1. Introduction
Hyperspectral image (HSI) is collected by the remote sensor on the surface of the earth, which consists of hundreds of narrow electromagnetic spectrums from the visible to the near-infrared wavelength ranges. Since the HSI can distinguish subtle variations from the spectral signatures of the land cover object, it has been widely applied in many fields, such as urban planning [
1], fine agriculture [
2], and mineral exploration [
3]. However, the complex statistical and geometrical properties of HSI datasets prevent the direct utilization of traditional analysis techniques for multispectral images to extract meaningful information from hyperspectral ones. As a result, many scholars focus on developing analysis techniques of artificial intelligence specifically for HSI datasets.
HSI classification is an important analysis technique in the hyperspectral community, which assigns each pixel of HSI to one certain class based on its spectral signatures [
4]. Traditional HSI classification techniques focus on exploring the shallow characteristics of the HSI dataset to extract discriminable information, such as the principal component analysis (PCA) [
5], independent component analysis (ICA) [
6], and linear discriminate analysis (LDA) [
7]). After that, machine learning techniques are used to classify the discriminable information of the HSI dataset, such as the support vector machines (SVMs) [
8], multinomial logistic regression [
9], and extreme learning machines (ELMs) [
10,
11]. These methods design hand-crafted descriptors for specific tasks to explore features, which depends on expert knowledge in the parameter setup phase. However, the expert knowledge is difficult to access in practice, which limits the applicability of these methods to process a large amount of heterogeneous HSI datasets in a consistent end-to-end manner.
In recent years, deep learning techniques have shown great potential in computer vision tasks, such as image classification [
12], object detection [
13], and semantic segmentation [
14]. Motivated by those successful applications, deep learning techniques have been introduced to HSI classification tasks. Different from the traditional HSI classification approaches, the deep learning techniques adaptively and hierarchically explore information from the original HSI dataset and obtain the shallow texture features and deep semantic features via different neural network layers. The parameters of the deep learning techniques can be learned automatically, which makes these approaches more suitable to deal with complex situations of HSI classification without expert knowledge and solve problems in a consistent manner.
Recently, many deep learning frameworks have been proposed, such as stacked auto-encoders (SAEs) [
15], deep belief networks (DBNs) [
16], convolutional neural networks (CNNs) [
17], recurrent neural networks (RNNs) [
18], and generative adversarial networks (GANs) [
19]. Among these frameworks, CNNs have achieved good performance in HSI classification and received great favor from scholars. The CNNs use convolutional layers to extract discriminable information from HSI and apply the weight-share mechanism to reduce the complexity of the network. According to the extracted features, the CNNs can be divided into spectral-based CNNs, spatial-based CNNs, and spectral–spatial-based CNNs. Specifically, the spectral-based CNNs focus on extracting informative features from the spectral signatures of HSI, whose input data are always a 1-dimensional (1D) vector. For example, Li et al. [
20] propose a pixel-pair method that is used to construct the testing pixel and make deep CNN learn pixel-pair features for more discriminative power. Gao et al. [
21] propose a CNN architecture for fully utilizing the spectral information of HSI data. Each 1D spectral vector that corresponds to a pixel is transformed into a 2-dimensional (2D) spectral feature matrix. The convolutional layers with
and
window sizes are used to extract the spectral features jointly. It can extract high-level features from HSI data meticulously and comprehensively solve the overfitting problem. The spatial-based CNNs are adept at extracting spatial information of HSI, and the input data are always a 2D matrix. For example, Zhao et al. [
22] propose a CNN framework to classify the HSI. Dimension reduction and deep learning techniques are used in the method. A convolutional neural network is utilized to automatically find spatial-related features at high levels. In [
23], a CNN system embedded with an extracted hashing feature is proposed for HSI classification. The spectral–spatial CNNs explore either spectral information or spatial information and can extract joint spectral–spatial-based information from the HSI dataset. The input data of the spectral–spatial-based CNN is always a 3-dimensional (3D) tensor. 3D convolutional layers are implemented to extract the discriminative information. For example, Li et al. [
24] propose a 3D-CNN framework that views the HSI cube data altogether without relying on any preprocessing or post-processing, extracting the deep spectral–spatial features. Paoletti et al. [
25] propose a 3D network to extract spectral and spatial information. The proposed network implements a border mirroring strategy to effectively process border areas in the image and can be efficiently implemented using graphics processing units. Roy et al. [
26] propose a bilinear fusion CNN network named FuSENet that fuses SENet with the residual unit. Jia et al. [
27] propose a lightweight CNN for HSI classification. Spatial–spectral Schrodinger eigenmaps and dual-scale convolution modules are implemented to extract spatial–spectral features. These CNN-based methods have achieved more positive classification results than the traditional hand-craft classification methods. However, CNNs suffer from gradient vanishing/exploding [
28] and network degradation [
29] when the networks are designed to be deeper. In addition, the CNNs are also restricted by the window size of the convolutional layers, also known as the receptive field problem, which makes the CNNs to be deficient in the ability to acquire global contextual information.
