1. Introduction
The agricultural sector supplies most food resources, guarantees food security, and promotes sustainable development [
1]. The need for accurate agricultural monitoring is increasing due to the impact of climate change on crop yield sustainability [
1]. Given these changing conditions and an uncertain future, it is critical to track and offer accurate projections of the effects of climate conditions on crop status to create early warning systems and manage limited resources efficiently [
2,
3,
4].
Forages, which are various herbaceous plant species used as animal feed, are essential in agriculture. Alfalfa (also called lucerne,
Medicago sativa L.) is one of the most widely grown forage crops globally, covering an area of 35 million hectares in more than 80 countries [
5]. Alfalfa is an extensively cultivated perennial legume forage species that is known for its superior quality and high productivity [
6]. In contrast to other silage crops like maize (
Zea mays L.) and soybean (
Glycine max L.), the growth of alfalfa is challenging to delineate using a conventional phenological curve due to its monthly harvesting and rapid regrowth [
7]. Given that it serves as a principal feedstock, declining alfalfa production is of considerable concern worldwide. It may result in a shortage of forage for grazing dairy animals.
Agricultural crops’ biophysical parameters, including biomass, leaf area index (LAI), and vegetation water content, are some of the most crucial indicators of crop productivity, growth, and health [
8,
9,
10,
11]. Crop height, which is among important crop biophysical parameters, provides essential insights into crop growth and serves as a significant factor in various agricultural practices, including crop health evaluation, phenological monitoring, biomass and yield calculation, and precision fertilization [
12,
13]. Accurate, reliable, and systematic monitoring and retrieval of crop height is essential, therefore, to support agricultural crop management operations [
14]. Maps indicating current crop height can assist farmers in making informed decisions and managing fields by zone [
15].
Conventional techniques for monitoring crop growth, such as quadrat or point-frame sampling and ground sensors, are time-intensive, challenging, and costly in collecting agricultural data [
16,
17]. Sampling methods frequently overlook spatial variability in most areas, resulting in the absence of optimal management that is adapted to in-field variability [
15,
18]. Employing ground sensors might, therefore, be unfeasible to implement over large areas [
19] or to acquire timely information on a broad scale [
17].
A Light Detection and Ranging (LiDAR) sensor is a common payload for crop height model development [
20], which measures the distance between the unmanned aerial vehicle (UAV) and the target using a laser scanner. Despite their high precision, survey-grade LiDAR sensors are currently costly [
21], require specialized operational skills, and have limited geographical coverage [
22], making them unsuitable for routine monitoring of remote areas.
To address these problems, satellite-based remote sensing technology allows large-scale surface monitoring with different temporal and spatial resolutions [
17]. Prior research has estimated the height of various crops utilizing synthetic aperture radar (SAR) [
12,
23,
24,
25] and optical satellite sensors [
22,
25,
26]. Among various crop parameters, plant height directly indicates vegetative growth and canopy development [
27], which is linked to spectral reflectance, because of changes in plant appearance due to phenological development [
28], and consequently, vegetation indices (VIs). Various optical satellite imagery has been used in the agricultural domains recently, such as RapidEye [
29,
30], Sentinel-2 [
31,
32,
33], Landsat missions [
31,
33], Worldview-2/3 [
34,
35], and MODIS [
36]. While Landsat multispectral missions, among freely available satellite images, have been used to estimate crop parameters in prior research [
37,
38,
39], these sensors do not include essential components, such as the red-edge region of the electromagnetic spectrum, which is essential for characterizing crop biophysical and biochemical parameters. Sentinel-2 ensures data continuity and interoperability with prior missions such as Landsat [
40], while offering higher spatial (up to 10 m), temporal (revisits of every 5 days), and spectral resolution (red-edge bands) [
41]. Using multispectral remote sensing imagery, plant biochemical and morphological characteristics, along with canopy structure, influence the canopy reflectance signature [
42]. However, to our knowledge, the relationship between Sentinel-2 spectral bands and VIs derived from Sentinel-2 imagery and alfalfa height remains unexplored.
