1. Introduction
In 2019, UNESCO assessed AI’s impact on education and introduced the Beijing Consensus on AI and Education, which provided guidelines for leveraging AI technologies to achieve the Education 2030 Goals [
1]. The European Framework for Digital Competence of Educators (DigCompEdu) defines digital competence as the skills, knowledge, and attitudes educators need to integrate technology into teaching and enhance student learning [
2]. The framework outlines four progressive levels of digital competence: awareness, which involves understanding digital technology and its impact on education; use, which focuses on effectively employing digital tools to support instruction; adaptation, which requires educators to keep pace with technological advancements to enhance teaching; and sustainability, which emphasizes continuous development to adapt to future innovations [
3,
4]. Digital learning relies on educator–learner interaction in a technology-driven environment, necessitating specific digital competencies. DigCompEdu enhances educators’ abilities by equipping them with the knowledge to integrate digital tools effectively [
5]. It also improves communication by facilitating educator–student–parent interactions through tools such as email, discussion forums, and learning management systems. Moreover, DigCompEdu supports students in developing 21st-century skills, including research, problem-solving, and innovation, preparing them for the demands of a digital society [
6]. By implementing DigCompEdu, educational institutions can create enriched learning environments that drive digital transformation, foster collaboration, and ensure that learning remains relevant in an ever-evolving technological landscape [
2].
Despite the growing body of literature on AI competency and readiness in medical education, there remains a notable research gap, both in Arabic and English, on AI competency and readiness for sustainable integration in medical education in developing nations, particularly in Saudi Arabia (KSA). This gap includes aspects such as (A) AI Awareness, (D) Development of AI skills, (E) AI Efficacy, (L) Leanings Towards AI, and (E) AI Enforcement within higher education, especially in medical education. Additionally, there is limited exploration of data-driven frameworks as models for monitoring and improving educators’ AI competency and readiness.
Thus, the article addresses this gap by pursuing two fundamental research objectives (ROs):
RO1: To conduct statistical analysis examining gender- and region-based differences, both across and within the Middle East and South Asia, and to evaluate their predictive impact on educators’ AI competency and readiness across the five key dimensions: Awareness, Development, Efficacy, Leanings, and Enforcement (A, D, E, L, E).
RO2: To propose the ADELE data-driven technique as a model to systematically measure, monitor, and enhance AI competency and readiness in the context of medical education in the Kingdom of Saudi Arabia (KSA).
Furthermore, these objectives align with two key research questions (RQs):
RQ1: How do gender and regional differences predict variations in educators’ AI competency and readiness (Awareness, Development, Efficacy, Leanings, and Enforcement) within medical education?
RQ2: What is the proposed vision of a data-driven technique to continuously assess and improve AI competency and readiness in medical education?
Moreover, the study is guided by seven research hypotheses (RHs):
RH1: There is a significant relationship between the five AI competencies (A, D, E, L, E) and AI readiness among medical educators.
RH2: There is a significant difference in AI competency and readiness between medical educators in the Middle East and those in South Asia.
RH3: There is a significant difference in AI competency and readiness between male and female medical educators across both regions.
RH4: There is a significant difference in AI competency and readiness between male medical educators in the Middle East and male medical educators in South Asia.
RH5: There is a significant difference in AI competency and readiness between female medical educators in the Middle East and female medical educators in South Asia.
RH6: There is a significant difference in AI competency and readiness between male and female medical educators within the Middle East.
RH7: There is a significant difference in AI competency and readiness between male and female medical educators within South Asia.
2. Literature Review
2.1. AI Competency: Frameworks and Readiness
The evolution of educational paradigms has progressed through four distinct generations. The first generation (1 GL) emphasized traditional, teacher-centered instruction. The second generation (2 GL) introduced multimedia and computer-assisted learning environments, while the third generation (3 GL) marked the emergence of online and e-learning platforms, enabling flexible and asynchronous learning [
7,
8]. Additionally, the current fourth generation (4 GL) is characterized by the integration of artificial intelligence (AI) into education, fostering personalized, adaptive, and data-driven learning experiences [
9]. In addition, this shift builds upon earlier methods through innovations such as intelligent automation, learner profiling, and real-time feedback systems [
10].
Recent studies by Cabero-Almenara et al. (2020) [
11], Mattar and Santos (2022) [
12], and Emre (2024) [
5] highlight the growing importance of AI-related competencies to support human–machine collaboration in education. These studies advocate for institutional strategies to foster digital proficiency among educators. Additionally, although AI is not a substitute for human educators, it is fundamentally reshaping their roles, responsibilities, and required skill sets. Also, research by Chen (2020) [
13], Ng et al. (2023) [
14], and Dhananjaya et al. (2024) [
15] emphasizes the need to redefine educator roles in AI-enhanced environments, calling for robust capacity-building initiatives and targeted reforms in teacher education. Likewise, a key aspect of educators’ digital competence in AI is their ability to understand its applications in education, such as analyzing educational data, providing personalized guidance, and delivering tailored learning content [
16].
One prominent initiative in this area is UNESCO’s AI Competency Framework for Educators (AI CFT), which adopts a human-centered approach to AI integration [
17]. Also, the framework is grounded in ethical principles—fairness, transparency, and accountability—and is structured around three progressive levels: acquisition (basic AI knowledge), deepening (application and data analysis), and creation (innovation in AI-enhanced pedagogy) [
18,
19]. While AI CFT and the DigCompEdu framework provide foundational guidance, they are largely conceptual and offer limited operational tools or validated metrics to measure educator progression. Moreover, they do not sufficiently address discipline-specific requirements, especially in medical education, where the intersection of AI, clinical judgement, and ethical practice presents unique challenges [
20,
21,
22]. In addition, the literature also points to critical barriers in adopting AI within higher education, particularly in developing countries such as Saudi Arabia. Consequently, these challenges include the lack of AI-trained faculty, insufficient infrastructure, and the need for ethical and privacy-conscious implementation [
23]. AI literacy, while frequently cited, is often narrowly defined in terms of technical proficiency, with minimal integration of ethical reasoning, institutional readiness, or attitudinal receptiveness into existing frameworks [
17].
To the best of our knowledge, the current literature exhibits several persistent limitations. Also, most AI competency frameworks, including AI CFT and DigCompEdu, are not empirically tailored to the complex ethical, pedagogical, and operational needs of medical education. Furthermore, there is a notable underrepresentation of developing nations in empirical AI research, resulting in limited insight into infrastructure constraints, cultural dynamics, and policy challenges specific to regions such as the Middle East and South Asia.