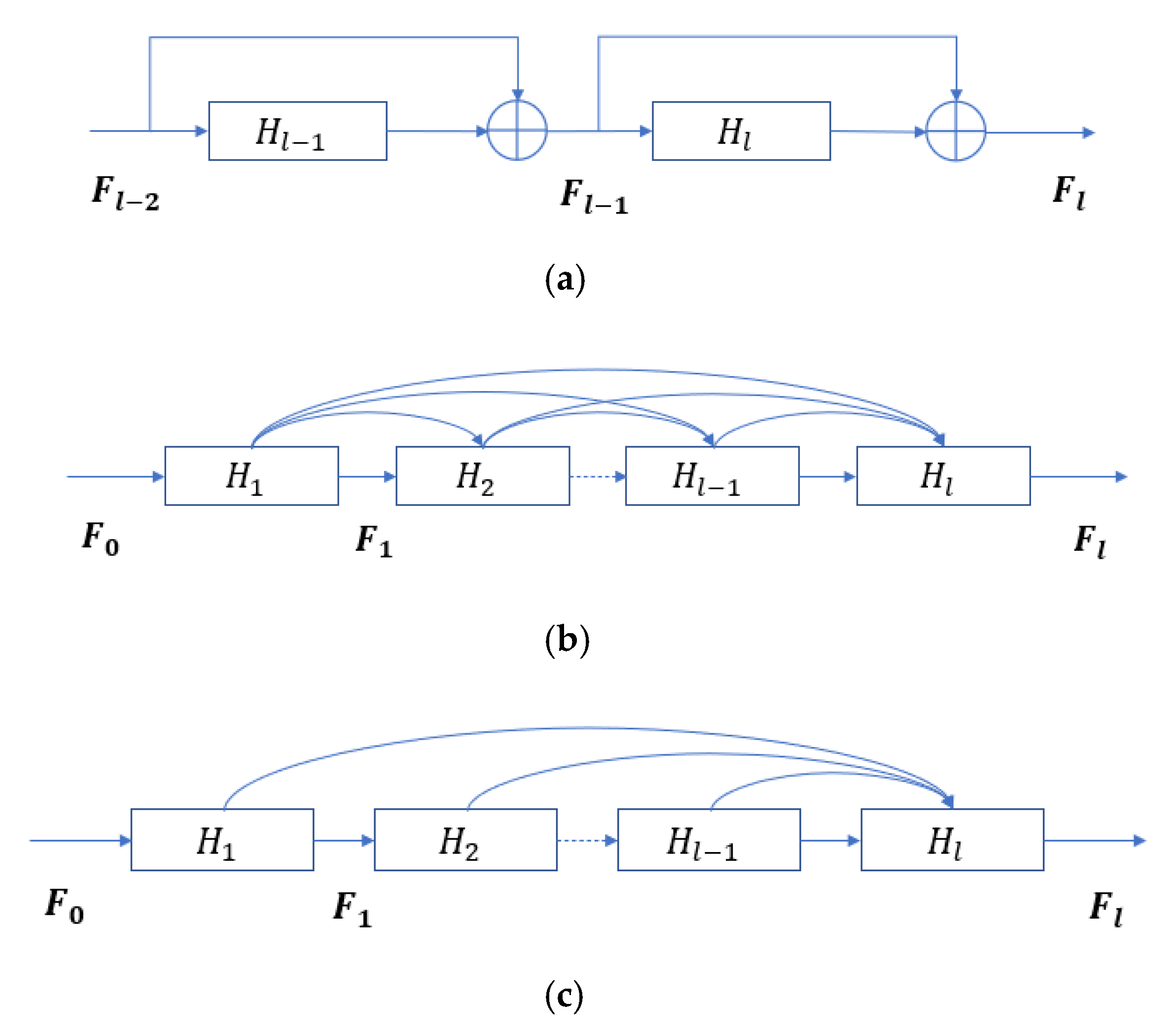
To solve the gradient vanishing/exploding and network degradation problems, residual connection [
30] and dense connection [
31,
32] are proposed to improve the CNNs. For example, Song et al. [
33] propose a deep feature fusion network for HSI classification. The residual learning is introduced to optimize the convolutional layers to make the network easy to be trained. In [
34], a new deep CNN architecture is presented specially designed for HSI data. The residual-based approach is used to group the pyramidal bottleneck residual blocks to involve more locations as the network depth increases and balances the workload among all convolutional units. Li et al. [
35] propose a two-branch CNN framework, and a dense connection is introduced to maintain the shallow features in the network. In addition, Batch Normalization (BN) [
36] and ReLU [
37] are applied to suppress the gradient vanishing/exploding problems. For instance, a high-performance two-stream spectral–spatial residual network is proposed for HSI classification in [
38]. The network employs a spectral residual network stream to extract spectral characteristics and uses a spatial residual network stream to extract spatial features. The BN layer is used to speed up the training process and improve accuracy. Experiments show that the proposed architecture can be trained with small-size datasets and outperforms the state-of-the-art methods in terms of overall accuracy. Banerjee et al. [
39] propose a 3D convolutional neural network together with BN layers to extract the spectral–spatial features from the HSI dataset. The shortcut connections and BN layers are added to get rid of the vanishing gradient problem. Sun et al. propose an improved 3D CNN to solve the problems of overfitting the in-sample training process and the difficulty in highlighting the role of discriminant features. The ReLU is used as a nonlinear activation function to suppress the gradient exploding problem.
To address the receptive field problem, the non-local self-attention methods are invited to capture long-range dependencies of feature maps as global contextual information. For example, Shi et al. [
40] propose a double-branch network with pyramidal convolution and iterative attention for HSI classification. In the architecture, the pyramidal convolution and iterative attention mechanism are applied to obtain finer spectral–spatial features to improve the classification performance. Experimental results demonstrate that the proposed model can yield a competitive performance compared to other state-of-the-art models. Li et al. [
41] present a spectral–spatial network with channel and position global context attention to capture discriminative features. Two novel global context attentions are proposed to optimize the spectral and spatial features, respectively, for feature enhancement. Experimental results demonstrate that the spectral–spatial network with global context attentions outperforms other related methods. Zhang et al. [
42] propose a spectral–spatial self-attention network for HSI classification. The network can adaptively integrate local features with long-range dependencies related to the pixel to be classified. The above approaches effectively improve the CNNs and enhance the ability of CNNs to extract spectral and spatial features from the HSI dataset. However, how to better fuse the extracted spectral and spatial features is still a worthy question to be investigated. Furthermore, the problem of a small sample, which is caused by difficulties in obtaining labeled samples from the HSI dataset, is also a question of concern.