Satellite imagery data includes a wealth of information described by variables that have complex interactions. Linear regression models are useful for comprehending interactions and drawing inferences, but they are constrained in their ability to capture intricate non-linear correlations among variables [
43]. Conversely, machine learning (ML) techniques provide improved accuracy and are designed to tackle complex interactions [
44]. Moreover, they are recognized as effective approaches to crop research [
1]. Machine learning algorithms, such as random forest (RF), support vector regression (SVR), extreme gradient boosting (XGB), and Gaussian Process Regression have been extensively employed in estimating crop parameter estimation [
11,
35,
45]. For example, Narin, Bayik, Sekertekin, Madenoglu, Pinar, Abdikan and Balik Sanli [
17] utilized the RF regression model to estimate wheat crop height using Sentinel-1. They reported a correlation of 0.87 in the early stage by using RF. In another research, Zhang et al. [
46] utilized several ML models, such as RF, SVR, and gradient-boosting regression tree to estimate maize crop height. They reported the R
2 value ranging from 0.79 to 0.99 using the gradient-boosting regression tree.
This study aims to develop a monitoring model for the intra-field variability of alfalfa height based on multispectral remote sensing data and machine learning techniques on a large scale. The specific objectives were (1) to evaluate the efficacy of VIs and the precision of machine learning models in predicting alfalfa crop height across various growth stages and locations, (2) to analyze the importance of different features in studying alfalfa crop height, and (3) to apply various feature selection strategies and assess the effect of feature reduction on the accuracy of the models.
2. Materials and Methods
2.1. Ground Measurements
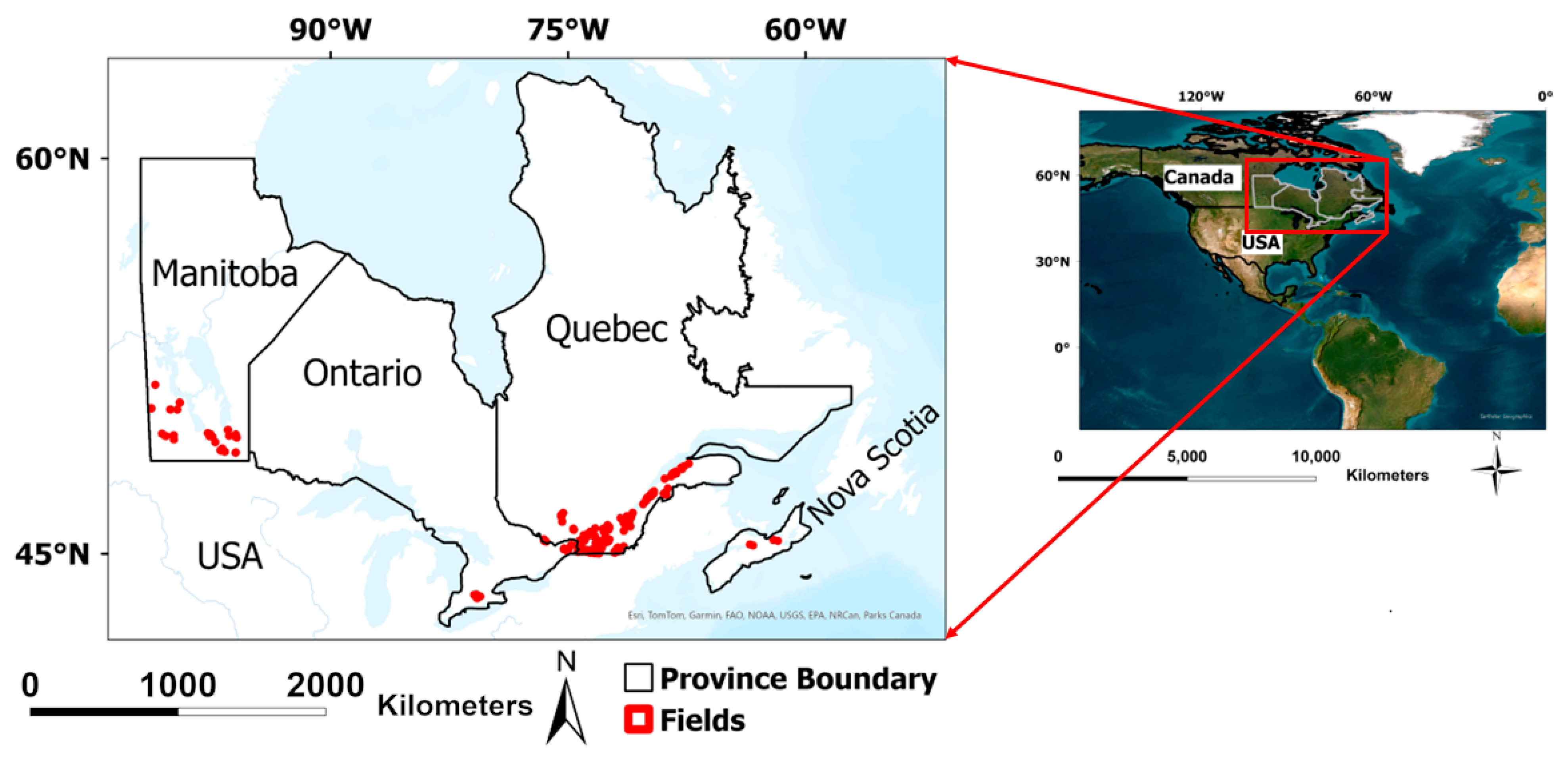
Ground measurements, including stem counts and crop heights, were collected over three years (2021, 2022, and 2023) across 597 alfalfa fields that are located in the Canadian provinces of Nova Scotia, Quebec, Ontario, and Manitoba (
Figure 1).