2.2. AI in Medical Education
Beyond general education, AI is revolutionizing medical education by transforming training methodologies, refining diagnostics, and optimizing patient care. AI-powered learning algorithms provide students with hands-on experience and real-time feedback, bridging the gap between theoretical knowledge and practical application [
24]. By leveraging AI-driven tools, medical education can become more personalized, efficient, and globally inclusive, equipping future healthcare professionals to meet the challenges of modern medicine [
25]. AI readiness and competency are crucial for successfully adopting AI in medical education. However, in developing nations, barriers such as limited digital infrastructure, a shortage of AI-trained faculty, and resistance to technological change impede AI implementation [
26]. Many educators and students require specialized training to develop AI literacy and effectively integrate it into their curricula. Building AI competency involves targeted professional development, institutional support, and strategic investments in technology to foster an AI-literate medical workforce [
27]. The sustainable integration of AI in medical education requires a strategic approach that prioritizes accessibility, adaptability, and ethical considerations [
28]. While AI offers immense benefits in training healthcare professionals, its implementation must align with local needs and infrastructure constraints [
29]. Cross-sectional studies are pivotal in assessing educators’ attitudes toward AI, providing valuable insights that inform policy decisions. By fostering a culture of AI-driven innovation, medical education can evolve to meet the demands of modern healthcare while ensuring equitable access to technological advancements [
27].
To the best of our knowledge, while the integration of AI in medical education holds transformative potential, the literature reveals a disparity between the technological promise and the reality of implementation, particularly in emerging settings. Moreover, bridging this gap requires more context-sensitive, empirically validated techniques that align AI integration with local needs, capabilities, and ethical imperatives.
2.3. Bridging the AI Divide in Global Medical Education
The integration of AI in medical education varies significantly between developed and developing nations. In high-income countries, AI-powered tools are widely employed for diagnostics, virtual training, and personalized learning [
30]. In contrast, resource-limited settings struggle with inadequate infrastructure, a lack of AI literacy, and limited access to cutting-edge technology. This disparity highlights the necessity of equitable AI adoption, ensuring that advancements in medical education are globally inclusive and do not widen existing educational and healthcare gaps [
20,
31]. Looking ahead, the future of medical education is poised for a transformative shift, driven by AI-powered innovations that enhance learning, diagnostics, and patient care [
32]. AI will enable adaptive learning environments, real-time clinical simulations, and data-driven decision making. By cultivating AI literacy, readiness, and competency among educators and students, institutions can prepare the next generation of healthcare professionals to navigate an AI-driven medical landscape [
33]. Integrating AI into medical education will lead to more efficient training, improved healthcare outcomes, and a more globally connected medical community [
34].
To the best of our knowledge, the current literature exhibits two significant geographical and linguistic gaps in AI competency research. Moreover, there is a paucity of robust empirical studies originating from the Middle East and South Asia. Additionally, existing frameworks predominantly originate from English-language academic contexts, which may limit their relevance to regional medical education systems with distinct linguistic and cultural contexts.
2.4. Empirical Foundation and Conceptual Basis of the ADELE Technique
Recent literature emphasizes the influence of structured, data-driven frameworks to address the widening gap in AI competency among educators in medical education, particularly in developing nations [
35,
36,
37]. Moreover, research has highlighted that successfully utilizing AI requires more than just having the technology; it also requires educators to be prepared, confident, and aware of the ethical issues [
38,
39,
40]. Additionally, frameworks such as UNESCO’s AI Competency Framework for Educators provide foundational guidance but often lack sufficient empirical validation in resource-constrained medical education contexts [
1,
17]. Likewise, Cabero-Almenara et al. (2020) [
11], Ng et al. (2023) [
14], and Emre (2024) [
5] contributed theoretical insights that highlight the importance of hands-on training, attitudinal engagement, and institutional support in cultivating AI competency. However, the existing models inadequately address localized challenges such as infrastructure disparities and cultural attitudes towards automation, particularly in the Middle East and South Asia.
Therefore, to help address this issue, this study presents the ADELE technique, a model based on real data that identifies five key areas essential for developing AI skills in medical education: Awareness (A), Development (D), Efficacy (E), Learning (L), and Enforcement (E)Rooted in data collected from educators across the Middle East and South Asia, ADELE offers a context-sensitive, scalable technique for assessing and developing AI readiness in medical education systems.
3. Research Methodology
3.1. Research Mapping
Table 1 systematically aligns each research objective (RO) with its corresponding research question (RQ), associated hypotheses (RHs), null hypotheses (RH
0s), operationalized independent and dependent variables (IVs/DVs), and implemented Statistical Analysis Techniques (SATs).
3.2. Research Population and Sample
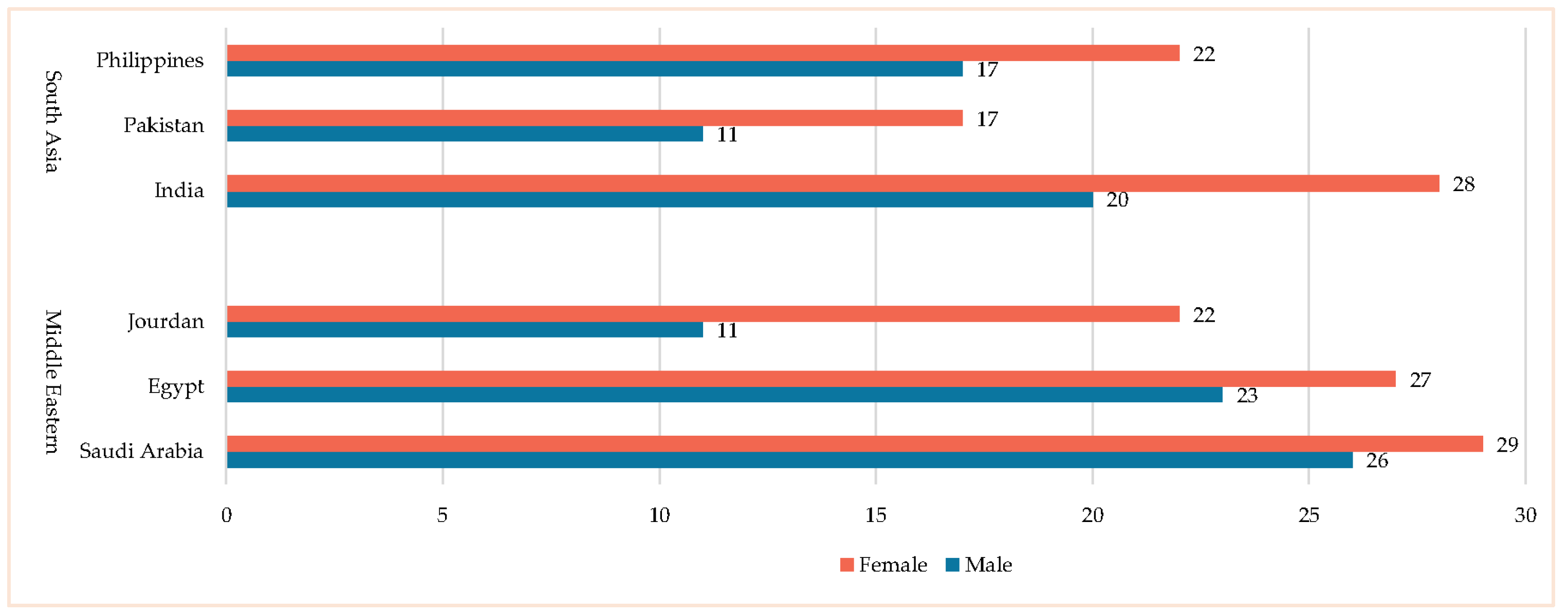
The research population for this study consisted of educators in medical schools across the Kingdom of Saudi Arabia. A total of 253 educators were selected, representing diverse nationalities from two regions: the Middle East (Saudi Arabia, Egypt, Jordan) and South Asia (India, Pakistan, Philippines) (see
Figure 1). To ensure a comprehensive understanding of AI competency and readiness, the sample was explicitly drawn from medical schools in three major regions of Saudi Arabia: Central, Western, and East. These regions were strategically chosen to provide a diverse representation of educators from various educational contexts and institutional types, including both public and private medical schools. This approach enhances the generalizability and validity of the findings, making them more applicable to the broader population of medical educators in Saudi Arabia.
