






A Semantic Segmentation Framework for Hyperspectral Imagery Based on Tucker Decomposition and 3DCNN Tested with Simulated Noisy Scenarios



Abstract
1. Introduction
1.1. Related Work
1.2. Contributions
- This work provides the remote sensing community with a framework based on a 3DCNN and Tucker Decomposition, performing semantic segmentation of noisy hyperspectral images, from an SNR of from 60 dB to 0 dB, outperforming other classical classifiers such as RF and SVM.
- Taking advantage of the spectral correlation of the data, we perform the Tucker Decomposition compressing only in the spectral domain; for example, for the three data sets studied to 40 new tensor bands and achieving a relative reconstruction error of less than 1%. This compression of the spectral domain of the input space reduces the computational complexity, consequently reducing the training time ratio by up to 29 times with respect to the original input space, depending on the case.
- TKD not only reduces the computational complexity but also increases the classification performance. This improvement was most significant for training set sizes on the order of from 5% to 3%. Furthermore, the behavior of TKD under different SNR are studied for the three used datasets.
2. Mathematical Background
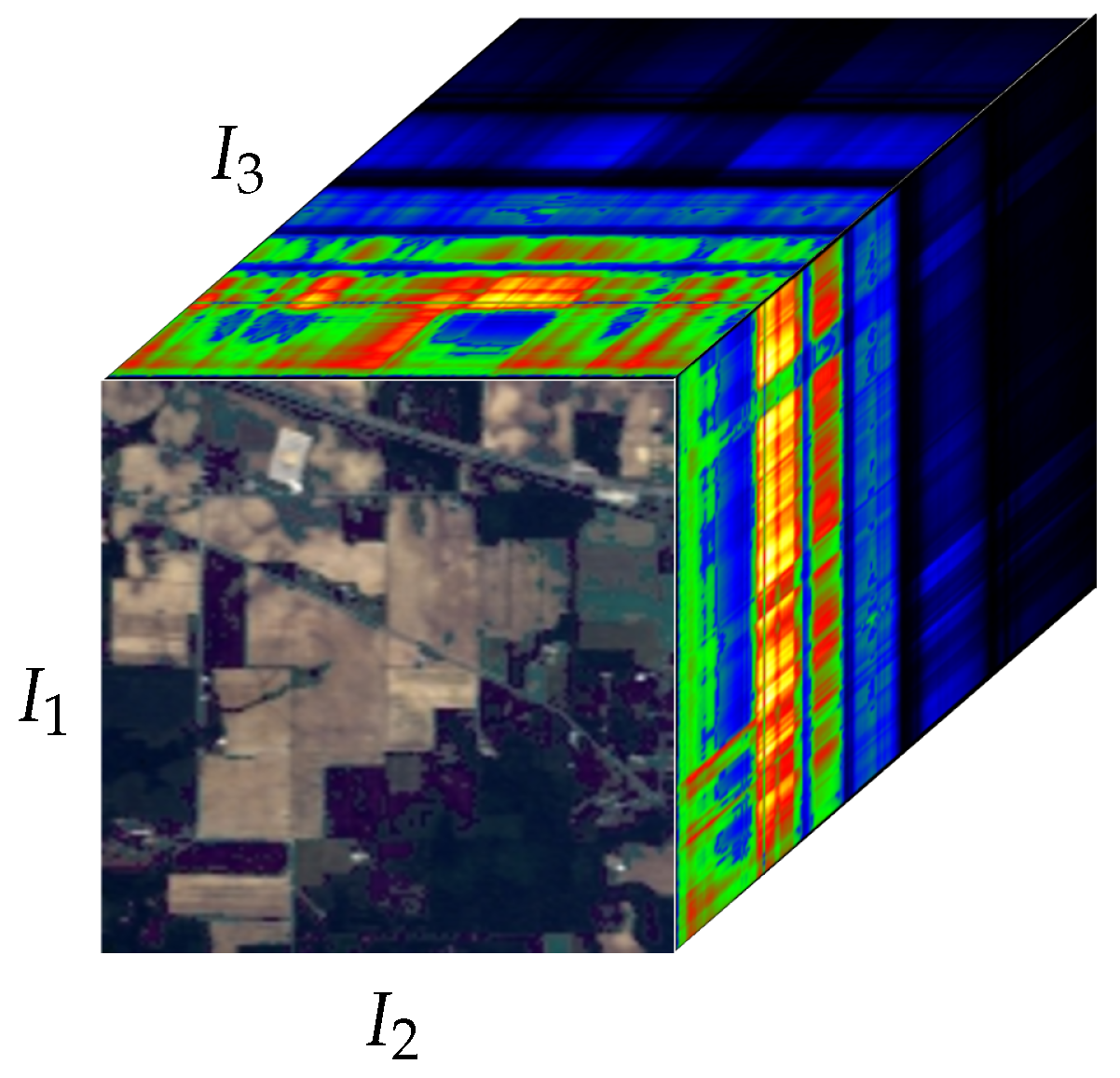
2.1. Tensor Algebra
2.2. Noise Model
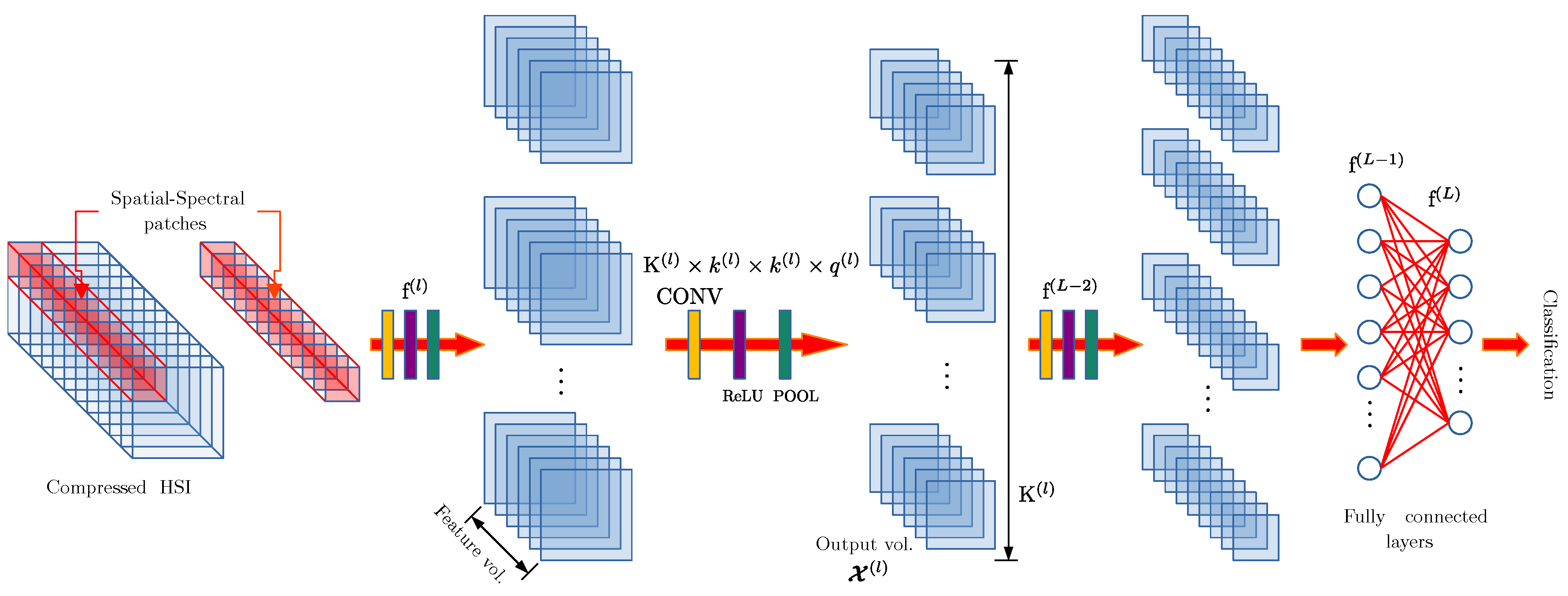
2.3. Spectral–Spatial Deep Learning Models
2.4. Unbalanced Classification Performance Metrics
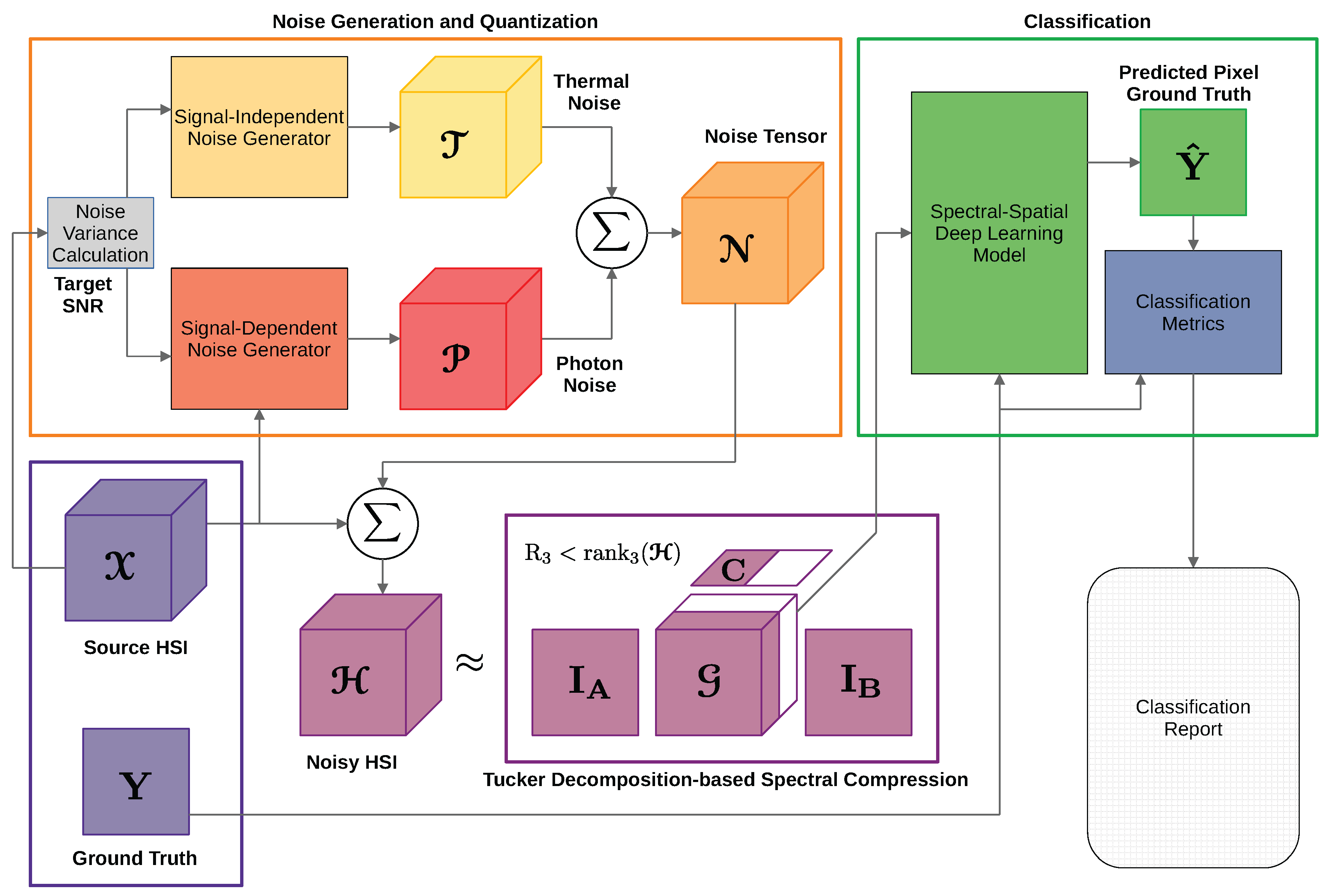
3. Proposed Framework
- Noise Generation and Quantization: Having as input the clean signal power, the variances for signal-dependent and independent noise processes are calculated for a specified SNR. In order to follow the non-negative integer values of a digital image, a quantization is performed.
- Tucker Decomposition: Transforms into a new input space through a core-tensor and factor matrices , and , where is a spectrally compressed version of .
- Deep Learning Model: The model is fitted in terms of the Softmax loss with and the class labels present in the ground truth , evaluating the prediction of the trained model with metrics that consider a possible unbalanced class scenario.