Table 1 provides province-specific information. There were 33 agronomist consultants and 192 producers who were involved in the field procedures. A randomized design for performing measurements was employed in each field. Each sampling location was represented by three sampling spots representing the corners of a 2 m isometric triangle. Five stems within a quadrat with an area of 1 ft × 1 ft (~0.3 m × 0.3 m) were randomly selected, and their height was measured for average height at each spot (
Figure 2). The average stem height at each location and date was calculated as the average height of the 15 stems measured at that location and date. The geographic coordinates of triangle centers were used to collocate remote sensing and associate them with the corresponding average height of each triangle (
Figure 2).
The histogram of the alfalfa crop height measurements collected during the three years is depicted in
Figure 3.
2.2. Satellite Data
The multispectral Sentinel-2 satellite dataset that was utilized in this study was acquired through the Google Earth Engine (GEE) Python API. GEE was launched in 2010 and is a parallel cloud computing platform that facilitates worldwide geospatial analysis using Google’s infrastructure [
47]. The system comprises a multi-petabyte data catalog that is designed for analysis with a high-performance, intrinsically parallel computing service [
47].
The Sentinel-2 mission consists of two satellites: Sentinel-2A, which was launched on 23 June 2015, and Sentinel-2B, which was launched on 7 March 2017. Sentinel-2 is a multispectral sensor including thirteen bands: eight in the Visible and Near-Infrared (VNIR) portions of the spectrum and five in the Shortwave Infrared (SWIR) range, featuring a 10-day revisit cycle for a single satellite and a 5-day cycle when employing both satellites. The images that are employed in this study were Sentinel-2 Level-2A data, the atmospheric correction of which had already been applied to the images. We utilized images from three days before and following the date of ground measurements. Only images with a cloud coverage percentage of less than 15% were considered, and masking for clouds and cloud shadows was applied to the images.
The Sentinel-2 multispectral datasets were extracted separately for the center of the triangles. For Sentinel-2 data, the spectral bands with 20 m spatial resolution were resampled to 10 m; 60 m spatial resolution bands (Bands 1 and 9) were not used in this study. A buffer zone with a radius of 10 m was applied around the field measurement center points. The reflectance of various bands was retrieved by computing the average value of the pixels within the buffer.
2.3. General Workflow
The flowchart of the proposed methodology is depicted in
Figure 4. In this study, Sentinel-2 images were collected from GEE, and several VIs were then computed. If Sentinel-2 images were unavailable during that period (three days before and after the ground measurement date) or if clouds and their shadows had affected areas adjacent to the sampling location, that sampling data were excluded from data analysis. The remaining data after preprocessing were randomly split into training and testing sets (70% and 30% of data points, respectively). We used 5 different “random_state” values in Python
TM to control the randomness in the dataset splits. The random_state parameter regulates the shuffling of data before the split implementation. We partitioned the data utilizing several random_state values and reported assessment metrics for each random_state. Then, we calculated the average assessment metrics for each model and plotted the distribution of the MAE and RMSE to determine the most stable models. We employed a stratified method for data separation to ensure that the data distribution is preserved in both training and testing sets. The regression data were categorized according to the year in which the ground measurements were taken, allowing thus to apply the same training and testing percentages (70% and 30% of the data, respectively) to each year.
