1. Introduction
Pipelines, as vital underground urban infrastructure, require regular inspection to mitigate issues such as inadequate maintenance, disorganized pipeline distribution, and pipeline aging. Ground-penetrating radar (GPR), as a nondestructive detection method, has gained widespread adoption in the field of underground detection [
1,
2,
3,
4,
5,
6]. In the B-scan image detected using GPR, buried pipelines are displayed as hyperbolic patterns in a two-dimensional image [
7]. GPR plays a crucial role in pipeline safety monitoring. However, during the operation of the system, the collected echo frequently encounters challenges, such as strong ground clutter and noise interference, which are influenced by the inherent characteristics of the system itself and complex environmental factors. When the target and ground clutter signals are seriously aliased, the clutter signal masks the target signal, making it difficult to distinguish the echo of underground hidden pipelines, which makes it impossible to detect the specific status of the underground pipelines. This has caused great difficulties for the subsequent imaging, positioning, and identification of underground targets. Therefore, it is crucial to correctly distinguish between target response and clutter in GPR images.
As a research focus in the field of GPR signal processing, the study of clutter suppression methods has been widely recognized and received significant attention from experts worldwide. In recent years, research in this area has made progress. At present, traditional GPR clutter suppression methods are mainly divided into two categories, including subspace-based methods and low-rank sparse decomposition methods. Common subspace filtering methods include SVD, PCA, and ICA, while common low-rank sparse decomposition methods include RPCA, GoDec, and RNMF.
The subspace method can extract the principal component signal as clutter and the remaining part as the target signal. SVD [
8] is a method based on matrix decomposition, which decomposes a matrix into the product of two orthogonal matrices and a diagonal matrix with singular values in descending order. The effectiveness of clutter suppression is heavily influenced by the size of the singular values. PCA [
9] is a method of decomposing the covariance matrix. By calculating the eigenvalue eigenvectors of the covariance matrix, the eigenvectors corresponding to the k features with the largest eigenvalues are selected to form a matrix. When this method faces multiple underground targets, the clutter suppression effect will be reduced, and the selection of the k value also affects the clutter suppression effect. ICA [
9] is a method to find hidden components in multidimensional data that can separate the source signal from the mixed signal. This method is extremely sensitive to noise and has the problem of a long iteration time, making it unable to cope with the complex environment of GPR underground detection.
In recent years, the development of low-rank sparse decomposition theory has gradually improved. However, due to the strong clutter interference, GPR signals will exhibit low-rank sparse characteristics. This has also led to this theory becoming a popular research topic in the field of GPR signal processing. In 2015, the RPCA [
10] method was successfully applied to the research on clutter suppression of GPR. This method decomposes the signal into low-rank and sparse components, which respectively represent the target response and clutter in the image. However, RPCA requires a large amount of SVD calculations, which seriously reduces the efficiency of signal processing. To solve this problem, Zhou proposed GoDec in [
11]. This method finely divides the original signal matrix and no longer requires the noise matrix to satisfy the sparse condition. In addition, this method uses bilateral random projection instead of continuous SVD calculation, thereby improving the operating efficiency of the method. However, this method relies heavily on the setting of the parameters. In 2018, relevant area experts applied NMF [
12] to the research on clutter suppression of GPR images. However, due to the lack of sparse components after decomposition, the performance of this method is average. D.Kumlu et al. made improvements based on the NMF method and proposed RNMF [
13], which can obtain sparse components during the decomposition process. The iterative process of this method is similar to RPCA, but it is faster, and the performance is better. However, due to its iterative characteristics, it is still not sufficient. Considering the limitations of traditional methods, more effective methods are needed to improve the clutter suppression performance in GPR underground environments.
With the emergence of convolutional neural networks (CNNs) [
14,
15], deep learning methods have gained wide applications in the field of image processing. These methods have been successfully employed in the analysis of GPR data for underground detection [
16]. Pham et al. pretrained a CNN on the open database Cifar-10 to obtain the initial parameters of the network and then trained GPR data and fine-tuned the Fast-RCNN framework [
17]. The accuracy of detecting hyperbolic echoes was higher than traditional machine learning methods, and the detection results also confirmed the effectiveness of the pretraining strategy. Xu et al. improved Faster R-CNN by combining feature cascading, adversarial spatial ASDN network, and data augmentation in reference [
18]. By combining multiscale features through feature cascading, the detection accuracy of small targets in GPR images has been improved. To identify hyperbolic features in GPR images, Lei et al., in [
19], used Faster R-CNN to detect hyperbolic region fitting curves in reference. While this method effectively extracts hyperbolic features, it may not capture other features present in GPR images. Qin et al., in [
20], proposed an automatic recognition method based on Mask R-CNN to identify features such as steel bars and voids from GPR images. This method is specifically applied to tunnel detection. In [
21], a novel approach for GPR target feature segmentation using CycleGAN is introduced. This method creates semantic segmentation labels corresponding to radar images, enabling the network to segment hyperbolic features in radar images through supervised learning. The proposed method showcases the ability to achieve faster and more precise segmentation of target features in GPR images. In [
22], a YOLOv3 model with four scale detection layers (FDL) was proposed, which improved the detection performance of the network by integrating multiscale fusion structures. This model is mainly applied to road crack detection.
