1. Introduction
Based on satellite and airborne platforms, remote sensing offers a comprehensive view from a macroscopic perspective and has long been an essential tool for monitoring and managing urban development and growth [
1]. Among various applications, the detection of changes in building structures plays a significant role in land cover monitoring [
2,
3], urban planning [
4,
5,
6], disaster assessment [
7,
8], military reconnaissance [
9], and environmental protection [
10,
11,
12]. The aim of building change detection is to generate pixel-level representations of alterations within a specified geographical area by comparing a pair of images acquired at different times.
Conventional change detection techniques focus on either the statistical processing of pixel-level information [
13,
14,
15,
16,
17] or shallow image features and manually designed features [
18,
19,
20,
21]. Although these approaches have achieved satisfactory results in specific applications, they still have limitations in capturing essential information from high-resolution remote sensing images, leading to issues such as missed detections, false positives, and incomplete identification of changes within buildings.
In recent years, the deep learning technique has played a significant role in advancing the field of computer vision, producing outstanding results in various tasks, such as image classification [
22], semantic segmentation [
23], pose estimation [
24], and object detection [
25]. Compared with conventional methods that rely on manually designed feature extractors [
26,
27,
28,
29], deep learning-based methods are capable of learning complex and discriminative deep features automatically. Since the task of building change detection can be viewed as a binary semantic segmentation problem, various approaches have been developed within a learning-based pipeline, yielding impressive results.
Existing deep learning-based methods for building change detection in remote sensing images can primarily be categorized into two groups [
30]: direct detection and classification-based detection. Direct detection methods typically leverage convolutional neural networks (CNNs) to directly extract change features from bi-temporal images. Since direct change detection requires simultaneous feature extraction from both temporal images, the Siamese architecture has been widely adopted as the backbone network due to the weight-sharing mechanism that ensures that the feature space of similar objects remains as close as possible. Depending on the loss functions, these strategies further split into semantic loss-based and contrast loss-based approaches. For instance, Daudt et al. [
31] introduced three fully convolutional networks for change detection: the early fusion-based (FC-EF), Siamese-concatenation (FC-Siam-conc), and Siamese-difference (FC-Siam-diff) networks. FC-EF is based on the U-Net model, which employs the concatenation of two patches as the network input. On the other hand, both FC-Siam-conc and FC-Siam-diff are Siamese-based methods. The former concatenates bi-temporal features, while the latter concatenates the difference in bi-temporal features. However, checkerboard artifacts may be introduced during the decoding process.
In another stride, Peng et al. [
32] combined bi-temporal images within a densely connected U-NET++. They introduced multi-scale supervision and directly generated binary maps for building change detection. To solve the foreground–background class imbalance, they further devised a weighted loss function by combining the Dice loss and the cross-entropy loss. Similarly, Fang et al. [
33] introduced an enhanced SNUNet by leveraging shared-weight encoders to independently extract features from bi-temporal images. In the final decoding stage, they incorporated an integrated channel attention mechanism to capture contextual information between features, leading to significantly improved accuracy in change detection. Leveraging the Euclidean distance between features from both temporal images, they employed a Contrastive loss function to reduce the distance between similar landcover features while increasing the distance between dissimilar ones. Chen et al. [
34] introduced a spatial–temporal self-attention module after the feature extraction module. They also weighted the loss function based on the proportions of changing and non-changing pixels. Furthermore, Chen et al. [
35] integrated a dual-path attention mechanism subsequent to a Siamese network. They utilized channel attention and position attention to establish connections among local features, thereby enhancing the global contextual information for distinguishing between changing and non-changing regions.
On the other hand, classification-based methods for change detection typically involve the use of semantic segmentation networks to generate binary building maps from bi-temporal images. Changes can be subsequently detected using pixel-wise comparisons. For instance, Maiya et al. [
36] employed a mask R-CNN to simultaneously detect and segment buildings in both time-phase images. They compared the detection and segmentation results between the two time phases to identify change locations and building masks. Zhang et al. [
37] utilized a U-Net model enhanced with dilated convolutions and a multi-scale pyramid pooling module to extract multi-class land cover maps. They then conducted pixel-wise comparisons with historical GIS maps to derive change patches. Recognizing the potential for noise introduction from registration errors during pixel-wise comparisons of binary maps, Ji et al. [
38] took a different approach by training a binary change detection network using simulated binary change samples. They combined the binary maps from the two time phases, generated by a one-stage semantic segmentation network, by stacking the channels. These combined maps were then input into the binary change detection network to generate the final change map.
