Abstract
Landslide susceptibility mapping (LSM) is significant for landslide risk assessment. However, there remains no consensus on which method is optimal for LSM. This study implements a dynamic approach to landslide hazard mapping by integrating spatio-temporal probability analysis with time-varying ground deformation velocity derived from the MT-InSAR (Multi-Temporal InSAR) method. Reliable landslide susceptibility maps (LSMs) can inform landslide risk managers and government officials. First, sixteen factors were selected to construct a causal factor system for LSM. Next, Pearson correlation analysis, multicollinearity analysis, information gain ratio, and GeoDetector methods were applied to remove the least important factors of STI, plan curvature, TRI, and slope length. Subsequently, information quantity (IQ), logistic regression (LR), frequency ratio (FR), artificial neural network (ANN), random forest (RF), support vector machine (SVM), and convolutional neural network (CNN) methods were performed to construct the LSM. The results showed that the distance to a river, slope angle, distance from structure, and engineering geological rock group were the main factors controlling landslide development. A comprehensive set of statistical indicators was employed to evaluate these methods’ effectiveness; sensitivity, F1-measure, and AUC (area under the curve) were calculated and subsequently compared to assess the performance of the methods. Machine learning methods’ training and prediction accuracy were higher than those of statistical methods. The AUC values of the IQ, FR, LR, BP-ANN, RBF-ANN, RF, SVM, and CNN methods were 0.810, 0.854, 0.828, 0.895, 0.916, 0.932, 0.948, and 0.957, respectively. Although the performance order varied for other statistical indicators, overall, the CNN method was the best, while the BP-ANN and RBF-ANN method was the worst among the five examined machine methods. Hence, adopting the CNN approach in this study can enhance LSM accuracy, catering to the needs of planners and government agencies responsible for managing landslide-prone areas and preventing landslide-induced disasters.
1. Introduction
Landslides are major natural disasters commonly occurring in mountainous areas worldwide, posing a significant threat to human life, property, and the natural environment. According to the global landslide database compiled by Froude and Petley (2018), more than 4862 fatal landslides were recorded from 2004 to 2016, resulting in 55,997 deaths worldwide. Landslide susceptibility has become a research hotspot in related fields, and many scholars are committed to landslide monitoring, early warning, landslide susceptibility mapping (LSM), etc. [1,2,3,4,5] to assess landslide hazards and risks [6,7,8,9,10].
In recent decades, the utilization of Geographic Information Systems (GIS) and Remote Sensing (RS) has resulted in the emergence of various models aimed at predicting landslide susceptibility (LSP) [11,12]. These models can be classified as qualitative or quantitative, with quantitative models further subdivided into data-driven or deterministic [6,13], which estimate landslide susceptibility by calculating the quantitative stability coefficient of the area under study [14,15]. The four primary types of landslide models include physical model experiments [16], numerical simulations [17,18], statistical models, and data-driven models [11,12]. Physical models require extensive and detailed data to yield reliable results, yet are restricted by size, leading to high financial and computational costs [19,20]. Despite efforts to consider factors such as model similarity ratios, accurately replicating the landslide soil remains challenging [21]. Consequently, physical-based models are presently unsuitable for large-scale landslide risk zoning exercises. Numerical simulation methods can broadly serve as discrete and finite element approaches [22]. In limited element models, accurately computing wave motion caused by landslides using grid-based Eulerian methods necessitates suitable interface tracking techniques, which have limitations in capturing free surfaces exhibiting significant deformations and are computationally time-consuming under practical circumstances. Discrete element methods, such as Particle Flow Code (PFC) [23,24] and MatDEM [25], provide effective means for modeling the movement of granular material (discontinuous models). Nonetheless, discrete element models are computationally demanding. In contrast, data-driven models can accurately determine landslide susceptibility indexes (LSIs) for extensive areas using input-output sampled data [1,13,26]. Consequently, data-driven models are more suitable for large-scale LSP in areas.
Generally, data-driven methodologies can be classified into two categories: methods and machine learning methods [10,27,28]. Considerable efforts have been directed toward the advancement of statistical methodologies to investigate and analyze the intricate relationships between causative factors and the occurrence of landslides [28,29,30,31]. Different statistical methods, such as the frequency ratio [32,33,34], weight of evidence [35,36], fuzzy logic [37,38], logistic regression [39,40], analytic hierarchy process [34,41], and integrated methods [40,42], have been widely implemented to map landslide susceptibility. However, traditional statistical methods fail to effectively model the complex nonlinear relationships between landslides and causative factors.
Machine learning methods, such as the radial basis function network [43,44], back-propagation artificial neural network [5,45], support vector machine [6,46], and random forest [47,48], are currently applied to increase the ability to handle multiple conditioning factors and improve the LSM accuracy. Recently, machine learning (ML) methods have proven more effective in identifying the relationships between hazards and causative factors than traditional methods or multi-criteria decision-making (MCDM) techniques [49]. However, conventional ML methods have certain limitations when directly classifying natural hazard data and elucidating the hidden relationships within data. These limitations hinder the improvement of the classification accuracy [50]. Indeed, these conventional and machine learning methods have several disadvantages: (1) Limited in their ability to comprehensively explore the linear and non-linear correlations among input variables, preventing the extraction of their inherent and deep features; (2) limited model training times and unstable convergence impede the local optimum, overfitting, and model parameter determination [49]; (3) a substantial amount of prior knowledge, such as labels, is required for feature learning and the models cannot automatically learn features from big data. Hence, developing a novel machine-learning method for landslide susceptibility prediction is essential.
More recently, deep learning algorithms have led to a series of breakthroughs in machine learning. That is, the emergence of deep learning has shown great promise in addressing these issues. Knowledge has demonstrated its ability to effectively tackle specific problems and surpass the performance of conventional ML approaches [51]. Compared to traditional machine learning methods, the CNN framework—a deep learning representative—incorporates convolutional and subsampling layers. Notably, these layers reduce parameter requirements, facilitating more efficient exploration of relationships within the data. As a result, deep learning algorithms that integrate CNNs have demonstrated superior performance compared to traditional machine learning techniques across various applications. Significantly, through extensive training on substantial datasets, deep learning models have exhibited superior capabilities in terms of power and accuracy. This enhanced performance enables the gradual acquisition of high-level features from complex data, employing an incremental learning approach. Geoscience classification tasks, such as flood and landslide susceptibility assessment, have greatly benefited from this approach, as evidenced by various studies [52,53]. Nevertheless, it is crucial to acknowledge the complexities that arise from the nature of landslide conditioning factors and their spatial variations within different study areas. Consequently, the ultimate robustness of landslide susceptibility mapping (LSM) constructed by a single machine learning or deep learning method has not been realized [29,47,54]. It is, therefore, essential to compare different machine learning methods to achieve optimal LSM results for a given set of environmental characteristics.
With the development of new remote sensing technologies, such as InSAR and photogrammetry, unique technical support has been provided for research. Synthetic aperture radar (SAR) is an active sensor with all-weather and all-day observation characteristics. Hence, the D-InSAR technology derived from SAR can effectively detect ground deformation information without being affected by weather. However, factors such as atmospheric delay and spatiotemporal decorrelation limit its application. To overcome these issues, [55] of Milan Polytechnic University in Italy proposed the permanent scatterer InSAR (PS-InSAR) technology, serving as the prelude to time-series SAR technology research. InSAR (interferometric synthetic aperture radar) techniques, including PS-InSAR (persistent scatterer interferometry), SqueeSAR (small baseline subset), and SBAS (small baseline subset) [55,56], have been widely employed in landslide identification and monitoring. These methods have proven effective by numerous research groups in measuring spatiotemporal deformation [57,58,59,60,61,62].
This study implemented a hybrid approach combining CNN deep learning and traditional learning techniques to generate accurate landslide susceptibility maps. The performance evaluation encompassed eight distinct models, with a meticulous comparison conducted. Furthermore, the deformation monitoring of selected representative landslides was successfully carried out by integrating InSAR data. Indeed, integrating data-driven spatial prediction for landslides with deformation monitoring remains an area of research that has yet to be fully achieved. As such, the findings obtained from this investigation provide valuable insights for researchers assessing the effective utility of these two models in developing susceptibility maps for natural hazards, particularly in the domain of landslide susceptibility mapping.
In this study, a comprehensive LSM assessment was conducted for Shiyan City, China, using eight data-driven methods, including statistical and machine learning methods. First, an overview of the study area is introduced in Section 2. Next, various statistical and machine learning methods, namely, information quantity, frequency ratio, logistic regression, artificial neural network (ANN), random forest, support vector machine, and convolutional neural network (CNN) methods, are introduced in Section 3. The method of assessing LSM and the methodological flowchart is also presented in this section. Furthermore, causal factor selection is performed in Section 4 using different sensitivity analysis methods, laying the foundation for constructing LSMs. Section 5 illustrates the parameter determination and modeling process of machine learning, followed by a comprehensive discussion of LSM in Section 6. Finally, we conclude the article in Section 7.
2. Study Area
The study area, Shiyan city, China, is located northwest of Hubei Province, east of Qinba mountain. The geographical location is shown in Figure 1, situated between longitudes ranging from 109°29′ to 111°16′E and latitudes from 31°30′ to 33°16′N, encompassing a total area of approximately 23,680 km2. The region’s elevation varies from 78 m above sea level at the river valley to a maximum of 2715 m at the highest peak. The terrain exhibits a distinctive topographic pattern, featuring a low northwest-oriented trend and a contrasting high southeast-oriented trend (Figure 1b).
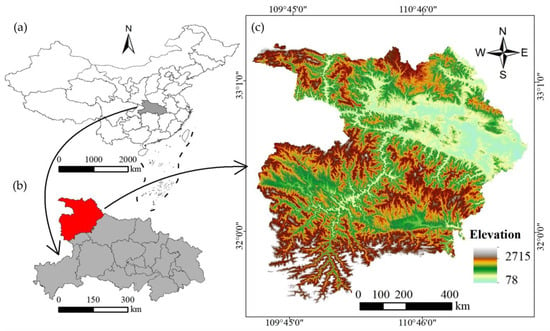
Figure 1.
Location and landslide distribution of the study area: (a) location in China; (b) location in Hubei Province; (c) location and landslide distribution in Shiyan city.
Geologically, the topography of Shiyan City is controlled by geological structure and lithology. As a result of long-term denudation and river cutting, three landforms have been formed in this area: tectonically denudated low mountain and hilly terrain, tectonically denudated soft mid-mountain terrain, and erosive accumulation terrain. The study area is located in the third uplift zone of the Neocaysian system, belonging to the Wudang Shanzan anticline and part of the Yunyun-Wudang Shanzan and Wudang Shanzan anticlines of the Qinling fold system. The strata series are exposed from the Proterozoic to the Cenozoic, including the Sinian, Cambrian, Cambrian-Ordovician Zhushan Formation, Silurian, and other meso-low metamorphic rocks, overlying the late Cretaceous-Cenozoic Quaternary clastic accumulation. The rock mass of Shiyan City is divided into five groups of engineering geological rocks: loose soil, stratified clastic rock, stratified karst carbonate rock, stratified metamorphic rock, and massive magmatic rock.
Regarding meteorological hydrology, Shiyan City experiences a subtropical monsoon climate characterized by an annual average temperature of 15.4 °C and average precipitation of 769.6 mm. The rainfall is primarily concentrated from June to September, with up to 456 mm of precipitation, accounting for 59.2% of the annual rainfall. There are 2489 rivers and valleys in Shiyan City, including the Du River, with a total length of 338.6 km and rainfall area of 12,431 km2, second only to the Qingjiang River among the small and medium-sized rivers in Hubei Province. The Han River is the transfer river of Shiyan City, flowing through Yunxi, Yun County, and Danjiangkou City, and is 216 km long.
In summary, the lithological strength of the study area is weak, the geological engineering conditions are poor, and the landslide-prone regions are widely distributed. According to the Hubei Geological Disaster Prevention Center survey, 5328 landslides occurred in Shiyan City from 2001 to 2017. Due to the intense tectonic movement in the area, metamorphic rocks are widely distributed, accounting for more than 60% of the city area. Situated amidst the Qingfeng fault zone, the study area exhibits a distinctive geomorphological context characterized as an intermountain valley featuring a denudation low mountain and hilly landform. The micro-geomorphology is predominantly characterized by hillside and gully formations. The region’s topography presents a notable pattern, with higher elevations in the east and north–south directions. Lower elevations are prevalent in the area’s west and central portions. From new to old, the outcrop beds within the territory are primarily Quaternary, Doushantuo Formation, Yaolinghe Group, and Proterozoic Wudang Mountain Group, accompanied by magmatic intrusion. Reservoir level fluctuation, rainfall, and human engineering activities are important trigger factors of landslides. For example, the Fuxi landslide was caused by heavy rainfall decline and human engineering activities (Figure 2), while the Lijiaping landslide was caused by continuous rainfall (Figure 3).

Figure 2.
Panoramic view of the Fuxi landslide and destruction pattern.

Figure 3.
Panoramic view of the Lijiaping landslide and destruction pattern.
3. Methodologies
3.1. Landslide Susceptibility Mapping
This study employed a diverse range of statistical analysis methods to delineate landslides’ susceptibility accurately. These methods encompassed information quantity (IQ), frequency ratio (FR), and logistic regression (LR). Complementing these techniques, advanced machine learning, such as ANN, random forest (RF), support vector machine (SVM), and CNN were also leveraged to achieve robust results.
3.1.1. Statistical Analysis Methods
- (a)
- Information quantity (IQ)
The IQ method is a mathematical statistical analysis based on the information theory. The landslide geological hazard phenomenon (I) is affected by various disaster-causing factor combinations, which are determined as follows:
In this context, I(xi, H) denotes the information measure associated with a specific disaster-causing factor in relation to landslide occurrence. S represents the overall count of evaluation units within the study area, while Si signifies the number of units encompassing the hazard factor under consideration. N represents the collective information content pertaining to landslide occurrence, as contributed by combinations of factors. Furthermore, Ni denotes the total count of units encompassing the distribution of landslide geological hazards within the study area.
- (b)
- Frequency ratio (FR)
The FR method is specifically formulated for analyzing the distribution and occurrence of landslides across the entirety of the study area, and is the ratio of the landslide area within a specific attribute interval to the whole study area. The contribution set of all indicator factors is the landslide susceptibility index (LSI), and its calculated as follows:
where Si is the area of the landslide within the classification, and S is the area within the category. In the research domain, Ai pertains to the extent of landslide occurrence within the designated study area, while A refers to the encompassing geographic region under comprehensive investigation. Ai is the total landslide area in the study area, and A is the comprehensive study area. However, the LSI lacks the inherent capacity to quantitatively measure the individual contributions of each influencing factor to the probability of landslides [63,64].
