The overall framework of our method is illustrated in
Figure 2. The network directly predicts the objects’ center points (including x and y coordinates), width, height, IoU, and rotation angle. We propose several techniques to improve YOLOX for fast and accurate oriented object detection, including the RE-Net and the DynamicOTA. Additionally, we add the SSM that enables full end-to-end object detection, eliminating the need for NMS. The following sections provide detailed descriptions of these modules.
3.1. Re-Parameterization Channel Expansion Network
Objects in aerial images are densely arranged, with large-scale variations and arbitrary orientations, making it difficult to detect objects accurately. The detector needs to extract high-level semantic information and features of the objects in the images for accurate object localization and classification. At the same time, UAVs are restricted to carrying embedded devices, limiting the parameters and computational load of the network. Therefore, improving the network’s feature extraction capability while meeting the requirements of implementing on embedded devices requires us to develop a high-accuracy, real-time UAV aerial object detection algorithm.
RepVGG [
33] improves the accuracy of the model without increasing the inference time by equivalently converting parallel 1 × 1 and 3 × 3 convolutions and identity connections into 3 × 3 convolutions. This method, called structural re-parameterization, streamlines the model structure and reduces the computational load. Linear over-parameterization [
34] converts the cascaded 1 × 1 and 3 × 3 convolutions into equivalent 3 × 3 convolutions and shows excellent performance.
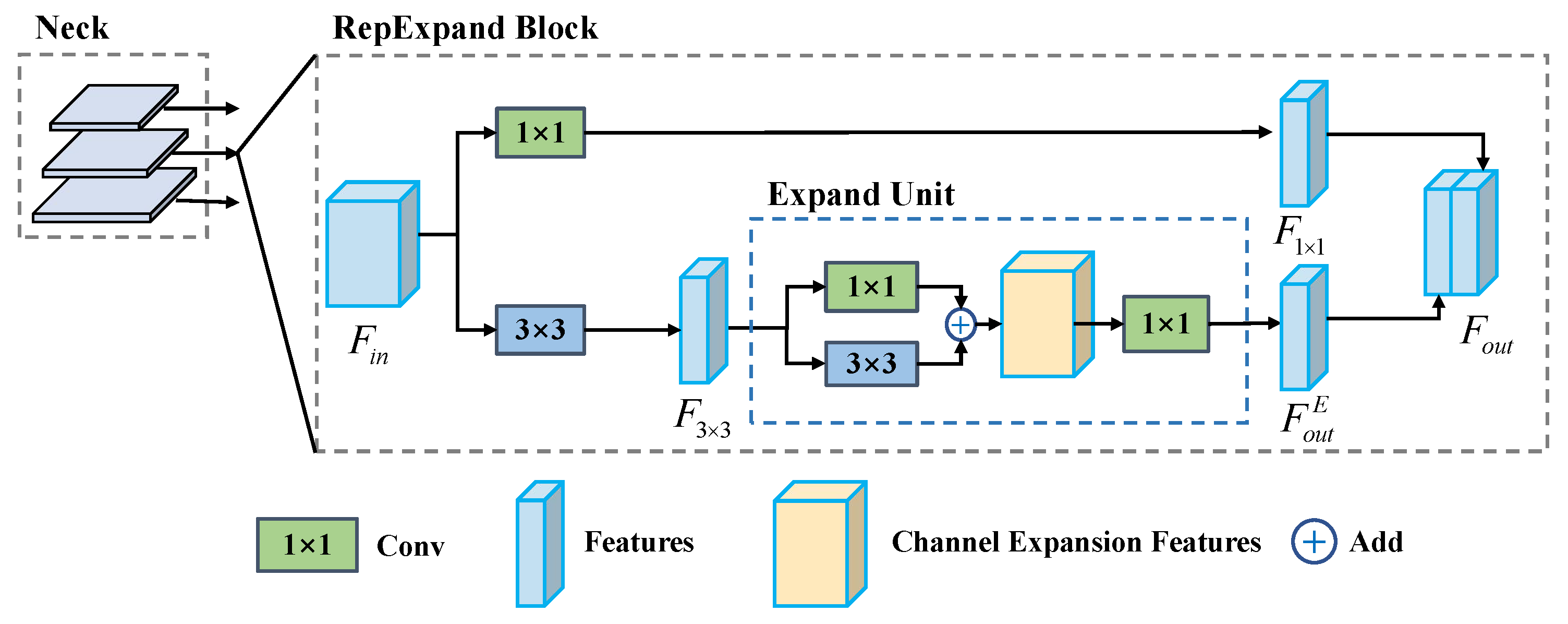
Inspired by these works, we design a novel re-parameterization expand block (RepExpand Block), with its structure illustrated in
Figure 3. Given the input feature map from Neck
, we first reduce the input features to half their channel size in two different branches with 1 × 1 and 3 × 3 convolutions, respectively:
in which
, ConvBNAct denote the performing of convolution layer, batch normalization layer and activation function in series.