While the aforementioned CNN-based methods primarily employ attention mechanisms to capture global information, they struggle to associate long-distance information in both spatial and temporal dimensions. To effectively model contextual information, Chen et al. [
39] proposed a bi-temporal image transformer (BIT) that combines CNN and Transformer. The BIT efficiently captures the global semantic information and employs semantic labels to highlight refined change areas. Based on the Transformer structure, Bandara et al. [
40] further proposed ChangeFormer, which establishes effective long-distance dependencies to model the global context.
Although these deep learning-based techniques have demonstrated improved performance in detection accuracy, they still impose two major challenges in terms of feature fusion and optimization strategies.
As demonstrated in our previous studies [
41,
42], performance in change detection is closely related to the feature fusion strategy of both bi-temporal feature fusion and multi-scale feature fusion. Existing approaches commonly employ either channel concatenation [
31,
32,
33,
38,
43] or algebraic calculation [
43,
44] for bi-temporal feature fusion. However, channel concatenation fails to adeptly establish temporal associations across feature pairs. Concurrently, algebraic calculations only consider correlations between individual pixel pairs and ignore contextual information. On the other hand, existing methods typically upscale deep-layer features directly and concatenate them with shallow features for hierarchical feature fusion [
8,
45], which proves sub-optimal when handling high-resolution remote sensing imagery enriched with complex geospatial entities.
In terms of optimization strategies, the cross-entropy loss is commonly utilized in the task of building change detection. However, in real remote sensing imagery, the proportion of actual changed building targets to background targets is very small, leading to a significant class imbalance problem. While functions such as Dice loss [
46], Contrastive loss [
47], and Triplet loss [
48] have been introduced to address this issue, it remains a challenge in change detection.
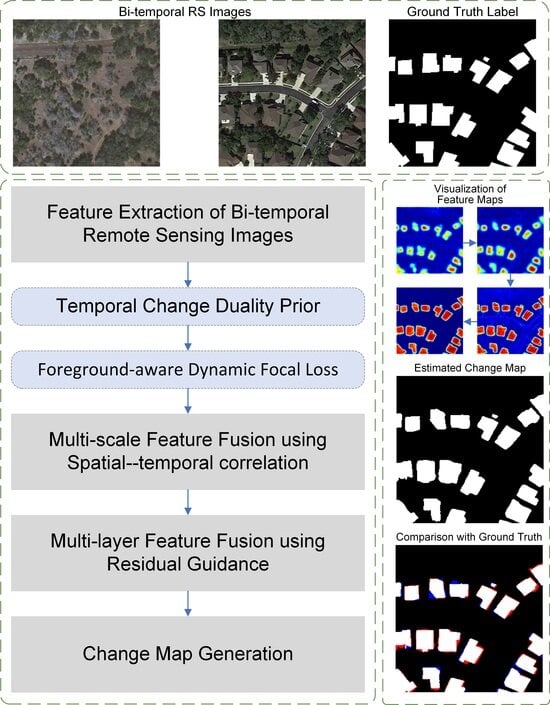
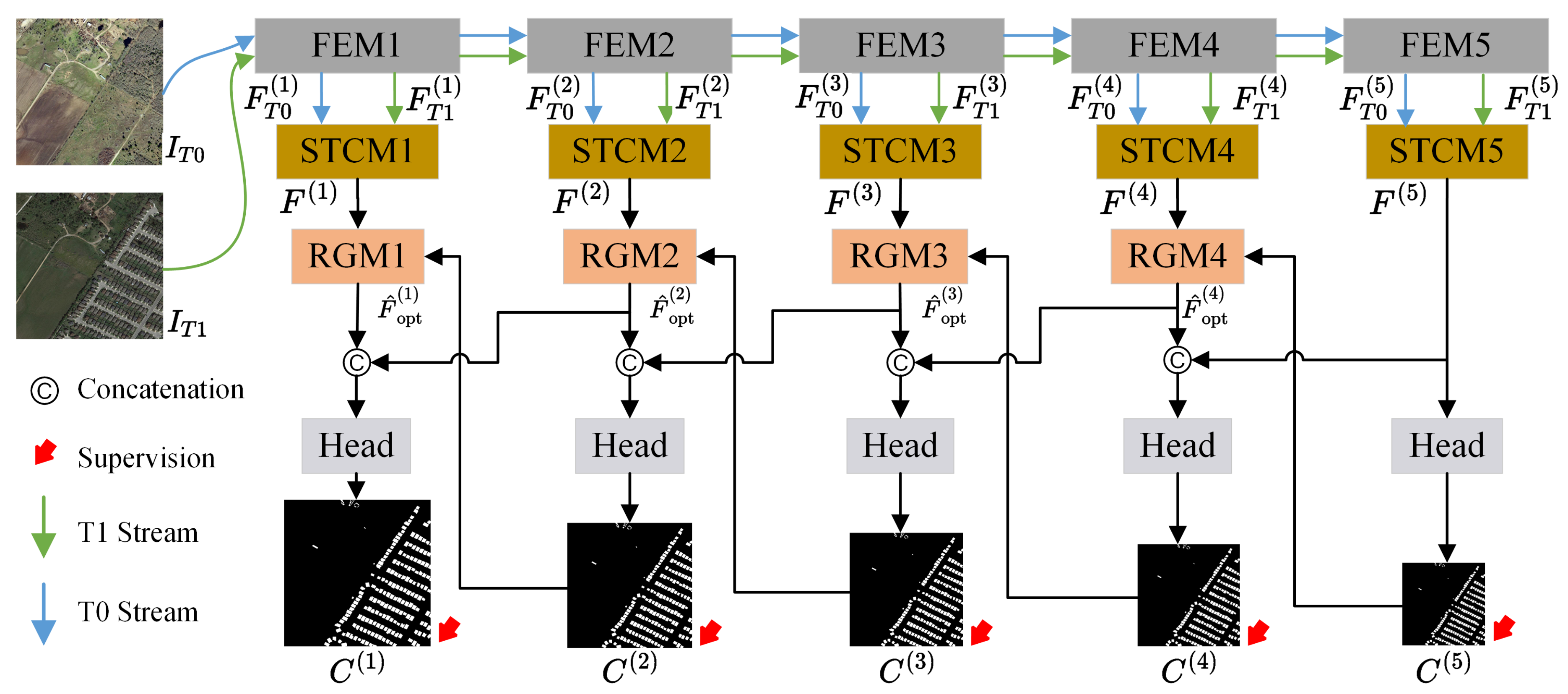
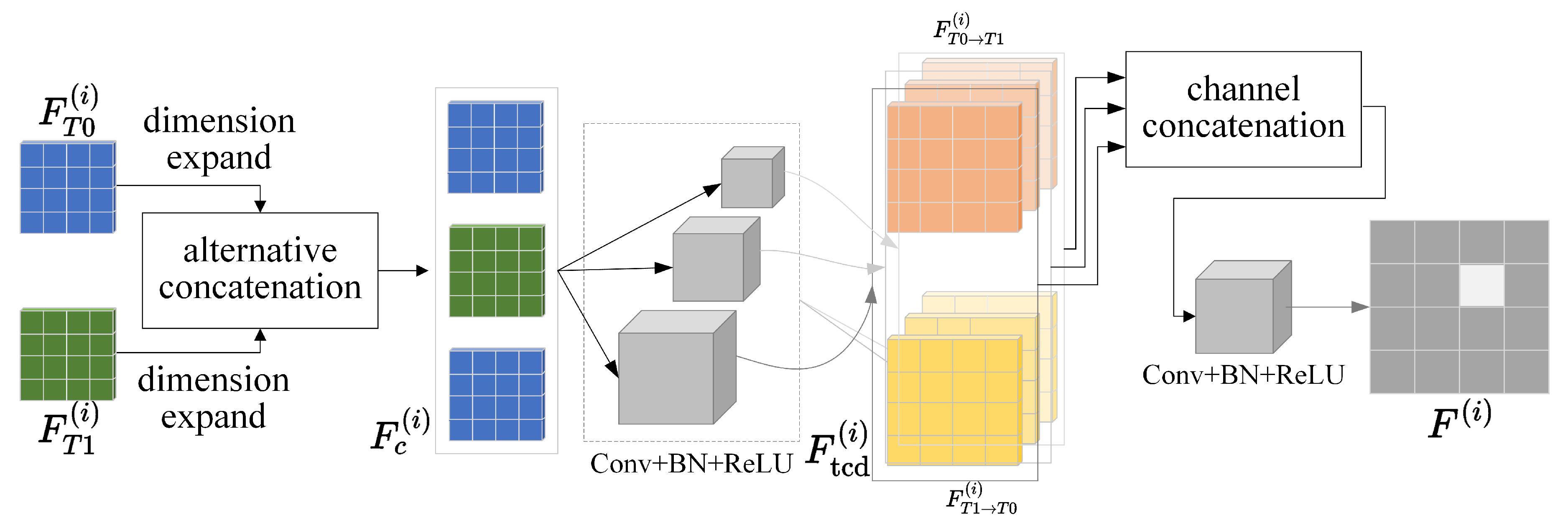
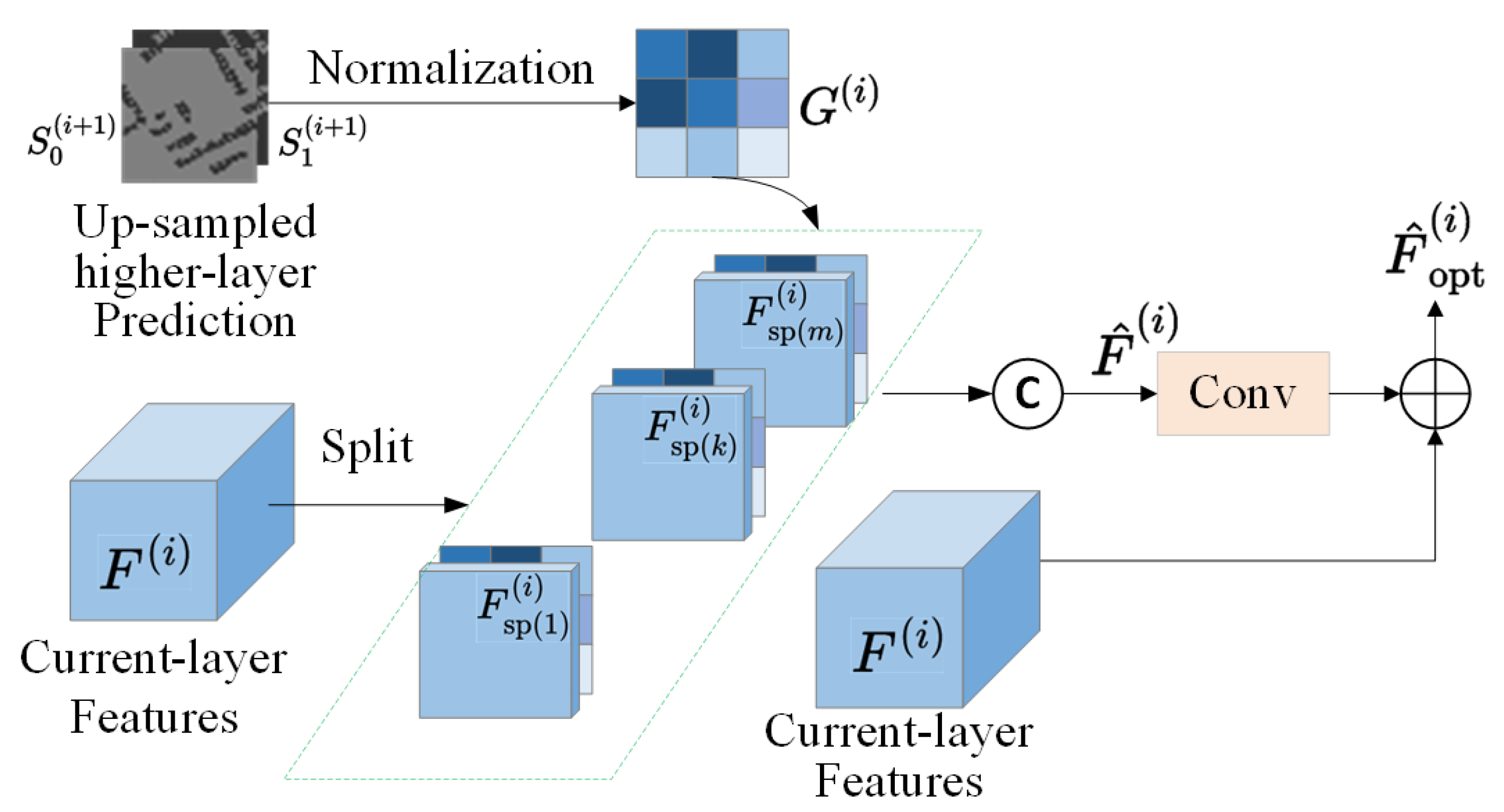
In this paper, we introduce EFP-Net, a novel approach for building change detection that utilizes effective feature fusion and foreground perception to address the aforementioned issues. Firstly, a spatial–temporal correlation module is designed to efficiently integrate features from bi-temporal images and enhance the representation capacity of change features. This module leverages the temporal change duality prior and multi-scale perception to augment the three-dimensional convolution capability to model spatial–temporal features in bi-temporal data. Secondly, to enhance hierarchical feature fusion, a residual-guided module is introduced. It optimizes shallow features guided by deep-layer change predictions, reducing noise introduced during the feature fusion process. Lastly, to address class imbalance, we further introduce a foreground-aware loss function that enables the model to focus on the challenging, sparsely distributed foreground samples.
