Abstract
A multi-hypothesis marginal multi-target Bayes filter for heavy-tailed observation noise is proposed to track multiple targets in the presence of clutter, missed detection, and target appearing and disappearing. The proposed filter propagates the existence probabilities and probability density functions (PDFs) of targets in the filter recursion. It uses the Student’s t distribution to model the heavy-tailed non-Gaussian observation noise, and employs the variational Bayes technique to acquire the approximate distributions of individual targets. K-best hypotheses, obtained by minimizing the negative log-generalized-likelihood ratio, are used to establish the existence probabilities and PDFs of targets in the filter recursion. Experimental results indicate that the proposed filter achieves better tracking performance than other filters.
1. Introduction
Multi-target tracking (MTT) is the process of estimating the states of multiple moving targets at different time steps according to a set of sensor observations. It has received extensive attention from scholars [1,2,3,4,5,6,7,8] due to its wide application in many real systems, such as intelligent transportation systems, video surveillance systems, radar tracking systems, etc. Two major groups of MTT algorithms have been reported in a lot of articles [9,10,11,12,13,14,15,16,17,18]. The first group includes conventional approaches, including the multiple hypothesis tracking (MHT) [9] and joint probabilistic data association (JPDA) filters [10]. The second group includes tracking approaches based on the random finite set (RFS) [1,2], including the probability hypothesis density (PHD) filter [11,12], the cardinality-balanced multi-Bernoulli (CBMeMber) filter [13], and their variants for tracking the extended targets [4,5,8,14,15,16,17] and multiple maneuvering targets [18].
Recently, labeled RFS [19,20] was proposed by Vo et al. to overcome the shortcomings of the RFS. Besides providing the object trajectory, the labeled RFS avoids the requirement of high signal-to-noise ratio. In terms of the labeled RFS, the generalized labeled multi-Bernoulli (GLMB) filter [21] and its variants [22,23,24,25] were reported to track various kinds of targets such as multiple weak targets [22], spawning targets [23], multiple maneuvering targets [24], and extended targets or group targets [25]. Unfortunately, the computational complexity of the GLMB filter is very high because it delivers hypotheses growing exponentially in the filter recursion. Aiming at this problem, Liu et al. developed a marginal multi-target Bayes filter with multiple hypotheses (MHMTB filter) [26]. Instead of delivering hypotheses growing exponentially, the MHMTB filter delivers the probability density function (PDF) of each target and its existence probability. It employs the K-best hypotheses, obtained by minimizing the negative log-generalized-likelihood ratio, to generate the existence probabilities and PDFs of potential targets. With a lower computational load, the MHMTB filter can achieve better tracking performance than the GLMB filter [26].
The MHMTB filter is efficient for tracking multiple objects in the presence of clutter, missed detection, and the appearance and disappearance of objects. However, the existing implementation of the MHMTB filter [26] supposes that both the process noise and observation noise follow a Gaussian distribution. Due to suffering from frequent outliers such as temporary sensor failure, irregular electromagnetic wave reflection, and random disturbance of the observation environment, the observation noise of a sensor is usually a heavy-tailed noise or glint noise in many real application systems [27,28,29]. In this case, assuming the Gaussian distribution of observation noise results in a poor tracking performance by the MHMTB filter. The motivation of this article is to extend the application of the MHMTB filter in a heavy-tailed observation noise.
Student’s t distribution is commonly employed to model heavy-tailed noise or glint noise [30,31,32]. Many articles have discussed its application in real systems where the heavy-tailed observation noise is represented by a Student’s t distribution [28,29,30,31,32]. Due to the significant difficulty of tractability in the use of Student’s t distribution, the variational Bayes (VB) technique is employed to acquire the approximate distribution to improve the computational efficiency of the filter [30,31,32].