Deep learning has significant advantages in the field of GPR image recognition; however, due to the interference of ground clutter during the detection process, it greatly increases the difficulty of identifying target echo in GPR images. To reduce the interference of clutter on target response, many researchers have conducted research on clutter suppression. In [
13], a network model constructed with 1-D convolutional layers is presented to distinguish target response and strong clutter during the ground-penetrating radar scanning process. Using low-rank components and sparse components decomposed using RNMF as strong clutter and a target response for the data, respectively, the network achieves similar performance with RNMF without tuning hyperparameters. In [
23], a robust method based on autoencoder is introduced. Due to its ability to provide nonlinear solutions, autoencoders perform better than traditional RPCA methods in terms of effectiveness. Moreover, this method effectively solved the low-rank and sparse matrix representation problem. In [
24], a network model based on CAE is presented to learn clutter removal in 2-D B-scans using a synthetic dataset. The clutter suppression effect of this method is significant, but its clutter suppression effect decreases on the measured GPR B-scan images. This is because the network is only trained on synthetic data and cannot capture sufficient clutter distribution information in complex underground environments in actual scenarios.
To cope with these problems, many researchers have tried to use different deep learning methods to suppress clutter in GPR data. Wang et al. [
25] proposed a supervised deep learning network to remove clutter from GPR steel bar detection data and improve the generation effect of target response. The results show that deep learning has good prospects for removing clutter from GPR data. However, supervised learning is a highly dependent method on paired datasets, and in the actual detection process, it is difficult to collect data with clutter and paired data without clutter. Cheng et al. [
26] proposed an improved network called CR-Net based on Generative U-Net. To prevent the loss of target response information in the network during the down-sampling process conducted by the encoder, skip connections are employed to combine the features of the encoder and decoder. However, rather than directly merging these features, the skip connection process incorporates the use of the residual dense module (RDB). This integration of the RDB within the skip connection process ensures the preservation of essential information throughout the network by adaptively retaining features related to target response and reducing unwanted clutter features through RDB. The results demonstrate that CR-Net is capable of effectively removing clutter from images. However, it still relies on paired clutter data and clutter-free data for training, which poses challenges in real-world scenarios in which it is difficult to collect clutter data and the corresponding counterpart simultaneously.
This paper proposes a clutter suppression method based on CycleGAN network. CycleGAN has significant performance in the field of image generation, and it has received widespread attention from scholars because it does not require paired datasets for training. This paper applies the style transfer idea of CycleGAN to the research on clutter suppression of GPR images. However, the original CycleGAN lacks the ability to retain crucial information during the conversion process, resulting in a converted image that lacks direct correlation with the original image. Consequently, while it can remove a significant portion of the clutter, it also adversely affects the generation of the target response, leading to the loss of essential hyperbolic characteristics in the resulting output. To increase the feature extraction ability and feature retention ability of target response feature information, this study improves the conventional CycleGAN by adding residual learning and channel attention mechanisms. This enhancement enables the transformation from cluttered images to clutter-free images, thereby addressing the issue of losing hyperbolic features in the target response.
The rest of this paper is as follows: first, the basic principles of CycleGAN are introduced, secondly, the network structure of the improved CycleGAN is introduced, and this paper will explain the structure and function of the network generator and discriminator. Then, this paper introduces the datasets used for network training. Finally, the applicability and effectiveness of the network were verified under simulated data and measured data, respectively, and the generation effect was quantitatively evaluated.
