






Semantic Segmentation of High-Resolution Remote Sensing Images Based on Sparse Self-Attention and Feature Alignment



Abstract
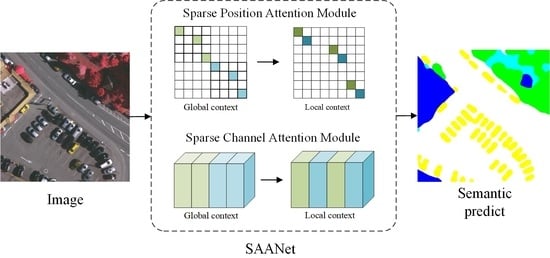
1. Introduction
- (1)
- The paper proposes SPAM and SCAM to efficiently model the position non-local information and channel-wise dependency, which reduces redundant information, contributing to the intraclass consistency of large objects and the segmentation accuracy of small objects.
- (2)
- The paper introduces FAM, which can align feature maps with different resolutions and further improve segmentation results.
- (3)
- Extensive experimental results demonstrate that SAANet achieves leading performance on ISPRS Vaihingen, Potsdam, and LoveDA datasets.
2. Materials and Methods
2.1. Overview
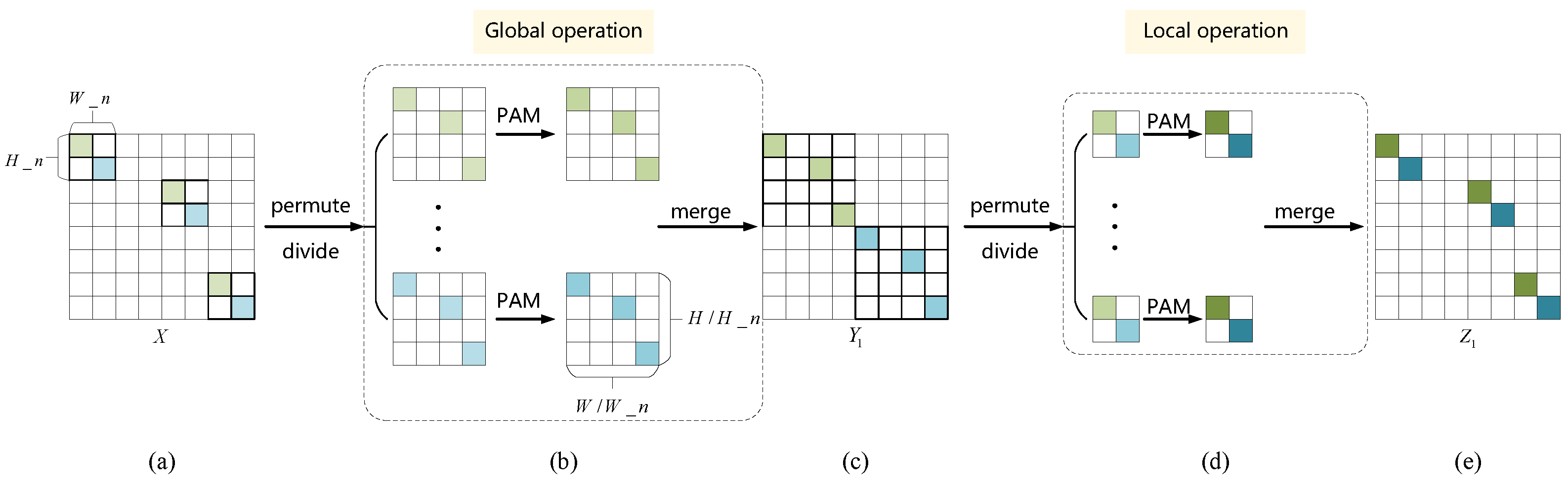
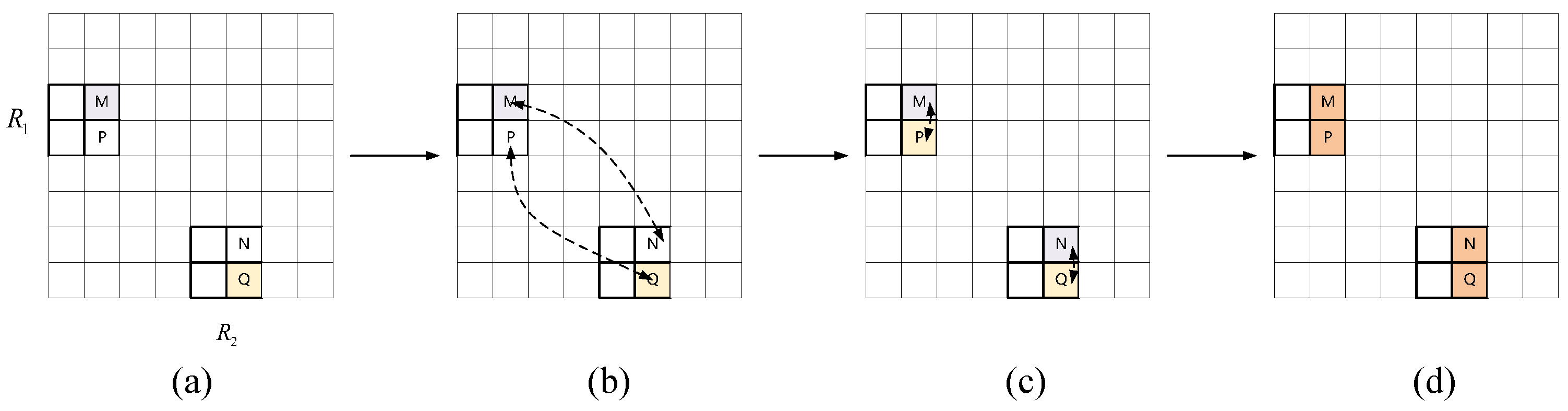
2.2. Sparse Position Self-Attention Module
2.2.1. Position Self-Attention Module
2.2.2. Sparse Position Self-Attention Module
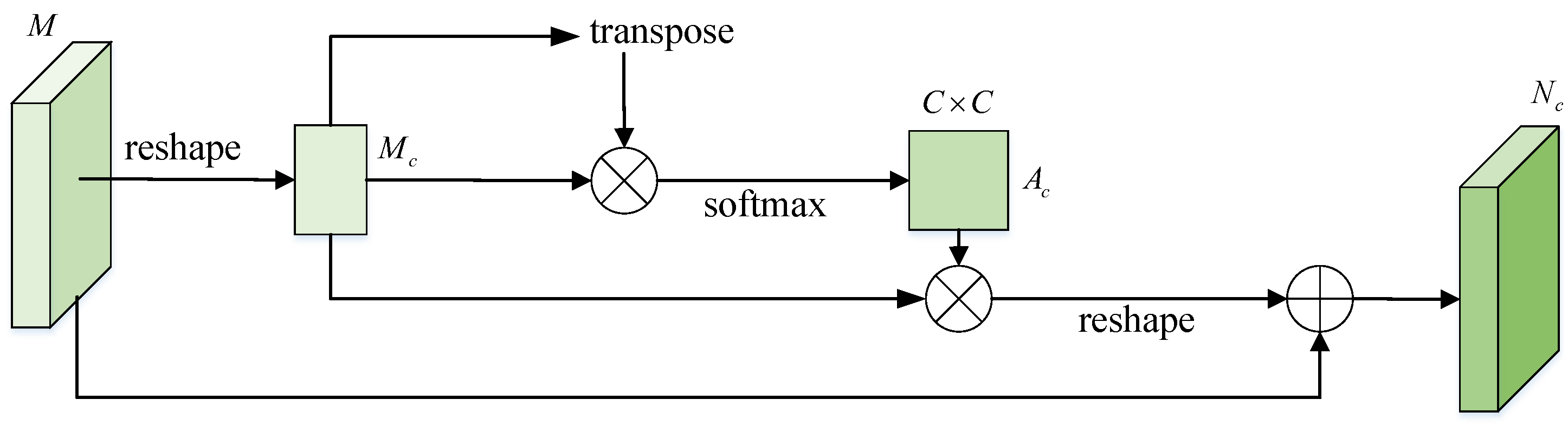
2.3. Sparse Channel Attention Module
2.3.1. Channel Self-Attention Module
2.3.2. Sparse Channel Self-Attention Module
2.4. Feature Alignment Module
3. Experiments
3.1. Datasets and Evaluation Metrics
3.2. Implementation Details
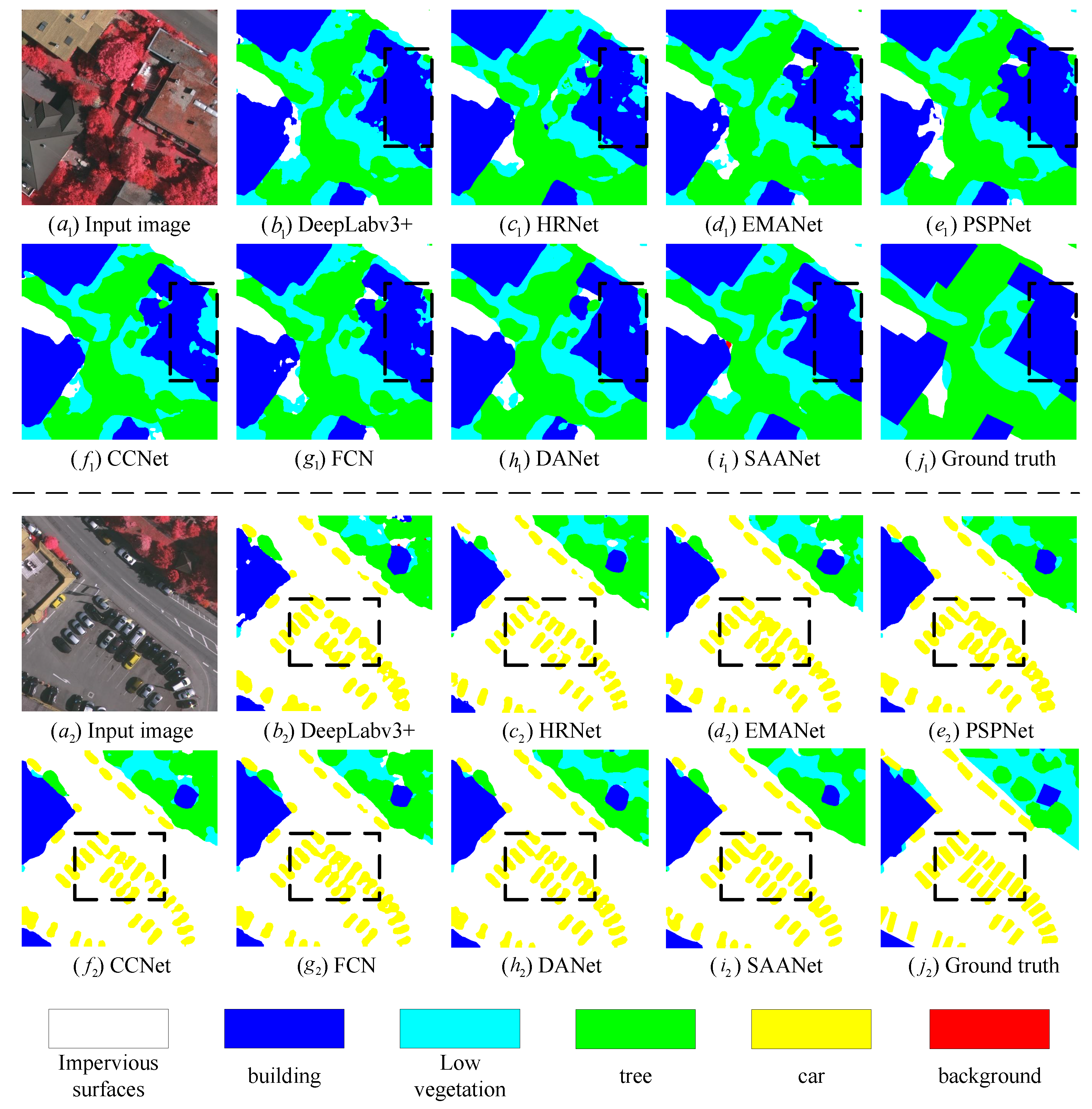
3.3. Comparison to State-of-the-Art
