Abstract
A novel Student’s t-based robust Poisson multi-Bernoulli mixture (PMBM) filter is proposed to effectively perform multi-target tracking under heavy-tailed process and measurement noises. To cope with the common scenario where the process and measurement noises possess different heavy-tailed degrees, the proposed filter models this noise as two Student’s t-distributions with different degrees of freedom. Furthermore, this method considers that the scale matrix of the one-step predictive probability density function is unknown and models it as an inverse-Wishart distribution to mitigate the influence of heavy-tailed process noise. A closed-form recursion of the PMBM filter for propagating the approximated Gaussian-based PMBM posterior density is derived by introducing the variational Bayesian approach and a hierarchical Gaussian state-space model. The overall performance improvement is demonstrated through three simulations.
1. Introduction
Multi-target tracking (MTT) aims to jointly estimate the time-varying number of targets and their states under the interference of various noises, false alarms, detection uncertainty, and data association uncertainty [1]. It has been widely used in civilian and military fields such as autonomous driving, air traffic control, missile warning, etc. In the past two decades, a new random finite set (RFS)-based MTT strategy, which models the multi-target state and sensor measurement as two individual RFSs, has been developed to avoid the data association required by the traditional MTT strategy [1,2,3].
The multi-target Bayesian (MTB) filter provides an optimal solution for the RFS-based MTT algorithms. However, due to the existence of multiple integrals, as well as the combinatorial nature stemming from the infinite-dimensional multi-target densities, the MTB filter is computationally intractable, which limits its application [1,2,4]. Recently, various suboptimal solutions have been successively developed, with two of the most well known being the probability hypothesis density (PHD) filter [1,5] and the multi-Bernoulli (MeMBer, MB) filter [6]. The PHD filter propagates the multi-target intensity (first-order statistic of the target RFS), which is computationally tractable but not accurate enough. The MeMBer filter propagates the MB density; however, its cardinality estimation has a certain bias. By introducing additional parameters, many variants, such as the cardinality balanced MeMBer (CBMeMBer) filter [7], -generalized labeled MeMBer (-GLMB) filter [8], and labeled MeMBer (LMB) filter [9], have been developed. It is worth mentioning that both the -GLMB filter and the LMB filter can achieve high tracking accuracy and output target trajectories but at the cost of high computational complexity. In recent years, a new variant called the Poisson multi-Bernoulli mixture (PMBM) filter has been developed [10]. The PMBM filter considers the birth process as a Poisson, which is different from the MB birth in the GLMB and LMB filters. The propagated conjugate prior is the combination of a Poisson point process (PPP) and an MB mixture (MBM), in which the former is the modeling of all targets that have never been detected, and the latter considers all the data association hypotheses and is implemented using the track-oriented multiple hypotheses tracking (TOMHT) formulation [10,11]. The PMBM filter achieves a much higher tracking accuracy compared to the aforementioned filters with a lower computational load, so it is a promising filter [12,13,14,15,16,17].
Conventional RFS-based MTT filters are mostly implemented by applying the standard Kalman filter in multi-target fields, so they are only suitable for the Gaussian process and measurement noises [2]. However, in engineering applications, such as maneuvering target tracking, as well as the presence of burst interference and unreliable sensors, the distributions of these noises are usually heavy-tailed non-Gaussian with many outliers. Compared to Gaussian noise, heavy-tailed noise statistically means a larger uncertainty in positions far from the mean, that is, the probability of target movement or measurement far from the mean is higher than that of Gaussian noise. In this situation, the tracking performance of these conventional filters may break down. To mitigate this, the Student’s t-distribution with naturally heavy-tailed characteristics is employed to model the heavy-tailed noise, but this can make obtaining a closed-form recursion intractable. The variational Bayesian (VB) inference provides a solution to this problem. This approach has been widely used for estimating the unknown covariance [3,17,18,19], in which the VB-LMB [18] and Gaussian inverse-Wishart (IW) mixture LMB (GIWM-LMB) [19] filters were proposed by modeling the unknown measurement covariance as inverse-Gamma and IW distributions, respectively. Using a combination of the VB approach and Student’s t-model, a filter called the VB Kalman filter (VB-KF) [20,21] for single-target tracking (STT) under heavy-tailed measurement noise is proposed. This strategy has been extended to MTT fields [22,23,24,25], but the drawback is that they cannot cope with the heavy-tailed process noise. As a generalization of the ubiquitous Kalman filter, the Student’s t-filter (STF) [26] models the process and measurement noises as Student’s t-distributions with the same degrees of freedom (DOF) and then propagates the Student’s t-based density, which can deal with these two noises in a natural manner. Based on this method, the Student’s t mixture CBMeMBer (STM-CBMeMBer) filter [27], the STM-LMB filter [2], and the STM-GLMB filter [28] are proposed, especially the latter two filters, achieving higher estimation accuracy.
However, the STF-based filters still have inherent shortcomings. First, the moment-matching approximation is introduced to prevent the DOF from increasing in the update step. This approximation can only capture the first two moments so it has a large error. Second, the STF-based filters require that the process and measurement noises have the same DOFs, which is seldom experienced in real-world scenarios [26]. Finally, compared to the Gaussian approximation of a posterior probability density function (PDF), the STF-based filters use Student’s t-distribution to approximate the posterior PDF, which proves to be unreasonable [29]. To avoid these drawbacks, a novel heavy-tailed-noise Kalman filter, which models these two noises as Student’s t-distributions with different DOFs, has been proposed to perform STT [29]. This filter uses the hierarchical Gaussian state-space model to approximate the posterior PDF. By introducing the VB approach, the target state is estimated iteratively, and the tracking performance is greatly improved.