2. Basic Principles of CycleGAN
CycleGAN, proposed by Zhu et al. [
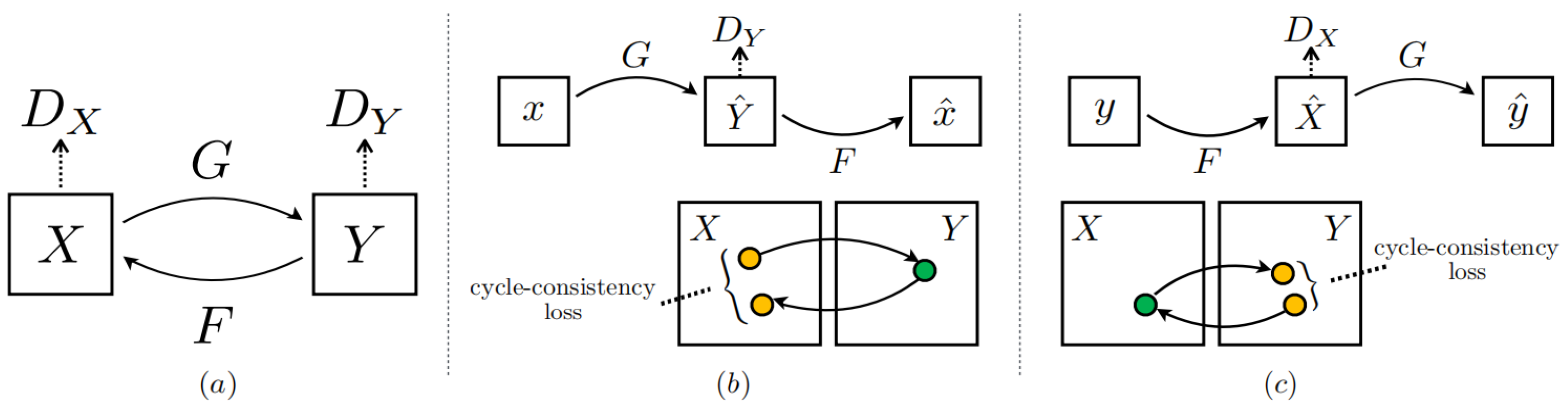
27], is an unsupervised learning image conversion network based on the framework of conditional generative adversarial networks. Unlike other deep learning models, CycleGAN primarily focuses on learning the mapping relationship between two distinct image domains. Its main objective is to facilitate the conversion of images between these domains. In addition, unlike previous research work, there is no need to use paired training data during network training. The network learns the mapping relationship between two image domains without paired training examples. The network structure is shown in
Figure 1.
The core idea of CycleGAN is cycle consistency. The introduction of cycle consistency loss in the generator ensures a certain level of memory, as it incorporates reverse mapping. This prevents the loss of essential feature information from the original image during the image generation process. The objective of cycle consistency is to facilitate the reconstruction of an image that is highly consistent with the original image through cyclic mappings between the two image domains during the conversion process. This can also avoid the problem of partial information loss during image conversion. The cycle-consistent loss of CycleGAN is divided into forward cycle-consistent loss and backward cycle-consistent loss. The forward loop consistent loss requires that all images in the
domain can be passed through the image conversion loop and restored to the original image, which is
. The backward loop consistent loss is similar to the former, that is
. The expression of cycle consistency loss is as follows [
28]:
As shown in Equation (1), the
L1 norm is used to reconstruct the image, making it close to the original input image, while regularizing the model to prevent overfitting by the generator. CycleGAN introduces cycle consistency loss to enable the network to learn the feature information of image domains
at the same time and establish a mutual mapping between the two domains. The complete objective function expression is as follows:
is represented as a balancing parameter that controls the relative importance of the two goals. The final optimization objective function expression of the network is as follows:
The purpose of the generators
and
is to minimize the value of the loss function, while the purpose of the discriminators
and
is to maximize the value of the loss function. In addition to the cycle consistency loss, CycleGAN incorporates GAN loss into the network to capture the adversarial learning processes [
28]. This helps determine the authenticity of the generated image by assessing its resemblance to real images. The expressions of the two adversarial learning GAN loss functions are as follows:
In the formula, and represent the image in the image domain and image domain respectively. In the formula, and are used to represent the distribution of the data, where represents the expectation. Equation (4) is the adversarial loss of the mapping function in the forward loop process of CycleGAN. The generator generates images similar to those in the image domain , and the discriminator is used to determine whether the input is the real image domain or the image is still an image generated by generator . The adversarial aspect is that the generator aims to minimize , while the discriminator needs to maximize . Equation (5) represents the adversarial loss of the mapping function during the backward circulation process of CycleGAN. The principle is the same as Equation (4).
CycleGAN has significant advantages in the image conversion area. Its training process does not require paired training data, and it still has efficient image conversion performance even when there is a large feature difference between the two image domains. However, CycleGAN also has certain limitations. Because the network adopts the idea of style transfer, it cannot guarantee that the generated image is exactly the same as the original image, and some feature information may even be lost during the generation process.