For the multi-feature fusion problem, most of the existing approaches try to feed the features extracted by multiple methods as input data to a fusion model. By fusing the multiple features, the models can extract finer discriminative information, which can help the model to improve the classification capability for HSI classification tasks. For example, Du et al. [
43] use the pre-trained CNN models as feature extractors and focus on investigating the performances of different CNN models. The multi-layer feature fusion framework is proposed to integrate multiple level features extracted by a pre-trained CNN model to improve the performance of HSI classification. In [
44], several different features are extracted for each pixel of HSI. Then, these features are fed to a deep random forest classifier. With a multiple-layer structure, the outputs of preceding layers will be used as the inputs of the subsequent layers. After the final layer, the classification probability will be computed. Zhang et al. [
45] propose a novel method named a specific two-dimensional-tree-dimensional fusion strategy. In the proposed method, two-dimensional convolutional layers and three-dimensional convolutional layers are used to extract rich features of the HSI dataset to keep the spectral and spatial information intact. Then, the spectral and spatial features are fused to classify the HSI dataset. Ma et al. [
46] propose a double-branch multi-attention mechanism network for HSI classification. The branches with two types of attention mechanisms are applied to extract multiple features from the HSI dataset. After that, the extracted features are fused for the classification tasks. Li et al. [
47] propose an HSI classification method based on octave convolution and multi-scale feature fusion. The octave convolution and attention mechanism are introduced to extract multi-scale features of the HSI dataset. Then, the spectral–spatial fusion features are fused for the classification task.
To address the problem of the small sample, many meaningful efforts have been done in this field. For example, Wang et al. [
48] propose to use the ResNet model to extract the ground scene semantics features from high-resolution remote sensing maps with abundant ground objects information, and then classify the GF-2 scene dataset with a small GF-2 data sample through transmigration. Zou et al. [
49] propose a graph induction learning method, which has a small parameter space, to solve the problem of a small sample in HSI classification. It treats each pixel of the HSI as a graph node and learns the aggregation function of adjacent vertices through graph sampling and graph aggregation operations to generate the embedding vector of the target vertex. The embedding vectors are used to classify the pixels of the HSI dataset. Wang et al. [
50] propose a modified depth-wise separable relational network to deeply capture the similarity between samples. The depth-wise separable convolution is introduced to reduce the computational cost of the model. The Leaky ReLU function is used to improve the training efficiency of the model. The cosine annealing learning rate adjustment strategy is introduced to avoid the model falling into the local optimal solution and enhance the robustness of the model. In [
35], a double-branch dual-attention mechanism network is proposed for HSI classification to improve the accuracy and reduce the training samples. Two branches are designed to capture plenty of spectral and spatial features contained in HSI. A channel attention block and a spatial attention block are applied to refine and optimize the extracted feature maps. Pan et al. [
51] propose a novel one-shot dense network with polarized attention for HSI classification. In this method, two independent branches are implemented to extract spectral and spatial features, respectively. A channel-only polarized attention mechanism and a spatial-only polarized attention mechanism are applied in the two branches. The polarized attention mechanisms can use a specially designed filtering method to reduce the complexity of the model while maintaining high internal resolution in both channel and spatial dimensions. The above methods solve the small sample problem by pre-training techniques or by reducing the complexity of the classification model. Moreover, data augmentation techniques are also introduced to solve the problem of a small sample. For example, Yu et al. [
52] proposed a method to generate labeled samples using the correlation of spectral bands for HSI classification to overcome the small sample problem. In the method, the correlation of spectral bands is fully utilized to generate multiple new sub-samples from each original sample. The number of labeled training samples is thus increased several times. In [
53], an auxiliary classifier-based Wasserstein generative adversarial network with gradient penalty is proposed. The framework includes an online generation mechanism and a sample selection algorithm to generate samples that are similar to real data. Experiments on three public HSI datasets show that the proposed framework achieved better classification accuracy with a small number of labeled samples. It is worth noting that the aggressive improvements effectively enhance the performance of the spectral–spatial convolutional neural network frameworks, and the improvements of the convolutional networks are not limited to the above-mentioned methods.
