
Semi-Supervised Person Detection in Aerial Images with Instance Segmentation and Maximum Mean Discrepancy Distance




Abstract
1. Introduction
- A semi-supervised learning strategy with pseudo-labels is developed for SaR scenarios, which mainly consists of three steps: training high-confidence teacher models from reliable labels, data augmentation with the instance segmentation copy-paste mechanism, and use of a teacher-student model with consistent loss function.
- To further boost the performance and effectiveness, the algorithm utilizes an MMD distance to evaluate the detector’s metrics, which can be easily embedded in single-stage and two-stage object detectors.
- The detection results of both public and optimized datasets are compared. Moreover, the detection results are also compared with other detection algorithms. The experimental results show that our proposed method achieved SOTA.
- To explore the robustness of person detection from aerial images for different SaR applications, datasets with multiple scenes are created and evaluated for non-commercial purposes.
2. Materials and Methods
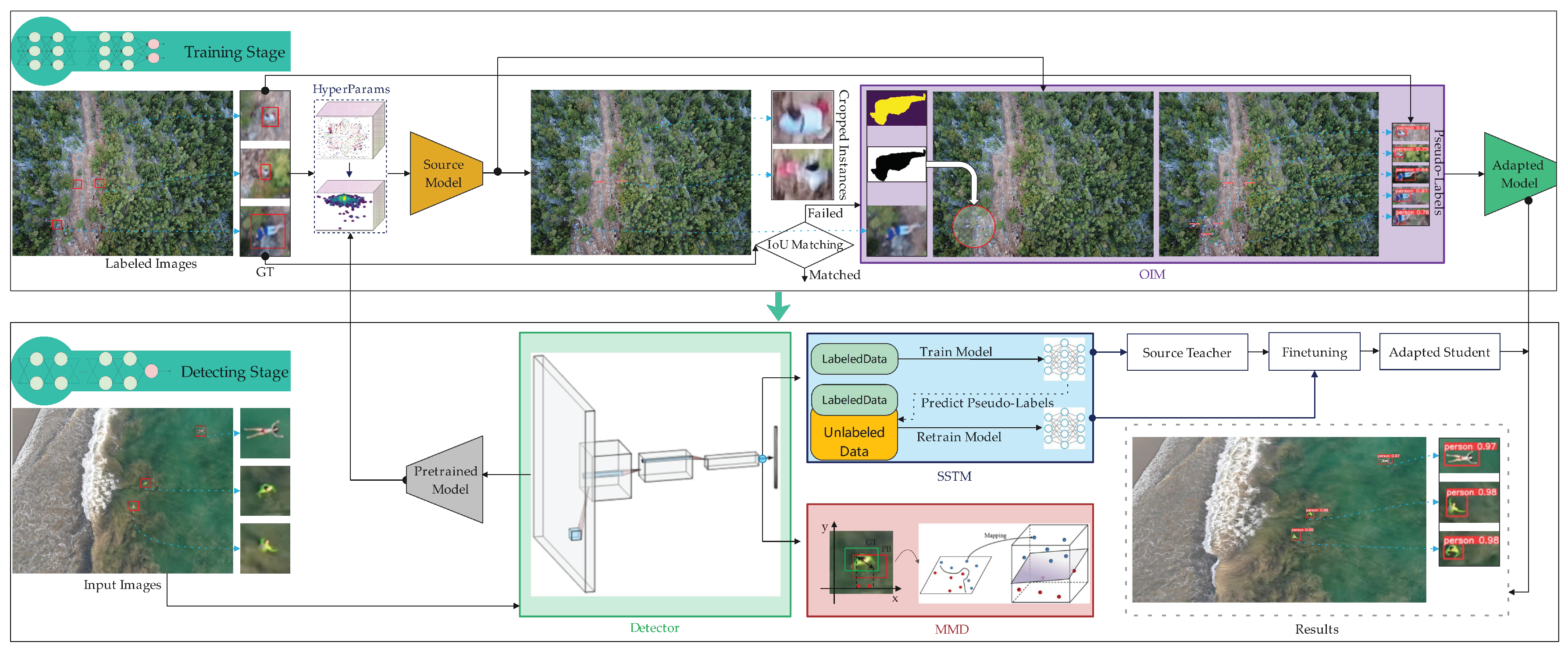
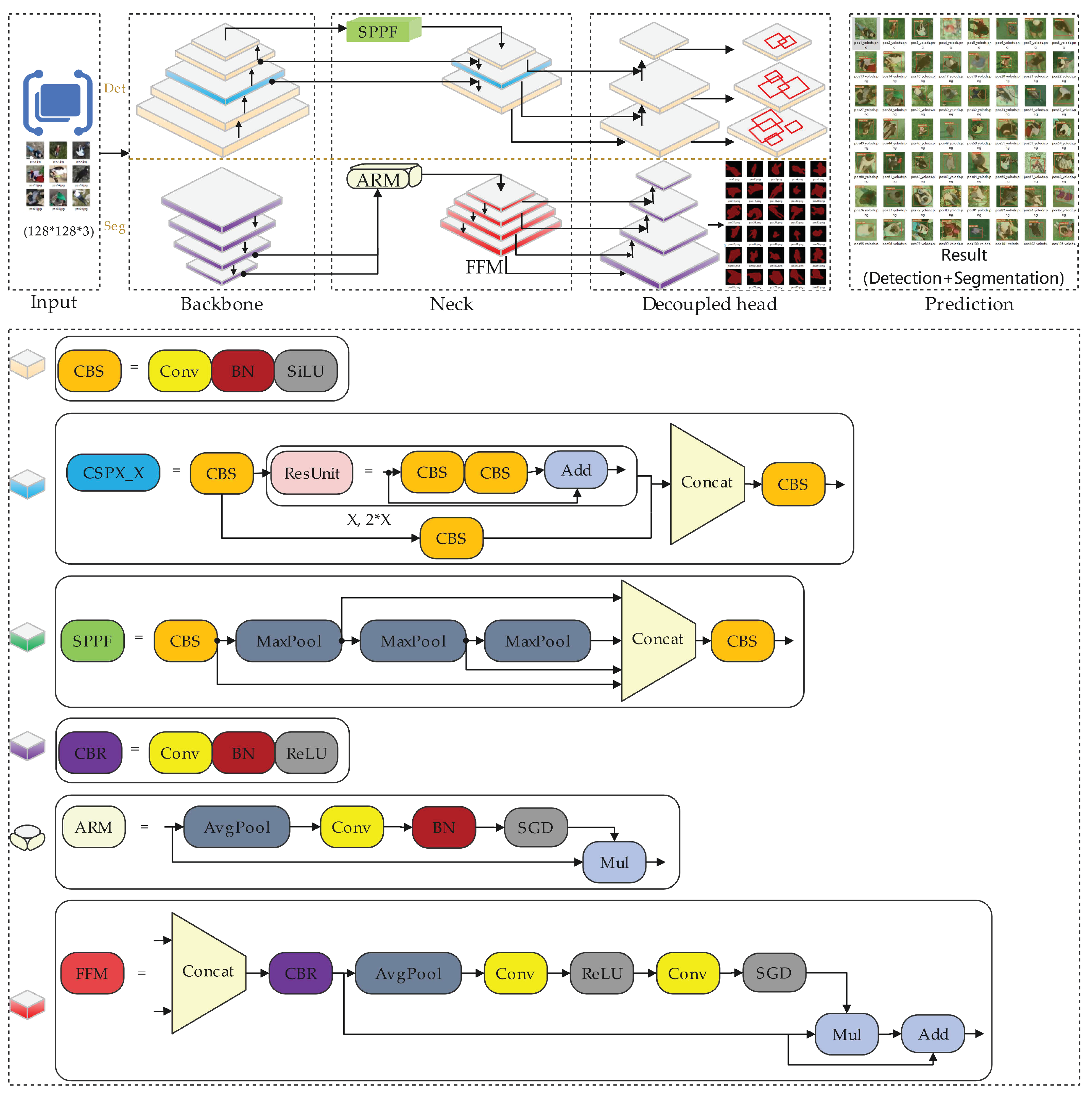
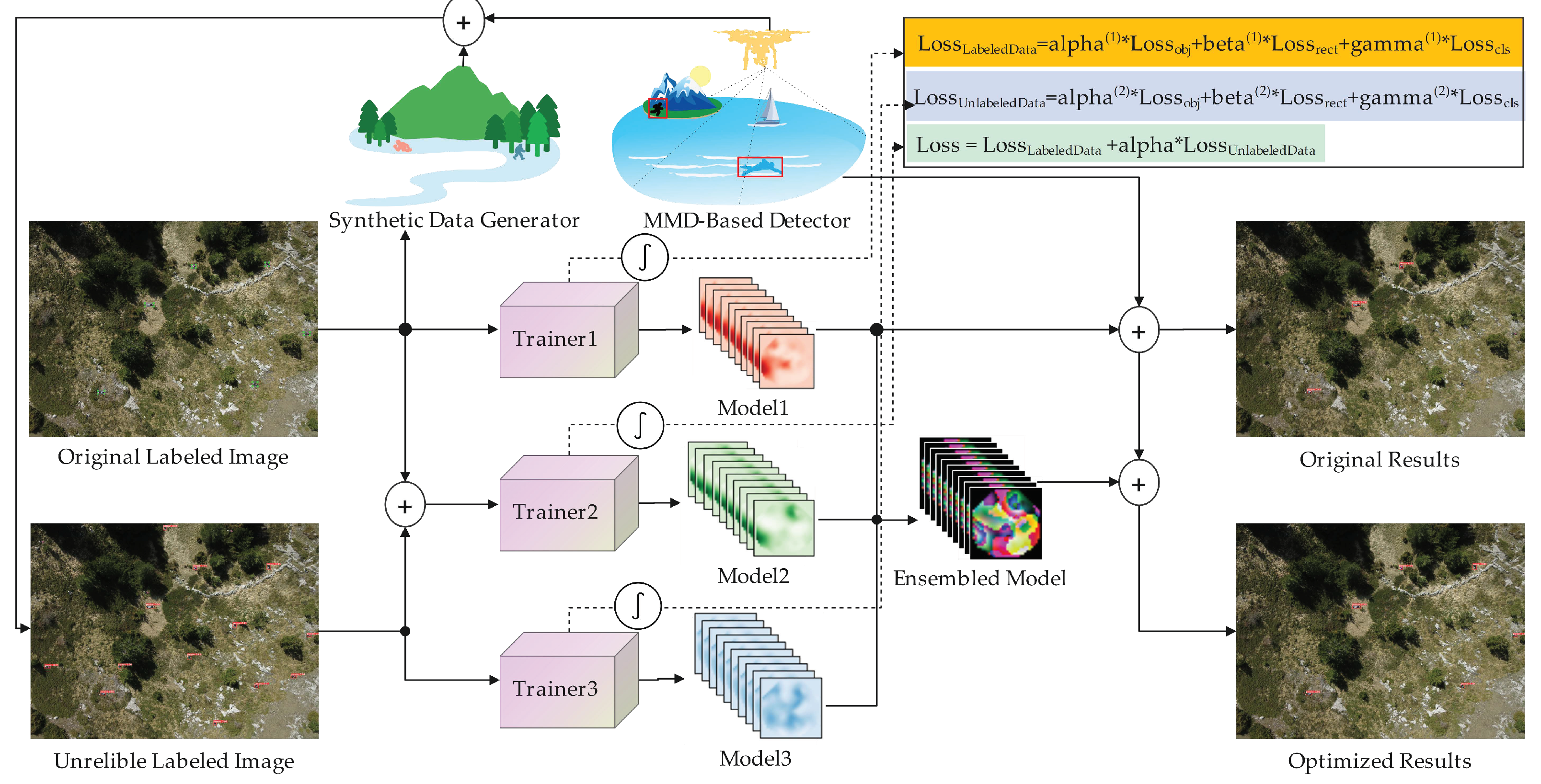
2.1. General Framework of Our Proposed Approach
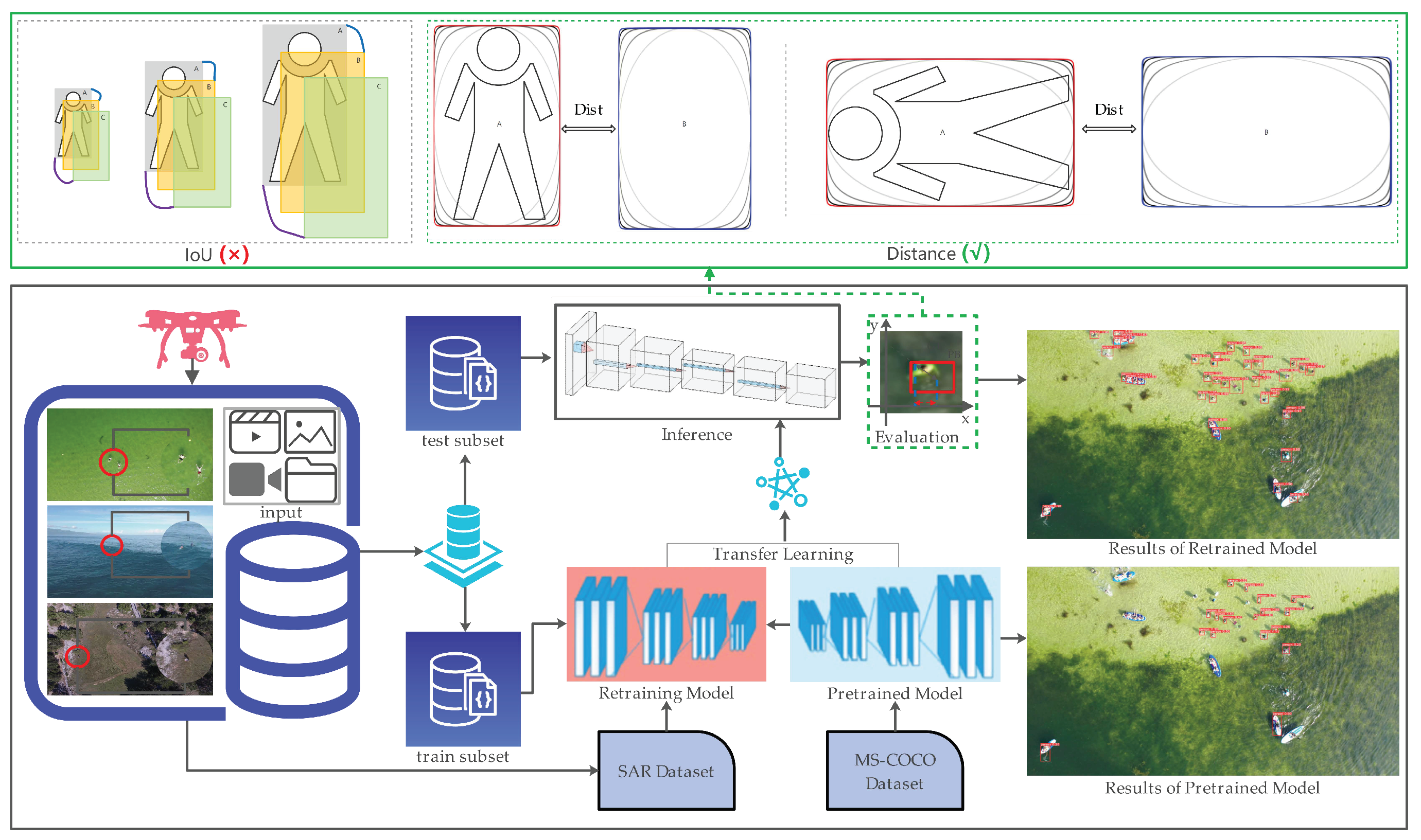
2.2. Anchor-Based Detectors with Maximum Mean Discrepancy Distance
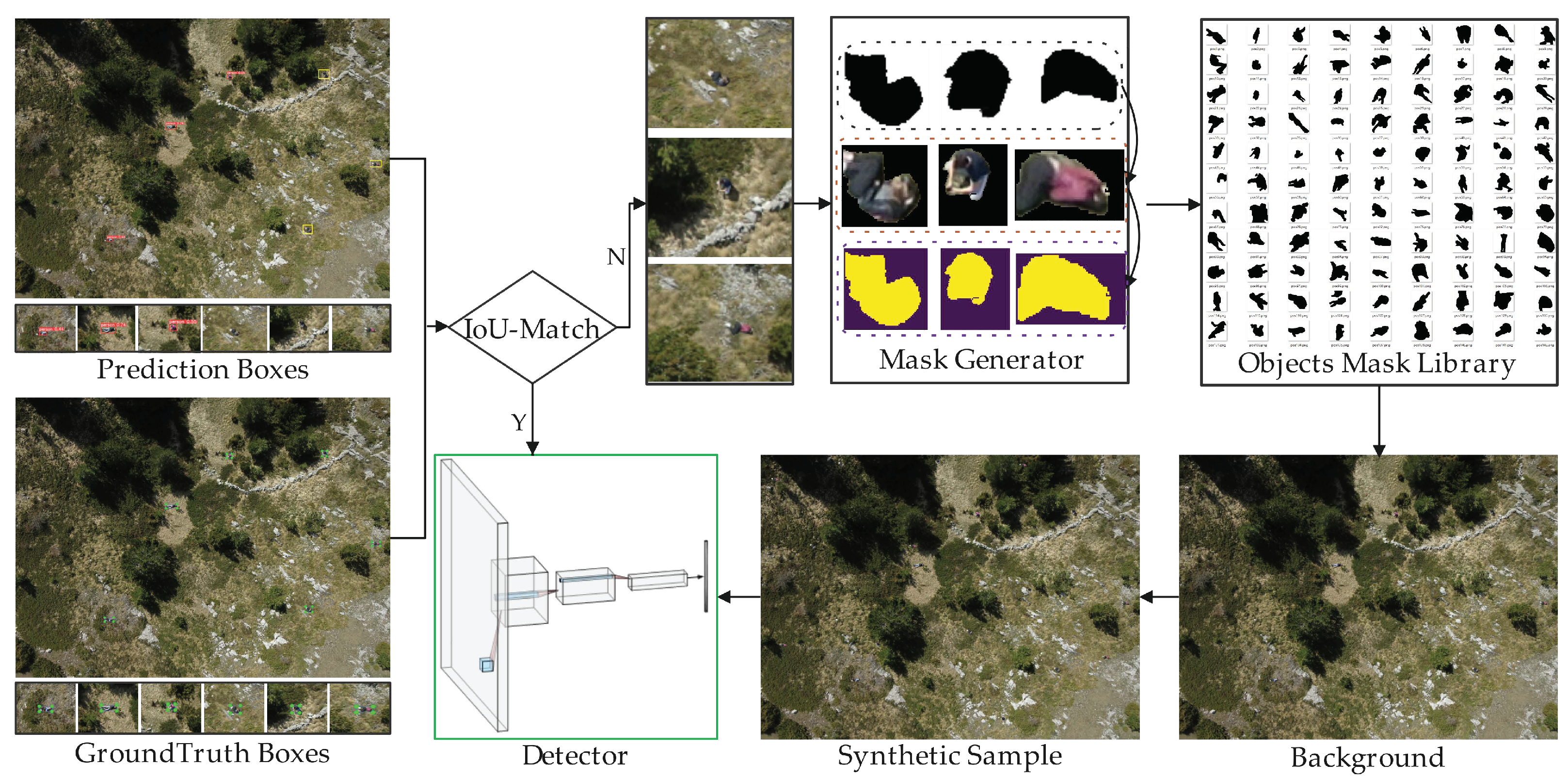
2.3. Synthetic Data Generation by Object Implantation
- The detector infers unlabeled images using the pretrained model and computes IoU matching between the GT and P-BBs to obtain undetected object instances.