3. Improved CycleGAN Basic Principles
The original CycleGAN exhibits limited feature extraction and expression capabilities for target responses, making it challenging to accurately eliminate clutter and achieve the desired clutter suppression effect. As a result, the clutter suppression effect does not reach expectations. Specific problems include that the generator has limited ability to extract hyperbolic features of the target response. Although it can remove most of the clutter, it will still be affected by clutter when generating images, and it will also affect the characteristics of some important hyperbolic feature information. The discrimination results of the discriminator are easily affected by secondary feature areas, and insufficient attention is paid to key target response features. During the training process, the generator and discriminator encounter the aforementioned issues, leading to the absence and distortion of hyperbolic features in some target responses of the resulting clutter-free pipeline image . At the same time, CycleGAN’s forward cycle consistency loss aims to make the original clutter data and reconstructed clutter data highly consistent at the pixel level. Due to the direct aliasing of clutter and target responses, it is difficult to achieve highly consistent reconstruction results during the reconstruction process. This contradiction also results in the generator incorporating redundant information while generating clutter-free images, leading to the deformation of certain target responses, and thereby impacting the overall quality of the generated target response.
In view of the above limitations of CycleGAN, the main improvement ideas of this paper are as follows:
- (1)
Design a deep learning network based on CycleGAN to eliminate clutter in GPR images during GPR underground pipeline detection.
- (2)
Design two sets of generators and discriminators in the network and analyze GPR data through unsupervised learning.
In this chapter, the improved CylceGAN training process and the settings of the loss function will be introduced, and the specific construction of the network’s generator and discriminator will be elaborated.
3.1. Network Training and Loss Function
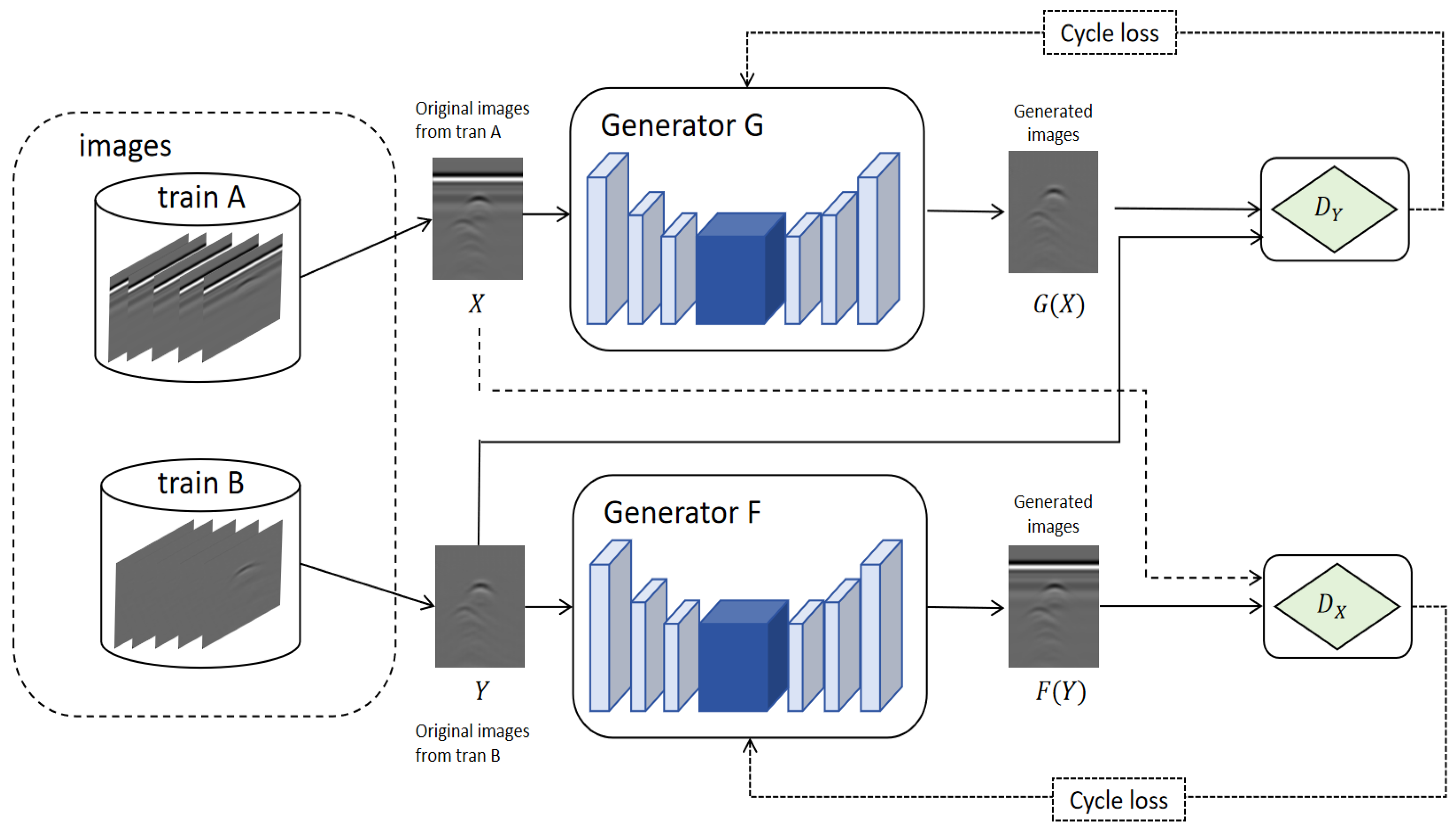
The overall network structure of the improved CycleGAN is shown in
Figure 2.
