

Fostering Agricultural Transformation through AI: An Open-Source AI Architecture Exploiting the MLOps Paradigm


Abstract
1. Introduction
- An AI architecture using open-source technologies for creating and producing AI models is presented, covering the whole life cycle of the AI model, from its creation to its deployment and monitoring.
- The architecture builds a workflow made of state-of-the-art tools that enable data scientists and ML engineers to work more efficiently and rapidly, solving many problems in their day-to-day lives.
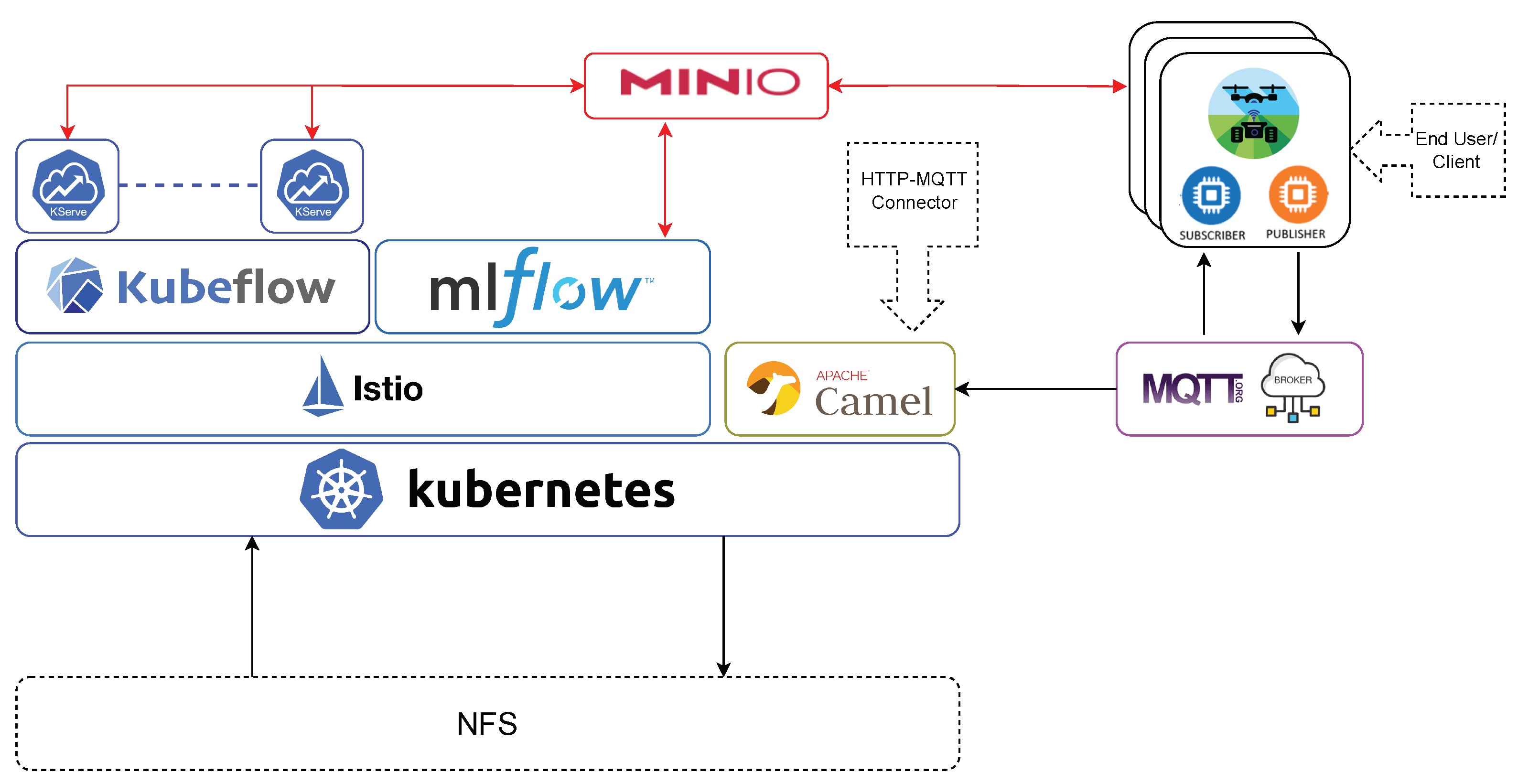
- The architecture supports the access through different types of IoT protocols, such as HTTP and MQTT, enabling ease of access and communication with diverse devices.
- The system is able to run different AI models at the same time, making optimal use of the hardware resources available in the cluster where the platform has been deployed.
2. Materials and Methods
2.1. Related Work
2.1.1. Artificial Intelligence in Agriculture
2.1.2. Open-Source Architectures and MLOps
2.1.3. Smart Agriculture and Agriculture 4.0
2.1.4. User Experience in Agricultural Systems
2.1.5. Recent Developments and Future Directions
2.1.6. Summary
2.2. Proposed Architecture
2.2.1. Fundamentals
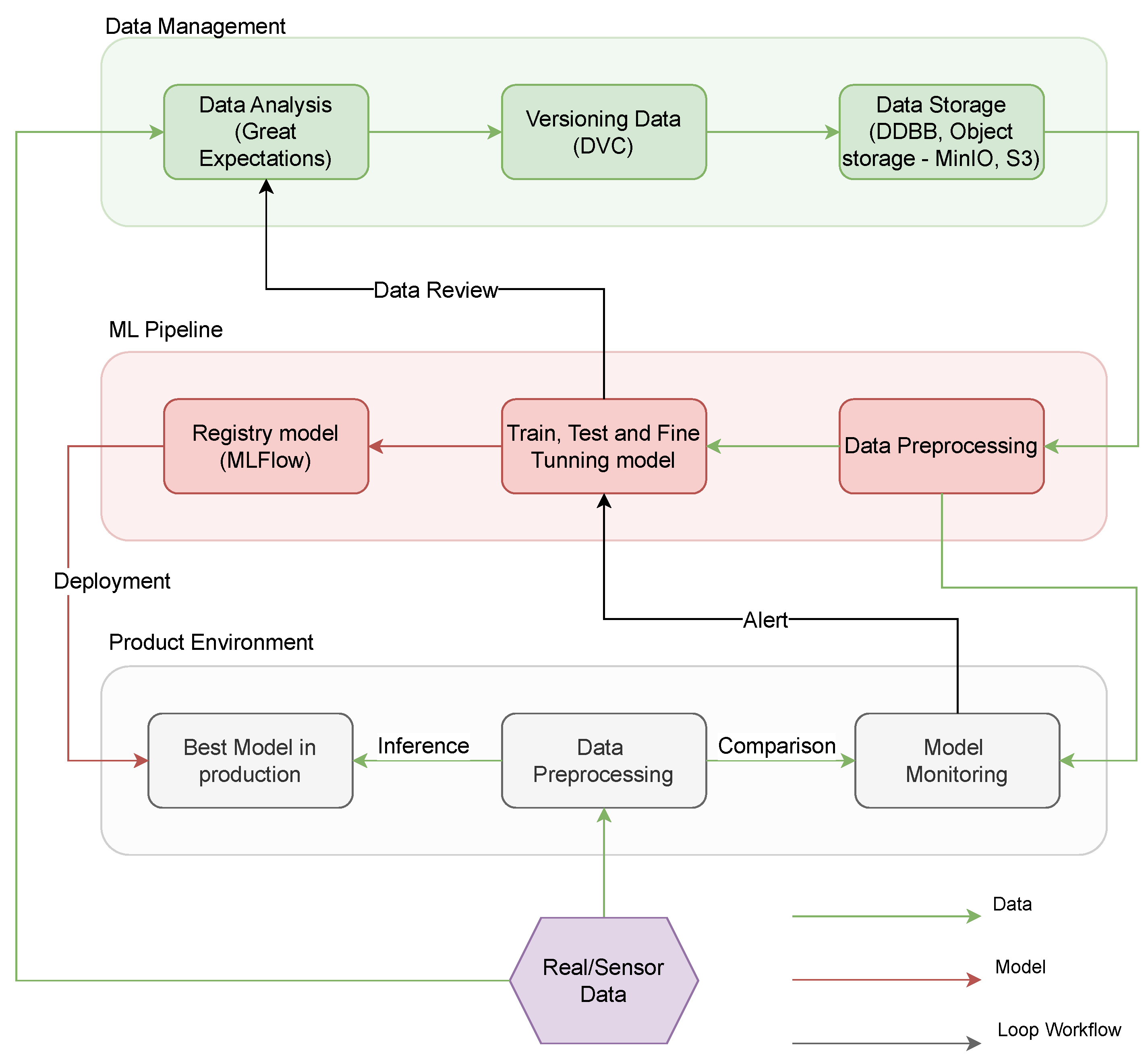
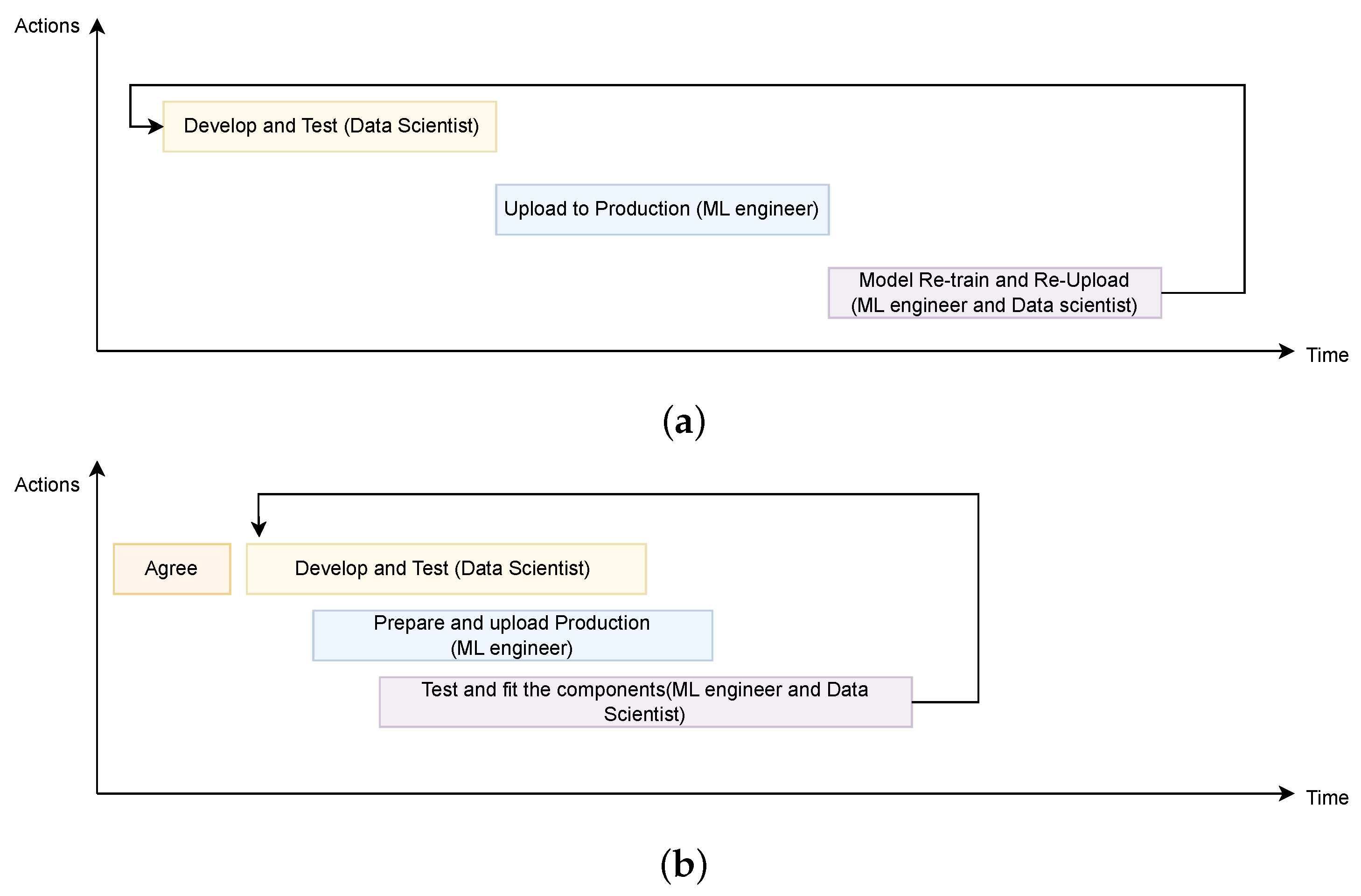
- Data management: the input dataset for an AI model is stored on the same local machine where the AI model is trained and tested. This makes it impossible to update the dataset in the case of new data being incorporated, as the memory consumption of that local machine would render the infrastructure inoperable.
- AI model versioning: tools that allow for the versioning of different trained models are not used, since this process normally involves exchanging considerable amounts of data.
- Teamwork: if a team is working on a local machine, the design of pipelines can only be performed and manipulated by one person.
- Production deployment: This process often involves additional considerations such as scalability, reliability, security, and monitoring. Furthermore, production deployment can hinder problem solving in a production environment, posing challenges when addressing errors efficiently and promptly.