- The generator obtains (as shown in Figure 3) masks of undetected object instances.
- Synthetic samples are created by randomly combining unreliable instances and backgrounds according to the objects’ mask library (OML, which comes from the results of instance segmentation).
| Algorithm 1: Object implantation with Instance Segmentation Copy-Paste (ISCP) based on the YOLOv5 detector |
|
2.4. Pseudo-Label-Assisted Trainers with Semi-Supervised Learning
- It reduces the reliance of machine learning models on labeled data significantly, especially when the project is in its early stages.
- Even if the data is unlabeled, the distribution of the unlabeled data can provide a wealth of information to guide model iteration.
- In most cases, unmarked data is easily accessible, and the amount of data is large. Quantity is more important than quality. When used correctly, it can be extremely beneficial.
| Algorithm 2: Training process of semi-supervised learning and model ensemble learning based on the YOLOv5 detector |
|
3. Experimental Results and Analysis
3.1. Experiment Setting
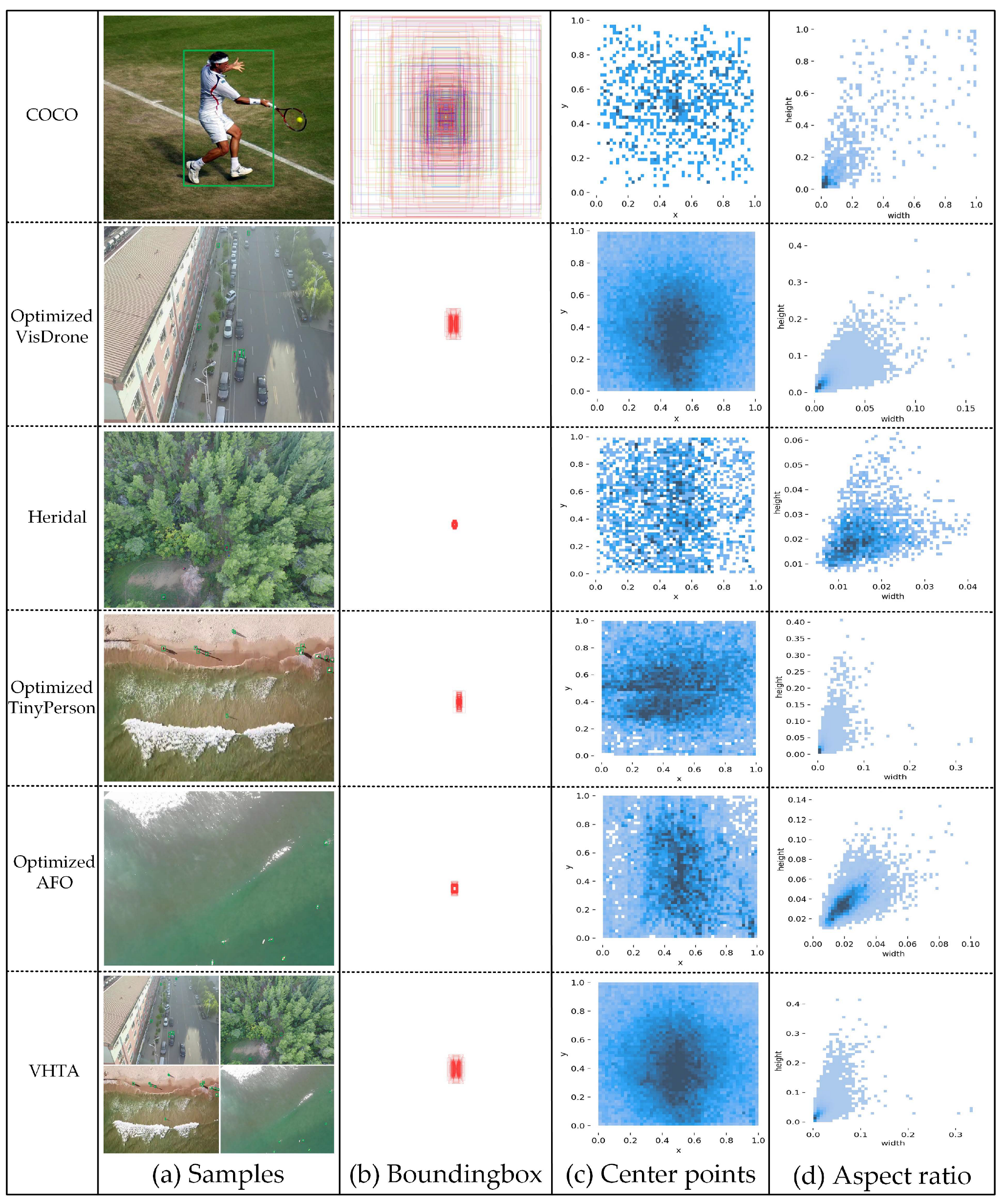
3.1.1. Datasets
- VisDrone dataset [33], which contains details of urban areas and neighborhoods. It includes 288 video clips, 261,908 frames, and 10,209 still images, with labels covering three domains: object detection, object tracking, and congestion counting.
- TinyPerson dataset [16], which consists of 1610 labeled images with 72,651 person instances and 759 unlabeled images, referring to dense and complex environments at sea or the seaside in faraway and large-scale scenes.
- Heridal dataset [5] based on collection of images by unmanned helicopters, including 1650 high-resolution images (4000 × 3000) containing persons from non-urban areas, such as mountains, forests, oceans, and deserts.
- AFO dataset [4], which contains 3647 images with close to 40,000 labeled floating objects (human, wind/sup-board, boat, buoy, sailboat, and kayak).
3.1.2. Parameter Settings
3.1.3. Evaluation Metrics
3.2. Experiments on Optimized Heridal Dataset
3.2.1. Experimental Results of MMD Evaluator
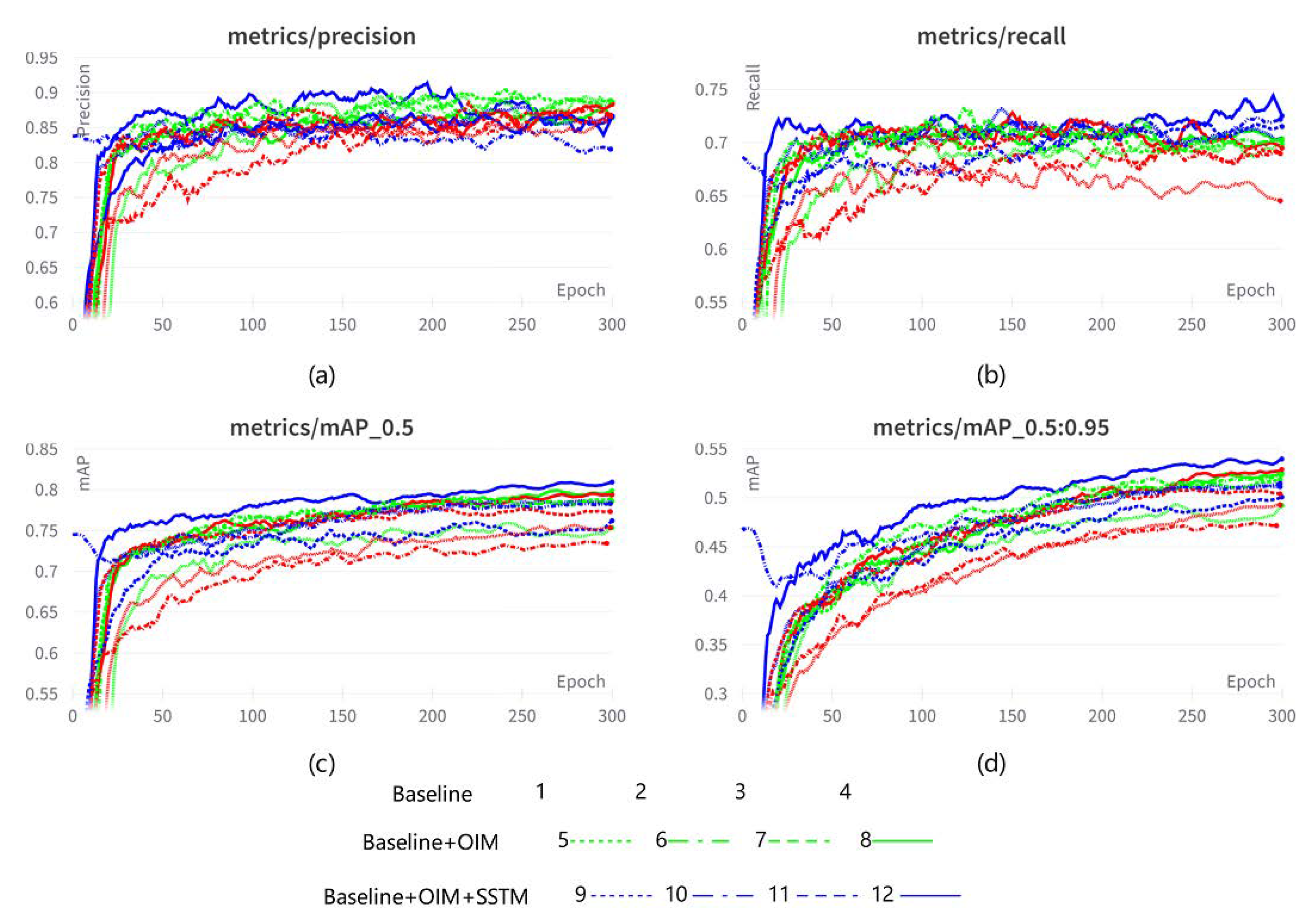
3.2.2. Analysis Results with OIM and SSTM
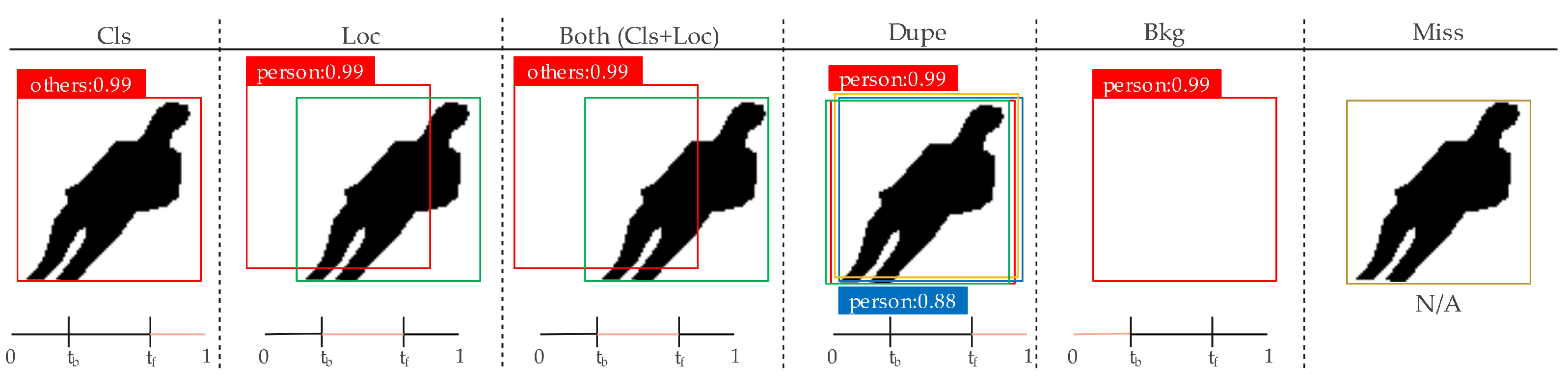
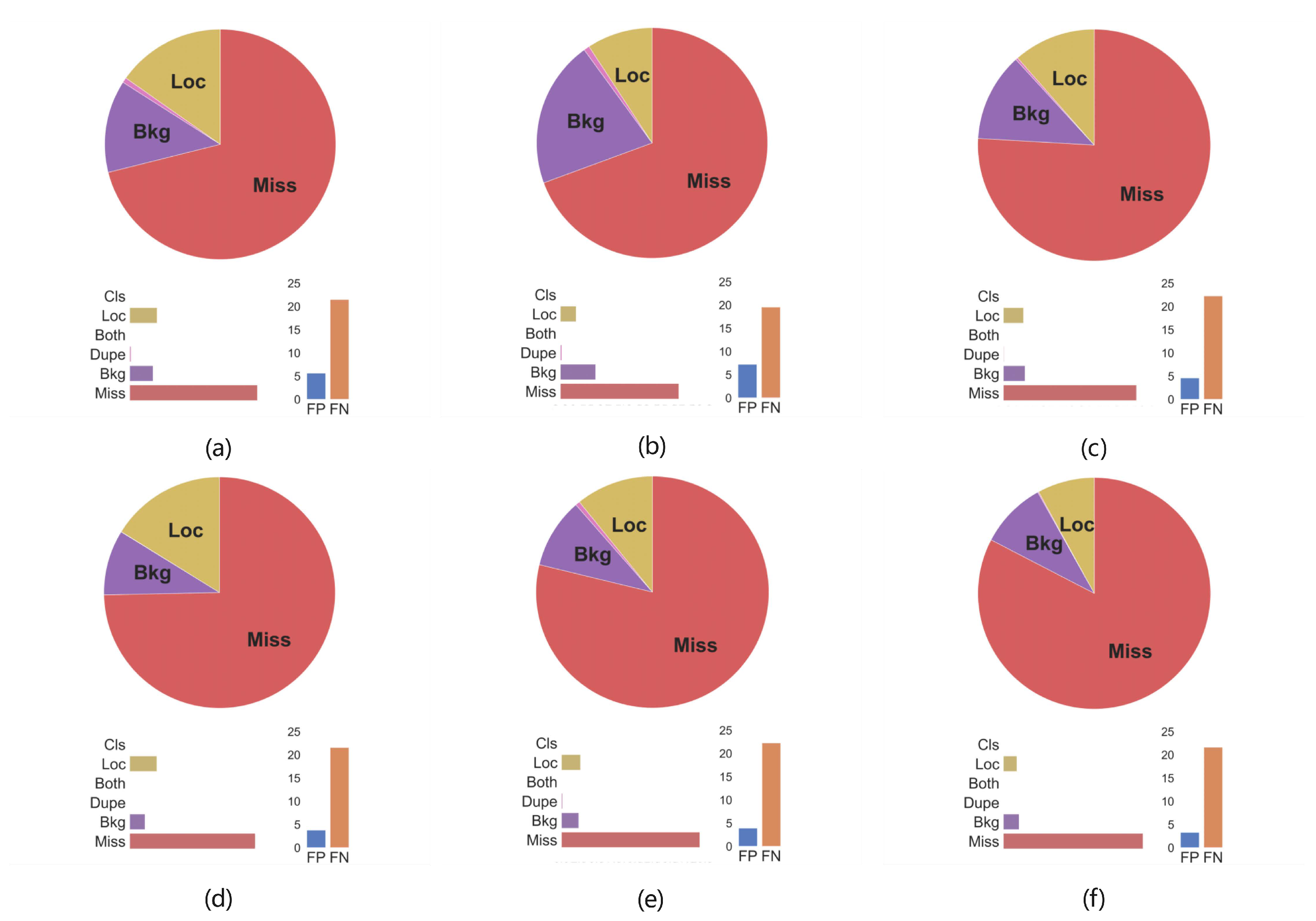
3.2.3. Error Analysis
- Classification error (Cls), ≥, which means localized correctly but classified incorrectly.
- Localization error (Loc), ≤≤, which means classified correctly but localized incorrectly.
- Classification and localization errors (Both), ≤≤, which means classified incorrectly and also localized incorrectly.
- Duplicate detection error (Dupe), ≥, which means multiple detection boxes with various confidence levels.
- Background error (Bkg), ≤, which means background detection boxes, but no instance.
- Missed GT error (Miss), which means all undetected ground truths, other than Cls and Loc errors.
3.2.4. Ablation Study
3.2.5. Discussions
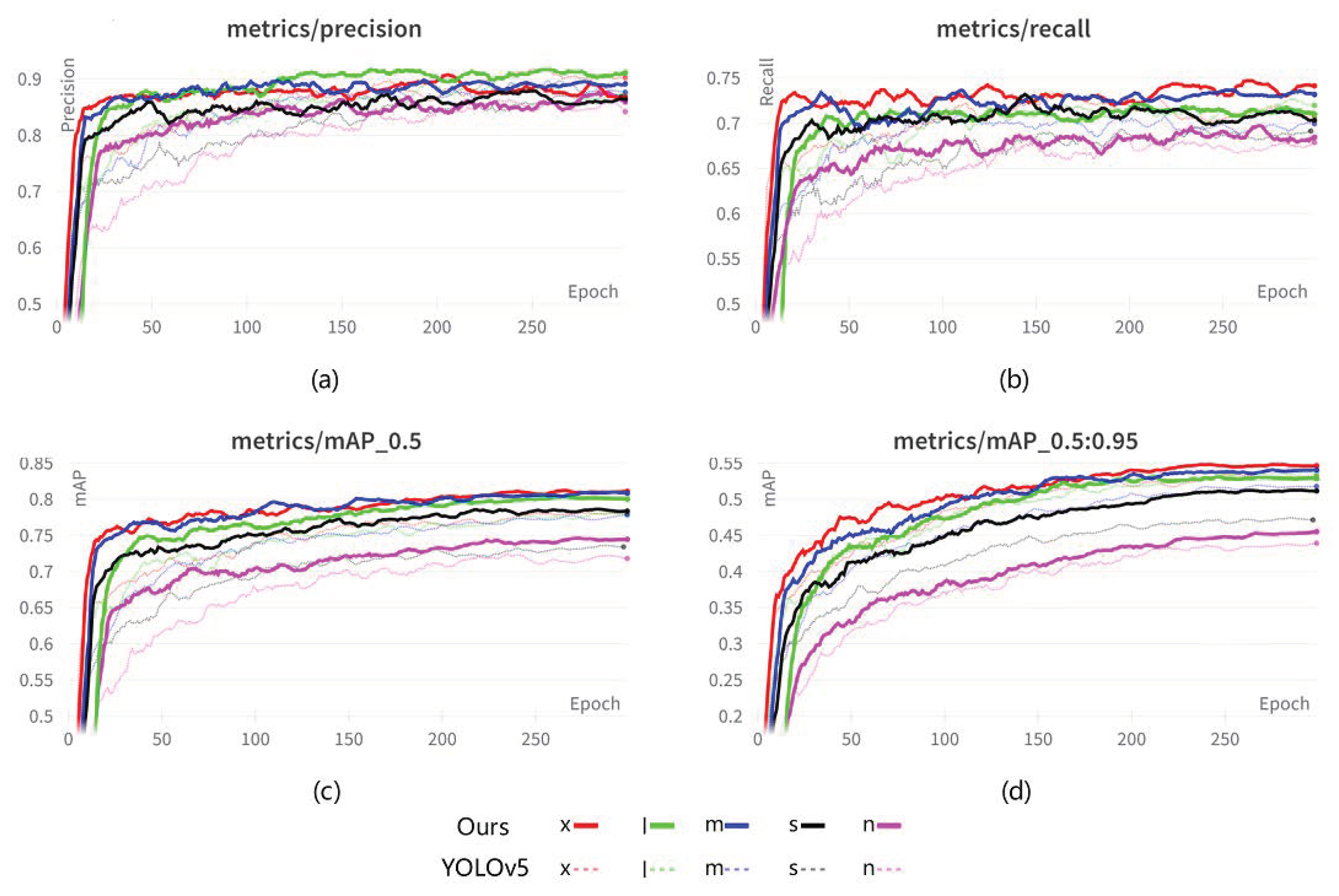
3.2.6. Comparisons with the State-of-The-Art
3.3. Experiments on Other Datasets
3.3.1. Comparative Experiments on Optimized Datasets
3.3.2. Visualization
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Martinez-Alpiste, I.; Golcarenarenji, G.; Wang, Q.; Alcaraz-Calero, J.M. Search and rescue operation using UAVs: A case study. Expert Syst. Appl. 2021, 178, 114937. [Google Scholar] [CrossRef]
- Niedzielski, T.; Jurecka, M.; Miziński, B.; Pawul, W.; Motyl, T. First Successful Rescue of a Lost Person Using the Human Detection System: A Case Study from Beskid Niski (SE Poland). Remote. Sens. 2021, 13, 4903. [Google Scholar] [CrossRef]
- Varga, L.A.; Kiefer, B.; Messmer, M.; Zell, A. SeaDronesSee: A Maritime Benchmark for Detecting Humans in Open Water. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2022. [Google Scholar] [CrossRef]
- Gasienica-Jozkowy, J.; Knapik, M.; Cyganek, B. An ensemble deep learning method with optimized weights for drone-based water rescue and surveillance. Integr. -Comput. -Aided Eng. 2021, 28, 221–235. [Google Scholar] [CrossRef]
- Božić-Štulić, D.; Marušić, Ž.; Gotovac, S. Deep Learning Approach in Aerial Imagery for Supporting Land Search and Rescue Missions. Int. J. Comput. Vis. 2019, 127, 1256–1278. [Google Scholar] [CrossRef]
- Pyrrö, P.; Naseri, H.; Jung, A. Rethinking Drone-Based Search and Rescue with Aerial Person Detection. arXiv 2021, arXiv:2111.09406. [Google Scholar]
- Marušić, Ž.; Božić-Štulić, D.; Gotovac, S.; Marušić, T. Region proposal approach for human detection on aerial imagery. In Proceedings of the 2018 3rd International Conference on Smart and Sustainable Technologies (SpliTech), Split, Croatia, 26–29 June 2018; pp. 1–6. [Google Scholar]
- Vasić, M.K.; Papić, V. Multimodel Deep Learning for Person Detection in Aerial Images. Electronics 2020, 9, 1459. [Google Scholar] [CrossRef]