First, the training dataset of the network is constructed. The dataset is divided into the clutter dataset A and the clutter-free dataset B. The data in the two datasets are used as inputs to generator
and generator
, respectively. In this paper, the image domain storing clutter pipeline data is denoted as
, and the image domain storing pipeline data without clutter is denoted as
. The process of clutter suppression is to use the generator
to convert the GPR B-scan image with clutter into a GPR B-scan image without clutter. The process of clutter suppression is shown in
Figure 3.
The network contains two generators and two discriminators. The two generators have the same structure and learn two mappings, and , respectively. Among them, and respectively represent two different GPR image domains. The domain contains GPR images with clutter, and the domain contains GPR images with only target responses. At the same time, the network contains two adversarial discriminators, and the two discriminators and also have the same structure. Among them, is used to distinguish whether the input image is a real image of the domain or an image generated by the generator , and is used to distinguish whether the input image is a real image of the domain or an image generated by the generator . At the same time, the parameters of the two generators are updated through cycle loss. Cycle loss uses L1 norm to regularize the model, and to avoid dependence on simulated data during model training, the network uses other graphs in the dataset to test the generators, further preventing over-fitting problems of generators and .
Through training, the network can learn generator and generator at the same time, thereby generating images with similar feature distributions to image domain and image domain respectively. However, in the process of clutter suppression, if the network has a large enough capacity, although the cluttered GPR data can be mapped into the clutter-free data target domain , these randomly generated clutter-free images have absolutely no relationship with the input.
To solve the above problems, CycleGAN also introduces forward cycle consistent loss and backward cycle consistent loss respectively. The forward cycle consistent loss requires that all images x in the domain can be transformed and recycled through image conversion and finally, restored to the original image, which is , the backward loop consistent loss is similar to the former, which is .
During training, the network optimizes the network by setting a loss function that calculates the difference between the output generated by the generator and the real image. The CycleGAN network sets three loss functions, namely cycle consistency loss, GAN loss, and identity loss. The cycle consistency loss and identity loss are both calculated using
L1 distance loss. Taking forward cycle consistency loss as an example, the expression of
L1 distance loss is as follows:
where
represents the input GPR clutter data,
represents the GPR clutter-free data,
is the generator, and
represents the output of the network. The calculation of
L1 distance loss allows the network to continuously approach the true value in the sense of
L1 distance when generating data. Moreover, using the
L1 distance loss function to calculate the identity loss can also better retain some feature information of the original image.
However, during the training process of the network, to avoid the problem of losing some feature information of the generated image, the network introduces two discriminators at the same time and introduces an adversarial loss function . The generator and the discriminator are jointly trained. In the adversarial loss function , the generator’s goal is to minimize the loss , and the discriminator’s goal is to maximize the loss .This paper updates the generator parameters through the adversarial loss function , thereby producing a clutter-free image that is indistinguishable from the real image. This paper extracts the feature information of the target response, discriminates the key feature information, and averages all the discrimination results to obtain the final output result.