Furthermore, this strategic sampling method enables the exploration of potential regional or institutional differences in AI competency and readiness. The insights gained from this study can inform targeted professional development initiatives, ensuring that training programs are tailored to the specific needs of educators in different regions and institutional settings. The minimum sample size required for this study was determined based on three factors: (1) the total student population, (2) a margin of error of ±5%, and (3) a confidence level of 95%. According to Hill [
41], sample size calculations should be based on the total number of measured variables, ensuring at least five responses per variable; in this study, 28 variables were considered. Furthermore, Muthen [
42] suggests that a sample size of at least 150 is adequate for robust statistical analysis. Given that 253 valid responses were collected, the sample size was deemed sufficient and statistically reliable.
Participant selection was based on voluntary participation, ensuring that there was no coercion or external influence. Surveys were distributed through personal social networks, including email, WhatsApp, and other digital platforms. Participants were clearly informed that the survey was intended exclusively for academic research purposes and that their responses would remain anonymous. Participation was entirely optional, and all necessary precautions were taken to ensure data confidentiality. To maintain privacy, personally identifiable information was removed from the publicly available analysis, ensuring that individual responses could not be traced back to specific participants. Additionally, optional demographic questions—such as name, gender, and age—were included but were not mandatory, allowing participants to provide only the information they were comfortable sharing.
3.3. Instrument Development
The next stage of the research methodology involved developing a research instrument to address RQ1. This instrument was specifically designed to measure AI competency and readiness among educators using AI tools in medical schools. It focused on five key components: (A) AI Awareness, (D) Development of AI Skills, (E) AI Efficacy, (L) Leanings Towards AI, and (E) AI Enforcement. These factors were selected to capture the essential competencies required for the effective integration of AI in medical education, ensuring that educators are adequately prepared to leverage AI technologies in teaching, learning, and clinical decision making. To develop the instrument, a comprehensive review of the recent literature was conducted, emphasizing the adoption and integration of AI technologies in medical education, such as in [
6,
20,
31,
32,
34,
43,
44]. This review focused on AI’s role in enhancing clinical training, decision support systems, medical diagnostics, personalized learning, and administrative efficiency in educational settings. Additionally, relevant theoretical frameworks were considered to provide a robust conceptual foundation for the study, including Piaget’s Cognitive Constructivism [
45], Skinner’s Behaviorism Learning [
46], and Self-regulated Learning (SRL) [
47]. These frameworks were selected due to their relevance to understanding how educators construct knowledge, perceive their competencies, and adopt innovative technologies such as AI.
Based on insights from the literature review and an analysis of interview responses gathered from medical educators and AI experts, an initial draft of the research survey was developed. The survey utilized a 5-point Likert scale (Strongly Agree (SA) = 5), (Agree (A) = 4), (Neutral (N) = 3), (Disagree (D) = 2), and (Strongly Disagree (SD) = 1) to measure educators’ perceptions of their AI competency and readiness. The scale was designed to evaluate the extent to which educators are aware of AI technologies in medical education, understand AI concepts, feel confident utilizing AI tools, perceive ethical implications, and actively apply AI competency in their teaching and research practices. To ensure the validity and relevance of the research instrument, the survey was distributed to 20 experts specializing in medical education, instructional technology, AI in healthcare, and digital pedagogy across Middle Eastern countries. Of these, 16 experts provided comprehensive feedback, while four did not respond. The feedback focused on clarity, relevance, and applicability within the medical education context. The initial version of the scale consisted of 48 items distributed across the five key factors. After reviewing the expert feedback, several modifications were made to improve the instrument’s clarity and content validity. This included refining item wording to better align with medical education terminology and removing redundant items.
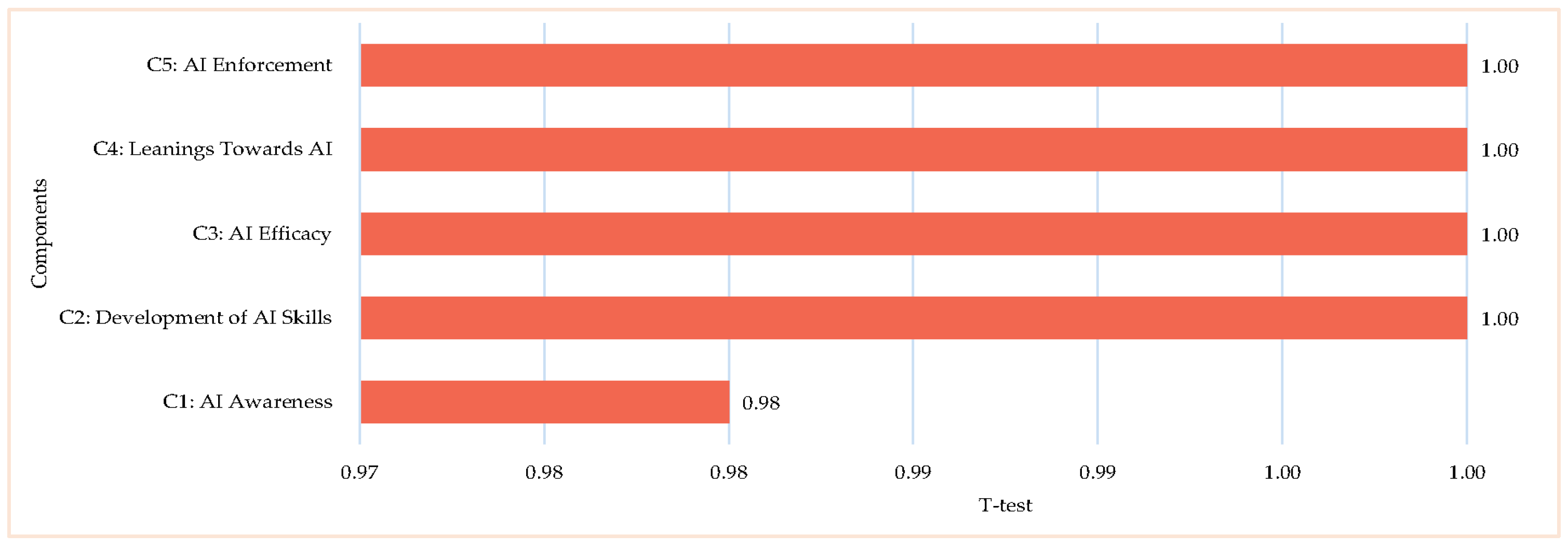
Consequently, the final version of the scale consisted of 40 items, distributed as follows: AI Awareness—8 items, Development of AI Skills—8 items, AI Efficacy—8 items, Leanings Towards AI—8 items, and AI Enforcement—8 items. Each item was carefully designed to assess educators’ preparedness to integrate AI into medical curricula, their ethical considerations, and their practical experiences with AI tools and methodologies relevant to medical teaching and research. To assess the reliability of the instrument, Cronbach’s Alpha (α) and McDonald’s Omega (Ω) coefficients were calculated, confirming high internal consistency across all five factors (See
Figure 2). This rigorous validation ensured that the research instrument effectively captured AI competency and readiness among medical educators, contributing valuable insights into the evolving landscape of AI integration in medical education.