The main contributions of the proposed EFP-Net are summarized as follows:
We introduce a spatial–temporal correlation module (STCM) to generate discriminative change features that can provide accurate localization of changed objects.
We introduce a residual-guided module (RGM) to enhance hierarchical feature fusion.
We propose a dynamic Focal loss with foreground awareness to address the class imbalance problem in building change detection.
Based on the STCM and RGM, we have developed EFP-Net, a novel building change detection algorithm for optical remote sensing images. Experimental results demonstrate the state-of-the-art performance of the proposed method on benchmark datasets.
The rest of the paper is organized as follows:
Section 2 provides a detailed presentation of the proposed method.
Section 3 presents experimental results, along with analysis and comparisons with state-of-the-art methods. Finally,
Section 4 concludes the paper.
3. Experiments
3.1. Experimental Datasets
The proposed EFP-Net is evaluated on three public change detection datasets: LEVIR-CD [
34], WHU-BCD [
4], LEVIR-CD [
34], and CDD [
52].
The LEVIR-CD is open-sourced by the LEVIR Lab of Beihang University and was collected in Texas, USA, between 2002 and 2018. It consists of 637 high-resolution bi-temporal image pairs, each with a spatial resolution of 0.5 m and a resolution of 1024 × 1024. LEVIR-CD contains various types of buildings, ranging from single-story houses and large warehouses to upscale apartments. The buildings undergoing change in the images are small and densely packed. Given the considerable time span between the image acquisition dates, achieving precise detection of building changes presents a significant challenge. In the original work [