Next, we compute the enhanced features constructed by the Expand Unit based on
:
in which
. The output of the RepExpand Block is the concatenation of
and
:
in which
. The key element of the RepExpand block is the Expand Unit, as shown in
Figure 4, which expands the input feature in the channel dimension by a factor of
E with the convolutions of
and
. This structure is designed to project features from a low-dimensional space into a higher-dimensional space, thus enhancing the network’s feature representation capability and consequently improving the accuracy of aerial object detection.
In the training phase, the Expand Unit’s structure is illustrated in
Figure 4a. Given the input feature map of Expand Unit
(
in
Figure 3, and
), we expand the feature channel to
as follows:
in which
. The output feature maps of the parallel 3 × 3 and 1 × 1 convolutions are then added, and the channels are finally narrowed to
C by 1 × 1 convolution to obtain the output of the Expand Unit:
where
. This design also resembles an inverted residual structure [
35], which enhances the ability of gradient propagation across the Expand Unit and improves network performance.
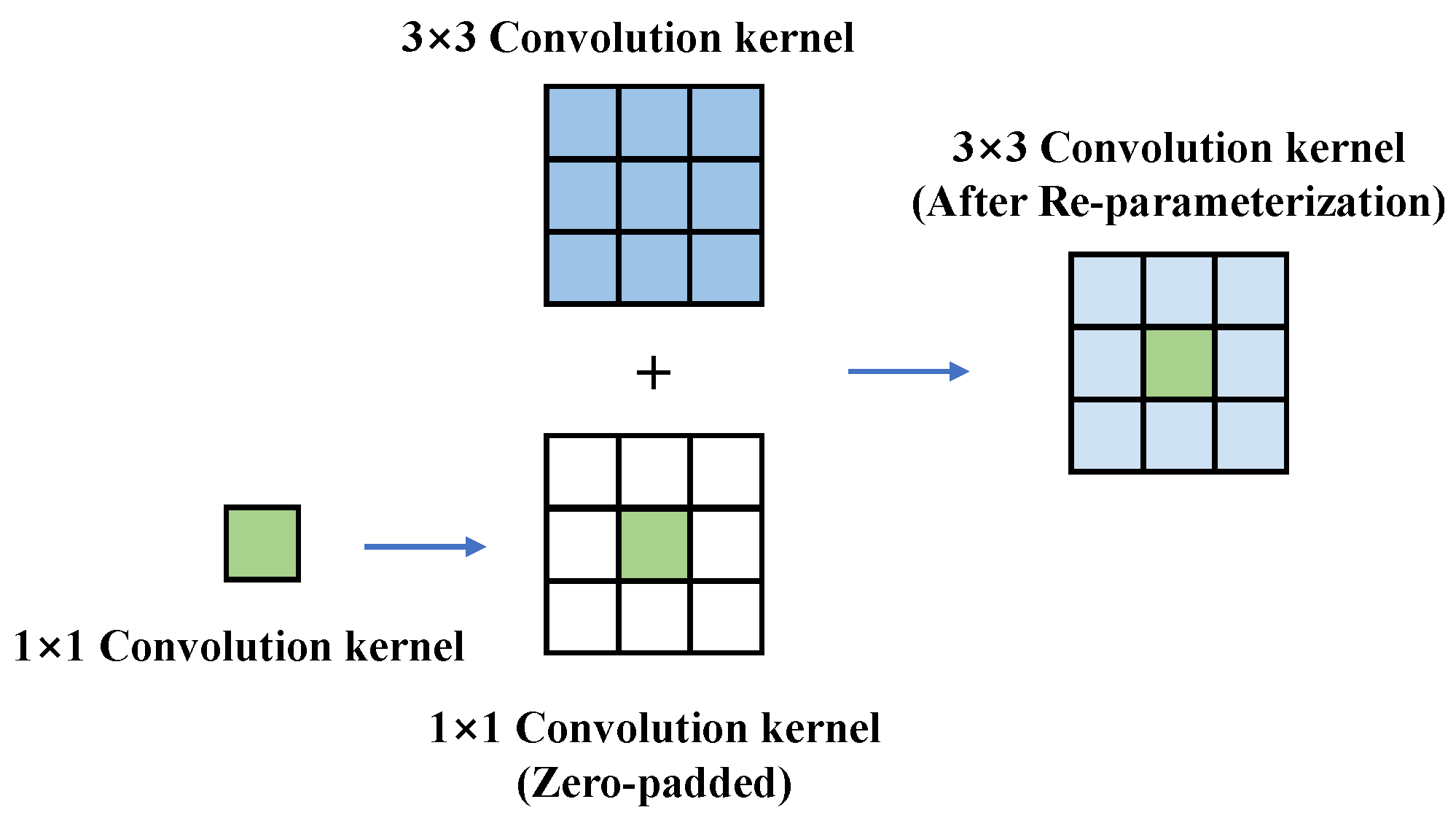
During the inference phase, the Expand Unit can be transformed into a single convolutional layer, significantly reducing parameters and computational load. As shown in
Figure 5, the parallel 1 × 1 convolution kernel is zero-padded to a 3 × 3 size and combined with the 3 × 3 convolution kernel, achieving structural re-parameterization transformation [
33]. The transformed structure is shown in
Figure 4b.