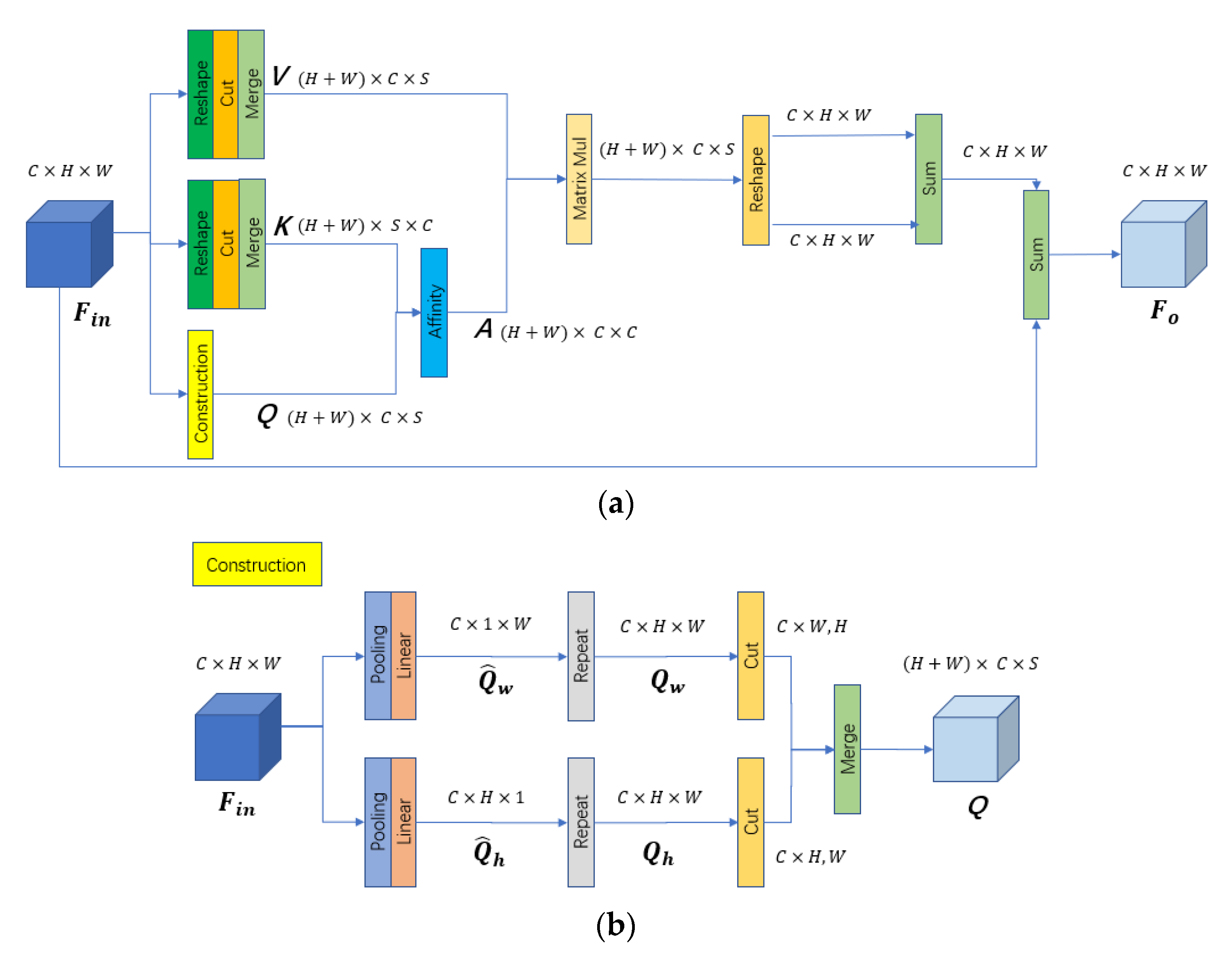
In the proposed framework, a two-branch structure is used to extract the spectral and spatial information of HSI, respectively. By simplifying the window sizes of the 3D convolutional layers, the complexity of the network is reduced to fit the small sample environments. Moreover, a one-shot connection [
51] is applied to connect the convolutional layers of the network. This approach allows the shallow features to be maintained in the deeper layers while these features are extracted again jointly with the deep semantic features. The one-shot connection can improve the efficiency of the network in extracting feature maps of different layers and adequately extract the features of the training sample. BN layers and PReLU [
54] activation function are implemented in the convolutional layers to suppress the gradient vanishing/exploding problem and network degradation problem. In the proposed architecture, we try to introduce the attention mechanism to solve the problem of feature fusion. We hope to use the attention mechanism to find discriminative abstract features that are worthy of attention. As a result, an improved full attention (FLA) mechanism [
55], named polarized full attention (PFLA), is implemented after the two-branch convolutional neural network to extract global contextual information and fuse the spectral and spatial features obtained from the two-branch network. The main contributions are summarized as follows.
- (1)
A two-branch neural network is proposed for HSI classification. The two-branch structure is applied to separately extract the spectral and spatial features of HSI. The one-shot connection is used to maintain the shallow features and make the network easy to be trained. The polarized full attention mechanism is implemented to provide global contextual information and fuse the spectral–spatial features.
- (2)
An improved full attention mechanism is presented. Sigmoid operation is introduced to obtain the attention weights. This approach can provide polarizability for full attention to keep a high internal resolution when fusing the spectral and spatial features.
- (3)
We explore a method that combines the CNN framework and self-attention mechanism for HSI classification and tries to use the attention mechanism to fuse the feature maps. The experimental results on four publicly published HSI datasets are reported.
The rest of the paper is organized as follows.
Section 2 introduces the related work of the proposed method.
Section 3 gives the details of PTCN.
Section 4 collects the experimental results.
Section 5 makes some discussions and
Section 6 gives the conclusions and future works.