The Cronbach’s Alpha values were 0.967, 0.921, 0.922, 0.951, and 0.901, while the McDonald’s Omega values were 0.981, 0.934, 0.944, 0.976, and 0.913. These values indicate high internal consistency, validating the study’s instrument for examining the impact of variations in Arabic–English AI competency and readiness. The survey, available in both Arabic and English, was launched in November 2024 and distributed over four weeks through participants’ private social networks, including email, WhatsApp, and other digital channels. The researchers monitored responses daily to ensure data integrity and completeness.
4. Results
This study investigated relationships and differences in AI competency and readiness to address RO1, answer RQ1, and to test seven research hypotheses (RH1 to RH7 and RH01 to RH07). The analytical approach followed established quantitative procedures [
48,
49,
50,
51], as below:
Independent-samples t-tests (ISTTs) were used to compare mean scores between unrelated groups (gender, region), verified through normality and homogeneity of variance tests (this test was selected because it is suitable for comparing the means of two independent groups, unlike single-sample or paired-samples t-tests, which were not applicable to our cross-sectional data);
Mann–Whitney U tests were employed when parametric assumptions were violated;
Spearman’s rho correlations to examine ordinal relationships between competency components and readiness scores, appropriate for Likert-scale data;
For each AI competency component (C1 to C5), a composite mean score was calculated by averaging participants’ responses across all items within the corresponding component;
These composite scores were used for all inferential analyses, including independent-samples t-tests, Mann–Whitney U tests, and correlation analyses.
4.1. The Statistics of AI Competency and Readiness Among Educators in Medical Schools
Figure 3 presents the statistical analysis of AI competency and readiness among medical school educators, providing empirical support for RH1.
Although skewness and kurtosis are traditionally applied to continuous variables, they are reported here to provide insight into the distributional characteristics of the Likert-scale items, which are often treated as approximately interval-level data for descriptive purposes in social and educational research [
52,
53]. Additionally, these statistics were interpreted with caution, acknowledging the ordinal nature of the original data.
4.1.1. AI Awareness
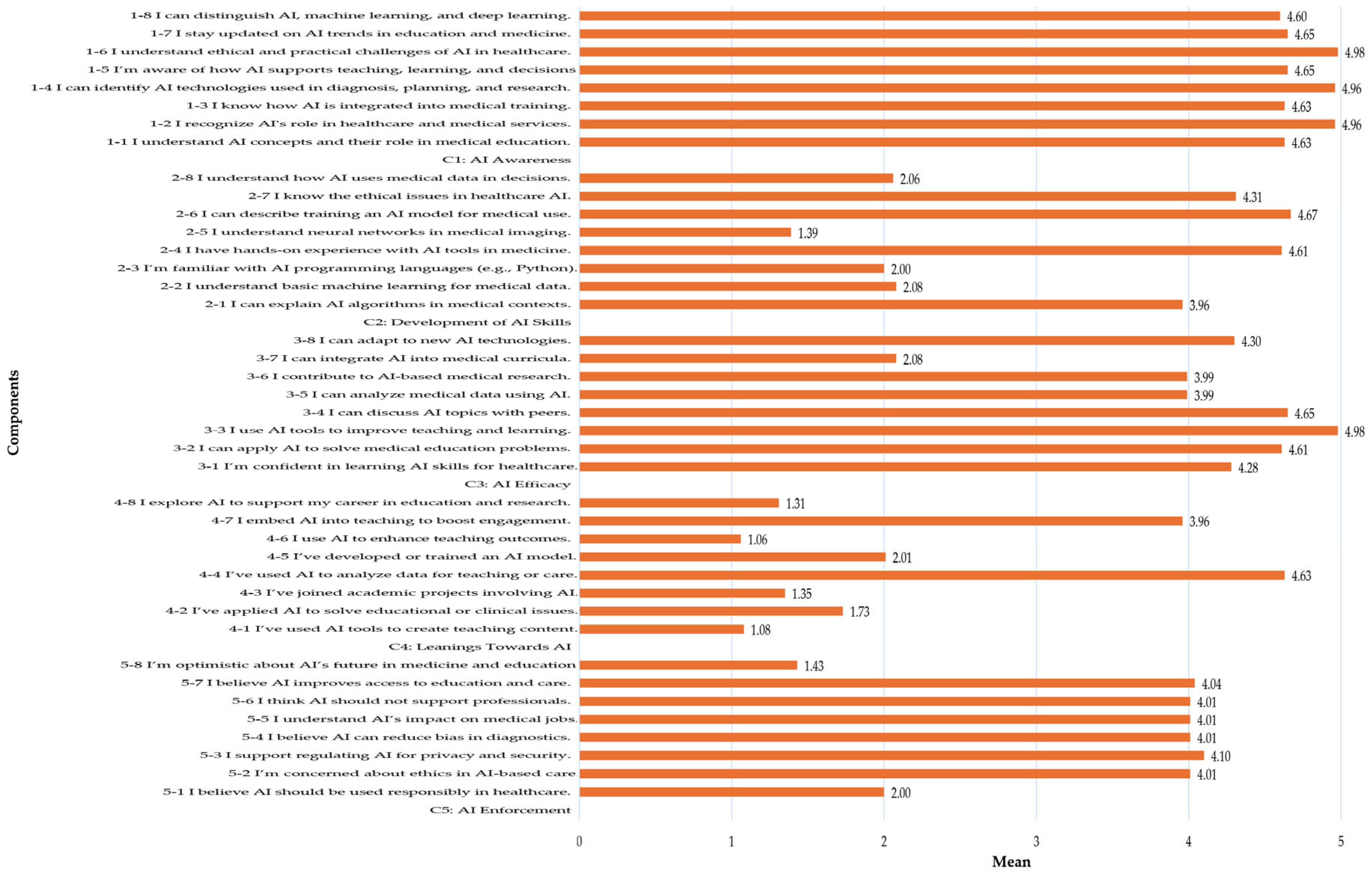
The mean scores ranged from 2.00 to 4.10, indicating moderate to high awareness among medical educators. The highest mean score (4.10) was observed in recognizing the role of AI in healthcare applications, while the lowest (2.00) was in fully understanding AI concepts. The slightly negative skewness (−0.18 to 0.13) and negative kurtosis (−1.13 to −1.52) suggest a relatively normal distribution with a flatter peak, indicating diverse awareness levels. These findings imply that while educators acknowledge AI’s significance in medical education, their conceptual understanding remains inconsistent. The broad distribution (negative kurtosis) suggests variability in how educators perceive and engage with AI-related information. For sustainable AI integration, the high awareness of AI applications reflects a positive initial acceptance. However, the inconsistency in conceptual understanding underscores the need for structured foundational AI education to standardize awareness levels.