The training data were then fed into three ML algorithms, including RF, SVR, and XGB. The accuracy of the models was then validated using the test dataset. The most accurate model was then used to map alfalfa height during the growing season.
The parameters of each machine-learning algorithm were optimized using GridSearch cross-validation (GridSearchCV) tool in the scikit-learn library [
48]. Determining the optimal values for the parameters in each model necessitates thoroughly adjusting the model’s hyperparameters with GridSearchCV. We employed 5-fold cross-validation for training purposes. Five equal, or roughly equal, segments are randomly chosen from the dataset. Four parts are utilized for model training, and the remaining part is designated for validation. Each iteration of this method uses a separate part as the validation set. The model’s total performance estimate is derived by averaging the performance metrics across the five iterations, including accuracy, precision, and recall. It should be noted that cross-validation was only applied to the training data.
While an increased number of variables may enhance the representation of features and improve ML accuracy, this does not ensure that such a strategy would consistently result in superior accuracy. Indeed, highly correlated input variables might adversely affect the performance of a modeling algorithm [
49]. The feature selection (FS) technique, which aims to identify the ideal subset of features that exhibit the lowest redundancy and maximal relevance to the objects, is highly effective in minimizing redundant information [
50].
After training the models with all features, we conducted an analysis utilizing several feature selection techniques to identify the most optimal and important features for alfalfa crop height estimation while minimizing computational complexity. This study employed RF feature importance to assess the importance of each input variable. Scikit-learn in Python includes a built-in feature importance calculator for RF. This approach employs the model’s internal computations to assess feature importance, including Gini importance and mean reduction in accuracy. This method quantifies the reduction in impurity within a decision tree node when a certain attribute is employed to partition the data. A higher score indicates that the variable will have a more significant influence on the model used to estimate alfalfa crop height.
In considering the aforementioned, feature selection was performed under various scenarios: (1) evaluating the correlation among all features, selecting those with an absolute correlation greater than r = 0.9, and eliminating the feature with the lower RF feature importance value; (2) assessing the correlation among VIs, selecting those with an absolute correlation greater than r = 0.9, eliminating the feature with the lower RF feature importance value; (3) focusing exclusively on bands; (4) concentrating solely on VIs; (5) choosing the 10 m bands (Blue, Green, Red, Near-Infrared). The reason behind selecting r = 90 is to eliminate the less important feature among highly correlated features. We can explore how correlated features and VIs impact the models’ accuracy by executing Scenarios 1 and 2, as well as whether eliminating highly correlated and redundant features will increase estimation accuracy. Additionally, we can determine if the estimation accuracy of bands or the VIs is superior by utilizing Scenarios 3 and 4. Lastly, we can determine whether greater spatial resolution bands can more accurately predict alfalfa crop height by using Scenario 5.
Table 2 presents the details of the VIs that were employed in this study. In total, 10 bands and 16 VIs were used for Sentinel-2.
2.4. Machine Learning Algorithms
2.4.1. Random Forests
RFs [
65] are ensemble learning models which are employed for classification and regression tree applications. Ensemble approaches utilize many learning algorithms to improve performance. Boosting and bagging are the main approaches in ensemble learning. Boosting involves developing a series of models, each of which is designed to correct the errors of its previous one. Several base models are individually trained in the bagging process, leading to a more stable composite model with less variation, thereby making it insensitive to the overfitting problem [
66]. A collection of decision trees is used and combined to enhance model accuracy utilizing RF [
66]. Each tree utilizes a random subset of training samples to predict the target values [
67]. The RF approach reduces model variance by averaging the outputs of all decision trees [
68]. The grid parameters that are used in this research for RF tuning are listed in
Table 3.
2.4.2. Support Vector Machine
The SVM model [
69] is a widely employed kernel-based ML algorithm for classification purposes. SVM aims to identify a hyperplane that maximizes the margins between different classes of training data [
68]. The SVM model can be modified for regression tasks [
70]. In ε-SVR, the goal is to identify a function f(x) that diverges from the targets by no more than epsilon (ε). Utilizing SVR, a flexible tube is formed around the estimation function, ignoring absolute error values below a specified threshold. Points that are located within the tube, regardless of their position relative to the prediction function, suffer no penalties; conversely, points that are situated outside the tube are penalized. The grid parameters that are utilized for SVM tuning in this study are presented in
Table 4.