Tracking the multiple targets under the circumstance with a low signal-to-noise ratio and a heavy-tailed observation noise is a challenging problem. The conventional approaches in [29,31,32] generally require the degree of freedom (DoF) of the Student’s t distribution observation noise to be larger than 2. These approaches are prone to divergence if the DoF of observation noise is less than or equal to 2. Therefore, in the simulations, the DoF of observation noise was set to 10 in [31] and it was set to 3 in [32]. The objective of this article is to deal with a heavy-tailed observation noise whose DoF is less than or equal to 2. In the Student’s t distribution, a smaller DoF means more heavy trailing [31].
The major contribution of the article is that we propose an MHMTB filter for heavy-tailed observation noise by applying the VB technique to the MHMTB filter in order to address the MTT problem under a heavy-tailed observation noise. In the proposed tracking filter, we use a Student’s t distribution to model the heavy-tailed observation noise, employ the VB technique to acquire the approximate distributions of individual targets, and use the K-best hypotheses to establish the existence probabilities and PDFs of individual targets in the filter recursion. The tracking performance of the proposed filter is illustrated by comparing it with the other filters, such as the original GLMB filter, original MHMTB filter, as well as the GLMB filter for a heavy-tailed observation noise. The advantage of the proposed filter is that it can deal with observation noise with a small DoF. The DoF of observation noise was set to 1 in the simulation.
The article is organized as follows. We provide some background on the MHMTB filter and models for target tracking in Section 2. Then, Section 3 gives the MHMTB filter for a heavy-tailed observation noise. A comparison of the proposed MHMTB filter with other filters is provided in Section 4 to evaluate the performance of the proposed filter. Conclusions are given in Section 5.
2. Background
2.1. MHMTB Filter
The MHMTB filter propagates the PDF of each target and its probability of existence [26]. Assume that the set of potential targets at time step is
where denotes the number of potential targets, is a set of observations up to time step ; , , and denote the state vector, track label, PDF and existence probability of target , respectively; and is a weighted sum of individual sub-PDFs and is given by
where denotes the sub-item number of target ; and denote the weight and PDF of sub-item of target , respectively; and the weights of individual sub-items of potential target satisfy .
In terms of the prediction equation of the MHMTB filter, the predicted PDF of potential target is
where ; ; ; ; denotes the state transition probability; and is given by
The predicted track label and existence probability of target are as follows:
where denotes the surviving probability.
In terms of the update equation of the MHMTB filter, the updated PDFs of potential target are given by
where and denote the number of observations and an observation at time step , respectively; is the likelihood between observation and state vector ; and denote the updated weight and PDF of sub-item of target , respectively; and they are as follows:
The probability that belongs to potential target is
K-best hypotheses are required in the MHMTB filter to determine whether a potential target is detected, undetected or disappearing. The generalized joint likelihood ratio for a hypothesis is given by
where , and are the binary variables and . The values of , and are either 0 or 1, and . Parameters , and are defined as
The K-best hypotheses are acquired by minimizing the negative log-generalized-likelihood ratio as
where denotes the detection probability and denotes the clutter density; where is the average clutter number and is the area (or volume) of the surveillance region.
In terms of the K-best hypotheses, the MHMTB filter acquires a set of potential targets at time step as
where denotes the number of potential targets; , and denote the track label, PDF and existence probability of potential target at time step , respectively; and is given by
where denotes the sub-item number of target ; and denote the weight and PDF of sub-item of target , respectively; and We refer readers to [26] for more detail.
2.2. Models for Target Tracking
In the considered models for target tracking, the target dynamic model is nonlinear as where process noise is assumed to be a zero-mean Gaussian noise with covariance ; and the observation model is also nonlinear as , where observation noise is a heavy-tailed non-Gaussian noise. The state transition probability in (3) and (4) is given by
where denotes a Gaussian distribution. We use a Student’s t distribution to model the heavy-tailed observation noise. According to [30,31,32], the observation likelihood function in (7) and (8) can be given by
where denotes a Student’s t distribution; denotes a Gamma function; denotes a Gamma distribution; and are the degree of freedom and scale matrix of observation noise, respectively; and is the dimension of observation vector.