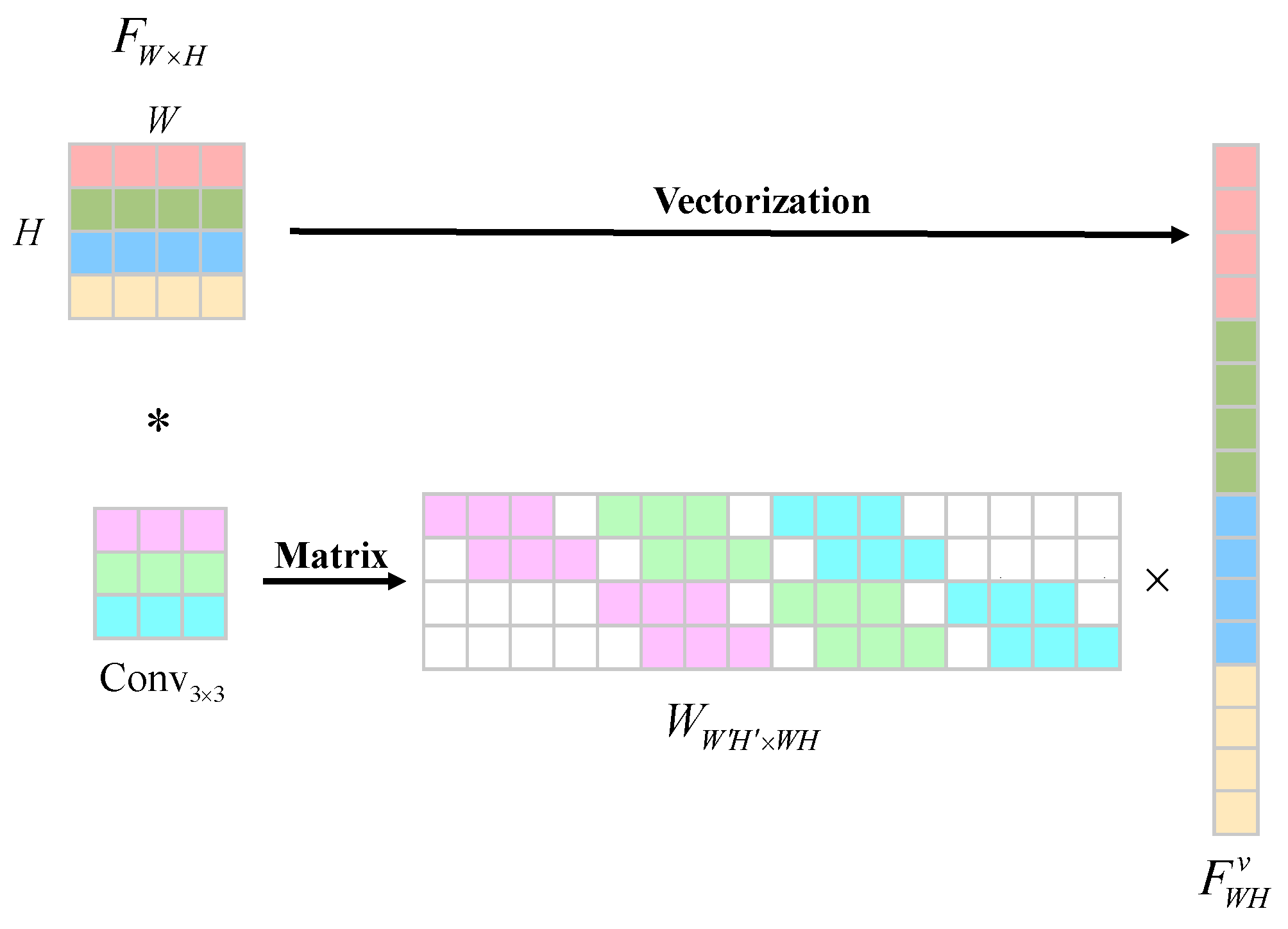
We next employ the linear over-parameterization method to further simplify the structure and reduce the parameters and computational load. As shown in
Figure 6, the convolution operation is expressed in the matrix form. Specifically, we let
denote the input feature map, and
denote the convolution operation. The convolution process can be formulated in the matrix as follows [
34]:
in which
represents the structured sparse matrix that contains the convolution kernel. Here,
C,
W, and
H denote the feature map’s channels, width, and height, respectively.
denotes the vectorized representation of the input features.
After representing the convolution process in matrix form, the cascade
and
convolution kernel matrices in the Expand Unit can be merged into a single
convolution layer with the convolution kernel in matrix form, as follows:
in which
and
are the structured sparse matrix of the
convolution and the
convolution in
Figure 4b, respectively.
is the structured sparse matrix for the transformed
convolution. Since the receptive fields remain the same before and after the transformation, we can obtain the merged convolution kernel from
, thus achieving the equivalent transformation from
Figure 4b to
Figure 4c.