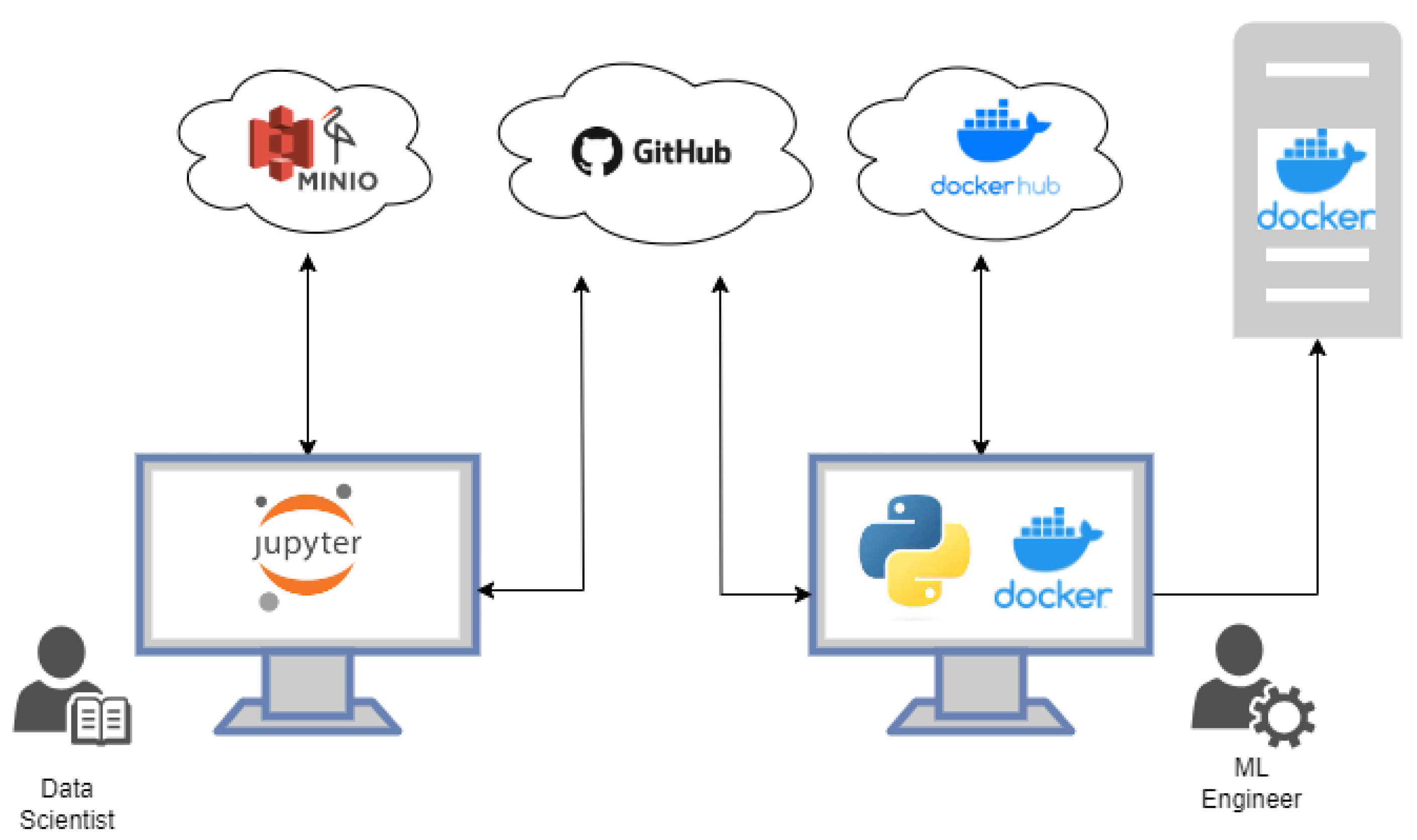
- Training Code: Normally, a Jupyter Notebook [70] is used for experimentations, so it contains the code used for model training, hyperparameter tuning, and evaluation.
- Trained Model with Artifacts and Versioning: The developers produce a trained model along with its associated artifacts. These artifacts are versioned to ensure reproducibility and allow for easy tracking of model changes.
- Stored and versioned Dataset: The dataset used for training is also versioned to maintain a record of its evolution.
- ML Pipelines: These pipelines automate key tasks, including data preprocessing, feature engineering, model (re)training, and evaluation. ML pipelines improve code modularity, facilitate version control, and enable collaboration among team members.
- Continuous Integration and Delivery (CI/CD) Pipeline: This pipeline includes steps such as formatting checks, execution of unit tests, and documentation verification. CI/CD ensures code quality, detects errors early, and allows for rapid iteration and deployment.
- Containerization and Deployment: In this step, the model, its dependencies, and the ML pipeline are encapsulated into a container, ensuring consistency across different environments. The containerized model is then deployed in the production infrastructure, ready to serve predictions.
- A Data scientist is responsible for gathering and preprocessing data, exploring and analyzing datasets, developing and training ML models, and evaluating their performance. Data scientists take the lead in the model development stage, experimenting with different algorithms, hyperparameters, and dataset improvements.
- An ML engineer specializes in implementing and operationalizing ML models in production environments. They bridge the gap between data science and software engineering, focusing on deploying, scaling, and maintaining ML systems. ML engineers work on developing robust ML pipelines, optimizing model performance, designing scalable architectures, and ensuring the reliability and scalability of production systems. They define formatting checks, unit tests, and documentation requirements to maintain code quality and ensure successful deployment.