3.1. Problem Statement
3.2. Noise Generation and Quantization
3.3. Tucker Decomposition-Based Spectral Compression
3.4. Deep Learning Model Architecture
4. Dataset Experiments and Results
4.1. Hardware
4.2. Datasets Description
4.2.1. Indian Pines
4.2.2. University of Pavia
4.2.3. Salinas
4.3. Data Pre-Processing for Reduction of Number of Bands
TKD Behavior for Low-SNR HSI Analysis
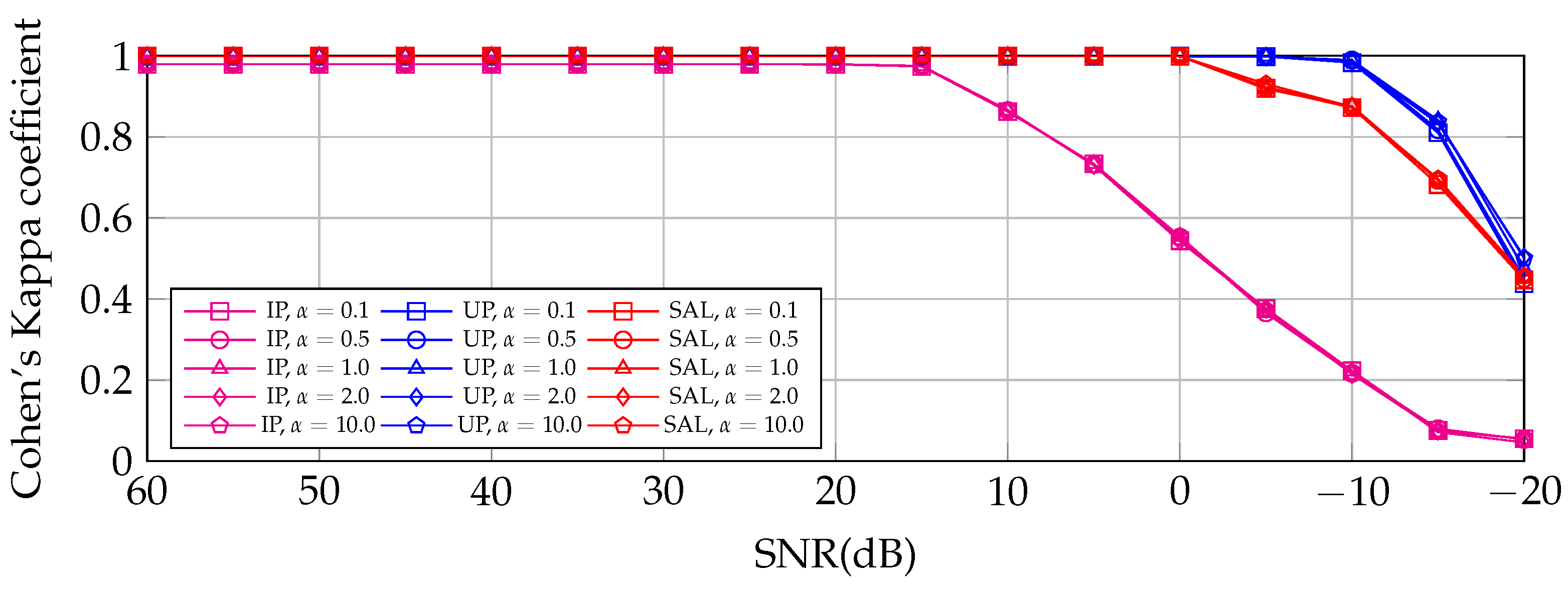
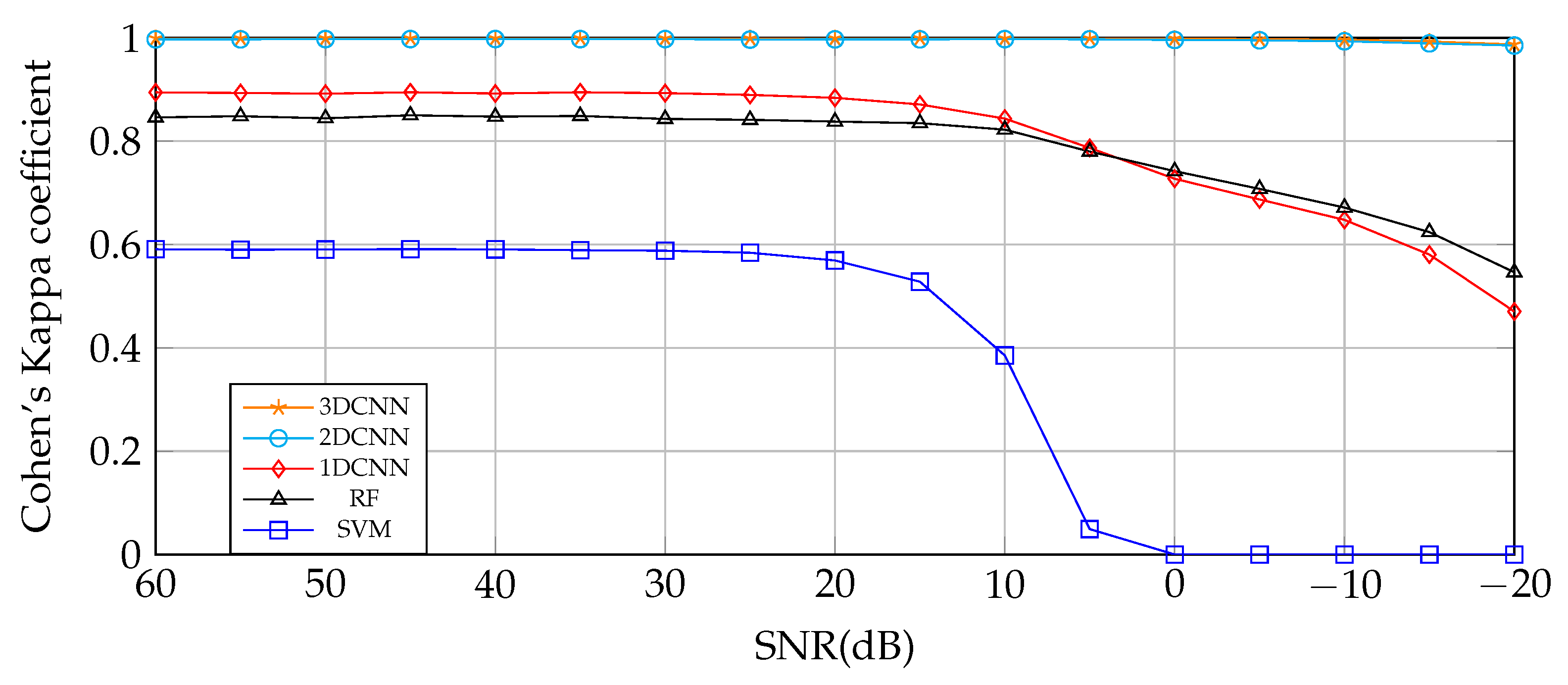
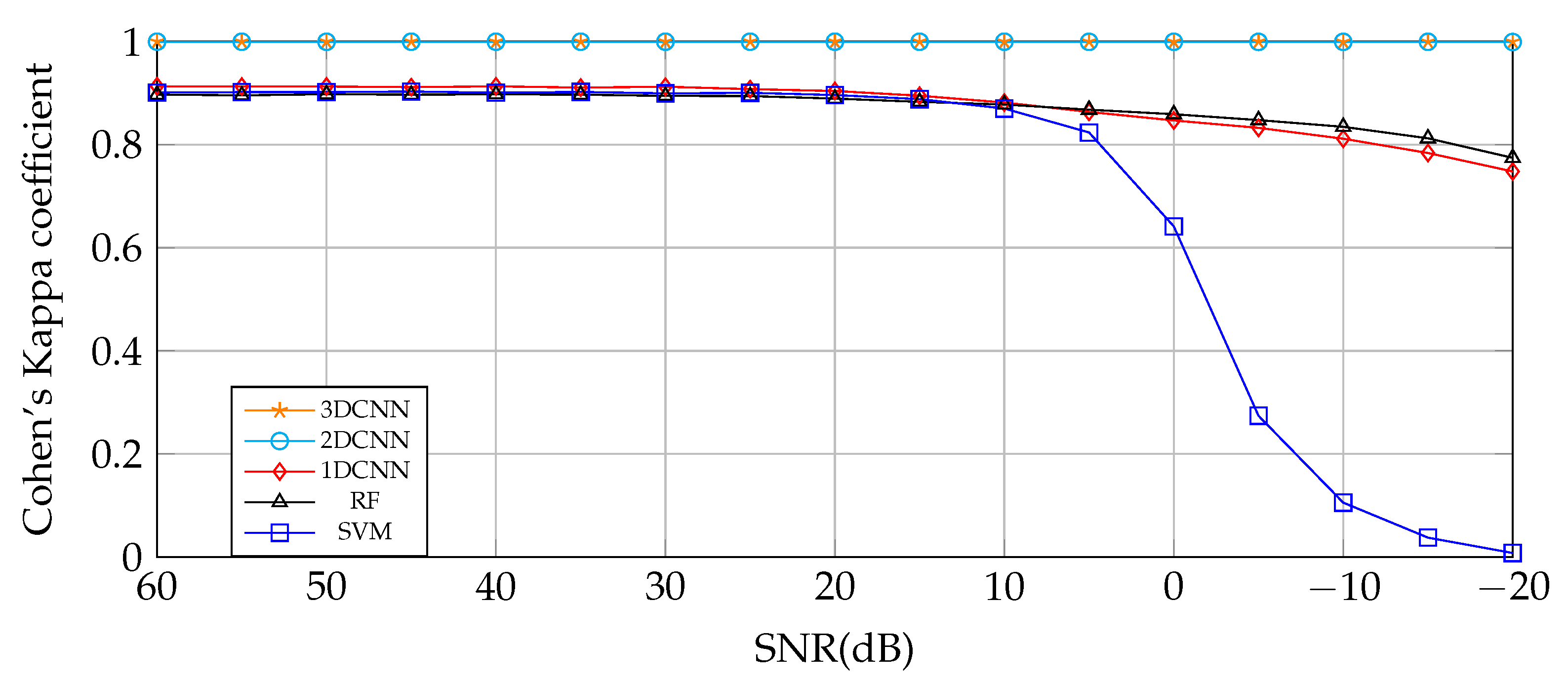
4.4. 3DCNN Prediction of Data with Variable SNR from 60 to −20 dB
4.5. Comparison between 3DCNN and Other Classical Algorithms
4.6. Performance, Computational Complexity, and Training Time Comparison between Original and Compressed Data Using TKD for 3DCNN Model
4.7. Framework Testing with Datasets for Different -Values and TS Percentage
5. Discussion
6. Conclusions
- This framework, based on a 3DCNN spectral–spatial deep learning feature extraction model and Tucker Decomposition, proved to be robust in most cases for different combinations and levels of simulated signal-dependent and signal-independent noises, even when the SNR is close to 0 dB.