To the best of our knowledge, the proposed R-ST-PMBM filter is the first efficient MTT filter that can theoretically handle process and measurement noises with different heavy-tailed degrees. Firstly, to match the characteristics of the heavy-tailed process and measurement noises, the one-step predicted PDF and measurement likelihood PDF are modeled as Student’s t-distributions, where the DOFs can be set inconsistently to cope with process and measurement noises with different heavy-tailed degrees. Secondly, due to the influence of heavy-tailed process noise, it is not possible to obtain an accurate scale matrix of the one-step predicted PDF. To handle this, we assume this scale matrix is unknown and model it as an IW distribution to improve the filtering performance. Finally, a hierarchical Gaussian state-space model, which includes the parameters of the Student’s t-distributions and IW distribution, is introduced into the standard PMBM filter, and then iteratively updates the PMBM posterior density through the VB approach. Note that we used an approximated Gaussian-based PMBM posterior rather than the Student’s t-based PMBM density to approximate the true posterior PDF, which is more reasonable. The moment-matching approximation in the update of the STF-based filters is avoided, thus preserving the high-order moments completely and achieving higher tracking accuracy. Simulation results in different scenarios demonstrate the effectiveness of our contribution.
The rest of this paper is outlined as follows. Section 2 presents some useful background information, including the related models, the PMBM RFS, and the VB approach. Section 3 presents an analytic implementation for the proposed R-ST-PMBM filter. Section 4 validates the effectiveness of the proposed filter, and Section 5 presents the conclusions.
2. Background
2.1. PMBM RFS
The PMBM RFS involved in this paper consists of two parts: the Poisson RFS and the MBM RFS. Firstly, assume that the RFS is a PPP, that is, its cardinality is Poisson. All the elements of X are independent and identically distributed (i.i.d.). The density of this Poisson RFS can be denoted by
where represents the single-target intensity. A single-Bernoulli component (single-target hypothesis) with a probability of survival r and density , can be denoted by
An MB RFS contains a finite number of single-Bernoulli components, that is,
where ⊎ stands for the disjoint union, and ∝ denotes the proportionality. Similarly, an MBM RFS can be denoted by
By combining the Poisson RFS and MBM RFS, we obtain the PMBM RFS
where j is the index of the MBM RFS, and is the weight of the i-th single-target hypothesis in the j-th MB RFS.
2.2. Models
We consider the linear state-space system with the target dynamic model and sensor measurement model given by
where and denote the target state and sensor measurement at time k. F and H are the state transition and measurement matrices. and denote the dimension of the target state and measurement, respectively. Here, we model the heavy-tailed process noise and the measurement noise as zero-mean Student’s t-distributions as follows:
where denotes a Student’s t-distribution with mean , scale matrix , and DOF . The resulting one-step predicted and likelihood PDFs can be represented by [30]
where is the PDF of a Gamma distribution with shape parameter and rate parameter . represents a Gaussian distribution with mean and covariance P. is the Gamma function [22]. To apply the hierarchical Gaussian state-space model in the single-target hypothesis prediction and update, we assume that the predicted posterior density is Gaussian with mean and nominal covariance . Then, we have
where Q denotes the nominal process noise covariance. We can derive the nominal single-target transition density as follows:
With the introduction of heavy-tailed process noise, Q is inaccurate and therefore not suitable as the scale matrix of the one-step predicted PDF. To handle this, we assume that the scale matrix in Equation (10) is unknown and model it as an IW distribution with the PDF given by
where denotes the DOF parameter. denotes the inverse scale matrix, which is a symmetric and positive definite matrix of dimension . is the d-variate Gamma function. When , [31]. Let , and we make the following assumptions:
where is the tuning parameter. Rewrite Equations (10) and (11) in the following hierarchical forms:
2.3. VB Approximation
As a deterministic approximation scheme, the VB approach is always used to obtain sub-optimal approximations of unknown or complex posterior distributions and has been widely applied in machine learning and neural networks [32]. For a single-target hypothesis of our work, the VB approach aims to derive a separable approximation of the posterior density, that is
where . The Kullback–Leibler divergence (KLD) between this posterior and its approximation is derived by
The joint PDF can be factored as
By minimizing Equation (23), we obtain
where is an arbitrary element of , and represents the set of all elements in except for . By substituting Equations (15), (18)–(21), and (24) into Equation (25), these individual approximate PDFs can be iteratively derived in the following forms:
where a denotes the number of iterations. Note that this VB approximation only requires the input of Gaussian parameters for prediction and updating. That is, the recursion of the single-target hypothesis involved in this paper can be considered as a propagation of Gaussian distribution (see Section 3.2 for the detailed iteration process). The approximated marginal PDF of the measurement can be denoted by
where
where is the digamma function. The proof of Equations (30) and (31) is provided in Appendix A.
3. R-ST-PMBM Filter
In this section, a detailed implementation of the proposed filter is described.