2.4.3. Extreme Gradient Boosting
XGB [
71] is a widespread implementation of gradient boosting, which was originally developed by Chen and Guestrin [
72]. The method employs a gradient-boosting framework and operates as an ensemble machine-learning technique. XGB enhances the performance, velocity, adaptability, and efficiency of a machine learning model.
Table 5 presents the grid search parameters that are employed for optimizing the XGB hyperparameters.
2.4.4. Evaluation Criteria
We assessed the performance of ML models in predicting the alfalfa stem heights using the root-mean-square error (RMSE), mean absolute error (MAE), and the coefficient of determination (R
2):
where
is the estimated crop height (cm), y is the observed crop height (cm), and n is the number of observations. RMSE and MAE (cm) provide a quantifiable assessment of the residuals’ distribution and distance between predicted and observed data, while R
2 allows quantifying the correlation between the predicted and observed data. Lower values of RMSE and MAE and higher values for R
2 indicate better model fit.
4. Discussion
A limited number of studies exist assessing alfalfa crop height [
73,
74,
75]. Sheffield et al. [
76] obtained an R
2 of 0.90 and RMSE of 4.5 cm in a linear regression model of measured average alfalfa canopy height, utilizing the 95th percentile of LiDAR-measured height as a sole predictor with LiDAR data. The RMSE reported in Sheffield, Dvorak, Smith, Arnold and Minch [
76] was better than that of us, as it was ~5.2 cm in XGB. Pittman, Arnall, Interrante, Moffet and Butler [
74] investigated the efficacy of terrestrial mobile sensing sensors, including laser, ultrasonic, and spectral sensors, for estimating biomass and canopy height of the alfalfa, bermudagrass, and wheat by establishing a relationship between height and mass. They stated that the canopy height estimates in alfalfa and the legume-grass mixture resulted in R
2 values of 0.61 or less. These studies employed terrestrial sensors, lasers, UAVs, or LiDAR data to acquire datasets, which are expensive to replicate on a broader scale. To the best of our knowledge, only one study [
75] has utilized several VIs, including NDVI, SAVI, and MSAVI, extracted from Landsat data to estimate alfalfa height. This study reported high sensitivity between all extracted VIs and alfalfa crop height (R
2 > 90). Nevertheless, this research employed only simple regression models, and the number of measurements was considerably lower than that employed in our study. Additionally, the area of interest in this study was limited to only one region. Our terrestrial measurements encompassed three years of extensive data, incorporating all growth cycles under diverse geographical regions and environmental conditions.