- Tucker Decomposition reduces from 103 to 224 bands to 40 new tensor bands with %, reducing the computational complexity for the classifier. Different to other compression algorithms, Tucker Decomposition does not affect the performance of the deep learning model; conversely, it improves the classification performance of the 3DCNN deep learning model in the three studied datasets. This improvement is more noticeable for the training set size in the order of from 5% to 3% for the three datasets tested.
- Tucker Decomposition performs well until SNR is close to 0 dB; for 0 dB, TKD cannot represent the useful information in the core tensor, resulting in an obvious loss of performance.
- With a representative number of labeled samples of each class (depending on the hyperspectral image and accuracy we want), for an SNR ≥ of 0 dB, our proposal is not affected by different -values; in other words, different noisy scenarios of signal-dependent and signal-independent noise.
Open Issues
- To test the spatial–spectral feature extraction of 3DCNN in other types of applications for hyperspectral imagery.
- An algorithm is needed to find the minimum n-rank that fully represents the data into the core tensor, reducing the computational and spatial complexity for posterior stages in the framework.
- To test the framework with a larger number of hyperspectral images, considering distributions of ground truth with less spatial correlation, and for RGB and multi-spectral imagery.
- Mathematical and statistical analysis of Tucker Decomposition for noisy data.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network. |
| DL | Deep Learning. |
| GT | Ground Truth. |
| HPC | High Performance Computing. |
| HSI | Hyperspectral Image. |
| IP | Indian Pines. |
| PCA | Principal Component Analysis. |
| SAL | Salinas. |
| SD | Signal Dependent. |
| SI | Signal Independent. |
| SNR | Signal-to-Noise Ratio. |
| TKD | Tucker Decomposition. |
| TS | Train Size. |
| UP | University of Pavia. |
Appendix A
Appendix A.1
Appendix A.2

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SNR | SVM | RF | 1DCNN | 2DCNN | 3DCNN | |
|---|---|---|---|---|---|---|
| Indian Pines | 60 dB | 0.6244 ± 0.0068 | 0.6664 ± 0.0111 | 0.6231 ± 0.0113 | 0.9654 ± 0.0059 | 0.9802 ± 0.0029 |
| 55 dB | 0.6241 ± 0.0087 | 0.6682 ± 0.0068 | 0.6250 ± 0.0099 | 0.9683 ± 0.0024 | 0.9803 ± 0.0024 | |
| 50 dB | 0.6303 ± 0.0066 | 0.6716 ± 0.0105 | 0.6186 ± 0.0104 | 0.9690 ± 0.0078 | 0.9817 ± 0.0040 | |
| 45 dB | 0.6289 ± 0.0090 | 0.6697 ± 0.0068 | 0.6193 ± 0.0086 | 0.9641 ± 0.0059 | 0.9793 ± 0.0056 | |
| 40 dB | 0.6223 ± 0.0029 | 0.6780 ± 0.0112 | 0.6203 ± 0.0139 | 0.9720 ± 0.0045 | 0.9799 ± 0.0050 | |
| 35 dB | 0.6148 ± 0.0103 | 0.6795 ± 0.0075 | 0.6133 ± 0.0103 | 0.9712 ± 0.0045 | 0.9781 ± 0.0029 | |
| 30 dB | 0.5985 ± 0.0105 | 0.6660 ± 0.0111 | 0.6008 ± 0.0061 | 0.9692 ± 0.0052 | 0.9793 ± 0.0035 | |
| 25 dB | 0.5501 ± 0.0100 | 0.6553 ± 0.0107 | 0.5803 ± 0.0093 | 0.9665 ± 0.0043 | 0.9773 ± 0.0033 | |
| 20 dB | 0.4354 ± 0.0066 | 0.6346 ± 0.0092 | 0.5303 ± 0.0126 | 0.9660 ± 0.0049 | 0.9737 ± 0.0059 | |
| 15 dB | 0.1919 ± 0.0093 | 0.6054 ± 0.0094 | 0.4856 ± 0.0108 | 0.9574 ± 0.0060 | 0.9673 ± 0.0043 | |
| 10 dB | 0.0248 ± 0.0037 | 0.5808 ± 0.0063 | 0.4419 ± 0.0131 | 0.9573 ± 0.0068 | 0.9628 ± 0.0035 | |
| 5 dB | 0.0006 ± 0.0003 | 0.5424 ± 0.0069 | 0.4106 ± 0.0063 | 0.9493 ± 0.0060 | 0.9522 ± 0.0061 | |
| 0 dB | 0.0000 ± 0.0001 | 0.5086 ± 0.0069 | 0.3831 ± 0.0128 | 0.9406 ± 0.0065 | 0.9425 ± 0.0081 | |
| −5 dB | 0.0000 ± 0.0000 | 0.4664 ± 0.0083 | 0.3433 ± 0.0120 | 0.9443 ± 0.0092 | 0.9404 ± 0.0068 | |
| −10 dB | 0.0000 ± 0.0000 | 0.4191 ± 0.0039 | 0.2826 ± 0.0130 | 0.9318 ± 0.0096 | 0.9299 ± 0.0042 | |
| −15 dB | 0.0000 ± 0.0000 | 0.3700 ± 0.0081 | 0.2246 ± 0.0085 | 0.9143 ± 0.0099 | 0.9083 ± 0.0079 | |
| −20 dB | 0.0000 ± 0.0000 | 0.2938 ± 0.0069 | 0.1534 ± 0.0099 | 0.9091 ± 0.0164 | 0.9002 ± 0.0079 | |
| University of Pavia | 60 dB | 0.5909 ± 0.0048 | 0.8461 ± 0.0036 | 0.8946 ± 0.0045 | 0.9973 ± 0.0009 | 0.9994 ± 0.0003 |
| 55 dB | 0.5900 ± 0.0043 | 0.8484 ± 0.0037 | 0.8935 ± 0.0044 | 0.9972 ± 0.0004 | 0.9994 ± 0.0003 | |
| 50 dB | 0.5904 ± 0.0041 | 0.8444 ± 0.0076 | 0.8920 ± 0.0061 | 0.9977 ± 0.0009 | 0.9995 ± 0.0005 | |
| 45 dB | 0.5911 ± 0.0033 | 0.8502 ± 0.0050 | 0.8948 ± 0.0052 | 0.9977 ± 0.0004 | 0.9995 ± 0.0004 | |
| 40 dB | 0.5906 ± 0.0040 | 0.8475 ± 0.0089 | 0.8924 ± 0.0042 | 0.9978 ± 0.0006 | 0.9994 ± 0.0003 | |
| 35 dB | 0.5890 ± 0.0050 | 0.8489 ± 0.0041 | 0.8947 ± 0.0069 | 0.9976 ± 0.0008 | 0.9996 ± 0.0002 | |
| 30 dB | 0.5880 ± 0.0034 | 0.8431 ± 0.0061 | 0.8931 ± 0.0050 | 0.9977 ± 0.0005 | 0.9994 ± 0.0002 | |