3. Methodology
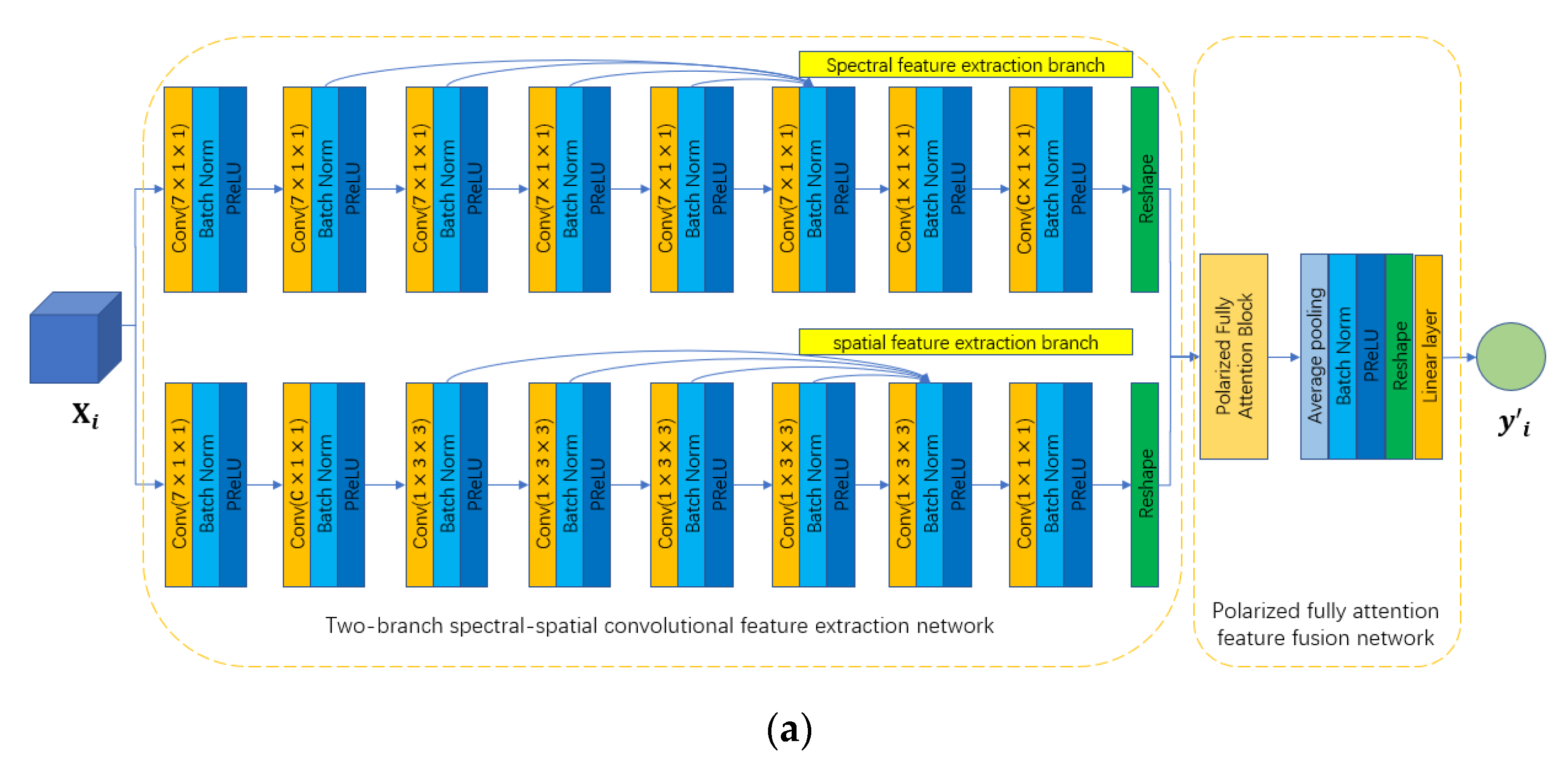
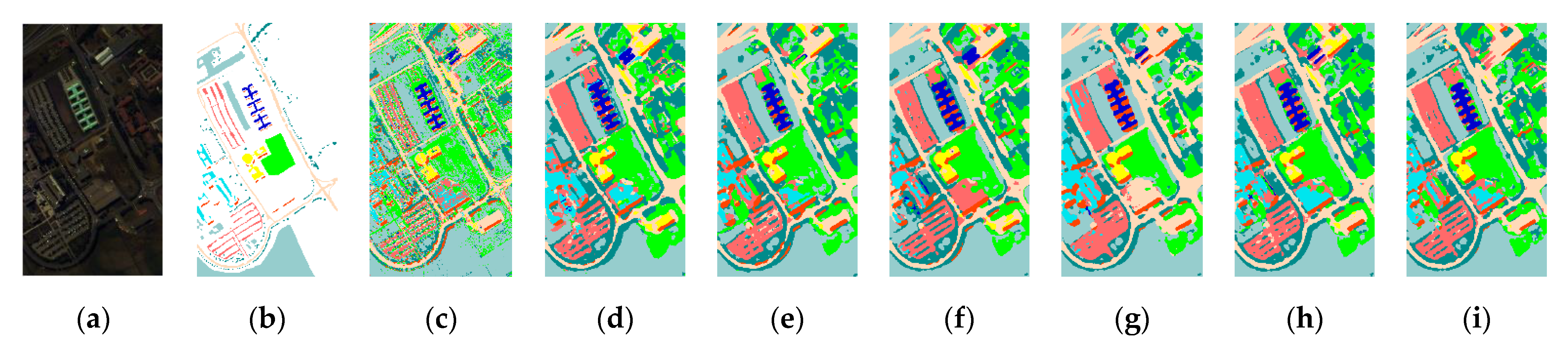
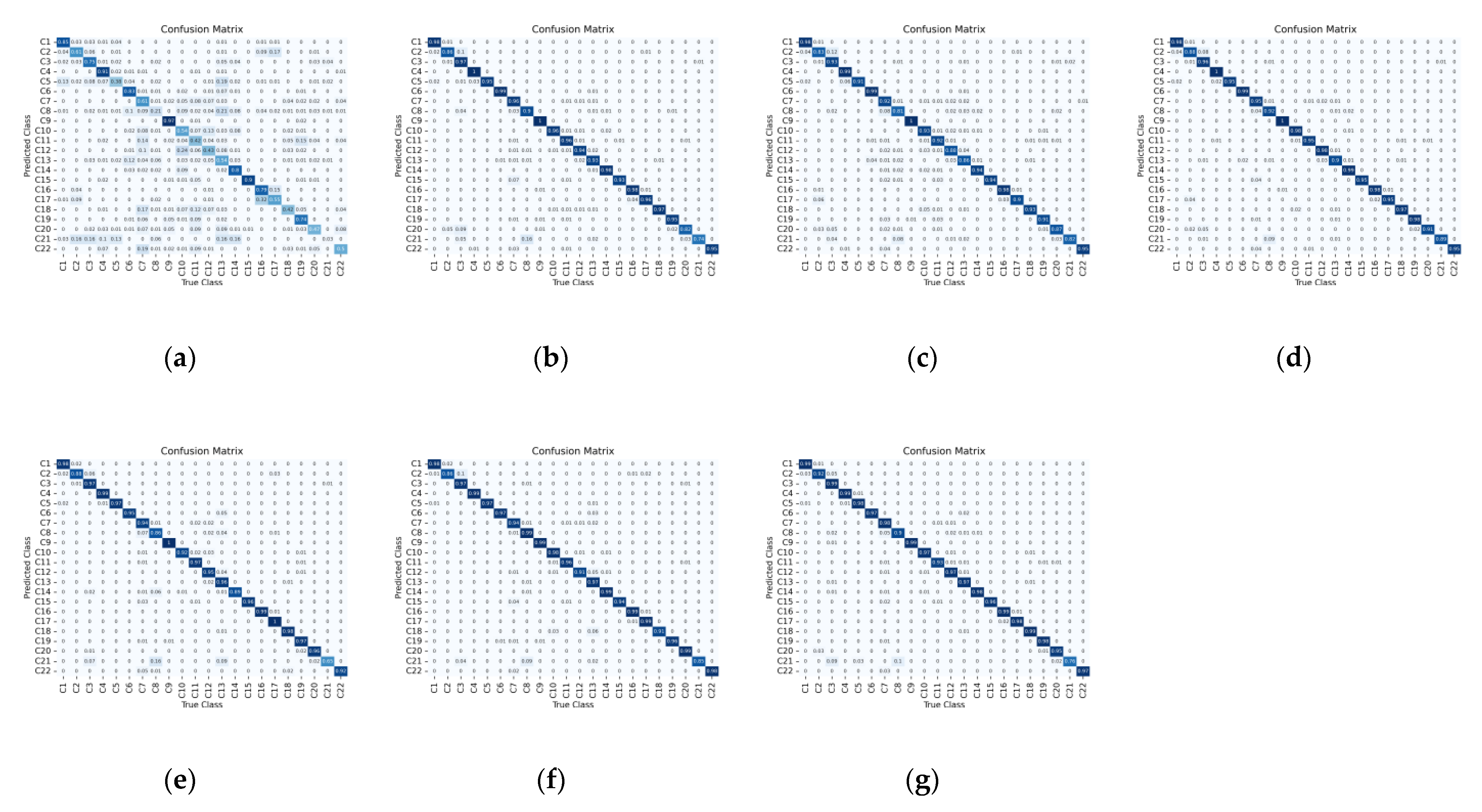
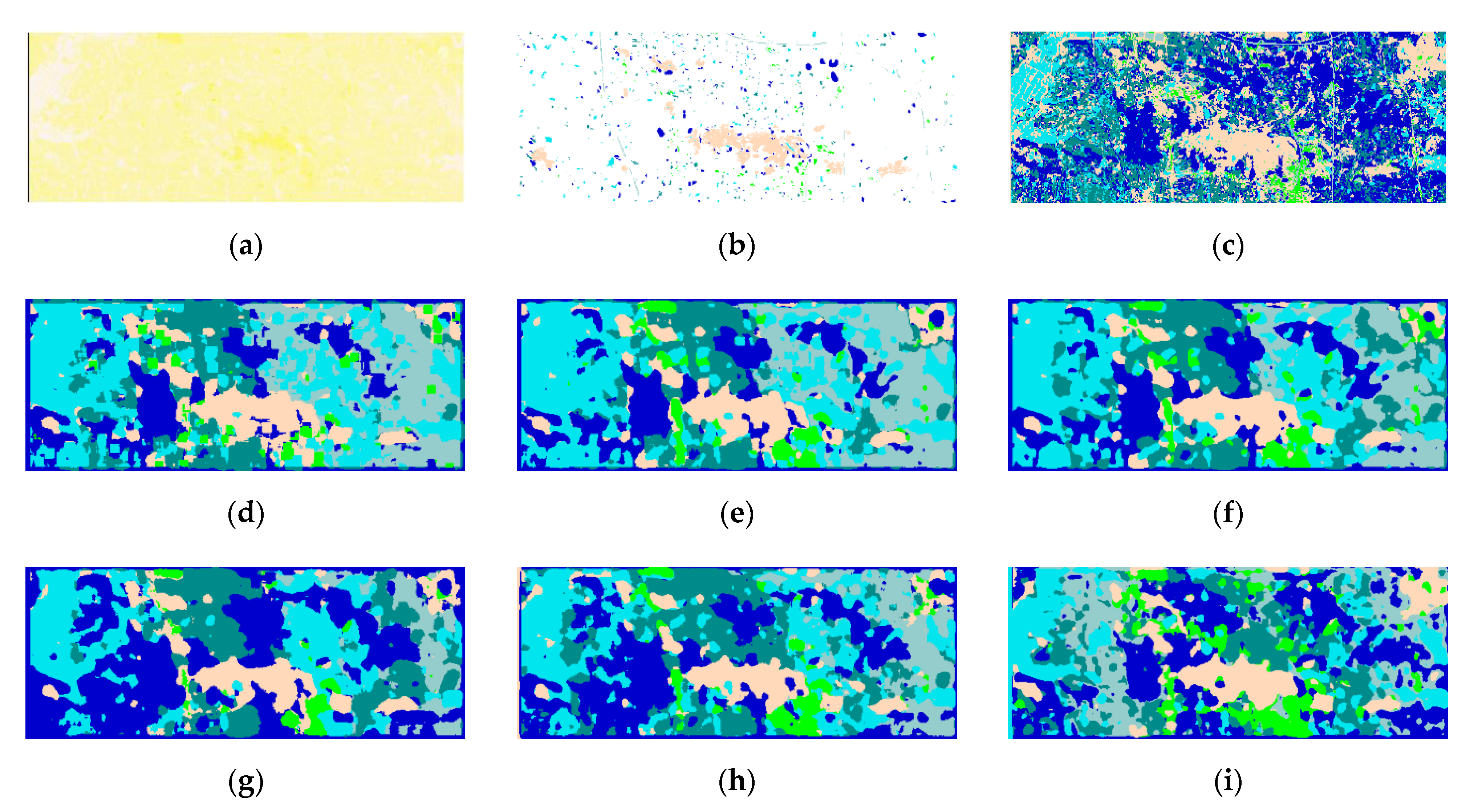
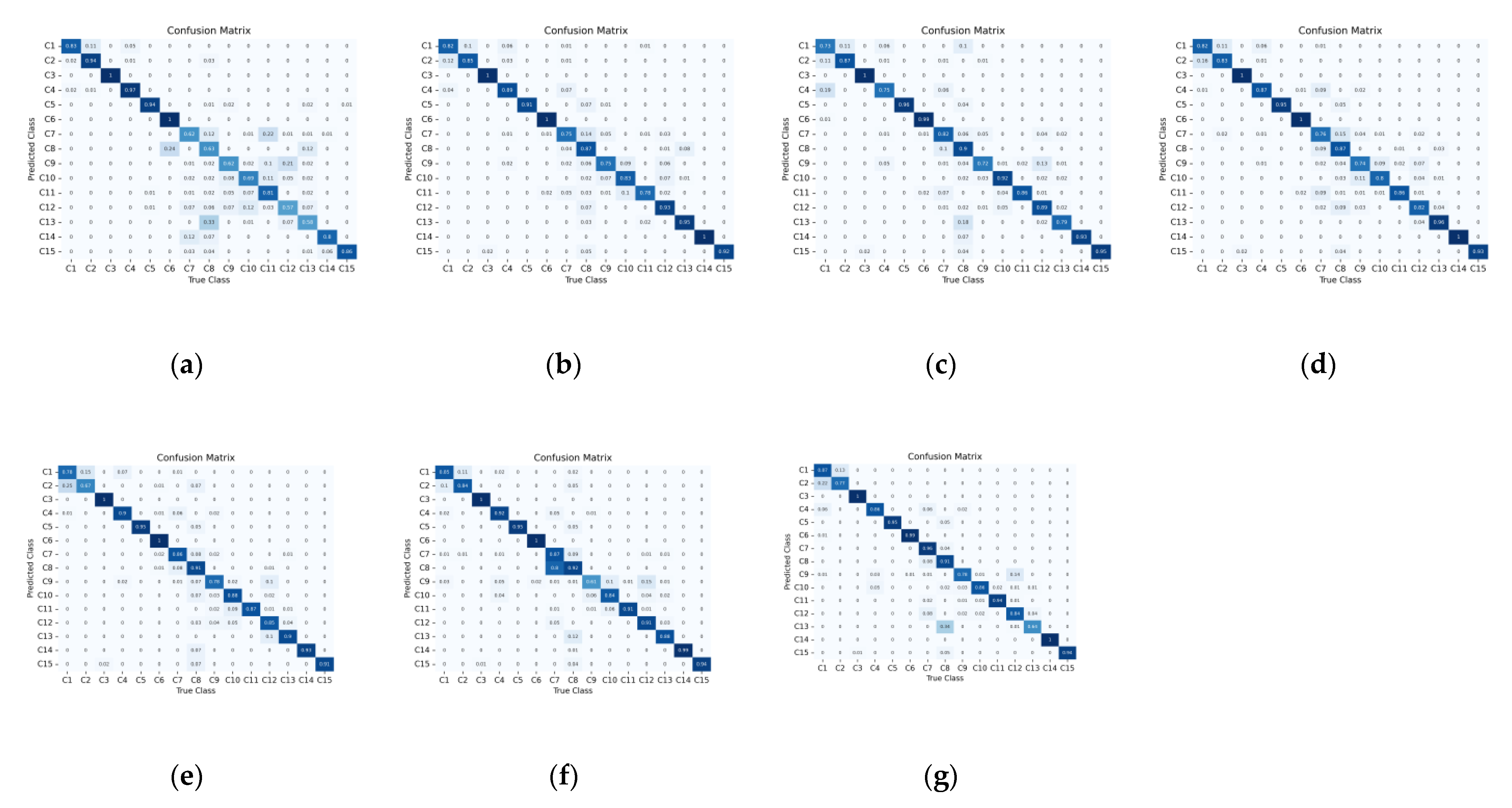
In this paper, we propose a two-branch deep neural network to extract the abundant spectral and spatial information of HSI. The workflow of the proposed network is shown in
Figure 3a. We can see that the proposed network is composed of two components: the two-branch spectral–spatial convolutional feature extraction network and the polarized full attention feature fusion network.
In the two-branch spectral–spatial convolutional feature extraction network, a two-branch structure is used to individually extract the spectral and spatial information along the spectral and spatial dimensions, respectively. Given an input dataset , where is the cube-based HSI data of