4.1.2. Development of AI Skills
The mean scores ranged from 1.06 to 4.63, with higher scores in awareness of ethical issues (3.96) and practical exposure to AI tools (4.63). However, significantly lower scores were observed in technical competencies such as programming (1.35) and training AI models (1.06). The narrow interquartile range (IQR 2–3, 2.0) suggests consistency in theoretical knowledge but a lack of practical AI experience. The slightly negative skewness indicates a concentration of higher scores, yet deep technical knowledge remains limited. These findings suggest that while educators understand AI concepts, they struggle with hands-on applications, particularly in programming and AI model development. The gap between theoretical knowledge and practical experience highlights the need for experiential development opportunities. To enhance AI skill development, institutions should focus on curricula that incorporate hands-on AI applications tailored to medical education.
4.1.3. AI Efficacy
The mean scores were moderate (3.0 to 4.0), with educators expressing higher confidence in acquiring AI skills but lower confidence in applying them to real-world medical challenges and research. The standard deviation (0.8) indicates variability in confidence levels. Skewness and kurtosis values were close to a normal distribution, but a slight skew towards lower confidence was observed, especially in advanced AI applications. These results suggest that while educators are motivated to learn AI, they lack confidence in its practical application and problem-solving ability. The findings indicate that educators are in a knowledge-rich but application-deficient environment, potentially due to a lack of hands-on AI training tailored to medical scenarios. To build AI efficacy, medical education programs should incorporate real-world AI applications, hands-on projects, and experiential development opportunities.
4.1.4. Leanings Towards AI
The lowest mean scores across all components were observed in Leanings Towards AI (2.5 to 3.5), indicating limited application of AI in medical teaching, research, and real-world healthcare scenarios. The narrow range and IQR suggest consistency in responses but at a low level of AI application. A positive skewness indicates that most educators rarely apply AI skills despite having awareness and theoretical knowledge. These findings highlight a significant gap between AI knowledge and real-world application, emphasizing a lack of exposure to AI-based teaching tools and research methodologies. To bridge this gap, institutions should integrate AI-driven simulations, case studies, and project-based learning into medical education curricula, fostering practical engagement with AI technologies.
4.1.5. AI Enforcement
For AI Enforcement (Ethical Perspectives and Attitudes), the mean scores were relatively high (4.0 to 4.5), reflecting strong ethical awareness and positive attitudes toward responsible AI implementation. The slightly negative skewness suggests a general consensus on ethical concerns, including privacy, bias, and AI’s societal impact. The low range and IQR indicate consistent ethical perspectives across educators. These findings suggest that medical educators recognize the importance of AI ethics and responsible AI integration. The high level of ethical concern and optimism towards AI’s potential highlights a well-balanced perspective that is essential for sustainable AI adoption in medical education.
Overall, the analysis revealed a statistically significant positive correlation between AI competency (A, D, E, L, E) and AI readiness, as indicated by consistent Spearman’s rho values (p < 0.01). Hence, these results strongly support RH1 and lead to the rejection of H01, confirming a meaningful association between AI competencies and readiness among medical educators.
4.2. Comparative Analysis of Middle East and South Asia
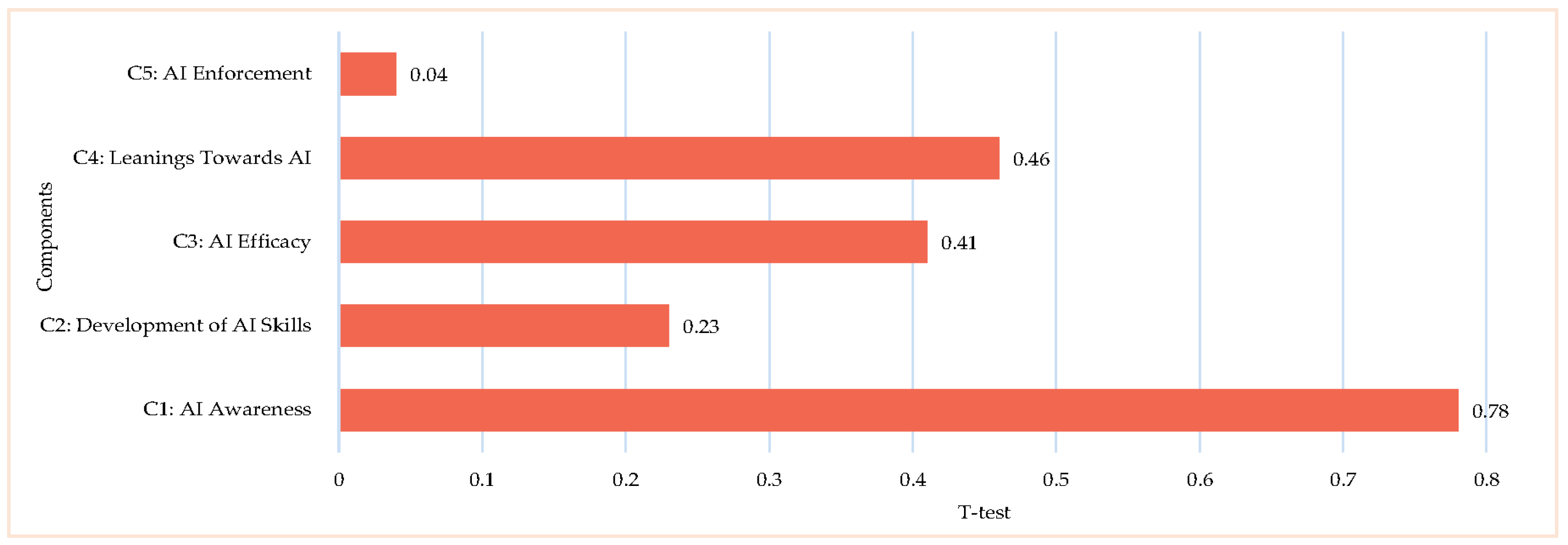
Figure 4 presents a comparative analysis of AI competency and readiness between Middle Eastern and South Asian medical educators across five components: AI Awareness, AI Skills Development, AI Efficacy, AI Leanings, and AI Enforcement, providing an empirical verification of RH2.
