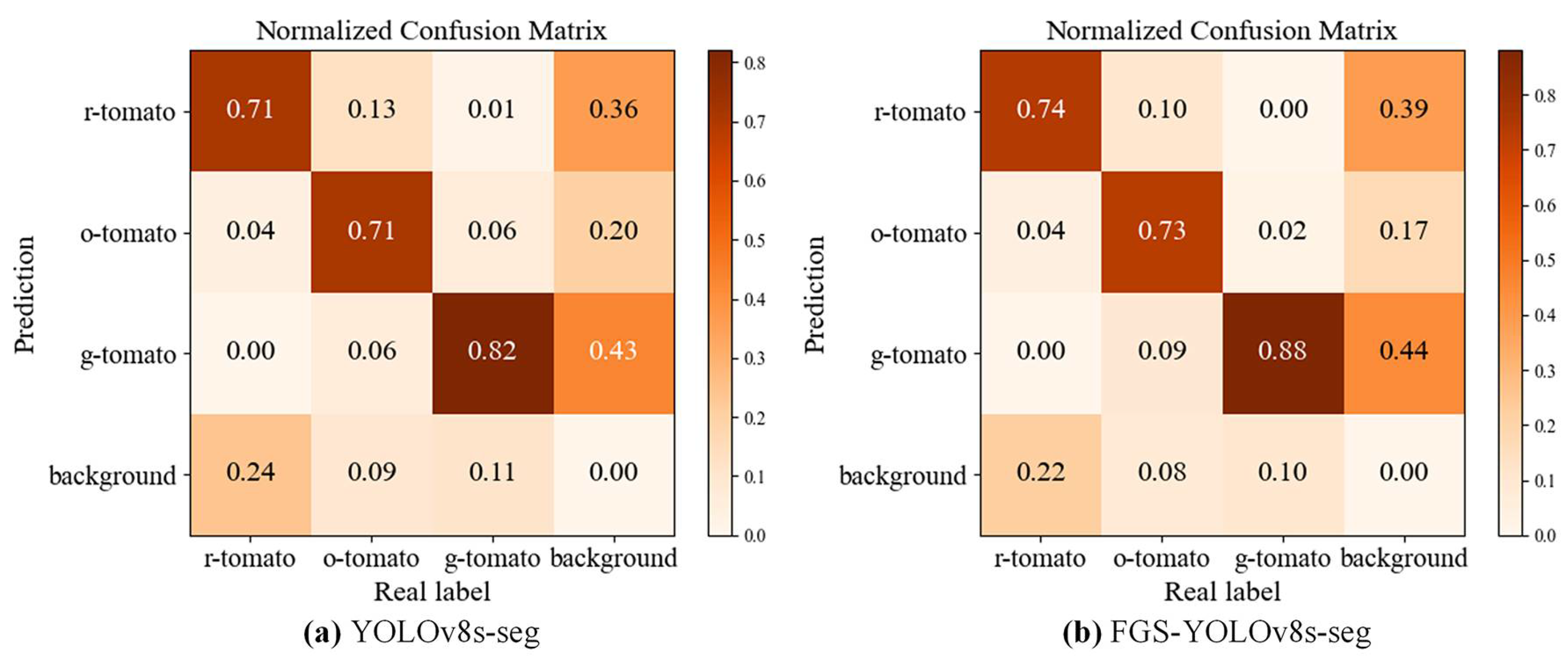
3.1. Evaluation of Improved Model and Baseline Model
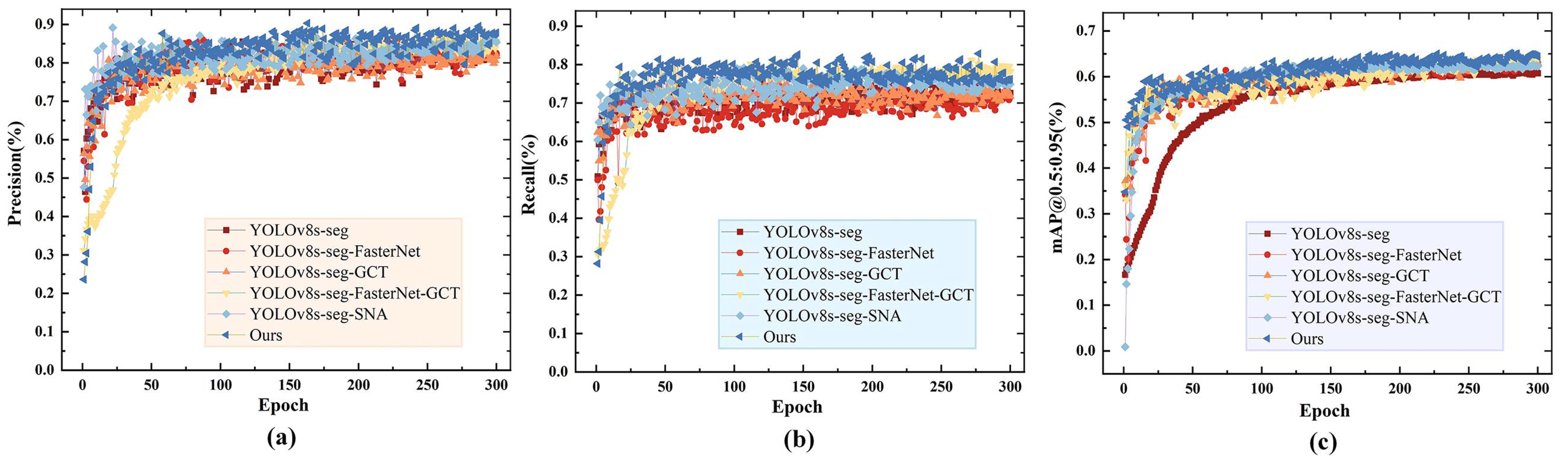
3.2. Ablation Experiment
3.3. Evaluation of Segmentation Performance with Different Network Models
3.4. Limitations and Future Perspectives
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, J.; Lyu, H.; Chen, J.; Cao, X.; Du, R.; Ma, L.; Wang, N.; Zhu, Z.; Rao, J.; Wang, J. Releasing a sugar brake generates sweeter tomato without yield penalty. Nature 2024, 635, 647–656. [Google Scholar] [CrossRef] [PubMed]
- Duret, S.; Aubert, C.; Annibal, S.; Derens-Bertheau, E.; Cottet, V.; Jost, M.; Chalot, G.; Flick, D.; Moureh, J.; Laguerre, O. Impact of harvest maturity and storage conditions on tomato quality: A comprehensive experimental and modeling study. Postharvest Biol. Technol. 2025, 219, 113286. [Google Scholar] [CrossRef]
- Kasampalis, D.S.; Tsouvaltzis, P.; Siomos, A.S. Chlorophyll fluorescence, non-photochemical quenching and light harvesting complex as alternatives to color measurement, in classifying tomato fruit according to their maturity stage at harvest and in monitoring postharvest ripening during storage. Postharvest Biol. Technol. 2020, 161, 111036. [Google Scholar] [CrossRef]
- Wang, S.; Jiang, H.; Yang, J.; Ma, X.; Chen, J.; Li, Z.; Tang, X. Lightweight tomato ripeness detection algorithm based on the improved RT-DETR. Front. Plant Sci. 2024, 15, 1415297. [Google Scholar] [CrossRef]
- Cano-Lara, M.; Rostro-Gonzalez, H. Tomato quality assessment and enhancement through Fuzzy Logic: A ripe perspective on precision agriculture. Postharvest Biol. Technol. 2024, 212, 112875. [Google Scholar] [CrossRef]
- Rizzo, M.; Marcuzzo, M.; Zangari, A.; Gasparetto, A.; Albarelli, A. Fruit ripeness classification: A survey. Artif. Intell. Agric. 2023, 7, 44–57. [Google Scholar] [CrossRef]
- Gupta, S.; Tripathi, A.K. Tripathi, Fruit and vegetable disease detection and classification: Recent trends, challenges, and future opportunities. Eng. Appl. Artif. Intell. 2024, 133, 108260. [Google Scholar] [CrossRef]
- Zhu, A.; Zhang, R.; Zhang, L.; Yi, T.; Wang, L.; Zhang, D.; Chen, L. YOLOv5s-CEDB: A robust and efficiency Camellia oleifera fruit detection algorithm in complex natural scenes. Comput. Electron. Agric. 2024, 221, 108984. [Google Scholar] [CrossRef]