34], each image was non-overlappingly cropped into 16 sub-images of 256 × 256. By default, the dataset was partitioned into training, validation, and test sets, comprising 445, 64, and 128 images, respectively. For fair comparisons with other methods, the training, validation, and test sets are created by cropping non-overlapping patches into 7120, 1024, and 2048 samples, respectively.
The WHU-BCD dataset is composed of a pair of bi-temporal remote sensing images with size of 15,354 × 32,507 and a spatial resolution of 0.2 m. These images were collected in the southwestern region of Queensland in 2012 and 2016, respectively. The original images are cropped into sub-images with a stride of 256. The sub-images are then randomly divided according to the ratio of 7:1:2, resulting in train/val/test sets comprising 5534, 762, and 1524 image pairs, respectively.
The CDD dataset comprises 11 image pairs, with specific resolutions ranging from 3 cm to 100 cm. Four of these pairs have a resolution of 1900 × 1000, while the remaining pairs are 4725 × 2200. CDD contains the change information of various land cover types, including vehicles, buildings, roads, etc. It is characterized by considerable variations in season, climate, and weather conditions. Following the original work, the raw images were segmented into non-overlapping sub-images of 256 × 256, yielding a total of 16,000 image pairs. Out of these, 10,000 pairs were designated for the training set, 3000 pairs for the validation set, and the remaining 3000 pairs for the test set.