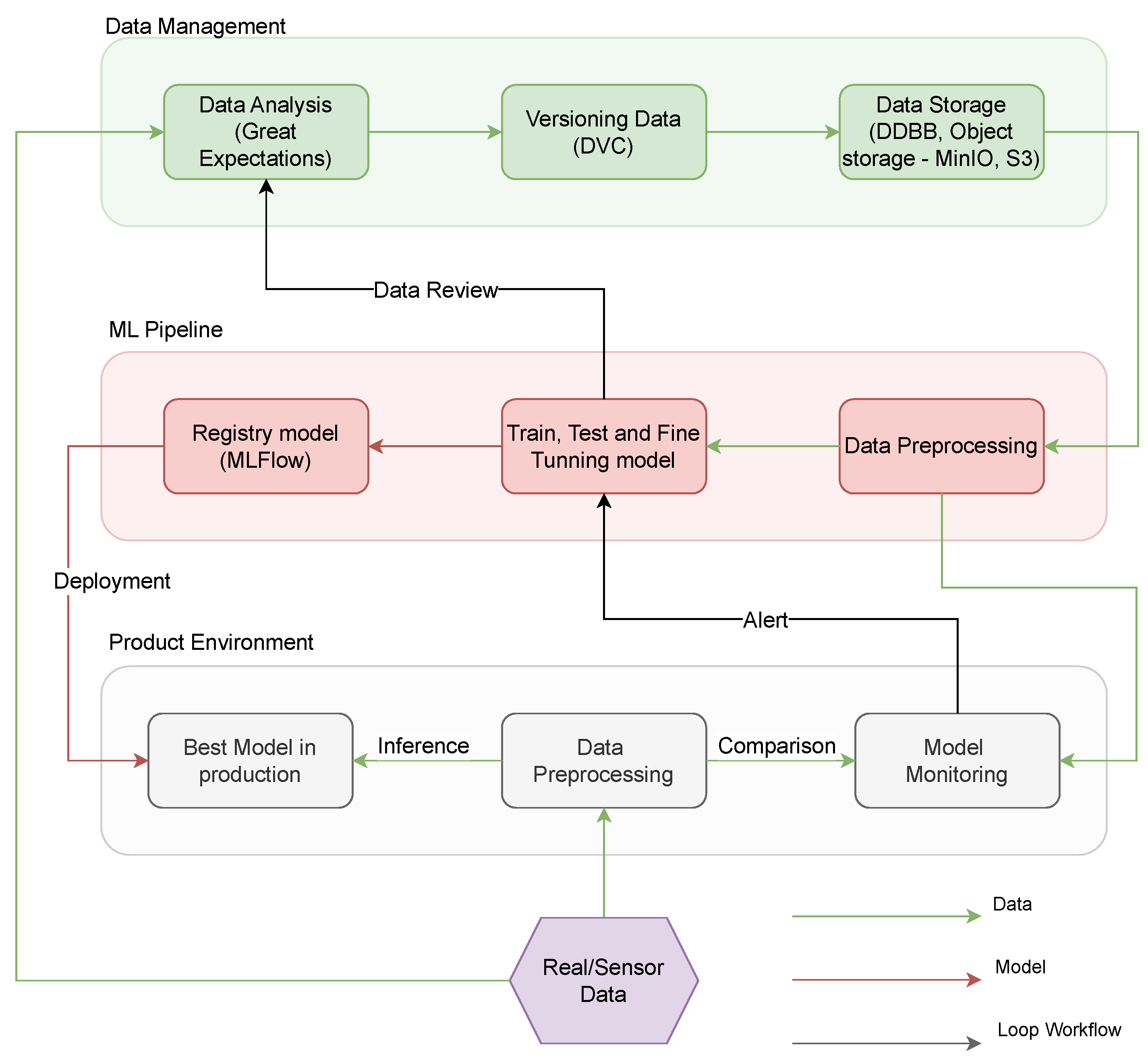
- Data Analysis Submodule: This module is tasked with assessing and integrating new data into the existing dataset. It maintains a connection with the logs from the Train, Test, and Fine-tuning Model submodule, offering insights into training performance and facilitating potential adjustments to the dataset format. As an example, Great Expectations tool [71] is an open-source Python-based library to ensure the reliability of data by asserting certain “expectations” or quality assessments on datasets.
- Data Versioning Submodule: Through meticulous documentation, areas for dataset improvement can be identified and the introduction of new dataset versions is registered, ensuring the maintenance of a dynamic dataset. As can be seen in the previous figure, DVC [72] is another open-source tool designed for versioning datasets, model weights, and intermediate files, enabling reproducibility and efficient data pipeline tracking.
- Data Storage Submodule: A plethora of technologies is available for data storage, such as MinIO, Amazon S3, PostgreSQL, etc. Notably, this submodule interacts directly with the Data Preprocessing submodule within the ML pipeline.
- Data Preprocessing: This submodule retrieves data from the database, undergoes cleaning operations, and restructures them to ensure the model’s optimal training. It is integral to the ML pipeline as it preprocesses data tailored for a specific AI model. Furthermore, the output of this submodule is interconnected with the Model Monitoring submodule in the Production Environment, ensuring the reference data remains updated.
- Train, Test, and Fine-tuning Model: This submodule ensures that the model’s accuracy, reliability, and performance are aligned with the desired outcomes. If data restructuring or modifications are required, a comprehensive Data Review is imperative, needing the invocation of the Data Analysis submodule again.