4.2.1. AI Awareness
The independent-samples t-test (p = 0.78) and Mann–Whitney U test (p = 0.76) showed no statistically significant differences between Middle Eastern and South Asian educators. The close average ranks (Middle East = 143.92, South Asia = 141.08) suggest a comparable level of awareness in both regions. However, a Spearman’s rho value of −0.34 (p = 0.001) indicates a significant negative correlation, suggesting that while overall awareness levels are similar, perceptions and emphasis on AI awareness may differ due to cultural or institutional influences.
4.2.2. Development of AI Skills
Regarding the development of AI skills, no significant differences were observed, as indicated by the t-test (p = 0.23) and Mann–Whitney U test (p = 0.72). The average ranks (Middle East = 140.87, South Asia = 144.13) were nearly identical, implying similar exposure to AI knowledge and skills training in both regions. However, the negative correlation (Spearman’s rho = −0.36, p = 0.001) suggests potential disparities in how AI knowledge is acquired and applied, possibly reflecting differences in educational curricula, training opportunities, or institutional support structures for AI education in medical fields.
4.2.3. AI Efficacy
For AI efficacy, which reflects confidence in AI-related skills, no significant differences emerged (t-test: p = 0.41, Mann–Whitney U: p = 0.72), with the average ranks of Middle East = 144.13 and South Asia = 140.87. Despite this, a significant negative correlation (Spearman’s rho = −0.36, p = 0.001) was observed, suggesting that AI Efficacy in AI competency inversely varies between the groups. This discrepancy may stem from differences in hands-on AI training, institutional AI integration, or the availability of AI-related professional development programs in each region.
4.2.4. Leanings Towards AI
The results remained consistent across both groups, with the t-test (p = 0.46) and Mann–Whitney U test (p = 0.73) confirming no significant differences. The average ranks (Middle East = 144.07, South Asia = 140.93) indicate that educators from both regions apply AI skills at similar levels. However, the negative correlation (Spearman’s rho = −0.28, p = 0.001) implies differences in the manner or frequency of AI application in educational and clinical settings. These variations could be influenced by components such as resource availability, technological infrastructure, or differences in AI curriculum integration across medical institutions.
4.2.5. AI Enforcement
In contrast to the other components, ethical perspectives and attitudes toward AI in healthcare revealed a significant difference between the two groups (t-test: p = 0.04). While the Mann–Whitney U test (p = 0.11) did not reach statistical significance, the notable gap in average ranks (Middle East = 148.98, South Asia = 136.02) suggests that Middle Eastern educators may have more conservative or cautious ethical views regarding AI compared to their South Asian counterparts. The Spearman’s rho value of −0.23 (p = 0.01) further supports this, indicating that ethical considerations surrounding AI adoption differ between the two regions. These differences could be influenced by cultural, societal, or religious components that shape attitudes toward AI’s role in healthcare, patient privacy, and decision-making processes.
Overall, a statistically significant difference was observed in Component C5: AI Enforcement (p = 0.04), reflecting distinct regional perspectives on the ethical implementation of AI. Thus, while Components C1–C4 did not show significant differences (p > 0.05), the notable divergence in ethical orientation supports RH2 and leads to the rejection of H02, indicating that the regional context influences how AI is perceived and adopted.
4.3. Gender-Based Comparison: Female vs. Male
The results in
Figure 5 provide a comparative analysis of the differences and correlations between female and male medical educators regarding AI competency and readiness, offering empirical verification of RH3.
4.3.1. AI Awareness
The results show no significant gender-based differences. Both the t-test (p = 0.98) and Mann–Whitney U test (p = 0.97) confirmed that female and male educators exhibited nearly identical levels of awareness (Females = 133.31, Males = 133.69). However, Spearman’s rho (−0.19, p = 0.03) revealed a weak but statistically significant negative correlation, suggesting a slight inverse relationship in awareness levels between genders. While this correlation is minor, it may reflect differences in exposure or emphasis on AI applications in medical education. Despite this, the overall similarity in scores indicates that both genders possess a comparable level of AI awareness.
4.3.2. Development of AI Skills
The findings demonstrated no significant gender differences, as indicated by the t-test (p = 0.81) and Mann–Whitney U test (p = 0.94). The nearly identical average ranks (Females = 133.16, Males = 133.84) suggest that both female and male educators have a consistent theoretical understanding of AI concepts. Additionally, the Spearman’s rho value (−0.13, p = 0.14) showed no meaningful correlation between genders, further confirming this balance. These results imply that educational resources and learning opportunities related to AI are equally accessible and effective for both groups, ensuring a level playing field in AI knowledge acquisition.
4.3.3. AI Efficacy
In terms of confidence in AI skills, no significant differences were found between genders, as evidenced by the t-test (p = 0.91) and Mann–Whitney U test (p = 0.94). The average ranks (Females = 133.84, Males = 133.16) were nearly identical, indicating similar AI Efficacy levels in acquiring and applying AI skills. Furthermore, the Spearman’s rho value (−0.13, p = 0.14) was not statistically significant, suggesting no strong relationship between gender and AI Efficacy in AI competency. These findings indicate that both female and male educators feel equally capable of engaging with AI technologies in medical education, reflecting an equitable learning environment where gender does not influence AI Efficacy in AI skill development.
4.3.4. Leanings Towards AI
For AI application in medical education, both the t-test (p = 0.76) and Mann–Whitney U test (p = 0.83) revealed no significant gender-based differences. The average ranks (Females = 132.52, Males = 134.48) were very close, suggesting that both genders apply AI skills at comparable levels in teaching and research. The Spearman’s rho value (−0.10, p = 0.26) was also not statistically significant, reinforcing the absence of a meaningful gender-based correlation. This suggests that both female and male educators equally integrate AI tools and methodologies into their educational practices. The results indicate that access to AI technologies and resources is not influenced by gender, ensuring a balanced application of AI in medical education.
4.3.5. AI Enforcement
In healthcare, no significant gender differences were observed, as shown by the t-test (p = 0.28) and Mann–Whitney U test (p = 0.34). While the average ranks showed slight variation (Females = 129.70, Males = 137.30), the difference was minimal. Additionally, Spearman’s rho (−0.07, p = 0.42) indicated a weak negative correlation that was not statistically significant. These findings suggest that both genders share similar ethical perspectives on AI in healthcare, including considerations related to privacy, bias, and societal impact. The consistency in ethical views highlights a common understanding of AI’s implications, regardless of gender.
Overall, no statistically significant gender-based differences were found across all components (p > 0.05), with nearly identical average ranks between male and female educators. Therefore, RH3 is rejected and H03 is supported, suggesting that gender does not significantly influence AI competency or readiness.
4.4. Comparing Female Educators in Middle East and South Asia
The results in
Figure 6 present a comparative analysis of the differences and correlations between female educators in the Middle East and South Asia, offering empirical verification of RH4.