3. MHMTB Filter for a Heavy-Tailed Observation Noise
The MHMTB filter for a heavy-tailed observation noise consists of the following steps.
3.1. Prediction
Given that the potential targets at time step are
where , and denote the track label, existence probability and sub-item number of target , respectively; and denote the weight and PDF of sub-item of target , respectively. According to [31,32], can be given by
where and are the shape parameters; and are the inverse scale parameters; and and denote the mean and covariance of sub-item of target .
The predicted potential targets at time step are
According to [31,32], the predicted PDF of sub-item of potential target , and its predicted existence probability and predicted track label can be given by
where is the spread factor.
Given that the potential birth targets at time step are
where denotes the birth target number; , and denote the given sub-item number, track label and existence probability of birth target ; and and denote the weight and PDF of sub-item of birth target . According to [31,32], can be given by
where is the given mean vector; is the given error covariance matrix; and are the given shape parameters; and and are the given inverse scale parameters.
In order to track the birth targets, it is necessary to combine the potential birth targets into the predicted potential targets. The predicted potential targets after combining are given by
where .
3.2. Update
Given the predicted potential targets in (26), the probability that observation belongs to potential target is
where and are the scale matrix and the degree of freedom of observation noise, respectively, and is given by
The updated weight of sub-item of potential target is
The updated PDF of sub-item of potential target is given by
where and are given by
According to the VB technique [31,32], an iteration procedure is required to determine mean vector , covariance and inverse scale parameters and . Firstly, the initial parameters for the iteration procedure are given by
The iteration procedure consists of Equations (33) to (43).
where is the derivative of and Idiag(X) is the main diagonal of matrix X.
The iteration procedure ends if , where is a given parameter. Mean vector , covariance and inverse scale parameters and in (30) can be given by
3.3. Obtaining K-Best Hypotheses and Potential Targets
The minimization problem in (12) can be recast as a two-dimensional (2-D) assignment problem [26]. The cost matrix of this 2-D assignment is given by ,where
Employing the optimizing Murty algorithm [33] to resolve the 2-D assignment problem, we can obtain K-best hypotheses. The K-best hypotheses and total costs of individual hypotheses can be denoted as
where is the column index of matrix , is the total cost of hypothesis , and and . We may determine whether target is detected, undetected or disappearing according to index . If , target is detected and observation belongs to target ; if , target is undetected; and if , target is disappearing. The weights of individual hypotheses are given by
We employ Algorithm 1 to acquire the potential targets at time step . The set of potential targets is
where
| Algorithm 1: Acquiring the potential targets |
| set . . , , . end else if , , . end end end end , , , . end output: . |
3.4. Extracting the Track Labels and Mean Vectors of Real Targets
Identical to the approach in [26], if the existence probability of potential target is greater than ,where is a given threshold, we identify that this potential target is a real target. Using Algorithm 2 to acquire a set consisting of mean vectors and track labels of real targets, the acquired set can be given by where denotes the estimated number of targets. This set is used as the output of the filter.
3.5. Pruning and Merging
Identical to the approach in [26], potential objects with a small existence probability and sub-items with a weak weight should be discarded to decrease the computational burden. For each potential target, the sub-items which are close together should be merged into a sub-item. Algorithm 3 describes the pruning and merging approach where , and are the given thresholds and
According to Algorithm 3, the residual potential targets after pruning and merging can be given by
where denotes the number of targets. These potential targets are propagated to the next time step.
| Algorithm 2: Extracting the track labels and mean vectors of real targets |
| set . , . , . end end . output: . |
| Algorithm 3: Pruning and merging |
| , . , , . . . , . repeat , (). . , . . , . , . . until . end output: . |
Identical to the MHMTB filter in [26], the proposed filter requires K-best hypotheses to generate the existence probabilities and PDFs of targets at each recursion. Unlike the original MHMTB filter that requires a Gaussian observation noise, the proposed filter obviates this requirement by modeling the heavy-tailed observation noise as a Student’s t distribution. The VB technique is applied in the proposed filter to acquire the approximate posterior distributions of individual targets.