| 25 dB | 0.5841 ± 0.0028 | 0.8415 ± 0.0040 | 0.8897 ± 0.0048 | 0.9967 ± 0.0011 | 0.9992 ± 0.0004 | |
| 20 dB | 0.5692 ± 0.0041 | 0.8380 ± 0.0051 | 0.8840 ± 0.0083 | 0.9972 ± 0.0013 | 0.9995 ± 0.0003 | |
| 15 dB | 0.5281 ± 0.0016 | 0.8350 ± 0.0037 | 0.8713 ± 0.0035 | 0.9972 ± 0.0008 | 0.9996 ± 0.0002 | |
| 10 dB | 0.3853 ± 0.0049 | 0.8224 ± 0.0032 | 0.8438 ± 0.0049 | 0.9977 ± 0.0008 | 0.9993 ± 0.0003 | |
| 5 dB | 0.0492 ± 0.0021 | 0.7800 ± 0.0036 | 0.7870 ± 0.0045 | 0.9973 ± 0.0004 | 0.9993 ± 0.0003 | |
| 0 dB | 0.0000 ± 0.0000 | 0.7421 ± 0.0035 | 0.7274 ± 0.0056 | 0.9961 ± 0.0011 | 0.9989 ± 0.0005 | |
| −5 dB | 0.0000 ± 0.0000 | 0.7077 ± 0.0028 | 0.6873 ± 0.0030 | 0.9954 ± 0.0011 | 0.9977 ± 0.0012 | |
| −10 dB | 0.0000 ± 0.0000 | 0.6716 ± 0.0032 | 0.6478 ± 0.0039 | 0.9934 ± 0.0018 | 0.9966 ± 0.0009 | |
| −15 dB | 0.0000 ± 0.0000 | 0.6241 ± 0.0030 | 0.5806 ± 0.0069 | 0.9894 ± 0.0013 | 0.9930 ± 0.0012 | |
| −20 dB | 0.0000 ± 0.0000 | 0.5463 ± 0.0026 | 0.4703 ± 0.0084 | 0.9853 ± 0.0028 | 0.9874 ± 0.0017 | |
| Salinas | 60 dB | 0.9010 ± 0.0021 | 0.8971 ± 0.0023 | 0.9131 ± 0.0036 | 0.9996 ± 0.0004 | 0.9999 ± 0.0001 |
| 55 dB | 0.9017 ± 0.0018 | 0.8954 ± 0.0026 | 0.9125 ± 0.0030 | 0.9995 ± 0.0002 | 0.9999 ± 0.0001 | |
| 50 dB | 0.9016 ± 0.0025 | 0.8977 ± 0.0040 | 0.9126 ± 0.0025 | 0.9994 ± 0.0004 | 0.9999 ± 0.0001 | |
| 45 dB | 0.9029 ± 0.0021 | 0.8967 ± 0.0019 | 0.9114 ± 0.0031 | 0.9995 ± 0.0002 | 0.9999 ± 0.0001 | |
| 40 dB | 0.9006 ± 0.0019 | 0.8975 ± 0.0020 | 0.9129 ± 0.0025 | 0.9995 ± 0.0002 | 0.9998 ± 0.0001 | |
| 35 dB | 0.9020 ± 0.0017 | 0.8968 ± 0.0021 | 0.9106 ± 0.0041 | 0.9995 ± 0.0003 | 0.9999 ± 0.0001 | |
| 30 dB | 0.8993 ± 0.0019 | 0.8944 ± 0.0019 | 0.9122 ± 0.0023 | 0.9995 ± 0.0003 | 0.9999 ± 0.0001 | |
| 25 dB | 0.9003 ± 0.0019 | 0.8940 ± 0.0028 | 0.9076 ± 0.0038 | 0.9995 ± 0.0001 | 0.9999 ± 0.0001 | |
| 20 dB | 0.8961 ± 0.0016 | 0.8892 ± 0.0017 | 0.9039 ± 0.0026 | 0.9995 ± 0.0003 | 0.9999 ± 0.0001 | |
| 15 dB | 0.8881 ± 0.0012 | 0.8828 ± 0.0026 | 0.8947 ± 0.0029 | 0.9994 ± 0.0003 | 0.9998 ± 0.0001 | |
| 10 dB | 0.8699 ± 0.0015 | 0.8777 ± 0.0015 | 0.8815 ± 0.0034 | 0.9996 ± 0.0002 | 0.9998 ± 0.0001 | |
| 5 dB | 0.8234 ± 0.0025 | 0.8677 ± 0.0022 | 0.8634 ± 0.0041 | 0.9993 ± 0.0003 | 0.9998 ± 0.0001 | |
| 0 dB | 0.6413 ± 0.0035 | 0.8589 ± 0.0020 | 0.8468 ± 0.0025 | 0.9994 ± 0.0003 | 0.9997 ± 0.0001 | |
| −5 dB | 0.2741 ± 0.0100 | 0.8474 ± 0.0025 | 0.8324 ± 0.0031 | 0.9992 ± 0.0003 | 0.9998 ± 0.0001 | |
| −10 dB | 0.1056 ± 0.0013 | 0.8344 ± 0.0020 | 0.8114 ± 0.0029 | 0.9993 ± 0.0003 | 0.9995 ± 0.0003 | |
| −15 dB | 0.0377 ± 0.0005 | 0.8121 ± 0.0015 | 0.7837 ± 0.0039 | 0.9994 ± 0.0003 | 0.9997 ± 0.0001 | |
| −20 dB | 0.0079 ± 0.0005 | 0.7743 ± 0.0027 | 0.7478 ± 0.0046 | 0.9989 ± 0.0004 | 0.9996 ± 0.0002 |
References
- Borengasser, M.; Hungate, W.S.; Watkins, R.L. Hyperspectral Remote Sensing: Principles and Applications; CRC Press: Boca Raton, FL, USA, 2008; p. 119. [Google Scholar]
- Paoletti, M.E.; Haut, J.M.; Plaza, J.; Plaza, A. Deep learning classifiers for hyperspectral imaging: A review. ISPRS J. Photogramm. Remote Sens. 2019, 158, 279–317. [Google Scholar] [CrossRef]
- Rasti, B.; Scheunders, P.; Ghamisi, P.; Licciardi, G.; Chanussot, J. Noise Reduction in Hyperspectral Imagery: Overview and Application. Remote Sens. 2018, 10, 482. [Google Scholar] [CrossRef]
- Bourennane, S.; Fossati, C.; Lin, T. Noise Removal Based on Tensor Modelling for Hyperspectral Image Classification. Remote Sens. 2018, 10, 1330. [Google Scholar] [CrossRef]
- Gu, S.; Zhang, L.; Zuo, W.; Feng, X. Weighted nuclear norm minimization with application to image denoising. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; IEEE Computer Society: Washington, DC, USA, 2014; pp. 2862–2869. [Google Scholar] [CrossRef]
- Karami, A.; Yazdi, M.; Zolghadre Asli, A. Noise reduction of hyperspectral images using kernel non-negative tucker decomposition. IEEE J. Sel. Top. Signal Process. 2011, 5, 487–493. [Google Scholar] [CrossRef]
- Yuan, Q.; Zhang, Q.; Li, J.; Shen, H.; Zhang, L. Hyperspectral image denoising employing a spatial-spectral deep residual convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1205–1218. [Google Scholar] [CrossRef]
- Fan, H.; Li, C.; Guo, Y.; Kuang, G.; Ma, J. Spatial-Spectral Total Variation Regularized Low-Rank Tensor Decomposition for Hyperspectral Image Denoising. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6196–6213. [Google Scholar] [CrossRef]
- Huang, Z.; Li, S.; Fang, L.; Li, H.; Benediktsson, J.A. Hyperspectral Image Denoising with Group Sparse and Low-Rank Tensor Decomposition. IEEE Access 2017, 6, 1380–1390. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef]