- (c)
- Logistic regression (LR)
The LR method is a well-established multivariate statistical analysis test utilized when the dependent variables are discrete or categorical. When applied to landslide susceptibility modeling (LSM), the primary objective of LR is to accurately quantify and describe the relationship between the probability of landslide occurrence and its various contributing factors. However, the LR model exhibits certain limitations when analyzing the impact of environmental factors at different hierarchy levels on landslide occurrence.
A logistic function for multivariate logistic regression can be written as
where p denotes the occurrence probability (0 or 1 in this paper), x is each evaluation factor in the landslide susceptibility evaluation index system, β0 is the intercept, and βi (i = 1, 2, …, n) denotes the LR coefficients.
3.1.2. Machine Learning Methods
- (a)
- Artificial neural network (ANN)
The supervised machine learning algorithm, ANN, was utilized in this study for predictive modeling guided by human perception [6]. This technique offers distinct advantages over traditional methods, such as IQ, FR, and LR, as it obviates the necessity for direct rule-based estimations of desired outcomes. The architecture of the hybrid ANN model employed in this research is exemplified in Figure 4. The neural network architecture includes three distinct layers. The input layer represents the research scope’s conditioning factors related to landslides. The hidden layer comprises individual neurons that generate landslide susceptibility class labels in the output layer. Lastly, the output layer indicates the class labels for landslides and non-landslides. Following the determination of the optimal number of hidden layers and processing units within each layer, the ANN initiates the learning process by analyzing the training samples [10].
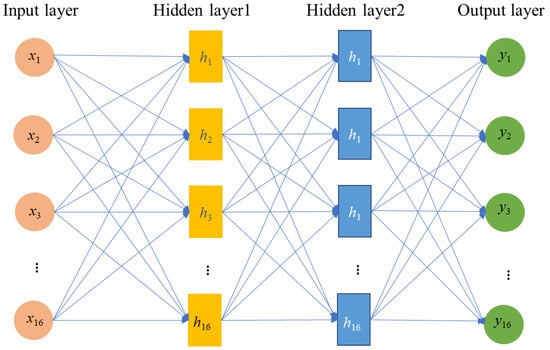
Figure 4.
Structure of the hybrid modeling process of the ANN architecture.
In our study, the neural network architecture employs radial basis function (RBF-ANN) and backpropagation (BP-ANN) strategies. RBF-ANN is a feedforward ANN multidimensional spatial interpolation technique. The input layer maps the vector directly to the hidden space and transmits the signal. The hidden layer facilitates the non-linear mapping of the network input using the radial basis function. Its radial symmetry, bilateral decay, and non-negativity characterize this function, making it an appropriate choice for capturing complex relationships within the network. Meanwhile, the BP-ANN employs an initial configuration of random connection weights within the network. This configuration is then trained using a set of stimulus couples referred to as learning examples. Each learning example comprises an input to the network and the corresponding expected output, enabling the network to adjust its weights and optimize its performance gradually. The optimal weight is obtained by iteratively solving for the minimum error between the training sample’s actual value and the method’s predicted value [5].
- (b)
- Random forest (RF)
The RF method is a relatively effective regression and unsupervised learning method [47,48] containing several categories for prediction. The category tree is generated randomly using “bagging” to create multiple independent training sets. Noticeably, these trees must be random and diverse. On the one hand, random trees can improve classification numbers. On the other hand, the diversity between the classification numbers can be increased by resampling the data with substitutions and randomly changing the set of predicted variables during different tree combinations. Generally, the RF method has good prediction performance and can be eliminated by summarizing many classification numbers. It has advantages in processing a large amount of data calculation, strong robustness, and the ability to identify outliers. This study used a selection of samples representing landslide and nonlandslide events to construct the classification tree. As part of the methodology, 30% of the samples were withheld from the training process, while a predetermined value of 500 nodes was established as the desired configuration.
- (c)
- Support vector machine (SVM)
The SVM is a powerful statistical learning algorithm renowned for its resilience. It is founded on structural risk minimization, facilitating the resolution of constrained optimization problems and ultimately generating an optimal solution. To achieve training and accurate classification outcomes in SVMs, an appropriate kernel function must be carefully selected [27]. SVMs commonly employ four distinct kernel function groups: the linear kernel (LN), polynomial kernel (PL), Gaussian radial basis function (Gaussian RBF) kernel, and sigmoid kernel (SIG). Each kernel function serves a specific purpose within the SVM modeling framework and contributes differently to the overall effectiveness of the classification process. In this study, RBF and SIG were adopted. The “Kernlab” package was used in R 3.0.2 for LSM. For Gaussian RBF, the parameters to be optimized included the penalty (C) and RBF kernel function parameter (gamma), which were set in the interval range of [0.1, 10] and searched with a step interval of 0.1. The default R2 was chosen as the scoring strategy, and a higher cross-validation score indicated better results. However, in practical application, R2 is greatly affected by the disunity of factor dimensions, and the selection of hyperparameters directly affects the accuracy and generalization ability of the model [3,6,39,49].
The regression function of SVM is:
where C is the penalty and relaxation factors and b is the offset. Finally, the Lagrange multiplier is used, and Wolf duality theory is applied to transform it into the following equivalent duality problem:
The SVM regression prediction model obtained through quadratic programming is:
- (d)
- Convolutional neural network (CNN)
The CNN method is a specific instance of deep learning that can automatically extract valuable features through hierarchical neural networks [51]. Figure 5 presents an overarching depiction of the architecture employed in CNN. The architectural framework encompasses one or more convolutional layers, pooling layers, and a series of fully connected layers, all seamlessly integrated within the network structure.
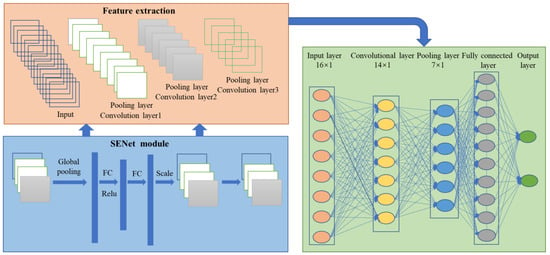
Figure 5.
Structure of the hybrid modelling process of the CNN architecture.
The output of the convolutional manipulation is defined as follows:
where f represents a nonlinear activation function, * denotes the convolutional operator, k is the number of convolutional kernels, and wj and bj denote the weight and bias, respectively.
The convolutional layer plays a crucial role in capturing distinctive representations in the input data by proficiently utilizing a diverse ensemble of convolutional kernels. Subsequently, the pooling (subsampling) operation is conventionally applied after the convolutional layer to reduce the dimensionality of feature vectors and mitigate concerns associated with overfitting. The subsequent step entails the reorganization of the extracted feature vectors through fully connected layers to generate the final output. To acquire an enhanced comprehension of the implementation of CNNs in relation to particular phenomena, various academic publications [47,51] offer exhaustive elucidations. In the context of the current investigation, the classification issue encompasses two distinct classes, resulting in an output size of two. The configuration of the CNN architecture, including the quantity of convolutional layers, pooling operations, and fully connected layers, can be tailored according to user-defined specifications and requirements. Increasing the number of layers can lead to a more complex network, facilitating the extraction of discernible features from the input image. However, CNN requires considerable computational resources and entails significant investment during the training and utilization stages. Moreover, CNN may not attain optimal performance when applied to small-scale image datasets. Consequently, researchers and practitioners should exercise caution when contemplating the implementation of CNN.
3.1.3. Time-Series InSAR Process
The SBAS-InSAR (small baseline subsets InSAR) methodology involves the usage of multiple differential interferogram sets. These sets comprise interferogram pairs with time and spatial baselines that meet the criterion of being below a specified threshold. Through this approach, the differential phase sequence of coherent pixels is over a specific timeframe, enabling the quantification of their temporal deformation. This methodology’s fundamental principle relies on acquiring coherent images demonstrating minimal material discrepancies and possessing short perpendicular baselines. The observed phase variation within these readable images indicates the disparity in the round-trip distance between the sensor and the target under surveillance.
Let , , , , and denote the specific phase components that are intrinsically linked to ground deformation, topographic error, atmospheric disturbance, inaccurate orbit information, and other sources of noise, respectively. Spatial and temporal filtering techniques can be deployed to effectively disentangle the ground deformation phase to mitigate the influence of other coexisting phase components. By implementing singular value decomposition and employing the minimum norm criterion, the estimation of deformation rates can be achieved, facilitating the derivation of time-series deformation products characterized by secular rates and cumulative displacement time series [56,59].
The Sentinel-1 synthetic aperture radar, launched in 2014, comprises a pair of near-polar orbit satellites outfitted with C-band SAR sensors and a revisit time of 12 days for each satellite, ensuring a continuous coverage interval between satellite pairs [65]. A large-scale surface deformation map can be drawn by interpreting SAR images, and surface deformation at different periods can be obtained. Accordingly, this study collected 16 ascending Sentinel-1 images from November 2020 to March 2023 (Figure 6).
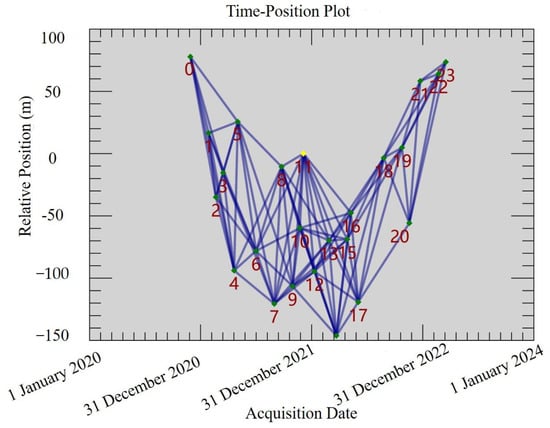
Figure 6.
The time distribution of Sentinel-1 imagery.
The processing methodology for radar imagery employing MT-InSAR comprises two essential stages: interferogram generation and time-series analysis. This investigation established well-defined thresholds for the time and perpendicular baselines set at 90 days and 1000 m, respectively. Subsequently, the MT-InSAR analysis was executed using the SBAS-InSAR module integrated within the StaMPS v.1, facilitating the derivation of time-series displacement and velocity parameters. We have chosen monitoring targets with a coherence value surpassing the 0.6 threshold [60,61]. Upon observing the study area’s predominant north–south orientation, it became apparent that the sensitivity of InSAR technology toward this particular direction was relatively variable. Consequently, the line of sight (LOS) measurement value was adopted rather than the downslope projection of LOS velocity, aligning with the recommendations articulated in previous reports [66,67,68].
3.2. Modelling Prediction and Performance
The ROC graph combined with a contingency table with skill score is a helpful tool for evaluating the reliability of rainfall-induced landslide thresholds [9]. The main concept is based on demarcation value or decision threshold, with the true positive rate sensitivity as the ordinate and the false-positive rate as the abscissa.
The contingency table defines the four following conditions. True rainfall conditions are above the threshold, and landslides occurred. True negative (TN) rainfall conditions are below the threshold, and no landslides occurred. False positive (FP) rainfall conditions are above the threshold, but no landslide occurred. False negative (FN) rainfall conditions are below the threshold, but landslides occurred [9]. From the contingency values, one can calculate the probability of detection (POD), probability of false detection (POFD), probability of false alarm (POFA), efficiency (Ef) of prediction, Hanssen and Kuipers (1965) (HK) skill score, and threat score (TS). The formulation is listed in Table 1.

Table 1.
Skill scores based on the contingencies used for threshold validation.
Sensitivity, also called recall, denotes the ability to maximize a model to identify all relevant cases in a dataset,
SPE is the number of no landslides correctly classified as nonlandslides and is calculated as follows:
ACC is employed to analyze the confusion matrix, providing a comprehensive assessment of the correct predictions relative to the total number of predictions made. This value varies between 0, indicating no accurate predictions, and 1, representing 100% accuracy with no prediction errors. The formula for ACC is:
The F1-measure is a metric that represents the weighted harmonic mean of precision (P = TP/(TP + FP)) and sensitivity and is calculated as follows:
The Jaccard coefficient represents a quantitative measure that captures the count of true positives among a group of samples classified as accurate or optimistic predictions. This coefficient is alternatively known as the threat score or critical success index. This formula for this coefficient is
The MCC comprehensively captures the complete dataset within a confusion matrix, where its numerical values range from −1 (indicating incorrect classification) to 1 (representing precise classification); it is calculated as follows:
The RMSE, MSE, MAE, MAPE, and SSE are defined as
where Xact and Xpred are the predicted and observed values, respectively, and N is the number of data points.
The area under the curve (AUC) is a quantitative measure that provides insights into the predictive efficacy of various methods by encompassing the performance across all conceivable decision boundaries and encompassing the entire range of possible classification thresholds. The formula for AUC is
where Sp is the sum of all ranked landslides and Np and Nn are the numbers of landslide (positive) and nonlandslide (negative) samples, respectively.
3.3. Methodological Flowchart
The overall study procedure is shown in Figure 7, including five basic steps to build the LSM. This study primarily included (i) Sentinel-1 datasets, (ii) co-registration, (iii) times-series InSAR process, (iv) land subsidence inventory map, and (v) classification data. The geological survey report was provided by the Hubei province geological environment geological survey of China geological survey station survey. The remote sensing images were visually interpreted via Google Earth (https://www.google//, accessed on 1 September 2020) combined with digital elevation model (DEM) data from 2019. The survey reports offer in-depth information pertaining to various landslide attributes, including their precise location, area, and volume, among other relevant parameters. This facilitates the creation of a specialized geographic information system (GIS)-based database for efficient storage and processing of the collected data. Furthermore, the acquired data was seamlessly integrated into the landslide distribution analysis within the ArcGIS platform.
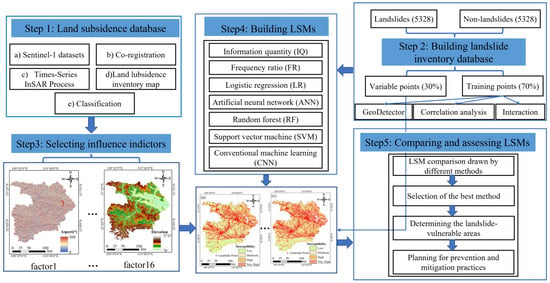
Figure 7.
Methodological flowchart used in this study.
