1. Introduction
Soybean (
Glycine max L.) is a globally significant crop for food, oil production, and industrial raw materials [
1]. However, with expanding cultivation areas and the impacts of global climate change, soybean diseases are occurring more frequently and with higher severity, posing a significant threat to yield and quality [
2]. Taking Heilongjiang Province, China’s largest soybean-growing region, as an example, its distinctive cold–temperate monsoon climate creates ideal conditions for the growth and dissemination of multiple pathogens. Notably, frogeye leaf spot (FLS) caused by
Cercospora sojina Hara is particularly prominent. This disease can lead to extensive necrosis of leaves and reduced photosynthetic capacity, and in severe cases, it can infect pods and seeds, causing yield losses of over 60% [
3]. Therefore, developing efficient and accurate soybean disease detection and grading technologies is not only vital for national food security but also provides key support for sustainable agricultural development.
Traditional field diagnosis of diseases primarily relies on manual visual inspection or laboratory-based chemical assays [
4]. However, manual surveys suffer from subjectivity, low accuracy, and high labor demands; while chemical assays provide precision, they require destructive sampling and expensive equipment, making them unsuitable for large-scale, rapid, and non-destructive monitoring. These limitations highlight the urgent need to improve field disease detection methods.
Recently, in controlled greenhouse or laboratory environments, numerous studies have demonstrated that integrating RGB or hyperspectral imaging (HSI) with artificial intelligence (AI) algorithms can achieve high-accuracy disease classification [
5]. For example, Alves et al. [
6] captured RGB images of leaves exhibiting different severity levels across five species under controlled lighting and homogeneous backgrounds, calculated ten spectral indices, and developed a boosted regression tree model, achieving over 97% accuracy in disease severity prediction. Zhang et al. [
7] used a spectral imaging setup to scan strawberry leaves 24 h post-inoculation with frogeye leaf spot and anthracnose, employed CARS and ReliefF for spectral fingerprint and vegetation index extraction, and classified with BPNN, SVM, and RF, reaching fusion accuracies of 97.78%, 94.44%, and 93.33%, respectively. Feng et al. [
8] proposed the DC
2Net—a network combining deformable and dilated convolutions—for greenhouse detection of Asian soybean rust, attaining 96.73% overall accuracy. However, the significant differences between controlled laboratory environments and real field conditions limit the applicability of these methods in open-field settings.
To facilitate crop disease surveillance in true open-field environments, RGB-equipped unmanned aerial vehicle (UAV) platforms combined with deep learning have attracted considerable attention. For example, Amarasingam et al. [
9] utilized UAV-acquired RGB imagery to detect sugarcane white leaf disease (WLD) and compared multiple detection models, including YOLOv5, YOLOR, DETR, and Faster R-CNN. YOLOv5 achieved the best performance, with mAP@0.50 and mAP@0.95 of 93% and 79%, respectively. Deng et al. [
10] employed ultra-high-resolution RGB UAV images along with the DeepLabv3+ semantic segmentation network to identify wheat stripe rust under field conditions, achieving an F1-score of 81%, thus demonstrating the potential for large-scale disease monitoring.
RGB imaging offers several advantages, including lower cost, high spatial resolution, ease of operation, and real-time processing capabilities. However, its limitations—especially under field conditions—include sensitivity to lighting fluctuations, atmospheric disturbances, and sensor noise, particularly when UAVs operate at lower altitudes and slower speeds to ensure adequate spatial resolution [
11,
12]. Castelão et al. [
13] found that soybean foliar disease classification accuracy peaked at 98.34% when flying at 1–2 m, but it dropped by approximately 2% for every 1 m increase in altitude, illustrating the trade-off between spatial resolution and acquisition efficiency. Despite the availability of high-resolution RGB cameras that can capture quality images at higher speeds and altitudes, performance may still degrade due to reduced spatial detail and increased environmental interference.