- Mei, S.; Geng, Y.; Hou, J.; Du, Q. Learning hyperspectral images from RGB images via a coarse-to-fine CNN. Sci. China Inf. Sci. 2021, 65. [Google Scholar] [CrossRef]
- Mei, S.; Li, X.; Liu, X.; Cai, H.; Du, Q. Hyperspectral Image Classification Using Attention-Based Bidirectional Long Short-Term Memory Network. IEEE Trans. Geosci. Remote. Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Mei, S.; Chen, X.; Zhang, Y.; Li, J.; Plaza, A. Accelerating Convolutional Neural Network-Based Hyperspectral Image Classification by Step Activation Quantization. IEEE Trans. Geosci. Remote. Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Cheng, G.; Lang, C.; Wu, M.; Xie, X.; Yao, X.; Han, J. Feature enhancement network for object detection in optical remote sensing images. J. Remote. Sens. 2021, 48, 19–32. [Google Scholar] [CrossRef]
- Fu, J.; Sun, X.; Wang, Z.; Fu, K. An Anchor-Free Method Based on Feature Balancing and Refinement Network for Multiscale Ship Detection in SAR Images. IEEE Trans. Geosci. Remote. Sens. 2021, 59, 1331–1344. [Google Scholar] [CrossRef]
- Wang, L.; Yang, X.; Tan, H.; Bai, X.; Zhou, F. Few-Shot Class-Incremental SAR Target Recognition Based on Hierarchical Embedding and Incremental Evolutionary Network. IEEE Trans. Geosci. Remote. Sens. 2023, 61, 1–11. [Google Scholar] [CrossRef]
- Fu, K.; Fu, J.; Wang, Z.; Sun, X. Scattering-Keypoint-Guided Network for Oriented Ship Detection in High-Resolution and Large-Scale SAR Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2021, 14, 11162–11178. [Google Scholar] [CrossRef]
- Yu, Z.; Chen, L.; Cheng, Z.; Luo, J. TransMatch: A Transfer-Learning Scheme for Semi-Supervised Few-Shot Learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR, Seattle, WA, USA, 13–19 June 2020. [Google Scholar] [CrossRef]
- Choi, J.; Elezi, I.; Lee, H.J.; Farabet, C.; Alvarez, J.M. Active Learning for Deep Object Detection via Probabilistic Modeling. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar] [CrossRef]
- Abuduweili, A.; Li, X.; Shi, H.; Xu, C.Z.; Dou, D. Adaptive Consistency Regularization for Semi-Supervised Transfer Learning. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar] [CrossRef]
- Li, H.; Wu, Z.; Shrivastava, A.; Davis, L.S. Rethinking Pseudo Labels for Semi-supervised Object Detection. Proc. AAAI Conf. Artif. Intell. 2022, 36, 1314–1322. [Google Scholar] [CrossRef]
- Jeong, J.; Lee, S.; Kim, J.; Kwak, N. Consistency-Based Semi-Supervised Learning for Object Detection. In Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., dAlché Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Brooklyn, NY, USA, 2019; Volume 32. [Google Scholar]
- Sohn, K.; Zhang, Z.; Li, C.L.; Zhang, H.; Lee, C.Y.; Pfister, T. A Simple Semi-Supervised Learning Framework for Object Detection. arXiv 2005, arXiv:cs/2005.04757. [Google Scholar]
- Zhou, Q.; Yu, C.; Wang, Z.; Qian, Q.; Li, H. Instant-Teaching: An End-to-End Semi-Supervised Object Detection Framework. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar] [CrossRef]
- Wang, Z.; Li, Y.; Guo, Y.; Fang, L.; Wang, S. Data-Uncertainty Guided Multi-Phase Learning for Semi-Supervised Object Detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar] [CrossRef]
- Liu, Y.C.; Ma, C.Y.; Kira, Z. Unbiased Teacher v2: Semi-supervised Object Detection for Anchor-free and Anchor-based Detectors. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar] [CrossRef]
- Jiang, B.; Luo, R.; Mao, J.; Xiao, T.; Jiang, Y. Acquisition of Localization Confidence for Accurate Object Detection. In Computer Vision–ECCV 2018; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 816–832. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12993–13000. [Google Scholar] [CrossRef]
- Zhang, Y.F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Pan, S.J.; Kwok, J.T.; Yang, Q. Transfer Learning via Dimensionality Reduction. In Proceedings of the 23rd National Conference on Artificial Intelligence—Volume 2; AAAI Press: Chicago, IL, USA, 2008; pp. 677–682. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Cheng, G.; Yuan, X.; Yao, X.; Yan, K.; Zeng, Q.; Han, J. Towards Large-Scale Small Object Detection: Survey and Benchmarks. arXiv 2022, arXiv:2207.14096. [Google Scholar]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. Bisenet v2: Bilateral network with guided aggregation for real-time semantic segmentation. Int. J. Comput. Vis. 2021, 129, 3051–3068. [Google Scholar] [CrossRef]
- Du, D.; Zhu, P.; Wen, L.; Bian, X.; Lin, H. VisDrone-DET2019: The Vision Meets Drone Object Detection in Image Challenge Results. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar] [CrossRef]
- Bolya, D.; Foley, S.; Hays, J.; Hoffman, J. TIDE: A General Toolbox for Identifying Object Detection Errors. In Computer Vision–ECCV 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 558–573. [Google Scholar] [CrossRef]
- Kisantal, M.; Wojna, Z.; Murawski, J.; Naruniec, J.; Cho, K. Augmentation for small object detection. In Proceedings of the 9th International Conference on Advances in Computing and Information Technology (ACITY 2019), Sydney, Australia, 21–22 December 2019. [Google Scholar]