Subsequently, the process of compiling a comprehensive inventory map of landslides entailed the identification of landslide and nonlandslide points. The dataset encompassing this inventory was subsequently partitioned, reserving 70% for training while allocating the remaining 30% for test samples. Next, the K-means clustering method was deployed to selectively identify and include additional training samples from areas with relatively lower risk to enrich the dataset. These newly identified samples were combined with the original training dataset, serving as input for the machine learning model’s training process. The conditioning factors for landslide occurrence were meticulously determined based on the unique characteristics inherent to the study area. In the fourth step, the LSM was constructed, adopting a wide array of data-driven methodologies. Finally, a rigorous quantitative comparison was conducted to evaluate and juxtapose the LSM outcomes garnered through diverse methods.
4. Selection of Causal Factors
4.1. Landslide Inventory Map
Landslide cataloging forms the fundamental basis of LSM. The attainment of precise and dependable landslide cataloging data is critical to ensuring the accuracy of landslide assessments.
In terms of scale, 95% of landslides in Shiyan City are small or medium-sized. They develop primarily in areas with metamorphic rock (e.g., schist, slate, phyllite) along river gullies, fault zones, and traffic arteries. For example, a large fault zone has a controlling role in forming landslides that often occur. In addition, landslide disasters along traffic arteries exhibit a banded distribution due to the influence of various factors, including topography, river systems, and human engineering activities. After conducting meticulous field investigations and rigorous analysis of landslide disasters within the study area, sixteen distinct landslide conditioning factors were identified, including elevation, slope, distance to the river, normalized difference vegetation index (NDVI), and road distance. These factors were extracted from the terrain data to establish a comprehensive index system that facilitates the evaluation of landslide susceptibility.
The topography factors included elevation, slope, aspect, relief, stream power index (SPI), sediment transport index (STI), topographical wetness index (TWI), plan, profile, slope length, and ground roughness. The distance to the river, lithology, and distance to the structure were considered hydrological environment and basic geological factors. NDVI was the land cover factor, and distance to the road was the human engineering activity factor. Generally, these factors were divided into discrete and continuous types. Regarding continuous factors, slope, for instance, was carried on a preliminary discretization to obtain the overall distribution curve of slope. It was then discretized again based on the critical value in the curve, combining the effect of landslide development under the same level into the same class.
ArcGIS 10.6 was adopted to construct a landslide database to determine sixteen influencing factors and landslide points. The ESRI file geographic database format extracted these factors. Consequently, to acquire the fundamental environmental factors associated with landslides in Shiyan City, all indicators were transformed into a raster format with a spatial resolution of 30 m × 30 m (Figure 8). The digital elevation model (DEM) dataset, characterized by a 30 m × 30 m grid resolution, was utilized to generate a thematic map encompassing topographic conditioning factors (Figure 8a–e,h). The NDVI thematic map, depicted in Figure 8i, was derived from Landsat-8 OLI images sourced from the online platform (http://www.gscloud.cn/, accessed on Landsat-8). The regional soil map, generated at a 1:200,000 scale, was procured from the Institute of Soil Science (Figure 8j). Additionally, the thematic map of lithology (Figure 8l) was employed. The Local Natural Resources Bureau provided the remaining conditioning factors (Figure 8f,g,k).
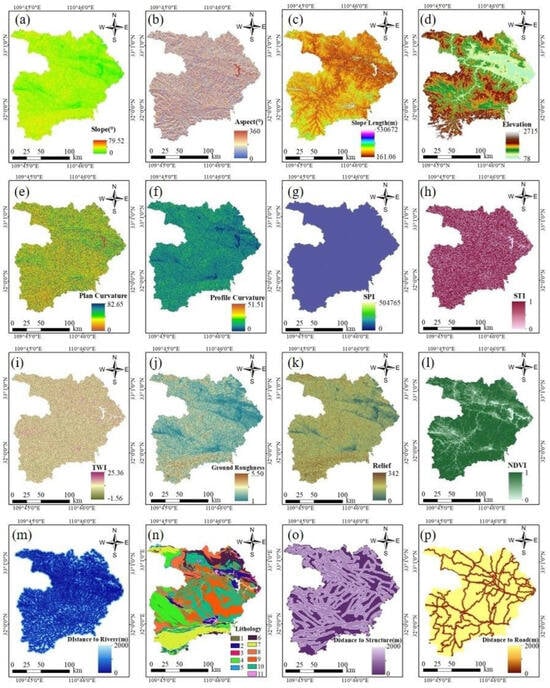
Figure 8.
Landslide factors used in this study. (a) slope, (b) aspect, (c) slope length, (d) elevation, (e) plan curvature, (f) profile curvature, (g) SPI, (h) STI, (i) TWI, (j) ground roughness, (k) relief, (l) NDVI, (m) distance to the river, (n) lithology, (o) distance to structure, (p) distance to road.
The topographical and geomorphological factors are typically considered the key conditional factors in landslide susceptibility mapping. Moreover, including slope is a significant aspect frequently considered when evaluating landslide susceptibility [62]. The slope values observed in the study ranged from 0 to 79.52. Taking the factor of slope as an example, over 80% of the landslide pixels were distributed in the area of 5° to 30° slope terrain (Figure 8a) in Shiyan City.
The elevation of the investigation region was 78–2715 m (Figure 8d). Regarding basic geology, the lithology map (Figure 8n) reveals that Shiyan City primarily comprises Silurian, Devonian, Carboniferous, Permian, Triassic, Jurassic, and Quaternary strata metamorphic rocks. Moreover, the map of distance to the fault (Figure 8o) shows that Shiyan City is in the southern part of the Yangtze platform region, bounded by the Qingfeng fault, belonging to the Qingfengtai fold bundle. Considering the land cover factor presented by the NDVI map (Figure 8i), more than 80% of landslide pixels were in the high vegetation area. The distance from the water system (Figure 8m) and road distance (Figure 8p) were mainly distributed in the ranges of 0 to 400 m and 0 to 600 m, respectively.
4.2. Contribution Analysis of Influencing Factors
A paramount step in constructing an LSM involves evaluating the significance of factors influencing landslide occurrence. Meanwhile, the collinearity between these indicators affects the performance evaluation. Therefore, performing a contribution analysis of influencing factors is necessary to identify correlations between them and avoid inputting landslide indicators with high correlations into the LSM. Various methodologies are available to undertake a quantitative assessment of the predictive capacity of influencing factors. Notably, the information gain ratio approach [5], least support vector machine method [69], Pearson correlation coefficient [18], multicollinearity analysis [31], and GeoDetector [48] are prominent examples. This study adopted Pearson correlation coefficients, multicollinearity analysis, information gain ratio (IGR), and the GeoDetector method to assess the relative importance.
IGR technology (AMIGR) is widely used for variable selection in machine learning [5,70]. To minimize the noise introduced during modeling, it is imperative to eliminate landslide condition factors that exhibit limited or predictive power (Khosravi et al., 2019). IGR can help determine the leading factors and those with little or no influence on the occurrence of landslides. Based on the average optimal value obtained by AMIGR, the ability of each landslide condition factor is listed in Table 2. The “structure” factor had the strongest predictive capacity (AMIGR = 0.673), followed by lithology (AMIGR = 0.575), distance to water (AMIGR = 0.523), elevation (AMIGR = 0.518), and slope angle (AMIGR = 0.453). Meanwhile, STI was excluded from the LSM as its AMIGR value was 0.082.
Table 2.
IGR of environmental factors.
In addition, this study used the interaction detector in GeoDetector to analyze the interactions between elements quantitatively. The outcomes of the factor detector are presented in Table 3. The Q-value signifies the explanatory power of the conditioning factors on landslides and provides an indication of their influence magnitude. Notably, slope exhibited the highest Q-value (Q = 0.745), followed by lithology (Q = 0.672), distance from fault (Q = 0.474), and distance to water (Q = 0.435), underscoring its significant contribution in relation to the landslides studied. Hence, slope exhibited the highest level of explanatory power in relation to landslides. Conversely, STI exhibited the weakest explanatory power, with minimal association between STI and the incidence of landslides within the study area.
Table 3.
Factor detector results.
The Pearson correlation analysis results for the sixteen factors are listed in Table 4. For the benefit of typesetting, the factors in the table are numbered by Arabic numerals, which are in the same order as in Figure 8. According to work by [71], the correlation threshold of the Pearson correlation coefficients between factors was set to 0.7. On this basis, most elements can be regarded as independent. For instance, the correlation between the SPI and road distance was zero. However, the correlation coefficients between STI and TRI and STI and plan curvature were 0.89 and −0.57, showing a relatively high correlation. Based on the coefficient threshold, STI and TRI were excluded from the LSM.
Table 4.
Pearson correlation coefficients between two influencing factors.
Furthermore, the multicollinearity analysis of sixteen selected leading factors using the R program was conducted; the results of the variance enlargement factor (VIF) and tolerance factor (TOL) are listed in Table 5. Referring to the work by [18], VIF > 10 or TOL ≤ 0.1 indicated severe collinearity of environmental factors. The TOL value of slope length was only 0.08, and the VIF value was >10, indicating that this factor should be excluded from the LSM. In addition, the TRI factor was excluded as its VIF value was also >10, which is consistent with the Pearson correlation results.
Table 5.
Multicollinearity of the causal factors (VIF and TOL).
Collectively, STI, plan curvature, TRI, and slope length were excluded based on the results of these four analyses. Therefore, the LSM modeling and analysis presented in the following section are based on the remaining twelve factors.
5. Landslide Susceptibility Modelling
5.1. Parameter Determination of Machine Learning
Following the establishment of the landslide inventory map and the influencing factor maps, the outcomes derived from the FR analysis were employed as input. Subsequently, machine learning techniques were utilized to generate the ultimate landslide susceptibility map (LSM). The study area comprised a total of 2,622,482 cells. Concurrently, the dataset contained 5328 landslides, partitioned into two subsets: 70% were randomly allocated as the training dataset, whereas the remaining 30% were utilized for model validation. While the ratio for splitting the training and validation datasets is customizable, the most commonly employed within the relevant fields is 70% and 30%, respectively [5,18,72].
An equivalent number and proportion of nonlandslide cells were likewise selected and allocated to provide essential insights into unfavorable conditions for landslide incidents. Consequently, during the training phase, the attribute matrix representing the influencing factors associated with these cells was designated as the input data. Conversely, the output data encompassed the probability matrix reflecting the occurrence of landslide events, presented as binary response data in the form of 0 and 1. Analogous configurations were established during the validation stage. The parameter configurations for all machine learning methods in this study can be found in Table 6 and Table 7.
Table 6.
Parameter settings for different methods.
Table 7.
Tuning parameters for the CNN.
5.2. Modelling Process of Machine Learning
The modeling process was executed utilizing the MATLAB 2021, with support vector machines (SVM) serving as a specific exemplification. This iterative process primarily encompassed the sequential execution of the following steps:
- (i)
- The training dataset was imported into the software, where the influence factor values for each unit were derived using the GIS and subsequently fed into the constructed SVM model. The probabilities of landslide occurrences within these units were computed, with all values standardized on a dimensionless scale spanning from 0 to 1.
- (ii)
- The factor values of all identified landslide points, combined with a comparable number of non-landslide points and their respective states (zero denoting non-landslide and one indicating landslide), were amalgamated into a consolidated matrix. This matrix was utilized as input for the MATLAB 2021 to assess the contribution of each factor. Following this analysis, the penalty and RBF kernel parameters were determined as the definitive configuration, documented in Table 6.
- (iii)
- The probability matrix, obtained from step (ii), indicating the likelihood of landslide occurrences, was imported into the SPSS 24.0. The K-means clustering algorithm was employed on the dataset to identify and define the five centroids. Data points near each centroid were subsequently reclassified into their respective groups, with each centroid representing the central focal point of its group. The average value between two adjacent centroids was implemented as the threshold for segregating distinct susceptibility bands, as it effectively discriminated between datasets exhibiting diverse properties. Accordingly, a comprehensive landslide susceptibility map was delineated, effectively partitioning the study area into four discrete susceptibility zones: low, medium, high, and extremely high.
- (iv)
- The model’s effectiveness, as assessed by diverse statistical indicators elucidated in Section 3.2, was substantiated by scrutinizing the spatial distribution of both landslide inventory points and randomly sampled points. This meticulous analysis facilitated a comprehensive assessment of performance relative to alternative methodologies.
6. Discussion and Comparison Analysis
6.1. Factor Effects on Landslides
The FR, LR, and IQ values of each category for the twelve influencing factors are listed in Table 8 and Figure 9. Without loss of generality, the topography factors considered slope, elevation, relief, and surface roughness as examples. Given the factor of the slope, the probability of a landslide was normally distributed with the slope and reached a peak at 20°. When the slope ranged from 10 to 20° and 20 to 30°, the probability of landslides was >0.25, and the FR values were 1.518 and 1.384, respectively. The LR and IQ values also had strong positive correlations. Similarly, the probability of a landslide was normally distributed with elevation. The elevation of Shiyan City was mainly concentrated in the range of 60 to 800 m and the ranges of 0 to 314 m, 314 to 482 m, 482 to 644 m, 644 to 806 m, 806 to 976 m, 976 to 1175 m, and 1175 to 2715 m, while the FR values were 2.12, 1.73, 1.33, 0.82, 0.42, 0.17, and 0.10, respectively. Meanwhile, the relief degree was mainly distributed from 0 to 50 m. The FR values of 0–20 m, 20–30 m, 30–40 m, 40–50 m, 50–60 m, 60–80 m, and 80–342 m were 1.49, 1.32, 0.86, 0.55, 0.36, 0.27, and 0.22, respectively. The corresponding IQ values were 0.58, 0.4, −0.21, −0.87, −1.47, −1.87, and −2.19, respectively. The maximum normalized LR value was 0.392. With an increase in surface roughness, the frequency ratio of landslides decreased, and the FR value of 0–1.05 m was the largest (1.43). The corresponding FR values of 0–1.05 m, 1.05–1.1 m, 1.1–1.15 m, 1.15–1.2 m, and 1.2–5.5 m were 1.43, 1.17, 0.86, 0.51 and 0.34, respectively.
Table 8.
The FR, LR, and IQ values of each category with twelve relative influencing factors.