To address these challenges, recent research has increasingly explored UAV-based hyperspectral imaging (HSI) for non-destructive, field-scale disease monitoring. Unlike RGB images, hyperspectral data, although more costly, provide rich spectral information across a wide range of wavelengths, offering the ability to detect subtle physiological changes—such as variations in chlorophyll content, water stress, or structural alterations—prior to the emergence of visible symptoms [
14,
15]. Additionally, HSI can reduce the influence of external noise caused by lighting and atmospheric variations, enabling disease detection at higher altitudes with consistent accuracy. However, due to its line-scan imaging mechanism, it requires slower flight speeds, and for both HSI and RGB sensors, higher altitudes reduce spatial resolution and increase sensitivity to atmospheric and lighting conditions [
16]. Abdulridha et al. [
17] applied UAV-based hyperspectral imaging on 960 wheat plots and used 14 spectral vegetation indices along with machine learning methods such as QDA, RF, decision tree, and SVM. RF achieved 85% classification accuracy across four severity levels, with binary classification reaching 88%. In another study, Li et al. [
18] assessed cotton disease severity using wavelet features and vegetation indices, achieving an R
2 of 0.9007 and RMSE of 6.0887 through GA/PSO/GWO-optimized SVM models. Zeng et al. [
19] detected powdery mildew in rubber trees using a low-altitude UAV-HSI system and a multi-scale attention CNN, achieving a maximum Kappa coefficient of 98.04%. Currently, few studies have quantitatively assessed soybean disease severity using UAV-based HSI. Meng et al. [