3.1. Prediction
The prediction step of the proposed filter includes two parts: the Poisson prediction and the MBM prediction. The former consists of the current newborn targets and the prediction of previously undetected newborn targets, whereas the latter involves the prediction of previously potentially detected targets.
3.1.1. Poisson Prediction
Suppose that the Poisson part of the updated posterior density at time is a Gaussian mixture of the form
where denotes the weight of the l-th Poisson component. The intensity of the newborn targets at time k is as follows:
Given the nominal single-target transition density (Equation (14)) and the probability of target survival , the Poisson prediction can be derived by
where,
3.1.2. MBM Prediction
Suppose that in the updated MBM RFS at time , the i-th single-target hypothesis of the j-th MB RFS has an existence probability , and the PDF is as follows:
The predicted single-target hypothesis at time k can be derived by
where the weight will not participate in the update step and
3.2. Update
Similar to the standard PMBM filter, the update step of our filter can be divided into three parts: an update for undetected targets, an update for potential targets detected for the first time, and an update for previously potentially detected targets.
3.2.1. Update for Undetected Targets
The undetected targets refer to the newborn targets that are missed by the sensor at the current and past times, and they are represented in the form of a Poisson RFS. Note that in this update, the form of these targets remains unchanged. Assume that the predicted Poisson RFS is as follows:
Given the detection probability , the update for undetected targets at time k can be derived by
3.2.2. Update for Potential Targets Detected for the First Time
Potential targets detected for the first time comprise two parts: the detected portion of the newborn targets at time k, and the previously undetected newborn targets that were first detected by the sensor at time k. In the prediction step, the newborn targets are modeled as a Poisson RFS, whereas the survival targets are represented as an MBM RFS. A detected newborn target will participate in the next recursion as a survival target; hence, the results of updating the potential targets detected for the first time are in the form of an MBM.
In this update, each measurement needs to go through all the elements of the predicted Poisson RFS that fall into the ellipsoidal gate, and then be combined by weight to construct an individual MB RFS. Given the predicted Poisson RFS at time k (see Equation (44)), for , the n-th element of the measurement RFS , we calculate the Mahalanobis distances from it to all the predicted Poisson components and preserve the closest ones. Assuming that is the component number of the predicted Poisson RFS that falls into the ellipsoidal gate, before this update, we rewrite the eligible components of Equation (44) in the following conditional form:
where and are the auxiliary variable and scale matrix of the equivalent one-step predicted density in the form of a Student’s t-distribution, respectively. Using Equations (15)–(22), (26)–(31), and (46), given the clutter intensity , the individual MB RFS updated by can be derived as follows:
where the distribution parameters can be obtained through iteration. First, we assign , , , , , and . We set the constant parameters , , and , and then iterate the following process:
3.2.3. Update for Previously Potentially Detected Targets
According to Section 3.2.2, the previously potentially detected targets refer to the survival targets, and the updated results remain in an MBM form. In this update, each predicted single-target hypothesis (single-Bernoulli component) needs to go through the sensor measurements and be updated by the measurements that fall into the ellipsoidal gate, and then create new single-target hypotheses. Since the survival targets may be misdetected by the sensor the next time, this update can also be divided into two parts: an update for undetected survival targets and an update for detected survival targets.
Considering the i-th predicted single-target hypothesis of the j-th MB RFS with existence probability (Equation (40)) and density (Equation (41)), the undetected survival target can be updated by
Assume that is the measurement RFS at time k, and is its subset with all elements falling into the gate. Similar to Section 3.2.2, we rewrite the density (Equation (41)) in the conditional form . For , the updated survival probability of this single-target hypothesis for the detected survival target can be denoted by
For the density update, when , we set
If , the updated density can be derived as follows:
where the updated parameters are obtained through iteration. We assign , , , , , and . The constant parameters are set as , , and . Then, the following iteration is executed:
The stopping conditions for this iteration are the same as in the previous section. When it stops, we assign the final values in Equation (73) such that , , , , and . Since our filter propagates the Gaussian-based PMBM posterior PDF, we approximate Equation (73) with the following weighted Gaussian form:
where , and
3.3. Organization Method of the Filter
To better show how the proposed filter works, we use pseudocode to demonstrate the key steps of the algorithm. Given that is the PMBM posterior at time , where , and for , the j-th subset of , it may contain several single-Bernoulli components, that is, , where i is its index. The filtering steps are shown in Algorithm 1.
| Algorithm 1 Pseudocode for one recursion of the filter |
|
The global hypotheses are a collection of all possible one-to-one correspondences between the potential targets and the measurements. In the update step, to construct the global hypothesis matrix, the cost matrix of all possible associations needs to be generated first.
Assume that at time k, m and n are the numbers of sensor measurements and predicted MB RFSs, respectively. Using the predicted global hypotheses and the updated single-target hypothesis weights, the cost matrix C can be denoted by
where , in which and are the component weights of Equations (88) and (70), respectively. v is the log weight of Equation (65). By applying Murty’s algorithm, all the possible associations are listed and arranged according to cost from low to high, and then the hypotheses with high costs are pruned. Finally, the corresponding component number of each element in the cost matrix is output. Note that the global hypotheses remain unchanged in the prediction step. The detailed global hypothesis weight calculation method and the state extraction method can be referred to as the standard PMBM filter [11].