- Registry Model: This submodule is dedicated to the preservation of the highest-performing AI models which were trained in the previous submodule. MLFlow tool could be used as an example to register a trained model [73]. As a model registry tool, it centralizes model management, tracks versions, and facilitates lifecycle transitions. The model deemed superior is subsequently deployed in the production environment, bridging the Registry Model submodule with the Best Model in Production submodule in the Production Environment pipeline.
- Data Preprocessing in Production: Upon collection, raw data undergoes preprocessing via the Data Preprocessing submodule. These refined data are then fed to the Model Monitoring submodule, where its coherence is meticulously analyzed.
- Best Model in production: The processed data from the previous component is then channeled into the submodule dedicated to model inference.
- Model Monitoring and Alerts: The output data are further integrated into the Model Monitoring submodule for an in-depth analysis. Should the data received from the sensors and the model’s output diverge beyond the acceptable variance, the system triggers an alert, highlighting the potential need for training a novel model.
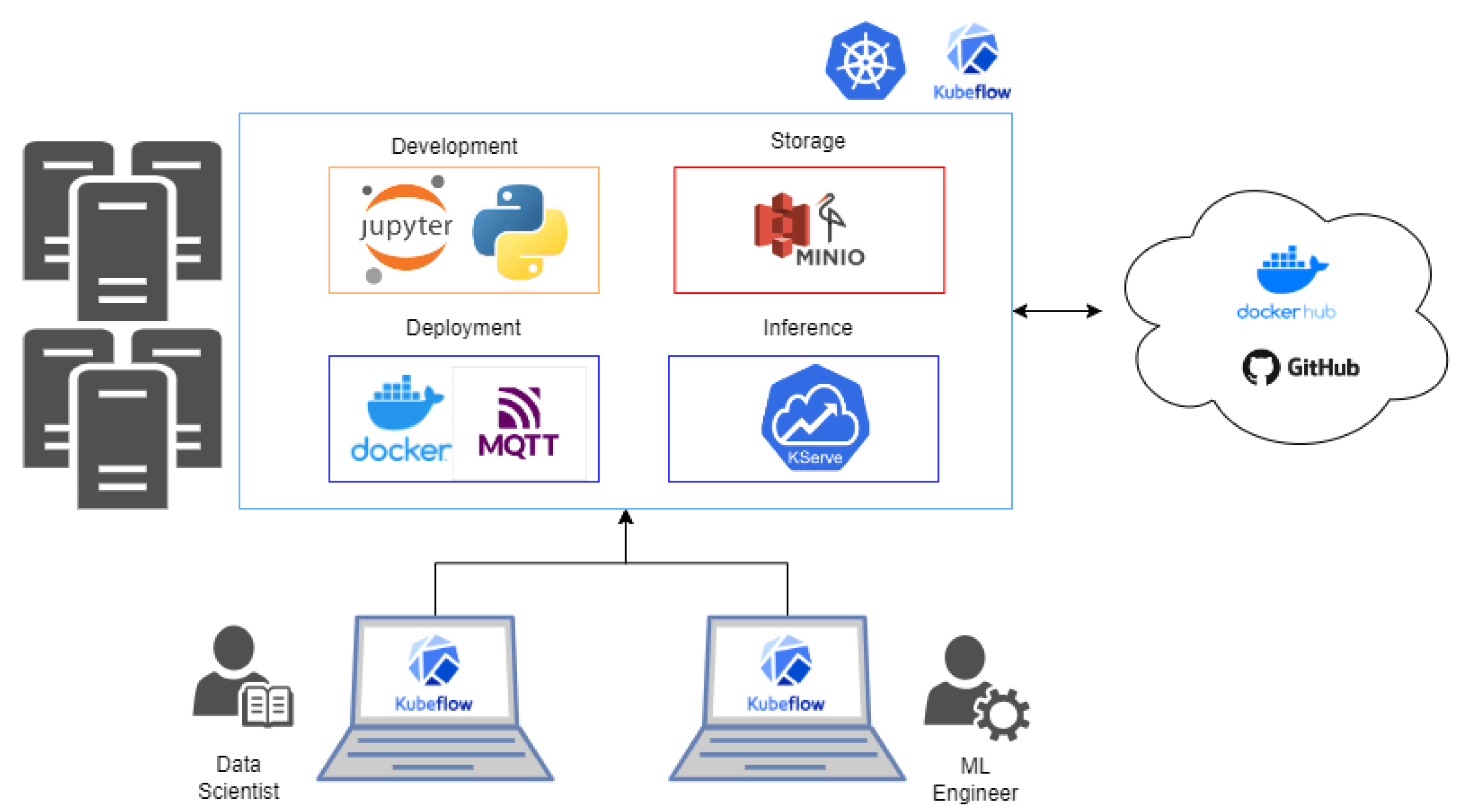
2.2.2. Technological Implementation
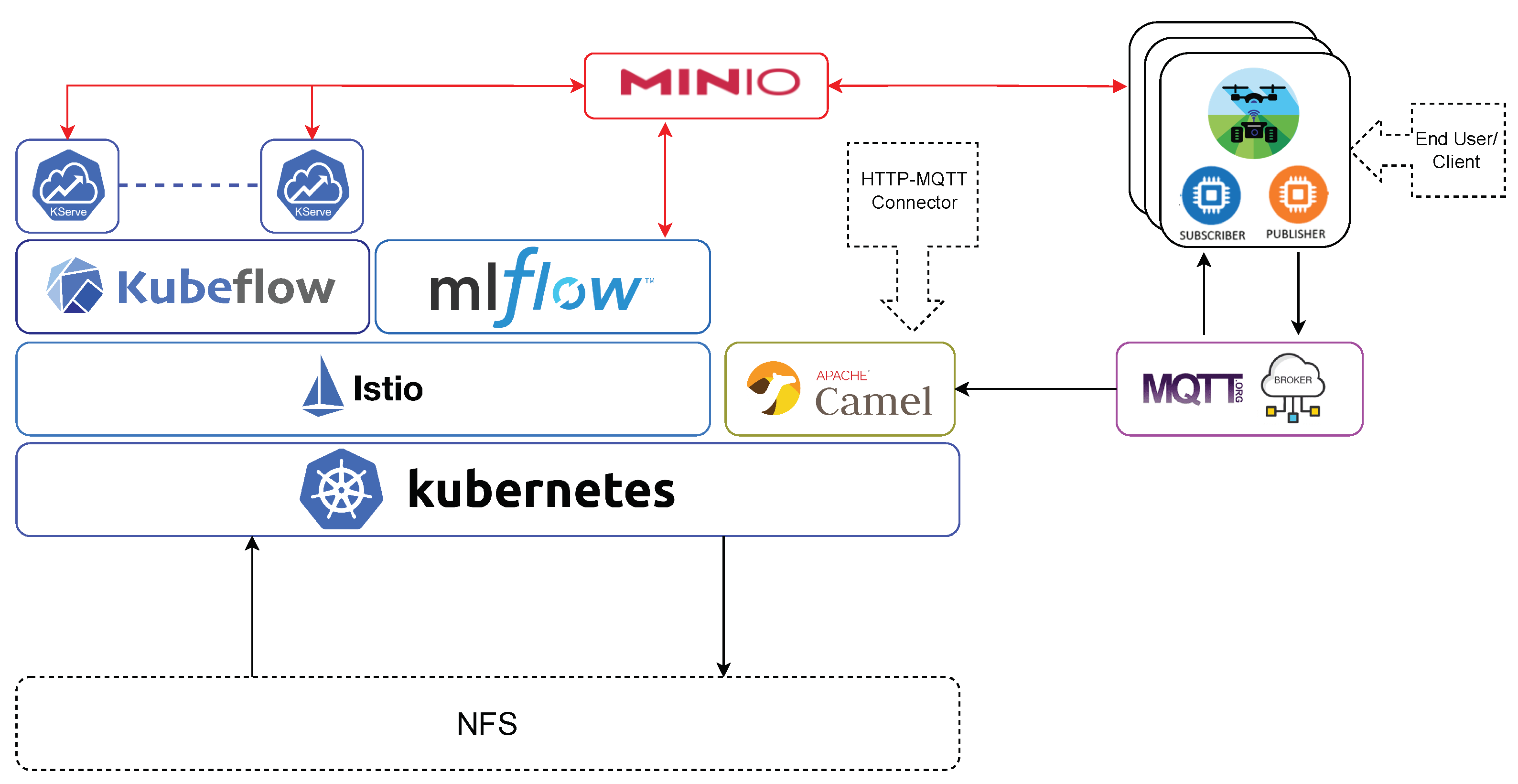
2.2.3. Data Management
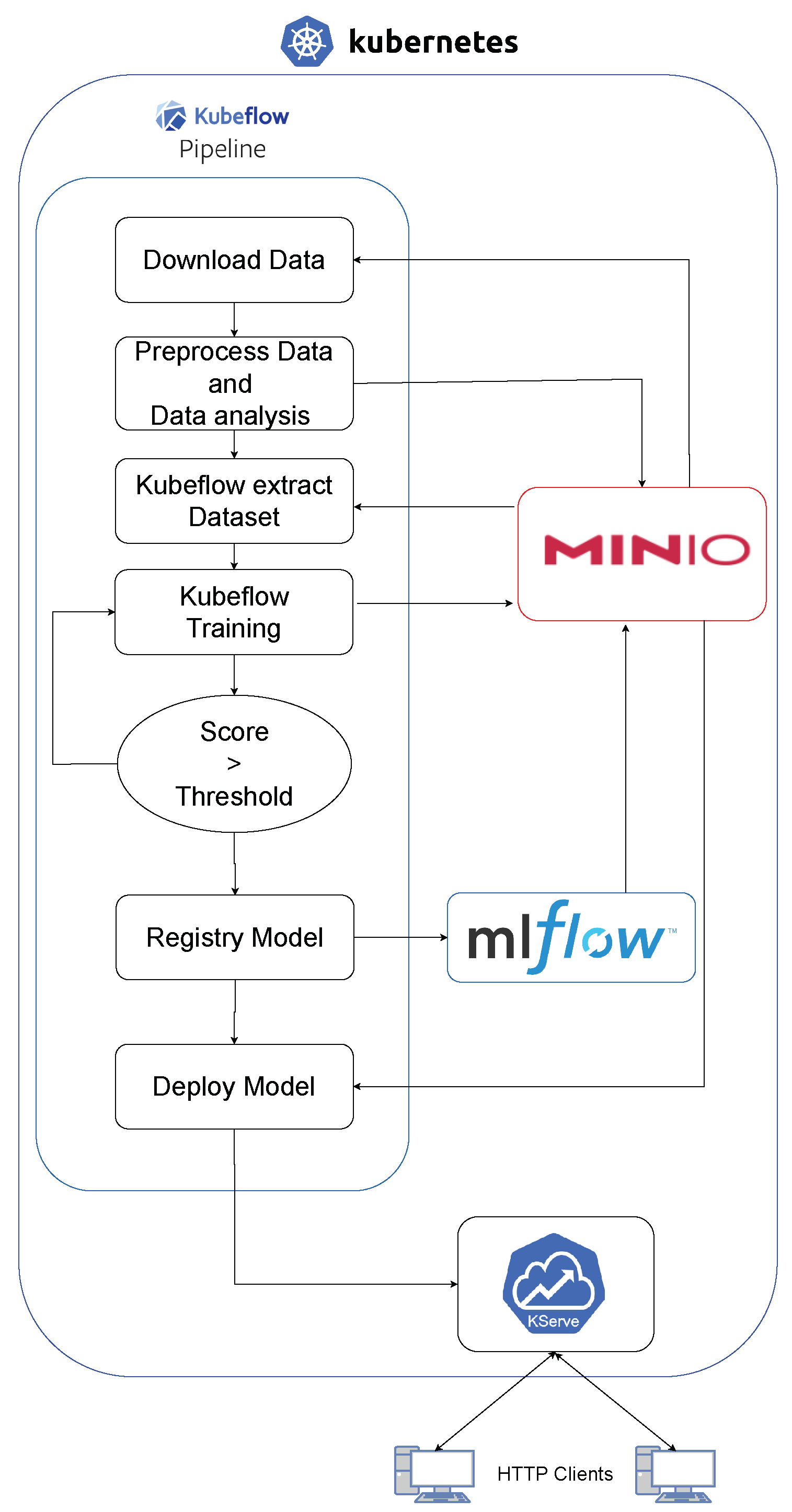
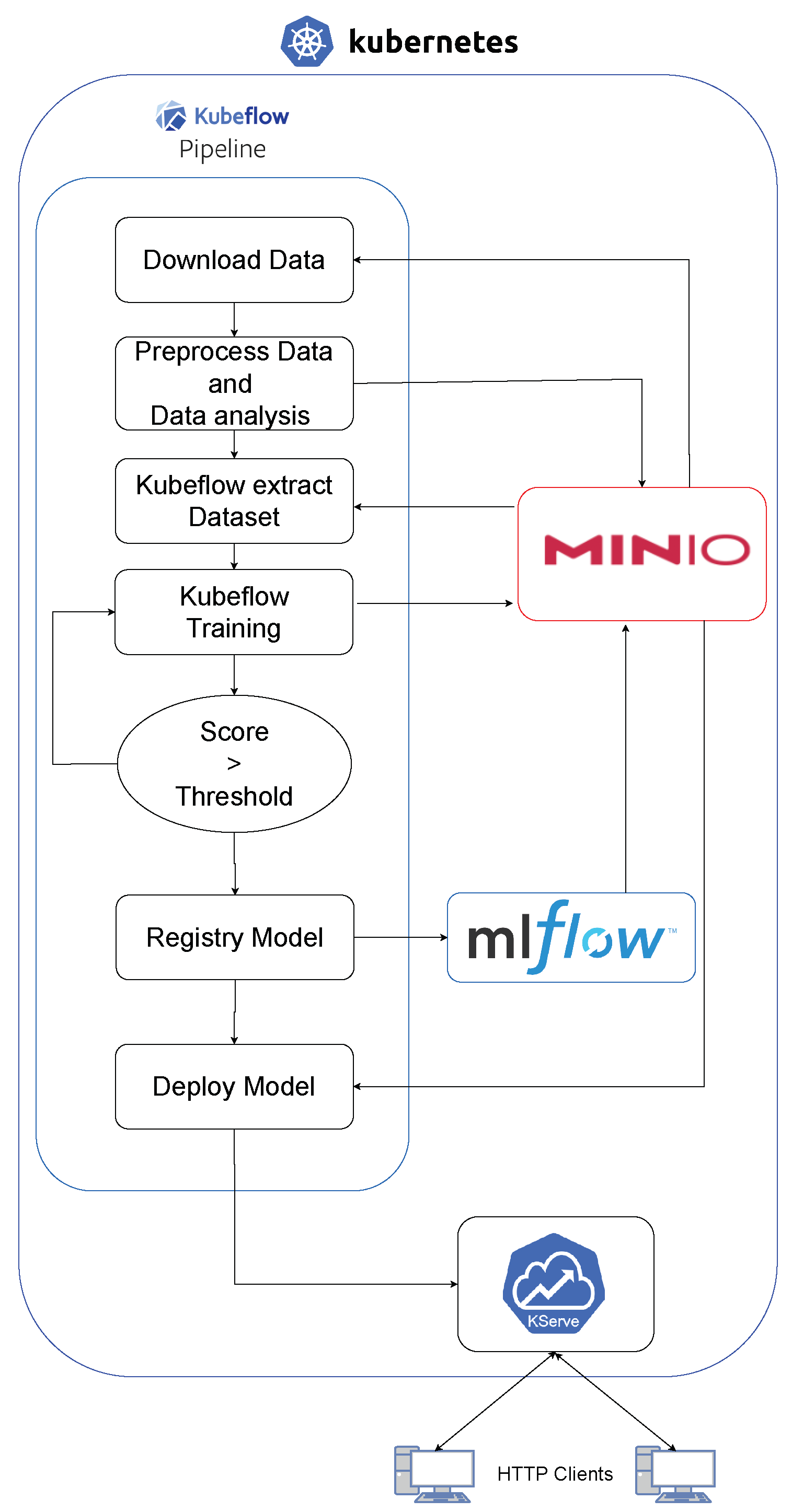
2.2.4. ML Pipeline
- For data preparation and task orchestration for training, Kubeflow Pipelines [82] offers a visual interface that facilitates the design and execution of data processing pipelines or automated model training.
- In terms of experimentation, development, and model training, Kubeflow integrates with popular ML frameworks such as TensorFlow [83], Pytorch [84], and scikit-learn [85]. Experiments and developments can be carried out by using its integrated Jupyter Notebook implementation. Jupyter Notebook is a web-based tool for creating, sharing, and executing files containing live code, visualizations, and explanatory text. These Jupyter Notebooks are managed as Docker [86] containers by Kubeflow, easing their deployment and versioning. Kubeflow provides tools such as Katib [87] for studying model hyperparameters during training.