- Ghiasi, G.; Cui, Y.; Srinivas, A.; Qian, R.; Lin, T.Y.; Cubuk, E.D.; Le, Q.V.; Zoph, B. Simple Copy-Paste is a Strong Data Augmentation Method for Instance Segmentation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar] [CrossRef]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond Empirical Risk Minimization. arXiv 2022, arXiv:1710.09412. [Google Scholar]
- Yun, S.; Han, D.; Chun, S.; Oh, S.J.; Yoo, Y.; Choe, J. CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- He, J.; Erfani, S.; Ma, X.; Bailey, J.; Chi, Y.; Hua, X.S. alphaIoU: A Family of Power Intersection over Union Losses for Bounding Box Regression. Adv. Neural Inf. Process. Syst. 2021, 34, 20230–20242. [Google Scholar]
- Gevorgyan, Z. SIoU Loss: More Powerful Learning for Bounding Box Regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Xu, C.; Wang, J.; Yang, W.; Yu, L. Dot Distance for Tiny Object Detection in Aerial Images; IEEE: Piscataway, NJ, USA, 2021; pp. 1192–1201. [Google Scholar]
- Xu, C.; Wang, J.; Yang, W.; Yu, H.; Yu, L.; Xia, G.S. Detecting Tiny Objects in Aerial Images: A Normalized Wasserstein Distance and a New Benchmark. ISPRS J. Photogramm. Remote. Sens. 2022, 190, 79–93. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. arXiv 2023, arXiv:2207.02696. [Google Scholar]
- Nagrath, P.; Jain, R.; Madan, A.; Arora, R.; Kataria, P.; Hemanth, J. SSDMNV2: A real time DNN-based face mask detection system using single shot multibox detector and MobileNetV2. Sustain. Cities Soc. 2021, 66, 102692. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Chen, Q.; Wang, Y.; Yang, T.; Zhang, X.; Cheng, J.; Sun, J. You Only Look One-Level Feature. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13039–13048. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Zhang, X.; Feng, Y.; Zhang, S.; Wang, N.; Mei, S. Finding Nonrigid Tiny Person With Densely Cropped and Local Attention Object Detector Networks in Low-Altitude Aerial Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2022, 15, 4371–4385. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar] [CrossRef]
- Liu, Z.; Gao, G.; Sun, L.; Fang, Z. HRDNet: High-Resolution Detection Network for Small Objects. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Description | Categories | Published_Year | Src_Size | Number of Samples | |||
|---|---|---|---|---|---|---|---|---|
| Train_Set | Val_Set | Test_Set | Total | |||||
| VisDrone2019 | UAVs collected samples from 14 different cities in China, including rectangular labels for 10 common objects. | [pedestrian, person, car, van, bus, bus, truck, motor, bicycle, awning tricycle, tricycle, ignore] | ICCV_2019 | 1920 × 1080, 1360 × 765, 960 × 540, etc. | 6471 | 548 | 1580 | 8599 |
| Heridal | Found lost persons in non-urban terrain: mountains, forests, deserts, etc. | [person] | IJCV_2019 | 4000 × 3000 | 1548 | - | 102 | 1650 |
| TinyPerson | The first long-distance person detection benchmark dataset. | [sea person, earth person, ignore] | WACV_2020 | 1920 × 1080, 1280 × 720, 1024 × 724, etc. | 794 | - | 816 | 1610 |
| AFO | Marine search and rescue operations with 40,000 hand- annotated persons and objects floating in the water. | [human, board, boat, buoy, sailboat, kayak] | ICAE_2021 | 3840 × 2160 | 2458 | 492 | 697 | 3647 |
| Optimized Dataset | Description | Categories | Published_Year | Src_Size | Number of Subset | |||
| Train_Set | Val_Set | Test_Set | Total | |||||
| VisDrone_CityPerson | Merge two classes [pedestrian, person] into single class [person]. | person | - | 1536 × 1536 | 5684 | 531 | 1267 | 7482 |
| Heridal_ForestPerson | Instances add to the background images for synthetic samples. | person | - | 1536 × 1536 | 878 | 100 | 101 | 1079 |
| Tiny_SeasidePerson | Merge two classes [sea person, earth person] into single class [person]. | person | - | 1536 × 1536 | 1017 | 100 | 381 | 1498 |
| AFO_SeaPerson | Pick out labels and samples that contain person. | person | - | 1536 × 1536 | 1696 | 211 | 200 | 2107 |
| VHTA_Person | Create a multi-scene, full-time, high-view, and small person search and rescue dataset by UAVs. | person | - | 1536 × 1536 | 9275 | 942 | 1949 | 12166 |
| Method | No. | Pretrained Model | Batch_Size | Precision | Recall | Params /M | GFLOPs /M | Training Time /h_m_s | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ours (MMD) | 1 | x | 4 | 0.8706 | 0.7389 | 0.8115 | 0.8106 | 0.5463 | 0.5412 | 85.4 | 204.9 | 19h_22m_55s |
| −3.43%↓ | +3.27% ↑ | +3.00%↑ | +3.77%↑ | +1.50% ↑ | +1.51% ↑ | |||||||
| 2 | l | 8 | 0.9152 | 0.7062 | 0.7998 | 0.7914 | 0.5273 | 0.5156 | 44.9 | 108.6 | 9h_22m_33s | |
| +4.39%↑ | −1.78%↓ | +1.88%↑ | +1.60% ↑ | −0.69% ↓ | −0.57% ↓ | |||||||
| 3 | m | 16 | 0.8914 | 0.7329 | 0.8079 | 0.8002 | 0.5405 | 0.5327 | 19.8 | 47.4 | 9h_34m_49s | |
| +1.73%↑ | +3.27% ↑ | +2.84%↑ | +2.70%↑ | +2.23% ↑ | +2.78% ↑ | |||||||