Assume that is the number of measurements at time k, and and are the predicted number of Poisson components and total number of single-Bernoulli components across all the predicted MB RFSs, respectively. The computational complexity of the proposed filter can be denoted by , which is the same as the standard PMBM filter. The increase in the computational load compared to the standard version is caused by the iterative update of the single-target hypothesis.
4. Simulations
In this section, we demonstrate the tracking performance of the proposed filter (R-ST-PMBM) with three examples and compare it with the existing filters. We evaluate the filtering performance using the Optimal Subpattern Assignment (OSPA) distance [33] and Generalized OSPA (GOSPA) metrics [34]. We also consider metrics such as running time and cardinality estimation accuracy.
4.1. Scenario with the Same Heavy-Tailed Degrees
We consider a two-dimensional region (in m) with uniform clutter and an unknown and time-varying number of targets. The clutter is Poisson with density m−2. The target state is denoted by , where and denote the position and velocity, respectively. We use the following models to execute this simulation:
where ⊗ denotes the Kronecker product, s is the sampling period, and is an identity matrix of dimension . The nominal standard derivations of process and measurement noises are set to m/s2 and m, respectively. Both the heavy-tailed process and measurement noises are constructed using the proportional superposition of two Gaussian distributions with significantly different covariances, which can be represented as follows [2]:
where and denote the superposition proportions, which can be used to adjust the heavy-tailed degrees of these two noises. In this test, we set to construct a scenario with the same heavy-tailed degrees. The newborn targets are Poisson with intensity
where , , , , , and . We set eight targets to appear and disappear successively in the restricted region, and each target has a survival probability of . Note that due to the influence of the heavy-tailed process noise, the targets may experience violent maneuvers. Figure 1a shows the target trajectories of a test.
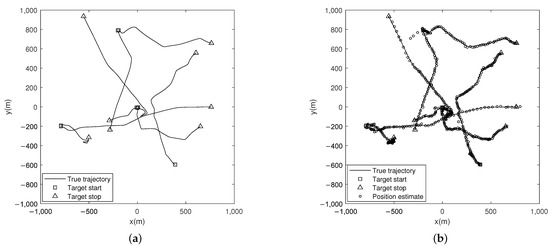
Figure 1.
(a) True trajectories of the targets in the scenario with the same heavy-tailed degrees. (b) Position estimates of this simulation.
For the parameters required in the update, we use a maximum number of iterations , a cutoff distance , and a tuning parameter . Each target has a probability of being detected by the sensor. The maximum number of global hypotheses is set to . The pruning weight thresholds of the Poisson and MBM components are set to and , respectively. The threshold of the ellipsoidal gating is set to . The Bernoulli components, whose existence probability is lower than , are removed.
In this test, to match the scenario of the same heavy-tailed degrees (), the DOFs of the process and measurement noises are set to . Figure 1b shows the position estimates for this simulation. Note that each boundary of the sparse and dense estimation points indicates a severe change in the target velocity.
Figure 2a and Figure 2b, respectively, show the comparisons of the OSPA distances (for and ) and cardinality estimates of the proposed filter with the STM-LMB, STM-GLMB, and STM-CBMeMBer filters after 100 Monte Carlo runs, indicating better performance compared to the existing filters. It is worth mentioning that the OSPA fluctuation at s in Figure 2a is caused by the gradual decrease in the component’s probability of existence when the target disappears. We also use the GOSPA metric, with parameters , , and , to further evaluate the tracking performance of the proposed filter. The comparisons of the GOSPA error, localization error (LE), missed targets error (ME), and false targets error (FE) are shown in Figure 3. It is evident that the R-ST-PMBM filter exhibits a smaller GOSPA error, LE, and ME most of the time. Note that all the errors are root-squared versions. From Figure 3c, we can conclude that the error at s in Figure 2a is caused by the misestimation of the true targets when the filtering process starts. These errors also exist in the simulation of other PMBM-based filters.
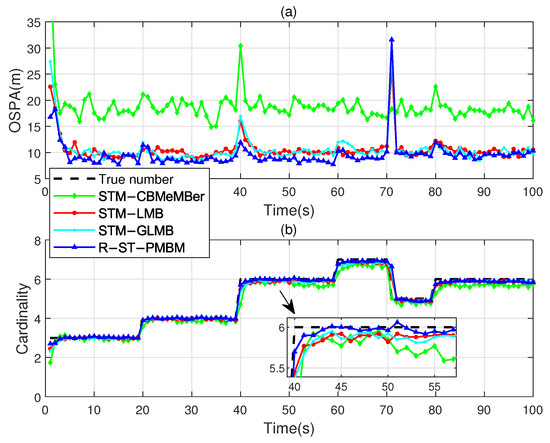
Figure 2.
(a) OSPA distances of the four filters versus time. (b) Cardinality estimates versus time.
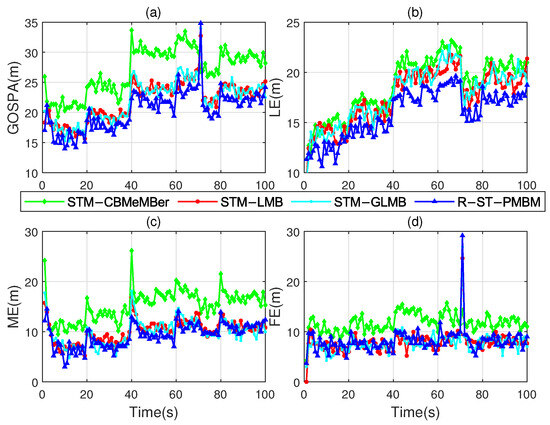
Figure 3.