- Gill, H.S.; Murugesan, G.; Mehbodniya, A.; Sajja, G.S.; Gupta, G.; Bhatt, A. Fruit type classification using deep learning and feature fusion. Comput. Electron. Agric. 2023, 211, 107990. [Google Scholar] [CrossRef]
- Gulzar, Y. Fruit image classification model based on MobileNetV2 with deep transfer learning technique. Sustainability 2023, 15, 1906. [Google Scholar] [CrossRef]
- Paul, A.; Machavaram, R.; Kumar, D.; Nagar, H. Smart solutions for capsicum Harvesting: Unleashing the power of YOLO for Detection, Segmentation, growth stage Classification, Counting, and real-time mobile identification. Comput. Electron. Agric. 2024, 219, 108832. [Google Scholar] [CrossRef]
- Azgomi, H.; Haredasht, F.R.; Motlagh, M.R.S. Diagnosis of some apple fruit diseases by using image processing and artificial neural network. Food Control 2023, 145, 109484. [Google Scholar] [CrossRef]
- Zhu, Y.; Sui, S.; Du, W.; Li, X.; Liu, P. Picking point localization method of table grape picking robot based on you only look once version 8 nano. Eng. Appl. Artif. Intell. 2025, 146, 110266. [Google Scholar] [CrossRef]
- Yousaf, J.; Abuowda, Z.; Ramadan, S.; Salam, N.; Almajali, E.; Hassan, T.; Gad, A.; Alkhedher, M.; Ghazal, M. Autonomous smart palm tree harvesting with deep learning-enabled date fruit type and maturity stage classification. Eng. Appl. Artif. Intell. 2025, 139, 109506. [Google Scholar] [CrossRef]
- Miao, Z.; Yu, X.; Li, N.; Zhang, Z.; He, C.; Li, Z.; Deng, C.; Sun, T. Efficient tomato harvesting robot based on image processing and deep learning. Precis. Agric. 2023, 24, 254–287. [Google Scholar] [CrossRef]
- Kaur, P.; Harnal, S.; Gautam, V.; Singh, M.P.; Singh, S.P. An approach for characterization of infected area in tomato leaf disease based on deep learning and object detection technique. Eng. Appl. Artif. Intell. 2022, 115, 105210. [Google Scholar] [CrossRef]
- Wang, Z.; Ling, Y.; Wang, X.; Meng, D.; Nie, L.; An, G.; Wang, X. An improved Faster R-CNN model for multi-object tomato maturity detection in complex scenarios. Ecol. Inform. 2022, 72, 101886. [Google Scholar] [CrossRef]
- Gu, Z.; Ma, X.; Guan, H.; Jiang, Q.; Deng, H.; Wen, B.; Zhu, T.; Wu, X. Tomato fruit detection and phenotype calculation method based on the improved RTDETR model. Comput. Electron. Agric. 2024, 227, 109524. [Google Scholar] [CrossRef]