Figure 5 and
Table 2 illustrate some samples of the bi-temporal images with ground-truth labels and summary information of the selected remote sensing image datasets for building change detection, respectively.
3.2. Implementation Details
We trained and tested our network on Ubuntu 18.04 with an Intel E5-2640 CPU and an Nvidia GTX 1080Ti GPU using PyTorch 1.12.0. We employed the Adam optimizer and set of the momentum to 0.5 and 0.9, respectively. The batch size was configured to 12, and the learning rate was initially set to . The model was trained for 120 epochs for all datasets. To mitigate the risk of over-fitting and enhance the generalization capabilities, data augmentation techniques such as random mirroring, flipping, and rotation were employed during the training stage.
In order to fully evaluate the performance of the proposed EFP-Net both qualitatively and quantitatively, seven SOTA approaches for building change detection were selected for comparison, including FC-EF [
31], FC-Siam-conc [
31], FC-Siam-diff [
31], IFNet [
53], SNUNet-CD [
33], BIT [
39], and ChangeFormer [
40].
We summarized the main characteristics of all compared methods in terms of network structure, change feature learning method, hierarchical feature fusion method, and the loss functions, as listed in
Table 3. In the table, Single and Siamese refer to the single-stream feature extraction network and Siamese feature extraction network, respectively. Cat represents the concatenate operation, and
stands for the
distance. SA denotes spatial attention, and CA refers to channel attention. CE, WCE, and DICE are the cross-entropy loss, the weighted cross-entropy loss, and the Dice loss, respectively.
3.3. Evaluation Metrics
In the experiments, five frequently utilized evaluation metrics were adopted: overall accuracy (
OA),
Precision,
Recall, F1-score (
F1), and intersection over union (
IoU). The calculations for each indicator are defined as follows:
where
TP (true positive) indicates pixels of the changed objects correctly predicted as the ‘change’ category.
TN (true negative) represents pixels of the unchanged objects correctly predicted as the ‘unchange’ category.
FP (false positive) means that pixels remaining unchanged are mistakenly predicted as the ‘change’ category.
FN (false negative) indicates that changed pixels are incorrectly predicted as the ‘unchange’ category.
3.4. Experimental Results
Figure 6,
Figure 7 and
Figure 8 illustrate the comparison results of different methods on LEVIR-CD, WHU-BCD, and CDD, respectively. It is intuitively observed in
Figure 6 that the results of SNUNet-CD, FC-Siam-diff, FC-Siam-conc, and KC-EF contain obvious false detections (indicated in blue and red). On the other hand, ChangeFormer, BIT, IFNet, and the proposed EFP-Net achieve satisfying results, and our method has better performance in extracting the interior structure of changed buildings. Overall, the results of the proposed method align with the ground truth most closely and outperform others in detecting changed building targets of varying scales and resisting interference from false changes. This is due to the employment of the STCM, which captures the contextual relationship between single-pixel values and multi-scale regions, enhancing the representation of change features and ensuring the integrity of changed objects. In addition, the RGM optimizes shallow features with the guidance of deep prediction maps, effectively reducing false detections caused by background noise, thereby achieving accurate detection around the edges of changing objects.
In
Figure 7, it is observed that compared with other methods, EFP-Net significantly reduces instances of missed and false detections while preserving the integrity of large-scale buildings. Specifically, as observed in the first row of
Figure 7, obvious false detections (FN, indicated in blue) can be noted in the results of all the compared methods. Furthermore, false negative detections (indicated in red) are generated by FC-Siam-diff, FC-Siam-conc, and KC-EF. While both EFP-Net and ChangeFormer have better performance, our EFP-Net generates fewer false detections. It is also noted that EFP-Net not only accurately achieves multi-scale change detection results in scenes with highly similar structures but also maintains the integrity of building interiors. As evidenced in both the first and last rows of
Figure 7, EFP-Net demonstrates remarkable resistance to false changes, with its detection results aligning with the reference labels most closely when compared with other methods.