4. Simulation Results
The proposed MHMTB filter for a heavy-tailed observation noise is referred to as the VB-MHMTB filter. The efficient implementation of the GLMB filter (EIGLMB filter) [21] and original MHMTB filter [26] are selected as the comparison objects in this experiment. The VB technique can also be applied to the EIGLMB filter to form an EIGLMB filter for a heavy-tailed observation noise (VB-EIGLMB filter). This filter is also used as a comparison object in this experiment. The performance of the VB-MHMTB filter is evaluated by comparing it with the original MHMTB filter, EIGLMB filter and VB-EIGLMB filter in terms of OSPA(2) error (i.e., the distance between two sets of tracks) [34] and average cardinality error (i.e., the difference between the estimated number of targets and the true number of targets).
For two sets of tracks and , if , the OSPA(2) error between and is defined as
where and are the order of the base distance, is a collection of weights, and it can be given by using a sliding window with the length of window . If , then . For more detail, we refer the reader to [34]. The parameters used in the OSPA(2) error are given by , and .
Unlike the OSPA error [35] used to measure the dissimilarity between the two sets of states, the OSPA(2) error is employed to evaluate the difference between the two sets of tracks. Since the above four filters can provide the target trajectory, it is better to select the OSPA(2) error as a metric in the experiment.
The simulated hardware and software environments are Lenovo ThinkPad T430, Windows 7 and Matlab R2015b (32 bits). Figure 1 illustrates a surveillance region where a radar located at [0, 0] observes the ten moving targets. The state of target at time step is given by where and are its position components; and are its velocity components; and is its turn rate. Table 1 gives the initial states of the ten targets and their appearing and disappearing times.
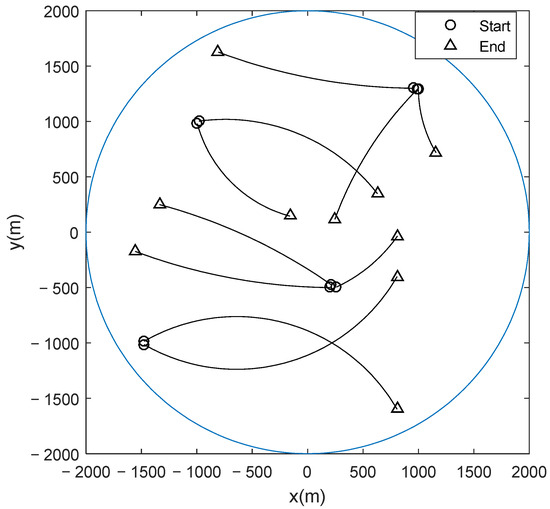
Figure 1.
Surveillance region and real trajectories of targets.

Table 1.
Initial state, appearing time and disappearing time of the target.
and in (15) and (22) are given by
where is the scan period; and and are the standard deviations of process noises.
in (16) and (28) is given by
where denotes the position of the radar. The observation noise is assumed to be a Student’s t distribution with degree of freedom and scale matrix , where and . Set , and to generate the observations. The simulated observations for a Monte Carlo run are given in Figure 2.
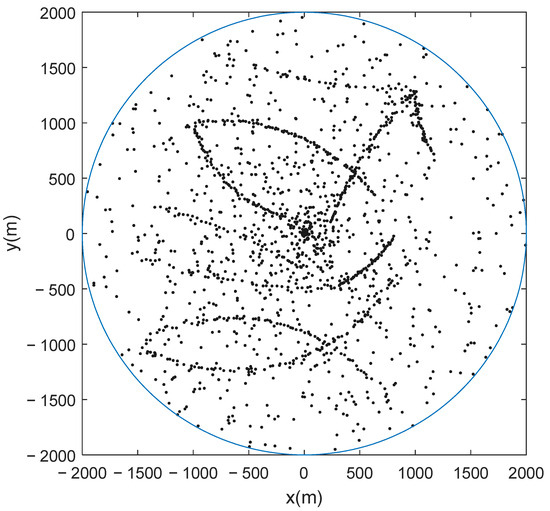
Figure 2.