- As for monitoring and observability, users can monitor model performance, track key metrics, and set up alerts to ensure the models function as intended.
2.2.5. Production Environment
3. Results
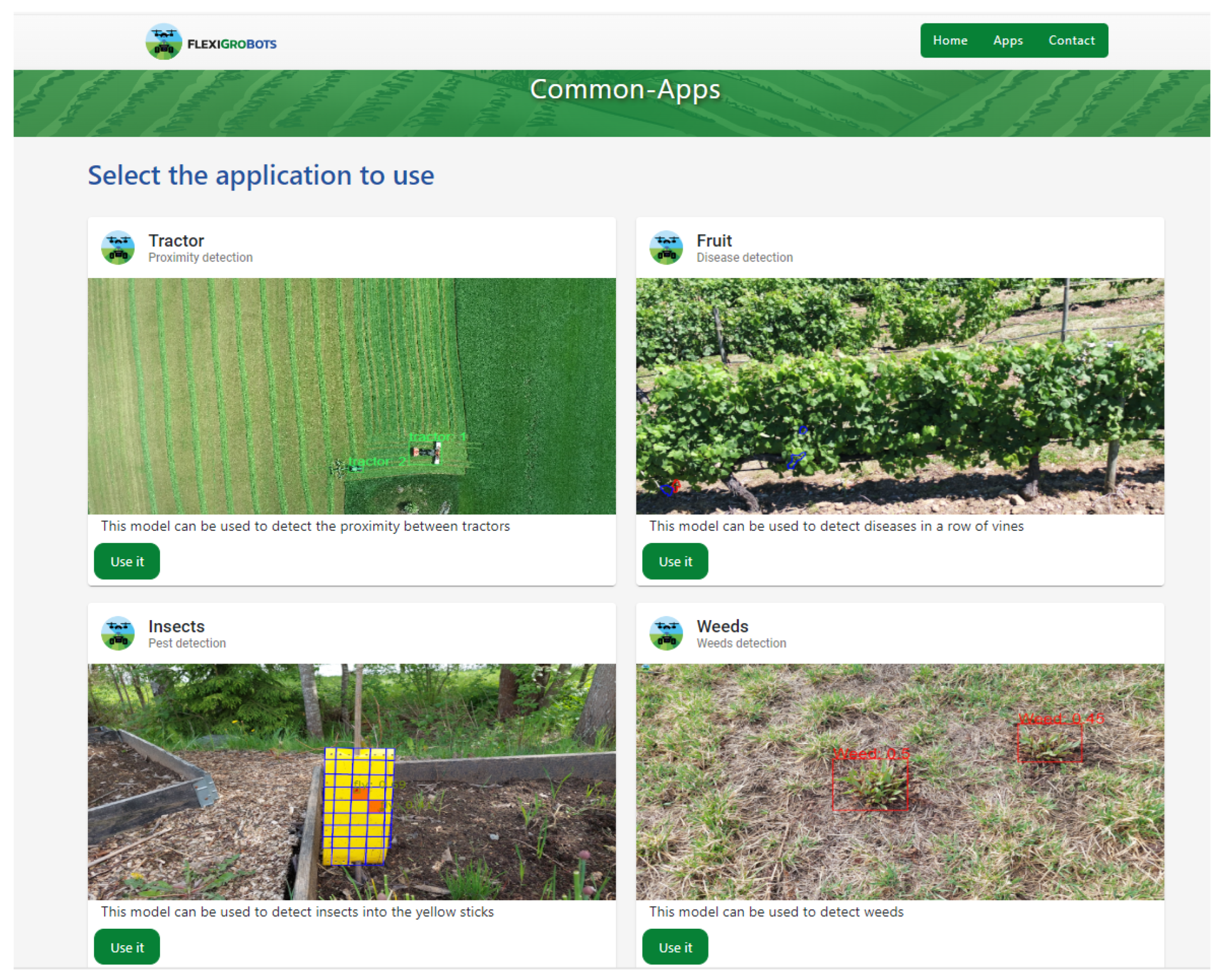
3.1. Web Platform
3.2. How to Use the Platform
3.3. Conducted Interviews
3.3.1. Contents and Structure of the Survey
3.3.2. Metrics
4. Discussion
5. Conclusions and Future Lines
- The platform provides access to high-performance infrastructure, enabling efficient utilization of computational power. This capability empowers users to tackle complex tasks and handle large datasets without being constrained by their local hardware limitations.
- The platform serves as a centralized entrypoint which enhances communication and collaboration among data scientists, ML engineers, and other stakeholders, such as domain experts and project managers. This unified platform facilitates the seamless sharing of code, documentation, and project updates, promoting efficient code review, feedback, and iteration cycles.
- The platform takes care of role and user management, eliminating the need for users to handle multiple credentials for various tools and services. This centralized approach simplifies user onboarding, access control, and overall security.
- The platform seamlessly manages the deployment and monitoring of ML models. This allows for timely issue detection and facilitates proactive maintenance and improvements.
- The platform incorporates centralized storage, streamlining the collaboration and sharing of datasets and ML artifacts. This centralized storage enables users to efficiently manage and access shared data, thereby accelerating the development process.
- Feedback from data scientists and ML engineers who have used the platform indicates its value for enhancing collaboration. However, they also mention that the initial steps can be somewhat challenging for new users. Despite this, they also highlight the need for structured and common methodologies to better organize resources within the platform and streamline day-to-day operations.