The RepExpand Block enhances feature representation capabilities through channel expansion, enabling the model to be more applicable to UAV aerial image detection and achieve superior performance. During the inference stage, the Expand Unit can be equivalently transformed into a single convolution layer, significantly reducing both parameters and computational costs.
Furthermore, inspired by [
4], we introduce the ELAN structure to improve performance. ELAN’s efficient feature aggregation offers benefits in balancing speed and accuracy. We introduce the ELAN structure to replace the CSP structure in the YOLOX to improve network performance. The structure of ELAN is shown in
Figure 7. Utilizing the ELAN structure, the network’s feature aggregation ability can be effectively improved, thereby achieving more accurate and efficient object detection.
3.2. DynamicOTA for Dense to Sparse Label Assignment
Label assignment is a critical issue in object detection, which directly affects the detector’s performance. Current label assignment strategies typically use preset matching rules or thresholds to determine positive and negative samples, but these methods do not consider the impact of the training process. SimOTA [
1], the label assignment strategy used by YOLOX, is faster than OTA [
36] and does not require additional hyperparameters. SimOTA determines the number of positive samples according to detection quality. It assigns
positive samples to each ground truth (GT), where
is calculated from the sum of the top 10 IoU values between predicted bounding boxes and GT.
During the experiment, we identify an issue with SimOTA, namely that it assigns an insufficient number of positive samples during the early stages of training. To analyze this issue, we performed a visualization analysis of the number and position of positive samples assigned to each GT during training in
Figure 8. In the early stages of training, SimOTA assigns only a small number of positive samples to each GT (in
Figure 8, it assigns only one positive sample to each GT). This is because it determines the number of positive samples based on the detection quality, which is poor in early training. The network convergence is slow and unstable due to the lack of positive samples, which has a negative impact on the final detection accuracy.
A straightforward resolution to this issue is increasing the number of positive samples assigned to each object. This helps the model learn object features and location information more effectively, discriminate between objects and backgrounds, and improve accuracy and network convergence. However, an excessive number of positive samples may lead to redundant detection. Therefore, it is necessary to control the ratio of positive and negative samples reasonably to avoid oversampling.
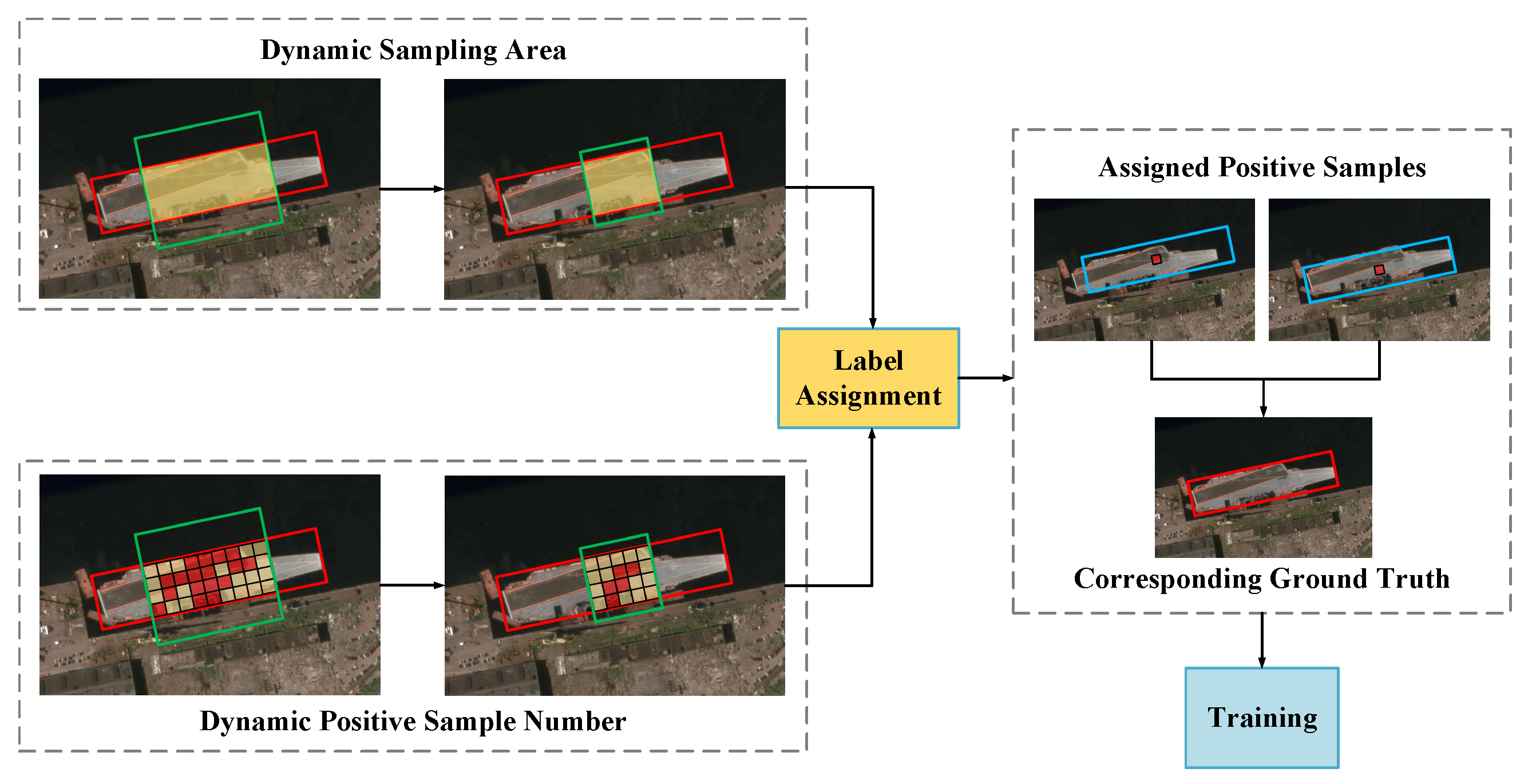
To address the above problem, we propose a label assignment strategy called DynamicOTA, as shown in
Figure 9, which consists of two parts:
The first part dynamically adjusts the sampling area. The distance threshold of the sample is calculated as follows:
where
is the distance threshold for the sample area. A sample is selected as positive if the distance between the sample center and the GT center is less than the
grid size.