- Hu, J.; Li, L.; Lin, Y.; Wu, F.; Zhao, J. A Comparison and Strategy of Semantic Segmentation on Remote Sensing Images. Adv. Intell. Syst. Comput. 2019, 1074, 21–29. [Google Scholar] [CrossRef]
- Niu, Z.; Liu, W.; Zhao, J.; Jiang, G. DeepLab-Based Spatial Feature Extraction for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2019, 16, 251–255. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Ma, L.; Jiang, H.; Zhao, H. Deep residual networks for hyperspectral image classification. In Proceedings of the International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2017; pp. 1824–1827. [Google Scholar] [CrossRef]
- Feng, J.; Yu, H.; Wang, L.; Cao, X.; Zhang, X.; Jiao, L. Classification of Hyperspectral Images Based on Multiclass Spatial-Spectral Generative Adversarial Networks. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5329–5343. [Google Scholar] [CrossRef]
- Hu, W.; Huang, Y.; Wei, L.; Zhang, F.; Li, H. Deep convolutional neural networks for hyperspectral image classification. J. Sens. 2015, 2015, 258619. [Google Scholar] [CrossRef]
- Xiao, H.; Wei, Y.; Liu, Y.; Zhang, M.; Feng, J. Transferable Semi-Supervised Semantic Segmentation. Proc. AAAI Conf. Artif. Intell. 2018, 32, 7420–7427. [Google Scholar] [CrossRef]
- Sun, R.; Zhu, X.; Wu, C.; Huang, C.; Shi, J.; Ma, L. Not all areas are equal: Transfer learning for semantic segmentation via hierarchical region selection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–19 June 2019; pp. 4355–4364. [Google Scholar] [CrossRef]
- Stan, S.; Rostami, M. Unsupervised Model Adaptation for Continual Semantic Segmentation. Proc. AAAI Conf. Artif. Intell. 2021, 35, 2593–2601. [Google Scholar] [CrossRef]
- Sun, J.; Wei, D.; Ma, K.; Wang, L.; Zheng, Y. Boost Supervised Pretraining for Visual Transfer Learning: Implications of Self-Supervised Contrastive Representation Learning. Proc. AAAI Conf. Artif. Intell. 2022, 36, 2307–2315. [Google Scholar] [CrossRef]
- Cui, B.; Chen, X.; Lu, Y. Semantic Segmentation of Remote Sensing Images Using Transfer Learning and Deep Convolutional Neural Network with Dense Connection. IEEE Access 2020, 8, 116744–116755. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. [Google Scholar] [CrossRef]
- Pasquali, G.; Iannelli, G.C.; Dell’Acqua, F. Building Footprint Extraction from Multispectral, Spaceborne Earth Observation Datasets Using a Structurally Optimized U-Net Convolutional Neural Network. Remote Sens. 2019, 11, 2803. [Google Scholar] [CrossRef]
- Wieland, M.; Li, Y.; Martinis, S. Multi-sensor cloud and cloud shadow segmentation with a convolutional neural network. Remote Sens. Environ. 2019, 230, 111203. [Google Scholar] [CrossRef]
- Giang, T.L.; Dang, K.B.; Le, Q.T.; Nguyen, V.G.; Tong, S.S.; Pham, V.M. U-net convolutional networks for mining land cover classification based on high-resolution UAV imagery. IEEE Access 2020, 8, 186257–186273. [Google Scholar] [CrossRef]
- Fu, H.; Zhang, A.; Sun, G.; Ren, J.; Jia, X.; Pan, Z.; Ma, H. A Novel Band Selection and Spatial Noise Reduction Method for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Prasad, S.; Li, W.; Fowler, J.E.; Bruce, L.M. Information fusion in the redundant-wavelet-transform domain for noise-robust hyperspectral classification. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3474–3486. [Google Scholar] [CrossRef]
- Duan, P.; Kang, X.; Li, S.; Ghamisi, P. Noise-robust hyperspectral image classification via multi-scale total variation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 1948–1962. [Google Scholar] [CrossRef]
- Gong, Z.; Zhong, P.; Yao, W.; Zhou, W.; Qi, J.; Hu, P. A CNN with noise inclined module and denoise framework for hyperspectral image classification. IET Image Process. 2022. [Google Scholar] [CrossRef]
- Chen, C.; Li, W.; Tramel, E.W.; Cui, M.; Prasad, S.; Fowler, J.E. Spectral–Spatial Preprocessing Using Multihypothesis Prediction for Noise-Robust Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 1047–1059. [Google Scholar] [CrossRef]
- Gao, L.; Zhao, B.; Jia, X.; Liao, W.; Zhang, B.; Wang, Q.; Younan, N.H.; López-Martínez, C.; Thenkabail, P.S. Optimized Kernel Minimum Noise Fraction Transformation for Hyperspectral Image Classification. Remote Sens. 2017, 9, 548. [Google Scholar] [CrossRef]
- Fu, P.; Sun, X.; Sun, Q. Hyperspectral Image Segmentation via Frequency-Based Similarity for Mixed Noise Estimation. Remote Sens. 2017, 9, 1237. [Google Scholar] [CrossRef]
- de Los Reyes, R.; Langheinrich, M.; Schwind, P.; Richter, R.; Pflug, B.; Bachmann, M.; Müller, R.; Carmona, E.; Zekoll, V.; Reinartz, P. PACO: Python-Based Atmospheric COrrection. Sensors 2020, 20, 1428. [Google Scholar] [CrossRef]