Simulated observations.
In the simulated experiment, the potential birth objects at each recursion are given by where , , , , and is given by (25) where , , , , , , , , , and . The parameters used in the VB-MHMTB filter are set to , , , , , and . We perform the four filters for 100 Monte Carlo runs. The results are shown in Table 2 and Figure 3 and Figure 4.
Table 2.
OSPA(2) errors, cardinality errors and performing times.
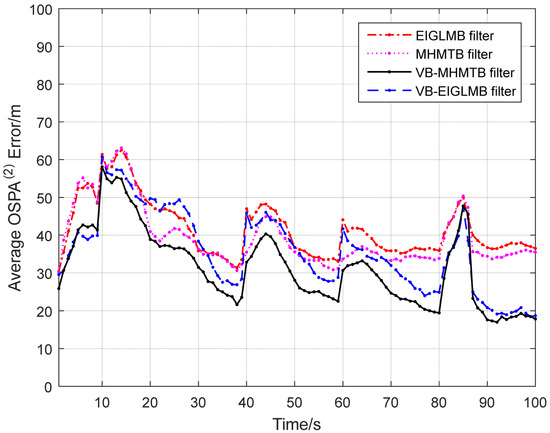
Figure 3.
Average OSPA(2) errors.
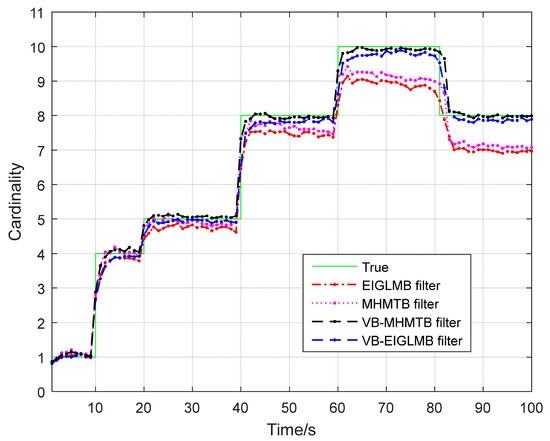
Figure 4.
Cardinality estimates.
The result in Figure 3 and the data in Table 2 are used to evaluate the performance of the VB-MHMTB filter and other filters. A smaller OSPA(2) error indicates that a filter has a better tracking accuracy, a low cardinality error means that a filter accurately estimates the number of targets, and a larger performing time implies that a filter has a higher computational load. The OSPA(2) errors and cardinality errors in Table 2 and Figure 3 illustrate that the VB-MHMTB filter and the VB-EIGLMB filter perform better than the MHMTB filter and the EIGLMB filter. The reason for this phenomenon is that the MHMTB filter and EIGLMB filter require a Gaussian observation noise. Direct application of the MHMTB filter and EIGLMB filter to a heavy-tailed observation noise leads to a deteriorated filter performance. By using the VB technique to acquire the approximate distributions of individual targets in the case of a heavy-tailed observation noise, the tracking performance of the VB-MHMTB filter and the VB-EIGLMB filter is improved. In terms of the results in Table 2 and Figure 3 and Figure 4, the VB-MHMTB filter outperforms the other filters because it has a smallest OSPA(2) error and provides the most accurate cardinality estimate (i.e., the lowest cardinality error) among the four filters. The performing times in Table 2 reveal that the VB-MHMTB filter requires a significantly lower computational cost than the EIGLMB filter and the VB-EIGLMB filter, and a slightly larger computational cost than the MHMTB filter. The application of the VB technique to the MHMTB filter increases the computational load of the filter.