x denotes the training process, taking values within the
range. As shown in
Figure 9, the green box represents the region defined by
, which gradually shrinks during training. This strategy enables training to focus on high-quality detection results, reducing unnecessary memory and computational overhead and ultimately improving the training efficiency and detection quality.
The second part dynamically adjusts the number of positive samples assigned to each GT based on the training process. We adjust the number of positive samples by constructing a decay function as follows:
where
x represents the training progress, with a value range between
. The number of positive samples
assigned to each GT is the sum of the top
IoU values (IoU calculated between the detection boxes and GT boxes). The maximum value of
is 50.
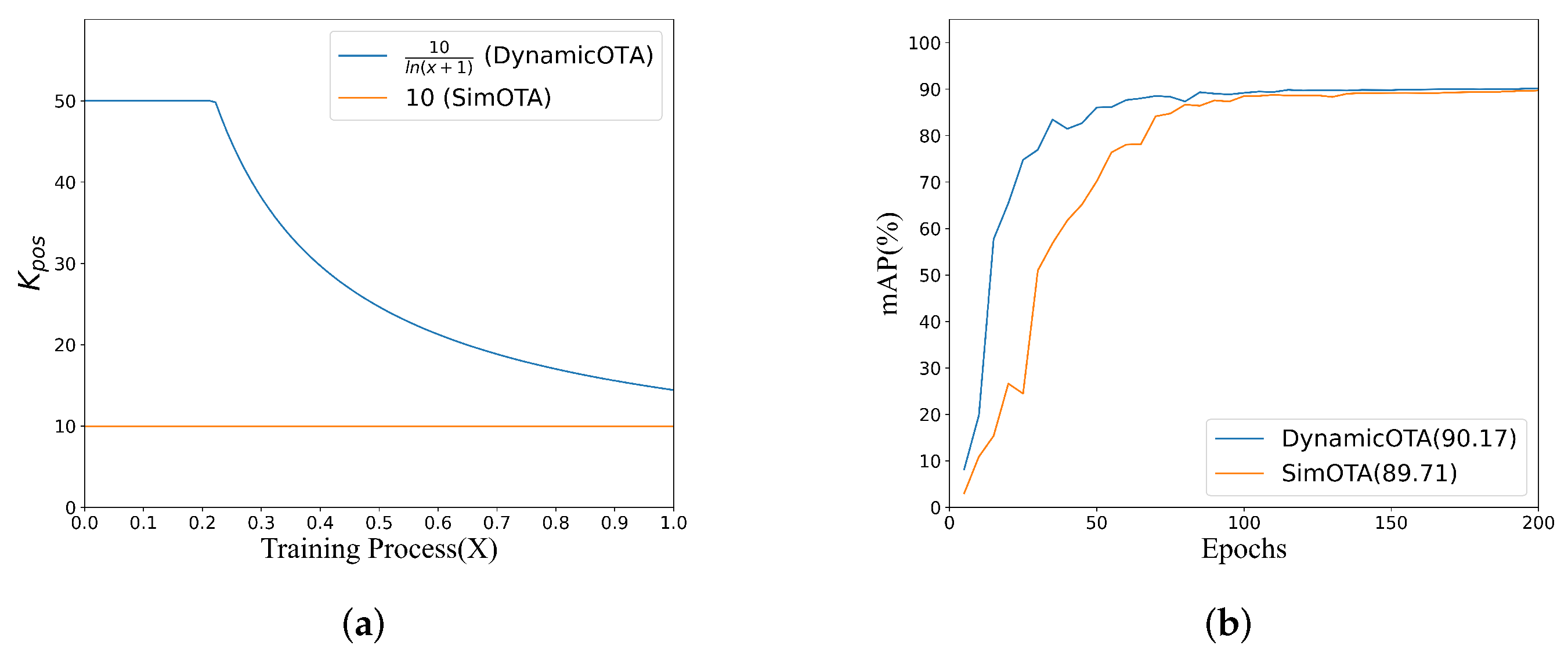
Figure 10a shows the function curve, where
is set to 10 in SimOTA, while our method dynamically adjusts
.