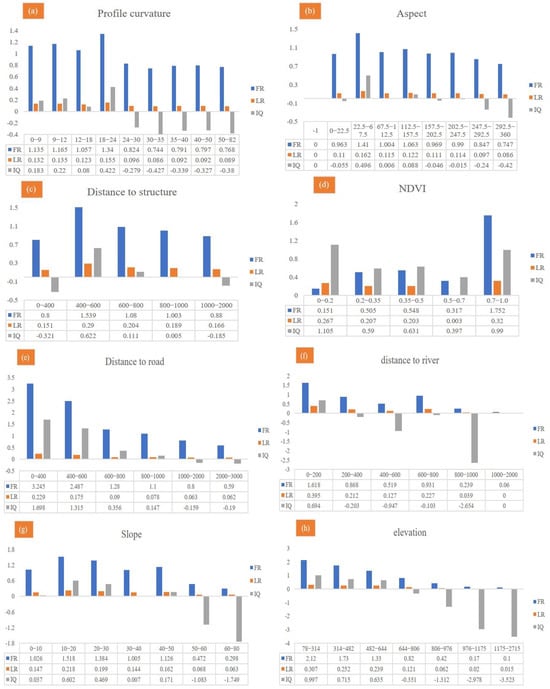
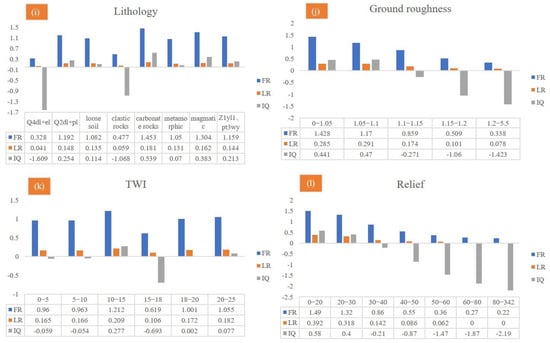
Figure 9.
The FR, LR, and IQ values with twelve relative influencing factors.
The distance from the water system can characterize the influence of the hydrological environment on landslide development. The FR analysis results in Table 8 differed regarding the distance from the river. The area near the river was prone to landslides, and the FR value was higher. The FR values were 1.62, 0.87, 0.52, 0.93, 0.24, and 0.06, corresponding to distances from the river of 0–200 m, 200–400 m, 400–600 m, 600–800 m, 800–1000 m, and 1000–1500 m, respectively, consistent with the results of Dou et al., (2020) [72] and Huang et al., (2020a) [3].
Rock and soil types represented the material basis of the landslide. According to previous studies, a higher FR value represents a larger landslide probability (Wang et al., 2020). The results in Table 8 showed that the occurrence probability of a landslide under a metamorphic rock was as high as 59.3%, with an FR value of 1.453. However, the occurrence probability of landslides under clastic rock conditions was only 29.1%, corresponding to an FR of 1.304. The IQ and LR values under these two lithologies were also positively correlated. Few carbonate rocks were in this area, and their FR value was 0.6. In short, landslides were relatively high in metamorphic and clastic rock areas and relatively low in magmatic rock areas. NDVI can quantitatively estimate vegetation growth and biomass. In this study, when the NDVI value ranged from 0.8 to 1.0, the probability of landslide occurrence was greater, and the FR IQ and normalized LR values were 1.75, 0.99, and 0.32, respectively. The maximum FR value occurred at a 0–400 m distance from the road with a value of 3.25.
6.2. Landslide Susceptibility Mapping
To conduct a comprehensive comparative analysis, Figure 9 presents graphical depictions of eight distinct landslide susceptibility maps created using the IQ, FR, LR, RBF-ANN, BP-ANN, RF, SVM, and CNN methodologies. Each map classifies susceptibility into four levels: low, moderate, high, and very high. An intricate evaluation was conducted to determine the proportionate distribution of these susceptibility classes for each respective method. The detailed results of this assessment can be found in Table 9.
Table 9.
Frequency ratio of landslide susceptibility classes using eight methods.
For all LSM results, the high and very high landslide susceptibility areas were mainly distributed on both sides of river gullies, faults, and metamorphic rock areas, which are likely related to structure and lithology. Specifically, LSM results generated by the IQ method (Figure 10a) showed that 16.8% of the area was in the very high class, and 31.2%, 27.9%, and 24.1% were in the high, medium, and low susceptibility classes. The results of the FR method revealed that the percentages from very high to low susceptivity were 34.5%, 32.8%, 23.5.9%, and 9.2%, respectively (Figure 10b). Meanwhile, the LSM results obtained by the LR method were 18.6%, 18.5%, 33.4%, and 29.5%, respectively (Figure 10c). Based on the statistical methods, the percentage of the very high class was approximately 16–35%, among which the proportion determined by the FR was the largest. However, the very high rate of LSM determined by the machine learning methods was smaller than that of the statistical methods. Based on the LSM by RBF-ANN, the model predicted that only 9.8% of the area was at a very high level, and 29.1%, 45.1%, and 15.9% were in the high, medium, and low susceptibility classes, respectively (Figure 10d). Considering the BP-ANN method (Figure 10e), the very high susceptibility zone accounted for 13.1%, while 28%, 36.6%, and 22.3% were assigned to the high, medium, and low landslide susceptibility zones. For the RF method, 18.4% was at a very high level (Figure 10f), while the SVM (Figure 10g) and CNN (Figure 10h) methods identified 16.8% and 10.7% of the area as being very highly susceptible to landslides, respectively. Moreover, the RF method identified 34.9%, 28.2%, and 18.4% of the area as being at high, medium, and low susceptivity levels. In comparison, the SVM method identified 31.3%, 27.9%, and 24.1%, and the CNN case classified 26.5%, 33.4%, and 29.5% of the area as having high, medium, and low susceptibly, respectively. For the RF method, 18.4% was at a very high level (Figure 10f). The SVM (Figure 10g) and CNN (Figure 10h) methods identified 16.8% and 10.7% of the area as highly susceptible to landslides, respectively. Moreover, the RF method identified 34.9%, 28.2%, and 18.4% of the area as being at high, medium, and low susceptivity levels. In comparison, the SVM method identified 31.3%, 27.9%, and 24.1%, and the CNN case classified 26.5%, 33.4%, and 29.5% of the area as having high, medium, and low susceptibility.
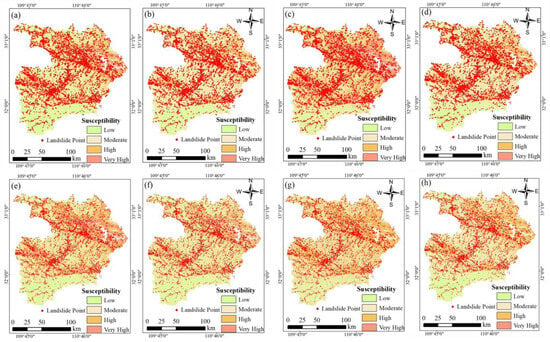
Figure 10.
LSM results by the (a) IQ, (b) FR, (c) LR, (d) RBF-ANN, (e) BP-ANN, (f) RF, (g) SVM, and (h) CNN methods.
The frequency values of all examined methods were <1.0 for low susceptibility levels (Table 9 and Figure 11). However, the frequency values increased sharply from moderate to very high susceptibility levels. Although IQ and LR are two different methods, the data laws of the contribution degree for each index factor classification in Table 9 were relatively the same, and the results of landslide susceptibility prediction were also similar. The frequency values of the five methods representing the higher level were 3.838 (CNN), 2.745 (SVM), 2.429 (RF), 2.322 (BP-ANN), and 2.294 (RBF-ANN), approximately four times the moderate and low susceptibility levels. Hence, with increased landslide sensitivity, the distribution of landslide pixels gradually concentrated. Among them, the CNN method had the best performance, demonstrated by the largest frequency value for very high and high sensitivity levels and the smallest frequency at low sensitivity. Thus, in the LSM drawn by the CNN method, the increased susceptibility area had the largest degree of landslide concentration, while fewer landslides were incorrectly classified as low susceptibility areas.
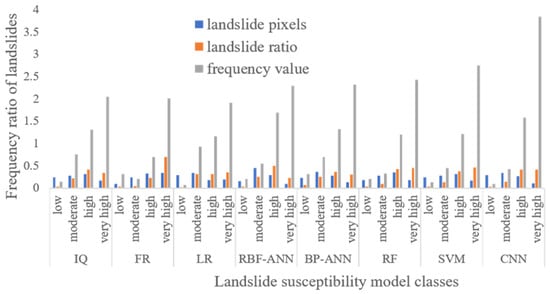
Figure 11.
Frequency ratio of landslide susceptibility classes using statistical and machine learning methods.
6.3. Accuracy Assessment and Comparison
This section adopted statistical metrics to assess and compare the accuracy of different methods. Table 10 lists the statistical results of the training and test datasets of the machine learning methods. The definitions and calculations of these statistical indices are addressed in Section 3.2.
Table 10.
Accuracy comparison of training and test datasets for different machine learning methods.
Among the five machine learning methods, CNN was the best based on the performance of training datasets, followed by the RF, SVM, and BP-ANN methods; the worst was RBF-ANN. The CNN method had the largest sensitivity (0.987), indicating that it could correctly classify 98.7% of landslide pixels as a landslide. The RF method had a slightly lower sensitivity (0.959). Considering the sensitivity of the test datasets, CNN also had the highest accuracy (0.985), followed by SVM (0.946), BP-ANN (0.942), RBF-ANN (0.927), and RF (0.919). For the F1-measure of the test datasets, the largest value was obtained for CNN (0.987), followed by SVM (0.940), RF (0.953), BP-ANN (0.953), and RBF-ANN (0.926). Regarding the other indices in Table 10, including SPE, ACC, and Jaccard, the performance order varied according to indicators. Overall, the CNN method was the best, and the BP-ANN or RBF-ANN methods were the worst.
The ROC curves of the eight methods were also calculated and compared in Figure 12. Interestingly, according to the AUC, the ROC curves differed for the various methods. Overall, the AUC values for the machine learning methods were larger than those for the traditional methods. For the five machine learning methods, the AUC values from largest to smallest were 95.7% (CNN), 94.8% (SVM), 93.2% (RF), 91.6% (RBF-ANN), and 89.5% (BP-ANN). All were > 70%, indicating that all LSMs drawn by machine learning methods exhibited sufficient performance.
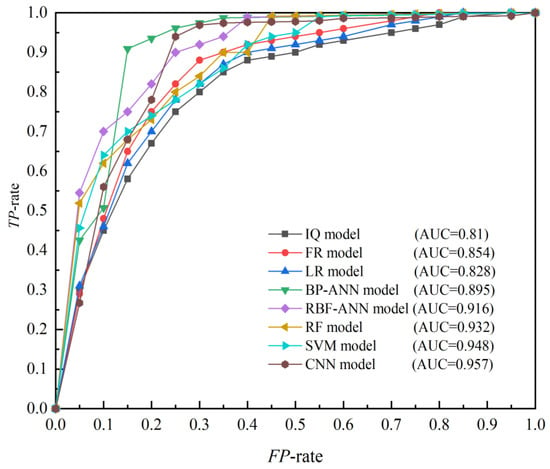
Figure 12.
ROC curves for the statistical and machine learning methods using the training dataset.
Moreover, MCC and RMSE are critical additional evaluation criteria, as a high AUC value does not invariably translate to high accuracy in spatial predictions. By computing the RMSE values for the five employed machine learning methods, a degree of alignment with the analysis conducted using other performance indicators was observed. The calculated RMSE values spanned from 0.076 to 0.469, further substantiating the reliability and coherence of the assessment. It revealed that CNN performed the best, followed by SVM and RF methods.
6.4. Typical Landslide Deformation Analysis
As an economically effective monitoring method, InSAR technology has been widely used in the deformation monitoring of landslides. To further analyze the deformation characteristics of typical landslides in high-risk areas, 16 sets of Sentinel-1 radar images from November 2020 to March 2023 were selected (the less coherent image was eliminated), and SBAS-InSAR technology was applied to extract the displacement time series of the landslide and project it onto the main sliding direction of the landslide. According to the SBAS-InSAR interpretation results in Figure 13, the landslide is in a continuous deformation state, and the annual deformation rate of most feature points is as high as 90 mm/year. Further field investigations of the landslide revealed that certain severe deformation points were consistent with the field survey, with the roads and houses on the landslide severely damaged. Time-series analysis of typical feature points revealed that they are in continuous deformation. Among them, PS2 exhibits the most serious deformation, reaching 30 mm during the interpretation period. Meanwhile, this feature point exhibited some rebound deformation during March 2022, which may be caused by the bulging of the frontal edge of the landslide due to continuous deformation [59,66]. The results obtained from the susceptibility assessment technique facilitated the classification of the spatial extent of the landslide. Using InSAR technology to monitor landslides without surface monitoring conditions has important implications for deformation warnings.
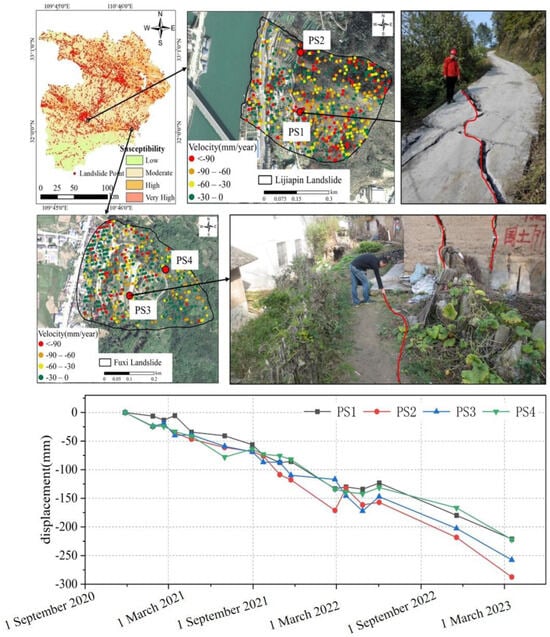
Figure 13.
InSAR deformation results for typical landslide.
7. Conclusions
This paper presents the realization of dynamic landslide hazard mapping by integrating spatio-temporal probability analysis with the time-varying deformation velocity of the ground, obtained using the MT-InSAR method. LSMs that can be relied upon are crucial resources for risk managers and governmental authorities in effectively mitigating landslide hazards. The LSMs of Shiyan City, China, were first drawn using different data-driven methods, including IQ, FR, LR, ANN, RF, SVM, and CNN. The database included 5328 landslide and 5328 nonlandslide points and was randomly divided into 70% training and 30% test samples. The main conclusions are as follows:
- (1)
- By remote sensing images and field investigations, sixteen landslide influencing factors, including topographical, hydrological environment, basic geological, and human engineering activity factors, were considered to construct the landslide inventory map. Additionally, different sensitivity analysis methods, such as Pearson correlation analysis, multicollinearity analysis, information gain ratio, and GeoDetector, were used to determine the importance of these factors to landslides. The results identified STI, plan curvature, TRI, and slope length as factors to be excluded when drawing LSMs.