20] combined multispectral UAV data with random forest regression to dynamically monitor bacterial blight in soybean via CCI and GNDVI. In summary, UAV-based hyperspectral imaging provides superior spectral sensitivity, enabling the detection of subtle physiological changes and early disease symptoms that are often not discernible through conventional imaging. Although its line-scan acquisition mechanism typically necessitates slower flight speeds, hyperspectral systems maintain diagnostic stability under variable environmental conditions and higher flight altitudes, offering significant advantages for precision disease monitoring.
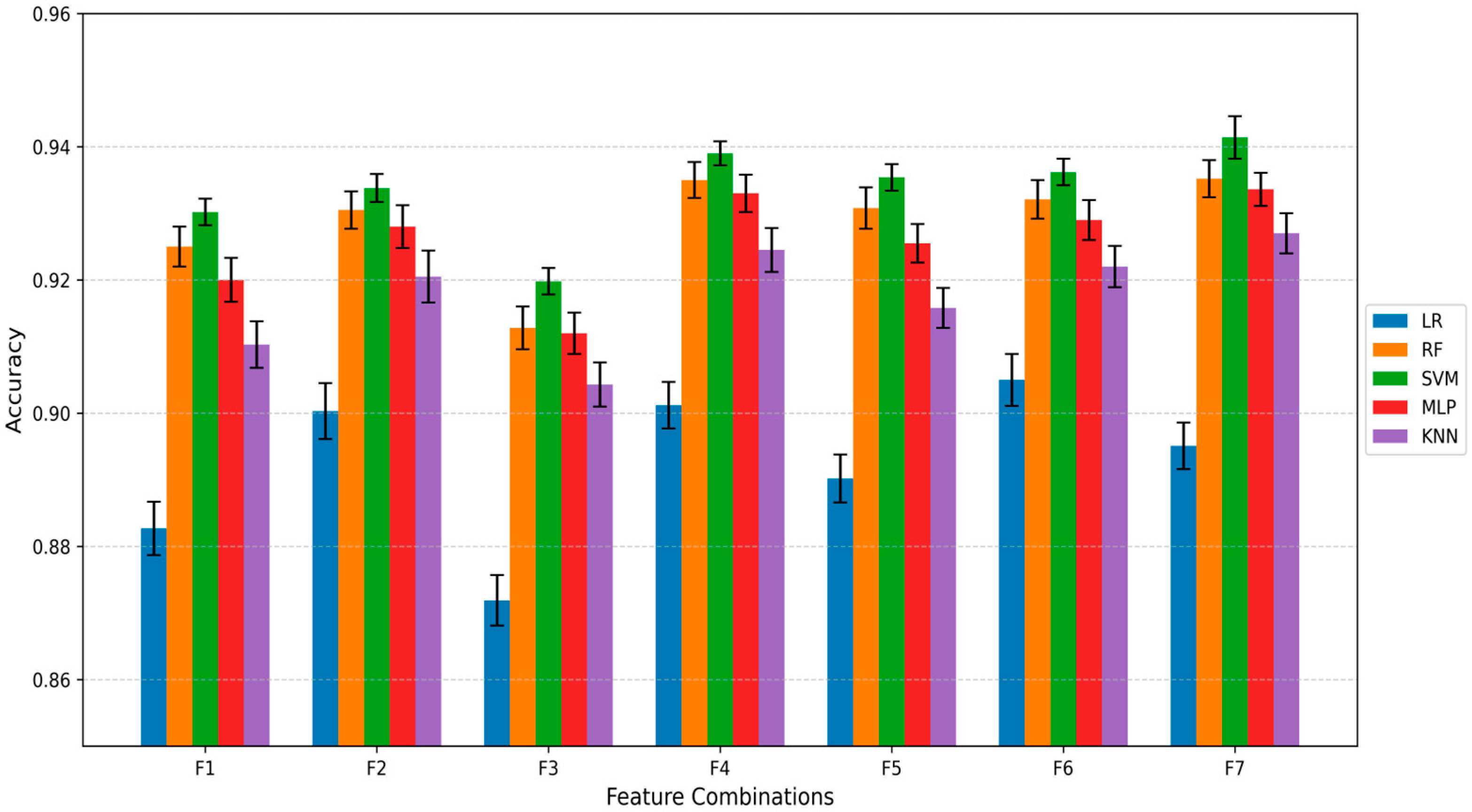
However, traditional machine learning methods such as SVM [
21] and RF [
22] rely on manual feature engineering, making it difficult to fully exploit the complex information inherent in hyperspectral data, and their generalization ability is limited. Existing deep learning architectures, such as CNNs, are primarily designed for two-dimensional images and require large datasets for training, making them unsuitable for directly handling high-dimensional tabular hyperspectral reflectance data [
23]. How to design efficient end-to-end deep learning models specifically for small-sample, high-dimensional hyperspectral tabular data remains an open challenge.
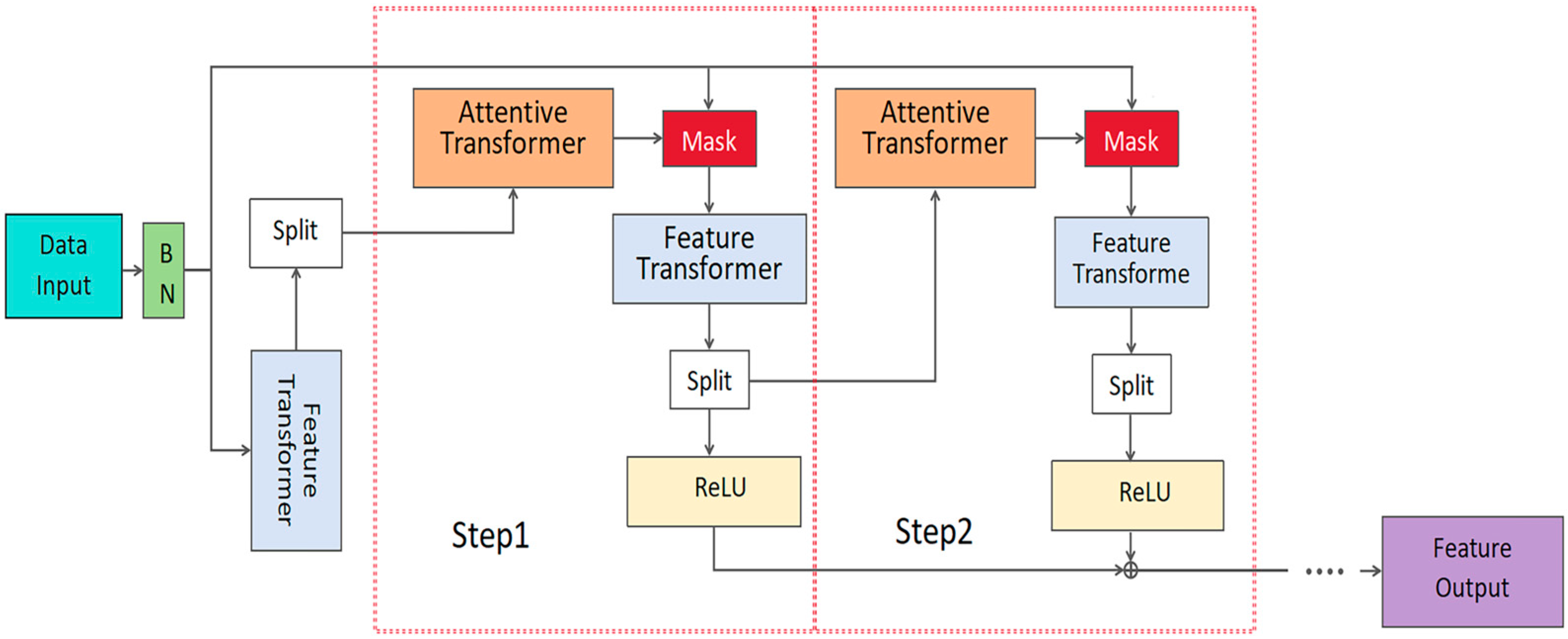
To address the above-mentioned challenges, we propose a novel dual-path deep learning framework—HSDT-TabNet. The TabNet path emphasizes sparse local feature selection, while the HSDT path captures hierarchical global interactions. These complementary features are dynamically fused via a multi-head attention mechanism. Furthermore, to enhance robustness and performance, the model employs tree-structured Parzen estimator (TPE) optimization for hyperparameter tuning. This work introduces a tabular deep learning model, providing a practical solution for field-based soybean disease grading.