- Zhang, J.; Xie, J.; Zhang, F.; Gao, J.; Yang, C.; Song, C.; Rao, W.; Zhang, Y. Greenhouse tomato detection and pose classification algorithm based on improved YOLOv5. Comput. Electron. Agric. 2024, 216, 108519. [Google Scholar] [CrossRef]
- Zeng, T.; Li, S.; Song, Q.; Zhong, F.; Wei, X. Lightweight tomato real-time detection method based on improved YOLO and mobile deployment. Comput. Electron. Agric. 2023, 205, 107625. [Google Scholar] [CrossRef]
- Chen, W.; Liu, M.; Zhao, C.; Li, X.; Wang, Y. MTD-YOLO: Multi-task deep convolutional neural network for cherry tomato fruit bunch maturity detection. Comput. Electron. Agric. 2024, 216, 108533. [Google Scholar] [CrossRef]
- Gao, J.; Zhang, J.; Zhang, F.; Gao, J. LACTA: A lightweight and accurate algorithm for cherry tomato detection in unstructured environments. Expert Syst. Appl. 2024, 238, 122073. [Google Scholar] [CrossRef]
- Liu, Z.; Wu, X.; Liu, H.; Zhang, M.; Liao, W. DNA methylation in tomato fruit ripening. Physiol. Plant. 2022, 174, e13627. [Google Scholar] [CrossRef]
- Charisis, C.; Argyropoulos, D. Deep learning-based instance segmentation architectures in agriculture: A review of the scopes and challenges. Smart Agric. Technol. 2024, 8, 100448. [Google Scholar] [CrossRef]
- Qi, Z.; Hua, W.; Zhang, Z.; Deng, X.; Yuan, T.; Zhang, W. A novel method for tomato stem diameter measurement based on improved YOLOv8-seg and RGB-D data. Comput. Electron. Agric. 2024, 226, 109387. [Google Scholar] [CrossRef]
- Zhang, Y.; Shi, N.; Zhang, H.; Zhang, J.; Fan, X.; Suo, X. Appearance quality classification method of Huangguan pear under complex background based on instance segmentation and semantic segmentation. Front. Plant Sci. 2022, 13, 914829. [Google Scholar] [CrossRef]
- Yue, X.; Qi, K.; Na, X.; Zhang, Y.; Liu, Y.; Liu, C. Improved YOLOv8-Seg network for instance segmentation of healthy and diseased tomato plants in the growth stage. Agriculture 2023, 13, 1643. [Google Scholar] [CrossRef]
- Liu, M.; Chen, W.; Cheng, J.; Wang, Y.; Zhao, C. Y-HRNet: Research on multi-category cherry tomato instance segmentation model based on improved YOLOv7 and HRNet fusion. Comput. Electron. Agric. 2024, 227, 109531. [Google Scholar] [CrossRef]
- Sapkota, R.; Ahmed, D.; Karkee, M. Comparing YOLOv8 and Mask R-CNN for instance segmentation in complex orchard environments. Artif. Intell. Agric. 2024, 13, 84–99. [Google Scholar] [CrossRef]
- GH/T 1193-2021; Tomato. China CO-OP: Beijing, China, 2021.