- (2)
- The LSM results by different methods demonstrated that the material basis and internal geological conditions of landslide development were mainly affected by internal factors such as slope structure (along slope), fault distance (<200 m), formation lithology, and slope degree (6°, 20°). For external factors, landslide occurrence was primarily affected by water distance (<200 m) and road distance (<50 m). Moreover, the comparison of frequency values showed that the CNN method had the best performance, supported by the highest frequency at very high and highly sensitive levels and the lowest frequency at low sensitivity levels among the different data-driven methods.
- (3)
- By comparing the model performance, it was determined that the training and prediction accuracy of machine learning methods was higher than that of the statistical methods. For example, the AUC values for the IQ, FR, LR, BP-ANN, RBF-ANN, RF, SVM, and CNN methods were 0.810, 0.854, 0.828, 0.895, 0.916, 0.932, 0.948, and 0.957, respectively. For the F1-measure of test datasets for different machine learning methods, the largest value was for CNN (0.987), followed by SVM (0.940), RF (0.953), BP-ANN (0.953), and RBF-ANN (0.926). Given other statistical indicators, such as SPE, ACC, and Jaccard, although the performance order varied according to indicators, overall, the CNN method was the best, and the BP-ANN and RBF-ANN methods were the worst. This indicates that CNN has better nonlinear predictive ability than the traditional statistical model. When the nonlinear relationship between landslides and their influencing factors is more complex, the advantage of CNN will be more apparent.
These findings demonstrate the importance of InSAR ground deformation measurements in the context of dynamic landslide hazard mapping. This technique proves instrumental in accurately delineating the boundaries of significant landslides, such as the Fuxi and Lijiaping landslides. The process of landslide hazard mapping necessitates the mitigation of false positive and false negative errors. By computing the deformation velocity, the accuracy of the preliminary disaster map and field survey outcomes can be effectively improved, rectifying erroneous assessments. Integrating ground velocities over a temporal dimension facilitates a more precise mapping of dynamic landslide hazards.
Author Contributions
Y.S. and Y.L. organized the data and wrote the paper; G.X. and W.C. analyzed and processed the data; B.J. and C.Z. supervised and reviewed the work. All authors have read and agreed to the published version of the manuscript.
Funding
The authors would like to acknowledge the financial support provided by the Key Research and Development Project of Hubei Province (No. 2021BCA219), supported by key research and development program of Hubei province (No. 2021BID009), Science and Technology Project of Hubei Provincial Department of Natural Resources (Grant No. ZRZY2022KJ17).
Data Availability Statement
Not applicable.
Acknowledgments
We would also like to thank the data support from the Geological Environmental Center of Hubei Province.
Conflicts of Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
References
- Chen, W.; Zhao, X.; Tsangaratos, P.; Shahabi, H.; Ilia, I.; Xue, W.; Wang, X.; Ahmad, B.B. Evaluating the usage of tree-based ensemble methods in groundwater spring potential mapping. J. Hydrol. 2020, 583, 124602. [Google Scholar] [CrossRef]
- Chikalamo, E.E.; Mavrouli, O.C.; Ettema, J.; van Westen, C.J.; Muntohar, A.S.; Mustofa, A. Satellite-derived rainfall thresholds for landslide early warning in Bogowonto Catchment, Central Java, Indonesia. Int. J. Appl. Earth Obs. Geoinf. 2020, 89, 102093. [Google Scholar] [CrossRef]
- Huang, F.; Cao, Z.; Guo, J.; Jiang, S.-H.; Li, S.; Guo, Z. Comparisons of heuristic, general statistical and machine learning models for landslide susceptibility prediction and mapping. Catena 2020, 191, 104580. [Google Scholar] [CrossRef]
- Khosravi, K.; Shahabi, H.; Pham, B.T.; Adamowski, J.; Shirzadi, A.; Pradhan, B.; Dou, J.; Ly, H.-B.; Gróf, G.; Ho, H.L.; et al. A comparative assessment of flood susceptibility modeling using Multi-Criteria Decision-Making Analysis and Machine Learning Methods. J. Hydrol. 2019, 573, 311–323. [Google Scholar] [CrossRef]
- Tien Bui, D.; Hoang, N.D.; Martinez-Alvarez, F.; Ngo, P.T.; Hoa, P.V.; Pham, T.D.; Samui, P.; Costache, R. A novel deep learning neural network approach for predicting flash flood susceptibility: A case study at a high frequency tropical storm area. Sci. Total Environ. 2020, 701, 134413. [Google Scholar] [CrossRef]
- Balogun, A.-L.; Rezaie, F.; Pham, Q.B.; Gigović, L.; Drobnjak, S.; Aina, Y.A.; Panahi, M.; Yekeen, S.T.; Lee, S. Spatial prediction of landslide susceptibility in western Serbia using hybrid support vector regression (SVR) with GWO, BAT and COA algorithms. Geosci. Front. 2021, 12, 101104. [Google Scholar] [CrossRef]
- Cai, H.; Chen, T.; Niu, R.; Plaza, A. Landslide Detection Using Densely Connected Convolutional Networks and Environmental Conditions. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 5235–5247. [Google Scholar] [CrossRef]
- Crawford, M.H.; Crowley, K.; Potter, S.H.; Saunders, W.S.A.; Johnston, D.M. Risk modelling as a tool to support natural hazard risk management in New Zealand local government. Int. J. Disaster Risk Reduct. 2018, 28, 610–619. [Google Scholar] [CrossRef]