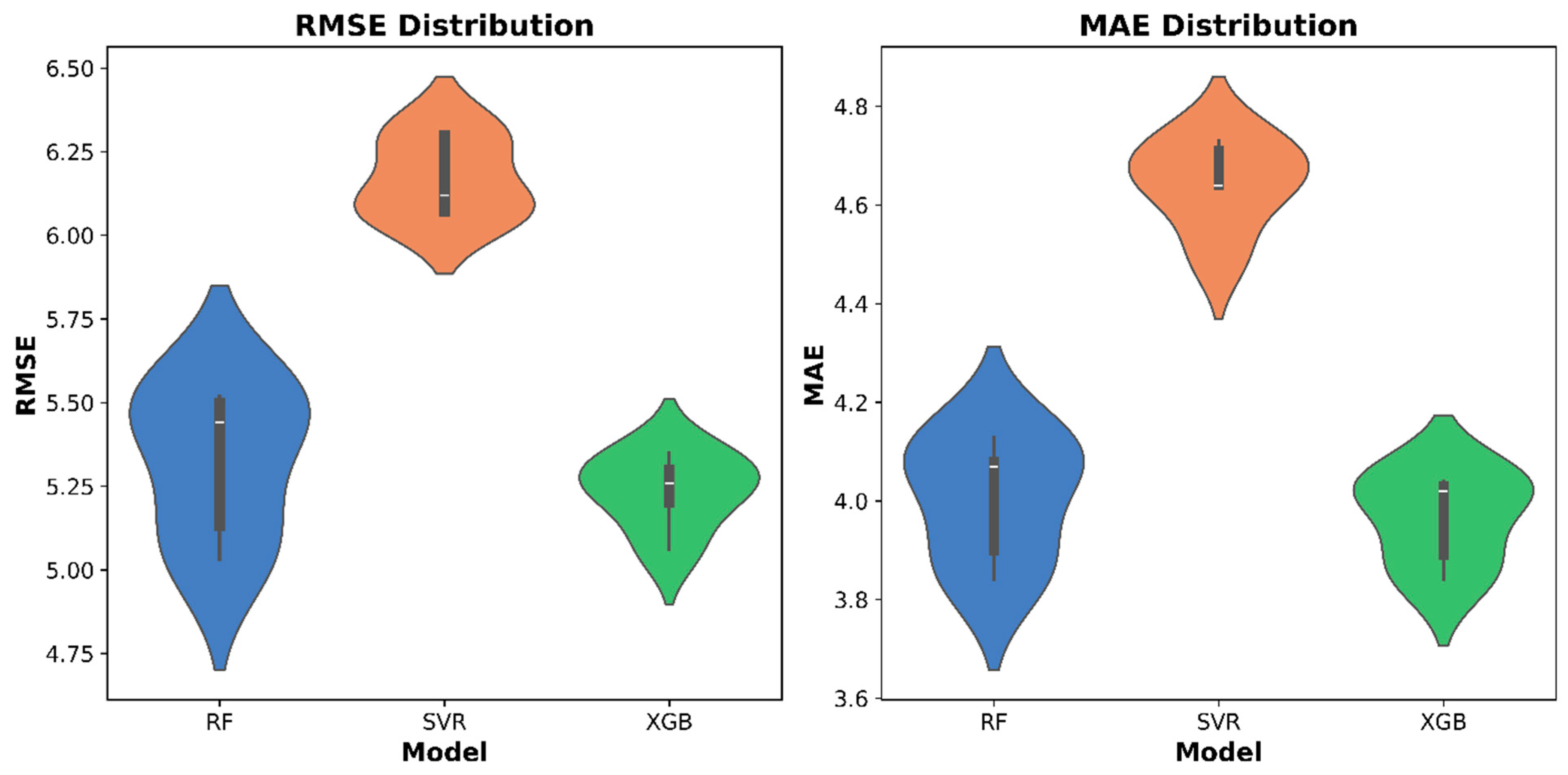
The evaluation of the performance of the non-parametric algorithms used in this study for alfalfa crop height indicated that the RF and XGB models surpassed the performance of the SVR model utilizing Sentinel-2 satellite data. Additionally, according to this study’s findings (
Figure 6), XGB was the most stable model as it was less affected by random initialization. However, the XGB model showed a sign of being overfitted to the training data. Despite the fact that the XGB model incorporates regularization terms into the loss function using the gradient lifting tree strategy, which effectively prevents overfitting and enhances generalization capabilities [
77], we were unable to reduce overfitting using all of the recommended techniques in the earlier research. The efficacy of RF and XGB in estimating crop height on the test data in our research agrees with similar results from the literature [
17,
78,
79,
80,
81]. However, the SVR model demonstrated a low estimation potential. Its lower performance compared to other machine learning algorithms concurs with findings from prior studies [
82,
83]. This poor performance can be linked to the sensitivity of the SVR model to the size of training data: the larger the dataset that is utilized, the lower the prediction accuracy can get because the training complexity increases quadratically with sample size [
84,
85]. Mountrakis et al. [
86] emphasized SVM models’ good generalization ability and comparable effectiveness when training data are limited but also pointed out that they are susceptible to dimensionality issues and noisy data. Furthermore, SVM techniques usually map input data to higher dimensional spaces to identify patterns. Consequently, apart from the potential increase in dimensionality attributed to the model, the intrinsic increase in dimensionality within the data itself can also give rise to analogous dimensionality challenges in SVMs [
86].
Deep learning, a subfield of machine learning, is defined by its ability to model complicated processes via deep, non-linear network architectures [
87]. A key advantage of deep learning is feature learning, which is the automatic extraction of features from unprocessed data. Features from higher levels of the hierarchy are created by combining features from lower levels [
88]. Numerous studies have demonstrated the effectiveness of deep learning techniques in a variety of agricultural sectors, most often achieving high levels of accuracy [
89,
90]. We intend to use deep learning models on the alfalfa dataset as a next step in our studies.