4. Discussion
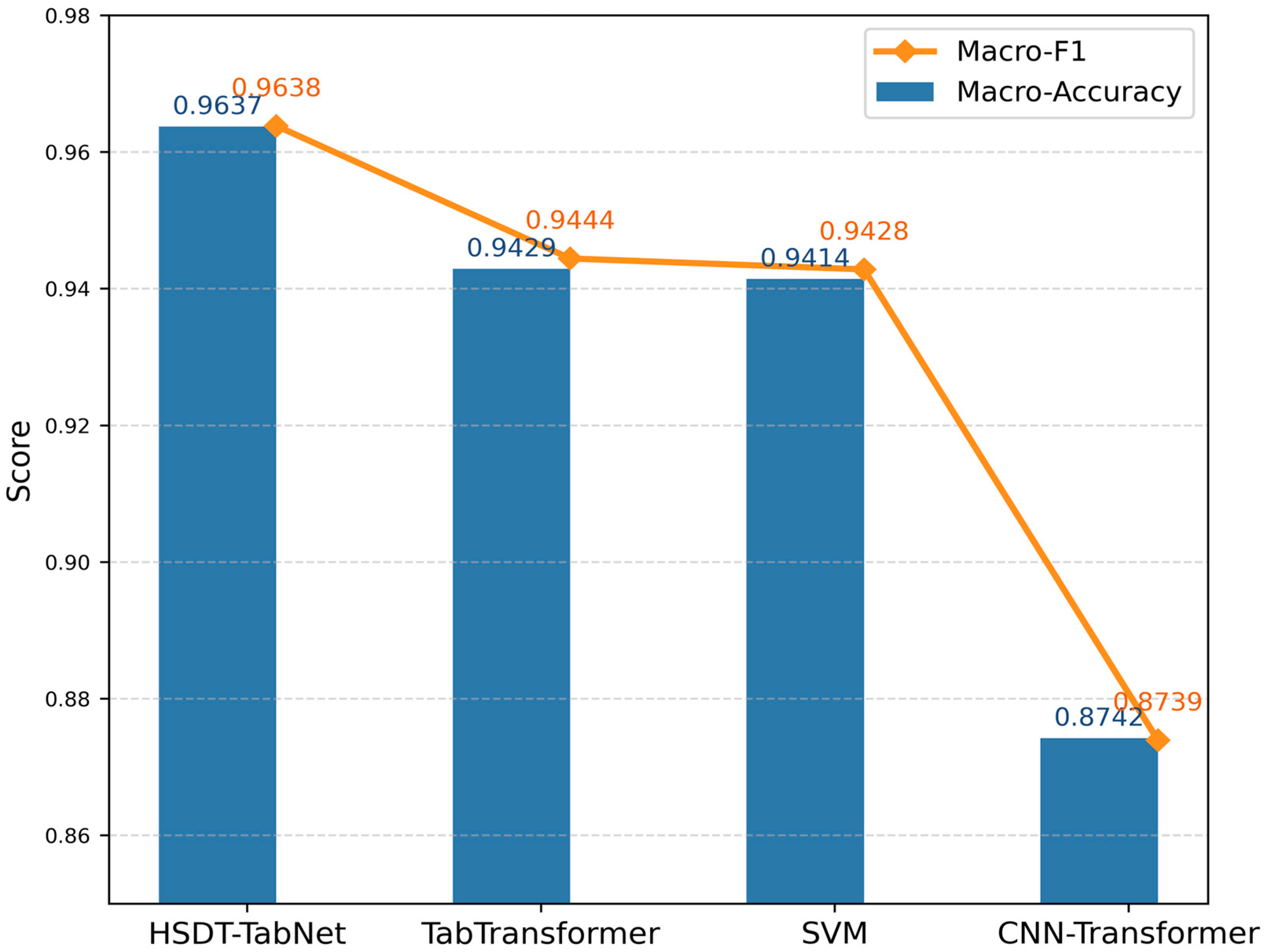
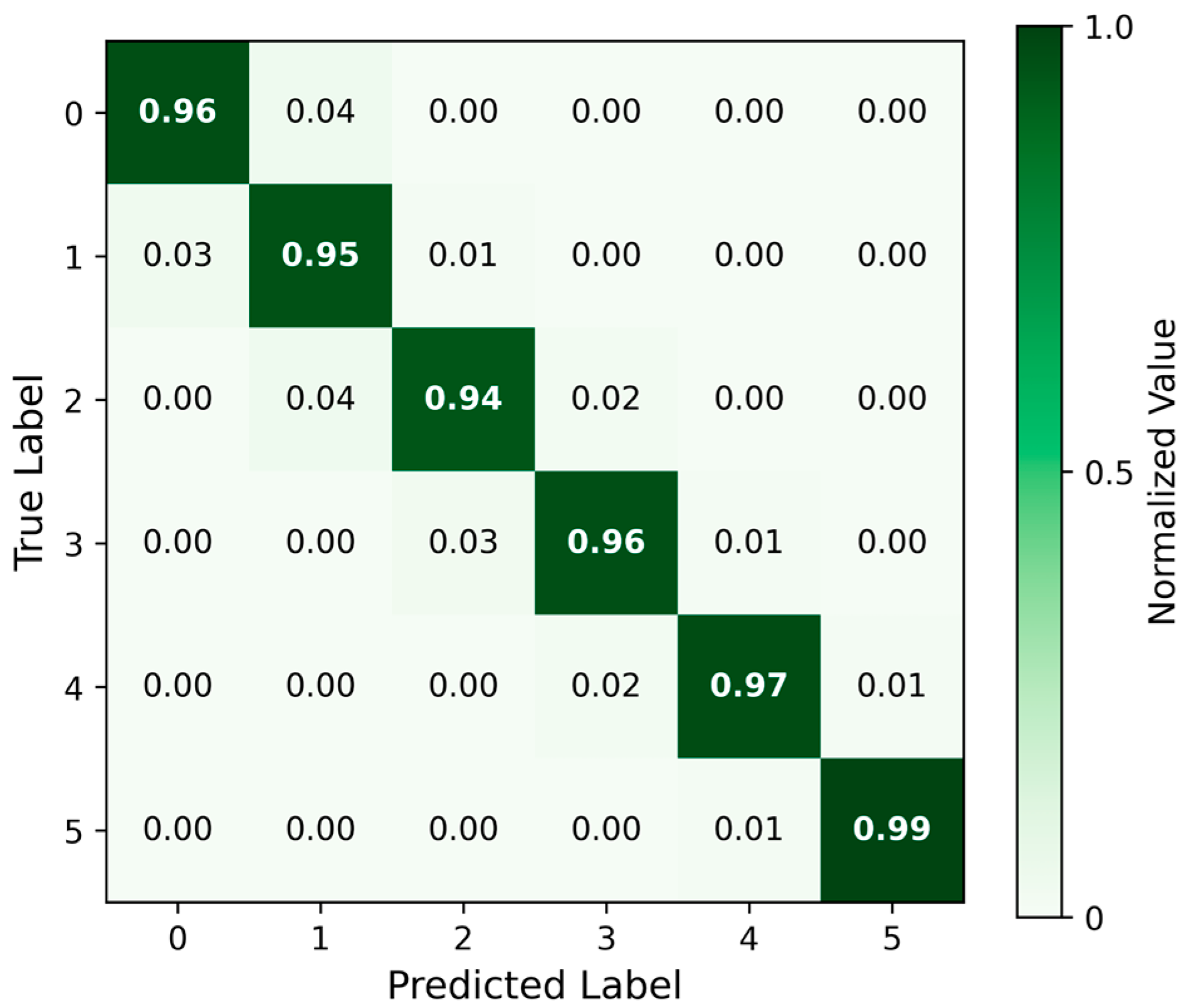
The proposed HSDT-TabNet model demonstrated excellent performance in classifying soybean FLS severity under field conditions, achieving a macro-accuracy of 96.37%, surpassing the TabTransformer model, CNN–transformer model, and conventional machine learning baselines. The significant performance gap compared to CNN–transformer arises from fundamental architectural differences. CNN–transformer leverages the inherent spatial structure of image data, capturing local–global dependencies via convolutional and attention mechanisms. However, hyperspectral reflectance data represented in tabular form lacks the underlying two-dimensional grid structure necessary for these spatial operations to be effective. These results match or surpass those reported in previous controlled-environment studies. For example, Gui et al. [
34] developed a CNN–SVM hybrid for early detection of soybean mosaic disease, achieving a test-set accuracy of 94.17% on hyperspectral data collected under laboratory conditions. Feng et al. [
8] employed a deformable and dilated convolutional neural network, DC
2Net, to detect Asian soybean rust in laboratory conditions, attaining an accuracy of 96.73%. Our dual-path architecture captured the hyperspectral disease signatures as effectively as these specialized models, validating that integrating local and global features is an effective strategy.