- Sheng, Y.; Li, Y.; Xu, G.; Li, Z. Threshold assessment of rainfall-induced landslides in Sangzhi County: Statistical analysis and physical model. Bull. Eng. Geol. Environ. 2022, 81, 388. [Google Scholar] [CrossRef]
- Youssef, A.M.; Pourghasemi, H.R. Landslide susceptibility mapping using machine learning algorithms and comparison of their performance at Abha Basin, Asir Region, Saudi Arabia. Geosci. Front. 2021, 12, 639–655. [Google Scholar] [CrossRef]
- Chang, Z.; Du, Z.; Zhang, F.; Huang, F.; Chen, J.; Li, W.; Guo, Z. Landslide Susceptibility Prediction Based on Remote Sensing Images and GIS: Comparisons of Supervised and Unsupervised Machine Learning Models. Remote Sens. 2020, 12, 502. [Google Scholar] [CrossRef]
- Hamedi, H.; Alesheikh, A.A.; Panahi, M.; Lee, S. Landslide susceptibility mapping using deep learning models in Ardabil province, Iran. Stoch. Environ. Res. Risk Assess. 2022, 36, 4287–4310. [Google Scholar] [CrossRef]
- Aditian, A.; Kubota, T.; Shinohara, Y. Comparison of GIS-based landslide susceptibility models using frequency ratio, logistic regression, and artificial neural network in a tertiary region of Ambon, Indonesia. Geomorphology 2018, 318, 101–111. [Google Scholar] [CrossRef]
- Kim, J.; Lee, K.; Jeong, S.; Kim, G. GIS-based prediction method of landslide susceptibility using a rainfall infiltration-groundwater flow model. Eng. Geol. 2014, 182, 63–78. [Google Scholar] [CrossRef]
- Liu, J.-J.; Liu, J.-C. Integrating deep learning and logging data analytics for lithofacies classification and 3D modeling of tight sandstone reservoirs. Geosci. Front. 2022, 13, 101311. [Google Scholar] [CrossRef]
- Pudasaini, S.P.; Mergili, M. A Multi-Phase Mass Flow Model. J. Geophys. Res. Earth Surf. 2019, 124, 2920–2942. [Google Scholar] [CrossRef]
- Heller, V.; Ruffini, G. A critical review about generic subaerial landslide-tsunami experiments and options for a needed step change. Earth-Sci. Rev. 2023, 242, 104459. [Google Scholar]
- Wang, H.; Jiang, Z.; Xu, W.; Wang, R.; Xie, W. Physical model test on deformation and failure mechanism of deposit landslide under gradient rainfall. Bull. Eng. Geol. Environ. 2022, 81, 02913. [Google Scholar] [CrossRef]
- Miao, F.; Wu, Y.; Li, L.; Tang, H.; Li, Y. Centrifuge model test on the retrogressive landslide subjected to reservoir water level fluctuation. Eng. Geol. 2018, 245, 169–179. [Google Scholar] [CrossRef]
- Miao, F.; Wu, Y.; Török, Á.; Li, L.; Xue, Y. Centrifugal model test on a riverine landslide in the Three Gorges Reservoir induced by rainfall and water level fluctuation. Geosci. Front. 2022, 13, 101378. [Google Scholar] [CrossRef]
- Sulpizio, R.; Castioni, D.; Rodriguez-Sedano, L.A.; Sarocchi, D.; Lucchi, F. The influence of slope-angle ratio on the dynamics of granular flows: Insights from laboratory experiments. Bull. Volcanol. 2016, 78, 77. [Google Scholar] [CrossRef]
- McDougall, S. 2014 Canadian Geotechnical Colloquium: Landslide runout analysis—Current practice and challenges. Can. Geotech. J. 2017, 54, 605–620. [Google Scholar] [CrossRef]
- Li, W.C.; Li, H.J.; Dai, F.C.; Lee, L.M. Discrete element modeling of a rainfall-induced flowslide. Eng. Geol. 2012, 149–150, 22–34. [Google Scholar] [CrossRef]
- Li, Y.; Chen, J.; Yan, J.; Zhou, F.; Wang, Q.; Li, Z.; Zhang, Y. Formation and evolution of a giant old deposit in the First Bend of the Yangtze River on the southeastern margin of the Qinghai-Tibet Plateau. Catena 2022, 213, 106138. [Google Scholar] [CrossRef]
- Zhu, Y.; Liu, C.; Liu, H.; Kou, Y.-D.; Shi, B. A multi-field and fluid–solid coupling method for porous media based on DEM-PNM. Comput. Geotech. 2023, 154, 105118. [Google Scholar] [CrossRef]
- Chen, W.; Li, Y.; Xue, W.; Shahabi, H.; Li, S.; Hong, H.; Wang, X.; Bian, H.; Zhang, S.; Pradhan, B.; et al. Modeling flood susceptibility using data-driven approaches of naive Bayes tree, alternating decision tree, and random forest methods. Sci. Total Environ. 2020, 701, 134979. [Google Scholar] [CrossRef]
- Pham, B.T.; Luu, C.; Phong, T.V.; Trinh, P.T.; Shirzadi, A.; Renoud, S.; Asadi, S.; Le, H.V.; von Meding, J.; Clague, J.J. Can deep learning algorithms outperform benchmark machine learning algorithms in flood susceptibility modeling? J. Hydrol. 2021, 592, 125615. [Google Scholar] [CrossRef]
- Reichenbach, P.; Rossi, M.; Malamud, B.D.; Mihir, M.; Guzzetti, F. A review of statistically-based landslide susceptibility models. Earth-Sci. Rev. 2018, 180, 60–91. [Google Scholar] [CrossRef]
- Ali, S.A.; Parvin, F.; Vojteková, J.; Costache, R.; Linh, N.T.T.; Pham, Q.B.; Vojtek, M.; Gigović, L.; Ahmad, A.; Ghorbani, M.A. GIS-based landslide susceptibility modeling: A comparison between fuzzy multi-criteria and machine learning algorithms. Geosci. Front. 2021, 12, 857–876. [Google Scholar] [CrossRef]
- Galanti, Y.; Barsanti, M.; Cevasco, A.; D’Amato Avanzi, G.; Giannecchini, R. Comparison of statistical methods and multi-time validation for the determination of the shallow landslide rainfall thresholds. Landslides 2018, 15, 937–952. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Gayen, A.; Edalat, M.; Zarafshar, M.; Tiefenbacher, J.P. Is multi-hazard mapping effective in assessing natural hazards and integrated watershed management? Geosci. Front. 2020, 11, 1203–1217. [Google Scholar] [CrossRef]