Previous studies have considerably used feature importance analysis to identify which features can most influence the target parameter [
91,
92]. Specifically, in the ML crop parameter inversion models and data preparation strategies, feature selection may be crucial, and using too many redundant variables may potentially result in overfitting or decreased model accuracy and robustness [
93,
94]. We examined different feature selection techniques and compared the results with the scenario in which all variables were given to the models. No feature selection strategy, however, could perform better than feeding all features into the models, according to our analysis in this study. This result agrees with the results from prior studies, as they indicated a decrease when applying feature selection strategies [
95,
96]. Additionally, according to the processing time for a single field covering an area of ~10 ha during the growth season, our investigation showed that it takes roughly two minutes to analyze 25 cloud-free images using the trained XGB ML model. This indicates that the model will be significantly important, cost-effective, and computationally efficient. Therefore, feeding all features as an input in this case is not computationally expensive and will not limit our proposed models. However, RF includes a built-in variable importance measure, and the variables with high scores can be considered to have a high information value. The results of RF feature importance indicated that all input variables influence alfalfa yield predictions, but to varying degrees. The analysis showed that NDRE was ranked the most important feature among all features that were used in this study. The NDRE index is derived from the red-edge spectrum, which is responsive to variations in chlorophyll concentrations within crop tissues [
79]. Chlorophyll content is the primary indicator of crop health and photosynthetic activity [
97]. Previous studies have thoroughly explained the sensitivity of red-edge wavelength to changes in crop growth [
98]. This can explain why NDRE was the most important feature in alfalfa crop height estimation, which is not surprising given that NDRE uses the red-edge wavelength of the spectrum in its formulation. The findings also demonstrated that in addition to NDRE, NDWI significantly contributed to alfalfa height estimation. These indices could be related to using the red region of the spectrum, which is more effective for assessing green biomass and vegetation density [
79]. NDWI also offers insights into vegetation water content [
99], which is tightly connected to total crop health, stress, and vigor.
The saturation phenomenon is commonly known to be a problem for crop monitoring using optical remote sensing [
100]. Furthermore, the model’s performance is significantly impacted by the saturation of optical input, particularly for tree ensemble machine learning algorithms that cannot learn from the spatial context of the observation at the pixel scale [
101], providing accurate estimations of dense canopies’ height. However, in the present study, when we assessed the model performance using test data, the RF and XGB did not show any saturation when estimating the alfalfa crop height. The only one with a slight sign of saturation was SVR. This is also consistent with the findings of the previous studies, as stated that XGB and RF are better at reducing overestimation and underestimation issues, while SVR has been found to have overestimation and underestimation problems [
87,
102,
103]. As stated in the literature, we strongly believe that over-smoothing is the source of the small saturation of the SVR since selecting a small value for the kernel width parameter may result in overfitting, while selecting a big value may result in over-smoothing [
74]. This issue is a general problem in kernel-based techniques (such as radial basis functions) and is not exclusive to SVM methods [
74].
5. Conclusions
This research examined the efficacy of three machine learning algorithms—Random Forest (RF), Support Vector Regression (SVR), and Extreme Gradient Boosting (XGB)—to predict alfalfa crop height utilizing Sentinel-2 multispectral images. Our results indicated that RF and XGB outperformed SVR in predicting crop height. However, XGB showed better stability with the random selection of the training and test data. Our findings demonstrated that alfalfa crop height may be obtained with a mean absolute error of around 4 cm utilizing Sentinel-2 data and either RF or XGB. Our findings showed that NDRE, NDWI, and Band 8 were the most important features, emphasizing the significance of near-infrared and red edges of the electromagnetic spectrum in assessing alfalfa crop height. Although this study assessed various feature selection scenarios, the results showed that no feature selection strategy could outperform the scenario with all features as input. In summary, we recommend using Sentinel-2 data to fulfill the need for enhanced information regarding alfalfa height.
The current research utilized publicly accessible satellite data (Sentinel-2) in the GEE Python API. Thus, the crop height maps can be generated quickly once the satellite data becomes available. The crop height maps that were generated in this study can be useful for identifying real-time growth issues at the intra-field level and facilitating decision-making for management zones. Agricultural research organizations can utilize these crop height maps to provide precise recommendations that assist alfalfa farmers in preventing output losses and customizing alfalfa crop insurance. Monitoring alfalfa crop height during various growth cycles offers valuable spatiotemporal data for crop management and may improve yields to satisfy rising worldwide market demands. Thus, the method is time-efficient, cost-effective, and reliable, and may be effectively replicated in various regions.

 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}