- Lee, Y.-S.; Patil, M.P.; Kim, J.G.; Seo, Y.B.; Ahn, D.-H.; Kim, G.-D. Hyperparameter optimization of apple leaf dataset for the disease recognition based on the YOLOv8. J. Agric. Food Res. 2025, 21, 101840. [Google Scholar] [CrossRef]
- Singh, A.; Yadav, A.; Verma, A.; Rana, P.S. Comparative Analysis of YOLO Models for Plant Disease Instance Segmentation. In Proceedings of the 2024 IEEE International Conference on Computer Vision and Machine Intelligence (CVMI), Prayagraj, India, 19–20 October 2024; pp. 1–6. [Google Scholar]
- Randar, S.; Shah, V.; Kulkarni, H.; Suryawanshi, Y.; Joshi, A.; Sawant, S. YOLOv8-based frameworks for liver and tumor segmentation task on LiTS. SN Comput. Sci. 2024, 5, 741. [Google Scholar] [CrossRef]
- Guo, M.-H.; Lu, C.-Z.; Hou, Q.; Liu, Z.; Cheng, M.-M.; Hu, S.-M. Segnext: Rethinking convolutional attention design for semantic segmentation. Adv. Neural Inf. Proc. Syst. 2022, 35, 1140–1156. [Google Scholar]
- Ruan, D.; Wang, D.; Zheng, Y.; Zheng, N.; Zheng, M. Gaussian Context Transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Chen, J.; Kao, S.-H.; He, H.; Zhuo, W.; Wen, S.; Lee, C.-H.; Chen, S.-H.G. Run,Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Deng, X.; Liu, Q.; Deng, Y.; Mahadevan, S. An improved method to construct basic probability assignment based on the confusion matrix for classification problem. Inf. Sci. 2016, 340, 250–261. [Google Scholar] [CrossRef]
- Song, X.; Zhang, W.; Pan, W.; Liu, P.; Wang, C. Real-time monitor heading dates of wheat accessions for breeding in-field based on DDEW-YOLOv7 model and BotSort algorithm. Expert Syst. Appl. 2025, 267, 126140. [Google Scholar] [CrossRef]
- Muhammad, M.B.; Yeasin, M. Eigen-cam: Class Activation Map Using Principal Components. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Maturity | Morphological Characteristics | Picking Situation |
|---|---|---|
| Immature Green | Fruit size not stabilized, small in shape, white-green skin | Not suitable for picking |
| Mature Green | Fruit size stabilized, skin transitioning from white-green to green | Suitable for artificial ripening or long-distance transportation |
| Turning Stage | Fruit size stabilized, 10% to 60% of surface turns red or orange | Suitable for storage or short-distance transportation |
| Firm Ripe | 60–90% of fruit surface fully red/orange | Picking for sale within 2 days |
| Environment Configuration | Parameter |
|---|---|
| Operating System | Windows 11 |
| CPU | Intel Core i7-12650H |
| GPU | NVIDIA GeForce RTX 4060 |
| Python | 3.8 |
| Pytorch | 2.3.1 |
| CUDA | 12.5 |
| lr0 | 0.0001 |
| lrf | 0.1 |
| Momentum | 0.937 |
| Batch Size | 16 |
| Epochs | 300 |
| Method | P (%) | R (%) | mAP@0.5 | F1-Score | GFLOPs | ||
|---|---|---|---|---|---|---|---|
| FasterNet | GCT | SNA | |||||