- Panahi, M.; Gayen, A.; Pourghasemi, H.R.; Rezaie, F.; Lee, S. Spatial prediction of landslide susceptibility using hybrid support vector regression (SVR) and the adaptive neuro-fuzzy inference system (ANFIS) with various metaheuristic algorithms. Sci. Total Environ. 2020, 741, 139937. [Google Scholar] [CrossRef] [PubMed]
- Regmi, A.D.; Devkota, K.C.; Yoshida, K.; Pradhan, B.; Pourghasemi, H.R.; Kumamoto, T.; Akgun, A. Application of frequency ratio, statistical index, and weights-of-evidence models and their comparison in landslide susceptibility mapping in Central Nepal Himalaya. Arab. J. Geosci. 2013, 7, 725–742. [Google Scholar] [CrossRef]
- Schlögel, R.; Marchesini, I.; Alvioli, M.; Reichenbach, P.; Rossi, M.; Malet, J.P. Optimizing landslide susceptibility zonation: Effects of DEM spatial resolution and slope unit delineation on logistic regression models. Geomorphology 2018, 301, 10–20. [Google Scholar] [CrossRef]
- Razavizadeh, S.; Solaimani, K.; Massironi, M.; Kavian, A. Mapping landslide susceptibility with frequency ratio, statistical index, and weights of evidence models: A case study in northern Iran. Environ. Earth Sci. 2017, 76, 499. [Google Scholar] [CrossRef]
- Zhu, A.X.; Miao, Y.; Liu, J.; Bai, S.; Zeng, C.; Ma, T.; Hong, H. A similarity-based approach to sampling absence data for landslide susceptibility mapping using data-driven methods. Catena 2019, 183, 104188. [Google Scholar] [CrossRef]
- Akgun, A.; Sezer, E.A.; Nefeslioglu, H.A.; Gokceoglu, C.; Pradhan, B. An easy-to-use MATLAB program (MamLand) for the assessment of landslide susceptibility using a Mamdani fuzzy algorithm. Comput. Geosci. 2012, 38, 23–34. [Google Scholar] [CrossRef]
- Ozer, B.C.; Mutlu, B.; Nefeslioglu, H.A.; Sezer, E.A.; Rouai, M.; Dekayir, A.; Gokceoglu, C. On the use of hierarchical fuzzy inference systems (HFIS) in expert-based landslide susceptibility mapping: The central part of the Rif Mountains (Morocco). Bull. Eng. Geol. Environ. 2019, 79, 551–568. [Google Scholar] [CrossRef]
- Mandal, K.; Saha, S.; Mandal, S. Applying deep learning and benchmark machine learning algorithms for landslide susceptibility modelling in Rorachu river basin of Sikkim Himalaya, India. Geosci. Front. 2021, 12, 101203. [Google Scholar] [CrossRef]
- Shafizadeh-Moghadam, H.; Valavi, R.; Shahabi, H.; Chapi, K.; Shirzadi, A. Novel forecasting approaches using combination of machine learning and statistical models for flood susceptibility mapping. J. Environ. Manag. 2018, 217, 1–11. [Google Scholar] [CrossRef]
- Zhao, G.; Pang, B.; Xu, Z.; Yue, J.; Tu, T. Mapping flood susceptibility in mountainous areas on a national scale in China. Sci. Total. Environ. 2018, 615, 1133–1142. [Google Scholar] [CrossRef]
- Li, W.; Fang, Z.; Wang, Y. Stacking ensemble of deep learning methods for landslide susceptibility mapping in the Three Gorges Reservoir area, China. Stoch. Environ. Res. Risk Assess. 2021, 36, 2207–2228. [Google Scholar] [CrossRef]
- Bragagnolo, L.; Silva, R.V.d.; Grzybowski, J.M.V. Artificial neural network ensembles applied to the mapping of landslide susceptibility. Catena 2020, 184, 104240. [Google Scholar] [CrossRef]
- Can, A.; Dagdelenler, G.; Ercanoglu, M.; Sonmez, H. Landslide susceptibility mapping at Ovacık-Karabük (Turkey) using different artificial neural network models: Comparison of training algorithms. Bull. Eng. Geol. Environ. 2017, 78, 89–102. [Google Scholar] [CrossRef]
- Sameen, M.I.; Pradhan, B.; Bui, D.T.; Alamri, A.M. Systematic sample subdividing strategy for training landslide susceptibility models. Catena 2020, 187, 104358. [Google Scholar] [CrossRef]
- Oh, H.-J.; Kadavi, P.R.; Lee, C.-W.; Lee, S. Evaluation of landslide susceptibility mapping by evidential belief function, logistic regression and support vector machine models. Geomat. Nat. Hazards Risk 2018, 9, 1053–1070. [Google Scholar] [CrossRef]
- Saha, S.; Saha, A.; Hembram, T.K.; Mandal, K.; Sarkar, R.; Bhardwaj, D. Prediction of spatial landslide susceptibility applying the novel ensembles of CNN, GLM and random forest in the Indian Himalayan region. Stoch. Environ. Res. Risk Assess. 2022, 36, 3597–3616. [Google Scholar] [CrossRef]
- Sun, D.; Shi, S.; Wen, H.; Xu, J.; Zhou, X.; Wu, J. A hybrid optimization method of factor screening predicated on GeoDetector and Random Forest for Landslide Susceptibility Mapping. Geomorphology 2021, 379, 107623. [Google Scholar] [CrossRef]
- Huang, F.; Zhang, J.; Zhou, C.; Wang, Y.; Huang, J.; Zhu, L. A deep learning algorithm using a fully connected sparse autoencoder neural network for landslide susceptibility prediction. Landslides 2019, 17, 217–229. [Google Scholar] [CrossRef]
- Wang, Y.; Fang, Z.; Wang, M.; Peng, L.; Hong, H. Comparative study of landslide susceptibility mapping with different recurrent neural networks. Comput. Geosci. 2020, 138, 104445. [Google Scholar] [CrossRef]
- Sameen, M.I.; Pradhan, B.; Lee, S. Application of convolutional neural networks featuring Bayesian optimization for landslide susceptibility assessment. Catena 2020, 186, 104249. [Google Scholar] [CrossRef]
- Achour, Y.; Pourghasemi, H.R. How do machine learning techniques help in increasing accuracy of landslide susceptibility maps? Geosci. Front. 2020, 11, 871–883. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.; Rostamzadeh, H.; Blaschke, T.; Gholaminia, K.; Aryal, J. A new GIS-based data mining technique using an adaptive neuro-fuzzy inference system (ANFIS) and k-fold cross-validation approach for land subsidence susceptibility mapping. Nat. Hazards 2018, 94, 497–517. [Google Scholar] [CrossRef]