Compared with the LEVIR-CD and WHU-BCD datasets, CDD not only contains changes in buildings but also includes changes in vehicles, roads, trees, etc. As shown in
Figure 8, EFP-Net is capable of achieving detailed change detection with high-quality change maps for both smaller areas like trees and vehicles, and complex areas like roads and buildings.
Based on above qualitative comparisons, it is evident that the STCM is capable of establishing contextual connections between individual pixel points and multi-scale regions, which significantly enhances the representational capacity for features depicting change, ensuring the preservation of the integrity of buildings. Concurrently, the RGM demonstrates its effectiveness in background noise suppression through guided optimization of shallow features, resulting in a notable reduction in false detections. This contributes to the precision in detecting edge pixels of changing structures and preserves the internal integrity of buildings.
In addition to subjective comparisons, we also conducted quantitative evaluations on the datasets LEVIR-CD, WHU-BCD, and CDD, as demonstrated in
Table 4,
Table 5 and
Table 6, respectively. ↑ indicates that performance improves as the score increases, and the best score is marked in bold. As illustrated in
Table 4, the proposed EFP-Net consistently outperforms the other compared methods in all evaluated metrics on the LEVIR-CD dataset, with respective values of 99.10%, 92.18%, 90.15%, 83.74%, and 91.15%. In particular, compared with the second-best model, ChangeFormer, our EFP-Net improves the values of overall accuracy, Precision, Recall, IoU, and F1-score by 0.06%/0.13%/1.35%/1.26%/0.75%, respectively. While ChangeFormer utilizes a Transformer architecture to establish global contextual relationships, its ability to represent change features is constrained by its straightforward feature concatenation strategy, resulting in a lower Recall score. The enhanced performance of our method in the Recall metric is mainly attributed to the specially designed STCM, which effectively leverages the spatial–temporal information of bi-temporal features. Moreover, the proposed RGM effectively mitigates background noise, leading to an improved Precision score.
Table 5 shows the performance evaluations on the WHU-BCD dataset. It is noted that the proposed EFP-Net exhibits remarkable results on scenes with highly similar structures. The EFP-Net consistently outperforms the compared models in all the metrics. Specifically, with regard to the Recall metric, EFP-Net surpasses the second-ranked model by 3.98%, which suggests the better capability of our method in accurately detecting building changes and subsequently reducing missed detections. Additionally, in the context of mitigating false detections, EFP-Net reaches a notable Precision score of 93.42%.
Table 6 further gives the performance evaluations on the CDD dataset. It can be observed that EFP-Net outperforms other methods across all metrics in diverse scenarios. Consequently, both qualitative and quantitative comparisons demonstrate the effectiveness and generalizability of the proposed EFP-Net.
3.5. Ablation Study
In order to verify the effectiveness of the proposed modules and the dynamic Focal loss, we performed ablation experiments by incrementally introducing the STCM, RGM, and dynamic Focal (DF) loss into the baseline model. The ablation experiments were carried out on all the three datasets, as demonstrated in
Table 7,
Table 8 and
Table 9, respectively. Specifically, the ’baseline’ model was constructed by replacing the STCM with a standard feature concatenate operation and removing the RGM. We also employed cross-entropy as the loss function in the baseline model.
3.5.1. Verification of Modules
As observed in the second row of each table, with the integration of the STCM, the model demonstrated notable advances in learning the dynamic changes between bi-temporal features, which is evidenced by the improvements in the metric values. Specifically, as illustrated in
Table 7 relative the verification on LEVIR-CD, compared with the baseline model, the values of OA, Precision, Recall, IoU, and F1 increased by 0.25%, 2.58%, 1.44%, 3.84%, and 2.00%, respectively. Improvements can also be observed in the ablation results on WHU-BCD and CDD, as listed in
Table 8 and
Table 9, respectively. On the WHU-BCD dataset, the incorporation of the STCM increases the value of OA, Precision, Recall, IoU, and F1 by 1.45%, 2.66%, 0.32%, 1.86%, and 1.46%, respectively. Meanwhile, on the CDD dataset, the increases are 0.62%, 1.17%, 1.22%, 3.44%, and 1.19%, respectively. This is primarily because the STCM utilizes the temporal change duality prior and multi-scale perception to augment the three-dimensional convolution capability, which is more robust in obtaining discriminative change features.