- Zekoll, V.; Main-Knorn, M.; Alonso, K.; Louis, J.; Frantz, D.; Richter, R.; Pflug, B. Comparison of Masking Algorithms for Sentinel-2 Imagery. Remote Sens. 2021, 13, 137. [Google Scholar] [CrossRef]
- Guanter, L.; Kaufmann, H.; Segl, K.; Foerster, S.; Rogass, C.; Chabrillat, S.; Kuester, T.; Hollstein, A.; Rossner, G.; Chlebek, C.; et al. The EnMAP Spaceborne Imaging Spectroscopy Mission for Earth Observation. Remote Sens. 2015, 7, 8830–8857. [Google Scholar] [CrossRef]
- Alonso, K.; Bachmann, M.; Burch, K.; Carmona, E.; Cerra, D.; de los Reyes, R.; Dietrich, D.; Heiden, U.; Hölderlin, A.; Ickes, J.; et al. Data Products, Quality and Validation of the DLR Earth Sensing Imaging Spectrometer (DESIS). Sensors 2019, 19, 4471. [Google Scholar] [CrossRef]
- López, J.; Torres, D.; Santos, S.; Atzberger, C. Spectral Imagery Tensor Decomposition for Semantic Segmentation of Remote Sensing Data through Fully Convolutional Networks. Remote Sens. 2020, 12, 517. [Google Scholar] [CrossRef]
- Padilla-Zepeda, E.; Torres-Roman, D.; Mendez-Vazquez, A. Noise analysis using Tucker decomposition and PCA on spectral images. ECORFAN J.-Boliv. 2020, 7, 10–16. [Google Scholar] [CrossRef]
- Kolda, T.G.; Bader, B.W. Tensor decompositions and applications. SIAM Rev. 2009, 51, 455–500. [Google Scholar] [CrossRef]
- Liu, X.; Bourennane, S.; Fossati, C. Reduction of signal-dependent noise from hyperspectral images for target detection. IEEE Trans. Geosci. Remote Sens. 2014, 52, 5396–5411. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, H.; Shen, Q. Spectral–Spatial Classification of Hyperspectral Imagery with 3D Convolutional Neural Network. Remote Sens. 2017, 9, 67. [Google Scholar] [CrossRef]
- Grandini, M.; Bagli, E.; Visani, G. Metrics for Multi-Class Classification: An Overview. arXiv 2020, arXiv:2008.05756. [Google Scholar]
- Luque, A.; Carrasco, A.; Martín, A.; de las Heras, A. The impact of class imbalance in classification performance metrics based on the binary confusion matrix. Pattern Recognit. 2019, 91, 216–231. [Google Scholar] [CrossRef]
- Gonzalez-Ramirez, A.; Lopez, J.; Torres-Roman, D.; Yañez-Vargas, I. Analysis of multi-class classification performance metrics for remote sensing imagery imbalanced datasets. ECORFAN J. Quant. Stat. Anal. 2021, 8, 11–17. [Google Scholar] [CrossRef]
- Makantasis, K.; Doulamis, A.D.; Doulamis, N.D.; Nikitakis, A. Tensor-based classification models for hyperspectral data analysis. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6884–6898. [Google Scholar] [CrossRef]
- Sidiropoulos, N.D.; De Lathauwer, L.; Fu, X.; Huang, K.; Papalexakis, E.E.; Faloutsos, C. Tensor Decomposition for Signal Processing and Machine Learning. IEEE Trans. Signal Process. 2017, 65, 3551–3582. [Google Scholar] [CrossRef]
- An, J.; Lei, J.; Song, Y.; Zhang, X.; Guo, J. Tensor Based Multiscale Low Rank Decomposition for Hyperspectral Images Dimensionality Reduction. Remote Sens. 2019, 11, 1485. [Google Scholar] [CrossRef]
- Kong, X.; Zhao, Y.; Xue, J.; Chan, J.C.W. Hyperspectral Image Denoising Using Global Weighted Tensor Norm Minimum and Nonlocal Low-Rank Approximation. Remote Sens. 2019, 11, 2281. [Google Scholar] [CrossRef]
- Lu, H.; Plataniotis, K.N.; Venetsanopoulos, A.N. MPCA: Multilinear principal component analysis of tensor objects. IEEE Trans. Neural Netw. 2008, 19, 18–39. [Google Scholar] [CrossRef] [PubMed]
- AVIRIS—eoPortal Directory—Airborne Sensors. Available online: https://aviris.jpl.nasa.gov/ (accessed on 15 June 2020).
- Tucker, L.R. Some mathematical notes on three-mode factor analysis. Psychometrika 1966, 31, 279–311. [Google Scholar] [CrossRef] [PubMed]
- Alparone, L.; Selva, M.; Aiazzi, B.; Baronti, S.; Butera, F.; Chiarantini, L. Signal-dependent noise modelling and estimation of new-generation imaging spectrometers. In Proceedings of the WHISPERS ’09—1st Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing, Grenoble, France, 26–28 August 2009. [Google Scholar] [CrossRef]
- Faraji, H.; MacLean, W.J. CCD noise removal in digital images. IEEE Trans. Image Process. 2006, 15, 2676–2685. [Google Scholar] [CrossRef]
- Jain, A.K. Fundamentals of Digital Image Processing; Prentice-Hall, Inc.: Hoboken, NJ, USA, 1989. [Google Scholar]
- Padilla-Zepeda, E. Noisy-Hyperspectral-Semantic-Segmentation-Framework-Based-on-Tucker-Decomposition-and-3D-CNN. 2022. Available online: https://github.com/EfrainPadilla/Noisy-Hyperspectral-Semantic-Segmentation-Framework-based-on-Tucker-Decomposition-and-3D-CNN (accessed on 10 March 2022).