The t-test results indicate a statistically significant difference in C5: AI Enforcement (ethical perspectives and attitudes toward AI) (p = 0.037), suggesting that female educators from these two regions hold distinct ethical viewpoints regarding AI integration. In contrast, no significant differences were observed in C1 to 4, including AI Awareness, Development of AI Skills, AI Efficacy, and Leanings Towards AI, implying a relative consistency in AI competency and AI Efficacy among female educators in both regions. The Mann–Whitney U test corroborates these findings, as the p-values for Components 1 to 4 exceeded 0.05, reinforcing the absence of significant differences. However, for Component 5, the Mann–Whitney U test yielded a p-value of 0.114, which, while not reaching statistical significance, suggests a trend warranting further investigation to confirm the observed variations in ethical perspectives.
The average rank scores reveal nuanced differences between the two groups, with female educators in the Middle East generally scoring slightly higher across most components compared to their South Asian counterparts. This trend is particularly evident in C5, aligning with the significant t-test result, suggesting that Middle Eastern educators may exhibit stronger ethical considerations regarding AI implementation. These variations in ethical perspectives could stem from cultural or contextual differences influencing how AI is perceived in medical education across the two regions. Furthermore, Spearman’s rho analysis indicates negative correlations across all components between the two groups, suggesting an inverse relationship—higher scores in one region tend to correspond with lower scores in the other. This pattern may reflect differences in AI competency emphasis or how AI is integrated within medical education curricula in Middle Eastern and South Asian institutions.
Overall, the analysis showed no statistically significant regional differences among male educators across all five components (C1–C5; p > 0.05). Accordingly, RH4 is rejected and H04 is supported, indicating that geographic region does not significantly impact male educators’ AI competency or readiness.
4.5. Comparing Male Educators in Middle East and South Asia
The results in
Figure 7 present a comparative analysis of the differences and correlations between male educators in the Middle East and those in South Asia, offering empirical verification of RH5.
The t-test results indicate no statistically significant differences between the two groups across all five components—AI Awareness, Development of AI Skills, AI Efficacy, Leanings Towards AI, and AI Enforcement—as all p-values exceeded 0.05. This suggests that male educators in both regions exhibit comparable levels of AI-related knowledge, AI Efficacy, application, and ethical perspectives, regardless of their academic backgrounds. The Mann–Whitney U test further supports these findings, confirming the absence of significant variations between the two groups. This consistency implies that male educators in both scientific and humanities disciplines share similar understandings and approaches to AI integration in medical education.
Although the average rank scores indicate slight variations, with male educators in the Middle East generally scoring marginally higher across most components, these differences remain minimal. This suggests that while regional or institutional factors may contribute to subtle distinctions in AI perception and application, the overall AI-related competencies among educators remain largely comparable. Additionally, the Spearman’s rho results show weak negative correlations across all components, indicating an inverse relationship between the two groups. However, these correlations lack statistical significance, suggesting that differences in AI perceptions are minor and unlikely to impact overall AI readiness or adoption. The weak inverse relationship could be influenced by variations in teaching methodologies, institutional AI exposure, or curriculum structures between scientific and humanities disciplines. Despite these slight differences, the overall findings emphasize that academic discipline does not play a significant role in shaping male educators’ AI awareness, skills, efficacy, or ethical perspectives in medical education.
Overall, a statistically significant difference was found in Component C5: AI Enforcement (p = 0.037) among female educators, confirming regional variation in ethical perspectives. Thus, although Components C1–C4 showed no significant differences, the observed divergence in C5 supports RH5 and leads to the rejection of H05, suggesting that the regional context shapes female educators’ ethical views toward AI implementation in medical education.
4.6. Gender Comparison Within the Middle East: Female vs. Male
Figure 8 presents a comparative gender analysis (female vs. male) of AI competency and readiness among Middle Eastern medical educators, providing empirical evidence to evaluate RH56.
The t-test results show that there were no significant differences between female and male educators across all five components: AI Awareness, Development of AI Skills, AI Efficacy, Leanings Towards AI, and AI Enforcement. The p-values for all components exceeded 0.05, indicating that AI-related competencies and perceptions remain relatively consistent across genders. Similarly, the Mann–Whitney U test confirmed these findings, showing no significant gender-based differences, further reinforcing the notion that male and female educators exhibit comparable AI knowledge, AI Efficacy, skills application, and ethical perspectives. The average rank scores for both genders were nearly identical across all components, reflecting a balanced distribution of AI-related competencies. This uniformity suggests that male and female educators have equitable access to AI education and training resources, ensuring similar levels of preparedness and engagement in AI-driven learning and teaching environments. The absence of significant disparities highlights the inclusivity of AI education within the academic and professional landscape of the Middle East.
However, Spearman’s rho correlation analysis revealed negative correlations across all components, suggesting an inverse relationship between gender groups. This indicates that higher scores in one group tend to correspond with lower scores in the other. While these correlations are statistically significant, they do not imply causation but rather point to subtle variations in how each gender perceives or prioritizes AI-related skills and attitudes. These differences could stem from cultural, educational, or experiential components unique to the Middle East context. Despite these nuanced distinctions, the overall findings indicate a high level of gender parity in AI competency and readiness, supporting the effectiveness of inclusive AI education and training efforts in the region.
Overall, no statistically significant gender differences were observed among Middle Eastern educators across all components (p > 0.05). Hence, RH6 is rejected and H06 is supported, indicating that gender does not significantly influence AI competency within this regional context.
4.7. Gender Comparison Within South Asia: Female vs. Male
Figure 9 presents a gender-based comparative analysis (female vs. male) of AI competency and readiness among South Asian medical educators, providing empirical evidence to evaluate RH7.
The t-test results revealed no statistically significant differences between female and male educators across all components, as all p-values exceeded 0.05. This indicates a comparable level of AI awareness, skill development, efficacy, inclination towards AI, and ethical considerations between genders. These findings suggest that both male and female educators possess a similar understanding and perception of AI-related competencies in medical education. Similarly, the Mann–Whitney U test results confirmed the absence of significant gender-based differences, reinforcing the observation that AI-related skills and perceptions are consistently distributed across genders. The average rank scores for male and female educators were nearly identical across all components, reflecting a balanced distribution of AI-related competencies and attitudes. Although male educators exhibited slightly higher ranks in AI Enforcement (ethical perspectives and attitudes towards AI), the differences were not statistically significant, indicating that both genders share similar ethical concerns and viewpoints on AI’s implications in medical education and healthcare.
Moreover, Spearman’s rho correlation analysis demonstrated no significant relationships between gender and any of the AI competency components, further supporting the finding that gender does not substantially influence AI awareness, skill confidence, application, or ethical perspectives. This lack of correlation suggests that both male and female educators are equally prepared to integrate AI into medical education, with no noticeable disparity in their AI-related competencies.
Overall, no statistically significant differences were found between male and female educators in South Asia across all components (p > 0.05). Thus, RH7 is rejected and H07 is supported, confirming that gender does not significantly affect AI competency in the South Asian context.