Our DynamicOTA algorithm is shown in Algorithm 1. We first calculate the classification and regression cost. Subsequently, we calculate the foreground–background cost based on the sampling area adjusted by
. Finally, we assign the
samples with the smallest total cost to the corresponding GT as the positive sample.
| Algorithm 1 DynamicOTA |
| Input: |
| I is the input images. A is the anchor points. G is the GT labels. X is the training process . |
| Output: |
| : Label assignment result. |
| 1: ; |
| 2: |
| 3: Compute classification : |
| 4: Compute regression : ; |
| 5: Dynamically adjust the sampling area ; |
| 6: Compute foreground-background : ; |
| 7: = |
| 8: Select the largest IoU values between and ; |
| 9: ; |
| 10: for do |
| 11: Select the smallest samples from the as the positive samples of ; |
| 12: end for |
| 13: return . |
Figure 11 shows a visualization of label assignment during training, where red boxes denote GT boxes and red dots denote positive samples. In the early stages of training, SimOTA assigns very few positive samples to each GT, resulting in slow network convergence. Our DynamicOTA has a more reasonable label assignment process that transitions from dense to sparse. In the early stages of training, DynamicOTA assigns more positive samples, facilitating stable and comprehensive learning and accelerating network convergence. As training progresses, the number of assigned positive samples is adaptively decreased to suppress the redundant detection results, which not only helps to accelerate the convergence process, but also can improve the detection precision by further training with fewer high-quality samples.
Figure 10b provides an experimental validation of DynamicOTA on the HRSC2016 dataset [
37] by comparing it with the original SimOTA. It shows that our method can significantly improve the convergence speed and the final accuracy of the detector.
3.3. Sample Selection Module for End-to-End Oriented Object Detection
The current detector uses one-to-many matching to assign multiple positive samples to a single GT. This approach leads to multiple detection boxes corresponding to a single object during inference, requiring NMS to eliminate duplicate bounding boxes. NMS is a heuristic algorithm in object detection that plays a similar role to that of the anchor. Analogous to anchor-Free detectors, NMS-free detectors have been introduced. DETR [
38] uses a transformer structure to fix 100 prediction results and achieves end-to-end detection. DeFCN [
39] uses a one-to-one matching strategy and 3D max filtering to achieve NMS-free detection. PSS [
40] implements NMS-free detection using a simple convolutional structure.
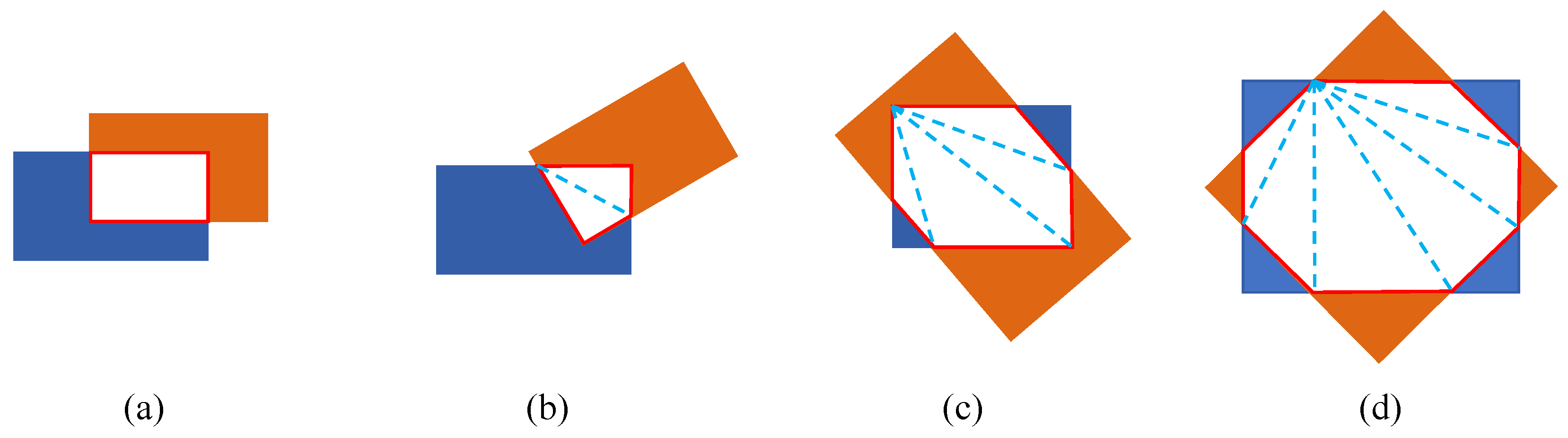
The NMS algorithm needs to calculate the IoU between different detection boxes to eliminate redundant detections. For HBB detection, the calculation of the IoU is relatively simple. However, for OBB detection, the calculation of rotated IoU is complex, requiring consideration of various cases as shown in
Figure 12. In addition, post-processing with NMS adds an extra algorithm module that prevents the network from being fully end-to-end. In comparison, the NMS-free method enables end-to-end detection and achieves comparable performance, facilitating network deployment on embedded devices.