3.2. Improve Generator and Discriminator
3.2.1. Generator Construction
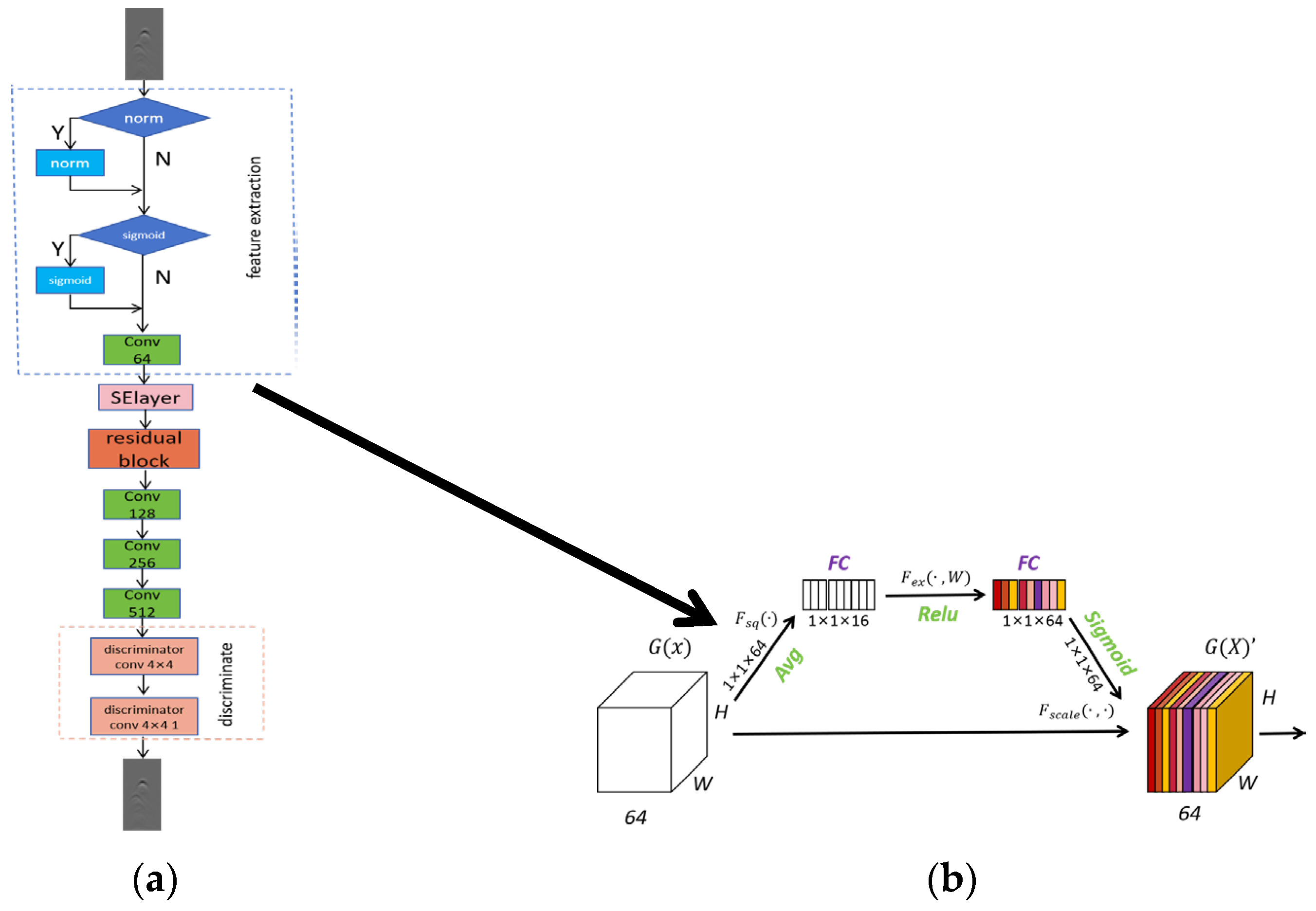
The generator
and
generator of CycleGAN have the same structure, and the structure of the generator is shown in
Figure 4a.
The function of the generator is to convert the original clutter-containing data into clutter-free data after clutter suppression, and the generator is to add clutter to the clutter-free data and convert it into clutter-containing data. The construction of the generator in this paper consists of three parts, namely the feature extraction module, the feature reconstruction module, and the image up sampling module. The input GPR image is first resized into an image with 64 256 pixels. Then, the feature information of the GPR image is extracted through multiple convolutions and down-sampling until the end of the feature reconstruction layer, and then up-sampling restores the scale of the image. In the feature extraction module, it consists of a filling layer and two convolution layers. First, a filling layer is constructed to prevent the image from losing resolution after passing through the convolution layer. Then there is a convolution layer with a kernel of 7 7, which is used to increase the input channel to 16. Finally, there is a convolution layer with a kernel of 3 3 for extracting feature information. During convolution, batch normalization and activation functions are performed on the image to improve the representation ability of the network.
The extracted image feature information is input to the feature reconstruction module. The function of this module is to reconstruct the features and further process the features. The feature reconstruction module of the original CycleGAN has a simple structure, consisting of only one filling layer and one convolution layer, and cannot process complex clutter feature information on GPR data detected by GPR underground pipelines. Moreover, considering that during the underground pipeline detection process of GPR, there is overlap between the target response and clutter, which seriously affects the network’s learning of the global characteristics of the target response. Therefore, to solve the problem of partial feature information loss during the target response generation process, after feature extraction, a four-layer residual module is added to replace the feature reconstruction module of the original CycleGAN. The idea of residual network was first proposed by Zhang et al. in the literature [
29]. The function of this module is to improve the generalization ability of the model, retain more useful information, and suppress useless information. Unlike the original CycleGAN network generator, the feature extraction effect is significantly improved through the skip connection part of the residual network.