| 4 | s | 32 | 0.8676 | 0.7003 | 0.7841 | 0.7795 | 0.5115 | 0.5023 | 6.7 | 15.2 | 9h_43m_37s | |
| −0.17%↓ | +0.89% ↑ | +4.98%↑ | +5.27%↑ | +4.02% ↑ | +3.71%↑ | |||||||
| 5 | n | 64 | 0.8504 | 0.6913 | 0.7455 | 0.7369 | 0.4566 | 0.4483 | 1.6 | 3.9 | 9h_35m_44s | |
| +1.18%↑ | +1.18% ↑ | +2.79%↑ | +2.75%↑ | +1.47% ↑ | +0.98%↑ | |||||||
| YOLOv5 (CIoU) | 6 | x | 4 | 0.9049 | 0.7062 | 0.7815 | 0.7729 | 0.5313 | 0.5261 | 85.4 | 204.9 | 19h_8m_27s |
| 7 | l | 8 | 0.8713 | 0.724 | 0.781 | 0.7754 | 0.5342 | 0.5213 | 44.9 | 108.6 | 9h_46m_46s | |
| 8 | m | 16 | 0.8741 | 0.7002 | 0.7795 | 0.7725 | 0.5182 | 0.5049 | 19.8 | 47.4 | 9h_26m_3s | |
| 9 | s | 32 | 0.8693 | 0.6914 | 0.7343 | 0.7268 | 0.4713 | 0.4652 | 6.7 | 15.2 | 9h_33m_5s | |
| 10 | n | 64 | 0.8386 | 0.6795 | 0.7176 | 0.7094 | 0.4419 | 0.4385 | 1.6 | 3.9 | 9h_34m_41s |
| Method | No. | Block_Size | Num_Pos | Num_Neg | Repeat | Number of Instance | |||
|---|---|---|---|---|---|---|---|---|---|
| Train_Set | Val_Set | Test_Set | Total | ||||||
| Copy-Paste | 1 | 32 × 32 | 3 | 0 | 77,055 | 5019 | 1692 | 83,766 | |
| 2 | 32 × 32 | 3 | 0 | ✓ | 154,110 | 10,038 | 1692 | 165,840 | |
| 3 | 32 × 32 | 3 | 1 | ✓ | 154,110 | 10,038 | 1692 | 165,840 | |
| 4 | 32 × 32 | 3 | 2 | ✓ | 154,110 | 10,038 | 1692 | 165,840 | |
| 5 | 32 × 32 | 5 | 0 | 128,425 | 8365 | 1692 | 138,482 | ||
| 6 | 32 × 32 | 7 | 0 | 179,795 | 11,711 | 1692 | 193,198 | ||
| 7 | 32 × 32 | 9 | 0 | 231,165 | 15,057 | 1692 | 247,914 | ||
| Instance Segmentation + Copy-Paste(Ours) | 8 | 32 × 32 | 3 | 0 | 77,055 | 5019 | 1692 | 83,766 | |
| 9 | 32 × 32 | 3 | 0 | ✓ | 154,110 | 10,038 | 1692 | 165,840 | |
| 10 | 32 × 32 | 3 | 1 | ✓ | 154,110 | 10,038 | 1692 | 165,840 | |
| 11 | 32 × 32 | 3 | 2 | ✓ | 154,110 | 10,038 | 1692 | 165,840 | |
| 12 | 32 × 32 | 5 | 0 | 128,425 | 8365 | 1692 | 138,482 | ||
| 13 | 32 × 32 | 7 | 0 | 179,795 | 11,711 | 1692 | 193,198 | ||
| 14 | 32 × 32 | 9 | 0 | 231,165 | 15,057 | 1692 | 247,914 | ||
| Method | No. | Model | Params | Precision | Recall | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Copy-Paste | Scale | Loss_Weights | Repeat | |||||||
| Baseline | 1 | YOLOv5s | 1 | 0.1 | 1 | × | 0.8679 | 0.6439 | 0.752 | 0.493 |
| 2 | 3 | 0.5 | 1 | × | 0.8693 | 0.6914 | 0.7343 | 0.4713 | ||
| 3 | 5 | 0.7 | 1 | × | 0.8721 | 0.6884 | 0.7729 | 0.5034 | ||
| 4 | 3 | 0.5 | 1 | × | 0.8926 | 0.6914 | 0.7962 | 0.5311 | ||
| OIM | 5 | 1 | 0.1 | 0.1 | ✓ | 0.8872 | 0.7003 | 0.7619 | 0.503 | |
| 6 | 3 | 0.7 | 0.5 | ✓ | 0.8842 | 0.7033 | 0.7875 | 0.526 | ||
| 7 | 5 | 0.5 | 0.5 | ✓ | 0.8876 | 0.7032 | 0.7884 | 0.5205 | ||
| 8 | 3 | 0.9 | 0.5 | ✓ | 0.8525 | 0.7033 | 0.8037 | 0.5287 | ||
| OIM+SSTM | 9 | 1 | 0.1 | 0.1 | ✓ | 0.8676 | 0.7003 | 0.7841 | 0.5115 | |
| 10 | 3 | 0.7 | 0.5 | ✓ | 0.8188 | 0.724 | 0.7837 | 0.5161 | ||
| 11 | 5 | 0.5 | 0.5 | ✓ | 0.87 | 0.7151 | 0.7712 | 0.5033 | ||
| 12 | 3 | 0.9 | 0.5 | ✓ | 0.8914 | 0.7162 | 0.8117 | 0.5436 | ||
| Method | No. | Main Error | Special Error | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Cls | Loc | Both | Dupe | Bkg | Miss | FALSE_Pos | FALSE_Neg | ||
| Baseline | 1 | 0 | 3.9 | 0 | 0.18 | 3.33 | 18.21 | 5.63 | 21.5 |
| 2 | 0 | 2.23 | 0 | 0.2 | 5 | 16.83 | 7.21 | 19.54 | |
| 3 | 0 | 4.75 | 0 | 0.03 | 3 | 18.34 | 5.4 | 21.88 | |
| 4 | 0 | 3.11 | 0 | 0.08 | 2.73 | 19.53 | 3.54 | 22.35 | |
| OIM | 5 | 0 | 2.86 | 0 | 0.08 | 3.08 | 18.98 | 4.59 | 22.25 |
| 6 | 0 | 3.62 | 0 | 0.01 | 2.46 | 20.57 | 3.42 | 24.3 | |
| 7 | 0 | 3.87 | 0 | 0.01 | 2.18 | 17.89 | 3.81 | 21.57 | |
| 8 | 0 | 2.95 | 0 | 0.07 | 2.59 | 18.79 | 3.9 | 21.61 | |
| OIM+SSTM | 9 | 0 | 2.7 | 0 | 0.16 | 2.45 | 19.72 | 3.92 | 22.26 |
| 10 | 0 | 3.45 | 0 | 0 | 2.42 | 20.76 | 3.33 | 25.35 | |
| 11 | 0 | 2.33 | 0 | 0.08 | 3.39 | 20.43 | 4.25 | 22.91 | |
| 12 | 0 | 1.91 | 0 | 0.03 | 2.16 | 19.9 | 3.3 | 21.64 | |
| Method | CP | OIM | SSTM | CIoU | MMD | Precision | Recall | ||
|---|---|---|---|---|---|---|---|---|---|
| Baseline | ✓ | 0.8679 | 0.6439 | 0.752 | 0.493 | ||||
| ✓ | ✓ | 0.8698 | 0.6492 | 0.763 | 0.4922 | ||||
| Ours | ✓ | ✓ | 0.8847 | 0.6729 | 0.7855 | 0.5023 | |||
| ✓ | ✓ | 0.8957 | 0.7022 | 0.8012 | 0.5241 | ||||
| ✓ | ✓ | ✓ | 0.9019 | 0.7123 | 0.8073 | 0.5304 | |||
| ✓ | ✓ | ✓ | 0.9049 | 0.724 | 0.8115 | 0.547 | |||
| ✓ | ✓ | ✓ | ✓ | 0.9152 (+4.73%↑) | 0.7389 (+9.5%↑) | 0.8079 (+5.59%↑) | 0.5436 (+5.02%↑) |
| Method | Model | Batch Size | Input Size | Params /M | GFLOPs /M | (Tx2 b1/ms) | (NX b1/ms) | (V100 b1/ms) | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Prep | Infer | NMS | Total Time | |||||||||
| Baseline | s | 2 | 1536 | 0.788 | 6.7 | 15.8 | 283.4 | 75.4 | 0.7 | 7.9 | 1.5 | 10.1 |
| Baseline + TTA | s | 2 | 1600 | 0.753 | 6.7 | 15.8 | 596.5 | 148.6 | 0.6 | 21.9 | 1.2 | 23.7 |
| s | 2 | 1920 | 0.791 | 6.7 | 15.8 | 612.3 | 173.2 | 0.9 | 25.7 | 1.2 | 27.8 | |
| s | 2 | 2400 | 0.798 | 6.7 | 15.8 | 814.9 | 246.5 | 2.7 | 33.4 | 1.1 | 37.2 | |
| s | 2 | 3200 | 0.79 | 6.7 | 15.8 | 1473.1 | 522 | 5.3 | 52.8 | 1 | 59.1 | |