Comparison of the errors among the four filters versus time. (a) GOSPA error. (b) LE. (c) ME. (d) FE.
Table 1 shows the indices of the average OSPA (AOSPA) distance [23], average GOSPA error (AGOSPA), average LE (ALE), average ME (AME), average FE (AFE), and average running time (ART) (in s) of the four filters after 100 Mont Carlo runs. These results demonstrate that our filter exhibits the best tracking performance in the scenario with the same heavy-tailed degrees. It should be noted that compared to the STF-based filters, the performance advantage of the proposed filter is mainly due to the combined effects of the following factors: avoiding the use of moment-matching approximations with large errors, using a Gaussian-based PMBM posterior to approximate the truth posterior, and inheriting the high performance of the standard PMBM filter.

Table 1.
Numerical results of the four filters in the scenario with the same heavy-tailed degrees.
4.2. Scenario with Different Heavy-Tailed Degrees
To evaluate the pertinence of the design of the proposed filter, we consider a scenario in which the process noise and the measurement noise have different heavy-tailed degrees. Before the test, to facilitate the selection of appropriate DOFs, we studied the tracking performance of the proposed filter under different heavy-tailed process and measurement noises with different DOF settings, and the results are shown in Figure 4. For Figure 4a, we set the process noise to null and , whereas for Figure 4b, we set and , and the remaining parameters were unchanged.
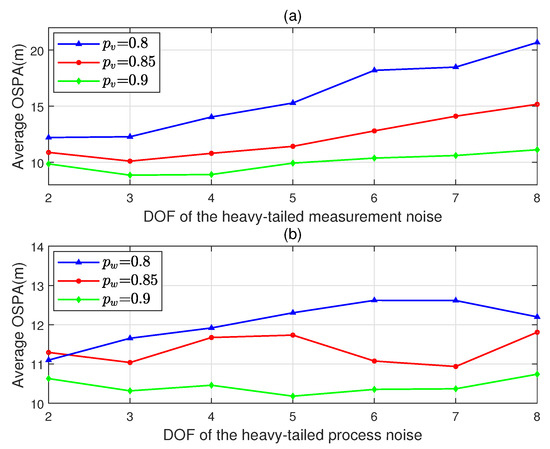
Figure 4.
AOSPA versus DOF under noises with different heavy-tailed degrees. (a) Process noise is null, . (b) , .
In this test, we change the superposition proportion of the process noise (see Equation (93)) to , which can increase the number of outliers in the mixed process noise and result in a larger heavy-tailed degree compared to the measurement noise. As shown in Figure 4b, the DOF of the process noise is set to , and the other noise parameters are consistent with the previous test.
Theoretically, to track the targets in this scenario, the one-step predicted PDF and likelihood PDF (see Equations (10) and (11)) are usually required to be set to different DOFs, i.e., . But this is impossible in the STM-CBMeMBer, STM-LMB, and STM-GLMB filters. Therefore, for these three filters, we successively set the DOFs to and (due to the existence of moment matching, in the STF-based filters, the DOFs cannot be set to 2). We set the DOFs of the R-ST-PMBM filter to and . Figure 5 and Figure 6 show comparisons of the OSPA distances, cardinality estimates, and GOSPA metrics, respectively.
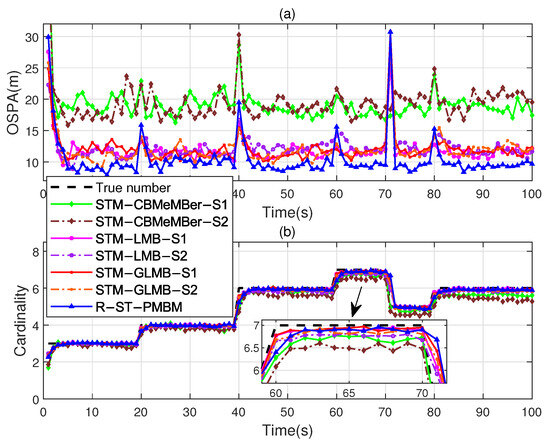
Figure 5.
(a) OSPA distances of the four filters with different DOF settings. (b) Cardinality estimates versus time.
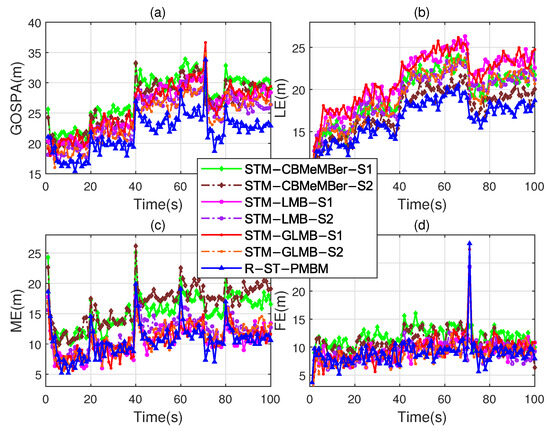
Figure 6.