The structure of the residual module is shown in
Figure 4b. It consists of two filling layers and two convolutional layers. The two convolutional layers are kernel 3
3 convolutions. The convolution process also requires batch normalization and activation functions to improve the operating efficiency of the network. In the input part, a skip connection is implemented to incorporate the image features extracted using the feature extraction module with the features obtained through residual convolution. This enables the generation of a new image feature that incorporates both sets of extracted features. Due to the reference of skip connections, the global features of the image can be better preserved.
Lastly, the image upsampling module is employed to restore the original image pixels and revert the number of image channels to match the input’s channel count. The upsampling part consists of a transposed convolution module, which is a transposed convolution with a kernel of 3 3. In the process of upsampling deconvolution, batch normalization and activation functions are still performed to improve the feature expression ability of the network. Then, the image information is further retained through a filling layer and a convolution layer with a kernel of 7 7, and finally the generated result of the generator is output.
3.2.2. Discriminator Construction
The discriminator
and discriminator
of CycleGAN also have the same structure. The structure of the discriminator is shown in
Figure 5a.
The discriminator is used to distinguish whether the input image is a real image in the domain or an image generated by the generator ; is used to distinguish whether the input image is a real image in the domain or an image generated by the generator . The discriminator in this paper consists of four parts, namely the feature extraction module, the attention mechanism module, the residual module, and the discriminant module. The discriminator is used to classify the input data and determine whether they are real data or generated data.