| Baseline++TTA + ME | s+m | 2 | 1536 | 0.796 | 19.9 | 47.9 | 588.7 | 139.5 | 0.9 | 19.7 | 1.1 | 21.7 |
| s+l | 2 | 1536 | 0.795 | 44 | 107.6 | 606.5 | 166.9 | 0.9 | 26.8 | 1.1 | 28.8 | |
| s+x | 2 | 1536 | 0.798 | 82.2 | 203.8 | 923.8 | 304.7 | 0.6 | 42.8 | 1.1 | 44.5 | |
| s+x | 2 | 2400 | 0.803 | 82.2 | 203.8 | 5129.6 | 1508.9 | 2 | 202 | 0.9 | 204.9 | |
| s+m+l | 2 | 1536 | 0.793 | 44 | 107.6 | 867.4 | 272.9 | 0.6 | 39.5 | 1.1 | 41.2 | |
| s+m+x | 2 | 1536 | 0.795 | 82.2 | 203.8 | 1369.5 | 481.2 | 1.2 | 55.3 | 1.1 | 57.6 | |
| Baseline+TTA+ME+WBF | s+x | 2 | 1536 | 0.806 | 82.2 | 203.8 | 1583.7 | 678.9 | 0.7 | 44.6 | 16.8 | 62.1 |
| s+x | 2 | 2400 | 0.809 | 82.2 | 203.8 | 6492.3 | 2225.1 | 2.5 | 205.8 | 49.3 | 257.6 | |
| s+m+x | 2 | 1536 | 0.805 | 44 | 107.6 | 1979.5 | 611.2 | 1.2 | 55.3 | 27.2 | 83.7 | |
| s+l+x | 2 | 1536 | 0.802 | 82.2 | 203.8 | 2647 | 806.3 | 1.8 | 56.9 | 43.2 | 101.9 | |
| Baseline | s | 2 | 1536 | 0.788 | 6.7 | 15.8 | 283.4 | 75.4 | 0.7 | 7.9 | 1.5 | 10.1 |
| BI | s | 4 | 1536 | 0.786 | 6.7 | 15.8 | 219.1 | 49.6 | 0.7 | 4.8 | 1.5 | 7 |
| s | 8 | 1536 | 0.789 | 6.7 | 15.8 | 178.8 | 33.4 | 0.4 | 3.7 | 1.7 | 5.8 | |
| LPPQ (fp16) | s | 4 | 1536 | 0.775 | 4.3 | 11.2 | 208.3 | 47.4 | 0.3 | 2.9 | 1.6 | 4.8 |
| s | 8 | 1536 | 0.774 | 4.3 | 11.1 | 171.2 | 32 | 0.3 | 2.6 | 1.3 | 4.2 | |
| s+x | 8 | 2400 | 0.794 | 57.9 | 147.8 | 3842.5 | 1124.9 | 2.5 | 114.7 | 49.3 | 166.5 | |
| Method | AP | AP | AP | AP | AP | AP | AR | AR | AR | AR | AR | AR |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IoU = 0.5:0.95 | IoU = 0.5 | IoU = 0.75 | small | medium | large | max = 1 | max = 10 | max = 100 | small | medium | large | |
| Data Augmentation | ||||||||||||
| Baseline | 0.5303 | 0.7625 | 0.6469 | 0.458 | 0.7264 | 0.8434 | 0.3316 | 0.7297 | 0.7646 | 0.6342 | 0.7612 | 0.8604 |
| Copy-Paste [35] | 0.533 | 0.7539 | 0.6207 | 0.4566 | 0.7288 | 0.8206 | 0.3345 | 0.7269 | 0.7581 | 0.6344 | 0.7511 | 0.8655 |
| Simple Copy-Paste [36] | 0.5417 | 0.7714 | 0.6486 | 0.4629 | 0.7296 | 0.8185 | 0.3367 | 0.73 | 0.7569 | 0.6376 | 0.753 | 0.8516 |
| Mixup [37] | 0.5288 | 0.7658 | 0.6503 | 0.4476 | 0.7164 | 0.8469 | 0.3352 | 0.7168 | 0.7522 | 0.6408 | 0.7489 | 0.86 |
| CutMix [38] | 0.5347 | 0.7842 | 0.6552 | 0.4521 | 0.7153 | 0.8385 | 0.3398 | 0.7285 | 0.7469 | 0.6415 | 0.7435 | 0.8579 |
| Mosaic [39] | 0.5385 | 0.7824 | 0.6523 | 0.4638 | 0.7254 | 0.8316 | 0.3373 | 0.7261 | 0.7454 | 0.6398 | 0.7527 | 0.8667 |
| CP + SSL (Ours) | 0.5476 | 0.7884 | 0.6582 | 0.4725 | 0.7396 | 0.8467 | 0.3527 | 0.7314 | 0.7528 | 0.6511 | 0.7508 | 0.872 |
| (+1.73%) | (+2.59%) | (+1.13%) | (+1.45%) | (+1.32%) | (+0.33%) | (+2.11%) | (+0.17%) | (−1.18%) | (+1.69%) | (−1.04%) | (+1.16%) | |
| Label Assignment + Data Augmentation | ||||||||||||
| CIoU [25] | 0.5476 | 0.7884 | 0.6582 | 0.4725 | 0.7396 | 0.8467 | 0.3527 | 0.7314 | 0.7528 | 0.6511 | 0.7508 | 0.872 |
| DIoU [27] | 0.5485 | 0.7743 | 0.6497 | 0.4618 | 0.7263 | 0.854 | 0.3461 | 0.7156 | 0.7422 | 0.6588 | 0.7369 | 0.86 |
| GIoU [26] | 0.5411 | 0.7659 | 0.632 | 0.4663 | 0.7285 | 0.8461 | 0.3414 | 0.7359 | 0.7396 | 0.6503 | 0.7386 | 0.8741 |
| EIoU [28] | 0.5359 | 0.7251 | 0.6378 | 0.4526 | 0.7148 | 0.8457 | 0.3369 | 0.7424 | 0.7457 | 0.6547 | 0.7454 | 0.8572 |
| Alpha-IoU [40] | 0.551 | 0.7752 | 0.6475 | 0.4588 | 0.7302 | 0.8489 | 0.3452 | 0.7366 | 0.7463 | 0.6419 | 0.7548 | 0.8601 |
| SIoU [41] | 0.5527 | 0.7639 | 0.6319 | 0.4627 | 0.7154 | 0.8432 | 0.3368 | 0.7364 | 0.7489 | 0.6437 | 0.7329 | 0.8547 |
| DotD [42] | 0.5426 | 0.7895 | 0.6456 | 0.469 | 0.7344 | 0.8475 | 0.3542 | 0.7115 | 0.7543 | 0.65 | 0.7246 | 0.8721 |
| NWD [43] | 0.5429 | 0.7963 | 0.6617 | 0.4733 | 0.7317 | 0.8526 | 0.3567 | 0.728 | 0.7499 | 0.6427 | 0.7363 | 0.8699 |
| CP+SSL+MMD (Ours) | 0.5436 | 0.8079 | 0.6698 | 0.4756 | 0.7386 | 0.8566 | 0.3524 | 0.7359 | 0.7637 | 0.6548 | 0.7511 | 0.8768 |
| (−0.4%) | (+1.95%) | (+1.16%) | (+0.31%) | (−0.1%) | (+0.99%) | (−0.3%) | (+0.45%) | (+1.09%) | (+0.37%) | (+0.3%) | (+0.48%) | |
| YOLO Series + Data Augmentation | ||||||||||||
| YOLO v4 [39] | 0.5368 | 0.7669 | 0.667 | 0.4814 | 0.7746 | 0.8306 | 0.3458 | 0.7455 | 0.7546 | 0.6608 | 0.7522 | 0.8692 |
| YOLO v5 [30] | 0.5476 | 0.7884 | 0.6582 | 0.4725 | 0.7396 | 0.8467 | 0.3527 | 0.7314 | 0.7528 | 0.6511 | 0.7508 | 0.872 |
| YOLO v6 [44] | 0.5445 | 0.7855 | 0.6716 | 0.4879 | 0.7452 | 0.8569 | 0.3429 | 0.7396 | 0.7549 | 0.6425 | 0.7513 | 0.8796 |
| YOLO v7 [45] | 0.5561 | 0.7954 | 0.6683 | 0.4962 | 0.7326 | 0.855 | 0.3414 | 0.7421 | 0.7607 | 0.636 | 0.7529 | 0.8807 |
| Others + Data Augmentation | ||||||||||||
| SSD [46] | 0.3856 | 0.6829 | 0.5347 | 0.3624 | 0.5208 | 0.7124 | 0.2043 | 0.6207 | 0.5453 | 0.5029 | 0.5189 | 0.6479 |
| Faster RCNN [48] | 0.5593 | 0.8144 | 0.6789 | 0.5329 | 0.7522 | 0.8546 | 0.4156 | 0.7496 | 0.7632 | 0.657 | 0.7623 | 0.8854 |
| Retinanet [47] | 0.5327 | 0.7865 | 0.6628 | 0.4668 | 0.7341 | 0.8323 | 0.3617 | 0.7401 | 0.7621 | 0.6842 | 0.7498 | 0.8726 |