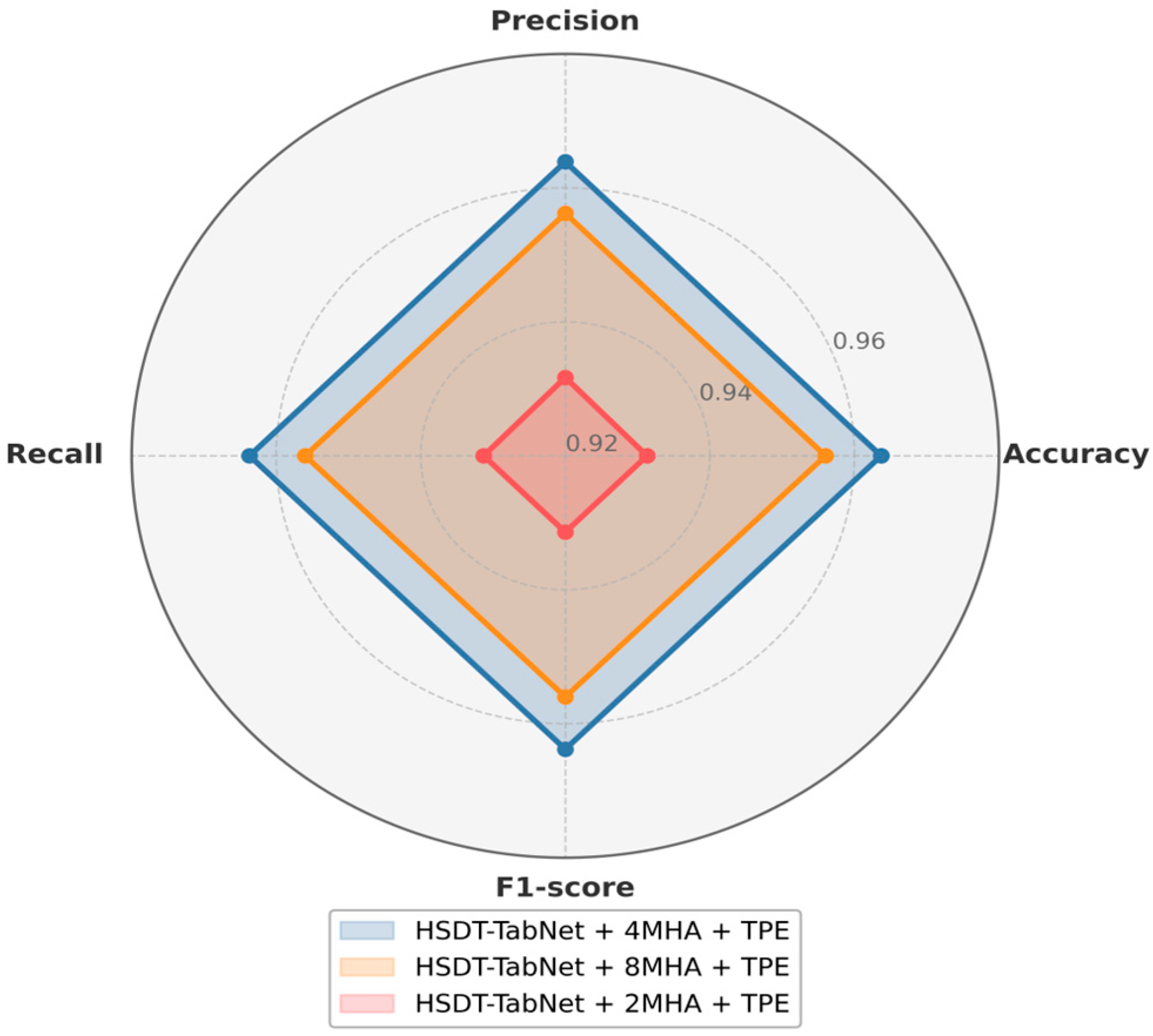
By introducing dual parallel paths, the model leverages the TabNet path to extract sparse local discriminative features, while the HSDT path captures global nonlinear interactions. This synergy increased accuracy by 1.93% over the original TabNet and by 2.39% over standalone HSDT. Hyperspectral tabular data presents unique challenges that make it distinct from typical datasets: it is high-dimensional, often comprising hundreds of spectral bands, which introduces the curse of dimensionality; it typically has small sample sizes due to the high cost and complexity of data collection in field conditions; and it exhibits strong inter-band correlations, leading to redundancy and multicollinearity that can confound traditional models. These characteristics often cause conventional approaches, such as SVM or random forests, to struggle with overfitting or fail to capture the complex nonlinear relationships inherent in the data. The HSDT-TabNet model is specifically tailored to address these issues. The TabNet path employs sparse feature selection to focus on the most relevant spectral bands, effectively reducing the impact of irrelevant or redundant features, while the HSDT path models global interactions across all bands, preserving the overall spectral signature critical for disease detection. Furthermore, the multi-head attention mechanism enhances the model’s