3.4. Evaluation in Efficiency
4. Discussions
4.1. Sparse Position and Channel Attention Module
4.2. Feature Alignment Module
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tokarczyk, P.; Wegner, J.D.; Walk, S.; Schindler, K. Features, Color Spaces, and Boosting: New Insights on Semantic Classification of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2014, 53, 280–295. [Google Scholar] [CrossRef]
- Tang, Y.; Zhang, L. Urban change analysis with multi-sensor multispectral imagery. Remote Sens. 2017, 9, 252. [Google Scholar] [CrossRef]
- Wu, L.; Lu, M.; Fang, L. Deep Covariance Alignment for Domain Adaptive Remote Sensing Image Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Liu, M.Y.; Tuzel, O.; Ramalingam, S.; Chellappa, R. Entropy rate superpixel segmentation. In Proceedings of the The 24th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011. [Google Scholar]
- Radman, A.; Zainal, N.; Suandi, S.A. Automated segmentation of iris images acquired in an unconstrained environment using HOG-SVM and GrowCut. Digit. Signal Process. 2017, 64, 60–70. [Google Scholar] [CrossRef]
- Thanh Noi, P.; Kappas, M. Comparison of random forest, k-nearest neighbor, and support vector machine classifiers for land cover classification using Sentinel-2 imagery. Sensors 2017, 18, 18. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Computer Society, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large kernel matters–improve semantic segmentation by global convolutional network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4353–4361. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 21–26 June 2018; pp. 7794–7803. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Li, X.; Zhong, Z.; Wu, J.; Yang, Y.; Lin, Z.; Liu, H. Expectation-maximization attention networks for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 9167–9176. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE/CVF international conference on computer vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Yuan, Y.; Huang, L.; Guo, J.; Zhang, C.; Chen, X.; Wang, J. OCNet: Object context for semantic segmentation. Int. J. Comput. Vis. 2021, 129, 2375–2398. [Google Scholar] [CrossRef]
- Shi, H.; Fan, J.; Wang, Y.; Chen, L. Dual attention feature fusion and adaptive context for accurate segmentation of very high-resolution remote sensing images. Remote Sens. 2021, 13, 3715. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Su, J.; Wang, L.; Atkinson, P.M. Multiattention network for semantic segmentation of fine-resolution remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation; Springer: Munich, Germany, 2015. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1925–1934. [Google Scholar]
- Sun, K.; Zhao, Y.; Jiang, B.; Cheng, T.; Wang, J. High-Resolution Representations for Labeling Pixels and Regions. arXiv 2019, arXiv:1904.04514. [Google Scholar]
- Takikawa, T.; Acuna, D.; Jampani, V.; Fidler, S. Gated-scnn: Gated shape cnns for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 5229–5238. [Google Scholar]
- Yuan, Y.; Xie, J.; Chen, X.; Wang, J. Segfix: Model-agnostic boundary refinement for segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 489–506. [Google Scholar]
- Liu, S.; Ding, W.; Liu, C.; Liu, Y.; Wang, Y.; Li, H. ERN: Edge loss reinforced semantic segmentation network for remote sensing images. Remote Sens. 2018, 10, 1339. [Google Scholar] [CrossRef]
- Zheng, X.; Huan, L.; Xia, G.S.; Gong, J. Parsing very high resolution urban scene images by learning deep ConvNets with edge-aware loss. ISPRS J. Photogramm. Remote Sens. 2020, 170, 15–28. [Google Scholar] [CrossRef]
- Li, X.; Li, T.; Chen, Z.; Zhang, K.; Xia, R. Attentively learning edge distributions for semantic segmentation of remote sensing imagery. Remote Sens. 2021, 14, 102. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Available online: https://www2.isprs.org/commissions/comm2/wg4/benchmark/2d-sem-label-vaihingen/ (accessed on 1 March 2021).