| Ours | ||||||||||||
| CP+SSL | 0.5476 | 0.7884 | 0.6582 | 0.4725 | 0.7396 | 0.8467 | 0.3527 | 0.7314 | 0.7528 | 0.6511 | 0.7508 | 0.872 |
| CP+SSL+MMD | 0.5436 | 0.8079 | 0.6698 | 0.4756 | 0.7386 | 0.8566 | 0.3524 | 0.7359 | 0.7637 | 0.6548 | 0.7511 | 0.8768 |
| CP + SSL + MMD + TTA | 0.5507 | 0.8142 | 0.6751 | 0.4721 | 0.7407 | 0.8553 | 0.3585 | 0.7427 | 0.764 | 0.6574 | 0.7512 | 0.8845 |
| CP + SSL + MMD + TTA + ME | 0.5584 | 0.8216 | 0.6769 | 0.4756 | 0.7463 | 0.8571 | 0.3614 | 0.7468 | 0.7639 | 0.6629 | 0.7569 | 0.8896 |
| CP + SSL + MMD + TTA + ME + WBF | 0.5601 | 0.8287 | 0.6842 | 0.4887↓ | 0.7548 | 0.8629 | 0.3685 | 0.7529 | 0.7748 | 0.6675↓ | 0.7637 | 0.8945 |
| (+1.25%) | (+4.03%) | (+2.6%) | (+1.25%) | (+1.52%) | (+1.62%) | (+1.58%) | (+2.15%) | (+2.2%) | (+1.64%) | (+1.29%) | (+2.25%) | |
| DataSet | Category | Method | InputSize | BackBone | PreTrainedModel | Precision/% | Recall/% | APval@0.5/% |
|---|---|---|---|---|---|---|---|---|
| VisDrone2019 [33] | pedestrian | YOLOv4 [39] | 608 | DarkNet-53 | yolov4-csp-x-swish | 0.68066 | 0.47852 | 0.48004 |
| YOLOF [49] | 608 | R-50-C5 | yolof_r50_c5_8x8_1x | 0.68759 | 0.45276 | 0.48772 | ||
| YOLOv5 [30] | 640 | DarkNet-53 + Focus | yolov5x6 | 0.67369 | 0.47169 | 0.47202 | ||
| YOLOX [50] | 640 | Darknet53 | yolox-x | 0.67008 | 0.46893 | 0.47257 | ||
| DCLANet [51] | 640 | DarkNet-53 + Focus | yolov5x6 | 0.69827 | 0.46751 | 0.47782 | ||
| VisDrone_CityPerson | person | Ours | 640 | DarkNet-53 + Focus | yolov5s | 0.71829(+2.002%) | 0.45636(−1.115%) | 0.49061(+1.279%) |
| Heridal [5] | person | SSD [46] | 1333 × 1000 | VGG16 | ssd512_coco | 4.33 | 94.36 | - |
| Faster RCNN [48] | 1333 × 1000 | ResNet101 + FPN | faster_rcnn_r101_fpn_1x_coco | 58.1 | 85 | - | ||
| [5] | 1333 × 1000 | RPM + SOD | faster_rcnn_r101_fpn_1x_coco | 34.8 | 88.9 | - | ||
| RPN [7] | 4000 × 3000 | ResNet101+FPN | rpn_x101_32x4d_fpn_1x_coco | 41.54 | 95.54 | - | ||
| RFCCD [8] | 4000 × 3000 | ResNet101+FPN | rpn_x101_32x4d_fpn_1x_coco | 68.89 | 94.65 | - | ||
| Heridal_ForestPerson | person | Ours | 1536 × 1536 | DarkNet-53 + Focus | yolov5s | 91.52 | 73.89 | 80.79 |
| yolov5x6 | 94.78(+25.89%) | 80.32(−14.33%) | 85.68 | |||||
| TinyPerson [16] | person | RetinaNet [47] | 640 × 512 | ResNet50 | retinanet_r50_fpn_1x_coco | - | - | 48.26 |
| Faster RCNN [48] | 640 × 512 | ResNet50 + FPN | faster_rcnn_r101_fpn_1x_coco | - | - | 63.18 | ||
| Faster RCNN [48] | 640 × 512 | ResNet50 + PANet + FPN | faster_rcnn_r101_panet_fpn_1x_coco | - | - | 70.32 | ||
| FCOS [52] | 640 × 512 | ResNet50 | fcos_r50_caffe_fpn_gn_head_1x_coco | - | - | 40.54 | ||
| Swin-T [53] | 640 × 512 | ResNet50 | retinanet_swin-t-p4-w7_fpn_1xcoco | - | - | 52.53 | ||
| Tiny_SeasidePerson | person | Ours | 1536 × 1536 | DarkNet-53+ Focus | yolov5s | 78.5 | 56.1 | 67.48(+14.95%) |
| AFO [4] | human+buoy | YOLOv4 [39] | 544 × 544 | CSPDarknet53-PANet-SPP | yolov4-csp-panet-spp-x-swish | - | - | 54.58 |
| SSD [46] | 300 × 300 | MobileNet v2 | ssd300_mobilenetv2_600e_coco | - | - | 24.34 | ||
| Faster RCNN [48] | 1333 × 750 | ResNet101 + FPN | faster_rcnn_r101_fpn_1x_coco | - | - | 64.11 | ||
| RetinaNet [47] | 1333 × 750 | ResNet101 + FPN | retinanet_r101_fpn_1x_coco | - | - | 65 | ||
| [4] | 1333 × 750 | ResNet101 + FPN | retinanet_r101_fpn_1x_coco | - | - | 70.53 | ||
| AFO_SeaPerson | person | Ours | 1536 × 1536 | DarkNet-53 + Focus | yolov5s | 95.55 | 93.37 | 96.34(+25.81%) |
| VHTA_Person(Ours) | person | Ours | 1536 × 1536 | DarkNet-53 + Focus | yolov5s | 74.39 | 52.16 | 63.28 |
| 1536 × 1536 | DarkNet-53 + Focus | yolov5m | 77.56 | 54.17 | 65.89 | |||
| 1536 × 1536 | DarkNet-53 + Focus | yolov5l | 75.35 | 56.29 | 64.8 | |||
| 1536 × 1536 | DarkNet-53 + Focus | yolov5x | 75.92 | 55.86 | 65.4 | |||
| 1536 × 1536 | DarkNet-53 + Focus | yolov5x6 | 76.59 | 57.32 | 66.37 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Feng, Y.; Zhang, S.; Wang, N.; Mei, S.; He, M. Semi-Supervised Person Detection in Aerial Images with Instance Segmentation and Maximum Mean Discrepancy Distance. Remote Sens. 2023, 15, 2928. https://doi.org/10.3390/rs15112928
Zhang X, Feng Y, Zhang S, Wang N, Mei S, He M. Semi-Supervised Person Detection in Aerial Images with Instance Segmentation and Maximum Mean Discrepancy Distance. Remote Sensing. 2023; 15(11):2928. https://doi.org/10.3390/rs15112928
Chicago/Turabian StyleZhang, Xiangqing, Yan Feng, Shun Zhang, Nan Wang, Shaohui Mei, and Mingyi He. 2023. "Semi-Supervised Person Detection in Aerial Images with Instance Segmentation and Maximum Mean Discrepancy Distance" Remote Sensing 15, no. 11: 2928. https://doi.org/10.3390/rs15112928
APA StyleZhang, X., Feng, Y., Zhang, S., Wang, N., Mei, S., & He, M. (2023). Semi-Supervised Person Detection in Aerial Images with Instance Segmentation and Maximum Mean Discrepancy Distance. Remote Sensing, 15(11), 2928. https://doi.org/10.3390/rs15112928