- The platform is tailored for agriculture, efficiently connecting with numerous sensors, compatible with MQTT, and built on adaptable open-source technologies, making it an ideal choice for diverse farming needs. The platform has specifically been designed considering the farmer’s needs, building it in such a way that the adoption of this architecture would only require a minimum hardware infrastructure to deploy the system.
- While this platform was originally developed for an agricultural environment, its modular and adaptable architecture allows for its application in diverse fields. With appropriate modifications, the platform could be extrapolated to cater to the specific needs and challenges of other sectors.
- Improving User Onboarding: Given the feedback regarding the initial challenges faced by new users, it becomes imperative to make the learning curve smoother. Interactive tutorials, context-sensitive help sections, and even AI-guided walkthroughs are potential solutions to better assist new users as they navigate and familiarize themselves with the platform.
- Model Monitoring: While the platform handles the entire lifecycle of ML models proficiently, there is a clear gap in terms of continuous model monitoring in a productive environment. The immediate next step, thus, is integrating well-established tools such as Grafana [95] and Prometheus [96], since they could provide real-time insights, performance metrics, and anomaly detection for deployed models.Although the platform efficiently manages the lifecycle of ML models, it lacks continuous model monitoring in a production environment. To address this, integrating tools like Grafana [95] and Prometheus [96] is essential for offering real-time insights and performance metrics, including anomaly detection for deployed models.
- More experimentation: The aim is to engage more data scientists and ML engineers on the platform to maximize its memory and computing capacities. This entails encouraging experts to perform resource-intensive tasks, challenging the system’s ability to handle extensive data processing and complex algorithms. By pushing the platform to its limits, it can showcase its scalability and effectiveness for demanding data science and machine learning tasks.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| CD | Continuous Delivery |
| CI | Continuous Integration |
| DL | Deep Learning |
| HTTP | Hypertext Transfer Protocol |
| IoT | Internet of Things |
| MLOps | Machine Learning Operations |
| ML | Machine Learning |
| MQTT | Message Queuing Telemetry Transport |
| NFS | Network File System |
| UAV | Unmanned Aerial Vehicles |
| UGV | Unmanned Ground Vehicles |
| UN | United Nations |
| WRI | World Resources Institute |
References
- Ranganathan, J.; Waite, R.; Searchinger, T.; Hanson, C. How to Sustainably Feed 10 Billion People by 2050, in 21 Charts. 2018. Available online: https://www.wri.org/insights/how-sustainably-feed-10-billion-people-2050-21-charts (accessed on 12 December 2023).
- De Clercq, M.; Vats, A.; Biel, A. Agriculture 4.0: The future of farming technology. In Proceedings of the World Government Summit, Dubai, United Arab Emirates, 29 December 2018; pp. 11–13. [Google Scholar]
- Wakchaure, M.; Patle, B.; Mahindrakar, A. Application of AI Techniques and Robotics in Agriculture: A Review. Artif. Intell. Life Sci. 2023, 3, 100057. [Google Scholar] [CrossRef]
- Eli-Chukwu, N.C. Applications of Artificial Intelligence in agriculture: A review. Eng. Technol. Appl. Sci. Res. 2019, 9, 4377–4383. [Google Scholar] [CrossRef]
- Elbasi, E.; Mostafa, N.; AlArnaout, Z.; Zreikat, A.I.; Cina, E.; Varghese, G.; Shdefat, A.; Topcu, A.E.; Abdelbaki, W.; Mathew, S. Artificial intelligence technology in the agricultural sector: A systematic literature review. IEEE Access 2022, 11, 171–202. [Google Scholar] [CrossRef]
- Shankar, P.; Werner, N.; Selinger, S.; Janssen, O. Artificial Intelligence driven crop protection optimization for sustainable agriculture. In Proceedings of the 2020 IEEE/ITU International Conference on Artificial Intelligence for Good (AI4G), Geneva, Switzerland, 21–25 September 2020; pp. 1–6. [Google Scholar]
- Allmendinger, A.; Spaeth, M.; Saile, M.; Peteinatos, G.G.; Gerhards, R. Precision chemical weed management strategies: A review and a design of a new CNN-based modular spot sprayer. Agronomy 2022, 12, 1620. [Google Scholar] [CrossRef]
- Saxena, R.; Joshi, A.; Joshi, S.; Borkotoky, S.; Singh, K.; Rai, P.K.; Mueed, Z.; Sharma, R. The role of artificial Intelligence strategies to mitigate abiotic stress and climate change in crop production. In Visualization Techniques for Climate Change with Machine Learning and Artificial Intelligence; Elsevier: Amsterdam, The Netherlands, 2023; pp. 273–293. [Google Scholar]
- Visentin, F.; Cremasco, S.; Sozzi, M.; Signorini, L.; Signorini, M.; Marinello, F.; Muradore, R. A mixed-autonomous robotic platform for intra-row and inter-row weed removal for precision agriculture. Comput. Electron. Agric. 2023, 214, 108270. [Google Scholar] [CrossRef]
- Conejero, M.; Montes, H.; Andujar, D.; Bengochea-Guevara, J.; Rodríguez, E.; Ribeiro, A. Collaborative smart-robot for yield mapping and harvesting assistance. In Precision Agriculture’23; Wageningen Academic: Wageningen, The Netherlands, 2023; pp. 1067–1074. [Google Scholar]
- Talib, M.A.; Majzoub, S.; Nasir, Q.; Jamal, D. A systematic literature review on hardware implementation of Artificial Intelligence algorithms. J. Supercomput. 2021, 77, 1897–1938. [Google Scholar] [CrossRef]
- Sufi, F. Algorithms in low-code-no-code for research applications: A practical review. Algorithms 2023, 16, 108. [Google Scholar] [CrossRef]
- Dogan, M.E.; Goru Dogan, T.; Bozkurt, A. The use of Artificial Intelligence (AI) in online learning and distance education processes: A systematic review of empirical studies. Appl. Sci. 2023, 13, 3056. [Google Scholar] [CrossRef]
- Mhlanga, D. Industry 4.0 in finance: The impact of Artificial Intelligence (ai) on digital financial inclusion. Int. J. Financ. Stud. 2020, 8, 45. [Google Scholar] [CrossRef]
- Enholm, I.M.; Papagiannidis, E.; Mikalef, P.; Krogstie, J. Artificial Intelligence and business value: A literature review. Inf. Syst. Front. 2022, 24, 1709–1734. [Google Scholar] [CrossRef]
- Cob-Parro, A.C.; Losada-Gutiérrez, C.; Marrón-Romera, M.; Gardel-Vicente, A.; Bravo-Muñoz, I. Smart video surveillance system based on edge computing. Sensors 2021, 21, 2958. [Google Scholar] [CrossRef]
- Rajpurkar, P.; Chen, E.; Banerjee, O.; Topol, E.J. AI in health and medicine. Nat. Med. 2022, 28, 31–38. [Google Scholar] [CrossRef] [PubMed]
- Huang, Z.; Shen, Y.; Li, J.; Fey, M.; Brecher, C. A survey on AI-driven digital twins in industry 4.0: Smart manufacturing and advanced robotics. Sensors 2021, 21, 6340. [Google Scholar] [CrossRef]
- Qazi, S.; Khawaja, B.A.; Farooq, Q.U. IoT-equipped and AI-enabled next generation smart agriculture: A critical review, current challenges and future trends. IEEE Access 2022, 10, 21219–21235. [Google Scholar] [CrossRef]
- Vincent, D.R.; Deepa, N.; Elavarasan, D.; Srinivasan, K.; Chauhdary, S.H.; Iwendi, C. Sensors driven AI-based agriculture recommendation model for assessing land suitability. Sensors 2019, 19, 3667. [Google Scholar] [CrossRef]
- Ben Ayed, R.; Hanana, M. Artificial Intelligence to improve the food and agriculture sector. J. Food Qual. 2021, 2021, 5584754. [Google Scholar] [CrossRef]
- Alla, S.; Adari, S.K.; Alla, S.; Adari, S.K. What is mlops? In Beginning MLOps with MLFlow: Deploy Models in AWS SageMaker, Google Cloud, and Microsoft Azure; Apress: New York, NY, USA, 2021; pp. 79–124. [Google Scholar]
- John, M.M.; Olsson, H.H.; Bosch, J. Towards mlops: A framework and maturity model. In Proceedings of the 2021 47th Euromicro Conference on Software Engineering and Advanced Applications (SEAA), Palermo, Italy, 1–3 September 2021; pp. 1–8. [Google Scholar]
- Ruf, P.; Madan, M.; Reich, C.; Ould-Abdeslam, D. Demystifying mlops and presenting a recipe for the selection of open-source tools. Appl. Sci. 2021, 11, 8861. [Google Scholar] [CrossRef]
- Hunkeler, U.; Truong, H.L.; Stanford-Clark, A. MQTT-S—A publish/subscribe protocol for Wireless Sensor Networks. In Proceedings of the 2008 3rd International Conference on Communication Systems Software and Middleware and Workshops (COMSWARE’08), Bangalore, India, 6–10 January 2008; pp. 791–798. [Google Scholar]
- Berners-Lee, T.; Fielding, R.; Frystyk, H. Hypertext Transfer Protocol–HTTP/1.0. 1996. Available online: https://www.rfc-editor.org/rfc/rfc1945.html (accessed on 12 December 2023).