Effect of spread factor : To provide guidance in selecting the spread factor , an analysis of the effect of spread factor on the tracking performance of the VB-MHMTB filter is needed. Table 3 illustrates the average OSPA(2) error and cardinality error of the VB-MHMTB filter over 100 Monte Carlo runs for various spread factors to reveal the effect of spread factor on the performance of the VB-MHMTB filter. The OSPA(2) error and cardinality error suggest that it is better to select the spread factor from the interval [0.93, 1.0].
Table 3.
OSPA(2) error and cardinality error for different .
Effect of picking probability : The picking probability is an important parameter in the VB-MHMTB filter and it is needed to provide guidance for the selection of this parameter. The average OSPA(2) and cardinality errors for different picking probabilities are given in Table 4 and reveal the effect of picking probability on the performance of the VB-MHMTB filter. According to the result in Table 4, it is better to choose the picking probability from the interval [0.3, 0.6], and the VB-MHMTB filter performs best at .
Table 4.
OSPA(2) error and cardinality error for different .
Computational complexity: Identical to the MHMTB filter, the computational complexity of the VB-MHMTB filter is ,where is the number of hypotheses, is the number of observations and is the number of potential targets. Compared with the MHMTB filter, the VB-MHMTB filter needs an iteration procedure to determine the updated mean vector and covariance of each sub-item. Therefore, it has a higher computational cost than the MHMTB filter.
In above simulation experiments, the number of time steps is 100, i.e., from 1 to 100; the true number of targets or cardinality at each time step is given by the green line in Figure 4; the average number of noise observations (i.e., average clutter number) at each time step is 10; and average clutter density is .
5. Conclusions
In this study, we apply the MHMTB filter to address the MTT problem under heavy-tailed observation noise. By using the Student’s t distribution to model a heavy-tailed observation noise and applying the VB technique to acquire the approximate distributions of individual targets, we proposed a VB-MHMTB filter. Identical to the MHMTB filter, the VB-MHMTB filter propagates the existence probabilities and PDFs of individual targets. The K-best hypotheses acquired by minimizing the negative log-generalized-likelihood ratio are used to establish the existence probabilities and PDFs of targets at each recursion. Experimental results indicate that the VB-MHMTB filter can achieve a better tracking performance than the selected comparison objects because it exhibits a lower cardinality error and a smaller OSPA(2) error. Experimental results also reveal that the VB-MHMTB filter has a significantly lower computational load than the EIGLMB filter and VB-EIGLMB filter, and a higher computational cost than the MHMTB filter.
Tracking multiple maneuvering targets and tracking the extended targets in a real-world environment are potential applications for the proposed filter. This is also a possible research topic in the future.
Author Contributions
Z.L.: Conceptualization, Methodology, Supervision, Writing—original draft preparation. J.L.: Software, Resources. C.Z.: Visualization, Writing—review and editing. All authors have read and agreed to the published version of the manuscript.
Funding
The National Natural Science Foundation of China (No. 62171287) and Science & Technology Program of Shenzhen (No. JCYJ20220818100004008) supported this study.