- Wang, J.; Zheng, Z.; Ma, A.; Lu, X.; Zhong, Y. LoveDA: A remote sensing land-cover dataset for domain adaptive semantic segmentation. arXiv 2021, arXiv:2110.08733. [Google Scholar]
- Zhao, Q.; Liu, J.; Li, Y.; Zhang, H. Semantic Segmentation with Attention Mechanism for Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Imp. Surf. | Building | Low Veg. | Tree | Car | Background | mIOU | mF1 | OA |
|---|---|---|---|---|---|---|---|---|---|
| DeepLabv3+ | 77.15 | 85.40 | 61.22 | 74.54 | 57.46 | 26.44 | 63.70 | 75.90 | 85.30 |
| HRNet | 79.12 | 85.78 | 62.46 | 75.69 | 60.46 | 25.87 | 64.90 | 76.70 | 86.10 |
| EMANet | 77.83 | 85.73 | 62.61 | 75.37 | 60.95 | 32.18 | 65.78 | 77.87 | 85.88 |
| PSPNet | 77.94 | 85.77 | 62.90 | 75.65 | 60.40 | 34.59 | 66.21 | 78.34 | 85.97 |
| CCNet | 77.73 | 85.64 | 62.35 | 75.42 | 61.61 | 36.22 | 66.50 | 78.66 | 85.83 |
| FCN | 77.99 | 85.82 | 62.84 | 75.39 | 61.86 | 36.76 | 66.78 | 78.89 | 85.96 |
| DANet | 78.48 | 86.67 | 63.19 | 75.74 | 63.73 | 37.67 | 67.58 | 79.50 | 86.35 |
| SAANet | 79.00 | 87.52 | 63.79 | 76.16 | 65.35 | 39.21 | 68.50 | 80.22 | 86.72 |
| Method | Imp. Surf. | Building | Low Veg. | Tree | Car | Background | mIOU | mF1 | OA |
|---|---|---|---|---|---|---|---|---|---|
| DeepLabv3+ | 81.87 | 90.32 | 71.75 | 73.58 | 83.12 | 34.19 | 72.47 | 82.50 | 87.45 |
| CCNet | 82.43 | 90.64 | 71.72 | 73.31 | 83.47 | 33.97 | 72.59 | 82.55 | 87.61 |
| PSPNet | 81.64 | 89.96 | 71.43 | 74.45 | 82.61 | 36.21 | 72.72 | 82.82 | 87.46 |
| HRNet | 82.65 | 89.99 | 72.17 | 74.16 | 83.58 | 35.06 | 72.94 | 82.87 | 87.76 |
| DANet | 82.80 | 90.94 | 72.23 | 74.42 | 83.70 | 33.87 | 72.99 | 82.80 | 87.96 |
| FCN | 82.30 | 90.66 | 71.62 | 74.37 | 83.55 | 36.03 | 73.09 | 83.03 | 87.73 |
| EMANet | 82.54 | 90.49 | 71.92 | 73.73 | 83.31 | 37.16 | 73.19 | 83.18 | 87.77 |
| SAANet | 83.40 | 90.78 | 72.46 | 74.53 | 84.12 | 37.46 | 73.79 | 83.57 | 88.22 |
| Method | Background | Building | Road | Water | Barren | Forest | Agricultural | mIOU | mF1 | OA |
|---|---|---|---|---|---|---|---|---|---|---|
| DeepLabv3+ | 35.31 | 59.73 | 56.23 | 54.95 | 19.45 | 42.05 | 31.17 | 42.70 | 58.46 | 57.99 |
| FCN | 34.13 | 59.60 | 54.99 | 68.42 | 26.91 | 47.90 | 23.27 | 45.03 | 60.39 | 58.38 |
| HRNet | 37.96 | 60.03 | 59.83 | 68.33 | 25.07 | 44.63 | 30.59 | 46.63 | 62.11 | 60.87 |
| PSPNet | 38.72 | 58.80 | 53.00 | 60.30 | 23.18 | 44.36 | 48.13 | 46.64 | 62.64 | 63.41 |
| DANet | 38.67 | 62.04 | 58.93 | 66.52 | 23.26 | 43.92 | 34.37 | 46.82 | 62.33 | 61.54 |
| CCNet | 38.83 | 60.31 | 56.04 | 63.89 | 39.74 | 46.96 | 29.61 | 47.91 | 63.92 | 61.62 |
| EMANet | 40.46 | 60.02 | 58.18 | 64.55 | 30.36 | 47.74 | 46.22 | 49.65 | 65.58 | 65.19 |
| SAANet | 42.09 | 61.25 | 57.26 | 63.64 | 33.14 | 44.32 | 48.38 | 50.01 | 66.03 | 65.45 |
| Method | GFLOPs (G) | Params (M) |