the pixel, is the number of feature maps ( is set to 1 when initializing the input dataset), is the number of spectral dimensions, is the size of the spatial dimensions, the output of the network is , where is the number of land cover categories. The spectral feature extraction branch contains eight convolutional layers with the BN layer and PReLU activation function layer. First, we employ a convolutional layer with window size to reduce the spectral dimension and increase the number of feature maps. After that, five convolutional layers with a window size are used to further extract the spectral information. A one-shot connection is implemented among these convolutional layers to maintain the previous feature maps. Next, a convolutional layer with a window size is deployed to compress the feature maps. Furthermore, a convolutional layer with a window size and reshape operation are used to squeeze the spectral dimension. Similarly, the spatial feature extraction branch employs eight convolutional layers with BN and PReLU to extract the spatial information. First, a convolutional layer with a window size is implemented to reduce the spectral dimension and increase the number of feature maps. After that, a convolutional layer with a window size is used to compress the spectral dimension. Next, five convolutional layers with a window size are applied to extract the spatial information. A one-shot connection is carried out among these convolutional layers to maintain the information. After that, a convolutional layer with a window size and reshape operation are conducted to compress the number of feature maps and squeeze the spectral dimension. Finally, the outputs of the spectral branch and spatial branch are concatenated to form the final feature maps.