| - | - | - | 84.3 | 72.5 | 79.7 | 78.0 | 42.4 |
| ✓ | - | - | 83.9 | 71.4 | 78.9 | 77.2 | 31.7 |
| - | ✓ | - | 86.4 | 71.7 | 83.1 | 78.4 | 43.8 |
| ✓ | ✓ | - | 85.6 | 78.2 | 81.1 | 81.7 | 33.1 |
| - | - | ✓ | 85.1 | 74.9 | 81.6 | 79.7 | 45.9 |
| ✓ | ✓ | ✓ | 86.9 (↑2.6) | 76.3 (↑3.8) | 84.8 (↑5.1) | 81.3 (↑3.3) | 35.6 (↓6.8) |
| Indicator | YOLOv8s-seg (Mean ± SD) | FGS-YOLOv8s-seg (Mean ± SD) | Mean Difference | p-Value | 95% Confidence Interval |
|---|---|---|---|---|---|
| P (%) | 84.2 ± 0.192 | 86.9 ± 0.152 | +2.76 | <0.001 | (2.5522, 2.9678) |
| R (%) | 72.4 ± 0.195 | 76.2 ± 0.274 | +3.76 | <0.001 | (3.3713, 4.1487) |
| mAP@0.5 (%) | 79.9 ± 0.270 | 84.6 ± 0.385 | +4.62 | <0.001 | (3.8781, 5.3618) |
| F1-score (%) | 77.9 ± 0.165 | 81.2 ± 0.193 | +3.34 | <0.001 | (3.1517, 3.5283) |
| Models | Precision (%) | Recall (%) | mAP@0.5 | F1-Score | GFLOPs |
|---|---|---|---|---|---|
| YOLOv5s-seg | 82.1 | 69.3 | 78.5 | 75.2 | 59.7 |
| YOLOv9-seg | 75.4 | 71.3 | 79.2 | 73.3 | 71.3 |
| YOLOv11-seg | 82.5 | 74.9 | 82.3 | 78.5 | 33.4 |
| Mask R-CNN | 51.2 | 52.8 | 55.8 | 52.0 | 91.1 |
| Cascade Mask R-CNN | 59.4 | 55.1 | 60.4 | 57.2 | 96.8 |
| FGS-YOLOv8s-seg | 86.9 (↑4.4) | 76.3 (↑1.4) | 84.8 (↑2.5) | 81.3 (↑2.8) | 35.6 (↑2.2) |
| Indicator | YOLOv11-seg (Mean ± SD) | FGS-YOLOv8s-seg (Mean ± SD) | Mean Difference | p-Value | 95% Confidence Interval |
|---|---|---|---|---|---|
| P (%) | 82.6 ± 0.219 | 86.9 ± 0.152 | +4.38 | <0.001 | (4.0355, 4.7245) |
| R (%) | 74.9 ± 0.274 | 76.2 ± 0.274 | +1.3 | <0.001 | (0.7176, 1.8824) |
| mAP@0.5 (%) | 82.3 ± 0.321 | 84.6 ± 0.385 | +2.22 | <0.001 | (1.5724, 2.8676) |
| F1-score (%) | 78.5 ± 0.184 | 81.2 ± 0.193 | +2.68 | <0.001 | (2.2204, 3.1396) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, D.; Liu, P.; Zhu, Y.; Li, T.; Zhang, K. FGS-YOLOv8s-seg: A Lightweight and Efficient Instance Segmentation Model for Detecting Tomato Maturity Levels in Greenhouse Environments. Agronomy 2025, 15, 1687. https://doi.org/10.3390/agronomy15071687
Song D, Liu P, Zhu Y, Li T, Zhang K. FGS-YOLOv8s-seg: A Lightweight and Efficient Instance Segmentation Model for Detecting Tomato Maturity Levels in Greenhouse Environments. Agronomy. 2025; 15(7):1687. https://doi.org/10.3390/agronomy15071687
Chicago/Turabian StyleSong, Dongfang, Ping Liu, Yanjun Zhu, Tianyuan Li, and Kun Zhang. 2025. "FGS-YOLOv8s-seg: A Lightweight and Efficient Instance Segmentation Model for Detecting Tomato Maturity Levels in Greenhouse Environments" Agronomy 15, no. 7: 1687. https://doi.org/10.3390/agronomy15071687
APA StyleSong, D., Liu, P., Zhu, Y., Li, T., & Zhang, K. (2025). FGS-YOLOv8s-seg: A Lightweight and Efficient Instance Segmentation Model for Detecting Tomato Maturity Levels in Greenhouse Environments. Agronomy, 15(7), 1687. https://doi.org/10.3390/agronomy15071687