5. Discussion
This study provides critical insights into AI competency and the readiness to use AI in higher education, particularly among medical educators in developing nations. The analysis revealed substantial variations between the five core competency categories (C1–C5), AI Awareness, skills development, efficacy, application, and ethical considerations. Also, these variations reflect differences in the overall preparedness and capabilities of educators across these domains. However, when examined within each category across different independent variables (e.g., gender and region), only a few statistically significant differences emerged, notably in ethical considerations. Likewise, these findings have significant implications for the sustainable integration of AI in medical education and highlight the need for targeted interventions to bridge the gap between theoretical knowledge and practical applications.
The study results indicate that medical educators demonstrate moderate to high awareness of AI’s role in healthcare applications, with a mean score of 4.10 for recognizing AI in medical education. However, their conceptual understanding of AI remains inconsistent, as indicated by a lower mean score of 2.00 for understanding AI concepts. The slight negative skewness and kurtosis values suggest diverse awareness levels, emphasizing the need to develop educators in specific competencies outlined in standardized AI literacy programs. These findings align with previous research, which underscores the necessity for structured AI education to ensure uniform competency among educators [
54,
55,
56].
Although AI Skill Development among medical educators presents a significant challenge, their technical proficiency is lacking. While they exhibit awareness of AI ethics (mean score of 3.96) and demonstrate practical exposure to AI tools (mean score of 4.63), lower scores in AI programming (1.35) and AI model training (1.06) suggest a gap in hands-on experience (See
Figure 3). The narrow interquartile ranges (IQR = 2–3) observed for the items related to AI programming and AI model training under the skills development domain (See
Figure 3) indicate consistency in theoretical knowledge but highlight the absence of experiential development opportunities. To address this gap, higher education institutions, especially medical schools, should encourage teachers to integrate practical training and AI-based learning modules into the classroom, thereby developing their practical skills to keep pace with the applied challenges of AI. These findings are consistent with the existing studies and recommendations [
20,
44,
57].
Educators exhibit moderate AI Efficacy in acquiring AI skills (mean score of 4.28) but lower AI Efficacy in applying these skills to real-world challenges (mean score of 3.99). The standard deviation values suggest variability in AI Efficacy levels, with skewness indicating a slight tendency toward lower self-efficacy in advanced AI applications. These findings imply that while educators recognize AI’s potential, they lack AI Efficacy in its practical application in educational and clinical settings. Similar trends have been observed in other studies [
6,
33,
57,
58].
The lowest mean scores were recorded in the application of AI within medical teaching and research (2.5 to 3.5), demonstrating a limited adoption of AI-based educational methodologies. Despite theoretical knowledge, practical implementation remains sparse, reinforcing the need for AI-driven case studies, interactive learning experiences, and faculty development initiatives. The discrepancy between knowledge and application underscores the importance of hands-on development and exposure to real-world AI applications in medical education [
6,
32].
Ethical considerations emerged as a strong component of AI competency, with high mean scores (4.0 to 4.5) reflecting a broad awareness of AI ethics, including patient privacy, bias mitigation, and responsible AI integration. The findings suggest that while educators are optimistic about AI’s potential in medical education and healthcare delivery, they emphasize ethical responsibility. The slight negative skewness across ethical components indicates a consensus among educators, reinforcing the need for ethical AI governance frameworks in medical institutions [
29,
57,
59].
The comparative analysis revealed no significant differences in AI awareness, skills development, efficacy, and application between Middle Eastern and South Asian educators. However, a notable difference was observed in ethical perspective, with Middle Eastern educators demonstrating a more cautious approach (
p = 0.04). These variations may be attributed to cultural, institutional, and regulatory factors influencing ethical considerations [
20,
31,
43].
The gender-based comparison found no statistically significant differences in AI awareness, skills, efficacy, or application between male and female educators. The consistency in mean scores and non-significant
p-values indicates equitable access to AI-related education and resources across genders. However, slight variations in ethical perspectives were noted, with female educators in the Middle East exhibiting stronger ethical considerations than their South Asian counterparts (
p = 0.037). These differences suggest cultural influences may shape AI-related ethical viewpoints rather than technical competency disparities [
2,
3,
4].
However, it is worth noting that despite the term “substantial variation” describing the observed spread of mean values across the five competencies, only 2 out of the 15 group comparisons (based on gender and region) demonstrated statistical significance (as shown in
Figure 4,
Figure 5,
Figure 6,
Figure 7 and
Figure 8). Also, these results suggest that while differences between competencies (e.g., high ethics vs. low programming skills) are pronounced, group-based comparisons within each competency (e.g., male vs. female educators) were largely consistent, with limited statistical divergence. Hence, this nuance should be considered when interpreting the findings.
The findings of this study highlight critical areas that require attention for the sustainable integration of AI in medical education. First, targeted training programs must be developed to enhance the conceptual understanding of AI, particularly in foundational AI principles. Second, hands-on learning opportunities should be expanded to bridge the gap between theoretical knowledge and practical application. Third, institutions must implement AI-based educational strategies, such as simulation learning, case-based reasoning, and AI-powered instructional tools, to encourage the practical application of AI in medical education. Finally, ethical AI development should be integrated into the medical curricula to ensure responsible AI implementation aligned with global standards.
7. Conclusions
The current study identified critical gaps and strengths in AI competencies and the readiness of medical educators across diverse regional and demographic groups. Also, while AI awareness and efficacy emerged as areas of strength, the development of AI skills, leanings toward AI, and AI enforcement were found to require more targeted support, particularly in regions such as the Middle East and South Asia. Additionally, to address these gaps, the study introduced the ADELE technique, which comprises five core components: (A) AI Awareness, (D) Development of AI Skills, (E) AI Efficacy, (L) Leanings Toward AI, and (E) AI Enforcement. Moreover, the ADELE technique provides higher education institutions, particularly in medical and clinical education, with a structured approach to integrating AI while maintaining a balance between technical proficiency and ethical responsibility. As such, the ADELE framework provides a foundational model for the responsible and sustainable implementation of AI in medical education.
8. Limitations and Future Study Opportunities
While this study offers valuable insights into the relationships between medical educators’ AI competencies (awareness, skills development, efficacy, attitudes, and enforcement) and their readiness to implement AI in education across regions (Middle East vs. South Asia) and gender groups (male vs. female), several limitations should be acknowledged. First, the quantitative cross-sectional design, while suitable for snapshot analysis, precludes examination of competency development over time; longitudinal studies could provide more comprehensive insights. Second, the reliance on self-reported data may lead to inflated proficiency estimates, highlighting the need for future research to incorporate objective performance-based assessments. Third, the study did not include qualitative components (e.g., open-ended questions) that could elucidate educators’ ethical reasoning and contextual perspectives on AI implementation. Finally, while the sample of 253 educators yields meaningful results, larger-scale studies would enhance the generalizability of the findings and strengthen the conclusions.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}