Comparison of the errors among the four filters with different DOF settings. (a) GOSPA error. (b) LE. (c) ME. (d) FE.
Note that the extensions “S1” and “S2” in the legends in Figure 5 and Figure 6 represent the DOF settings and , respectively. It is evident that the OSPA distance and the GOSPA error of the R-ST-PMBM filter are lower compared to the existing filters, except for the fluctuation when the target number is reduced (at s). Table 2 provides a comparison of the different indices, where we can see that the overall performance of the R-ST-PMBM filter is better compared to the existing filters. Compared to the previous test, the performance advantage of the R-ST-PMBM filter in the scenario of noises with different heavy-tailed degrees is enhanced. It should be pointed out that the operational efficiency advantage of the proposed filter stems from its linear computational complexity in the number of hypotheses, whereas the complexity of the STM-LMB and STM-GLMB filters is quadratic.
Table 2.
Numerical results of the four filters in the scenario with different heavy-tailed degrees.
4.3. Real Data Scenario
The effectiveness of the R-ST-PMBM filter is also verified in a real data scenario. Essentially, all the target maneuvers and sensor measurement outliers can be considered as the affected results of the heavy-tailed process and measurement noises, respectively. The larger the heavy-tailed degree of the noise, the more severe the target motion or the sensor measurement outliers, and vice versa. In this simulation, the surveillance area is restricted to [8000, 11,000] × [1000, 7000] (in m), and the real data are obtained from radar measurements of two aircraft in the surveillance area. The target motions and sensor measurements are projected onto a two-dimensional plane. Two targets appeared successively in this area, lasting 64 s, and were detected 48 times by the sensor.
The scanning interval T (see Equation (91)) of the sensor is not constant. The newborn parameters are set to , , and . The nominal standard deviations of the process and measurement noises are set to m/s2 and m, and the DOFs are set to . The parameters not mentioned can be referred to in Section 4.1. Figure 7 shows the true trajectories and position estimates. Figure 8 shows the OSPA distance and cardinality estimate comparisons of the four filters. It can be seen that the R-ST-PMBM filter has the best tracking effect among these filters. The comparison results of the GOSPA metrics, shown in Figure 9, also support this conclusion. Note that the large fluctuation of the proposed filter at time step is directly caused by the sudden increase in the radar scanning period.
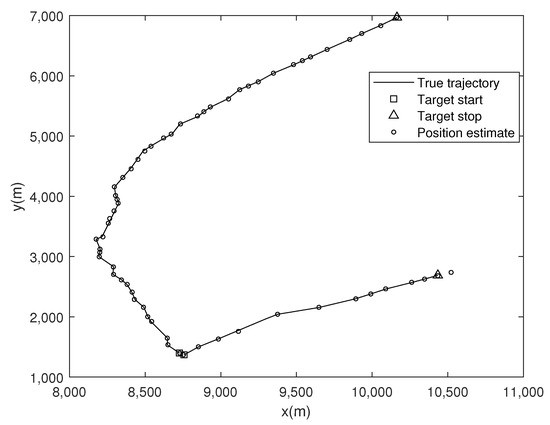
Figure 7.
True trajectories and position estimates in the real data scenario.
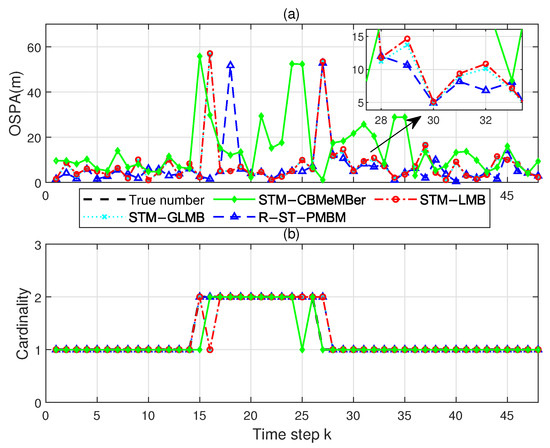
Figure 8.
(a) OSPA distances of the four filters in the real data scenario. (b) Cardinality estimates versus time.
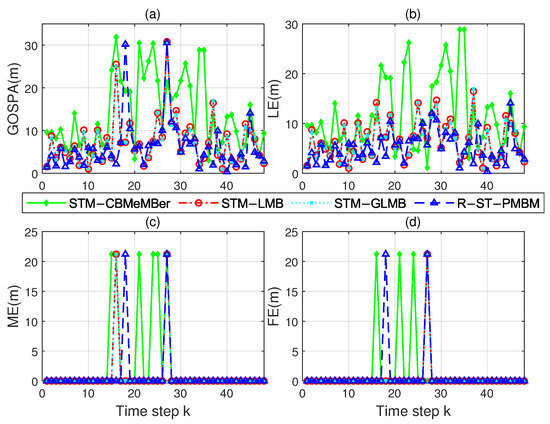
Figure 9.
Comparison of the errors among the four filters in the real data simulation. (a) GOSPA error. (b) LE. (c) ME. (d) FE.
The numerical results of the four filters are provided in Table 3. It can be seen that, compared to the other filters, the R-ST-PMBM filter demonstrates a significant overall performance advantage in this real data scenario.