ability to focus on different parts of the spectrum simultaneously, capturing subtle and complex patterns that distinguish disease states, particularly valuable when sample sizes are limited. Moreover, we observed that four attention heads (4MHA) outperform configurations with two or eight heads, indicating that while sufficient multi-view projections capture complex spectral–spatial patterns, excessive heads incur diminishing returns and higher variance, consistent with Liang et al. [
35], who showed that although multi-head attention enhances expressiveness, too many heads dramatically increase parameter count and computational cost, risking overfitting and instability. In addition, Guo et al. [
36] adopted a similar dual-path CNN–transformer architecture and achieved over 97% accuracy on crop classification tasks across multiple UAV-based hyperspectral datasets, further corroborating the merits of hybrid designs. Finally, by employing TPE hyperparameter optimization, we automated the search for critical parameters, improving both convergence speed and generalization ability—thereby validating the effectiveness of this approach.
In severity grading, level 0 (healthy) and levels 4–5 (severe) were easily separable, aligning with the gradual progression of disease [
37]. However, soybean FLS exhibits continuity in its levels, with minimal differences in lesion area and severity between adjacent levels, causing blurred boundaries for intermediate levels (1–3) and leading to potential model confusion. Similar observations have been reported in other disease studies [
38,
39,
40], where intermediate stages pose greater classification difficulty under gradual disease progression. To address this, we analyzed misclassifications within the intermediate levels and plan to explore improved optimization strategies to enhance performance in future work.
In summary, HSDT-TabNet was specifically designed for high-dimensional, small-sample, and strong inter-band correlation datasets by integrating dual-path feature extraction, multi-head attention mechanism, and TPE hyperparameter optimization. This approach effectively overcomes the limitations of traditional models in separating local and global features, achieving outstanding performance in hyperspectral crop disease grading tasks and proving particularly suitable for complex agricultural scenarios. The performance gains over traditional baselines, consistent with recent advanced studies, underscore the scientific value of our model. By concurrently modeling local and global feature relations and optimizing hyperparameters, the model markedly enhances detection accuracy and robustness. These findings represent an advancement in UAV-based crop disease monitoring, showcasing the innovation and potential impact of hybrid deep learning models in agriculture.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}