As mentioned previously, the RGM leverages deep-layer change map predictions to fine-tune shallow-layer change features, which strategically directs the model’s focus towards areas of significant change while suppressing background noise. As observed in the second row of each table, compared with the baseline, the integration of the RGM increased the values of OA, Precision, Recall, IoU, and F1 by 0.39%, 2.72%, 1.97%, 3.98%, and 2.33% on LEVIR-CD; by 1.27%, 3.46%, 3.10%, 2.30%, and 3.28% on WHU-BCD; and by 0.73%, 0.93%, 1.08%, 3.57%, and 1.00% on CDD. The performance improvement is a result of the RGM’s effective fusion of multi-layer features, whereby it suppresses background noise guided by the deep prediction map, ensuring that the detailed information of the change object is accurately restored.
With both STCM and RGM added, the ’baseline + STCM + RGM’ configuration yields further improvements in OA, Precision, Recall, IoU, and F1 by 0.52%, 3.14%, 2.48%, 4.33%, and 2.8% on LEVIR-CD; 2.06%, 4.08%, 3.16%, 3.53%, and 3.61% on WHU-BCD; 1.64%, 3.36%, 1.52%, 3.7%, and 2.44% on CDD. Furthermore, the model shows significant improvements under the constraint of the proposed dynamic Focal loss. Compared with the baseline model, the proposed EFP-Net demonstrates significant enhancements in the metrics of OA, Precision, Recall, IoU, and F1, with improvements of 0.57%, 3.45%, 3.05%, 5.07%, and 3.24%, respectively.
We also present visualizations of the refined feature maps generated by the RGM on LEVIR-CD.
Figure 9a,b display a pair of bi-temporal RS images, while (c) and (d) are the ground-truth label and the predicted change maps of EFP-Net, respectively.
Figure 9e–h are the feature maps derived from ‘baseline’, ‘baseline’ + STCM, ‘baseline’ + RGM, and EFP-Net, respectively.
The comparison between
Figure 9e,f demonstrates improved confidence in detecting building changes, which proves the effectiveness of the STCM in reducing background noise and identifying building change locations. Similarly, it is observed in the comparison between
Figure 9e,g that integrating the RGM enhances the network’s capability to recover the fine details of changed buildings. Furthermore,
Figure 9h reveals that the incorporation of both the STCM and RGM further enhances the contrast between changed buildings and the background. These observations collectively offer compelling evidence of the effectiveness of the proposed STCM and RGM.
3.5.2. Verification of Loss Function
We also verified the effectiveness of the proposed dynamic Focal (DF) loss. As observed in the last two rows of
Table 7,
Table 8 and
Table 9, the performance of the ‘baseline’ + STCM + RGM model is further improved under the constraint of the DF loss. This is because the proposed DF loss enables the model to focus on the changing foreground samples during training, thereby mitigating the impact of class imbalance on model performance.
In addition, we also compared the effectiveness of the proposed dynamic Focal loss with other loss functions commonly used in change detection on LEVIR-CD. In particular, cross-entropy (CE) loss, weighted cross-entropy (WCE) loss, and Focal loss were employed for comparisons. As shown in
Table 10, compared with the CE loss, the WCE loss enhances the weights of the loss for a small number of foreground samples, resulting in an improvement in the Recall metric. The Recall metric is further improved with the Focal loss, as it reduces the weights assigned to easily classified samples. Relative to other loss functions, the proposed DF loss achieves the best scores across all the metrics, demonstrating its effectiveness.
3.5.3. Verification of Parameter
In the RGM, higher-layer features
are evenly split in to
g groups and then concatenated with
G to model the initial change feature,
. We also verified the impact of the number of groups
g in the RGM on the performance of the EFP-Net. Specifically, experiments were carried out with
g values of 1, 2, 4, 8, 16, and 32. As revealed in
Table 11, the performance of the model improves progressively as the value of
g increases and peaks when the value of
g reaches eight. However, the performance of the model starts to decline as the value of
g continues to increase, implying that an excessive number of groups leads to redundancy in
. Consequently, we fixed the number of groups at eight in our experiments.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}