Data Availability Statement
The data presented in this study are partly available on request from the corresponding author. The data are not publicly available due to their current restricted access.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Mahler, R. Statistical Multisource-Multitarget Information Fusion; Artech House: Norwood, MA, USA, 2007. [Google Scholar]
- Mahler, R. Advances in Statistical Multisource-Multitarget Information Fusion; Artech House: Boston, MA, USA, 2014. [Google Scholar]
- Bar-Shalom, Y. Multitarget-Multisensor Tracking: Applications and Advances–Volume III; Artech House: Boston, MA, USA, 2000. [Google Scholar]
- Yang, Z.; Li, X.; Yao, X.; Sun, J.; Shan, T. Gaussian process Gaussian mixture PHD filter for 3D multiple extended target tracking. Remote Sens. 2023, 15, 3224. [Google Scholar] [CrossRef]
- Li, Y.; Wei, P.; You, M.; Wei, Y.; Zhang, H. Joint detection, tracking, and classification of multiple extended objects based on the JDTC-PMBM-GGIW filter. Remote Sens. 2023, 15, 887. [Google Scholar] [CrossRef]
- Zhu, J.; Xie, W.; Liu, Z. Student’s t-based robust Poisson multi-Bernoulli mixture filter under heavy-tailed process and measurement noises. Remote Sens. 2023, 15, 4232. [Google Scholar] [CrossRef]
- Liu, Z.X.; Chen, J.J.; Zhu, J.B.; Li, L.Q. Adaptive measurement-assignment marginal multi-target Bayes filter with logic-based track initiation. Digit. Signal Process. 2022, 129, 103636. [Google Scholar] [CrossRef]
- Du, H.; Xie, W.; Liu, Z.; Li, L. Track-oriented marginal Poisson multi-Bernoulli mixture filter for extended target tracking. Chin. J. Electron. 2023, 32, 1106–1119. [Google Scholar] [CrossRef]
- Blackman, S.S. Multiple hypothesis tracking for multiple target tracking. IEEE Trans. Aerosp. Electron. Syst. Mag. 2004, 19, 5–18. [Google Scholar] [CrossRef]
- Tugnait, J.K.; Puranik, S.P. Tracking of multiple maneuvering targets using multiscan JPDA and IMM filtering. IEEE Trans. Aerosp. Electron. Syst. 2007, 43, 23–35. [Google Scholar]
- Mahler, R. Multitarget Bayes filtering via first-Order multitarget moments. IEEE Trans. Aerosp. Electron. Syst. 2003, 39, 1152–1178. [Google Scholar] [CrossRef]
- Vo, B.N.; Ma, W.K. The Gaussian mixture probability hypothesis density filter. IEEE Trans. Signal Process. 2006, 54, 4091–4104. [Google Scholar] [CrossRef]
- Vo, B.T.; Vo, B.N.; Cantoni, A. The cardinality balanced multi-target multi-Bernoulli filter and its implementations. IEEE Trans. Signal Process. 2009, 57, 409–423. [Google Scholar]
- Granstrom, K.; Orguner, U.; Mahler, R.; Lundquist, C. Extended target tracking using a Gaussian mixture PHD filter. IEEE Trans. Aerosp. Electron. Syst. 2017, 53, 1055–1058. [Google Scholar] [CrossRef]
- Hu, Q.; Ji, H.B.; Zhang, Y.Q. A standard PHD filter for joint tracking and classification of maneuvering extended targets using random matrix. Signal Process. 2018, 144, 352–363. [Google Scholar] [CrossRef]
- Zhang, Y.Q.; Ji, H.B.; Hu, Q. A fast ellipse extended target PHD filter using box-particle implementation. Mech. Syst. Signal Process. 2018, 99, 57–72. [Google Scholar] [CrossRef]
- Zhang, Y.Q.; Ji, H.B.; Gao, X.B.; Hu, Q. An ellipse extended target CBMeMBer filter using gamma and box-particle implementation. Signal Process. 2018, 149, 88–102. [Google Scholar] [CrossRef]
- Dong, P.; Jing, Z.L.; Gong, D.; Tang, B.T. Maneuvering multi-target tracking based on variable structure multiple model GMCPHD filter. Signal Process. 2017, 141, 158–167. [Google Scholar] [CrossRef]