- Shankar, R.H.; Veeraraghavan, A.; Sivaraman, K.; Ramachandran, S.S. Application of UAV for pest, weeds and disease detection using open computer vision. In Proceedings of the 2018 International Conference on Smart Systems and Inventive Technology (ICSSIT), Tirunelveli, India, 13–14 December 2018; pp. 287–292. [Google Scholar]
- Nalluri, S.; Ramasubbareddy, S.; Kannayaram, G. Weather prediction using clustering strategies in machine learning. J. Comput. Theor. Nanosci. 2019, 16, 1977–1981. [Google Scholar] [CrossRef]
- Ukhurebor, K.E.; Adetunji, C.O.; Olugbemi, O.T.; Nwankwo, W.; Olayinka, A.S.; Umezuruike, C.; Hefft, D.I. Precision agriculture: Weather forecasting for future farming. In AI, Edge and IoT-Based Smart Agriculture; Elsevier: Amsterdam, The Netherlands, 2022; pp. 101–121. [Google Scholar]
- Kendler, S.; Aharoni, R.; Young, S.; Sela, H.; Kis-Papo, T.; Fahima, T.; Fishbain, B. Detection of crop diseases using enhanced variability imagery data and convolutional neural networks. Comput. Electron. Agric. 2022, 193, 106732. [Google Scholar] [CrossRef]
- Karunathilake, E.; Le, A.T.; Heo, S.; Chung, Y.S.; Mansoor, S. The path to smart farming: Innovations and opportunities in precision agriculture. Agriculture 2023, 13, 1593. [Google Scholar] [CrossRef]
- Suryawanshi, Y.; Patil, K. Advancing agriculture through image-based datasets in plant science: A review. EPRA Int. J. Multidiscip. Res. (IJMR) 2023, 9, 233–236. [Google Scholar]
- Agarwal, S.; Hiran, D.; Kothari, H.; Singh, S. Leveraging data processing for optimizing organic farming practices. J. Data Acquis. Process. 2023, 38, 3243. [Google Scholar]
- Rogelja, T.; Ludvig, A.; Weiss, G.; Prah, J.; Shannon, M.; Secco, L. Analyzing social innovation as a process in rural areas: Key dimensions and success factors for the revival of the traditional charcoal burning in Slovenia. J. Rural. Stud. 2023, 97, 517–533. [Google Scholar] [CrossRef]
- Khudyakova, E.; Shitikova, A.; Stepantsevich, M.N.; Grecheneva, A. Requirements of Modern Russian Agricultural Production for Digital Competencies of an Agricultural Specialist. Educ. Sci. 2023, 13, 203. [Google Scholar] [CrossRef]
- Garske, B.; Bau, A.; Ekardt, F. Digitalization and AI in European agriculture: A strategy for achieving climate and biodiversity targets? Sustainability 2021, 13, 4652. [Google Scholar] [CrossRef]
- Nova, K. AI-enabled water management systems: An analysis of system components and interdependencies for water conservation. Eig. Rev. Sci. Technol. 2023, 7, 105–124. [Google Scholar]
- Liang, P.; Tang, Y.; Zhang, X.; Bai, Y.; Su, T.; Lai, Z.; Qiao, L.; Li, D. A Survey on Auto-Parallelism of Large-Scale Deep Learning Training. IEEE Trans. Parallel Distrib. Syst. 2023, 34, 2377–2390. [Google Scholar] [CrossRef]
- Chheda, S.; Curtis, A.; Siegmann, E.; Chapman, B. Performance Study on CPU-based Machine Learning with PyTorch. In Proceedings of the HPC Asia 2023 Workshops, Singapore, 27 February–2 March 2023; pp. 24–34. [Google Scholar]
- Kreuzberger, D.; Kühl, N.; Hirschl, S. Machine learning operations (mlops): Overview, definition, and architecture. IEEE Access 2023, 11, 31866–31879. [Google Scholar] [CrossRef]
- Hassani, H.; Huang, X.; MacFeely, S. Enabling Digital Twins to Support the UN SDGs. Big Data Cogn. Comput. 2022, 6, 115. [Google Scholar] [CrossRef]
- Dharmaraj, V.; Vijayanand, C. Artificial Intelligence (AI) in agriculture. Int. J. Curr. Microbiol. Appl. Sci. 2018, 7, 2122–2128. [Google Scholar] [CrossRef]
- Pistor, N. Accelerating University-Industry Collaborations with MLOps: A Case Study about the Cooperation of Aimo and the Linnaeus University. Master’s Thesis, Linnaeus University, Växjö, Sweden, 2023. [Google Scholar]
- Yang, X.; Cao, D.; Chen, J.; Xiao, Z.; Daowd, A. AI and IoT-based collaborative business ecosystem: A case in Chinese fish farming industry. Int. J. Technol. Manag. 2020, 82, 151–171. [Google Scholar] [CrossRef]
- Lubua Dr, E.W. The influence of socioeconomic factors to the use of mobile phones in the agricultural sector of Tanzania. Afr. J. Inf. Syst. 2019, 11, 2. [Google Scholar]
- Kumara, I.; Arts, R.; Di Nucci, D.; Van Den Heuvel, W.J.; Tamburri, D.A. Requirements and Reference Architecture for MLOps: Insights from Industry. TechRxiv 2023. [Google Scholar] [CrossRef]
- Hewage, N.; Meedeniya, D. Machine Learning Operations: A Survey on MLOps Tool Support. arXiv 2022, arXiv:2202.10169. [Google Scholar]
- Fujii, T.Y.; Hayashi, V.T.; Arakaki, R.; Ruggiero, W.V.; Bulla, R., Jr.; Hayashi, F.H.; Khalil, K.A. A digital twin architecture model applied with MLOps techniques to improve short-term energy consumption prediction. Machines 2021, 10, 23. [Google Scholar] [CrossRef]
- Zhou, Y.; Yu, Y.; Ding, B. Towards mlops: A case study of ml pipeline platform. In Proceedings of the 2020 International Conference on Artificial Intelligence and Computer Engineering (ICAICE), Beijing, China, 23–25 October 2020; pp. 494–500. [Google Scholar]
- Klerkx, L.; Jakku, E.; Labarthe, P. A review of social science on digital agriculture, smart farming and agriculture 4.0: New contributions and a future research agenda. NJAS-Wagening. J. Life Sci. 2019, 90, 100315. [Google Scholar] [CrossRef]
- Rose, D.C.; Chilvers, J. Agriculture 4.0: Broadening responsible innovation in an era of smart farming. Front. Sustain. Food Syst. 2018, 2, 87. [Google Scholar] [CrossRef]
- Placidi, P.; Gasperini, L.; Grassi, A.; Cecconi, M.; Scorzoni, A. Characterization of low-cost capacitive soil moisture sensors for IoT networks. Sensors 2020, 20, 3585. [Google Scholar] [CrossRef]
- Farooq, M.S.; Riaz, S.; Abid, A.; Abid, K.; Naeem, M.A. A Survey on the Role of IoT in Agriculture for the Implementation of Smart Farming. IEEE Access 2019, 7, 156237–156271. [Google Scholar] [CrossRef]
- Morar, C.; Doroftei, I.; Doroftei, I.; Hagan, M. Robotic applications on agricultural industry. A review. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2020; Volume 997, p. 012081. [Google Scholar]
- Kamilaris, A.; Kartakoullis, A.; Prenafeta-Boldú, F.X. A review on the practice of big data analysis in agriculture. Comput. Electron. Agric. 2017, 143, 23–37. [Google Scholar] [CrossRef]
- Akkem, Y.; Biswas, S.K.; Varanasi, A. Smart farming using Artificial Intelligence: A review. Eng. Appl. Artif. Intell. 2023, 120, 105899. [Google Scholar] [CrossRef]
- Siregar, R.R.A.; Seminar, K.B.; Wahjuni, S.; Santosa, E. Vertical farming perspectives in support of precision agriculture using Artificial Intelligence: A review. Computers 2022, 11, 135. [Google Scholar] [CrossRef]
- Araújo, S.O.; Peres, R.S.; Barata, J.; Lidon, F.; Ramalho, J.C. Characterising the agriculture 4.0 landscape—Emerging trends, challenges and opportunities. Agronomy 2021, 11, 667. [Google Scholar] [CrossRef]
- Rejeb, A.; Abdollahi, A.; Rejeb, K.; Treiblmaier, H. Drones in agriculture: A review and bibliometric analysis. Comput. Electron. Agric. 2022, 198, 107017. [Google Scholar] [CrossRef]
- Palei, H. Artificial Intelligence in precision agriculture: A review. Arch. Comput. Methods Eng. 2021, 28, 1627–1647. [Google Scholar]
- Samui, P. Machine Learning Applications in Agriculture: A Comprehensive Review. Agriculture 2022, 12, 56. [Google Scholar]
- Bargoti, S.; Underwood, J. Deep Fruit Detection in Orchards. arXiv 2017, arXiv:1703.08236. [Google Scholar]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep Learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Prema, P.; Veeramani, A.; Sivakumar, T. Machine Learning Applications in Agriculture. J. Agric. Res. Technol. 2022, 1, 126. [Google Scholar] [CrossRef]
- Sozzi, M.; Kayad, A.; Ferrari, G.; Zanchin, A.; Grigolato, S.; Marinello, F. Connectivity in rural areas: A case study on internet connection in the Italian agricultural areas. In Proceedings of the 2021 IEEE International Workshop on Metrology for Agriculture and Forestry (MetroAgriFor), Trento-Bolzano, Italy, 3–5 November 2021; pp. 466–470. [Google Scholar]
- Visconti, P.; de Fazio, R.; Velázquez, R.; Del-Valle-Soto, C.; Giannoccaro, N.I. Development of sensors-based agri-food traceability system remotely managed by a software platform for optimized farm management. Sensors 2020, 20, 3632. [Google Scholar] [CrossRef]
- Lee, M.; Wang, Y.R.; Huang, C.F. Design and development of a friendly user interface for building construction traceability system. Microsyst. Technol. 2021, 27, 1773–1785. [Google Scholar] [CrossRef]
- Dhehibi, B.; Rudiger, U.; Moyo, H.P.; Dhraief, M.Z. Agricultural technology transfer preferences of smallholder farmers in Tunisia’s arid regions. Sustainability 2020, 12, 421. [Google Scholar] [CrossRef]
- Desai, R.; Nisha, T. Best practices for ensuring security in devops: A case study approach. In Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2021; Volume 1964, p. 042045. [Google Scholar]
- Official Jupyter Web Site. Available online: https://jupyter.org/ (accessed on 19 June 2023).