|---|---|---|
| DeepLabv3+ | 254.56 | 60.21 |
| HRNet | 93.73 | 65.85 |
| EMANet | 246.63 | 58.71 |
| PSPNet | 256.63 | 65.60 |
| CCNet | 278.57 | 66.45 |
| FCN | 275.88 | 66.12 |
| DANet | 277.26 | 66.45 |
| SAANet | 283.46 | 66.85 |
| Dataset | H_n | W_n | C_n | mIOU | mF1 | OA |
|---|---|---|---|---|---|---|
| Vaihingen | / | / | / | 65.19 | 77.32 | 85.60 |
| 4 | 4 | 2 | 68.19 | 79.99 | 86.64 | |
| 4 | 4 | 4 | 67.82 | 79.67 | 86.47 | |
| 8 | 8 | 2 | 67.73 | 79.71 | 86.24 | |
| 8 | 8 | 4 | 67.82 | 79.75 | 86.40 | |
| 16 | 16 | 2 | 67.67 | 79.52 | 86.42 | |
| 16 | 16 | 4 | 68.04 | 79.75 | 86.40 | |
| Potsdam | / | / | / | 72.03 | 82.04 | 87.43 |
| 4 | 4 | 2 | 73.65 | 83.49 | 88.09 | |
| 4 | 4 | 4 | 73.38 | 83.28 | 87.96 | |
| 8 | 8 | 2 | 73.44 | 83.22 | 88.15 | |
| 8 | 8 | 4 | 73.11 | 83.04 | 87.89 | |
| 16 | 16 | 2 | 73.54 | 83.45 | 87.98 | |
| 16 | 16 | 4 | 72.57 | 82.39 | 87.89 |
| Dataset | SPAM | SCAM | FPN | FAM | mIOU | mF1 | OA |
|---|---|---|---|---|---|---|---|
| Vaihingen | 65.19 | 77.32 | 85.6 | ||||
| ✔ | 65.73 | 78.06 | 85.61 | ||||
| ✔ | 65.38 | 77.41 | 85.85 | ||||
| ✔ | ✔ | 68.19 | 79.99 | 86.64 | |||
| ✔ | ✔ | ✔ | 66.82 | 78.88 | 86.11 | ||
| ✔ | ✔ | ✔ | ✔ | 68.50 | 80.22 | 86.72 | |
| Potsdam | 72.03 | 82.04 | 87.43 | ||||
| ✔ | 73.18 | 83.12 | 87.88 | ||||
| ✔ | 72.80 | 82.80 | 87.73 | ||||
| ✔ | ✔ | 73.65 | 83.49 | 88.09 | |||
| ✔ | ✔ | ✔ | 73.63 | 83.45 | 88.07 | ||
| ✔ | ✔ | ✔ | ✔ | 73.79 | 83.57 | 88.22 |
| Dataset | Method | mIOU | F1 | OA |
|---|---|---|---|---|
| Vaihingen | baseline + SPAM + SCAM | 35.68 | 51.88 | 55.19 |
| baseline + SPAM + SCAM + FAM | 36.52 | 52.92 | 55.42 | |
| Potsdam | baseline + SPAM + SCAM | 38.32 | 54.34 | 56.48 |
| baseline + SPAM + SCAM + FAM | 38.81 | 54.82 | 56.90 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, L.; Zou, H.; Wei, J.; Cao, X.; He, S.; Li, M.; Liu, S. Semantic Segmentation of High-Resolution Remote Sensing Images Based on Sparse Self-Attention and Feature Alignment. Remote Sens. 2023, 15, 1598. https://doi.org/10.3390/rs15061598
Sun L, Zou H, Wei J, Cao X, He S, Li M, Liu S. Semantic Segmentation of High-Resolution Remote Sensing Images Based on Sparse Self-Attention and Feature Alignment. Remote Sensing. 2023; 15(6):1598. https://doi.org/10.3390/rs15061598
Chicago/Turabian StyleSun, Li, Huanxin Zou, Juan Wei, Xu Cao, Shitian He, Meilin Li, and Shuo Liu. 2023. "Semantic Segmentation of High-Resolution Remote Sensing Images Based on Sparse Self-Attention and Feature Alignment" Remote Sensing 15, no. 6: 1598. https://doi.org/10.3390/rs15061598
APA StyleSun, L., Zou, H., Wei, J., Cao, X., He, S., Li, M., & Liu, S. (2023). Semantic Segmentation of High-Resolution Remote Sensing Images Based on Sparse Self-Attention and Feature Alignment. Remote Sensing, 15(6), 1598. https://doi.org/10.3390/rs15061598