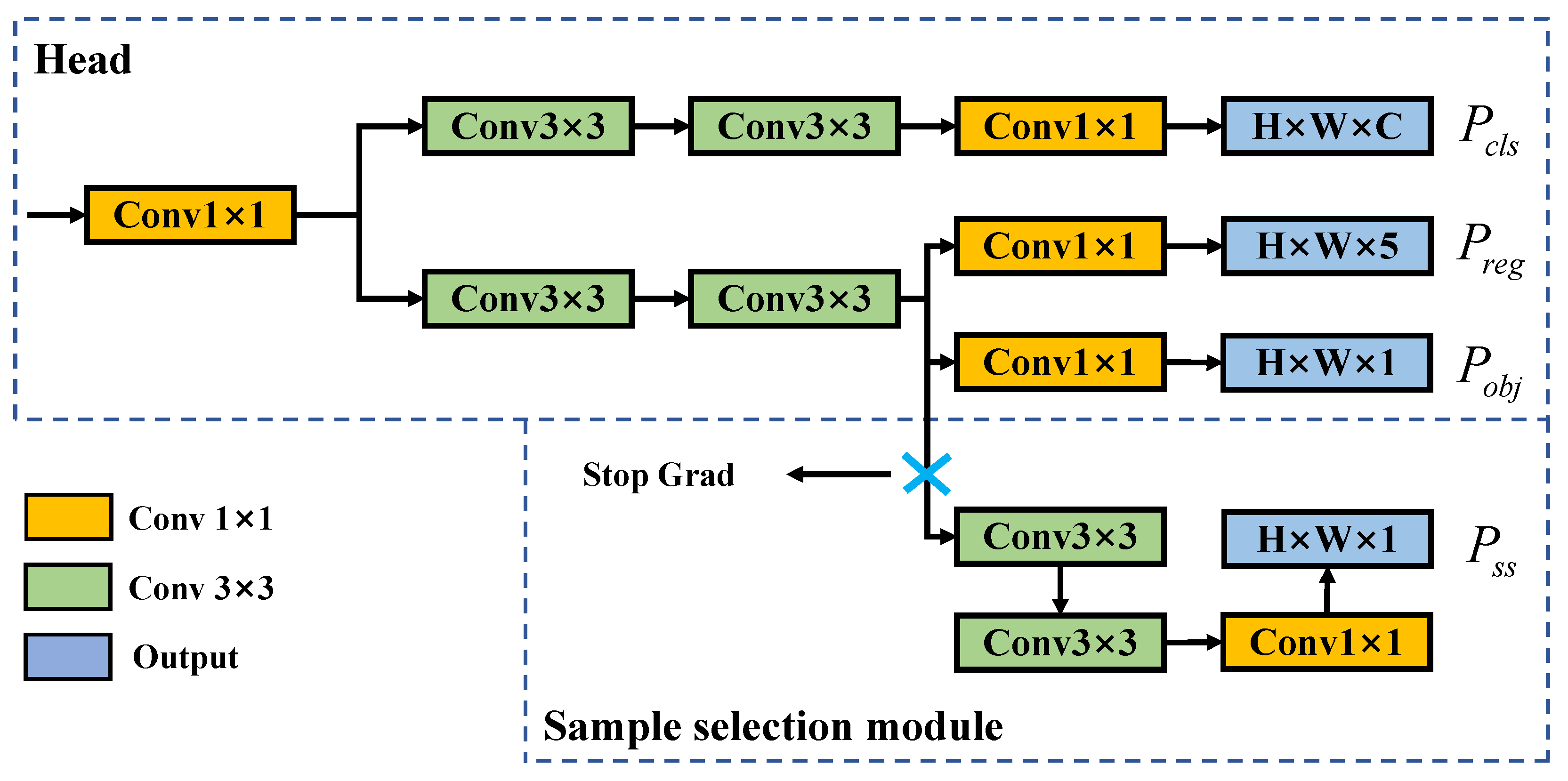
We implement full end-to-end object detection using a convolutional structure to facilitate deployment and engineering applications. We add an SSM to the detection head, as shown in
Figure 13. The SSM outputs a map corresponding to each GT box, where the map is 1 at the optimal detection position and 0 at other anchor points. We can remove the redundant detections by multiplying the output map with the detection result, thus eliminating the need for the NMS algorithm.
The SSM consists of two
convolution layers and one
convolution layer, as shown in
Figure 14. The detection results can be filtered as follows:
in which
denotes the sigmoid activation function,
is the SSM output,
is the confidence output, and
is the one-to-one confidence score corresponding to the GT. The
is the confidence output of the final detection result and does not require NMS processing.
The SSM is trained with the following cross-entropy (CE) loss function:
in which
denotes the SSM output, indicating the samples that should be selected and those that should be discarded.
denotes the map of the GT, with each GT set to 1 at the position with the best detection result and 0 at other positions.
is the number of positive samples; it is employed to normalize the calculation of the loss function.