Table 3.
Numerical results of the four filters in the real data simulation.
5. Conclusions
In this paper, an improved PMBM filter, called the R-ST-PMBM filter, was proposed to better perform MTT under heavy-tailed process and measurement noises, which provided a Student’s t-based Gaussian approximation to the components of the PMBM density. The one-step prediction and measurement likelihood were modeled as Student’s t-distributions with different DOFs, enabling our filter to be more adaptable to real environments. The scale matrix of the one-step predicted PDF was assumed to be unknown and modeled as an IW distribution, increasing the filter’s robustness. The resulting Student’s t-based hierarchical Gaussian state-space model was iterated to derive a posterior PDF by introducing the auxiliary variables and the VB approach and then approximated to Gaussian to obtain a closed-form recursion in the update step. The simulation results show that in the heavy-tailed process and measurement noise environment, the R-ST-PMBM filter achieves better overall performance compared to the existing filters, even under these noises with different heavy-tailed degrees.
In our future work, maneuvering target tracking in a real-world environment will become an application field for the proposed filter. Applying this filter to extended target tracking is also a possible research topic.
Author Contributions
J.Z.: Conceptualization, Validation, Writing—original draft preparation. W.X.: Resources, Software, Review, Supervision. Z.L.: Methodology, Writing—review and editing, Project administration. All authors have read and agreed to the published version of the manuscript.
Funding
This work was funded by the National Natural Science Foundation of China under grant 62171287 and the Shenzhen Science and Technology Program under grants JCYJ20190808120417257 and JCYJ20220818100004008.
Data Availability Statement
The data presented in this study are partly available on request from the corresponding author. The data are not publicly available due to their current restricted access.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
By applying the approximate inference theory described, we can derive the log-marginal PDF of measurement as follows [32]:
where
which denotes the evidence lower bound (ELOB). Assuming that is the error of this inference when minimizing the KLD in Equation (A1), we can derive the log-marginal PDF by
where
Reference [29] provides the following expectations:
For , we have [35]
References
- Vo, B.T.; Ma, W.K. The Gaussian mixture probability hypothesis density filter. IEEE Trans. Signal Process. 2006, 54, 4091–4104. [Google Scholar] [CrossRef]
- Dong, P.; Jing, Z.; Leung, H.; Wang, J. Student-t mixture labeled multi-Bernoulli filter for multi-target tracking with heavy-tailed noise. Signal Process. 2018, 152, 331–339. [Google Scholar] [CrossRef]
- Lian, Y.; Lian, F.; Hou, L. Robust labeled multi-Bernoulli filter with inaccurate noise covariances. In Proceedings of the 25th International Conference on Information Fusion, Linköping, Sweden, 4–7 July 2022. [Google Scholar]
- Wang, X.; Xie, W.; Li, L. Labeled Multi-Bernoulli Maneuvering Target Tracking Algorithm via TSK Iterative Regression Model. Chinese J. Electron. 2022, 31, 227–239. [Google Scholar]
- Yang, Z.; Li, X.; Yao, X.; Sun, J.; Shan, T. Gaussian process Gaussian mixture PHD filter for 3D multiple extended target tracking. Remote Sens. 2023, 15, 3224. [Google Scholar] [CrossRef]
- Mahler, R. Statistical Multisource-Multitarget Information Fusion; Artech House, Inc.: Norwood, MA, USA, 2007. [Google Scholar]
- Vo, B.T.; Vo, B.N.; Cantoni, A. The cardinality balanced multi-target multi-Bernoulli filter and its implementations. IEEE Trans. Signal Process. 2009, 57, 409–423. [Google Scholar]
- Vo, B.N.; Vo, B.T.; Hoang, H.G. An efficient implementation of the generalized labeled multi-Bernoulli filter. IEEE Trans. Signal Process. 2017, 65, 1975–1987. [Google Scholar] [CrossRef]
- Reuter, S.; Vo, B.T.; Vo, B.N.; Dietmayer, K. The labeled multi-Bernoulli filter. IEEE Trans. Signal Process. 2014, 62, 3246–3260. [Google Scholar]
- Williams, J.L. Marginal multi-Bernoulli filters: RFS derivation of MHT, JIPDA, and association-based MeMBer. IEEE Trans. Aerosp. Electron. Syst. 2015, 51, 1664–1687. [Google Scholar] [CrossRef]
- García-Fernández, A.F.; Williams, J.L.; Granstöm, K. Poisson multi-Bernoulli mixture filter: Direct derivation and implementation. IEEE Trans. Aerosp. Electron. Syst. 2018, 54, 1883–1901. [Google Scholar] [CrossRef]
- Xia, Y.; Granström, K.; Svensson, L.; García-Fernández, A.F. Performance evaluation of multi-Bernoulli conjugate priors for multi-target filtering. In Proceedings of the 20th International Conference on Information Fusion, Xi’an, China, 10–13 July 2017. [Google Scholar]