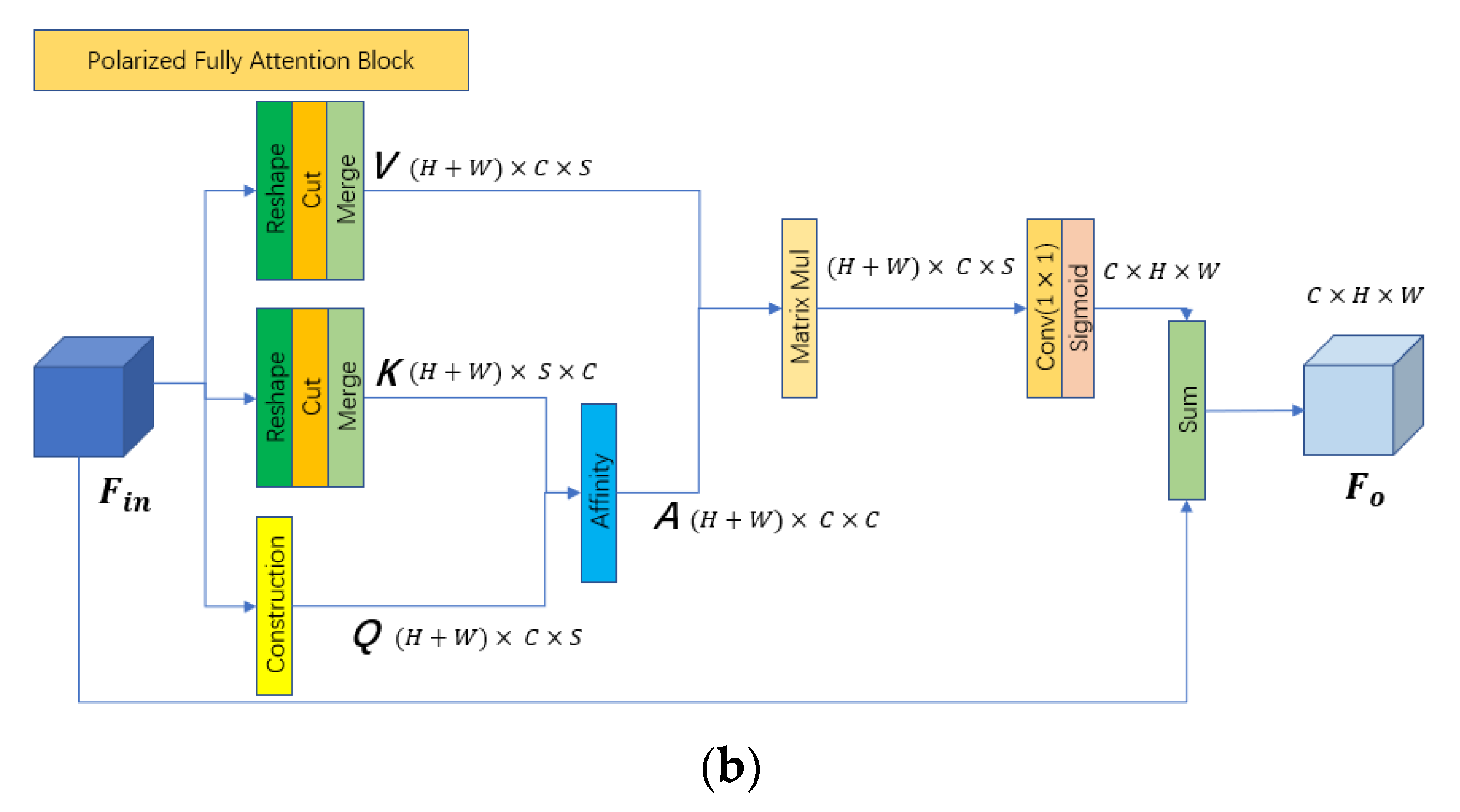
The polarized full attention feature fusion network is deployed after the two-branch spectral–spatial convolutional feature extraction network and is used to fuse the previous feature maps to generate the final classification results. From
Figure 3a, we can see that the polarized full attention feature fusion network is composed of PFLA, an average pooling layer with a BN layer, PReLU activation function layer, reshape operation, and Linear layer. First, the PFLA is implemented to further extract interesting information from the feature maps extracted by the previous two-branch network by the self-attention mechanism. Different from the traditional FLA, the proposed PFLA employs a convolutional layer with a
window size to generate the global contextual information and use the Sigmoid operation to provide polarizability to keep high internal resolution when fusing the channel-wise attentions. The workflow of the PFLA is shown in
Figure 3b. We can see that most of the processes of PFLA are the same as the FLA, with the difference that the convolutional layer and Sigmoid operation are deployed after the matrix multiplication of
and
. Next, an average pooling layer with BN layer and PReLU activation function layer is conducted to compress the spatial dimension and fuse the features. Finally, a reshape operation is used to squeeze the spatial dimension, and a Linear layer is used to generate the final classification results. To illustrate the details of the proposed network, the dataflows of the two-branch spectral–spatial convolutional feature extraction network and polarized full attention feature fusion network are shown in
Table 1,
Table 2 and
Table 3, when the input data are set to
. Cross entropy loss is applied to train the proposed network and is expressed as follows:
where
is the land cover label of the
pixel.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}