- Ullah, K.; Wang, Y.; Fang, Z.; Wang, L.; Rahman, M. Multi-hazard susceptibility mapping based on Convolutional Neural Networks. Geosci. Front. 2022, 13, 101425. [Google Scholar] [CrossRef]
- Ferretti, A.; Fumagalli, A.; Novali, F.; Prati, C.; Rocca, F.; Rucci, A. A New Algorithm for Processing Interferometric Data-Stacks: SqueeSAR. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3460–3470. [Google Scholar] [CrossRef]
- Berardino, P.; Fornaro, G.; Lanari, R.; Sansosti, E. A new algorithm for surface deformation monitoring based on small baseline differential SAR interferograms. IEEE Trans. Geosci. Remote Sens. 2002, 40, 2375–2383. [Google Scholar] [CrossRef]
- Bekaert, D.P.S.; Handwerger, A.L.; Agram, P.; Kirschbaum, D.B. InSAR-based detection method for mapping and monitoring slow-moving landslides in remote regions with steep and mountainous terrain: An application to Nepal. Remote Sens. Environ. 2020, 249, 111983. [Google Scholar] [CrossRef]
- Handwerger, A.L.; Booth, A.M.; Huang, M.H.; Fielding, E.J. Inferring the Subsurface Geometry and Strength of Slow-Moving Landslides Using 3-D Velocity Measurements From the NASA/JPL UAVSAR. J. Geophys. Res. Earth Surf. 2021, 126, e2020JF005898. [Google Scholar] [CrossRef]
- Wang, W.; Motagh, M.; Mirzaee, S.; Li, T.; Zhou, C.; Tang, H.; Roessner, S. The 21 July 2020 Shaziba landslide in China: Results from multi-source satellite remote sensing. Remote Sens. Environ. 2023, 295, 113669. [Google Scholar] [CrossRef]
- Wasowski, J.; Pisano, L. Long-term InSAR, borehole inclinometer, and rainfall records provide insight into the mechanism and activity patterns of an extremely slow urbanized landslide. Landslides 2019, 17, 445–457. [Google Scholar] [CrossRef]
- Zhou, C.; Cao, Y.; Hu, X.; Yin, K.; Wang, Y.; Catani, F. Enhanced dynamic landslide hazard mapping using MT-InSAR method in the Three Gorges Reservoir Area. Landslides 2022, 19, 1585–1597. [Google Scholar] [CrossRef]
- Zhou, C.; Cao, Y.; Yin, K.; Intrieri, E.; Catani, F.; Wu, L. Characteristic comparison of seepage-driven and buoyancy-driven landslides in Three Gorges Reservoir area, China. Eng. Geol. 2022, 301, 106590. [Google Scholar] [CrossRef]
- Ng, C.W.W.; Yang, B.; Liu, Z.Q.; Kwan, J.S.H.; Chen, L. Spatiotemporal modelling of rainfall-induced landslides using machine learning. Landslides 2021, 18, 2499–2514. [Google Scholar] [CrossRef]
- Shahabi, H.; Hashim, M.; Ahmad, B.B. Remote sensing and GIS-based landslide susceptibility mapping using frequency ratio, logistic regression, and fuzzy logic methods at the central Zab basin, Iran. Environ. Earth Sci. 2015, 73, 8647–8668. [Google Scholar] [CrossRef]
- Dai, K.; Li, Z.; Xu, Q.; Burgmann, R.; Milledge, D.G.; Tomas, R.; Fan, X.; Zhao, C.; Liu, X.; Peng, J.; et al. Entering the Era of Earth Observation-Based Landslide Warning Systems: A Novel and Exciting Framework. IEEE Geosci. Remote Sens. Mag. 2020, 8, 136–153. [Google Scholar] [CrossRef]
- Liu, X.; Zhao, C.; Zhang, Q.; Lu, Z.; Li, Z.; Yang, C.; Zhu, W.; Liu-Zeng, J.; Chen, L.; Liu, C. Integration of Sentinel-1 and ALOS/PALSAR-2 SAR datasets for mapping active landslides along the Jinsha River corridor, China. Eng. Geol. 2021, 284, 106033. [Google Scholar] [CrossRef]
- Hu, X.; Bürgmann, R.; Fielding, E.J.; Lee, H. Internal kinematics of the Slumgullion landslide (USA) from high-resolution UAVSAR InSAR data. Remote Sens. Environ. 2020, 251, 112057. [Google Scholar] [CrossRef]
- Intrieri, E.; Carla, T.; Farina, P.; Bardi, F.; Ketizmen, H.; Casagli, N. Satellite Interferometry as a Tool for Early Warning and Aiding Decision Making in an Open-Pit Mine. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 5248–5258. [Google Scholar] [CrossRef]
- Pham, B.T.; Jaafari, A.; Prakash, I.; Bui, D.T. A novel hybrid intelligent model of support vector machines and the MultiBoost ensemble for landslide susceptibility modeling. Bull. Eng. Geol. Environ. 2018, 78, 2865–2886. [Google Scholar] [CrossRef]
- Dou, J.; Yunus, A.P.; Merghadi, A.; Shirzadi, A.; Nguyen, H.; Hussain, Y.; Avtar, R.; Chen, Y.; Pham, B.T.; Yamagishi, H. Different sampling strategies for predicting landslide susceptibilities are deemed less consequential with deep learning. Sci. Total Environ. 2020, 720, 137320. [Google Scholar] [CrossRef]
- Avand, M.; Janizadeh, S.; Bui, D.T.; Pham, V.H.; Ngo, P.T.T.; Nhu, V.H. A tree-based intelligence ensemble approach for spatial prediction of potential groundwater. Int. J. Digit. Earth 2020, 13, 1408–1429. [Google Scholar] [CrossRef]
- Chen, L.; Guo, H.; Gong, P.; Yang, Y.; Zuo, Z.; Gu, M. Landslide susceptibility assessment using weights-of-evidence model and cluster analysis along the highways in the Hubei section of the Three Gorges Reservoir Area. Comput. Geosci. 2021, 156, 104899. [Google Scholar] [CrossRef]
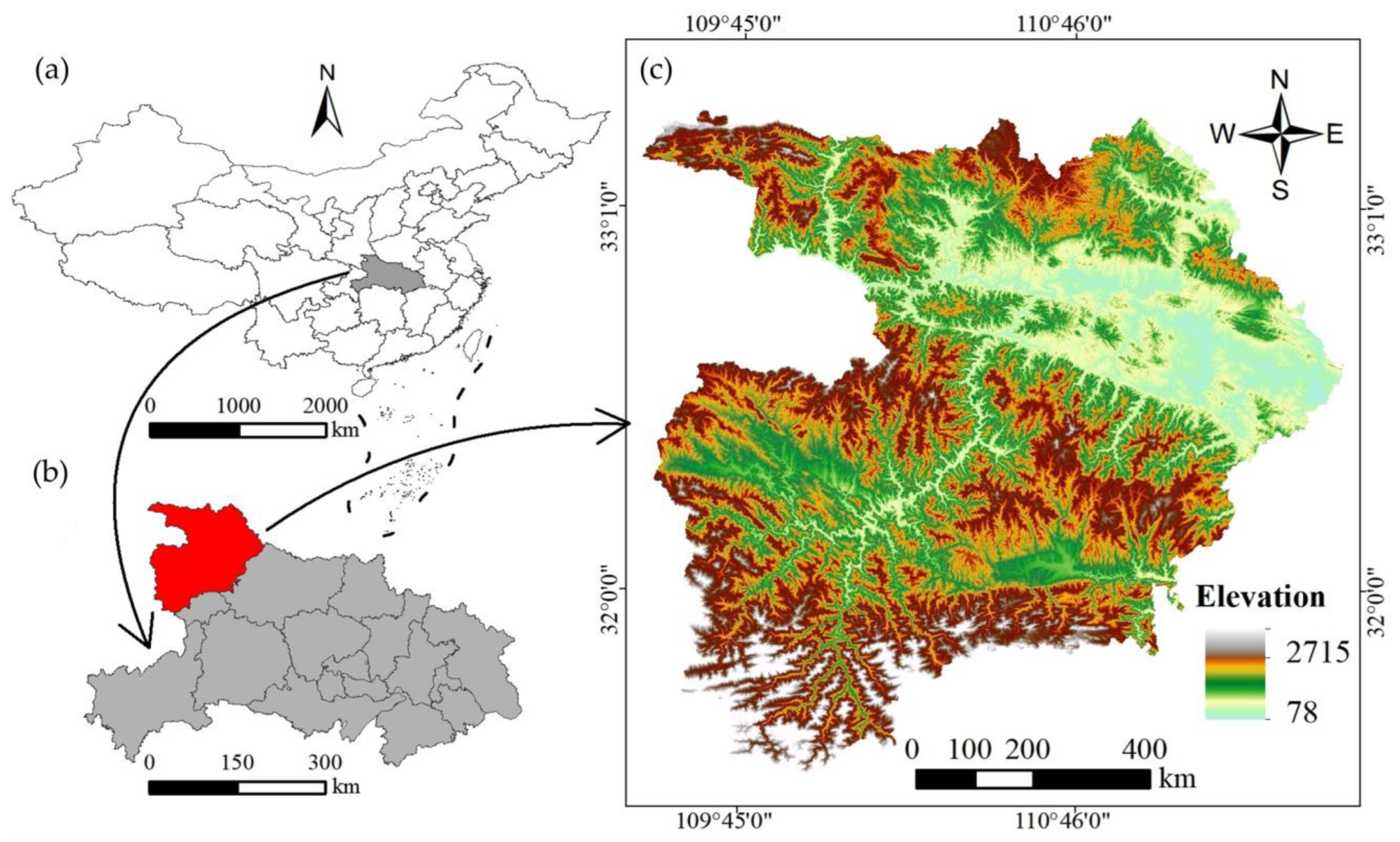


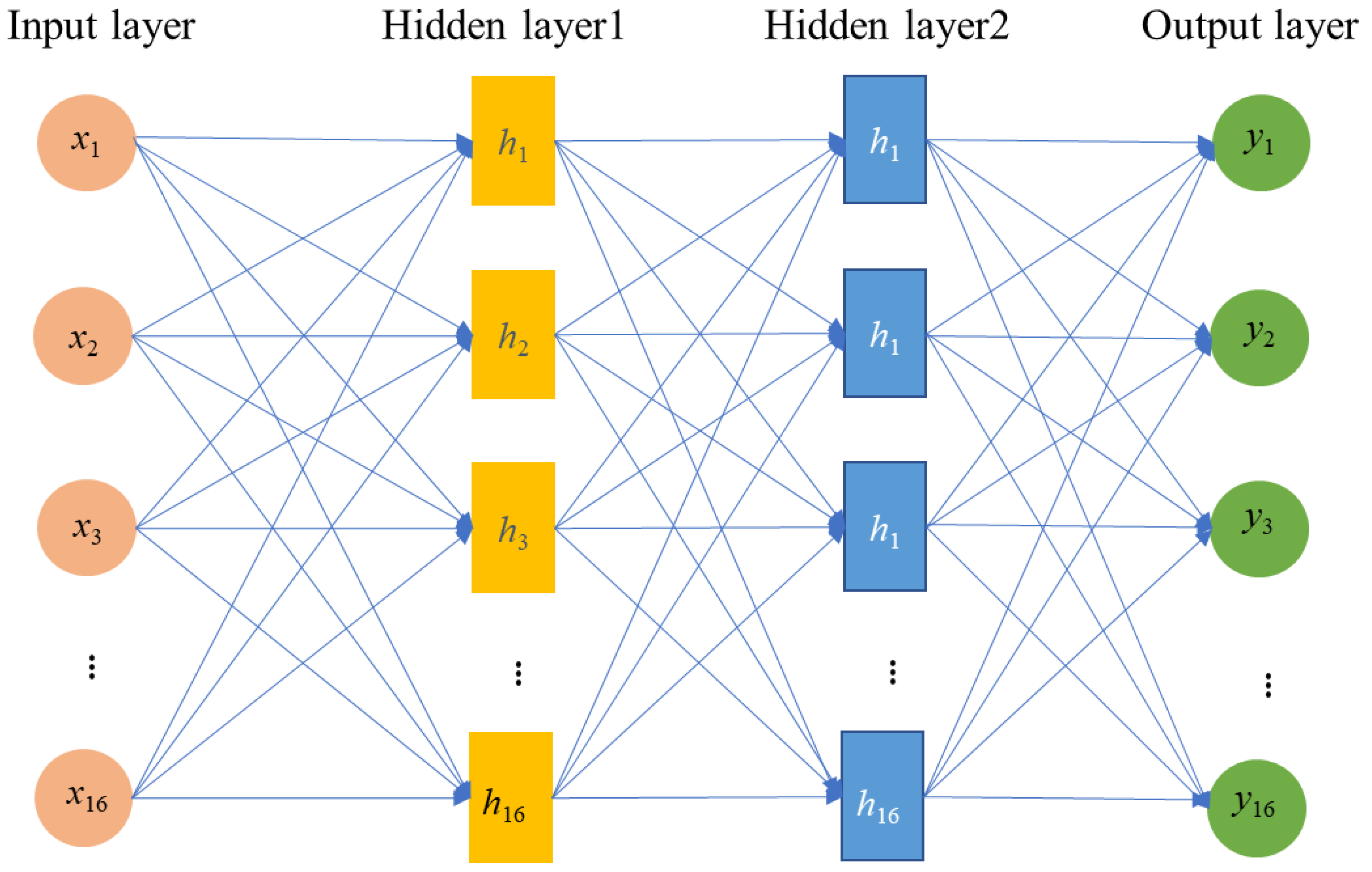
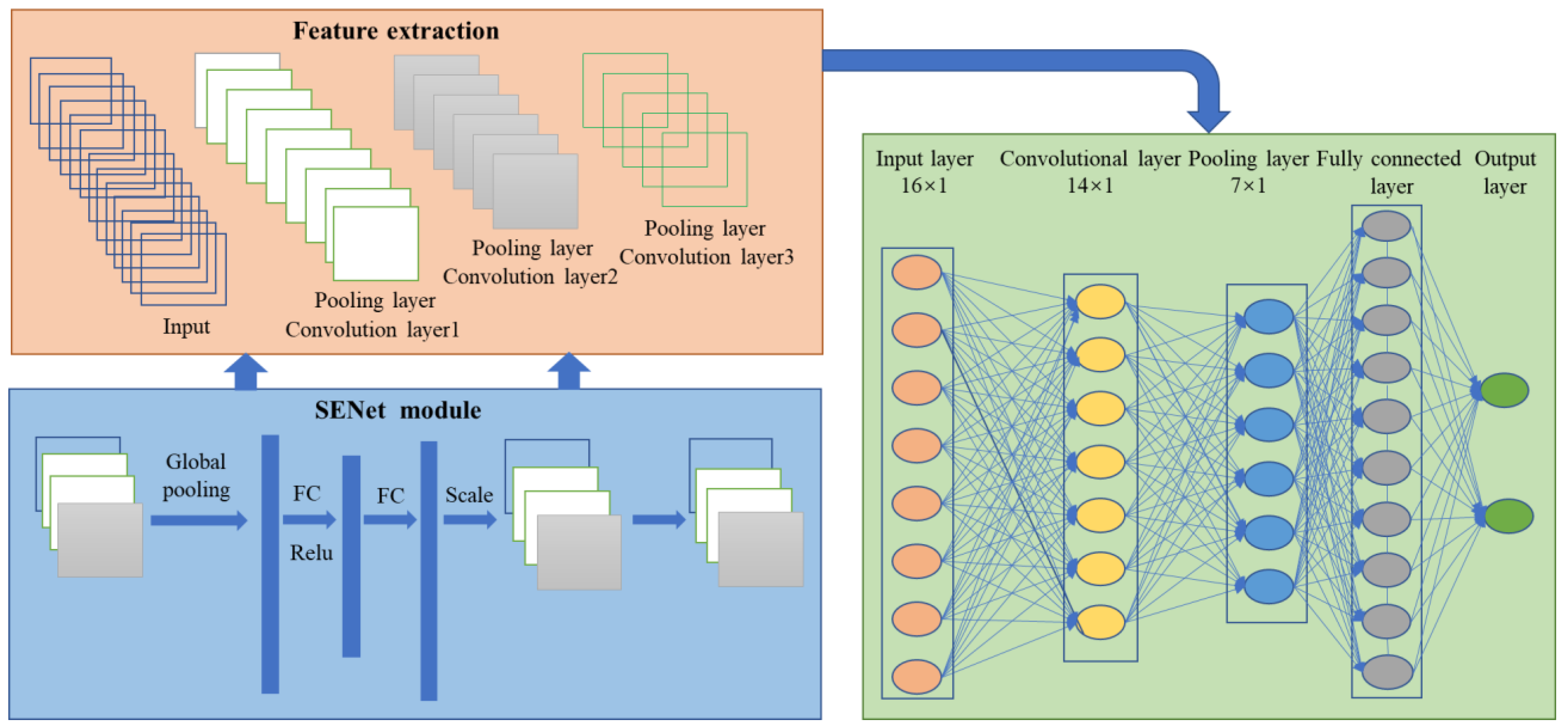
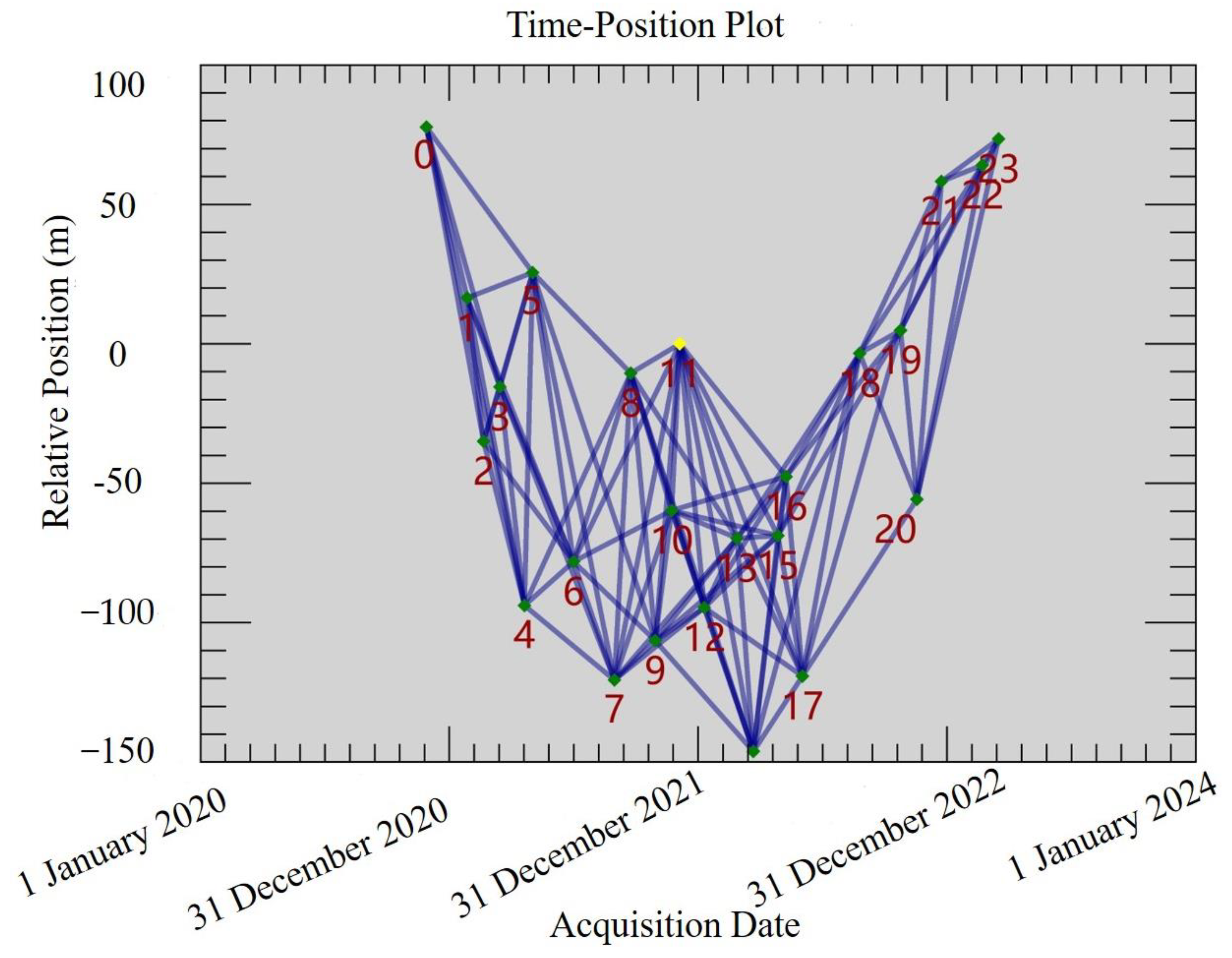
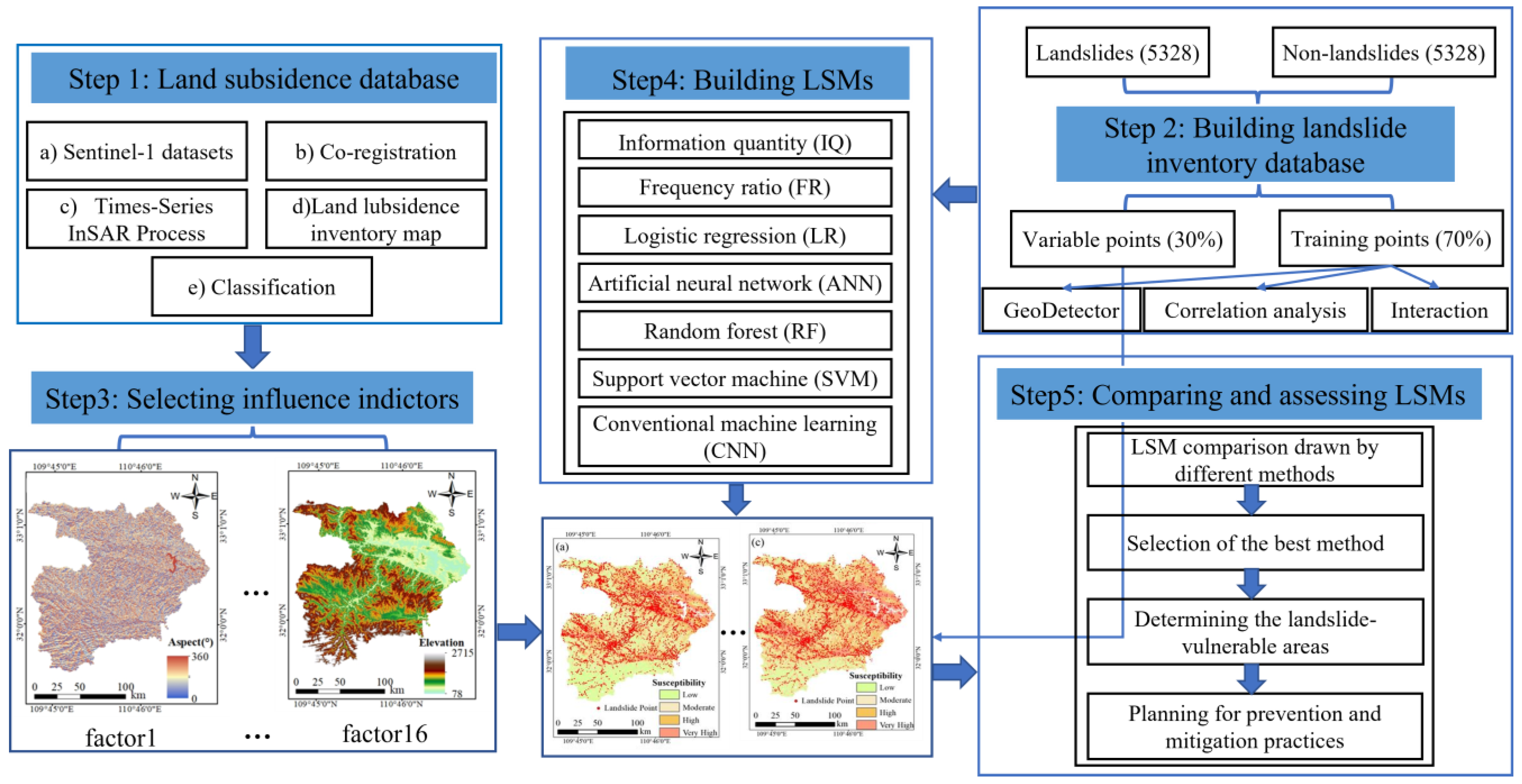
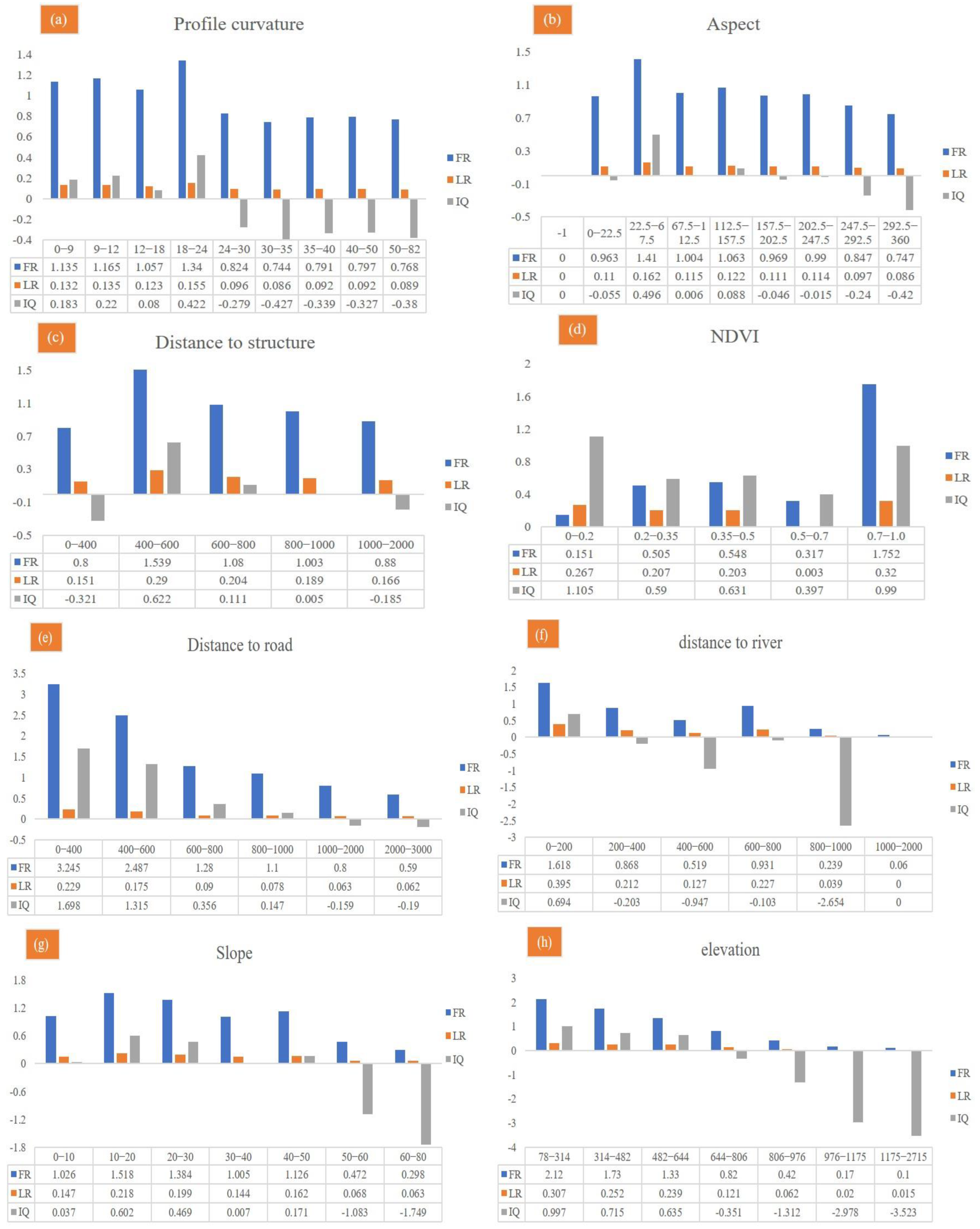
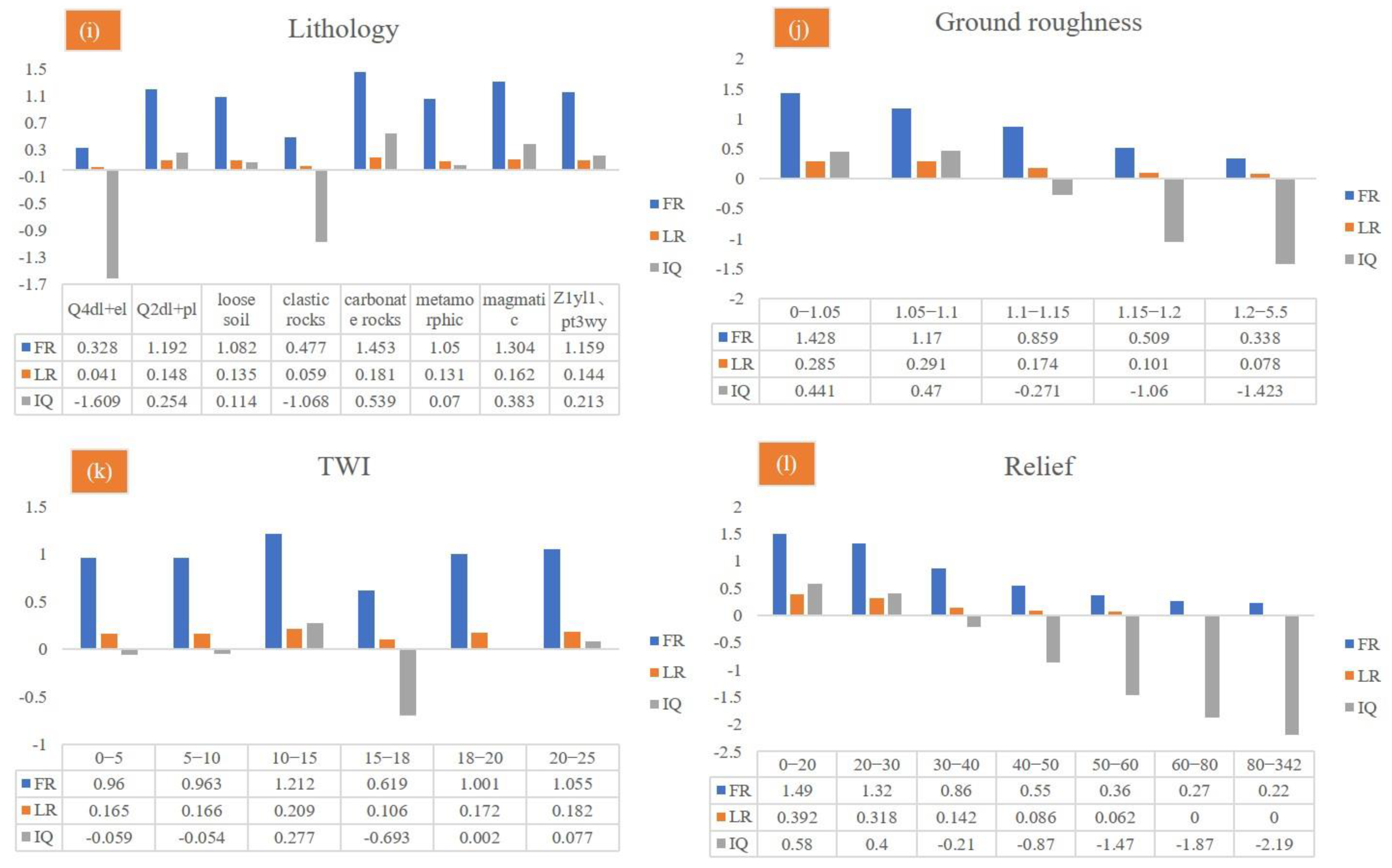
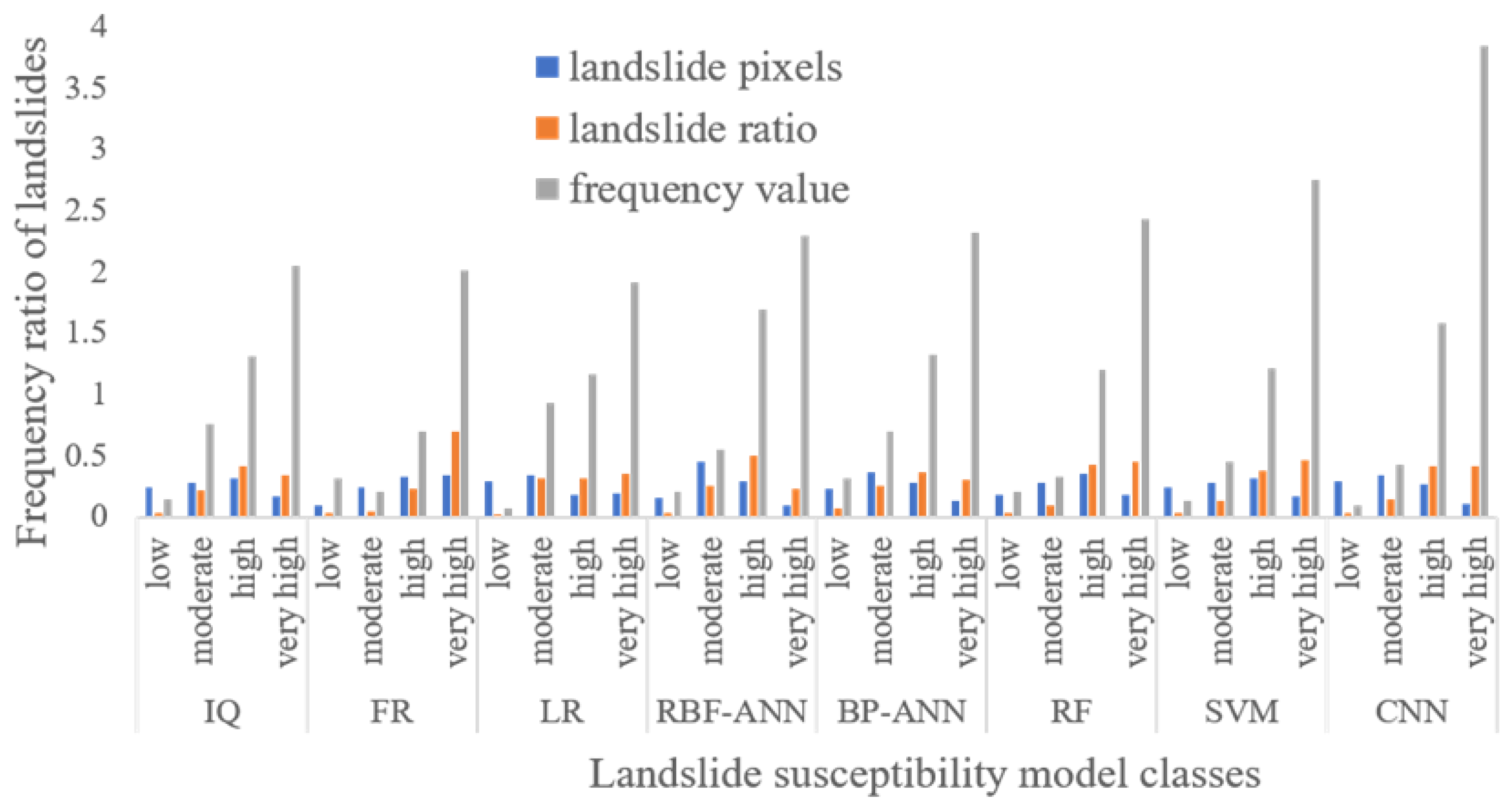
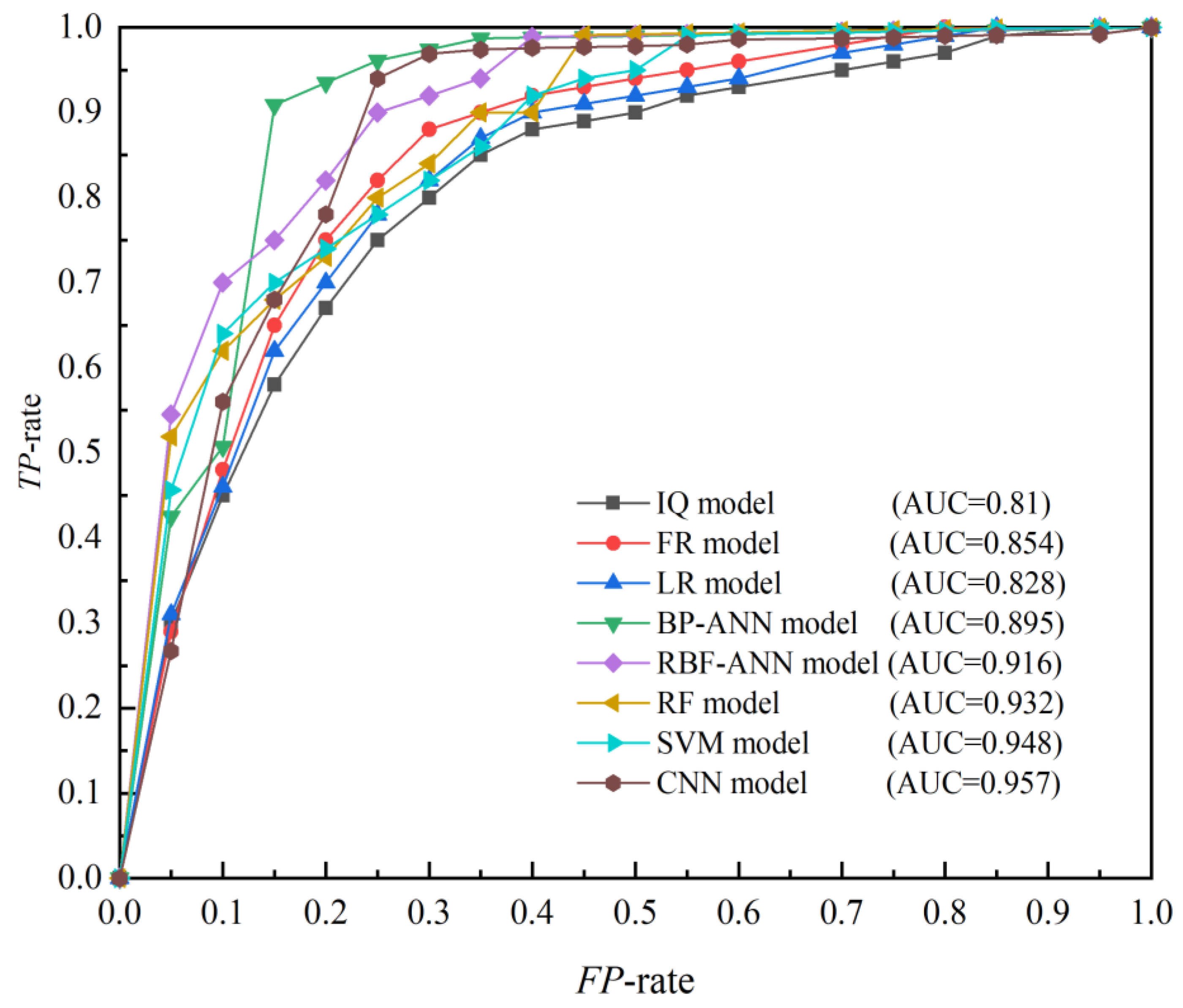
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).