The confidence output calculates losses by considering multiple positive samples for each GT. Conversely, the SSM output calculates losses with only the best positive sample for each GT, establishing a one-to-one matching, which reduces redundant detection boxes. However, this can cause negative samples from the SSM branch to be considered positive by the confidence branch, leading to gradient conflicts during training. To address this issue, PSS [
40] adopts a strategy of stopping gradient backpropagation. As shown in
Figure 14, we introduce this approach to achieve better performance. Furthermore, we observe that adding the SSM directly to the training results in slower convergence and decreased accuracy. Therefore, we adopte an alternative approach using the model weights trained without the SSM as the pre-trained weights to guide the training process.
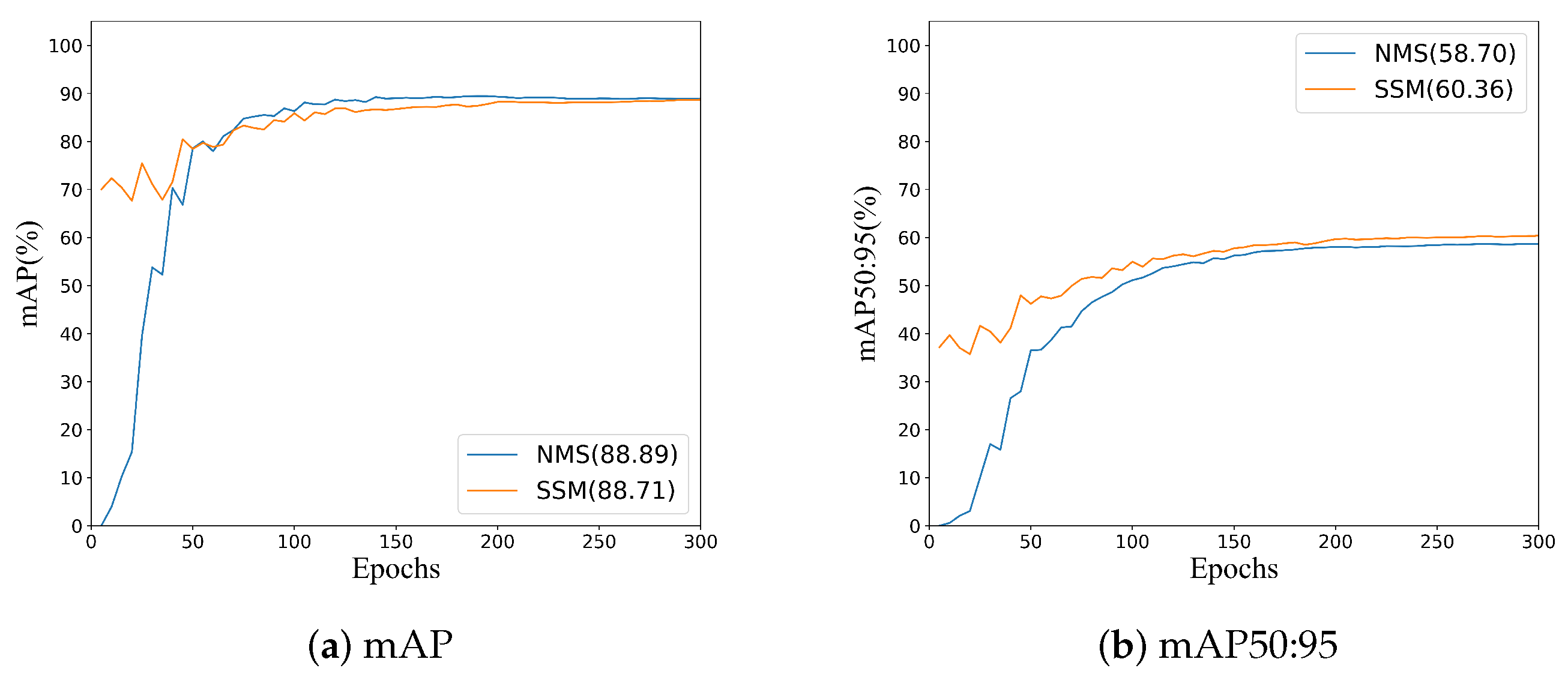
As shown in
Figure 15, our method shows comparable performance to that of the NMS method on the mAP (IoU threshold is 0.5) metric and a significant improvement on the mAP50:95 metric, which concerns more the evaluation of higher-precision detection. This demonstrates the advantage of one-to-one matching between GT and the best positive sample in training for high-precision detection. In addition, SSM employs a pure convolutional structure, making it more suitable for network deployment in embedded devices. However, there is a slight decrease in mAP. Therefore, we set the SSM as an optional component. Specifically, when deploying networks on high-performance GPU and preferring to achieve higher detection accuracy in terms of mAP, the network without SSM can be used; when deploying networks on embedded devices, adding SSM to enable NMS-free detection offers deployment benefit and can typically obtain higher localizing precision (in terms of mAP50:95).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}