- Official Great Expectations Tool Web Site. Available online: https://greatexpectations.io/ (accessed on 19 June 2023).
- Official DVC Web Site. Available online: https://discuss.dvc.org/ (accessed on 19 June 2023).
- Official MlFlow Web Site. Available online: https://mlflow.org/ (accessed on 19 June 2023).
- Smith, J.; Doe, J. Challenges and Opportunities in Internet of Things (IoT): A Comprehensive Survey. J. IOT Res. 2021, 4, 25–60. [Google Scholar]
- Official FlexiGroBot Repository. Available online: https://github.com/FlexiGroBots-H2020/AI-platform (accessed on 19 June 2023).
- FlexiGroBots Entrypoint to Test Kserve Inference Model. Available online: https://web.platform.flexigrobots-h2020.eu/apps (accessed on 19 June 2023).
- Official FlexiGroBot Kubeflow Access. Available online: https://kubeflow.flexigrobots-h2020.eu/ (accessed on 19 June 2023).
- Official Kubernetes Web Site. Available online: https://kubernetes.io/ (accessed on 19 June 2023).
- Official Kubeflow Web Site. Available online: https://www.kubeflow.org/ (accessed on 19 June 2023).
- Official Istio Web Site. Available online: https://istio.io/ (accessed on 19 June 2023).
- Ladisa, P.; Plate, H.; Martinez, M.; Barais, O. Sok: Taxonomy of attacks on open-source software supply chains. In Proceedings of the 2023 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 21–25 May 2023; pp. 1509–1526. [Google Scholar]
- Official Kubeflow Pipeline Web Site. Available online: https://www.kubeflow.org/docs/components/pipelines/v1/introduction/ (accessed on 19 June 2023).
- Official TensorFlow Web Site. Available online: https://www.tensorflow.org/ (accessed on 19 June 2023).
- Official Pytorch Web Site. Available online: https://pytorch.org/ (accessed on 19 June 2023).
- Official Sklearn Web Site. Available online: https://scikit-learn.org/stable/ (accessed on 19 June 2023).
- Official Docker Web Site. Available online: https://www.docker.com/ (accessed on 19 June 2023).
- Official Katib Web Site. Available online: https://www.kubeflow.org/docs/components/katib/overview/ (accessed on 19 June 2023).
- Official TFX Web Site. Available online: https://www.tensorflow.org/tfx/guide/serving (accessed on 19 June 2023).
- Official Seldon Web Site. Available online: https://www.seldon.io/ (accessed on 19 June 2023).
- Official Kserve Web Page. Available online: https://www.kubeflow.org/docs/external-add-ons/kserve/kserve/ (accessed on 17 August 2023).
- Choi, K.; Yi, J.; Park, C.; Yoon, S. Deep Learning for anomaly detection in time-series data: Review, analysis, and guidelines. IEEE Access 2021, 9, 120043–120065. [Google Scholar] [CrossRef]
- Official Camel Web Site. Available online: https://camel.apache.org/ (accessed on 19 June 2023).
- Jahanshahi, H.; Alijani, Z.; Mihalache, S.F. Towards Sustainable Transportation: A Review of Fuzzy Decision Systems and Supply Chain Serviceability. Mathematics 2023, 11, 1934. [Google Scholar] [CrossRef]
- Tomasiello, S.; Alijani, Z. Fuzzy-based approaches for agri-food supply chains: A mini-review. Soft Comput. 2021, 25, 7479–7492. [Google Scholar] [CrossRef]
- Official Grafana Web Site. Available online: https://grafana.com/ (accessed on 19 June 2023).
- Official Prometheus Web Site. Available online: https://prometheus.io (accessed on 19 June 2023).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Scientists | |||||
|---|---|---|---|---|---|
| Criterion | 1 | 2 | 3 | 4 | 5 |
| Learning Curve | 0 | 0 | 1 | 3 | 2 |
| Teamwork | 0 | 0 | 0 | 3 | 3 |
| Interaction with Other Profiles | 0 | 0 | 1 | 3 | 2 |
| Production | 0 | 0 | 1 | 2 | 3 |
| Data Management | 0 | 0 | 2 | 2 | 2 |
| Handover | 0 | 0 | 0 | 2 | 4 |
| Data Scientists | ||||
|---|---|---|---|---|
| Learning Curve | 4.16 | 0.68 | 3.47 | 4.85 |
| Teamwork | 4.5 | 0.50 | 4.00 | 5.00 |
| Interaction with Other Profiles | 4.16 | 0.68 | 3.47 | 4.85 |
| Production | 4.33 | 0.74 | 3.58 | 5.00 |
| Data Management | 4.0 | 0.81 | 3.18 | 4.81 |
| Handover | 4.66 | 0.47 | 4.19 | 5.12 |
| Machine Learning Engineers | |||||
|---|---|---|---|---|---|
| Criterion | 1 | 2 | 3 | 4 | 5 |
| Learning Curve | 0 | 0 | 0 | 1 | 4 |
| Teamwork | 0 | 0 | 0 | 3 | 2 |
| Interaction with Other Profiles | 0 | 0 | 1 | 4 | 0 |
| Production | 0 | 0 | 0 | 5 | 0 |
| Data Management | 0 | 0 | 2 | 1 | 2 |
| Handover | 0 | 0 | 1 | 2 | 2 |
| Machine Learning Engineers | ||||
|---|---|---|---|---|
| Learning Curve | 4.80 | 0.40 | 4.40 | 5.20 |
| Teamwork | 4.40 | 0.49 | 3.91 | 4.89 |
| Interaction with Other Profiles | 3.80 | 0.40 | 3.40 | 4.20 |
| Production | 4.37 | 0.48 | 3.89 | 4.85 |
| Data Management | 4.00 | 0.89 | 3.10 | 4.89 |
| Handover | 4.20 | 0.74 | 3.45 | 4.94 |
| Aspect | Data Scientists | Machine Learning Engineers |
|---|---|---|
| Learning Curve | Initial learning curve is steep, especially with Kubeflow. | Initial learning curve with Kubeflow, |
| Becomes intuitive after initial phase. | eased by prior knowledge in Kubernetes. | |
| Teamwork | Task division is challenging due to diverse technologies. | Facilitates collaboration but requires |
| Some level of simultaneous collaboration is possible. | well-organized team and clear methodologies. | |
| Interaction with Other Profiles | Facilitates interaction but requires initial organization. | Smooth interaction with Data Scientists, allows |
| for parallel work streams. | ||
| Production | Simplified by tools such as MLFlow and KServe. | Considered to streamline the process. |
| Data Management | Centralized data storage in MinIO is beneficial. | Centralized data storage in MinIO allows for easy |
| sharing and customization. | ||
| Handover and Data Sharing | Time-consuming if the other party is not familiar | Straightforward if both parties |
| with the technologies. Otherwise, straightforward. | are familiar with the platform. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cob-Parro, A.C.; Lalangui, Y.; Lazcano, R. Fostering Agricultural Transformation through AI: An Open-Source AI Architecture Exploiting the MLOps Paradigm. Agronomy 2024, 14, 259. https://doi.org/10.3390/agronomy14020259
Cob-Parro AC, Lalangui Y, Lazcano R. Fostering Agricultural Transformation through AI: An Open-Source AI Architecture Exploiting the MLOps Paradigm. Agronomy. 2024; 14(2):259. https://doi.org/10.3390/agronomy14020259
Chicago/Turabian StyleCob-Parro, Antonio Carlos, Yerhard Lalangui, and Raquel Lazcano. 2024. "Fostering Agricultural Transformation through AI: An Open-Source AI Architecture Exploiting the MLOps Paradigm" Agronomy 14, no. 2: 259. https://doi.org/10.3390/agronomy14020259
APA StyleCob-Parro, A. C., Lalangui, Y., & Lazcano, R. (2024). Fostering Agricultural Transformation through AI: An Open-Source AI Architecture Exploiting the MLOps Paradigm. Agronomy, 14(2), 259. https://doi.org/10.3390/agronomy14020259