- Du, H.; Xie, W. Extended target marginal distribution Poisson multi-Bernoulli mixture filter. Sensors 2020, 20, 5387. [Google Scholar] [CrossRef]
- García-Fernández, A.F.; Svensson, L.; Williams, J.L.; Xia, Y.; Granstöm, K. Trajectory Poisson multi-Bernoulli filters. IEEE Trans. Signal Process. 2020, 68, 4933–4945. [Google Scholar] [CrossRef]
- Li, Y.; Wei, P.; You, M.; Wei, Y.; Zhang, H. Joint detection, tracking, and classification of multiple extended objects based on the JDTC-PMBM-GGIW filter. Remote Sens. 2023, 15, 887. [Google Scholar] [CrossRef]
- Li, G.; Kong, L.; Yi, W.; Li, X. Multiple model Poisson multi-Bernoulli mixture filter for maneuvering targets. IEEE Sens. J. 2021, 21, 3143–3154. [Google Scholar] [CrossRef]
- Li, W.; Gu, H.; Su, W. Robust Poisson multi-Bernoulli mixture filter with inaccurate process and measurement noise covariances. IEEE Access 2020, 8, 52209–52220. [Google Scholar] [CrossRef]
- Qiu, H.; Huang, G.; Gao, J. Variational Bayesian labeled multi-Bernoulli filter with unknown sensor noise statistics. Chin. J. Aeronaut. 2016, 29, 1378–1384. [Google Scholar]
- Li, G.; Wei, P.; Li, Y.; Gao, L.; Zhang, H. A robust fast LMB filter for superpositional sensors. Signal Process. 2020, 174, 107606. [Google Scholar] [CrossRef]
- Ting, J.A.; Theodorou, E.; Schaal, E. Learning an outlier-robust Kalman filter. In Proceedings of the 18th European Conference on Machine Learning, Warsaw, Poland, 17–21 September 2007; pp. 748–756. [Google Scholar]
- Zhu, H.; Leung, H.; He, Z. A variational Bayesian approach to robust sensor fusion based on Student-t distribution. Inf. Sci. 2013, 221, 201–214. [Google Scholar] [CrossRef]
- Li, W.; Jia, Y.; Du, J.; Zhang, J. PHD filter for multi-target tracking with glint noise. Signal Process. 2014, 94, 48–56. [Google Scholar] [CrossRef]
- Liu, Z.; Huang, B.; Zou, Y.; Li, L. Multi-object Bayesian filter for jump Markov system under glint noise. Signal Process. 2019, 157, 131–140. [Google Scholar] [CrossRef]
- Dong, P.; Leung, H.; Jing, Z.; Shen, K.; Li, M. The labeled multi-Bernoulli filter for multitarget tracking with glint noise. IEEE Trans. Aerosp. Electron. Syst. 2019, 55, 2253–2268. [Google Scholar] [CrossRef]
- Hou, L.; Lian, F.; Tan, S.; Xu, C.; De Abreu, G.T.F. Robust generalized labeled multi-Bernoulli filter for multitarget tracking with unknown non-stationary heavy-tailed measurement noise. IEEE Access 2021, 9, 94438–94453. [Google Scholar] [CrossRef]
- Roth, M.; Özkan, E.; Gustafsson, F. A Student’s t filter for heavy-tailed process and measurement noise. In Proceedings of the 2013 IEEE Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013. [Google Scholar]
- Wang, M.; Ji, H.; Zhang, Y.; Hu, X. A Student’s t mixture cardinality-balanced multi-target multi-Bernoulli filter with heavy-tailed process and measurement noises. IEEE Access 2018, 6, 51098–51109. [Google Scholar] [CrossRef]
- Hu, X.; Zhang, Q.; Song, B.; Zhao, M.; Xia, Z. Student-t mixture GLMB filter with heavy-tailed noises. In Proceedings of the 2013 IEEE Conference on Signal Processing, Communications and Computing, Xi’an, China, 25–27 October 2022. [Google Scholar]
- Huang, Y.; Zhang, Y.; Li, N.; Wu, Z. A novel robust Student’s t-based Kalman filter. IEEE Trans. Aerosp. Electron. Syst. 2017, 53, 1545–1554. [Google Scholar] [CrossRef]
- Huang, Y.; Zhang, Y.; Li, N.; Wu, Z. A robust Gaussian approximate fixed-interval smoother for nonlinear systems with heavy-tailed process and measurement noises. IEEE Signal Proc. Let. 2016, 23, 468–472. [Google Scholar] [CrossRef]
- O’Hagan, A.; Forster, J. Kendall’s Advanced Theory of Statistics, Vol 2B: Bayesian Inference; Arnold Publishers: London, UK, 2004; pp. 402–406. [Google Scholar]
- Bishop, C. Pattern Recognition and Machine Learning (Information Science and Statistics); Springer: New York, NY, USA, 2006; pp. 462–466. [Google Scholar]
- Schihmacher, D.; Vo, B.T.; Vo, B.N. A consistent metric for performance evaluation of multi-object filters. IEEE Trans. Signal Process. 2008, 56, 3447–3457. [Google Scholar] [CrossRef]
- Rahmathullah, A.S.; García-Fernández, A.F.; Svensson, L. Generalized optimal sub-pattern assignment metric. In Proceedings of the 20th International Conference on Information Fusion, Xi’an, China, 10–13 July 2017. [Google Scholar]
- Huang, Y. Researches on High-Accuracy State Estimation Methods and Their Applications to Target Tracking and Cooperative Localization. Ph.D. Dissertation, Harbin Engineering University, Harbin, China, 2018; pp. 162–163. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).