- Green, R.O.; Eastwood, M.L.; Sarture, C.M.; Chrien, T.G.; Aronsson, M.; Chippendale, B.J.; Faust, J.A.; Pavri, B.E.; Chovit, C.J.; Solis, M.; et al. Imaging spectroscopy and the Airborne Visible/Infrared Imaging Spectrometer (AVIRIS). Remote Sens. Environ. 1998, 65, 227–248. [Google Scholar] [CrossRef]
- Kunkel, B.; Blechinger, F.; Lutz, R.; Doerffer, R.; van der Piepen, H.; Schroder, M. ROSIS (Reflective Optics System Imaging Spectrometer) - A Candidate Instrument For Polar Platform Missions. Optoelectron. Technol. Remote Sens. Space SPIE 1988, 868, 134. [Google Scholar] [CrossRef]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef]
- Kossaifi, J.; Panagakis, Y.; Anandkumar, A.; Pantic, M. TensorLy: Tensor Learning in Python. J. Mach. Learn. Res. 2019, 20, 1–6. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]



















| Author | Contribution | |
|---|---|---|
| Tensor | Kolda and Bader [38] | Tensor theory |
| López et al. [36] | Use of the TKD for semantic segmentation tasks | |
| Noise | Bourennane et al. [4] | Noise theory and noise model |
| Liu et al. [39] | Noise model and noise generation | |
| Rasti et al. [3] | Noise theory and classification test methodology | |
| Classification | Paoletti et al. [2] | Classifiers code, architectures, and theory |
| Chen et al. [10] | Spatial–Spectral feature extraction theory | |
| Li et al. [40] | 3DCNN architecture | |
| Fu et al. [25] | Noisy-robust classification | |
| Metrics | Grandini et al. [41] | Metrics used for multi-class classification evaluation |
| Luque et al. [42] | Impact of class unbalance for classification performance metrics |
| Main Layer | Normalization | Activation Function | Downsampling |
|---|---|---|---|
| Linear input () | - | - | - |
| CONV | BN | ReLU | - |
| CONV | BN | ReLU | POOL |
| FC | BN | ReLU | - |
| FC | - | Softmax | - |
| Hardware | Cinvestav Guadalajara HPC Server |
|---|---|
| CPU | ×2 Intel Xeon 2.20 GHz 13.75 MB Cache L3 |
| Cores per CPU | 10 |
| Threads | 40 |
| RAM | 6 × 16 GB 96 GB DDR4 HPE Smart 2666 MHz ECC |
| GPU | ×1 NVIDIA Tesla V100 PCIe 3.0 |
| GPU Memory | 16 GB HBM2 |
| CUDA cores | 5120 |
| Class Number-Name | Samples | Color | Ground Truth | True RGB |
|---|---|---|---|---|
| “0-Background | 10,776 |  |  |  |
| 1-Alfalfa | 46 |  | ||
| 2-Corn-notill | 1428 |  | ||
| 3-Corn-mintill | 830 |  | ||
| 4-Corn | 237 |  | ||
| 5-Grass-pasture | 483 |  | ||
| 6-Grass-trees | 730 |  | ||
| 7-Grass-pasture-mowed | 28 |  | ||
| 8-Hay-windrowed | 478 |  | ||
| 9-Oats | 20 |  | ||
| 10-Soybean-notill | 972 |  | ||
| 11-Soybean-mintill | 2455 |  | ||
| 12-Soybean-clean | 593 |  | ||
| 13-Wheat | 205 |  | ||
| 14-Woods | 1265 |  | ||
| 15-Buildings-Grass-Trees-Drives | 386 |  | ||
| 16-Stone-Steel-Towers” | 93 |  |
| Class Number-Name | Samples | Color | Ground Truth | True RGB |
|---|---|---|---|---|
| “0-Background | 164,624 |  |  |  |
| 1-Asphalt | 6631 |  | ||
| 2-Meadows | 18,649 |  | ||
| 3-Gravel | 2099 |  | ||
| 4-Trees | 3064 |  | ||
| 5-Painted metal sheets | 1345 |  | ||
| 6-Bare Soil | 5029 |  | ||
| 7-Bitumen | 1330 |  | ||
| 8-Self-Blocking Bricks | 3682 |  | ||
| 9-Shadows” | 947 |  |
| Class number-name | Samples | Color | Ground Truth | True RGB |
|---|---|---|---|---|
| “0-Background | 56,975 |  |  |  |
| 1-Brocoli-green-weeds-1 | 2009 |  | ||
| 2-Brocoli-green-weeds-2 | 3726 |  | ||
| 3-Fallow | 1976 |  | ||
| 4-Fallow-rough-plow | 1394 |  | ||
| 5-Fallow-smooth | 2678 |  | ||
| 6-Stubble | 3959 |  | ||
| 7-Celery | 3579 |  | ||
| 8-Grapes-untrained | 11,271 |  | ||
| 9-Soil-vinyard-develop | 6203 |  | ||
| 10-Corn-senesced-green-weeds | 3278 |  | ||
| 11-Lettuce-romaine-4wk | 1068 |  | ||
| 12-Lettuce-romaine-5wk | 1927 |  | ||
| 13-Lettuce-romaine-6wk | 916 |  | ||
| 14-Lettuce-romaine-7wk | 1070 |  | ||
| 15-Vinyard-untrained | 7268 |  | ||
| 16-Vinyard-vertical-trellis” | 1807 |  |
| HSI | TKD Running Time (s) | |
|---|---|---|
| IP | 0.994 % | 2.89 |
| UP | 0.019 % | 16.83 |
| SAL | 0.027 % | 12.41 |
| Compressed HSI (40 Bands) | Patches Generation Running Time (s) |
|---|---|
| IP | 0.71 |
| UP | 18.51 |
| SAL | 10.53 |
| HSI | Set | 20% | 15% | 10% | 5% | 3% | 1% |
|---|---|---|---|---|---|---|---|
| IP | Training | 2049 | 1537 | 1024 | 512 | - | - |
| Testing | 8200 | 8712 | 9225 | 9737 | - | - | |
| UP | Training | - | 6416 | 4277 | 2138 | 1283 | 427 |
| Testing | - | 36,360 | 38,499 | 40,638 | 41,493 | 42,349 | |
| SAL | Training | - | 8118 | 5412 | 2706 | 1623 | 541 |
| Testing | - | 46,011 | 48,717 | 51,423 | 52,506 | 53,588 |
| 15% TS | 10% TS | 5% TS | 1% TS | ||
|---|---|---|---|---|---|
| Indian Pines | Original-200 bands (s) | 1889.73 | 1702.36 | 1469.47 | 1284.38 |
| TKD-40 bands (s) | 67.56 | 63.54 | 58.43 | 55.32 | |
| Time reduction ratio | 27.97 | 26.79 | 25.49 | 22.56 | |
| University of Pavia | Original-103 bands (s) | 2987.26 | 2660.66 | 2321.35 | 2041.95 |
| TKD-40 bands (s) | 255.90 | 239.80 | 228.65 | 208.53 | |
| Time reduction ratio | 11.67 | 11.09 | 10.15 | 9.79 | |
| Salinas | Original-204 bands (s) | 9762.00 | 8783.62 | 7714.61 | 6692.29 |
| TKD-40 bands (s) | 328.07 | 302.23 | 279.74 | 266.59 | |
| Time reduction ratio | 29.75 | 29.06 | 25.57 | 25.10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Padilla-Zepeda, E.; Torres-Roman, D.; Mendez-Vazquez, A. A Semantic Segmentation Framework for Hyperspectral Imagery Based on Tucker Decomposition and 3DCNN Tested with Simulated Noisy Scenarios. Remote Sens. 2023, 15, 1399. https://doi.org/10.3390/rs15051399
Padilla-Zepeda E, Torres-Roman D, Mendez-Vazquez A. A Semantic Segmentation Framework for Hyperspectral Imagery Based on Tucker Decomposition and 3DCNN Tested with Simulated Noisy Scenarios. Remote Sensing. 2023; 15(5):1399. https://doi.org/10.3390/rs15051399
Chicago/Turabian StylePadilla-Zepeda, Efrain, Deni Torres-Roman, and Andres Mendez-Vazquez. 2023. "A Semantic Segmentation Framework for Hyperspectral Imagery Based on Tucker Decomposition and 3DCNN Tested with Simulated Noisy Scenarios" Remote Sensing 15, no. 5: 1399. https://doi.org/10.3390/rs15051399
APA StylePadilla-Zepeda, E., Torres-Roman, D., & Mendez-Vazquez, A. (2023). A Semantic Segmentation Framework for Hyperspectral Imagery Based on Tucker Decomposition and 3DCNN Tested with Simulated Noisy Scenarios. Remote Sensing, 15(5), 1399. https://doi.org/10.3390/rs15051399