- Vo, B.T.; Vo, B.N. Labeled random finite sets and multi-object conjugate priors. IEEE Trans. Signal Process. 2013, 61, 3460–3475. [Google Scholar] [CrossRef]
- Vo, B.N.; Vo, B.T.; Phung, D. Labeled random finite sets and the Bayes multi-target tracking filter. IEEE Trans. Signal Process. 2014, 62, 6554–6567. [Google Scholar] [CrossRef]
- Vo, B.N.; Vo, B.T.; Hoang, H.G. An efficient implementation of the generalized labeled multi-Bernoulli filter. IEEE Trans. Signal Process. 2017, 65, 1975–1987. [Google Scholar] [CrossRef]
- Cao, C.H.; Zhao, Y.B.; Pang, X.J.; Suo, Z.L.; Chen, S. An efficient implementation of multiple weak targets tracking filter with labeled random finite sets for marine radar. Digit. Signal Process. 2020, 101, 102710. [Google Scholar] [CrossRef]
- Bryant, D.S.; Vo, B.T.; Vo, B.N.; Jones, B.A. A generalized labeled multi-Bernoulli filter with object spawning. IEEE Trans. Signal Process. 2018, 66, 6177–6189. [Google Scholar] [CrossRef]
- Wu, W.H.; Sun, H.M.; Cai, Y.C.; Jiang, S.R.; Xiong, J.J. Tracking multiple maneuvering targets hidden in the DBZ based on the MM-GLMB Filter. IEEE Trans. Signal Process. 2020, 68, 2912–2924. [Google Scholar] [CrossRef]
- Liang, Z.B.; Liu, F.X.; Li, L.Y.; Gao, J.L. Improved generalized labeled multi-Bernoulli filter for non-ellipsoidal extended targets or group targets tracking based on random sub-matrices. Digit. Signal Process. 2020, 99, 102669. [Google Scholar] [CrossRef]
- Liu, Z.X.; Chen, W.; Chen, Q.Y.; Li, L.Q. Marginal multi-object Bayesian filter with multiple hypotheses. Digit. Signal Process. 2021, 117, 103156. [Google Scholar] [CrossRef]
- Du, H.Y.; Wang, W.J.; Bai, L. Observation noise modeling based particle filter: An efficient algorithm for target tracking in glint noise environment. Neurocomputing 2015, 158, 155–166. [Google Scholar] [CrossRef]
- Huang, Y.L.; Zhang, Y.G.; Li, N.; Wu, Z.M.; Chambers, J.A. A novel robust Student’s t-based Kalman filter. IEEE Trans. Aerosp. Electron. Syst. 2017, 53, 1545–1554. [Google Scholar] [CrossRef]
- Dong, P.; Jing, Z.L.; Leung, H.; Shen, K.; Wang, J.R. Student-t mixture labeled multi-Bernolli filter for multi-target tracking with heavy-tailed noise. Signal Process. 2018, 152, 331–339. [Google Scholar] [CrossRef]
- Zhu, H.; Leung, H.; He, Z.S. A variational Bayesian approach to robust sensor fusion based on Student-t distribution. Inf. Sci. 2013, 221, 201–214. [Google Scholar] [CrossRef]
- Li, W.L.; Jia, Y.M.; Du, J.P.; Zhang, J. PHD filter for multi-target tracking with glint noise. Signal Process. 2014, 94, 48–56. [Google Scholar] [CrossRef]
- Liu, Z.X.; Huang, B.J.; Zou, Y.N.; Li, L.Q. Multi-object Bayesian filter for jump Markov system under glint noise. Signal Process. 2019, 157, 131–140. [Google Scholar] [CrossRef]
- Miller, M.; Stone, H.; Cox, I. Optimizing Murty’s ranked assignment method. IEEE Trans. Aerosp. Electron. Syst. 1997, 33, 851–862. [Google Scholar] [CrossRef]
- Beard, M.; Vo, B.T.; Vo, B.N. OSPA(2): Using the OSPA metric to evaluate multi-target tracking performance. In Proceedings of the International Conference on Control, Automation and Information Sciences (ICCAIS), Chiang Mai, Thailand, 31 October–1 November 2017; pp. 86–91. [Google Scholar]
- Schuhmacher, D.; Vo, B.T.; Vo, B.N. A consistent metric for performance evaluation of multi-object filters. IEEE Trans. Signal Process. 2008, 56, 3447–3457. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).