The original CycleGAN discriminator has a simple structure and only consists of a feature extraction part and a discrimination module. The discriminator first extracts features from the input image. During the feature extraction process, the feature discrimination results of the local area will affect the discrimination results of the entire image. Sometimes even if the local features of the target response are poorly generated or even missing, the discriminator will still judge the overall image as true. Therefore, only using CycleGAN’s original discriminator to discriminate the generated clutter-free image will have the problem of poor local target response generation. To enhance the generation effect of target response, this paper introduces the channel attention mechanism SE module and residual module based on the original CycleGAN discriminator.
Among them, the channel attention mechanism SE module was first proposed by Hu in the literature [
30]. This module can establish the interdependence between convolutional feature channels to improve the feature extraction capability of the network. The channel attention mechanism is introduced to enable the network to perform feature recalibration, through which global information can be effectively preserved, thereby selectively increasing the degree of attention to target response characteristic information and suppressing the degree of attention to useless characteristic information caused by useless clutter interference. At the same time, it helps the model better extract the hyperbolic features of the target response and avoids the discriminator being affected by irrelevant feature areas. The structure of the SE module of the attention mechanism is shown in
Figure 5b. It mainly consists of a global average pooling layer and two fully connected layers, as well as the corresponding activation functions ReLu and Sigmoid of the fully connected layer. The discriminator retains the characteristic information of the target response through the attention mechanism, then further extracts features through the residual module, and finally obtains the final discrimination result through the discriminant module.








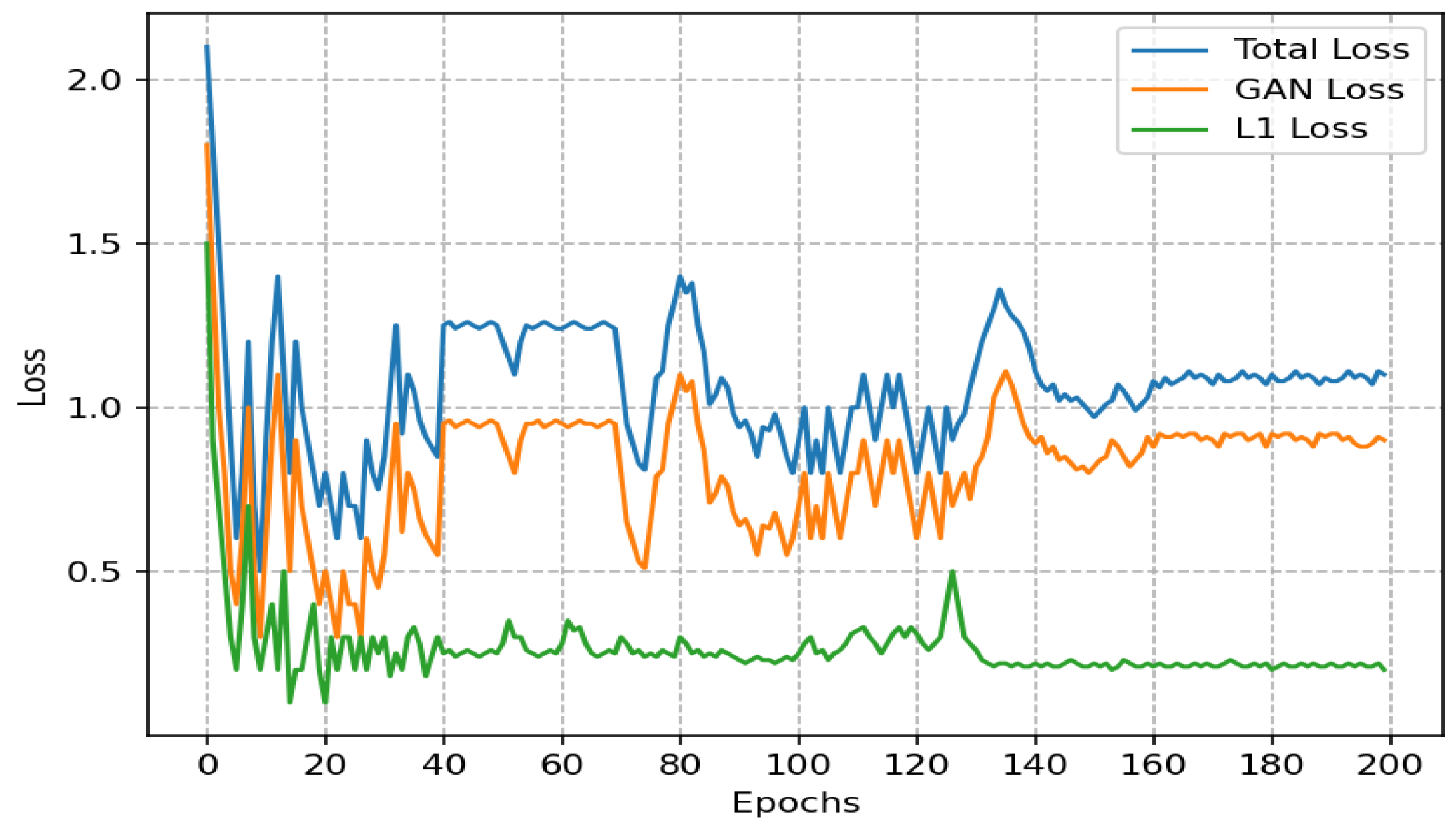
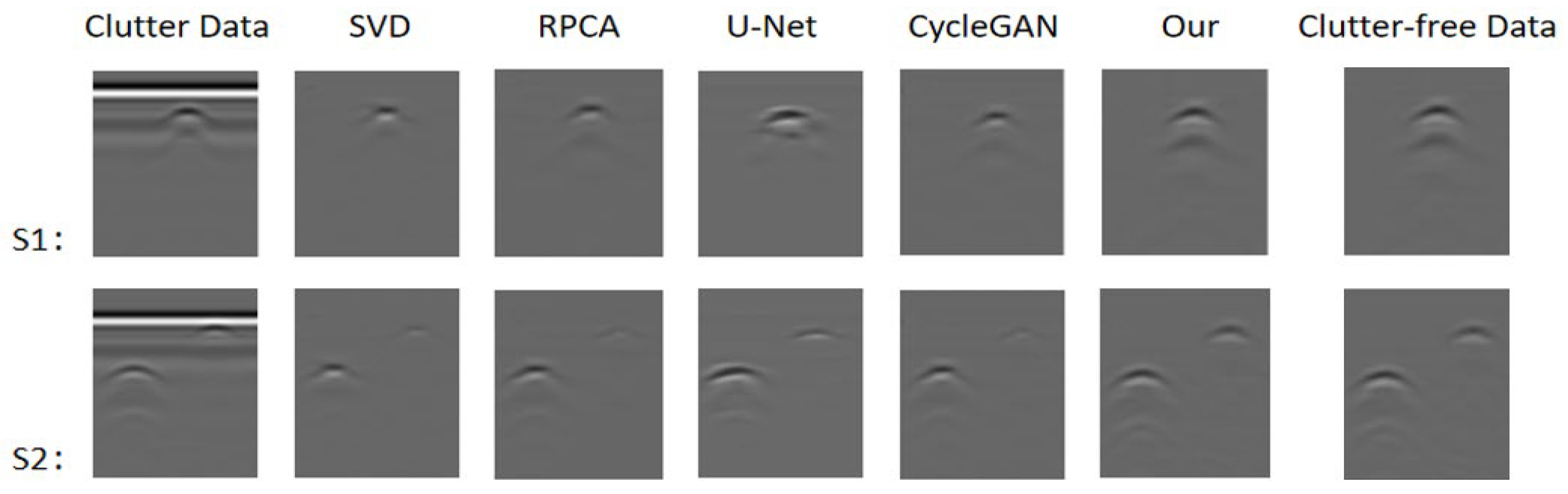



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}